机器学习算法实战案例:时间序列数据最全的预处理方法总结
文章目录
- 1 缺失值处理
- 1.1 统计缺失值
- 1.2 删除缺失值
- 1.3 指定值填充
- 1.4 均值/中位数/众数填充
- 1.5 前后项填充
- 2 异常值处理
- 2.1 3σ原则分析
- 2.2 箱型图分析
- 3 重复值处理
- 3.1 重复值计数
- 3.2 drop_duplicates重复值处理
- 3 数据归一化/标准化
- 3.1 0-1标准化
- 3.2 Z-score标准化
- 技术交流
1 缺失值处理
数据缺失主要包括记录缺失和字段信息缺失等情况,其对数据分析会有较大影响,导致结果不确定性更加显著,缺失值的处理:
- 删除记录
- 数据插补
- 不处理
首先导入相应的库文件,处理缺失值的库主要是pandas。
import matplotlib.pyplot as plt
首先参加示例数据用于分析:
df = pd.DataFrame({'time':['2023-12-11 00:00','2023-12-11 01:00','2023-12-11 02:00','2023-12-11 03:00','2023-12-11 04:00','2023-12-11 05:00','2023-12-11 06:00','2023-12-11 07:00','2023-12-11 08:00','2023-12-11 09:00','2023-12-11 010:00'],'feature1':[12,33,45,23,np.nan,np.nan,66,54,np.nan,99,190],'feature2':[np.nan,3.3,4.5,np.nan,5.2,np.nan,6.6,5.4,np.nan,9.9,1.0]})

1.1 统计缺失值
(1) df.info()和df.describe()函数
可以通过df.info()函数大概查看缺失值情况,df.info()可以查看列的数据类型,数据数量信息,df.describe()函数用于查看数据的统计信息。
- info: info方法返回DataFrame中的行数,列数,DataFrame中每一列的名称以及该列的非空值的数目以及每一列的数据类型。
- describe: describe方法返回有关DataFrame中数字数据的一些有用统计信息,例如均值,标准偏差,最大值和最小值以及一些百分位数。
df.info()

(2) isnull,notnull判断是否是缺失值
- isnull:缺失值为True,非缺失值为False
- notnull:缺失值为False,非缺失值为True
df[df['feature2'].notnull()]df["column_name"].isnull().sum(axis=0)
1.2 删除缺失值
当数据存在缺失值,可以通过不同的方式删除缺失值
df.dropna()#只要某个数据行中有缺失值,则此操作就会将该行删除df.dropna(subset=['column_1', 'column_2'])#如果column_1和column_2两列数据中存在缺失值,则将缺失值所在的行删除,而不需要考虑其他列是否为缺失值df.dropna(axis=1,how="all")df.dropna(axis=0,subset=["Name","Age"])#将会删除"Name"和“Age"中有缺失值的行
1.3 指定值填充
缺失值插补有多种方法,可以通过df.fillna()函数实现:
- 均值/中位数/众数插补
- 临近值插补
- 插值法
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None,
- value 参数表示要填充的值
- method 参数表示填充的方法
- axis 参数表示要填充的轴(0 表示行,1 表示列)
- inplace 参数表示是否在原数据框上进行修改
- limit 参数表示最多填充多少个空值
- downcast 参数表示在填充完成后对数据进行类型转换。
指定值填充可以通过df.fillna和df.replace实现
df1.fillna(0,inplace = True)
# df.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None)df2['feature1'].replace(np.nan,'0',inplace = True)
1.4 均值/中位数/众数填充
均值/中位数/众数可以通过 mean()、median()、mode()实现
df4['feature1'].fillna(df4['feature1'].mean(),inplace = True)df4['feature1'].fillna(df4['feature1'].median(),inplace = True)df4['feature1'].fillna(df4['feature1'].mode(),inplace = True)
1.5 前后项填充
前后项填充用前面和后面的值进行填充,一般两个一起用,避免最前面和最后面一行的值填充不到。
# pad / ffill → 用之前的数据填充 # backfill / bfill → 用之后的数据填充 df4['feature2'].fillna(method = 'pad',inplace = True)

