RabbitMQ解决消息丢失以及重复消费问题
文章目录
- 1、概念
- 2、基于ACK/NACK机制
- 2.1 基于Spring AMQP框架整合ACK/NACK机制
- 2.2 测试消费失败1.0
- 2.3 测试结果1.0
- 2.4 测试MQ宕机
- 2.5 测试结果2.0
- 3、RabbitMQ 如何实现幂等性设计
- 3.1 幂等服务设计思路
- 3.1.1 通过雪花算法生成分布式唯一ID
- 3.1.2 通过枚举类,设计Message消费状态
- 3.1.3 生产者
- 3.1.4 消费者
- 3.1.5 测试结果
1、概念
RabbitMQ作为一款消息中间件,其设计目标之一就是保证消息的可靠性。要实现RabbitMQ消息不丢失,可以从以下几个方面进行配置和优化:
- 生产者确认机制(Publisher Confirms): 生产者在发布消息时,可以开启publisher confirms机制。当消息投递到RabbitMQ Broker后,Broker会返回一个确认信息给生产者。如果Broker没有正确接收到消息或存储失败,则不会发送确认。这样生产者可以根据是否收到确认来决定是否需要重新发送消息。
- 持久化消息(Message Durability):
- 对于队列(Queue),设置其为持久化的(durable)。即使RabbitMQ服务器重启,持久化的队列也会被恢复。
- 对于消息(Message),在发布时设置delivery mode为2,这将使得消息在队列中持久化。持久化消息会在磁盘上存储备份,即使RabbitMQ服务重启也能保持消息不丢失。
- 消费者ACK确认机制: 消费者在消费消息后,需要发送ACK确认给RabbitMQ。如果消费者在处理完消息之前意外终止(如进程崩溃),RabbitMQ会认为该消息未被正确处理,从而重新将消息投入队列等待其他消费者消费。
- 集群部署: 通过集群部署的方式提高RabbitMQ服务的可用性和容灾能力,即使部分节点出现问题,其他节点依然能保证消息的正常收发。
- 预拉取策略调整: 避免因消费者的消费速度慢于生产者的发送速度而导致的消息积压无法持久化的问题,可以通过调整prefetch count限制消费者预拉取消息的数量。
- 监控与告警: 建立完善的监控系统,实时关注RabbitMQ的各项指标,包括队列深度、磁盘使用率等,及时发现可能造成消息丢失的风险点并采取措施。
以上这些方法综合应用,可以在很大程度上确保RabbitMQ消息的不丢失。但需要注意的是,完全避免消息丢失在分布式系统中往往难以做到,只能尽可能地降低这种可能性。
2、基于ACK/NACK机制
在Java中使用RabbitMQ的ACK/NACK机制时,通常会利用Channel对象来进行消息确认。
使用Spring AMQP框架,可以结合Acknowledgment注解或者容器级别的配置来更方便地管理ACK/NACK操作。


2.1 基于Spring AMQP框架整合ACK/NACK机制
import com.rabbitmq.client.Channel;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.rabbit.listener.api.ChannelAwareMessageListener;
import org.springframework.stereotype.Service;/*** RabbitMqConsumer :** @author zyw* @create 2024-01-08 14:48*/@Slf4j
@Service
public class RabbitMqConsumer implements ChannelAwareMessageListener {@Override@RabbitListener(queues = "direct.queue", ackMode = "MANUAL")public void onMessage(Message message, Channel channel) throws Exception {try {// 处理消息逻辑processMessage(message);// 成功处理后手动确认消息long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicAck(deliveryTag, false);} catch (Exception e) {// 处理失败,可以选择重新入队列(取决于业务需求)if (shouldRequeueOnFailure()) {long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicNack(deliveryTag, false, true);} else {long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicReject(deliveryTag, false);}}}private boolean shouldRequeueOnFailure() {// 根据业务需求决定是否重新入队列return true; // 或者 false}/*** 消费逻辑* @param message* @throws Exception*/private void processMessage(Message message) throws Exception {System.out.println("Processing message: " + new String(message.getBody()));System.out.println("Processing : " + n);}
}
2.2 测试消费失败1.0
这里我基于RabbitMq的direct交换机模式,通过循环发送三条消息
public void sendQueueBatch(String message) {for (int i = 0; i < 3; i++) {rabbitTemplate.convertAndSend("direct.exchange", "direct.key", message + "{}i:" + i);}log.info("3个消息都发送成功");}
消费的业务逻辑中,我模拟第三次消费的时候会报错
//消费计数 private int n = 0;/*** 消费逻辑* @param message* @throws Exception*/private void processMessage(Message message) throws Exception {n++;if (n==3){throw new Exception("模拟消费失败");}System.out.println("Processing message: " + new String(message.getBody()));System.out.println("Processing : " + n);}
2.3 测试结果1.0

