《Training language models to follow instructions》论文解读--训练语言模型遵循人类反馈的指令
目录
1摘要
2介绍
方法及实验细节
3.1高层次方法论
3.2数据集
3.3任务
3.4人体数据收集
3.5模型
3.6评价
4 结果
4.1 API分布结果
4.2公共NLP数据集的结果
4.3定性结果
问题
1.什么是rm分数
更多资料
1摘要
使语言模型更大并不能使它们更好地遵循用户的意图。例如,大型语言模型可能生成不真实的、有害的或对用户没有帮助的输出。换句话说,这些模型与它们的用户并不一致。在本文中,我们展示了一种方法,通过对人类反馈进行微调(核心idea),在广泛的任务中使语言模型与用户意图保持一致。从一组标注器编写的提示和通过OpenAI API提交的提示开始,我们收集了一个标注器演示所需模型行为的数据集,我们使用它来使用监督学习对GPT-3进行微调(步骤一)。然后我们收集模型输出排名的数据集,我们使用从人类反馈中使用强化学习来进一步微调(步骤二)这个监督模型。我们将生成的模型称为InstructGPT(名称)。在我们的提示分布的人工评估中,尽管参数少了100倍,但来自13 b参数的InstructGPT模型的输出比来自175B参数的GPT-3的输出更受欢迎。此外,在公共NLP数据集上,InstructGPT模型显示出真实性的提高和有毒输出的减少,同时具有最小的性能回归。尽管InstructGPT仍然会犯一些简单的错误,但我们的结果表明,根据人类反馈进行微调是使语言模型与人类意图保持一致的一个有希望的方向(更小更安全)。
2介绍
大型语言模型(LMs)可以被“提示”执行一系列自然语言处理(NLP)任务,给出一些任务示例作为输入。然而,这些模型经常表达意想不到的行为,如编造事实,产生有偏见或有毒的文本,或根本不遵循用户指示(Bender等人,2021;Bommasani et al., 2021;Kenton et al., 2021;Weidinger et al., 2021;Tamkin et al., 2021;Gehman et al., 2020)。这是因为最近许多大型机器学习使用的语言建模目标——预测互联网网页上的下一个令牌——不同于“有效且安全地遵循用户的指示”的目标(Radford等人,2019;Brown et al., 2020;Fedus等人,2021;Rae et al., 2021;Thoppilan et al., 2022)。因此,我们说语言建模目标是不一致的。避免这些意想不到的行为对于在数百个应用程序中部署和使用的语言模型尤其重要。 我们通过训练语言模型按照用户的意图行事,在对齐语言模型方面取得了进展(Leike et al., 2018)。这既包括明确的意图,如遵循指示,也包括隐含的意图,如保持诚实,不偏见,不有毒,或其他有害的。使用Askell等人(2021)的语言,我们希望语言模型是有用的(他们应该帮助用户解决他们的任务),诚实的(他们不应该捏造信息或误导用户),无害的(他们不应该对人或环境造成身体、心理或社会伤害)。我们将在第3.6节详细说明这些标准的评估。
我们专注于调整语言模型的微调方法。具体来说,我们使用来自人类反馈的强化学习(RLHF;Christiano et al., 2017;Stiennon et al., 2020)微调GPT-3以遵循广泛的书面指令(见图2)。该技术使用人类偏好作为奖励信号来微调我们的模型。我们首先雇佣了一个由40名承包商组成的团队,根据他们在筛选测试中的表现来标记我们的数据(详见第3.4节和附录B.1)。然后,我们收集提交给OpenAI API 3的提示(主要是英语)和一些标注器编写的提示的期望输出行为的人工编写演示数据集,并使用它来训练我们的监督学习基线。接下来,我们在一组更大的API提示符上收集模型输出之间的人工标记比较数据集。然后,我们在这个数据集上训练一个奖励模型(RM)来预测我们的标注器更喜欢哪个模型输出。最后,我们使用该RM作为奖励函数,并使用PPO算法微调我们的监督学习基线以最大化该奖励(Schulman et al., 2017)。我们在图2中说明了这个过程。这一过程将GPT-3的行为与特定人群(主要是我们的标注者和研究人员)的既定偏好相一致,而不是与任何更广泛的“人类价值观”概念相一致;我们将在5.2节进一步讨论这一点。我们将生成的模型称为InstructGPT。 我们主要通过让我们的标签器对我们的测试集上的模型输出的质量进行评价来评估我们的模型,测试集由来自闲置客户(未在训练数据中表示的客户)的提示组成。我们还对一系列公共NLP数据集进行自动评估。我们训练了三种模型尺寸(1.3B、6B和175B参数),我们所有的模型都使用GPT-3架构。我们的主要发现如下: 与GPT-3的输出相比,标注者明显更喜欢InstructGPT的输出。在我们的测试集中,尽管参数少了100倍以上,但来自13 b参数的InstructGPT模型的输出比来自175B的GPT-3的输出更受欢迎。这些模型具有相同的体系结构,不同之处在于InstructGPT对我们的人类数据进行了微调。即使我们在GPT-3中添加几次提示以使其更好地遵循指示,这个结果仍然成立。我们的175B InstructGPT输出在85±3%的时间内优于175B GPT-3输出,在71±4%的时间内优于少量的175B GPT-3输出。InstructGPT模型还根据我们的标注器生成更合适的输出,并且更可靠地遵循指令中的显式约束。 与GPT-3相比,InstructGPT模型的真实性有所提高。在TruthfulQA基准测试中,InstructGPT生成真实且信息丰富的答案的频率是GPT-3的两倍。我们的结果在没有针对GPT-3对抗性选择的问题子集上同样强大。