Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)

对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更是让JupyterNoteBook的脚本运行形式如虎添翼。
本次我们利用Bert-vits2的最终版Bert-vits2-v2.3和JupyterNoteBook的脚本来复刻生化危机6的人气角色艾达王(ada wong)。
本地调试JupyterNoteBook
众所周知,GoogleColab虽然可以免费提供GPU让用户用于模型训练和推理,但是每一个JupyterNoteBook文件脚本最多只能运行12小时,随后就会被限制,所以为了避免浪费宝贵的GPU使用时间,我们可以在线下调试自己的JupyterNoteBook脚本,调试成功后,就可以把脚本直接上传到GoogleColab平台。
首先通过pip命令进行本地安装:
python3 -m pip install jupyter
随后运行启动命令:
jupyter notebook
此时,访问本地的notebook地址:
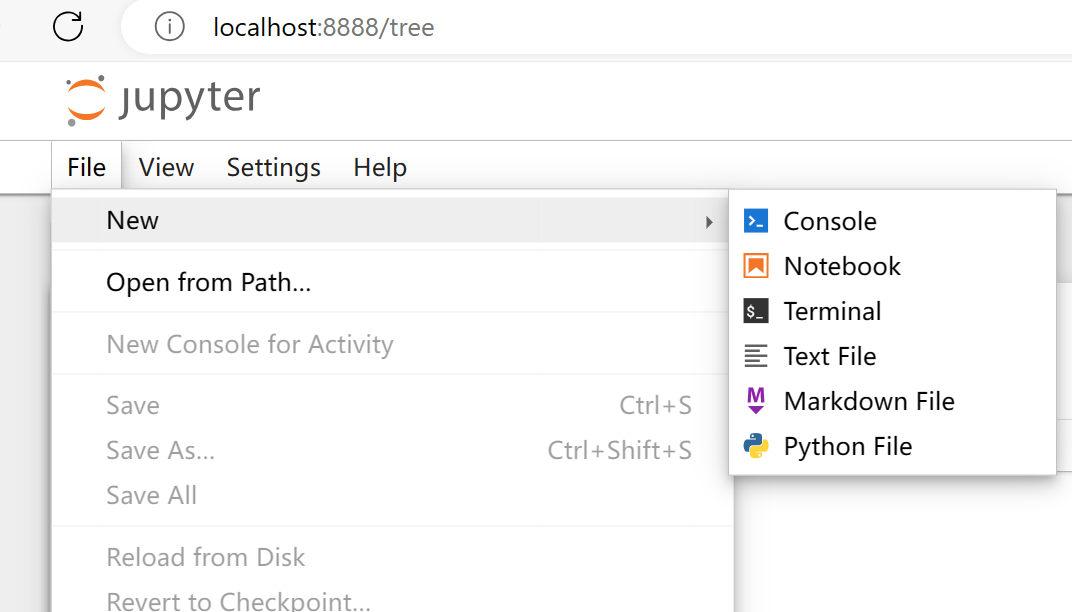
随后选择文件-》新建-》Notebook 即可。
输入笔记内容:
#@title 查看显卡
!nvidia-smi
点击运行单元格:
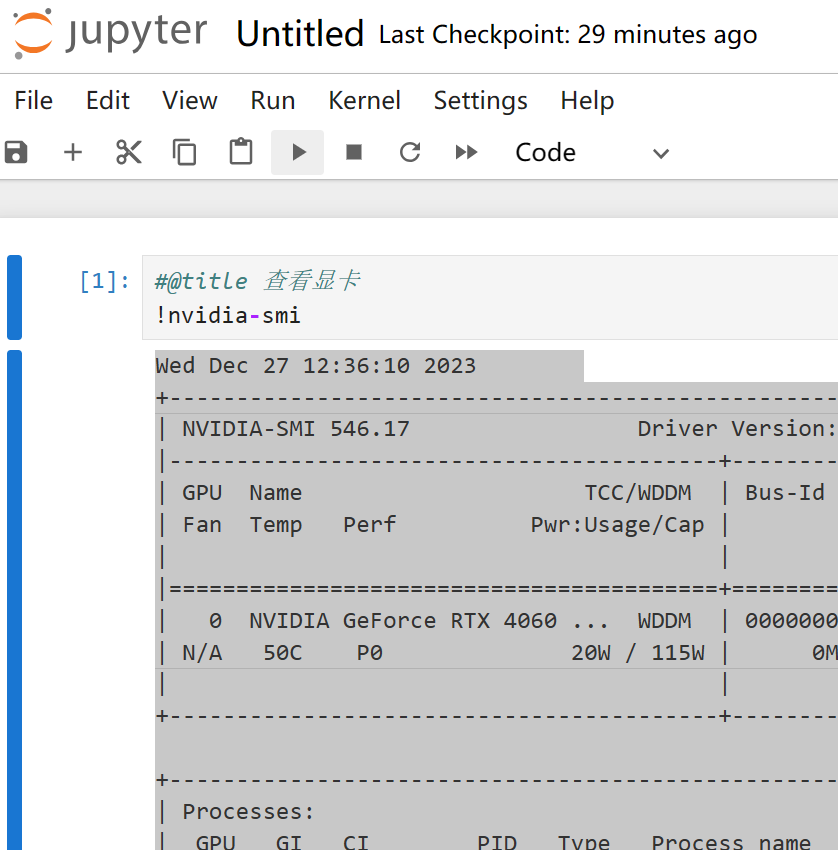
程序返回:
#@title 查看显卡
!nvidia-smi
Wed Dec 27 12:36:10 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 546.17 Driver Version: 546.17 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4060 ... WDDM | 00000000:01:00.0 Off | N/A |
| N/A 50C P0 20W / 115W | 0MiB / 8188MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
至此,就可以在本地调试NoteBook了。
安装ffmpeg
新增单元格:
#@title 安装ffmpeg
import os, uuid, re, IPython
import ipywidgets as widgets
import time from glob import glob
from google.colab import output, drive from IPython.display import clear_output
import os, sys, urllib.request
HOME = os.path.expanduser("~")
pathDoneCMD = f'{HOME}/doneCMD.sh'
if not os.path.exists(f"{HOME}/.ipython/ttmg.py"): hCode = "https://raw.githubusercontent.com/yunooooo/gcct/master/res/ttmg.py" urllib.request.urlretrieve(hCode, f"{HOME}/.ipython/ttmg.py") from ttmg import ( loadingAn, textAn,
) loadingAn(name="lds")
textAn("Cloning Repositories...", ty='twg')
!git clone https://github.com/XniceCraft/ffmpeg-colab.git
!chmod 755 ./ffmpeg-colab/install
textAn("Installing FFmpeg...", ty='twg')
!./ffmpeg-colab/install
clear_output()
print('Installation finished!')
!rm -fr /content/ffmpeg-colab
!ffmpeg -version
由于语音转写需要ffmpeg的参与,所以需要安装ffmpeg的最新版本。
程序返回:
Installation finished!
c Copyright (c) 2000-2023 the FFmpeg developers
built with gcc 9 (Ubuntu 9.4.0-1ubuntu1~20.04.1)