2 异常值处理
异常值是指样本中的个别值,其数值明显偏离其余的观测值,异常值也称离群点,异常值的分析也称为离群点的分析
- 异常值分析 → 3σ原则 / 箱型图分析
- 异常值处理方法 → 删除 / 修正填补
首先创建一组数据用于分析:
data = pd.Series(np.random.randn(10000)*100)
2.1 3σ原则分析
首先计算均值和标准差,然后绘制密度曲线,发现数据服从正态分布。
mean = data.mean() # 计算均值std = data.std() # 计算标准差print('均值为:%.3f,标准差为:%.3f' % (mean, std))stats.kstest(data, 'norm', (mean, std))fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6))data.plot(kind='kde', grid=True, style='-k', title='密度曲线', ax=ax1)
然后根据计算的均值和标准差通过3σ原则可视化异常值。
error = data[np.abs(data - mean) > 3 * std]data_c = data[np.abs(data - mean) <= 3 * std]print('异常值共%i条' % len(error))# 筛选出异常值error、剔除异常值之后的数据data_cax2.scatter(data_c.index, data_c, color='b', marker='.', alpha=0.3, label='正常值')ax2.scatter(error.index, error, color='r', marker='.', alpha=0.5, label='异常值')ax2.set_xlim([-10, 10010])

2.2 箱型图分析
与上面3σ原则分析类似,知识检测的标准笔筒,箱型图分析采用四分位数进行统计。首先计算基本的统计量,然后绘值箱型图。
data = pd.Series(np.random.randn(10000) * 100)fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6))print('分位差为:%.3f,下限为:%.3f,上限为:%.3f' % (iqr, mi, ma))color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')data.plot.box(vert=False, grid=True, color=color, ax=ax1, label='样本数据')
然后根据计算的统计量通过四分位数可视化异常值。
# 筛选出异常值error、剔除异常值之后的数据data_cerror = data[(data < mi) | (data > ma)]data_c = data[(data >= mi) & (data <= ma)]print('异常值共%i条' % len(error))ax2.scatter(data_c.index, data_c, color='b', marker='.', alpha=0.3, label='正常值')ax2.scatter(error.index, error, color='r', marker='.', alpha=0.5, label='异常值')ax2.set_xlim([-10, 10010])

3 重复值处理
3.1 重复值计数
同样创建一组数据用于分析,数据的1和2行是重复数据:
df = pd.DataFrame({'time':['2023-12-11 00:00','2023-12-11 00:00','2023-12-11 01:00','2023-12-11 02:00','2023-12-11 03:00','2023-12-11 04:00','2023-12-11 05:00','2023-12-11 06:00','2023-12-11 07:00','2023-12-11 08:00','2023-12-11 09:00','2023-12-11 010:00'],'feature1':[12,12,33,45,23,np.nan,np.nan,66,54,np.nan,99,190],'feature2':[5.8,5.8,3.3,4.5,np.nan,5.2,np.nan,6.6,5.4,np.nan,9.9,1.0]})

可以通过下面的的语句查看重复值,可以看到有1个重复项:
df.duplicated().value_counts()

3.2 drop_duplicates重复值处理
用df.drop_duplicates的方法对某几列下面的重复行删除。
df.drop_duplicates(subset=None, keep='first', inplace=False)
-
subset:是用来指定特定的列,默认为所有列
-
keep:
当keep='first'时,就是保留第一次出现的重复行,其余删除 当keep='last'时,就是保留最后一次出现的重复行,其余删除 当keep=False时,就是删除所有重复行 -
inplace是指是否直接在原数据上进行修改,默认为否
df.drop_duplicates(keep='first',inplace=True)

3 数据归一化/标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上
- 0-1标准化
- Z-score标准化
3.1 0-1标准化
将数据的最大最小值记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理,计算公式
- x = (x - Min) / (Max - Min)
同样创建一组数据用于分析:
df = pd.DataFrame({"feature1": np.random.rand(10) * 20, 'feature2': np.random.rand(10) * 100})

使用公式进行标准化:
def data_norm(df, *cols):max_val = df_n[col].max()min_val = df_n[col].min()df_n[col] = (df_n[col] - max_val) / (max_val - min_val)df_n = data_norm(df, 'feature1', 'feature2')

