cuda上使用remap函数
在使用opencv中的remap函数时,发现运行时间太长了,如果使用视频流进行重映射时根本不能实时,因此只能加速
1.使用opencv里的cv::cuda::remap函数
cv::cuda::remap函数头文件是#include <opencv2/cudawarping.hpp>,编译opencv时需要用cuda进行编译
//1.重映射矩阵转成cuda处理的数据格式//map_x,map_y是重映射表,数据类型是CV_32FC1cv::cuda::GpuMat m_mapx = ::cv::cuda::GpuMat(map_x);cv::cuda::GpuMat m_mapy = ::cv::cuda::GpuMat(map_y);//2.原图像转成cuda处理的数据格式cv::cuda::GpuMat src(img);//3.计算结果cv::cuda::GpuMat gpuMat2;cv::cuda::remap(src, gpuMat2, m_mapx, m_mapy, cv::INTER_LINEAR);//4.结果转成Matcv::Mat dstimage; gpuMat2.download(dstimage);
示例
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/cudawarping.hpp>using namespace cv;int main(int argc, char** argv)
{Mat img = imread("image.jpg", IMREAD_COLOR);if (img.empty()){std::cout << "Could not open the input image" << std::endl;exit(1);}int in_width = img.cols;int in_height = img.rows;Mat map_x(in_height, in_width, CV_32FC1);Mat map_y(in_height, in_width, CV_32FC1);// 创建重映射映射表for (int y = 0; y < in_height; y++) {for (int x = 0; x < in_width; x++) {map_x.at<float>(y, x) = (x + 20) / (float)in_width * in_width;map_y.at<float>(y, x) = y / (float)in_height * in_height;}}cv::cuda::GpuMat m_mapx = ::cv::cuda::GpuMat(map_x);cv::cuda::GpuMat m_mapy = ::cv::cuda::GpuMat(map_y);cv::cuda::GpuMat gpuMat1(img);double time0 = static_cast<double>(cv::getTickCount());//记录起始时间cv::cuda::GpuMat gpuMat2;cv::cuda::remap(gpuMat1, gpuMat2, m_mapx, m_mapy, cv::INTER_LINEAR);cv::Mat GPUimage;gpuMat2.download(GPUimage); time0 = ((double)cv::getTickCount() - time0) / cv::getTickFrequency();std::cout << "GPU运行remap函数的时间为:" << time0 * 1000 << "ms" << std::endl;double time1 = static_cast<double>(cv::getTickCount());//记录起始时间cv::Mat CPUimage;cv::remap(img, CPUimage, map_x, map_y, cv::INTER_LINEAR);time1 = ((double)cv::getTickCount() - time1) / cv::getTickFrequency();std::cout << "CPU运行remap函数的时间为:" << time1 * 1000 << "ms" << std::endl;return 0;
}
经过实际运行,在我电脑上速度快了15倍左右
2.在cuda上重写remap函数
这是在csdn上看到的一篇文章上写的代码,在我的实际应用中变换的结果是错误的,由于我实际的应用时,我的图像输入尺寸和输出尺寸是不相同的,因此运行错误,但是在输入输出是相同尺寸时是正确的,因为使用了cv::cuda::remap,我也没修改这个程序。
建立.cu文件,可以生成静态库使用,也可以不生成使用
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <cuda_runtime_api.h>
#include <stdio.h>
#include <math.h>__global__ void remap_kernel(const unsigned char* src, int src_width, int src_height,unsigned char* dst, int dst_width, int dst_height,const float* map_x, const float* map_y)
{int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;if (x < dst_width && y < dst_height) {int index = (y * dst_width + x) * 3;float src_x = map_x[index / 3];float src_y = map_y[index / 3];if (src_x >= 0 && src_x < src_width - 1 && src_y >= 0 && src_y < src_height - 1) {int x0 = floorf(src_x);int y0 = floorf(src_y);int x1 = x0 + 1;int y1 = y0 + 1;float tx = src_x - x0;float ty = src_y - y0;int src_index00 = (y0 * src_width + x0) * 3;int src_index10 = (y0 * src_width + x1) * 3;int src_index01 = (y1 * src_width + x0) * 3;int src_index11 = (y1 * src_width + x1) * 3;for (int i = 0; i < 3; i++) {float value00 = src[src_index00 + i];float value10 = src[src_index10 + i];float value01 = src[src_index01 + i];float value11 = src[src_index11 + i];float value0 = value00 * (1.0f - tx) + value10 * tx;float value1 = value01 * (1.0f - tx) + value11 * tx;float value = value0 * (1.0f - ty) + value1 * ty;dst[index + i] = static_cast<unsigned char>(value);}}}
}extern "C" void remap_gpu(const unsigned char* in, int in_width, int in_height,unsigned char* out, int out_width, int out_height,const float* map_x, const float* map_y) {unsigned char* d_in, * d_out;float* d_map_x, * d_map_y;cudaMalloc((void**)&d_in, in_width * in_height * 3);cudaMalloc((void**)&d_out, out_width * out_height * 3);cudaMalloc((void**)&d_map_x, out_width * out_height * sizeof(float));cudaMalloc((void**)&d_map_y, out_width * out_height * sizeof(float));cudaMemcpy(d_in, in, in_width * in_height * 3, cudaMemcpyHostToDevice);cudaMemcpy(d_map_x, map_x, out_width * out_height * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_map_y, map_y, out_width * out_height * sizeof(float), cudaMemcpyHostToDevice);dim3 block(32, 32, 1);dim3 grid((out_width + block.x - 1) / block.x, (out_height + block.y - 1) / block.y, 1);remap_kernel << <grid, block >> > (d_in, in_width, in_height, d_out, out_width, out_height, d_map_x, d_map_y);cudaMemcpy(out, d_out, out_width * out_height * 3, cudaMemcpyDeviceToHost);cudaFree(d_in);cudaFree(d_out);cudaFree(d_map_x);cudaFree(d_map_y);
}
重新新建一个.cpp文件
#include <iostream>
#include <opencv2/opencv.hpp>using namespace cv;extern "C" void remap_gpu(const unsigned char* in, int in_width, int in_height,unsigned char* out, int out_width, int out_height,const float* map_x, const float* map_y);int main(int argc, char** argv)
{cv::Mat img = imread("image.jpg", IMREAD_COLOR);if (img.empty()) {std::cout << "Could not open the input image" << std::endl;exit(1);}int in_width = img.cols;int in_height = img.rows;cv::Mat map_x(in_height, in_width, CV_32FC1);cv::Mat map_y(in_height, in_width, CV_32FC1);// 创建重映射映射表for (int y = 0; y < in_height; y++) {for (int x = 0; x < in_width; x++) {map_x.at<float>(y, x) = (x + 20) / (float)in_width * in_width;map_y.at<float>(y, x) = y / (float)in_height * in_height;}}double time0 = static_cast<double>(cv::getTickCount());//记录起始时间cv::Mat CPUimage;remap(img, CPUimage, map_x, map_y, cv::INTER_LINEAR, cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));time0 = ((double)cv::getTickCount() - time0) / cv::getTickFrequency();std::cout << "CPU 运行remap函数时间为:" << time0 * 1000 << "ms" << std::endl;int out_width = in_width;int out_height = in_height; unsigned char* out = (unsigned char*)malloc(out_width * out_height * 3);double time1 = static_cast<double>(cv::getTickCount());//记录起始时间unsigned char* in = (unsigned char*)img.data;remap_gpu(in, in_width, in_height, out, out_width, out_height, (float*)map_x.data, (float*)map_y.data);cv::Mat GPUimage(out_height, out_width, CV_8UC3, out);time1 = ((double)cv::getTickCount() - time1) / cv::getTickFrequency();std::cout << "GPU 运行remap函数时间为:" << time1 * 1000 << "ms" << std::endl;free(out);return 0;
}
只运行一帧时cpu上运行的remap较快,运行多帧时,GPU上运行的remap函数要比CPU上运行快5倍左右
总结
如果自己编译的opencv带cuda,最好还是使用cv::cuda::remap函数,耗时较少
相关文章:

