mysql原理--InnoDB的Buffer Pool
1.缓存的重要性
对于使用 InnoDB 作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以 页 的形式存放在 表空间 中的,而所谓的 表空间 只不过是 InnoDB 对文件系统上一个或几个实际文件的抽象,也就是说我们的数据说到底还是存储在磁盘上的。
InnoDB 存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其 缓存 起来,这样将来有请求再次访问该页面时,就可以省去磁盘 IO 的开销了。
2.InnoDB的Buffer Pool
2.1.啥是个Buffer Pool
设计 InnoDB 的大叔为了缓存磁盘中的页,在 MySQL 服务器启动的时候就向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做 Buffer Pool (中文名是 缓冲池 )。默认情况下 Buffer Pool 只有 128M 大小。当然如果你嫌弃这个 128M 太大或者太小,可以在启
动服务器的时候配置 innodb_buffer_pool_size 参数的值,它表示 Buffer Pool 的大小,就像这样:
[server]
innodb_buffer_pool_size = 268435456
其中, 268435456 的单位是字节,也就是我指定 Buffer Pool 的大小为 256M 。需要注意的是, Buffer Pool 也不能太小,最小值为 5M (当小于该值时会自动设置成 5M )。
2.2.Buffer Pool内部组成
Buffer Pool 中默认的缓存页大小和在磁盘上默认的页大小是一样的,都是 16KB 。为了更好的管理这些在 Buffer Pool 中的缓存页,设计 InnoDB 的大叔为每一个缓存页都创建了一些所谓的 控制信息 ,这些控制信息包括该页所属的表空间编号、页号、缓存页在 Buffer Pool 中的地址、链表节点信息、一些锁信息以及 LSN 信息(锁和 LSN 我们之后会具体唠叨,现在可以先忽略),当然还有一些别的控制信息,我们这就不全唠叨一遍了,挑重要的说嘛~
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块 吧,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边,所以整个 Buffer Pool 对应的内存空间看起来就是这样的: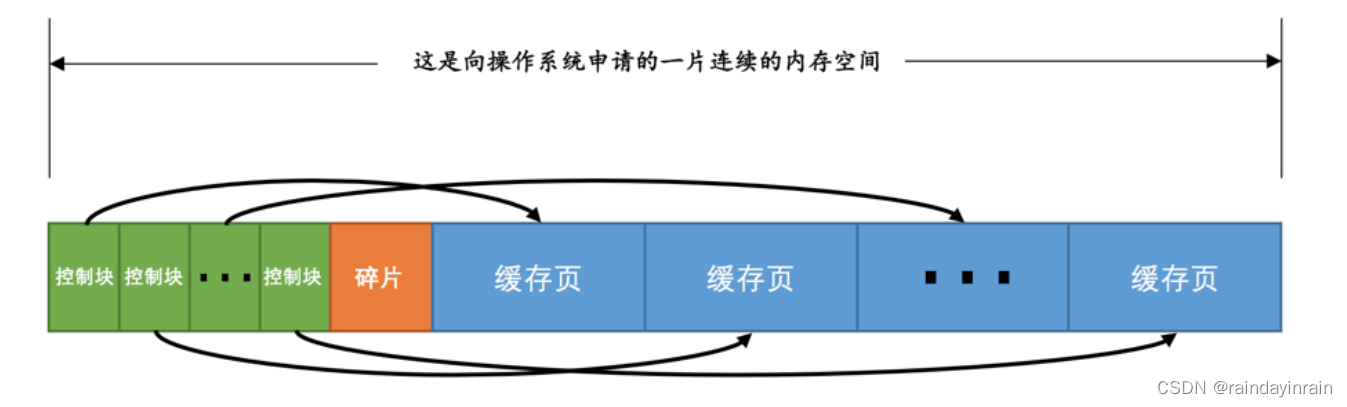
控制块和缓存页之间的那个 碎片 是个什么玩意儿?你想想啊,每一个控制块都对应一个缓存页,那在分配足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,自然就用不到喽,这个用不到的那点儿内存空间就被称为 碎片 了。当然,如果你把 Buffer Pool 的大小设置的刚刚好的话,也可能不会产生 碎片 ~
每个控制块大约占用缓存页大小的5%,在MySQL5.7.21这个版本中,每个控制块占用的大小是808字节。我们设置的innodb_buffer_pool_size并不包含这部分控制块占用的内存空间大小,也就是说InnoDB在为Buffer Pool向操作系统申请连续的内存空间时,这片连续的内存空间一般会比innodb_buffer_pool_size的值大5%左右。
关于有了操作系统的页缓存机制后,依然在用户态新增Buffer Pool机制的原因,个人猜测是:
(1). 利用页缓存时,数据读取,数据写入涉及用户态,内核态切换,系统调用开销,内核态和用户态间的内存拷贝。
(2). 直接使用用户态的Buffer Pool,在数据读取,数据写入时,无上述开销。
2.3.free链表的管理
当我们最初启动 MySQL 服务器的时候,需要完成对 Buffer Pool 的初始化过程,就是先向操作系统申请 Buffer Pool 的内存空间,然后把它划分成若干对控制块和缓存页。但是此时并没有真实的磁盘页被缓存到 Buffer Pool 中(因为还没有用到),之后随着程序的运行,会不断的有磁盘上的页被缓存到 Buffer Pool 中。
那么,从磁盘上读取一个页到 Buffer Pool 中的时候该放到哪个缓存页的位置呢?或者说怎么区分 Buffer Pool 中哪些缓存页是空闲的,哪些已经被使用了呢?
