AUTO SEG-LOSS SEARCHING METRIC SURROGATES FOR SEMANTIC SEGMENTATION
AUTO SEG-LOSS: 搜索度量替代语义分割

论文链接:https://arxiv.org/abs/2010.07930
项目链接:https://github.com/fundamentalvision/Auto-Seg-Loss
ABSTRACT
设计合适的损失函数是训练深度网络的关键。特别是在语义分割领域,针对不同的场景提出了不同的评价指标。尽管广泛采用的交叉熵损失及其变体取得了成功,但损失函数和评估指标之间的不一致会降低网络性能。同时,手动设计每个特定度量的损失函数需要专业知识和大量人力。在本文中,我们提出通过搜索每个度量的可微代理损失来自动设计度量特定的损失函数。我们用参数化函数代替度量中的不可微操作,并进行参数搜索以优化损失曲面的形状。引入两个约束来正则化搜索空间,提高搜索效率。在PASCAL VOC和Cityscapes上进行的大量实验表明,搜索的代理损失始终优于手动设计的损失函数。搜索损失可以很好地推广到其他数据集和网络。
1 INTRODUCTION
损失函数是训练深度网络不可缺少的组成部分,因为它们驱动着具有特定评估指标的各种应用的特征学习过程。然而,大多数指标,如常用的0-1分类误差,其原始形式是不可微的,无法通过基于梯度的方法直接优化。经验表明,交叉熵损失可以作为一种有效的替代目标函数用于各种分类任务。这种现象在图像语义分割中尤其普遍,其中已经设计了各种评估指标来解决专注于不同场景的不同任务。一些指标衡量的是整个图像的准确性,而另一些指标则更多地关注分割边界。尽管交叉熵及其变体在许多指标上都能很好地工作,但网络训练和评估之间的不一致仍然存在,并不可避免地导致性能下降。
通常,在语义分割中有两种设计度量特定损失函数的方法。第一种是修改标准交叉熵损失以满足目标度量(Ronneberger et al ., 2015; Wu et al, 2016)。另一种是为特定的评估指标设计其他聪明的替代损失(Rahman & Wang, 2016; Milletari et al, 2016)。尽管有了改进,但是这些手工制作的损失需要专业知识,并且不能简单地扩展到其他评估指标。
与手动设计损失函数相比,另一种方法是找到一个框架,该框架可以自动地为不同的评估指标设计适当的损失函数,这是由AutoML的最新进展推动的(Zoph & Le, 2017; Pham et al., 2018; Liu et al., 2018; Li et al, 2019)。尽管自动化损失函数的设计过程很有吸引力,但将AutoML框架应用于损失函数也不是很简单。典型的AutoML算法需要适当的搜索空间,一些搜索算法在其中进行。先前的搜索空间要么不适合损失设计,要么过于笼统而无法有效搜索。最近Li等人(2019)和Wang等人(2020)提出了基于现有手工制作的损失函数的搜索空间。算法搜索最佳组合。然而,这些搜索空间仍然局限于交叉熵损失的变体,因此不能很好地解决不对齐问题。
在本文中,我们提出了一个搜索主流不可微分割度量的代理损失的通用框架。关键思想是我们可以根据评价指标的形式来构建搜索空间。这样,培训标准和评价指标就统一了。同时,搜索空间足够紧凑,可以进行高效的搜索。具体地说,通过将大多数度量中不可微部分的单热预测和逻辑运算替换为它们的可微近似,将度量松弛到连续域。引入参数化函数来逼近逻辑运算,保证了损失面光滑的同时又能准确训练。损失参数化函数可以是任意族,定义在[0, 1]。对选择的族进一步进行参数搜索,在给定评价指标的验证集上优化网络性能。引入两个基本约束来正则化参数搜索空间。我们发现搜索到的代理损失可以有效地推广到不同的网络和数据集。在Pascal VOC (Everingham et al, 2015)和Cityscape (Cordts et al, 2016)上进行的大量实验表明,我们的方法提供的准确性优于为单个分割指标专门设计的现有损失,并且计算开销较小。
我们的贡献可以总结如下:1)我们的方法是主流分割指标的代理损失搜索的第一个通用框架。2)提出了一种有效的参数正则化和参数搜索算法,该算法可以在较小的计算开销下找到优化目标度量性能的损失代理。3)通过所提出的搜索框架获得的替代损失促进了我们对损失函数设计的理解,并且它们本身是新的贡献,因为它们不同于现有的专门为单个指标设计的损失函数,并且可以在不同的数据集和网络之间转移。
2 RELATED WORK
损失函数设计是深度网络训练中的一个活跃话题(Ma, 2020)。在图像语义分割领域,交叉熵损失被广泛应用(Ronneberger et al ., 2015; Chen et al, 2018)。但交叉熵损失是为了优化全局精度度量而设计的(Rahman & Wang, 2016; Patel et al, 2020),这与许多其他指标不一致。为设计合适的损失函数进行了大量的研究。对于mIoU度量,许多工作(Ronneberger et al ., 2015; Wu et al ., 2016)纳入类频率以缓解类不平衡问题。对于边界F1分数,边界区域的损失加权上升(Caliva et al ., 2019; Qin et al ., 2019),从而提供更准确的边界。这些作品仔细分析了具体评价指标的性质,并以完全手工制作的方式设计了损失函数,这需要专业知识。相比之下,我们提出了一个统一的框架来推导各种评估指标的参数化代理损失。其中,通过强化学习自动搜索参数。用搜索的替代损失训练的网络提供的准确性与那些最好的手工损失相当甚至更好。
不可微评价指标的直接损失优化早已被研究用于结构支持向量机模型(Joachims, 2005; Yue et al, 2007;Ranjbar et al, 2012)。然而,这些方法不能得到梯度的w.r.t.特征。因此,它们不能通过反向传播来驱动深度网络的训练。Hazan等(2010)提出用梯度下降法优化结构支持向量机,利用损失增强推理得到评价指标期望的梯度。Song等人(2016)进一步将这种方法扩展到非线性模型(例如,深度神经网络)。然而,梯度下降算法每一步的计算量都非常高。尽管Song等人(2016)和Mohapatra等人(2018)已经为平均精度(AP)指标设计了高效的算法,但其他指标仍然需要专门设计的高效算法。相比之下,我们的方法对于主流分割指标是通用的。由于具有良好的泛化性,我们的方法只需要对一个特定的度量执行一次搜索过程,之后可以直接使用搜索到的代理损失。将搜索损失应用于训练网络只带来很少的额外计算成本。
引入代理损失来推导不可微评价指标的损失梯度。通常有两种设计替代损失的方法。首先是手工构造一个近似的可微度量函数。对于IoU度量,Rahman & Wang(2016)提出使用可微形式的softmax概率分别近似交集和并,并显示其在二值分割任务上的有效性。Berman等人(2018)通过凸Lovasz扩展将mIoU从二进制输入扩展到连续域,进一步处理多类分割问题,他们的方法在“多类分割任务”中优于标准交叉熵损失。对于F1测度,Milletari等人(2016)通过用softmax概率代替二值预测,提出了骰子损失作为直接目标。尽管取得了成功,但它们并不适用于其他指标。
第二个解决方案是训练一个网络来近似目标度量。Nagenda等人(2018)训练一个网络来近似mIoU。Patel等人(2020)设计了一个神经网络来学习预测的嵌入和除分割以外的任务的基本事实。这方面的研究侧重于最小化目标度量的近似误差。但不能保证它们的近似为训练提供良好的损失信号。这些近似损失仅用于后调优设置,仍然依赖于交叉熵预训练模型。我们的方法有很大的不同,因为我们搜索代理损失来直接优化应用程序中的评估指标。
AutoML是机器学习长期追求的目标(He et al, 2019)。最近,AutoML的一个子领域,神经架构搜索(NAS),由于其在自动化神经网络架构设计过程中的成功而引起了广泛关注(Zoph & Le, 2017; Pham et al, 2018; Liu et al, 2018)。损失函数作为一种基本元素,其设计过程的自动化也引起了研究人员的兴趣。Li et al .(2019)和Wang et al .(2020)基于现有的人为设计的损失函数设计搜索空间,并搜索最佳组合参数。有两个问题:a)搜索过程输出整个网络模型,而不是损失函数。对于每一个新的网络或数据集,都要重新进行昂贵的搜索过程,并且 b)搜索空间中充满了交叉熵的变体,这无法解决交叉熵损失与许多目标指标之间的不一致。相比之下,我们的方法输出搜索代理损失函数与目标指标的接近形式,这是可在网络和数据集之间转移的。
3 REVISITING EVALUATION METRICS FOR SEMANTIC SEGMENTATION
为语义分割定义了各种评估指标,以解决不同场景下的不同任务。其中大多数是三种典型的类型:基于Acc,基于iou和基于F1分数。本节在一个统一的符号集下回顾评估度量。
表1总结了主流的评估指标。符号如下:假设验证集由 N N N个图像组成,标记为 C C C类(包括背景)的类别。让 I n , n ∈ { 1 , … , N } I_n, n \in\{1, \ldots, N\} In,n∈{1,…,N}为第 n n n张图像, Y n Y_n Yn为对应的ground-truth分割掩码。其中 Y n = { y n , c , h , w } c , h , w Y_n=\left\{y_{n, c, h, w}\right\}_{c, h, w} Yn={yn,c,h,w}c,h,w是一个one-hot向量,其中 y n , c , h , w ∈ { 0 , 1 } y_{n, c, h, w} \in\{0,1\} yn,c,h,w∈{0,1}表示像素在空间位置 ( h , w ) (h, w) (h,w)属于第 c c c类 ( c ∈ { 1 , … , C } ) (c \in\{1, \ldots, C\}) (c∈{1,…,C})。在评估中,将ground-truth分割掩码 Y n Y_n Yn与网络预测 Y ^ n = { y ^ n , c , h , w } c , h , w \hat{Y}_n=\left\{\hat{y}_{n, c, h, w}\right\}_{c, h, w} Y^n={y^n,c,h,w}c,h,w进行比较,其中 y ^ n , c , h , w ∈ { 0 , 1 } \hat{y}_{n, c, h, w} \in\{0,1\} y^n,c,h,w∈{0,1} 。 y ^ n , c , h , w \hat{y}_{n, c, h, w} y^n,c,h,w是由网络产生的连续分数(通过argmax操作)量化的。