cuda上使用remap函数
在使用opencv中的remap函数时,发现运行时间太长了,如果使用视频流进行重映射时根本不能实时,因此只能加速 1.使用opencv里的cv::cuda::remap函数 cv::cuda::remap函数头文件是#include <opencv2/cudawarping.hpp>,编译ope…...
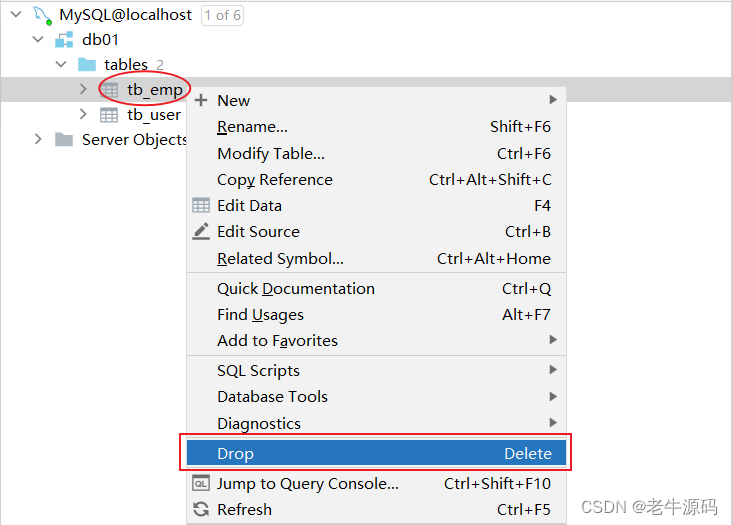
【JaveWeb教程】(18) MySQL数据库开发之 MySQL数据库设计-DDL 如何查询、创建、使用、删除数据库数据表 详细代码示例讲解
目录 2. 数据库设计-DDL2.1 项目开发流程2.2 数据库操作2.2.1 查询数据库2.2.2 创建数据库2.2.3 使用数据库2.2.4 删除数据库 2.3 图形化工具2.3.1 介绍2.3.2 安装2.3.3 使用2.2.3.1 连接数据库2.2.3.2 操作数据库 2.3 表操作2.3.1 创建2.3.1.1 语法2.3.1.2 约束2.3.1.3 数据类…...

