Java-网络爬虫(二)
文章目录
- 前言
- 一、WebMagic
- 二、使用步骤
- 1. 搭建 Maven 项目
- 2. 引入依赖
- 三、入门案例
- 四、核心对象&组件
- 1. 核心对象
- Sipder
- Request
- Site
- Page
- ResultItems
- Html(Selectable)
- 2. 四大组件
- Downloader
- PageProcessor
- Scheduler
- Pipeline
上篇:Java-网络爬虫(一)
下篇:Java-网络爬虫(三)
前言
之前有介绍过传统实现爬虫的技术 HttpClient 和 Jsoup,并提供了一些案例,但是作为企业级的应用,还是远远不够的,竟然如此就需要一些更深入的技术 WebMagic。
一、WebMagic

官网:https://webmagic.io/
WebMagic 是一款基于 Java 的开源网络爬虫框架,底层是 HttpClient 和 Jsoup,它提供了简单、灵活、强大的爬取功能,可以用于抓取网页数据、图片、文件等。WebMagic 的设计参考了 Scapy ,但是实现方式更 Java 化一些。
该框架分为核心和扩展两个部分,核心部分是一个精简、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。
- 核心部分(
webmagic core):提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫 - 扩展部分(
webmagic extension):提供一些便捷的功能,例如注解模式编写爬虫等,同时内置了一些常用的组件,便于开发
优点:
- 多语言支持:提供了
Python和Scala等语言的版本,能够适应不同开发者的需求 - 任务调度:能够与
Quartz等任务调度框架结合使用,实现定时爬取数据的功能 - 多线程支持:能够利用多核
CPU提高爬虫效率 - 功能强大:支持
Cookie、代理等功能,能够模拟登录、避免反爬等操作 - 数据存储:支持多种格式的数据存储,如
MySQL、Redis、Elasticsearch等,方便后续数据处理 - 常处理:能够处理一些异常情况,如页面
404、解析错误等,提高爬虫的健壮性 - 易于学习和使用:
WebMagic的核心非常简单,但是覆盖了爬虫的整个流程,也是很好的学习爬虫开发的材料。它提供简单灵活的API,只需少量代码即可实现一个爬虫 - 模块化和可扩展性:采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义
UA/cookie等功能 - 支持爬取动态渲染的页面:支持爬取
js动态渲染的页面 - 无框架依赖:无框架依赖,可以灵活地嵌入到项目中
架构介绍:

WebMagic 的结构分为 Downloader、PageProcessor、Scheduler、Pipeline 四大组件,这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。
Downloader:- Downloader 负责从互联网上下载页面,以便后续处理,WebMagic 默认使用了 Apache HttpClient 作为下载工具
PageProcessor:- PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并基于其开发了解析 XPath 的工具 Xsoup
Scheduler:- Scheduler 负责管理待抓取的 URL,以及一些去重的工作。WebMagic 默认提供了 JDK 的内存队列来管理 URL,并用集合来进行去重。也支持使用 Redis 进行分布式管理
Pipeline:- Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic 默认提供了 “输出到控制台” 和 “保存到文件” 两种结果处理方案
用于数据流转的对象:
Request:- Request 是对 URL 地址的一层封装,一个 Request 对应一个 URL 地址,它是 PageProcessor 于 Downloader 交互的载体,也是 PageProcessor 控制 Downloader 的唯一方式。除了 URL 本身,它还包含一个 Key-Value 结构的字段 extra,可以在 extra 中保存一些特殊的属性,然后在其它地方读取,以完成不同的功能
Page:- Page 代表了从 Downloader 下载到的一个页面 — 可能是 HTML,也可能是 JSON 或者其它文本格式的内容。Page 是 WebMagic 抽取过程的核心对象,它提供了一些方法可供抽取、结果保存等
ResultItems:- ResultItems 相当于一个 Map,它保存 PageProcessor 处理的结果,供 Pipeline 使用,它的 API 与 Map 很类似,值得注意的是它有一个字段 skip,若设置为 true 则不应被 Pipeline 处理
而 Spider 则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为 Spider 是一个大的容器,它也是 WebMagic 逻辑的核心。
工作原理:
从架构图中可以得知:
- ① 一个
http请求(其实http请求之后也会转换为Request)进入到Downloader之后会进行页面下载,输出Page - ②
Page经过PageProcessor之后开始解析页面,会有两种输出类型:Request和ResultItems,对应两种情况- 情况一:输出的是
Request- ③ 根据解析的逻辑如果发现需要进一步爬取的
url地址,则产生一些新的Request进入Scheduler等待进一步抓取 - ④
Downloader会从Scheduler拉取待处理的Request - ⑤ 执行 ①
- ③ 根据解析的逻辑如果发现需要进一步爬取的
- 情况二:输出的是
ResultItems- ③ 需要抽取的数据会封装到
ResultItems中,再流转至Pipeline - ④
Pipeline对抽取的结果进行处理
- ③ 需要抽取的数据会封装到
- 情况一:输出的是
二、使用步骤
1. 搭建 Maven 项目
如果有一个 Maven 工程的项目,可跳过
打开 IDEA 工具,点击 File -> New -> Project... 创建一个项目
选择 Maven

设置项目保存地址,点击 Finish

创建完成
不过使用 WebMagic 一般会将爬取到的结果数据持久到数据中,所以这里建议是搭建 SpringBoot 或者 SpringCloud 项目,但是搭建这些项目不是本文的重点,如果想要搭建简单的 SpringBoot 项目可参见 SpringBoot - 快速搭建
2. 引入依赖
WebMagic 分为两个部分:核心和扩展,可在 Maven 仓库 中查询这这两个依赖
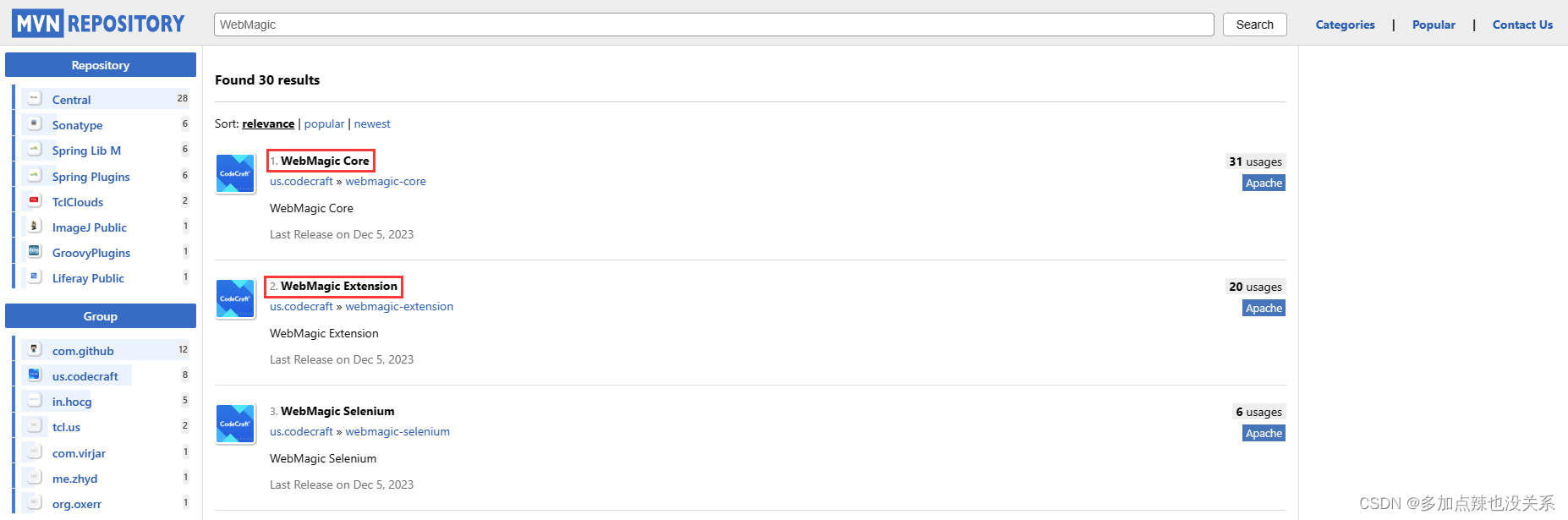
<!-- webMagic -->
<dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>0.10.0</version>
</dependency>
<dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><version>0.10.0</version>
</dependency>
三、入门案例
还是使用 WebMagic 爬取一个网站为例作为入门,在上篇博客中我们爬取了 https://www.rgbku.com/chaxun.html(rgb颜色查询器) 这个网站的表格信息,现在我们使用 WebMagic 获取底部链接的信息

html 源码:

查看 html 源码可知只需要获取到<div> 为类 .zh -> <div> -> <span> -> <a>,然后再拿到 <a> 标签的 href 属性内容即可
代码编写:
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;import java.util.ArrayList;
import java.util.List;public class TestProcessorDemo implements PageProcessor {@Overridepublic void process(Page page) {// 通过 page 获取 Html 对象Html html = page.getHtml();// 通过 Html 可以获取到 DocumentDocument document = html.getDocument();// 有了 Document 就能够通过 Jsoup 的一些操作进行解析,比如说获取 <a> 标签元素Elements aElements = document.select("div.zh > div > span > a");// 创建 List 集合用于存放 <a> 标签的超链接信息List<String> links = new ArrayList<>();for (Element aElement : aElements) {// 获取 <a> 标签中的链接String href = aElement.attr("href");// 添加到集合中links.add(href);}System.err.println("links = " + links);/** 不过一般也不会用 Jsoup 的方式来解析 Html* WebMagic 有一些解析器可以较为方便的拿到这些元素,比如使用 css 解析器*/List<String> href = html.css("div.zh > div > span > a", "href").all();// 在将结果封装到 ResultItems(默认设置下会打印在控制台上)page.putField("href", href);}@Overridepublic Site getSite() {return PageProcessor.super.getSite();}public static void main(String[] args) {Spider.create(new TestProcessorDemo())// 设置起始的 URL.addUrl("https://www.rgbku.com/chaxun.html")// 在当前线程中执行爬虫//.run();// 在新线程中执行爬虫.start();}
}
运行结果如下:

可以看到是能够成功获取得到想要的数据。
如果查看过 WebMagic 的核心包中的源码,可以发现其实有几个现成的 demo 案例
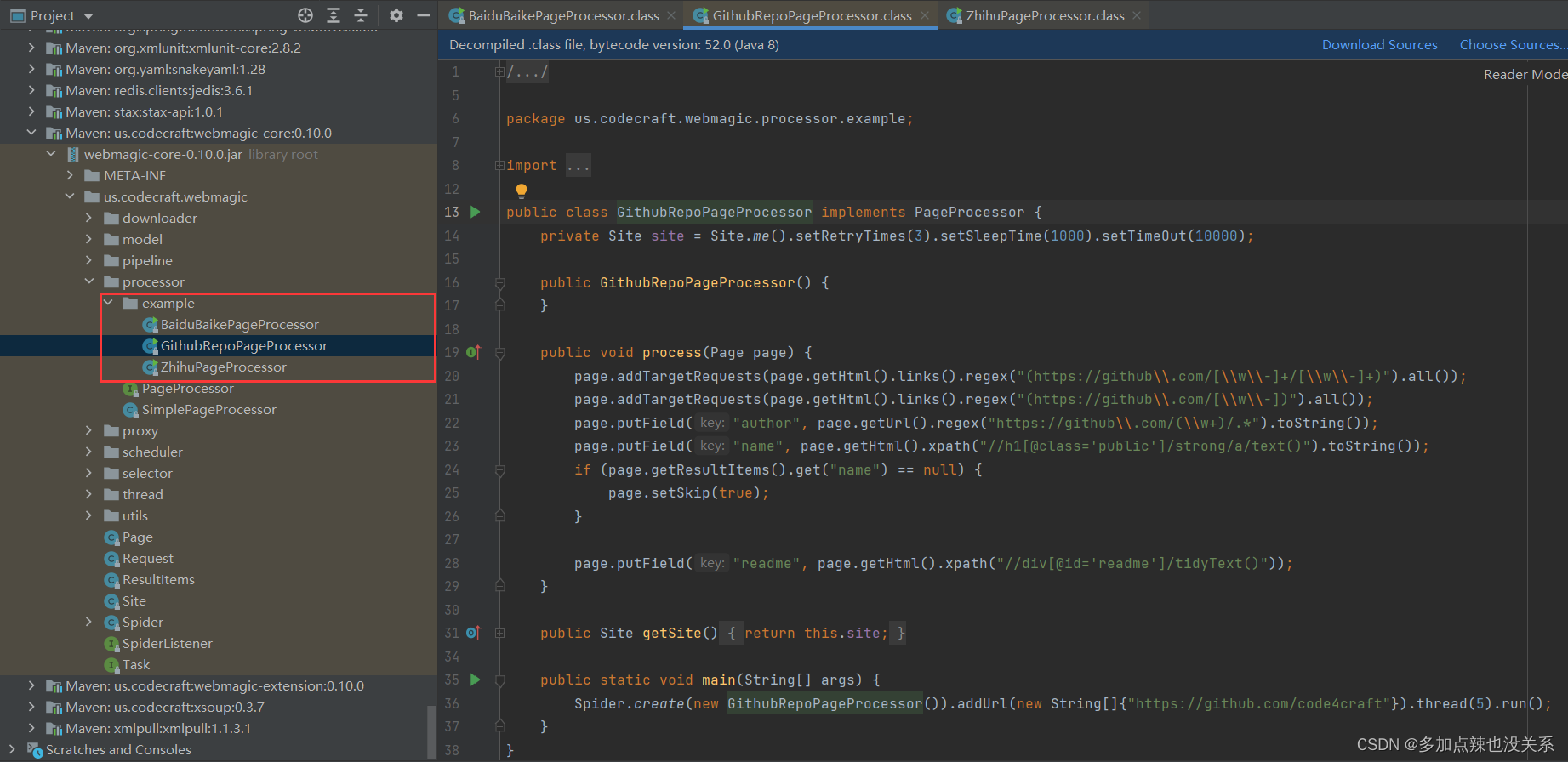
四、核心对象&组件
在上述案例中有使用过 PageProcessor、Page、Site、ResultItems、Spider 等对象,以下内容我会结合源码对这些对象和组件的一些概要说明

