python_selenium零基础爬虫学习案例_知网文献信息
案例最终效果说明:
去做这个案例的话是因为看到那个博主的分享,最后通过努力,我基本实现了进行主题、关键词、更新时间的三个筛选条件去获取数据,并且遍历数据将其导出到一个CSV文件中,代码是很简单的,没有太多的逻辑去判断,但是作为一个小白来说,如果刚刚学完selenium的朋友们可以做这个案例,那这个案例的话我就是用selenium的基本知识去完成的。同时所用到的python的基本知识也是比较简单的。
目录
1.网页分析
2.selenium元素定位&实现
2.1找【高级检索】
2.2找【输入框】
2.3找【检索】
2.4汇总一
2.5附加筛选条件
2.6汇总二
3.数据解析
3.1网页分析
3.2储存数据
3.3第一次尝试(23-01-08)
3.4第二次尝试(23-01-09)
3.5第三次尝试(最终版)(23-01-09)
4.总结
4.1第一次总结(23-01-08)
4.2第二次总结(23-01-09)
4.3第三次总结(23-01-09)
学习笔记,根据这篇文章学习的,讲的很细致。
Python爬虫实战(5) | 爬取知网文献信息(已优化代码) - 知乎 (zhihu.com)
这个博主是利用selenium来爬取的,关于selenium的学习可以参考之前的笔记。
python_selenium_安装&基础学习-CSDN博客
1.网页分析
目标网站:中国知网官网中国知网 (cnki.net)
需求分析:高级检索——>输入查询信息——>点击检索
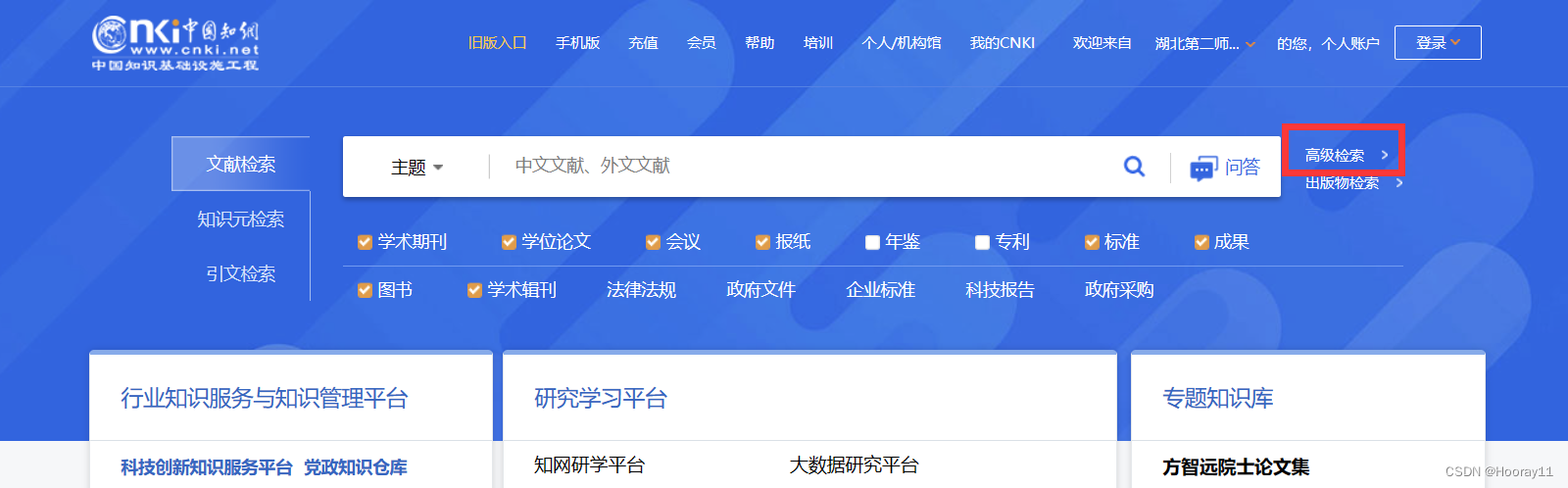