如图我们可以看到第三次消费失败后,系统自动再次尝试执行了第四次消费
2.4 测试MQ宕机
这里我们模拟每个消息的执行耗时4秒钟,在这期间我们手动关闭RabbitMq服务,模拟MQ宕机/网络波动。之后再手动重启MQ服务,查看之前未完成消费的消息是否能重新执行成功。
//计数 private int n = 0;/*** 消费逻辑* @param message* @throws Exception*/private void processMessage(Message message) throws Exception {n++;//模拟MQ宕机Thread.sleep(4000);System.out.println("Processing message: " + new String(message.getBody()));System.out.println("Processing : " + n);}
2.5 测试结果2.0
这里我们可以看到消费第二个消息的过程中,MQ宕机了

MQ重启之后,第二个和第三个消息都被执行了。通过我们设置的变量计数n以及消息的标识i我们可以发现,第二个消息被重复执行了。

RabbitMq宕机时已经开始消费但还未消费结束的消息,重启MQ之后会重复执行
在RabbitMQ中,如果消费者在消费消息时宕机或者网络故障导致服务器没有接收到确认(acknowledgement),那么这条消息可能会被重新投递。具体来说:
- 当消费者从队列中接收一条消息后,默认情况下RabbitMQ会将消息标记为“不可见”(除非使用了manual acknowledgment模式)。
- 消费者在处理完消息并发送ack给RabbitMQ之前,若发生宕机或网络中断等情况,RabbitMQ无法得知该消息是否已经被正确处理。
- RabbitMQ会在一个称为
prefetch count(预取数量)限制范围内持续尝试重新投递未被确认的消息。
因此,在RabbitMQ服务重启之后,那些之前已经开始消费但未被确认的消息会被认为是没有被正确处理,从而重新放回队列等待被其他消费者获取并处理,这就可能导致消息重复执行。为了避免这种情况造成的影响,通常需要在业务逻辑层面实现幂等性设计,即确保消息无论被消费多少次,其结果都是相同的,并且只产生一次有效操作。此外,可以使用事务、发布确认和高级消息确认机制来更好地控制消息的可靠性。
3、RabbitMQ 如何实现幂等性设计
在RabbitMQ中实现幂等性设计,确保消息无论被消费多少次都不会对业务状态造成重复影响,需要结合消息队列的机制以及业务逻辑的设计。以下是一些建议和方法:
-
业务层幂等处理:
- 每个消息携带一个全局唯一ID,在业务处理过程中,首先检查这个ID是否已经被处理过。例如,将已处理消息的ID记录到数据库的“已处理消息表”中,下次收到同样ID的消息时直接返回成功而不进行实际操作。
- 对于更新型操作,可以使用乐观锁或分布式锁来保证同一事务多次执行结果相同,例如通过版本号(version)控制更新操作,只有当版本号未变时才执行更新。
- 对于创建型操作,确保即使多次调用也不会生成多个资源,例如通过查询是否存在相同的唯一键来决定是否创建新的资源。
-
确认模式选择:
- 使用
acknowledgement模式,消费者接收到消息后必须发送确认给RabbitMQ,只有收到确认后RabbitMQ才会从队列中移除消息,否则会在连接恢复后重新投递。 - 设置
publisher confirms,生产者可以得到消息发布的确认,确保消息确实到达了MQ服务器并持久化存储。
- 使用
-
死信队列与重试策略:
- 配置死信交换机和死信队列,对于那些重复投递依然无法正确处理的消息,可以转移到死信队列,并设置相应的重试策略及最大重试次数,超过限制则记录日志、报警或手动介入处理。
-
幂等服务设计:
- 设计能够应对重复调用的服务接口,这些接口内部应该包含足够的逻辑判断以识别重复请求并作出正确的响应。
-
事务与补偿机制:
- 对于涉及多个系统的分布式事务场景,可以考虑采用TCC(Try-Confirm-Cancel)模式或其他分布式事务解决方案,使得整个流程具有幂等性。
总结来说,在RabbitMQ中实现幂等性主要依赖于业务逻辑层面的改造和优化,同时配合RabbitMQ自身的消息确认机制来确保消息不会因为异常情况而重复处理。
3.1 幂等服务设计思路
我们可以给每一个消息绑定一个分布式唯一ID,在通过Redis记录该消息的消费状态,保证每条消息只能被消费一次

