序列模型(4)—— Scaling Laws
- 本文介绍 LLM 训练过程中重要的 Scaling Laws,这是一个经验规律,指出了固定训练成本(总计算量FLOPs) C C C 时,如何调配模型规模(参数量) N N N 和训练 Token 数据量 D D D,才能实现最高的效率。利用 Scaling Laws,我们可以利用较小模型的训练经验预测更大模型的性能表现
- 本文主要是对论文 Scaling Laws for Neural Language Models 的解析,只关注汇总结果的话可以直接看第 5 节
- 文章链接:Scaling Laws for Neural Language Models
- 发表:arxiv 2020
- 作者:OpenAI
- 摘要:我们研究了 LM 在交叉熵损失上的经验缩放规律(empirical scaling laws)。(测试)损失随着模型大小、数据集大小和训练计算量的增加呈幂律减小,有时这种趋势可以横跨七个数量级以上;相比而言,网络宽度或深度等其他架构细节在较大范围内几乎没有影响。过拟合与模型规模/数据集大小的依赖关系、训练速度与模型大小的依赖关系都可以用简单的方程进行描述,这些关系使我们能够确定计算量预算的最佳分配方式。较大模型具有更高的样本效率,因此在最高效的计算训练中,应该在相对较少的数据上训练非常大的模型,并在收敛之前很久停止训练(stopping significantly before convergence)
文章目录
- 0. 背景和方法
- 0.1 Transformer 模型的参数量和计算量
- 0.2 实验方法
- 1. Basic Power Laws
- 1.1 模型形状基本不影响性能
- 1.2 参数量和性能呈现幂律关系
- 1.3 数据量 & 计算量和性能呈现幂律关系
- 2. 利用 Scaling Laws 计算避免过拟合所需的数据量
- 2.1 参数量 N N N 和数据量 D D D 对模型性能的联合影响
- 2.2 实验验证
- 2.3 预测数据集尺寸以避免过拟合
- 3. 模型大小和训练时间的缩放定律
- 4. 计算量的优化分配
- 5. 总结
0. 背景和方法
0.1 Transformer 模型的参数量和计算量
-
原文符号有点乱,直接引用前文的分析结论,详见:序列模型(3)—— LLM的参数量和计算量。首先给出符号约定
参数 符号 说明 Decoder 层数 l l l Token 嵌入维度 d d d Attention 层嵌入维度 d d d MLP 隐藏层维度 4 d 4d 4d 通常设置为嵌入维度4倍 Attention head 数量 n n n 要求其整除 d d d 词表尺寸 V V V 模型输入长度 s s s 代表模型处理的上下文长度 训练 batch data x \pmb{x} x 张量尺寸 R B × s × d \mathbb{R}^{B\times s\times d} RB×s×d 训练步数 S S S 即模型参数更新次数 交叉熵损失 L L L 本文中主要指测试损失,可用于指示模型性能 batch_size B B B 模型参数量 N N N 训练数据量(Token) D D D 训练计算量(FLOPs) C C C 损失的幂律指数 α X \alpha_X αX Scaling Laws 就是 L ( X ) ∝ 1 / X α x L(X)\propto1/X^{\alpha x} L(X)∝1/Xαx,其中 X X X 可以是 N , D , C N,D,C N,D,C 之中的任意一个 -
Decoder-only Transformer 模型的参数量 N N N、计算量 C C C 和数据量 D D D 之间有以下关系
- 模型总参数量近似为 N ≈ 12 l d 2 N\approx 12ld^2 N≈12ld2
- 对于一次训练迭代过程,输入 token 数据量为 D = B s D=Bs D=Bs,总计算量(FLOPs)近似为 C ≈ 72 B s l d 2 C \approx 72Bsld^2 C≈72Bsld2
- 训练过程中, N , C , D N,C,D N,C,D 之间有关系 C ≈ 6 N D C\approx 6ND C≈6ND
0.2 实验方法
- 模型:主要考察 Decoder-only Transformer 模型(GPT1),同时也对 Encoder-Decoder Transformer 模型(Universal transformers)和 LSTM 等传统序列模型进行了小规模实验。除非特殊说明,则上下文长度固定为 1024
- 数据集:使用 WebText2 数据集进行训练,它使用字节对编码进行分词,词表大小为 50257
- 训练方法:
- 优化自回归交叉熵损失(损失具体设计为一条轨迹上所有 token 预测交叉熵损失的平均值)
- 除非专门说明,使用 Adam 优化器进行训练 2.5 × 1 0 5 2.5 × 10^5 2.5×105 步, B = 512 , s = 1024 B=512, \space\space s=1024 B=512, s=1024
- 除非专门说明,所有训练过程的学习率调度为:3000 步线性预热,然后余弦衰减至 0
- 实验设置:为了考察语言模型的缩放规律,作者在大量不同设置下进行训练,调整的参数包括
- 模型规模:参数量 N N N 从 768 到 15 亿不等(不含嵌入层参数)
- 数据集大小:Token 数量 D D D 从 2200 万到 230 亿
- 模型形状:调整深度、宽度、注意力头和前馈维度等的设计,并维持总参数量基本不变
- 上下文长度:大多数训练中为 s = 1024 s=1024 s=1024,但也会尝试了更短的上下文
- 批量大小:大多数训练中为 2 19 2^{19} 219
1. Basic Power Laws
1.1 模型形状基本不影响性能
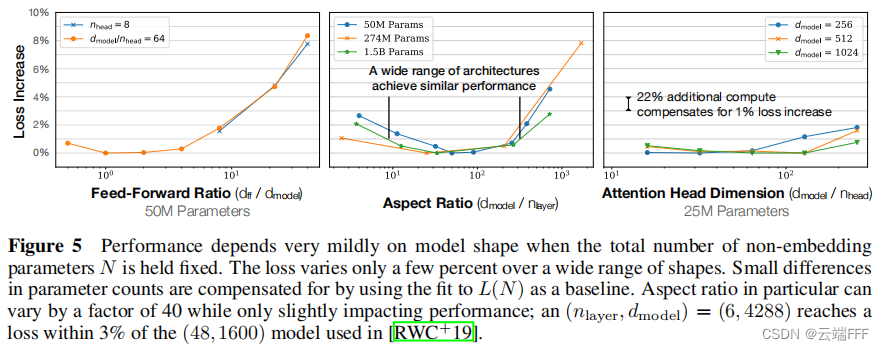
- 当保持模型规模 N N N 固定时,Transformer 性能对模型深度,注意力头数和前馈网络宽度等的依赖性非常弱