在我们的API提示分布中的“闭域”任务中,输出不应该包含输入中不存在的信息(例如摘要和闭域QA), InstructGPT模型弥补输入中不存在的信息的频率约为GPT-3的一半(分别为21%和41%的幻觉率)。 与GPT-3相比,InstructGPT在毒性方面略有改善,但没有偏倚。为了测量毒性,我们使用RealToxicityPrompts数据集(Gehman等人,2020)并进行自动和人工评估。当提示尊重时,InstructGPT模型产生的有毒输出比GPT-3少25%。在Winogender (Rudinger et al., 2018)和CrowSPairs (Nangia et al., 2020)数据集上,InstructGPT与GPT-3相比没有显著改善。 我们可以通过修改我们的RLHF微调过程来最小化公共NLP数据集上的性能回归。在RLHF微调期间,我们观察到与GPT-3相比,在某些公共NLP数据集上的性能回归,特别是SQuAD (Rajpurkar等人,2018)、DROP (Dua等人,2019)、HellaSwag (Zellers等人,2019)和WMT 2015法语到英语的翻译(Bojar等人,2015)。这是一个“对齐税”的例子,因为我们的对齐过程是以我们可能关心的某些任务的较低性能为代价的。我们可以通过混合PPO更新和增加预训练分布(PPO-ptx)的日志似然的更新来大大减少这些数据集上的性能回归,而不会影响标签器偏好得分。 我们的模型推广到没有产生任何训练数据的“搁置”标注者的偏好。为了测试我们模型的泛化,我们对伸出的标记器进行了初步实验,发现它们更喜欢InstructGPT输出而不是GPT-3输出,其速率与我们的训练标记器大致相同。然而,需要做更多的工作来研究这些模型在更广泛的用户群体上的表现,以及它们在人类不同意期望行为的输入上的表现。
公共NLP数据集不能反映我们的语言模型是如何被使用的。我们比较了在人类偏好数据(即InstructGPT)上进行微调的GPT-3与在两种不同的公共NLP任务汇编上进行微调的GPT-3: FLAN (Wei等人,2021)和T0 (Sanh等人,2021)(特别是t0++变体)。这些数据集由各种NLP任务组成,并结合每个任务的自然语言指令。在我们的API提示分布上,我们的FLAN和T0模型的表现略差于我们的SFT基线,而标注者明显更喜欢InstructGPT而不是这些模型(与我们的基线相比,InstructGPT的胜率为73.4±2%,而我们的T0和FLAN版本分别为26.8±2%和29.8±2%)。 InstructGPT模型对RLHF调优分布之外的指令显示出有希望的泛化。我们定性地考察了InstructGPT的功能,发现它能够遵循总结代码的指令,回答有关代码的问题,有时还可以遵循不同语言的指令,尽管这些指令在微调发行版中非常罕见。相比之下,GPT-3可以执行这些任务,但需要更仔细的提示,并且通常不遵循这些领域的指示。这个结果令人兴奋,因为它表明我们的模型能够概括“遵循指令”的概念。即使在他们很少得到直接监督信号的任务上,他们也会保持一定的一致性。 讲师仍然会犯一些简单的错误。例如,InstructGPT仍然可能无法遵循指令,编造事实,对简单的问题给出冗长的模棱两可的答案,或者无法检测带有错误前提的指令。 总的来说,我们的研究结果表明,使用人类偏好对大型语言模型进行微调可以显著改善它们在广泛任务中的行为,尽管要提高它们的安全性和可靠性还有很多工作要做。 本文的其余部分结构如下:我们首先在第2节详细介绍相关工作,然后在第3节深入介绍我们的方法和实验细节,包括我们的高级方法(3.1),任务和数据集细节(3.3和3.2),人类数据收集(3.4),我们如何训练我们的模型(3.5),以及我们的评估程序(3.6)。然后,我们在第4节中展示了我们的结果,分为三个部分:API提示分布的结果(4.1),公共NLP数据集的结果(4.2)和定性结果(4.3)。最后,我们在第5节中对我们的工作进行了扩展讨论,包括对齐研究的含义(5.1),我们对齐的内容(5.2),限制(5.3),开放问题(5.4)以及本工作的更广泛影响(5.5)。
方法及实验细节
3.1高层次方法论
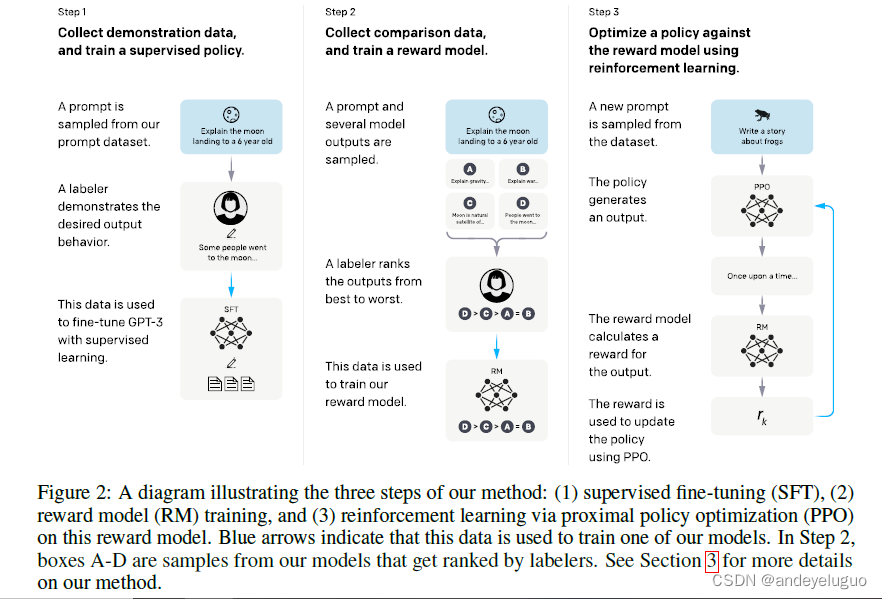
我们的方法遵循Ziegler等人(2019)和Stiennon等人(2020)的方法,他们将其应用于风格转换和总结(summarization)领域(方法还是老方法,用到新的领域上)。我们从预训练的语言模型开始(Radford et al., 2019;Brown et al., 2020;Fedus等人,2021;Rae et al., 2021;Thoppilan et al., 2022),我们希望我们的模型产生一致输出的提示分布,以及训练有素的人类标注员团队(详见第3.4节)。然后我们应用以下三个步骤(图2)。 步骤1:收集演示数据,并训练受监督的策略。我们的标签器在输入提示分布上提供了所需行为的演示(有关此分布的详细信息,请参阅第3.2节)。然后,我们使用监督学习对该数据的预训练GPT-3模型进行微调。 步骤2:收集比较数据,训练奖励模型。我们收集模型输出之间比较的数据集,其中标注者指出他们更喜欢给定输入的输出。然后我们训练一个奖励模型来预测人类偏好的输出。 步骤3:使用PPO针对奖励模型优化策略。我们使用RM的输出作为标量奖励。我们使用PPO算法微调监督策略以优化该奖励(Schulman et al., 2017)。 步骤2和步骤3可以连续迭代;收集更多当前最佳策略的比较数据,用于训练新的RM,然后训练新的策略。在实践中,我们的大部分比较数据来自我们的监督保单,还有一些来自我们的PPO保单。
3.2数据集