3.1.1 通过雪花算法生成分布式唯一ID
我们可以将雪花算法的工具类抽出到微服务分布式系统的公共组件中,通过maven的依赖引用来使用。
在每个服务的配置文件中去配置专属的工作节点ID和数据中心ID,不同的服务去引用雪花算法工具类时,读取自身配置文件中的工作节点ID和数据中心ID。
zyw:# 工作节点ID(0~31)workerId: 0# 数据中心ID(0~31)datacenterId: 0
通过专属工作节点ID和数据中心ID构建专属的雪花算法工具类SnowflakeIdWorker
import org.springframework.beans.factory.annotation.Value;
import java.util.concurrent.atomic.AtomicLong;/*** SnowflakeIdWorker : 雪花算法** @author zyw* @create 2024-01-09 10:46*/public class SnowflakeIdWorker {// 起始的时间戳 (2010-01-01)private final long twepoch = 1288834974657L;// 机器标识位数private final long workerIdBits = 5L;private final long datacenterIdBits = 5L;// 序列号位数private final long sequenceBits = 12L;// 工作机器ID最大值private final long maxWorkerId = -1L ^ (-1L << workerIdBits);// 数据中心ID最大值private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);// 每一部分向左的偏移量private final long workerIdShift = sequenceBits;private final long datacenterIdShift = sequenceBits + workerIdBits;private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;// 时间戳边界值private long lastTimestamp = -1L;// 工作节点ID(0~31)@Value("${zyw.workerId}")private long workerId;// 数据中心ID(0~31)@Value("${zyw.datacenterId}")private long datacenterId;// 每个节点每毫秒内的序列号private AtomicLong sequence = new AtomicLong(0L);/*** 通过专属工作节点ID和数据中心ID构建专属的雪花算法工具类*/public SnowflakeIdWorker() {if (this.workerId > maxWorkerId || this.workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (this.datacenterId > maxDatacenterId || this.datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}}/*** 分布式唯一ID生成* @return*/public synchronized long nextId() {long timestamp = timeGen();// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}// 如果是同一时间生成的,则进行序列号的自增if (lastTimestamp == timestamp) {sequence.incrementAndGet();// 判断是否溢出if (sequence.get() > (-1L ^ (-1L << sequenceBits))) {// 阻塞到下一个时间戳timestamp = tilNextMillis(lastTimestamp);}} else {// 时间戳改变,重置序列号sequence.set(0L);}// 上次生成ID的时间截lastTimestamp = timestamp;// 移位并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) | sequence.get();}/*** 从给定的最后时间戳中获取下一个时间戳** @param lastTimestamp 最后时间戳* @return 下一个时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 生成当前时间的毫秒数。** @return 当前时间的毫秒数。*/protected long timeGen() {return System.currentTimeMillis();}
}
3.1.2 通过枚举类,设计Message消费状态
import java.util.Arrays;
import java.util.List;/*** RabbitStatusEnum :** @author zyw* @create 2024-01-09 11:18*/public enum RabbitStatusEnum {CONSUME(0, "待消费"),BEGIN(1, "开始消费"),SUCCESS(2, "成功"),FAIL(3, "失败"),;private Integer code;private String message;RabbitStatusEnum(Integer code, String message) {this.code = code;this.message = message;}public int getCode() {return code;}public void setCode(Integer code) {this.code = code;}public String getMessage() {return message;}/*** 获取需要执行的状态集合* @return*/public static List<Integer> getNeedExecuteList(){return Arrays.asList(CONSUME.getCode(),FAIL.getCode());}/*** 获取不需要执行的状态集合* @return*/public static List<Integer> getCompletionExecuteList(){return Arrays.asList(CONSUME.getCode(),FAIL.getCode());}}
3.1.3 生产者
生产者发送消息时,生成专属分布式唯一业务ID,通过Redis记录消息的消费状态
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.example.demo.config.mq.RabbitStatusEnum;
import com.example.demo.config.redis.RedisKeyEnum;
import com.example.demo.uitls.RedisUtils;
import com.example.demo.uitls.SnowflakeIdWorker;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.HashMap;
import java.util.Map;/*** MqService :** @author zyw* @create 2023-12-19 16:26*/@Service
@Slf4j
