Transformer 的双向编码器表示 (BERT)
一、说明
本文介绍语言句法中,最可能的单词填空在self-attention的表现形式,以及内部原理的介绍。
二、关于本文概述
在我之前的博客中,我们研究了关于生成式预训练 Transformer 的完整概述,关于生成式预训练 Transformer (GPT) 的博客- 预训练、微调和不同用例应用程序。以及有关所有仅解码器模型的解码策略的博客。
让我们看看如何使用 Transformer 的编码器(仅编码器模型)来构建语言模型
就 GPT 而言,我们使用因果语言模型,这意味着我们从左到右输入输入,当我们预测当前单词时,我们只查看历史记录,而不查看之后的任何其他内容,但这里 BERT 是用稍微不同的意图是我们想要捕捉文本的本质,在这种情况下,如果我们查看当前单词之后的单词,这也可能有助于建立单词之间的关系,即当前单词之前的单词以及就像它之后一样。
这就是 GPT 中发生的情况,例如,如果我们有一个句子

我们可以为下一个单词提供不同的输出,这非常适合文本生成等任务,并且这在当前一代的 LLM 中比这些仅编码器模型(如 BERT)更流行 - 我们知道目前大多数大规模 LLM大约是仅解码器模型或仅编码器-解码器模型。
诸如命名实体识别 (NER) 之类的任务怎么样?在这种情况下,我们可能需要依赖当前单词之后可能出现的单词来决定它是什么类型的 NER。在这里,我们需要进行双向表示或交互,例如“我从德里去了果阿”。在这种情况下,“前往果阿”也可能有助于确定德里的 NER 位置。因此,这就是我们可以查看当前单词两侧的单词的动机,如果我们查看像“主语宾语动词”这样的语言,其中宾语与两侧的主语和动词都有关系。或者“主语动词宾语”其中动词与主语和宾语有关系。
假设我们有填空的任务 -
— — — — — 已将其新操作系统运送到 — — — — 手机上。
在这种情况下,根据空白后面的所有内容 - 我们可以预测它是一个已经发货的公司名称,并且它必须是compnay。因此,此类任务需要双方的上下文,因此研究允许我们使用双方输入的模型是有意义的,这也是 BERT 背后的基本思想。那么我们如何从输入数据的两侧启用上下文建模,为此他们提出了掩码语言建模。在GPT 的情况下,我们从左到右获取上下文,该建模称为因果语言建模。
我们需要查看两个方向(周围的单词)来预测屏蔽单词
i — — — — — 读取 — — — — -[eos]
使用两个方向的上下文单词预测屏蔽单词(如 CBOW)。这称为掩码语言建模 (MLM)。现在我们不能使用变压器的解码器组件,因为它本质上是单向的。所以这里我们可以使用变压器的编码器部分。现在,问题被转换为

我们预测的掩码是相互独立的,即,如果我们屏蔽了第二个和第八个标记,并且我们在第二个标记处预测了某些内容,那么我们不会使用该信息来预测第八个标记。对于第 8 个标记,我们仍然认为第二个标记仍然是掩码,对于第二个标记,我们仍然认为第 8 个标记是掩码。我们可以将一个句子视为 20 个标记 - 一些 3 个标记被屏蔽,我们需要通过仅查看剩余的 17 个标记来预测这 3 个标记,并且我们不会按顺序执行此操作,即,我们不会先预测第二个标记,然后再预测被屏蔽的第 8 个令牌现在识别 18 个令牌,而不是最初可用的 17 个令牌。因此,仅使用 17 个令牌即可预测一切。
现在让我们看看是否可以屏蔽一些输入并为这些屏蔽的单词生成输出。在仅解码器模型(因果语言建模)中,我们看到当前单词焦点之后的单词看不到,并且它们被屏蔽以进行预测(第 i 个单词之后的单词或标记以顺序方式屏蔽,其中具有无穷大值的超训练矩阵使用 - 请参阅之前的博客)。


这里我们也可以屏蔽掉一些单词,看看屏蔽掉的单词是什么?我们知道,在自注意力层中,每个单词都会关注单词序列中的每个其他单词。我们的目标是随机屏蔽一些单词并预测被屏蔽的单词

掩码不是连续的,但它们出现在随机位置,我们将它们的位置放置为无穷大值,它们对注意力权重解决方案的贡献为零。

我们可以像 CLM 中那样屏蔽要屏蔽的单词的注意力权重吗?
假设我们要屏蔽第一个单词和第四个单词的单词或标记——我们可以有这样的掩码矩阵。我们可以像下面这样引入Mask吗?没有为什么?


