WeNet2.0:提高端到端ASR的生产力
摘要
最近,我们提供了 WeNet [1],这是一个面向生产(=工业生产环境需求)的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时(built-in runtime)来处理流式和非流式解码模式。
为了进一步提高 ASR 性能并满足各种生产需求,在本文中,我们介绍了 WeNet 2.0 的四个重要更新。
-
我们提出了 U2++,这是一个具有双向注意力解码器的统一双通道框架(two-pass framework with bidirectional attention decoders),其中包括从右到左注意力解码器(注意,是right-to-left方向!)的未来上下文信息,以提高共享编码器的表示能力(representative ability)和重新评分阶段(rescoring stage)的性能。
-
我们在 WeNet 2.0 中引入了基于 n-gram 的语言模型和基于 WFST 的解码器,促进了富文本数据(rich text data)在生产场景中的使用。 【这个好!可以说,上一代的代表kaldi的重要的功能,目前在WeNet2.0中进行很好的idea和方法论的继承和实现】
-
我们设计了一个统一的上下文偏置框架(unified contextual biasing framework),该框架利用用户特定的上下文(例如联系人列表-contact lists)为生产提供快速适应能力,并在“有 LM” 和“无 LM”两大场景中提高 ASR 准确性。
-
我们设计了一个统一的 IO 来支持大规模数据进行有效的模型训练。
综上所述,全新的 WeNet 2.0 在各种语料库上比原来的 WeNet 实现了高达 10% 的相对识别性能提升,并提供了几个面向生产的重要特性。
索引词:U2++,语言模型,上下文偏置(contextual biasing),UIO
论文地址:https://arxiv.org/pdf/2203.15455.pdf
github地址:https://github.com/wenet-e2e/wenet
1 简介
端到端 (end-to-end, E2E) 方法,例如连接主义时间分类 (connectionist temporal classification - CTC) [2, 3]、循环神经网络转换器 (RNN-T) [4, 5, 6, 7] 和基于注意力的编码器-解码器 ( attention-based encoder-decoder: AED) [8, 9, 10, 11, 12],在过去几年中引起了对自动语音识别 (ASR) 的极大兴趣。
最近的工作 [13, 14, 15] 表明 E2E 系统不仅极大地简化了语音识别管道,而且在准确性上也超过了传统的混合 ASR 系统(hybrid ASR systems)。
考虑到 E2E 模型的优势 [16],将新兴的 E2E ASR 框架部署到具有稳定和高效特性的实际生产中变得很有必要。然而,几乎所有著名的 E2E 语音识别工具包,例如 ESPnet [17] 和 SpeechBrain [18],都是面向研究而非面向生产的。【鉴于ESPnet是几位日本人研究者开发的,所以,对于日文的支持,有一定的优势。一些日本的企业,也仍然在使用ESPnet来训练他们的ASR模型。】
在 [1] 中,我们提出了一个生产优先和生产就绪(production first and production ready = PFPR,这个词好!)的 E2E 语音识别工具包 WeNet1,它专注于解决实际生产中基于 Transformer [19] 或 Conformer [20] 的 E2E 模型的棘手问题。
