【机器学习】模型参数优化工具:Optuna使用分步指南(附XGB/LGBM调优代码)

常用的调参方式和工具包
常用的调参方式包括网格搜索(Grid Search)、**随机搜索(Random Search)和贝叶斯优化(Bayesian Optimization)**等。
工具包方面,Scikit-learn提供了GridSearchCV和RandomizedSearchCV等用于网格搜索和随机搜索的工具。另外,有一些专门用于超参数优化的工具包,如Optuna、Hyperopt等。
这些方法各自有优缺点。网格搜索和随机搜索易于理解和实现,但在超参数空间较大时计算代价较高。贝叶斯优化考虑了不同参数之间的关系,可以在较少实验次数内找到较优解,但实现较为复杂。
Optuna是什么?
Optuna是一个基于贝叶斯优化的超参数优化框架。它的目标是通过智能的搜索策略,尽可能少的实验次数找到最佳超参数组合。Optuna支持各种机器学习框架,包括Scikit-learn、PyTorch和TensorFlow等。
Optuna的优势和劣势
个人使用体验:比起网格搜索和随机搜索,Optuna最明显的优势就是快。虽然最后的提升效果未必有前两种好,但是在整体效率上来看,Optuna能够大大减少调参时间。
优势:
- 智能搜索策略: Optuna使用TPE(Tree-structured Parzen Estimator)算法进行贝叶斯优化,能够更智能地选择下一组实验参数,从而加速超参数搜索。
- 轻量级: Optuna的设计简单而灵活,易于集成到现有的机器学习项目中。
- 可视化支持: 提供结果可视化工具,帮助用户直观地了解实验过程和结果。
- 并行优化: Optuna支持并行优化,能够充分利用计算资源,提高搜索效率。
劣势:
- 适用范围: 对于超参数空间较小或者问题较简单的情况,Optuna的优势可能不如其他方法显著。
如何使用Optuna进行调参?
使用Optuna进行调参的基本步骤如下:
- 定义超参数搜索空间: 使用Optuna的API定义超参数的搜索范围,例如学习率、层数等。
- 定义目标函数: 编写一个目标函数,用于评估给定超参数组合的模型性能。
- 运行Optuna优化: 使用Optuna的optimize函数运行优化过程,选择适当的搜索算法和优化目标。
- 获取最佳超参数: 通过Optuna提供的API获取找到的最佳超参数组合。
调参代码示例
主要分为几个步骤:
- 定义目标函数: 1)定义参数搜索范围 2)定义、训练和评估模型
- 运行Optuna优化
- 获取最佳超参数
1. SVM调优例子
以下是一个使用Optuna进行超参数优化的简单示例,假设我们使用Scikit-learn中的SVM进行分类:
import optuna
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC# 载入数据
data = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2)# 定义目标函数
def objective(trial):# 定义超参数搜索范围C = trial.suggest_loguniform('C', 1e-5, 1e5)gamma = trial.suggest_loguniform('gamma', 1e-5, 1e5)# 构建SVM模型model = SVC(C=C, gamma=gamma)# 训练和评估模型model.fit(X_train, y_train)accuracy = model.score(X_test, y_test)return accuracy# 运行Optuna优化
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)# 获取最佳超参数
best_params = study.best_params
print("最佳超参数:", best_params)
2.LGBM调优例子
def objective(trial):params = {'objective': 'multiclass','metric': 'multi_logloss', # Use 'multi_logloss' for evaluation'boosting_type': 'gbdt','num_class': 3, # Replace with the actual number of classes'num_leaves': trial.suggest_int('num_leaves', 2, 256),'learning_rate': trial.suggest_loguniform('learning_rate', 0.001, 0.1),'feature_fraction': trial.suggest_uniform('feature_fraction', 0.1, 1.0),'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.1, 1.0),'bagging_freq': trial.suggest_int('bagging_freq', 1, 10),'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),}model = lgb.LGBMClassifier(**params)model.fit(X_train, y_train)y_pred = model.predict_proba(X_val) loss = log_loss(y_val, y_pred)return lossstudy = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=50,show_progress_bar=True)# Get the best parameters
best_params = study.best_params
print(f"Best Params: {best_params}")
3.XGB调优例子
def objective(trial):params = {'objective': 'multi:softprob', # 'multi:softprob' for multiclass classification'num_class': 3, # Replace with the actual number of classes'booster': 'gbtree','eval_metric': 'mlogloss', # 'mlogloss' for evaluation'max_depth': trial.suggest_int('max_depth', 2, 10),'learning_rate': trial.suggest_loguniform('learning_rate', 0.001, 0.1),'subsample': trial.suggest_uniform('subsample', 0.1, 1.0),'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.1, 1.0),'min_child_weight': trial.suggest_int('min_child_weight', 1, 10),}model = XGBClassifier(**params)model.fit(X_train, y_train)y_pred = model.predict_proba(X_val)loss = log_loss(y_val, y_pred)return lossstudy = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=50, show_progress_bar=True)# Get the best parameters
best_params = study.best_params
print(f"Best Params: {best_params}")
通过这个示例,你可以看到Optuna的简洁和易用性。通过定义搜索空间和目标函数,Optuna会自动选择最优的超参数组合。
总结
Optuna作为一个高效的超参数优化工具,在调参过程中具有明显的优势。通过智能的搜索策略和轻量级的设计,它可以显著减少调参的时间和计算资源成本。当面对大规模超参数搜索问题时,Optuna是一个值得考虑的利器,能够帮助机器学习和数据科学领域的从业者更高效地优化模型性能。
参考链接
官网:https://optuna.org/
说明文档:https://optuna.readthedocs.io/en/stable/
中文文档:https://optuna.readthedocs.io/zh-cn/latest/
相关文章:
【机器学习】模型参数优化工具:Optuna使用分步指南(附XGB/LGBM调优代码)
常用的调参方式和工具包 常用的调参方式包括网格搜索(Grid Search)、**随机搜索(Random Search)和贝叶斯优化(Bayesian Optimization)**等。 工具包方面,Scikit-learn提供了GridSearchCV和RandomizedSearchCV等用于网格搜索和随机搜索的工具。另外,有一…...

