Spark的内核调度
目录
概述
RDD的依赖
DAG和Stage
DAG执行流程图形成和Stage划分
Stage内部流程
Spark Shuffle
Spark中shuffle的发展历程
优化前的Hash shuffle
经过优化后的Hash shuffle
Sort shuffle
Sort shuffle的普通机制
Job调度流程
Spark RDD并行度
概述
Spark内核调度任务:
1.构建DAG有向无环图
2.划分stage夹断
3.Driver底层的运转
4.分区的划分(线程)
的Spark内核调度的目的:尽可能用最少的资源高效地完成任务计算
RDD的依赖
RDD的依赖:一个RDD的形成可能由一个或者多个RDD得到的,此时这个RDD和之前的RDD之间产生依赖关系
Spark中,RDD之间的依赖关系,只要有两种类型:宽依赖和窄依赖
窄依赖:
作用:能够让Spark程序并行计算,也就是一个分区数据计算出现问题的时候,其它分区不受影响
特点:父RDD的分区和子RDD的分区是一对一关系,也就是父RDD分区的数据会整个被下游子RDD的分区接收

宽依赖:
作用:划分stage的重要依据,宽依赖也叫shuffle依赖
特点:父RDD的分区和子RDD的分区关系是一对多的关系,也就是父RDD的分区数据会被划成多份给到下游子RDD的多个分区做接收
注意:如果有宽依赖,shuffle下游的其他操作,必须等待shuffle执行完成以后才能够继续执行,为了避免数据的不完整
算子中一般以ByKey结尾的会发生shuffle;另外是重分区算子会发生shuffle

DAG和Stage
DAG:有向无环图,只要描述一段执行任务,从开始一直往下走,不允许出现回调操作
Spark应用程序中,遇到一个Action算子,就会触发一个JOB任务的产生
对于每个JOB的任务,都会产生一个DAG执行流程图,流程图的形成的层级关系如下:
层级关系:
1.一个spark应用程序→遇到一个Action算子,就会触发形成一个JOB任务
2.一个JOB任务只有一个DAG有向无环图
3.一个DAG有向无环图→有多个stage
4.一个stage→有多个Task线程
5.一个RDD→有多个分区
6.一个分区会被一个Task线程所处理
DAG执行流程图形成和Stage划分

1.spark应用程序遇到Action算子后,就会触发一个JOB任务的产生,JOB任务就会将它所依赖的算子全部加载进来,形成一个stage
2.接着从action算子从后往前回溯,遇到窄依赖就将算子放在同一个stage中,如果遇到宽依赖,就划分形成新的stage,最后一直到回溯完成
Stage内部流程

默认并行度值的确认:
1.使用textFile读取HDFS上的文件,因此RDD分区数=max(文件的block块数量,defaultminpartition),继续需要知道defaultminpartition的值是多少
2.defaultminpartition=min(spark.default.parallelism,2)取最小值,最终确认spark.default.parallelism的参数值就能最终确认RDD的分区数有多少个
spark.default.parallelism参数值的确认:
1.如果有父RDD,就取父RDD的最大分区数
2.如果没有父RDD,根据集群模式进行取值
本地模式:机器的最大cpu核数
Mesos:默认是8
其它模式:所有执行节点上的核总数或2,以较大者为准
Spark Shuffle
Spark中shuffle的发展历程
1- 在1.1版本以前,Spark采用Hash shuffle (优化前 和 优化后)
2- 在1.1版本的时候,Spark推出了Sort Shuffle
3- 在1.5版本的时候,Spark引入钨丝计划(优化为主)
4- 在1.6版本的时候,将钨丝计划合并到sortShuffle中
5- 在2.0版本的时候,将Hash Shuffle移除,将Hash shuffle方案移植到Sort Shuffle
优化前的Hash shuffle

存在的问题:
上游(map端)的每个Task会产生与下游Task个数相等的小文件个数,导致上游有非常多的小文件,下游(reduce端)来拉取文件的时候,会有大量的网络IO和磁盘IO过程,因为要打开和读取多个小文件
经过优化后的Hash shuffle

优化后的Hash shuffle:
变成了由每个Executor进程产生与下游Task个数相等的小文件数,这样可以大量减少小文件的产生,以及降低下游拉取文件时候的网络IO和磁盘IO过程
Sort shuffle