Acc-based指标。全局精度度量(gAcc)计算正确分类的像素数量。可以用逻辑运算符AND写成公式(1)。gAcc度量对每个像素的计数是相等的,所以长尾分类的结果对度量数的影响很小。平均精度(mAcc)指标通过在每个类别内进行归一化来缓解这种情况,如公式(2)所示。
IoU-based指标。评估是基于集合相似度而不是像素精度。对每个类别的预测与ground-truth 掩模之间的交叉超并度(IoU)评分进行了评估。平均IoU (mIoU)度量将所有类别的IoU分数平均,如公式(3)所示。
在变体中,频率加权IoU (FWIoU)度量根据类别像素数对每个类别IoU得分进行加权,如公式(4)所示。边界IoU (BIoU) (Kohli et al ., 2009)度量只关心边界周围的分割质量,因此它在评估中挑选出边界像素,而忽略其余像素。可由公式(5)计算,其中BD( y n y_n yn)表示ground-truth y n y_n yn中的边界区域。BD( y n y_n yn)是通过对最小池ground-truth掩模进行异或运算得到的。Min-Pooling(·)的步长为1。
F1-score-based指标。F1-score是一个同时考虑准确率和召回率的标准。这种类型的一个众所周知的度量是边界F1-score (BF1-score) (Csurka et al, 2013),它被广泛用于评估边界分割精度。BF1-score中 precision和recall的计算如公式(6)所示,其中BD( y ^ n \hat{y}_n y^n)和BD( y n y_n yn)由公式(5)推导而来。边界区域采用stride为1的Max- pooling(·),允许容错。
4 AUTO SEG-LOSS FRAMEWORK
在Auto Seg-Loss框架中,将评估指标转化为具有可学习参数的连续代理损失,并对其进行进一步优化。图1说明了我们的方法。