1. 核心对象
Sipder
可以认为 Spider 是一个大的容器,它也是 WebMagic 逻辑的核心。它的作用是:将各个组件组织起来,使它们能够相互协作,形成一个完整的爬虫系统。它负责管理和调度各个组件的运行,以确保整个爬虫过程的顺利进行。
获取 Spider 对象的方法有两个,要么通过构造方法 new 出来,要么使用静态方法 create(PageProcessor pageProcessor) 创建出来:
public class Spider implements Runnable, Task {...public static Spider create(PageProcessor pageProcessor) {return new Spider(pageProcessor);}public Spider(PageProcessor pageProcessor) {this.newUrlCondition = this.newUrlLock.newCondition();this.pageCount = new AtomicLong(0L);this.emptySleepTime = 30000L;this.pageProcessor = pageProcessor;this.site = pageProcessor.getSite();}...}
例如上述入门案例中就是使用 create 的方式
Spider spider = Spider.create(new TestProcessorDemo());
从源码上也可以看到 Spider 中包含了 webMaigc 的四大组件的影子
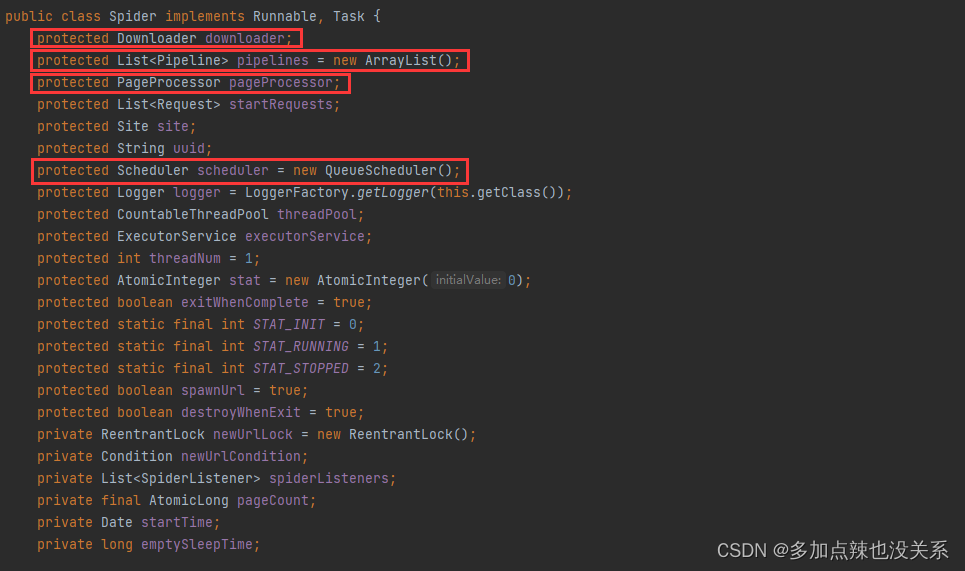
所以才说它是一个大的容器,同时 Spider 中有各个组件的配置以及线程相关的方法,是 webMagic 的核心
相关 API
| 方法 | 说明 |
|---|---|
| static Spider create(PageProcessor pageProcessor) | 创建 Spider |
| Spider addUrl(String… urls) | 添加初始 URL |
| Spider thread(int threadNum) | 开启 n 个线程 |
| void run() | 启动,会阻塞当前线程执行 |
| void start() | 异步启动,当前线程继续执行 |
| void runAsync() | 异步启动,当前线程继续执行 |
| void stop() | 停止爬虫 |
| Spider addPipeline(Pipeline pipeline) | 添加一个 Pipeline |
| Spider setPipelines(List pipelines) | 添加多个 Pipeline |
| Spider setScheduler(Scheduler scheduler) | 设置 Scheduler |
| Spider setDownloader(Downloader downloader) | 设置 Downloader |
| T get(String url) | 同步调用,并直接获取结果 |
| List getAll(Collection urls) | 同步调用,并直接取得一堆结果 |
Request
Request 是对 URL 地址的一层封装,一个 Request 对象对应一个 URL 地址。
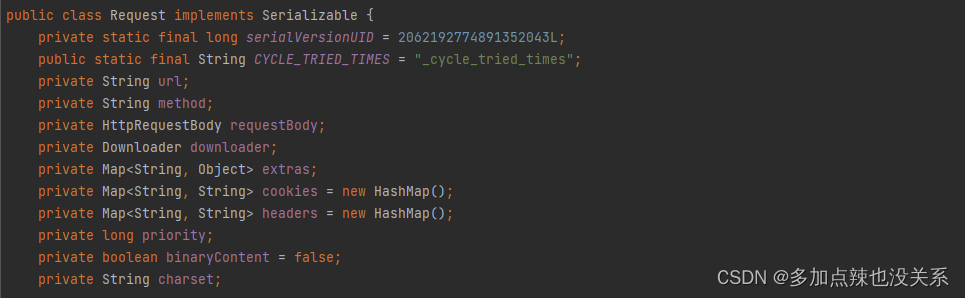
从源码上可以看到 Request 对象中包含了发送一个 http 请求的所有要素,包括 url 地址、请求类型、请求参数、cookie 和 header 等等,还包含一个 Key-Value 结构的字段 extra 。可以在 extra 中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。
之前说 http 在进入到下载组件 Download 是便会转化成 Request 对象,可以通过入门案例中的代码
spider.addUrl("https://www.rgbku.com/chaxun.html")
进入到 addUrl(String... urls) 方法中看到
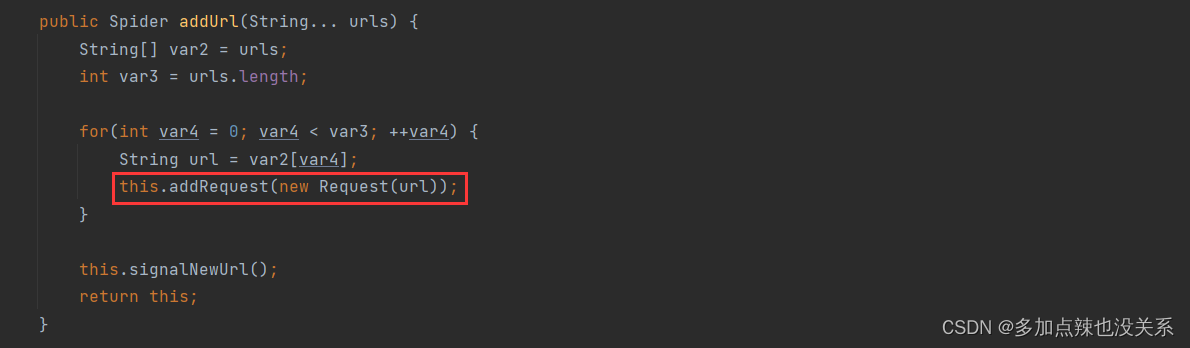
public class Spider implements Runnable, Task {...public Spider addUrl(String... urls) {String[] var2 = urls;int var3 = urls.length;for(int var4 = 0; var4 < var3; ++var4) {String url = var2[var4];// 将 url 转化成 Request 对象,加载到调度器 Scheduler 中 this.addRequest(new Request(url));}this.signalNewUrl();return this;}...}
Site
Site 对象用于配置站点本身的一些配置信息,例如编码、HTTP 头、超时时间、重试策略等、代理等。其中待解析的域名存放在 domain 这个属性中