2.selenium元素定位&实现
先把要用到的包准备好,创建浏览器对象去访问网站,这里就直接展示代码了。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://www.cnki.net/'
browser.get(url)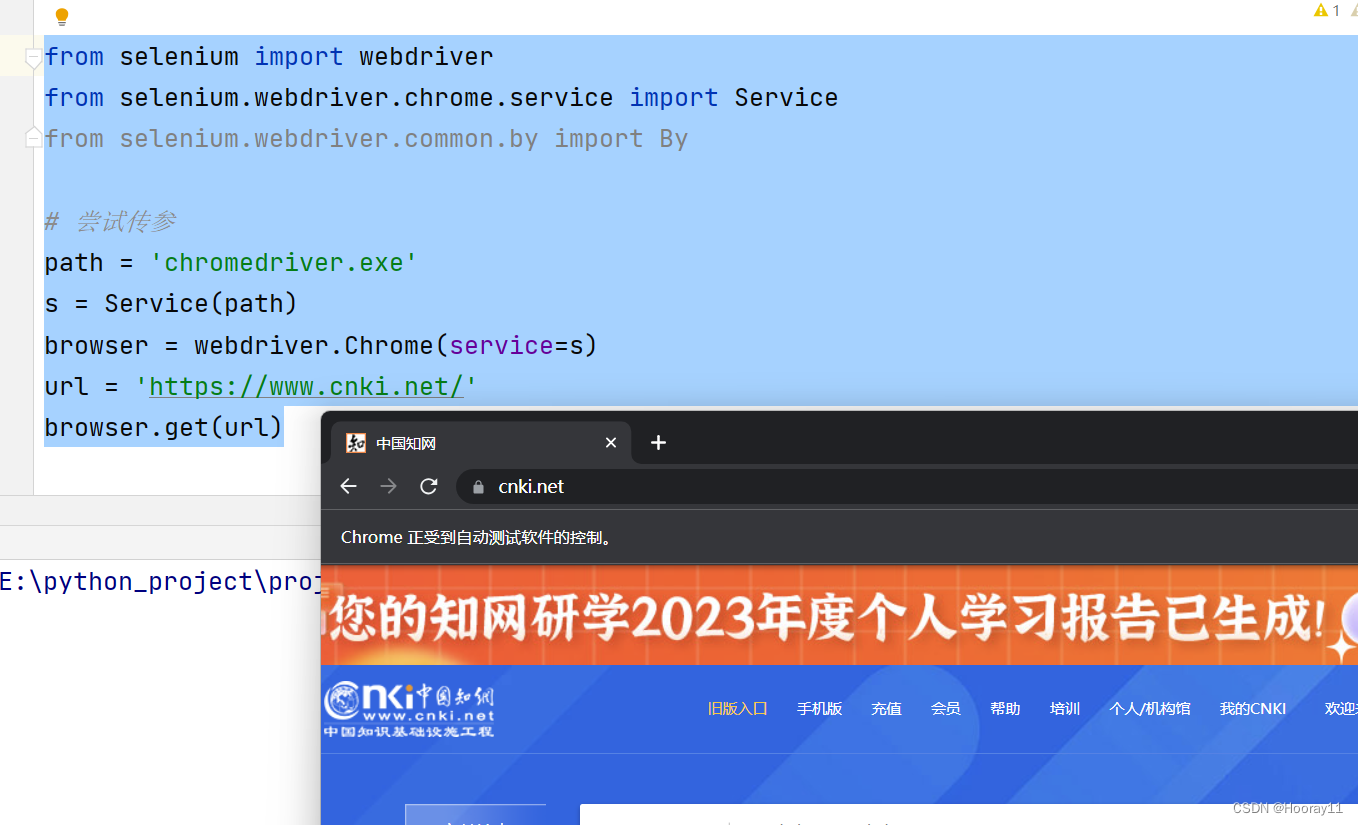
2.1找【高级检索】
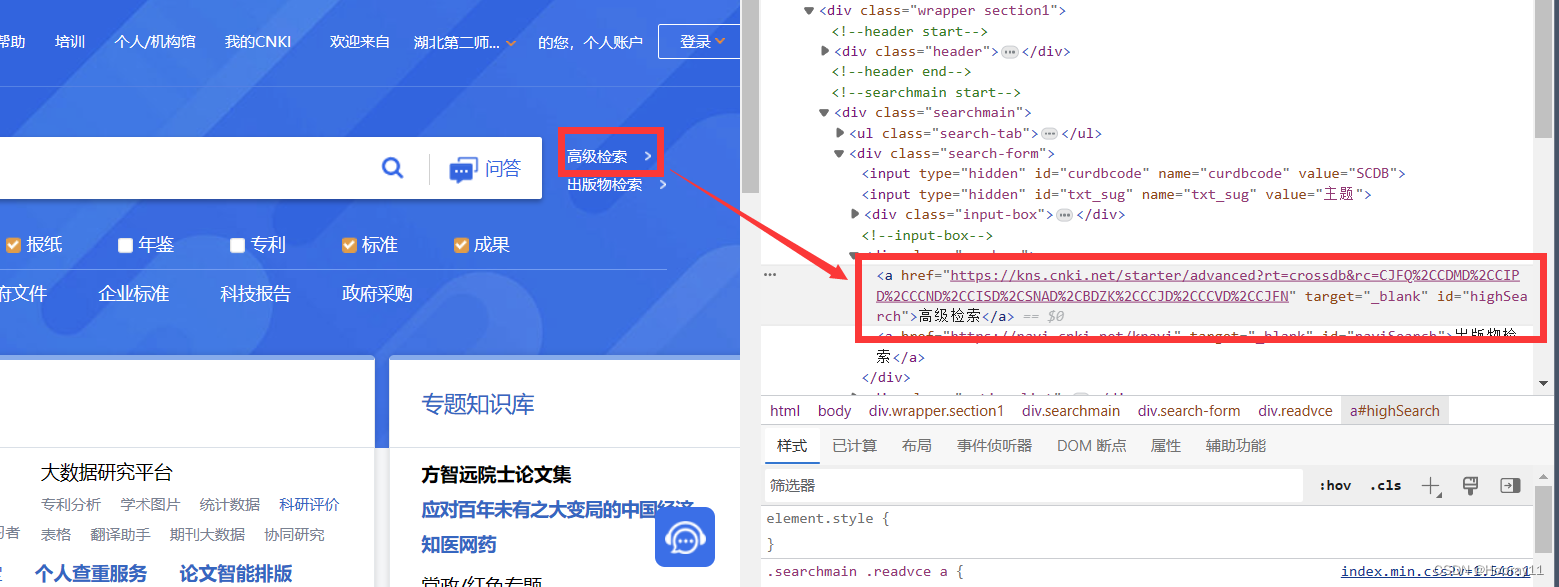
这里可以直接复制到完整的xpath,就不用我们自己去寻找了了。
# 找高级检索
highSearch = browser.find_element(by='xpath',value='//*[@id="highSearch"]')
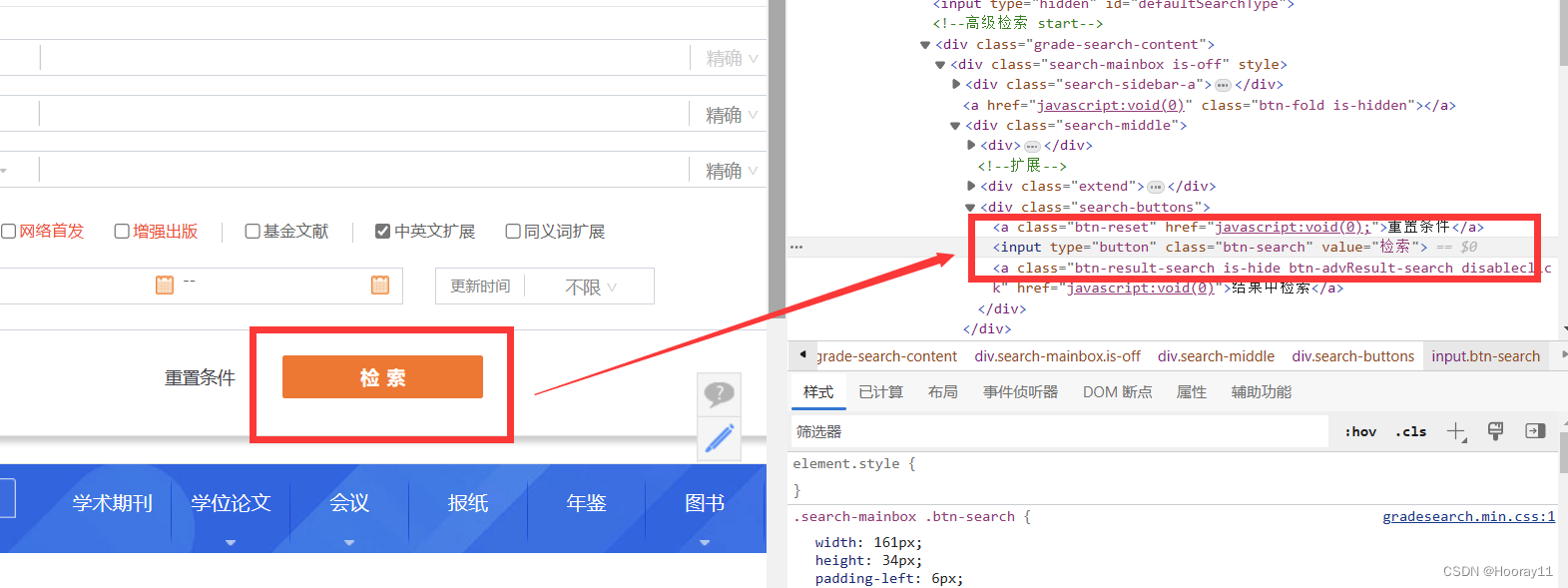
print(highSearch)2.2找【输入框】
注意:找输入框的时候我遇到了困难,因为点击高级检索之后,url变了,所以用之前的url对象不行,然后仔细看了那个作者发现,他的url直接就是高级检索的页面,所以这里我就也全部改了。
所以从这里开始,后面是新的,前面的是有问题的。
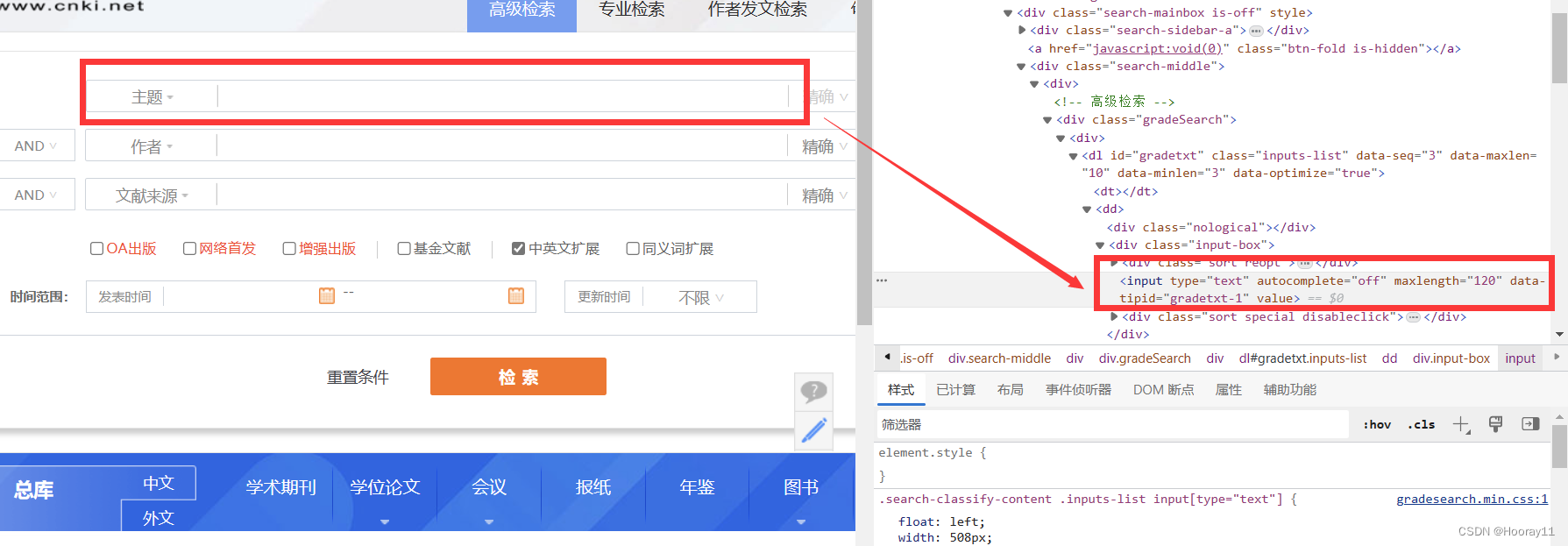
input = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[1]/div[2]/input')2.3找【检索】
2.4汇总一
那截止到现在的话,我总共是写了这么多的代码。
那基本实现的就是在主题输入框内输入【教育信息化】,然后点击检索这样的功能。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)import time
time.sleep(2)#找输入框
input = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
print(input)
time.sleep(2)
# 输入查询内容
input.send_keys('教育信息化')
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
search.click()
time.sleep(2)
2.5附加筛选条件
有时候做文献综述的时候,会要求有主题、关键词、篇文摘等要求,有时候要求的是近十年的文章,这种应该怎么办。
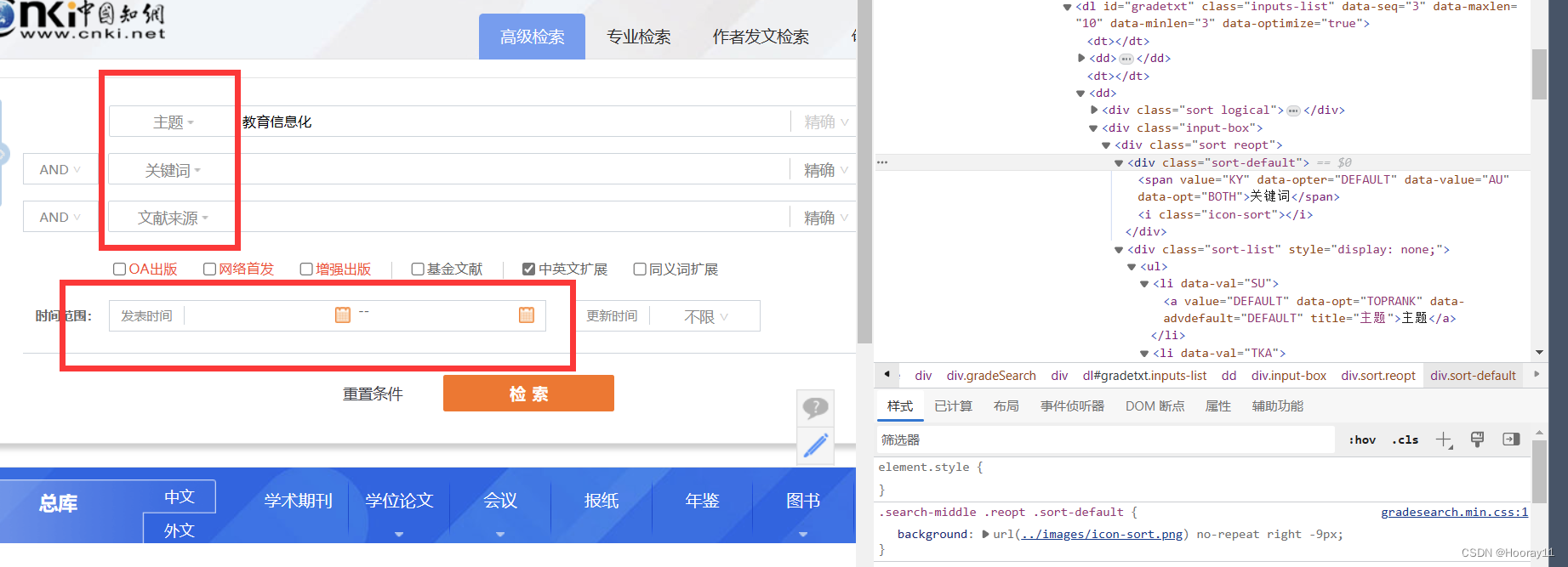
首先对于图中主题、关键词、文献来源这种看起来像下拉选择框的,通过仔细分析源码才发现其实不是下拉选择,而是对其他的选线进行了隐藏,只要点击其所在的盒子就可以出现选项。
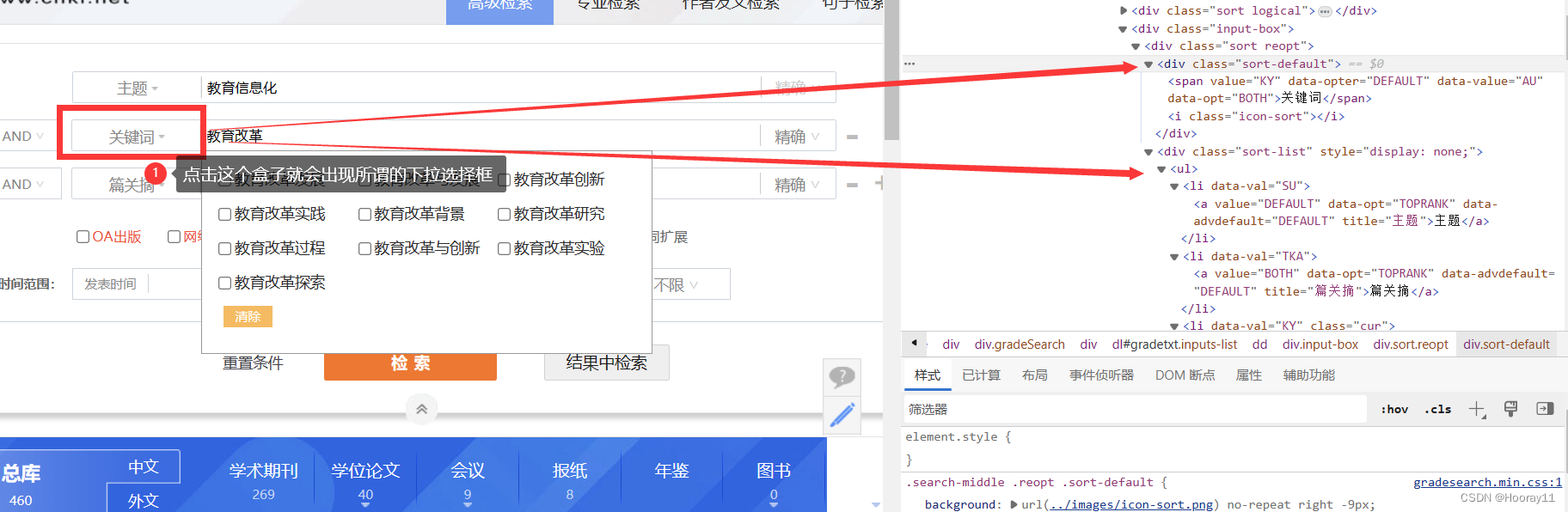
然后我就发现了一个特别有意思的现象。下面的两种情况,第一种的检索是可以点击的,也就是我们可以看到这个检索按钮,第二种情况,检索按钮被遮挡了,那后面运行点击检索按钮的时候就会报错,但是其实元素定位是没有问题的,就是运行click有问题。
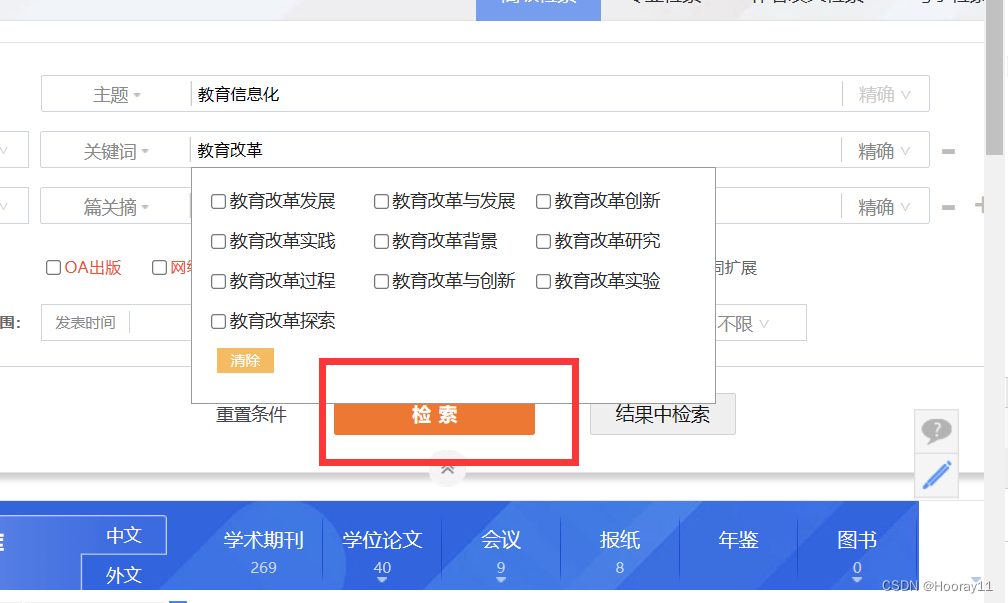
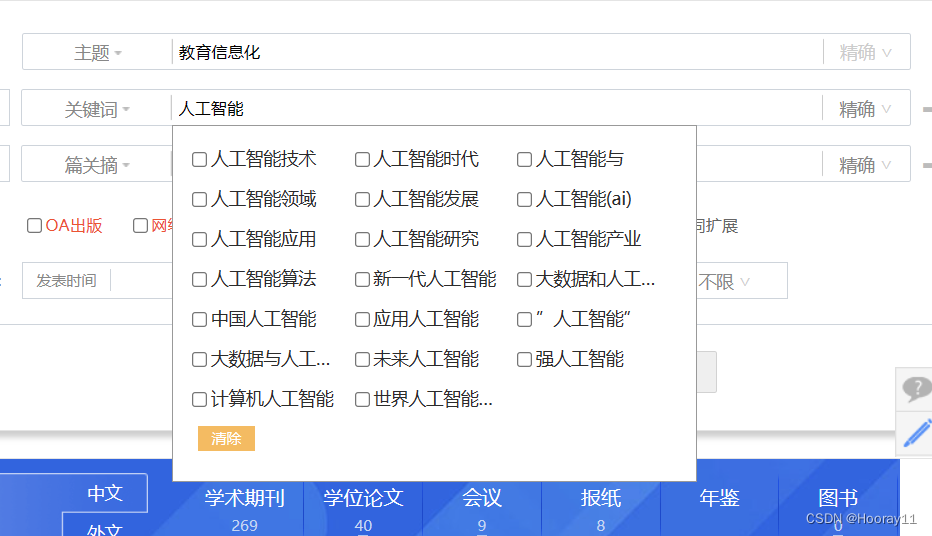
