训练自己的GPT2
训练自己的GPT2
- 1.预训练与微调
- 2.准备工作
- 2.在自己的数据上进行微调
1.预训练与微调
所谓的预训练,就是在海量的通用数据上训练大模型。比如,我把全世界所有的网页上的文本内容都整理出来,把全人类所有的书籍、论文都整理出来,然后进行训练。这个训练过程代价很大,首先模型很大,同时数据量又很大,比如GPT3参数量达到了175B,训练数据达到了45TB,训练一次就话费上千万美元。如此大代价学出来的是一个通用知识的模型,他确实很强,但是这样一个模型,可能无法在一些专业性很强的领域上取得比较好的表现,因为他没有针对这个领域的数据进行训练过。
因此,大模型火了之后,很多人都开始把大模型用在自己的领域。通常也就是把自己领域的一些数据,比如专业书、论文等等整理出来,使用预训练好的大模型在新的数据集上进行微调。微调的成本相比于预训练就要小得多了。
2.准备工作
首先需要安装第三方库transformers,transformers是一个用于自然语言处理(NLP)的Python第三方库,实现Bert、GPT-2和XLNET等比较新的模型,支持TensorFlow和PyTorch。以及下载预训练好的模型权重。
pip install transformers
安装完成之后,我们可以直接使用下面的代码,来构造一个预训练的GPT2
from transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
当运行的时候,代码会自动从hugging face上下载模型。但是由于hugging face是国外网站,可能下载起来很慢或者无法下载,因此我们也可以自己手动下载之后在本地读取。
打开hugging face的网站,搜索GPT2。或者直接进入GPT2的页面。

下载上图中的几个文件到本地,假设下载到./gpt2文件夹
然后就可以使用下面的代码来尝试预训练的模型直接生成文本你的效果。
from transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained("./gpt2")
model = GPT2LMHeadModel.from_pretrained("./gpt2")q = "tell me a fairy story"ids = tokenizer.encode(q, return_tensors='pt')
final_outputs = model.generate(ids,do_sample=True,max_length=100,pad_token_id=model.config.eos_token_id,top_k=50,top_p=0.95,
)print(tokenizer.decode(final_outputs[0], skip_special_tokens=True))
回答如下:

