《动手学深度学习》学习笔记 第8章 循环神经网络
本系列为《动手学深度学习》学习笔记
书籍链接:动手学深度学习
笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看
关于本系列笔记: 书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很多,笔记只保留主要内容,同时也是对之前知识的查漏补缺
8. 循环神经网络
到目前为止我们默认数据都来自于某种分布,并且所有样本都是独立同分布的(independently and identically distributed,i.i.d.)。然而,大多数的数据并非如此。
如果说卷积神经网络可以有效地处理空间信息,那么本章的**循环神经网络(recurrent neural network, RNN)**则可以更好地处理序列信息。
8.1 序列模型
8.1.1 统计工具
处理序列数据需要统计工具和新的深度神经网络架构。为了简单起见,以 图8.1.1所示的股票价格(富时100指数)为例。

图8.1.1: 近30年的富时100指数
其中,用 x t x_t xt表示价格,即在时间步(time step) t ∈ Z + t ∈ Z^+ t∈Z+时,观察到的价格 x t x_t xt( t t t对于本文中的序列通常是离散的,并在整数或其子集上变化)
假设一个交易员想在 t t t日的股市中表现良好,于是通过以下途径预测 x t x_t xt:
x t ∼ P ( x t ∣ x t − 1 , . . . , x 1 ) . ( 8.1.1 ) x_t ∼ P(xt | x_{t−1}, . . . , x_1). (8.1.1) xt∼P(xt∣xt−1,...,x1).(8.1.1)
自回归模型
主要问题:输入数据的数量,输入 x t − 1 , . . . , x 1 x_{t−1}, . . . , x_1 xt−1,...,x1本身因t而异。也就是说,输入数据的数量会随着遇到的数据量的增加
而增加,因此需要一个近似方法来使这个计算变得容易处理。
如何有效估计 P ( x t ∣ x t − 1 , . . . , x 1 ) P(x_t | x_{t−1}, . . . , x_1) P(xt∣xt−1,...,x1)? 简单地说,它归结为以下两种策略:
- 第一种策略,假设在现实情况下很长的序列 x t − 1 , . . . , x 1 x_{t−1}, . . . ,x_1 xt−1,...,x1可能是不必要的,只需要满足某个长度为 τ τ τ的时间跨度,即使用观测序列 x t − 1 , . . . , x t − τ x_{t−1}, . . . , x_{t−τ} xt−1,...,xt−τ。这样的好处就是参数的数量总是不变的,至少在 t > τ t >τ t>τ时如此。这种模型被称为自回归模型(autoregressive models),因为它们是对自己执行回归。
- 第二种策略,如 图8.1.2所示,保留一些对过去观测的总结 h t h_t ht,并且同时更新预测 x ^ t \hat{x}_t x^t和总结 h t h_t ht。这就产生了基于 x ^ t = P ( x t ∣ h t ) \hat{x}t =P(x_t | h_t) x^t=P(xt∣ht)的估计 x t x_t xt,以及公式 h t = g ( h t − 1 , x t − 1 ) h_t = g(h_{t−1}, x_{t−1}) ht=g(ht−1,xt−1)更新的模型。由于 h t h_t ht从未被观测到,这类模型也被称为隐变量自回归模型(latent autoregressive models)。

图8.1.2: 隐变量自回归模型
这两种情况都有一个显而易见的问题:如何生成训练数据?
一个经典方法是使用历史观测来预测下一个未来观测。显然,我们并不指望时间会停滞不前。然而,一个常见的假设是虽然特定值xt可能会改变,但是序列本身的动力学(可以理解为变化趋势或者变化)不会改变。这样的假设是合理的,因为新的动力学一定受新的数据影响,而我们不可能用目前所掌握的数据来预测新的动力学。统计学家称不变的动力学为静止的(stationary)。因此,整个序列的估计值都将通过以下的方式获得:
P ( x 1 , . . . , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , . . . , x T ) P( x_1, . . . , x_T) = \prod \limits_{t=1}^TP( x_t|x_1, . . . , x_T) P(x1,...,xT)=t=1∏TP(xt∣x1,...,xT)
注意,如果处理的是离散的对象(如单词),上述的考虑仍然有效。唯一的差别是,对于离散的对象,需要使用分类器而不是回归模型来估计 P ( x t ∣ x t − 1 , . . . , x 1 ) P(x_t | x_{t−1}, . . . , x_1) P(xt∣xt−1,...,x1)。
马尔可夫模型
回想一下,在自回归模型的近似法中,我们使用 x t − 1 , . . . , x t − τ x_{t−1}, . . . , x_{t−τ} xt−1,...,xt−τ 而不是 x t − 1 , . . . , x 1 x_{t−1}, . . . , x_1 xt−1,...,x1来估计 x t x_t xt。只要这种是近似精确的,就说序列满足马尔可夫条件(Markov condition)。特别是,如果 τ = 1 τ = 1 τ=1,得到一个 一阶马尔可夫模型(first‐order Markov model), P ( x ) P(x) P(x)由下式给出:
P ( x 1 , . . . , x T ) = ∏ t = 1 T P ( x t ∣ x t − 1 ) 当 P ( x 1 ∣ x 0 ) = P ( x 1 ) P( x_1, . . . , x_T) = \prod \limits_{t=1}^TP( x_t|x_{t-1})当P(x_1|x_0)=P(x_1) P(x1,...,xT)=t=1∏TP(xt∣xt−1)当P(x1∣x0)=P(x1)
当假设 x t x_t xt仅是离散值时,使用动态规划可以沿着马尔可夫链精确地计算结果。例如,可以高效地计算 P ( x t + 1 ∣ x t − 1 ) P(x_{t+1} | x_{t−1}) P(xt+1∣xt−1):

