2023 IoTDB Summit:天谋科技高级开发工程师苏宇荣《汇其流:如何用 IoTDB 流处理框架玩转端边云融合》...
12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到天谋科技高级开发工程师,Apache IoTDB PMC Member 苏宇荣参加此次大会,并做主题报告——《汇其流:如何用 IoTDB 流处理框架玩转端边云融合》。以下为内容全文。
目录
端边云场景的挑战
端边云流处理框架
基于流处理框架的应用
线上线下的朋友们大家下午好,我是苏宇荣,天谋科技的高级开发工程师,目前是正在指导我们的流处理框架的开发。今天给大家带来的题目是:如何用 IoTDB 流处理框架来玩转我们的端边云融合。这里有两个关键词,第一个就是我们的流处理框架,这是一个新东西;第二个就是我们的应用场景,端边云融合。我们将从技术和应用两个部分给大家来剖析一下我们的这个主题。
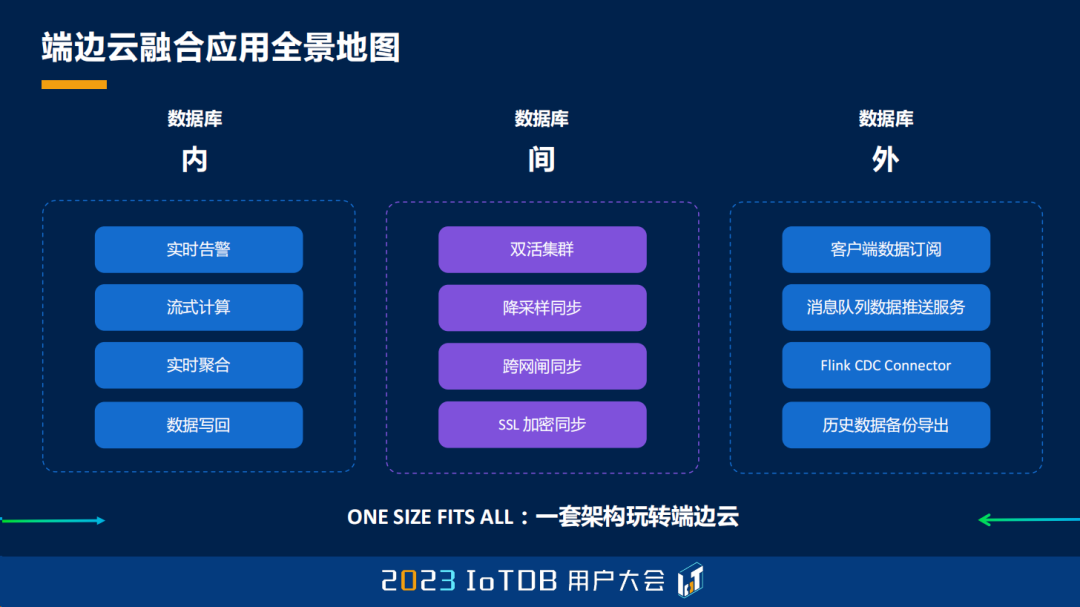
我们的内容主要分为三个部分:第一个,我们先看看端边云融合的一些场景,以及目前解决方案的一些痛点。第二个,我们就通过痛点,来看看我们的一个新的解决方案。最后,我们会开枝散叶,去讲解基于流处理框架的一些应用,包括数据同步、双活集群、实时告警、数据推送等等,你想要的,我相信应有尽有。
01
端边云场景的挑战
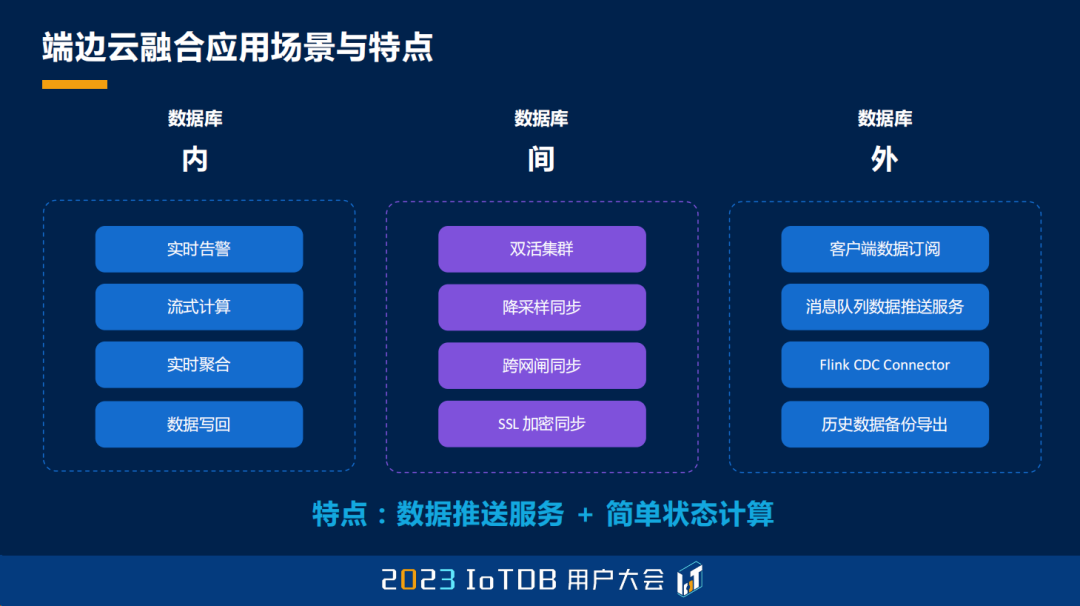
首先,我们来看看端边云场景的整个挑战。首先我们来看看端边云这个应用场景的特点,从分类上来说,我想把它分为三类,一个叫数据库内,一个叫数据库间,一个叫数据库外。在端边云里面,我们可能想在端侧做一些实时的告警,充分地利用端侧较弱,但是能分布起来、scale 起来的性能。我们也可能想在云侧做一些流式计算,对于上报汇聚上来的数据做一些统一的处理,可能还会有一些比如说实时聚合,数据写回等等的应用。
数据库间这个场景就更加典型了,我们在今天早上的论坛,包括前面的讲解里面都提到过,我们会有各种各样的同步,那今天也会给大家带来比如说跨网闸同步、降采样同步,以及正常的一些集群间的高性能同步等等场景。
数据库外,我们又可以基于这种流处理框架,去做比如说客户端订阅、消息队列数据推送,以及 Flink CDC Connector 这样的一些技术实践。我们希望我们的解决方案能够融合这些特点。
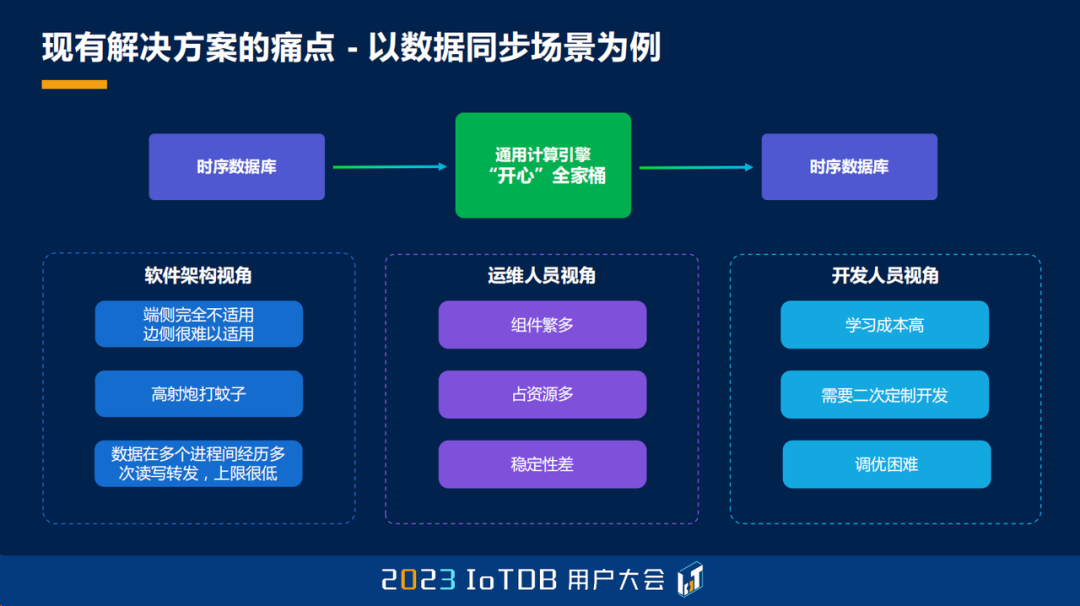
我们先来看看传统的解决方案是怎么样的?以这个数据同步的场景为例,我们两个时序数据库中间往往要引入一些通用计算引擎或者流引擎,比如说 Kafka。那这样的话,可不仅仅是引入 Kafka 一个组件这么简单,可能还有 ZK,更可能会出现像 Flink、Spark 这样的衔接工具。
那从软件架构的视角来说,我们在端侧本来性能就很羸弱了,这一套架构其实完全不适用;从功能上来说,似乎又有一些“高射炮打蚊子”。我们还可以再继续往下想,数据在多个进程之间来回的流转,多次的读写转发,实际上它的性能上限很低,其实也不适用。
从运维人员的角度来说,我们也跟很多的客户去聊过,他们感觉这个组件这么多,运营起来很繁杂,资源占用也很多,稳定性也很差,那他们是拒绝的。
从开发人员的视角来说,大家如果用过 Flink 可能就会知道,其实它的 API 相对比较复杂,它的学习曲线很陡峭,要让一个正常的、低成本的开发去做这件事情成本很高,他们二次开发可能也做不好。这些问题其实一直都存在,没有一个很好的解决方法。
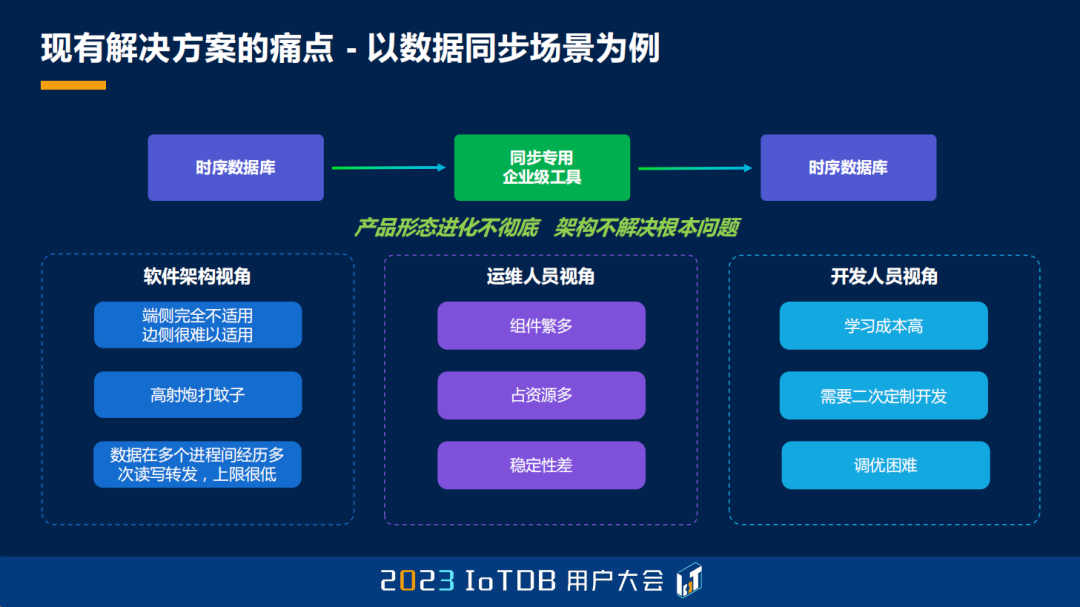
那我们也看到有一些时序数据库产品,针对像数据同步这样的场景,引入了一些比如说企业级的工具,但是它从根本上来说没有改变之前的这种架构,它的产品形态其实进化是不彻底的,它的架构也不解决根本的问题。