1.2 参数量和性能呈现幂律关系
- 作者通过调整模型层数 l l l 和嵌入维度 d d d 设置了一系列不同参数规模的模型,参数范围从小模型 ( l , d ) = ( 2 , 128 ) (l,d)=(2,128) (l,d)=(2,128) 到具有十亿参数规模的大模型,形状从 ( 6 , 4288 ) (6,4288) (6,4288) 到 ( 207 , 768 ) (207,768) (207,768),所有模型都训练到接近收敛,并确保没有观测到过拟合
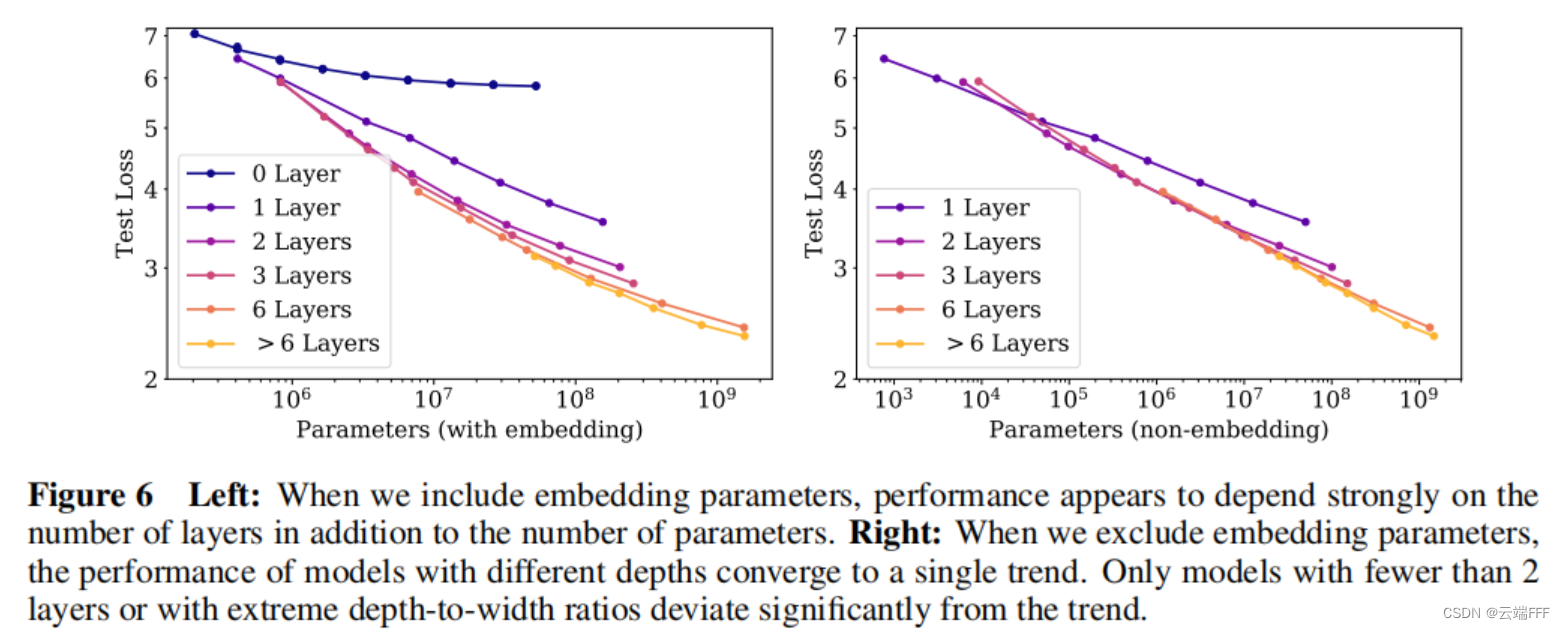
- 如图所示,注意到考虑嵌入层参数时,模型深度也会在总参数量之外影响性能规律;不考虑嵌入层参数时,性能和总参数量 N N N 具有稳定的幂律关系,可以表示为
L ( N ) ≈ ( N c N ) α N L(N) \approx \left(\frac{N_c}{N}\right)^{\alpha_N} L(N)≈(NNc)αN- 作者进一步考察了其他序列模型以及模型的泛化性能
- 作者验证了 LSTM 和 Encoder-Decoder 类模型都服从以上幂律关系
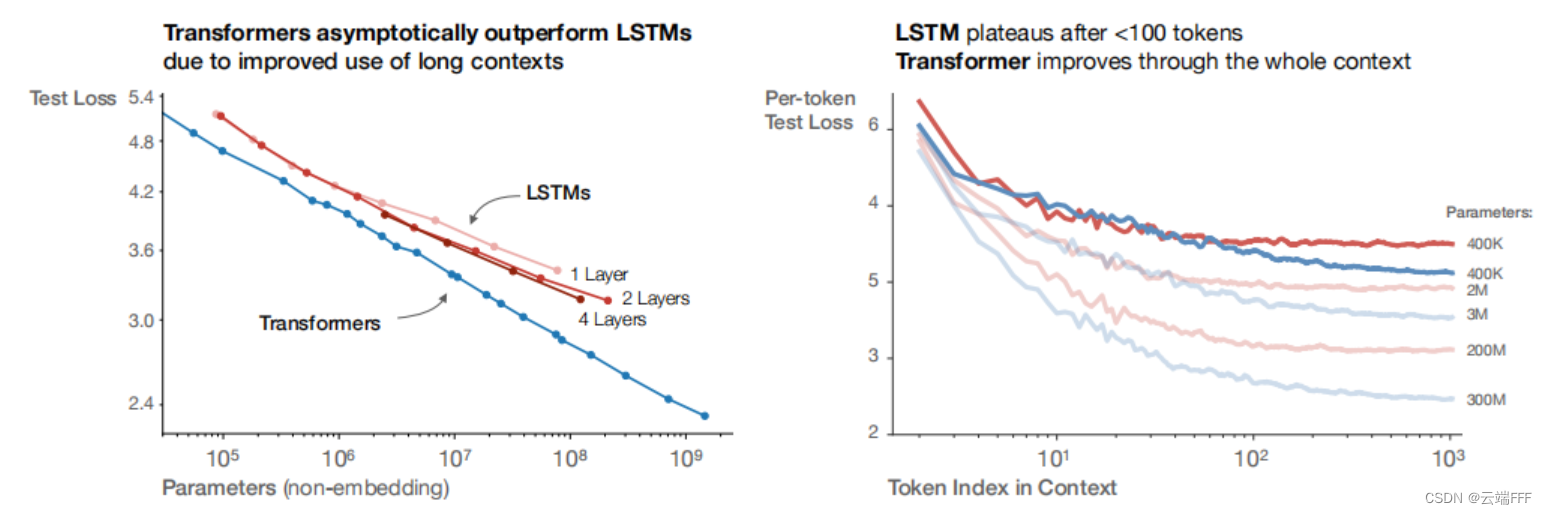
左图显示了 LSTM/Transformer 模型的参数规模与性能间的幂律关系,从中也可发现 Transformer 模型总能用较少的参数量实现更好的性能;右图显示了上下文长度和预测性能的关系,可见 LSTM 仅在早期 Token 部分和 Transformer 模型性能类似,长跨度下性能不如 Transformer
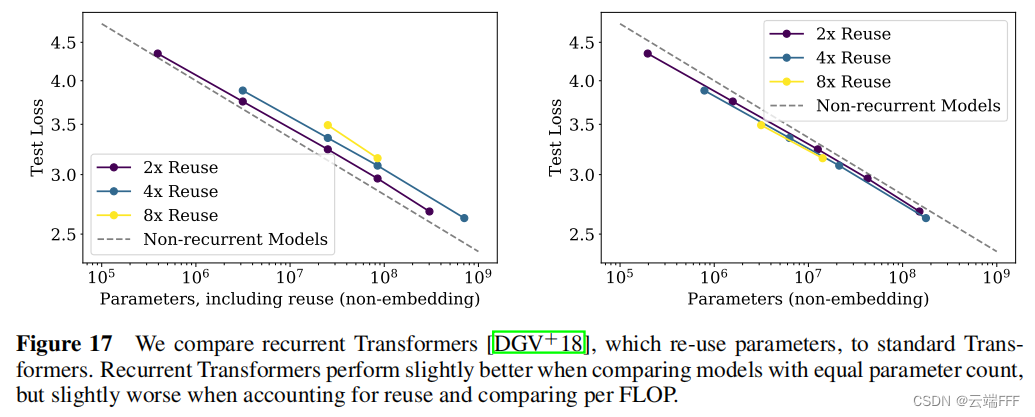
这里考察的是带有递归循环和参数复用结构的 Encoder-Decoder Transformer 模型 Universal Transformers,可见参数量和性能间也满足幂律关系 - 作者验证了模型泛化性能也服从以上幂律关系
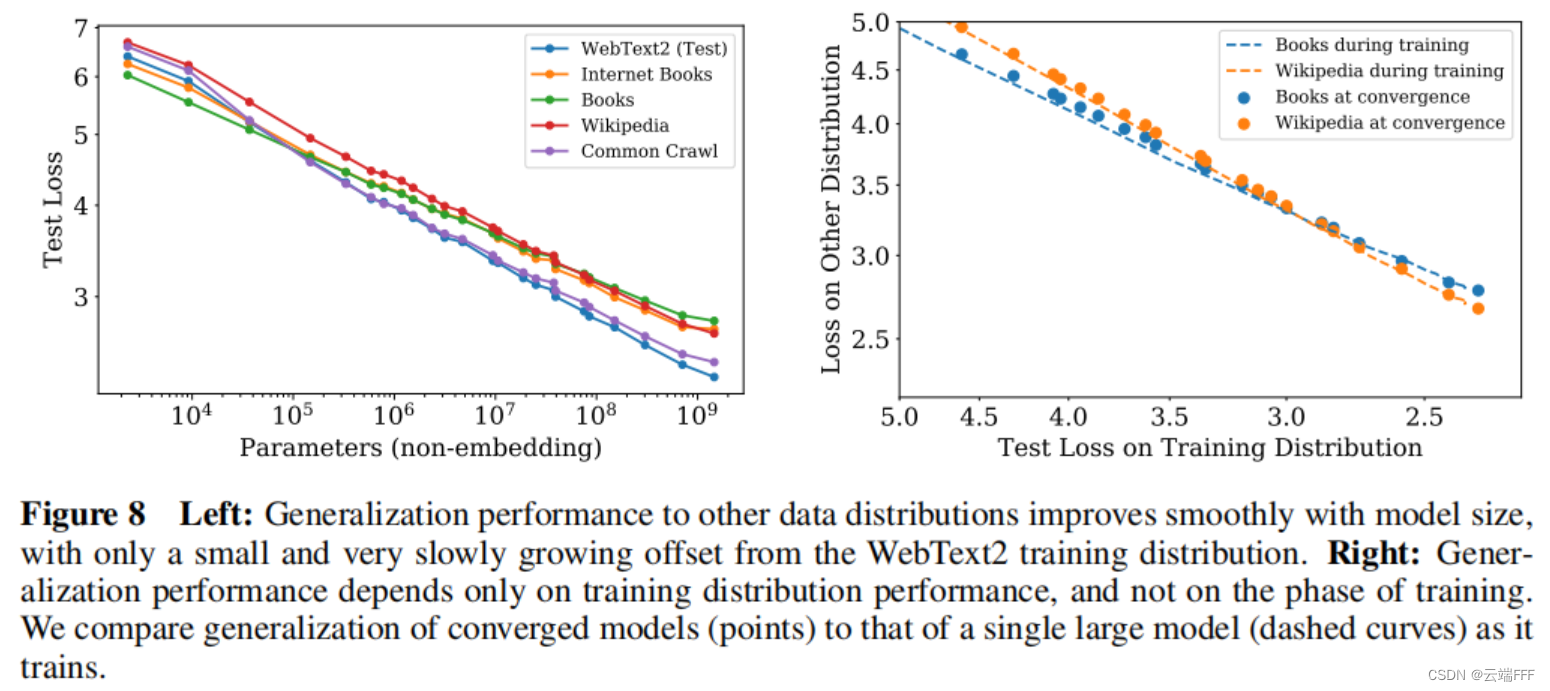
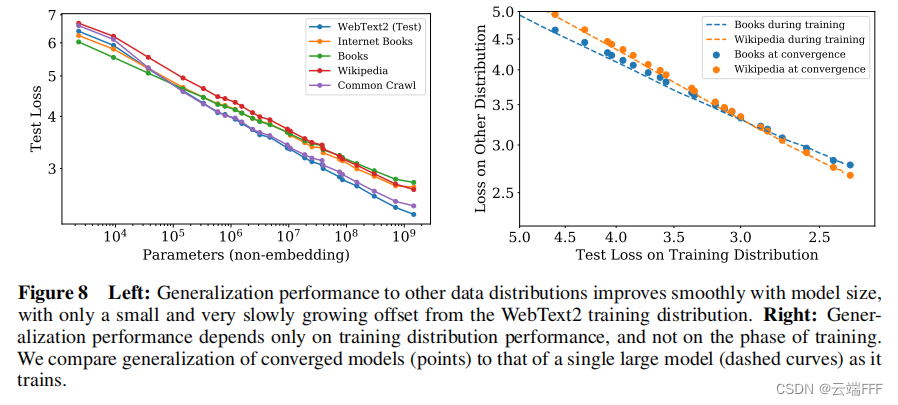
左图显示了在 WebText2 上训练模型,然后在多种数据集上测试的泛化性能表现,显示出一致的幂律关系;右图说明泛化性能仅取决于训练分布上的性能,而与训练阶段无关
- 作者验证了 LSTM 和 Encoder-Decoder 类模型都服从以上幂律关系
- 作者进一步考察了其他序列模型以及模型的泛化性能
1.3 数据量 & 计算量和性能呈现幂律关系
- 作者发现数据量 & 计算量也都和模型性能呈现幂律关系,如下所示

