k8s的yaml文件中的kind类型都有哪些?(详述版Part1/2)
目录
综述
分块详述
1、Pod
2、Deployment
3、Service
4、DaemonSet
5、ReplicaSet
6、ServiceAccount
7、PodDisruptionBudget
8、PersistentVolumeClaim
9、PersistentVolume
10、Job
11、CronJob
12、StatefulSet
综述
通过yaml文件中的kind可以大致了解kubernetes中都有哪些资源类型,但是每一种资源是什么样的?有哪些特性?使用该资源能达到什么效果?本文对照上一篇的清单逐个进行说明,本文是第一部分。
分块详述
1、Pod
Pod 是容器编排的基本单位,是最小的可调度和可管理的计算单元。它是一组相关的容器(即应用程序容器)的集合,共享相同的网络和存储资源。
Pod 的特性包括:
-
最小调度单元:Pod 是 Kubernetes 调度和管理的最小单位。一个 Pod 可以包含一个或多个容器,它们共享相同的资源和生命周期。
-
应用程序容器的集合:Pod 中的多个容器可以与同一网络命名空间和存储卷进行交互和协作,实现应用程序的完整功能。
-
共享网络和存储资源:Pod 中的所有容器共享同一个 IP 地址和端口号空间,实现容器内的服务发现和通信。同时,它们还可以共享存储卷,以实现数据的持久化和跨 Pod 的共享。
-
故障恢复:Pod 为应用程序容器提供互备机制,当一个容器失败时,它会被自动重启,以保证应用程序的容错性和可用性。
Pod 的主要目标是提供容器之间的协同工作和通信环境。使用 Pod 实现目标的方法:
-
多容器应用程序:将相关的容器组织在同一个 Pod 中,可更好地管理和调度容器的资源、实现容器之间的通信和协作,提供故障恢复的能力。
-
具有依赖关系的容器:一些应用程序组件可能需要另一个组件的支持和环境,Pod 可以提供多个容器,让它们共享相同的环境变量,共享同一资源,方便彼此间的通信和协作。
-
数据共享:通过将存储卷挂载到 Pod 中,可在多个容器之间实现数据的共享和持久化。
-
自动化容器部署:在 Kubernetes 中,用户可以创建 Pod 模板文件,以实现对容器的自动化部署、资源管理和故障恢复,从而使部署更加便捷和可靠。
Pod 提供了一个抽象层,使得应用程序可以作为一个集合来管理,而不是一个个独立的容器。它可以更好地管理和调度容器的资源,实现容器之间的协同工作和通信,提供故障恢复的能力。
2、Deployment
Deployment 是一种控制器(Controller),它基于 Pod 和 ReplicaSet 构建而成,用于管理 Pod 的创建、更新和销毁。Deployment 通过自动化管理应用程序的版本控制和滚动更新,同时还具有弹性和简便的水平扩展性。
Deployment 的主要特性包括:
-
简化应用程序的管理:Deployment 可以自动化和简化应用程序的版本部署和更新,以及维护应用程序的健康和可靠性。
-
滚动更新:Deployment 可以平滑地完成应用程序的版本更新,通过逐步停止旧 Pod 并逐步启动新 Pod 来实现。这可以保证应用程序在更新过程中的连续性和稳定性。
-
弹性伸缩:Deployment 可以根据应用程序的负载情况,自动进行水平扩展和缩容,在充分利用资源的同时,确保应用程序的性能和可靠性。
-
回滚和历史记录:Deployment 可以实现应用程序版本的回滚和历史记录,以便管理者和开发者能够轻松地跟踪应用程序的部署历史和变更情况。
Deployment 的主要目标包括:
-
提供健康和高可用性:通过对 Pod 的管理和控制,Deployment 可以确保应用程序的运行状态始终处于健康和高可用性的状态。
-
应用程序的连续更新和升级:Deployment 可以实现滚动更新操作,在保证应用程序运行的同时,完成应用程序的版本更新和升级。
-
应对负载变化:Deployment 可以根据应用程序的负载情况自动执行水平扩展和缩容操作,当容器负载高峰期出现时,能够自适应地增加容器数量,以满足应用程序的负载需求。
-
快速回滚:Deployment 可以实现应用程序版本的回滚操作,在应用程序版本升级失败时可以快速回滚到之前的版本,保证应用程序运行的连续性和稳定性。
总而言之,Deployment 为我们提供了一个简单高效的方式来管理和控制应用程序的部署、更新和升级,从而降低了系统管理者的工作负担,并提高了应用程序运行的健康和可靠性。
3、Service