具体来说,WeNet 采用联合 CTC/AED (例如,主要是指综合ctc loss和attention loss)结构作为基本模型结构。然后,提出了一个统一的两通(two-pass,U2)框架来解决流式传输问题,其中在训练过程中应用动态块掩码策略(dynamic chunk masking)将流式和非流式模式统一在一个统一的神经模型中,并提供“构建运行时”(built-in runtime),开发人员可以在其中运行 x86 和 android E2E 系统以进行开箱即用的语音识别。
WeNet 极大地减少了在实际应用中部署 E2E 模型的工作量,因此被研究人员和开发人员广泛采用,用于在实际生产中实现语音识别。
在本文中,我们介绍了 WeNet 2.0,它介绍了 WeNet 中最新的发展和更新的解决方案,用于面向生产的语音识别。 WeNet 2.0 的主要更新如下。
- U2++:我们将原来的U2框架升级为U2++(嗯!估计下次再升级,就是U2#了,++++),同时利用标注序列的从左到右和从右到左的双向上下文信息,在训练阶段学习更丰富的上下文信息,结合前向和反向预测,以在解码阶段获得更准确的结果。实验表明,与原始 U2 框架相比,U2++ 实现了高达 10% 的相对改进(细节代码学习,后续安排上!TODO)。
- 生产(产品-production)语言模型解决方案:我们支持一个可选的 n-gram LM,在流式 CTC 解码阶段,它将与基于加权有限状态自动机 (WFST) [21] 的解码图中的 E2E 建模单元组成。
n-gram LM 可以在丰富的生产积累文本数据上快速训练,这是面向生产的重要特征。实验表明,n-gram 语言模型可以提供高达 8% 的相对性能提升(这也凸显了基于更大规模文本语料,训练出来的语言模型,的有效性!)。
- 上下文偏置(contextual biasing):我们设计了一个统一的上下文偏置框架,它提供了在流解码阶段利用或不使用 LM 的用户特定上下文信息的机会。利用用户特定的上下文信息(例如,联系人列表、特定对话状态、呈现给用户的选项、对话主题、位置等)在提高 ASR 准确性和在语音生成中提供快速适应能力方面发挥着重要作用。【这个对于很多场景有用:例如长时间的电话会议的会议内容转录,长时间的视频的语音理解,等等!】实验表明,我们的上下文偏差解决方案可以为有 LM 和没有 LM 的情况带来显着的改进。
- 统一IO(UIO):我们设计了一个统一的IO系统来支持大规模数据集进行有效的模型训练。 UIO 系统为不同的存储(即本地磁盘或云)和不同规模的数据集(即小型或大型数据集)提供统一的接口。
对于小型数据集,UIO 保持样本级随机访问能力。而对于大型数据集,UIO 将数据样本聚合到分片shard(有关详细信息,请参阅图 4)并提供分片级随机访问能力。
多亏有了 UIO,WeNet 2.0 可以弹性地支持几小时到数百万小时数据的训练。
总而言之,我们全新的 WeNet 2.0 提供了几个重要的面向生产的功能,与原始 WeNet 相比,它实现了显著的 ASR 改进,并使其自身成为更高效的 E2E 语音识别工具包。
2 WeNet 2.0
在本节中,我们将分别详细描述面向生产的关键更新:U2++ 框架、生产语言模型解决方案、上下文偏置和统一 IO。
2.1 U2++
U2++ 是一个统一的两通(two-pass)联合 CTC/AED 框架,带有双向注意力解码器,为统一流式和非流式模式提供了理想的解决方案。
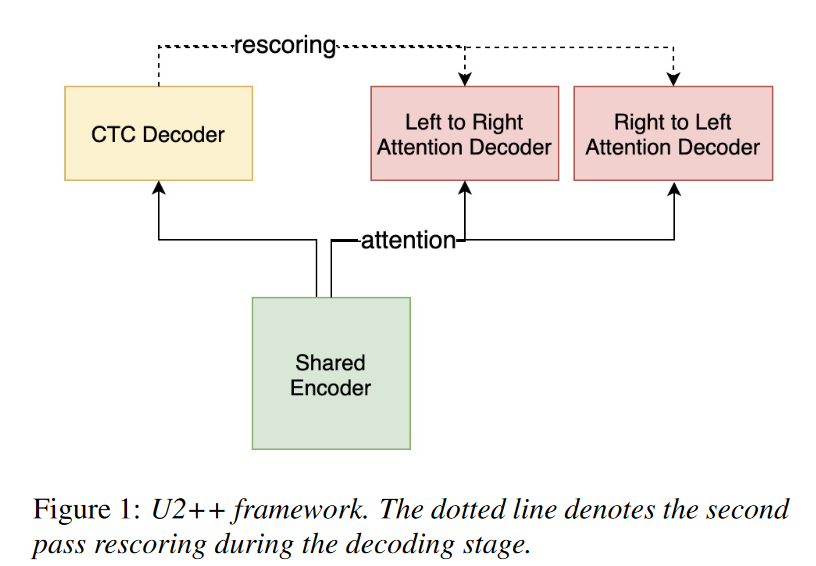
U2++框架;左边一路是ctc loss;右边是attention decoder/loss(而且右边又包括了,从左到右,从右到左的两个方向)
如图1所示,U2++由四部分组成。
1) 对声学特征信息进行建模的共享编码器(shared encoder)。
共享编码器由多个 Transformer [19] 或 Conformer [20] 层组成,它们只考虑有限的右侧上下文(limited right contexts)以保持平衡的延迟(balanced latency)。