使用库函数实现0-1标准化:
from sklearn.preprocessing import MinMaxScalerX_scaled = scaler.fit_transform(df['feature1'].values.reshape(-1, 1))
3.2 Z-score标准化
Z分数(z-score),是一个分数与平均数的差再除以标准差的过程 → z=(x-μ)/σ,其中x为某一具体分数,μ为平均数,σ为标准差,Z值的量代表着原始分数和母体平均值之间的距离,是以标准差为单位计算。在原始分数低于平均值时Z则为负数,反之则为正数。
同样创建一组数据用于分析:
df = pd.DataFrame({"feature1":np.random.rand(10) * 100,'feature2':np.random.rand(10) * 100})
使用公式进行标准化,归一化后可以检测数据的均值和标准差:
def data_Znorm(df, *cols):u = df_n[col].mean()std = df_n[col].std()df_n[col] = (df_n[col] - u) / std# 使用功能函数实现Z-score标准化并替换原始数据df = data_Znorm(df, 'feature1', 'feature2')
使用库函数实现z-score标准化:
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()X_scaled = scaler.fit_transform(df['feature1'].values.reshape(-1, 1))
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
方式②、添加微信号:dkl88194,备注:来自CSDN + 技术交流
我们打造了《机器学习算法实战案例宝典》,特点:从0到1轻松学习,方法论及原理、代码、案例应有尽有,所有案例都按照这样的节奏进行的整理。

相关文章:
机器学习算法实战案例:时间序列数据最全的预处理方法总结
文章目录 1 缺失值处理1.1 统计缺失值1.2 删除缺失值1.3 指定值填充1.4 均值/中位数/众数填充1.5 前后项填充 2 异常值处理2.1 3σ原则分析2.2 箱型图分析 3 重复值处理3.1 重复值计数3.2 drop_duplicates重复值处理 3 数据归一化/标准化3.1 0-1标准化3.2 Z-score标准化 技术交…...
MongoDB高级集群架构设计
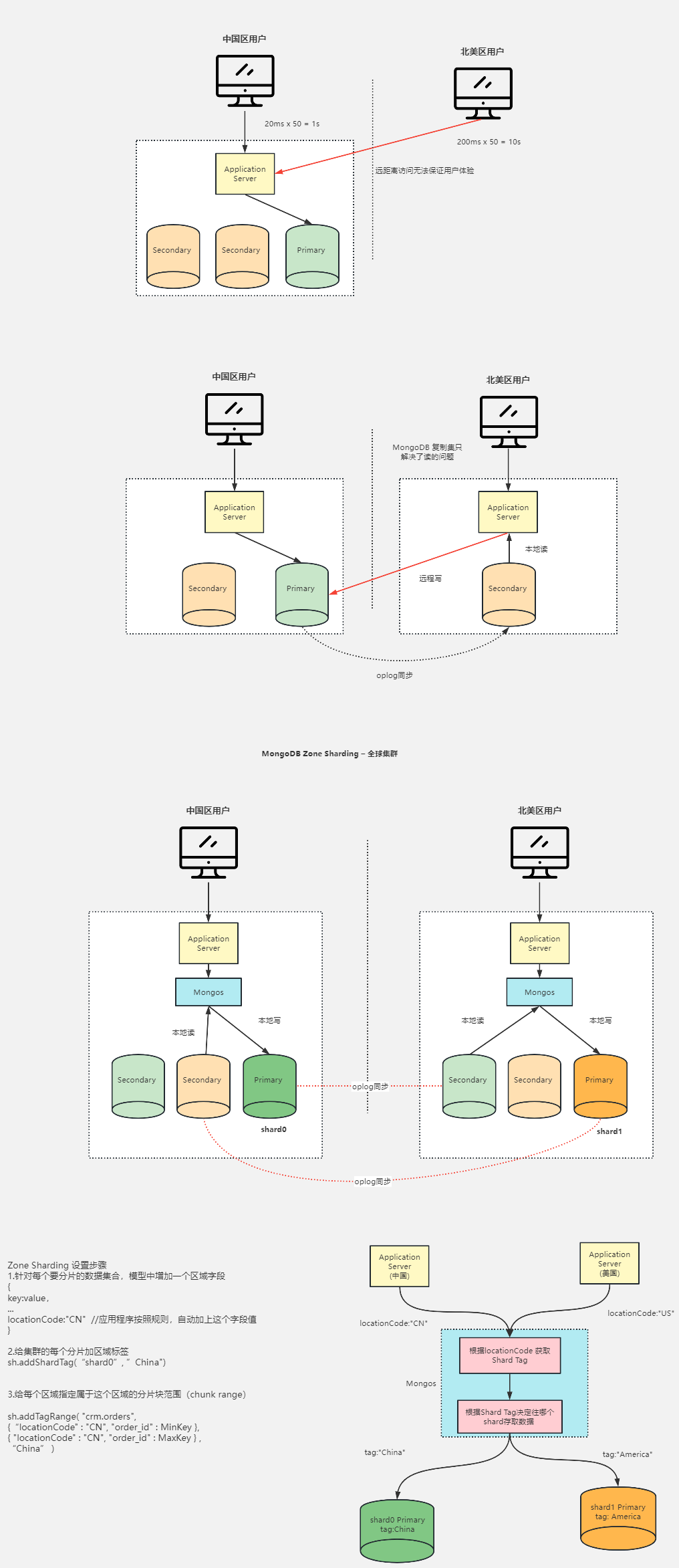
两地三中心集群架构设计 容灾级别 RPO & RTO RPO(Recovery Point Objective):即数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量。RTO(Recovery Time Objective):即恢复时间目标&…...