因为我们希望模型了解(注意)空白是什么,这样它们就不会从方程中删除。我们可以将掩码视为破坏原始输入文本的噪声。然后模型的任务是恢复原始令牌。这类似于自动编码器的去噪目标。因此,掩码语言建模(MLM)也被称为预训练去噪目标。因此,我们不能使用屏蔽自我注意力,但我们可以使用称为屏蔽令牌的特殊令牌,即,这些成为词汇表中的单词之一,与我们所使用的单词相同,例如,我、你、我等,所以这里是“屏蔽”也是词汇表中的单词之一。

变压器的输入是带有随机屏蔽数据的序列,这会将其传递给编码器,编码器将在每一层生成 T 个表示,直到最后一层。在最后一层的适当点,我们想要预测实际的单词是什么。
假设我们只有 1 层——在这一层的末尾,我们可以通过这种方式看到分布。

请注意,仅预测一组 M 个屏蔽词,因此计算这些预测的交叉熵损失。通常,输入序列中 15% 的单词被屏蔽。非常高的掩蔽会导致服务器丢失上下文信息,并且模型将无法学习良好的表示。另一方面,很少的掩蔽需要很长时间才能收敛(因为梯度值相对较小)并且使训练效率低下。但是,可以根据模型大小、掩蔽方案和优化算法进行权衡。
多层双向变压器编码器架构
BERT 基础模型包含 12 层,每层 12 个注意力头

输入序列中的屏蔽词(15%)被均匀采样。其中,80% 被替换为 [mask] token,10% 被替换为随机单词,其余 10% 保留原样。(为什么?)
假设我们有 200 个标记的输入序列,并且我们选择其中 15% 被屏蔽,那么 200 个(30 个单词)中的 15% 将被屏蔽。在这 30 个单词中,其中 80%(24 个单词)被替换为mask token ,这 3 个单词(30 个单词)中的 10% 被随机单词替换,另外 10%(30 个单词)3 个单词被保留为原样 —我们为什么要在保留方面这样做?
在适应下游任务时,特殊掩码标记不会成为数据集的一部分。
我们还有一个目标函数,称为
三、下一句话预测(NSP):
现在,让我们用一对句子 (A,B) 和指示句子 B 是否自然地跟随句子 A 的标签来扩展输入。
输入:句子:A
输入:设置:B
标签 : 下一个

我们这里有特殊的标记,如“CLS”(句子开头)和“SEP”(分隔符)。原始序列将变为 T +2 个令牌,因此每一层的输出也将具有 T+2 表示。我们的目标是检查第二个句子是否实际上是第一个句子的下一个句子。因此,首先我们将采用属于“CLS”的第一个表示,从这里我们将尝试解决简单的二元任务,即第二个句子是否实际上是第一个句子的下一个句子。那么我们如何创建用于创建此任务的训练数据呢?我们已经有了带有 a、b 的自然句子,它们是句子对和代表下一个句子标志的标签 (1/0)。在训练过程中,我们传递两个输入(a,b)和一个标签,它的工作是最大化概率(1/0)。总的来说,我们看到了两个目标,第一个目标是使用词汇表上的交叉熵损失正确预测屏蔽标记,第二个目标是下一个句子预测,这只是一个二元分类问题。
在 50% 的情况下,句子 B 是句子 A 之后的自然句子。在 50% 的情况下,句子 B 是来自标记为 NotNext 的语料库的随机句子。使用 NSP 目标进行预训练可显着提高问答 (QA) 和类似任务的性能。

这是早期的发现,但一年后,这个 NSP 目标对下游任务并没有多大帮助,之后通常会被删除, 并且在 BERT 的衍生版本中只使用了屏蔽语言建模目标。
我们将有令牌嵌入,其中我们得到 |v| 的所有单词的嵌入矩阵 x dmodel(v — 是词汇表,dmodel 是维度)。除此之外,我们还为每个分段提供了分段嵌入,其中它是 2 x dmodel。我们还有位置嵌入,将所有这些加起来为变压器提供一个统一的嵌入。