我们的提示数据集主要由提交给OpenAI API的文本提示组成,特别是那些在Playground界面上使用早期版本的InstructGPT模型(通过监督学习在我们的演示数据子集上进行训练)的文本提示。使用Playground的客户被告知,他们的数据可以在任何时候使用InstructGPT模型时通过循环通知来训练进一步的模型。在本文中,我们没有使用客户在生产中使用API的数据。我们通过检查提示是否共享一个很长的公共前缀来启发式地去重复提示,并且我们将每个用户ID的提示数量限制为200。我们还基于用户ID创建训练、验证和测试分割(使用用户也贡献了客户的),这样验证和测试集就不包含来自训练集中的用户的数据。为了避免模型学习到潜在的敏感客户细节,我们过滤了训练分割中的所有提示,以获取个人身份信息(PII)。 为了训练第一个InstructGPT模型,我们要求标注者自己写提示。这是因为我们需要一个初始的类似指令的提示源来引导过程,而这些类型的提示通常不会提交给API上的常规GPT-3模型。我们要求贴标员写出三种提示(雇佣的40个人):
•简单:我们简单地要求标签员提出一个任意的任务,同时确保任务具有足够的多样性。
•Few-shot:我们要求标注者提出一条指令,以及针对该指令的多个查询/响应对。
•基于用户:我们在OpenAI API的等待列表应用程序中列出了许多用例。我们要求标注者提出与这些用例相对应的提示。
根据这些提示,我们生成了用于微调过程的三个不同的数据集:
(1)我们的SFT数据集,包含用于训练SFT模型的标记器演示;
(2)我们的RM数据集,包含用于训练RM的模型输出的标记器排名;
(3)我们的PPO数据集,没有任何人工标签,用作RLHF微调的输入。
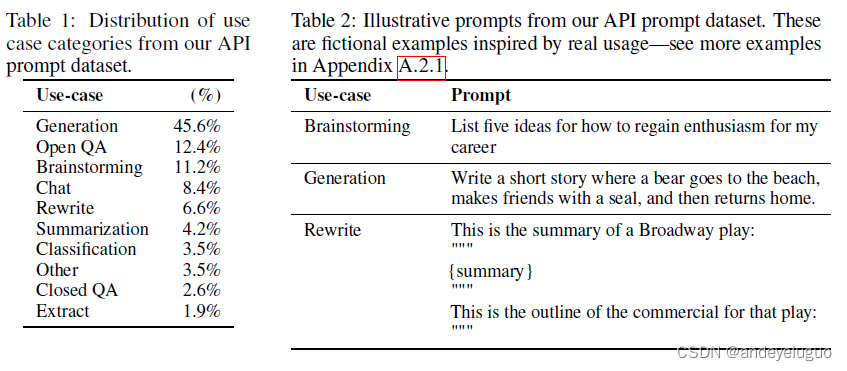
SFT数据集包含大约13k个训练提示(来自API和标注器编写),RM数据集有33k个训练提示(来自API和标注器编写),PPO数据集有31k个训练提示(仅来自API)。表6提供了关于数据集大小的更多细节。 为了给我们的数据集的组成一种感觉,在表1中,我们显示了我们的承包商标记的API提示(特别是RM数据集)的用例类别的分布。大多数用例都是生成的,而不是分类或QA。我们还在表2中展示了一些说明性提示(由研究人员编写,以模仿提交给InstructGPT模型的提示类型);提交给InstructGPT模型的更多提示见附录A.2.1,提交给GPT-3模型的提示见附录A.2.2。我们在附录A中提供了关于我们数据集的更多细节。
3.3任务
我们的培训任务有两个来源:(1)由我们的标注者编写的提示数据集和(2)提交给我们API上的早期InstructGPT模型的提示数据集(见表6)。这些提示非常多样化,包括生成、问答、对话、摘要、提取和其他自然语言任务(见表1)。我们的数据集超过96%是英语,但是在第4.3节中,我们还探讨了我们的模型响应其他语言指令和完成编码任务的能力。 对于每个自然语言提示,任务通常是通过自然语言指令直接指定的(例如“写一个关于聪明青蛙的故事”),但也可以通过少量例子间接指定(例如给出两个青蛙故事的例子,并提示模型生成一个新的)或隐含的延续(例如提供一个关于青蛙的故事的开始)。在每种情况下,我们都要求标注者尽最大努力推断出写提示的用户的意图,并要求他们跳过任务非常不清楚的输入。此外,在我们提供给他们的指示(见附录B)和他们的最佳判断的指导下,我们的标注者还考虑到隐含的意图,如回应的真实性,以及潜在的有害输出,如有偏见或有毒的语言。
3.4人体数据收集
为了制作我们的演示和比较数据,并进行我们的主要评估,我们在Upwork和ScaleAI上雇佣了一个大约40人的承包商团队。与早期收集人类对总结任务的偏好数据的工作相比(Ziegler et al., 2019;Stiennon et al., 2020;Wu et al., 2021),我们的输入跨越了更广泛的任务范围,并且偶尔可能包括有争议和敏感的话题。我们的目标是选择一组对不同人口群体的偏好敏感的标签者,他们善于识别潜在有害的输出。因此,我们进行了筛选测试,旨在衡量这些轴上的标签器性能。我们选择了在这个测试中表现良好的贴标员;有关我们的选择程序和标签商人口统计的更多信息,请参见附录B.1。 在培训和评估期间,我们的校准标准可能会发生冲突:例如,当用户请求潜在的有害响应时。在培训期间,我们优先考虑对用户的帮助(不这样做需要做出一些困难的设计决策,我们把这些决策留给未来的工作;更多讨论请参见5.4节)。然而,在我们最后的评估中,我们要求标签商优先考虑真实性和无害性(因为这是我们真正关心的)。 正如Stiennon等人(2020)所述,我们在项目过程中与标签商密切合作。我们有一个培训项目标注员的入职过程,为每个任务编写详细的说明(参见附录B.2),并在共享聊天室中回答标注员的问题。 作为一项初步研究,看看我们的模型如何很好地推广到其他标注员的偏好,我们雇佣了一组单独的标注员,他们不产生任何训练数据。这些标签来自相同的供应商,但没有经过筛选测试。 尽管任务很复杂,但我们发现注释者之间的一致性率相当高:训练标注者的一致性率为72.6±1.5%,而未训练的标注者的一致性率(大家都认可)为77.3±1.3%。相比之下,在Stiennon et al.(2020)的总结工作中,研究者与研究者的一致性为73±4%。
3.5模型
我们从Brown等人(2020)的GPT-3预训练语言模型开始。这些模型是在广泛分布的互联网数据上进行训练的,可以适应广泛的下游任务,但行为特征不佳。从这些模型开始,我们用三种不同的技术训练模型:
1. 监督微调(SFT)。我们使用监督学习对标记器演示中的GPT-3进行微调。我们训练了16个epoch,使用余弦学习率衰减,残差为0.2。我们根据验证集上的RM分数进行最终的SFT模型选择。与Wu等人(2021)类似,我们发现我们的SFT模型在1个历元后的验证损失上过拟合;然而,我们发现,尽管存在过拟合,但更多的训练对RM分数和人类偏好评级都有帮助。