我们最好在某个地方记录一下Buffer Pool中哪些缓存页是可用的,这个时候缓存页对应的 控制块 就派上大用场了,我们可以把所有空闲的缓存页对应的控制块作为一个节点放到一个链表中,这个链表也可以被称作 free链表 (或者说空闲链表)。刚刚完成初始化的 Buffer Pool 中
所有的缓存页都是空闲的,所以每一个缓存页对应的控制块都会被加入到 free链表 中,假设该 Buffer Pool 中可容纳的缓存页数量为 n ,那增加了 free链表 的效果图就是这样的:
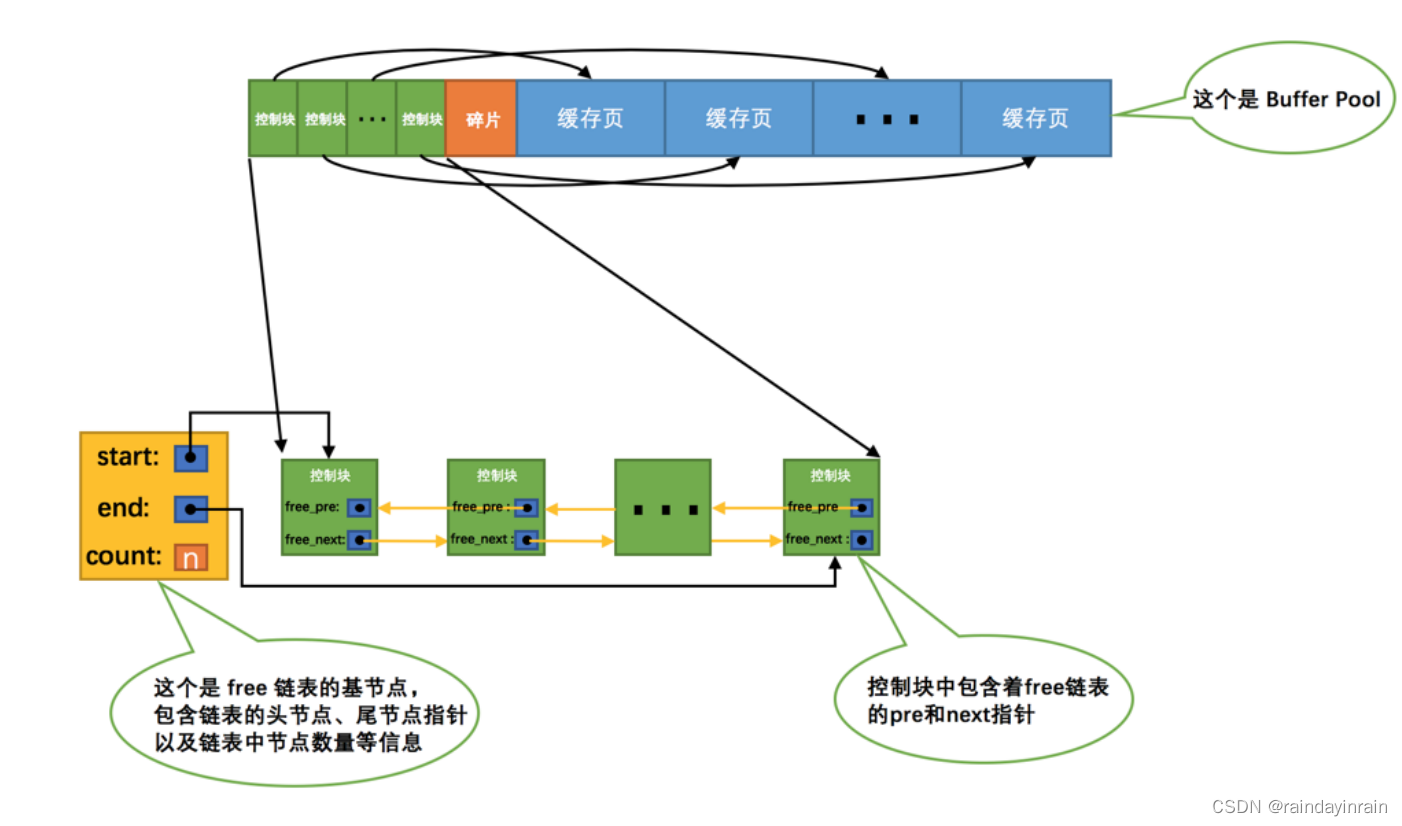
从图中可以看出,我们为了管理好这个 free链表 ,特意为这个链表定义了一个 基节点 ,里边儿包含着链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。这里需要注意的是,链表的基节点占用的内存空间并不包含在为 Buffer Pool 申请的一大片连续内存空间之内,而是单独申请的一块内存空间。
链表基节点占用的内存空间并不大,在MySQL5.7.21这个版本里,每个基节点只占用40字节大小。后边我们即将介绍许多不同的链表,它们的基节点和free链表的基节点的内存分配方式是一样一样的,都是单独申请的一块40字节大小的内存空间,并不包含在为Buffer Pool申请的一大片连续内存空间之内。
有了这个 free链表 之后事儿就好办了,每当需要从磁盘中加载一个页到 Buffer Pool 中时,就从 free链表 中取一个空闲的缓存页,并且把该缓存页对应的 控制块 的信息填上(就是该页所在的表空间、页号之类的信息),然后把该缓存页对应的 free链表 节点从链表中移除,表示该缓存页已经被使用了~
2.4.缓存页的哈希处理
我们前边说过,当我们需要访问某个页中的数据时,就会把该页从磁盘加载到 Buffer Pool 中,如果该页已经在 Buffer Pool 中的话直接使用就可以了。那么问题也就来了,我们怎么知道该页在不在 Buffer Pool 中呢?
我们其实是根据 表空间号 + 页号 来定位一个页的,也就相当于 表空间号 + 页号 是一个 key ,缓存页 就是对应的 value ,怎么通过一个 key 来快速找着一个 value 呢?哈哈,那肯定是哈希表喽~
所以我们可以用 表空间号 + 页号 作为 key , 缓存页 作为 value 创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据 表空间号 + 页号 看看有没有对应的缓存页,如果有,直接使用该缓存页就好,如果没有,那就从 free链表 中选一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。
2.5.flush链表的管理
如果我们修改了 Buffer Pool 中某个缓存页的数据,那它就和磁盘上的页不一致了,这样的缓存页也被称为 脏页 (英文名: dirty page )。当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,至于这个同步的时间点我们后边会作说明说明的,现在先不用管哈~
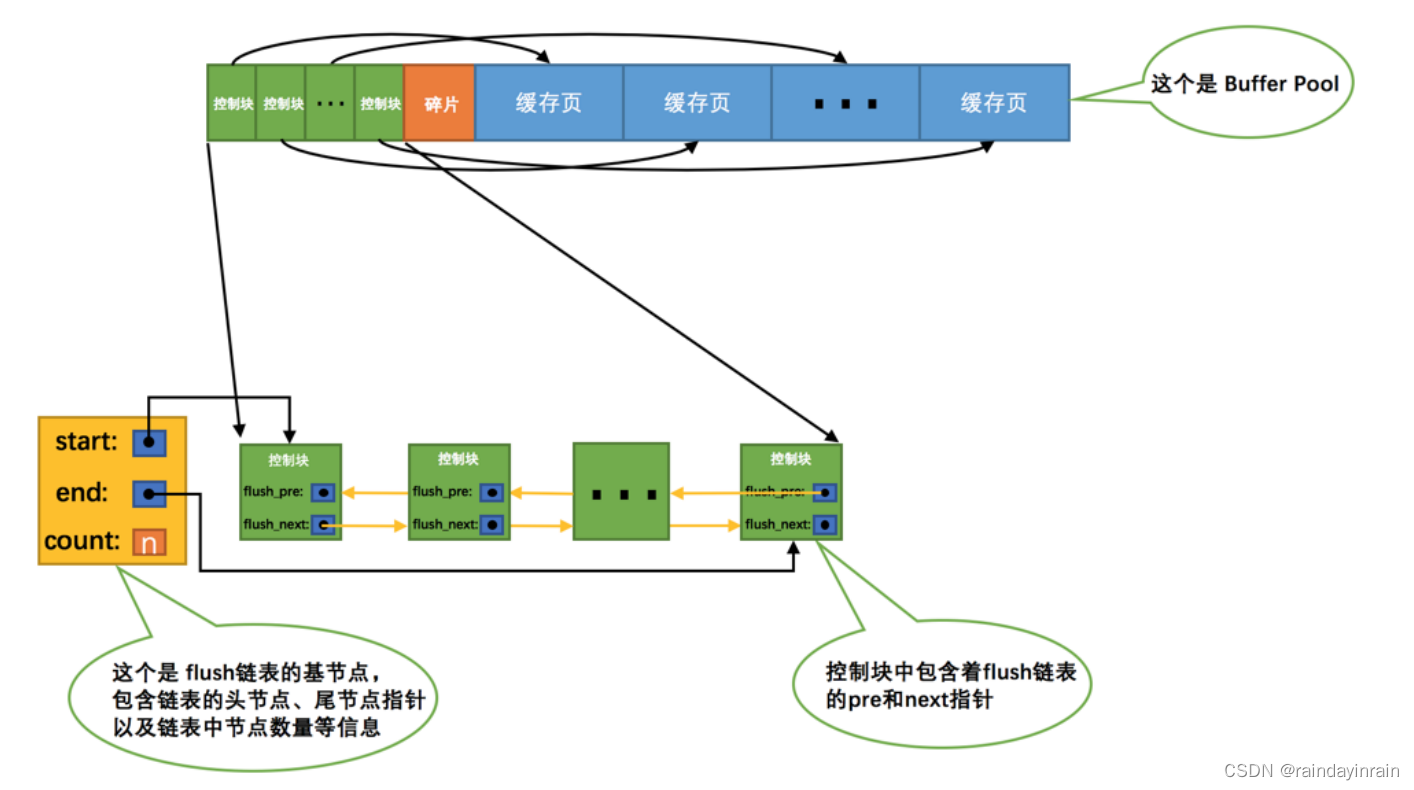
但是如果不立即同步到磁盘的话,那之后再同步的时候我们怎么知道 Buffer Pool 中哪些页是 脏页 ,哪些页从来没被修改过呢?总不能把所有的缓存页都同步到磁盘上吧,假如 Buffer Pool 被设置的很大,比方说 300G ,那一次性同步这么多数据岂不是要慢死!所以,我们不得不再创建一个存储脏页的链表,凡是修改过的缓存页对应的控制块都会作为一个节点加入到一个链表中,因为这个链表节点对应的缓存页都是需要被刷新到磁盘上的,所以也叫 flush链表 。链表的构造和 free链表 差不多,假设某个时间点 Buffer Pool 中的脏页数量为 n ,那么
对应的 flush链表 就长这样:
2.6.LRU链表的管理
2.6.1.缓存不够的窘境
Buffer Pool 对应的内存大小毕竟是有限的,如果需要缓存的页占用的内存大小超过了 Buffer Pool 大小,也就是 free链表 中已经没有多余的空闲缓存页的时候岂不是很尴尬,发生了这样的事儿该咋办?当然是把某些旧的缓存页从 Buffer Pool 中移除,然后再把新的页放进来喽~ 那么问题来了,移除哪些缓存页呢?