最后具体原因我也不知道,总之后面换成了运行javaScript的代码时没问题的。
到现在的话就是增加了可以更改选项多条件检索的。
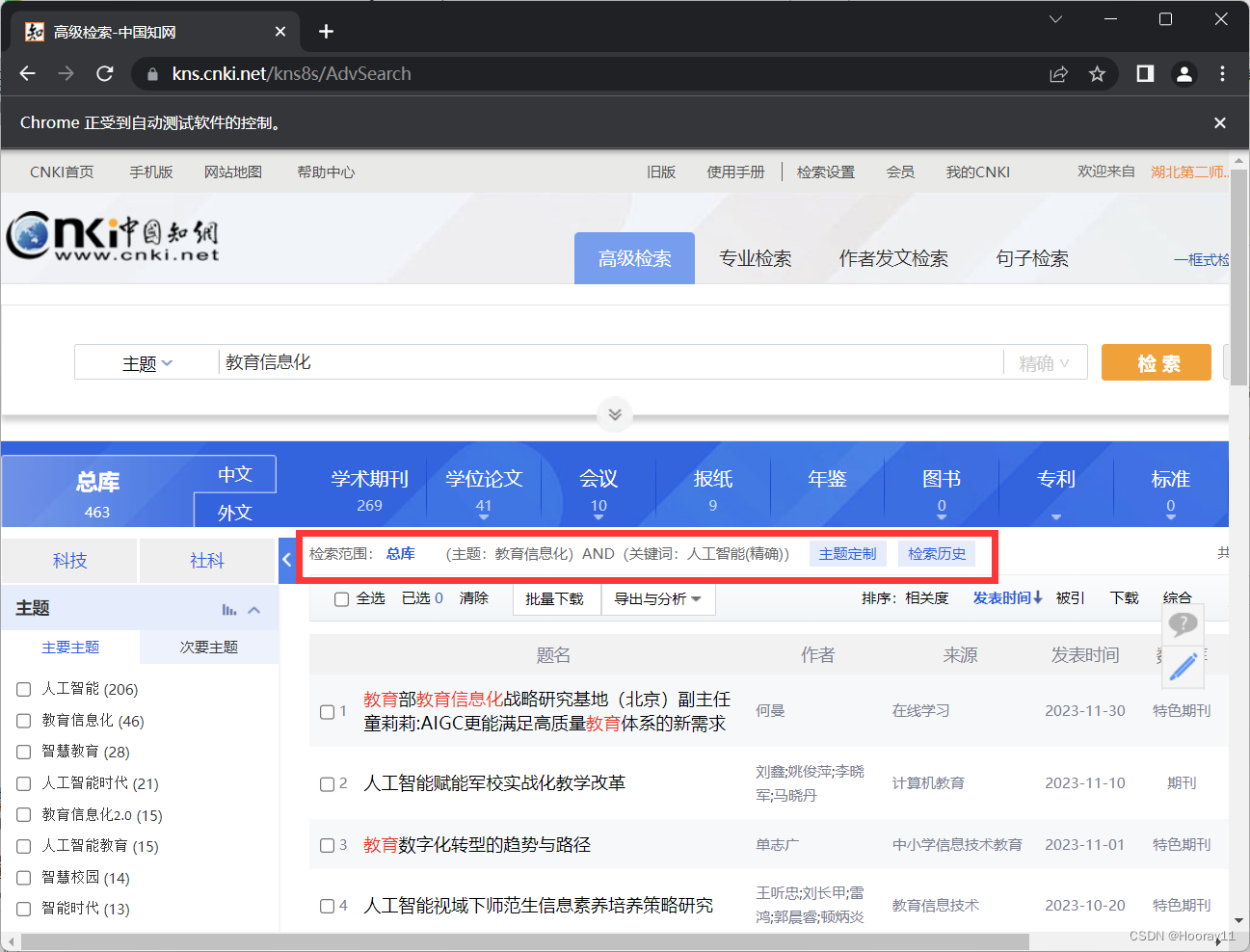
现在就来到了时间的板块,关于这个发表时间的日历选择方法,我不知道怎么解决。如果后面解决了就来更新吧。
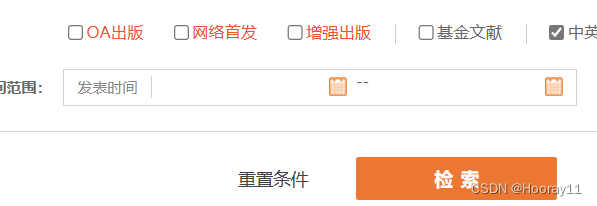
那我只能尝试解决这个,这一个它是由多种选择的.
那这个的基本原理跟之前的一样,看似是一个下拉选择框其实也是隐藏的一个盒子。
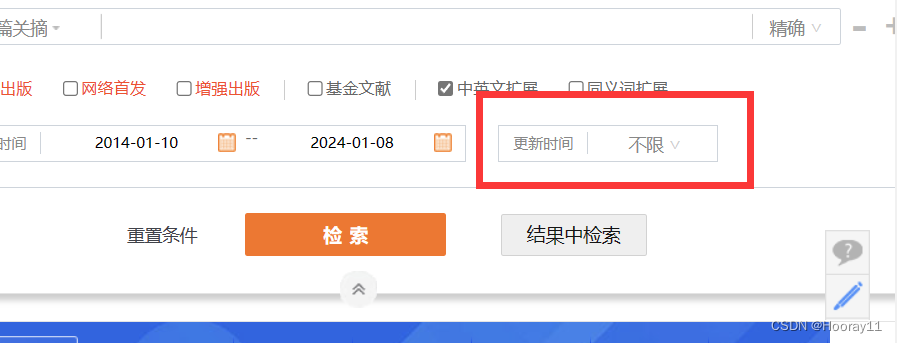
然后就基本附加了一些筛选条件进行检索。
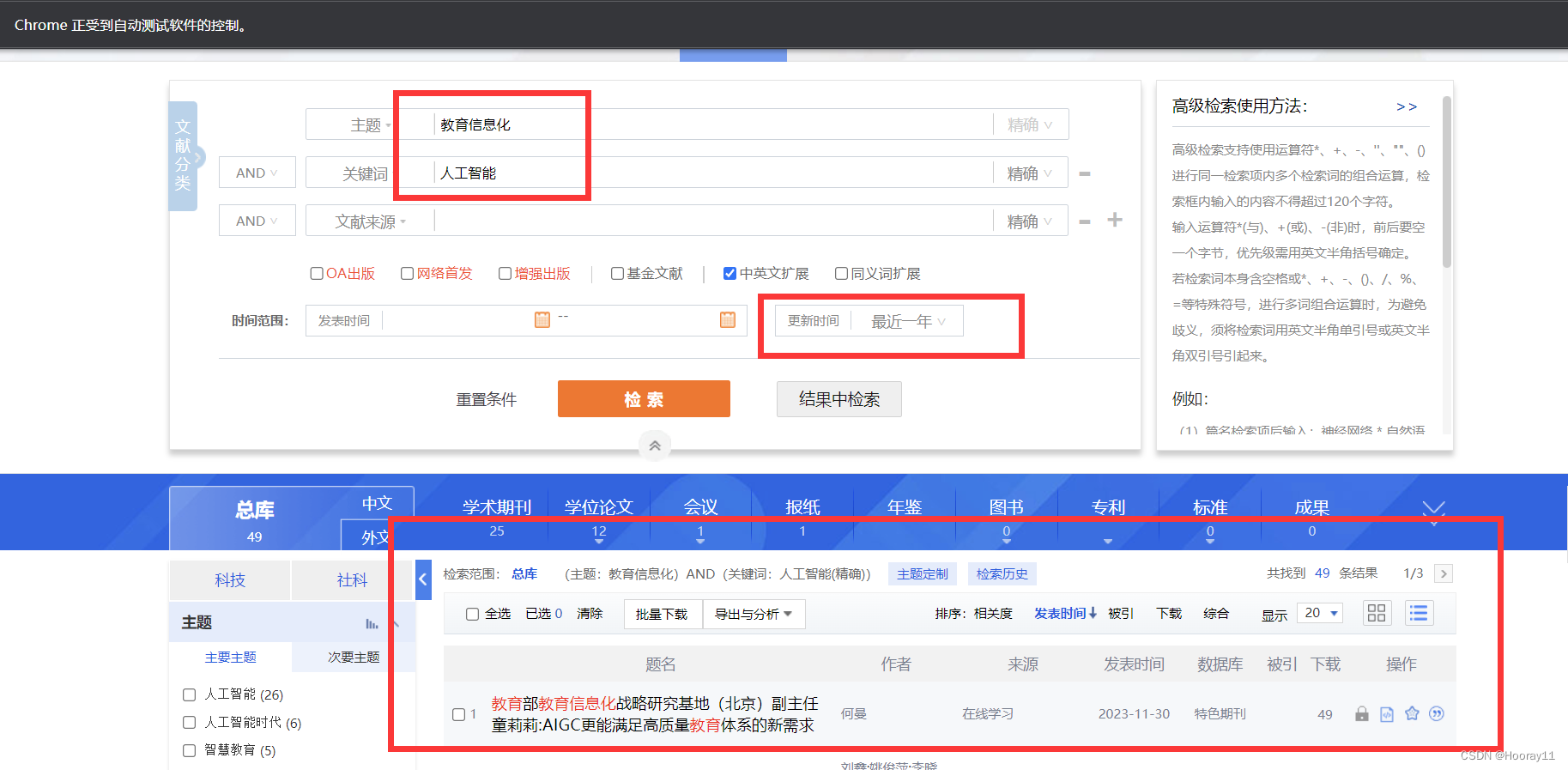
2.6汇总二
纯属小白写的代码哈哈哈哈。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://kns.cnki.net/kns8s/AdvSearch'
browser.get(url)import time
time.sleep(2)#找输入框
input1 = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')
time.sleep(2)
# 输入查询内容
input1.send_keys('教育信息化')
time.sleep(2)
# 更改选项——关键词
select = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')
select.click()
time.sleep(2)
key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')
key_word.click()
time.sleep(2)
# 输入查询内容
input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')
input2.send_keys('人工智能')
time.sleep(2)# 更改时间
time_change = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')
time_change.click()
time.sleep(2)select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')
select_time.click()
time.sleep(2)
# 找检索
search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')
time.sleep(2)
# 点击检索
# search.click() #这个方法没用
browser.execute_script("arguments[0].click();", search) #这个方法有用
# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用
time.sleep(2)
3.数据解析
3.1网页分析