02
端边云流处理框架
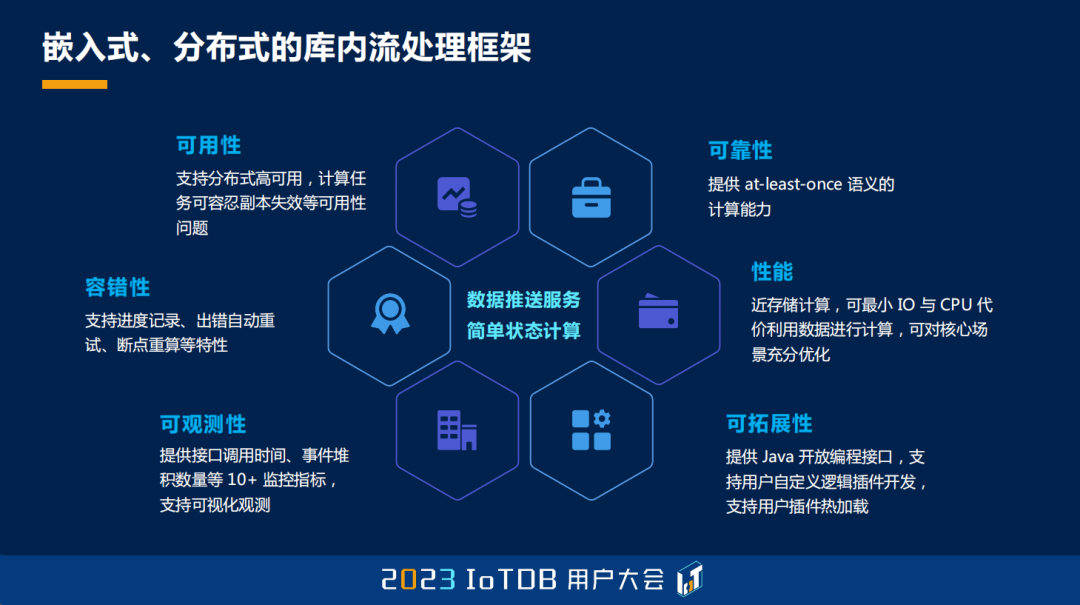
有了这些思考之后,我们是怎么想的呢?我们引入了一个为端边云融合而生的数据库内的流式计算框架,我们称之为嵌入式、分布式的库内流处理框架,它有 6 大特点。第一就是它的高可用性,在分布式的场景部署的情况下,我们的计算是高可用的,任意的副本的失效不会影响它的可用性。第二个就是可靠性,我们这个框架提供一个 at-least-once 的计算语义。第三个就是容错性,我们这个框架支持进度的记录,出错自动的重试,断点自动重算等等。
第四个就是我们的性能,我们是做到了一个库内的引擎,所以它的本质其实是一个近存储的计算,可以以最小 I/O 与 CPU 的代价去利用数据进行计算。同时我们也可以针对一些特殊的场景,比如数据同步,做一些内核级别的优化。第五个就是我们提供了非常好的可观测性,我们提供了接口调用时间、事件堆积的数量等 10 余个指标,可以给用户去提供查看功能。最后就是可扩展性,我们既然说我们研发的是一个框架,那肯定是支持自定义的。我们提供了 Java 的开放编程接口,支持用户以自定义的方式去进行插件的开发,同时对于插件我们也是支持热插拔的。
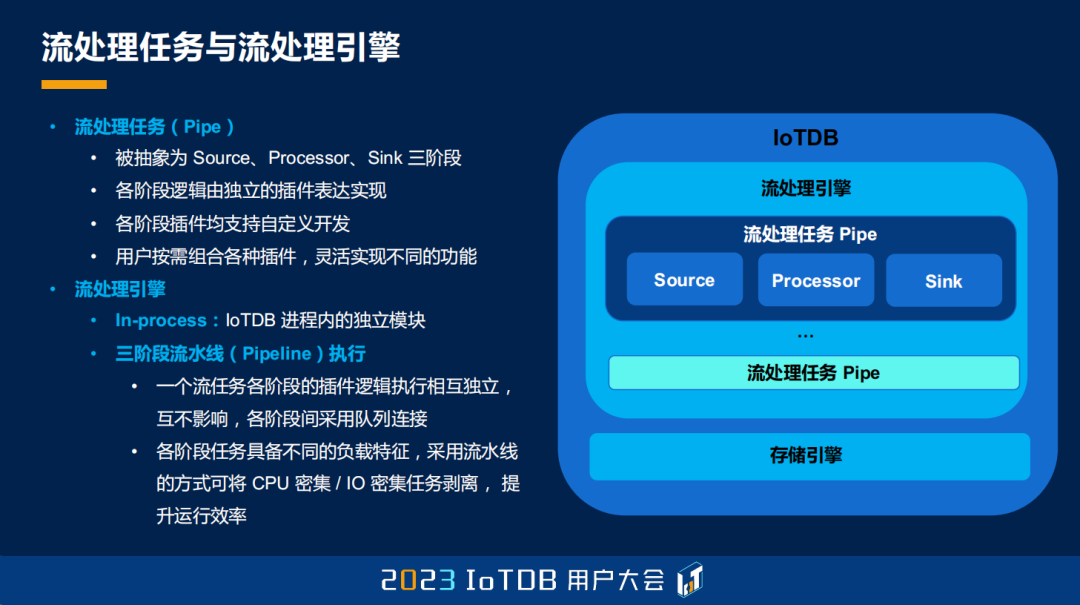
那么有了这些特性之后,不妨来看看我们在数据库内怎么去定义一个流处理任务。我们把这个流处理任务叫做 Pipe,而流水线 Pipeline 被抽象成三个阶段:第一个阶段我们叫做 Source,第二阶段是 Processor,第三个叫 Sink。各个阶段的逻辑都是由独立的插件来进行表达的,各阶段的插件也均支持用户去自定义地开发。最后一点就是,用户开发好的插件,它是具有复用性的,可以通过组合各个插件来灵活地实现不同的功能。一会儿我们会从场景上举例,大家也可以看到这个能力。
从执行侧来说,我们就稍微深入一点点,说一下它的两个特点:第一个就是 In-process,它是进程内的一个独立模块;第二个就是它的流水线的执行逻辑。我们刚才说流水线是一个定义,但实际上它在执行层面也是流水线式的。也就是说,一个流任务有三个阶段,每个阶段之间会并行计算,互不影响,然后各个阶段之间我们采用队列做连接。我们这样做有一个好处,就是各个阶段它可能是具有不同的任务特性的,比如说我们的 Processor 可能是 CPU 密集的,我们的 Sink 可能是 I/O 密集的,这样一来我们就给它做了一个 I/O 和 CPU 密集的解耦,它的运行效率就会很高。
在大概知道了这个定义和内部的执行逻辑之后,我们不妨来看看怎么用一个 SQL 去定义一个流处理任务。这里我们展示了一个 IoTDB 和 IoTDB 之间、端到端的一个数据同步的简单例子。我们可以看到 Source 叫 iotdb-source,它是一个插件;Processor 叫 do-nothing-processor,也是一个插件,就是啥事都不做;Sink 其实就是一个对端的 IoTDB,将数据发送到另一个 IoTDB 的 Sink。
我们整个流任务的定义以一个 CREATE PIPE 的语句作为引导,下面每一个阶段我们就以 WITH SOURCE、WITH PROCESSOR、WITH SINK 的方式去做定义,每个阶段我们可以指定插件以及插件所对应的那些属性。就这样通过简简单单的几行代码,我们就可以把一个流式的任务表达出来。同时我们也可以看到有很多的可扩展性,比如说我们在中间的 WITH PROCESSOR 里面加一些语句,比如做一些数据处理,把一些东西简化掉,或者把一些东西降采样掉,我们都可以在中间进行修改。这是一个 SQL 定义流任务的方法。