Sort shuffle分成了两种:普通机制和bypass机制,具体使用哪种由spark底层决定
Sort shuffle的普通机制
普通机制的运行过程:
每个上游task线程处理数据,数据处理完以后,先放在内存中,接着对内存中的数据进行分区,排序,将内存中的数据溢写到磁盘,形成一个个小文件,溢写完成后,将多个小文件合并成一个大的磁盘文件,并且针对每个大的磁盘文件,提供一个索引文件,接着是下游Task根据索引文件来读取相应的数据
Sort shuffle的bypass机制
bypass机制 :就是在普通机制的基础上,省略了排序的过程
bypass机制的触发条件:
1.上游的RDD数量不能超过100个
2.上游不能对数据进行提前聚合操作(因为提前聚合,需要先进行分组操作,而分组的操作实际上是有排序的操作)
Job调度流程
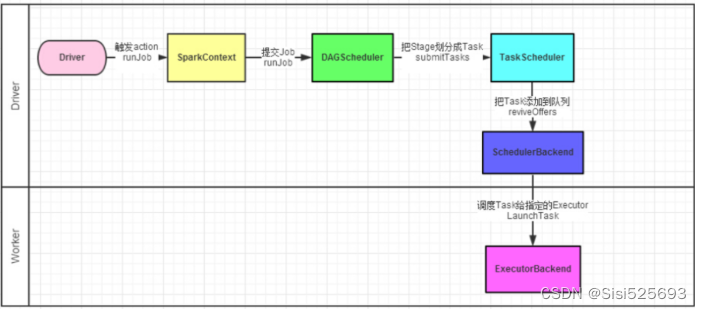
主要是讨论:在Driver内部,是如何调度任务
1.Driver进程启动后,底层PY4J创建SparkContext顶级对象,在创建该对象的进程中,还会创建另外两个对象,分别是:DAGScheduler和TaskScheduler
DAGScheduler:DAG调度器,将Job任务形成DAG有向无环图和划分Stage的阶段
TaskScheduler:Task调度器,将Task线程分配给到具体的Executor执行
2.一个saprk程序遇到一个action算子触发产生一个job任务,SparkContext将job任务给到DAG调度器,拿到job任务后,会将job任务形成有向无环图和划分stage阶段,并且确定每个stage有多少个Task线程,会将众多的Task线程放到TaskSet的集合中,DAG调度器将TaskSet集合给到Task调度器
3.Task调度器拿到TaskSet集合以后,将Task分配给到具体的Executor执行,底层是基于SchedulerBackend调度队列来实现的
4.Executor开始执行任务,并且Driver会监控各个Executor的执行状态,知道所有的Executor执行完成,就认为任务运行结束
5.Driver通知Namenote释放资源
Spark RDD并行度
整个Spark应用中,影响并行度的因素有以下两个原因:
1.资源的并行度:Executor数量和CPU核数以及内存的大小
2.数据的并行度:Task的线程和分区数量
一般将Task想层数量设置为CPU核数的2-3被,另外每个线程分配3-5GB的内存资源
说明: spark.default.parallelism该参数是SparkCore中的参数。该参数只会影响shuffle以后的分区数量。另外该参数对parallelize并行化本地集合创建的RDD不起作用。
import timefrom pyspark import SparkConf, SparkContext
import os# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':print("Spark入门案例: WordCount词频统计")# 1- 创建SparkContext对象conf = SparkConf()\.set("spark.default.parallelism", "5")\.setAppName('spark_wordcount_demo')\.setMaster('local[*]')# 设置并行度参数方式一# conf.set("spark.default.parallelism", "4")sc = SparkContext(conf=conf)# 2- 数据输入init_rdd = sc.textFile("file:///export/data/gz16_pyspark/01_spark_core/data/content.txt")# 3- 数据处理flatmap_rdd = init_rdd.flatMap(lambda line: line.split(" "))map_rdd = flatmap_rdd.map(lambda word: (word,1))# shuffle前分区数print("shuffle前分区数",map_rdd.getNumPartitions())result = map_rdd.reduceByKey(lambda agg,curr: agg+curr)# shuffle后分区数print("shuffle后分区数", result.getNumPartitions())# 4- 数据输出print(result.collect())# 5- 释放资源sc.stop()通过parallelize构建得到RDD的分区情况(了解):
from pyspark import SparkConf, SparkContext
import os# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("并行化本地集合创建RDD")# 1- 创建SparkContext对象conf = SparkConf().setAppName('parallelize_rdd').setMaster('local[1]')# 设置并行度参数conf.set("spark.default.parallelism", 4)sc = SparkContext(conf=conf)# 2- 数据输入# 并行化本地集合得到RDDinit_rdd = sc.parallelize([1,2,3,4,5])# shuffle前分区数print("分区数", init_rdd.getNumPartitions())# 3- 数据处理# 4- 数据输出# 获取分区数print(init_rdd.getNumPartitions())# 获取具体分区内容print(init_rdd.glom().collect())# 5- 释放资源sc.stop()相关文章:
Spark的内核调度
目录 概述 RDD的依赖 DAG和Stage DAG执行流程图形成和Stage划分 Stage内部流程 Spark Shuffle Spark中shuffle的发展历程 优化前的Hash shuffle 经过优化后的Hash shuffle Sort shuffle Sort shuffle的普通机制 Job调度流程 Spark RDD并行度 概述 Spark内核调度任务: 1…...