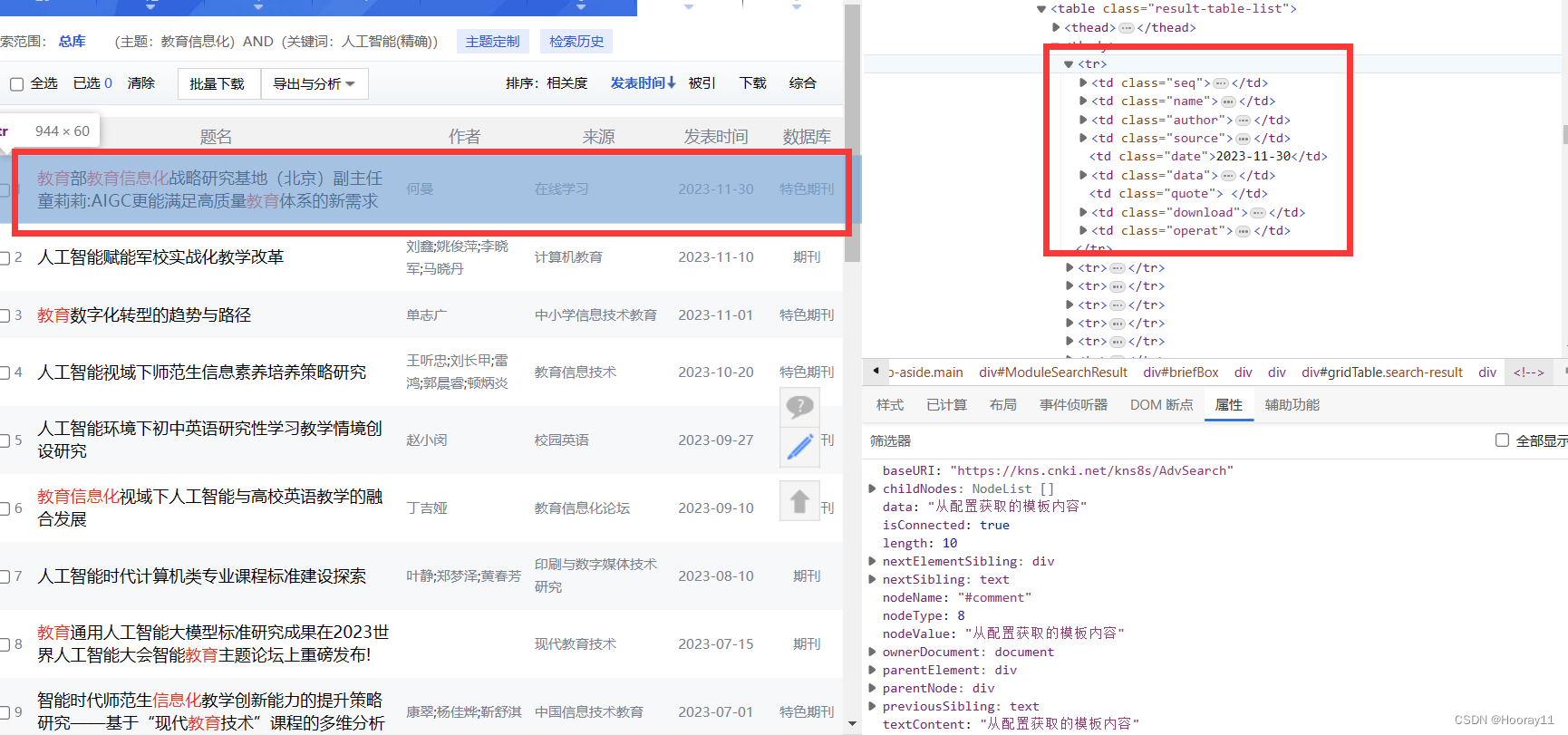
对于一篇文章的xpath我们可以发现:
题名:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]
作者:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[3]
来源:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[4]
可以发现一些规律,td[2]到td[6]都是这篇文献的信息。
但是我们无法获得这篇文献的关键字以及摘要等信息,就需要点进去才可以看到。
对于一整页的每一篇文章我们可以发现:
第一条:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]
第二条:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[2]
第三条:/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[3]
那么tr[1]到tr[20]对应的就是每一条信息,这对于我们后面分析xpath路径有关。