然后就是我们怎么去定义这个自定义的逻辑。我们刚才提到了,流任务是由插件的组合所表达出来的,对于自定义的插件,我们提供了 Java 的编程接口供用户去开发,每个阶段都对应每个阶段自有的一个数据开发插件的逻辑。同时,每一个我们生成的插件也支持使用 SQL 热装载的方式,来把这个插件定义到 IoTDB 里头。同时我们有一个特性,可能对这个端边云的场景特别适用,就是我们去支持了像手机一样的 OTA 升级。我们可以依据 SQL 指令来指导 IoTDB 从资源服务器去拉下 Jar 包,然后装载并启动插件,因此不需要工程师到现场去进行一些 cd、pwd 等等的这些目录操作,比较地方便。
下面就是一个例子,我们通过 CREATE PIPEPLUGIN 的方式,从远程的 http 资源服务器拉取并装载了一个插件,装载之后我们就可以用刚才的 CREATE SQL 语句立即去定义一个流任务。

03
基于流处理框架的应用
这是我们流处理框架的一些基本的内容,那么今天主要给大家展示的还是我们基于这套流处理框架的各种应用。
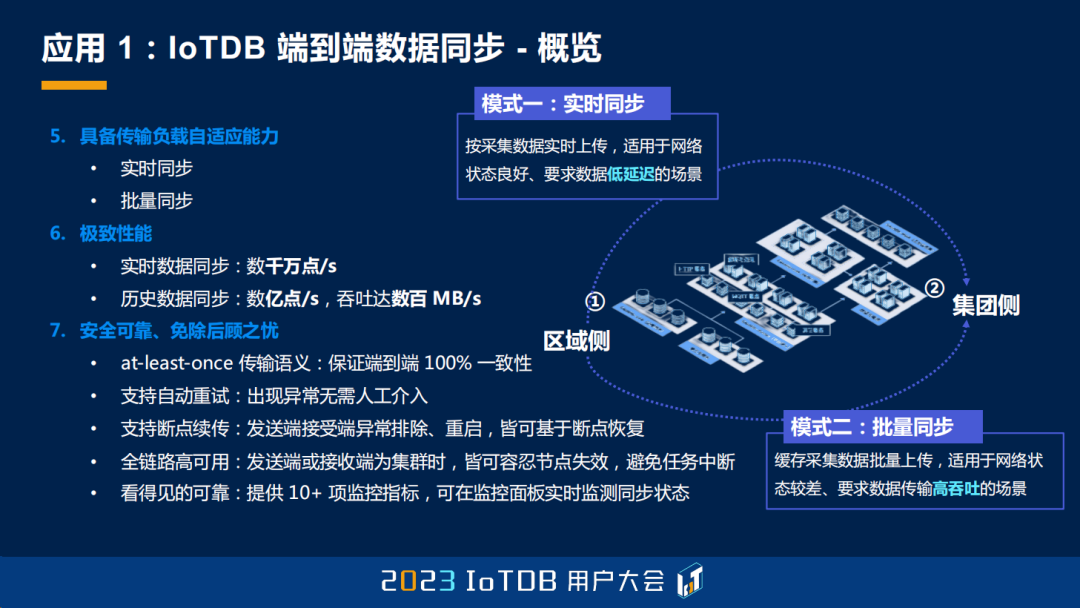
首先给大家带来的是 IoTDB 端到端的数据同步,这里有几个特点给大家一次性地进行一个概览。第一就是我们轻量便捷、开箱即用。我们跟很多其它的时序数据库的特点不同,我们做数据同步不需要任何的外部组件支持,我们只需要使用 SQL 就能够一键配置、一键启动。
第二个就是我们的发送端、接收端支持的范围很广,可以是单机的,也可以是分布式的。在任何 IoTDB 的共识协议下,任何副本数的情况下,都能够做到最高效地执行。
第三点就是我们的同步规则是非常的灵活的。在时间范围上,我们可以选择全量的、历史的、实时的;在序列的模式上,因为我们是树型模型,我们可以选择中间任意节点,比如说 root 级别、device 级别、measurement 级别,都可以。
第四个就是我们支持的传输协议的种类非常多。除了各种各样常见的网络协议之外,我们还深化了比如对正反向网闸的支持,以及对 SSL 加密传输的支持。
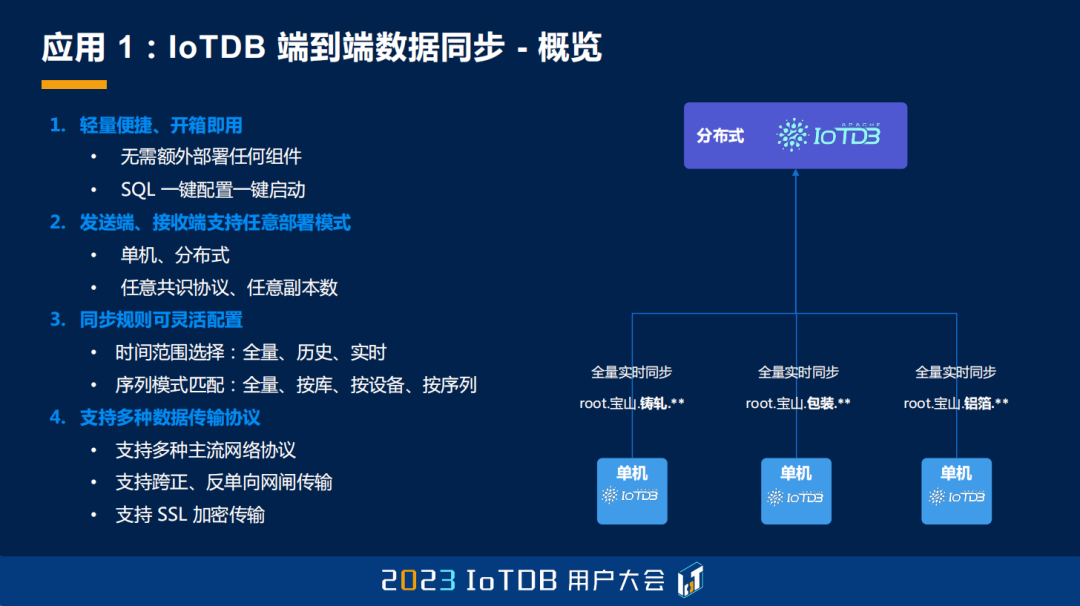
第五点,也是我们想特别强调的,就是我们的同步具备传输负载自适应的能力,我们有两种模式,一种叫实时模式,一种叫批量模式。实时模式其实类似于日志同步,来一个操作就同步一个操作,但是它这个实时模式是能够随着你的负载进行降级的。实时模式如果一个日志、一个操作就做同步可能赶不及,尤其是在 IoT 这种高吞吐、大并发的情况下,因此它能降级成文件级的同步,就能实现资源占用比较低,每次同步的效率就比较高,这就是我们的实时同步。第二种是我们的批量同步,它就是固定的以文件的方式进行同步,它的资源占用其实是比较低的,特别适用于端侧到边侧同步的这个场景。
第六点我们想强调的是,我们的同步具有极致的性能。什么叫极致?我们都知道,IoTDB 的写入性能其实可以达到千万点每秒的写入,我们的同步能够实时地跟上这个写入速度,这是一个基本要求,我觉得不算什么。但对于历史数据同步的场景,我们可以达到数亿点每秒的速度,吞吐可以达到数百 MB 每秒,当然这个是在网络带宽合适的情况下。我们在线上是有一个实例能够支撑这样的数据的,也推荐大家直接去试一试。我们有了这个能力之后,就可以很方便地去做比如历史数据的导出、历史数据的备份等等。
第七点,我们想说的可能是大家都关注的一个问题,尤其是线上场景关注的问题,就是它是否安全可靠?那现在就来解答大家,它支持 5 点语义,以免除大家的后顾之忧。第一就是我们支持一个 at-least-once 的传输语义,能够保证端到端 100% 的等价一致,通过幂等操作来实现。第二个就是我们支持自动重试,当我们发送端或接收端出现异常的时候,不要紧,它会自动地去进行重试的机制,不需要人工介入。第三个就是我们支持断点续传,比如说我们的接收端宕掉了,或者网闸本身就有开放时间的限制,早上能同步晚上不能同步,那也不要紧,我们一旦能同步之后,数据就会自动接上、跟上去,也不需要现场去进行任何的运维,也不需要进行任何的重传。第四个就是我们全链路高可用的特性,当我们的发送端或者接收端为集群的时候,都可以容忍节点的失效,避免任务的中断。最后就是这个可靠性大家是看得见的,通过我们提供的监控指标,可以看到实时同步的状态。
刚才讲到了一些大的特点,对大家来说可能不直观,所以我们直接来看一些应用吧。其实早上的时候,宝武集团的赵主任给我们介绍了他们的应用场景,实际上这个就是以他们的应用为例子。
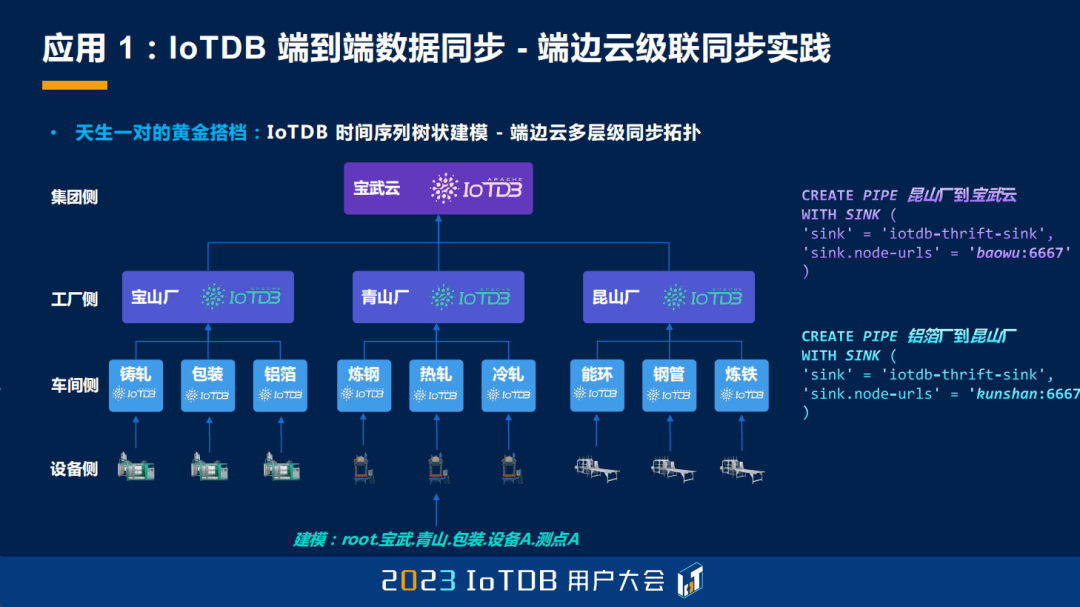