webview全屏处理,即插即用
去年双十一有个直播的需求,听起来很简单,技术也都很成熟,但是真的开始实现后,还是有不少坑的,首先第一个uc内核不支持webRTC协议,需要重新开发chrome内核的webview,其次webview全屏处理、悬浮窗…...
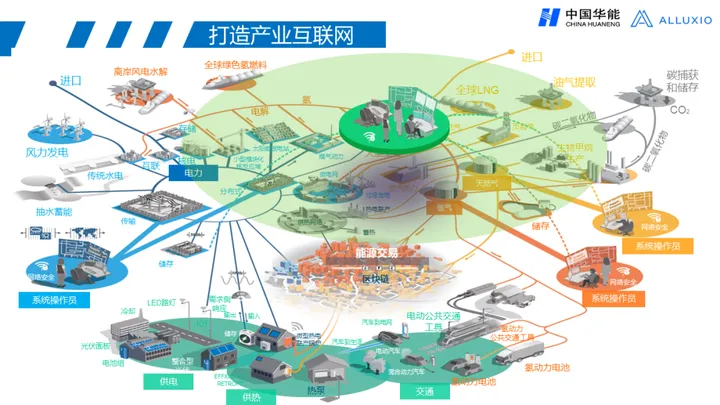
实录分享 | 央企大数据平台架构发展趋势与应用场景的介绍
分享嘉宾: 孟子涵-中国华能集团信息中心平台架构师 2021年华能就与Alluxio建立了合作,共同写了整个华能统一纳管的架构方案。这个方案我认为是现在我们在央企里边比较核心的一套体系,能让全集团所有我们认为重要的数字化资源实现真正的统一集…...
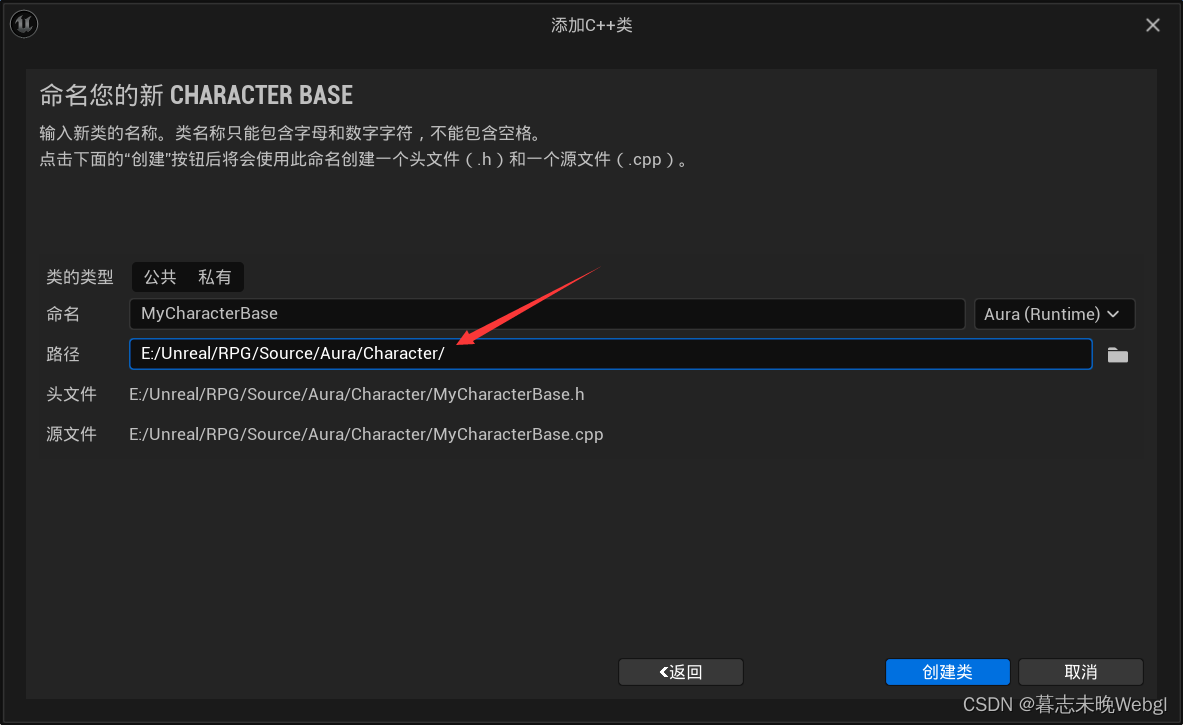
UE5 将类修改目录
有个需求,需要修改ue里面类的位置,默认在Public类下面,我想创建一个二级目录,将所有的类分好位置,方便查看。 上图为创建一个类所在的默认位置。 接下来,将其移动到一个新的目录中。 首先在资源管理器中找…...