ElasticSearch学习笔记-SpringBoot整合Elasticsearch7
项目最近需要接入Elasticsearch7,顺带记录下笔记。 Elasticsearch依赖包版本 <properties><elasticsearch.version>7.9.3</elasticsearch.version><elasticsearch.rest.version>7.9.3</elasticsearch.rest.version> </propertie…...

[足式机器人]Part2 Dr. CAN学习笔记 - Ch02动态系统建模与分析
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记 - Ch02动态系统建模与分析 1. 课程介绍2. 电路系统建模、基尔霍夫定律3. 流体系统建模4. 拉普拉斯变换(Laplace)传递函数、微分方程4.1 Laplace Transform 拉式变换4.2 收…...

【一周年创作总结】人生是远方的无尽旷野呀
那一眼瞥见的伟大的灵魂,却似模糊的你和我 文章目录 📒各个阶段的experience🔎大一寒假🔎大一下学期🔎大一暑假🔎大二上学期(现在) 🍔相遇CSDN🛸自媒体&#…...

金融帝国实验室(Capitalism Lab)V10版本游戏平衡性优化与改进
即将推出的V10版本中的各种游戏平衡性优化与改进: ————————————— 一、当玩家被提议收购一家即将破产的公司时,显示商业秘密。 当一家公司濒临破产,玩家被提议收购该公司时,如果玩家有兴趣评估该公司,则无…...

[SpringBoot]接口的多实现:选择性注入SpringBoot接口的实现类
最近在项目中遇到两种情况,准备写个博客记录一下。 情况说明:Service层一个接口是否可以存在多个具体实现,此时应该如何调用Service(的具体实现)? 其实之前的项目中也遇到过这种情况,只不过我采…...

