基于多反应堆的高并发服务器【C/C++/Reactor】(中)HttpRequest 提取请求行、解析请求行和优化 以及解析请求头并存储
### 知识点1:读取网络数据
- 客户端发送给服务器的通信数据通过封装的bufferSocketRead函数读取
- 读取的数据存储在struct Buffer结构体实例中,可将该实例作为参数传递给解析函数
回顾Buffer.c中的bufferSocketRead函数
// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd) {struct iovec vec[2]; // 根据自己的实际需求// 初始化数组元素int writeableSize = bufferWriteableSize(buf); // 得到剩余的可写的内存容量// 0号数组里的指针指向buf里边的数组,记得 要加writePos,防止覆盖数据vec[0].iov_base = buf->data + buf->writePos;vec[0].iov_len = writeableSize;char* tmpbuf = (char*)malloc(40960); // 申请40k堆内存vec[1].iov_base = buf->data + buf->writePos;vec[1].iov_len = 40960;// 至此,结构体vec的两个元素分别初始化完之后就可以调用接收数据的函数了int result = readv(fd, vec, 2);// 表示通过调用readv函数一共接收了多少个字节if(result == -1) {return -1;// 失败了}else if (result <= writeableSize) { buf->writePos += result;}else {buf->writePos = buf->capacity; // 需要先更新buf->writePosbufferAppendData(buf, tmpbuf, result - writeableSize);}free(tmpbuf);return result;
}### 知识点2:从Buffer中读取请求行
- 需要编写一个操作函数,根据换行符(\r\n)从buffer中提取一行数据
- memem函数应返回找到的子数据块在内存中的起始位置----注意数据块的大小,并在函数中指定
一、解析请求行(通过指针方式解析非 sscanf 方式)
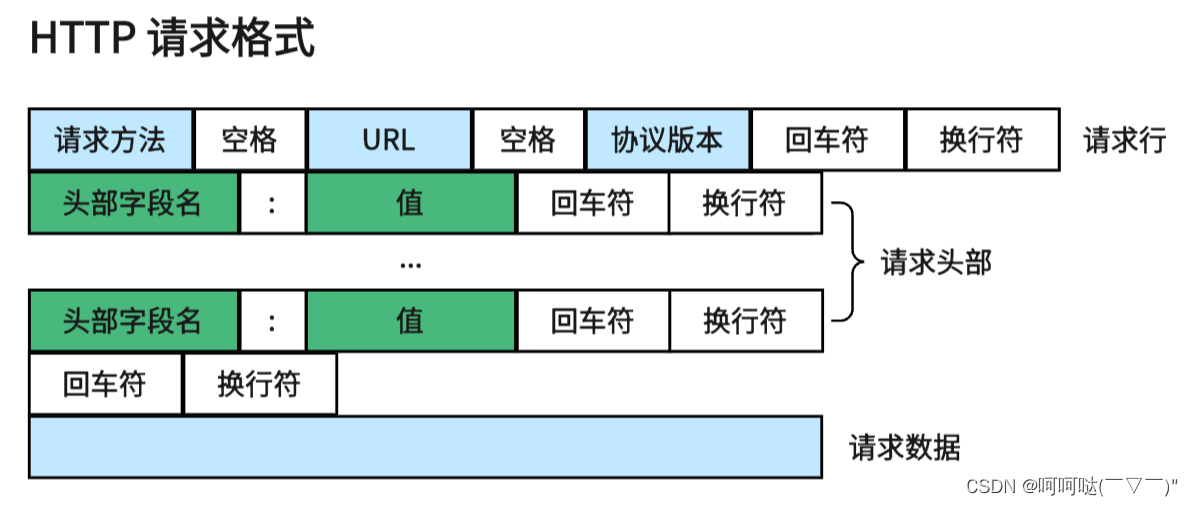
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: BAIDUID=6729CB682DADC2CF738F533E35162D98:FG=1;
BIDUPSID=6729CB682DADC2CFE015A8099199557E; PSTM=1614320692; BD_UPN=13314752;
BDORZ=FFFB88E999055A3F8A630C64834BD6D0;
__yjs_duid=1_d05d52b14af4a339210722080a668ec21614320694782; BD_HOME=1;
H_PS_PSSID=33514_33257_33273_31660_33570_26350;
BA_HECTOR=8h2001alag0lag85nk1g3hcm60q
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
空行
请求数据为空>>http get请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)提示: 每项信息之间都需要一个\r\n,是由http协议规定************************************************
************************************************
>>http post请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
请求体提示: 请求体就是浏览器发送给服务器的数据>>提取请求行
(1)在Buffer.h新增一个函数,叫 bufferFindCRLF函数,其功能是:根据\r\n取出一行,找到其在数据块中的位置,返回该位置
// 根据\r\n取出一行,找到其在数据块中的位置,返回该位置
char* bufferFindCRLF(struct Buffer* buf);// CRLF表示\r\n
char* bufferFindCRLF(struct Buffer* buf) {// strstr --> 从大字符串中去匹配子字符串(遇到\0结束)// memmem --> 从大数据块中去匹配子数据块(需要指定数据块大小)char* ptr = memmem(buf->data + buf->readPos,bufferReadableSize(buf),"\r\n",2);return ptr;
}(2)HttpRequest.h 新增一个函数,叫 parseHttpRequestLine函数,用于解析请求行