利用这一事实,只需要考虑过去观察中的一个非常短的历史: P ( x t + 1 ∣ x t , x t − 1 ) = P ( x t + 1 ∣ x t ) P(x_{t+1} | x_t, x_{t−1}) = P(x_{t+1} | x_t) P(xt+1∣xt,xt−1)=P(xt+1∣xt)。隐马尔可夫模型中的动态规划超出了本节的范围(将在 9.4节再次遇到),而动态规划这些计算工具已经在控制算法和强化学习算法广泛使用。
因果关系
原则上,可以将 P ( x 1 , . . . , x T ) P(x_1, . . . , x_T ) P(x1,...,xT)倒序展开。基于条件概率公式,可以写出:
P ( x 1 , . . . , x T ) = ∏ t = T 1 P ( x t ∣ x t + 1 , . . . , x T ) P( x_1, . . . , x_T) = \prod \limits_{t=T}^1 P( x_t|x_{t+1}, . . . , x_T) P(x1,...,xT)=t=T∏1P(xt∣xt+1,...,xT)
事实上,如果基于一个马尔可夫模型,还可以得到一个反向的条件概率分布。
然而,在许多情况下,数据存在一个自然的方向,即在时间上是前进的。很明显,未来的事件不能影响过去。因此,如果我们改变 x t x_t xt,可能会影响未来发生的事情 x t + 1 x_{t+1} xt+1,但不能反过来(也就是说,如果我们改变 x t x_t xt,基于过去事件得到的分布不会改变。)
因此,解释 P ( x t + 1 ∣ x t ) P(x_{t+1} | x_t) P(xt+1∣xt)应该比解释 P ( x t ∣ x t + 1 ) P(x_t | x_{t+1}) P(xt∣xt+1)更容易。例如,在某些情况下,对于某些可加性噪声 ϵ ϵ ϵ,显然可以找到 x t + 1 = f ( x t ) + ϵ x_{t+1} = f(x_t) + ϵ xt+1=f(xt)+ϵ,而反之则不行 (Hoyer et al., 2009)。
8.1.2 训练
了解了上述统计工具后,在实践中尝试一下!
首先,生成一些数据:使用正弦函数和一些可加性噪声来生成序列数据,时间步为1, 2, . . . , 1000。
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2lT = 1000 # 总共产生1000个点
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))d2l.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))

接下来,将这个序列转换为特征-标签(feature‐label)对。基于嵌入维度 τ τ τ,将数据映射为数据对 y t = x t y_t = x_t yt=xt和 x t = [ x t − τ , . . . , x t − 1 ] x_t = [x_{t−τ} , . . . , x_{t−1}] xt=[xt−τ,...,xt−1]。这比数据样本少了 τ τ τ个( x 0 到 x τ x_0到x_τ x0到xτ),因为我们没有足够的历史记录来描述前τ个数据样本。一个简单的解决办法是:
- 如果拥有足够长的序列就丢弃这几项;
- 另一个方法是用零填充序列。
在这里,我们仅使用前600个 “特征-标签” 对进行训练。
tau = 4
features = torch.zeros((T - tau, tau))
for i in range(tau):features[:, i] = x[i: T - tau + i]labels = x[tau:].reshape((-1, 1))
batch_size, n_train = 16, 600# 只有前n_train个样本用于训练
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),batch_size, is_train=True)
其中:features[:, i] = x[i: T - tau + i] 就是根据 x t = [ x t − τ , . . . , x t − 1 ] x_t = [x_{t−τ} , . . . , x_{t−1}] xt=[xt−τ,...,xt−1]生成的数据特征
在这里,使用一个相当简单的架构训练模型:拥有两个全连接层的多层感知机,ReLU激活函数和平方损失。
# 初始化网络权重的函数
def init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)# 一个简单的多层感知机
def get_net():net = nn.Sequential(nn.Linear(4, 10),nn.ReLU(),nn.Linear(10, 1))net.apply(init_weights)return net
# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')
现在,准备训练模型。实现下面的训练代码:
def train(net, train_iter, loss, epochs, lr):trainer = torch.optim.Adam(net.parameters(), lr)for epoch in range(epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.sum().backward()trainer.step()print(f'epoch {epoch + 1}, 'f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')net = get_net()train(net, train_iter, loss, 5, 0.01)
==========================================================
epoch 1, loss: 0.076846
epoch 2, loss: 0.056340
epoch 3, loss: 0.053779
epoch 4, loss: 0.056320
epoch 5, loss: 0.051650
8.1.3 预测
由于训练损失很小,因此期望模型能有很好的工作效果。这在实践中意味着什么?
首先是检查模型预测下一个时间步的能力,也就是单步预测(one‐step‐ahead prediction)。
onestep_preds = net(features)
d2l.plot([time, time[tau:]],[x.detach().numpy(), onestep_preds.detach().numpy()], 'time','x', legend=['data', '1-step preds'], xlim=[1, 1000],figsize=(6, 3))

单步预测效果不错。即使这些预测的时间步超过了 600 + 4 ( n t r a i n + t a u ) 600 + 4(n_train + tau) 600+4(ntrain+tau),其结果看起来仍然是可信的。
然而有一个小问题:如果数据观察序列的时间步只到604,需要一步一步地向前迈进:
x ^ 605 = f ( x 601 , x 602 , x 603 , x 604 ) , . . . ( 8.1.6 ) \hat{x}_{605} = f(x_{601}, x_{602}, x_{603}, x_{604}),. . .(8.1.6) x^605=f(x601,x602,x603,x604),...(8.1.6)
x ^ 606 = f ( x 602 , x 603 , x 604 ) , x 605 , . . . ( 8.1.6 ) \hat{x}_{606} = f(x_{602}, x_{603}, x_{604}),x_{605}, . . .(8.1.6) x^606=f(x602,x603,x604),x605,...(8.1.6)
… … …… ……
通常,对于直到 x t x_t xt的观测序列,其在时间步 t + k t + k t+k处的预测输出 x ^ t + k \hat{x}_{t+k} x^t+k 称为 k k k步预测(k‐step‐ahead‐prediction)。
由于我们的观察已经到了 x 604 x_{604} x604,它的 k k k步预测是 x ^ 604 + k \hat{x}_{604+k} x^604+k。
换句话说,必须使用我们自己的预测(而不是原始数据)来进行多步预测。 让我们看看效果如何。
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]for i in range(n_train + tau, T):multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1, -1)))d2l.plot([time, time[tau:], time[n_train + tau:]],[x.detach().numpy(), onestep_preds.detach().numpy(),multistep_preds[n_train + tau:].detach().numpy()], 'time','x', legend=['data', '1-step preds', 'multistep preds'],xlim=[1, 1000], figsize=(6, 3))