C++中JSON与string格式互转
1、JSON-》string 操作步骤: 1、在C中新建一个json对象并赋值,然后将其转给char *data。 2、在使用 #include <json.h> 头文件时,通常是使用第三方库 jsoncpp。由于它不是标准库的一部分,所以需要从官网http://jsoncpp.sou…...

2023一带一路暨金砖国家技能发展与技术创新大赛 【企业信息系统安全赛项】国内赛竞赛样题
2023一带一路暨金砖国家技能发展与技术创新大赛 【企业信息系统安全赛项】国内赛竞赛样题 2023一带一路暨金砖国家技能发展与技术创新大赛 【企业信息系统安全赛项】国内赛竞赛样题第一阶段: CTF 夺旗项目1. CTF 夺旗任务一 命令注入任务二 SQL 注入 项目2. 序列化漏…...

【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现
带注释版本的实现被写到了这里:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/apex 由于有很多个人理解,读者可配合当前文章谨慎理解。 0x0. 背景 我也是偶然在知乎的一个问题下看到这个问题,大概就是说在使用apex的…...
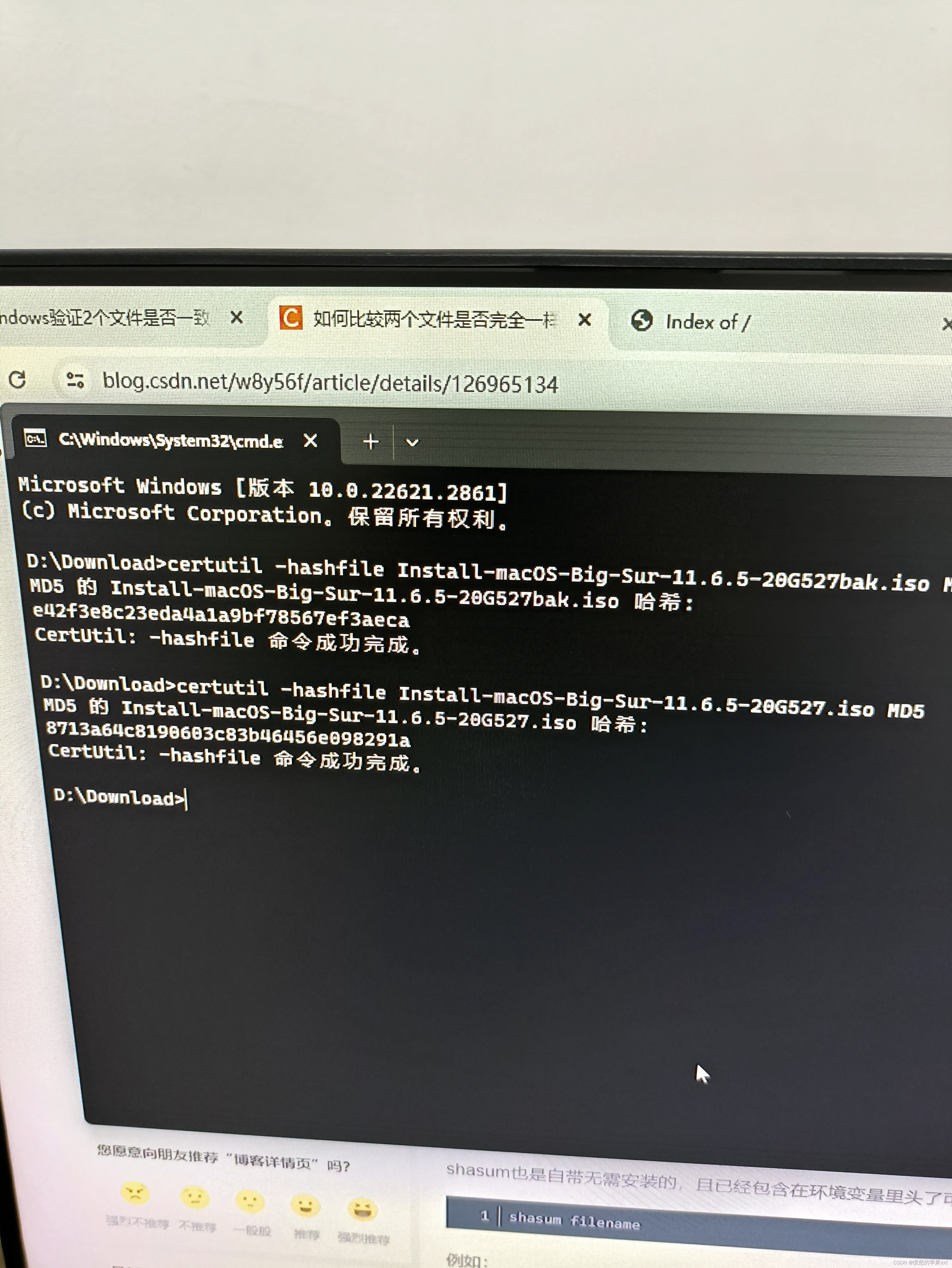
安装Mac提示安装无法继续,因为安装器已损坏
目录 事件起因报错原因 事件起因 有两台电脑,由于电脑1下载镜像文件很快,于是我先用电脑1下载这个大文件,然后安装openresty,电脑2用http链接下载这个大文件。电脑2安装中途就报安装无法继续,因为安装器已损坏。 报错原因 不知…...