// 解析请求行
bool parseHttpRequestLine(struct HttpRequest* req,struct Buffer* readBuf);// 解析请求行
bool parseHttpRequestLine(struct HttpRequest* req,struct Buffer* readBuf) {// 读取请求行char* end = bufferFindCRLF(readBuf);// 保存字符串起始位置char* start = readBuf->data + readBuf->readPos;// 保存字符串结束地址int lineSize = end - start;if(lineSize>0) {// get /xxx/xx.txt http/1.1// 请求方式char* space = memmem(start,lineSize," ",1);assert(space!=NULL);int methodSize = space - start;req->method = (char*)malloc(methodSize + 1);strncpy(req->method,start,methodSize);req->method[methodSize] = '\0';// 请求静态资源start = space + 1;space = memmem(start,end-start," ",1);assert(space!=NULL);int urlSize = space - start;req->url = (char*)malloc(urlSize + 1);strncpy(req->url,start,urlSize);req->url[urlSize] = '\0';// http 版本start = space + 1;req->version = (char*)malloc(end-start + 1);strncpy(req->version,start,end-start);req->version[end-start] = '\0';// 解析请求行完毕,为解析请求头做准备readBuf->readPos += lineSize;readBuf->readPos += 2;// 修改状态 解析请求头req->curState = ParseReqHeaders;return true;}retrun false;
}二、优化解析请求行代码
如果想要在一个函数里边给外部的一级指针分配一块内存,那么需要把外部的一级指针的地址传递给函数。外部的一级指针的地址也就是二级指针,把二级指针传进来之后,对它进行解引用,让其指向我们申请的一块堆内存,就可以实现外部的一级指针被初始化了,也就分配到了一块内存
- 注意:传入指针的地址(二级指针),这个函数涉及给指针分配一块内存,指针在作为参数的时候会产生一个副本
- 而把指针的地址作为参数传入不会产生副本
char* splitRequestLine(const char* start,const char* end,const char* sub,char** ptr) {char* space = (char*)end;if(sub != NULL) {space = memmem(start,end-start,sub,strlen(sub));assert(space!=NULL);}int length = space - start;char* tmp = (char*)malloc(length+1);strncpy(tmp,start,length);tmp[length] = '\0';*ptr = tmp;// 对ptr进行解引用=>*ptr(一级指针),让其指向tmp指针指向的地址return space+1;
}// 解析请求行
bool parseHttpRequestLine(struct HttpRequest* req,struct Buffer* readBuf) {// 读取请求行char* end = bufferFindCRLF(readBuf);// 保存字符串起始位置char* start = readBuf->data + readBuf->readPos;// 保存字符串结束地址int lineSize = end - start;if(lineSize>0) {start = splitRequestLine(start,end," ",&req->method);// 请求方式start = splitRequestLine(start,end," ",&req->url);// url资源splitRequestLine(start,end,NULL,&req->version);// 版本
#if 0// get /xxx/xx.txt http/1.1// 请求方式char* space = memmem(start,lineSize," ",1);assert(space!=NULL);int methodSize = space - start;req->method = (char*)malloc(methodSize + 1);strncpy(req->method,start,methodSize);req->method[methodSize] = '\0';// 请求静态资源start = space + 1;space = memmem(start,end-start," ",1);assert(space!=NULL);int urlSize = space - start;req->url = (char*)malloc(urlSize + 1);strncpy(req->url,start,urlSize);req->url[urlSize] = '\0';// http 版本start = space + 1;req->version = (char*)malloc(end-start + 1);strncpy(req->version,start,end-start);req->version[end-start] = '\0';
#endif// 为解析请求头做准备readBuf->readPos += lineSize;readBuf->readPos += 2;// 修改状态req->curState = ParseReqHeaders;return true;}return false;
}三、解析请求头并存储
### 解析请求头数据
1.数据存储在对应的Buffer结构内存块中。解析时,需要将readPos更新到请求头的起始位置parseHttpRequestLine函数中已经为解析请求头做好了准备。
- 回顾一下parseHttpRequestLine函数:
bool parseHttpRequestLine(struct HttpRequest* request, struct Buffer* readBuf) {...if (lineSize>0){start = splitRequestLine(start, end, " ", &request->method);start = splitRequestLine(start, end, " ", &request->url);splitRequestLine(start, end, NULL, &request->version);// 为解析请求头做准备readBuf->readPos += lineSize;readBuf->readPos += 2;// 修改状态request->curState = ParseReqHeaders;return true;}return false;
}2.请求头的每行为一对键值对,包含一个key值和一个value值
3.将数据行存储到堆内存中,并将堆内存地址传递给httpRequestAddHeader函数
- 回顾一下httpRequestAddHeader函数:
void httpRequestAddHeader(struct HttpRequest* request, const char* key, const char* value) {request->reqHeaders[request->reqHeadersNum].key = (char*)key;request->reqHeaders[request->reqHeadersNum].value = (char*)value;request->reqHeadersNum++;
}### 解析请求头数据 该函数处理请求头中的一行