Service 是一种抽象层,用于定义一组 Pod 的访问方式和网络连接。Service 为运行在不同 Pod 上的应用程序提供一个统一的入口点,并负责对外暴露应用程序的服务。
Service 的主要特性包括:
-
持久的虚拟 IP 地址(Cluster IP):Service 分配一个稳定的虚拟 IP 地址给 Pod 组,作为外界访问该服务的入口。这个虚拟 IP 地址只在集群内部可用,对外部用户是不可见的。
-
负载均衡:Service 可以通过负载均衡算法,将传入的请求均匀地分发给集群中的多个 Pod,从而实现请求的负载均衡,提高应用程序的可用性和性能。
-
服务发现:Service 提供一个稳定的 DNS 名称,用于将服务的名称解析到对应的 IP 地址。这使得其他应用程序可以通过服务名来访问服务,而不需要关心底层 Pod 的变化或重启。
-
会话保持(Session Affinity):Service 支持会话保持,可以将相同用户的请求发送到同一个 Pod,确保在一段时间内的会话持续连接到同一个后端 Pod。
-
外部访问(External IP):Service 还可以将集群内的服务公开到集群外部,通过分配一个外部 IP 地址,并将流量路由到对应的 Pod。这使得可以从集群外访问应用程序。
Service 的主要目标包括:
-
提供稳定的访问入口:Service 为每个服务分配一个稳定的虚拟 IP 地址,使得应用程序的访问入口与底层的 Pod 可以分离。这提供了更好的灵活性和可扩展性。
-
实现负载均衡:Service 可以将流量均匀地分发给后端的 Pod,通过负载均衡算法实现请求的平衡和高可用性。
-
服务发现和解耦:Service 提供一个稳定的 DNS 名称,使得应用程序可以通过服务名来访问服务,而不需要关心底层 Pod 的变化。这降低了应用程序之间的耦合性。
-
外部访问:Service 可以将集群内的服务公开到集群外部,允许外部用户访问应用程序和服务。
总而言之,Service 为运行在 Kubernetes 集群中的应用程序提供了一个统一的入口点和稳定的网络连接,通过负载均衡、服务发现和外部访问等特性,提供了应用程序的可用性、可伸缩性和弹性。
4、DaemonSet
DaemonSet是一种资源对象,用于保证在集群中的每个节点都运行一个副本(Pod)的副本集。这样可以确保一组Pod在整个集群中覆盖每个可分配的节点上,通常用于运行一些系统级别或网络服务,例如日志收集、监控代理、容器网络插件等。
DaemonSet对象的一些特性和功能包括:
-
自动调度:DaemonSet中的Pod会自动调度到可分配的节点上,不需要手动干预。
-
自动伸缩:当节点的数量发生变化时,DaemonSet会自动伸缩Pod的数量,保证在集群中的每个节点上都有一个Pod实例。
-
自动更新:在更新DaemonSet时,Kubernetes会自动更新Pod的副本保证所有Pod都进入到同一个版本,从而实现DaemonSet的自动化管理。
通过使用DaemonSet,可以确保集群中的每个节点都有一组Pod运行,并且这些Pod都是同样的版本,提供可靠的基础设施运维。同时,DaemonSet同样支持负载均衡、服务发现、自动伸缩等一系列Kubernetes的功能和特性。
5、ReplicaSet
ReplicaSet是一种资源对象,用于确保指定数量的Pod副本(Replicas)在集群中运行。它是一种强大的高级控制器,用于管理Pod的复制和伸缩。
ReplicaSet对象具有以下几个重要的功能和特点:
-
副本管理:ReplicaSet负责管理一组Pod副本,可以根据指定的副本数目自动扩缩容。当Pod数量少于期望值时,ReplicaSet会自动创建新的Pod副本。当Pod数量多于期望值时,ReplicaSet会自动删除多余的Pod副本。
-
自动恢复:当Pod失败或被删除时,ReplicaSet会自动创建新的Pod来替代,以确保指定数量的Pod一直保持运行。
-
选择器匹配:ReplicaSet使用标签选择器(Label Selector)来选择要管理的一组Pod。通过标签选择器,可以灵活地定义要跟踪和管理的Pod集合。
-
版本管理:通过修改ReplicaSet的配置,可以对所管理的Pod进行版本升级或回滚。这样可以保证应用程序版本的平滑更新。
-
平滑扩缩容:通过修改ReplicaSet的副本数目,可以实现自动扩缩容的功能。Kubernetes会根据实际负载自动增减Pod的数量,以确保应用程序始终具有足够的副本来处理请求。