title_list = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "fz14")))上面的代码时从原作者那里复制过来的,根据上下文的意思应该就是需要知道每一页有多少条数据,但是我看了好久才知道他这个写的奥妙,一开始我在想怎么去获取表单数据然后将其储存为列表,但是搜了好久都没找到方法,然后我就根据这个博主的代码去结合网页源码看,结果发现其实这个博主就是很简化了这个问题,只要能获取表单数据的条数就可以了。
那这个作者就是根据题名来找到所有类属性为fz14的数据,就可以知道他的表单数据的长度了。
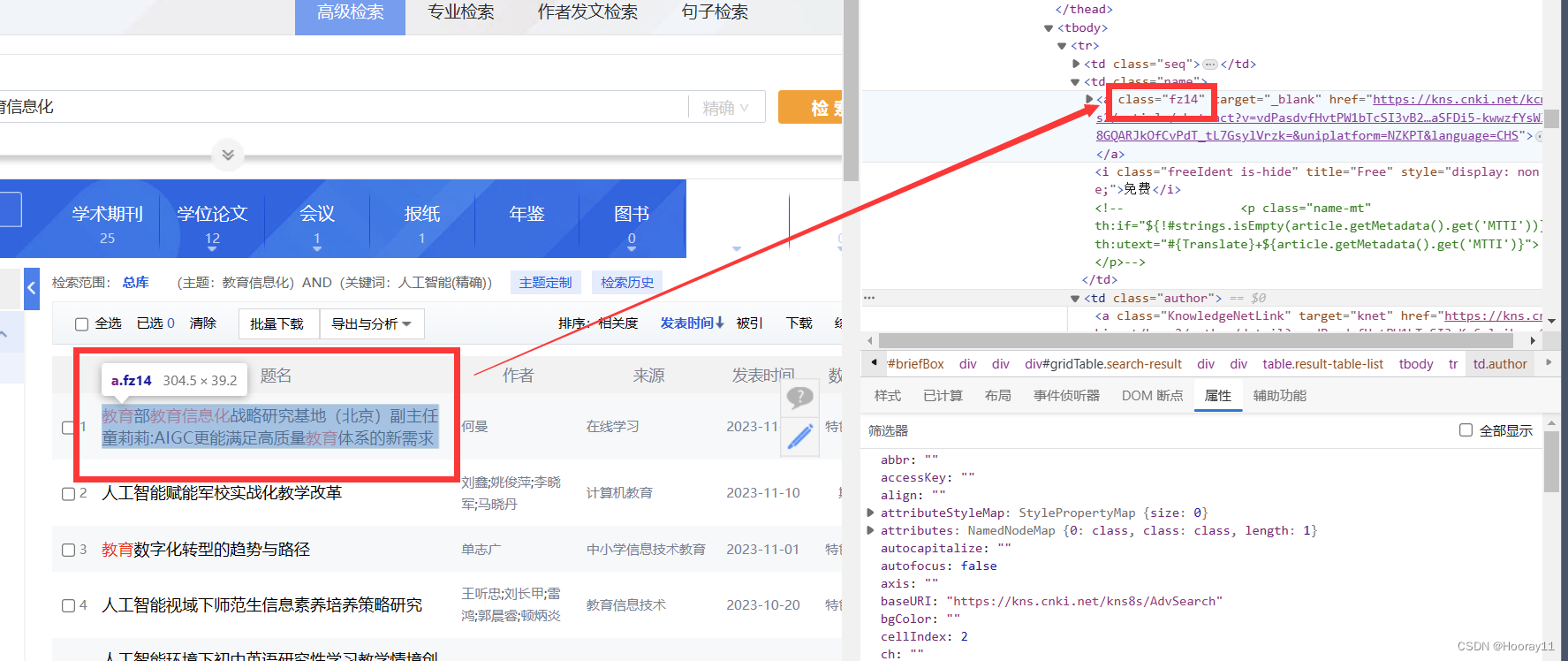
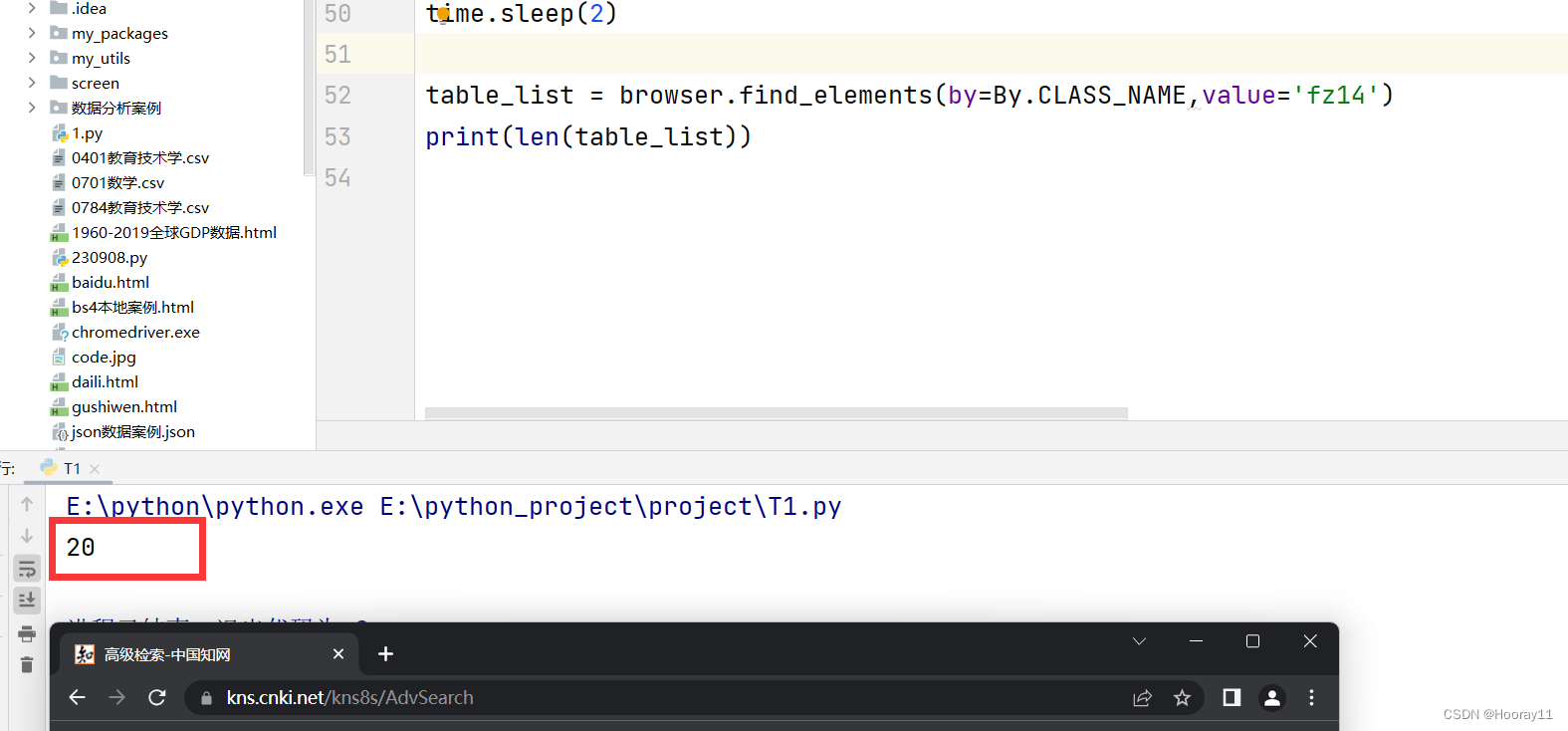
那么现在就是要根据之前所找到的规律去写xpath路径了,同时通过解析得到我们想要的数据。然后再多次的尝试下我终于成功拿到了数据。