- 标准HTTP协议中,键值和值之间使用冒号分隔,冒号后有一个空格
- 使用memem函数检查中间指针是否指向冒号
// 解析请求头
bool parseHttpRequestHeader(struct HttpRequest* req,struct Buffer* readBuf);// 该函数处理请求头中的一行
bool parseHttpRequestHeader(struct HttpRequest* req,struct Buffer* readBuf) {char* end = bufferFindCRLF(readBuf);if(end!=NULL) {char* start = readBuf->data + readBuf->readPos;int lineSize = end - start;// 基于: 搜索字符串char* middle = memmem(start,lineSize,": ",2); if(middle!=NULL) {// 拿出键值对char* key = malloc(middle - start + 1);strncpy(key,start,middle - start);key[middle - start] = '\0';// 获得keychar* value = malloc(end - middle - 2 + 1);// end-(middle+2) + 1 = end - middle - 2 + 1strncpy(value,middle+2,end - middle - 2);value[end - middle - 2] = '\0';// 获得valuehttpRequestAddHeader(req,key,value);// 添加键值对// 移动读数据的位置readBuf->readPos += lineSize;readBuf->readPos += 2;}else {// 请求头被解析完了,跳过空行readBuf->readPos += 2;// 修改解析状态// 本项目忽略 post 请求,按照 get 请求处理req->curState = ParseReqDone;}return true;}return false;
}## 注意事项
总结提取请求行 和 解析请求行和优化 这篇博客和 本文需要注意的细节如下:
- 在解析请求行和头部时,需要提供相应的解析函数
- 解析函数应返回布尔值,表示解析是否成功
- 在读取网络数据时,需要使用封装的bufferSocketRead函数来读取数据
- 读取的数据存储在struct Buffer结构体实例中,该实例作为参数传递给解析函数
相关文章:
基于多反应堆的高并发服务器【C/C++/Reactor】(中)HttpRequest 提取请求行、解析请求行和优化 以及解析请求头并存储
### 知识点1:读取网络数据 客户端发送给服务器的通信数据通过封装的bufferSocketRead函数读取读取的数据存储在struct Buffer结构体实例中,可将该实例作为参数传递给解析函数 回顾Buffer.c中的bufferSocketRead函数 // 写内存 2.接收套接字数据 int b…...

