论文笔记(三十九)Learning Human-to-Robot Handovers from Point Clouds
Learning Human-to-Robot Handovers from Point Clouds
- 文章概括
- 摘要
- 1. 介绍
- 2. 相关工作
- 3. 背景
- 3.1. 强化学习
- 3.2. 移交模拟基准
- 4. 方法
- 4.1. Handover Environment
- 4.2. 感知
- 4.3. 基于视觉的控制
- 4.4. 师生两阶段培训 (Two-Stage Teacher-Student Training)
- 5. 实验
- 5.1. 模拟评估
- 5.2. 模拟对模拟传输
- 5.3. 模拟到真实的传输
- 6. 结论
文章概括
作者:Sammy Christen,Wei Yang,Claudia P´erez-D’Arpino,Otmar Hilliges,Dieter Fox,Yu-Wei Chao
来源:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9654-9664)
原文:https://openaccess.thecvf.com/content/CVPR2023/papers/Christen_Learning_Human-to-Robot_Handovers_From_Point_Clouds_CVPR_2023_paper.pdf
代码、数据和视频:
系列文章目录:
上一篇:
https://blog.csdn.net/xzs1210652636/article/details/134431873
下一篇:
摘要
我们提出了第一个框架,用于学习基于视觉的人机交互控制策略,这是人机交互的一项关键任务。虽然嵌入式人工智能研究在模拟环境中训练机器人代理方面取得了重大进展,但由于模拟人类的困难,与人类的交互仍然具有挑战性。幸运的是,最近的研究已经为人与机器人的交接开发出了逼真的模拟环境。利用这一成果,我们引入了一种方法,通过一个两阶段的师生框架,利用运动和抓握规划、强化学习和自我监督,进行人机交互训练。我们在模拟基准、模拟到模拟的传输和模拟到真实的传输上展示了比基线更高的性能。视频和代码见 https://handover-sim2real.github.io。
1. 介绍
人与机器人之间的物品交接是人机交互(HRI)的一项重要任务[35]。它允许机器人在日常协作活动中协助人类,例如帮助准备饭菜,或在制造环境中与人类合作者交换工具和零件。要成功、安全地完成这些任务,人类和机器人之间需要进行复杂的协调。这是一项具有挑战性的任务,因为机器人必须对人类的行为做出反应,同时只能获得稀少的感官输入,例如视野有限的单个摄像头。因此,我们需要能够纯粹通过视觉输入来解决交接等交互任务的方法。
在真实世界中对机器人进行引导训练既不安全又耗时。因此,嵌入式人工智能的最新趋势集中在训练代理在模拟(仿真)环境中行动和互动[11, 12, 19, 43, 45, 46, 51]。随着渲染和物理模拟技术的进步,模型已被训练成能将原始感官输入映射到动作输出,甚至可以直接从模拟环境转移到真实世界[2, 42]。特别是在机器人导航、操纵或两者结合的一系列任务方面,已经取得了许多成功。与这些领域相比,与人机交互相关的任务进展甚微。这在很大程度上受到在这些环境中嵌入现实人类代理的挑战的阻碍,因为对现实人类进行建模和模拟是一项挑战。
尽管存在这些挑战,但越来越多的工作尝试在模拟环境中嵌入逼真的人类代理[6, 9, 16, 36-38, 48]。值得注意的是,最近的一项工作为人与机器人的交接(H2R)引入了一个模拟环境(“HandoverSim”)[6]。为了确保逼真的人机交接动作,他们使用了一个大型动作捕捉数据集[7]来驱动模拟中虚拟人的动作。不过,尽管机器人训练具有巨大潜力,但 [6] 的工作仅评估了先前工作中的现成模型,并未探索在机器人所处环境中与人类一起进行任何策略训练。
我们的目标是缩小这一差距,为 H2R 移交引入一个基于视觉的学习框架,该框架通过人在环中进行训练(见图 1)。特别是,我们提出了一种基于模仿学习(IL)和强化学习(RL)的新型混合方法,通过在 HandoverSim 中与人类互动进行训练。我们的方法借鉴了最近一种从点云中学习抓取静态物体策略的方法[50],但提出了几个关键的变化,以应对 H2R 移交中的挑战。在静态物体抓取中,策略只需要物体信息,与之不同的是,我们在策略输入中额外编码了人手信息。此外,与没有人的静态抓取相比,我们在训练监督中明确考虑了人的碰撞。最后,静态物体抓取与交接之间的关键区别在于交接过程中手和物体的动态性质。为了出色完成任务,机器人需要对人类的动态行为做出反应。之前的工作通常依赖于开环运动规划器 [49] 来生成专家示范,这可能会导致动态情况下的次优监督。为此,我们提出了一个两阶段训练框架。在第一阶段,我们将人类固定为静止状态,并通过运动和抓握规划器获得的专家示范来部分指导 RL 策略的训练。在第二阶段,我们在人类和机器人同时移动的原始动态环境中对 RL 策略进行微调。我们提出了一种自我监督方案,而不是依赖于规划器,在这种方案中,预先训练好的 RL 策略可作为下游策略的老师。
我们在三个 "世界 "中评估我们的方法(见图 1)。首先,我们在 HandoverSim [6] 中的 "原生 "测试场景上进行评估,这些场景使用相同的后端物理模拟器(Bullet [10])作为训练,但使用了模拟人类的未见交接动作。接下来,我们对使用不同物理模拟器(Isaac Gym [29])实现的测试场景进行模拟到模拟评估。最后,我们通过在真实机器人系统上评估政策来研究模拟到真实的转移,并展示我们方法的优势。