2) 一个 CTC 解码器,它对声学特征(acoustic features)和token单元(token units)之间的帧级对齐信息(frame-level alignment information)进行建模。
CTC 解码器由一个线性层组成,它将共享编码器输出转换为 CTC 激活。
3)一个从左到右的注意力解码器(L2R),它对从左到右的有序标记序列进行建模,以表示过去的上下文信息。
4)一个从右到左的注意力解码器(R2L),它对从右到左的反向标记序列进行建模,以表示未来的上下文信息。
L2R 和 R2L 注意力解码器由多个 Transformer 解码器层组成。
在解码阶段,CTC 解码器在第一遍以流模式运行,L2R 和 R2L 注意力解码器在非流模式下重新评分,以提高第二遍的性能。
与 U2 [1] 相比,我们增加了一个额外的从右到左注意力解码器来增强我们模型的上下文建模能力,使得上下文信息不仅来自过去(从左到右解码器),而且来自未来(从右到左的解码器)。
这提高了共享编码器的代表能力、整个系统的泛化能力以及重新评分阶段的性能。
组合 CTC 和 AED 损失Losses,用于训练 U2++:

与U2类似,采用动态块掩码策略(dynamic chunk masking strategy)来统一流式(streaming)和非流式(non-streaming)模式。
在训练阶段,我们首先从均匀分布 :
C ∼ U(1, max batch length T)
中采样一个随机块大小 C。
然后,输入被分成几个具有所选块大小的块。
最后,当前块在训练中分别对自身和 L2R/R2L 注意力解码器中的前/后块进行双向块级注意(注意力的计算)。
在解码阶段,从第一遍 CTC 解码器获得的 n-best 结果由 L2R 和 R2L 注意力解码器重新评分,其相应的声学信息由共享编码器生成。
根据经验,更大的块大小会导致更好的结果和更高的延迟。
由于采用了动态策略,U2++ 学会了使用任意块大小进行预测,从而可以通过“在解码中调整块大小”来简化准确性和延迟的平衡。
2.2.语言模型
为了促进富文本数据在生产场景中的使用,我们在 WeNet 2.0 中提供了统一的 LM 集成框架,如图 2 所示。

通过 n-best 结果。
其一,当没有提供 LM 时,应用 CTC 前缀波束搜索(CTC prefix beam search)来获得 n 个最佳候选。
其二,当提供了 LM 时,WeNet 2.0 将 n-gram LM (G)、词典 (L) 和端到端建模 CTC 拓扑 (topology-T) 编译成基于 WFST 的解码图 (TLG) :
TLG = T ◦ min(det(L ◦ G)), (3)
然后应用 CTC WFST 波束搜索来获得 n 个最佳候选。
最后,通过 Attenion Rescoring 模块对 n 个最佳候选者进行重新评分,以找到最佳候选者。
我们重用 Kaldi[22] 中的算法和代码进行解码,在 WeNet 2.0 框架中表示为 CTC WFST 波束搜索。
为了加快解码速度,采用了空白帧跳过(blank frame skipping)[23]技术。
2.3.上下文偏置
利用用户特定(user-specific)的上下文信息(例如,联系人列表、驾驶员导航)在语音生成中起着至关重要的作用,它始终显著提高准确性并提供快速适应能力。
在 [24, 25, 26] 中研究了传统和 E2E 系统的上下文偏置(contextual biasing)技术。
在 WeNet 2.0 中,为了在流解码阶段利用 LM 和无 LM 情况下的用户特定上下文信息,受 [25] 的启发,我们在已知一组偏置短语时,动态构建“上下文相关的 WFST 解码图”。
we construct a contextual WFST graph on the fly when a set of biasing phrases are known in advance.