2. 奖励建模(RM)。从移除最后的非嵌入层的SFT模型开始,我们训练了一个模型来接收提示和响应,并输出标量奖励。在本文中我们只使用6B RM,因为这样可以节省大量的计算,我们发现175B RM训练可能是不稳定的,因此不太适合作为RL中的值函数(详见附录C)。 在Stiennon et al.(2020)中,RM在相同输入的两个模型输出之间的比较数据集上进行训练。他们使用交叉熵损失,以比较作为标签——奖励的差异代表了人类标记者更喜欢一种反应的对数赔率。 为了加速比较收集,我们提供了K = 4到K = 9之间的任何标签器对rank的响应。这将为显示给标记器的每个提示生成K 2比较。自 在每个标记任务中,比较是非常相关的,我们发现如果我们简单地将比较洗牌到一个数据集中,那么对数据集的一次传递就会导致奖励模型过拟合。相反,我们将每个提示的所有k2 比较作为单个批处理元素进行训练。这在计算效率上要高得多,因为每次完井只需要RM的一次前向传递(而不是K次前向传递K次完井),而且因为它不再过拟合 2 实现了大大改进的验证准确性和日志丢失。 具体来说,奖励模型的损失函数为:其中r θ (x, y)是奖励模型对提示x和完成y的标量输出,参数为θ, y w是y w和y l对中的首选完成,D是人类比较的数据集。 日志_{5}\(\θ)= - \压裂{1}{(2)}E (E, g _ {2}) (1) 最后,由于RM损失对奖励的变化是不变的,我们使用偏差对奖励模型进行规范化,以便在进行强化学习之前标记器演示达到平均得分0。

3. 强化学习(RL)。继Stiennon等人(2020)之后,我们再次使用PPO对环境中的SFT模型进行了微调(Schulman等人,2017)。环境是一个强盗环境,它呈现随机的客户提示并期望对提示做出响应。给定提示和反应,它会产生由奖励模型决定的奖励,并结束情节。此外,我们在每个令牌上添加了来自SFT模型的每个令牌KL惩罚,以减轻奖励模型的过度优化。从RM初始化值函数。我们称这些模型为“PPO”。 我们还尝试将预训练梯度混合到PPO梯度中,以修复公共NLP数据集上的性能回归。我们称这些模型为“PPO-ptx”。我们在强化学习训练中最大化以下组合目标函数:

其中π φ RL为学习到的RL策略,π SFT为监督训练模型,D预训练为预训练分布。KL奖励系数β和预训练损失系数γ分别控制KL惩罚和预训练梯度的强度。对于“PPO”模型,γ设置为0。除另有说明外,本文中InstructGPT指PPO-ptx型号。 基线。我们将我们的PPO模型的性能与我们的SFT模型和GPT-3进行比较。我们还比较了GPT-3,它提供了几个前缀来“提示”它进入指令遵循模式(GPT-3提示)。此前缀附加在用户指定的指令之前。6 我们还将InstructGPT与FLAN (Wei等人,2021)和T0 (Sanh等人,2021)数据集上的微调175B GPT-3进行了比较,这两个数据集都由各种NLP任务组成,并结合了每个任务的自然语言指令(数据集在包括的NLP数据集和使用的指令风格上有所不同)。我们分别在大约100万个样本上对它们进行微调,并选择在验证集中获得最高奖励模型分数的检查点。更多培训细节见附录C。
3.6评价
为了评估我们的模型是如何“对齐”的,我们首先需要澄清在这个上下文中对齐意味着什么。对齐的定义历来是一个模糊而令人困惑的话题,有各种相互竞争的建议(Chen et al., 2021;Leike et al., 2018;盖伯瑞尔,2020)。继Leike等人(2018)之后,我们的目标是训练与用户意图一致的模型。更实际的是,为了我们的语言任务的目的,我们使用了类似于Askell等人(2021)的框架,他们定义了如果模型有帮助、诚实和无害,则将其对齐。 为了提供帮助,模型应该遵循说明,但也可以从几个提示或另一个可解释的模式(如“Q: {question}\nA:”)中推断意图。由于给定提示的意图可能不明确或模棱两可,我们依赖于标签者的判断,我们的主要度量是标签者偏好评级。然而,由于我们的标注者并不是生成提示的用户,因此在用户的实际意图和标注者仅通过阅读提示而想到的意图之间可能存在分歧。 目前尚不清楚如何在纯生成模型中衡量诚实;这需要将模型的实际输出与它对正确输出的“信念”进行比较,由于模型是一个大黑箱,我们无法推断它的信念。相反,我们使用两个指标来衡量真实性——模型对世界的陈述是否真实:(1)评估我们的模型在封闭领域任务(“幻觉”)上构成信息的倾向,(2)使用TruthfulQA数据集(Lin等人,2021)。不用说,这只抓住了真实的一小部分含义。 与诚实类似,衡量语言模型的危害也带来了许多挑战。在大多数情况下,语言模型的危害取决于它们的输出在现实世界中的使用方式。例如,生成有毒输出的模型在部署的聊天机器人的上下文中可能是有害的,但如果用于数据增强以训练更准确的毒性检测模型,甚至可能是有帮助的。在项目早期,我们让标签员评估某个输出是否有“潜在危害”。但是,我们停止了这项工作,因为它需要对最终如何使用产出进行过多的猜测;特别是因为我们的数据也来自与Playground API接口交互的客户(而不是来自生产用例)。 因此,我们使用一套更具体的代理标准,旨在捕获已部署模型中可能最终有害的行为的不同方面:我们有标签器评估输出是否在客户助理的上下文中不适当,诋毁受保护的类别,或包含性或暴力内容。我们还在旨在测量偏倚和毒性的数据集上对我们的模型进行基准测试,例如RealToxicityPrompts (Gehman等人,2020)和CrowS-Pairs (Nangia等人,2020)。