-
考察计算量 C C C 与性能的关系时(左图),作者先用充足的数据训练多种不同参数规模 N N N 的模型只收敛,然后对任意给定的 C C C,考察所有模型,找到第 S = C 6 N B S=\frac{C}{6NB} S=6NBC 步时最优的模型性能绘制(为此需保持所有模型训练时 B B B 不变,我们将在第 4 节进一步讨论更高效的训练方案)。注意到幂律关系
L ( C ) ≈ ( C c C ) α C L(C) \approx \left(\frac{C_c}{C}\right)^{\alpha_C} L(C)≈(CCc)αC- 值得注意的时,以上幂律关系在 LLM 多模态任务中依然存在
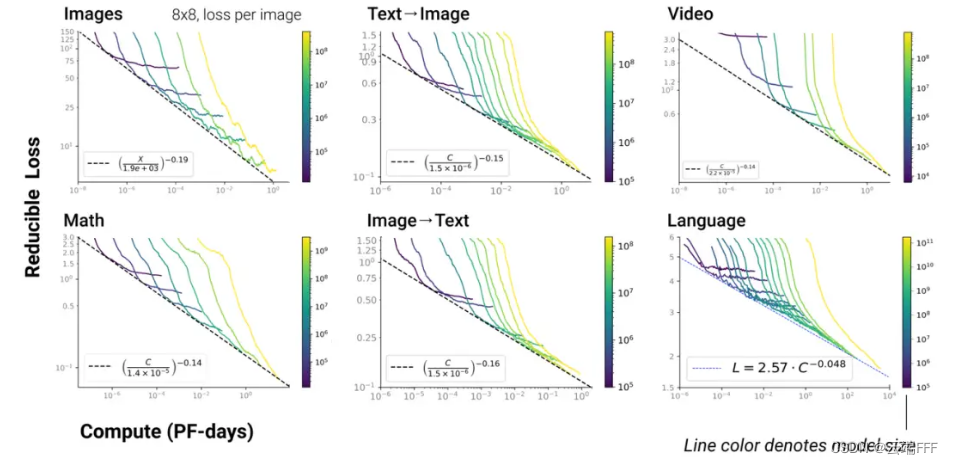
- 值得注意的时,以上幂律关系在 LLM 多模态任务中依然存在
-
考察数据量 D D D 与性能的关系时(中图),作者训练规模为 ( l , d ) = ( 36 , 1280 ) (l,d)=(36,1280) (l,d)=(36,1280) 的模型直到收敛。注意到幂律关系
L ( D ) ≈ ( D c D ) α D L(D) \approx \left(\frac{D_c}{D}\right)^{\alpha_D} L(D)≈(DDc)αD
-
2. 利用 Scaling Laws 计算避免过拟合所需的数据量
- 第一节分析的三个幂律关系 L ( C ) , L ( D ) , L ( N ) L(C),L(D),L(N) L(C),L(D),L(N) 都是单独考察的,即考察一个量时,总是调整其他两个量的取值,使模型性能仅受被考察的量影响
- 本节中,进一步考察模型性能如何同时受到 N N N 和 D D D 两个量的影响,这可以指导我们如何在控制过拟合的情况下,考察训练模型所需的数据量
2.1 参数量 N N N 和数据量 D D D 对模型性能的联合影响
- 基于第一节发现的幂律关系,作者直接将 L ( N , D ) L(N,D) L(N,D) 的表达式假设为
L ( N , D ) = [ ( N c N ) α N α D + D c D ] α D L(N,D) = \left[\left(\frac{N_c}{N}\right)^{\frac{\alpha_N}{\alpha_D}} + \frac{D_c}{D}\right]^{\alpha_D} L(N,D)=[(NNc)αDαN+DDc]αD 此设计很好地适配了数据,其形式基于以下三个原则- 词表大小或 tokenize 方法的变化应当会对损失值进行整体的缩放(rescale the loss by an overall factor),这种缩放需要被自然地考虑到
该设计中我们可以通过调节 N c , D c N_c,D_c Nc,Dc 来适应这些变化
- 固定 D D D, N → ∞ N\to \infin N→∞ 时应有 L ( N , D ) → L ( D ) L(N,D)\to L(D) L(N,D)→L(D);固定 N N N, D → ∞ D\to \infin D→∞ 时应有 L ( N , D ) → L ( N ) L(N,D)\to L(N) L(N,D)→L(N)
有限的 D D D 下,任何模型都无法接近最佳损失(即文本的熵);同样固定大小 N N N 的模型将受到容量限制。另一方面,有 L ( ∞ , D ) = L ( D ) , L ( N , ∞ ) = L ( N ) L(\infin,D)= L(D), \space\space L(N,\infin)= L(N) L(∞,D)=L(D), L(N,∞)=L(N)
- L ( N , D ) L(N,D) L(N,D) 应该在 D → ∞ D\to\infin D→∞ 时进行分析(通常有足够的数据训练模型),这时它应具有以整数次幂的 1 D \frac{1}{D} D1 为变量的级数展开(即形如 f ( D ) = a 0 + a 1 D + a 2 D 2 + . . . f(D)=a_0+\frac{a_1}{D}+\frac{a_2}{D^2}+... f(D)=a0+Da1+D2a2+...),因此以上设计中 N N N 和 D D D 并不完全对称
这个原则更具推测性,由于过拟合应该与数据集的方差或信噪比相关,而它们按 1 D \frac{1}{D} D1 成比例缩放,所以我们通常期望过拟合在非常大的 D D D 下也成比例于 1 D \frac{1}{D} D1 进行缩放。这个期望对于任何平滑的损失函数都应该成立。然而,这假设 1 D \frac{1}{D} D1 的修正项在方差的其他来源(如有限 batch size)上占主导地位,这还没有经验证实
- 词表大小或 tokenize 方法的变化应当会对损失值进行整体的缩放(rescale the loss by an overall factor),这种缩放需要被自然地考虑到
- 利用以上定义,可以将模型的过拟合程度形式化表示为
δ L ( N , D ) ≡ L ( N , D ) L ( N , ∞ ) − 1 ≈ ( 1 + ( N N c ) α N α D D c D ) α D − 1 \begin{aligned} \delta L(N, D) &\equiv \frac{L(N, D)}{L(N, \infty)}-1 \\ &\approx\left(1+\left(\frac{N}{N_{c}}\right)^{\frac{\alpha_{N}}{\alpha_{D}}} \frac{D_{c}}{D}\right)^{\alpha_{D}}-1 \end{aligned} δL(N,D)≡L(N,∞)L(N,D)−1≈(1+(NcN)αDαNDDc)αD−1 这意味着模型的过拟合程度和 N α N α D / D N^{\frac{\alpha_N}{\alpha_D}}/D NαDαN/D 成幂律关系
2.2 实验验证
- 作者用 10% 的 dropout 对所有模型进行正则化,训练直到测试损失不再下降(早停策略),结果如下所示