public class MqService {@Resourceprivate RabbitTemplate rabbitTemplate;@Resourceprivate SnowflakeIdWorker snowflakeIdWorke;@Resourceprivate RedisUtils redisUtils;/*** 批量发送消息** @param message*/public void sendQueueBatch(String message) {//请求头设置消息id(messageId)Map<String, Object> map = new HashMap<>();map.put("message", message);for (int i = 0; i < 3; i++) {long id = snowflakeIdWorker.nextId();map.put("id", id);JSONObject entries = JSONUtil.parseObj(map);redisUtils.setCacheObject(RedisKeyEnum.MQ_STATUS.getKey() + id, RabbitStatusEnum.CONSUME.getCode());rabbitTemplate.convertAndSend("direct.exchange", "direct.key", entries);}log.info("3个消息都发送成功");}}
3.1.4 消费者
我定义了一个实现ChannelAwareMessageListener接口的消费者类,并在@RabbitListener注解中设置了ackMode="MANUAL",这意味着消息确认将由开发者手动完成。当接收到消息时,可以通过获取的Channel对象调用basicAck()、basicNack()或basicReject()方法来进行消息确认或者拒绝操作。
- 消息开始消费时,记录开始消费的状态
- 消息成功完成后,记录成功消费的状态
这里是为了避免在消息开始消费后,RabbitMq宕机了,此时MQ并不知道这个消息最终有没有消费完成,因此重启MQ之后,MQ会重新消费这条消息。
因此我们只运行执行“待消费”和“消费失败”状态的消息。
- 如果在执行消费的过程中,出错了(抛出Exception),则记录消费失败的状态,MQ会再次尝试去进行消费
- 我们可以设置最多重试次数,以及两次重试消费的间隔时间
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.example.demo.config.mq.RabbitStatusEnum;
import com.example.demo.config.redis.RedisKeyEnum;
import com.example.demo.uitls.RedisUtils;
import com.rabbitmq.client.Channel;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.rabbit.listener.api.ChannelAwareMessageListener;
import org.springframework.stereotype.Service;/*** RabbitMqConsumer : 消费者** @author zyw* @create 2024-01-08 14:48*/@Slf4j
@Service
public class RabbitMqConsumer implements ChannelAwareMessageListener {@Resourceprivate RedisUtils redisUtils;/*** 记录消费次数*/private int n = 0;@Override@RabbitListener(queues = "direct.queue", ackMode = "MANUAL")public void onMessage(Message message, Channel channel) throws Exception {JSONObject entries = JSONUtil.parseObj(new String(message.getBody()));Integer status = redisUtils.getCacheObject(RedisKeyEnum.MQ_STATUS.getKey() + entries.get("id"));try {//只有代消费和消费失败的能进行消费if (RabbitStatusEnum.getNeedExecuteList().contains(status)) {//记录开始消费redisUtils.setCacheObject(RedisKeyEnum.MQ_STATUS.getKey() + entries.get("id"), RabbitStatusEnum.BEGIN.getCode());// 处理消息逻辑processMessage(entries);System.out.println("执行成功了:" + entries.get("id"));//记录消费成功redisUtils.setCacheObject(RedisKeyEnum.MQ_STATUS.getKey() + entries.get("id"), RabbitStatusEnum.SUCCESS.getCode());// 成功处理后手动确认消息long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicAck(deliveryTag, false);}} catch (Exception e) {// 处理失败,可以选择重新入队列(取决于业务需求)if (shouldRequeueOnFailure()) {long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicNack(deliveryTag, false, true);System.out.println("执行失败了:" + entries.get("id"));//记录消费失败redisUtils.setCacheObject(RedisKeyEnum.MQ_STATUS.getKey() + entries.get("id"), RabbitStatusEnum.FAIL.getCode());} else {long deliveryTag = message.getMessageProperties().getDeliveryTag();channel.basicReject(deliveryTag, false);}}}/*** 根据业务需求决定是否重新入队列* @return*/private boolean shouldRequeueOnFailure() {return true;}/*** 消费逻辑** @param entries* @throws Exception*/private void processMessage(JSONObject entries) throws Exception {n++;//模拟MQ消费时长Thread.sleep(4000);//消费System.out.println("Processing id: " + RedisKeyEnum.MQ_STATUS.getKey() + entries.get("id"));System.out.println("Processing message: " + entries.get("message"));System.out.println("第" + n + "次消费");}
}
3.1.5 测试结果
这里我在第二条消息的执行消费过程中,手动关闭了RabbitMQ服务(模拟RabbitMQ宕机/网络波动),等待几秒后,重启RabbitMQ服务。
可以看到三条消息都被正常消费完成,解决了之前MQ重启后,重复消费的问题,解决了RabbitMQ消息不丢失的问题。