通过设置 Site 对象,可以对爬虫的行为进行详细配置,以满足不同的需求。具体来说,Site 对象可以设置以下配置信息:
- 编码:用于指定站点的字符编码方式,以确保爬虫能够正确解析页面内容
HTTP头:用于设置请求头信息,以模拟浏览器行为,增加爬虫的隐蔽性- 超时时间:用于设置爬虫请求的超时时间,以避免因网络延迟等原因导致请求等待过长时间
- 重试策略:用于设置爬虫在遇到请求失败时是否进行重试以及重试的次数和间隔等
- 代理:用于设置代理服务器地址和端口等信息,以便通过代理访问目标站点
Site 对象提供的配置方法如下:
| 方法 | 说明 |
|---|---|
| setCharset(String charset) | 设置字符编码方式,以确保爬虫能够正确解析页面内容 |
| setUserAgent(String userAgent) | 设置用户代理,用于标识发送请求的客户端应用或设备,更好的模拟游览器发送请求 |
| Site setDomain(String domain) | 设置域名,需要设置域名后,addCookie() 才会生效 |
| setSleepTime(int sleepTime) | 设置爬虫在抓取下一个页面之前等待的时间,以避免过于频繁的请求导致被目标站点封禁 |
| setTimeOut(int timeOut) | 设置爬虫请求的超时时间,以避免因网络延迟等原因导致请求等待过长时间 |
| setRetrySleepTime(int retrySleepTime) | 设置爬虫在遇到请求失败时的重试间隔时间 |
| setRetryTimes(int retryTimes) | 设置爬虫在遇到请求失败时的重试次数 |
| addHeader(String key, String value) | 添加请求头信息,以模拟浏览器行为,增加爬虫的隐蔽性 |
| addCookie(String key, String value) | 添加 Cookie 信息,以模拟浏览器会话信息,增加爬虫的隐蔽性 |
通过合理配置 Site 对象的参数,可以优化爬虫的性能,提高爬虫的效率和成功率,增加爬虫的隐蔽性。
之前提到过 domian 存放的是待解析域名,从入门案例中的 addUrl(String... urls) -> addRequest(Request request) 可以看到这条逻辑,当然不止这一处
public class Spider implements Runnable, Task {...private void addRequest(Request request) {if (this.site.getDomain() == null && request != null && request.getUrl() != null) {// 将清洗过的 url 存放到 Site 的 domain 属性中this.site.setDomain(UrlUtils.getDomain(request.getUrl()));}this.scheduler.push(request, this);}...}
在 上篇:Java-网络爬虫(一) 博客中有通过 HttpClient 的 execute(HttpUriRequest var1) 方法来发送请求(HttpGet、HttpPost...均实现了 HttpUriRequest)
// 创建 httpClient 对象CloseableHttpClient httpClient = HttpClients.createDefault();// 创建 httpGet 对象,设置访问 URLHttpGet httpGet = new HttpGet("https://www.rgbku.com/chaxun.html");// 发送请求response = httpClient.execute(httpGet);
在 webMagic 中底层也是使用 HttpClient 来发送请求的,不够首先要通过 Site 和 Request 获取到 HttpUriRequest 和 HttpContext 对象,进而就可以执行HttpClient 的 execute(HttpUriRequest var1, HttpContext var2) 方法发送请求获取响应信息了
Page
Page 对象是用于处理和封装从目标网站下载得到的 HTML 页面内容的一种对象
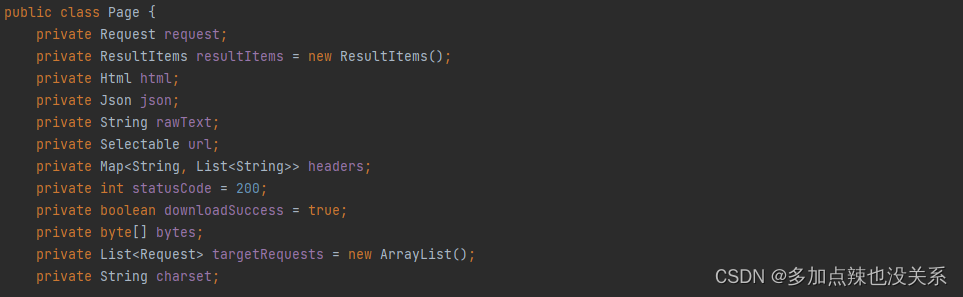
该对象最重要的两个作用就是获取 Html 对象,而 Html 对象是解析网页十分重要的对象,其次是该 Page 对象能够能够将封装好的 ResultItems 对象传送给存储器 Pipeline 做持久化处理
常用方法:
| 方法 | 说明 |
|---|---|
| getHtml() | 获取当前页面的 Html对象 |
| String getRawText() | 获取当前页面的文本内容 |
| putField(String key, Object field) | 以 key-value 的形式封装信息到 ResultItems 中 |
| addTargetRequests(Iterable requests) | 用于添加目标请求的方法 |
ResultItems
ResultItems 是一个 Map 对象,用于保存 PageProcessor 处理的结果,供Pipeline使用。它的 API 与 Map 类似,可以保存各种类型的数据,包括字符串、列表、字典等

ResultItems 的主要作用是作为 PageProcessor 和 Pipeline 之间的数据传输媒介。当 PageProcessor 处理完一个页面后,可以将处理结果保存到 ResultItems 中,然后由 Pipeline 进行处理。这样可以方便地实现数据的提取、清洗、过滤等操作,并将结果持久化到文件、数据库等地方
ResultItems 还提供了一些额外的方法来控制结果的输出和处理。例如,可以通过 setSkip(true) 方法来跳过当前的结果,不进行后续的处理和输出。此外,ResultItems 还提供了 getExtra() 方法,用于获取一些自定义的数据和属性
总的来说,WebMagic 中的 ResultItems 是一个重要的组件,它充当了 PageProcessor 和 Pipeline 之间的桥梁,使得数据的处理和输出更加灵活和方便。
Html(Selectable)
通过入门案例中使用 page.getHtml() 能够获取到一个 Html 对象,解析相关的操作都与该对象有关,而这个对象实现了 Selectable