脚本编程游戏引擎会遇到哪些问题
在游戏开发中,脚本编程已经成为了一种非常常见的方式,用来实现游戏逻辑和功能。但是脚本编程游戏引擎也可能会面临一些挑战和问题。下面简单的探讨一下都会遇到哪些问题,并且该如果做。 性能问题 脚本语言通常需要运行时解释执行࿰…...
什么软件可以做报表?
数据报表,是商业领域中不可或缺的一部分,它通过表格、图表等形式,将复杂的数据进行整理、分析并呈现出来,帮助用户更好地理解数据的趋势和关系。数据报表不仅展示了业务现状和趋势,还支持多种数据分析和挖掘功能&#…...

数据结构学习 jz39 数组中出现次数超过一半的数字
关键词:排序 摩尔投票法 摩尔投票法没学过所以没有想到,其他的都自己想。 题目:库存管理 II 方法一: 思路: 排序然后取中间值。因为超过一半所以必定在中间值是我们要的结果。 复杂度计算: 时间复杂度…...

基于Linux的Flappy bird游戏开发
项目介绍 主要是使用C语言实现,开启C项目之旅。 复习巩固C语言、培养做项目的思维。 功能: 按下空格键小鸟上升,不按下落; 显示小鸟需要穿过的管道; 小鸟自动向右飞行;(管道自动左移和创建&a…...

排序算法6---快速排序(非递归)(C)
回顾递归的快速排序,都是先找到key中间值,然后递归左区间,右区间。 那么是否可以实现非递归的快排呢?答案是对的,这里需要借助数据结构的栈。将右区间左区间压栈(后进先出),然后取出…...