综上所述,我们可以将定量评估分为两个独立的部分:API分布评估。我们的主要指标是人类对一组提示的偏好评级,这些提示来自与我们的训练分布相同的来源。当使用来自API的提示进行评估时,我们只选择培训中没有包括的客户的提示。然而,考虑到我们的训练提示被设计为与InstructGPT模型一起使用,它们很可能会使GPT-3基线处于劣势。因此,我们还对API上提交给GPT-3模型的提示进行了评估;这些提示通常不是“指令跟随”式的,而是专门为GPT-3设计的。在这两种情况下,对于每个模型,我们计算其输出优先于基线策略的频率;我们选择我们的175B SFT模型作为基准,因为它的性能接近中间。此外,我们要求标注者在1-7李克特量表上判断每个回答的整体质量,并为每个模型输出收集一系列元数据(见表3)。 对公共NLP数据集的评估。我们对两种类型的公共数据集进行了评估:一种是捕获语言模型安全性的一个方面,特别是真实性、毒性和偏见,另一种是捕获传统NLP任务(如问答、阅读理解和总结)的零射击性能。我们还在RealToxicityPrompts数据集上对毒性进行了人体评估(Gehman等人,2020)。我们正在从所有基于采样的NLP任务的模型中发布样本。
4 结果
在本节中,我们为第1节中的主张提供了实验证据,分为三部分:API提示分布的结果、公共NLP数据集的结果和定性结果。 GPT GPT(提示) SFT PPO PPO-ptx
4.1 API分布结果
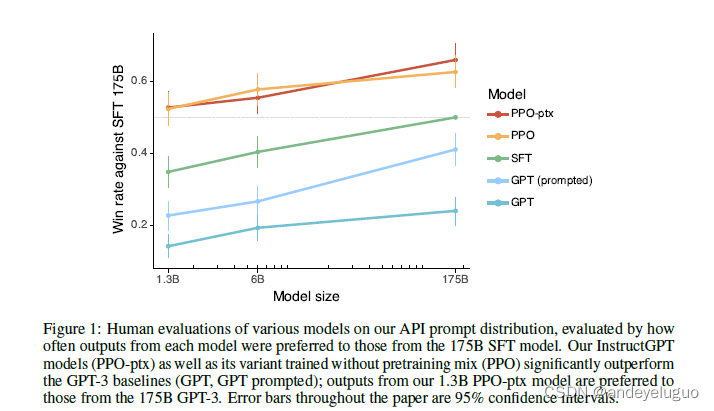
与GPT-3的输出相比,标注者明显更喜欢InstructGPT的输出。在我们的提示测试集上,我们的标注器明显更喜欢不同模型大小的InstructGPT输出。这些结果如图1所示。我们发现GPT-3输出表现最差,可以通过使用精心设计的少数镜头提示(GPT-3(提示)),然后使用监督学习(SFT)对演示进行训练,最后使用PPO对比较数据进行训练,从而获得显着的步长改进。在PPO期间添加预训练组合的更新不会导致标签者偏好的大变化。为了说明我们的增益幅度:当直接比较时,175B InstructGPT输出在85%±3%的情况下优于GPT-3输出,在71±4%的情况下优于少量GPT-3输出。 我们还发现,当对提交给API上的GPT-3模型的提示进行评估时,我们的结果没有显著变化(参见图3),尽管我们的PPO-ptx模型在更大的模型尺寸下表现略差。 在图4中,我们展示了标记器还沿着几个更具体的轴对InstructGPT输出进行了有利的评价。具体来说,与GPT-3相比,InstructGPT的输出更适合于客户助理的上下文,更经常遵循指令中定义的明确约束(例如“用2段或更短的时间写出你的答案”)。),不太可能完全遵循正确的指示,并且在封闭领域的任务中不太经常编造事实(“幻觉”)。这些结果表明,与GPT-3相比,InstructGPT模型更可靠,更易于控制。我们发现我们的其他元数据类别在我们的API中出现的频率太低,无法在我们的模型之间获得统计上显著的差异。 我们的模型推广到没有产生任何训练数据的“搁置”标注者的偏好。hold -out标注者与我们用来生成训练数据的工作者有着相似的排名偏好(参见图3)。特别是,根据hold -out标注者的说法,我们所有的InstructGPT模型仍然大大优于GPT-3基线。因此,我们的InstructGPT模型并不是简单地过度拟合训练标注器的偏好。 我们从奖励模型的泛化能力中看到了进一步的证据。我们进行了一个实验,我们将标签器分成5组,并使用5倍交叉验证(在4组中进行训练,并在保留组中进行评估)训练5个RMs(带有3个不同的种子)。这些均方根值在预测未完成组的标注者偏好方面的准确度为69.6±0.9%,与他们在预测训练集中的标注者偏好方面的准确度72.4±0.4%相比略有下降。 公共NLP数据集不能反映我们的语言模型是如何被使用的。在图5中,我们还将InstructGPT与我们在FLAN (Wei et al., 2021)和T0 (Sanh et al., 2021)数据集上微调的175B GPT-3基线进行了比较(详见附录C)。我们发现这些模型比GPT-3表现更好,与GPT-3在精心选择的提示下相当,比我们的SFT基线差。这表明这些数据集的多样性不足以提高我们的API提示分发的性能。在头对头的比较中,我们的175B InstructGPT模型输出优于我们的FLAN模型(78±4%),优于我们的T0模型(79±4%)。这些模型的Likert分数如图5所示。 我们认为我们的InstructGPT模型优于FLAN和T0有两个原因。首先,公共NLP数据集旨在捕获易于使用自动度量进行评估的任务,例如分类、问答以及一定程度上的摘要和翻译。然而,分类和QA只是API客户使用我们的语言模型的一小部分(约18%),而根据标注者,开放式生成和头脑风暴构成了我们提示数据集的约57%(见表1)。其次,公共NLP数据集很难获得非常高的输入多样性(至少,在现实世界用户可能感兴趣的输入类型上)。当然,在NLP数据集中发现的任务确实代表了我们希望语言模型能够解决的一种指令,因此最广泛的类型指令遵循模型将结合两种类型的数据集。
4.2公共NLP数据集的结果
与GPT-3相比,InstructGPT模型的真实性有所提高。根据人类对TruthfulQA数据集的评估,与GPT-3相比,我们的PPO模型在生成真实和信息丰富的输出方面显示出微小但显著的改进(见图6)。这种行为是默认的:我们的模型不需要特别指示来告诉真相以显示改进的真实性。有趣的是,我们的13 b PPO-ptx模型是个例外,它的性能比相同大小的GPT-3模型略差。当仅对未与GPT-3对抗性选择的提示进行评估时,我们的PPO模型仍然比GPT-3更加真实和信息丰富(尽管绝对改进减少了几个百分点)。 继Lin等人(2021)之后,我们还给出了一个有用的“指令+QA”提示,指示模型在不确定正确答案时回答“我没有评论”。在这种情况下,我们的PPO模型更倾向于诚实和不提供信息,而不是自信地说假话;基线GPT-3模型在这方面就不那么好了。 我们在真实性方面的改进还可以通过以下事实得到证明:我们的PPO模型在API分布的闭域任务上出现幻觉(即捏造信息)的频率降低了,如图4所示。 与GPT-3相比,InstructGPT在毒性方面略有改善,但没有偏倚。我们首先在RealToxicityPrompts数据集上评估我们的模型(Gehman et al., 2020)。