在 WebMagic 中,Selectable 是一个重要的接口,它定义了一系列链式 API 调用方式
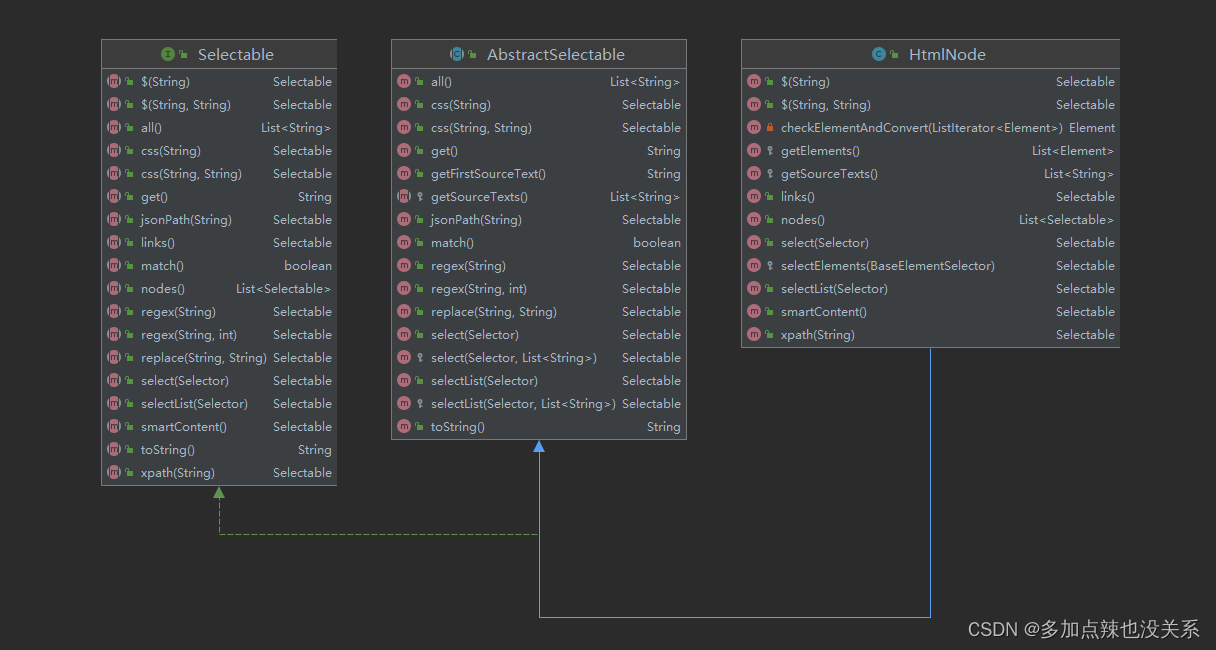
抽取元素的四种方式:
Selectable 里主要支持了四种抽取技术:XPath、正则表达式和 CSS 选择器。另外,对于 JSON 格式的内容,可使用 JsonPath 进行解析。
- 方式一:XPath 选择器
XPath 的教程可参考:https://www.w3cschool.cn/xpath/
例如:入门案例中获取<a>标签中的链接的代码可改写为:
List<String> href = html.xpath("//div[@class=zh]/div/span/a/@href").all();
- 方式二:regex(正则表达式)选择器
正则表达式-基础教程:https://blog.csdn.net/xhmico/article/details/126729869
正则表达式是一种通用的文本抽取语言,一般会用这种方式获取 url 地址等
例如:入门案例中获取<a>标签中的链接的代码可改写为:
page.putField("links", page.getHtml().regex("[a-zA-z]+://[^\\s][^\" ]*").all());
- CSS 选择器
入门案例中使用的就是这种方式获取元素,CSS 选择器是与 XPath 类似的语言,但相对于 XPath 而言简单一点,只要对 css 语法熟悉,写起来应该是比较简单的。比方说入门案例<a>标签中的链接的代码还可以改成:
List<String> href = html.css(".zh a", "href").all();
- JsonPath 选择器
JsonPath 是于 XPath 很类似的一个语言,它用于从 Json 中快速定位一条内容
关于它的使用可参考:JsonPath完全介绍及详细使用教程
API:
Selectable 提供了一系列链式 API 调用方式,支持多种选择器,包括 xpath、css、regex和 jsonPath 等。用户可以使用这些选择器方便地获取所需元素的信息,同时还提供了诸如获取链接等便利方法。简单来说就是根据特定的方法抽取 html 页面的信息。使用 Selectable 接口,可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。
public interface Selectable {Selectable xpath(String var1);Selectable $(String var1);Selectable $(String var1, String var2);Selectable css(String var1);Selectable css(String var1, String var2);Selectable smartContent();Selectable links();Selectable regex(String var1);Selectable regex(String var1, int var2);Selectable replace(String var1, String var2);String toString();String get();boolean match();List<String> all();Selectable jsonPath(String var1);Selectable select(Selector var1);Selectable selectList(Selector var1);List<Selectable> nodes();
}
以下是 Selectable 常用 API 的介绍
| 方法 | 说明 | 示例 |
|---|---|---|
| Selectable xpath(String var1) | 使用 XPath 选择器 | html.xpath(“//div[@class=‘title’]”) |
| Selectable regex(String var1) | 使用正则表达式抽取 | html.regex(“(.*?)”) |
| Selectable regex(String var1, int var2) | 使用正则表达式抽取,并指定捕获组 | html.regex(“(.*?)”,1) |
| Selectable $(String var1) | 使用 Css 选择器选择 | html.$(“div.title”) |
| Selectable $(String var1, String var2) | 使用 Css 选择器选择 | html.$(“div.title”,“text”) |
| Selectable css(String var1) | 功能同$(),使用 Css 选择器选择 | html.css(“div.title”) |
| Selectable css(String var1, String var2) | 功能同$(),使用Css选择器选择 | html.css(“div.title”,“text”) |
| Selectable jsonPath(String var1) | 使用 JsonPath 选择器选择 | html.jsonPath(“$.*”) |
Selectable links() | 获取所有链接,如果链接为相对地址会自动拼接 | html.links() |
| Selectable replace(String regex, String replacement) | 替换内容 | html.replace(“”,“”) |
| String get() | 返回一条String类型的结果 | String link= html.links().get() |
| String toString() | 功能同 get(),返回一条 String 类型的结果 | String link= html.links().toString() |
| List all() | 返回所有抽取结果 | List links= html.links().all() |
| boolean match() | 是否有匹配结果 | boolean result = html.links().match() |
Html 除了 Selectable 这些常用的 API 外还有如下几个方法用得也比较多
| 方法 | 说明 |
|---|---|
| Document getDocument() | 获取 Document 对象 |
| static Html create(String text) | 通过文本获取 Html 对象 |
从这些 API 中可以看出,那些抽取元素的方法返回的都是 Selectable 对象,也就是说抽取是支持链式调用的,
例如:入门案例中获取<a>标签中的链接的代码可改写为:
List<String> href = html// css 选择类为 zh 的标签.css(".zh")// 获取其下所有的链接.links() // 使用这种方式获取链接,如果链接是相对地址的形式会自动进行拼接.all();
输出:

2. 四大组件
Downloader
前面就有提到过 Downloader 的作用就是负责从互联网上下载页面

Downloader 的输入是 Request 输出是 Pag,可见 Downloader.java 源码:
public interface Downloader {Page download(Request var1, Task var2);void setThread(int var1);
}
默认情况下 Spider 配置的 Downloader 为 HttpClientDownloader,可以从 initComponent() 方法中得出


查看 HttpClientDownloader.java 源码中的 download() 方法
public class HttpClientDownloader extends AbstractDownloader {...public Page download(Request request, Task task) {if (task != null && task.getSite() != null) {CloseableHttpResponse httpResponse = null;// 获取 HttpClient 对象CloseableHttpClient httpClient = this.getHttpClient(task.getSite());Proxy proxy = this.proxyProvider != null ? this.proxyProvider.getProxy(request, task) : null;// 通过 Request 和 Site 得到 HttpUriRequest、HttpContextHttpClientRequestContext requestContext = this.httpUriRequestConverter.convert(request, task.getSite(), proxy);Page page = Page.fail(request);Page var9;try {// 发起请求httpResponse = httpClient.execute(requestContext.getHttpUriRequest(), requestContext.getHttpClientContext());// 解析响应体并封装成 Page 返回page = this.handleResponse(request, request.getCharset() != null ? request.getCharset() : task.getSite().getCharset(), httpResponse, task);this.onSuccess(page, task);this.logger.info("downloading page success {}", request.getUrl());Page var8 = page;return var8;} catch (IOException var13) {this.onError(page, task, var13);this.logger.info("download page {} error", request.getUrl(), var13);var9 = page;} finally {if (httpResponse != null) {EntityUtils.consumeQuietly(httpResponse.getEntity());}if (this.proxyProvider != null && proxy != null) {this.proxyProvider.returnProxy(proxy, page, task);}}return var9;} else {throw new NullPointerException("task or site can not be null");}}...
}
如果希望下载页面时进行一些其它的操作,可以自定义 Downloader,要么实现 Downloader 接口,要么继承实现了 Downloader 接口的子类,比如:HttpClientDownloader
如果想要自定义的 Downloader 生效,就需要在 spider.setDownloader() 方法中进行设置,比如:
Spider.create(new TestProcessorDemo())// 设置起始的 URL.addUrl("https://www.rgbku.com/chaxun.html")// 设置自定义 Downloader.setDownloader(new MyDownload())// 在当前线程中执行爬虫.run();// 在新线程中执行爬虫//.start();
PageProcessor
PageProcessor 的作用就是负责解析页面的

它的输入是 Page 对象,process() 方法中实现页面解析的逻辑,PageProcessor.java 源码如下:
public interface PageProcessor {void process(Page var1);default Site getSite() {return Site.me();}
}
而页面的解析是开发者根据需求去编写,也就是说要开发者去实现,webMaic 也没办法提供默认的 PageProcessor, 所以使用 webMaigc 编写爬虫的时候都需要去实现 PageProcessor 接口或者继承实现了 PageProcessor 接口的类,比如:SimplePageProcessor。而解析的结果最好是封装到 ResultItems 中交给 Pipeline 进行处理,Page 对象中可以通过 putField(String key, Object field) 方法直接将对象封装到 ResultItems 中
public class Page {...public void putField(String key, Object field) {this.resultItems.put(key, field);}...
}
Scheduler
Scheduler 负责管理待抓取的 URL