因此,在上面我们可以看到很多编码器层,其中最后一层将包含最终表示的详细信息。我们将对下一句预测目标进行预测,并且还将预测屏蔽语言模型。所以这里的总损失是语言建模的损失+下一个句子预测的损失。

四、预训练和参数
数据集:

模型架构:






参数计算

我们的词汇量为 30000,每个单词或标记都以 768 个维度表示。

有 3 个矩阵 (Wk, Wq, Wv) ,每个矩阵都有 768 维的输入,12 个注意力头生成 - 12 … 64 维嵌入,当我们连接它们时,我们将得到 768 维。对于 Wo 矩阵,一旦连接我们就得到了 768 x 768 ~0.6M 的线性层。
在 FFN 中,768 向量将转换为 3072,而这个 3072 将转换回 768,然后我们就有偏差 (3072 + 768) 。
五、适应下游任务
现在我们已经完成了预训练,输入来自维基百科语料库(25 亿个单词)和书籍语料库(8 亿个单词),其中我们有长度为 512 的句子或段落,我们将整个内容作为输入,其中一些单词被屏蔽,我们知道这些屏蔽单词是什么,因为它们存在于维基百科中,并且我们知道正确的输出是什么样的。此训练是通过大量训练示例完成的,并非针对任何特定任务(问答、NER 等)进行训练。这种预训练只是为了学习语言而进行的。现在我们想使用这个预训练模型,我们相信它现在对语言有了更好的理解。鉴于这已经学到了很多关于我们的语言的知识,我们只是希望通过合理数量的标记数据,我们将在所有下游任务上获得良好的性能。当时有两种流行的方法。

六、分类:基于特征

现在假设我们已经对模型进行了预训练,我们有一个称为“CLS”的特殊标记,当我们在每一层计算 CLS 的后续表示时,它当然会看到输入句子中的所有单词,因为它正在采取加权注意力。如果我们将其用于下游任务,则句子中不会有任何掩码。我们可以假设“CLS”充当聚合器,因为它本身没有任何意义,因为它是一个特殊的代币。
假设我们已经通过情感分析对评论数据进行了标记,并且希望在情感分析这一下游任务中使用这些预先训练的知识。

获取这个输入序列并将其传递给 BERT(这句话的长度小于 512,如果需要,可以进行适当的填充),在 12 层 BERT 之后,它给出了所有标记的最终结果表示 - 我们只采用 CLS 标记的表示,我们认为这是输入序列的丰富表示,因为这种表示是基于经过训练的 BERT 模型构建的,该模型已经看到了大量语言数据,因此它知道语言交互是什么以及如何捕获它们,然后给出一种表示。在传统的机器学习中,我们有特征表示,然后在其之上我们使用机器学习模型——我们可以在这里使用相同的想法,只不过特征表示来自 BERT。我们从最后一层获取 CLS 最终表示并将其用作输入 - 这种表示优于仅连接单个单词的表示(例如 word2vec),或者例如逻辑回归或任何其他分类模型。


BERT的所有参数都被冻结,只有分类头从头开始训练。

在上面的身体部分 - 我们没有在这里训练任何东西,因为训练已经完成了。整个过程是静态的,因为我们只进行一次训练,然后将 X 与所有训练数据结合起来,转换为 X 个特征,然后忘记我们之前的 BERT。当然,当我们在测试时有新的评论时,我们将转换为 X 特征并将该特征作为输入传递给 ML 模型。
分类: 微调:
取一个长度小于 512 的句子并将其作为 BERT 的输入(如果需要,可以使用适当的填充)
添加分类头(同样可以是任何合适的 ML 模型)。随机初始化分类头的参数。
现在,训练整个模型,包括新数据集预训练 BERT 的参数。但请注意,我们不会屏蔽输入序列中的单词(这就是我们在预训练期间用随机单词替换 10% 的屏蔽单词的原因)。据观察,分类头中使用的模型比基于特征的方法使用更少数量的标记训练样本来快速收敛。

我们将从整个网络反向传播——我们可以训练这里引入的新参数(768 x 2),并且还学习整个 Wq、Wk、Wv——实际上,这里发生的事情是网络中的所有内容开始专门用于该任务情感分析意味着它将尝试调整参数并在这项任务上做得很好。我们之前讨论的另一种方法将冻结上面显示的蓝色块,并且它不会通过该块进行反向传播,并且该块将保持静态。

