行云部署成长之路 -- 慢 SQL 优化之旅 | 京东云技术团队
当项目的SQL查询慢得像蜗牛爬行时,用户的耐心也在一点点被消耗,作为研发,我们可不想看到这样的事。这篇文章将结合行云部署项目的实践经验,带你走进SQL优化的奇妙世界,一起探索如何让那些龟速的查询飞起来!
序章:EXPLAIN - 揭开查询的神秘面纱
EXPLAIN命令是数据库管理员和SQL开发人员的一项强大工具,它可以帮助理解MySQL如何执行特定的查询。它显示了MySQL执行查询的详细信息,包括如何连接表以及连接的顺序,是否使用了索引,以及每个表的读取行数等。通过这些信息,你可以判断查询性能瓶颈,并对查询或表结构进行相应的优化。
使用EXPLAIN的常见列解释:
•id:查询的标识符,如果是复杂查询,会有多个id,数字越大,优先级越高。
•select_type:查询的类型,比如SIMPLE(简单的SELECT查询),SUBQUERY(子查询中的第一个SELECT),DERIVED(派生表的SELECT)等。
•table:显示这一行的数据是来自哪个表的。
•partitions:如果查询涉及分区表,这一列显示分区的信息。
•type:显示连接类型,这是MySQL如何查找表中行的重要信息。性能由高到低排列 system > const > eq_ref > ref > ref_or_null > index_merge > range > index > ALL
•possible_keys:显示MySQL可能使用哪些索引来优化查询。
•key:实际使用的索引。如果没有使用索引,值是NULL。
•key_len:使用的索引的长度。较短的索引通常更优,因为它们占用更少的空间。
•ref:显示索引查找使用了哪些列或者常量。
•rows:MySQL预估的返回请求数据需要扫描的行数。
•filtered:表示返回结果的行数占扫描行数的百分比。
•Extra:包含不适合在其他列中显示的额外信息,如“Using index”表示表示查询能够使用一个覆盖索引(Covering Index)来获取数据。
使用EXPLAIN的例子:
假设我们有一个简单的查询:
EXPLAIN SELECT * FROM users WHERE name ='zhangsan';
这将返回一个表,显示上面提到的各种列的信息。如果你看到type列是ALL,这意味着MySQL正在进行全表扫描。如果possible_keys列指出了可以使用的索引,而key列是NULL,这意味着MySQL没有使用索引,这就是创建索引或者优化语句来提升查询速度的一个机会。
如何基于EXPLAIN的结果进行优化:
1.避免全表扫描:如果type列是ALL,考虑添加索引来减少扫描的行数。
2.使用正确的索引:possible_keys和key列可以帮助你知道可能使用哪些索引以及实际使用了哪些索引。如果没有使用索引,或者使用了不正确的索引,你可能需要重新考虑索引策略。
3.索引覆盖扫描:如果Extra列包含“Using index”,这意味着查询可以仅通过索引来获取数据,这通常是性能最好的查询之一。
4.优化子查询:如果select_type是SUBQUERY,你可能需要优化子查询。
5.减少读取的行数:rows列告诉你MySQL预计要扫描多少行来执行查询。减少这个数字通常会提高查询性能。
通过深入理解EXPLAIN的输出并据此进行调整索引和语句,可以显著提高查询的性能。不过需要注意的是EXPLAIN只是预测查询执行计划,并不总是100%准确,实际执行时可能会有所不同。因此,优化是一个迭代的过程,需要结合实际的查询执行结果来进行。
第一章:索引 - 数据库的速度之翼
想象一下,你是一个图书管理员,面前摆着成千上万的书籍,但是没有任何目录或索引,你要如何找到想要的书籍呢。这就是没有索引的数据库的真实写照。索引是优化查询的第一步,它能够让数据库引擎像猎鹰一样迅速地找到它的猎物——也就是你需要的数据。
1.1 索引的创建与运用
我们需要在经常参与查询的列上创建索引:
CREATE INDEX idx_column ON table_name(column_name);
1.2 索引的选择与剪枝
索引也并不是越多越好,再美味的食物,吃太多也会消化不良。每个额外的索引都会增加数据插入和更新时的负担,并且有些索引会干扰到数据库对选择索引的判断,导致查询变慢。所以,选择正确的索引和定期“剪枝”不必要的索引是至关重要的。
以下几种情况都是不合适建立索引的:
1.在WHERE条件中用不到的字段不需要索引
2.列里基本上都是重复数据的最好不要创建索引,比如逻辑删除字段deleted,只有0或1两个值
3.已经创建了联合索引的情况下基本不需要再单独创建索引
正好在近几天的优化中碰到了类似的问题:
在workflow表中有联合索引idx_status_type(status, apply_type)和索引idx_remind_deploy(has_remind_deploy)
我们可以看到这个下面这个sql完全达不到预期,简单的查询时间却来到308ms