【Verilog】期末复习——设计带异步清零且高电平有效的4位循环移位寄存器
系列文章 数值(整数,实数,字符串)与数据类型(wire、reg、mem、parameter) 运算符 数据流建模 行为级建模 结构化建模 组合电路的设计和时序电路的设计 有限状态机的定义和分类 期末复习——数字逻辑电路分…...

银行网络安全实战对抗体系建设实践
文章目录 前言一、传统攻防演练面临的瓶颈与挑战(一)银行成熟的网络安全防护体系1、缺少金融特色的演练场景设计2、资产测绘手段与防护体系不适配3、效果评价体系缺少演练过程维度相关指标 二、实战对抗体系建设的创新实践(一)建立…...

SwiftUI之深入解析Alignment Guides的超实用实战教程
一、Alignment Guide 简介 Alignment guides 是一个强大的布局工具,但通常未被充分利用。在很多情况下,它们可以帮助我们避免更复杂的选项,比如锚点偏好。如下所示,对对齐的更改也可以自动(并且容易地)动画…...

java获取视频文件的编解码器
java获取视频文件的编解码器 引入jar包: <dependency><groupId>org.bytedeco</groupId><artifactId>javacv-platform</artifactId><version>1.5.9</version></dependency>测试类 package com.jd.brand.approve.…...
)
动态规划Day06(完全背包)
完全背包 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 完全背包和01背包问题唯一不同…...
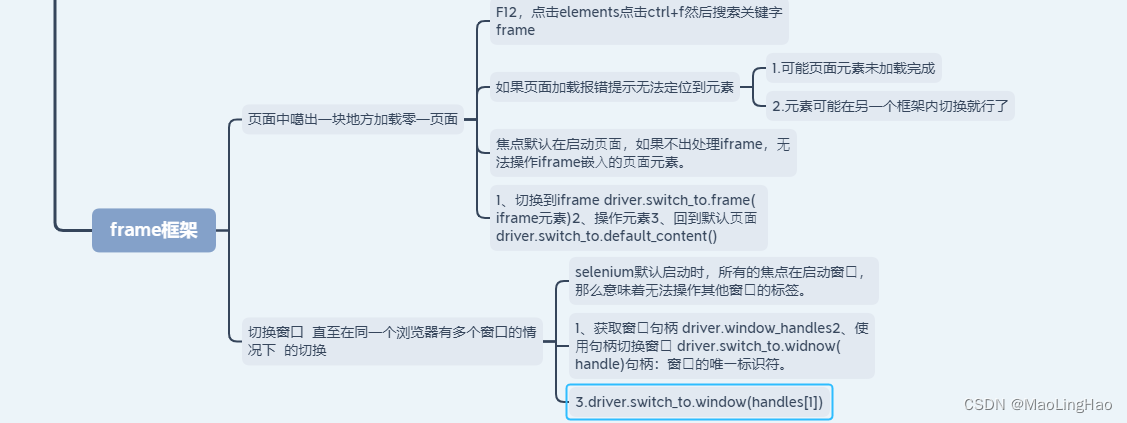
selenium之框架之窗口
...
)
华为OD机试 - 最小矩阵宽度(Java JS Python C)
题目描述 给定一个矩阵,包含 N * M 个整数,和一个包含 K 个整数的数组。 现在要求在这个矩阵中找一个宽度最小的子矩阵,要求子矩阵包含数组中所有的整数。 输入描述 第一行输入两个正整数 N,M,表示矩阵大小。 接下来 N 行 M 列表示矩阵内容。 下一行包含一个正整数 K…...