宝武的端边云的同步中,从端侧到云侧,其实经历了设备、车间、工厂、集团,那我们到底怎么样去定义它的多级的同步呢?其实大家可以看到最右边的这个 SQL 语句,我们通过一个简单的 CREATE PIPE 语句以及它的名字,加上一个 WITH SINK 的定义,就能够把整个车间的数据上传到工厂,工厂的数据同样也是以类似的方式上传到集团侧,非常的便捷。
然后我们可以细想一下,今天我们也提到了建模的事情,其实大家能想到,我们这个建模跟同步,其实可能是天生一对的黄金搭档。因为就建模而言,比如说以最下面的宝武云下的青山厂下的热轧厂为例子,我们同步上去的数据互相在模型上是隔离的,但汇集起来之后又能聚集起来使用,互相不影响,而且相互之间在同步之后、聚集之后又可以产生联系。这就是一个多级同步的应用。
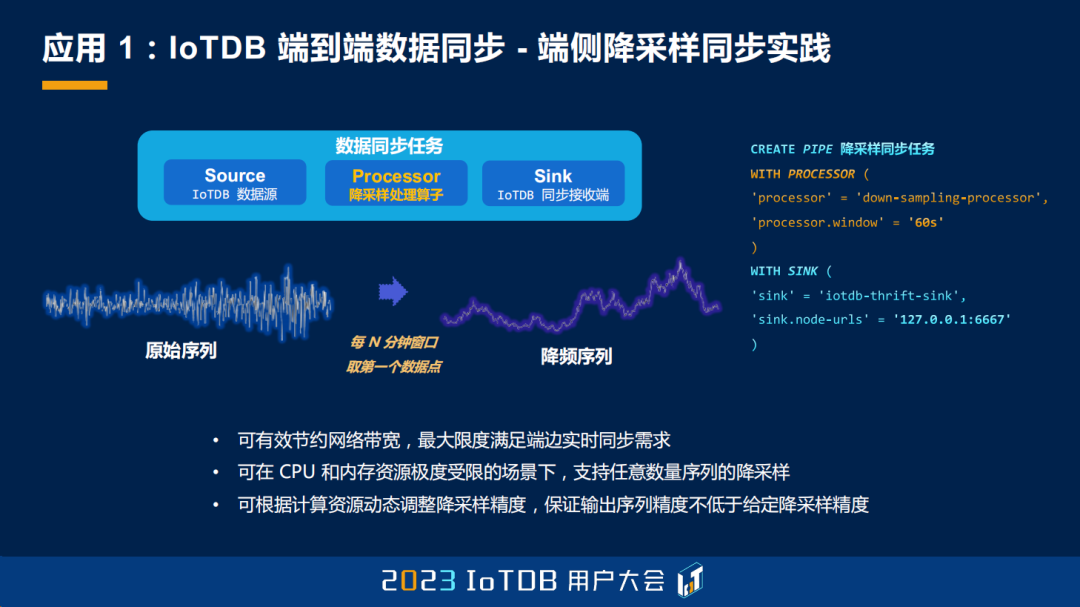
还有一个就是端侧的降采样同步,这是一个什么场景呢?其实很多情况下,我们在边侧采集的数据就想在边侧存了,但是为什么要传上去?可能就是我们想看看它到底是一个什么样的趋势。所以其实明细数据对于云侧,或者更高层次的这些厂家或者集团来说,是没有价值的,但是它的趋势有价值,我们可能就想一分钟采一个点。那这个事情之前我们是没有办法做到的,现在有了流处理框架之后,我们只需要引入一个 Processor,就是中间的这个降采样的处理插件,就能够实现。我们可以实现每 N 分钟的窗口取一个数据点来进行同步,我们也实现了一个叫 down-sampling-processor 的中间算子,最终能达到生产可用的几个特点。
第一就是它确实能够节省大量的网络带宽,最大限度地来满足这种趋势同步的需求。第二,我们这个 Processor 能够在 CPU 和内存极度受限的情况下,支持任意序列的降采样。第三,我们还能够根据计算的资源去动态调整它的降采样精度,如果资源不够了、CPU 不够了,那我们就少降采样一些,但是我们保证输出的序列精度不低于给定的这个序列降采样的精度,提供一个最少的语义。这是能保证让大家放心的,不会存在需要 N 分钟降采样一个点,但是实际 2N 分钟才降采样一次的情况,而是能做到在 N/2 分钟的时间降采样一次。
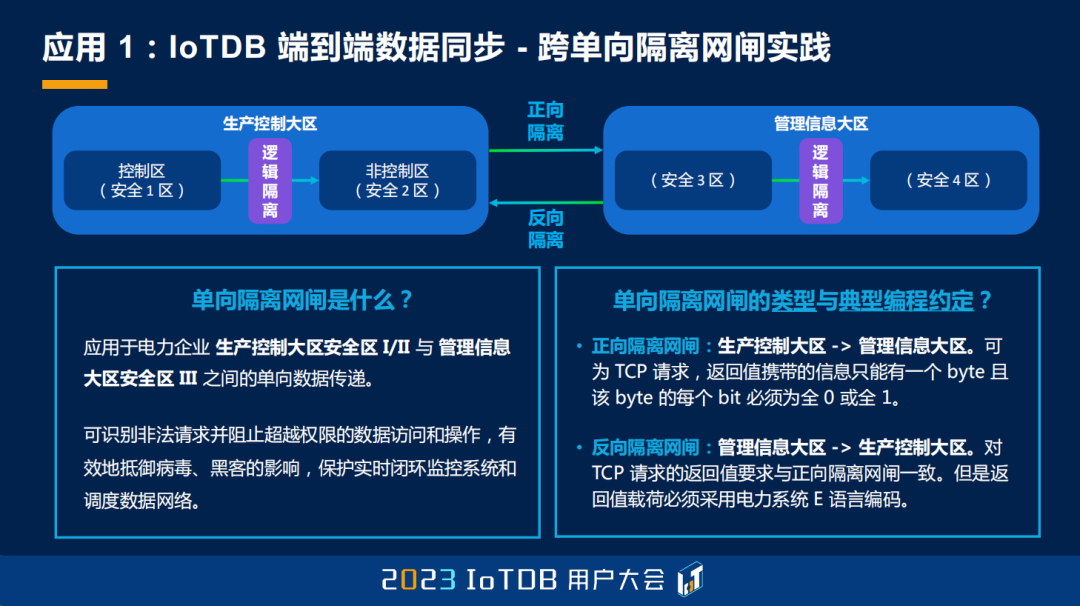
第三个部分其实想给大家展示一下,我们跨单向隔离网闸同步的实践。我相信在座的各位有很多是来自电力系统的朋友们,那么大家肯定很熟悉这幅图,就是对电力系统来说,它往往分为生产控制大区和信息管理大区。生产控制大区里面又分为控制区和非控制区,也就是大家常说的 1 区和 2 区。1 区和 2 区会经过一个正向隔离网闸之后,才能把数据穿透到 3 区,同时也会有一些从管理信息大区 3 区,把数据同步反向穿透到生产控制大区的需求。这就是我们说的隔离网闸的一个应用场景。这个概念的出现,主要还是为了识别非法请求,当数据在生产控制大区和信息管理大区之间进行相互穿越时,能够有效地避免一些黑客手段的侵入。
为什么说穿正向隔离网闸或单向隔离网闸是一个麻烦的事情呢?主要还是因为它有一些额外的编程约定,这里给大家稍微深入地讲一下。比如说在正向隔离网闸里面,从左边到右边,它要求可以是 TCP 请求,但是你的应用层的回包只能有一个 byte,而且这个 byte 的每个 bit 必须是全 0 或者全 1 的,那么正常的 RPC 请求就完全不可能适用,所以编程上其实有非常大的麻烦。那反向网闸在前面的基础上就更加麻烦了,你不仅要满足刚才那个需求,而且还要在应用层上,以一定的编码方式来传递数据,在电力系统中应该叫 E 语言。
但是没有关系,我们也依循这个编程框架去做了一个实现。实现方式也非常简单,因为 IoTDB 的流处理框架是支持插件的,那我们自然就做一个插件化的开发,把跨单向隔离网闸的这个插件也做进去。同时我们在 IoTDB 的接收端做一个对应的接入层,去接收这个跨单向网闸的数据。
这里面还有两个细节可以给大家分享,就是如何去做到安全可用?一个是我们在数据包上的设计,做到了非常精妙。我们通过冗余的方式和校验码的方式来确保这个数据穿透网闸之后,没有被网闸通过一些手段进行修改,来保证数据的正确性。第二个就是我们的网络编程选型,我们采取了 Java 纯原生的方式,进行了从 0 到 1 的编程。然后我们去做性能测试,也发现相比 IoTDB 正常使用 RPC 实现同步的情况,我们的性能相当,特性也没有得到削弱。
最终的应用效果,就是我们基于这套框架去支持了跨正反向的隔离网闸,也支持比如自动重试、断点续传、最终一致等等特性,这个功能也在某个发电场景下已经正式的上线了。