- 左图:对于较大的 D D D,性能表现出关于 N N N 的幂律关系;对于较小的 D D D,随着 N N N 的增加模型开始过拟合。虚线是拟合结果,验证了以上定义的有效性
- 右图:考察过拟合情况,实线拟合了 N α N α D / D N^{\frac{\alpha_N}{\alpha_D}}/D NαDαN/D 和过拟合程度间的幂律关系,验证了以上定义的有效性
2.3 预测数据集尺寸以避免过拟合
- 利用大量小规模实验的结果,可以拟合出当 Scaling Laws 中的一些关键常数,这里为

设不同随机种子下的验证损失变化约为 2%,这意味着在训练达到我们所需的收敛阈值时,避免过拟合需要
D ≥ ( 5 × 1 0 3 ) N 0.74 D \geq\left(5 \times 10^{3}\right) N^{0.74} D≥(5×103)N0.74 通过这种关系,可在 token 数据量 D D D 为 22B 的数据集上以最小的过拟合训练参数量 N N N 不超过 1 0 9 10^9 109 的模型 - 这一节的重要意义在于给出了一种利用 Scaling Laws 进行预测的思路,即首先进行大量小规模实验,然后用基于 Scaling Laws 的关系式对结果进行拟合,最后用拟合曲线预测更大规模模型的情况
3. 模型大小和训练时间的缩放定律
-
现在我们讲起 Scaling Laws 时,主要关注的通常就是前两节(特别是第一节)所述内容。但是原始论文中还进行了进一步分析,使其更符合现实情况。在进一步分析之前,首先引入一些新符号
参数 符号 说明 关键 batch size B crit B_{\text{crit}} Bcrit 以此 batch size 进行训练大致上在时间和计算效率之间提供了一个最优的折衷 最小计算量 C min C_{\min} Cmin 达到给定损失值最小计算量,这是模型以远小于 B crit B_{\text{crit}} Bcrit 的 batch size 训练时的计算量 最小训练步骤 S min S_{\min} Smin 达到给定损失值的最小训练步数。这是模型以远大于 B crit B_{\text{crit}} Bcrit 的 batch size 训练时的步数 最小处理数据量(Token) E min E_{\min} Emin 达到给定损失值所处理的最小数据量 -
设置过大的 batch size 会影响计算效率,因为足够大的 batch size 下计算的梯度方向已经足够准确,继续加大的意义不大。一般认为训练过程中存在一个临界 batch size B crit B_{\text{crit}} Bcrit:当 B ≤ B crit B\leq B_{\text{crit}} B≤Bcrit 时,加大 B B B 对计算效率无明显影响;当 B > B crit B > B_{\text{crit}} B>Bcrit 时,加大 B B B 会使得计算效率下降。
- 以 B ≈ B crit B\approx B_{\text{crit}} B≈Bcrit 进行训练可以最大化训练的计算效率,即到达相同性能用时最短
- 以 B ≫ B crit B\gg B_{\text{crit}} B≫Bcrit 进行训练可以最小化训练步骤数量, S → S min S \to S_{\min} S→Smin,但达相同性能耗时更长
- 以 B ≪ B crit B\ll B_{\text{crit}} B≪Bcrit 可以最小化计算量, C → C min C \to C_{\min} C→Cmin,但达相同性能耗时更长
3.1 拟合 B crit ( L ) B_{\text{crit}}(L) Bcrit(L), S min ( S ) S_{\min }(S) Smin(S) 和 C min ( C ) C_{\min }(C) Cmin(C)
- 作者通过实验发现,为了达成任意固定的性能损失 L L L,训练步数 S S S 和训练处理数据量 E = B S E=BS E=BS 之间存在反比例关系
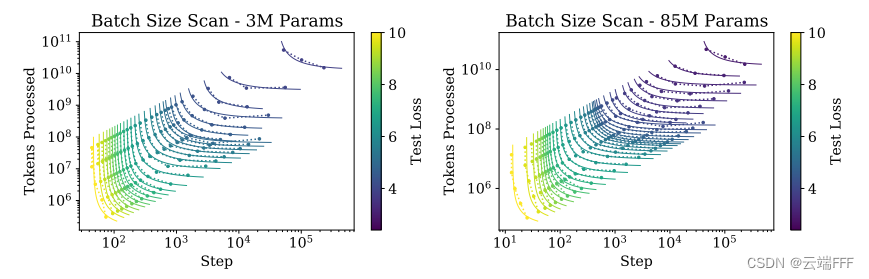
如图所示,作者使用不同参数量的两个 Transformer 模型,考察达到指定性能损失(颜色表示)所需的训练步数 S S S 和处理 Token 数量 E E E 之间的关系。图像说明,为了达成固定的 L L L,随着 S S S 增大,所需处理的 Token 数量 E E E 在减少- 为了达成固定的 L L L,从左到右训练步数 S S S 越多,处理的 Token 数量 E E E 越少, B B B 越小,总计算量 C C C 越小
- 注意到每一条线都呈现反比例关系,作者提出它们服从如下关系
( S S min − 1 ) ( E E min − 1 ) = 1 \left(\frac{S}{S_{\min}}-1\right)\left(\frac{E}{E_{\min}}-1\right) = 1 (SminS−1)(EminE−1)=1 注意到这本质就是一个反比例函数,两个 − 1 -1 −1 是把坐标轴移动到曲线所在位置
- 每一条线最左边的点对应 B max = E max S min B_{\max} = \frac{E_{\max}}{S_{\min}} Bmax=SminEmax,最右边的点对应 B min = E min S max B_{\min} = \frac{E_{\min}}{S_{\max}} Bmin=SmaxEmin,它们对应训练效率的两个低点, B crit B_{\text{crit}} Bcrit 应该在二者之间,作者将其定义为
B crit ( L ) ≡ E m i n S min B_{\text {crit }}(L) \equiv \frac{E_{\mathrm{min}}}{S_{\text {min }}} Bcrit (L)≡Smin Emin 作者发现这种定义和另一种可以估计 B crit B_{\text {crit }} Bcrit 的方法 “噪声梯度度量” 得到的结果类似。根据拟合情况,以 B crit B_{\text {crit }} Bcrit 训练大约需要 2 S min 2S_{\min} 2Smin 的训练步骤和 2 E min 2E_{\min} 2Emin 的数据量 - 作者通过实验验证了 B critc B_{\text{critc}} Bcritc 也和模型性能(用损失表示)之间呈现幂律关系