首先,根据 LM-free 情况下的 E2E 建模单元(E2E modeling units)或 with-LM 情况下的词汇词(vocabulary words),将偏置短语拆分为偏置单元(biasing units)。
然后,“上下文相关 WFST 图”,按如下方式动态构建:
(1)每个具有提升分数(boosted score)的偏置单元(biasing unit)按顺序放置在相应的弧上,以生成可接受的链(acceptable chain)。
(2) 对于可接受链的每个中间状态(intermediate state),添加一个具有负累积提升分数(negative accumulated boosted score)的特殊失败弧(special failure arc)。
当仅匹配部分偏置单元而不是整个短语时,失败弧(failure arc)用于移动提升的分数(move the boosted scores)。
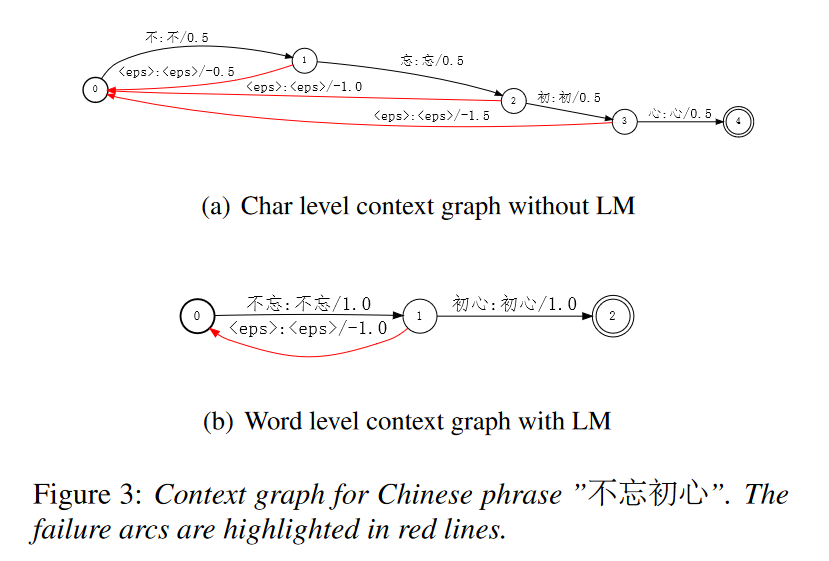
在上面的图 3 中,分别显示了:
LM-free 情况下的 char(E2E 建模单元)级【单个文字】上下文图,和,
with-LM 情况下的单词级【不忘+初心】上下文图。
最后,在流式(streaming)解码阶段,当波束搜索结果,通过“上下文相关的 WFST 图”与偏置单元匹配时,立即添加一个 boosted score,如

其中 P_C (y) 是偏置分数,λ 是一个可调超参数,用于控制上下文 LM 对整体模型分数的影响程度。
特别是当一些有偏见的短语共享相同的前缀时,我们会进行贪婪匹配以简化实现。
2.4. UIO
通常,生产规模的语音数据集包含数万小时的标记语音,其中始终包含大量小文件。
海量的小文件会导致以下问题:
• 内存不足(OOM):我们必须保留所有小文件的索引信息,这对于大型数据集来说非常消耗内存。
• 训练速度慢:随机访问海量小文件时,读取数据的时间非常长,成为训练的瓶颈。
针对上述大规模生产数据集的问题,同时保持小数据集的高效率,我们设计了一个统一的IO系统,为不同的存储(即本地磁盘或云)和不同的规模提供统一的接口数据集(即小型或大型数据集)。
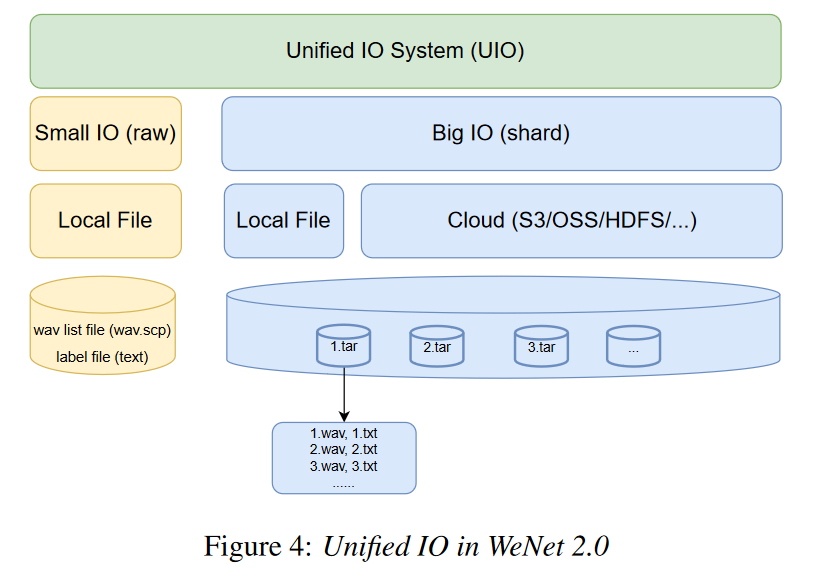
整个框架如图 4 所示。
对于大型数据集,受 TFReord (Tensorflow) [27] 和 AIStore [28] 的启发,我们将每个批处理的较小样本(例如 1000 个样本)及其相关元数据信息打包到相应的更大分片中,这是由 GNU tar 完成的,它是一种开源、开放格式、无处不在且得到广泛支持的存档工具。
Tar 文件显着节省内存并有效克服 OOM 问题。在训练阶段,在内存中进行on-the-fly(在线,动态)解压,顺序读取同一个压缩分片中的数据,解决了随机数据访问的耗时问题,加快了训练过程。
同时可以随机读取不同的分片,保证数据的全局随机性。对于小数据集,我们也可以直接加载训练样本。特别是在大数据集使用分片时,我们支持从本地磁盘和分布式存储(例如 S3、OSS、HDFS 等)加载分片。与TFRecord类似,设计了即时处理数据的链式操作,使统一IO可扩展且易于调试。