S和E都是可学习的参数。
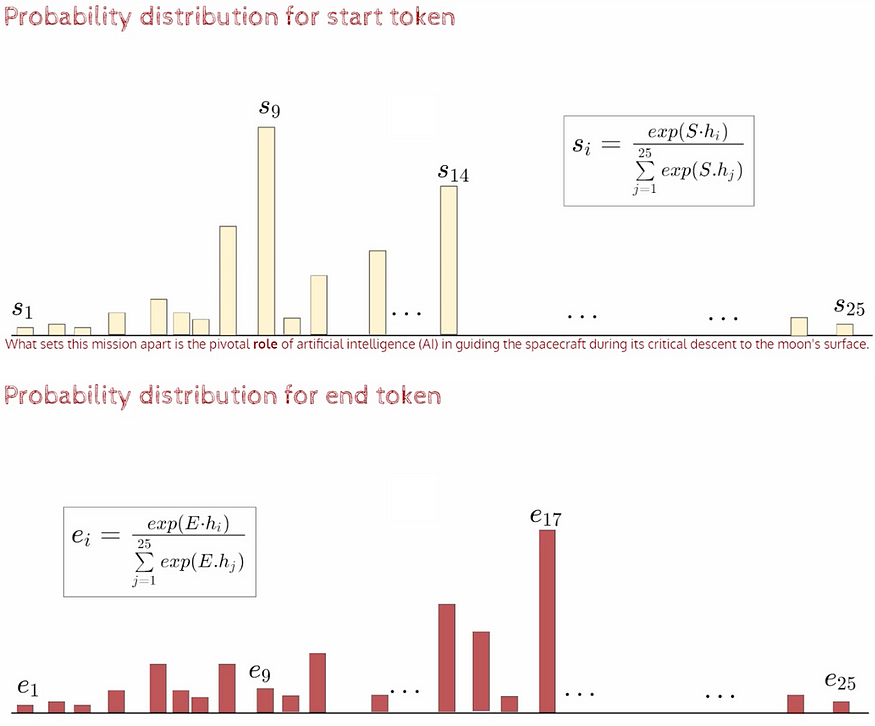

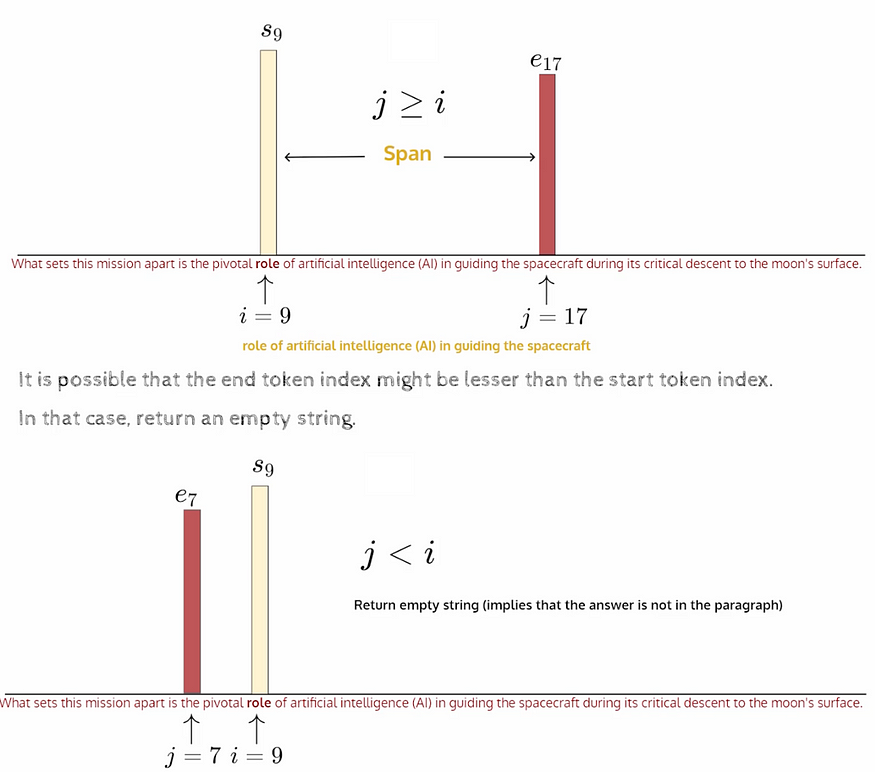
如果觉得有帮助请点赞👏或者评论❤️🙏
参考:
大型语言模型简介 —讲师:Mitesh M. Khapra
相关文章:
Transformer 的双向编码器表示 (BERT)
一、说明 本文介绍语言句法中,最可能的单词填空在self-attention的表现形式,以及内部原理的介绍。 二、关于本文概述 在我之前的博客中,我们研究了关于生成式预训练 Transformer 的完整概述,关于生成式预训练 Transformer (GPT) 的…...
关于LwRB环形缓冲区开源库的纯C++版本支持原子操作
1、LwRB环形缓冲区开源库: GitHub - MaJerle/lwrb: Lightweight generic ring buffer manager libraryLightweight generic ring buffer manager library. Contribute to MaJerle/lwrb development by creating an account on GitHub.https://github.com/MaJerle/l…...
微信小程序Canvas画布绘制图片、文字、矩形、(椭)圆、直线
获取CanvasRenderingContext2D 对象 .js onReady() {const query = wx.createSelectorQuery()query.select(#myCanvas).fields({ node: true, size: true }).exec((res) => {const canvas = res[0].nodeconst ctx = canvas.getContext(2d)canvas.width = res[0].width * d…...