为了回答这个问题,我们还需要回到我们设立 Buffer Pool 的初衷,我们就是想减少和磁盘的 IO 交互,最好每次在访问某个页的时候它都已经被缓存到 Buffer Pool 中了。假设我们一共访问了 n 次页,那么被访问的页已经在缓存中的次数除以 n 就是所谓的 缓存命中率 ,我们的期望就是让 缓存命中率 越高越好~ 从这个角度出发,回想一下我们的微信聊天列表,排在前边的都是最近很频繁使用的,排在后边的自然就是最近很少使用的,假如列表能容纳下的联系人有限,你是会把最近很频繁使用的留下还是最近很少使用的留下呢?废话,当然是留下最近很频繁使用的了~
2.6.2.简单的LRU链表
管理 Buffer Pool 的缓存页其实也是这个道理,当 Buffer Pool 中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。不过,我们怎么知道哪些缓存页最近频繁使用,哪些最近很少使用呢?
我们可以再创建一个链表,由于这个链表是为了 按照最近最少使用 的原则去淘汰缓存页的,所以这个链表可以被称为 LRU链表 (LRU的英文全称:Least Recently Used)。当我们需要访问某个页时,可以这样处理 LRU链表 :
(1). 如果该页不在 Buffer Pool 中,在把该页从磁盘加载到 Buffer Pool 中的缓存页时,就把该缓存页对应的控制块 作为节点塞到链表的头部。
(2). 如果该页已经缓存在 Buffer Pool 中,则直接把该页对应的 控制块 移动到 LRU链表 的头部。
也就是说:只要我们使用到某个缓存页,就把该缓存页调整到 LRU链表 的头部,这样 LRU链表 尾部就是最近最少使用的缓存页喽~ 所以当 Buffer Pool 中的空闲缓存页使用完时,到 LRU链表 的尾部找些缓存页淘汰就OK啦,真简单,啧啧…
2.6.2.划分区域的LRU链表
上边的这个简单的 LRU链表 用了没多长时间就发现问题了,因为存在这两种比较尴尬的情况:
(1). InnoDB 提供了一个看起来比较贴心的服务—— 预读 (英文名: read ahead )。所谓 预读 ,就是 InnoDB 认为执行当前的请求可能之后会读取某些页面,就预先把它们加载到 Buffer Pool 中。根据触发方式的不同, 预读 又可以细分为下边两种:
a. 线性预读
设计 InnoDB 的大叔提供了一个系统变量 innodb_read_ahead_threshold ,如果顺序访问了某个区( extent )的页面超过这个系统变量的值,就会触发一次 异步 读取下一个区中全部的页面到 Buffer Pool 的请求,注意 异步 读取意味着从磁盘中加载这些被预读的页面并不会影响到当前工作线程的正常执行。这个 innodb_read_ahead_threshold 系统变量的值默认是 56 ,我们可以在服务器启动时通过启动参数或者服务器运行过程中直接调整该系统变量的值,不过它是一个全局变量,注意使用 SET GLOBAL 命令来修改哦。
b.随机预读
如果 Buffer Pool 中已经缓存了某个区的13个连续的页面,不论这些页面是不是顺序读取的,都会触发一次 异步 读取本区中所有其的页面到 Buffer Pool 的请求。设计 InnoDB 的大叔同时提供了 innodb_random_read_ahead 系统变量,它的默认值为 OFF ,也就意味着 InnoDB 并不会默认开启随机预读的功能,如果我们想开启该功能,可以通过修改启动参数或者直接使用 SET GLOBAL 命令把该变量的值设置为 ON 。
预读 本来是个好事儿,如果预读到 Buffer Pool 中的页成功的被使用到,那就可以极大的提高语句执行的效率。可是如果用不到呢?这些预读的页都会放到 LRU 链表的头部,但是如果此时 Buffer Pool 的容量不太大而且很多预读的页面都没有用到的话,这就会导致处在 LRU链表 尾部的一些缓存页会很快的被淘汰掉,也就是所谓的 劣币驱逐良币 ,会大大降低缓存命中率。
(2). 有的小伙伴可能会写一些需要扫描全表的查询语句(比如没有建立合适的索引或者压根儿没有WHERE子句的查询)。
扫描全表意味着什么?
意味着将访问到该表所在的所有页!假设这个表中记录非常多的话,那该表会占用特别多的 页 ,当需要访问这些页时,会把它们统统都加载到 Buffer Pool 中,这也就意味着吧唧一下,Buffer Pool 中的所有页都被换了一次血,其他查询语句在执行时又得执行一次从磁盘加载到 Buffer Pool 的操作。而这种全表扫描的语句执行的频率也不高,每次执行都要把 Buffer Pool 中的缓存页换一次血,这严重的影响到其他查询对 Buffer Pool 的使用,从而大大降低了缓存命中率。
总结一下上边说的可能降低 Buffer Pool 的两种情况:
(1). 加载到 Buffer Pool 中的页不一定被用到。
(2). 如果非常多的使用频率偏低的页被同时加载到 Buffer Pool 时,可能会把那些使用频率非常高的页从 Buffer Pool 中淘汰掉。
因为有这两种情况的存在,所以设计 InnoDB 的大叔把这个 LRU链表 按照一定比例分成两截,分别是:
(1). 一部分存储使用频率非常高的缓存页,所以这一部分链表也叫做 热数据 ,或者称 young区域 。
(2). 另一部分存储使用频率不是很高的缓存页,所以这一部分链表也叫做 冷数据 ,或者称 old区域 。
为了方便大家理解,我们把示意图做了简化,各位领会精神就好:
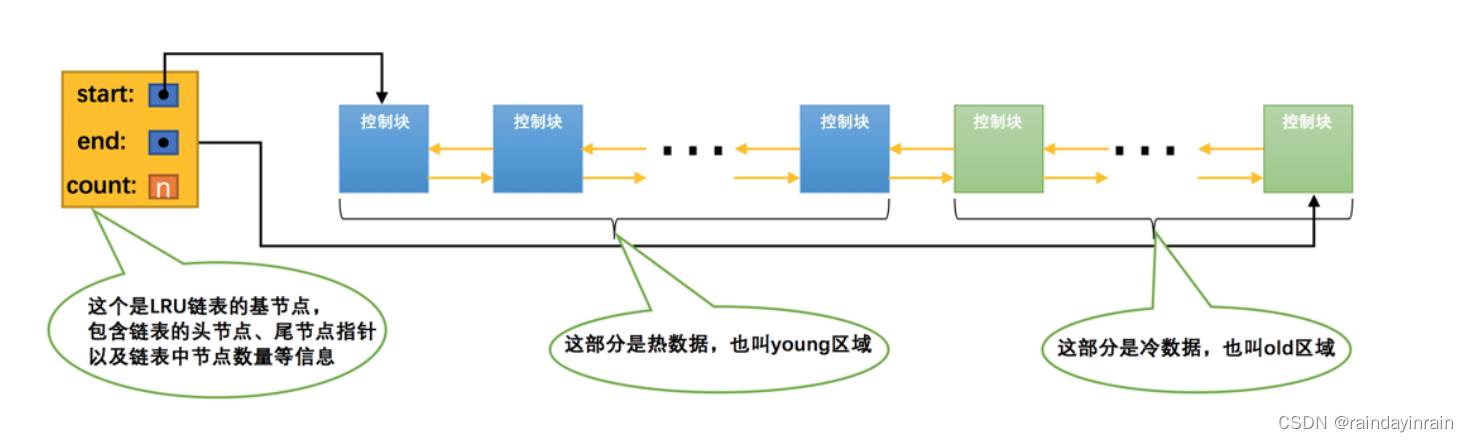
大家要特别注意一个事儿:我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于 InnoDB 存储引擎来说,我们可以通过查看系统变量 innodb_old_blocks_pct 的值来确定 old 区域在 LRU链表 中所占的比例,比方说这样:
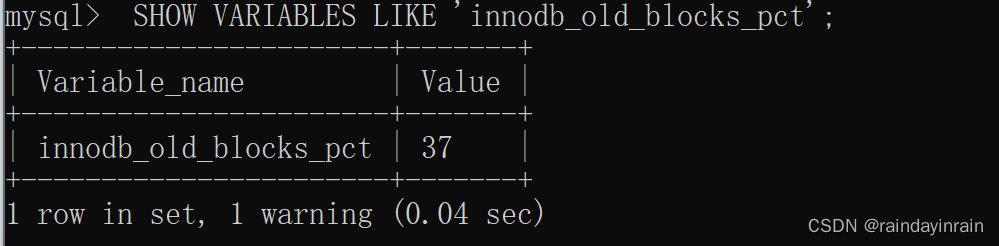
从结果可以看出来,默认情况下, old 区域在 LRU链表 中所占的比例是 37% ,也就是说 old 区域大约占 LRU链表 的 3/8 。这个比例我们是可以设置的,我们可以在启动时修改 innodb_old_blocks_pct 参数来控制 old 区域在 LRU链表 中所占的比例,比方说这样修改配置文件:
[server]
innodb_old_blocks_pct = 40
这样我们在启动服务器后, old 区域占 LRU链表 的比例就是 40% 。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于 全局变量 ,一经修改,会对所有客户端生效,所以我们只能这样修改:SET GLOBAL innodb_old_blocks_pct = 40;