北京大学 wlw机器学习2022春季期末试题分析
北京大学 wlw机器学习2022春季期末试题分析 前言新的开始第一题第二题第三题 前言 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。 新的开始 第…...
)
前端文件下载方法(包含get和post)
export const downloadFileWithIframe (url, name) > {const iframe document.createElement(iframe);iframe.style.display none; // 防止影响页面iframe.style.height 0; // 防止影响页面iframe.name name;iframe.src url;document.body.appendChild(iframe); // 这…...
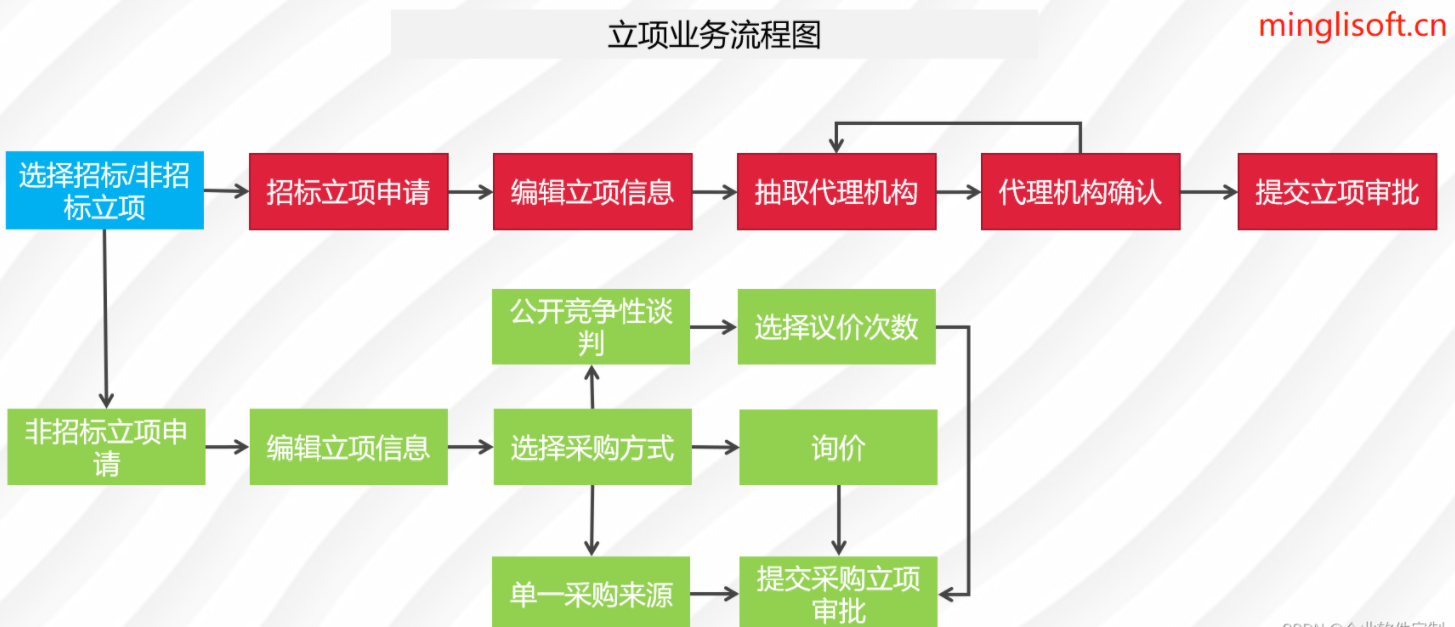
高性能、可扩展、支持二次开发的企业电子招标采购系统源码
在数字化时代,企业需要借助先进的数字化技术来提高工程管理效率和质量。招投标管理系统作为企业内部业务项目管理的重要应用平台,涵盖了门户管理、立项管理、采购项目管理、采购公告管理、考核管理、报表管理、评审管理、企业管理、采购管理和系统管理等…...

2645. 构造有效字符串的最少插入数
Problem: 2645. 构造有效字符串的最少插入数 文章目录 解题思路解决方法复杂度分析代码实现 解题思路 解决此问题需要确定如何以最小的插入次数构造一个有效的字符串。首先,我们需要确定开头的差距,然后决定中间的补足,最后决定末尾的差距。…...
C#,快速排序算法(Quick Sort)的非递归实现与数据可视化
排序算法是编程的基础。 常见的四种排序算法是:简单选择排序、冒泡排序、插入排序和快速排序。其中的快速排序的优势明显,一般使用递归方式实现,但遇到数据量大的情况则无法适用。实际工程中一般使用“非递归”方式实现。 快速排序(Quick Sor…...