ReplicaSet通常与Deployment对象一起使用。Deployment提供了一个声明式的方式来管理ReplicaSet,并且支持滚动更新、回滚以及其他高级部署策略。通过使用ReplicaSet和Deployment,可以实现应用程序的弹性扩展、自动恢复和高可用性。
6、ServiceAccount
ServiceAccount是用于身份验证和授权的资源对象。它是用来让Pod或其他资源以特定身份(identity)与Kubernetes API进行交互的机制。
每个Pod都可以关联一个ServiceAccount,以便在Pod内部进行身份验证,并以该ServiceAccount所定义的身份与Kubernetes集群进行通信。当Pod需要访问Kubernetes API、其他服务或资源时,它可以使用与之关联的ServiceAccount进行身份验证,并且根据该ServiceAccount所分配的权限进行授权。
ServiceAccount对象有以下几个重要的属性和功能:
-
唯一身份标识:每个ServiceAccount都有一个唯一的身份标识(Identity),用于在Kubernetes集群中识别该ServiceAccount所代表的实体。
-
访问令牌:每个ServiceAccount都会分配一个与之对应的访问令牌(Access Token)。Pod可以使用该访问令牌来对Kubernetes API进行身份验证,以获取授权的访问权限。
-
权限和授权:ServiceAccount可以与Role、ClusterRole以及RoleBinding、ClusterRoleBinding等资源对象进行关联,以定义其所具有的权限和授权范围。这样可以确保Pod以合适的权限进行操作,以满足安全性和隔离性的需求。
通过使用ServiceAccount,可以实现以下目标:
- 根据需求将不同的Pod分配到不同的ServiceAccount,以限制它们的访问权限。
- 在Pod内部,通过访问令牌与Kubernetes API进行身份验证,并以ServiceAccount所定义的权限进行授权。
- 与其他身份验证机制(如RBAC)结合使用,以便更精确地控制Pod的访问和操作权限。
需要注意的是,默认情况下,每个Namespace都会自动创建一个默认的ServiceAccount,但Pod不会自动与之关联。如果要将Pod与特定的ServiceAccount关联,必须在Pod的配置中指定它。
7、PodDisruptionBudget
PodDisruptionBudget(PDB)是一种资源对象,用于定义对于部署的敏感性和可靠性要求,限制在进行维护操作或节点故障时,允许同时终止的Pod的最大数量。
PodDisruptionBudget的作用是确保在Pod的调度、维护或恢复过程中,不会对关键应用程序的可用性造成过大的影响。通过限制同时终止的Pod数量,PodDisruptionBudget可以防止过多的Pod在同一时间被终止,从而保证应用程序的稳定性。
PodDisruptionBudget对象具有以下几个重要的属性和功能:
-
最小可用性:PodDisruptionBudget可以定义一个最小可用性(minAvailable)的值,表示在进行维护操作或节点故障期间,需要保持可用的最小Pod数量。这可以防止过多的Pod同时不可用,确保业务的连续性。
-
最大中断数量:PodDisruptionBudget可以定义一个最大中断数量(maxUnavailable)的值,表示在进行维护操作或节点故障期间,允许同时终止的最大Pod数量。这可以防止操作过程中过多的Pod同时终止,以避免对业务造成过大的影响。
-
与Deployment、StatefulSet等对象结合:PodDisruptionBudget通常与Deployment、StatefulSet等控制器对象结合使用,以控制对应的Pod在故障情况下的终止数量。可以根据业务需求为特定的控制器对象定义PodDisruptionBudget。
通过使用PodDisruptionBudget,可以实现以下目标:
- 控制故障时同时终止的Pod数量,以确保应用程序可用性。
- 防止过多的Pod在同一时间被终止,减少业务中断的风险。
- 设定对应用程序的最低保证可用性和可靠性要求,以满足业务需求。
需要注意的是,PodDisruptionBudget只能保证在Kubernetes集群自身的维护操作或节点故障情况下的可用性。对于应用程序级别的故障处理,需要借助其他机制和策略来实现,如多区域部署、应用层负载均衡等。
8、PersistentVolumeClaim