如上面的例子所示,绿线的预测显然并不理想。经过几个预测步骤之后,预测的结果很快就会衰减到一个常数。
为什么这个算法效果这么差呢? 事实是由于错误的累积:
- 假设在步骤1之后,积累了一些错误 ϵ 1 = ϵ ^ + c ϵ 1 ϵ_1 = \hat{ϵ}+ cϵ_1 ϵ1=ϵ^+cϵ1。
- 于是,步骤2的输入被扰动了 ϵ 1 ϵ1 ϵ1,结果积累的误差是依照次序的 ϵ 2 = ¯ ϵ + c ϵ 1 ϵ2 = ¯ϵ + cϵ1 ϵ2=¯ϵ+cϵ1(其中 c c c为某个常数)
- 后面的预测误差依此类推。
因此误差可能会相当快地偏离真实的观测结果。(例如,未来24小时的天气预报往往相当准确,但超过这一点,精度就会迅速下降)。
我们将在本章及后续章节中讨论如何改进这一点。
基于 k = 1 , 4 , 16 , 64 k = 1, 4, 16, 64 k=1,4,16,64,通过对整个序列预测的计算,更仔细地看一下k步预测的困难。
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):features[:, i] = x[i: i + T - tau - max_steps + 1]# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):features[:, i] = net(features[:, i - tau:i]).reshape(-1)steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],figsize=(6, 3))

以上例子清楚地说明了当我们试图预测更远的未来时,预测的质量是如何变化的。虽然“4步预测”看起来仍然不错,但超过这个跨度的任何预测几乎都是无用的。
小结
- 内插法(在现有观测值之间进行估计)和外推法(对超出已知观测范围进行预测)在实践的难度上差别很大。因此,对于所拥有的序列数据,在训练时始终要尊重其时间顺序,即最好不要基于未来的数据进行训练。
- 序列模型的估计需要专门的统计工具,两种较流行的选择是自回归模型和隐变量自回归模型。
- 对于时间是向前推进的因果模型,正向估计通常比反向估计更容易。
- 对于直到时间步t的观测序列,其在时间步t +k的预测输出是“k步预测”。随着我们对预测时间k值的增加,会造成误差的快速累积和预测质量的极速下降。
8.2 文本预处理
对于序列数据处理问题,在 8.1节中评估了所需的统计工具和预测时面临的挑战。
本节中,将解析文本的常见预处理步骤。这些步骤通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
import collections
import re
from d2l import torch as d2l
8.2.1 读取数据集
首先,从H.G.Well的时光机器99中加载文本。这是一个相当小的语料库,只有30000多个单词,而现实中的文档集合可能会包含数十亿个单词。(下面的函数将数据集读取到由多条文本行组成的列表中,其中每条文本行都是一个字符串。为简单起见,在这里忽略了标点符号和字母大写。)
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine(): #@save"""将时间机器数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])
==============================================================
Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
# 文本总行数: 3221
the time machine by h g wells
twinkled and his usually pale face was flushed and animated the
8.2.2 词元化
下面的tokenize函数
- 将文本行列表(lines) 作为输入,列表中的每个元素是一个文本序列(如一条文本行)。
- 每个文本序列又被拆分成一个词元列表,词元(token) 是文本的基本单位。
- 最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
def tokenize(lines, token='word'): #@save"""将文本行拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)
tokens = tokenize(lines)
for i in range(11):print(tokens[i])['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
[]
[]
[]
[]
['i']
[]
[]
['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him']
['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
8.2.3 词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。
现在,让我们构建一个字典,通常也叫做词表(vocabulary),用来将字符串类型的词元映射到从0开始的数字索引中。
- 先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计,得到的统计结果称之为语料(corpus)。
- 然后根据每个唯一词元的出现频率,为其分配一个数字索引。很少出现的词元通常被移除,这可以降低复杂性。
- 另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“”。
可以选择增加一个列表,用于保存那些被保留的词元,例如:填充词元(“”);序列开始词元(“”);序列结束词元(“”)。
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# 按出现频率排序counter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # 未知词元的索引为0return 0@propertydef token_freqs(self):return self._token_freqsdef count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line]return collections.Counter(tokens)首先使用时光机器数据集作为语料库来构建词表,然后打印前几个高频词元及其索引。
vocab = Vocab(tokens)print(list(vocab.token_to_idx.items())[:10])[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8),→('that', 9)]
现在,可以将每一条文本行转换成一个数字索引列表。
for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab[tokens[i]])=======================================================================
文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
索引: [1, 19, 50, 40, 2183, 2184, 400]
文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and','animated', 'the']
索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
8.2.4 整合所有功能
在使用上述函数时,将所有功能打包到load_corpus_time_machine函数中,该函数返回corpus(词元索引列表) 和vocab(时光机器语料库的词表)。
在这里所做的改变是:
- 为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
- 时光机器数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""lines = read_time_machine()tokens = tokenize(lines, 'char')vocab = Vocab(tokens)# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,# 所以将所有文本行展平到一个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocab
corpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)
===================================================================
(170580, 28)
小结
- 文本是序列数据的一种最常见的形式之一。
- 为了对文本进行预处理,我们通常将文本拆分为词元,构建词表将词元字符串映射为数字索引,并将文本数据转换为词元索引以供模型操作。
8.3 语言模型和数据集
在 8.2节中,了解了如何将文本数据映射为词元,以及将这些词元可以视为一系列离散的观测,例如单词或字符。假设长度为T的文本序列中的词元依次为 x 1 , . . . , x T x_1, . . . , x_T x1,...,xT。于是, x t ( 1 ≤ t ≤ T ) x_t(1 ≤ t ≤ T) xt(1≤t≤T)可以被认为是文本序列在时间步t处的观测或标签。在给定这样的文本序列时,语言模型(language model)的目标是估计序列的联合概率
P ( x 1 , . . . , x T ) . ( 8.3.1 ) P(x_1, . . . , x_T ). (8.3.1) P(x1,...,xT).(8.3.1)
8.3.1 学习语言模型
我们面对的问题是如何对一个文档,甚至是一个词元序列进行建模。假设在单词级别对文本数据进行词元化,可以依靠在 8.1节中对序列模型的分析。让我们从基本概率规则开始:
P ( x 1 , . . . , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , . . . , x T ) P( x_1, . . . , x_T) = \prod \limits_{t=1}^TP( x_t|x_1, . . . , x_T) P(x1,...,xT)=t=1∏TP(xt∣x1,...,xT)
例如,包含了四个单词的一个文本序列的概率是:
P ( d e e p , l e a r n i n g , i s , f u n ) = P ( d e e p ) P ( l e a r n i n g ∣ d e e p ) P ( i s ∣ d e e p , l e a r n i n g ) P ( f u n ∣ d e e p , l e a r n i n g , i s ) . ( 8.3.3 ) P(deep, learning, is,fun) = P(deep)P(learning | deep)P(is | deep, learning)P(fun | deep, learning, is).(8.3.3) P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is).(8.3.3)
为了训练语言模型,我们需要计算单词的概率,以及给定前面几个单词后出现某个单词的条件概率。这些概率本质上就是语言模型的参数。
这里,我们假设训练数据集是一个大型的文本语料库。比如,维基百科的所有条目、古登堡计划101,或者所有发布在网络上的文本。训练数据集中词的概率可以根据给定词的相对词频来计算。
例如,可以将估计值 P ^ ( d e e p ) \hat{P}(deep) P^(deep) 计算为任何以单词“deep”开头的句子的概率。一种(稍稍不太精确的)方法是统计单词“deep”在数据集中的出现次数,然后将其除以整个语料库中的单词总数。特别是对于频繁出现的单词,这种方法效果不错。
接下来,可以尝试估计
P ^ ( l e a r n i n g ∣ d e e p ) = n ( d e e p , l e a r n i n g ) n ( d e e p ) \hat{P}(learning | deep) = \frac{n(deep, learning)}{n(deep)} P^(learning∣deep)=n(deep)n(deep,learning)
不幸的是,由于连续单词对 “deep learning” 的出现频率要低得多,所以估计这类单词正确的概率要困难得多。特别是对于一些不常见的单词组合,要想找到足够的出现次数来获得准确的估计可能都不容易。除非我们提供某种解决方案,来将这些单词组合指定为非零计数,否则将无法在语言模型中使用它们。
一种常见的策略是执行某种形式的拉普拉斯平滑(Laplace smoothing),具体方法是在所有计数中添加一个小常量。用 n n n表示训练集中的单词总数,用 m m m表示唯一单词的数量。