configuration: --prefix=/home/ffmpeg-builder/release --pkg-config-flags=--static --extra-libs=-lm --disable-doc --disable-debug --disable-shared --disable-ffprobe --enable-static --enable-gpl --enable-version3 --enable-runtime-cpudetect --enable-avfilter --enable-filters --enable-nvenc --enable-nvdec --enable-cuvid --toolchain=hardened --disable-stripping --enable-opengl --pkgconfigdir=/home/ffmpeg-builder/release/lib/pkgconfig --extra-cflags='-I/home/ffmpeg-builder/release/include -static-libstdc++ -static-libgcc ' --extra-ldflags='-L/home/ffmpeg-builder/release/lib -fstack-protector -static-libstdc++ -static-libgcc ' --extra-cxxflags=' -static-libstdc++ -static-libgcc ' --extra-libs='-ldl -lrt -lpthread' --enable-ffnvcodec --enable-gmp --enable-libaom --enable-libass --enable-libbluray --enable-libdav1d --enable-libfdk-aac --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libkvazaar --enable-libmp3lame --enable-libopus --enable-libopencore_amrnb --enable-libopencore_amrwb --enable-libopenh264 --enable-libopenjpeg --enable-libshine --enable-libsoxr --enable-libsrt --enable-libsvtav1 --enable-libtheora --enable-libvidstab --ld=g++ --enable-libvmaf --enable-libvorbis --enable-libvpx --enable-libx264 --enable-libx265 --enable-libxvid --enable-libzimg --enable-openssl --enable-zlib --enable-nonfree --extra-libs=-lpthread --enable-pthreads --extra-libs=-lgomp
libavutil 58. 2.100 / 58. 2.100
libavcodec 60. 3.100 / 60. 3.100
libavformat 60. 3.100 / 60. 3.100
libavdevice 60. 1.100 / 60. 1.100
libavfilter 9. 3.100 / 9. 3.100
libswscale 7. 1.100 / 7. 1.100
libswresample 4. 10.100 / 4. 10.100
libpostproc 57. 1.100 / 57. 1.100
这里安装的是最新版ffmpeg version 6.0
克隆代码库
接着克隆代码库:
#@title 克隆代码仓库
!git clone https://github.com/v3ucn/Bert-vits2-V2.3.git
程序返回:
Cloning into 'Bert-vits2-V2.3'...
remote: Enumerating objects: 234, done.
remote: Counting objects: 100% (234/234), done.
remote: Compressing objects: 100% (142/142), done.
remote: Total 234 (delta 80), reused 232 (delta 78), pack-reused 0
Receiving objects: 100% (234/234), 4.16 MiB | 14.14 MiB/s, done.