4.1 将度量标准扩展到代理
如第3节所示,大多数分割指标是不可微的,因为它们以一个热点预测映射作为输入,并且包含二进制逻辑操作。我们通过平滑内部的不可微操作,将这些度量扩展为连续损失代理。
扩展one-hot操作。one-hot预测图, Y ^ n = { y ^ n , c , h , w } c , h , w \hat{Y}_{n}=\{\hat{y}_{n,c,h,w}\}_{c,h,w} Y^n={y^n,c,h,w}c,h,w,通过在每个像素上选择得分最高的类别得到,并进一步转化为one-hot形式。在这里,我们用softmax概率近似one-hot预测,为,
y ^ n , c , h , w ≈ y ~ n , c , h , w = S o f t m a x c ( z n , c , h , w ) , (7) \hat{y}_{n,c,h,w}\approx\tilde{y}_{n,c,h,w}=\mathrm{Softmax}_{c}(z_{n,c,h,w}), \tag{7} y^n,c,h,w≈y~n,c,h,w=Softmaxc(zn,c,h,w),(7)
式中, z n , c , h , w ∈ R z_{n,c,h,w}\in\mathbb{R} zn,c,h,w∈R为网络输出的类别得分(未归一化)。近似的one-hot预测用 y ~ n , c , h , w {{\tilde{y}}}_{n,c,h,w} y~n,c,h,w表示。
扩展逻辑操作。如表1所示,不可微逻辑运算fAND(y1,y2),fOR(y1,y2)和fXOR(y1,y2)是这些度量中不可或缺的组成部分。因为异或运算可以由AND和OR构造,所以fXOR(y1;y2) = fOR(y1,y2)−fAND(y1,y2),重点是扩展fAND(y1,y2)和fOR(y1,y2)到连续定义域。
按照惯例,用算术运算符代替逻辑运算符
f A N D ( y 1 , y 2 ) = y 1 y 2 , f O R ( y 1 , y 2 ) = y 1 + y 2 − y 1 y 2 , (8) f_{\mathrm{AND}}(y_{1},y_{2})=y_{1}y_{2},f_{\mathrm{OR}}(y_{1},y_{2})=y_{1}+y_{2}-y_{1}y_{2}, \tag{8} fAND(y1,y2)=y1y2,fOR(y1,y2)=y1+y2−y1y2,(8)
其中 y 1 , y 2 ∈ { 0 , 1 } y_{1},y_{2}\in\{0,1\} y1,y2∈{0,1}。公式(8)可以直接扩展为取连续的 y 1 , y 2 ∈ [ 0 , 1 ] \begin{aligned}y_1,y_2&\in[0,1]\end{aligned} y1,y2∈[0,1]作为输入。通过这种扩展,再加上近似的one-hot操作,可以获得可微替代损失的一个新版本。这种替代的优势在于它们直接来自度量,这大大减少了训练和评估之间的差距。然而,不能保证由naively扩展公式(8)形成的损失面提供准确的损失信号。为了调整损失面,我们将AND和OR函数参数化为
h A N D ( y 1 , y 2 ; θ A N D ) = g ( y 1 ; θ A N D ) g ( y 2 ; θ A N D ) , h O R ( y 1 , y 2 ; θ O R ) = g ( y 1 ; θ O R ) + g ( y 2 ; θ O R ) − g ( y 1 ; θ O R ) g ( y 2 ; θ O R ) , (9) \begin{aligned} &h_{\mathrm{AND}}(y_{1},y_{2};\theta_{\mathrm{AND}})=g(y_{1};\theta_{\mathrm{AND}})~g(y_{2};\theta_{\mathrm{AND}}), \\ &h_{\mathrm{OR}}(y_{1},y_{2};\theta_{\mathrm{OR}})=g(y_{1};\theta_{\mathrm{OR}})+g(y_{2};\theta_{\mathrm{OR}})-g(y_{1};\theta_{\mathrm{OR}})~g(y_{2};\theta_{\mathrm{OR}}), \end{aligned} \tag{9} hAND(y1,y2;θAND)=g(y1;θAND) g(y2;θAND),hOR(y1,y2;θOR)=g(y1;θOR)+g(y2;θOR)−g(y1;θOR) g(y2;θOR),(9)
在 g ( y ; θ ) : [ 0 , 1 ] → R g(y;\theta):[0,1]\to\mathbb{R} g(y;θ):[0,1]→R是用θ参数化的标量函数。
参数化函数g(y;θ)可以来自任意函数族,定义在[0;1],如分段线性函数、分段贝塞尔曲线等。通过选择函数族,参数θ控制损失曲面的形状。我们寻求搜索最优参数θ以使给定的评价度量最大化。
同时,最优参数搜索是非平凡的。在引入的参数下,损失面具有较强的塑性。参数化的损失面很可能是混沌的,或者即使在二进制输入时也远离目标评价指标。为了更有效地搜索参数,我们通过引入g(y;θ)。
引入真值表约束来强制代理损失面在二值输入处取与评价度量分数相同的值。这是通过强制来实现的
g ( 0 ; θ ) = 0 , g ( 1 ; θ ) = 1. (10) g(0;\theta)=0, g(1;\theta)=1. \tag{10} g(0;θ)=0,g(1;θ)=1.(10)
因此,参数化函数 h ( y 1 , y 2 ; θ ) h(y_1,y_2;θ) h(y1,y2;θ)保持相应的逻辑运算 f ( y 1 , y 2 ) f(y_1,y_2) f(y1,y2)对二进制输入 y 1 , y 2 ∈ { 0 , 1 } y_{1},y_{2}\in\{0,1\} y1,y2∈{0,1}。
基于对与与或真值表单调性倾向的观察,引入单调性约束。它将失去的表面推向一个良性的景观,避免了戏剧性的不平滑。单调性约束在 h AND ( y 1 , y 2 ) h_\text{AND}(y_1,y_2) hAND(y1,y2)和 h OR ( y 1 , y 2 ) h_\text{OR}(y_1,y_2) hOR(y1,y2),
∂ h A N D / ∂ y i ≥ 0 , ∂ h O R / ∂ y i ≥ 0 , ∀ y i ∈ [ 0 , 1 ] , i = 1 , 2. \partial h_{\mathrm{AND}}/\partial y_{i}\geq0,\partial h_{\mathrm{OR}}/\partial y_{i}\geq0,\forall y_{i}\in[0,1],i=1,2. ∂hAND/∂yi≥0,∂hOR/∂yi≥0,∀yi∈[0,1],i=1,2.
应用链式法则和真值表约束,得到了单调性约束
∂ g ( y ; θ ) / ∂ y ≥ 0 , ∀ y ∈ [ 0 , 1 ] . (11) \begin{aligned}\partial g(y;\theta)/\partial y\geq0,\forall y\in[0,1].\end{aligned} \tag{11} ∂g(y;θ)/∂y≥0,∀y∈[0,1].(11)
根据经验,我们发现在参数化中加强这两个约束是很重要的。
扩展评估指标。现在我们可以通过以下方式将度量扩展到代理损失:a)用softmax概率替换one-hot预测,b)用参数化函数替换逻辑操作。注意,如果度量包含几个逻辑操作,那么它们的参数将不会被共享。一个度量中的参数集合记为Θ。对于分割网络N和评价数据集S,评价指标的得分记为ξ(N;S)。参数化代理损失记为 ξ ^ Θ ( N ; S ) \hat{ξ}_Θ(N;S) ξ^Θ(N;S)。
4.2 代理参数化
参数化函数可以是定义在[0,1]上的任意函数族,如分段Bezier曲线和分段线性函数。这里我们选择分段Bezier曲线来参数化g(y;θ),它广泛应用于计算机图形学,并且易于通过其控制点执行约束。我们还验证了参数化g(y;θ)通过分段线性函数。图2为可视化,详见附录B。