8.3.2 马尔可夫模型与n元语法
回想在 8.1节中对马尔可夫模型的讨论,并且将其应用于语言建模。如果 P ( x t + 1 ∣ x t , . . . , x 1 ) = P ( x t + 1 ∣ x t ) P(xt+1 | xt, . . . , x1) = P(xt+1 | xt) P(xt+1∣xt,...,x1)=P(xt+1∣xt),则序列上的分布满足一
阶马尔可夫性质。阶数越高,对应的依赖关系就越长。
这种性质推导出了许多可以应用于序列建模的近似公式:

通常,涉及一个、两个和三个变量的概率公式分别被称为 一元语法(unigram)、二元语法(bigram) 和三元语法(trigram) 模型。下面,我们将学习如何去设计更好的模型。
8.3.3 自然语言统计
根据 8.2节中介绍的时光机器数据集构建词表,并打印前10个
最常用的(频率最高的)单词。
import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10]
==========================
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
正如所看到的,最流行的词看起来很无聊,这些词通常被称为停用词(stop words),因此可以被过滤掉。尽管如此,它们本身仍然是有意义的,我们仍然会在模型中使用它们。
此外,还有个明显的问题是词频衰减的速度相当地快。例如,最常用单词的词频对比,第10个还不到第1个的1/5。
freqs = [freq for token, freq in vocab.token_freqs]d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',xscale='log', yscale='log')

通过此图我们可以发现:词频以一种明确的方式迅速衰减:单词的频率满足齐普夫定律(Zipf’s law),即第i个最常用
单词的频率ni为:
n i ∝ 1 i α n_i ∝\frac{1}{i^α} ni∝iα1
等价于
l o g n i = − α l o g i + c , log n_i = −α log i + c, logni=−αlogi+c,
其中 α α α是刻画分布的指数, c c c是常数。
这告诉我们想要通过计数统计和平滑来建模单词是不可行的,因为这样建模的结果会大大高估尾部单词的频率,也就是所谓的不常用单词。
直观地对比三种模型中的词元频率:一元语法、二元语法和三元语法。
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])

- 除了一元语法词,单词序列似乎也遵循齐普夫定律,尽管公式 (8.3.7)中的指数α更小(指数的大小受序列长度的影响);
- 词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构,这些结构给了我们应用模型的希望;
- 很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。作为代替,我们将使用基于深度学习的模型。
8.3.4 读取长序列数据
假设我们将使用神经网络来训练语言模型,模型中的网络一次处理一个小批量序列(小批量序列:具有预定义长度(例如n个时间步))。
首先,由于文本序列可以是任意长的,例如整本《时光机器》(The Time Machine),可以选择任意偏移量来指示初始位置。