Resolving deltas: 100% (80/80), done.
安装项目依赖
随后进入项目的目录,安装依赖:
#@title 安装所需要的依赖
%cd /content/Bert-vits2-V2.3
!pip install -r requirements.txt
下载必要的模型
新增单元格,下载模型:
#@title 下载必要的模型
!wget -P slm/wavlm-base-plus/ https://huggingface.co/microsoft/wavlm-base-plus/resolve/main/pytorch_model.bin
!wget -P emotional/clap-htsat-fused/ https://huggingface.co/laion/clap-htsat-fused/resolve/main/pytorch_model.bin
!wget -P emotional/wav2vec2-large-robust-12-ft-emotion-msp-dim/ https://huggingface.co/audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim/resolve/main/pytorch_model.bin
!wget -P bert/chinese-roberta-wwm-ext-large/ https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/pytorch_model.bin
!wget -P bert/bert-base-japanese-v3/ https://huggingface.co/cl-tohoku/bert-base-japanese-v3/resolve/main/pytorch_model.bin
!wget -P bert/deberta-v3-large/ https://huggingface.co/microsoft/deberta-v3-large/resolve/main/pytorch_model.bin
!wget -P bert/deberta-v3-large/ https://huggingface.co/microsoft/deberta-v3-large/resolve/main/pytorch_model.generator.bin
!wget -P bert/deberta-v2-large-japanese/ https://huggingface.co/ku-nlp/deberta-v2-large-japanese/resolve/main/pytorch_model.bin
下载底模文件
接着下载预训练模型的底模:
#@title 下载底模文件 !wget -P Data/ada/models/ https://huggingface.co/OedoSoldier/Bert-VITS2-2.3/resolve/main/DUR_0.pth
!wget -P Data/ada/models/ https://huggingface.co/OedoSoldier/Bert-VITS2-2.3/resolve/main/D_0.pth
!wget -P Data/ada/models/ https://huggingface.co/OedoSoldier/Bert-VITS2-2.3/resolve/main/G_0.pth
!wget -P Data/ada/models/ https://huggingface.co/OedoSoldier/Bert-VITS2-2.3/resolve/main/WD_0.pth
注意2.3版本的底模是4个。
切分数据集
接着把艾达王的音频素材上传到Data/ada/raw/ada.wav
随后新建单元格:
#@title 切分数据集 !python3 audio_slicer.py
素材就会被切分。
转写和标注
此时我们需要把切片素材转写:
#@title 转写和标注
!pip install git+https://github.com/openai/whisper.git
!python3 short_audio_transcribe.py
注意这里单独安装whisper,很多人直接用 pip install whisper,其实这不是正确的安装方式,需要单独指定安装源:pip install git+https://github.com/openai/whisper.git,切记,否则会报错。
执行完毕后会在角色目录生成转写文件esd.list:
./Data\ada\wavs\ada_0.wav|ada|EN|I do. The kind you like.
./Data\ada\wavs\ada_1.wav|ada|EN|Now where's the amber?
./Data\ada\wavs\ada_10.wav|ada|EN|Leave the girl. She's lost no matter what.
./Data\ada\wavs\ada_11.wav|ada|EN|You walk away now, and who knows?
./Data\ada\wavs\ada_12.wav|ada|EN|Maybe you'll live to meet me again.
./Data\ada\wavs\ada_13.wav|ada|EN|And I might get you that greeting you were looking for.
./Data\ada\wavs\ada_14.wav|ada|EN|How about we continue this discussion another time?
./Data\ada\wavs\ada_15.wav|ada|EN|Sorry, nothing yet.
./Data\ada\wavs\ada_16.wav|ada|EN|But my little helper is creating
./Data\ada\wavs\ada_17.wav|ada|EN|Quite the commotion.
./Data\ada\wavs\ada_18.wav|ada|EN|Everything will work out just fine.
./Data\ada\wavs\ada_19.wav|ada|EN|He's a good boy. Predictable.
./Data\ada\wavs\ada_2.wav|ada|EN|The deal was, we get you out of here when you deliver the amber. No amber, no protection, Louise.
./Data\ada\wavs\ada_20.wav|ada|EN|Nothing personal, Leon.
./Data\ada\wavs\ada_21.wav|ada|EN|Louise and I had an arrangement.