我们通过两种方式做到这一点:我们通过Perspective API 8运行模型样本以获得自动毒性评分,这是该数据集的标准评估程序,我们还将这些样本发送给标记者以获得绝对毒性,相对于提示,连续性和总体输出偏好的毒性评级。我们根据提示毒性从该数据集中统一采样提示,以更好地评估我们的模型在高输入毒性下的表现(见附录E中的图39);这与该数据集的标准提示抽样不同,因此我们的绝对毒性数值被夸大了。 我们的结果如图7所示。我们发现,当指示产生安全和尊重的输出(“尊重提示”)时,根据Perspective API, InstructGPT模型产生的有毒输出比GPT-3模型产生的有毒输出少。当恭敬的提示被删除(“无提示”)时,这种优势就消失了。有趣的是,当显式提示生成有毒输出时,InstructGPT输出的毒性比GPT-3的要大得多(参见图39)。 这些结果在我们的人类评估中得到了证实:在“尊重提示”设置下,InstructGPT的毒性比GPT-3小,但在“无提示”设置下表现相似。我们在附录e中提供了扩展结果。总结:根据提示,我们所有的模型都被评为毒性低于预期(它们在-1到1的范围内得到负值,其中0表示“毒性与预期一样”)。我们的SFT基线是我们所有模型中毒性最小的,但也具有最低的连续性,并且在我们的排名中是最不受欢迎的,这可能表明模型产生非常短的或退化的响应。
为了评估模型产生偏见语音的倾向(见附录E),我们还在Winogender (Rudinger et al., 2018)和CrowS-Pairs (Nangia et al., 2020)数据集的修改版本上评估了InstructGPT。这些数据集由句子对组成,可以突出潜在的偏见。我们计算每对句子产生的相对概率,以及相关二进制概率分布的熵(以比特为单位)。完全无偏模型将在每对句子之间没有偏好,因此将具有最大的熵。根据这个指标,我们的模型的偏差并不比GPT-3小。PPO-ptx模型显示出与GPT-3相似的偏差,但当指示尊重行为时,它显示出更低的熵,因此更高的偏差。偏倚的模式尚不清楚;看来,受指导的模型对它们的输出更加确定,而不管它们的输出是否表现出刻板行为。 我们可以通过修改我们的RLHF微调过程来最小化公共NLP数据集上的性能回归。默认情况下,当我们在API分布上训练PPO模型时,它会遭受“对齐税”,因为它在几个公共NLP数据集上的性能会下降。我们想要一个避免校准税的校准过程,因为它鼓励使用非校准但在这些任务上更有能力的模型。 提示: 下面代码中的列表C的目的是什么? Def binomial_coefficient(n, r): C = [0 for i in range(r + 1)]; C[0] = 1; 对于I在(1,n + 1)范围内: J = min(i, r); 当j > 0时: C[j] += C[j - 1]; J -= 1; 返回C[r] GPT-3 175B完成: A.存储C的值[0] B.存储C的值[1] C.存储C的值[i] D.存储C[i - 1]的值 列表C在此代码中用于存储 二项式系数 n和r的值,用于计算值 对于给定的n和二项式系数 方法的最终返回值中存储结果 函数。 在图29中,我们展示了将预训练更新添加到PPO微调(PPO-ptx)中,可以减轻所有数据集上的这些性能回归,甚至超过HellaSwag上的GPT-3。PPO-ptx模型在DROP、SQuADv2、翻译等方面的性能仍落后于GPT-3;需要做更多的工作来研究和进一步消除这些性能回归。 混合预训练更新比增加KL系数的简单解决方案表现更好。在图33中,我们展示了一个预训练混合系数的值,它既反转了SQuADv2和DROP(我们用于测试的数据集)上的性能回归,又在验证奖励上有最小的减少。相反,增加KL系数(图34)会导致验证奖励显著减少,并且在DROP和SQuAD上永远无法完全恢复。将KL模型从PPO初始化更改为GPT-3会得到类似的结果。
4.3定性结果
InstructGPT模型对RLHF调优分布之外的指令显示出有希望的泛化。特别是,我们发现InstructGPT显示了遵循非英语语言指令的能力,并对代码执行摘要和问答。这是提示: 有趣的是,非英语语言和代码构成了我们微调数据的一小部分,9并且它表明,在某些情况下,对齐方法可以推广到在人类没有直接监督的输入上产生所需的行为。 我们没有定量地跟踪这些行为,但是我们在图8中展示了一些定性的例子。我们的175B PPO-ptx模型能够可靠地回答有关代码的问题,并且还可以遵循其他语言的说明;然而,我们注意到,即使指令是另一种语言,它也经常输出英语。相比之下,我们发现GPT-3可以执行这些任务,但需要更仔细的提示,并且很少遵循这些领域的指令。 讲师仍然会犯一些简单的错误。在与我们的175B PPO-ptx模型交互时,我们注意到它仍然会犯简单的错误,尽管它在许多不同的语言任务上表现出色。举几个例子:(1)当给出一个带有错误前提的指令时,模型有时会错误地假设前提为真;(2)模型可能会过度对冲;当给出一个简单的问题时,它有时会说这个问题没有一个答案,并给出多个可能的答案,即使上下文中有一个相当明确的答案,并且(3)当指令包含多个明确的约束(例如“列出20世纪30年代以法国为背景拍摄的10部电影”)或当约束对语言模型具有挑战性时(例如用指定数量的句子写摘要),模型的性能会下降。 我们在图9中展示了这些行为的一些示例。我们怀疑行为(2)的出现部分是因为我们指示标注者奖励认知上的谦卑;因此,他们可能倾向于奖励那些对冲的产出,这被我们的奖励模型捕捉到了。我们怀疑行为(1)的发生是因为训练集中很少有假设错误前提的提示,而且我们的模型不能很好地泛化到这些例子。我们相信这两种行为都可以通过对抗性数据收集而大大减少(Dinan et al., 2019b)。
问题
1.什么是rm分数