Redis中记录了每条消息消费的状态

相关文章:
RabbitMQ解决消息丢失以及重复消费问题
文章目录 1、概念2、基于ACK/NACK机制2.1 基于Spring AMQP框架整合ACK/NACK机制2.2 测试消费失败1.02.3 测试结果1.02.4 测试MQ宕机2.5 测试结果2.0 3、RabbitMQ 如何实现幂等性设计3.1 幂等服务设计思路3.1.1 通过雪花算法生成分布式唯一ID3.1.2 通过枚举类,设计Me…...

docker 安装redis集群
一、准备6台机器 二、6台机器分别拉取镜像: docker pull redis三、6台机器分别建立挂载文件夹 mkdir -p /home/redis/data四、6台机器分别执行容器操作 docker run --restartalways -d --name redis-node-1 --net host --privilegedtrue -v /home/redis/data:/da…...

锂电池制造设备中分布式IO模块优势
在“碳达峰、碳中和”目标推动下,新能源汽车当下发展势头正盛,而纯电动车的核心部件则是:锂电池。动力型锂电池作为新能源汽车核心零部件,其发展与新能源汽车行业息息相关,迎来广阔的市场空间。 为何采用I/O模块&#…...

Android Room数据库升级Migration解决方案
一、介绍 Android Room 是 Android 官方提供的一个轻量级数据库框架,用于在 Android 应用程序中管理数据持久性。它简化了数据库访问,提供了更安全、更快速的数据存储方式,并使得数据操作更加便捷。 二、Room的特点(八股文可以参考) 以下是…...

离线安装docker和docker-compose
1.下载 docker Index of linux/static/stable/x86_64/ docker-compose Overview of installing Docker Compose | Docker Docs 2.docker /etc/systemd/system/docker.service [Unit] DescriptionDocker Application Container Engine Documentationhttps://docs.docker.…...