如图可见, B crit ( L ) B_{\text {crit }}(L) Bcrit (L) 仅和性能 L L L 相关,而与模型规模等其他因素无关。作者将幂律关系表示为为
B crit ( L ) ≈ B ∗ L 1 / α B B_{\text {crit }}(L) \approx \frac{B_{*}}{L^{1 / \alpha_{B}}} Bcrit (L)≈L1/αBB∗ 其中 B ∗ B_* B∗ 和 α B \alpha_B αB 是需要拟合的参数,这种表示可以使 B crit ( L ) B_{\text {crit }}(L) Bcrit (L) 的估计值在 L → 0 L\to 0 L→0 时发散,以保持和另一种估计方法 “噪声梯度度量” 的一致性。 - 给定任意训练过程参数 C , N , B , S C, N, B, S C,N,B,S,如前文所述它们之间满足 C ≈ 6 N B S C\approx 6NBS C≈6NBS,设该训练过程达成的性能(损失表示)为 L L L,可以借助 B crit B_{\text{crit}} Bcrit 表示出达成相同 L L L 对应的 S min S_{\min} Smin 和 C min C_{\min} Cmin
S min ( S ) ≡ S 1 + B crit ( L ) / B ( minimum steps, at B ≫ B crit ) C min ( C ) ≡ C 1 + B / B crit ( L ) (minimum compute, at B ≪ B crit ) \begin{aligned} &S_{\min }(S) \equiv \frac{S}{1+B_{\text {crit }}(L) / B} &&\quad\left(\text { minimum steps, at } B \gg B_{\text {crit }}\right) \\ &C_{\min }(C) \equiv \frac{C}{1+B / B_{\text {crit }}(L)} &&\quad \text { (minimum compute, at } B \ll B_{\text {crit }} \text {)} \end{aligned} Smin(S)≡1+Bcrit (L)/BSCmin(C)≡1+B/Bcrit (L)C( minimum steps, at B≫Bcrit ) (minimum compute, at B≪Bcrit ) 总体上可以看出就是按上面的反比例关系调整了一下,但具体为什么如此调整定义说实话有点没看懂。由于 B crit ( L ) B_{\text{crit}}(L) Bcrit(L) 可以拟合表示,这里的 S min ( S ) S_{\min }(S) Smin(S) 和 C min ( C ) C_{\min }(C) Cmin(C) 也都可以拟合表示了
3.2 拟合 L ( N , S ) L(N,S) L(N,S)
- 作者通过实验验证了,在无数据量限制的情况下,对给定参数量 N N N 的模型以足够大的 batch size 训练 S min S_{\min} Smin 步之后,如下右图所示

模型性能与 N N N 和 S min S_{\min} Smin 之间存在以下幂律关系关系
L ( N , S min ) = ( N c N ) α N + ( S c S min ) α S L\left(N, S_{\min }\right)=\left(\frac{N_{c}}{N}\right)^{\alpha_{N}}+\left(\frac{S_{c}}{S_{\min }}\right)^{\alpha_{S}} L(N,Smin)=(NNc)αN+(SminSc)αS 再配合上一节中 S min S_{\min } Smin 的定义,在无数据限制的情况下对参数量为 N N N 的模型训练 S S S 步后得到的性能可以用下式拟合
L ( N , S ) = ( N c N ) α N + ( S c S min ( S ) ) α S L\left(N, S\right)=\left(\frac{N_{c}}{N}\right)^{\alpha_{N}}+\left(\frac{S_{c}}{S_{\min}(S)}\right)^{\alpha_{S}} L(N,S)=(NNc)αN+(Smin(S)Sc)αS - 作者进一步在无数据限制的情况下拟合了不同参数量 N N N 下性能和计算量 C C C 以及训练步数 S S S 的关系

良好的拟合结果也验证了以上提出 L ( N , S ) L\left(N, S\right) L(N,S), S min ( S ) S_{\min }(S) Smin(S) 和 C min ( C ) C_{\min }(C) Cmin(C) 等表达式的有效性
4. 计算量的优化分配
-
第 1 节已经分析了,在不考虑 N N N 和 D D D 限制的情况下,计算量 C C C 与性能的之间存在幂律关系
L ( C ) ≈ ( C c C ) α C L(C) \approx \left(\frac{C_c}{C}\right)^{\alpha_C} L(C)≈(CCc)αC 但是这个结果的前提是以固定 batch size B B B 进行训练,事实上,我们可以按第 3 节所述的 B crit B_{\text{crit}} Bcrit 进行训练,从而提高训练效率。本节中我们进一步分析这种情况 -
作者首先对性能和 C min C_{\min} Cmin 的关系进行拟合(不考虑 N N N 和 D D D 的约束),如下所示

这里作者使用远低于 B crit B_{\text {crit }} Bcrit 的 batch size 训练以考察性能和 C min C_{\min} Cmin 的关系。注意到 C min C_{\min} Cmin 同样和性能间存在幂律关系 L ( C min ) L(C_{\min}) L(Cmin),但是具体的表达式和 C C C 的幂律关系 L ( C ) L(C) L(C) 有所区别
-
作者进一步考察可以最高效训练的最优模型参数量 N ( C min ) N(C_{\min}) N(Cmin),拟合结果如下所示

如左图所示,最优参数量和最小计算量之间也存在幂律关系,拟合结果约为
N ( C min ) ∝ C min 0.73 N(C_{\min})\propto C_{\min}^{0.73} N(Cmin)∝Cmin0.73 进一步地,注意到
( 3.1 节拟合结果 ) B crit ∝ L − 4.8 ( 4.1 节拟合结果 ) L ∝ C min − 0.05 ⇒ B crit ∝ C min 0.24 \begin{aligned} &(3.1 节拟合结果) &&B_{\text {crit }} \propto L^{-4.8} \\ &(4.1节拟合结果) &&L\propto C_{\min}^{-0.05} \end{aligned} \Rightarrow B_{\text {crit }} \propto C_{\min}^{0.24} (3.1节拟合结果)(4.1节拟合结果)Bcrit ∝L−4.8L∝Cmin−0.05⇒Bcrit ∝Cmin0.24 又根据定义 C min ≡ 6 N ( C min ) B crit S C_{\min} \equiv 6N(C_{\min}) {B_{\text {crit }}}S Cmin≡6N(Cmin)Bcrit S,可以推出
C min ∝ 6 C min 0.73 C min 0.24 S ⇒ S min ∝ C min 0.03 C_{\min} \propto 6C_{\min}^{0.73} C_{\min}^{0.24}S \Rightarrow S_{\min} \propto C_{\min}^{0.03} Cmin∝6Cmin0.73Cmin0.24S⇒Smin∝Cmin0.03 这个结果也和拟合结果相吻合,如上右图所示PS:这里说根据定义我觉得有点问题,因为根据定义 C min C_{\min} Cmin 应该是在用远小于 B crit B_{\text{crit}} Bcrit 的 batch size 训练得到的,这里应该是假设了这个小 batch size 仍然和 B crit B_{\text{crit}} Bcrit 有相同的数量级
-
总之我们可以得出结论:当不受训练数据量限制时,随着总计算量的提高,存在有对应的最优模型规模(训练效率最高)