3 实验
在本节中,我们将描述我们的实验设置、测试集并分析实验结果。 WeNet recipes 中提供了大多数实验设置。
实验在以下全部或部分语料库上进行:
- AISHELL-1 [29]、
- AISHELL-2 [30]、
- LibriSpeech [31]、
- GigaSpeech [32] 和最近发布的
- WenetSpeech [33]。
这五个语料库包括不同的语言(英语和普通话)、录制环境(干净和嘈杂)和大小(100 - 10000 小时)。
3.1 U2++
为了评估我们的 U2++ 模型的有效性,我们对上面列出的所有 5 个 ASR 语料库进行了实验。对于大多数实验,具有 25ms 窗口和 10ms 偏移的 80 维 log Mel 滤波器组 (FBANK) 用作声学特征。
SpecAugment [34] 即时应用于数据增强。
在编码器的前面使用了两个内核大小为 3*3 和步幅为 2 的卷积子采样层。
我们的编码器中,使用 12 个conformer layers。
为了保持 U2/U2++ 的可比参数,我们为 U2 使用 6 个transformer 解码器层,为 U2++ 使用 3 个从左到右和 3 个从右到左的解码器层。
此外,我们通过模型平均(model averaging)获得最终模型。
在 AISHELL-1 和 AISHELL-2 中,注意力层使用注意力维度 256、前馈 2048 和 4-head attention。
在 LibriSpeech、GigaSpeech 和 WenetSpeech 中,注意力层使用注意力维度 512、前馈 2048 和 8-head attention。
五个语料库的卷积模块的内核大小分别为 8/8/31/31/15。累积梯度用于稳定训练(accumulated gradient,例如如果batch=16,累计梯度=2,那么其实是32个样本,更新一次梯度的adam等优化搜索)。

在表 1 中,我们报告了每个语料库的:
字符错误率 (CER)、单词错误率 (WER) 或混合错误率 (MER)。
它表明 U2++ 在大多数语料库上都优于 U2,并且相对于 U2 实现了高达 10% 的相对改进。
从结果来看,我们认为 U2++ 在各种类型和大小的 ASR 语料库中始终表现出优异的性能。
3.2. N-gram 语言模型
语言模型解决方案在 AISHELL-1、AISHELL-2 和 LibriSpeech 上对第 3.1 节中列出的模型进行评估。对于 AISHELL-1 和 AISHELL-2,使用在其自己的训练语料库上训练的 tri-gram。
对于 LibriSpeech,使用了官方预训练的4-gram大语言模型(fglarge)。
为了加快解码速度,当一帧“空白”符号的概率大于 0.98 时,将跳过该帧。

表 2 展示了三个语料库在有 LM 和无 LM 场景中的比较结果。 with-LM 解决方案在 AISHELL-1 上显示 5% 的增益,在 AISHELL-2 上的可比结果,在 LibriSpeech 上测试清洁的可比结果,以及在 LibriSpeech 上的其他测试中的卓越改进 (8.42%)。