有了这个被划分成 young 和 old 区域的 LRU 链表之后,设计 InnoDB 的大叔就可以针对我们上边提到的两种可能降低缓存命中率的情况进行优化了:
(1). 针对预读的页面可能不进行后续访情况的优化
设计 InnoDB 的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到 Buffer Pool 却不进行后续访问的页面就会被逐渐从old 区域逐出,而不会影响 young 区域中被使用比较频繁的缓存页。
(2). 针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到 Buffer Pool 的页被放到了 old 区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到 young 区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。
有同学会想:可不可以在第一次访问该页面时不将其从 old 区域移动到 young 区域的头部,后续访问时再将其移动到 young 区域的头部。回答是:行不通!因为设计 InnoDB 的大叔规定每次去页面中读取一条记录时,都算是访问一次页面,而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。
咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在 old 区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。这个间隔时间是由系统变量innodb_old_blocks_time 控制的,你看:
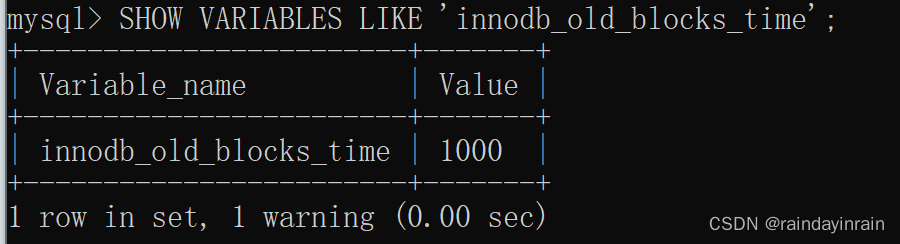
这个 innodb_old_blocks_time 的默认值是 1000 ,它的单位是毫秒,也就意味着对于从磁盘上被加载到 LRU 链表的 old 区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于 1s (很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过 1s ),那么该页是不会被加入到 young 区域的~
当然,像 innodb_old_blocks_pct 一样,我们也可以在服务器启动或运行时设置 innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~ 这里需要注意的是,如果我们把 innodb_old_blocks_time 的值设置为 0 ,那么每次我们访问一个页面时就会把该页面放到 young 区域的头部。
综上所述,正是因为将 LRU 链表划分为 young 和 old 区域这两个部分,又添加了 innodb_old_blocks_time 这个系统变量,才使得预读机制和全表扫描造成的缓存命中率降低的问题得到了遏制,因为用不到的预读页面以及全表扫描的页面都只会被放到 old 区域,而不影响 young 区域中的缓存页。
2.6.3.更进一步优化LRU链表
对于 young 区域的缓存页来说,我们每次访问一个缓存页就要把它移动到 LRU链表 的头部,这样开销是不是太大啦,毕竟在 young 区域的缓存页都是热点数据,也就是可能被经常访问的,这样频繁的对 LRU链表 进行节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出一些优化策略,比如只有被访问的缓存页位于 young 区域的 1/4 的后边,才会被移动到 LRU链表 头部,这样就可以降低调整 LRU链表 的频率,从而提升性能(也就是说如果某个缓存页对应的节点在 young 区域的 1/4 中,再次访问该缓存页时也不会将其移动到 LRU 链表头部)。
我们之前介绍随机预读的时候曾说,如果Buffer Pool中有某个区的13个连续页面就会触发随机预读,这其实是不严谨的(不幸的是MySQL文档就是这么说的[摊手]),其实还要求这13个页面是非常热的页面,所谓的非常热,指的是这些页面在整个young区域的头1/4处。
但是不论怎么优化,千万别忘了我们的初心:尽量高效的提高 Buffer Pool 的缓存命中率。
2.7.其他的一些链表
为了更好的管理 Buffer Pool 中的缓存页,除了我们上边提到的一些措施,设计 InnoDB 的大叔们还引进了其他的一些 链表 ,比如 unzip LRU链表 用于管理解压页, zip clean链表 用于管理没有被解压的压缩页, zip free数组 中每一个元素都代表一个链表,它们组成所谓的 伙伴系统 来为压缩页提供内存空间等等,反正是为了更好的管理这个 Buffer Pool 引入了各种链表或其他数据结构,具体的使用方式就不啰嗦了,大家有兴趣深究的再去找些更深的书或者直接看源代码吧。
2.8.刷新脏页到磁盘
后台有专门的线程每隔一段时间负责把脏页刷新到磁盘,这样可以不影响用户线程处理正常的请求。主要有两种刷新路径:
(1). 从 LRU链表 的冷数据中刷新一部分页面到磁盘。
后台线程会定时从 LRU链表 尾部开始扫描一些页面,扫描的页面数量可以通过系统变量 innodb_lru_scan_depth 来指定,如果从里边儿发现脏页,会把它们刷新到磁盘。这种刷新页面的方式被称之为 BUF_FLUSH_LRU 。
(2). 从 flush链表 中刷新一部分页面到磁盘。
后台线程也会定时从 flush链表 中刷新一部分页面到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新页面的方式被称之为 BUF_FLUSH_LIST 。
有时候后台线程刷新脏页的进度比较慢,导致用户线程在准备加载一个磁盘页到 Buffer Pool 时没有可用的缓存页,这时就会尝试看看 LRU链表 尾部有没有可以直接释放掉的未修改页面,如果没有的话会不得不将 LRU链表 尾部的一个脏页同步刷新到磁盘(和磁盘交互是很慢的,这会降低处理用户请求的速度)。这种刷新单个页面到磁盘中的刷新方式被称之为 BUF_FLUSH_SINGLE_PAGE 。
当然,有时候系统特别繁忙时,也可能出现用户线程批量的从 flush链表 中刷新脏页的情况,很显然在处理用户请求过程中去刷新脏页是一种严重降低处理速度的行为(毕竟磁盘的速度慢的要死),这属于一种迫不得已的情况,不过这得放在后边唠叨 redo 日志的 checkpoint 时说了。
3.多个Buffer Pool实例
