深入理解 go chan
go 里面,在实际程序运行的过程中,往往会有很多协程在执行,通过启动多个协程的方式,我们可以更高效地利用系统资源。
而不同协程之间往往需要进行通信,不同于以往多线程程序的那种通信方式,在 go 里面是通过 channel (也就是 chan 类型)来进行通信的,
实现的方式简单来说就是,一个协程往 channel 里面写数据,然后其他的协程可以从 channel 中将其读取出来。
(注意:文中的 chan 表示是 go 语言里面的 chan 关键字,而 channel 只是我们描述它的时候用的一个术语)
通道(chan)的模型
在开始讲 channel 之前,也许了解一下它要解决什么样的问题会比较好,所以先来聊聊一些背景知识。
关于通道,一个比较潦草的图大概是下面这个样子的:

在图中,协程 A 将消息 msg 写入到 channel 中,然后协程 B 从 channel 中读取消息,如果 B 没来得及从中读取消息,那么消息会在 chan 中存留。
这就是 go 的哲学:通过通信来实现共享内存。这不同于以往的多线程程序,在多线程程序中,往往是一块内存在不同线程之间进行共享,
然后通过一些保护机制,保证不允许多个线程同时对这块内存进行读写,比如通过 synchronized 关键字。
可能很多人都没有真正写过多线程的程序,但好像我们都有一种共识,多线程不安全。
多线程为什么不安全?
这是因为我们的程序除了通过共享一段内存之外,每一个 CPU 核心都有它本地的缓存,而 CPU 上的缓存是不共享的,
而线程可以同时在不同的 CPU 上执行。CPU 的执行过程是,先从内存中读取数据到 CPU 中,CPU 做完计算再更新到内存中。
这样一来,就有可能存在不同线程对同一段内存同时读写的问题。
这是什么问题呢?比如,A 线程计算完了但是还没有写回内存的时候,B 线程从内存读取出了 A 线程写入计算结果前的数据,
但是按我们的逻辑,B 应该是拿 A 线程的结算结果来进行逻辑运算的,这样就会出现数据不一致了,代码如下:
public class Main {int a = 0;public static void main(String[] args) throws InterruptedException {Main main = new Main();main.run();}// 将 a 加 1private void add() {a++;}public void run() throws InterruptedException {// 启动两个线程来对 a 进行加 1 的操作Thread t1 = new Thread(() -> {for (int i = 0; i < 10000; i++) {add();}});Thread t2 = new Thread(() -> {for (int i = 0; i < 10000; i++) {add();}});// 启动线程t1.start();t2.start();// 等待线程结束t1.join();t2.join();// 我们的预期结果是 20000,但是实际运行显示了 14965System.out.println(a);}
}
在上面的代码中,我们预期的运行结果是 20000 的,但是实际得到了 14965(实际上,每次执行结果都会不一样),这也就是我上面所说的问题,
其中有一个线程读取到了另一个线程的计算结果写入内存前的数据,也就是说,这个线程的计算结果被覆盖了,
因为线程将计算结果写回内存的时候是相互覆盖的。
所以我们可以回答刚才的问题了,多线程不安全是因为多个线程可以对同一段内存进行读写,这就存在其中一个线程还没来得及更新内存,
然后另一个线程读取到的数据是旧的。(也即数据竞争的问题)
具体可以看下图:

CPU 执行的时候,会需要将数据从内存读取到 CPU 中,计算完毕之后,再更新内存里面的数据。
错乱发生的过程大概如下:
CPU 1先计算完了,计算的结果是a = 3,但是还没来得及写入内存CPU 2也从内存里面获取a来进行计算,但是这个时候a还没有被CPU 1更新,所以CPU 2拿到的还是 2CPU 2进行计算的时候,CPU 1将它的计算结果写入了内存,所以这个时候内存中的a是 3CPU 2计算完毕,将等于 2 的变量a加 1 得到结果 3CPU 2将结果 3 写入到内存,这个时候a的内存被更新,但是结果依然是 3
一种可行的办法 - 锁
其中一种可行的办法就是,给 add 方法加上 synchronized 关键字:
private synchronized void add() {a++;
}
这个时候,在我们的代码中,对 a 读写的代码都被 synchronized 保护起来了,在这段更新之后的代码中,我们得到了正确的结果 20000。
a++其实包含了读和写两个操作,程序运行的时候,会先将 a 读取出来,将其加上 1,然后写回到内存中。
synchronized 是同步锁,它修饰的方法不允许多个线程同时执行。synchronized 锁的粒度可大可小,粒度太大的话对性能影响也较大。
正如我们所看到的那样,
synchronized允许修饰一段代码,但是在实际中我们往往只是想保护其中某一个变量而已,
如果直接使用synchronized关键字来修饰一大段代码,那就意味着一个线程在执行这段代码的时候,其他线程就只能等待,
但是实际上,其中那些不涉及数据竞争的代码我们也无法执行,这样效率自然会降低,具体降低多少,取决于我们synchronized
块的代码有多大。
go 中的处理办法
上面我们说到的多线程是通过共享内存来进行通信的,而在 go 里面,采用了 CSP(communicating sequential processes)并发模型,
CSP 模型用于描述两个独立的并发实体通过共享 channel(管道)进行通信的并发模型。
CSP 是一套很复杂的东西,go 语言并没有完全实现它,仅仅是实现了 process 和 channel 这两个概念。process 就是 go 语言
中的 goroutine,每个 goroutine 之间是通过 channel 通讯来实现数据共享的。
然后我们上面说到,java 里面的 synchronized 关键字的粒度可能会比较大,这个是相比 go 里面的 channel 而言的,
在 go 里面,我们的代码在通信过程中很常见的一种阻塞场景是:
goroutine需要从channel读取数据才能继续执行,但是channel里面还没数据,这个时候goroutine需要等待(会阻塞)另一个goroutine往channel写入数据。
对于这种场景,它隐含的逻辑是,阻塞的这个 goroutine 需要等待其他 goroutine 的结果才能继续往下执行,也就是 CSP 中的 sequential。下图是实际运行中的 chan:

我们上面的 chan 模型那个图,读和写都只有一个协程,但在实际中,读 chan 和写 chan 的协程都有一个队列来保存。
我们需要明确的一点事实是:队列中的协程会一个接一个执行,队列头的协程先执行,然后我们对 chan 的读写是按顺序来读写的,先取 chan 队列头的元素,然后下一个元素。
对应到上面 java 这个例子,我们在 go 里面可以怎么做呢?我们先把没有锁的 java 代码先写成 go 的代码:
package mainimport "fmt"var a = 0func add(ch chan int, done chan<- struct{}) {for i := 0; i < 10000; i++ {a++}done <- struct{}{}
}func main() {done := make(chan struct{}, 2)// ch 充当协程之间同步的角色ch := make(chan int, 1)// 这里可以传任意数字ch <- 1go add(ch, done)go add(ch, done)// 等待 2 个协程执行完毕<-done<-donefmt.Println(a) // 15504 每次结果不一样
}
在 go 里面,我们可以把 add 方法改成下面这个样子:
func add(ch chan int, done chan<- struct{}) {for i := 0; i < 10000; i++ {// 阻塞,只有另外一个协程往 ch 里面写入数据的时候,// <-ch 才得以解除阻塞状态<-ch// 这一行同一时刻只能一个协程执行a++// 往 ch 写入数据,// 等待从 ch 中读取数据的协程得以继续执行ch <- i}done <- struct{}{}
}
这种写法看起来很笨拙,我们在实际使用中可能会稍有不同,所以不需要太纠结这个例子的合理性,这里想表达的是:在 go 中,我们的协程使用 chan 的时候只会阻塞在 chan 读写的地方,其他代码不受影响,当然,这个例子也没能很好体现。
假设我们有很大一段代码,但是涉及到数据竞争的时候,协程只会阻塞在
chan读写的那一行代码上。这样一来我们就不用通过锁来覆盖一大段代码。
这里,我们可以看到 chan 其中一个很明显的优势是,我们没有了 synchronized 那种大粒度的锁,我们的 goroutine 只会阻塞在某一个 channel 上,
在读取 channel 之前的代码,goroutine 都是可以执行的,这样就在语言层面帮我们解决了一个很大的问题,
因为粒度更小,我们的代码自然也就能处理更大的并发请求了。
进程的几种状态
在开始讲述 channel 之前,再来回忆一下进程的几种状态会便于我们理解。
我们知道,我们的电脑上,同一时刻会有很多进程一直在运行,但是我们也发现很多进程的 CPU 占用其实都是 0%,也就是不占用 CPU。
其实进程会有几种状态,进程不是一直在运行的,一般来说,会有 执行、阻塞、就绪 几种状态,进程不是运行态的时候,那它就不会占用你的 CPU,因此会看到 CPU 占用是 0%,它们之间的转换如下图:

执行:这表示进程正在运行中,是正在使用 CPU 的进程。在就绪状态的进程会在得到CPU时间片的时候得以执行。阻塞:这表示进程因为某些需要的资源得不到满足而挂起了(比如,正在进行磁盘读写),这种状态下,是不用占用CPU资源的。就绪:这表示一个状态所需要的资源都准备好了,可以继续执行了。
进程的几种状态跟 channel 有什么关系?
在 go 里面,其实协程也存在类似的调度机制,在协程需要的资源得不到满足的时候,也会被阻塞,然后协程调度器会去执行其他可以执行的协程。
比如下面这个例子:
func main() {done := make(chan struct{})// 这个协程在 main 协程序阻塞的时候依然在执行go func() {// 陷入睡眠状态time.Sleep(time.Second)fmt.Println("done")// 往 done 这个 chan 写入数据done <- struct{}{}}()// main 协程陷入阻塞状态<-done
}
在这个例子中 done <- struct{}{} 这一行往 done 这个 chan 写入了数据,之前一直在等待 chan 的 main 协程的阻塞状态解除,得以继续执行。
goroutine 在等待 chan 返回数据的时候,会陷入阻塞状态。一个因为读取 chan 陷入阻塞状态的 goroutine 在获取到数据的时候,会继续往后执行。
channel 是什么?
我们在文章开头的第一张图,其实不是很准确。在 go 里面,channel 实际上是一个队列(准确来说是环形队列),大概长得像下面这样:

队列我们都知道,我们可以从队列头读取数据,也可以将数据推入到队列尾。上图中,1 是队列头,当我们从 channel 读取数据的时候,
读取到的是 1,6 是队列尾,当我们往 channel 中写入数据的时候,写入的位置是 6 后面的那个空间。
channel是一个环形队列,goroutine 通过 channel 通信的方式是,一个 goroutine 将数据写入队列尾,然后另一个 goroutine 将数据从队列头读数据。
如何使用 channel
我们再仔细看看上面的例子:
package mainimport ("fmt""time"
)func main() {done := make(chan struct{})go func() {time.Sleep(time.Second)fmt.Println("done")// 发送取消信号done <- struct{}{}}()// 等待结束信号<-done
}
这里面包含了使用 channel 的基本用法:
done := make(chan struct{}):创建channel,在 go 里面是使用chan关键字来代表一个channel的。而在这个语句中,创建了一个接收struct{}类型数据的chan。done <- struct{}{}:写入到chan,这里,我们创建了一个空结构体,然后通过<-操作符将这个空结构体写入到了chan中。<-done:从chan中读取数据,也是使用了<-操作符,然后我们丢弃了它的返回结果。
这段代码的执行过程如下图:

CPU 1上启动了main协程- 接着在
main协程中通过go func启动了一个新的协程,go 的调度机制允许不同的协程在不同的线程上执行,所以main执行的时候,go func也在执行,然后,因为done这个chan中没有数据,所以main协程陷入阻塞。 go func在短暂的睡眠之后,输出了done,然后向名字为done这个chan中发送了一个空结构体实例。- 在
done里面没有写入数据之前,main一直阻塞,在go func写入数据之后,main的<-done,解除了阻塞状态,得以继续执行 5和6因为可能是在不同的线程上执行的,所以哪一个先结束其实不一定。
下面详细说说 channel 的具体用法
创建 chan
chan是 go 的关键字,channel是我用来描述chan所表示的东西的一个术语而已,我们在 go 里面使用的话还是得用chan关键字。
创建 chan 是通过 make 关键字创建的:
ch := make(chan int)
make 函数的参数是 chan 然后加一个数据类型,这个数据类型是我们的 chan 这个环形队列里面所能存储的数据类型。
不能传递不同的类型进一个 chan 里面。
也可以传递第二个参数作为 chan 的容量,比如:
ch := make(chan int, 3)
这里第二个参数表明了 ch 这个 chan 到底能存储多少个 int 类型的数据。
不传递或者传 0 表示
chan本身不能存储数据,go 底层会直接在两个 goroutine 之间传递,而不经过chan的复制。
(如果第二个参数大于 0,我们往chan写数据的时候,会先复制到chan这个数据结构,然后其他的goroutine从chan中读取数据的时候,chan会将数据复制到这个goroutine中)
chan 读写的几种操作
- 写:
ch <- x,将x发送到 channel 中 - 读:
x = <-ch,从channel中接收,保存到x中 - 读,但是忽略返回值(用作协程同步,上面的例子就是):
<-ch,从ch中接收,但是忽略接收到的结果 - 读,并且判断是否是关闭前发送的:
x, ok := <-ch,这里使用了两个返回值接收,第二个返回值表明了接收到的x是不是chan关闭之前发送进去的,true就代表是。
需要注意的是 <-ch 和 ch<- 这两个看起来好像一样,但是效果是完全不同的,ch 位于 <- 操作符右边的时候,
表示是
有一个简单区分的方法是,将 <- 想象为数据流动的方向,具体来说就是看数据是流向 chan 还是从 chan 流出,流向 chan 就是写入到 chan,从 chan 流出就是读取。
缓冲 chan 与非缓冲 chan
上面我们说到,创建 chan 的时候可以传递第二个参数表示 chan 的容量是多少,这个容量表示的是,
在没有 goroutine 从这个 chan 读取数据的时候,chan 能存放多少数据,也就是 chan 底层环形队列的长度。
下面描述了缓冲的实际场景:
无缓冲 chan
还是用我们上面的那段代码:
package mainimport "fmt"func main() {done := make(chan struct{})go func() {fmt.Println("done")done <- struct{}{}}()<-done
}
这里 make(chan struct{}),只有一个参数,所以 done 是一个无缓冲的 chan,这种 chan 会在发送的时候阻塞,直到有另一个协程从 chan 中获取数据。

有缓冲 chan
有缓冲的 chan 在协程往里面写入数据的时候,可以进行缓冲。缓冲的作用是,在需要读取 chan 的 goroutine 的处理速度比较慢的时候,写入 chan 的 goroutine 也可以持续运行,直到写满 chan 的缓冲区

上图的 chan 是一个有缓冲的 chan,在 chan 里面的数据还没来得及被接收的时候,chan 可以充当一个缓冲的角色。但是,如果 chan 的数据一直没有被接收,然后满了的时候,往 chan 写入数据的协程依然会陷入阻塞。但这种阻塞状态会在 chan 的数据被读取的时候解除。
下面是一个例子:
package mainimport ("fmt""time"
)func main() {done := make(chan struct{})// 定义一个缓冲数量为 2 的 chanch := make(chan int, 2)go func() {for {// 模拟比较慢的处理速度time.Sleep(time.Second)i, ok := <-ch// ok 为 false 表示 ch 已经关闭并且数据已经被读取完// 这个时候中断循环if !ok {break}fmt.Printf("[%d] get from ch: %d\n", time.Now().Unix(), i)}// 处理完数据之后,发送结束的信号done <- struct{}{}}()go func() {// 在循环结束之后关闭 chandefer close(ch)for i := 0; i < 3; i++ {// 在写入 2 个数之后,会陷入阻塞状态// 直到上面那个协程从 ch 读取出数据,ch 才会有空余的地方可以继续接收数据ch <- ifmt.Printf("[%d] write to ch: %d\n", time.Now().Unix(), i)}}()// 收到结束信号,解除阻塞状态,继续往下执行<-done
}
输出如下:
[1669381752] write to ch: 0
[1669381752] write to ch: 1
[1669381753] get from ch: 0
[1669381753] write to ch: 2
[1669381754] get from ch: 1
[1669381755] get from ch: 2
我们可以看到,写入 chan 的协程在 1669381752 的时候没有写入了,然后在读取 chan 的协程从 chan 中读取了一个数出来后才能继续写入。
nil chan
chan 的零值是 nil,close 一个 nil 通道会引发 panic。往 nil 通道写入或从中读取数据会永久阻塞:
package mainfunc main() {var ch chan int<-ch
}
执行的时候会报错:fatal error: all goroutines are asleep - deadlock!
len 和 cap
len:通过len我们可以查询一个chan的长度,也就是有多少被发送到这个chan但是还没有被接收的值。cap:通过cap可以查询一个容道的容量,也就是我们传给make函数的第二个参数,它表示chan最多可以容纳多少数据。
如果
chan是nil,那么len和cap都会返回 0。
chan 的方向
chan 还有一个非常重要的特性就是它是可以有方向的,这里说的方向指的是,数据的流向。在我们上面的例子中,数据既可以流入 chan,也可以从 chan 中流出,因为我们没有指定方向,没有指定那么 chan 就是双向的。
具体来说,有以下几种情况:
chan,没有指定方向,既可以读又可以写。chan<-,只写chan,只能往chan中写入数据,如果从中读数据的话,编译不会通过。<-chan,只读chan,只能从chan中读取数据,如果往其中写入数据的话,编译不会通过。
另外,无方向的 chan 可以转换为 chan<- 或者 <-chan,但是反过来不行
在实际使用 chan 的时候,在某些地方我们其实是只允许往 chan 里面写数据,然后另一个地方只允许从 chan 中读数据。比如下面这个例子:
package mainimport "fmt"var done = make(chan struct{})// ch 是只写 chan,如果在这个函数里面从 ch 读取数据编译不会通过
func producer(ch chan<- int) {for i := 0; i < 3; i++ {ch <- ifmt.Printf("produce %d\n", i)}// 发送 3 个数之后,关闭 chanclose(ch)
}// ch 是只读 chan,如果在这个函数里往 ch 写入数据编译不会通过
func consumer(ch <-chan int) {for {i, ok := <-chif !ok {// chan 的数据已经被全部接收完,// 发送 done 信号done <- struct{}{}break}fmt.Printf("consume %d\n", i)}
}func main() {nums := make(chan int, 10)go producer(nums)go consumer(nums)// 收到结束信号之后继续往下执行<-done
}
在这个例子中,producer 这个协程里面往 chan 写入数据,写入 3 个数之后关闭,然后 consumer 这个协程序从 chan 读取数据,
在读取完所有数据之后,发送结束信号(通过 done 这个 chan),最后 main 协程收到 done 信号后退出。
这样有个好处就是,从语法层面限制了对 chan 的读写操作。而不用担心有误操作。
什么时候阻塞?什么时候不阻塞?
在开始这个话题之前,很有必要说一下,go 里面 chan 的一些实现原理,在 chan 的实现中,维护了三个队列:
- 数据缓冲队列(
chan):也就是上面说的环形队列,是一种先进先出结构(FIFO,“First In, First Out”),它的长度是chan的容量。此队列存放的都是同一种类型的元素。 - 接收数据协程队列(
recvq):当chan里面没有数据可以读取的时候,这个队列会有数据,这个队列中的协程都在等待从chan中读取数据。 - 发送数据协程队列(
sendq):当数据缓冲队列满了的时候(又或者如果是一个无缓冲的chan),那么这个队列不为空,这个队列中的协程都在等待往chan中写入数据。
大家在实际使用的时候可以参考一下下图,下图列出了对 chan 操作的所有场景:

对于阻塞或者非阻塞,其实有一个很简单的判断标准,下面描述了所有会阻塞的情况:
- 发送:如果没有地方能存放发送的数据,则阻塞,具体有下面几种情况:
nil chan- 有缓冲但是缓冲满了
- 无缓冲并且没有协程在等待从
chan中读取数据
- 接收:如果没有可以读取的数据,则阻塞,具体有下面几种情况:
nil chan- 有缓冲,但是缓冲区空的
- 无缓冲,但是没有协程正在往
chan中发送数据
大家觉得抽象可以结合下面这个图想象一下:

结合现实场景想象一下,我们可以把 chan 想象成为配送员,sendq 想象为商家,recvq 想象成用户,配送员装餐点的箱子想象成缓冲区:
一个假设的前提:假设商家只能在送出去一份餐点后,才能开始制作下一份餐点。
- 发送
nil chan。没有配送员了,商家的餐点肯定是送不出去了,商家只能等着关门大吉了。- 有缓冲但是缓冲满了。配送员会有一个箱子(缓冲区)来存放外卖,但是这个箱子现在满了,虽然接了一个单,但是没有办法再从商家那里取得外卖来送了
- 无缓冲并且没有协程在等待从
chan中读取数据。这个外卖是用户自取的订单,但是用户联系不上。(当然现实中商家不用等,我们假设现在商家只能送出去一份后才能开始制作下一份)
- 接收
nil chan。没有配送员,用户的餐没人送,用户只能等着饿死了。- 有缓冲,但是缓冲区空的。商家还没制作好餐点,配送员没有取到餐,这个时候用户打电话给配送员叫他快点送,但是这个时候配送员也没有办法,因为他也没有拿到用户的餐点。这个时候用户快饿死了,但也没有办法,只有干等着,先吃饱才能搬砖。
- 无缓冲,但是没有协程正在往
chan中发送数据。这天,用户是下了自取的订单,然后去到店里的时候,商家还没做好,这个时候,用户啥事也干不了,也只能等了。
需要注意的是,上图中发送和接收只有一个协程,但是在实际中,正如这一节开头讲的那样,发送和接收都维护了一个队列的。
对应到上面那个现实的例子,那就是配送员可以同时从多个商家那里取餐,也可以同时给多个用户送餐,这个过程,有可能多个商家在制作需要这个配送员配送的餐点,也有可能有多个用户在等着这个配送员送餐。
<- 操作符只是语法糖
在 go 里面我们操作 chan 的方式好像非常简单,就通过 <- 操作符就已经绰绰有余了,这也是 go 的设计理念吧,尽量把语言设计得简单。
(但是,简单并不容易)但是,从另外一个角度看,go 把对 chan 的操作简化成我们现在看到的这个样子,也说明了 chan 在 go 里面的地位(一等公民)。
在 go 中,chan 实际上是一个结构体(runtime/chan.go 里面的 hchan 结构体),而且,还是一个非常复杂的结构体,但是我们在使用的时候却非常简单,
这其实是 go 设计者给开发者提供的一种语法糖,直接在语法层面极大地简化了开发者对 chan 的使用,
如果没有这个语法糖,那就需要开发者自己去创建 hchan 结构体,然后发送或者接收的时候还需要调用这个结构体的方法。
相比之下,<- 就写一个操作符就行了,而且这个符号还非常形象,指向哪就代表了数据是流向 chan (写)还是从 chan 流出(读)。
for…range 语法糖
我们上面说过了,从 chan 读取数据的时候,可能需要用两个值来接收 chan 的返回值,第二个值用来判断接收到的值是否是 chan 关闭之前发送的。
而 for...range 语法也可以用来从 chan 中读取数据,它会循环,直到 chan 关闭,这样直接免去了我们判断的操作,比如:
package mainimport "fmt"func main() {done := make(chan struct{})nums := make(chan int)go func() {for i := 0; i < 3; i++ {fmt.Printf("send %d\n", i)nums <- i}close(nums)}()go func() {// 传统写法//for {// num, ok := <-nums// if !ok {// break// }// fmt.Printf("receive %d\n", num)//}// range 语法糖for num := range nums {fmt.Printf("receive %d\n", num)}done <- struct{}{}}()<-done
}
select 语句里面使用 chan
go 里面有一个关键字 select,可以让我们同时监听几个 chan,在任意一个 chan 有数据的时候,select 里面的 case 块得以执行:
package mainimport ("fmt""time"
)func main() {ch1 := make(chan int)ch2 := make(chan int)// ch1 会先收到数据go func() {time.Sleep(time.Second)ch1 <- 1}()go func() {time.Sleep(time.Second * 2)ch2 <- 1}()// select 会阻塞,直到其中某一个分支收到数据select {case <-ch1:// 执行这一行代码fmt.Println("from ch1")case <-ch2:// 这一行不会被执行fmt.Println("from ch2")}