图 1. 我们介绍了一种从点云输入学习人与机器人交接策略的框架。我们的策略从安装在手腕上的摄像头获取输入,并直接为机器人的末端效应器生成动作输出。我们在模拟交接环境中训练策略,并对未见过的交接动作和姿势进行评估。我们还将模型移植到物理模拟器和真实机器人平台中。
我们的贡献包括:i) 首个通过人在回路中的视觉输入训练人与机器人交接任务的框架;ii) 在人和机器人共同移动的环境中训练的新型师生方法;iii) 经验评估表明,我们的方法在 HandoverSim 基准上优于基线方法;iv) 转移实验表明,与基线方法相比,我们的方法能带来更稳健的模拟到模拟和模拟到真实的转移。
2. 相关工作
人与机器人的交接 在大型手与物体交互数据集[5, 7, 17, 20, 21, 28, 32, 47, 54, 55]的引入帮助下,手与物体姿态估计[22, 26, 27]取得了令人鼓舞的进展。这些发展使得基于模型的抓取规划 [3,4,31] 能够应用于 H2R 切换 [7,41],这是一种经过充分研究的方法,其中需要完整的姿势估计和跟踪。不过,这些方法需要物体的三维形状模型,无法处理未见物体。另外,最近的一些研究[13, 30, 40, 52, 53]通过采用基于学习的抓取规划器,从原始视觉输入(如图像或点云)为新物体生成抓取[33, 34],从而实现 H2R 移交。虽然这些方法已经取得了可喜的成果,但它们只适用于开环顺序环境,在这种环境下,一旦机器人开始移动,人手就必须保持不动[40],或者需要复杂的人手设计成本函数来选择抓手[52],以及进行机器人运动规划[30, 53],以实现反应式切换,这需要机器人运动和控制方面的专业知识。因此,这些方法很难在新环境中复制和部署。基于学习的方法[48]利用状态输入在动态同步运动方面取得了进展,但直接接收视觉输入的训练策略仍是一个挑战。与此相反,我们建议通过深度神经网络,以端到端方式从分割的点云中学习控制策略和抓取预测,从而实现交接。为了便于对不同的交接方法进行简单而公平的比较,[6] 提出了一种物理模拟环境,其中包含各种物体和由 mocap 系统收集的逼真的人类交接行为[7]。他们提供了之前几种切换系统的基准结果,包括用静态物体训练的基于学习的抓取策略[50]。然而,在有人类在环的情况下,学习安全高效的交接策略并非易事,我们在这项工作中要解决这个问题。
抓取物体的策略学习 抓取物体是许多机器人任务(包括交接)的基本技能。先前的研究通常是在已知三维物体几何形状(如物体形状或姿势)的基础上生成抓取姿势 [3, 4, 31],而要从真实世界的感官输入(如图像或点云)中获取这些信息并非易事。为了克服这一问题,最近的研究对深度神经网络进行了训练,以便从传感器数据中预测抓取位置[25],并计算轨迹以达到预测的抓取姿势。虽然不再需要三维物体几何图形,但由于抓取预测和轨迹规划是分开计算的,因此无法保证可行性。最近的一些研究直接从原始传感器数据中学习抓取策略。[24] 提出了一种基于 RGB 图像的自监督 RL 框架,从真实世界的抓取动作中学习深度 Q 函数。为了提高数据效率,[44] 使用低成本的手持设备,通过安装在手腕上的摄像头收集抓握演示。他们利用这些演示训练基于 RL 的 6-DoF 闭环抓取策略。[50]将专家数据的模仿学习与 RL 结合起来,从点云中学习物体抓取的控制策略。虽然在 HandoverSim [6] 中,当人手不动时,这种方法表现良好,但由于策略是通过静态物体学习的,因此很难与动态人手协调。相反,我们的策略是从真实世界中获取的大规模动态手-物体轨迹中直接学习的。为了方便动态情况下的训练,我们提出了一个两阶段师生框架,其概念灵感来源于文献[8],该框架已被实验证明是至关重要的。
3. 背景
3.1. 强化学习
MDP 我们将 RL 形式化为马尔可夫决策过程(Markov Decision Process,MDP),它由 5 个元组 M = ( S , A , R , T , γ ) \mathcal{M = (S, A, R, T , γ)} M=(S,A,R,T,γ) 组成,其中 S \mathcal{S} S 是状态空间, A \mathcal{A} A 是行动空间, R \mathcal{R} R 是标量奖励函数, T \mathcal{T} T 是将状态行动对映射到状态分布的转换函数, γ \mathcal{γ} γ 是贴现因子(discount factor)。目标是找到一个能使长期回报最大化的策略: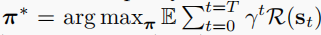 ,其中
,其中  。
。
学习算法 在这项工作中,我们使用 TD3 [18],这是一种常见的连续控制算法。它是一种行为批评方法,由一个策略 π θ ( s ) π_θ(s) πθ(s)(行为者)和一个 Q 函数近似值 Q ϕ ( s , a ) Q_ϕ(s,a) Qϕ(s,a)(批评者)组成, Q ϕ ( s , a ) Q_ϕ(s,a) Qϕ(s,a)可预测状态-行为对的预期收益。两者均由带有参数 θ θ θ 和 ϕ ϕ ϕ 的神经网络表示。TD3 是非政策性的,因此有一个重放缓冲区来存储训练转换。在训练过程中,演员和评论者都会使用缓冲区中的样本进行更新。为了更新批判者,我们要尽量减小贝尔曼误差:

(1) \tag {1} (1)
对于行动者网络,策略参数的训练是为了使 Q 值最大化:

(2) \tag {2} (2)
更多详情,请读者参阅 [18]。
3.2. 移交模拟基准
HandoverSim [6] 是在模拟中评估 H2R 移交策略的基准。任务设置包括一个装有不同物体的桌面、一个熊猫 7DoF 机械臂(带抓手和安装在手腕上的 RGB-D 摄像头)和一只模拟人手。任务开始时,人类抓住一个物体并将其移动到交接位置。机器人应移动到物体前并抓住它。如果物体从人类手中抓取时没有发生碰撞,并被带到指定位置而没有掉落,则任务成功。为了准确地模拟人类,我们在模拟中重放了 DexYCB 数据集[7]中的轨迹,该数据集包含大量的人-物互动序列。我们还提供了几种基线[49,50,52]进行比较。HandoverSim 中的设置仅用于交接性能评估目的,而在本工作中,我们将其用作学习环境。
4. 方法
整个管道如图 2 所示,由三个不同的模块组成:感知、基于视觉的控制和交接环境。感知模块接收来自交接环境的以自我为中心的视觉信息,并将其处理为分割点云。基于视觉的控制模块接收点云,并预测机器人的下一步行动,以及是接近还是抓取物体。这些信息会传递给交接环境,交接环境会更新机器人状态,并将新的视觉信息发送给感知模块。请注意,我们方法的输入来自于腕上的摄像头,也就是说,并没有向机器人提供明确的信息,如物体或手的姿势。接下来,我们将对本方法的各个模块进行详细说明。
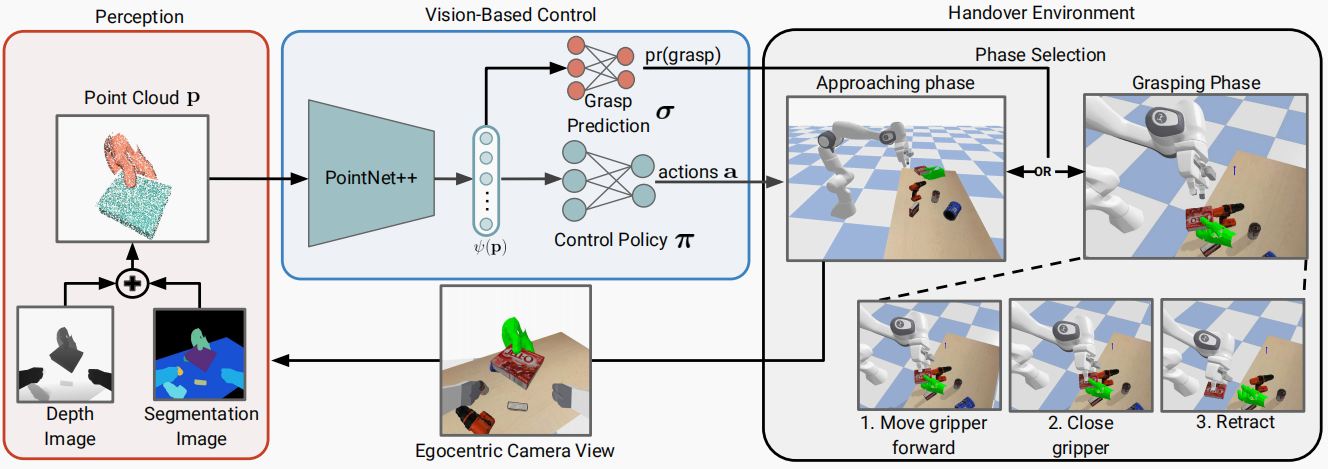
图 2. 方法概览。感知模块从环境中获取以自我为中心的 RGB-D 和分割图像,并输出手部/物体分割点云。然后,分割后的点云被传递给基于视觉的控制模块,并由 PointNet++ [39] 进行处理,以获得低维表示。这种嵌入将作为控制策略和抓取预测器的输入。交接环境中的每个任务情节都分为两个阶段:在接近阶段,机器人在控制策略 π 的驱动下向抓取前姿势移动,控制策略 π 输出末端执行器动作 a: 1. 将抓手从预抓取姿势向前移动到抓取姿势 2. 关闭抓手 3. 将物体缩回到指定位置,然后结束本集。
4.1. Handover Environment
我们将移交任务分为两个不同的阶段(见图 2)。首先,在接近阶段,机器人通过运行学习到的控制策略π,移动到接近物体的预抓取姿势。经过学习的抓取预测器 σ 不断计算抓取概率,以确定系统何时可以进入第二阶段。一旦达到预抓取姿势,并且抓取预测有把握从人类手中接过物体,任务就会切换到抓取阶段,在这一阶段,末端执行器以开环方式向前移动到最终抓取姿势,并关闭抓手以抓取物体。最后,在抓取物体后,机器人按照预定轨迹缩回到基座位置,完成整个过程。这一任务逻辑在我们的模拟环境和实际机器人部署中都得到了应用。在动态抓取方面,基于预抓取姿势的排序在文献中得到了广泛应用 [1]。
我们采用 HandoverSim 任务设置 [6],通过重放 DexYCB 数据集 [7] 中的数据来模拟人手和物体(见第 3.2 节)。首先,从策略 π ( a ∣ s ) π(a|s) π(a∣s)中接收下一个 6DoF 末端效应器姿势(平移和旋转)形式的动作 a a a。然后,我们利用逆运动学将末端执行器姿势转换为目标机器人配置。之后,我们使用 PD 控制器计算扭矩,并将其应用于机器人。最后,视觉信息由安装在机器人手腕上的 RGB-D 摄像头呈现,并发送至感知模块。
4.2. 感知
我们的策略网络将分割的手部和物体点云作为输入。在交接环境中,我们首先通过腕部摄像头渲染以自我为中心的 RGB-D 图像。然后,我们通过将地面实况分割掩码与 RGB-D 图像叠加,获得物体点云 p o p_o po 和手点云 p h p_h ph。由于从当前的自我中心视图不一定总能看到手和物体,因此我们会跟踪最近可用的点云。然后将最新可用的点云发送给控制模块。
4.3. 基于视觉的控制
输入表示法 根据手部点云 p h p_h ph 和物体点云 p o p_o po 中包含的点的数量,我们将它们缩小或放大到恒定大小。接下来,我们将两个点云合并为一个点云 p p p,并添加两个单次编码向量来表示 p p p 中物体点和手部点的位置。然后,我们通过 PointNet++ [39],将点云编码为较低维度的表示形式 ψ ( p ) ψ(p) ψ(p)。最后,将低维编码 ψ ( p ) ψ(p) ψ(p) 传递给控制策略 π π π 和抓取预测网络 σ σ σ。
控制策略 策略网络 π ( a ∣ ψ ( p ) ) π(a|ψ(p)) π(a∣ψ(p))是一个小型的双层 MLP,它将 PointNet++ 嵌入作为输入状态 ( s = ψ ( p ) ) (s = ψ(p)) (s=ψ(p)),并预测与 6DoF 末端执行器姿势变化相对应的动作 a a a。这些信息将传递给交接环境。
抓取预测 我们引入了一个抓取预测网络 σ ( ψ ( p ) ) σ(ψ(p)) σ(ψ(p)),它可以预测机器人何时应该从接近抓取动作切换到执行抓取动作(参见图 2)。我们将抓取预测建模为二元分类任务。输入对应于 PointNet++ 嵌入 ψ ( p ) ψ(p) ψ(p),它通过一个 3 层 MLP 输入。输出结果是一个概率,表示在当前点云特征下成功抓取的可能性。如果概率高于可调阈值,我们就会执行开环抓取动作。该模型是通过 [15] 获得的抓取前姿势进行离线训练的。我们通过在抓取前姿势中添加随机噪音来增强数据集。为了确定标签,我们在物理仿真中用预抓取姿势初始化机器人,并执行前向抓取动作。如果抓取成功,则标签为 1,否则为 0。我们使用二元交叉熵损失进行训练。
4.4. 师生两阶段培训 (Two-Stage Teacher-Student Training)
我们的目标是训练一种能够与人类同时移动的交接策略。在动态运动环境中直接训练这种策略具有挑战性,因为只有当人处于静止状态时,才能获得专家示范和开环规划器来指导训练。我们工作的一个主要贡献是采用两阶段切换训练方案,以渐进方式训练策略,从而缓解这一难题。在第一阶段,我们在人停止后机器人才开始移动(顺序)的情况下进行预训练。在第二阶段,人和机器人同时移动(同步),对预训练策略进行进一步微调。
顺序设置中的预训练 在顺序设置中,一旦人类停止,机器人就开始移动(见图 3 左上角)。为了从静止的人类手中抓取物体,我们利用运动规划提供专家示范。在数据收集过程中,我们交替进行运动规划和基于 RL 的探索。在这两种情况下,我们都会将转换 d t = { p t , a t , g t , r t , p t + 1 , e t } d_t=\{p_t, a_t, g_t, r_t, p_{t+1}, e_t\} dt={pt,at,gt,rt,pt+1,et} 保存在重放缓冲区 D 中,并在网络训练时从中采样。术语 p t p_t pt 和 p t + 1 p_{t+1} pt+1 表示点云和下一个点云, a t a_t at 表示动作, g t g_t gt 表示抓取前的目标姿势, r t r_t rt 表示奖励, e t e_t et 表示过渡是否来自专家。