我们上边说过, Buffer Pool 本质是 InnoDB 向操作系统申请的一块连续的内存空间,在多线程环境下,访问 Buffer Pool 中的各种链表都需要加锁处理啥的,在 Buffer Pool 特别大而且多线程并发访问特别高的情况下,单一的 Buffer Pool 可能会影响请求的处理速度。所以在 Buffer Pool 特别大的时候,我们可以把它们拆分成若干个小的 Buffer Pool ,每个 Buffer Pool 都称为一个 实例 ,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置 innodb_buffer_pool_instances 的值来修改 Buffer Pool 实例的个数,比方说这样:
[server]
innodb_buffer_pool_instances = 2
这样就表明我们要创建2个 Buffer Pool 实例,示意图就是这样:
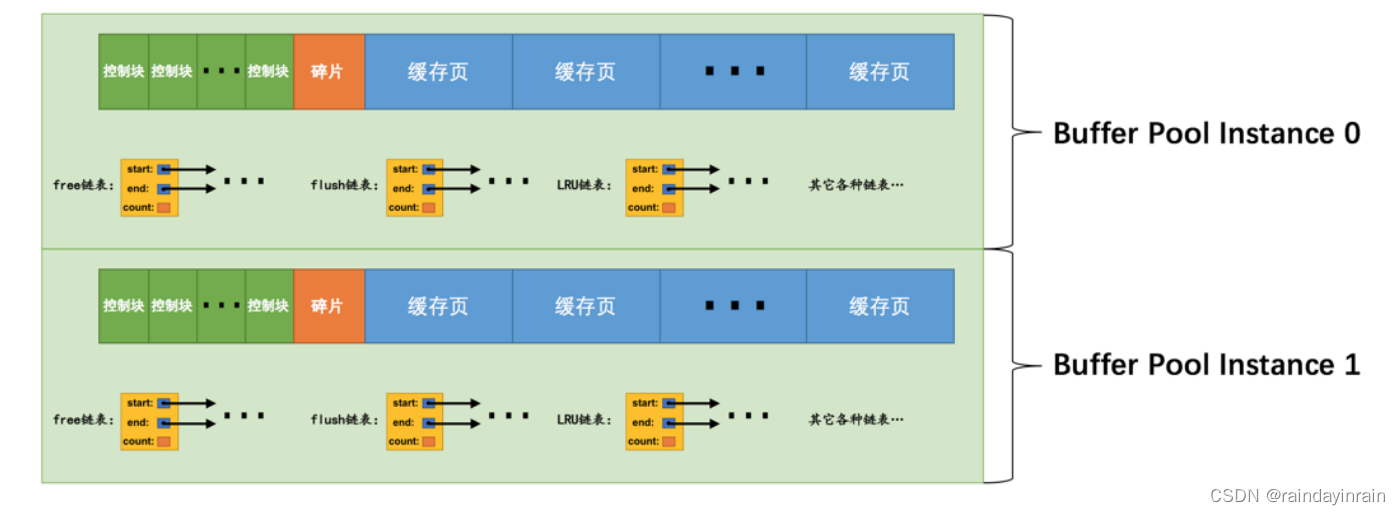
那每个 Buffer Pool 实例实际占多少内存空间呢?其实使用这个公式算出来的:innodb_buffer_pool_size/innodb_buffer_pool_instances。
也就是总共的大小除以实例的个数,结果就是每个 Buffer Pool 实例占用的大小。
不过也不是说 Buffer Pool 实例创建的越多越好,分别管理各个 Buffer Pool 也是需要性能开销的,设计 InnoDB 的大叔们规定:当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把 innodb_buffer_pool_instances 的值修改为1。而我们鼓励在 Buffer Pool 大小或等于1G的时候设置多个 Buffer Pool 实例。
4.innodb_buffer_pool_chunk_size
在 MySQL 5.7.5 之前, Buffer Pool 的大小只能在服务器启动时通过配置 innodb_buffer_pool_size 启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过设计 MySQL 的大叔在 5.7.5 以及之后的版本中支持了在服务器运行过程中调整 Buffer Pool 大小的功能,但是有一个问题,就是每次当我们要重新调整 Buffer Pool 大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的 Buffer Pool 中的内容复制到这一块新空间,这是极其耗时的。所以设计 MySQL 的大叔们决定不再一次性为某个 Buffer Pool 实例向操作系统申请一大片连续的内存空间,而是以一个所谓的 chunk 为单位向操作系统申请空间。也就是说一个 Buffer Pool 实例其实是由若干个 chunk 组成的,一个 chunk 就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块,画个图表示就是这样:
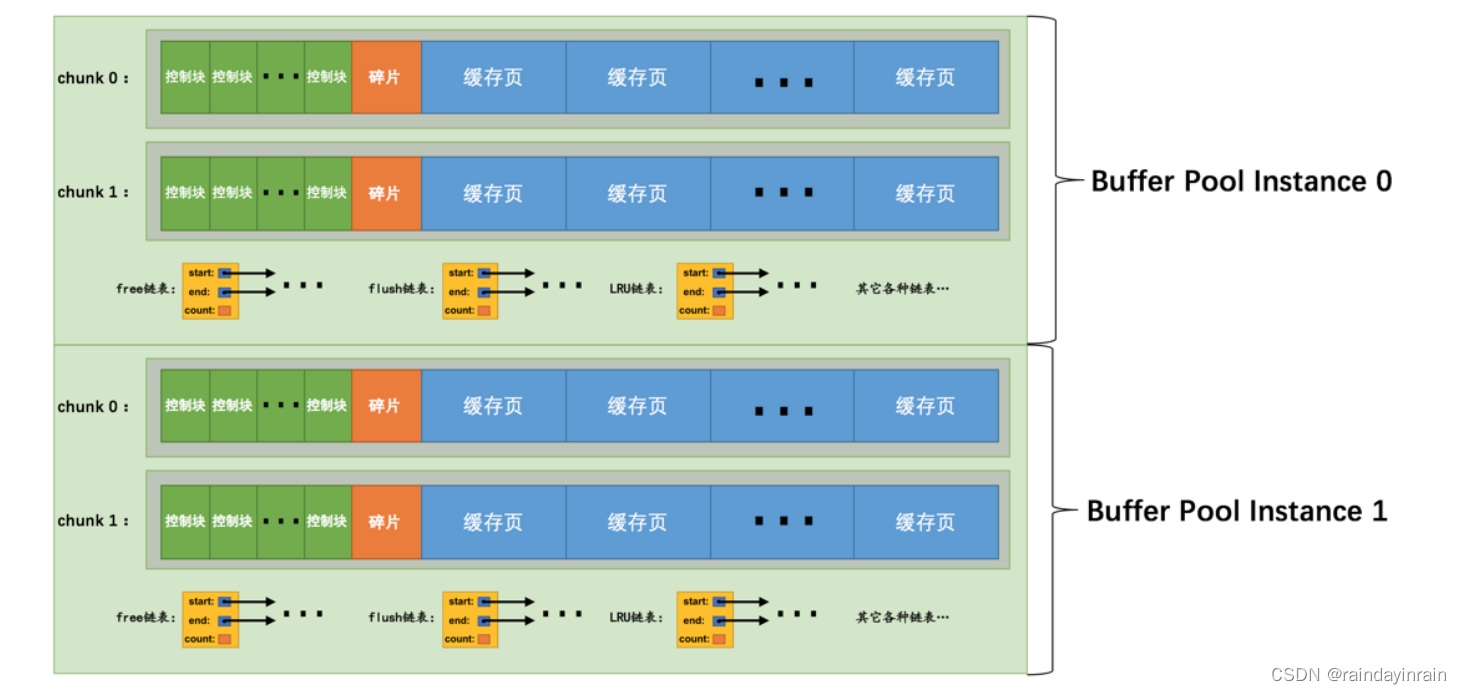
上图代表的 Buffer Pool 就是由2个实例组成的,每个实例中又包含2个 chunk 。
正是因为发明了这个 chunk 的概念,我们在服务器运行期间调整 Buffer Pool 的大小时就是以 chunk 为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的 chunk 的大小是我们在启动操作 MySQL 服务器时通过 innodb_buffer_pool_chunk_size 启动参数指定的,它的默认值是 134217728 ,也就是 128M 。注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
这个innodb_buffer_pool_chunk_size的值并不包含缓存页对应的控制块的内存空间大小,所以实际上InnoDB向操作系统申请连续内存空间时,每个chunk的大小要比innodb_buffer_pool_chunk_size的值大一些,约5%。
5.配置Buffer Pool时的注意事项
(1). innodb_buffer_pool_size 必须是 innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances 的倍数。
假设我们指定的 innodb_buffer_pool_chunk_size 的值是 128M , innodb_buffer_pool_instances 的值是16 ,那么这两个值的乘积就是 2G ,也就是说 innodb_buffer_pool_size 的值必须是 2G 或者 2G 的整数倍。比方说我们在启动 MySQL 服务器是这样指定启动参数的: mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16。
默认的 innodb_buffer_pool_chunk_size 值是 128M ,指定的 innodb_buffer_pool_instances 的值是 16 ,所以 innodb_buffer_pool_size 的值必须是 2G 或者 2G 的整数倍,上边例子中指定的innodb_buffer_pool_size 的值是 8G ,符合规定,所以在服务器启动完成之后我们查看一下该变量的值就是我们指定的 8G (8589934592字节)。
如果我们指定的 innodb_buffer_pool_size 大于 2G 并且不是 2G 的整数倍,那么服务器会自动的把innodb_buffer_pool_size 的值调整为 2G 的整数倍。
(2). 如果在服务器启动时, innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances 的值已经大于 innodb_buffer_pool_size 的值,那么 innodb_buffer_pool_chunk_size 的值会被服务器自动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances 的值。
比方说我们在启动服务器时指定的 innodb_buffer_pool_size 的值为 2G ,innodb_buffer_pool_instances 的值为16, innodb_buffer_pool_chunk_size 的值为 256M 。