2.在自己的数据上进行微调
首先把我们的数据,也就是文本,全部整理到一起。比如可以把所有文本拼接到一起。
假设所有的文本数据都存到一个文件中。那么可以直接使用下面的代码进行训练。
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification, AdamW, GPT2LMHeadModel
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments, TextDatasetdef load_data_collator(tokenizer, mlm = False):data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=mlm,)return data_collatordef load_dataset(file_path, tokenizer, block_size = 128):dataset = TextDataset(tokenizer = tokenizer,file_path = file_path,block_size = block_size,)return datasetdef train(train_file_path, model_name,output_dir,overwrite_output_dir,per_device_train_batch_size,num_train_epochs,save_steps):tokenizer = GPT2Tokenizer.from_pretrained(model_name)train_dataset = load_dataset(train_file_path, tokenizer)data_collator = load_data_collator(tokenizer)tokenizer.save_pretrained(output_dir)model = GPT2LMHeadModel.from_pretrained(model_name)model.save_pretrained(output_dir)training_args = TrainingArguments(output_dir=output_dir,overwrite_output_dir=overwrite_output_dir,per_device_train_batch_size=per_device_train_batch_size,num_train_epochs=num_train_epochs,)trainer = Trainer(model=model,args=training_args,data_collator=data_collator,train_dataset=train_dataset,)trainer.train()trainer.save_model()train_file_path = "./train.txt" # 你自己的训练文本
model_name = './gpt2' # 预训练的模型路径
output_dir = './custom_data' # 你自己设定的模型保存路径
overwrite_output_dir = False
per_device_train_batch_size = 96 # 每一台机器上的batch size。
num_train_epochs = 50
save_steps = 50000# Train
train(train_file_path=train_file_path,model_name=model_name,output_dir=output_dir,overwrite_output_dir=overwrite_output_dir,per_device_train_batch_size=per_device_train_batch_size,num_train_epochs=num_train_epochs,save_steps=save_steps
)
训练完成之后,推理的话,直接使用第二节里的代码,将预训练模型路径换成自己训练的模型路径就行了
相关文章:
训练自己的GPT2
训练自己的GPT2 1.预训练与微调2.准备工作2.在自己的数据上进行微调 1.预训练与微调 所谓的预训练,就是在海量的通用数据上训练大模型。比如,我把全世界所有的网页上的文本内容都整理出来,把全人类所有的书籍、论文都整理出来,然…...
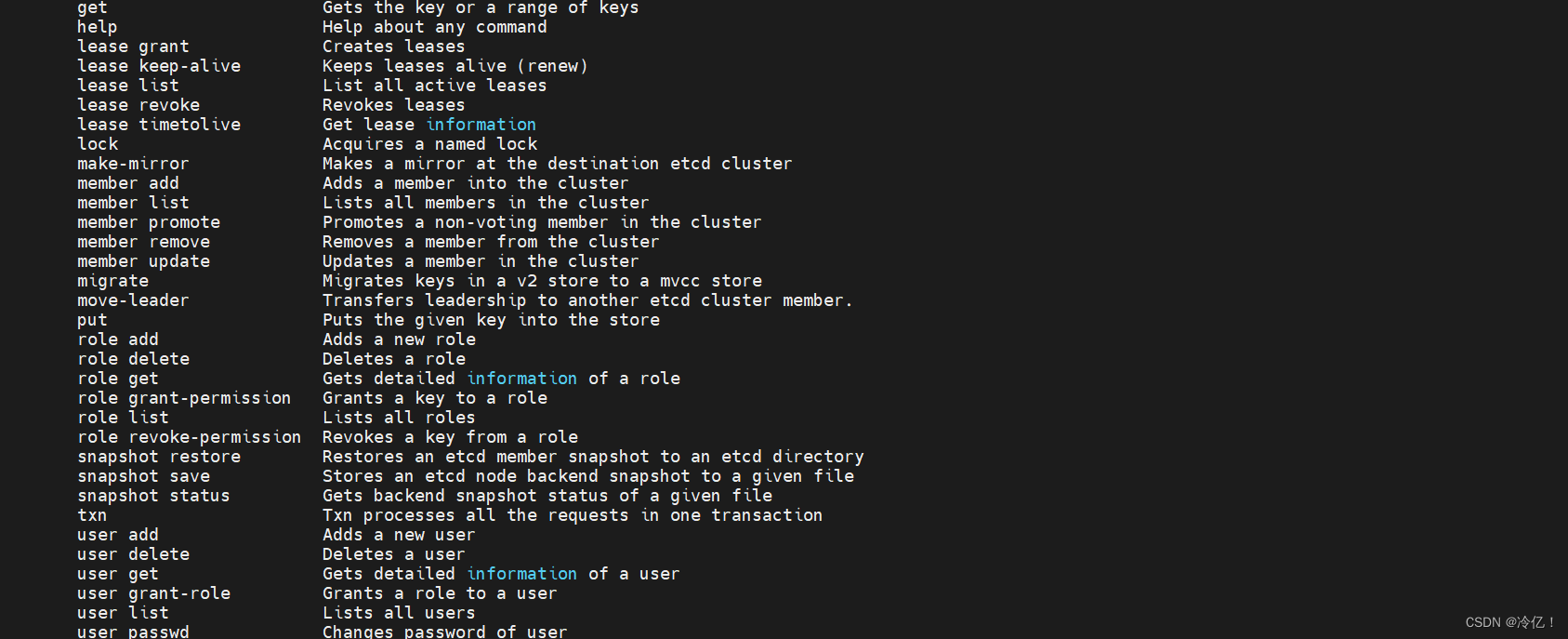
etcd储存安装
目录 etcd介绍: etcd工作原理 选举 复制日志 安全性 etcd工作场景 服务发现 etcd基本术语 etcd安装(centos) 设置:etcd后台运行 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管。etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册…...