Scheduler.java 源码:
public interface Scheduler {void push(Request var1, Task var2);Request poll(Task var1);
}
Scheduler 默认是 QueueScheduler,可查看 Spider.java 的源码得出
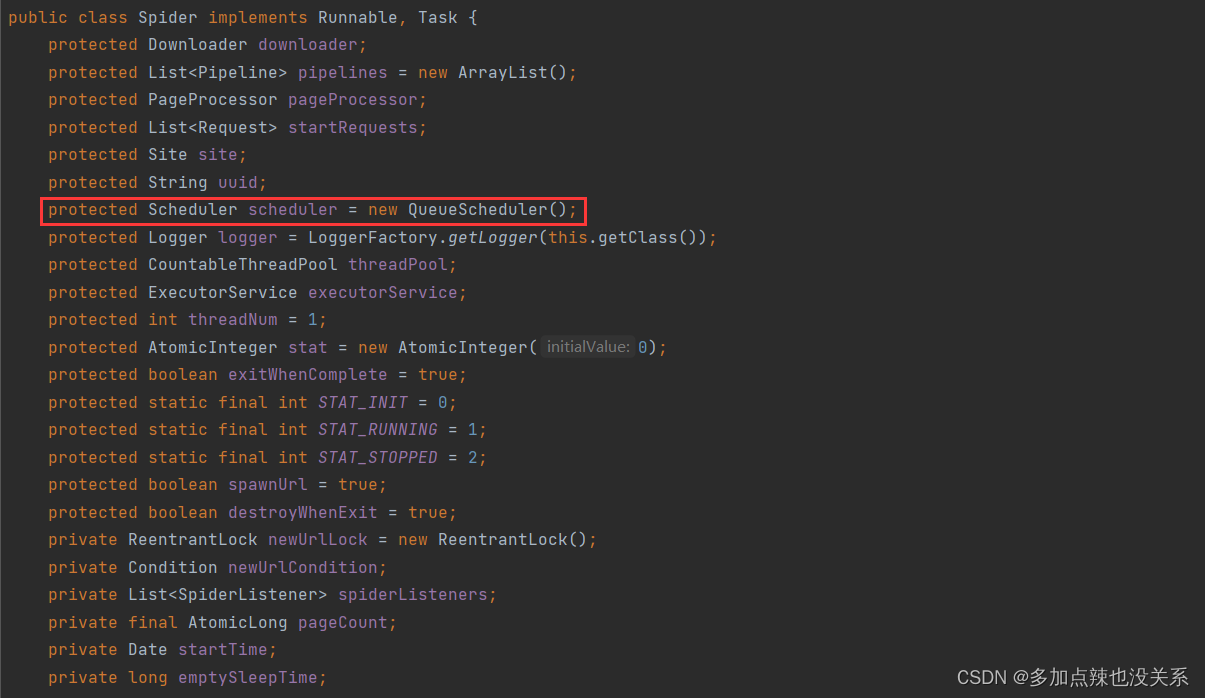
而 QueueScheduler 的底层就如同它的类名一样,是个队列

之前说过 Downloader 下载页面时需要 Request 对象,而这些 Request 对象都是从 Scheduler 中拉取而来的,包括起始的 url 也是会先放到 Scheduler,可以从入门案例中的 spider.addUrl() 方法去追溯源码证实


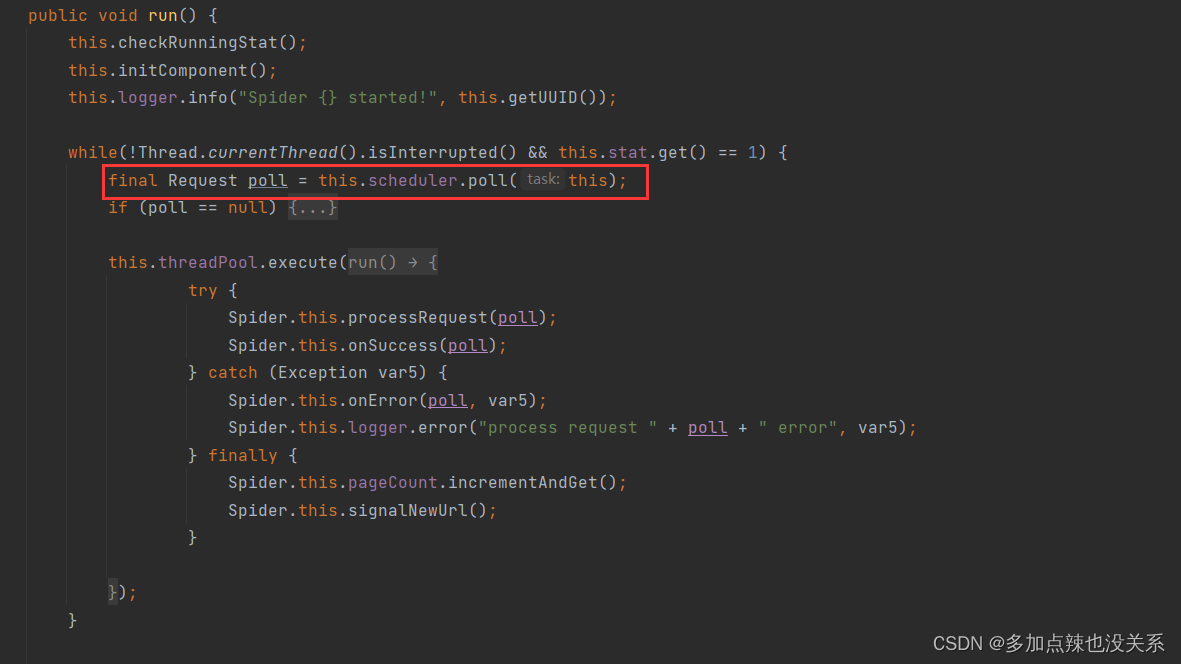
也可以从进入入门案例 sipder.run() 方法中看到传入 Downloader 的 Request 是从 Scheduler 中获取的

同时 Scheduler 也可以自定义,只需要实现 Scheduler 接口或者继承其实现类,比如:QueueScheduler 即可,然后通过 spider.setScheduler() 方法去设置,例如:
Spider.create(new TestProcessorDemo())// 设置起始的 URL.addUrl("https://www.rgbku.com/chaxun.html")// 设置自定义 Scheduler.setScheduler(new MyScheduler())// 在当前线程中执行爬虫.run();// 在新线程中执行爬虫//.start();
Pipeline
Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等