图 3. 训练程序。 在预训练阶段(左上角方框),人手处于静止状态。我们通过运动规划和使用 RL 策略 π p r e π_{pre} πpre 探索数据来交替收集专家示范。在训练过程中(右侧绿色方框),从回放缓冲区随机采样的一批转换将通过 PointNet++ 以及演员和评论家网络。在微调阶段(左下框),人和机器人同时运动。专家运动规划器由专家策略 π e x p π_{exp} πexp 代替,它共享预训练策略 π p r e π_{pre} πpre 的权重。该策略网络将在剩余的训练过程中保持冻结,并作为 RL 代理的正则化器。RL 代理的行动者网络 π ∗ π_∗ π∗ 和批评者网络 Q ∗ Q_∗ Q∗ 也使用预训练代理网络的权重进行初始化,但模型将在微调过程中进行更新。在这一阶段,转换被存储在一个新的重放缓冲区 D ∗ D_∗ D∗中。在微调过程中,数据仅从该缓冲区采样。
受文献[50]的启发,我们使用 OMG 计划器[49]收集专家轨迹,该计划器利用了地面实况。需要注意的是,规划器生成的某些专家轨迹会与手部发生碰撞,因此我们引入了离线预过滤方案。我们首先解析 ACRONYM 数据集 [14],寻找潜在的抓取点。然后,我们进行碰撞检查,过滤掉机器人和人手碰撞的抓取。对于剩余的无碰撞抓取,我们规划抓取物体的轨迹,并以开环方式执行。另一方面,RL 策略 π p r e π_{pre} πpre 会探索环境并获得稀疏奖励,即如果任务成功完成,奖励为 1,否则为 0。因此,与人类的碰撞将因得不到任何正奖励而受到隐性惩罚。
同步设置中的微调 在这种情况下,人类和机器人同时移动。因此,我们不能依靠运动和抓取规划来指导策略。另一方面,在没有专家参与的情况下,简单地从顺序设置中提取预先训练好的策略 π p r e π_{pre} πpre 并继续训练,会导致性能立即下降。因此,出于稳定性考虑,我们引入了自监督方案,即我们希望微调策略与预训练策略保持一致。为此,我们用专家策略 π e x p π_{exp} πexp 代替顺序设置中的专家规划器,专家策略 π e x p π_{exp} πexp 使用预训练策略 πpre 的权重进行初始化,预训练策略 π p r e π_{pre} πpre 已经提供了合理的先验策略(见图 3 左下角)。因此,我们有两种策略:i) 专家策略 π e x p π_{exp} πexp 作为运动和抓取规划器的代理。我们将冻结该策略的网络权重;ii) 微调策略 π ∗ π_∗ π∗ 和批判者 Q ∗ Q_∗ Q∗,它们分别以预训练策略 π p r e π_{pre} πpre 和批判者 Q p r e Q_{pre} Qpre 的权重进行初始化。接下来,我们将使用损失函数对这两个网络进行训练。
网络训练 在训练过程中,我们会从重放缓冲区 D 中抽取一批随机转换样本。策略网络的训练结合了行为克隆、基于 RL 的损失和辅助目标。具体来说,我们使用以下损失函数更新策略:

其中, L B C L_{BC} LBC 是行为克隆损失,用于保持策略接近专家策略; L D D P G L_{DDPG} LDDPG 是公式 2 中描述的标准行为批判损失; L A U X L_{AUX} LAUX 是辅助目标,用于预测末端执行器的抓取目标姿势。系数 λ λ λ 平衡了行为克隆和 RL 目标。批评损失的定义是

其中, L B E L_{BE} LBE 表示公式 1 中的贝尔曼误差, L A U X L_{AUX} LAUX 是公式 3 中使用的辅助损耗。更多详情请读者参阅补充材料或 [50]。
5. 实验
我们首先使用 HandoverSim 基准对我们的方法进行模拟评估(第 5.1 节)。接下来,我们通过在由不同物理引擎驱动的测试环境中评估训练有素的模型,研究模拟到模拟的传输性能(第 5.2 节)。最后,我们将训练好的模型应用于真实世界的机器人系统,并分析模拟到现实的传输性能(第 5.3 节)。
5.1. 模拟评估
设置 HandoverSim [6] 包含 1,000 个独特的 H2R 移交场景,分为训练、评估和测试三个部分。每个场景都包含一个独特的人类交接动作。我们对包含 720 个训练场景和 144 个测试场景的 "s0 "设置进行了评估。关于未见物体、主体和手的评估,请参见补充材料。根据[6]中对 GA-DDPG [50] 的评估,我们考虑了两种设置:(1) "顺序 "设置,即机器人只有在人类的手到达交接位置后才允许移动,并保持静止不动(即[6]中的 “保持”);(2) "同步 "设置,即允许机器人从一开始就移动(即 [6] 中的 “w/o hold”)。
衡量标准 我们遵循 HandoverSim [6] 中的评估协议。如果机器人从人类手中抓住物体并将其移动到指定位置,则认为交接成功。如果出现以下三种情况中的任何一种,则认为交接失败,并终止交接过程: (1) 机器人与人的手发生碰撞(接触),(2) 机器人将物体掉落(掉落),或 (3) 达到最大时间限制(超时)。除了效率,该基准还报告了时间效率。时间指标进一步细分为:(1) 执行时间 (exec),即实际移动机器人的时间;(2) 规划时间 (plan),即运行策略所花费的时间。所有报告的指标都是测试场景中滚动时间的平均值。
基准 我们的主要基准是 GA-DDPG [50]。除了与原始模型(即在 [50] 中针对桌面抓取训练并在 [6] 中进行评估的模型)进行比较外,我们还与在 HandoverSim 上进行了微调的变体(“GADDPG [50] finetuned”)进行了比较。为完整起见,我们还纳入了 [6] 中的另外两个基线: “OMG Planner [49]” 和 “Yang 等人[52]”。不过,这两个基线都是根据 [6] 中的地面实况输入进行评估的,因此不能与我们的方法直接比较。
结果 表 1 报告了测试场景的评估结果。在连续场景中,我们的方法在成功率方面明显优于所有基线方法,甚至优于使用基于状态输入的方法。就切换所需的总时间而言,我们的方法平均略慢于 GA-DDPG。在同步环境下,我们的方法明显优于成功率较低的 GA-DDPG。我们观察到,GA-DDPG 在物体仍在移动时直接尝试从用户手中抓取物体,而我们的方法是跟随手的移动,并在手停止后找到可行的抓取方式,从而在整体执行时间上进行了权衡。我们在图 4 (a) 和补充视频中提供了这一行为的定性示例。我们还在补充材料中讨论了局限性,并对我们的管道在噪声观测下的鲁棒性进行了分析。

表 1. HandoverSim 基准评估。我们的方法与 HandoverSim 基准[6]中各种基线的比较。在顺序设置中,我们发现我们的基线比其他基线取得了更好的整体成功率。在同时设置中,我们的方法远远优于适用的基线。我们方法的结果是 3 个随机种子的平均值。†:两种方法 [49, 52] 都是根据 [6] 中的地面实况进行评估的,因此不能与我们的方法直接比较。
消融术 我们在一项消融研究中评估了我们的设计选择,并在表 2 中报告了结果。2. 我们用处理 RGB 和深度/分割 (DM) 图像的 ResNet18 [23]取代 PointNet++ 对视觉骨干网进行了分析。与 GA-DDPG 的结果类似,PointNet++ 骨干网的性能更好。接下来,我们从第三人称视角而非自我中心视角训练我们的方法,并且不进行主动手部分割(不含手部点云),即策略只感知物体点云而不感知手部点云。我们还取消了辅助预测(w/o aux prediction),并评估了直接学习接近和抓取物体的变体,而不是使用接近和抓取两个任务阶段(w/o standoff)。最后,我们将模型与我们的预训练模型进行了比较,后者仅在不进行微调的情况下进行了顺序训练(w/o finetuning)。我们发现,消减成分是我们方法的重要组成部分。结果表明,在所有消融过程中,手部碰撞或物体掉落的数量都有所增加。在同步设置中进行的仔细分析显示,我们的微调模型优于预训练模型。