}
select-case 的用法类似于 switch-case,也有一个 default 语句,在 select 里面
- 如果
default之前的case都不满足,则执行default块的代码。 - 如果没有
default语句,则会一直阻塞,直到某一个case上面的chan返回(有数据、或者chan被关闭都会返回)
当然,case 后面可以从 chan 读取数据,也可以往 chan 写数据,比如:
package mainimport ("fmt""time"
)func main() {ch1 := make(chan int)// 往 nil chan 写入数据会阻塞var ch2 chan int// ch1 会先收到数据go func() {time.Sleep(time.Second)ch1 <- 1}()// 会阻塞,直到其中一个 case 返回select {case <-ch1:// 执行这一行代码fmt.Println("from ch1")case ch2 <- 1: // 永远不会满足,因为 ch2 是 nilfmt.Println("from ch2")}
}
select 的另外一种很常见的用法是,等待一个 chan 和一个定时器(实现控制超时的功能),比如:
package mainimport ("fmt""time"
)func main() {ch1 := make(chan int)// ch1 一秒后才收到数据go func() {time.Sleep(time.Second)ch1 <- 1}()select {case <-ch1:fmt.Println("from ch1")case <-time.After(time.Millisecond * 100):// 执行如下代码,因为这个 case 在 100ms 后就返回了fmt.Println("from ch2")}
}
如果我们需要控制某些操作的超时时间,那么就可以在时间到了之后,做一些清理操作,然后终止一些工作,最后退出协程。
总结
- go 里面通过
chan来实现协程之间的通信,chan大概就是一个协程给另一个协程发送信息的代理。 - 多线程程序执行的时候,因为有 CPU 缓存,然后需要对同一块内存进行并发读写,可能会导致数据竞争的问题。
- 在很多语言中,都提供了锁的机制,来保护一片内存同一时刻只能一个线程操作,比如 java 里面的
synchronized关键字。 - go 里面很多情况下,在不同协程之间通信都是使用
chan来实现的。 - 进程会有阻塞态、运行态,go 里面的协程也有阻塞的状态,当需要的资源得不到满足的时候就会陷入阻塞。比如等待别的协程往
chan里面写入数据。 chan的几种常见操作:make创建、<-chan读、chan<-写、len获取chan中未读取的元素个数、cap获取chan的缓冲区容量。chan类型上不加<-表示是一个可读可写的chan,<-chan T表示只读chan,chan<- T表示只写chan,双向的chan可以转换为只读或者只写chan,但是反过来不行,只读chan和只写chan之间也不能相互转换。- 协程的阻塞跟不阻塞,很简单的判断方式就是,发送的时候就看有没有地方能接得住,接收的时候就看有没有数据可以拿,没有则陷入阻塞。
<-是 go 语言在设计层面提供给开发者的一种语法糖,chan底层是一个很复杂的结构体。for...range结构在遍历chan的时候不用判断返回值是否有效,因为返回值无效的时候会退出循环。- 我们可以通过
select来同时等待多个chan的操作返回。
相关文章:
深入理解 go chan
go 里面,在实际程序运行的过程中,往往会有很多协程在执行,通过启动多个协程的方式,我们可以更高效地利用系统资源。 而不同协程之间往往需要进行通信,不同于以往多线程程序的那种通信方式,在 go 里面是通过…...
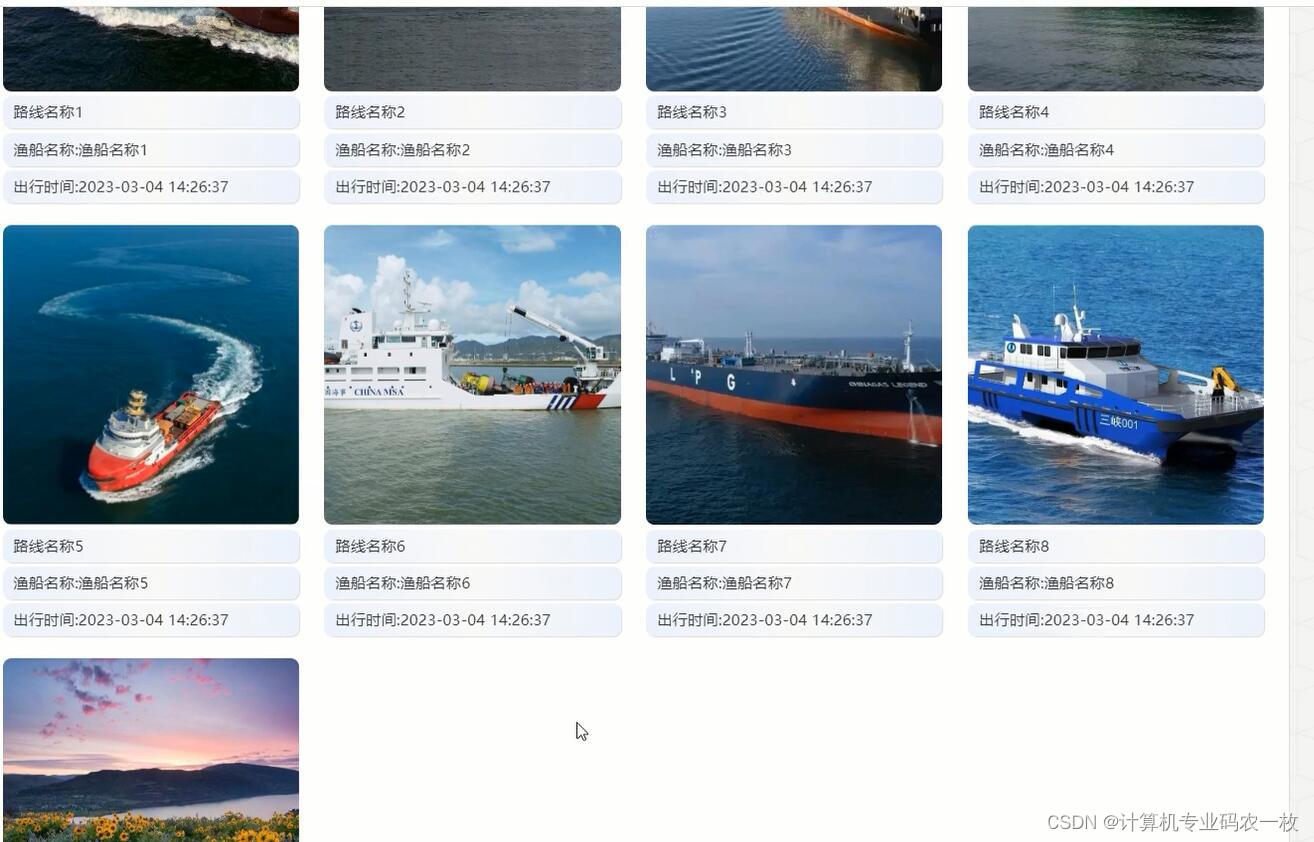
java+vue基于Spring Boot的渔船出海及海货统计系统
该渔船出海及海货统计系统采用B/S架构、前后端分离进行设计,并采用java语言以及springboot框架进行开发。该系统主要设计并完成了管理过程中的用户注册登录、个人信息修改、用户信息、渔船信息、渔船航班、海货价格、渔船海货、非法举报、渔船黑名单等功能。该系统操…...
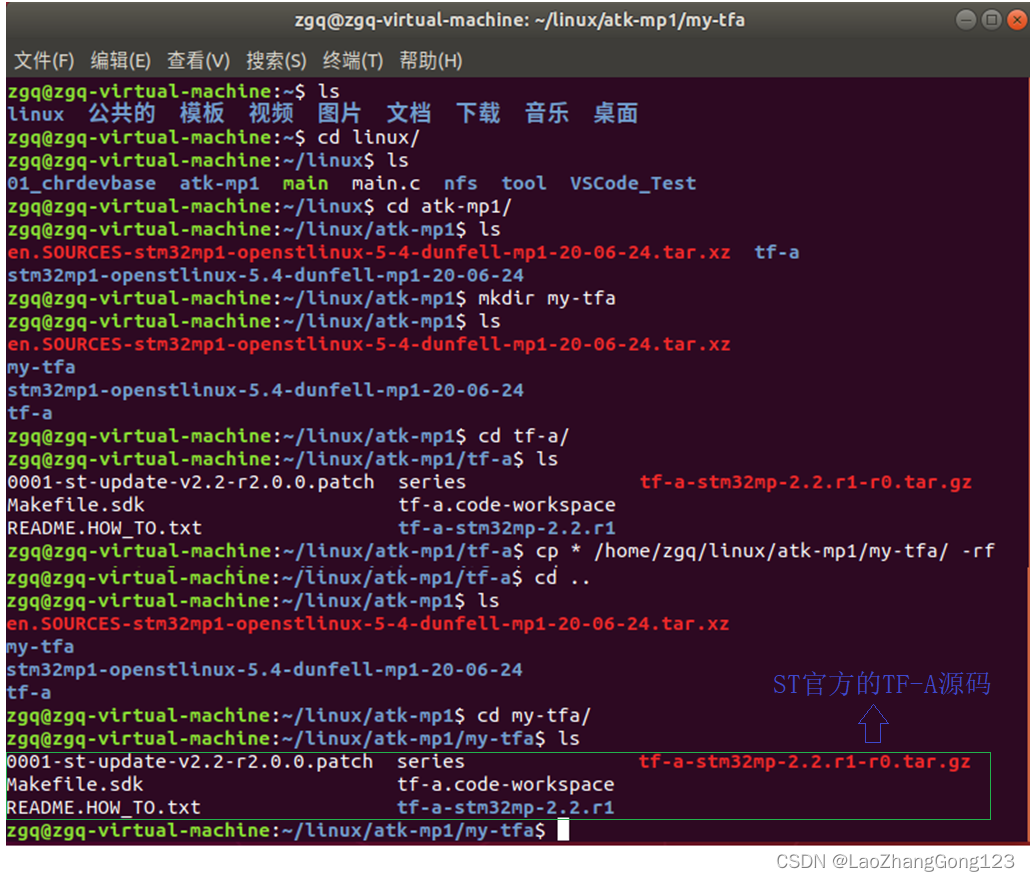
Linux第25步_在虚拟机中备份“ST官方的TF-A源码”
TF-A是ARM公司提供的,ST公司通过修改它,做了一个自己的TF-A代码。因为在后期开发中,若硬件被改变了,我们需要通过修改"ST官方的TF-A源码"就可以自己的TF-A代码了。为了防止源文件被误改了,我们需要将"S…...
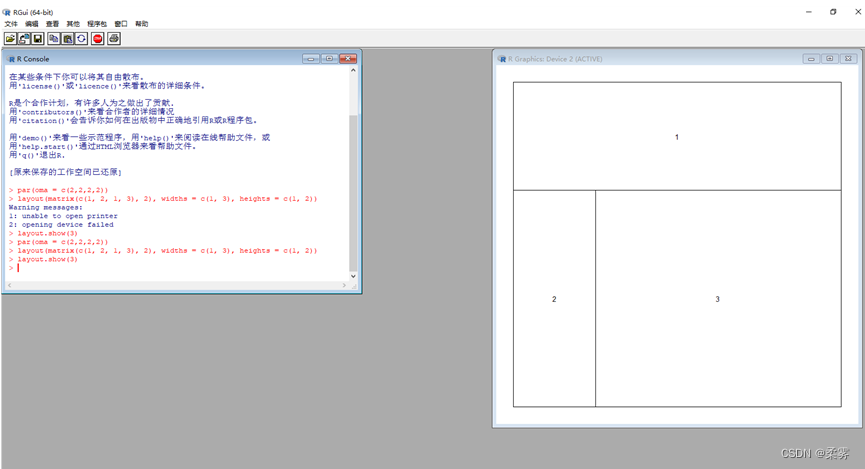
统计学-R语言-4.1
文章目录 前言编写R函数图形的控制和布局par函数layout函数 练习 前言 安装完R软件之后就可以对其进行代码的编写了。 编写R函数 如果对数据分析有些特殊需要,已有的R包或函数不能满足,可以在R中编写自己的函数。函数的定义格式如下所示: …...