Unity Editor实用功能:Hierarchy面板的对象上绘制按按钮并响应
目录 需求描述上代码打个赏吧 需求描述 现在有这样一个需求: 在Hierarchy面板的对象上绘制按钮点击按钮,弹出菜单再点击菜单项目响应自定义操作在这里的响应主要是复制对象层级路路径 看具体效果请看动图: 注: 核心是对Edito…...
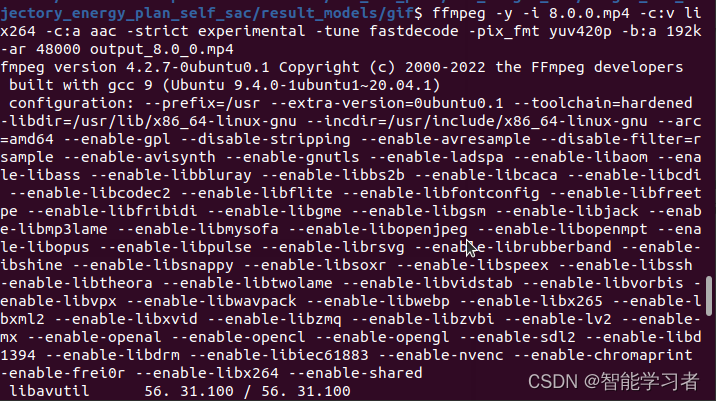
解决录制的 mp4 视频文件在 windows 无法播放的问题
解决录制的 mp4 视频文件在 windows 无法播放的问题 kazam 默认录制保存下来的 mp4 视频文件在 windows 中是无法直接使用的,这是由于视频编码方式的问题。解决办法: 首先安装 ffmeg 编码工具: sudo apt-get install ffmpeg 然后改变视频的…...

一键与图片对话!LLM实现图片关键信息提取与交互
本期文心开发者说邀请到飞桨开发者技术专家徐嘉祁,主要介绍了如何通过小模型与大模型的结合,解决数据分析中的问题。 项目背景 在智能涌现的大模型时代,越来越多的企业和研究机构开始探索如何利用大模型来提升工作效率,助力业务智…...

洛谷 P8833 [传智杯 #3 决赛] 课程 讲解
前言: 大家好! 我们又见面啦~~~ 对于我20多天没上号,深表歉意!! 希望大家给我的account点一个赞,加一个粉丝,谢谢! 也对CSDN的所有博主们送上衷心的祝福! 如有错误…...

中国IT产经新闻:新能源汽车发展前景与燃油车的利弊之争
随着科技的进步和环保意识的提高,新能源汽车在全球范围内逐渐受到重视。然而,在新能源汽车迅速发展的同时,燃油车仍然占据着主导地位。本文将从新能源与燃油车的利弊、新能源汽车的发展前景两个方面进行分析,以期为读者提供全面的…...