./Data\ada\wavs\ada_22.wav|ada|EN|Don't worry, I'll take good care of it.
./Data\ada\wavs\ada_23.wav|ada|EN|Just one question.
./Data\ada\wavs\ada_24.wav|ada|EN|What are you planning to do with this?
./Data\ada\wavs\ada_25.wav|ada|EN|So, we're talking millions of casualties?
./Data\ada\wavs\ada_26.wav|ada|EN|We're changing course. Now.
./Data\ada\wavs\ada_3.wav|ada|EN|You can stop right there, Leon.
./Data\ada\wavs\ada_4.wav|ada|EN|wouldn't make me use this.
./Data\ada\wavs\ada_5.wav|ada|EN|Would you? You don't seem surprised.
./Data\ada\wavs\ada_6.wav|ada|EN|Interesting.
./Data\ada\wavs\ada_7.wav|ada|EN|Not a bad move
./Data\ada\wavs\ada_8.wav|ada|EN|Very smooth. Ah, Leon.
./Data\ada\wavs\ada_9.wav|ada|EN|You know I don't work and tell.
这里一共27条切片语音,对应27个转写文本,注意语言是英语。
音频重新采样
对素材音频进行重新采样的操作:
#@title 重新采样
!python3 resample.py --sr 44100 --in_dir ./Data/ada/raw/ --out_dir ./Data/ada/wavs/
预处理标签文件
接着处理转写文件,生成训练集和验证集:
#@title 预处理标签文件
!python3 preprocess_text.py --transcription-path ./Data/ada/esd.list --t
程序返回:
pytorch_model.bin: 100% 1.32G/1.32G [00:10<00:00, 122MB/s]
spm.model: 100% 2.46M/2.46M [00:00<00:00, 115MB/s]
The cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a one-time only operation. You can interrupt this and resume the migration later on by calling `transformers.utils.move_cache()`.
0it [00:00, ?it/s]
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /root/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to /root/nltk_data...
[nltk_data] Unzipping corpora/cmudict.zip.
100% 27/27 [00:00<00:00, 4457.63it/s]
总重复音频数:0,总未找到的音频数:0
训练集和验证集生成完成!
生成 BERT 特征文件
最后生成bert特征文件:
#@title 生成 BERT 特征文件
!python3 bert_gen.py --config-path ./Data/ada/configs/config.json
对应27个素材:
100% 27/27 [00:33<00:00, 1.25s/it]
bert生成完毕!, 共有27个bert.pt生成!
模型训练
万事俱备,开始训练:
#@title 开始训练
!python3 train_ms.py
模型会在models目录生成,项目默认设置了训练间隔是50步,可以根据自己的需求修改config.json配置文件。
模型推理
一般情况下,训练了50步或者100步左右,可以推理一下查看效果,然后继续训练:
#@title 开始推理
!python3 webui.py
返回:
| numexpr.utils | INFO | NumExpr defaulting to 2 threads.
/usr/local/lib/python3.10/dist-packages/torch/nn/utils/weight_norm.py:30: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm. warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
| utils | INFO | Loaded checkpoint 'Data/ada/models/G_150.pth' (iteration 25)
推理页面已开启!
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://814833a6f477ba151c.gradio.live
点击第二个公网地址进行推理即可。
结语
至此,我们已经完成了基于JupyterNoteBook的数据切分、转写、预处理、训练以及推理流程。最后奉上线上GoogleColab,以飨众乡亲:
https://colab.research.google.com/drive/1-H1DGG5dTy8u_8vFbq1HACXPX9AAM76s?usp=sharing
相关文章:
Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更…...
Asp .Net Web应用程序(.Net Framework4.8)网站发布到IIS
开启IIS 如果已开启跳过这步 打开控制面板-程序 打开IIS 发布Web程序(.Net Framework 4.8 web网页) 进入IIS管理器新建一个应用池 新建一个网站 网站创建完毕 为文件夹添加访问权限 如果不添加访问权限,运行时将会得到如下错误 设置权限 勾…...

vue element plus Typography 排版
我们对字体进行统一规范,力求在各个操作系统下都有最佳展示效果。 字体# 字号# LevelFont SizeDemoSupplementary text12px Extra SmallBuild with ElementBody (small)13px SmallBuild with ElementBody14px BaseBuild with ElementSmall Title16px MediumBuild w…...

理论U3 决策树
文章目录 一、决策树算法1、基本思想2、构成1)节点3)有向边/分支 3、分类步骤1)第1步-决策树生成/学习、训练2)第2步-分类/测试 4、算法关键 二、信息论基础1、概念2、信息量3、信息熵: 二、ID3 (Iterative Dichotomis…...