C++(1) —— 基础语法入门
目录 一、C初识 1.1 第一个C程序 1.2 注释 1.3 变量 1.4 常量 1.5 关键字 1.6 标识符命名规则 二、数据类型 2.1 整型 2.2 sizeof 关键字 2.3 实型(浮点型) 2.4 字符型 2.5 转义字符 2.6 字符串型 2.7 布尔类型 bool 2.8 数据的输入 三…...
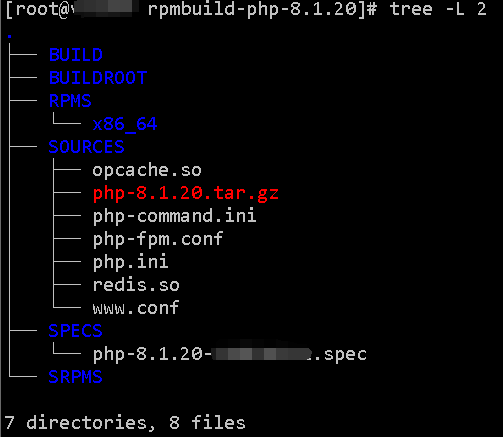
构建基于RHEL8系列(CentOS8,AlmaLinux8,RockyLinux8等)的支持63个常见模块的PHP8.1.20的RPM包
本文适用:rhel8系列,或同类系统(CentOS8,AlmaLinux8,RockyLinux8等) 文档形成时期:2023年 因系统版本不同,构建部署应略有差异,但本文未做细分,对稍有经验者应不存在明显障碍。 因软件世界之复杂和个人能力…...
)
Vue-插槽(Slots)
1. 介绍 在Vue.js中,插槽是一种强大的功能,它允许你创建可重用的模板,并在使用该模板的多个地方插入自定义内容。 插槽为你提供了一种方式,可以在父组件中定义一些“插槽”,然后在子组件中使用这些插槽,插…...