PersistentVolumeClaim(PVC)是Kubernetes中用于声明持久化存储资源的对象。它允许应用程序声明对特定存储资源的需求,而无需关注底层的存储实现细节。
通过创建PersistentVolumeClaim,应用程序可以请求使用具有特定属性(例如容量、访问模式等)的持久化存储。这样,应用程序可以独享持久性存储,而无需与其他应用程序共享或关注如何配置存储。
PersistentVolumeClaim的配置中可能包含以下信息:
-
StorageClassName:指定了用于提供持久化存储的存储类别。存储类别定义了存储的类型和属性,如提供商、存储介质、复制级别等。 -
AccessModes:定义了存储的访问模式。常见的访问模式包括ReadWriteOnce(只能被单个节点以读写模式挂载)和ReadOnlyMany(可以由多个节点以只读模式挂载)。 -
Resources:指定所需的存储容量。
创建PersistentVolumeClaim后,Kubernetes集群会尝试将这个声明与符合要求的PersistentVolume(PV)进行绑定。PersistentVolume是集群中预先定义的持久化存储资源。一旦绑定成功,PVC将被分配给应用程序,使其可以使用持久化存储来保存数据。
通过使用PersistentVolumeClaim,应用程序可以与持久化存储资源解耦,提供了一种可移植和可扩展的方式来管理应用程序的持久化数据需求。
9、PersistentVolume
PersistentVolume(PV)是一种抽象的存储资源,用于提供独立于Pod的持久化存储。PV可以是集群中的任何一种存储,例如物理存储、网络存储或云存储。
PersistentVolume有以下几个重要的属性:
-
容量和访问模式:PV定义了存储资源的容量、访问模式和存储类别等属性。容量用于指定PV的存储空间大小,而访问模式定义了允许该PV被多个Pod以何种方式访问,例如ReadWriteOnce(只读一次)、ReadOnlyMany(只读多次)或ReadWriteMany(多次读写)。
-
持久化存储后端:PV可以与实际的持久化存储后端进行关联,例如物理存储设备、网络存储卷(NFS、iSCSI等)或云存储(AWS EBS、Azure Disk等)。这样,Pod可以通过PV来访问和使用这些持久化存储资源。
-
生命周期管理:PV的生命周期与Kubernetes集群无关,它是一个独立的资源对象。管理员可以手动创建、删除和管理PV,并在集群中的不同节点之间迁移或重新分配PV。
-
与PersistentVolumeClaim关联:PV可以被动态或静态地与
PersistentVolumeClaim(PVC)对象进行关联。PVC是Pod对持久化存储的请求,而PV是PVC实际绑定的目标。PVC定义了Pod对存储的需求,而PV满足这些需求。
通过使用PersistentVolume,可以实现以下目标:
- 提供稳定的、独立于Pod的持久化存储资源,确保数据的持久性和可靠性。
- 将存储资源从Pod中解耦,使得Pod能够独立于存储的生命周期而存在。
- 在多个Pod之间共享和访问同一个PV,实现数据共享和协作。
需要注意的是,PersistentVolume需要管理员手动进行创建和管理,而PersistentVolumeClaim是由用户或开发人员来请求和使用的。管理员可以根据集群中的存储资源情况和用户需求来创建和配置PV,而用户则可以通过PVC来使用和访问这些PV。
10、Job
Job是一种控制器对象,用于管理短暂、一次性任务的运行。Job可以确保任务的成功或失败,以及处理任务的重试和清理工作。
Job对象有以下几个重要的属性和功能:
-
任务定义:Job通过
Pod对象来定义任务的容器、镜像、环境变量、命令和参数等信息。任务可以是一次性的、短暂的,也可以是需要长时间运行的。 -
任务控制:Job控制任务的启动、运行和完成。在任务启动时,Job会自动创建一个Pod并将任务分配给这个Pod。在任务完成之后,Job会监控Pod的状态并根据任务结果进行处理。
-
任务结果处理:Job会根据Pod的退出状态来判断任务的成功或失败,并在任务失败时进行重试和后续处理。可以通过设置任务的
backoffLimit属性来指定重试的次数。在任务成功或失败后,Job将删除Pod并释放相应的资源。 -
任务生命周期管理:Job管理任务的整个生命周期,包括创建、启动、监控和清理。可以通过设置
activeDeadlineSeconds属性来指定Job的最大执行时间,如果任务在该时间内未能完成,Job将终止任务并删除Pod。
通过使用Job,可以实现以下目标:
- 管理短暂、一次性任务的运行,如批量处理、数据导入等。
- 确保任务的成功或失败,并自动进行重试和后续处理。
- 管理任务的生命周期,包括创建、启动、监控和清理,以避免资源和状态的泄漏。
需要注意的是,Job适用于短暂、一次性的任务,不适用于需要长时间运行的任务。对于需要长时间运行的任务,需要使用其他的控制器对象,例如Deployment或StatefulSet。
11、CronJob
CronJob是一种控制器对象,用于管理周期性任务(也称为定时任务)的运行。CronJob可以基于时间表达式(类似于Cron表达式)调度任务,并确保任务按照指定的时间点或时间间隔周期性地运行。
CronJob对象具有以下几个重要属性和功能:
-
任务定义:CronJob通过
Job对象来定义任务的容器、镜像、环境变量、命令和参数等信息。任务可以是一次性的、短暂的,也可以是需要长时间运行的。 -
调度规则:CronJob基于时间表达式来调度任务,并根据时间点或时间间隔周期性地运行任务。时间表达式由5个时间字段组成,分别表示分钟、小时、日期、月份和星期几。
-
任务控制:CronJob控制任务的启动、运行和完成。在任务启动时,CronJob会自动创建一个Job对象并将任务分配给这个Job。在任务完成之后,CronJob会监控Job的状态,并根据任务结果进行处理。
-
任务结果处理:CronJob会根据Job的状态来判断任务的成功或失败,并在任务失败时进行重试和后续处理。可以通过设置任务的
backoffLimit属性来指定重试的次数。在任务成功或失败后,CronJob将删除Job并释放相应的资源。
通过使用CronJob,可以实现以下目标:
- 管理周期性任务的运行,例如备份、清理、同步等。
- 基于时间表达式调度任务,并确保任务按照指定的时间点或时间间隔周期性地运行。
- 确保任务的成功或失败,并自动进行重试和后续处理。
- 管理任务的生命周期,包括创建、启动、监控和清理,以避免资源和状态的泄漏。
需要注意的是,CronJob适用于周期性任务的管理,但不适用于需要长时间运行的任务。对于需要长时间运行的任务,需要使用其他的控制器对象,例如Deployment或StatefulSet。
12、StatefulSet
StatefulSet是一种控制器对象,用于管理需要唯一标识和持久状态的有状态应用程序的部署。StatefulSet确保每个Pod都有唯一的网络标识和稳定的存储,以便实现有状态应用程序的可靠部署和数据持久化。
StatefulSet对象具有以下几个重要属性和功能:
-
标识和顺序性:StatefulSet为每个Pod分配了唯一的网络标识,即Pod的名称和稳定DNS名称。这些标识和顺序性可用于有状态应用程序内部的服务发现和通信。
-
持久化存储:StatefulSet通过
PersistentVolumeClaim(PVC)为每个Pod提供了稳定的持久化存储。每个Pod可以绑定到一个独立的PV并保持与之关联,以确保数据的持久性。 -
有序部署和扩展:StatefulSet在部署和缩放有状态应用程序时,会按特定的顺序逐个启动、更新或删除Pod。这种有序性能够确保应用程序在进行扩展、滚动更新或故障恢复时保持数据的一致性和可用性。
-
稳定的网络标识:StatefulSet为每个Pod分配了稳定的网络标识,以便其他应用程序或服务可以可靠地与具体的Pod进行通信。这种稳定性在部署、删除或故障转移时都能得到保持。
通过使用StatefulSet,可以实现以下目标:
- 部署和管理有状态应用程序,如数据库、消息队列、缓存等。
- 为每个Pod提供稳定的网络标识和持久化存储,以确保数据的持久性和一致性。
- 实现有序的部署、扩展和更新,以避免数据的丢失和不一致。
- 支持应用程序内部的服务发现和通信。
需要注意的是,StatefulSet适用于需要唯一标识和持久状态的有状态应用程序。对于无状态的应用程序,可以使用其他的控制器对象,例如Deployment或ReplicaSet。
相关文章:
)
k8s的yaml文件中的kind类型都有哪些?(详述版Part1/2)
目录 综述 分块详述 1、Pod 2、Deployment 3、Service 4、DaemonSet 5、ReplicaSet 6、ServiceAccount 7、PodDisruptionBudget 8、PersistentVolumeClaim 9、PersistentVolume 10、Job 11、CronJob 12、StatefulSet 综述 通过yaml文件中的kind可以大致了解kube…...