表 2. 消融。我们对视觉骨干、手部感知和自我中心视图进行了消减。我们还研究了微调、辅助预测以及将任务分为两个阶段的效果。所有设计选择都是我们的方法在整体性能方面的关键因素。结果为 3 个随机种子的平均值。
5.2. 模拟对模拟传输
我们首先通过将模型转移到不同的物理模拟器来评估模型的鲁棒性,而不是直接转移到真实世界。除了将后端物理引擎从 Bullet [10] 替换为 Isaac Gym [29]之外,我们按照 [6] 中介绍的机制重新构建了 HandoverSim 环境。然后,我们在由 Isaac Gym 支持的测试场景上评估在基于 Bullet 的原始环境中训练的模型。结果见表 3。我们发现,在这两种情况下,GA-DDPG 的成功率都大幅下降(即低于 20%)。从质量上看,我们发现抓取往往要么完全错过,要么只能部分抓取(见图 4 (b))。另一方面,我们的方法能够保持较高的成功率。当然,我们的方法在性能上也有损失。我们分析了我们的抓取预测器对转移性能的影响,并与我们在固定时间后执行抓取动作的变体(Ours w/o grasp pred.)进行了比较,后者将留给机器人足够的时间来找到抓取前的姿势。性能下降的部分原因是抓取预测器在错误的时间启动了抓取阶段,这可以在今后的工作中加以改进。
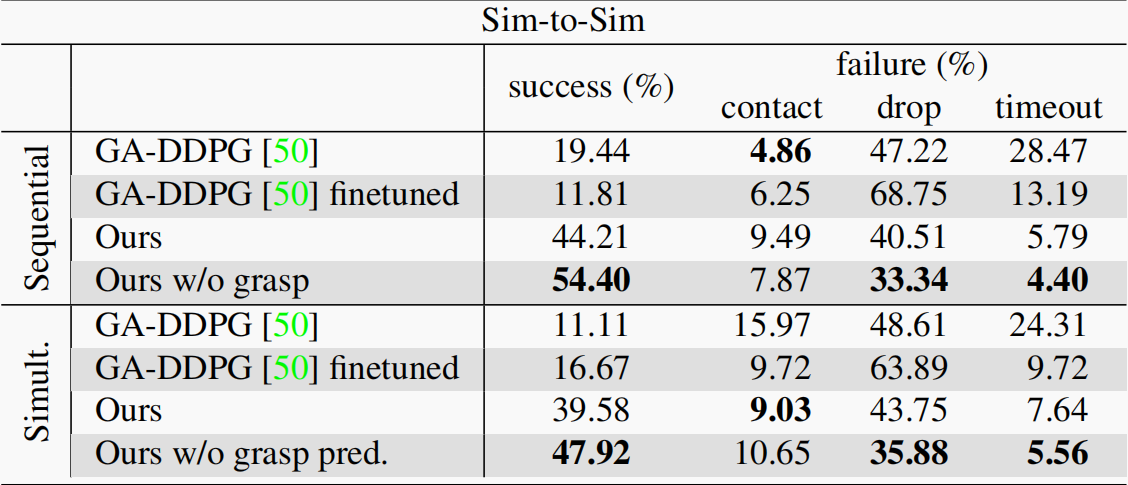
表 3. 模拟到模拟实验。我们评估了基于学习的方法在 Isaac Gym [29] 中的仿真迁移情况,与 GA-DDPG [50] 相比,我们的方法显示出更好的迁移能力。