一、数据结构
一、 数组 1.1 数组 定义 遍历 // 遍历数组 传递指针 func traverse() {var b [...]int{1, 2, 3} //长度为3 元素为 1 2 3var ptr &b //ptr是指向数组的指针fmt.Println(b[0], b[1]) // 打印数组的前 2 个元素fmt.Println(ptr[0], ptr[1]) // 通…...

案例分享:各行业销售岗位的KPI指标制定分享
在当今竞争激烈的市场环境中,销售岗位的绩效考核至关重要。有效的绩效考核能帮助企业了解销售人员的业绩,激励他们提高效率,并确保销售战略的实现。关键绩效指标(KPI)作为绩效考核的核心,能精炼地反映销售人…...

【办公类-19-01】20240108图书统计登记表制作(23个班级)EXCEL复制表格并合并表格
背景需求: 制作一个EXCEL模板,每个班级的班主任统计 班级图书量(一个孩子10本,最多35个孩子350本) EXCEL模板 1.0版本: 将这个模板制作N份——每班一份 项目:班级图书统计表 核心:一个EXCEL模板批量生成…...
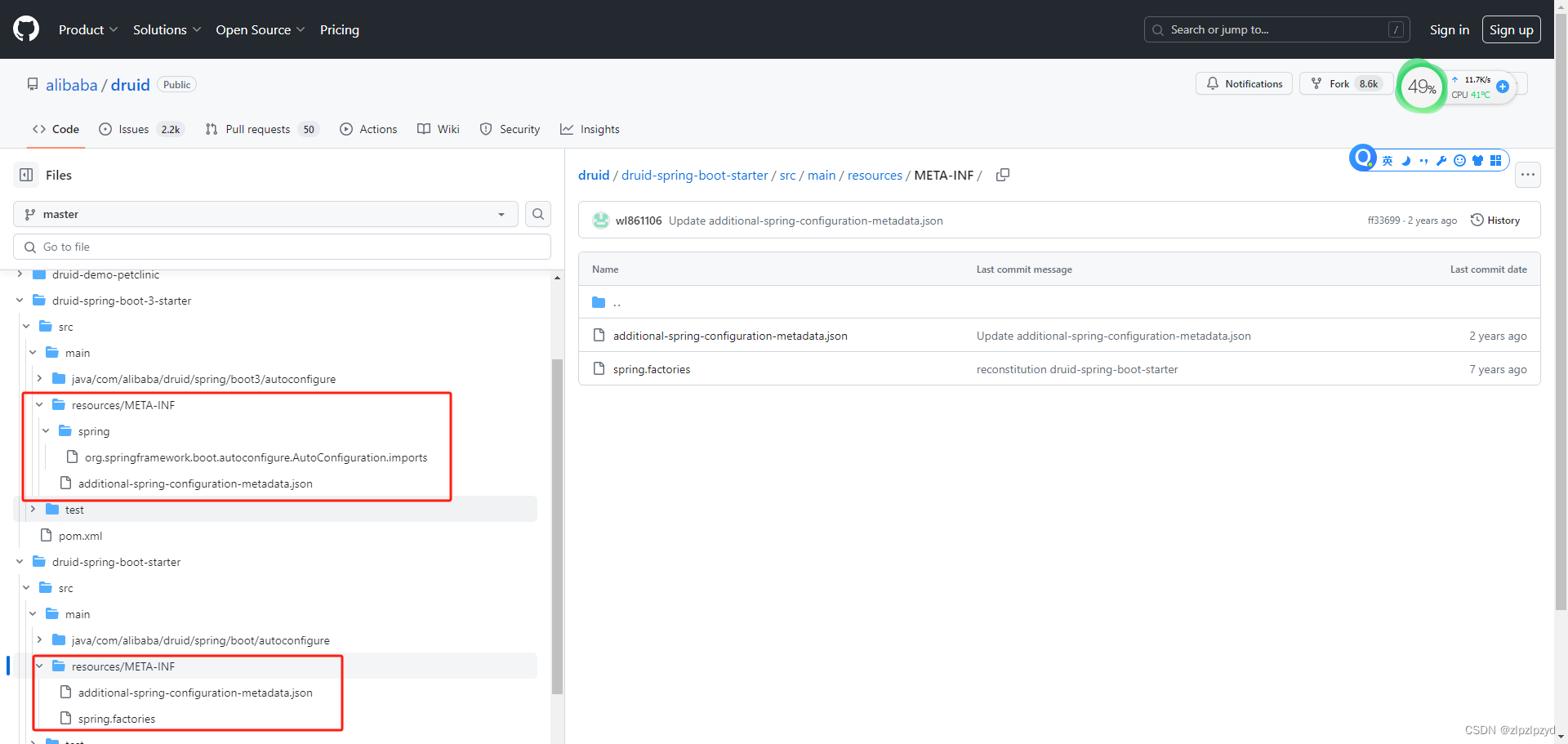
spring boot 2升级为spring boot 3中数据库连接池druid的问题
目录 ConfigurationClassPostProcessor ConfigurationClassBeanDefinitionReader MybatisPlusAutoConfiguration ConditionEvaluator OnBeanCondition 总结 近期给了一个任务,要求是对现有的 spring boot 2.x 项目进行升级,由于 spring boot 2.x 版…...