3.2储存数据
我是将其存在一个CSV文件里。
简单学习了一下CSV的存储,大家也可以参考这个博主的文章。
python - csv 文件读取、处理、写入_csv_writer = csv.writer(f)-CSDN博客

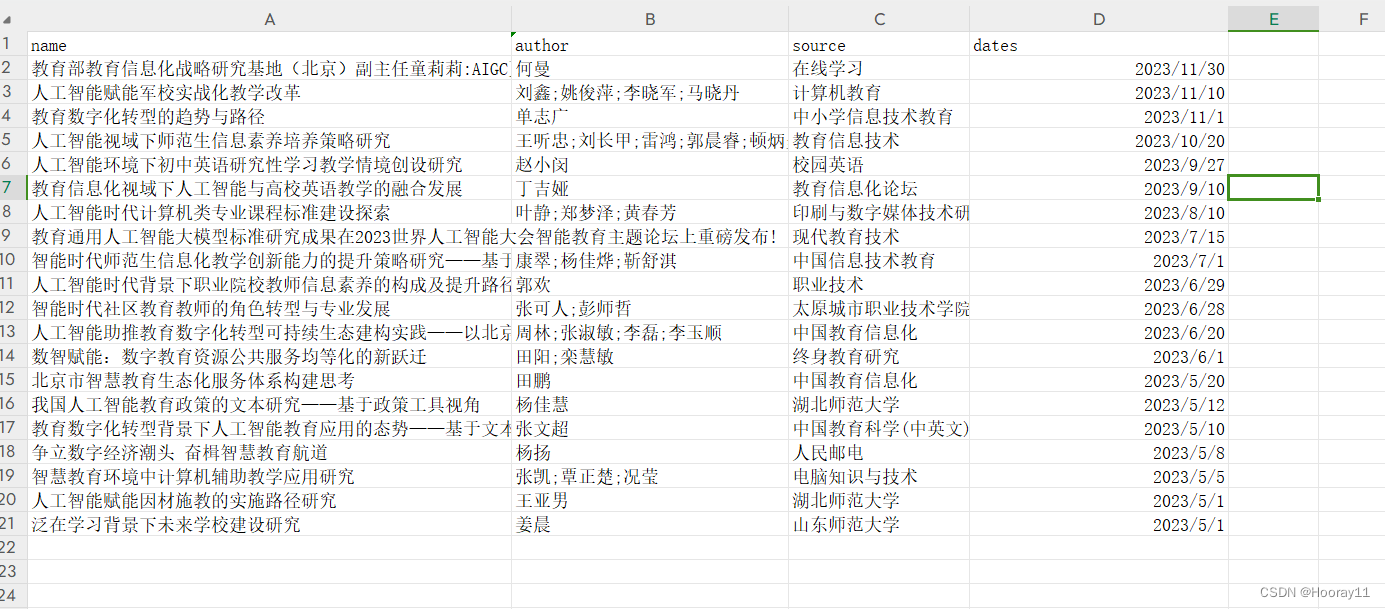
那截止到现在的话,我总共时实现了一个页面的存储,现在的话就是尝试将所有页面进行存储,所以就需要将他们封装成函数方法进行调用,希望我可以成功吧。
3.3第一次尝试(23-01-08)
那今天的尝试,没有实现翻页后继续存储,之后我在看看是咋回事,那现在的话就是我知道最后检索出来的结果是49条数据,总共3页,然后我自己设置了函数方法的调用次数,之后再思考怎么解决这个问题。
当然我写的代码由许多的不足,性能也比较差,也不太稳定,我得再研究研究别人的。今天就到这里吧!
附上我目前的代码。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import csv
import timeflag = 0# CSV文件的创建与初始化
header = ['name', 'author ','source', 'dates']
with open('CNKI.csv', 'w', encoding='UTF8', newline='') as f:writer = csv.writer(f)writer.writerow(header)def open_page():# 尝试传参path = 'chromedriver.exe's = Service(path)browser = webdriver.Chrome(service=s)url = 'https://kns.cnki.net/kns8s/AdvSearch'browser.get(url)time.sleep(2)#找输入框input1 = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')time.sleep(2)# 输入查询内容input1.send_keys('教育信息化')time.sleep(2)# 更改选项——关键词select = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')select.click()time.sleep(2)key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')key_word.click()time.sleep(2)# 输入查询内容input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')input2.send_keys('人工智能')time.sleep(2)# 更改时间time_change = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')time_change.click()time.sleep(2)select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')select_time.click()time.sleep(2)# 找检索search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')time.sleep(2)# 点击检索# search.click() #这个方法没用browser.execute_script("arguments[0].click();", search) #这个方法有用# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用time.sleep(2)return browser# name = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]').text
# print(name)def analyz(browser):global flag# 获取每一页的数据长度table_list = browser.find_elements(by=By.CLASS_NAME,value='fz14')# 循环遍历数据for term in range(1,len(table_list)+1):# 定义xpath语句name_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]'author_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]'source_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]'date_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]'# 获取文本信息name = browser.find_element(by='xpath',value=name_xpath).textauthor = browser.find_element(by='xpath',value=author_xpath).textsource = browser.find_element(by='xpath',value=source_xpath).textdates = browser.find_element(by='xpath',value=date_xpath).textprint(name,author,source,dates)# 写入CSV文件data = [name, author,source,dates]with open('CNKI.csv', 'a', encoding='UTF8', newline='') as f:writer = csv.writer(f)writer.writerow(data)# if term == len(table_list):# flag = 1def change_page():global flag# 滑倒底部js = 'window.scrollTo(0,document.body.scrollHeight)'browser.execute_script(js)time.sleep(2)# 获取下一页的按钮next = browser.find_element(by='xpath', value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a')# 点击下一页next.click()time.sleep(2)if __name__ == "__main__":browser = open_page()analyz(browser)change_page()analyz(browser)change_page()analyz(browser)
3.4第二次尝试(23-01-09)
那这一次的尝试是基于之前的代码做了一些修改。
那这一次的话,我在open_page这个函数方法中去获取检索结果的总共条目以及总共的页数,这两个数据非常重要。
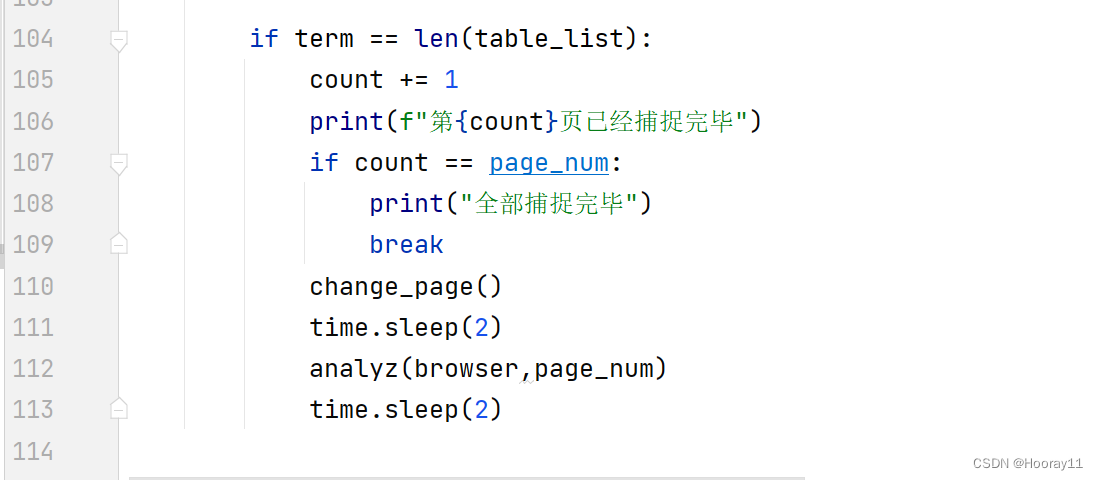
获取总共的结果数目很简单可以直接通过xpath解析可以获得,那总共由多少页,我是通过元素的信息去获取的,因为我发现data-pagenum这个属性刚好就是页数,所以可以直接运用get_attribute方法去获得数据,但是这里需要注意的是,所获取的page_num一定要转成Int,我当时就是没有转成int导致无法从递归中跳出来,真的是搞了好久才发现。
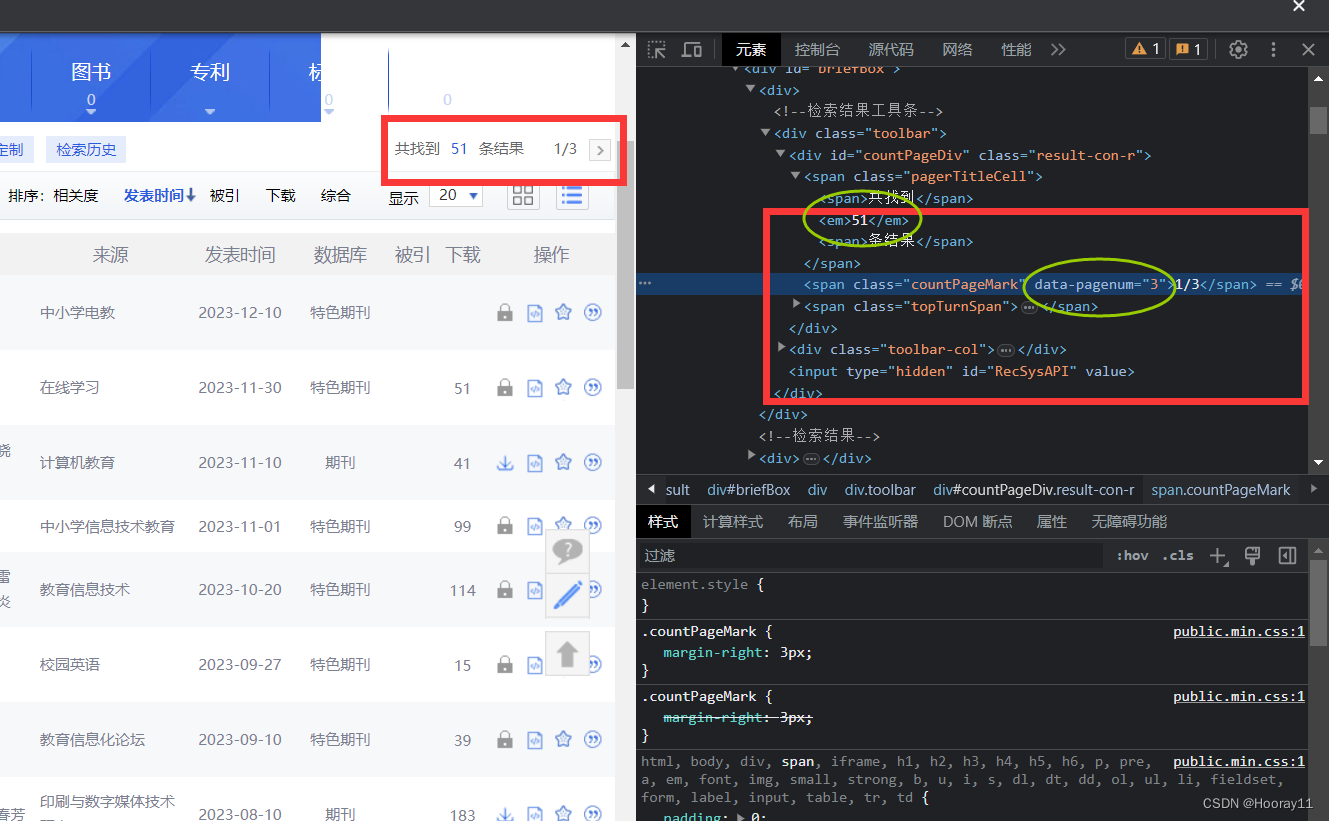
那我就是递归调用analyze这个函数方法,然后设置好递归出口就可以了,递归出口就是统计页数然后当页数等于page_num的时候就跳出来,就可以基本实现功能了。
附上代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import csv
import timecount = 0# CSV文件的创建与初始化
header = ['name', 'author ','source', 'dates']
with open('CNKI.csv', 'w', encoding='UTF8', newline='') as f:writer = csv.writer(f)writer.writerow(header)def open_page():# 尝试传参path = 'chromedriver.exe's = Service(path)browser = webdriver.Chrome(service=s)url = 'https://kns.cnki.net/kns8s/AdvSearch'browser.get(url)time.sleep(2)#找输入框input1 = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[1]/div[2]/input')time.sleep(2)# 输入查询内容input1.send_keys('教育信息化')time.sleep(2)# 更改选项——关键词select = browser.find_element(by='xpath',value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')select.click()time.sleep(2)key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')key_word.click()time.sleep(2)# 输入查询内容input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')input2.send_keys('人工智能')time.sleep(2)# 更改时间time_change = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')time_change.click()time.sleep(2)select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')select_time.click()time.sleep(2)# 找检索search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')time.sleep(2)# 点击检索# search.click() #这个方法没用browser.execute_script("arguments[0].click();", search) #这个方法有用# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用time.sleep(2)# 获得检索出来的所有条目个数res_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[1]/em').text# 去除千分位的逗号res_num = int(res_num.replace(",",""))# 获取结果页数page_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[2]')page_num = page_num.get_attribute('data-pagenum')# 打印结果print((f"共找到 {res_num} 条结果,共 {page_num} 页。"))return browser , page_num# name = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]').text
# print(name)def analyz(browser,page_num):global count# 获取每一页的数据长度table_list = browser.find_elements(by=By.CLASS_NAME,value='fz14')# 循环遍历数据for term in range(1,len(table_list)+1):# 定义xpath语句name_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]'author_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]'source_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]'date_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]'# 获取文本信息name = browser.find_element(by='xpath',value=name_xpath).textauthor = browser.find_element(by='xpath',value=author_xpath).textsource = browser.find_element(by='xpath',value=source_xpath).textdates = browser.find_element(by='xpath',value=date_xpath).textprint(name,author,source,dates)# 写入CSV文件data = [name, author,source,dates]with open('CNKI.csv', 'a', encoding='UTF8', newline='') as f:writer = csv.writer(f)writer.writerow(data)if term == len(table_list):count += 1print(f"第{count}页已经捕捉完毕")if count == page_num:print("全部捕捉完毕")breakchange_page()time.sleep(2)analyz(browser,page_num)time.sleep(2)def change_page():global flag# 滑倒底部js = 'window.scrollTo(0,document.body.scrollHeight)'browser.execute_script(js)time.sleep(2)# 获取下一页的按钮next = browser.find_element(by='xpath', value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a')# 点击下一页next.click()time.sleep(2)if __name__ == "__main__":tuple1 = open_page()browser = tuple1[0]page_num = int(tuple1[1])print(page_num)analyz(browser,page_num)browser.quit()
3.5第三次尝试(最终版)(23-01-09)
这一次我改变了一点点的结构,然后怎么优化代码目前只是说让打开网页的时候不去加载图片来提高效率吧。然后其次就是遇到了一些没有考虑到的情况去修改检查,避免报错吧。总之,这个案例的话大致就是完成了,虽然可能不能真正用来去处理爬取真正有用的数据,但是对selenium的学习以及实际的应用中有了更加深刻的认识,算是巩固自己刚刚学习的知识吧。
附上代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
import timecount = 0# CSV文件的创建与初始化
header = ['name', 'author ', 'source', 'dates']
with open('CNKI.csv', 'w', encoding='UTF8', newline='') as f:writer = csv.writer(f)writer.writerow(header)# 打开网页获取数据
def open_page(theme,key_words):# 尝试传参path = 'chromedriver.exe'# 设置不加载图片browser_option = webdriver.ChromeOptions()browser_option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建对象s = Service(path)browser = webdriver.Chrome(service=s,options=browser_option)url = 'https://kns.cnki.net/kns8s/AdvSearch'browser.get(url)time.sleep(2)# 找输入框input1 = browser.find_element(by='xpath', value='//*[@id="gradetxt"]/dd[1]/div[2]/input')time.sleep(2)# 输入查询内容input1.send_keys(f'{theme}')time.sleep(2)# 更改选项——关键词select = browser.find_element(by='xpath', value='//*[@id="gradetxt"]/dd[2]/div[2]/div[1]/div[1]')select.click()time.sleep(2)key_word = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/div[1]/div[2]/ul/li[3]')key_word.click()time.sleep(2)# 输入查询内容input2 = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/div/dl/dd[2]/div[2]/input')input2.send_keys(f'{key_words}')time.sleep(2)# 更改时间time_change = browser.find_element(by='xpath', value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/div')time_change.click()time.sleep(2)select_time = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li[5]')select_time.click()time.sleep(2)# 找检索search = browser.find_element(by='xpath',value='/html/body/div[2]/div[1]/div[1]/div/div[2]/div/div[1]/div[1]/div[2]/div[3]/input')time.sleep(2)# 点击检索# search.click() #这个方法没用browser.execute_script("arguments[0].click();", search) # 这个方法有用# webdriver.ActionChains(browser).move_to_element(search).perform() #这个方法没用time.sleep(2)# 考虑到结果的页数没有或者条目为0的情况try:# 获得检索出来的所有条目个数res_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[1]/em').text# 去除千分位的逗号res_num = int(res_num.replace(",", ""))except:res_num = 0try:# 获取结果页数page_num = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[1]/div/div[1]/span[2]')page_num = page_num.get_attribute('data-pagenum')except:page_num = 1# 打印结果print((f"共找到 {res_num} 条结果,共 {page_num} 页。"))return browser, page_num# name = browser.find_element(by='xpath',value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[1]/td[2]').text
# print(name)# 数据解析并导出
def analyz(browser, page_num):global count# 获取每一页的数据长度table_list = browser.find_elements(by=By.CLASS_NAME, value='fz14')# 循环遍历数据for term in range(1, len(table_list) + 1):# 定义xpath语句name_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[2]'author_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[3]'source_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[4]'date_xpath = f'/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[1]/div/div/table/tbody/tr[{term}]/td[5]'# 获取文本信息name = browser.find_element(by='xpath', value=name_xpath).textauthor = browser.find_element(by='xpath', value=author_xpath).textsource = browser.find_element(by='xpath', value=source_xpath).textdates = browser.find_element(by='xpath', value=date_xpath).textprint(name, author, source, dates)# 写入CSV文件data = [name, author, source, dates]with open('CNKI.csv', 'a', encoding='UTF8', newline='') as f:writer = csv.writer(f)writer.writerow(data)# 递归捕捉每一页的数据if term == len(table_list):count += 1print(f"第{count}页已经捕捉完毕")if count == page_num:print("全部捕捉完毕")breakchange_page()time.sleep(2)analyz(browser, page_num)time.sleep(2)# 切换页面点击下一页
def change_page():global flag# 滑倒底部js = 'window.scrollTo(0,document.body.scrollHeight)'browser.execute_script(js)time.sleep(2)# 获取下一页的按钮next = browser.find_element(by='xpath', value='/html/body/div[2]/div[2]/div[2]/div[2]/div/div[2]/div/div[2]/a')# 点击下一页next.click()time.sleep(2)if __name__ == "__main__":# 设置查找的主题和关键词theme = '人工智能'key_words = '教育'tuple1 = open_page(theme,key_words)browser = tuple1[0]page_num = int(tuple1[1])analyz(browser, page_num)browser.quit()4.总结
4.1第一次总结(23-01-08)
那这是我初学selenium第一次做的实际案例,体验感还是很不错的。虽然中间的过程也很艰辛,就是在不断地去思考下一步怎么做,虽然是根据别的博主的案例来学习的,但是我也尽量的以自己现在的一个学习状况来完成这些代码,所以跟原博主的还是由很大的差别,感觉别人写得很高级,然而我的水平还没到,我只能用自己现在所学来解决这个问题。
当然我觉得案例学习的方法很好,不仅引导自己主动去思考新学的知识,主动查阅资料,自己调试代码,去思考,还可以让自己去接触一些在日常生活中无法系统去学习到的知识。
给自己加油吧哈哈哈哈哈哈哈!
4.2第二次总结(23-01-09)
那这一次的修改其实很简单,昨天晚上的时候就一直在思考怎么去根据页数来调用,然后就增加了两个变量,在打开网页进行检索的时候就尽可能地去观察有用地信息,当然如果利用信息条目数量去判断地话也是可以的。
那现在的话我在尝试去优化代码的性能,因为现在加载的就是比较慢。并且递归调用函数方法这个算法绝对也是不咋行的。还是要去学习学习其他的哈哈哈哈哈。
4.3第三次总结(23-01-09)
那关于这一个案例就已经差不多结束了,目前可能比较适合跟我一样刚刚学完selenium来练手的案例吧,做到去真正的实际运用,可能后面只能简单的对这些数据进行一些统计。
总之基本的功能是可以实现的。但是关于页面的跳转可能还需要继续学习,比如去点击没一排你文章到里面去获得他的关键词和摘要啊。后面可以根据这个再进行改进。
在这里记录一个大佬的分享;selenium 谷歌 火狐 浏览器设置参数_java火狐修改window.navigator.webdriver-CSDN博客
相关文章:
python_selenium零基础爬虫学习案例_知网文献信息
案例最终效果说明: 去做这个案例的话是因为看到那个博主的分享,最后通过努力,我基本实现了进行主题、关键词、更新时间的三个筛选条件去获取数据,并且遍历数据将其导出到一个CSV文件中,代码是很简单的,没有…...