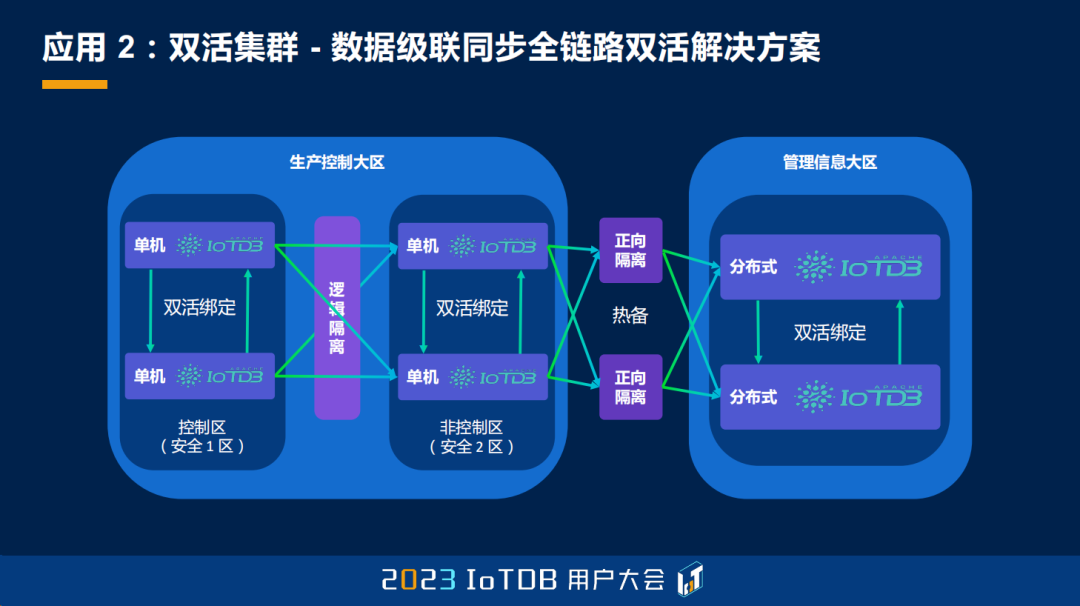
第二个应用,我想跟大家谈一下双活集群,我相信这也是很多工业场景下,大家喜欢的一个特性。那什么是双活集群?首先,它是基于两个完全独立的集群,配置完全独立,皆可实现独立的读写,业务其实是通过双活客户端去绑定两个集群进行操作的。第二个,就是我们提供一个最终一致性的保证,每一个独立的集群可以异步地同步数据到另一个集群,来实现最终的一致。第三个就是高可用,当其中一个集群停止服务的时候,另一个集群是完全不受影响的;当停止服务的集群再次启动的时候,另一个集群会重新将这些数据正常地同步过来。
我们来想想双活集群的价值,其实也就两个点,第一个是它能实现最低成本的高可用。正常情况下,这些分布式的协议都需要有一个 Quorum 写,但是我们现在就允许物理节点少于 3 的情况下来实现这件事情,整体在 2 个节点的配置下依然可以容忍 1 个集群的故障。第二个就是,我们有时候也能通过这种方式去解决弱网环境下构建高可用集群的困难,比如说我们想去做跨云的复制集群,或者跨正反向网闸的双活集群。