用explain看一下执行计划:可以看到,这里数据库选择的index_merge这种方式,而表里的has_remind_deploy只有0和1两个值,导致效率反而比只用idx_status_type降低

此时,考虑去掉索引idx_remind_deploy,强制索引idx_status_type后,果然速度变快
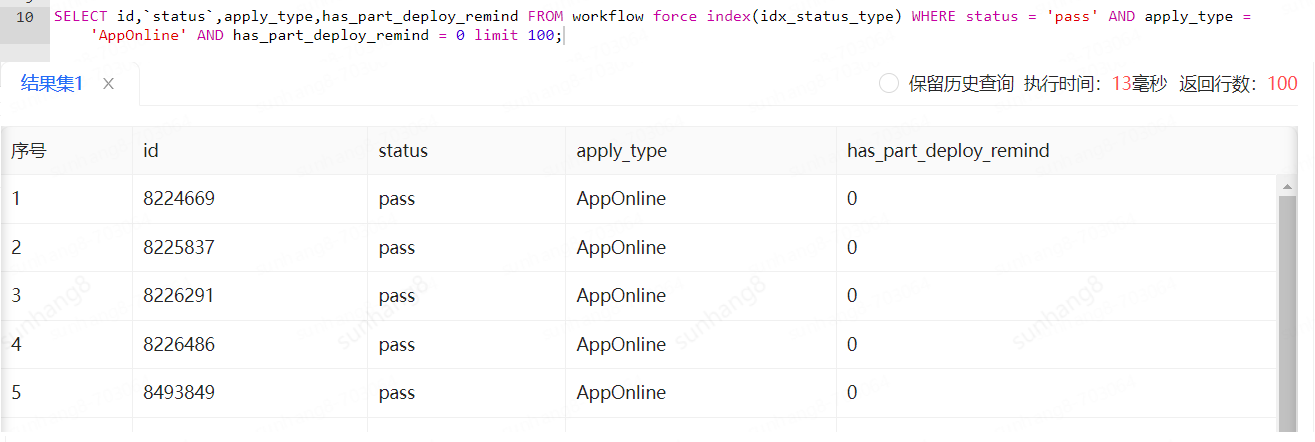
再看一下执行计划,type成为了ref。查询资料发现:index_merge查询时,当一个索引包含大量重复的值时,MySQL需要合并更多的行,这可能导致大量的随机I/O操作,因为它需要从不同的索引中检索和合并行。这种随机I/O通常比连续的I/O(如单个索引扫描)更慢

1.3 联合索引:如何实现1+1>2
当查询中需要根据两个或更多的列来检索数据时,联合索引显得尤为重要。它可以让数据库在多个列上同时进行高效的查找。注意,联合索引的第一项无需再单独建立索引:
CREATE INDEX idx_column1_column2 ON your_table (column1, column2);
联合索引需要注意:联合索引一般遵循最左匹配原则,例如
CREATE INDEX idx_sys_app_group ON groups (system_name, app_name, group_name);
#优化前 963ms
select * from groups where app_name = 'testApp' and group_name = 'testGroup';
#优化后 42ms
select * from groups where system_name= 'test' and app_name = 'testApp' and group_name = 'testGroup';
由此可以看出,当查询group_name时,必须带上联合索引的前两个列一起查询,也就是最左匹配原则,如果直接从联合索引的第二个字段开始查询的话,可能会走全表扫描,要小心这种1+1<2的情况
想要避免这种情况的话,不使用SELECT * 或许是一个不错的方法:
使用SELECT * 时,可以看到,查询走的全表扫描

如果只用app_name和group_name这俩创建了联合索引的列进行查询的话,就可以走索引啦!