我们应该以最佳的计算分配来扩大语言模型,即

- 主要按 N ( C min ) ∝ C min 0.73 N(C_{\min})\propto C_{\min}^{0.73} N(Cmin)∝Cmin0.73 的幂律关系模型参数规模
- 通过 B ∝ B c r i t B\propto B_{crit} B∝Bcrit,即 B ∝ C min 0.24 B\propto C_{\min}^{0.24} B∝Cmin0.24 来扩大 batch size
- 训练步数 S S S 的增量可以忽略不计
5. 总结
- 本文只涵盖了原文中的核心结论,部分更进一步的分析假设比较强就没有写了,请参考原文。
- 下面对本文通过实验发现的 Scaling Laws 进行总结
-
模型性能与规模密切相关,与模型形状关系较弱:模型性能主要取决于模型参数量(不包括嵌入) N N N、数据集(Token)大小 D D D 以及训练计算量(FLOPs) C C C。在合理范围内,性能对其他超参数(如深度与宽度的比例、训练学习率调度方案)的依赖程度很低

-
平滑的幂律关系:当不被其他两个因素限制时,模型性能与 N N N、 D D D、 C C C 之间存在幂律关系,这种关系在很大范围内一直保持(跨越六个以上数量级)。这种幂律关系在 Decoder-Only Transformer、Encoder-Decoder Transformer、LSTM 等多种序列模型上都有体现,对于 NLP 以外的多模态任务也成立。
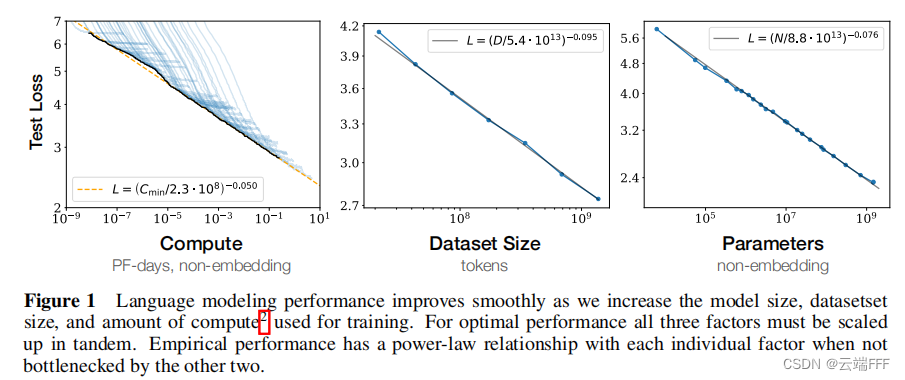
通过在小模型上拟合以下幂律关系,可以外推预测大模型、大数据量和大计算量下的性能表现
- 控制模型参数量 N N N,用足够数据训练至收敛,性能与 N N N 的关系满足(不包含嵌入参数)
L ( N ) ≈ ( N c N ) α N L(N) \approx \left(\frac{N_c}{N}\right)^{\alpha_N} L(N)≈(NNc)αN - 控制训练数据量 D D D,使用早停策略训练足够大的大规模模型,性能与 D D D 的关系满足
L ( D ) ≈ ( D c D ) α D L(D) \approx \left(\frac{D_c}{D}\right)^{\alpha_D} L(D)≈(DDc)αD - 控制训练计算量 C min C_{\min} Cmin,使用足够大的数据集对最优尺寸的模型,以足够小的 batch size 进行训练(此时计算量最小)时,性能与 C min C_{\min} Cmin 满足
L ( C min ) ≈ ( C c min C min ) α c min L(C_{\min}) \approx \left(\frac{C_c^{\min}}{C_{\min}}\right)^{\alpha_c^{\min}} L(Cmin)≈(CminCcmin)αcmin
- 控制模型参数量 N N N,用足够数据训练至收敛,性能与 N N N 的关系满足(不包含嵌入参数)
-
过度拟合的普遍规律:在不考虑训练数据量 C C C 的限制时,只要同时扩大 N N N 和 D D D,性能就会可预测地提高,但如果固定 N N N 或 D D D 中的一个而增加另一个,就会进入回报递减的领域。过拟合程度和 N α N α D / D N^{\frac{\alpha_N}{\alpha_D}}/D NαDαN/D 之间存在幂律关系。这意味着每当模型大小 N N N 增加 8 倍,将数据量 D D D 增加 8 α N α D 8^{\frac{\alpha_N}{\alpha_D}} 8αDαN 倍就可以维持过拟合程度不增加
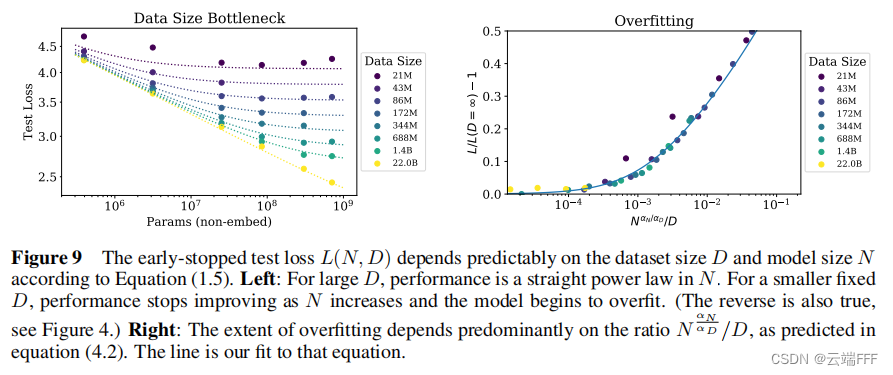
不考虑训练计算量限制时,性能受到 N N N 和 D D D 的联合影响
L ( N , D ) = [ ( N c N ) α N α D + D c D ] α D L(N,D) = \left[\left(\frac{N_c}{N}\right)^{\frac{\alpha_N}{\alpha_D}} + \frac{D_c}{D}\right]^{\alpha_D} L(N,D)=[(NNc)αDαN+DDc]αD 过拟合程度可以表示为
δ L ( N , D ) ≡ L ( N , D ) L ( N , ∞ ) − 1 ≈ ( 1 + ( N N c ) α N α D D c D ) α D − 1 \begin{aligned} \delta L(N, D) &\equiv \frac{L(N, D)}{L(N, \infty)}-1 \\ &\approx\left(1+\left(\frac{N}{N_{c}}\right)^{\frac{\alpha_{N}}{\alpha_{D}}} \frac{D_{c}}{D}\right)^{\alpha_{D}}-1 \end{aligned} δL(N,D)≡L(N,∞)L(N,D)−1≈(1+(NcN)αDαNDDc)αD−1 这意味着过拟合程度和 N α N α D / D N^{\frac{\alpha_N}{\alpha_D}}/D NαDαN/D 成幂律关系 -
训练的普遍规律:训练曲线遵循可预测的幂律,通过外推训练曲线的早期部分,我们可以大致预测如果我们训练更长时间会达到的损失
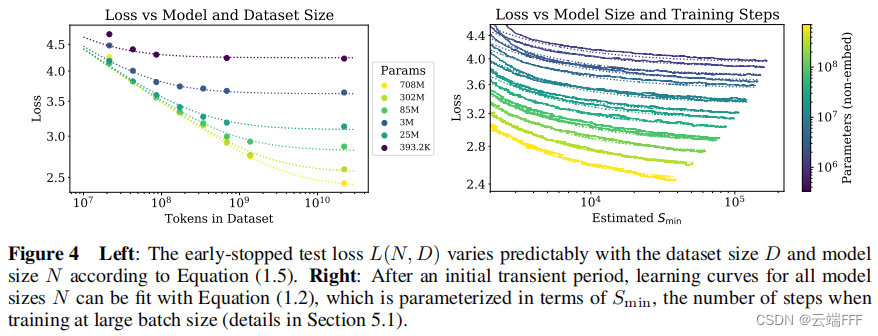
在无数据限制的情况下,对参数量为 N N N 的模型训练 S S S 步后得到的性能可以用下式拟合