分段贝塞尔曲线由一系列二次曲线组成,其中一个曲线段的最后一个控制点与下一个曲线段的第一个控制点重合。如果分段贝塞尔曲线有n个线段,则第k段定义为
B ( k , s ) = ( 1 − s ) 2 B 2 k + 2 s ( 1 − s ) B 2 k + 1 + s 2 B 2 k + 2 , 0 ≤ s ≤ 1 (12) B(k,s)=(1-s)^{2}B_{2k}+2s(1-s)B_{2k+1}+s^{2}B_{2k+2},0\leq s\leq1 \tag{12} B(k,s)=(1−s)2B2k+2s(1−s)B2k+1+s2B2k+2,0≤s≤1(12)
其中s横切第k段, B 2 k + i = ( B ( 2 k + i ) , u , B ( 2 k + i ) , v ) ( i = 0 , 1 , 2 ) B_{2k+i}=(B_{(2k+i),u},B_{(2k+i),v})~(i=0,1,2) B2k+i=(B(2k+i),u,B(2k+i),v) (i=0,1,2)表示第k段上的第i个控制点,其中 u , v u,v u,v表示二维平面轴。n条分段贝塞尔曲线总共有2n + 1个控制点。参数化g(y;θ),我们赋值
y = ( 1 − s ) 2 B 2 k , u + 2 s ( 1 − s ) B ( 2 k + 1 ) , u + s 2 B ( 2 k + 2 ) , u , g ( y ; θ ) = ( 1 − s ) 2 B 2 k , v + 2 s ( 1 − s ) B ( 2 k + 1 ) , v + s 2 B ( 2 k + 2 ) , v , s . t . B 2 k , u ≤ y ≤ B ( 2 k + 2 ) , u , \begin{align} &\text{y} =(1-s)^{2}B_{2k,u}+2s(1-s)B_{(2k+1),u}+s^{2}B_{(2k+2),u}, \tag{13a} \\ g(y;\theta)& =(1-s)^{2}B_{2k,v}+2s(1-s)B_{(2k+1),v}+s^{2}B_{(2k+2),v}, \tag{13b}\\ &\mathrm{s.t.}B_{2k,u}\leq y\leq B_{(2k+2),u},\tag{13c} \end{align} g(y;θ)y=(1−s)2B2k,u+2s(1−s)B(2k+1),u+s2B(2k+2),u,=(1−s)2B2k,v+2s(1−s)B(2k+1),v+s2B(2k+2),v,s.t.B2k,u≤y≤B(2k+2),u,(13a)(13b)(13c)
式中, θ \theta θ为控制点集 B 2 k , u < B ( 2 k + 1 ) , u < B ( 2 k + 2 ) , u , 0 ≤ k ≤ n − 1 B_{2 k, u}<B_{(2 k+1), u}<B_{(2 k+2), u}, 0 \leq k \leq n-1 B2k,u<B(2k+1),u<B(2k+2),u,0≤k≤n−1。给定输入 y y y,段索引 k k k和截线参数 s s s分别由公式 (13c)和公式(13a)导出。然后 g ( y ; θ ) g(y ; \theta) g(y;θ)赋值为公式 (13b)。因为 g ( y ; θ ) g(y ; \theta) g(y;θ)在 y ∈ [ 0 , 1 ] y \in[0,1] y∈[0,1],我们将 u u u轴上的控制点排列为, B 0 , u = 0 , B 2 n , u = 1 B_{0, u}=0, B_{2 n, u}=1 B0,u=0,B2n,u=1,其中第一个控制点和最后一个控制点的 u u u坐标分别为0和1。
分段贝塞尔曲线的优势在于,曲线形状是通过控制点明确定义的。在这里,我们通过以下方式在控制点上强制真值表和单调性约束:
B 0 , v = 0 , B 2 n , v = 1 ; ( t r u t h − t a b l e c o n s t r a i n t ) B 2 k , v ≤ B ( 2 k + 1 ) , v ≤ B ( 2 k + 2 ) , v , k = 0 , 1 , … , n − 1. ( m o n o t o n i c i t y c o n s t r a i n t ) \begin{gathered} B_{0,v}=0,B_{2n,v}=1; &(truth-table\; constraint) \\ B_{2k,v}\leq B_{(2k+1),v}\leq B_{(2k+2),v},\quad k=0,1,\ldots,n-1. &(monotonicity \;constraint) \end{gathered} B0,v=0,B2n,v=1;B2k,v≤B(2k+1),v≤B(2k+2),v,k=0,1,…,n−1.(truth−tableconstraint)(monotonicityconstraint)
为在优化中满足上述约束条件,参数的具体形式为
θ = { ( B i , u − B ( i − 1 ) , u B 2 n , u − B ( i − 1 ) , u , B i , v − B ( i − 1 ) , v B 2 n , v − B ( i − 1 ) , v ) ∣ i = 1 , 2 , … , 2 n − 1 } , \theta=\left\{\left(\frac{B_{i,u}-B_{(i-1),u}}{B_{2n,u}-B_{(i-1),u}},\frac{B_{i,v}-B_{(i-1),v}}{B_{2n,v}-B_{(i-1),v}}\right)\mid i=1,2,\ldots,2n-1\right\}, θ={(B2n,u−B(i−1),uBi,u−B(i−1),u,B2n,v−B(i−1),vBi,v−B(i−1),v)∣i=1,2,…,2n−1},
与 B 0 = ( 0 , 0 ) B_{0}=(0,0) B0=(0,0), B 2 n = ( 1 , 1 ) B_{2n}=(1,1) B2n=(1,1)固定的。所以每个 θ i = ( θ i , u , θ i , v ) \theta_i=(\theta_{i,u},\theta_{i,v}) θi=(θi,u,θi,v)在 [ 0 , 1 ] 2 [0,1]^2 [0,1]2,从这个参数化的形式计算控制点的实际坐标是很直接的。这种参数化使得各 θ i θ_i θi相互独立,从而简化了优化。默认情况下,我们使用两段分段贝塞尔曲线来参数化g(y;θ)。
4.3 代理参数优化
算法1描述了参数搜索算法。在搜索算法中,训练集被分成两个子集,分别是用于训练的Strain和用于评估的Shold-out。具体来说,假设我们有一个分割网络 N ω N_\omega Nω对于权值 ω \omega ω,我们的搜索目标是在hold-out训练集 ξ ( N ω ; S h o l d − o u t ) \xi(\mathrm{N}_{\omega};\mathcal{S}_{\mathrm{hold-out}}) ξ(Nω;Shold−out)
max Θ ξ ( Θ ) = ξ ( N ω ∗ ( Θ ) ; S h o l d − o u t ) , s . t . ω ∗ ( Θ ) = arg max ω ξ ~ Θ ( N ω ; S u r a i n ) . (14) \max_{\Theta}\xi(\Theta)=\xi(\mathrm{N}_{\omega^{*}(\Theta)};\mathcal{S}_{\mathrm{hold-out}}),\quad\mathrm{s.t.}\quad\omega^{*}(\Theta)=\arg\max_{\omega}\widetilde{\xi}_{\Theta}(\mathrm{N}_{\omega};\mathcal{S}_{\mathrm{urain}}). \tag{14} Θmaxξ(Θ)=ξ(Nω∗(Θ);Shold−out),s.t.ω∗(Θ)=argωmaxξ Θ(Nω;Surain).(14)
为了优化公式(14),我们将SGD作为内层问题来训练分割网络。在外部层面,我们使用强化学习作为搜索算法,遵循AutoML的常见做法(Zoph & Le, 2017; Pham et al, 2018)。其它搜索算法,例如进化算法,也可以被采用。具体来说,通过PPO2算法搜索代理参数(Schulman et al, 2017)。该过程由T个采样步骤组成。在第t步中,我们的目标是从t- 1开始探索它周围的搜索空间。在这里,M个参数 { Θ i ( t ) } i = 1 M \{\Theta_{i}^{(t)}\}_{i=1}^{M} {Θi(t)}i=1M独立于截断的正态分布(Burkardt, 2014)进行采样,如 Θ ∼ N t r u n c [ 0 , 1 ] ( μ t , σ 2 I ) \Theta\sim\mathcal{N}_{\mathrm{trunc}[0,1]}(\mu_{t},\sigma^{2}I) Θ∼Ntrunc[0,1](μt,σ2I),每个变量的取值范围为[0, 1]。其中, µ t µ_t µt和 σ 2 I σ^2 I σ2I表示母正态分布的均值和协方差(σ在本文中固定为0.2)。 µ t µ_t µt总结了(t−1)-步的信息。利用采样参数构造M个替代损失,分别驱动M个分割网络的训练。为了优化外部层次问题,我们使用目标度量对这些模型进行评估,并将评估分数作为PPO2的奖励。根据PPO2算法, µ t + 1 µ_{t+1} µt+1计算为 μ t + 1 = arg max μ 1 M ∑ i = 1 M R ( μ , μ t , Θ i ) \mu_{t+1}=\arg\max_{\mu}\frac{1}{M}\sum_{i=1}^{M}R(\mu,\mu_{t},\Theta_{i}) μt+1=argmaxμM1∑i=1MR(μ,μt,Θi),其中奖励 R ( μ , μ t , Θ i ) R(\mu,\mu_{t},\Theta_{i}) R(μ,μt,Θi)是
R ( μ , μ t , Θ i ) = min ( p ( Θ i ; μ , σ 2 I ) p ( Θ i ; μ t , σ 2 I ) ξ ( Θ i ) , C L I P ( p ( Θ i ; μ , σ 2 I ) p ( Θ i ; μ t , σ 2 I ) , 1 − ϵ , 1 + ϵ ) ξ ( Θ i ) ) , R(\mu,\mu_{t},\Theta_{i})=\min\left(\frac{p(\Theta_{i};\mu,\sigma^{2}I)}{p(\Theta_{i};\mu_{t},\sigma^{2}I)}\xi(\Theta_{i}),\mathrm{CLIP}\left(\frac{p(\Theta_{i};\mu,\sigma^{2}I)}{p(\Theta_{i};\mu_{t},\sigma^{2}I)},1-\epsilon,1+\epsilon\right)\xi(\Theta_{i})\right), R(μ,μt,Θi)=min(p(Θi;μt,σ2I)p(Θi;μ,σ2I)ξ(Θi),CLIP(p(Θi;μt,σ2I)p(Θi;μ,σ2I),1−ϵ,1+ϵ)ξ(Θi)),
其中min(·,·)从其输入中选取较小的项, C L I P ( x , 1 − ϵ , 1 + ϵ ) \mathrm{CLIP}(x,1-\epsilon,1+\epsilon) CLIP(x,1−ϵ,1+ϵ)剪辑x在 1 − ϵ 1-\epsilon 1−ϵ和 1 + ϵ 1+\epsilon 1+ϵ之间, p ( Θ i ; μ , σ 2 I ) p(\Theta_{i};\mu,\sigma^{2}I) p(Θi;μ,σ2I)为截断正态分布的PDF。注意,为了更好地收敛,在计算 ξ ( Θ i ) ξ(Θ_i) ξ(Θi)时,M个样本的平均奖励被减去。经过T步后,输出具有最高平均评价分数的平均值 µ T µ_T µT作为最终参数 Θ ∗ Θ^∗ Θ∗。
经验表明,搜索损失具有良好的可转移性,即可以应用于不同的数据集和网络。得益于此,我们使用轻量级代理任务进行参数搜索。在它中,我们利用了更小的图像大小,更短的学习时间表和轻量级的网络。因此,整个搜索过程非常高效(在PASCAL VOC上使用8个NVIDIA Tesla V100 GPU 8小时)。更多的细节见附录a。此外,对于一个特定的度量,搜索过程只能进行一次,由此产生的替代损失可以直接用于以后的训练。
5 EXPERIMENTS
我们对PASCAL VOC 2012 (Everingham et al, 2015)和citylandscapes (Cordts et al, 2016)数据集进行了评估。我们使用Deeplabv3+ (Chen et al, 2018)和ResNet-50/101 (He et al, 2016)作为网络模型。在代理参数搜索中,我们随机抽取PASCAL VOC中的1500张训练图像和cityscape中的500张训练图像,形成hold-out集Shold-out。剩下的训练图像组成搜索训练集Strain。µ0设置为g(y;θ) = y。骨干网为ResNet-50。图像被下采样到128 × 128的分辨率。SGD只持续1000次迭代,小批大小为32。在搜索过程之后,我们使用ResNet-101在完整的训练集上使用搜索损失重新训练分割网络,并在实际的验证集上评估它们。重新训练的设置与Deeplabv3+相同(Chen et al, 2018),只是损失函数被获得的代理损失所取代。搜索时间计算在8个NVIDIA Tesla V100 GPU上。更多细节见附录A。
5.1 搜索不同的指标
在表2中,我们将搜索到的代理损失与广泛使用的交叉熵损失及其变体以及其他一些特定度量的代理损失进行了比较。我们还试图与Li等人(2019)中基于automl的方法进行比较,该方法最初是为其他任务设计的。但由于收敛性问题,我们无法得到合理的结果。结果表明,我们的搜索损失在目标指标上与之前的损失持平或更好。值得注意的是,获得的边界度量的替代值(如BIoU和BF1)只关注边界区域,见附录C进一步讨论。我们还尝试训练由搜索的mIoU和BIoU/BF1替代损失驱动的分割网络。这样的综合损失在保持合理的全球表现的同时,细化了边界。