总之,我们的生产 LM 解决方案在三个语料库上显示出一致的增益,这说明 n-gram 语言模型在集成到 E2E 语音识别系统时效果很好。
得益于该方案,生产系统(production system)可以享受到丰富的生产积累文本数据。
3.3.上下文偏置
我们评估接触场景中的上下文偏置,我们设计了两个从 AISHELL-2 测试集中选择的测试集。
• test_p:带有相关上下文的正测试集(positive test set)。我们选择了 107 个带有人名的话语,所有的人名在解码时都作为上下文偏置短语附加。
• test_n:在正测试集中没有任何上下文偏置短语(即名称)的负测试集(negative test set)。
我们随机选择 107 个符合条件的话语作为负测试集()。我们在有和没有 LM 的 AISHELL-1 U2++ 模型上进行了测试。我们表明,可以通过切换提升分数来控制上下文偏差的强度。在我们的实验中,提升分数从 0 到 10 不等,其中 0 表示未应用上下文偏差。
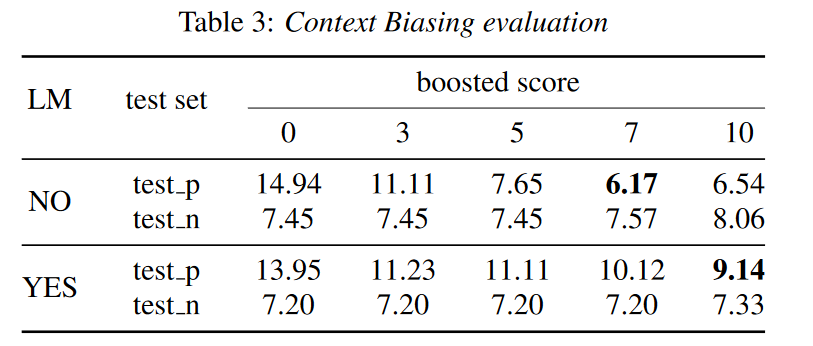
如表 3 所示,我们的解决方案降低了正测试集的错误率,并且更大的提升分数通常会带来更好的改进。
此外,当设置适当的提升分数时,我们可以提高正测试集的性能,同时避免负测试集的性能下降。
3.4. UIO
我们评估了 UIO 在 AISHELL-1 [29] 和 WenetSpeech [33] 上的性能,包括准确性、可扩展性和训练速度。
具体来说,我们在一台机器上为 AISHELL-1 使用 8 个 GPU,在三台机器上为 WenetSpeech 使用 24 个 GPU。
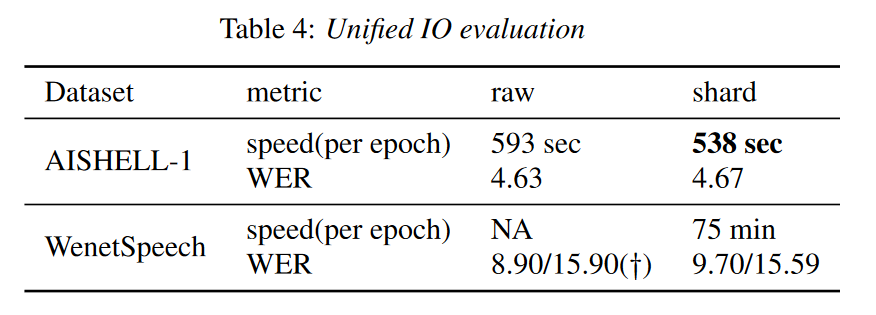
如表 4 所示,UIO 在 AISHELL-1 上的 raw 和 shard 模式下显示出接近的准确性,而 shard 模式在训练速度方面得到了大约 9.27% 的加速。
对于 WenetSpeech,由于只使用 raw 模式进行训练太慢,所以没有显示训练速度。我们采用 ESPnet 的结果(标有†)作为我们的基线,它与我们的模型具有相同的配置。
通过分片模式在 WenetSpeech 上训练的模型的结果与 ESPnet 相当,这进一步说明了 UIO 的有效性。
4 结论和未来工作
在本文中,我们提出了更具生产力的 E2E 语音识别工具包 WeNet 2.0,它引入了几个重要的面向生产的特性并实现了显著的 ASR 性能改进。
我们正在开发 WeNet 3.0,主要专注于无监督自学习、设备端模型探索和优化以及其他生产工作。
相关文章:
WeNet2.0:提高端到端ASR的生产力
摘要 最近,我们提供了 WeNet [1],这是一个面向生产(工业生产环境需求)的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时(built-in runtime)…...