C++代码重用:继承与组合的比较
目录 一、简介 继承 组合 二、继承 三、组合 四、案例说明 4.1一个电子商务系统 4.1.1继承方式 在上述代码中,Order类继承自User类。通过继承,Order类获得了User类的成员函数和成员变量,并且可以添加自己的特性。我们重写了displayI…...

暴打小苹果
欢迎来到程序小院 暴打小苹果 玩法:鼠标左键点击任意区域可发招暴打,在苹果到达圆圈时点击更容易击中, 30秒挑战暴打小苹果,打中一次20分,快去暴打小苹果吧^^。开始游戏https://www.ormcc.com/play/gameStart/247 htm…...

【BetterBench】2024年都有哪些数学建模竞赛和大数据竞赛?
2024年每个月有哪些竞赛? 2024年32个数学建模和数据挖掘竞赛重磅来袭!!! 2024年数学建模和数学挖掘竞赛时间目录汇总 一月 (1)2024年第二届“华数杯”国际大学生数学建模竞赛 报名时间:即日起…...

Vue-9、Vue事件修饰符
1、prevent 阻止默认事件 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>事件修饰符</title><!--引入vue--><script type"text/javascript" src"https://cdn.jsdeliv…...

前端面试题集合六(高频)
1、vue实现双向数据绑定原理是什么? <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>…...
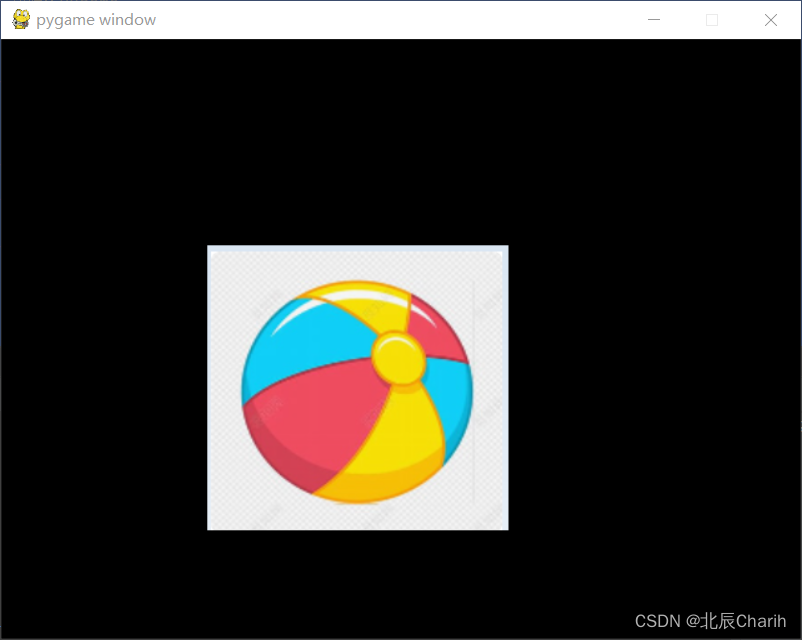
使用Pygame库创建了一个窗口,并在窗口中加载了一个名为“ball.png“的图片,通过不断改变物体的位置,实现了一个简单的动画效果
import pygame import sys# 初始化Pygame pygame.init()# 创建窗口 screen pygame.display.set_mode((640, 480))# 加载图片 image pygame.image.load("ball.png")# 将物体初始位置设为屏幕左上角 x 0 y 0# 游戏循环 while True:# 处理事件for event in pygame.e…...