innodb_buffer_pool_chunk_size 值会被服务器改写为innodb_buffer_pool_size/innodb_buffer_pool_instances 的值,也就是: 2G/16 = 128M (134217728字节)
6.Buffer Pool中存储的其它信息
Buffer Pool 的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息,这些内容等我们之后遇到了再详细讨论哈~
7.查看Buffer Pool的状态信息
设计 MySQL 的大叔贴心的给我们提供了 SHOW ENGINE INNODB STATUS 语句来查看关于 InnoDB 存储引擎运行过程中的一些状态信息,其中就包括 Buffer Pool 的一些信息,我们看一下(为了突出重点,我们只把输出中关于 Buffer Pool 的部分提取了出来):
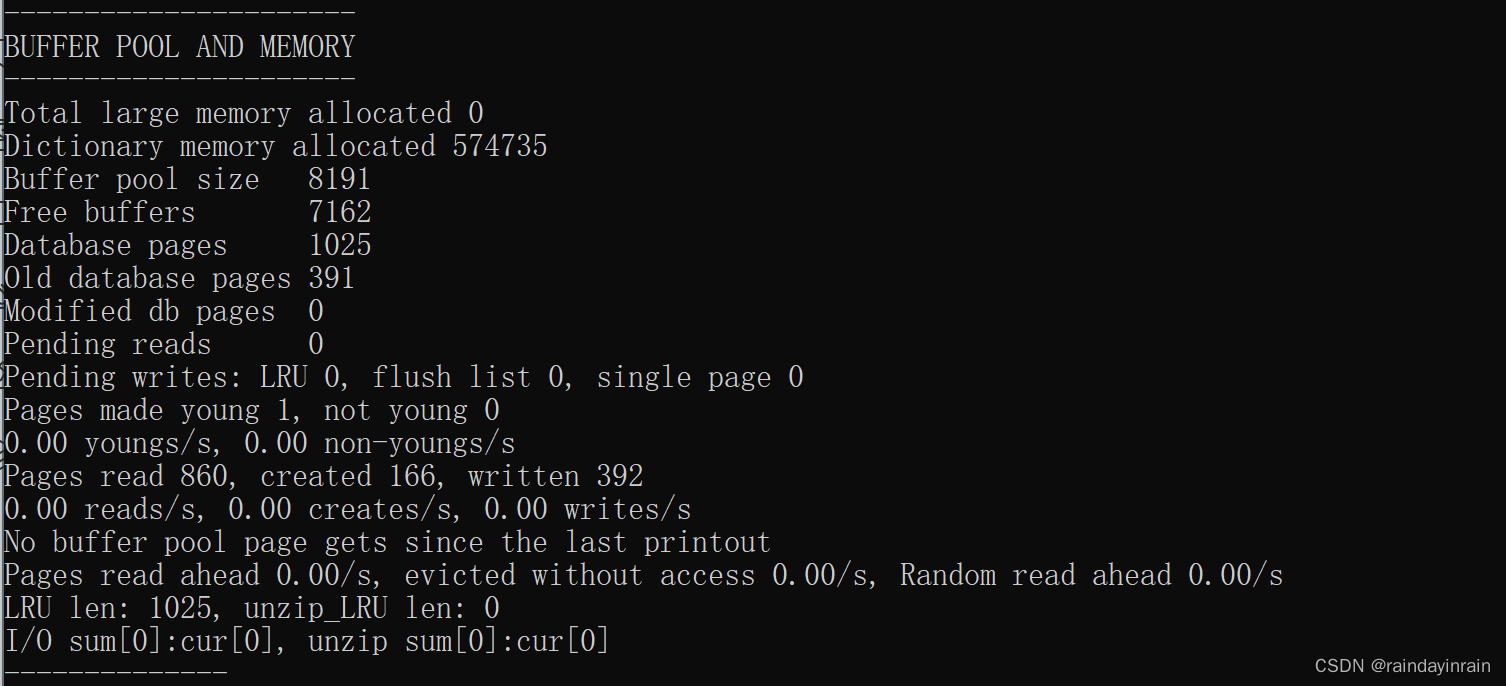
我们来详细看一下这里边的每个值都代表什么意思:
(1). Total memory allocated :代表 Buffer Pool 向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。
(2). Dictionary memory allocated :为数据字典信息分配的内存空间大小,注意这个内存空间和 Buffer Pool 没啥关系,不包括在 Total memory allocated 中。
(3). Buffer pool size :代表该 Buffer Pool 可以容纳多少缓存 页 ,注意,单位是 页 !
(4). Free buffers :代表当前 Buffer Pool 还有多少空闲缓存页,也就是 free链表 中还有多少个节点。
(5). Database pages :代表 LRU 链表中的页的数量,包含 young 和 old 两个区域的节点数量。
(6). Old database pages :代表 LRU 链表 old 区域的节点数量。
(7). Modified db pages :代表脏页数量,也就是 flush链表 中节点的数量。
(8). Pending reads :正在等待从磁盘上加载到 Buffer Pool 中的页面数量。
当准备从磁盘中加载某个页面时,会先为这个页面在 Buffer Pool 中分配一个缓存页以及它对应的控制块,然后把这个控制块添加到 LRU 的 old 区域的头部,但是这个时候真正的磁盘页并没有被加载进来, Pending reads 的值会跟着加1。
(9). Pending writes LRU :即将从 LRU 链表中刷新到磁盘中的页面数量。
(10). Pending writes flush list :即将从 flush 链表中刷新到磁盘中的页面数量。
(11). Pending writes single page :即将以单个页面的形式刷新到磁盘中的页面数量。
(12). Pages made young :代表 LRU 链表中曾经从 old 区域移动到 young 区域头部的节点数量。
这里需要注意,一个节点每次只有从 old 区域移动到 young 区域头部时才会将 Pages made young 的值加 1,也就是说如果该节点本来就在 young 区域,由于它符合在 young 区域1/4后边的要求,下一次访问这个页面时也会将它移动到 young 区域头部,但这个过程并不会导致 Pages made young 的值加1。
(13). Page made not young :在将 innodb_old_blocks_time 设置的值大于0时,首次访问或者后续访问某个处在 old 区域的节点时由于不符合时间间隔的限制而不能将其移动到 young 区域头部时, Page made not young 的值会加1。
这里需要注意,对于处在 young 区域的节点,如果由于它在 young 区域的1/4处而导致它没有被移动到 young 区域头部,这样的访问并不会将 Page made not young 的值加1。
(14). youngs/s :代表每秒从 old 区域被移动到 young 区域头部的节点数量。
(15). non-youngs/s :代表每秒由于不满足时间限制而不能从 old 区域移动到 young 区域头部的节点数量。
(16). Pages read 、 created 、 written :代表读取,创建,写入了多少页。后边跟着读取、创建、写入的速率。
(17). Buffer pool hit rate :表示在过去某段时间,平均访问1000次页面,有多少次该页面已经被缓存到 Buffer Pool 了。
(18). young-making rate :表示在过去某段时间,平均访问1000次页面,有多少次访问使页面移动到 young 区域的头部了。
需要大家注意的一点是,这里统计的将页面移动到 young 区域的头部次数不仅仅包含从 old 区域移动到 young 区域头部的次数,还包括从 young 区域移动到 young 区域头部的次数(访问某个 young 区域的节点,只要该节点在 young 区域的1/4处往后,就会把它移动到 young 区域的头部)。
(19). not (young-making rate) :表示在过去某段时间,平均访问1000次页面,有多少次访问没有使页面移动到 young 区域的头部。
需要大家注意的一点是,这里统计的没有将页面移动到 young 区域的头部次数不仅仅包含因为设置了 innodb_old_blocks_time 系统变量而导致访问了 old 区域中的节点但没把它们移动到 young 区域的次数,还包含因为该节点在 young 区域的前1/4处而没有被移动到 young 区域头部的次数。
(20). LRU len :代表 LRU链表 中节点的数量。
(21). unzip_LRU :代表 unzip_LRU链表 中节点的数量(由于我们没有具体唠叨过这个链表,现在可以忽略它的值)。
(22). I/O sum :最近50s读取磁盘页的总数。
(23). I/O cur :现在正在读取的磁盘页数量。
(24). I/O unzip sum :最近50s解压的页面数量。
(25). I/O unzip cur :正在解压的页面数量。
相关文章:
mysql原理--InnoDB的Buffer Pool
1.缓存的重要性 对于使用 InnoDB 作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以 页 的形式存放在 表空间 中的,而所谓的 表空间 只不过是 InnoDB 对…...