Redis 常用操作
一、Redis常用的5种数据类型 字符串(String):最基本的数据类型,可以存储字符串、整数或浮点数。哈希(Hash):键值对的集合,可以在一个哈希数据结构中存储多个字段和值。列表…...

c# 使用Null合并操作符例子
在这个示例中,我们定义了两个字符串变量 name 和 defaultName。变量 name 被赋值为 null,而变量 defaultName 被赋值为 “John Doe”。 接下来,我们使用 Null 合并操作符 ?? 来获取一个非空值。如果 name 不为 null,则 result 的…...
【Docker】docker部署conda并激活环境
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、新建dockerfile文件二、使用build创建镜像1.报错:Your shell has not been properly configured to use conda activate.…...
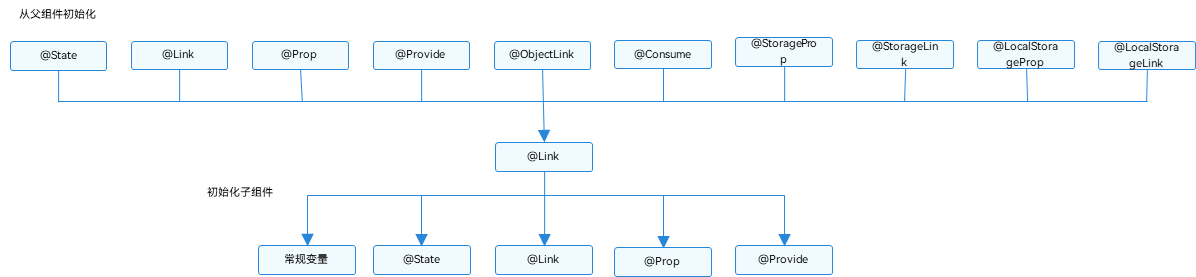
HarmonyOS@Link装饰器:父子双向同步
Link装饰器:父子双向同步 子组件中被Link装饰的变量与其父组件中对应的数据源建立双向数据绑定。 说明 从API version 9开始,该装饰器支持在ArkTS卡片中使用。 概述 Link装饰的变量与其父组件中的数据源共享相同的值。 装饰器使用规则说明 Link变…...
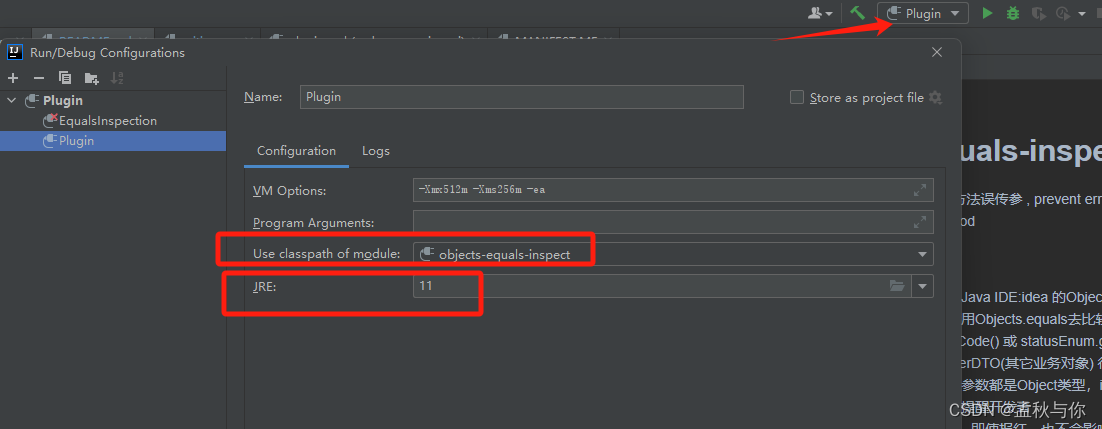
【idea】idea插件编写教程,博主原创idea插件 欢迎下载
前言:经常使用Objects.equals(a,b)方法的同学 应该或多或少都会因为粗心而传错参, 例如日常开发中 我们使用Objects.equals去比较 status(入参),statusEnum(枚举), 很容易忘记statusEnum.getCode() 或 statusEnum.getVaule() ,再比…...