Pipeline.java 源码:
public interface Pipeline {void process(ResultItems var1, Task var2);
}
默认情况下,webMaigc 的使用的 Pipeline 是 ConsolePipeline,可查看 Spider.initComponent() 的方法源码得知:
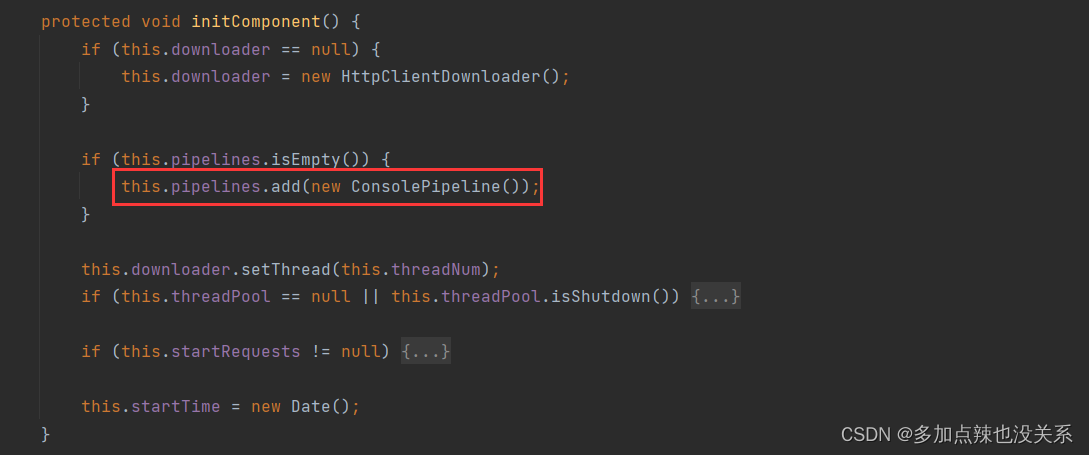
ConsolePipeline 的处理就是将封存在 ResultItems 里的内容打印到控制台上
ConsolePipeline.java 源码:
public class ConsolePipeline implements Pipeline {public ConsolePipeline() {}public void process(ResultItems resultItems, Task task) {System.out.println("get page: " + resultItems.getRequest().getUrl());Iterator var3 = resultItems.getAll().entrySet().iterator();while(var3.hasNext()) {Entry<String, Object> entry = (Entry)var3.next();System.out.println((String)entry.getKey() + ":\t" + entry.getValue());}}
}
Spider 中可以配置多个 Pipeline
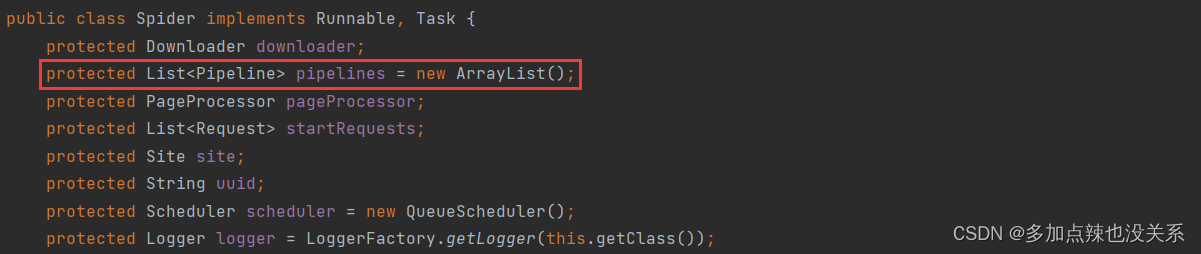
通常情况下开发者会自定义 Pipeline,将爬取的数据存放在数据库中,自定义的方式就是实现 Pipeline 接口重写 process() 方法,通过 spider.setPipelines() 来设置,例如:
List<Pipeline> pipelines = new ArrayList<>();// 添加输出到控制台的 Pipeline:ConsolePipelinepipelines.add(new ConsolePipeline());// 添加保存到文本的 Pipeline:FilePipelinepipelines.add(new FilePipeline());// 添加自定义自定义 Pipelinepipelines.add(new MyPipeline());Spider.create(new TestProcessorDemo())// 设置起始的 URL.addUrl("https://www.rgbku.com/chaxun.html")// 设置 Pipeline.setPipelines(pipelines)// 在当前线程中执行爬虫.run();// 在新线程中执行爬虫//.start();
上篇:Java-网络爬虫(一)
下篇:Java-网络爬虫(三)
参考博客:
WebMagic:https://blog.csdn.net/weixin_40055163/article/details/123541437
JsonPath完全介绍及详细使用教程:https://blog.csdn.net/software_test010/article/details/125427926
相关文章:
Java-网络爬虫(二)
文章目录 前言一、WebMagic二、使用步骤1. 搭建 Maven 项目2. 引入依赖 三、入门案例四、核心对象&组件1. 核心对象SipderRequestSitePageResultItemsHtml(Selectable) 2. 四大组件DownloaderPageProcessorSchedulerPipeline 上篇:Java-网…...
【android】rk3588-android-bt
文章目录 蓝牙框架HCI接口蓝牙VENDORLIBvendorlib是什么 代码层面解读vendorlib1、 vendorlib实现,协议栈调用2、协议栈实现,vendorlib调用(回调函数)2.1、 init函数2.2、BT_VND_OP_POWER_CTRL对应处理2.3、BT_VND_OP_USERIAL_OPE…...

如何在 Microsoft Edge 浏览器中启用自动刷新
你是否经常发现自己在使用 Microsoft Edge 时点击刷新按钮?如果您需要一个网页以设定的时间间隔自动更新,那么请接着往下看。 在这篇博文中,我们探讨如何在 Microsoft Edge 浏览器中启用和管理自动刷新功能。 为什么选择自动刷新࿱…...
Redis之集群方案比较
哨兵模式 在redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般&a…...

WPF 布局
了解 WPF中所有布局如下,我们一一尝试实现,本文档主要以图形化的形式展示每个布局的功能。 布局: Border、 BulletDecorator、 Canvas、 DockPanel、 Expander、 Grid、 GridView、 GridSplitter、 GroupBox、 Panel、 ResizeGrip、 Separat…...

#Uniapp:uni-app中vue2生命周期--11个
uni-app中vue2生命周期 生命周期钩子描述H5App端小程序说明beforeCreate在实例初始化之后被调用 详情√√√created在实例创建完成后被立即调用 详情√√√beforeMount在挂载开始之前被调用 详情√√√mounted挂载到实例上去之后调用 详情 注意:此处并不能确定子组…...

pytorch 分布式 Node/Worker/Rank等基础概念
分布式训练相关基本参数的概念如下: Definitions Node - A physical instance or a container; maps to the unit that the job manager works with. Worker - A worker in the context of distributed training. WorkerGroup - The set of workers that execute the same f…...

《动手学深度学习》学习笔记 第8章 循环神经网络
本系列为《动手学深度学习》学习笔记 书籍链接:动手学深度学习 笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看 关于本系列笔记: 书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很…...
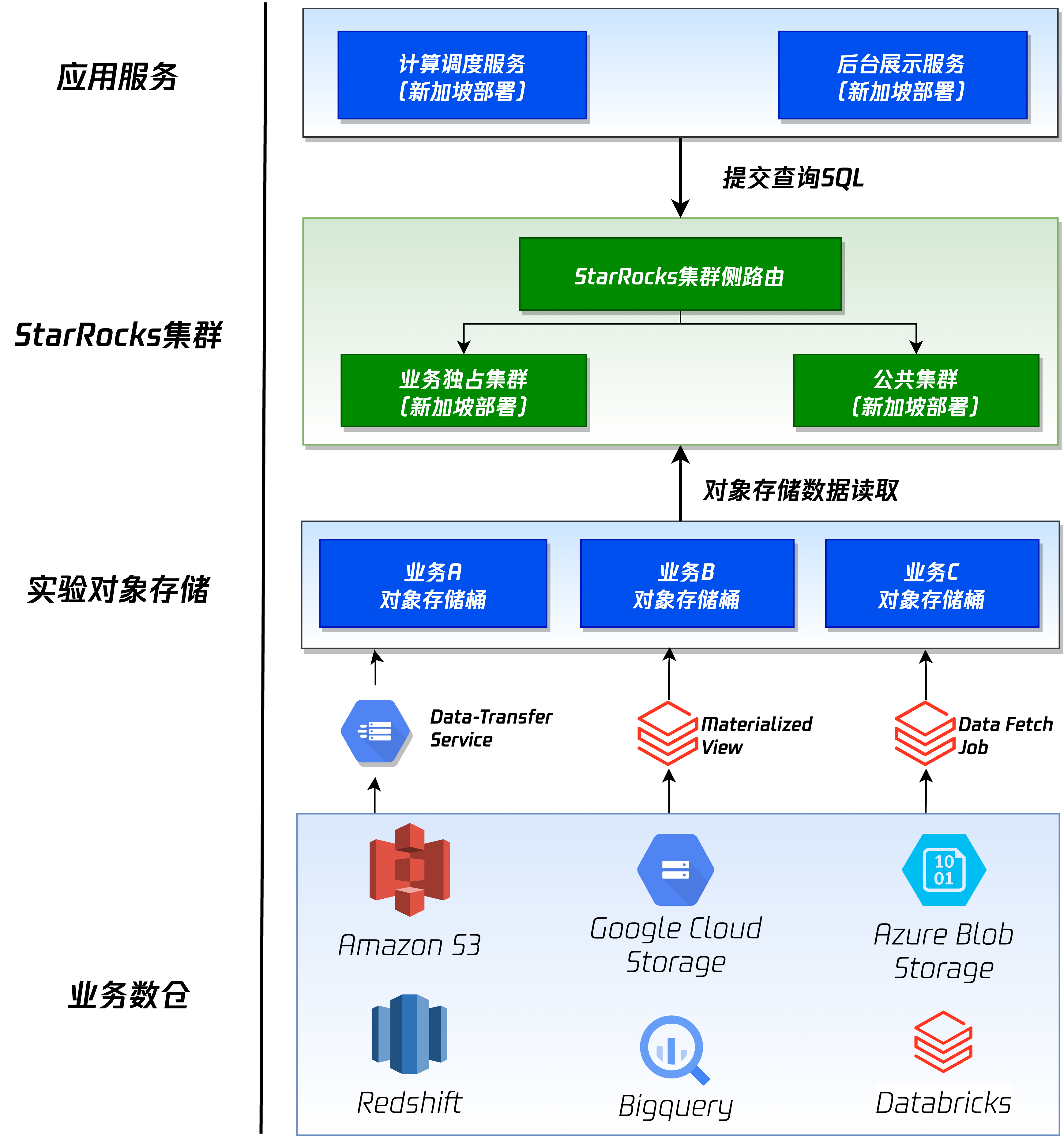
腾讯实验平台基于 StarRocks 构建湖仓底座
作者: 腾讯大数据平台部科学实验中心Tech Lead、专家工程师 马金勇博士 腾讯大数据平台部科学实验中心数据负责人、专家工程师 胡明杰 StarRocks Contributor、腾讯高级工程师 刘志行 在 2022 年,腾讯 A/B Test 团队启动了海外商业化版本 ABetterChoice …...