企业培训系统源码:构建智能、可扩展的学习平台
企业培训系统在现代企业中扮演着至关重要的角色。本文将通过深度解析企业培训系统的源码,介绍如何构建一个智能、可扩展的学习平台,涉及关键技术和代码实例。 1. 技术栈选择与项目初始化 在构建企业培训系统之前,选择适当的技术栈是至关重…...

设计模式—行为型模式之状态模式
设计模式—行为型模式之状态模式 状态(State)模式:对有状态的对象,把复杂的“判断逻辑”提取到不同的状态对象中,允许状态对象在其内部状态发生改变时改变其行为。 状态模式包含以下主要角色: 环境类&am…...

Linux习题3
解析: grep:查找文件内的内容 gzip:压缩文件,文件经压缩后会增加 gz:扩展名 find:在指定目录下查找文件 解析: A hosts文件是Linux系统上一个负责ip地址与域名快速解析的文件,以…...

SpringBoot+策略模式实现多种文件存储模式
一、策略模式 背景 针对某种业务可能存在多种实现方式;传统方式是通过传统if…else…或者switch代码判断; 弊端: 代码可读性差扩展性差难以维护 策略模式简介 策略模式是一种行为型模式,它将对象和行为分开,将行…...
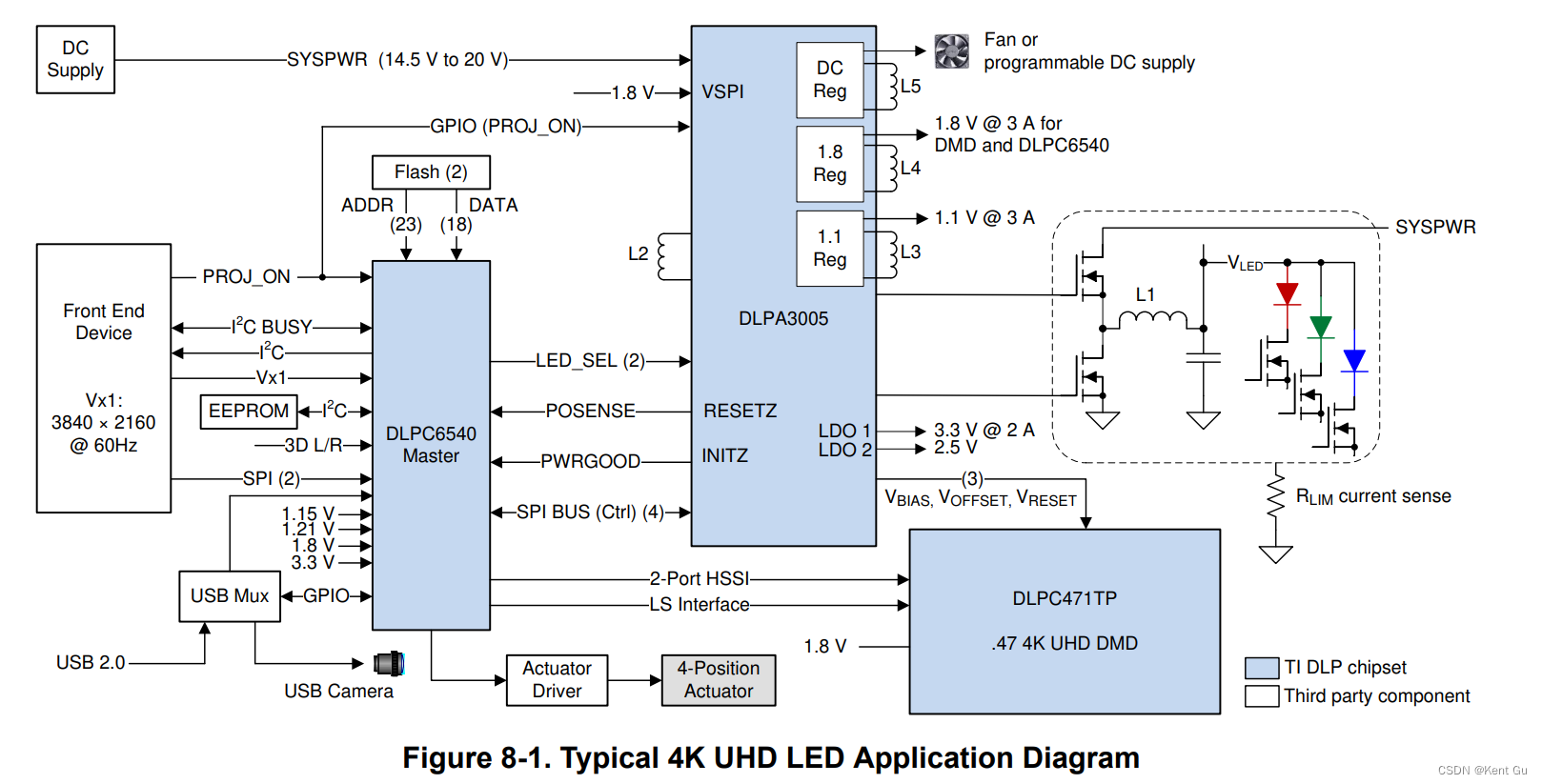
细说DMD芯片信号-DLP3
1, Block diagram 2. 信号介绍 2.1, LS interface: LD_Data_P/N(i), LD_CLK_P/N(i), LS_RDATA_A_BIST(O) 2.2, 视频信号: HSSI(High speed serial interface) High speed Differential Data pair lan A0~7 P/N, High speed Differential Clock A High…...

MySQL从0到1全教程【1】MySQL数据库的基本概念以及MySQL8.0版本的部署