数据结构-测试1
一、判断题 1.队列中允许插入的一端叫队头,允许删除的一端叫队尾(F) 队列中允许删除的一端叫队头(front),允许插入的一端叫队尾(rear) 2. 完全二叉树中,若一个结点没有左孩子&#…...
【设计模式】01-前言
23 Design Patterns implemented by C. 从本文开始,一系列的文章将揭开设计模式的神秘面纱。本篇博文是参考了《设计模式-可复用面向对象软件的基础》这本书,由于该书的引言 写的太好了,所以本文基本是对原书的摘抄。 0.前言 评估一个面向对…...
SpringBoot源码分析
一:简介 由Pivotal团队提供的全新框架其设计目的是用来简化新Spring应用的初始搭建以及开发过程使用了特定的方式来进行配置快速应用开发领域 二:运行原理以及特点 运行原理: SpringBoot为我们做的自动配置,确实方便快捷&#…...
约数个数和约数之和算法总结
知识概览 约数个数 基于算数基本定理,假设N分解质因数的结果为 可得对于N的任何一个约数d,有 因为N的每一个约数和~的一种选法是一一对应的,根据乘法原理可得, 一个数的约数个数为 约数之和 一个数的约数之和公式为 多项式乘积的…...
数据结构-怀化学院期末题(322)
图的深度优先搜索 题目描述: 图的深度优先搜索类似于树的先根遍历,是树的先根遍历的推广。即从某个结点开始,先访问该结点,然后深度访问该结点的第一棵子树,依次为第二顶子树。如此进行下去,直到所有的结点…...

小手也能用的高性能鼠标,自定义空间还挺高,雷柏VT9Pro mini上手
今年搭载PAW3395传感器的电竞鼠标很受欢迎,雷柏就出了不少型号,满足各种喜好的玩家选择,像是近期新出的搭载3395高定版的VT9Pro和VT9Pro mini,就在轻量化的基础上,满足了各种手型的玩家的使用需要,而且价格…...
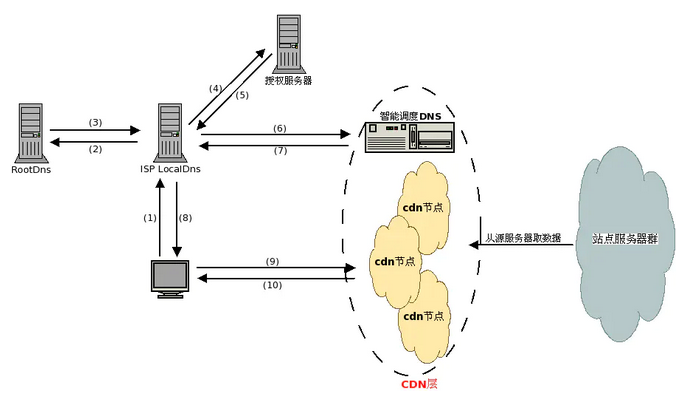
CDN加速原理详解
一、CDN加速是什么意思 CDN是Content Delivery Network)英文首字母的缩写,中文翻译为内容分发网络,由于CDN是为加快网络访问速度而被优化的网络覆盖层,因此被形象地称为”网络加速器”,即CDN加速。CDN加速是通过将网站…...