RM分数是指奖励建模(Reward Modeling)训练中使用的评估指标。在训练语言模型时,通过比较两个模型输出在相同输入上的表现,使用交叉熵损失函数来训练奖励模型(RM),其中比较的结果作为标签,奖励模型的输出表示一个模型输出相对于另一个模型输出被人类标注者更喜欢的对数几率。RM分数则表示奖励模型在验证集上的性能表现。
在本文中,RM分数被用于选择最终的SFT模型(Supervised Fine-Tuning)和评估奖励模型的性能。研究人员发现,相比于验证损失,RM分数更能预测人类偏好结果。因此,通过优化RM分数,可以提高模型的性能和人类偏好度。
更多资料
【1】 InstructGPT 论文精读【论文精读·48】_哔哩哔哩_bilibili
相关文章:
《Training language models to follow instructions》论文解读--训练语言模型遵循人类反馈的指令
目录 1摘要 2介绍 方法及实验细节 3.1高层次方法论 3.2数据集 3.3任务 3.4人体数据收集 3.5模型 3.6评价 4 结果 4.1 API分布结果 4.2公共NLP数据集的结果 4.3定性结果 问题 1.什么是rm分数 更多资料 1摘要 使语言模型更大并不能使它们更好地遵循用户的意图。例…...

Redis的实现二: c、c++的网络通信编程技术,让服务器处理多个client
看过上期的都知道,我是搞java的,所以对这些可能理解不是很清楚,各位看完可以尽情发言。 事件循环和非阻塞IO 在服务器端网络编程中,有三种处理并发连接的方法。 它们是:分叉、多线程和事件循环。分叉为每个客户端连接创建新…...
QT上位机开发(动画效果)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 不管是仿真,还是对真实环境的一比一模拟,动画都是非常好的一种呈现方式。目前在qt上面,实现动画主要有两种方法…...

手写实现 bind 函数
Function.prototype.myBind function(context) {if (typeof this ! function) {return}const args [...arguments].slice(1)const fn thisreturn function Fn() {// 判断函数作为构造函数的情况,这个时候需要传入当前的函数的this给apply调用,其余情况…...

安卓Android Studio读写MifareOne M1 IC卡源码
本示例使用的发卡器:https://item.taobao.com/item.htm?id615391857885&spma1z10.5-c-s.w4002-21818769070.11.3d2f789eOUPJBK <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xm…...
一二三应用开发平台文件处理设计与实现系列之5——MinIO技术预研
背景 上篇介绍了文件读写框架设计与实现,同时顺便说明了本地磁盘存储模式的实现模式。 今天来说下基于文件读写框架,如何集成对象存储组件minio,集成之前,需要对minio进行必要的了解,本篇是minio的技术预研。 minio简…...

Native.js是什么
Native.js 是一个开源项目,旨在通过 JavaScript 调用原生 Android API。它的目标是让 JavaScript 开发者能够使用 Android 原生 API,从而在不编写原生代码的情况下构建 Android 应用。 使用 Native.js,开发者可以使用 JavaScript 调用 Andro…...

Vant-ui图片懒加载
核心代码 在你的全局顶部引入和初始化 Vue.use(vant.Lazyload, {loading: /StaticFile/img/jiazai.jpg,error: /StaticFile/img/jiazai.jpg,lazyComponent: false, });//图片懒加载 <img v-lazy"https://img-blog.csdnimg.cn/direct/3d2c8a7e2c0040488a8128c3e381d58…...
创建EasyCodeMybatisCodeHelperPro模板文件用于将数据库表生成前端json文件
在intellij idea中,通过插件EasyCodeMybatisCodeHelperPro,从现有的模板文件中选择一个复制粘贴,然后稍为修改,即可得到一个合适的模板文件。 现在的前端,越来越像后端。TypeScript替代了JavaScript,引入了…...
华为端口安全常用3种方法配置案例
安全动态mac地址学习功能 [Huawei]int g0/0/01 interface GigabitEthernet0/0/1 port-security enable //开启安全 port-security max-mac-num 2 //最多为2个mac地址学习 port-security protect-action restrict //丢包带警告 port-security aging-time 1 //mac地址的老化时间…...

RH850P1X芯片学习笔记-Flash Memory
文章目录 FeaturesClock Supply Block DiagramFlash SizeMemory ConfigurationRegistersRegister Base AddressList of RegistersRegister Reset Condition 与Flash Memory相关的操作模式Functional OverviewOption BytesOPBT0 — Option Byte 0OPBT1 — Option Byte 1OPBT2 —…...