Redis不同环境缓存同一条数据,数据内部值不同
背景 现实中,本地环境(dev)和开发环境(feature)会共同使用相同的中间件(本篇拿Redis举例),对于不同环境中的,图片、视频、语音等资源类型的预览地址url,需要配…...
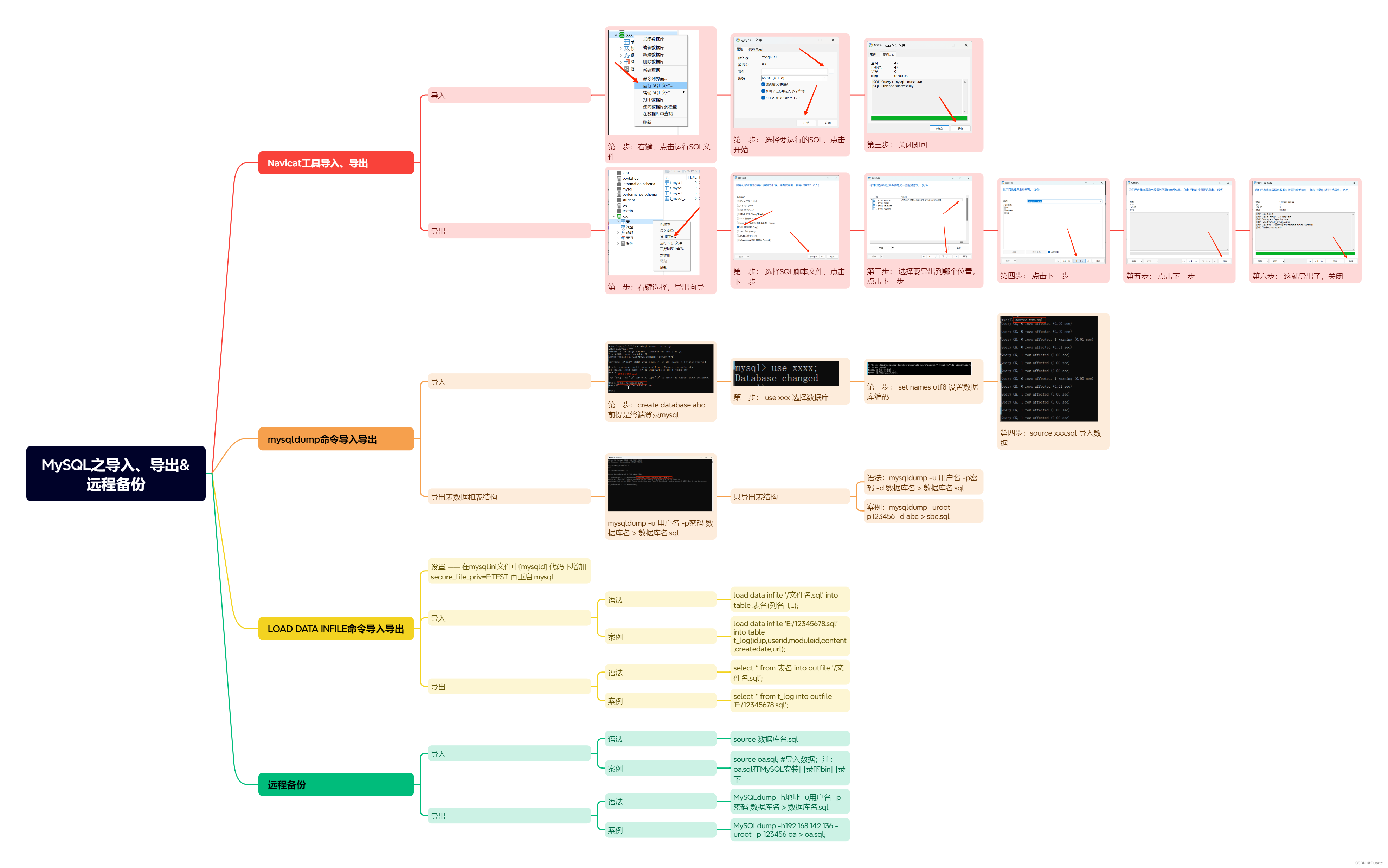
MySQL之导入、导出远程备份
一、Navicat工具导入、导出 1.1 导入 第一步: 右键,点击运行SQL文件 第二步: 选择要运行的SQL,点击开始 第三步: 关闭即可 1.2 导出 第一步: 右键选择,导出向导 第二步: 选择SQL脚…...
OpenGL学习笔记-Blending
混合方程中,Csource是片段着色器输出的颜色向量(the color output of the fragment shader),其权重为Fsource。Cdestination是当前存储在color buffer中的颜色向量(the color vector that is currently stored in the …...
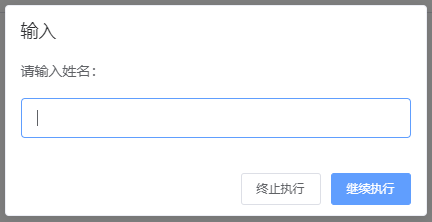
支持 input 函数的在线 python 运行环境 - 基于队列
支持 input 函数的在线 python 运行环境 - 基于队列 思路两次用户输入三次用户输入 实现前端使用 vue element uiWindows 环境的执行器子进程需要执行的代码 代码仓库参考 本文提供了一种方式来实现支持 input 函数,即支持用户输的在线 python 运行环境。效果如下图…...

欧拉Euler release 21.10 (LTS-SP2)升级openssh至9版本记录
背景:安扫漏洞,需要对openssh经行升级 1.先查看升级前的openssh版本 2.避免升级失败断开远程登录,先开启telnt服务用于远程连接(这步可查看其他博客) 3.从欧拉官网下载rpm包,https://www.openeuler.org/zh…...