如何彻底卸载Microsoft Edge浏览器
一、引语 随着微软推出全新的Edge浏览器,许多用户可能想要尝试或完全切换到其他浏览器。在这篇文章中,我们将向您介绍如何彻底卸载Microsoft Edge浏览器,以确保您的系统干净整洁。 二、通过系统设置卸载 1、首先,右键单击桌面上…...
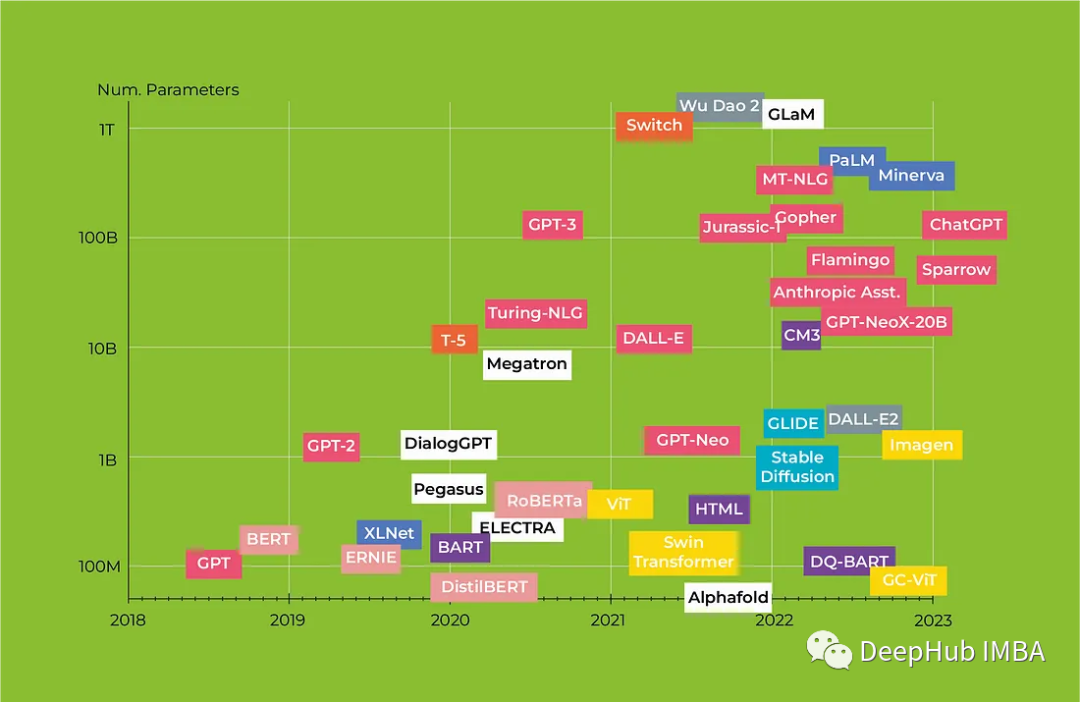
Transformers 2023年度回顾 :从BERT到GPT4
人工智能已成为近年来最受关注的话题之一,由于神经网络的发展,曾经被认为纯粹是科幻小说中的服务现在正在成为现实。从对话代理到媒体内容生成,人工智能正在改变我们与技术互动的方式。特别是机器学习 (ML) 模型在自然语言处理 (NLP) 领域取得…...

判断两个对象某些字段的值是否相同
1、借助mybatis plus的方法 import com.baomidou.mybatisplus.core.toolkit.LambdaUtils; import com.baomidou.mybatisplus.core.toolkit.support.SFunction; import com.baomidou.mybatisplus.core.toolkit.support.SerializedLambda; import lombok.SneakyThrows; import o…...

TYPE-C接口取电芯片介绍和应用场景
随着科技的发展,USB PDTYPE-C已经成为越来越多设备的充电接口。而在这一领域中,LDR6328Q PD取电芯片作为设备端协议IC芯片,扮演着至关重要的角色。本文将详细介绍LDR6328Q PD取电芯片的工作原理、应用场景以及选型要点。 一、工作原理 LDR63…...

基于TI TPSXX系列 Buck电路应用计算-外围器件详细计算过程
TPS54202 Buck电路应用计算 1、电气特性2、内部框图3、典型应用电路4、设计需求5、计算EN引脚电阻6、FB引脚电阻估算7、查看反馈电压电压基准8、输入电容计算10、FB引脚反馈电阻计算11、功率电感计算12、输出电容计算13、前馈电容计算15、Layout布局TPS54202-中文版 1、电气特…...
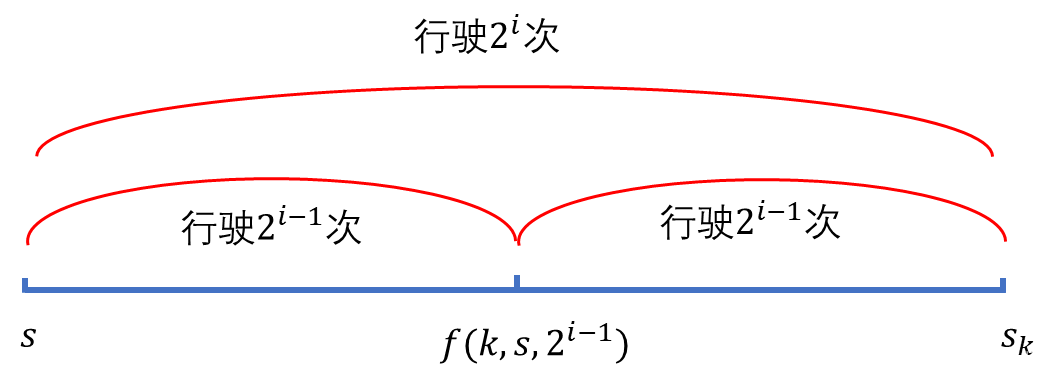
NOIP2012提高组day1-T3:开车旅行
题目链接 [NOIP2012 提高组] 开车旅行 题目描述 小 A \text{A} A 和小 B \text{B} B 决定利用假期外出旅行,他们将想去的城市从 1 1 1 到 n n n 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同…...