那我们怎么去构建一个双活集群呢?也非常简单,就是在发送端和接收端,或者说两个集群,分别去构建一个 create pipe 语句,就能够实现。而且解绑和绑定的时机也相对的比较灵活,我们可以在任意的时候,去把一个不支持双活的集群升级成一个支持双活的集群。大家如果有兴趣,我觉得可以进行尝试。

基于刚才我们说的数据同步和双活集群的功能,我们在这种电力系统的场景下,就能够实现数据级联同步+全链路双活高可用的一个解决方案。我们可以看到从控制区的安全 1 区、安全 2 区到 3 区,每一区不管是单机还是集群,甚至是正向隔离网闸,我们都能够实现双机的热备。中间任何一个层次,我们把其中的一个节点摘掉,或者让它不可用,都不影响整个链路的高可用,这个是很有意思的。
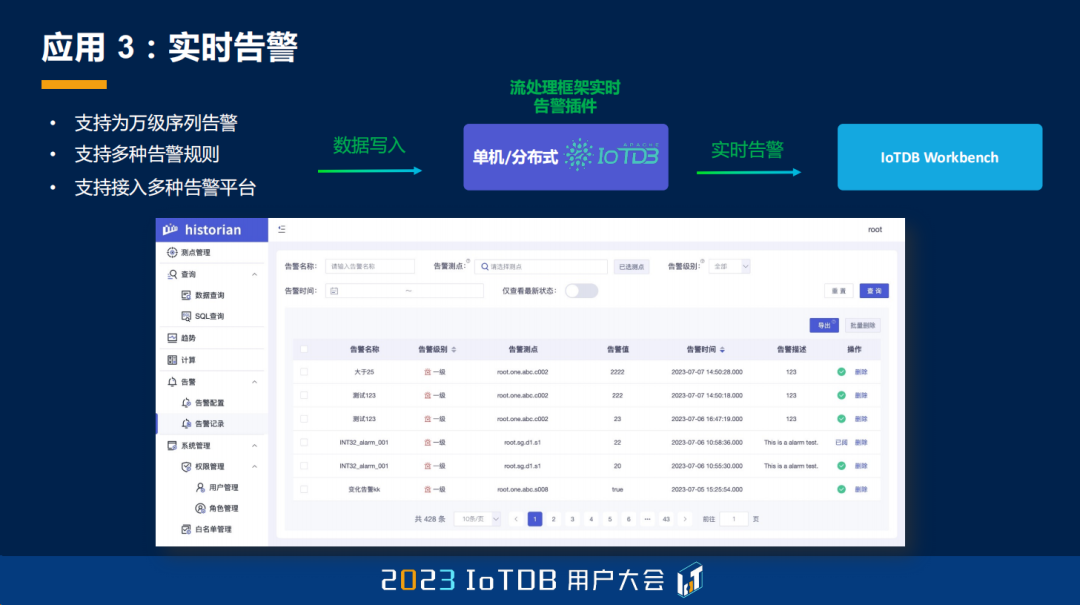
我们的第三个应用就给大家介绍一些别的方面,比如实时告警。前面的同学也跟大家介绍过了,其实我们的可视化控制台是支持了多序列的告警能力的,那么它的底层实际上就是用了我们的这个流处理框架进行实现,目前能支持到万级别的序列告警,支持多种告警的规则,同时也支持接入多种的告警平台。
第四个应用是客户端的数据订阅,那么客户端数据订阅是什么呢?就是我们 IoTDB 的集群或者单机,接受像数据写入、文件装载、数据同步等等的数据载入方式之后,这些东西能瞬间或者在一定时间之后,反映到我们 IoTDB 的客户端。它提供了另一种数据消费的模式,具体来说就像是我们去消费 Kafka 里面的数据,去提供一个 Pub/Sub 的能力。
那它也有三个特点:第一就是轻量便捷、开箱即用。我们在 IoTDB 的多语言客户端里面会提供订阅的 SDK,暴露类 Kafka 的订阅接口。此外客户端可以直接地去启动订阅,无需额外的组件,那 IoTDB 相对来说它可能就像一个 MQ。第二个是我们订阅的规则比较灵活,就类似于数据同步的规则,它的时间范围可以是全量的、历史的、实时的,序列的匹配模式也可以是全量的、按库的、按设备的、按序列的。最后一个特点就是,我们保证一个最少一次的订阅语义,客户端也支持自动或手动的去进行 commit,也支持从保存点去恢复,进行重新的消费,同时也支持断点续传。