5.2 损失泛化
数据集之间的泛化。表3评估了我们搜索的损失代理在不同数据集之间的泛化能力。由于计算资源有限,我们只使用搜索到的mIoU、BF1和mAcc代理损失来训练网络。结果表明,我们的搜索代理损失在两个场景和类别完全不同的数据集之间泛化得很好。

分割网络之间的泛化。用ResNet50 + DeepLabv3+在PASCAL VOC上搜索代理损失。搜索到的损失驱动ResNet-101 + DeepLabv3+、PSPNet (Zhao et al ., 2017)和HRNet (Sun et al ., 2019)在PASCAL VOC上的训练。表4显示了结果。结果表明,我们的搜索损失函数可以应用于各种语义分割网络。

5.3 消融实验
参数化和约束。表5删除了参数化和搜索空间约束。其中,不带参数的代理表达式为公式(8),其定义域从离散点{0,1}扩展到连续区间[0,1]。这种简单的代理提供的准确性要低得多,这表明了参数化的本质。如果没有真值表约束,训练过程一开始就会发散,损失梯度变成“NaN”。如果不强制执行单调性约束,则性能会下降。如果没有约束,性能会下降,甚至算法会失败。

参数搜索代理任务。表6说明了这一点。最下面一行是我们的默认设置,它具有轻量级主干、低采样图像大小和较短的学习时间表。默认设置提供与较重设置相同的精度。这与我们的替代损失的泛化能力相一致。因此,我们可以通过轻代理任务来提高搜索效率。
参数搜索算法。图3所采用的PPO2 (Schulman et al ., 2017)算法与随机搜索算法的对比。PPO2更好的性能表明代理损失搜索是非平凡的,强化学习有助于提高搜索效率。

6 CONCLUSION
引入的Auto Seg-Loss是一种强大的框架,用于搜索主流分割评估指标的参数化代理损失。不可微算子被其参数化的连续算子所取代。优化参数以改进具有基本约束的最终评价指标。将这个框架扩展到更多的任务上会很有趣,比如物体检测、姿态估计和机器翻译问题。
Appendix
A. 实现细节

B. 分段线性函数的参数化

C. 边界分割的可视化与讨论



相关文章:
AUTO SEG-LOSS SEARCHING METRIC SURROGATES FOR SEMANTIC SEGMENTATION
AUTO SEG-LOSS: 搜索度量替代语义分割 论文链接:https://arxiv.org/abs/2010.07930 项目链接:https://github.com/fundamentalvision/Auto-Seg-Loss ABSTRACT 设计合适的损失函数是训练深度网络的关键。特别是在语义分割领域,针对不同的场…...

openssl3.2 - 官方demo学习 - 索引贴
文章目录 openssl3.2 - 官方demo学习 - 索引贴概述笔记工程的搭建和调试环境BIOBIO - client-arg.cBIO - client-conf.cBIO - saccept.cBIO - sconnect.cBIO - server-arg.cBIO - server-cmod.cBIO - server-conf.cBIO - 总结certsciphercipher - aesccm.ccipher - aesgcm.ccip…...

textarea文本框根据输入内容自动适应高度
第一种: <el-input auto-completeoff typetextarea :autosize"{minRows:3,maxRows:10}" class"no-scroll"> </el-input> /* 页面的样式表 */ .no-scroll textarea {overflow: hidden; /* 禁用滚动条 */resize: none; /* 禁止用户…...
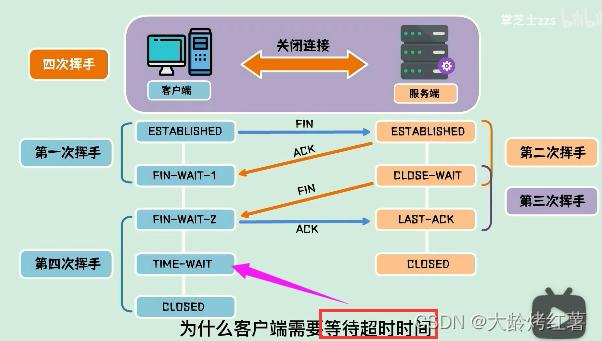
【JAVA基础--计算机网络】--TCP三次握手+四次挥手
三次握手四次挥手 写在前面1. 三次握手1.1 作用: 为了在不可靠的信道上建立起可靠的连接;1.2 建立过程1.3 面试提问 2. 四次挥手2.1 作用:为了在不可靠的网络信道中进行可靠的连接断开确认2.2 断开过程2.3 面试提问 写在前面 三次握手建立连…...

最新靠谱可用的-Mac-环境下-FFmpeg-环境搭建
最近在尝试搭建 FFmpeg 开发环境时遇到一个蛋疼的事,Google 了 N 篇文章竟然没有一篇是可以跑起来的! 少部分教程是给出了自我矛盾的配置(是的,按照贴出来的代码和配置,他自己都跑不起来),大部…...

【漏洞复现】Hikvision SPON IP网络对讲广播系统存在命令执行漏洞CVE-2023-6895
漏洞描述 Hikvision Intercom Broadcasting System是中国海康威视(Hikvision)公司的一个对讲广播系统。 Hikvision Intercom Broadcasting System是中国海康威视(Hikvision)公司的一个对讲广播系统。Hikvision Intercom Broadcasting System 3.0.3_20201113_RELEASE(HIK)版…...