客服系统配置之Nginx处理静态资源和动态请求
Nginx直接处理静态资源,接口动态请求走反向代理到后端 这样可以减轻后端服务的压力 location / {try_files $uri kefu; }location kefu {# 这里是命名位置 kefu 的配置proxy_pass http://backend-server;# 其他反向代理的配置... }如果请求的是静态资源(…...

Golang 切片
前言 在Go语言中,切片是一个引用类型,它提供了对数组的动态窗口。切片并不存储任何数据,它只是描述了底层数组中的一个片段。切片的定义包括三个部分:指向数组的指针、切片的长度和切片的容量 基本使用 声明切片:声…...

防止公司办公终端文件数据 | 资料外泄,——自动智能透明加密防泄密软件系统
天锐绿盾公司电脑文件数据资料透明加密防泄密软件系统是一款专门用于保护企业电脑文件数据安全的软件系统。它采用透明加密技术,能够在不影响员工正常工作的情况下,对电脑上的文件数据进行自动加密,从而有效防止企业数据泄密。 PC端访问地址&…...

C#-枚举
枚举类型 (enum type) 是具有一组命名常量的独特的值类型。 下面的示例声明并使用一个名为 Color 的枚举类型,该枚举具有三个常量值 Red、Green 和 Blue: using System; using System;enum Color {Red,Green,Blue }class Test {static void PrintColor(…...
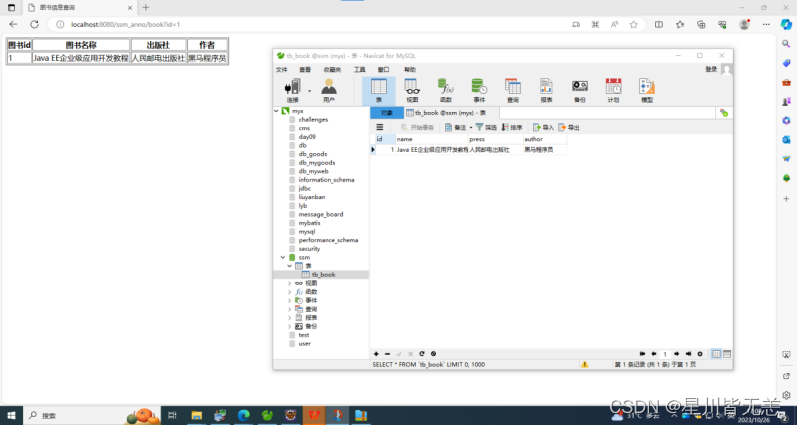
Java后端开发——SSM整合实验
文章目录 Java后端开发——SSM整合实验一、常用方式整合SSM框架二、纯注解方式整合SSM框架 Java后端开发——SSM整合实验 一、常用方式整合SSM框架 1.搭建数据库环境:MySQL数据库中创建一个名称为ssm的数据库,在该数据库中创建一个名称为tb_book的表 …...
VMware虚拟机安装Ubuntu
准备:Ubuntu的镜像文件,VMware,手. 1.新建虚拟机,选择自定义,下一步。 2.硬件兼容性,选择Workstation 16.x,下一步。 3.选择安装程序光盘映像文件,路径为映像文件所在文件夹,下一步。 4. 创建用户和设置密…...