第二章:查询重写 - 用巧妙的笔触画出高效SQL
2.1 别让数据库“吃撑”:告别SELECT *,享受轻盈查询
在日常写代码的途中最好能够避免使用SELECT *,在餐厅点餐时,我们也不会把菜单上的菜都来一份,使用SELECT *就像是点了一份满汉全席,而你却只想吃其中几道。请明确告诉数据库你需要的数据,以减轻它的负担。
如果表数据量很大,又需要查所有数据的情况下,可以先查出对应数据的主键id列表,再根据id列表查询;
2.2 给 GROUP BY 和 ORDER BY 减负
在使用GROUP BY或ORDER BY时,请先确保涉及的列已经建立索引。此外,避免在其中使用复杂的表达式或函数,会影响查询速度。
#优化前 1840ms
SELECT app_name,group_name,COUNT(*) FROM groups GROUP BY CONCAT(app_name,'-',group_name);
#优化后 42ms
SELECT app_name,group_name,COUNT(*) FROM groups GROUP BY app_name,group_name;
在使用group by分组时,最好先用where条件过滤掉不需要的数据后再分组,而不是分组后再用having筛选
#优化前 431ms
select * from groups group by app_name having app_name like 'jdos%';
#优化后 122ms
select * from groups where app_name like 'jdos%' group by app_name;
2.3 大分页查询的优化:赢在起跑线上
在处理大分页查询时,使用传统的LIMIT OFFSET方法会先扫描offset+limit行,然后再丢弃掉前offset行,再返回需要的limit行数据。而基于游标的分页则是将起跑线置于终点附近,通过使用上一页最后一条记录的ID来避免OFFSET,可以大幅提高分页的效率,不过这种方式只适合滚动加载或者迭代查询的情况,在需要跳页查询的情况下基本不太能使用。
#优化前 563ms
SELECT * from groups order by id limit 300000,100;
#优化后 78ms
SELECT * from groups where id > 976797 order by id limit 100;
对于需要跳页的大分页的数据,考虑不用一次查出所有数据,可以先查出主键id,再根据id列表查询详情
#优化后 72ms
SELECT id from groups order by id limit 300000,100;
2.4 EXPLAIN的妙用,分析sql执行计划,选择最佳索引
明明app_name和wf_version都有索引,数据量也不是很大,为啥执行时间这么慢呢

用explain看下执行计划,发现用到了wf_version索引,但是由于需要判空会扫描572353行

优化一下sql语句,使索引能够走到app_name,查询速度来到了50ms

再看下查询计划,发现走app_name索引的话只需要扫描289行就可以了

查询的时候,最好能让索引落在能够筛掉最多数据的列上
2.5 JOIN和IN怎么都不走索引?编码集搞的鬼
不知道大家有没有遇到过join或者in的查询,明明应该走索引的情况下,数据库却一直宁愿全表扫描也不走索引,正好最近排查了一个类似问题,在这里分享一下。
下面的查询中,workflow和workflow_scale_down_pod表中都有apply_number这个索引,关联查询的时候明明只返回一条数据速度却非常慢,这里选择join查询进行演示,可以看到,在两表都有索引的情况下只返回一条数据也耗时1900ms

于是分析一下执行计划,发现右表workflow根本没走索引!甚至用上强制索引也不选择索引:

难道是mysql又在抽什么风了?更改语句,用apply_number筛选右表,强制走索引,发现扫描行数也大有问题,明明左表中只有一条数据,右表却扫描了771034行,能看出来只有like的部分走了索引