MindSpore Serving基于昇腾910B实现大模型部署
一、Why MindSpore Serving 大模型时代,作为一个开发人员更多的是关注一个大模型如何训练好、如何调整模型参数、如何才能得到一个更高的模型精度。而作为一个整体项目,只有项目落地才能有其真正的价值。那么如何才能够使得大模型实现落地?如…...
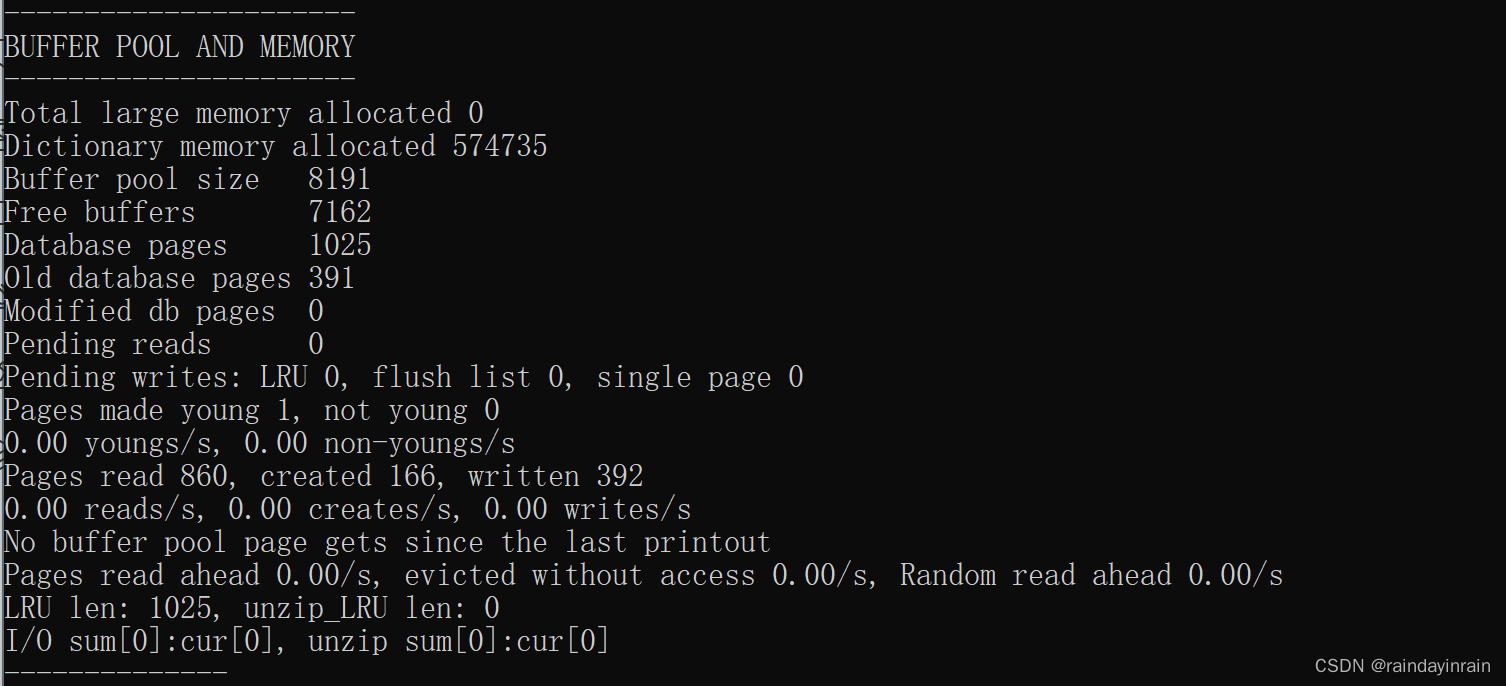
mysql原理--InnoDB的Buffer Pool
1.缓存的重要性 对于使用 InnoDB 作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以 页 的形式存放在 表空间 中的,而所谓的 表空间 只不过是 InnoDB 对…...
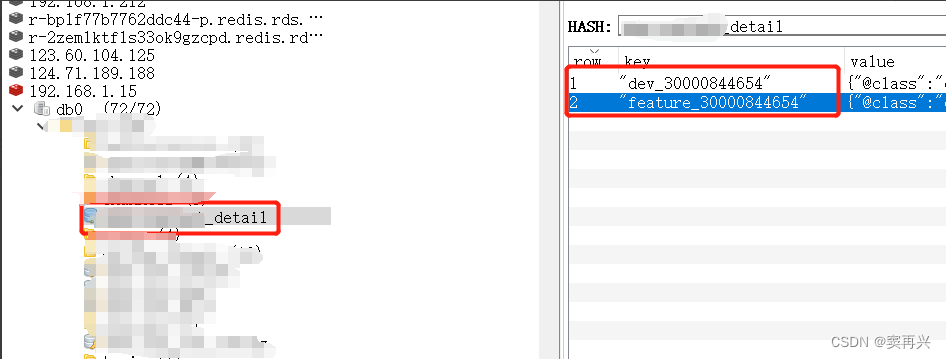
Redis不同环境缓存同一条数据,数据内部值不同
背景 现实中,本地环境(dev)和开发环境(feature)会共同使用相同的中间件(本篇拿Redis举例),对于不同环境中的,图片、视频、语音等资源类型的预览地址url,需要配…...
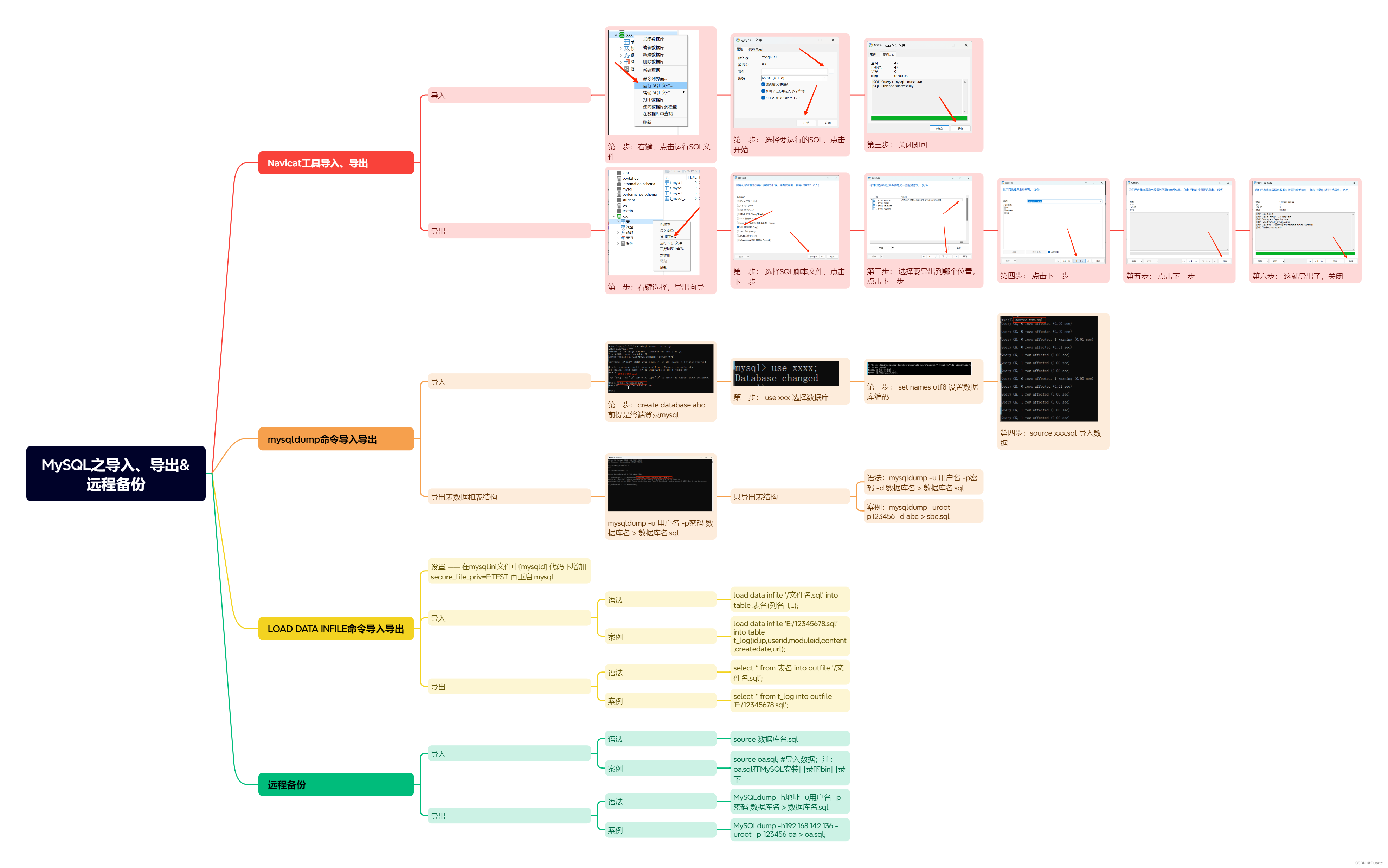
MySQL之导入、导出远程备份
一、Navicat工具导入、导出 1.1 导入 第一步: 右键,点击运行SQL文件 第二步: 选择要运行的SQL,点击开始 第三步: 关闭即可 1.2 导出 第一步: 右键选择,导出向导 第二步: 选择SQL脚…...
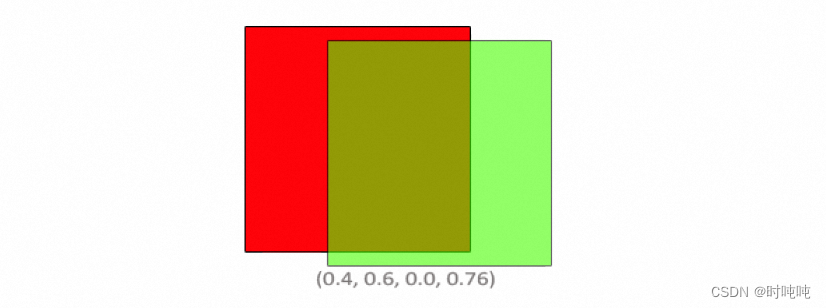
OpenGL学习笔记-Blending
混合方程中,Csource是片段着色器输出的颜色向量(the color output of the fragment shader),其权重为Fsource。Cdestination是当前存储在color buffer中的颜色向量(the color vector that is currently stored in the …...
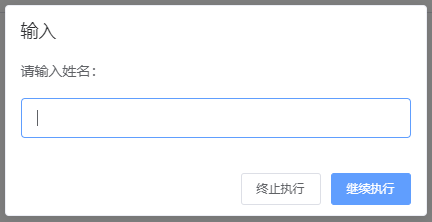
支持 input 函数的在线 python 运行环境 - 基于队列
支持 input 函数的在线 python 运行环境 - 基于队列 思路两次用户输入三次用户输入 实现前端使用 vue element uiWindows 环境的执行器子进程需要执行的代码 代码仓库参考 本文提供了一种方式来实现支持 input 函数,即支持用户输的在线 python 运行环境。效果如下图…...