用一个简单的例子说明单细胞分析中的dgCMatrix数据的结构
dgCMatrix用来存储矩阵的一种数据格式,这种数据格式很适合存储稀疏矩阵(即矩阵中大部分值为0)。dgCMatrix使用三个数组(分别是i,p,x)来存储矩阵。怎么存的呢? 先举一个普通矩阵的例…...
【小工具】pixi-live2d-display,直接可用的live2d的交互网页/桌面应用
效果: <script src"https://cubism.live2d.com/sdk-web/cubismcore/live2dcubismcore.min.js"></script> <script src"https://cdn.jsdelivr.net/gh/dylanNew/live2d/webgl/Live2D/lib/live2d.min.js"></script> <…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
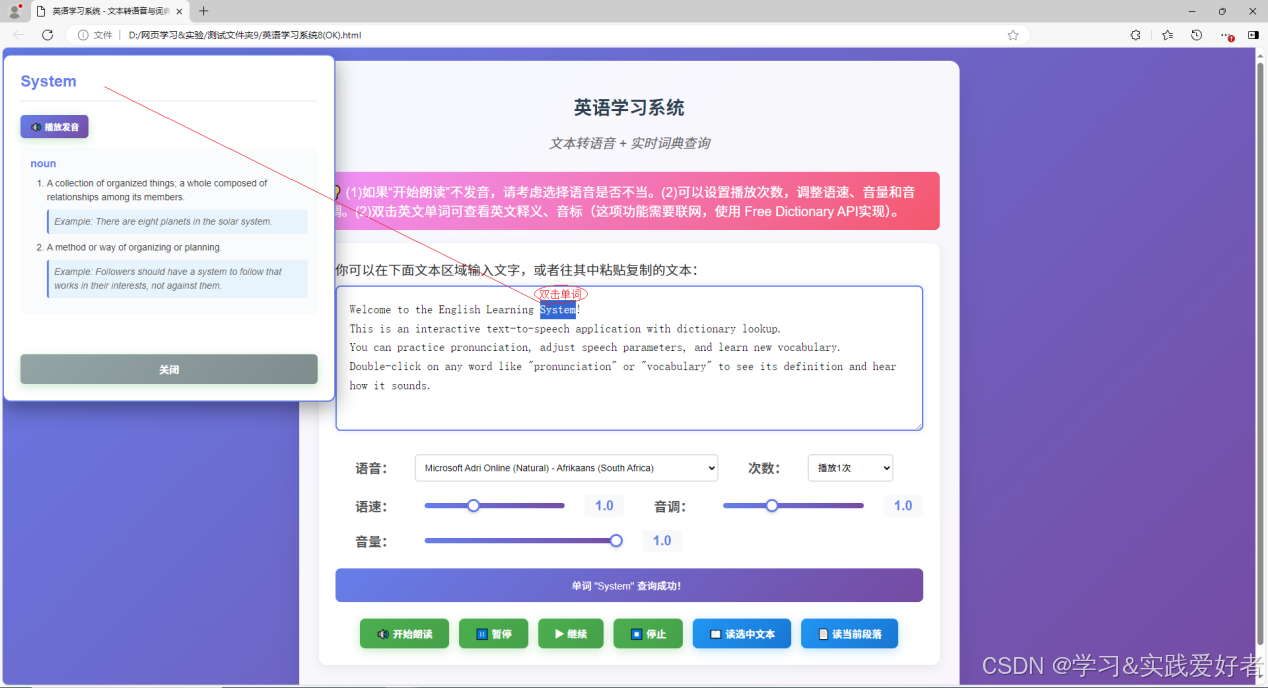
HTML版英语学习系统
HTML版英语学习系统 这是一个完全免费、无需安装、功能完整的英语学习工具,使用HTML CSS JavaScript实现。 功能 文本朗读练习 - 输入英文文章,系统朗读帮助练习听力和发音,适合跟读练习,模仿学习;实时词典查询 - 双…...

多模态大语言模型arxiv论文略读(110)
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving ➡️ 论文标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving ➡️ 论文作者:Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, …...

[学习笔记]使用git rebase做分支差异化同步
在一个.NET 项目中,使用了Volo.Abp库,但出于某种原因,需要源码调试,因此,使用源码方式集成的项目做了一个分支archive-abp-source 其中引用方式变更操作的提交为:7de53907 后续,在master分支中…...