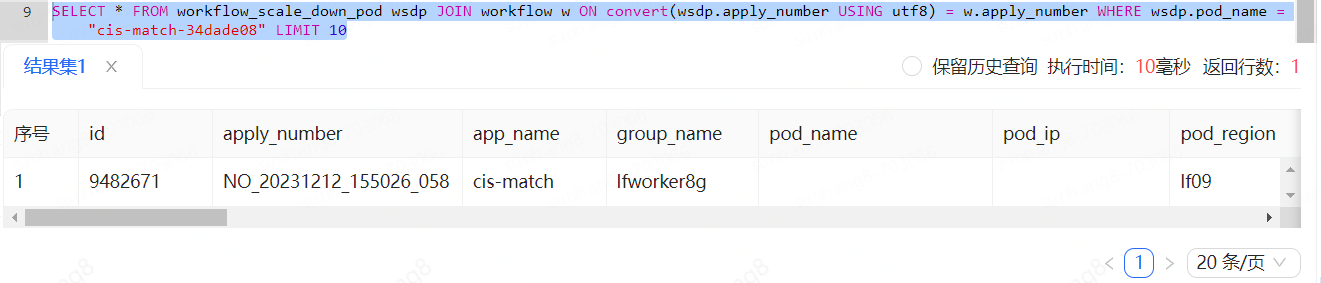
后面经过一段时间查找资料发现可能是编码集问题导致索引失效,于是排查两表的编码集,发现确实不一样,workflow用的是utf8而workflow_scale_down_pod用的是utf8mb4

转换一下编码后再join,分析一下执行计划,看样子终于对了

执行一下看看所需时间,发现来到了9ms,真是可喜可贺
2.6 VARCHAR类型不走索引
与2.5类似,在表字段为varchar类型,存储的数据是数字时,直接用int类型查也会导致不走索引,需要加上引号用String类型来查询
第三章:数据库设计 - 优化的基石
上面我们说完了查询方面的优化,接下来说一下对表整体的优化。设想你的数据库表是一座精心设计的高效工厂,每个表都是一个生产线,它们的设计直接影响着整个工厂的产出效率。垂直分表和水平分表是两种让生产线更高效的设计策略。
3.1 垂直分表:各司其职
垂直分表就像是对工厂的生产线进行专业化改造,将一个多功能生产线拆分成几个高度专业化的小团队,每个团队都只负责一部分任务。这样可以减少每次查询加载的数据量,从而提高效率。举个常用的例子:概览表和详情表,一般情况下用户只需要知道概览就可以了,当需要看某一条数据的具体情况时,再通过概览关联的详情id单独去查详情表
-- 原始表
CREATE TABLE task (id INT,name VARCHAR(100),operator VARCHAR(64), detail VARCHAR(2000)
);-- 垂直分表
CREATE TABLE task (id INT,name VARCHAR(100),operator VARCHAR(64), detail_id INT
);CREATE TABLE task_detail (id INT,detail VARCHAR(2000)
);3.2 水平分表:各得其所
水平分表,像是将一个超负荷的生产线拆分成几个并行的小生产线,每条线都在做相同的事情,但只处理一部分产品。这样可以大大减轻每条生产线的压力,提高整体的处理能力。根据一定的规则将原表拆成几个表结构相同的表,查询时根据一定的路由规则分配到对应的表里,让每个表的数据都不会过于臃肿
-- 原始表
CREATE TABLE task (id INT,name VARCHAR(100),operator VARCHAR(64), detail VARCHAR(2000)
);-- 水平分表 按年份分表
CREATE TABLE task_2022 (id INT,name VARCHAR(100),operator VARCHAR(64), detail VARCHAR(2000)
);CREATE TABLE task_2023 (id INT,name VARCHAR(100),operator VARCHAR(64), detail VARCHAR(2000)
);3.3 数据归档:轻装前行
数据归档和水平分表类似,是将基本不可能用到的数据移到备份表中,对数据库来一次“断舍离”。举个例子:现在数据库表删除数据时基本上都是逻辑删除,当表里的数据非常多,而且被删除的数据和还存在的数据差不多的时候,就可以考虑将逻辑删除的数据移到备份表中,这样不仅缩小了表的数据量,还可以在查询的时候去掉对逻辑删除字段的筛选,查询更快人一步。
结语:持续的优化之路
优化SQL查询是一个动态且持续的过程,它要求我们不断地进行监控、评估和调整。每一次微小的调优都有可能使数据库的查询速度显著提升。现在,你已经了解了优化的相关知识,准备好了吗?是时候启动引擎,让你的数据库和行云部署一样起飞了!
讨论:欢迎分享
大家在SQL优化方面还遇到过哪些有趣或棘手的场景呢?请在评论区畅所欲言,让我们一起学习、探讨和解决这些问题。相信大家的经验会为大家带来启发和帮助,让我们共同进步,成为SQL优化的高手!
同时,如果你有任何关于数据库优化的问题,也可以在评论区提问,我们也会尽力为大家解答。让我们互相学习,共创美好未来!
作者:京东科技 孙航
来源:京东云开发者社区 转载请注明来源
相关文章:
行云部署成长之路 -- 慢 SQL 优化之旅 | 京东云技术团队
当项目的SQL查询慢得像蜗牛爬行时,用户的耐心也在一点点被消耗,作为研发,我们可不想看到这样的事。这篇文章将结合行云部署项目的实践经验,带你走进SQL优化的奇妙世界,一起探索如何让那些龟速的查询飞起来!…...
Windows权限提升
0x01 简介 提权可分为纵向提权与横向提权: 纵向提权:低权限角色获得高权限角色的权限; 横向提权:获取同级别角色的权限。 Windows常用的提权方法有:系统内核溢出漏洞提权、数据库提权、错误的系统配置提权、组策略首…...
win系统搭建Minecraft世界服务器,MC开服教程,小白开服教程
Windows系统搭建我的世界世界服务器,Minecraft开服教程,小白开服教程,MC 1.19.4版本服务器搭建教程。 此教程使用 Mohist 1.19.4 服务端,此服务端支持Forge模组和Bukkit/Spigot/Paper插件,如果需要开其他服务端也可参…...