图8.3.1: 分割文本时,不同的偏移量会导致不同的子序列
如果只选择一个偏移量,那么用于训练网络的、所有可能的子序列的覆盖范围将是有限的。因此,可以从随机偏移量开始划分序
列,以同时获得覆盖性(coverage)和随机性(randomness)。
下面,将描述如何实现随机采样(random sampling) 和 顺序分区(sequential partitioning) 策略。
随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。对于语言建模,目标是基于到目前为止我们看到的词元来预测下一个词元,因此标签是移位了一个词元的原始序列。
下面的代码每次可以从数据中随机生成一个小批量。
- 参数batch_size指定了每个小批量中子序列样本的数目,
- 参数num_steps是每个子序列中预定义的时间步数。
def seq_data_iter_random(corpus, batch_size, num_steps): #@save"""使用随机抽样生成一个小批量子序列"""# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1corpus = corpus[random.randint(0, num_steps - 1):]# 减去1,是因为我们需要考虑标签num_subseqs = (len(corpus) - 1) // num_steps# 长度为num_steps的子序列的起始索引initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 在随机抽样的迭代过程中,# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻random.shuffle(initial_indices)def data(pos):# 返回从pos位置开始的长度为num_steps的序列return corpus[pos: pos + num_steps]num_batches = num_subseqs // batch_sizefor i in range(0, batch_size * num_batches, batch_size):# 在这里,initial_indices包含子序列的随机起始索引initial_indices_per_batch = initial_indices[i: i + batch_size]X = [data(j) for j in initial_indices_per_batch]Y = [data(j + 1) for j in initial_indices_per_batch]yield torch.tensor(X), torch.tensor(Y)
下面生成一个从0到34的序列。批量大小(num_steps)为2,时间步数(num_steps)为5,这意味着可以生成 ⌊(35 − 1)/5⌋ = 6个“特征-标签”子序列对。
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)
---------------------------------------------------------------
X: tensor([[13, 14, 15, 16, 17],[28, 29, 30, 31, 32]])
Y: tensor([[14, 15, 16, 17, 18],[29, 30, 31, 32, 33]])
X: tensor([[ 3, 4, 5, 6, 7],[18, 19, 20, 21, 22]])
Y: tensor([[ 4, 5, 6, 7, 8],[19, 20, 21, 22, 23]])
X: tensor([[ 8, 9, 10, 11, 12],[23, 24, 25, 26, 27]])
Y: tensor([[ 9, 10, 11, 12, 13],[24, 25, 26, 27, 28]])
顺序分区
在迭代过程中,还可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的。这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save"""使用顺序分区生成一个小批量子序列"""# 从随机偏移量开始划分序列offset = random.randint(0, num_steps)num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_sizeXs = torch.tensor(corpus[offset: offset + num_tokens])Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)num_batches = Xs.shape[1] // num_stepsfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i: i + num_steps]Y = Ys[:, i: i + num_steps]yield X, Y
基于相同的设置,通过顺序分区读取每个小批量的子序列的特征X和标签Y。通过将它们打印出来可以发现:迭代期间来自两个相邻的小批量中的子序列在原始序列中确实是相邻的。
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
X: tensor([[ 0, 1, 2, 3, 4],[17, 18, 19, 20, 21]])
Y: tensor([[ 1, 2, 3, 4, 5],[18, 19, 20, 21, 22]])
X: tensor([[ 5, 6, 7, 8, 9],[22, 23, 24, 25, 26]])
Y: tensor([[ 6, 7, 8, 9, 10],[23, 24, 25, 26, 27]])
X: tensor([[10, 11, 12, 13, 14],[27, 28, 29, 30, 31]])
Y: tensor([[11, 12, 13, 14, 15],[28, 29, 30, 31, 32]])
将上面的两个采样函数包装到一个类中
class SeqDataLoader: #@save"""加载序列数据的迭代器"""def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):if use_random_iter:self.data_iter_fn = d2l.seq_data_iter_randomelse:self.data_iter_fn = d2l.seq_data_iter_sequentialself.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)self.batch_size, self.num_steps = batch_size, num_stepsdef __iter__(self):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
定义一个函数load_data_time_machine,它同时返回数据迭代器和词表。
def load_data_time_machine(batch_size, num_steps,use_random_iter=False, max_tokens=10000):"""返回时光机器数据集的迭代器和词表"""data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter, max_tokens)return data_iter, data_iter.vocab
小结
- 语言模型是自然语言处理的关键。
- n元语法通过截断相关性,为处理长序列提供了一种实用的模型。
- 齐普夫定律支配着单词的分布,这个分布不仅适用于一元语法,还适用于其他n元语法。
- 通过拉普拉斯平滑法可以有效地处理结构丰富而频率不足的低频词词组。
- 读取长序列的主要方式是随机采样和顺序分区。在迭代过程中,后者可以保证来自两个相邻的小批量中的子序列在原始序列上也是相邻的。
8.4-8.7为最初循环神经网络的实现过程,算是基础和发展历程,有助于理解下一章9.现代循环神经网络。不过其中的方法大多被弃用或者被优化为现代循环神经网络了,所以这里就不再更新这部分内容了,可以直接看下一章。
相关文章:
《动手学深度学习》学习笔记 第8章 循环神经网络
本系列为《动手学深度学习》学习笔记 书籍链接:动手学深度学习 笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看 关于本系列笔记: 书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很…...
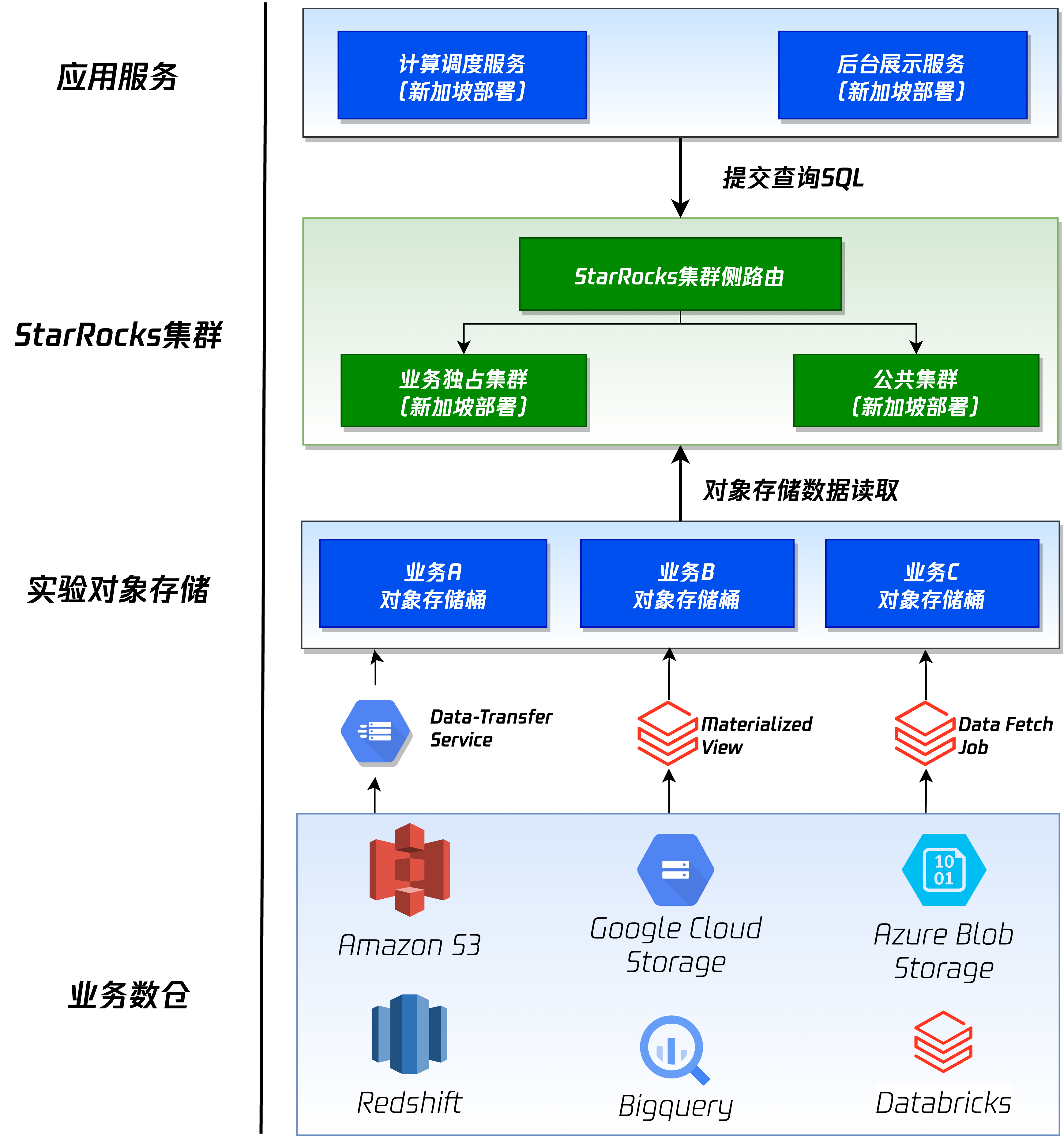
腾讯实验平台基于 StarRocks 构建湖仓底座
作者: 腾讯大数据平台部科学实验中心Tech Lead、专家工程师 马金勇博士 腾讯大数据平台部科学实验中心数据负责人、专家工程师 胡明杰 StarRocks Contributor、腾讯高级工程师 刘志行 在 2022 年,腾讯 A/B Test 团队启动了海外商业化版本 ABetterChoice …...