1 MySQL数据库的相关概念 1.1 数据库中的专业术语 1.1.1 数据库 (DB) 数据库是指:保存有组织的数据的容器(通常是一个文数据库 (database)件或一组文件)。 1.1.2 数据库管理系统 (DBMS) 数据库管理系统(DBMS)又称为数据库软件(产品),用于管理DB中的数据 注意:…...

grep常用命令
1. grep常用参数 -i忽略大小写-w精准匹配整词-v结果取反(匹配指定的字符串以外的内容)-A关键字所在行的后几行也一起显示-B关键字所在行的前几行也一起显示-C关键字所在行的前后几行行一起显示 2. 常用命令 2.1 从文件中查找关键词 # 精准匹配 grep linux test.txt# 从多个…...

Spring Data JPA 使用总结
本文记录了Spring data JPA 的一些细碎的规则。 findBy语法规则 :findOOXXByName 实际上等价 > findByName 比如: User findFirstByOrderByLastnameAsc();User findTopByOrderByAgeDesc();Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);…...
融云 CEO 董晗荣获 51CTO 「2023 年度科技影响力人物奖」
(👆点击获取《社交泛娱乐出海作战地图》) 1 月 5 日,由知名 IT 技术媒体 51CTO 主办的第十八届“中国企业年终评选”正式揭晓榜单,融云 CEO 董晗荣获“2023 年度科技影响力人物奖”。关注【融云全球互联网通信云】了解…...

数据洞察力,驱动企业财务变革
我们不得不面对一个现实,就是数据量的剧增。加上大部分企业并不愿意删除历史数据,以防未来预测分析时需要,这造成数据就像一个雪球,越滚越大。然而,过多的数据和数据不足一样会成为企业发展和理解分析的障碍。从海量数…...