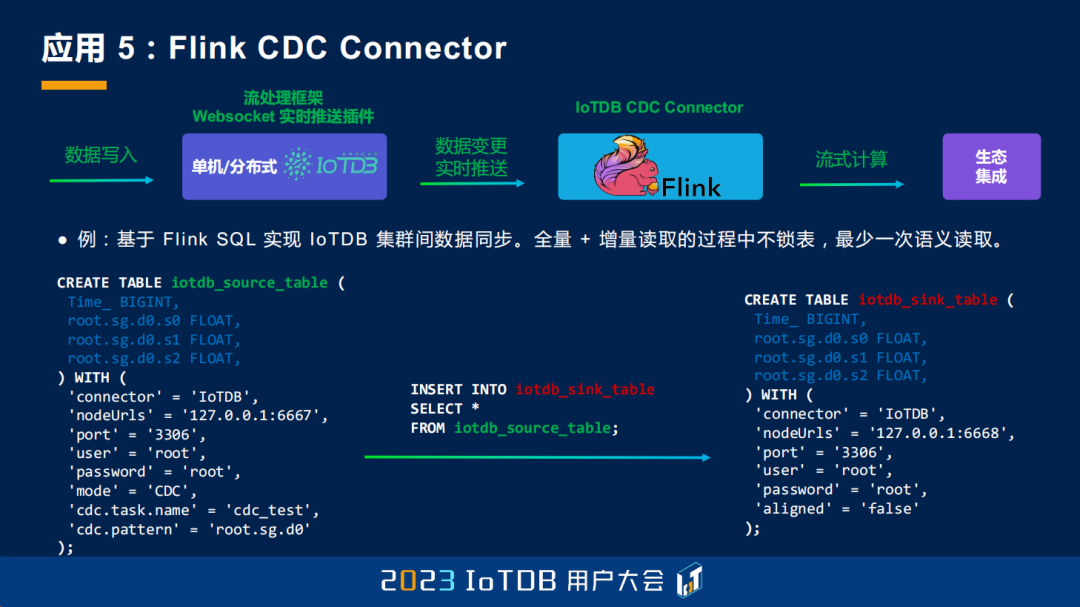
第五个应用,我想给大家介绍的是 Flink CDC Connector 的实现。CDC 全称叫 Change Data Capture,是用于捕获数据库中状态变更的一种技术,应用场景也是类似于我们前面说的数据库的同步,但是我们这个场景主要还是想强调它能够跟大数据生态进行集成的能力。我们可以看一下这个整个的数据链路,当一个单机或者分布式的 IoTDB 接受数据写入之后,我们这里面有一个叫 Websocket 的实时的推流插件,也就是前面提到的 Sink,它能将数据的变更实时地推送到我们在 Flink 里面实现的 CDC Connector。在 CDC Connector 接到这个数据之后,就能以流式计算的方式把这个数据向外进行推送。
我们这里举了一个最简单的例子,就是我们使用 Flink SQL 来实现 IoTDB 集群之间的数据同步。同样的,也能做到 CDC 常常要求的,比如说全量+增量数据读取的过程不锁表,和最少一次的语义读取。那怎么去做呢?我们在源端去定义一个流表 iotdb_source_table,connector 选择 IoTDB,mode 选择 CDC,然后在另一个 IoTDB 的 Sink 中去定义 connector 为 IoTDB。同时我们再定义一个流变换,就是 INSERT INTO,SELECT * 来做这个事情。最后我们启动这个 Flink SQL,瞬间就能够实现这个功能。当然这只是一个起步,我们还可以基于这种方式去实现,比如说从 IoTDB 到 Oracle/MySQL,或者 MySQL/Oracle 到 IoTDB 的能力。
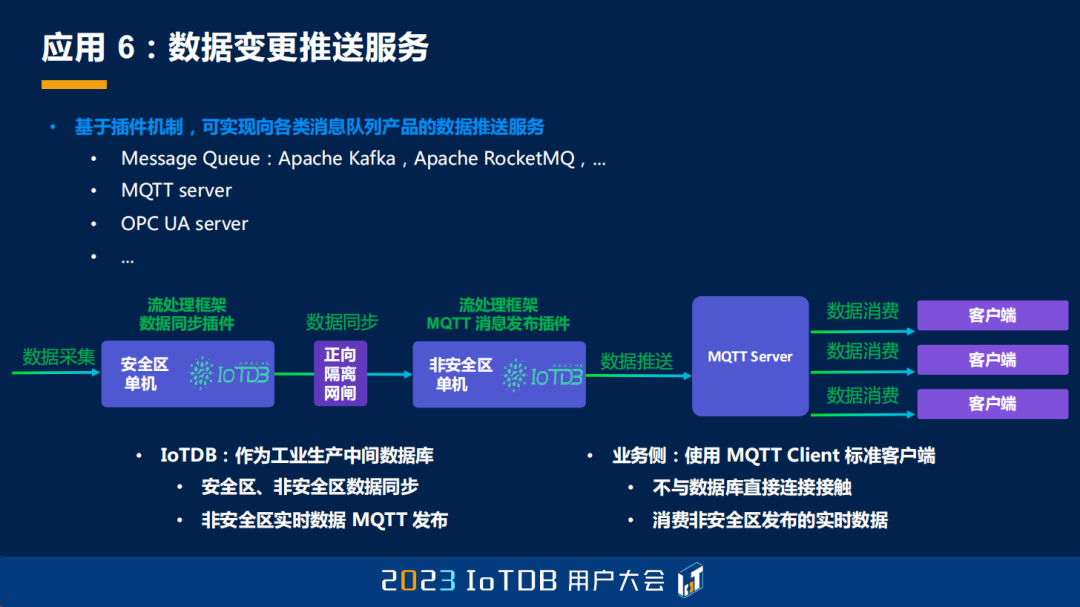
最后一个想跟大家分享的应用,就是数据变更推送服务的能力。基于我们灵活的插件机制,本质上来说,我们可以实现 IoTDB 内数据的变更向各类消息队列产品的推送,比如 Apache Kafka、Apache RocketMQ,再比如 MQTT Server,或者大家在工业里面常见的,比如 OPC-UA Server。
我们在这里给大家分享一个真实的线上场景,看他们是怎么去用这个功能的。首先,他们有安全区和非安全区的概念,也是一个多级数据同步的场景。IoTDB 在安全区的前面,是作为工业生产的中间数据库的,它主要承担的就是安全区和非安全区的数据同步任务;在非安全区,IoTDB 主要是承担信息发布的功能。发布出去之后,在业务侧用户是使用了 MQTT Client,向我们发布出去的 MQTT Server 进行订阅,这样能够做到不与 IoTDB 数据库进行直接的接触,能够保证我们以一种非常安全的方式来消费实时数据。
我给大家一口气介绍了六个应用,其实可能不止六个,因为我们在每个应用里面还说了很多其它的一些组合的场景。通过这些其实就想告诉大家,我们这个流式处理框架,是想要以 one size fits all 的形式,以一套架构的方式来玩转端边云,这是我们从技术角度出发的想法。那从另一个角度,我们也想通过这种一体化的方式,来真正地降低大家在端边云上的用户成本,我们希望这个框架能让比如我们的运维人员有时间喝杯咖啡,能让我们的领导在休息的时候把这个成果给吃下来,这就是我们的一个愿景。
希望对大家来说这个框架能够真正的好用。这是一个新东西,所以我们也希望大家能够实操起来,下载下来、玩转一下,同时给予我们反馈,期待大家今后的反馈。谢谢大家。
可加欧欧获取大会相关PPT
微信号:apache_iotdb

相关文章:
2023 IoTDB Summit:天谋科技高级开发工程师苏宇荣《汇其流:如何用 IoTDB 流处理框架玩转端边云融合》...
12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新…...
Pygame程序的屏幕显示
不同对象的绘制与显示过程 在Pygame中,需要将所有需要在屏幕上显示的内容都绘制在一个display surface上。该Surface通常称为screen surface,它是pygame.display.set_mode()函数返回的Surface对象。 在绘制不同对象时,可以使用不同的绘制方…...
LVGL的List控件的触摸按键和实体按键的处理
在LVGL的List控件使用过程中,虽然通过触摸按键选择item,但是有些场景需要实体按键选取item,但是LVGL 的V8.3中没有像Emwin那样有函数选择list item的函数。LVGL中List引入了Group的概念,把列表项都添加到同一个group中。然后通过更…...
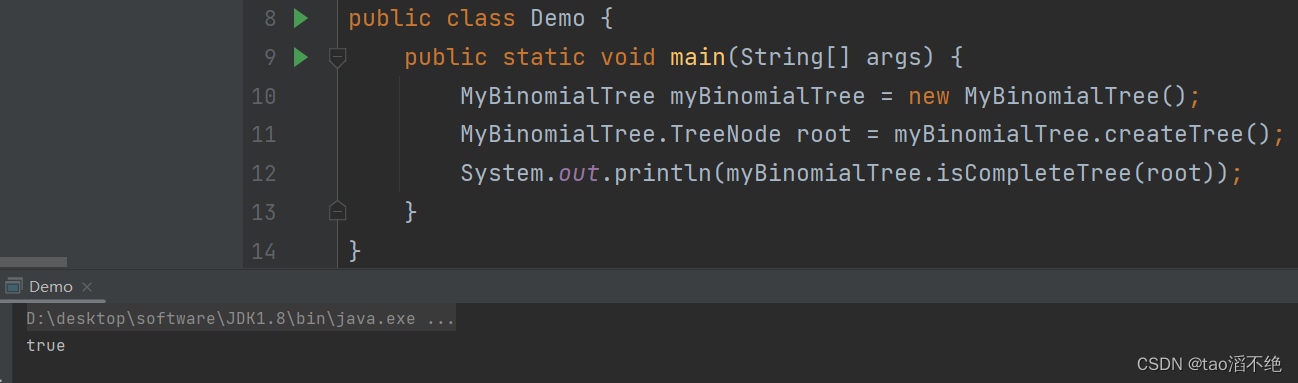
数据结构 模拟实现二叉树(孩子表示法)
目录 一、二叉树的简单概念 (1)关于树的一些概念 (2)二叉树的一些概念及性质 定义二叉树的代码: 二、二叉树的方法实现 (1)createTree (2)preOrder (…...