【基础工具篇使用】ADB 的安装和使用
文章目录 ADB的命令安装ADB 命令使用查看帮助 ——adb help查看连接设备 ADB的命令安装 ADB 命令的全称为“Android Debug Bridge”,从英文中看出主要是用作安卓的调试工具。ADB 命令在嵌入式开发中越来越常用了 在 Windows 上按“win”“R”组合件打开运行, 输入 …...

数字图像处理练习题
数字图像处理练习题 文章目录 数字图像处理练习题第 一 章1.什么是数字图像?2.数字图像有哪些特点?3.数字图像处理的目的是什么?4.简述数字图像的历史。5.数字图像有哪些主要应用?6.列举生活中数字图像的获得途径。7.结合自己的生活实例,举出一个数字图像的应用实例8.数字图…...
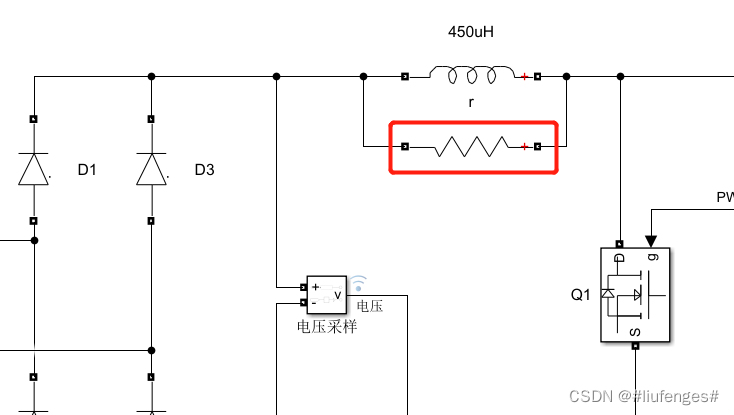
开关电源PFC电路原理详解及matlab仿真
PFC全称“Power Factor Correction”,意为“功率因数校正”。PFC电路即能对功率因数进行校正,或者说能提高功率因数的电路。是开关电源中很常见的电路。 在电学中,功率因数PF指有功功率P(单位w)与视在功率S(…...
SpringBoot+Hutool实现图片验证码
图片验证码在注册、登录、交易、交互等各类场景中都发挥着巨大作用,能够防止操作者利用机器进行暴力破解、恶意注册、滥用服务、批量化操作和自动发布等行为。 创建一个实体类封装,给前端返回的验证码数据: Data public class ValidateCodeV…...