word2vec中的CBOW和Skip-gram
word2cev简单介绍 Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇…...

在ios上z-index不起作用问题的总结
最近在维护一个H5老项目时,遇到一个问题,就是在ios上z-index不起作用,在安卓上样式都是好的。 项目的架构组成是vue2.x vux vuex vue-router等 用的UI组件库是vux 在页面中有一个功能点,就是点选择公司列表的时候,会…...

力扣labuladong一刷day59天动态规划
力扣labuladong一刷day59天动态规划 文章目录 力扣labuladong一刷day59天动态规划一、509. 斐波那契数二、322. 零钱兑换 一、509. 斐波那契数 题目链接:https://leetcode.cn/problems/fibonacci-number/description/ 思路:这是非常典型的一道题&#x…...

pyenv环境找不到sqlite:No module named _sqlite3
前言 一般遇到这个问题都在python版本管理或者虚拟环境切换中遇到,主要有两个办法解决,如下: 解决方法1 如果使用的pyenv管理python环境时遇到没有_sqlite3 库,可以将当前pyenv的python环境卸载 pyenv uninstall xxx然后在系统…...

Histone H3K4me2 Antibody, SNAP-Certified™ for CUTRUN
EpiCypher是一家为表观遗传学和染色质生物学研究提供高质量试剂和工具的专业制造商。EpiCypher推出的CUT&RUN级别的Histone H3K4me2 Antibody符合EpiCypher的批次特异性SNAP-CertifiedTM标准,在CUT&RUN中具有特异性和高效的靶点富集。通过SNAP-CUTANA™K-Me…...
我用 Laf 开发了一个非常好用的密码管理工具
【KeePass 密码管理】是一款简单、安全简洁的账号密码管理工具,服务端使用 Laf 云开发,支持指纹验证、FaceID,N 重安全保障,可以随时随地记录我的账号和密码。 写这个小程序之前,在国内市场找了很多密码存储类的 App …...

windows项目部署
文章目录 一、项目部署1.1 先准备好文件1.2安装jdk1.3 配置环境1.4 安装tomcat1.5 MySQL安装本机测试的话:远程连接测试 1.6 项目部署 一、项目部署 1.1 先准备好文件 1.2安装jdk 下一步 下一步 下一步 1.3 配置环境 变量名:JAVA_HOME 变量值:jdk的…...

http首部
1. htttp 报文首部 报文结构为:首部 空行(CRLF)主体 在请求中 http报文首部由请求方法,URI,http版本,首部字段等构成 在响应中:状态码,http版本,首部字段3部分构成 2…...