【基础工具篇使用】ADB 的安装和使用
文章目录 ADB的命令安装ADB 命令使用查看帮助 ——adb help查看连接设备 ADB的命令安装 ADB 命令的全称为“Android Debug Bridge”,从英文中看出主要是用作安卓的调试工具。ADB 命令在嵌入式开发中越来越常用了 在 Windows 上按“win”“R”组合件打开运行, 输入 …...

数字图像处理练习题
数字图像处理练习题 文章目录 数字图像处理练习题第 一 章1.什么是数字图像?2.数字图像有哪些特点?3.数字图像处理的目的是什么?4.简述数字图像的历史。5.数字图像有哪些主要应用?6.列举生活中数字图像的获得途径。7.结合自己的生活实例,举出一个数字图像的应用实例8.数字图…...
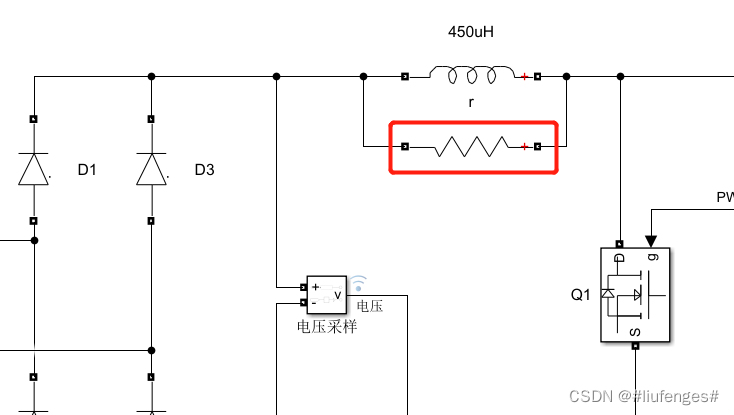
开关电源PFC电路原理详解及matlab仿真
PFC全称“Power Factor Correction”,意为“功率因数校正”。PFC电路即能对功率因数进行校正,或者说能提高功率因数的电路。是开关电源中很常见的电路。 在电学中,功率因数PF指有功功率P(单位w)与视在功率S(…...
SpringBoot+Hutool实现图片验证码
图片验证码在注册、登录、交易、交互等各类场景中都发挥着巨大作用,能够防止操作者利用机器进行暴力破解、恶意注册、滥用服务、批量化操作和自动发布等行为。 创建一个实体类封装,给前端返回的验证码数据: Data public class ValidateCodeV…...

【MySQL】MySQL版本8+ 窗口函数 Lead 的两种使用
力扣题 1、题目地址 1709. 访问日期之间最大的空档期 2、模拟表 表:UserVisits Column NameTypeuser_idintvisit_datedate 该表没有主键,它可能有重复的行该表包含用户访问某特定零售商的日期日志。 3、要求 假设今天的日期是 ‘2021-1-1’ 。 …...
Hive 的 安装与使用
目录 1 安装 MySql2 安装 Hive3 Hive 元数据配置到 MySql4 启动 Hive5 Hive 常用交互命令6 Hive 常见属性配置 Hive 官网 1 安装 MySql 为什么需要安装 MySql? 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户…...
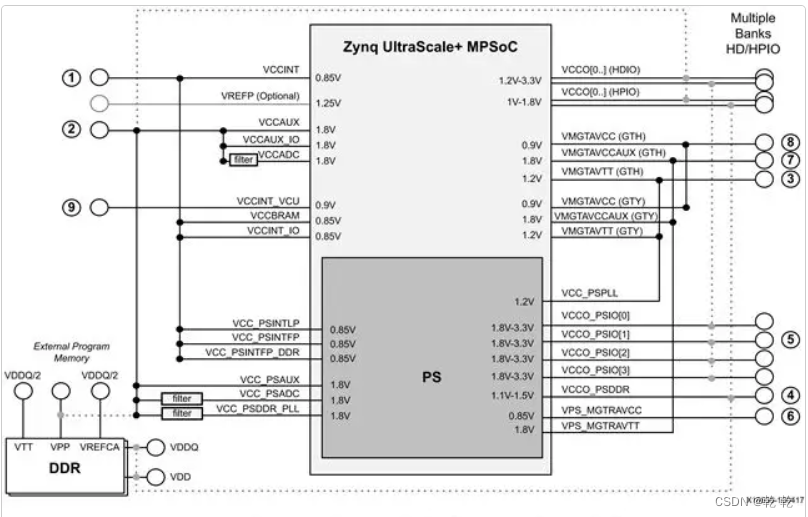
Zynq 电源
ZYNQ芯片的电源分PS系统部分和PL逻辑部分,两部分的电源分别是独立工作。PS系统部分的电源和PL逻辑部分的电源都有上电顺序,不正常的上电顺序可能会导致ARM系统和FPGA系统无法正常工作。 PS部分的电源有VCCPINT、VCCPAUX、VCCPLL和PS VCCO。 VCCPINT为PS内…...

DevOps系列之 Python操作数据库
pymysql操作mysql数据库 安装pymysql pip install pymysql pymysql操作数据库 1.连接数据库 使用Connect方法连接数据库 pymysql.Connections.Connection(hostNone, userNone, password, databaseNone, port0, charset) 参数说明: host – 数据库服务器所在的主机…...

【AI视野·今日NLP 自然语言处理论文速览 第七十四期】Wed, 10 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 10 Jan 2024 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Model Editing Can Hurt General Abilities of Large Language Models Authors Jia Chen Gu, Hao Xiang Xu, J…...

TDengine 签约积成电子
随着电力系统的复杂性和数据量不断增加,电力负荷、电压、频率等庞大的时序数据需要更高效的存储和处理能力,才能确保数据的可靠性和实时性。此外,电力系统还需要对实时数据进行快速分析和决策,以确保电网的稳定运行。然而…...
C++ 数组分页,经常有用到分页,索性做一个简单封装 已解决
在项目设计中, 有鼠标滑动需求,但是只能说能力有限,索性使用 php版本的数组分页,解决问题。 经常有用到分页,索性做一个简单封装、 测试用例 QTime curtime QTime::currentTime();nHour curtime.hour();nMin curtim…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...