【操作系统xv6】学习记录2 -RISC-V Architecture
说明:看完这节,不会让你称为汇编程序员,知识操作系统的前置。 ref:https://binhack.readthedocs.io/zh/latest/assembly/mips.html https://www.bilibili.com/video/BV1w94y1a7i8/?p7 MIPS MIPS的意思是 “无内部互锁流水级的微…...
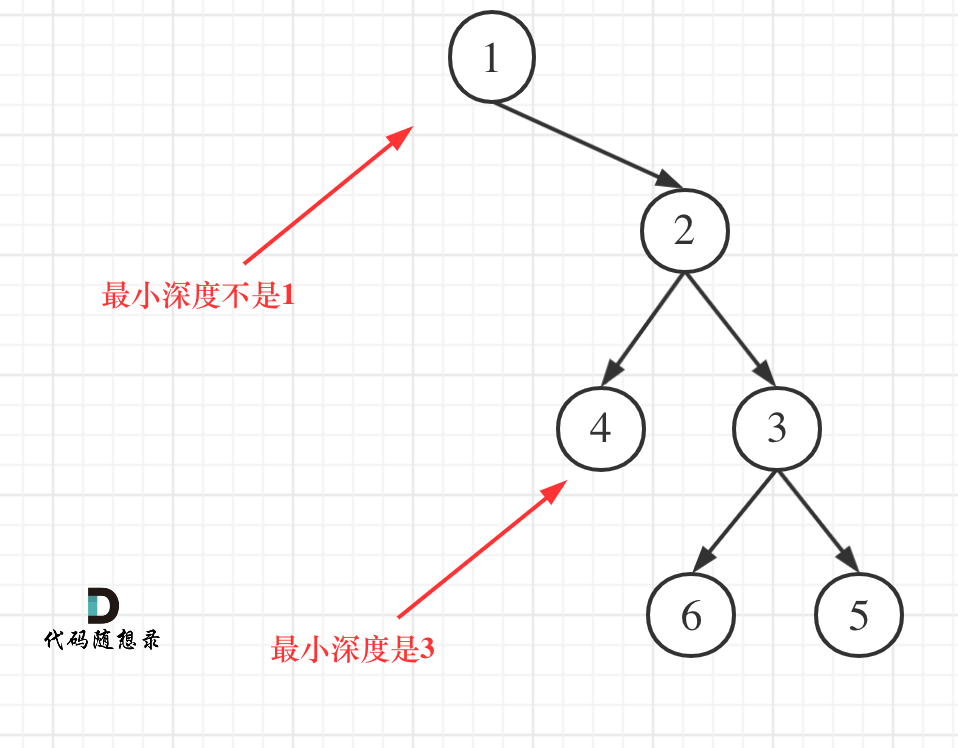
C++力扣题目111--二叉树的最小深度
力扣题目链接(opens new window) 给定一个二叉树,找出其最小深度。 最小深度是从根节点到最近叶子节点的最短路径上的节点数量。 说明: 叶子节点是指没有子节点的节点。 示例: 给定二叉树 [3,9,20,null,null,15,7], 返回它的最小深度 2 思路 看完了这篇104.二…...
)
【图像拼接】源码精读:Adaptive As-Natural-As-Possible Image Stitching(AANAP/ANAP)
第一次来请先看这篇文章:【图像拼接(Image Stitching)】关于【图像拼接论文源码精读】专栏的相关说明,包含专栏内文章结构说明、源码阅读顺序、培养代码能力、如何创新等(不定期更新) 【图像拼接论文源码精读】专栏文章目录 【源码精读】As-Projective-As-Possible Imag…...
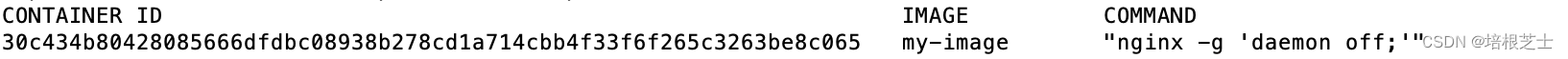
解决docker run报错:Error response from daemon: No command specified.
将docker镜像export/import之后,对新的镜像执行docker run时报错: docker: Error response from daemon: No command specified. 解决方法: 方案1: 查看容器的command: docker ps --no-trunc 在docker run命令上增加…...

算法第十二天-最大整除子集
最大整除子集 题目要求 解题思路 来自[宫水三叶] 根据题意:对于符合要求的[整除子集]中的任意两个值,必然满足[较大数]是[较小数]的倍数 数据范围是 1 0 3 10^3 103,我们不可能采取获取所有子集,再检查子集是否合法的暴力搜解法…...