常见的AdX程序化广告交易模式有哪些?媒体如何选择恰当的交易模式?
程序化广告的核心目的是:让需求方能自由地选择流量与出价,程序化广告在数字广告投放中的主导地位日益巩固。 程序化广告“交易模式”有哪些?以下是详细解读,帮助媒体选择恰当的交易方式,从而实现广告价值的最大化。 …...

VCG 网格平滑之Laplacian平滑
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 由于物理采样过程固有的局限性,三维扫描仪获得的网格通常是有噪声的。为了消除这种噪声,所谓的平滑算法被开发出来。这类方法有很多,VCG主要为我们提供了一种是较为经典的Laplace平滑算法,这个方法很多库都有实…...

Jupyter Markdown格式
穿插在程序中,太复杂了喧宾夺主,太简单了不如注释。这样就刚刚好: Headers # header 1 ## header 2 ### header 3 #### header 4Output: header 1 header 2 header 3 header 4 2. Horizontal Line Use any of three to draw a horizon…...

Vue3 实时显示时间
记录一下代码,方便以后使用 参考的文章链接 做了以下修改 修改了formateDate方法中传入参数这个不合理的地方给定时器增加了间隔时间增加了取消定时器的方法 <!-- template中的代码 --> <span>当前时间:{{ nowTime }}</span>// sc…...
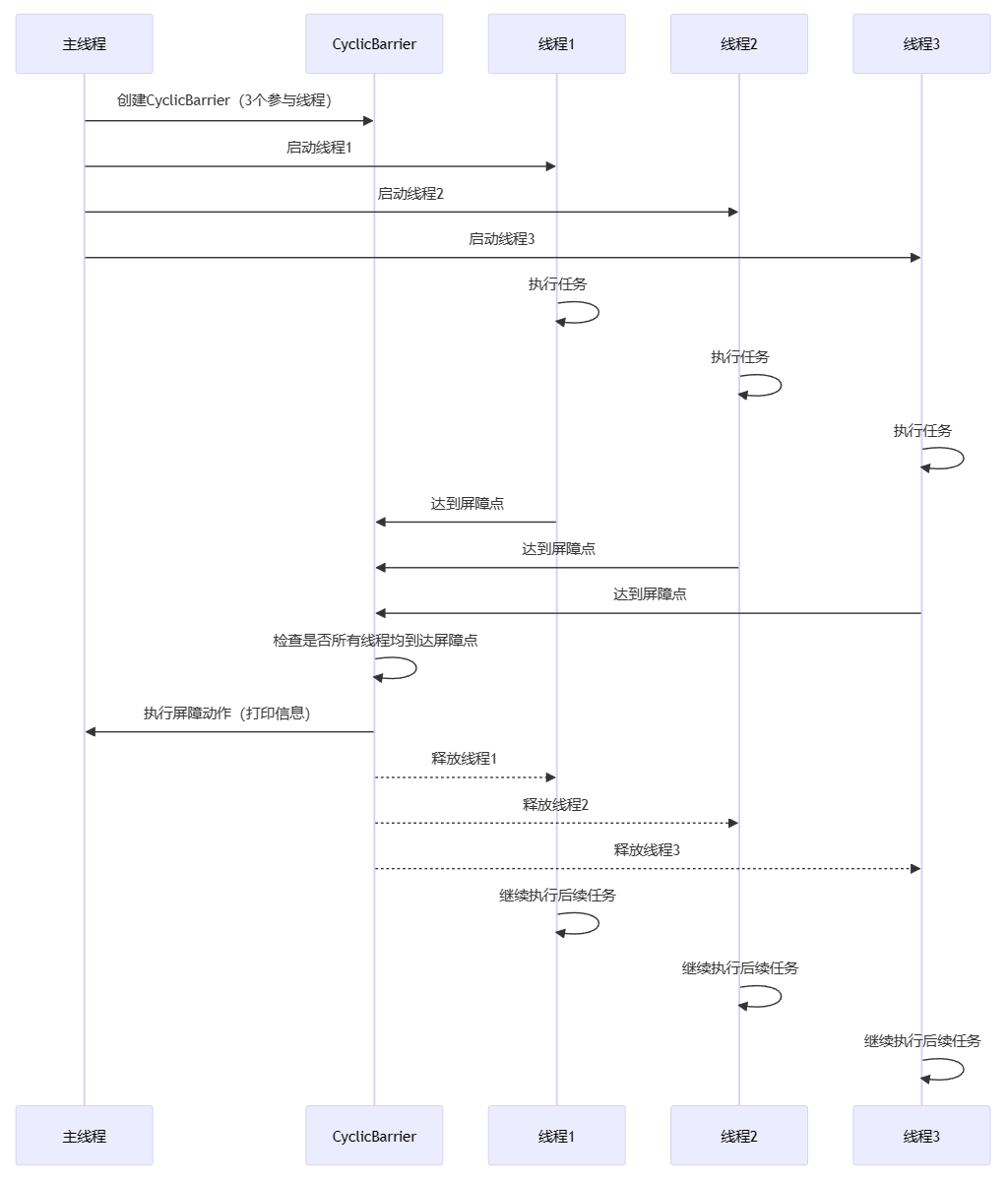
详解Java多线程之循环栅栏技术CyclicBarrier
第1章:引言 大家好,我是小黑,工作中,咱们经常会遇到需要多个线程协同工作的情况。CyclicBarrier,直译过来就是“循环屏障”。它是Java中用于管理一组线程,并让它们在某个点上同步的工具。简单来说…...