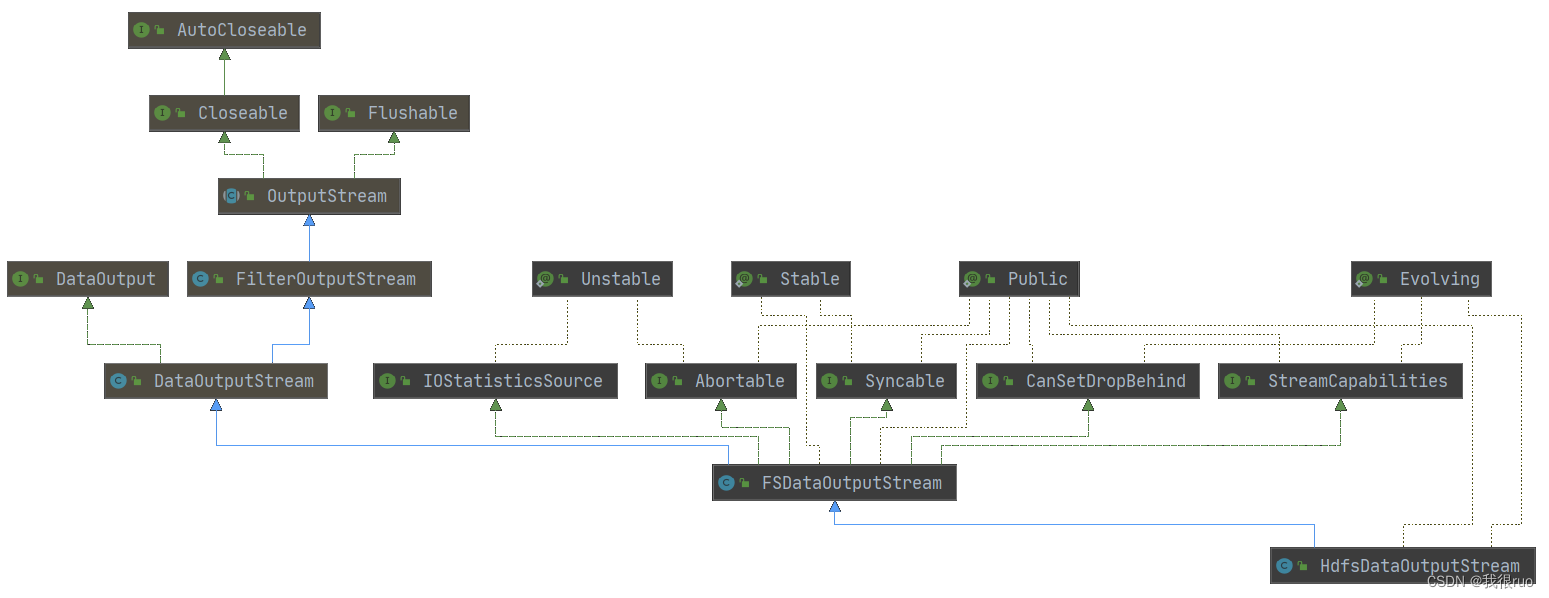
深入理解 Hadoop (四)HDFS源码剖析
HDFS 集群启动脚本 start-dfs.sh 分析 启动 HDFS 集群总共会涉及到的角色会有 namenode, datanode, zkfc, journalnode, secondaryName 共五种角色。 JournalNode 核心工作和启动流程源码剖析 // 启动 JournalNode 的核心业务方法 public void start() throws IOException …...
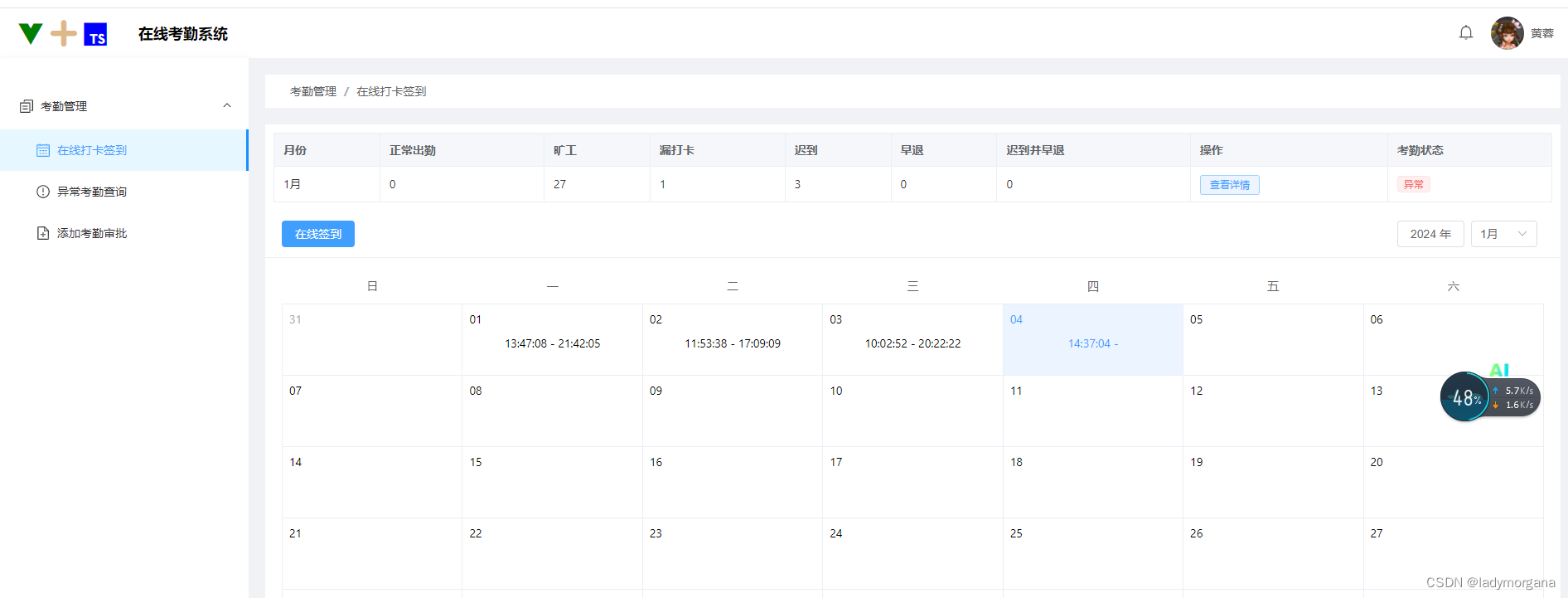
【Vue3+React18+TS4】1-1 : 课程介绍与学习指南
本书目录:点击进入 一、为什么做这样一门课程? 二、本门课的亮点有哪些? 2.1、轻松驾驭 2.2、体系系统 2.3、高效快捷 2.4、融合贯通 三、课程内容包括哪些? 四、项目实战 《在线考勤系统》 五、课适合哪些同学? 一、为什么做这样一门课程? 近十年内前端…...

Nacos与Eureka的区别详解
Nacos与Eureka的区别详解 在微服务架构中,服务注册与发现是核心组件之一,它们允许服务实例在启动时自动注册,并且能被其他服务发现,从而实现服务之间的互相通信。Nacos和Eureka都是现代微服务体系中广泛使用的服务注册与发现工具。本文将深入分析二者的区别,并为您提供一…...
【算法刷题】Day28
文章目录 1. 买卖股票的最佳时机 III题干:算法原理:1. 状态表示:2. 状态转移方程3. 初始化4. 填表顺序5. 返回值 代码: 2. Z 字形变换题干:算法原理:1. 模拟2. 找规律 代码: 1. 买卖股票的最佳时…...

深入了解pnpm:一种高效的包管理工具