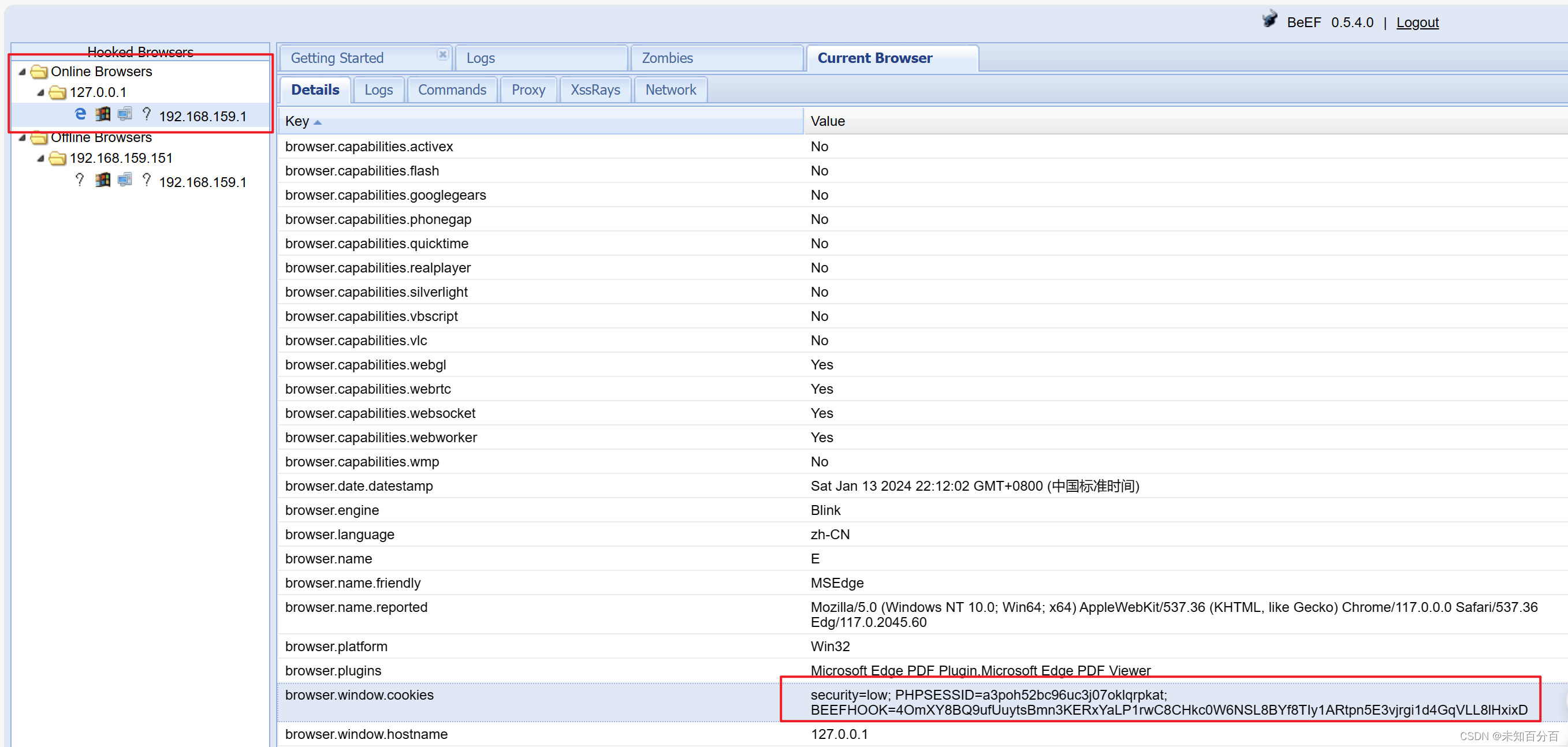
利用XSS漏洞打cookie
目录 1、为什么要打cookie? 2、怎样利用XSS来打cookie? 3、利用Bluelotus_xssReceiver平台来打cookie 4、利用beef-xss平台来打cookie 上一篇给大家介绍了xss漏洞的基础知识,在本篇章将会介绍和演示一下利用xss漏洞打cookie的演示&#x…...

用java写个redis工具类
下面是一个简单的Redis工具类的示例,使用Java语言编写: import redis.clients.jedis.Jedis;public class RedisUtils {private static Jedis jedis;public static void connect(String host, int port) {jedis new Jedis(host, port);}public static v…...

实现防抖函数
// 防抖就是,事件触发 delay 秒后再执行,如果有重新的触发,重新计时 function debounce(func, delay) {if(typeof func ! function) {return}let timer 0return function () {if (timer) {clearTimeout(timer)timer null}timer setTimeout…...

MetaGPT task1学习
基础知识学习了解: 安装环境: 获取MetaGPT 使用pip获取MetaGPT pip install -i https://pypi.tuna.tsinghua.edu.cn/simple metagpt0.5.2 配置MetaGPT 完成MetaGPT后,我们还需要完成一些配置才能开始使用这个强力的框架,包括配…...

关于量子计算机的设想
从CPU架构说起 CISCRISCNISCCCSC CISC是复杂指令集计算机,以x86为代表; RISC是精简指令集计算机,以ARM为代表; NISC是无指令集计算机,CCSC是核-电路分离计算机,这两个是本文要讨论的内容。 如果没有指令…...
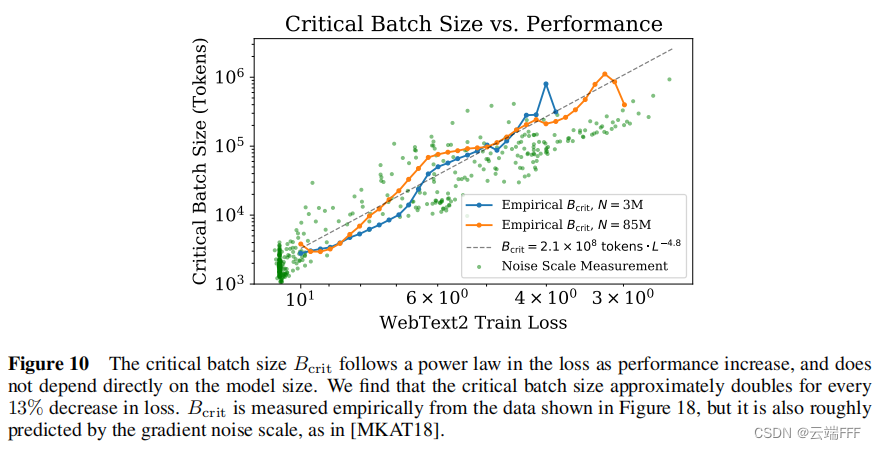
序列模型(4)—— Scaling Laws
本文介绍 LLM 训练过程中重要的 Scaling Laws,这是一个经验规律,指出了固定训练成本(总计算量FLOPs) C C C 时,如何调配模型规模(参数量) N N N 和训练 Token 数据量 D D D,才能实现…...
【软件测试学习笔记1】测试基础
1.软件测试的定义 软件的定义:控制计算机硬件工作的工具 软件的基本组成:页面客户端,代码服务器,数据服务器 软件产生的过程:需求产生(产品经理),需求文档,设计效果图…...

pytorch详细探索各种cnn卷积神经网络
目录 torch.nn.functional子模块详解 conv1d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv2d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv3d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv_transpose1d 用法…...

OpenCV——八邻域断点检测
目录 一、理论基础1、八邻域2、断点检测 二、代码实现三、结果展示四、参考链接 OpenCV——八邻域断点检测由CSDN点云侠原创,爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、理论基础 1、八邻域 图1 八邻域示意图 图…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...