微软为Windows内置记事本应用开发AI功能;2024年15个 AI 语音生成器
🦉 AI新闻 🚀 微软为Windows内置记事本应用开发AI功能 摘要:微软正在开发一个新的生成式AI功能,名为"Cowriter",用于Windows内置的记事本应用。该功能类似于画图应用中的"Cocreator"功能&#x…...
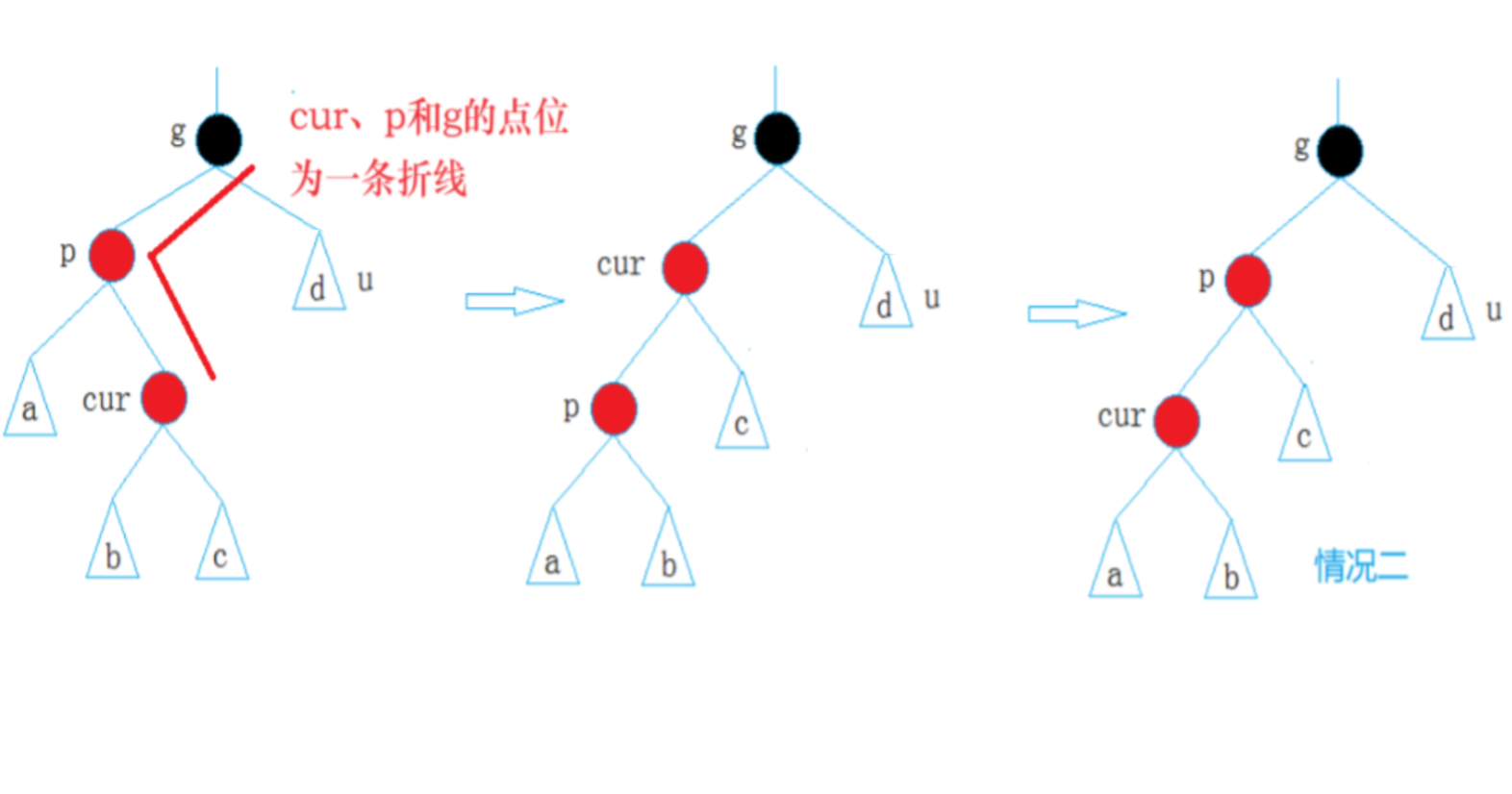
【C++进阶06】红黑树图文详解及C++模拟实现红黑树
一、红黑树的概念及性质 1.1 红黑树的概念 AVL树用平衡因子让树达到高度平衡 红黑树可以认为是AVL树的改良 通过给每个节点标记颜色让树接近平衡 以减少树在插入节点的旋转 在每个结点新增一个存储位表示结点颜色 可以是Red或Black 通过对任何一条从根到叶子的路径上 各个结点…...

2023年最严重的10起0Day漏洞攻击事件
根据谷歌公司威胁分析小组去年 7 月发布的报告显示,2022 年全球共有 41 个 0day 漏洞被利用和披露。而研究人员普遍认为,2023 年被利用的 0Day 漏洞数量会比 2022 年更高,这些危险的漏洞被广泛用于商业间谍活动、网络攻击活动以及数据勒索攻击…...

Linux之Iptables简易应用
文档形成时期:2009-2024年 和iptables打交道有15年了,经过无数实践后,形成一个简易应用文档。 文档主题是简易应用,所以其原理不详述了。 因软件世界之复杂和个人能力之限,难免疏漏和错误,欢迎指正。 文章目…...

树状结构查询 - 华为OD统一考试
OD统一考试 分值: 200分 题解: Java / Python / C++ 题目描述 通常使用多行的节点、父节点表示一棵树,比如: 西安 陕西 陕西 中国 江西 中国 中国 亚洲 泰国 亚洲 输入一个节点之后,请打印出来树中他的所有下层节点。 输入描述 第一行输入行数,下面是多行数据,每行以…...
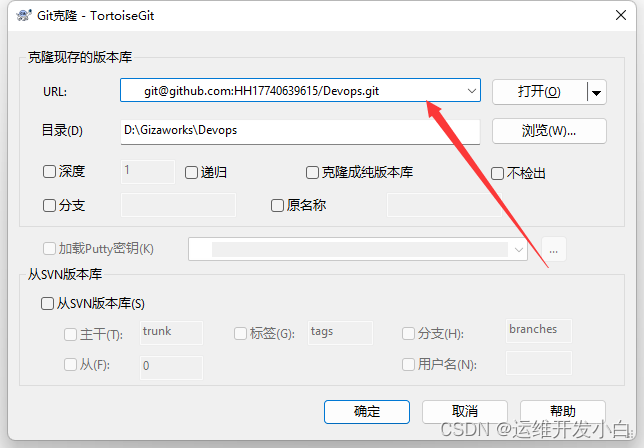
版本控制系统教程
1.Git的基本介绍 1.1 Git的概念 Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目.Git是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件.Git与常用的版本控制工具CVS,Subversion等不同ÿ…...

Java多线程并发篇----第十篇
系列文章目录 文章目录 系列文章目录前言一、start 与 run 区别二、JAVA 后台线程三、什么是乐观锁前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。 一、start 与 r…...