sqlachemy orm create or delete table
sqlacehmy one to one ------detial to descript 关于uselist的使用。如果你使用orm直接创建表关系,实际上在数据库中是可以创建成多对多的关系,如果加上uselistFalse 你会发现你的orm只能查询出来一个,如果不要这个参数orm查询的就是多个,一对多的…...
科普小米手机、华为手机、红米手机、oppo手机、vivo手机、荣耀手机、一加手机、realme手机如何设置充电提示音
用空空鱼就可以设置,上面还有很多提示音素材还可以设置满电和低电提醒...
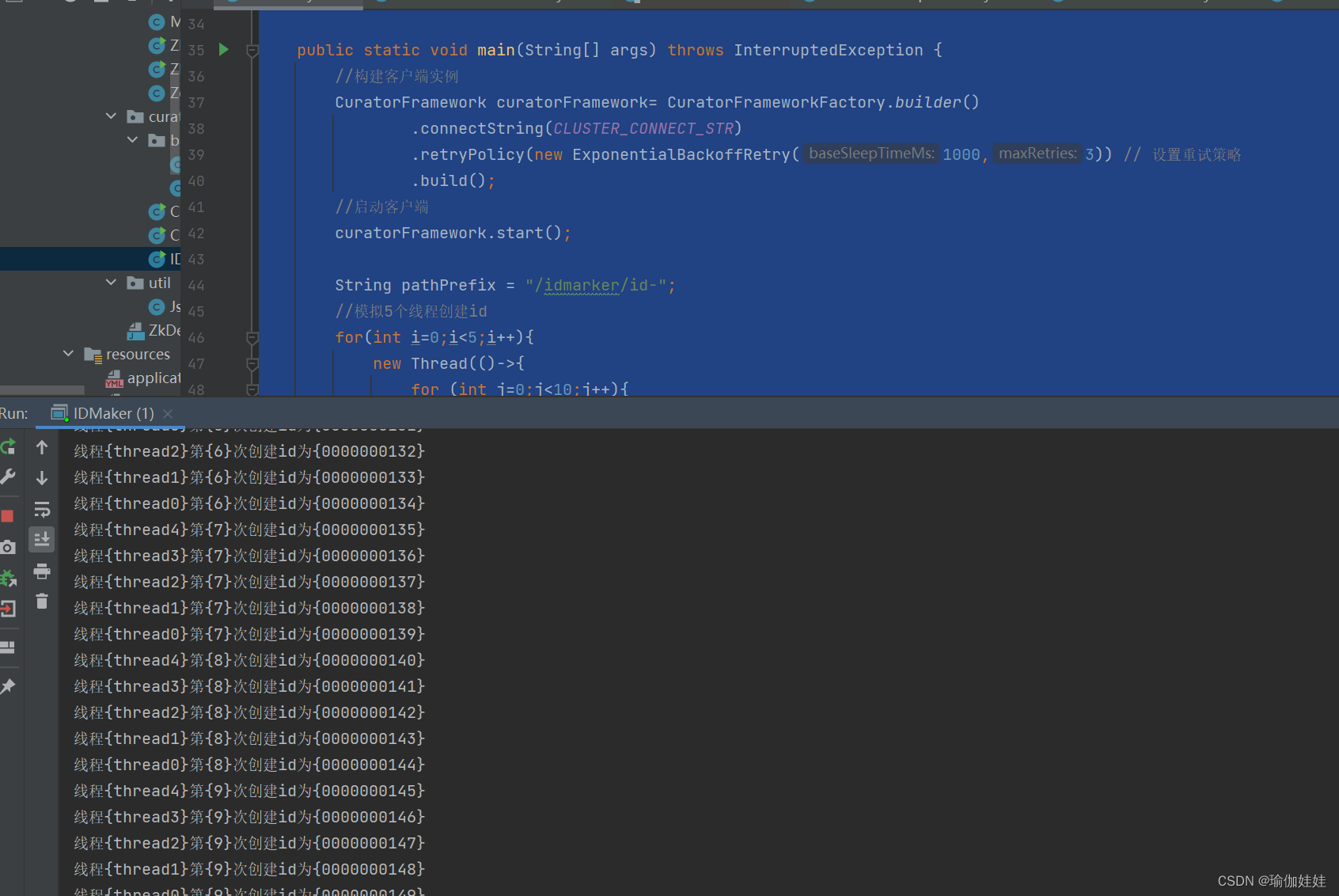
zookeeper应用场景之分布式的ID生成器
1. 分布式ID生成器的使用场景 在分布式系统中,分布式ID生成器的使用场景非常之多: 大量的数据记录,需要分布式ID。大量的系统消息,需要分布式ID。大量的请求日志,如restful的操作记录,需要唯一标识&#x…...
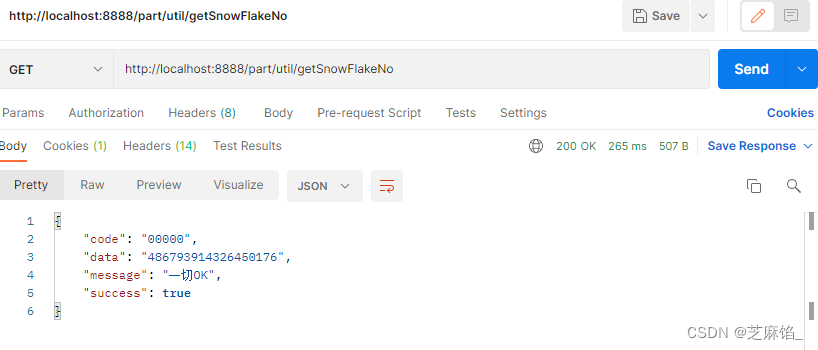
Java--Spring项目生成雪花算法数字(Twitter SnowFlake)
文章目录 前言步骤查看结果 前言 分布式系统常需要全局唯一的数字作为id,且该id要求有序,twitter的SnowFlake解决了这种需求,生成了符合条件的这种数字,本文将提供一个接口获取雪花算法数字。以下为代码。 步骤 SnowFlakeUtils …...