Golang Web框架性能对比
Golang Web框架性能对比 github star排名依次: Gin Beego Iris Echo Revel Buffalo 性能上gin、iris、echo网上是给的数据都是五星,beego三星,revel两星 beego是国产,有中文文档,文档齐全 根据star数,性能,易用程度…...

【OCR】 - Tesseract OCR在mac系统中安装
Tesseract OCR 在Mac环境下安装Tesseract OCR(Optical Character Recognition)通常可以通过Homebrew包管理器进行。以下是安装步骤: 安装Homebrew 如果你还没有安装Homebrew,请访问 https://brew.sh/ 并按照页面上的说明安装。…...
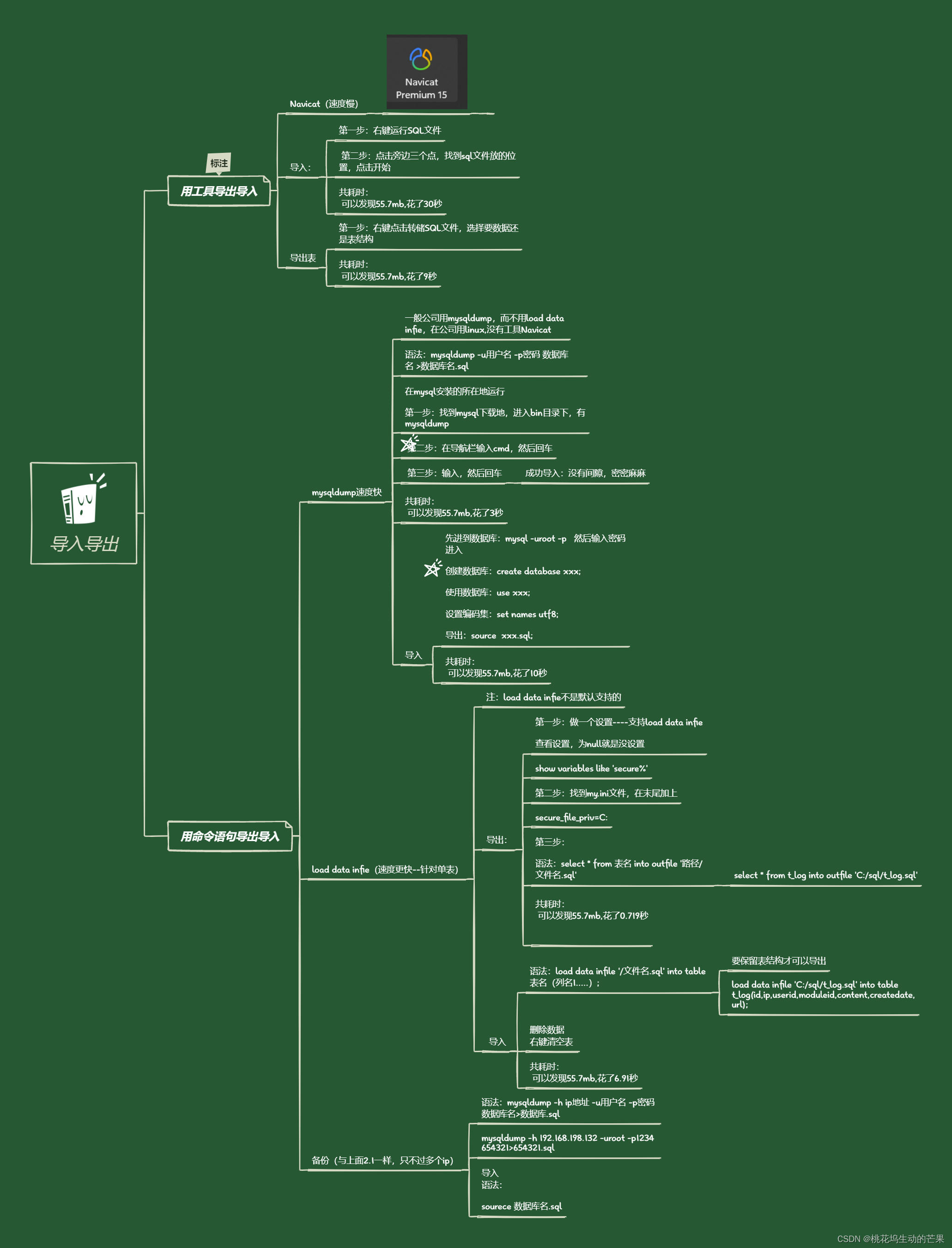
了解不同方式导入导出的速度之快
目录 一、用工具导出导入 Navicat(速度慢) 1.1、导入: 共耗时: 1.2、导出表 共耗时: 二、用命令语句导出导入 2.1、mysqldump速度快 导出表数据和表结构 共耗时: 只导出表结构 导入 共耗时&…...