L ( N , S ) = ( N c N ) α N + ( S c S min ( S ) ) α S L\left(N, S\right)=\left(\frac{N_{c}}{N}\right)^{\alpha_{N}}+\left(\frac{S_{c}}{S_{\min}(S)}\right)^{\alpha_{S}} L(N,S)=(NNc)αN+(Smin(S)Sc)αS 其中 S min ( S ) ≡ S 1 + B crit ( L ) / B ( minimum steps, at B ≫ B crit ) S_{\min }(S) \equiv \frac{S}{1+B_{\text {crit }}(L) / B} \quad\left(\text { minimum steps, at } B \gg B_{\text {crit }}\right) Smin(S)≡1+Bcrit (L)/BS( minimum steps, at B≫Bcrit ) -
迁移随着测试性能的提高而提高:当我们使用与训练数据不同的分布对文本进行模型评估时,结果与训练验证集上的结果高度相关,损失大致恒定。换句话说,迁移到不同的分布会导致恒定的损失,但其他方面会大致与训练集上的性能保持一致
-
样本效率:大型模型比小型模型更具样本效率,使用更少的优化步数和更少的数据点就能达到相同的性能水平
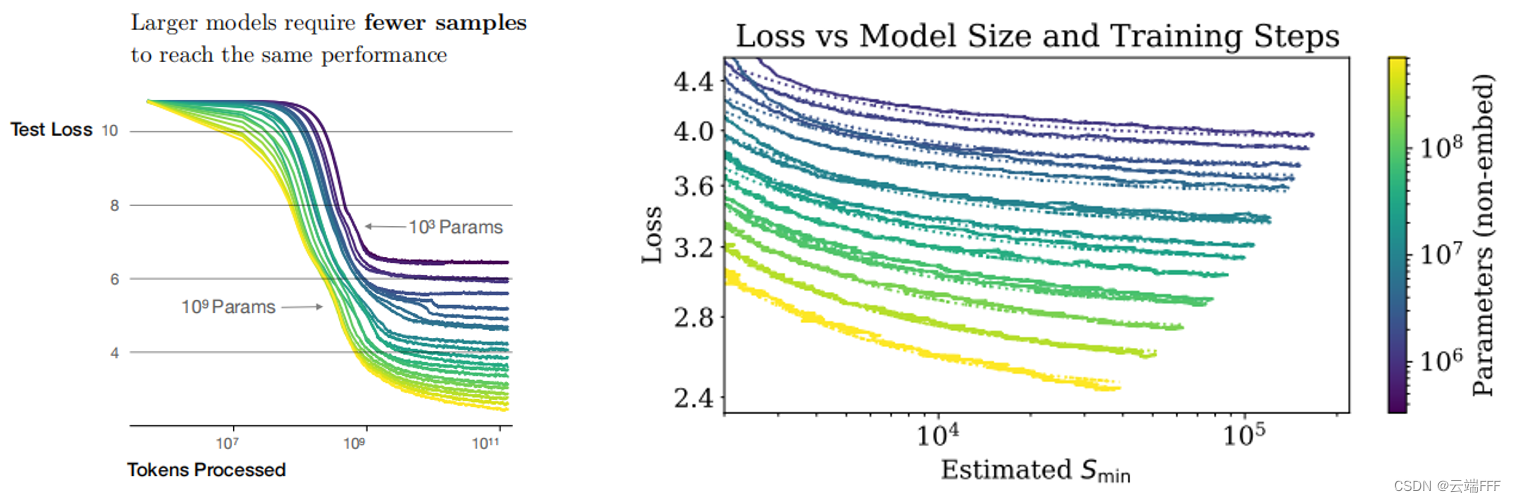
-
收敛效率低:随着 C C C 的增大,为了达成最高训练效率,数据 D D D 的增量要显著小于模型参数量 N N N 的增量。因此当固定计算量预算 C C C 而不限制模型大小 N N N 和可用数据 D D D 时,可以通过训练非常大的模型并在明显缺乏收敛性时停止来获得最佳性能,这比将小模型训练至收敛的训练效率高很多
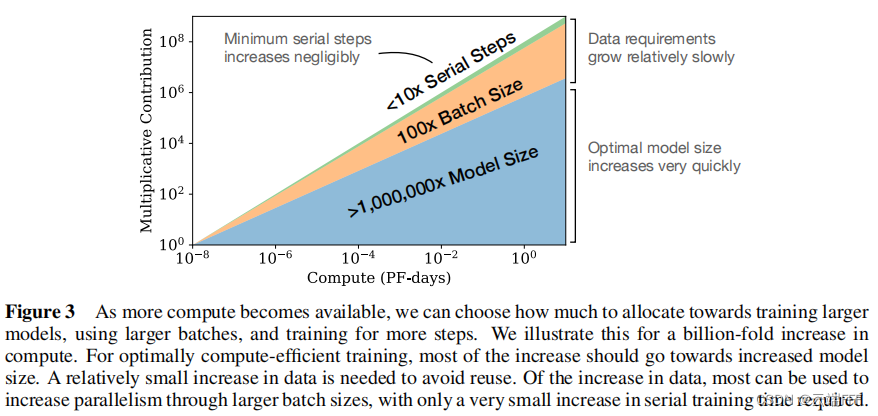
当固定训练总计算量 C C C 而没有其他任何限制时,可以基于 L ( N , S ) = ( N c N ) α N + ( S c S min ( S ) ) α S L\left(N, S\right)=\left(\frac{N_{c}}{N}\right)^{\alpha_{N}}+\left(\frac{S_{c}}{S_{\min}(S)}\right)^{\alpha_{S}} L(N,S)=(NNc)αN+(Smin(S)Sc)αS 预测最优模型大小 N N N 、最优批量大小 B B B 、最优步骤数 S S S 和数据集大小 D D D 应按如下方式增长
N ∝ C C α C min / α N , B ∝ C α C min / α B , S ∝ C C α C min / α S , D = B ⋅ S N \propto C_{C}^{\alpha_{C}^{\min } / \alpha_{N}},\quad B \propto C^{\alpha_{C}^{\min } / \alpha_{B}}, \quad S \propto C_{C}^{\alpha_{C}^{\min } / \alpha_{S}}, \quad D=B \cdot S N∝CCαCmin/αN,B∝CαCmin/αB,S∝CCαCmin/αS,D=B⋅S 其中
α C min = 1 / ( 1 / α S + 1 / α B + 1 / α N ) \alpha_{C}^{\min }=1 /\left(1 / \alpha_{S}+1 / \alpha_{B}+1 / \alpha_{N}\right) αCmin=1/(1/αS+1/αB+1/αN) 作者拟合的最优结果为 N ( C min ) ∝ C min 0.73 , B crit ∝ C min 0.24 , S min ∝ C min 0.03 N(C_{\min})\propto C_{\min}^{0.73}, \space\space B_{\text {crit }} \propto C_{\min}^{0.24}, \space\space S_{\min} \propto C_{\min}^{0.03} N(Cmin)∝Cmin0.73, Bcrit ∝Cmin0.24, Smin∝Cmin0.03,这意味着随着计算量预算 C C C 的提高,应该更多地增加模型参数量 N N N,较少地增加训练数据量 D D D -
最优 batch size:使用合适的 batch size 进行训练可以实现最高的训练效率,关键 batch size 的大小 B crit B_{\text{crit}} Bcrit 可以通过测量梯度噪声规模来确定,作者进一步验证了它仅和目标性能(损失值)有关,且呈现幂律关系,而与模型规模等其他因素无关
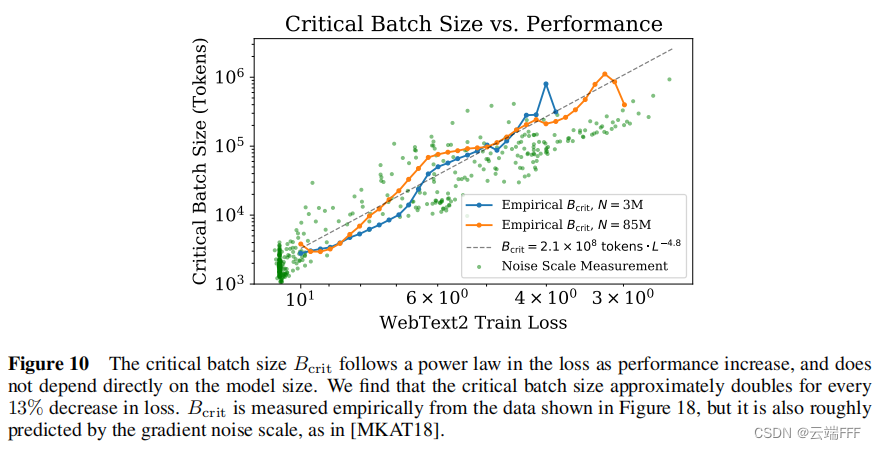
最佳 batch size B crit ( L ) B_{\text {crit }}(L) Bcrit (L) 仅和性能 L L L 相关,而与模型规模等其他因素无关。幂律关系表示为为
B crit ( L ) ≈ B ∗ L 1 / α B B_{\text {crit }}(L) \approx \frac{B_{*}}{L^{1 / \alpha_{B}}} Bcrit (L)≈L1/αBB∗ 其中 B ∗ B_* B∗ 和 α B \alpha_B αB 是需要拟合的参数,这种表示可以使 B crit ( L ) B_{\text {crit }}(L) Bcrit (L) 的估计值在 L → 0 L\to 0 L→0 时发散,以保持和另一种估计方法 “噪声梯度度量” 的一致性
-
- 最后,必须注意以上 Scaling Laws 都是针对 “最大化训练效率” 而言的。有时我们会故意违反它,比如 LLaMa 就使用更多的数据训练了较小的模型,虽然训练效率低,但是可以减少部署和推理成本
相关文章:
序列模型(4)—— Scaling Laws
本文介绍 LLM 训练过程中重要的 Scaling Laws,这是一个经验规律,指出了固定训练成本(总计算量FLOPs) C C C 时,如何调配模型规模(参数量) N N N 和训练 Token 数据量 D D D,才能实现…...
【软件测试学习笔记1】测试基础
1.软件测试的定义 软件的定义:控制计算机硬件工作的工具 软件的基本组成:页面客户端,代码服务器,数据服务器 软件产生的过程:需求产生(产品经理),需求文档,设计效果图…...