简单易懂的PyTorch 损失函数:优化机器学习模型的关键
目录 torch.nn子模块Loss Functions详解 nn.L1Loss 用途 用法 使用技巧 注意事项 代码示例 nn.MSELoss 用途 用法 使用技巧 注意事项 代码示例 nn.CrossEntropyLoss 用途 用法 使用技巧 注意事项 代码示例 使用类别索引 使用类别概率 nn.CTCLoss 用途 …...

Kubernetes/k8s的存储卷/数据卷
k8s的存储卷/数据卷 容器内的目录和宿主机的目录挂载 容器在系统上的生命周期是短暂的,delete,k8s用控制创建的pod,delete相当于重启,容器的状态也会回复到初始状态 一旦回到初始状态,所有的后天编辑的文件都会消失…...
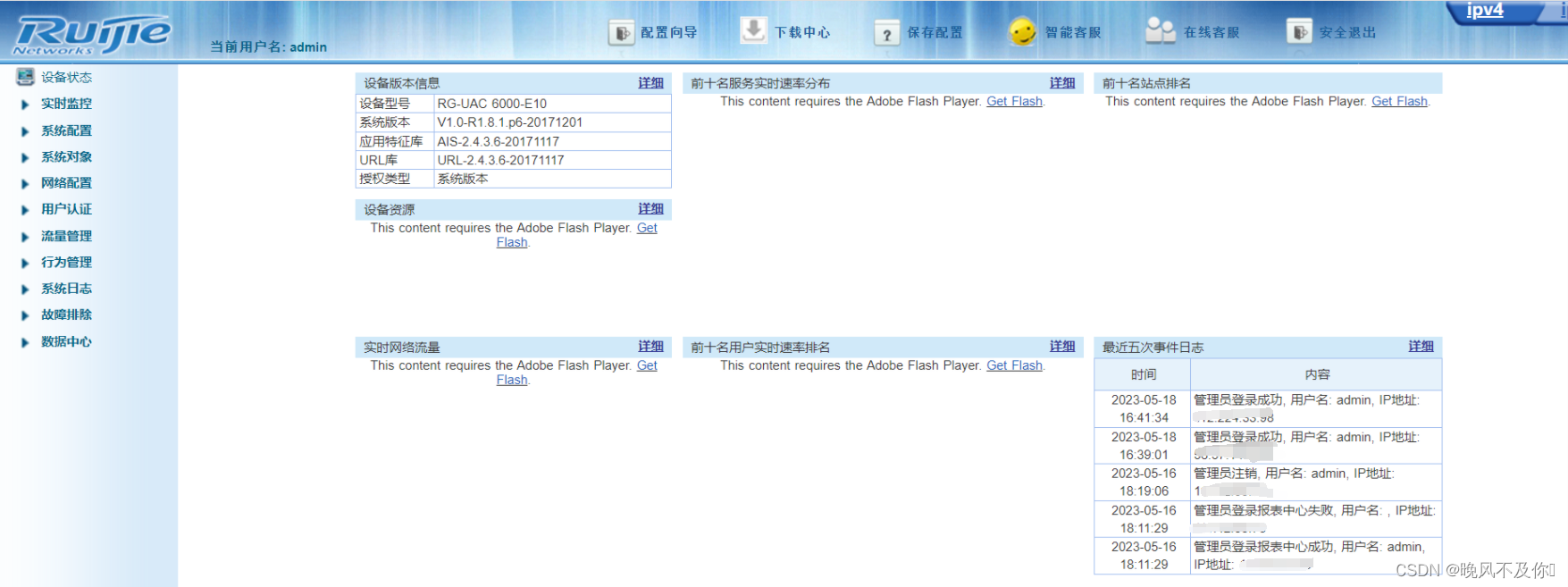
【漏洞复现】锐捷RG-UAC统一上网行为管理系统信息泄露漏洞
Nx01 产品简介 锐捷网络成立于2000年1月,原名实达网络,2003年更名,自成立以来,一直扎根行业,深入场景进行解决方案设计和创新,并利用云计算、SDN、移动互联、大数据、物联网、AI等新技术为各行业用户提供场…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...