2024.1.8 Day04_SparkCore_homeWork
目录 1. 简述Spark持久化中缓存和checkpoint检查点的区别 2 . 如何使用缓存和检查点? 3 . 代码题 浏览器Nginx案例 先进行数据清洗,做后续需求用 1、需求一:点击最多的前10个网站域名 2、需求二:用户最喜欢点击的页面排序TOP10 3、需求三&#x…...
09.简单工厂模式与工厂方法模式
道生一,一生二,二生三,三生万物。——《道德经》 最近小米新车亮相的消息可以说引起了不小的轰动,我们在感慨SU7充满土豪气息的保时捷设计的同时,也深深的被本土品牌的野心和干劲所鼓舞。 今天我们就接着这个背景&…...
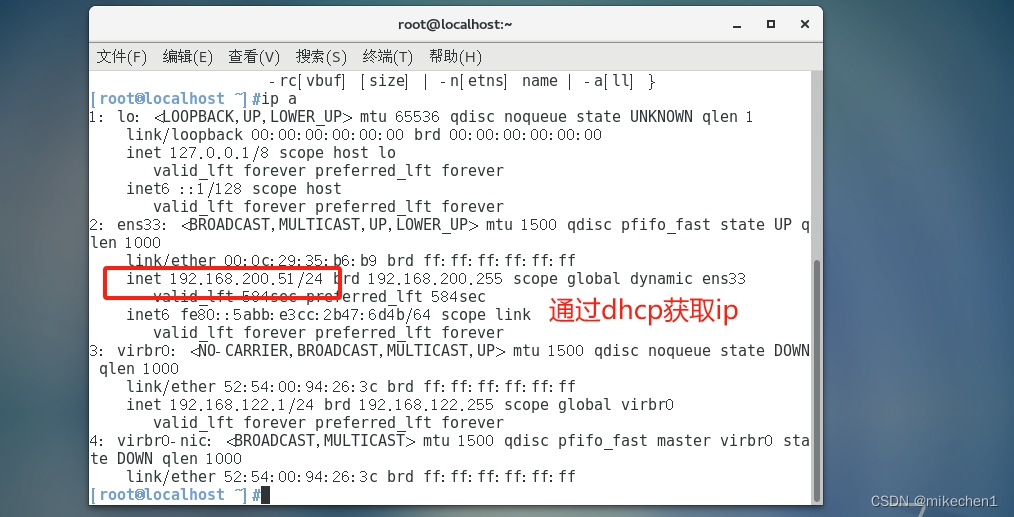
DHCP,怎么在Linux和Windows中获得ip
一、DHCP 1.1 什么是dhcp DHCP动态主机配置协议,通常被应用在大型的局域网络环境中,主要作用是集中地管理、分配IP地址,使网络环境中的主机动态的获得IP地址、DNS服务器地址等信息,并能够提升地址的使用率。 DHCP作为用应用层协…...
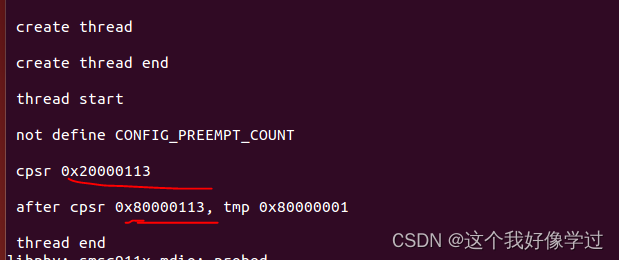
读写锁(arm)
参考文章读写锁 - ARM汇编同步机制实例(四)_汇编 prefetchw-CSDN博客 读写锁允许多个执行流并发访问临界区。但是写访问是独占的。适用于读多写少的场景 另外好像有些还区分了读优先和写优先 读写锁定义 typedef struct {arch_rwlock_t raw_lock; #if…...

【第33例】IPD体系进阶:市场细分
目录 内容简介 市场细分原因 市场细分主要活动 市场细分流程 作者简介 内容简介 这节内容主要来谈谈 IPD 市场管理篇的市场细分步骤。 其中,市场管理(Market Management)是一套系统的方法。 用于对广泛的机会进行选择性收缩,...