Postgresql常见(花式)操作完全示例
案例说明 将Excel数据导入Postgresql,并实现常见统计(数据示例如下) 导入Excel数据到数据库 使用Navicat工具连接数据库,使用导入功能可直接导入,此处不做过多介绍,详细操作请看下图: 点击“下…...
【Docker】数据管理
🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Docker的相关操作吧 目录 🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 前言 一.数据卷 示例演示 示例剖析…...
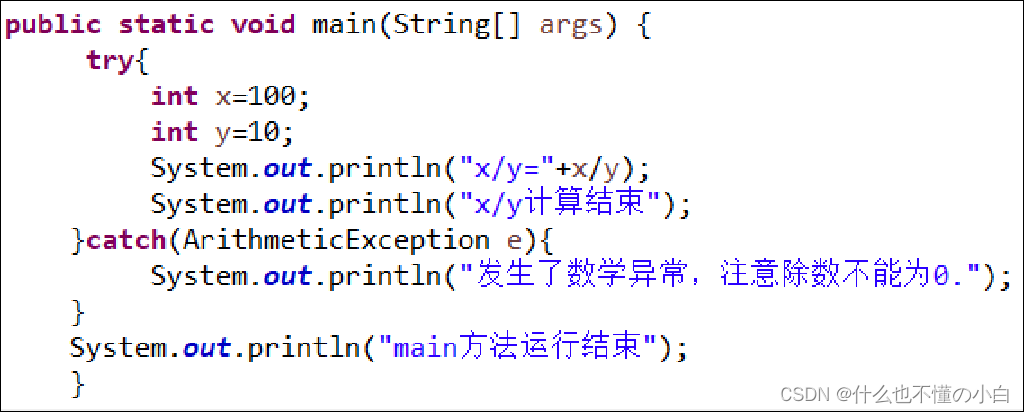
认识异常及异常处理机制之try-catch
异常类 什么是异常?就像人会犯错一样,程序在运行的过程中也会犯错。程序中的错误有两类,一类称为Error(错误),另一类称为Exception(异常)。Error类和Exception类都为Throwable的子类…...

html学习之路:简述html文档头部 <meta> 的 http-equiv 属性
🧋当输入网址打开网页时,设置html头部meta的http-equiv属性,可以帮助浏览器更加精确和正常却的显示网页内容,比如设置网页多久自动刷新,设置网页在浏览器缓存中的时限,设置多少事件跳转到指定的网页地址&am…...
逆矩阵计算
目录 一、逆矩阵的定义 核心:AB BA E 1)定义 2)注意 3)逆矩阵存在的条件|A| ! 0 二、核心公式: 三、求逆矩阵(核心考点) 1、伴随矩阵法 2、初等变换法(重点掌握ÿ…...

《豫鄂烽火燎原大小焕岭》:一部穿越时空的历史史诗
《豫鄂烽火燎原大小焕岭》:一部穿越时空的历史史诗 一部赓续红色血脉的生动教材 一部讴歌时代英雄和人民精神宝典 当历史的烽烟渐渐远去,留下的是一页页泛黄的记忆和无数英雄的壮丽诗篇。李传铭的力作《豫鄂烽火燎原大小焕岭》正是这样一部深情的回望&am…...

浅研究下 DHCP 和 chrony
服务程序: 1.如果有默认配置,请先备份,再进行修改 2.修改完配置文件,请重启服务或重新加载配置文件,否则不生效 有些软件,安装包的名字和系统里服务程序的名字不一样(安装包名字:…...
【算法】动态中位数(对顶堆)
题目 依次读入一个整数序列,每当已经读入的整数个数为奇数时,输出已读入的整数构成的序列的中位数。 输入格式 第一行输入一个整数 P,代表后面数据集的个数,接下来若干行输入各个数据集。 每个数据集的第一行首先输入一个代表…...

mysql服务多实例运行
1、官网下载mysql安装包 https://downloads.mysql.com/archives/community/ 2、解压安装包 tar -zxvf mysql-8.1.0-linux-glibc2.28-aarch64.tar.xz -C /usr/localmv /usr/local/mysql-8.1.0-linux-glibc2.28-aarch64 /usr/local/mysql 3、创建mysql用户组 groupadd…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...