Android14之解决刷机报错:Can not load Android system. Your data may be corrupt(一百七十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

二阶贝塞尔曲线生成弧线
概述 本文分享一个二阶贝塞尔曲线曲线生成弧线的算法。 效果 实现 1. 封装方法 class ArcLine {constructor(from, to, num 100) {this.from from;this.to to;this.num num;return this.getPointList();}getPointList() {const { from, to } thisconst ctrlPoint thi…...
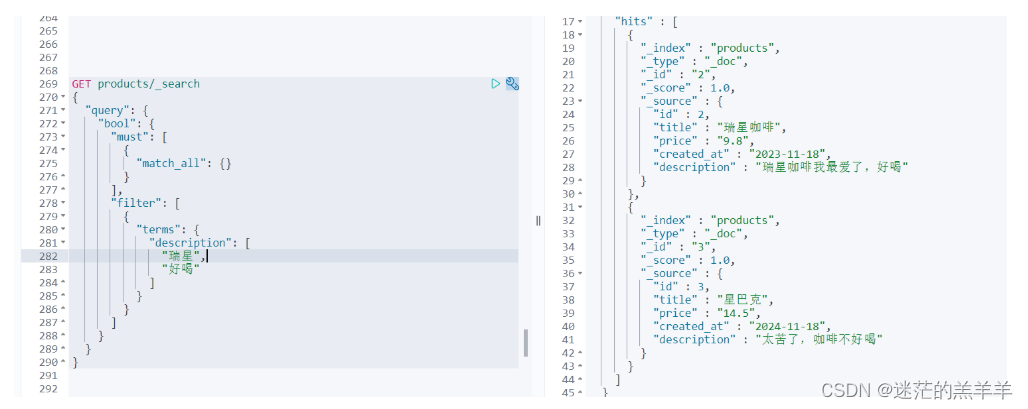
FilterQuery过滤查询
ES中的查询操作分为两种:查询和过滤。查询即是之前提到的query查询,它默认会计算每个返回文档的得分,然后根据得分排序。而过滤只会筛选出符合条件的文档,并不计算得分,并且可以缓冲记录。所以我们在大范围筛选数据时&…...

java多线程(并发)夯实之路-线程池深入浅出
线程池 Thread Pool:线程池,存放可以重复使用的线程(消费者) Blocking Queue:阻塞队列,存放等待执行的任务(生产者) poll方法(有时限地获取任务)相对take注…...

数据库-列的类型-字符串char类型
char 和 varchar 类型 char 类型懂得都懂就是固定的字符串类型 char (maxLen) 例如 char(5) 这个长度为5 但插入数据‘a’时 是5 插入abc 也是5 即使插满固定 就像C/C语言里 char 字符数组一样 char str[64]; maxLen255 哈哈最多有255个字符多了我认为你是错误 varchar…...

大话 JavaScript(Speaking JavaScript):第二十一章到第二十五章
第二十一章:数学 原文:21. Math 译者:飞龙 协议:CC BY-NC-SA 4.0 Math对象用作多个数学函数的命名空间。本章提供了一个概述。 数学属性 Math的属性如下: Math.E 欧拉常数(e) Math.LN2 2 …...

ICMP协议
ICMP协议是网络层协议, 利用ICMP协议可以实现网络中监听服务和拒绝服务,如 ICMP重定向的攻击。 一、ICMP基本概念 1、ICMP协议 ICMP是Internet控制报文协议,用于在IP主机、路由器之间传递控制消息,控制消息指网络通不通、主机是…...
环信服务端下载消息文件---菜鸟教程
前言 在服务端,下载消息文件是一个重要的功能。它允许您从服务器端获取并保存聊天消息、文件等数据,以便在本地进行进一步的处理和分析。本指南将指导您完成环信服务端下载消息文件的步骤。 环信服务端下载消息文件是指在环信服务端上,通过调…...
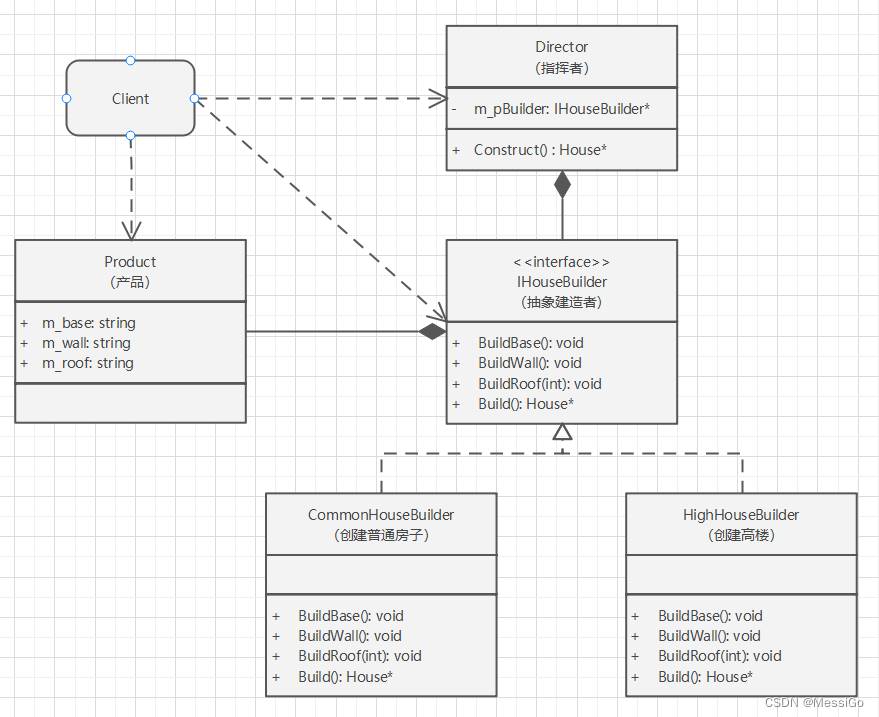
创建型模式 | 建造者模式
一、建造者模式 1、原理 建造者模式又叫生成器模式,是一种对象的构建模式。它可以将复杂对象的建造过程抽象出来,使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。创建者模式是一步一步创建一个复杂的对象…...

MVC设计模式
在当今的软件开发领域,MVC(Model-View-Controller)设计模式已经成为了一种广泛使用的架构模式。它为应用程序提供了一种结构化的方法,将数据、用户界面和业务逻辑分开,从而使得应用程序更易于维护、扩展和重用。 一、…...
 ERROR: CreateProcessEntryCommon:493: chdir 错误解决)
WSL (2103) ERROR: CreateProcessEntryCommon:493: chdir 错误解决
[TOC](WSL (2103) ERROR: CreateProcessEntryCommon:493: chdir 错误解决) 1. 错误信息 <3>WSL (2103) ERROR: CreateProcessEntryCommon:493: chdir(/mnt/d/Program Files/PowerShell/7) failed 52. 解决方法 wsl --shutdownwslrefer: https://github.com/microsoft/…...
【二、自动化测试】为什么要做自动化测试?哪种项目适合做自动化?
自动化测试是一种软件测试方法,通过编写和使用自动化脚本和工具,以自动执行测试用例并生成结果。 自动化旨在替代手动测试过程,提高测试效率和准确性。 自动化测试可以覆盖多种测试类型,包括功能测试、性能测试、安全测试等&…...
)
用ChatGPT来造一个ChatGPT:计算机领域智能问答系统实践(2)
在PHP语言中,你可以使用MySQL数据库来存储知识库,并使用PHP来实现系统的逻辑。以下是一个简单的示例: 创建数据库表: 首先,创建一个名为 computer_knowledge 的表来存储计算机知识。可以使用以下SQL语句:…...

Ubuntu开机自动挂载硬盘
前言: 因为我的电脑是WIN10 Ubuntu18.04双系统,且两个系统都装在C盘上,而D盘作为数据和代码存储盘,经常会开机就被访问,例如上一次关机前用VS Code访问D盘代码,然后下一次开机的时候打开VSCode发现打不开…...

vue3基础:单文件组件介绍
介绍 Vue 的单文件组件 (即 *.vue 文件,简称 SFC,全称是single file component) 是一种特殊的文件格式,使我们能够将一个 Vue 组件的模板、逻辑与样式封装在单个文件中。下面是一个单文件组件的示例: <script> export def…...

OCR字符识别:开始批量识别身份证信息
身份证信息批量识别OCR是一项解决方案,它能够将身份证照片打包成zip格式或通过URL地址进行提交,并能够识别照片中的文本信息。最终,用户可以将识别结果生成为excel文件进行下载。 API接口功能: 1. 批量识别:支持将多…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...