欧拉Euler release 21.10 (LTS-SP2)升级openssh至9版本记录
背景:安扫漏洞,需要对openssh经行升级 1.先查看升级前的openssh版本 2.避免升级失败断开远程登录,先开启telnt服务用于远程连接(这步可查看其他博客) 3.从欧拉官网下载rpm包,https://www.openeuler.org/zh…...
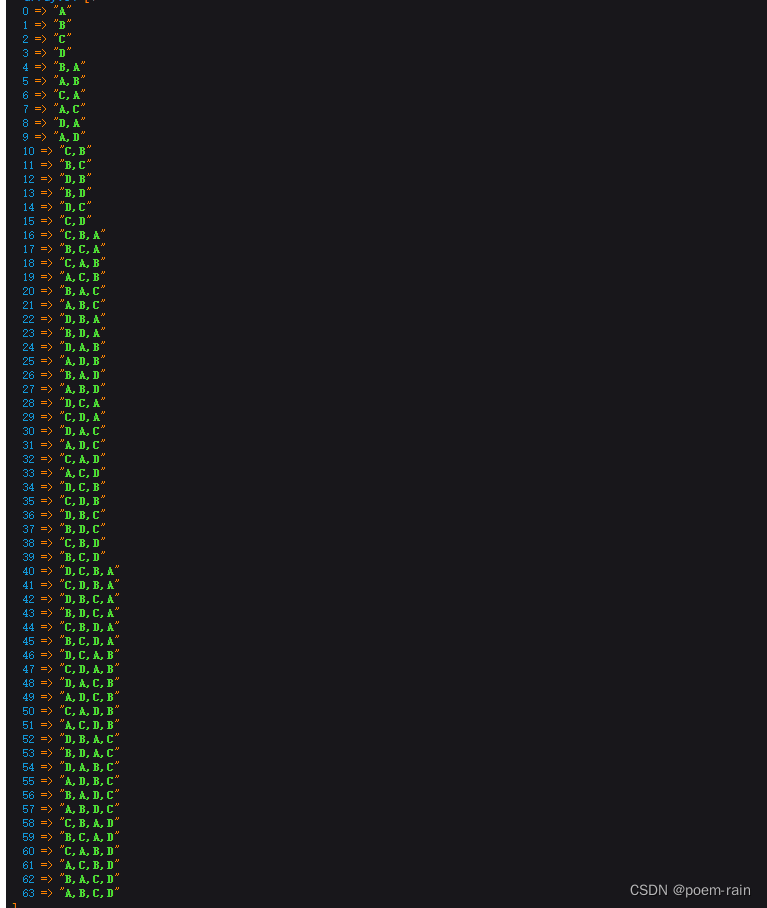
php 数组中的元素进行排列组合
需求背景:计算出数组[A,B,C,D]各种排列组合,希望得到的是数据如下图 直接上代码: private function finish_combination($array, &$groupResult [], $splite ,){$result [];$finish_result [];$this->diffArrayItems($array, $…...
Python从入门到网络爬虫(OS模块详解)
前言 本章介绍python自带模块os,os为操作系统 operating system 的简写,意为python与电脑的交互。os 模块提供了非常丰富的方法用来处理文件和目录。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面页可以极大增强…...

人机交互不是人机融合智能
一、人机交互和人机融合智能是两个不同的概念 人机交互是指人类与计算机之间的信息交流和操作方式,包括输入和输出界面、交互技术、用户体验等方面。人机交互的目标是提供用户友好的界面和自然的交互方式,使人类能够与计算机更加高效地进行沟通和协作。 …...

RabbitMQ解决消息丢失以及重复消费问题
文章目录 1、概念2、基于ACK/NACK机制2.1 基于Spring AMQP框架整合ACK/NACK机制2.2 测试消费失败1.02.3 测试结果1.02.4 测试MQ宕机2.5 测试结果2.0 3、RabbitMQ 如何实现幂等性设计3.1 幂等服务设计思路3.1.1 通过雪花算法生成分布式唯一ID3.1.2 通过枚举类,设计Me…...

docker 安装redis集群
一、准备6台机器 二、6台机器分别拉取镜像: docker pull redis三、6台机器分别建立挂载文件夹 mkdir -p /home/redis/data四、6台机器分别执行容器操作 docker run --restartalways -d --name redis-node-1 --net host --privilegedtrue -v /home/redis/data:/da…...

锂电池制造设备中分布式IO模块优势
在“碳达峰、碳中和”目标推动下,新能源汽车当下发展势头正盛,而纯电动车的核心部件则是:锂电池。动力型锂电池作为新能源汽车核心零部件,其发展与新能源汽车行业息息相关,迎来广阔的市场空间。 为何采用I/O模块&#…...

Android Room数据库升级Migration解决方案
一、介绍 Android Room 是 Android 官方提供的一个轻量级数据库框架,用于在 Android 应用程序中管理数据持久性。它简化了数据库访问,提供了更安全、更快速的数据存储方式,并使得数据操作更加便捷。 二、Room的特点(八股文可以参考) 以下是…...

离线安装docker和docker-compose
1.下载 docker Index of linux/static/stable/x86_64/ docker-compose Overview of installing Docker Compose | Docker Docs 2.docker /etc/systemd/system/docker.service [Unit] DescriptionDocker Application Container Engine Documentationhttps://docs.docker.…...

奇怪的事情记录:外置网卡和外置显示器不兼容
身为程序员,不应该对世界上的稀奇古怪的事情感到惊讶(毕竟,大部分都是程序员自己搞出来的)。 外置网卡和外置显示器不兼容 mbp2019intel版,win10,外接有线网卡,平时用得很好,接上外…...
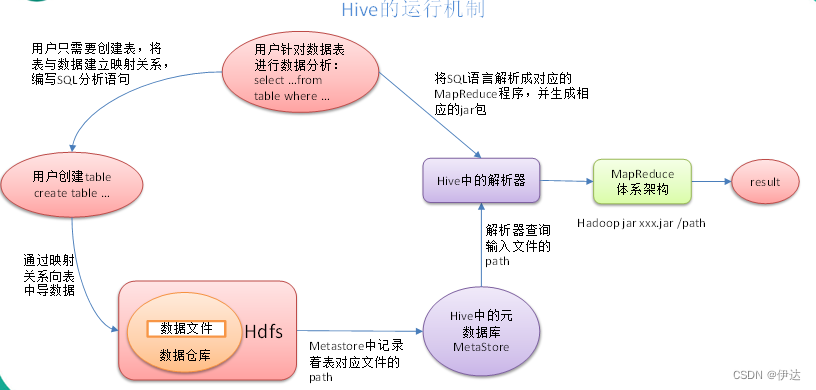
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门
目录 1、什么是Hive 2、Hive的优缺点 2.1、 优点 2.2、 缺点 2.2.1、Hive的HQL表达能力有限 2.2.2、Hive的效率比较低 3、Hive架构原理 3.1、用户接口:Client 3.2、元数据:Metastore 3.3、Hadoop 3.4、驱动器:Driver Hive运行机制…...

第三代量子计算机交付,中国芯片开辟新道路,光刻机难挡中国芯
日前安徽本源量子宣布第三代超导量子计算系统正式上线,这是中国最先进的量子计算机,计算量子比特已达到72个,在全球已居于较为领先的水平,这对于中国芯片在原来的硅基芯片受到光刻机阻碍无疑是巨大的鼓舞。 据悉本源量子的第一代、…...
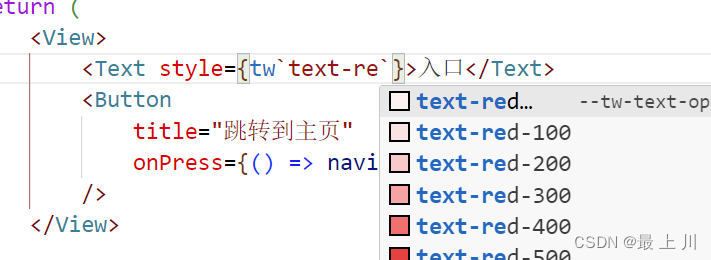
react native中使用tailwind并配置自动补全
使用的第三方库是tailwind-react-native-classnames,同类的也有tailwind-rn,但是我更喜欢前者官方demo: import { View, Text } from react-native; import tw from twrnc;const MyComponent () > (<View style{twp-4 android:pt-2 b…...

从CubeMX到ARM_MATH_CM4:手把手解锁STM32F4的DSP运算潜能
1. 为什么STM32F4需要DSP库? 很多刚接触STM32F4的开发者可能不知道,这颗Cortex-M4内核其实隐藏着强大的数字信号处理能力。我刚开始用F407做电机控制时,发现用标准库函数做FFT运算要写几十行代码,而换成DSP库只需要3行——这就是硬…...

基于OpenFast联合仿真的独立变桨与统一变桨风电机组控制模型
openfast与simlink联合仿真模型,风电机组独立变桨控制与统一变桨控制。 独立变桨控制。 OpenFast联合仿真。 基于载荷反馈的独立变桨控制 风机变桨控制基于FAST与MATLAB SIMULINK联合仿真模型的非线性风力发电机的PID独立变桨和统一变桨控制下仿真模型。 5MW非线性风…...

jmeter5.6.3源代码编译运行调试
1. jmeter源码编译运行过程 1.1配置java、运行变量,idea中运行 (1)下载jmeter源码,并解压。右键点击“open folder as intellij idea project” (2) 下载gradle8.7安装包,并配置环境变量 (3)下载jdk17并安装,配置环境变量,17版本只需指定JAVA_HOME、path中增加…...

【技术实战】Spring Task与WebSocket在外卖系统中的高效应用
1. 为什么外卖系统需要定时任务和实时通信 每次点外卖的时候,你可能没注意过背后的技术细节。比如超时未支付的订单会自动取消,商家接单后你的手机会立即收到通知,这些看似简单的功能其实都藏着精妙的技术实现。 我在开发外卖系统时发现&…...

现在不看就晚了:MCP v2.4 Sampling协议升级倒计时30天!5大兼容性断点+迁移checklist+回滚熔断预案全公开
第一章:MCP v2.4 Sampling协议升级全景概览MCP(Model Control Protocol)v2.4 Sampling 协议是面向大模型服务编排与推理采样控制的关键演进版本,聚焦于动态采样策略调度、跨模型一致性保障及低延迟响应能力提升。本次升级并非简单…...

为什么选择RE:DOM?5大优势解析与性能对比
为什么选择RE:DOM?5大优势解析与性能对比 【免费下载链接】redom Tiny (2 KB) turboboosted JavaScript library for creating user interfaces. 项目地址: https://gitcode.com/gh_mirrors/re/redom RE:DOM是一个仅2 KB大小的轻量级JavaScript UI库…...
Transformer-BiLSTM、Transformer、CNN-BiLSTM、BiLSTM、CNN五模型时序预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
TensorBoard报错?手把手教你用官方诊断脚本解决Duplicate plugins问题(附详细步骤)
TensorBoard报错?手把手教你用官方诊断脚本解决Duplicate plugins问题 当你兴致勃勃地准备使用TensorBoard可视化训练过程时,突然遭遇"ValueError: Duplicate plugins for name projector"这样的报错信息,确实让人头疼。这种插件重…...

LightOnOCR-2-1B快速上手:小白也能轻松搭建的OCR识别工具
LightOnOCR-2-1B快速上手:小白也能轻松搭建的OCR识别工具 1. 引言:为什么你需要一个轻量好用的OCR工具? 想象一下,你手头有一堆纸质合同、发票或者PDF文档,需要把它们变成可编辑的电子文本。手动打字?太慢…...

大疆上云API实战:用Java把无人机数据实时推送到你的Web后台
大疆上云API实战:用Java构建无人机数据实时推送系统 1. 云端数据集成架构设计 在物联网应用场景中,无人机作为空中数据采集终端,其价值实现的关键在于如何将飞行数据实时、可靠地传输到业务系统。大疆上云API提供了两种主流协议支持ÿ…...