)
第九部分 使用函数 (四)
目录 一、foreach 函数 二、if 函数 三、call 函数 一、foreach 函数 foreach 函数和别的函数非常的不一样。因为这个函数是用来做循环用的,Makefile 中的 foreach 函数几乎是仿照于 Unix 标准 Shell(/bin/sh)中的 for 语句,或…...
一文读懂「Prompt Engineering」提示词工程
在了解提示过程之前,先了解一下什么是提示prompt,见最后附录部分 一、什么是Prompt Engingering? 提示工程(Prompt Engingering),也被称为上下文提示(In-Context Prompting)&#x…...

微信小程序(一)简单的结构及样式演示
注释很详细,直接上代码 涉及内容: view和text标签的使用类的使用flex布局水平方向上均匀分布子元素垂直居中对齐子元素字体大小文字颜色底部边框的宽和颜色 源码: index.wxml <view class"navs"><text class"active…...

【设计模式】外观模式
前言 1. 单例模式(Singleton Pattern):保证一个类只有一个实例,并提供一个全局的访问点。 2. 工厂模式(Factory Pattern):定义一个创建对象的接口,但由子类决定要实例化的类是哪一…...
优先级队列(Priority Queue)
文章目录 优先级队列(Priority Queue)实现方式基于数组实现基于堆实现方法实现offer(E value)poll()peek()isEmpty()isFull() 优先级队列的实现细节 优先级队列(Priority Queue) 优先级队列是一种特殊的队列,其中的元素…...
12-桥接模式(Bridge)
意图 将抽象部分与它的实现部分分离,使他们可以独立地变化 个人理解 一句话概括就是只要是在抽象类中聚合了某个接口或者抽象类,就是使用了桥接模式。 抽象类A中聚合了抽象类B(或者接口B),A的子类的方法中在相同的场…...

Zookeeper+Kafka概述
一 Zookeeper 1.1 Zookeeper定义 Zookeeper是一个开源的、分布式的,为分布式框架提供协调服务的Apache项目。 1.2 Zookeeper特点 Zookeeper:一个领导者(leader),多个跟随者(Follower)组成的…...
架构师 - 架构师是做什么的 - 学习总结
架构师核心定义 架构师是什么 架构师是业务和技术之间的桥梁 架构师的核心职责是消除不确定性、和降低复杂性 架构设计环 架构师的三个核心能力 架构师的三个关键思维 架构师主要职责 架构设计 Vs 方案设计 架构设计前期 主要任务 澄清不确定性 明确利益干系人的诉求消除冲…...
全链路压测方案(一)—方案调研
一、概述 在业务系统中,保证系统稳定至关重要,直接影响线上业务稳定和性能。测试工作作为保证生产质量的最后一关,扮演者重要的角色。全链路压测是一种重要的测试工具和手段。可以解决系统中多环节多节点无法全流程打满流量的痛点问题&a…...

c++关键字const
C中的const是一种常量修饰符。在变量、函数参数和成员函数中使用const可以限制其对数据的修改。 const修饰的数据在定义时必须进行初始化,且不能被修改,因此使用const可以提高代码的安全性和可读性。在C中,const修饰的成员函数表示该函数保证…...