奇怪的事情记录:外置网卡和外置显示器不兼容
身为程序员,不应该对世界上的稀奇古怪的事情感到惊讶(毕竟,大部分都是程序员自己搞出来的)。 外置网卡和外置显示器不兼容 mbp2019intel版,win10,外接有线网卡,平时用得很好,接上外…...
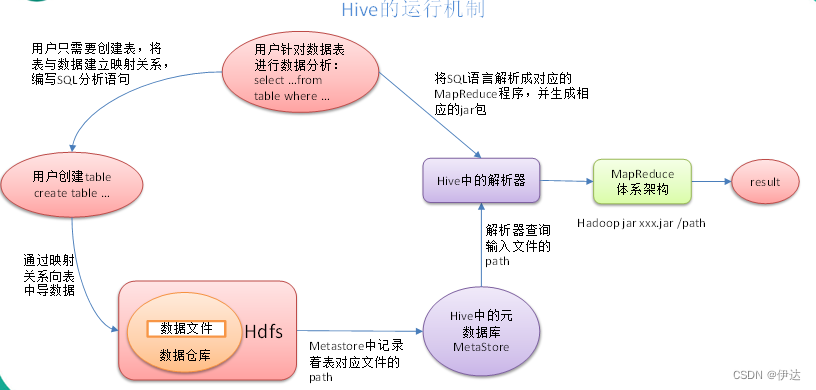
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门
目录 1、什么是Hive 2、Hive的优缺点 2.1、 优点 2.2、 缺点 2.2.1、Hive的HQL表达能力有限 2.2.2、Hive的效率比较低 3、Hive架构原理 3.1、用户接口:Client 3.2、元数据:Metastore 3.3、Hadoop 3.4、驱动器:Driver Hive运行机制…...