新火种AI|GPT-5前瞻!GPT-5将具备哪些新能力?
作者:小岩 编辑:彩云 Sam Altman在整个AI领域,乃至整个科技领域都被看作是极具影响力的存在,而2023年OpenAI无限反转的宫斗事件更是让Sam Altman刷足了存在感,他甚至被《时代》杂志评为“2023年度CEO”。 也正因此&…...
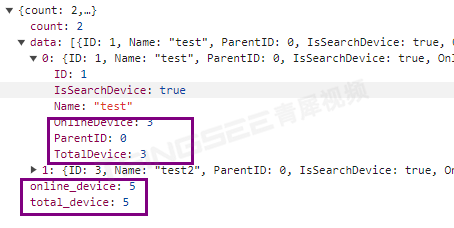
安防视频监控系统EasyCVR设备分组中在线/离线数量统计的开发与实现
安防视频监控EasyCVR系统具备较强的兼容性,它可以支持国标GB28181、RTSP/Onvif、RTMP,以及厂家的私有协议与SDK,如:海康ehome、海康sdk、大华sdk、宇视sdk、华为sdk、萤石云sdk、乐橙sdk等。EasyCVR平台可覆盖多类型的设备接入&am…...

spring cloud之集成sentinel
写在前面 源码 。 本文一起看下spring cloud的sentinel组件的使用。 1:准备 1.1:理论 对于一个系统来说,最重要的就是高可用,那么如何实现高可用呢?你可能会说,集群部署不就可以了,但事实并…...

让车辆做到“耳听八方”,毫米波雷达芯片与系统设计
摘要: 毫米波雷达,是指工作在毫米波波段(一般为30~300GHz频域,波长1~10mm)探测的雷达。毫米波雷达体积小、质量轻、空间分辨率高,穿透“雾烟灰”的能力强,还具备全天候全天时工作的优势。在智能网联汽车体系中,毫米波雷达是系统感知层不可或缺的重要硬件,能让智能驾…...

Python如何实现数据驱动的接口自动化测试
大家在接口测试的过程中,很多时候会用到对CSV的读取操作,本文主要说明Python3对CSV的写入和读取。下面话不多说了,来一起看看详细的介绍吧。 1、需求 某API,GET方法,token,mobile,email三个参数 token为必填项mobil…...

高级分布式系统-第15讲 分布式机器学习--联邦学习
高级分布式系统汇总:高级分布式系统目录汇总-CSDN博客 联邦学习 两种常见的架构:客户-服务器架构和对等网络架构 联邦学习在传统的分布式机器学习基础上的变化。 传统的分布式机器学习:在数据中心或计算集群中使用并行训练,因为…...