嵌入式linux_C应用学习之API函数
1.文件IO 1.1 open打开文件 #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode);pathname:字符串类型,用于标…...
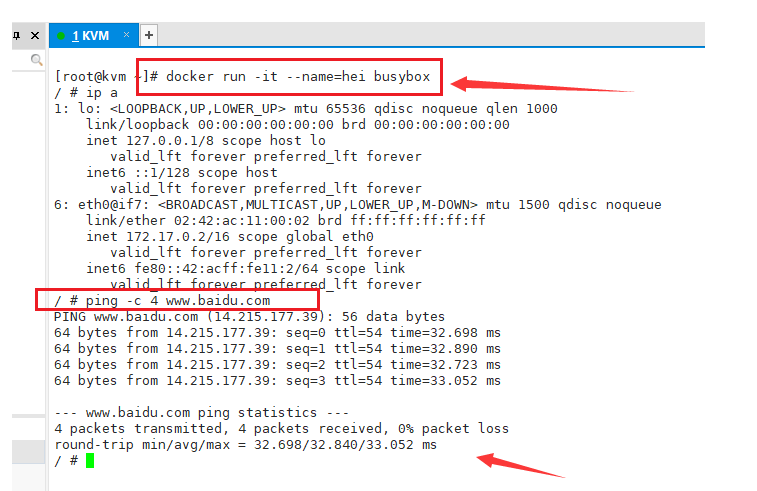
【ubuntu】docker中如何ping其他ip或外网
docker中如何ping其他ip或外网 示例图: 运行下面命令: docker run -it --namehei busybox看情况需要加权限 sudo,即: sudo docker run -it --namehei busyboxping 外网 ping -c 4 www.baidu.comping 内网 ping -c 4 192.168.…...

杰理之立体声利用数字音量节点实现左右声道平衡【篇】
利用数字音量通过dB转换,去设置LR声道的数据大小,实现LR声道数据幅值不同达到声道平衡的目的,适配用户人耳情况...

QT直方图进阶:QBarSeries的10个美化技巧让你的图表脱颖而出
QT直方图进阶:QBarSeries的10个美化技巧让你的图表脱颖而出 在数据可视化领域,直方图是最基础也最常用的图表类型之一。QT框架中的QBarSeries为开发者提供了强大的直方图绘制能力,但要让图表真正吸引眼球、提升用户体验,仅靠基础功…...

台达PLC控制步进电机实战:从接线到ST语言编程全流程
台达PLC控制步进电机实战:从硬件配置到高级编程技巧 在工业自动化领域,精确的运动控制一直是核心需求之一。步进电机以其独特的开环控制特性、精准的定位能力和相对简单的驱动架构,成为许多自动化设备的首选执行元件。而台达PLC作为工业控制的…...

shacct.dll文件丢失找不到 免费下载修复方法分享
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

量子计算商业化时代:2026年量子科技品牌建设的五大设计法则
2026年,量子计算正式迈入商业化爆发的关键拐点——政府工作报告将量子科技列为未来产业,全球量子产业产值加速向万亿级跨越,量子计算不再是实验室里的“炫技”,而是逐渐渗透到生物医药、金融科技、新材料研发等千行百业的核心生产…...

新概念英语第一册037_Making a bookcase
Lesson 37: Making a bookcase. Watch the story and answer the question What is Susan’s favourite colour? Pink.Key words and expressions work 工作hard adv. 努力地make 做bookcase 书橱,书架hammer 锤子paint …...

作业:在AI工具的辅助下,创建一个校园管理系统——主营方向是二手物品交易
-- 1. 插入用户信息(12条) INSERT INTO user_info (user_no, user_name, user_type, user_phone, user_college) VALUES (20240101, 张三, student, 13800138001, 计算机学院), (20240102, 李四, student, 13800138002, 电子工程学院), (20240103, 王五,…...

计算机网络相关知识
1. 计算机网络基础概念计算机网络是指通过通信设备和线路将地理位置不同的、具有独立功能的计算机系统连接起来,在网络软件的支持下实现资源共享和信息传递的系统。按照覆盖范围可分为:局域网(LAN):覆盖范围较小&#…...

别盲目入行网安!一文看懂所有网安岗位岗位职责与发展方向
网络安全可以从事哪些岗位 伴随着社会的发展,网络安全被列为国家安全战略的一部分,因此越来越多的行业开始迫切需要网安人员,也有不少人转行学习网络安全。那么网络安全可以从事哪些岗位?岗位职责是什么?相信很多人都不太了解,…...

庭院桌椅一上AI就穿帮,我后来这样挑工具
“这把椅子怎么是悬着的?”客户把截图放大给我看,草地上的阴影往左跑,椅脚却像踩在空气里,藤编靠背还多长出两截。地点就在样板庭院旁的会议桌边,反常的是:那批图第一眼都像宣传片,真拿来做户外…...