【低照度图像增强系列(5)】Zero-DCE算法详解与代码实现(CVPR 2020)

前言
☀️ 在低照度场景下进行目标检测任务,常存在图像RGB特征信息少、提取特征困难、目标识别和定位精度低等问题,给检测带来一定的难度。
🌻使用图像增强模块对原始图像进行画质提升,恢复各类图像信息,再使用目标检测网络对增强图像进行特定目标检测,有效提高检测的精确度。
⭐本专栏会介绍传统方法、Retinex、EnlightenGAN、SCI、Zero-DCE、IceNet、RRDNet、URetinex-Net等低照度图像增强算法。
👑完整代码已打包上传至资源→低照度图像增强代码汇总
目录
前言
🚀一、Zero-DCE介绍
☀️1.1 Zero-DCE简介
🚀二、Zero-DCE网络结构及核心代码
☀️2.1 网络结构
☀️2.2 核心代码
🚀三、Zero-DCE损失函数及核心代码
☀️3.1 Lspa—Spatial Consistency Loss(空间一致性损失)
☀️3.2 Lexp—Exposure Control Loss(曝光控制损失)
☀️3.3 Lcol—Color Constancy Loss(颜色恒定损失)
☀️3.4 LtvA—Illumination Smoothness Loss(照明平滑度损失)
🚀四、Zero-DCE代码复现
☀️4.1 环境配置
☀️4.2 运行过程
☀️4.3 运行效果

🚀一、Zero-DCE介绍
相关资料:
- 论文题目:《Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement》(用于低光图像增强的零参考深度曲线估计)
- 原文地址:https://arxiv.org/abs/2001.06826
- 论文精读:CVPR2020|ZeroDCE《Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement》论文超详细解读(翻译+精读)
- 源码地址:项目概览 - Zero-DCE - GitCode
☀️1.1 Zero-DCE简介
本文发表在CVPR2020,主要提出了一个零参考深度曲线估计Zero-Reference Deep Curve Estimation(Zero-DCE),将光线增强转换为了一个image-specific曲线估计问题(图像作为输入,曲线作为输出),通过非参考损失函数实现,从而获得增强图像。
另外,通过训练一个轻量级的网络(DCE-NET),来预测一个像素级的,高阶的曲线,并通过该曲线来调整图像。
 主要贡献:
主要贡献:
- 是第一个不依赖于成对和非成对训练数据的弱光增强网络,从而避免了过拟合的风险。
- 设计一种特定的曲线,能够迭代运用于自身来近似像素和高阶曲线。这种曲线能够在动态范围内有效的进行映射
- 提出了一种无参的损失函数,来直接估计增强图像的质量。
取得成效:
- 整个方法在多个数据集上都取得了SOTA
-
在黑暗中的人脸检测取得成效