小程序基础学习(事件处理)
原理:组件内部设置点击事件,然后冒泡到页面捕获点击事件 在组件内部设置点击事件 处理点击事件,并告诉页面 页面捕获点击事件 页面处理点击事件 组件代码 <!--components/my-info/my-info.wxml--> <view class"title"…...
网络协议与攻击模拟_01winshark工具简介
一、TCP/IP协议簇 网络接口层(没有特定的协议) 物理层:PPPOE宽带拨号(应用场景:宽带拨号,运营商切网过来没有固定IP就需要拨号,家庭带宽一般都采用的是拨号方式)数据链路层网络层…...

【linux学习笔记】网络
目录 【linux学习笔记】网络检查、监测网络ping-向网络主机发送特殊数据包traceroute-跟踪网络数据包的传输路径netstat-检查网络设置及相关统计数据 通过网络传输文件ftp 【linux学习笔记】网络 检查、监测网络 ping-向网络主机发送特殊数据包 最基本的网络连接命令就是pin…...

JUC-线程中断机制和LockSupport
线程中断机制 概念 java提供了一种用于停止线程的协商机制-中断。称为中断标识协商机制。 常用API public void interrupt() 仅仅让线程的中断标志位设置为true。不进行其他操作。public boolean isInterrupted() 获取中断标志位的状态。public static boolean interrupted…...
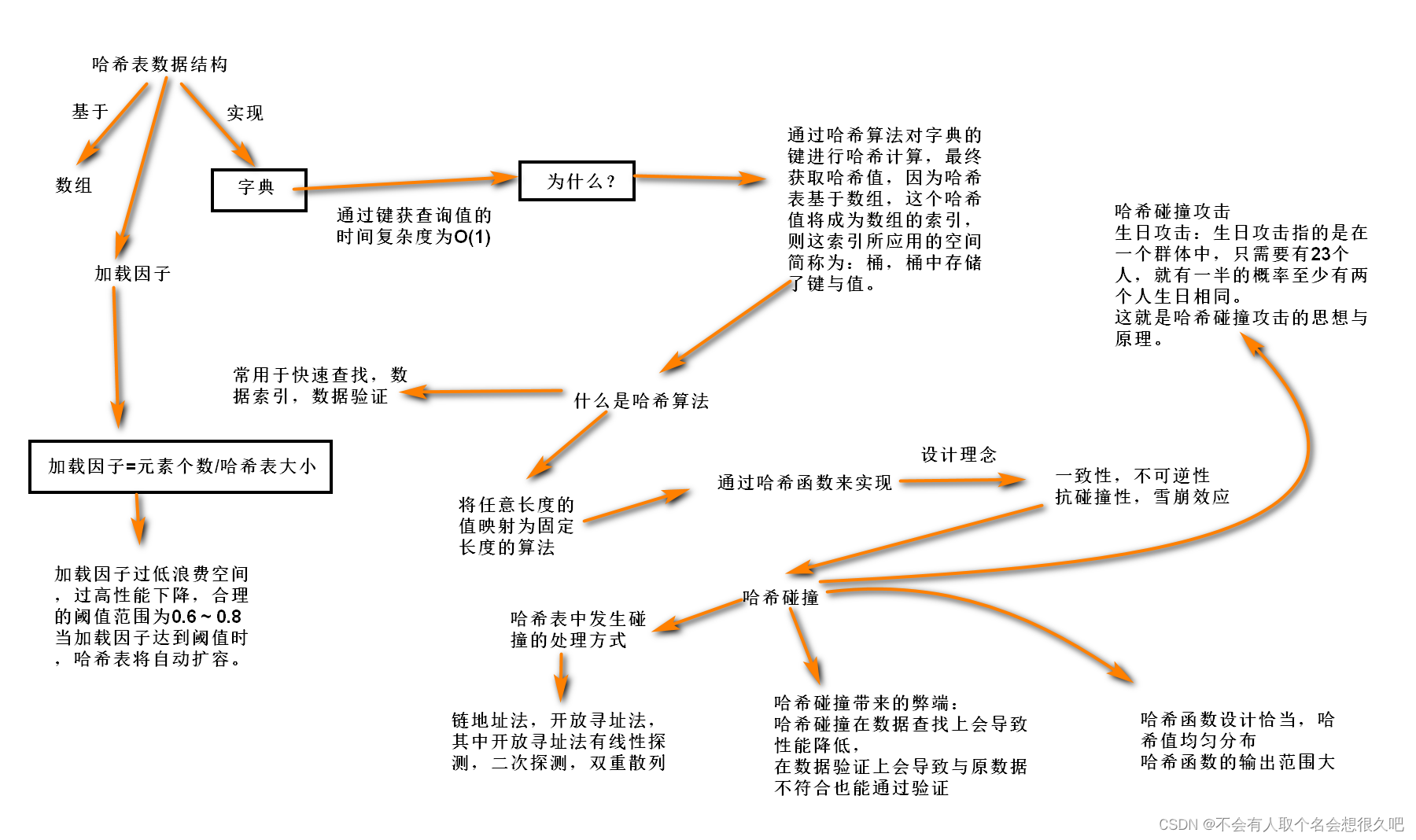
哈希表与哈希算法(Python系列30)
在讲哈希表数据结构和哈希算法之前,我想先刨析一下数组和python中的列表 首先来讲一下数组,我想在这提出一个疑问: 为什么数组通过索引查询数据的时间复杂度为O(1),也就是不管数组有多大,算法的执行时间都是不变的。…...

『 C++ 』AVL树详解 ( 万字 )
🦈STL容器类型 在STL的容器中,分为几种容器: 序列式容器(Sequence Containers): 这些容器以线性顺序存储元素,保留了元素的插入顺序。 支持随机访问,因此可以使用索引或迭代器快速访问任何位置的元素。 主要的序列式…...

Python下载安装pip方法与步骤_pip国内镜像
前提:下载安装好 python 打开命令提示符winR->cmd(不需要进入 python,直接在终端输入指令执行即可,也可以再 pycharm 终端执行命令)加入要安装ipython,需要执行以下命令: pip install **<…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...