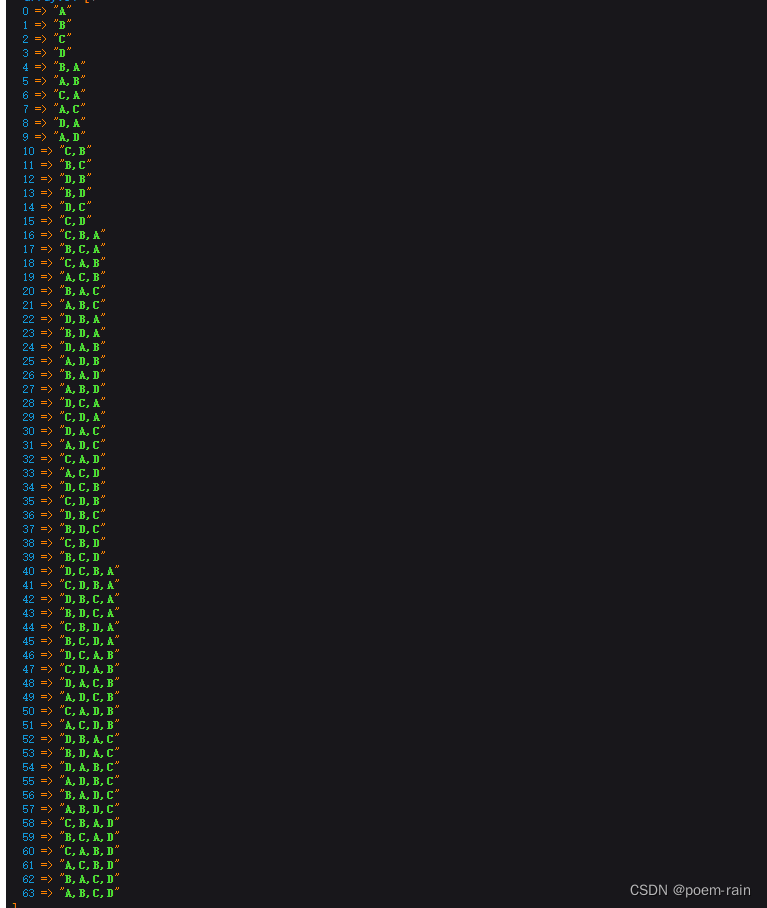
php 数组中的元素进行排列组合
需求背景:计算出数组[A,B,C,D]各种排列组合,希望得到的是数据如下图 直接上代码: private function finish_combination($array, &$groupResult [], $splite ,){$result [];$finish_result [];$this->diffArrayItems($array, $…...
Python从入门到网络爬虫(OS模块详解)
前言 本章介绍python自带模块os,os为操作系统 operating system 的简写,意为python与电脑的交互。os 模块提供了非常丰富的方法用来处理文件和目录。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面页可以极大增强…...

人机交互不是人机融合智能
一、人机交互和人机融合智能是两个不同的概念 人机交互是指人类与计算机之间的信息交流和操作方式,包括输入和输出界面、交互技术、用户体验等方面。人机交互的目标是提供用户友好的界面和自然的交互方式,使人类能够与计算机更加高效地进行沟通和协作。 …...

RabbitMQ解决消息丢失以及重复消费问题
文章目录 1、概念2、基于ACK/NACK机制2.1 基于Spring AMQP框架整合ACK/NACK机制2.2 测试消费失败1.02.3 测试结果1.02.4 测试MQ宕机2.5 测试结果2.0 3、RabbitMQ 如何实现幂等性设计3.1 幂等服务设计思路3.1.1 通过雪花算法生成分布式唯一ID3.1.2 通过枚举类,设计Me…...

docker 安装redis集群
一、准备6台机器 二、6台机器分别拉取镜像: docker pull redis三、6台机器分别建立挂载文件夹 mkdir -p /home/redis/data四、6台机器分别执行容器操作 docker run --restartalways -d --name redis-node-1 --net host --privilegedtrue -v /home/redis/data:/da…...

锂电池制造设备中分布式IO模块优势
在“碳达峰、碳中和”目标推动下,新能源汽车当下发展势头正盛,而纯电动车的核心部件则是:锂电池。动力型锂电池作为新能源汽车核心零部件,其发展与新能源汽车行业息息相关,迎来广阔的市场空间。 为何采用I/O模块&#…...

Android Room数据库升级Migration解决方案
一、介绍 Android Room 是 Android 官方提供的一个轻量级数据库框架,用于在 Android 应用程序中管理数据持久性。它简化了数据库访问,提供了更安全、更快速的数据存储方式,并使得数据操作更加便捷。 二、Room的特点(八股文可以参考) 以下是…...

离线安装docker和docker-compose
1.下载 docker Index of linux/static/stable/x86_64/ docker-compose Overview of installing Docker Compose | Docker Docs 2.docker /etc/systemd/system/docker.service [Unit] DescriptionDocker Application Container Engine Documentationhttps://docs.docker.…...

奇怪的事情记录:外置网卡和外置显示器不兼容
身为程序员,不应该对世界上的稀奇古怪的事情感到惊讶(毕竟,大部分都是程序员自己搞出来的)。 外置网卡和外置显示器不兼容 mbp2019intel版,win10,外接有线网卡,平时用得很好,接上外…...
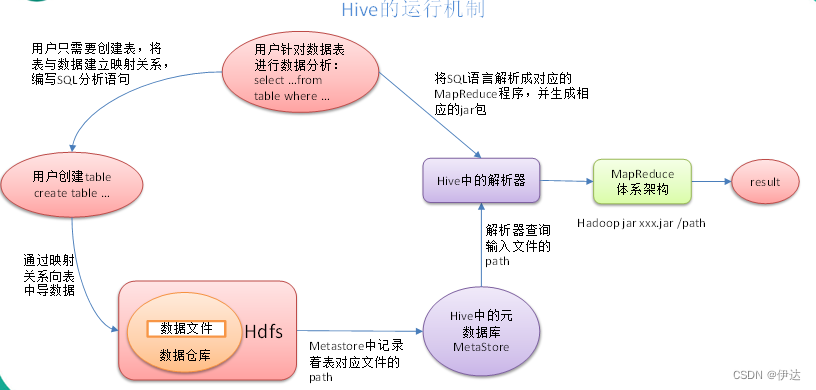
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门
目录 1、什么是Hive 2、Hive的优缺点 2.1、 优点 2.2、 缺点 2.2.1、Hive的HQL表达能力有限 2.2.2、Hive的效率比较低 3、Hive架构原理 3.1、用户接口:Client 3.2、元数据:Metastore 3.3、Hadoop 3.4、驱动器:Driver Hive运行机制…...

第三代量子计算机交付,中国芯片开辟新道路,光刻机难挡中国芯
日前安徽本源量子宣布第三代超导量子计算系统正式上线,这是中国最先进的量子计算机,计算量子比特已达到72个,在全球已居于较为领先的水平,这对于中国芯片在原来的硅基芯片受到光刻机阻碍无疑是巨大的鼓舞。 据悉本源量子的第一代、…...
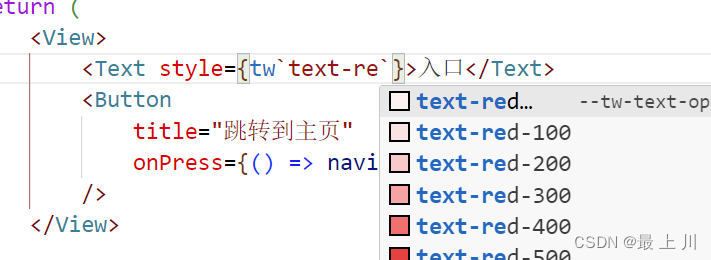
react native中使用tailwind并配置自动补全
使用的第三方库是tailwind-react-native-classnames,同类的也有tailwind-rn,但是我更喜欢前者官方demo: import { View, Text } from react-native; import tw from twrnc;const MyComponent () > (<View style{twp-4 android:pt-2 b…...
数据分析——火车信息
任务目标 任务 1、整理火车发车信息数据,结果的表格形式为: 2、并输出最终的发车信息表 难点 1、多文件 一个文件夹,多个月的发车信息,一个excel,放一天的发车情况 2、数据表的格式特殊 如何分析表是一个难点 数…...
Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

aardio 自动识别验证码输入
技术尝试 上周在发学习日志时有网友提议“在网页上识别验证码”,于是尝试整合图像识别与网页自动化技术,完成了这套模拟登录流程。核心思路是:截图验证码→OCR识别→自动填充表单→提交并验证结果。 代码在这里 import soImage; import we…...

HTTPS证书一年多少钱?
HTTPS证书作为保障网站数据传输安全的重要工具,成为众多网站运营者的必备选择。然而,面对市场上种类繁多的HTTPS证书,其一年费用究竟是多少,又受哪些因素影响呢? 首先,HTTPS证书通常在PinTrust这样的专业平…...