模型\视图一般步骤:为什么经常要用“选择模型”QItemSelectionModel?
一、“使用视图”一般的步骤: //1.创建 模型(这里是数据模型!) tabModelnew QSqlTableModel(this,DB);//数据表 //2.设置 视图的模型(这里是数据模型!) ui->tableView->setModel(tabModel); 模型种类: QStringListModel…...
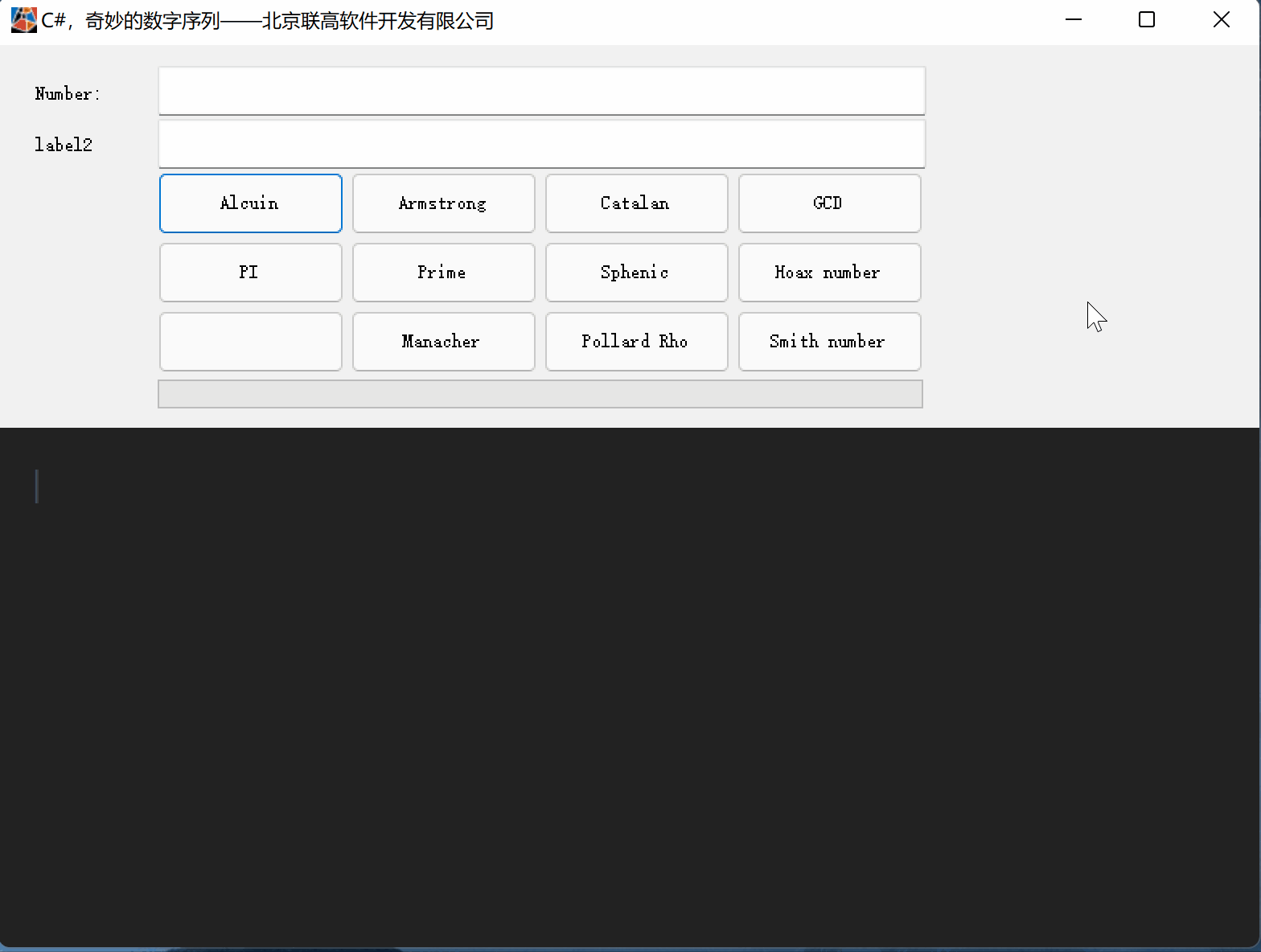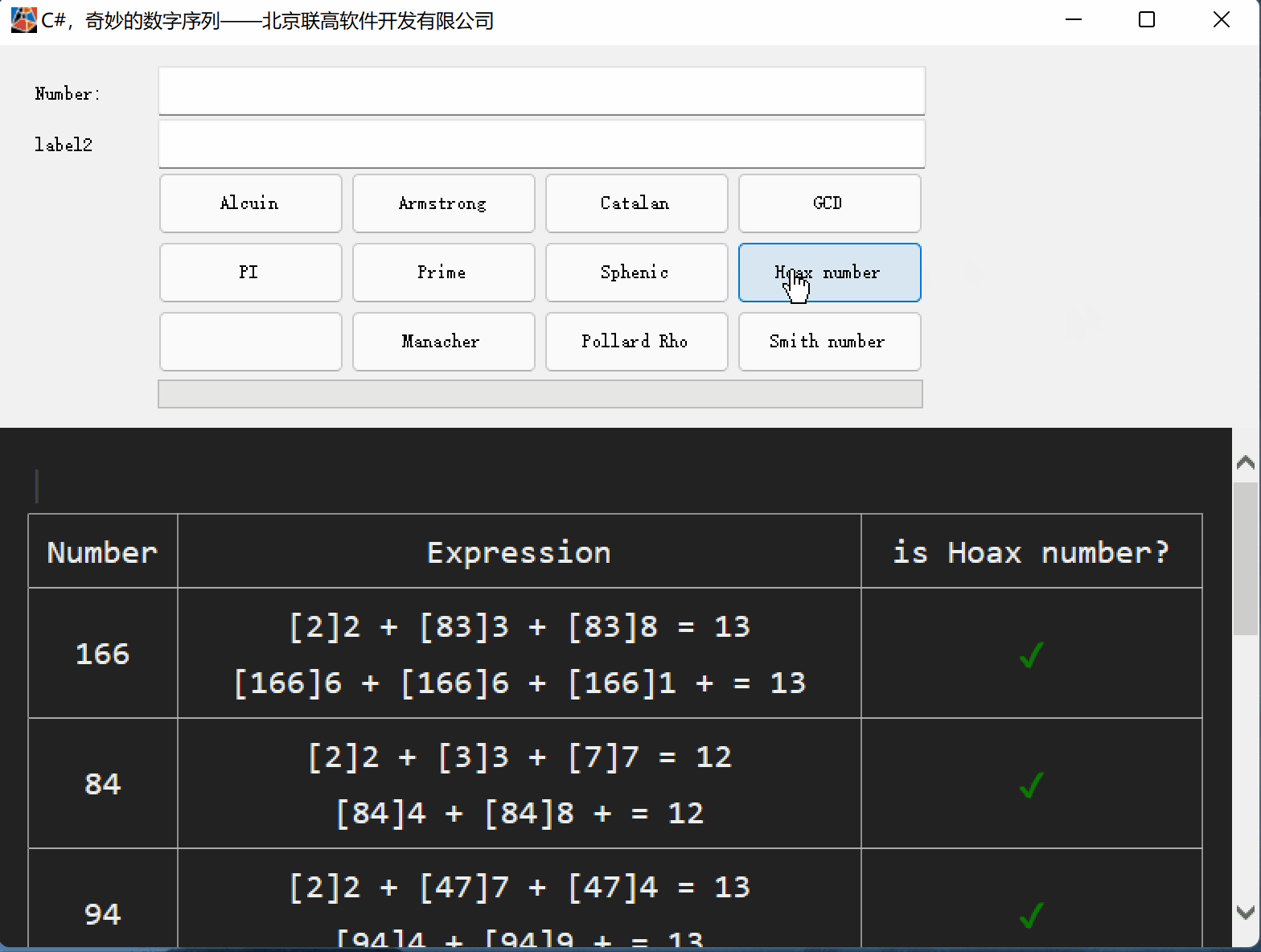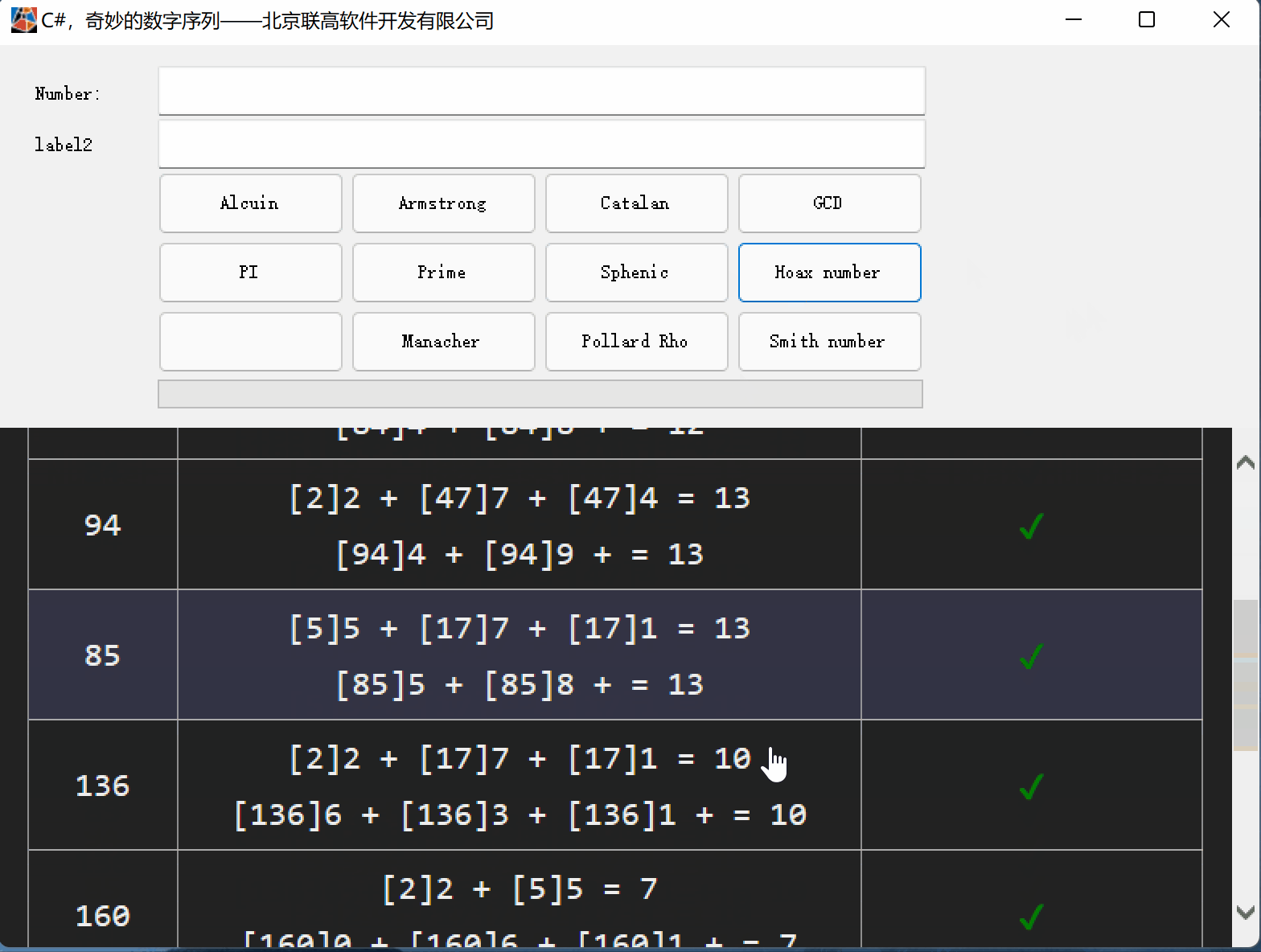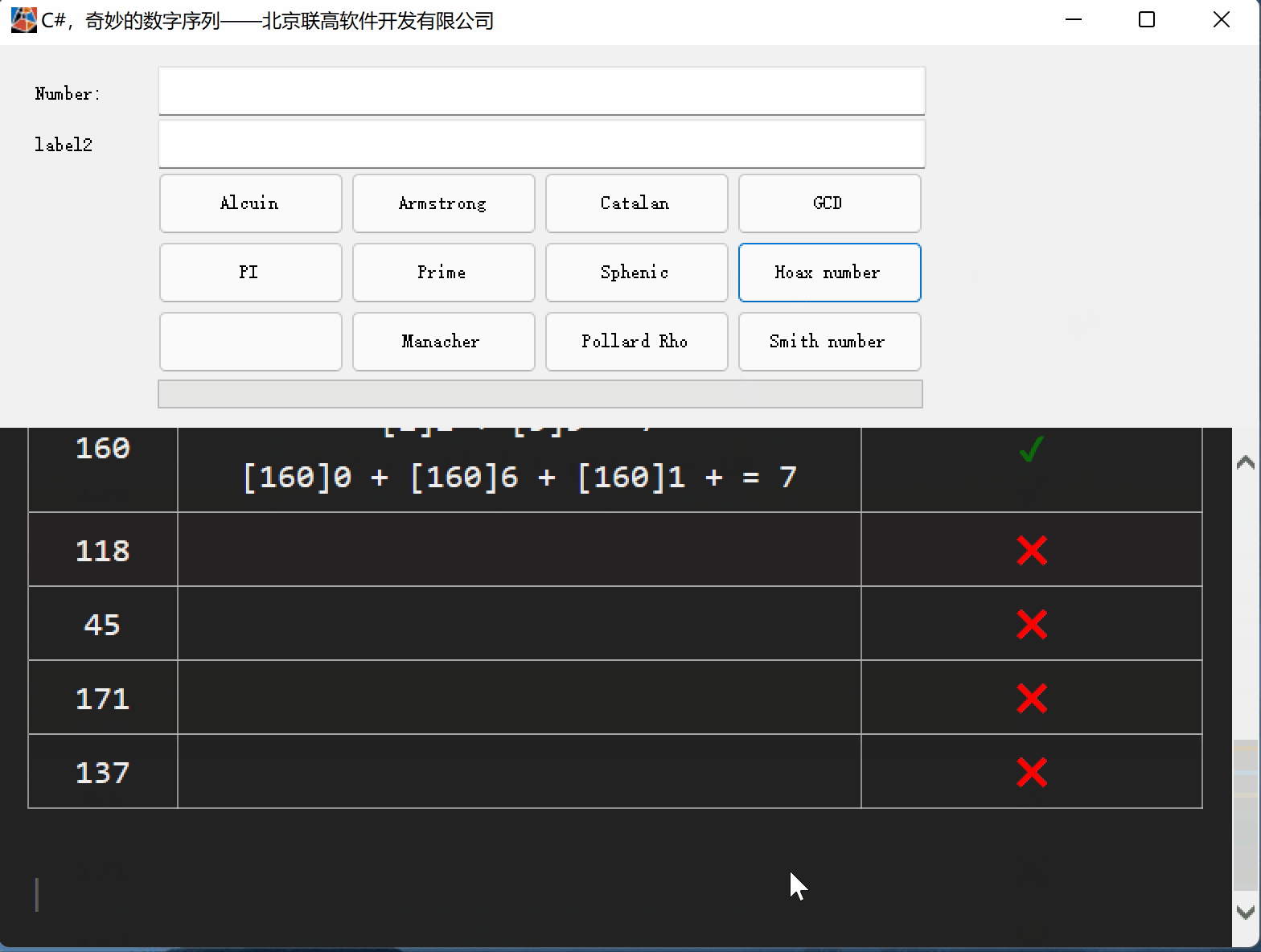
C#,愚弄数(Hoax Number)的计算方法与源代码
一、愚弄数(Hoax Number) 愚弄数(Hoax Number)是一种组合数字, 其数字总和等于其不同质因数的数字总和。 注:1不被视为质数, 因此它不包含在不同质因数的总和中。 有些愚弄数(Hoax Number)数字也…...