GPT实战系列-ChatGLM3管理工具的API接口
GPT实战系列-ChatGLM3管理外部借力工具 用ChatGLM的工具可以实现很多查询接口和执行命令,外部工具该如何配置使用?如何联合它们实现大模型查询助手功能?例如调用工具实现股票信息查询,网络天气查询等助手功能。 LLM大模型相关文章…...

Python 列表、元组、字典区别
1.列表、元组和字典都是序列 2.列表字典可以修改和删除序列中的某个元素,而元组就是一个整体,不能修改和删除,一定要修改或删除的话,只能修改和删除整个元组。 3.既然元组不能删除和修改,有什么作用呢? 1…...
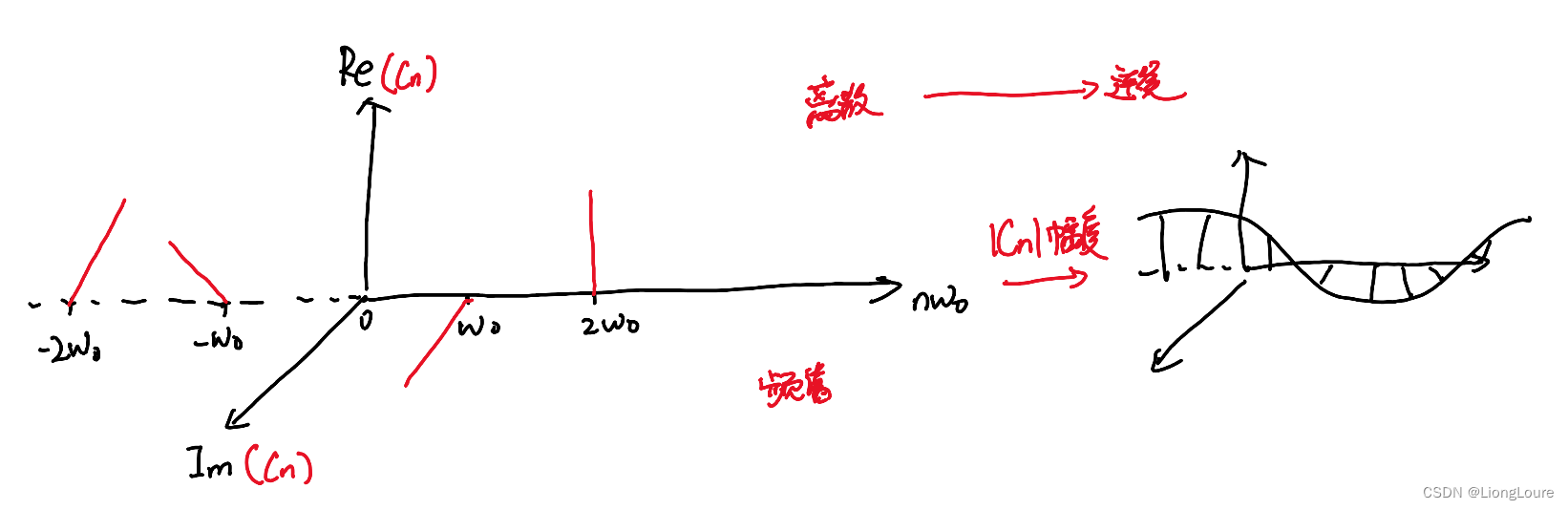
[足式机器人]Part2 Dr. CAN学习笔记 - Ch03 傅里叶级数与变换
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-Ch03 傅里叶级数与变换 1. 三角函数的正交性2. 周期为 2 π 2\pi 2π的函数展开为傅里叶级数3. 周期为 2 L 2L 2L的函数展开4. 傅里叶级数的复数形式5. 从傅里叶级数推导傅里叶变换FT6. 总结 1. …...