分布式计算平台 Hadoop 简介
Hadoop简介 Hadoop是一种分析和处理大数据的软件平台,是一个用Java语言实现的Apache的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。其主要采用MapReduce分布式计算框架,包括根据GFS原理开发的分布式文件系统HDFS、…...

系统学习Python——警告信息的控制模块warnings:常见函数-[warnings.warn]
分类目录:《系统学习Python》总目录 warnings.warn(message, categoryNone, stacklevel1, sourceNone, \*, skip_file_prefixesNone)常备用于引发警告、忽略或者触发异常。 如果给出category参数,则必须是警告类别类 ;默认为UserWarning。 或…...

监听键盘事件vue3封装hooks
监听页面键盘事件,执行对应方法 使用第三方API:vueuse 我封装的: 1. useKeyboardEvent.ts import { useMagicKeys } from vueuse/coreexport function enterKey(f: Function) {const { enter } useMagicKeys()watch(enter, v > {if (…...

Java Stream简化代码
使用原始流以获得更好的性能 使用 int、long 和 double 等基本类型时,请使用IntStream、LongStream 和 DoubleStream 等基本流,而不是 Integer、Long 和 Double 等装箱类型流。原始流可以通过避免装箱和拆箱的成本来提供更好的性能。 var array new i…...
py爬虫入门笔记(request.get的使用)
文章目录 Day11. 了解浏览器开发者工具2. Get请求http://baidu.com3. Post请求https://fanyi.baidu.com/sug4. 肯德基小作业 Day21. 正则表达式2. 使用re模块3. 爬取豆瓣电影Top250的第一页4. 爬取豆瓣电影Top250所有的250部电影信息 Day31. xpath的使用2. 认识下载照片线程池的…...

openssl3.2 - 官方demo学习 - encode - rsa_encode.c
文章目录 openssl3.2 - 官方demo学习 - encode - rsa_encode.c概述笔记END openssl3.2 - 官方demo学习 - encode - rsa_encode.c 概述 命令行参数 server_priv_key.pem client_priv_key.pem 这2个证书是前面certs目录里面做的 官方这个程序有bug, 给出2个证书, 还要从屏幕上输…...
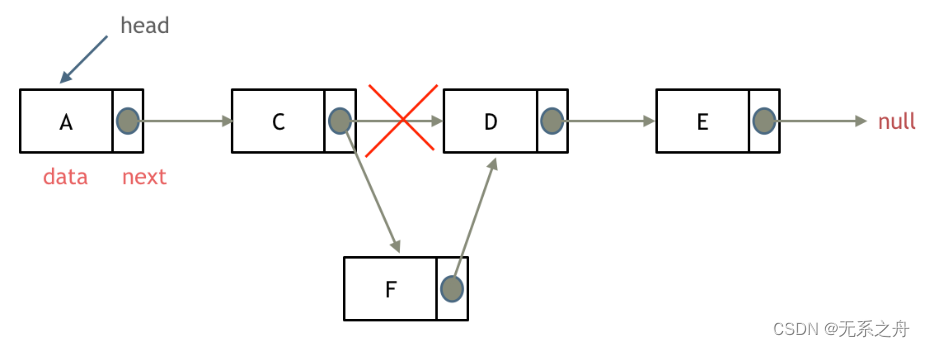
Day03
今日任务 链表理论基础203.移除链表元素707.设计链表206.反转链表 链表理论基础 1)单链表 单链表中的指针域只能指向节点的下一个节点 2)双链表 双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个…...

adb 常用命令汇总
目录 adb 常用命令 1、显示已连接的设备列表 2、进入设备 3、安装 APK 文件到设备 4、卸载指定包名的应用 5、从设备中复制文件到本地 6、将本地文件复制到设备 7、查看设备日志信息 8、重启设备 9、截取设备屏幕截图 10、屏幕分辨率 11、屏幕密度 12、显示设备的…...
ubuntu 2022.04 安装vcs2018和verdi2018
主要参考网站朋友们的作业。 安装时参考: ubuntu18.04安装vcs、verdi2018_ubuntu安装vcs-CSDN博客https://blog.csdn.net/qq_24287711/article/details/130017583 编译时参考: 【ASIC】VCS报Error-[VCS_COM_UNE] Cannot find VCS compiler解决方法_e…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...