【MySQL】MySQL版本8+ 窗口函数 Lead 的两种使用
力扣题 1、题目地址 1709. 访问日期之间最大的空档期 2、模拟表 表:UserVisits Column NameTypeuser_idintvisit_datedate 该表没有主键,它可能有重复的行该表包含用户访问某特定零售商的日期日志。 3、要求 假设今天的日期是 ‘2021-1-1’ 。 …...
Hive 的 安装与使用
目录 1 安装 MySql2 安装 Hive3 Hive 元数据配置到 MySql4 启动 Hive5 Hive 常用交互命令6 Hive 常见属性配置 Hive 官网 1 安装 MySql 为什么需要安装 MySql? 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户…...
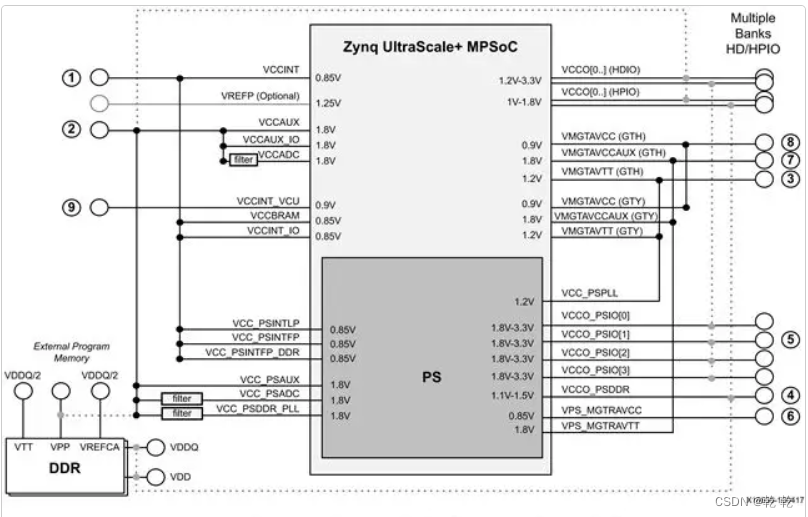
Zynq 电源
ZYNQ芯片的电源分PS系统部分和PL逻辑部分,两部分的电源分别是独立工作。PS系统部分的电源和PL逻辑部分的电源都有上电顺序,不正常的上电顺序可能会导致ARM系统和FPGA系统无法正常工作。 PS部分的电源有VCCPINT、VCCPAUX、VCCPLL和PS VCCO。 VCCPINT为PS内…...

DevOps系列之 Python操作数据库
pymysql操作mysql数据库 安装pymysql pip install pymysql pymysql操作数据库 1.连接数据库 使用Connect方法连接数据库 pymysql.Connections.Connection(hostNone, userNone, password, databaseNone, port0, charset) 参数说明: host – 数据库服务器所在的主机…...

【AI视野·今日NLP 自然语言处理论文速览 第七十四期】Wed, 10 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 10 Jan 2024 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Model Editing Can Hurt General Abilities of Large Language Models Authors Jia Chen Gu, Hao Xiang Xu, J…...

TDengine 签约积成电子
随着电力系统的复杂性和数据量不断增加,电力负荷、电压、频率等庞大的时序数据需要更高效的存储和处理能力,才能确保数据的可靠性和实时性。此外,电力系统还需要对实时数据进行快速分析和决策,以确保电网的稳定运行。然而…...
C++ 数组分页,经常有用到分页,索性做一个简单封装 已解决
在项目设计中, 有鼠标滑动需求,但是只能说能力有限,索性使用 php版本的数组分页,解决问题。 经常有用到分页,索性做一个简单封装、 测试用例 QTime curtime QTime::currentTime();nHour curtime.hour();nMin curtim…...

Redis管道操作
文章目录 1. 问题提出2. 解决方案3. 案例演示4. 总结 1. 问题提出 如何优化频繁命令往返造成的性能瓶颈? Redis是一种基于C/S一级请求响应协议的TCP服务,一个请求会遵循一下步骤: 客户端向服务端发送命令分四步(发送命令-> …...

新一代通信协议 - Socket.D
一、简介 Socket.D 是一种二进制字节流传输协议,位于 OSI 模型中的5~6层,底层可以依赖 TCP、UDP、KCP、WebSocket 等传输层协议。由 Noear 开发。支持异步流处理。其开发背后的动机是用开销更少的协议取代超文本传输协议(HTTP),HTTP 协议对于…...