c JPEG编码,此程序没有处现MCU中亮度分量的排序
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <stdlib.h> #include <unistd.h> #include <sys/ioctl.h> #include <linux/videodev2.h> //v4l2 头文件 #include <strin…...
前端规范扩展
前端编程规范是基于原有vue2基础上那套《编码风格及标准》上,应用于vue3、typescript、vite2基础上延伸出来的扩展补充,持续完善 一、编码规范 ESLint 代码检测工具 Pretter 代码格式化工具配合双校验代码 Git 规范 - 编码工具 vscode 同步参考文档中…...

【AI视野·今日NLP 自然语言处理论文速览 第七十二期】Mon, 8 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 8 Jan 2024 Totally 17 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers DeepSeek LLM: Scaling Open-Source Language Models with Longtermism Authors DeepSeek AI Xiao Bi, Deli Ch…...

RT-Thread基于AT32单片机的CAN应用
1 硬件电路 2 RT-Thread驱动配置 RT-Studio中没有CAN相关的图形配置,需要手动修改board.h。在board.h的末尾,增加相关的BSP配置。 #define RT_CAN_USING_HDR #define BSP_USING_CAN13 IO配置 at32_msp.c中的IO配置是PB9和PB10,掌上实验室V…...

LeetCode---121双周赛---数位dp
题目列表 2996. 大于等于顺序前缀和的最小缺失整数 2997. 使数组异或和等于 K 的最少操作次数 2998. 使 X 和 Y 相等的最少操作次数 2999. 统计强大整数的数目 一、大于等于顺序前缀和的最小缺失整数 简单的模拟题,只要按照题目的要求去写代码即可,…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...