pytorch详细探索各种cnn卷积神经网络
目录 torch.nn.functional子模块详解 conv1d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv2d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv3d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv_transpose1d 用法…...

OpenCV——八邻域断点检测
目录 一、理论基础1、八邻域2、断点检测 二、代码实现三、结果展示四、参考链接 OpenCV——八邻域断点检测由CSDN点云侠原创,爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、理论基础 1、八邻域 图1 八邻域示意图 图…...

leetcode238:除自身以外数组的乘积
文章目录 1.使用除法(违背题意)2.左右乘积列表3.空间复杂度为O(1)的方法 在leetcode上刷到了这一题,一开始并没有想到好的解题思路,写篇博客再来梳理一下吧。 题目要求: 不使用除法在O(n)时间复杂度内 1.使用除法&am…...
VTK开发调试环境下载(VTK开发环境一步到位直接开发,无需自己配置编译 VS2017+Qt5.12.10+VTK)
一、无与伦比的优势 直接下载代码就可以调试的VTK代码仓库。 二、资源制作原理 这个资源根据VTK源码 编译出动态库文件 pdb lib dll 文件( x64 debug ) 并将这两者同时放在一个代码仓库里,下载就能用。 三、使用方法(vtk-so…...

【JAVA】在 Queue 中 poll()和 remove()有什么区别
🍎个人博客:个人主页 🏆个人专栏:JAVA ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 poll() 方法: remove() 方法: 区别总结: 结语 我的其他博客 前言 在Java的Queue接口中&…...

常用Java代码-Java中的Optional类和null安全编程
在Java中,Optional 是一个可以为null的容器对象。如果值存在则isPresent()方法返回true。调用get()方法会返回值,如果值为null则抛出NullPointerException。以下是一个详细的代码详解。 在之前的Java版本中,程序员需要手动检查是否为null&am…...

android.os.NetworkOnMainThreadException
问题 android.os.NetworkOnMainThreadException详细问题 核心代码如下: import android.os.Bundle;import androidx.appcompat.app.AppCompatActivity;import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ja…...

Java生成四位数随机验证码
引言: 我们生活中登录的时候都要输入验证码,这些验证码是为了增加注册或者登录难度,减少被人用脚本疯狂登录注册导致的一系列危害,减少数据库的一些压力。 毕竟那些用脚本生成的账号都是垃圾账号 本次实践:生成这样的…...
)
编程探秘:Python深渊之旅-----数据可视化(八)
客户提出了对数据报告和图表的具体要求,这使得团队需要快速掌握数据可视化的技巧。派超决定深入了解 Python 中的数据可视化工具。 派超(兴奋地):我们有机会做些真正酷炫的数据报告了!我听说 Python 有很棒的图表库。…...
上海亚商投顾:创业板指冲高回落 光伏、航运股逆势走强
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指1月12日冲高回落,创业板指午后跌近1%。北证50指数跌超6%,倍益康、华信永道、众诚科…...

Python3 中常用字符串函数介绍
介绍 Python 中有几个与 字符串数据类型相关的内置函数。这些函数让我们能够轻松修改和操作字符串。我们可以将函数视为在代码元素上执行的操作。内置函数是在 Python 编程语言中定义的,并且可以随时供我们使用的函数。 在本教程中,我们将介绍在 Pytho…...

Python - 深夜数据结构与算法之 AVL 树 红黑树
目录 一.引言 二.高级树的简介 1.树 2.二叉树 3.二叉搜索树 4.平衡二叉树 三.AVL 树 ◆ 插入节点 ◆ 左旋 ◆ 右旋 ◆ 左右旋 ◆ 右左旋 ◆ 一般形式 ◆ 实际操作 ◆ 总结 四.红黑树 ◆ 概念 ◆ 示例 ◆ 对比 五.总结 一.引言 前面我们介绍了二叉树、二叉…...

Zookeeper使用详解
介绍 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布…...
)
C#属性(Property)
文章目录 一、C#属性(Property)?二、属性的用法总结 一、C#属性(Property)? C#属性(Property)是一种访问器(accessor),用于封装一个类的字段&…...

在docker中搭建部署clickhouse
因需要给网关日志拉取并存储供数据分析师分析,由于几十个项目的网关请求数量很大,放在mysql不合适,MongoDB不适合分析,于是准备存放在clickhouse,clickhouse对于读写支持也比较友好,说干就干 1、在服务器中…...
)
第九部分 使用函数 (三)
目录 一、文件名操作函数 1、dir 2、notdir 3、suffix 4、basename 5、addsuffix 6、addprefix 7、join 一、文件名操作函数 下面我们要介绍的函数主要是处理文件名的。每个函数的参数字符串都会被当做一个或是 一系列的文件名来对待。 1、dir $(dir <names..>…...

基础命令继续
1:创建目录命令 mkdir命令 注意:创建文件夹需要修改权限,请确保操作均在HOME目录内,不要在Home外操作,涉及到权限问题,HOME外无法识别 小结: 练习: 2:touch创建文件 2:c…...

uni-app做A-Z排序通讯录、索引列表
上图是效果图,三个问题 访问电话通讯录,拿数据拿到用户的联系人数组对象,之后根据A-Z排序根据字母索引快速搜索 首先说数据怎么拿 - 社区有指导https://ask.dcloud.net.cn/question/64117 uniapp 调取通讯录 // #ifdef APP-PLUSplus.contac…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...

flow_controllers
关键点: 流控制器类型: 同步(Sync):发布操作会阻塞,直到数据被确认发送。异步(Async):发布操作非阻塞,数据发送由后台线程处理。纯同步(PureSync…...

TJCTF 2025
还以为是天津的。这个比较容易,虽然绕了点弯,可还是把CP AK了,不过我会的别人也会,还是没啥名次。记录一下吧。 Crypto bacon-bits with open(flag.txt) as f: flag f.read().strip() with open(text.txt) as t: text t.read…...