国产系统-银河麒麟桌面版安装wps
0安装版本 系统版本 版本名称:银河麒麟桌面版操作系统V10(SP1) 软件版本 wps个人版2019 1双击安装 1.1卸载自带wps 为什么要卸载没有序列号,授权过期,不是免费的,通过先安装/在升级个人版跳过输入序列号问题等等原因 1.1.1当前自带的wps版本 1.1.2卸载 不卸载无法安装在…...
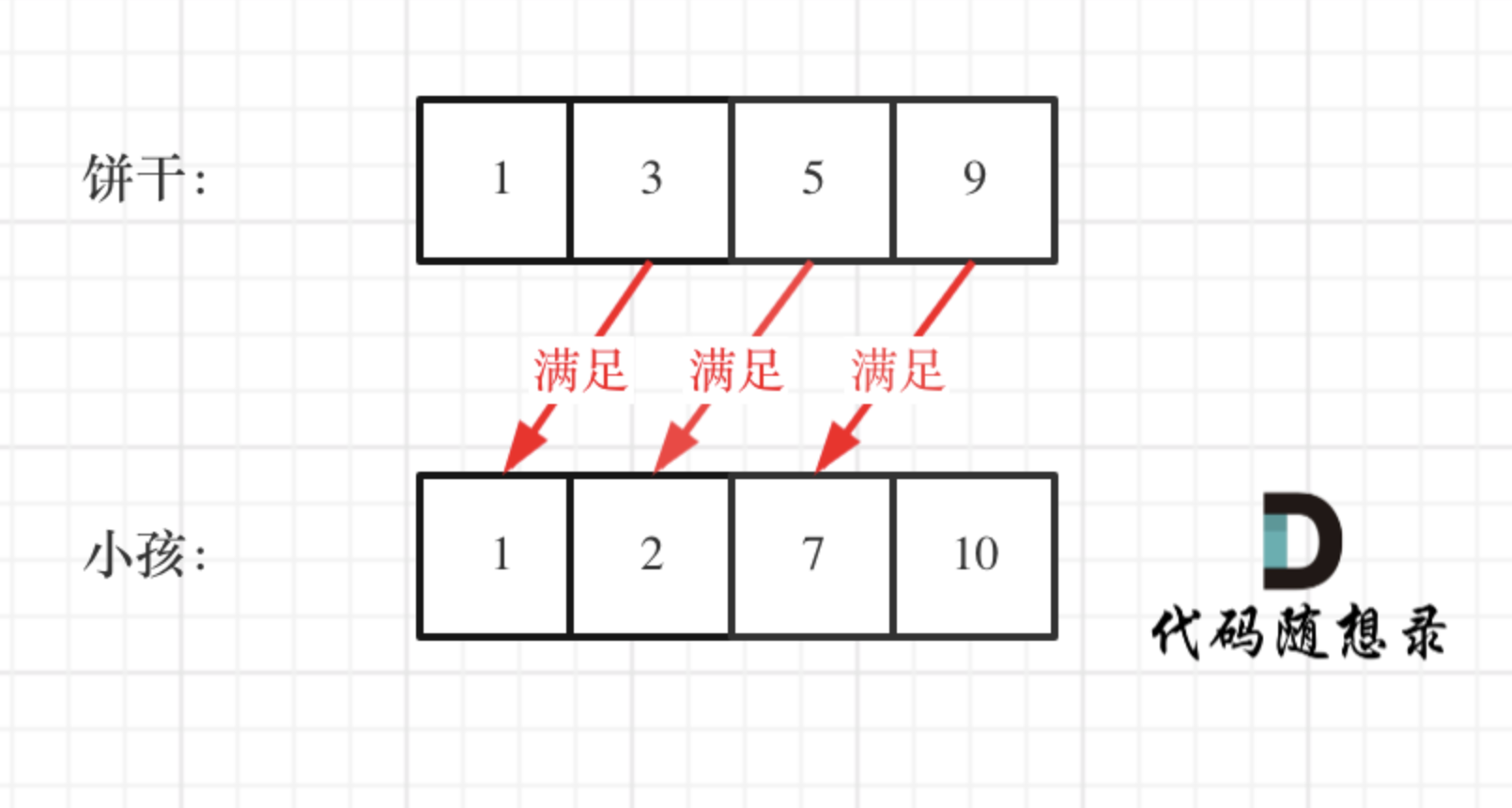
Day31 贪心算法 part01 理论基础 455.分发饼干 376.摆动序列 53.最大子序和
贪心算法 part01 理论基础 455.分发饼干 376.摆动序列 53.最大子序和 理论基础(转载自代码随想录) 什么是贪心 贪心的本质是选择每一阶段的局部最优,从而达到全局最优。 这么说有点抽象,来举一个例子: 例如&#…...
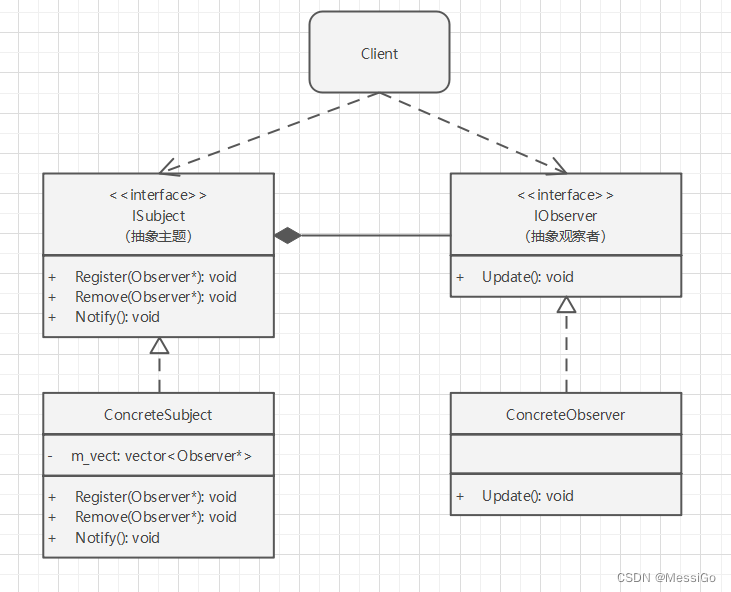
行为型模式 | 观察者模式
一、观察者模式 1、原理 观察者模式又叫做发布-订阅(Publish/Subscribe)模式,定义了一种一对多的依赖关系。让多个观察者对象同时监听某一个主题对象,这个主题对象在状态上发生变化时,会通知所有观察者对象࿰…...
Python面向对象之继承
【 一 】什么是继承(Inheritance) 继承允许创建一个新类(称为子类或派生类),从已存在的类(称为父类或基类)继承属性和方法。子类可以继承父类的特性,并可以通过添加新的属性和方法来…...
如何使用CFImagehost结合内网穿透搭建私人图床并无公网ip远程访问
[TOC] 推荐一个人工智能学习网站点击跳转 1.前言 图片服务器也称作图床,可以说是互联网存储中最重要的应用之一,不仅网站需要图床提供的外链调取图片,个人或企业也用图床存储各种图片,方便随时访问查看。不过由于图床很不挣钱&a…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...