第三代量子计算机交付,中国芯片开辟新道路,光刻机难挡中国芯
日前安徽本源量子宣布第三代超导量子计算系统正式上线,这是中国最先进的量子计算机,计算量子比特已达到72个,在全球已居于较为领先的水平,这对于中国芯片在原来的硅基芯片受到光刻机阻碍无疑是巨大的鼓舞。 据悉本源量子的第一代、…...
react native中使用tailwind并配置自动补全
使用的第三方库是tailwind-react-native-classnames,同类的也有tailwind-rn,但是我更喜欢前者官方demo: import { View, Text } from react-native; import tw from twrnc;const MyComponent () > (<View style{twp-4 android:pt-2 b…...
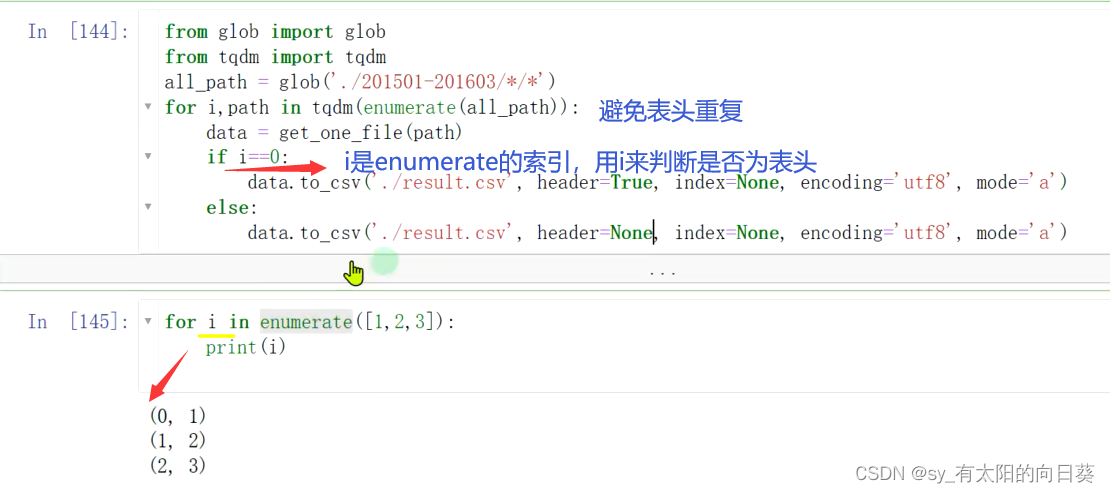
数据分析——火车信息
任务目标 任务 1、整理火车发车信息数据,结果的表格形式为: 2、并输出最终的发车信息表 难点 1、多文件 一个文件夹,多个月的发车信息,一个excel,放一天的发车情况 2、数据表的格式特殊 如何分析表是一个难点 数…...
Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更…...
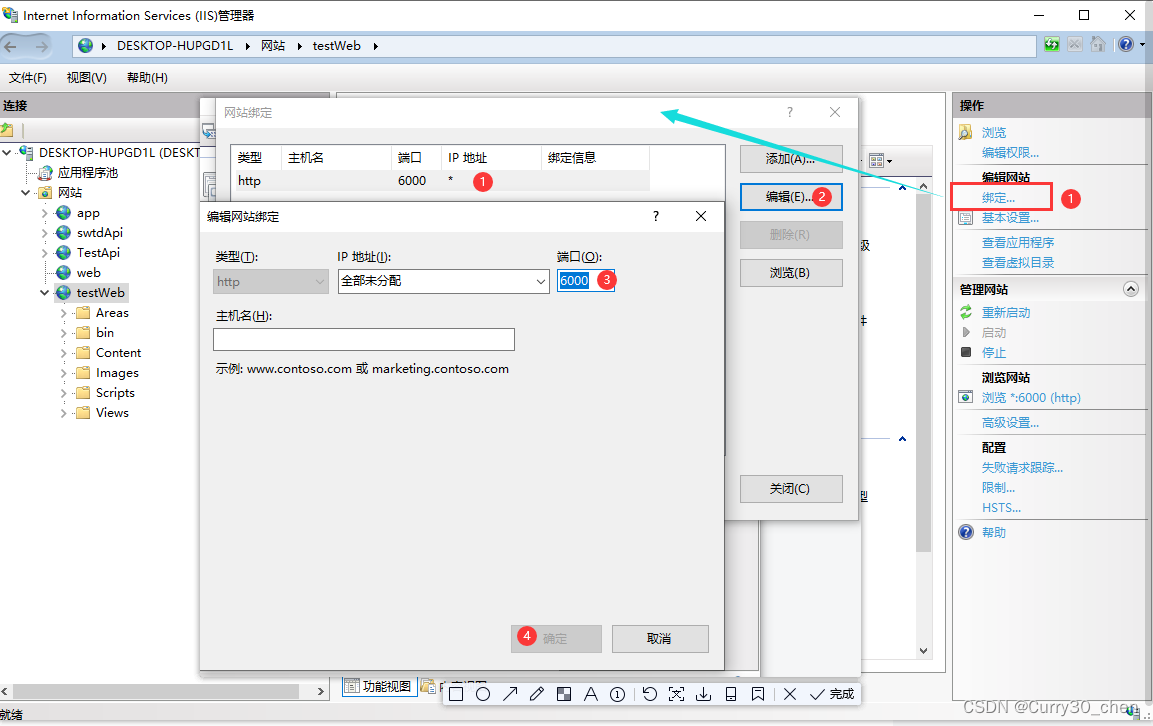
Asp .Net Web应用程序(.Net Framework4.8)网站发布到IIS
开启IIS 如果已开启跳过这步 打开控制面板-程序 打开IIS 发布Web程序(.Net Framework 4.8 web网页) 进入IIS管理器新建一个应用池 新建一个网站 网站创建完毕 为文件夹添加访问权限 如果不添加访问权限,运行时将会得到如下错误 设置权限 勾…...

vue element plus Typography 排版
我们对字体进行统一规范,力求在各个操作系统下都有最佳展示效果。 字体# 字号# LevelFont SizeDemoSupplementary text12px Extra SmallBuild with ElementBody (small)13px SmallBuild with ElementBody14px BaseBuild with ElementSmall Title16px MediumBuild w…...

理论U3 决策树
文章目录 一、决策树算法1、基本思想2、构成1)节点3)有向边/分支 3、分类步骤1)第1步-决策树生成/学习、训练2)第2步-分类/测试 4、算法关键 二、信息论基础1、概念2、信息量3、信息熵: 二、ID3 (Iterative Dichotomis…...