图 4. 定性结果。我们通过对比显示了我们的方法与 GA-DDPG [50] 相比的优势。(a) 我们的方法会对移动的人类做出反应,而基线方法则试图直接抓取,从而导致碰撞。(b) 在模拟到模拟的转移过程中,我们经常发现基线方法无法抓住物体。© 在模拟到实际的实验中,GA-DDPG 通常会直接尝试抓取,而我们的方法会先将抓手调整到稳定的抓取姿势。更多定性实例,请参阅补充材料中的视频。
5.3. 模拟到真实的传输
最后,我们在真实机器人平台上部署在 HandoverSim 中训练的模型。我们沿用 [50,52] 中使用的感知管道,为策略生成分割的手部和物体点云,并使用输出更新末端效应器的目标位置。我们通过两组实验将我们的方法与 GA-DDPG [50] 进行了比较: (1) 使用受控切换姿势的试验研究;(2) 使用自由形式切换的用户评估。有关实验细节和全部结果,请参阅补充材料。
试点研究 我们首先对两名受试者进行了试点研究。我们指导受试者从 HandoverSim 中抓取 10 个物体,并以受控姿势展示这些物体。对于每个物体,我们使用 6 个姿势(每只手 3 个姿势)进行测试,物体方向和手部遮挡程度各不相同,因此每个受试者有 60 个姿势。在测试我们的模型和 GA-DDPG [50] 时使用的是同一组姿势。成功率见表 4。结果表明,在总体成功率上,我们的方法优于 GADDPG [50](即 41/60 而实验对象 1 为 21/60)。从质量上看,我们观察到 GA-DDPG [50] 在不稳定抓取和手部碰撞方面更容易失败。图 4 © 显示了两个真实世界中交接试验的例子。
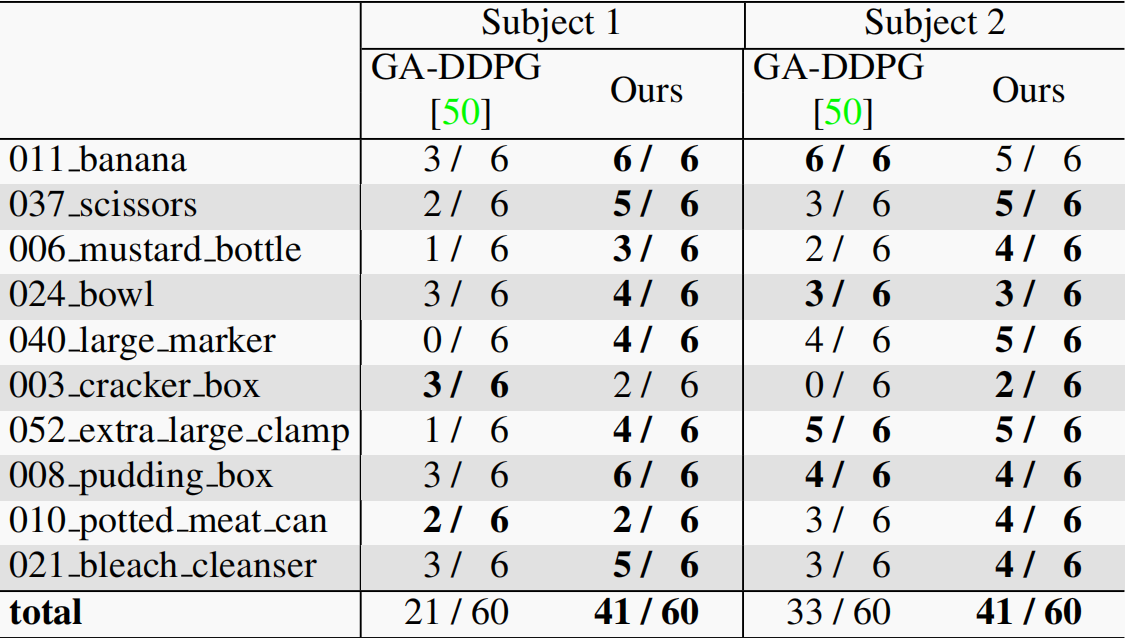
表 4. 模拟到真实实验。试验研究的成功率。在两个实验对象上,我们的方法都优于 GA-DDPG [50]。
用户评价 我们还招募了 6 名用户对两种方法进行比较,并通过李克特量表和开放式问题问卷收集反馈意见。与试验研究不同的是,我们要求用户以最舒适的方式交接 10 件物品。我们对两种方法重复了相同的实验过程,并平衡了顺序以避免偏差。从参与者的反馈来看,大多数人都认为我们的方法时间安排更恰当,而且我们的方法能更好地在不同物体姿势之间进行调整。机器人运动的可解释性也得到了他们的认可。更多详情,请参阅补充材料。
6. 结论
在这项工作中,我们提出了一个基于学习的框架,通过模拟人在回路中的视觉输入实现人与机器人之间的切换。我们引入了师生两阶段训练程序。实验表明,我们的方法在 HandoverSim 基准 [6] 上的表现明显优于基线方法。此外,我们还证明了我们的方法在转换到不同的物理模拟器和真实机器人系统时更具鲁棒性。
致谢
感谢陈涛和 Adithyavairavan Murali 奠定了基础,感谢王立瑞在 GA-DDPG 方面提供的帮助,感谢 Mert Albaba、Christoph Gebhardt、Thomas Langerak 和 Juan Zarate 对手稿的反馈意见。
相关文章:
论文笔记(三十九)Learning Human-to-Robot Handovers from Point Clouds
Learning Human-to-Robot Handovers from Point Clouds 文章概括摘要1. 介绍2. 相关工作3. 背景3.1. 强化学习3.2. 移交模拟基准 4. 方法4.1. Handover Environment4.2. 感知4.3. 基于视觉的控制4.4. 师生两阶段培训 (Two-Stage Teacher-Student Training) 5. 实验5.1. 模拟评估…...

浅学Linux之旅 day2 Linux系统及系统安装介绍
答案在时间,耐心是生活的关键 ——24.1.15 一、Linux系统介绍 林纳斯.托瓦兹在1991年开发了Linux内核(开源免费) Linux系统组成 Linux内核 系统库 系统程序 Linux内核和Linux发行版 Linux内核 -> 开源免费,林纳斯开发 Linux发行…...

探索未来餐饮:构建创新连锁餐饮系统的技术之旅
随着数字化时代的发展,连锁餐饮系统的设计和开发不再仅仅关乎订单处理,更是一场充满技术创新的冒险。在本文中,我们将深入研究连锁餐饮系统的技术实现,带你探索未来餐饮业的数字化美食之旅。 1. 构建强大的后端服务 在设计连锁…...
Unity组件开发--AB包打包工具
1.项目工程路径下创建文件夹:ABundles 2.AB包打包脚本: using System.Collections.Generic; using System.IO; using UnityEditor; using UnityEditor.SceneManagement; using UnityEngine; using UnityEngine.SceneManagement;public class AssetBundle…...
毕业设计:基于python微博舆情分析系统+可视化+Django框架 K-means聚类算法(源码)✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏) 毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总 🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题ÿ…...

xbox如何提升下载速度?
提高Xbox的下载速度可以通过以下几种方法: 连接稳定的网络:使用有线以太网连接而不是无线连接,因为有线连接通常更稳定且速度更快。 关闭正在运行的游戏和应用程序:运行游戏或应用程序会消耗网络资源和处理能力,关闭它…...

day13 滑动窗口最大值 前K个高频元素
题目1:239 滑动窗口最大值 题目链接:239 滑动窗口最大值 题意 长度为K的滑动窗口从整数数组的最左侧移动到最右侧,每次只移动1位,求滑动窗口中的最大值 不能使用优先级队列,如果使用大顶堆,最终要pop的…...

Unity——VContainer的依赖注入
一、IOC控制反转和DI依赖倒置 1、IOC框架核心原理是依赖倒置原则 C#设计模式的六大原则 使用这种思想方式,可以让我们无需关心对象的生成方式,只需要告诉容器我需要的对象即可,而告诉容器我需要对象的方式就叫做DI(依赖注入&…...