紫光展锐M6780丨画质增强——更炫的视觉体验
智能显示被认为是推动数字化转型和创新的重要技术之一。研究机构数据显示,预计到2035年底,全球智能显示市场规模将达到1368.6亿美元,2023-2035年符合年增长率为36.4%。 随着消费者对高品质视觉体验的需求不断增加,智能手机、平板…...

控制el-table的列显示隐藏
控制el-table的列显示隐藏,一般的话可以通过循环来实现,但是假如业务及页面比较复杂的话,list数组循环并不好用。 在我们的页面中el-table-column是固定的,因为现在是对现有的进行维护和迭代更新。 对需要控制列显示隐藏的页面进…...

2024上海国际冶金及材料分析测试仪器设备展览会
2024上海国际冶金及材料分析测试仪器设备展览会 时间:2024年12月18~20日 地点:上海新国际博览中心 ◆ 》》》组织机构: 主办单位:全联冶金商会、中国宝武钢铁集团有限公司、上海市金属学会 支持单位ÿ…...

商业定位,1元平价商业咨询:豪威尔咨询!平价咨询。
在做生意之前,就需要对企业整体进行一完整的商业定位,才能让商业定位带动企业进行飞速发展。 所以,包含商业定位的有效工作内容就显得极为重要,今天,小编特地为大家整理出了商业定位所需要的筹备的工作,如下…...
2. Presto应用
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 1、Presto安装使用2、事件分析3、漏斗分析4、漏斗分析UDAF开发开发UDF插件开发UDAF插件 5、漏斗测试 1、Presto安装使用 参考官方文档:https://prestodb.io/docs/current/ P…...

工业级安卓PDA超高频读写器手持掌上电脑,RFID电子标签读写器
掌上电脑,又称为PDA。工业级PDA的特点就是坚固,耐用,可以用在很多环境比较恶劣的地方。 随着技术的不断发展,加快了数字化发展趋势,RFID技术就是RFID射频识别及技术,作为一种新兴的非接触式的自动识别技术&…...

Prompt提示工程上手指南:基础原理及实践(一)
想象一下,你在装饰房间。你可以选择一套标准的家具,这是快捷且方便的方式,但可能无法完全符合你的个人风格或需求。另一方面,你也可以选择定制家具,选择特定的颜色、材料和设计,以确保每件家具都符合你的喜…...

Redis如何保证缓存和数据库一致性?
背景 现在我们在面向增删改查开发时,数据库数据量大时或者对响应要求较快,我们就需要用到Redis来拿取数据。 Redis:是一种高性能的内存数据库,它将数据以键值对的形式存储在内存中,具有读写速度快、支持多种数据类型…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...