你想使用域名访问一个ip的网页,你应该怎么办呢?
你想使用域名访问一个ip的网页,你应该怎么办呢? eg:你想用https://test.com/访问http://1.1.1.1/方法: eg:你想用https://test.com/访问http://1.1.1.1/ 方法: 1.首先,如果你是服务器的管理者,你需要在服务器的官网申请一个test.com的域名,然后在官网将域名映射到1.1.1.1上. …...
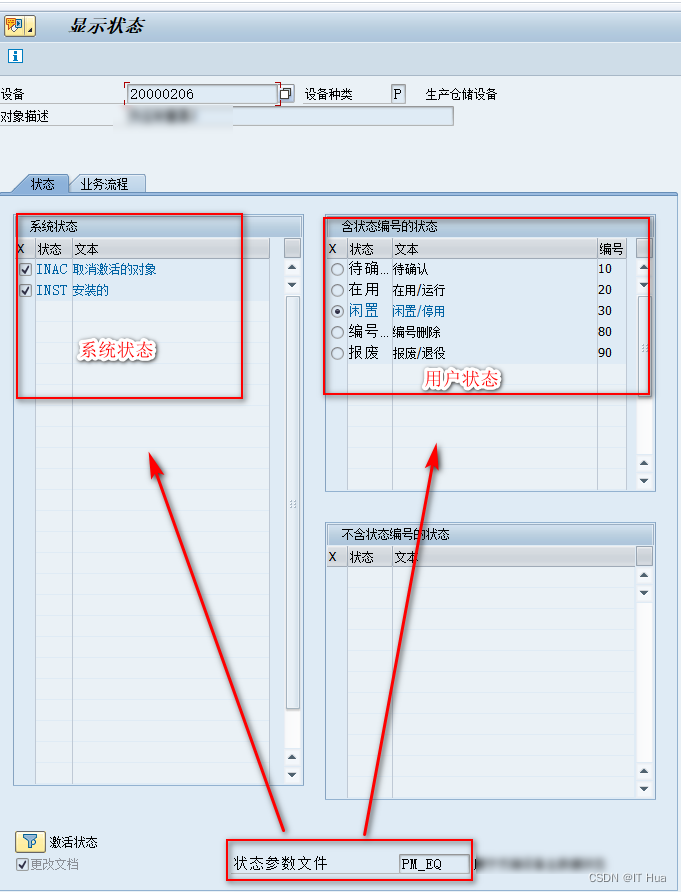
SAP存放状态的几个常用表
SAP存放状态的几个常用表 在sap中,包括订单、项目、计划、设备主数据等,存在审批流程的业务单据,这些业务对象都会有状态的属性,用来控制和约束该业务当前的操作。 主要的表 JEST:存放了该对象编号的当前状态 JCDS…...