✨专栏介绍 在当今数字化时代,Web应用程序已经成为了人们生活和工作中不可或缺的一部分。而要构建出令人印象深刻且功能强大的Web应用程序,就需要掌握一系列前端技术。前端技术涵盖了HTML、CSS和JavaScript等核心技术,以及各种框架、库和工具…...
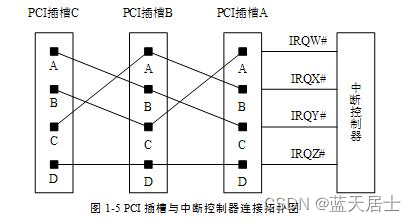
QEMU源码全解析 —— PCI设备模拟(1)
接前一篇文章: 1. PCI设备简介 PCI是用来连接外设的一种局部(local)总线,其主要功能是连接外部设备。PCI总线规范在20世纪90年代提出以后,其逐渐取代了其它各种总线,被各种处理器所支持。直到现在…...
Vue-10、Vue键盘事件
1、vue中常见的按键别名 回车 ---------enter <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>键盘事件</title><!--引入vue--><script type"text/javascript" src"h…...
胡圆圆的暑期实习经验分享
背景 实验室一般是在研究生二年级的时候会放实习,在以后的日子就是自己完成毕业工作要求,基本上不再涉及实验室的活了,目前是一月份也是开始准备暑期实习的好时间。实验室每年这个时候都会有学长学姐组织暑期实习经验分享,本着不…...
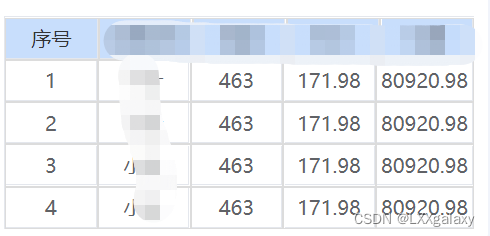
基于uniapp封装的table组件
数据格式 tableData: [{elcInfo: [{tableData:[1,293021.1,293021.1,293021.1,293021.1,]}]},{elcInfo: [{tableData:[1,293021.1,293021.1,293021.1,293021.1,]}]},{elcInfo: [{tableData:[1,293021.1,293021.1,293021.1,293021.1,]}]},/* {title: "2",elcInfo: [{…...