Redis 常用操作
一、Redis常用的5种数据类型 字符串(String):最基本的数据类型,可以存储字符串、整数或浮点数。哈希(Hash):键值对的集合,可以在一个哈希数据结构中存储多个字段和值。列表…...

c# 使用Null合并操作符例子
在这个示例中,我们定义了两个字符串变量 name 和 defaultName。变量 name 被赋值为 null,而变量 defaultName 被赋值为 “John Doe”。 接下来,我们使用 Null 合并操作符 ?? 来获取一个非空值。如果 name 不为 null,则 result 的…...
【Docker】docker部署conda并激活环境
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、新建dockerfile文件二、使用build创建镜像1.报错:Your shell has not been properly configured to use conda activate.…...
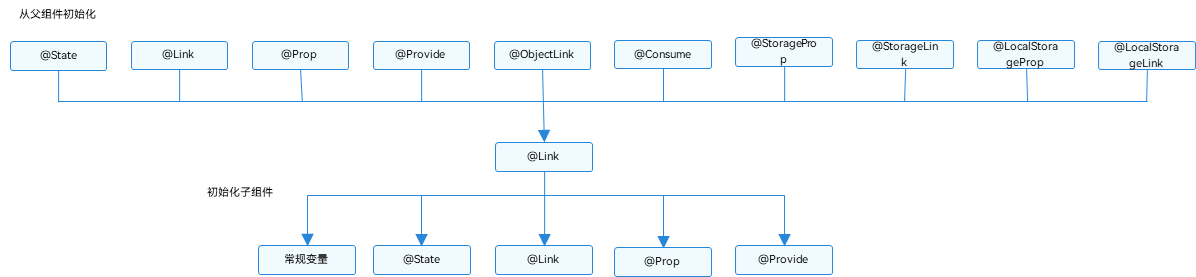
HarmonyOS@Link装饰器:父子双向同步
Link装饰器:父子双向同步 子组件中被Link装饰的变量与其父组件中对应的数据源建立双向数据绑定。 说明 从API version 9开始,该装饰器支持在ArkTS卡片中使用。 概述 Link装饰的变量与其父组件中的数据源共享相同的值。 装饰器使用规则说明 Link变…...
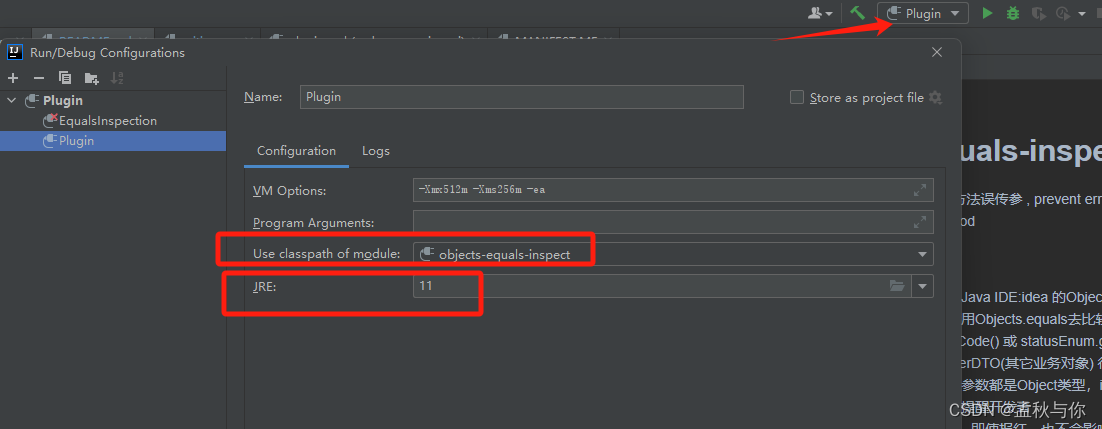
【idea】idea插件编写教程,博主原创idea插件 欢迎下载
前言:经常使用Objects.equals(a,b)方法的同学 应该或多或少都会因为粗心而传错参, 例如日常开发中 我们使用Objects.equals去比较 status(入参),statusEnum(枚举), 很容易忘记statusEnum.getCode() 或 statusEnum.getVaule() ,再比…...
深入理解 Hadoop (四)HDFS源码剖析
HDFS 集群启动脚本 start-dfs.sh 分析 启动 HDFS 集群总共会涉及到的角色会有 namenode, datanode, zkfc, journalnode, secondaryName 共五种角色。 JournalNode 核心工作和启动流程源码剖析 // 启动 JournalNode 的核心业务方法 public void start() throws IOException …...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...