AUTO SEG-LOSS SEARCHING METRIC SURROGATES FOR SEMANTIC SEGMENTATION
AUTO SEG-LOSS: 搜索度量替代语义分割 论文链接:https://arxiv.org/abs/2010.07930 项目链接:https://github.com/fundamentalvision/Auto-Seg-Loss ABSTRACT 设计合适的损失函数是训练深度网络的关键。特别是在语义分割领域,针对不同的场…...

openssl3.2 - 官方demo学习 - 索引贴
文章目录 openssl3.2 - 官方demo学习 - 索引贴概述笔记工程的搭建和调试环境BIOBIO - client-arg.cBIO - client-conf.cBIO - saccept.cBIO - sconnect.cBIO - server-arg.cBIO - server-cmod.cBIO - server-conf.cBIO - 总结certsciphercipher - aesccm.ccipher - aesgcm.ccip…...

textarea文本框根据输入内容自动适应高度
第一种: <el-input auto-completeoff typetextarea :autosize"{minRows:3,maxRows:10}" class"no-scroll"> </el-input> /* 页面的样式表 */ .no-scroll textarea {overflow: hidden; /* 禁用滚动条 */resize: none; /* 禁止用户…...
【JAVA基础--计算机网络】--TCP三次握手+四次挥手
三次握手四次挥手 写在前面1. 三次握手1.1 作用: 为了在不可靠的信道上建立起可靠的连接;1.2 建立过程1.3 面试提问 2. 四次挥手2.1 作用:为了在不可靠的网络信道中进行可靠的连接断开确认2.2 断开过程2.3 面试提问 写在前面 三次握手建立连…...

最新靠谱可用的-Mac-环境下-FFmpeg-环境搭建
最近在尝试搭建 FFmpeg 开发环境时遇到一个蛋疼的事,Google 了 N 篇文章竟然没有一篇是可以跑起来的! 少部分教程是给出了自我矛盾的配置(是的,按照贴出来的代码和配置,他自己都跑不起来),大部…...

【漏洞复现】Hikvision SPON IP网络对讲广播系统存在命令执行漏洞CVE-2023-6895
漏洞描述 Hikvision Intercom Broadcasting System是中国海康威视(Hikvision)公司的一个对讲广播系统。 Hikvision Intercom Broadcasting System是中国海康威视(Hikvision)公司的一个对讲广播系统。Hikvision Intercom Broadcasting System 3.0.3_20201113_RELEASE(HIK)版…...

微软为Windows内置记事本应用开发AI功能;2024年15个 AI 语音生成器
🦉 AI新闻 🚀 微软为Windows内置记事本应用开发AI功能 摘要:微软正在开发一个新的生成式AI功能,名为"Cowriter",用于Windows内置的记事本应用。该功能类似于画图应用中的"Cocreator"功能&#x…...
【C++进阶06】红黑树图文详解及C++模拟实现红黑树
一、红黑树的概念及性质 1.1 红黑树的概念 AVL树用平衡因子让树达到高度平衡 红黑树可以认为是AVL树的改良 通过给每个节点标记颜色让树接近平衡 以减少树在插入节点的旋转 在每个结点新增一个存储位表示结点颜色 可以是Red或Black 通过对任何一条从根到叶子的路径上 各个结点…...

2023年最严重的10起0Day漏洞攻击事件
根据谷歌公司威胁分析小组去年 7 月发布的报告显示,2022 年全球共有 41 个 0day 漏洞被利用和披露。而研究人员普遍认为,2023 年被利用的 0Day 漏洞数量会比 2022 年更高,这些危险的漏洞被广泛用于商业间谍活动、网络攻击活动以及数据勒索攻击…...

Linux之Iptables简易应用
文档形成时期:2009-2024年 和iptables打交道有15年了,经过无数实践后,形成一个简易应用文档。 文档主题是简易应用,所以其原理不详述了。 因软件世界之复杂和个人能力之限,难免疏漏和错误,欢迎指正。 文章目…...

树状结构查询 - 华为OD统一考试
OD统一考试 分值: 200分 题解: Java / Python / C++ 题目描述 通常使用多行的节点、父节点表示一棵树,比如: 西安 陕西 陕西 中国 江西 中国 中国 亚洲 泰国 亚洲 输入一个节点之后,请打印出来树中他的所有下层节点。 输入描述 第一行输入行数,下面是多行数据,每行以…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...