ebpf学习
学习ebpf相关知识 参考资料: awesome-ebpf 文章目录 初识准备ebpf.io介绍cilium的介绍内核文档Brendan Greggs Blog 的介绍书籍Learning eBPFWhat is eBPF? 交互式环境视频 基础知识学习学习环境搭建书籍阅读 项目落地流程整理环境搭建内核编译bcc环境变量zliblibelflibbpflib…...
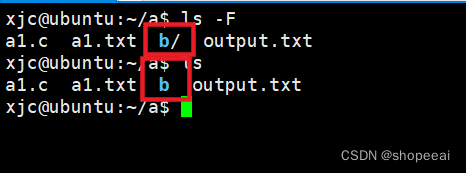
【Linux】Linux系统编程——ls命令
【Linux】Linux 系统编程——ls 命令 1.命令概述 ls 命令是 Linux 和其他类 Unix 操作系统中最常用的命令之一。ls 命令是英文单词 list 的缩写,正如 list 的意思,ls 命令用于列出文件系统中的文件和目录。使用此命令,用户可以查看目录中的…...

QA面试题
1、质量保证(QA)是什么? QA代表质量保证。QA 是一组活动,旨在确保开发的软件满足 SRS 文档中提到的所有规范或要求。QA 遵循 PDCA 循环: 计划/Plan - 计划是质量保证的一个阶段,组织在此阶段确定构建高质量软件产品所需的过程。做…...
【国产mcu填坑篇】华大单片机(小华半导体)一、SPI的DMA应用(发送主机)HC32L136
最近需要用华大的hc32l136的硬件SPIDMA传输,瞎写很久没调好,看参考手册,瞎碰一天搞通了。。。 先说下我之前犯的错误,也是最宝贵的经验,供参考 没多看参考手册直接写(即使有点烂仍然提供了最高的参考价值。…...
【前后端的那些事】treeSelect树形结构数据展示
文章目录 tree-selector1. 新增表单组件2. 在父组件中引用3. 父组件添加新增按钮4. 树形组件4.1 前端代码4.2 后端代码 前言:最近写项目,发现了一些很有意思的功能,想写文章,录视频把这些内容记录下。但这些功能太零碎,…...
(Java JS Python C))
华为OD机试 - 最长子字符串的长度(二)(Java JS Python C)
题目描述 给你一个字符串 s,字符串 s 首尾相连成一个环形,请你在环中找出 l、o、x 字符都恰好出现了偶数次最长子字符串的长度。 输入描述 输入是一串小写的字母组成的字符串 输出描述 输出是一个整数 备注 1 ≤ s.length ≤ 5 * 10^5s 只包含小写英文字母用例 输入alolob…...

【VRTK】【Unity】【游戏开发】更多技巧
课程配套学习项目源码资源下载 https://download.csdn.net/download/weixin_41697242/88485426?spm=1001.2014.3001.5503 【概述】 本篇将较为零散但常用的VRTK开发技巧集合在一起,主要内容: 创建物理手震动反馈高亮互动对象【创建物理手】 非物理手状态下,你的手会直接…...

Spark 读excel报错,scala.MatchError
Spark3详细报错: scala.MatchError: Map(treatemptyvaluesasnulls -> true, location -> viewfs://path.xlsx, inferschema -> false, addcolorcolumns -> true, header -> true) (of class org.apache.spark.sql.catalyst.util.CaseInsensitiveMap)scala代码…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...