response 拦截器返回的二进制文档(同步下载excel)如何配置
response 拦截器返回的二进制文档(同步下载excel)如何配置 一、返回效果图二、response如何配置 一、返回效果图 二、response如何配置 service.interceptors.response.use(response > {// 导出excel接口if (response.config.isExport) {return resp…...
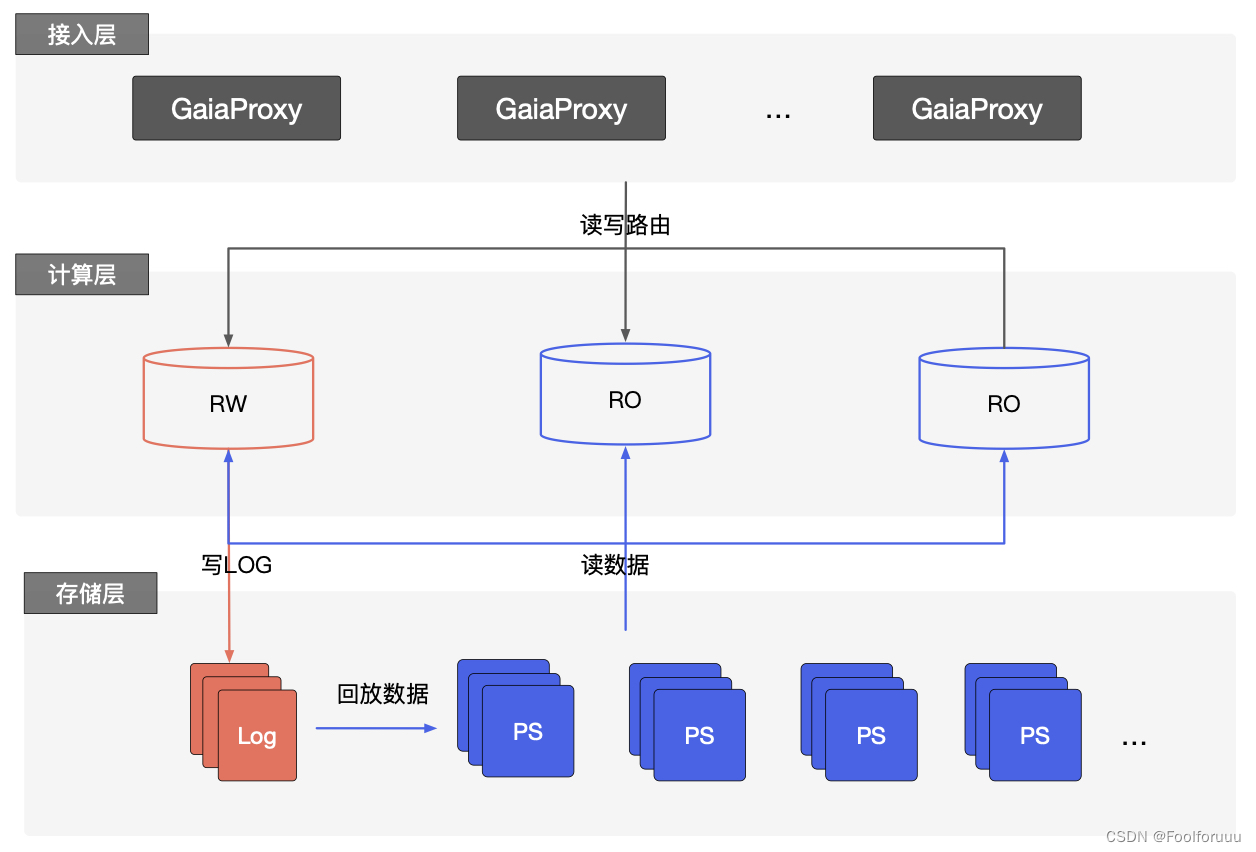
为什么要使用云原生数据库?云原生数据库具体有哪些功能?
相比于托管型关系型数据库,云原生数据库极大地提高了MySQL数据库的上限能力,是云数据库划代的产品;云原生数据库最早的产品是AWS的 Aurora。AWS Aurora提出来的 The log is the database的理念,实现存储计算分离,把大量…...

05- OpenCV:图像操作和图像混合
目录 一、图像操作 1、读写图像 2、读写像素 3、修改像素值 4、Vec3b与Vec3F 5、相关的代码演示 二、图像混合 1、理论-线性混合操作 2、相关API(addWeighted) 3、代码演示(完整的例子) 一、图像操作 1、读写图像 (1)…...

人脸识别(Java实现的)
虹软人脸识别: 虹软人脸识别的地址:虹软视觉开放平台—以免费人脸识别技术为核心的人脸识别算法开放平台 依赖包: 依赖包是从虹软开发平台下载的 在项目中引入这个依赖包 pom.xml <!-- 人脸识别 --><dependency><gr…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...