【面试突击】Spring 面试实战
🌈🌈🌈🌈🌈🌈🌈🌈 欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术 的推送 发送 资料 可领取 深入理…...
)
【Linux】Ubuntu 22.04 上安装最新版 Nextcloud Hub 7 (28.0.1)
在 Ubuntu 22.04 上安装 PHP 版本 安装多个 PHP 版本的最简单方法是使用来自 Debian 开发人员 Ondřej Sur 的 PPA。要添加此 PPA,请在终端中运行以下命令。如果要从 PPA 安装软件,则需要 software-properties-common 包。它会自动安装在 Ubuntu 桌面上,但可能会在您的 Ubuntu…...
PHP项目如何自动化测试
开发和测试 测试和开发具有同等重要的作用 从一开始,测试和开发就是相向而行的。测试是开发团队的一支独立的、重要的支柱力量。 测试要具备独立性 独立分析业务需求,独立配置测试环境,独立编写测试脚本,独立开发测试工具。没有…...
WEB 3D技术 three.js 3D贺卡(1) 搭建基本项目环境
好 今天 我也是在网上学的 带着大家一起来做个3D贺卡 首先 我们要创建一个vue3的项目、 先创建一个文件夹 装我们的项目 终端执行 vue create 项目名称 例如 我的名字想叫 greetingCards 就是 vue create greetingcards因为这个名录 里面是全部都小写的 然后 下面选择 vue3 …...

短视频IP运营流程架构SOP模板PPT
【干货资料持续更新,以防走丢】 短视频IP运营流程架构SOP模板PPT 部分资料预览 资料部分是网络整理,仅供学习参考。 抖音运营资料合集(完整资料包含以下内容) 目录 抖音15秒短视频剧本创作公式 在抖音这个短视频平台上&#…...
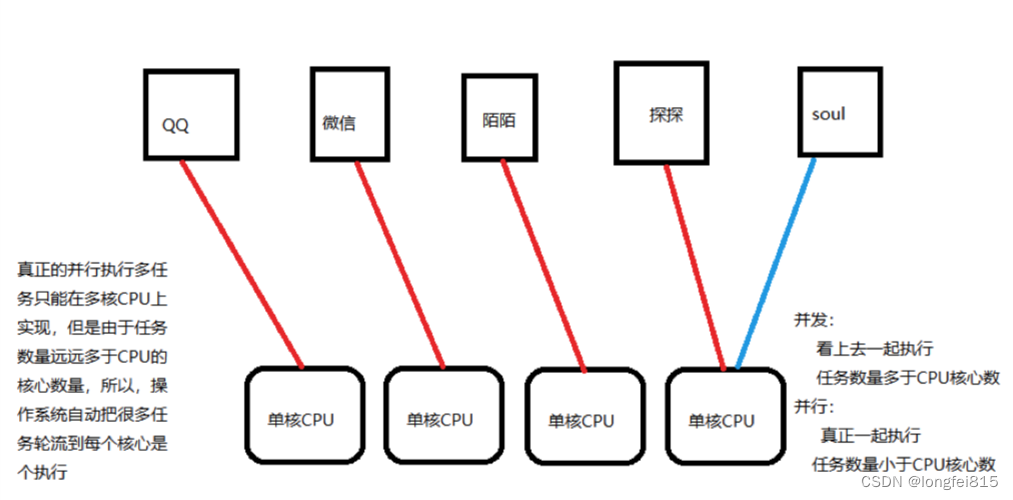
python爬虫之线程与多进程知识点记录
一、线程 1、概念 线程 在一个进程的内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”叫做线程 是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指…...

基于Java (spring-boot)的停车场管理系统
一、项目介绍 基于Java (spring-boot)的停车场管理系统、预订车位系统、停车缴费系统功能: 登录、注册、后台首页、用户信息管理、车辆信息管理、新增车辆、车位费用设置、停泊车辆查询、车辆进出管理、登录日志查询、个人中心、预定停车位、缴费信息。 适用人群&…...
微软Office 2019 批量授权版
软件介绍 微软办公软件套件Microsoft Office 2019 专业增强版2024年1月批量许可版更新推送!Office2019正式版2018年10月份推出,主要为多人跨平台办公与团队协作打造。Office2019整合对过去三年在Office365里所有功能,包括对Word、Excel、Pow…...
ChatGLM2-6B 大语言模型本地搭建
ChatGLM模型介绍: ChatGLM2-6B 是清华 NLP 团队于不久前发布的中英双语对话模型,它具备了强大的问答和对话功能。拥有最大32K上下文,并且在授权后可免费商用! ChatGLM2-6B的6B代表了训练参数量为60亿,同时运用了模型…...
WindowsServer安装mysql最新版
安装 下载相应mysql安装包: MySQL :: Download MySQL Installer 选择不登陆下载 双击运行下载好的mysql-installer-community-*.*.*.msi 进入类型选择页面,本人需要mysql云服务就选择了server only server only(服务器)&#x…...

gin切片表单验证
在Gin中对切片进行表单验证的步骤与对其他类型的字段进行验证类似。以下是一些基本步骤,我们可以根据具体的需求进行调整: 定义结构体: 创建一个结构体,用于存储表单数据。确保结构体中的字段类型与你预期的表单数据类型一致。 使…...

openssl3.2 - 官方demo学习 - certs
文章目录 openssl3.2 - 官方demo学习 - certs概述笔记官方的实验流程mkcerts.sh - 整理ocsprun.sh - 整理ocspquery.sh - 整理从mkcerts.sh整理出来的27个.bata1_create_certificate_directly.cmda2_Intermediate_CA_request_first.cmda3_Sign_request_CA_extensions.cmda4_Ser…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...