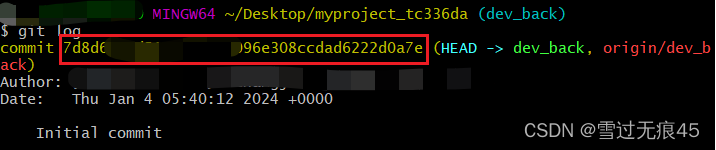
Git删除远程仓库某次提交记录后的所有提交
1、鼠标右键->git bash here,然后cd切换到代码目录; 2、git log查看提交记录,获取commit id 3、git reset commit id(commit id指要保留的最新的提交记录id) 4、git push --force,强制push 如果出现…...
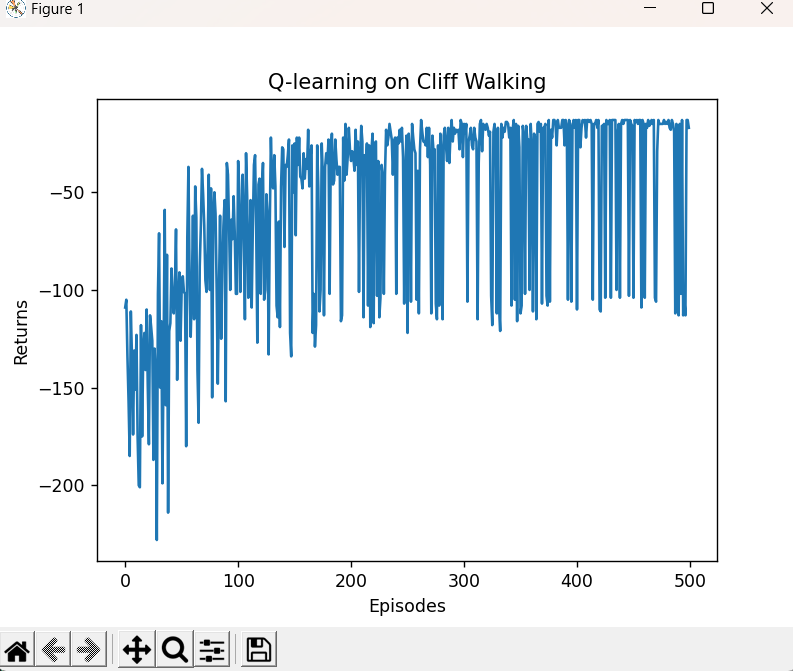
强化学习10——免模型控制Q-learning算法
Q-learning算法 主要思路 由于 V π ( s ) ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) V_\pi(s)\sum_{a\in A}\pi(a\mid s)Q_\pi(s,a) Vπ(s)∑a∈Aπ(a∣s)Qπ(s,a) ,当我们直接预测动作价值函数,在决策中选择Q值最大即动作价值最大的动作&…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...
【1】跨越技术栈鸿沟:字节跳动开源TRAE AI编程IDE的实战体验
2024年初,人工智能编程工具领域发生了一次静默的变革。当字节跳动宣布退出其TRAE项目(一款融合大型语言模型能力的云端AI编程IDE)时,技术社区曾短暂叹息。然而这一退场并非终点——通过开源社区的接力,TRAE在WayToAGI等…...
高端性能封装正在突破性能壁垒,其芯片集成技术助力人工智能革命。
2024 年,高端封装市场规模为 80 亿美元,预计到 2030 年将超过 280 亿美元,2024-2030 年复合年增长率为 23%。 细分到各个终端市场,最大的高端性能封装市场是“电信和基础设施”,2024 年该市场创造了超过 67% 的收入。…...

前端工具库lodash与lodash-es区别详解
lodash 和 lodash-es 是同一工具库的两个不同版本,核心功能完全一致,主要区别在于模块化格式和优化方式,适合不同的开发环境。以下是详细对比: 1. 模块化格式 lodash 使用 CommonJS 模块格式(require/module.exports&a…...

Pandas 可视化集成:数据科学家的高效绘图指南
为什么选择 Pandas 进行数据可视化? 在数据科学和分析领域,可视化是理解数据、发现模式和传达见解的关键步骤。Python 生态系统提供了多种可视化工具,如 Matplotlib、Seaborn、Plotly 等,但 Pandas 内置的可视化功能因其与数据结…...

作为点的对象CenterNet论文阅读
摘要 检测器将图像中的物体表示为轴对齐的边界框。大多数成功的目标检测方法都会枚举几乎完整的潜在目标位置列表,并对每一个位置进行分类。这种做法既浪费又低效,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将物体建模为单…...