2024年第九届计算机与通信系统国际会议(ICCCS2024) ,邀您相约西安!
会议官网: ICCCS2024 | Xian China 时间: 2024年4月19-22日 地点: 中国西安 会议简介: 近年来,信息通信在不断发展,为计算机网络的进步与发展提供了先进可靠的技术支持。随着计算机网络与通信技术的深入发展,计算机通信技术、数…...

获取直播间的最新评论 - python 取两个list的差集
python 取两个list的差集 作用:比如我要获取评论区列表,先获取了一遍,这个时候有人评论了几条,我再获取一遍后,找出多的那几条 使用set数据类型来取两个列表的差集。差集表示仅包含在第一个列表中而不在第二个列表中…...

2023年度总结:但行前路,不负韶华
🦁作者简介:一名喜欢分享和记录学习的在校大学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS &#x…...

智数融合|低代码入局,推动工业数字化转型走"深"向"实"
当下,“数字化、智能化”已经不再是新鲜词汇。事实上,早在几年前,就有企业开始大力推动数字化转型,并持续进行了一段时间。一些业内人士甚至认为,“如今的企业数字化已经走过了成熟期,进入了深水区。” 但事…...

初学者的基本 Python 面试问题和答案
文章目录 专栏导读1、什么是Python?列出 Python 在技术领域的一些流行应用。2、在目前场景下使用Python语言作为工具有什么好处?3、Python是编译型语言还是解释型语言?4、Python 中的“#”符号有什么作用?5、可变数据类型和不可变…...
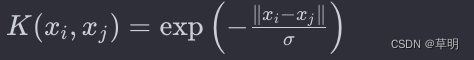
支持向量机(Support Vector Machines,SVM)
什么是机器学习 支持向量机(Support Vector Machines,SVM)是一种强大的机器学习算法,可用于解决分类和回归问题。SVM的目标是找到一个最优的超平面,以在特征空间中有效地划分不同类别的样本。 基本原理 超平面 在二…...

golang一个轻量级基于内存的kv存储或缓存
golang一个轻量级基于内存的kv存储或缓存 go-cache是一个轻量级的基于内存的key:value 储存组件,类似于memcached,适用于在单机上运行的应用程序。 它的主要优点是,本质上是一个具有过期时间的线程安全map[string]interface{}。interface的结…...

henauOJ 1103: 统计元音
题目描述 统计每个元音字母在字符串中出现的次数。 输入 输入数据首先包括一个整数n,表示测试实例的个数,然后是n行长度不超过100的字符串。 输出 对于每个测试实例输出5行,格式如下: a:num1 e:num2 i:num3 o:num4 u:num5 多…...

虚幻引擎:开创视觉与创意的新纪元
先看看据说虚幻5做出来的东西吧: 虚幻引擎5!!!4K画质PS5实机演示! 好了,用文字认识一下吧: 虚幻引擎5.3对UE5的核心工具集作了进一步优化,涉及渲染、世界构建、程序化内容生成&…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...