🚀二、Zero-DCE网络结构及核心代码
☀️2.1 网络结构
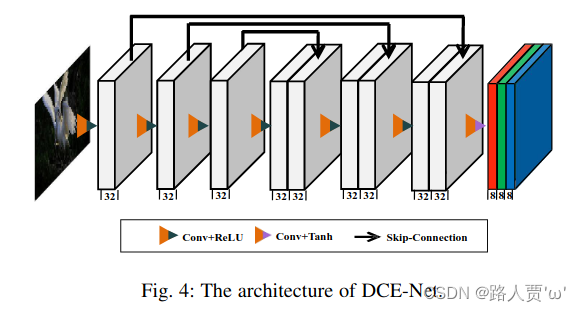
- (1)backbone: DCE-Net包含七个具有对称跳跃连接的卷积层:conv-ReLU 重复 6 次 + conv-Than。(注意:它具有对称的级联,即第 1/2/3 层输出和第 6/5/4 层输出进行通道级联)
- (2)conv层: 由32个3x3的卷积核组成,stride=1
- (3)参数: 整个网络的参数量为79,416
- (4)Flops: Flops为5.21G(input 为256x256x3)
☀️2.2 核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
#import pytorch_colors as colors
import numpy as npclass enhance_net_nopool(nn.Module):def __init__(self):super(enhance_net_nopool, self).__init__()self.relu = nn.ReLU(inplace=True)# 一共有32个模块number_f = 32# 7个3*3,padding=1,stride=1的卷积核self.e_conv1 = nn.Conv2d(3,number_f,3,1,1,bias=True) self.e_conv2 = nn.Conv2d(number_f,number_f,3,1,1,bias=True) self.e_conv3 = nn.Conv2d(number_f,number_f,3,1,1,bias=True) self.e_conv4 = nn.Conv2d(number_f,number_f,3,1,1,bias=True) self.e_conv5 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True) self.e_conv6 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True) self.e_conv7 = nn.Conv2d(number_f*2,24,3,1,1,bias=True) # 最大池化层self.maxpool = nn.MaxPool2d(2, stride=2, return_indices=False, ceil_mode=False) # 双线性插值上采样层 self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)def forward(self, x):x1 = self.relu(self.e_conv1(x))# p1 = self.maxpool(x1)x2 = self.relu(self.e_conv2(x1))# p2 = self.maxpool(x2)x3 = self.relu(self.e_conv3(x2))# p3 = self.maxpool(x3)x4 = self.relu(self.e_conv4(x3))x5 = self.relu(self.e_conv5(torch.cat([x3,x4],1)))# x5 = self.upsample(x5)x6 = self.relu(self.e_conv6(torch.cat([x2,x5],1)))# 通过tanh激活函数处理得到增强后的图像enhance_imagex_r = F.tanh(self.e_conv7(torch.cat([x1,x6],1)))# 通过torch.split将enhance_image分割成8个通道,分别表示不同的增强效果r1,r2,r3,r4,r5,r6,r7,r8 = torch.split(x_r, 3, dim=1)x = x + r1*(torch.pow(x,2)-x)x = x + r2*(torch.pow(x,2)-x)x = x + r3*(torch.pow(x,2)-x)enhance_image_1 = x + r4*(torch.pow(x,2)-x) x = enhance_image_1 + r5*(torch.pow(enhance_image_1,2)-enhance_image_1) x = x + r6*(torch.pow(x,2)-x) x = x + r7*(torch.pow(x,2)-x)enhance_image = x + r8*(torch.pow(x,2)-x)r = torch.cat([r1,r2,r3,r4,r5,r6,r7,r8],1)return enhance_image_1,enhance_image,r这段代码平平无奇,就是实现图像增强操作。具体来说,主要通过多层卷积和连接操作,以及一些激活函数,学习图像的增强信息。
首先,初始化定义了32个模块,每个模块由7个3*3,padding=1,stride=1的卷积核组成。
然后,前6个卷积层使用ReLU激活函数,第7层使用tanh激活函数,得到增强后的图像enhance_image。
接着, 通过torch.split将enhance_image分割成8个通道,分别表示不同的增强效果。
最后,将这些效果叠加到原始输入图像上,得到最终的增强图像。
🚀三、Zero-DCE损失函数及核心代码
其实这四个损失函数,才是本文最大的亮点。
☀️3.1 Lspa—Spatial Consistency Loss(空间一致性损失)
目的
通过保持输入图像与增强图像相邻区域的梯度促进图像的空间一致性。
方法
-
首先计算输入图像和增强图像在通道维度的平均值(将R、G、B三通道加起来求平均),得到两个灰度图像
-
然后分解为若干个4×4patches(不重复,覆盖全图)
-
最后计算patch内中心i与相邻j像素差值,求平均
公式
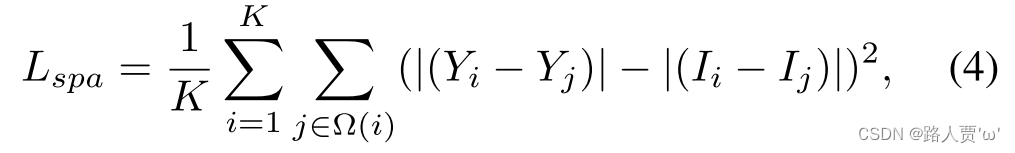
-
:局部区域的数量
-
:是以区域 i为中心的四个相邻区域(顶部、下、左、右)
-
:增强版本的局部区域的平均强度值
-
:输入版本的局部区域的平均强度值
代码
class L_spa(nn.Module):def __init__(self):super(L_spa, self).__init__()# print(1)kernel = torch.FloatTensor(kernel).unsqueeze(0).unsqueeze(0)kernel_left = torch.FloatTensor( [[0,0,0],[-1,1,0],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)kernel_right = torch.FloatTensor( [[0,0,0],[0,1,-1],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)kernel_up = torch.FloatTensor( [[0,-1,0],[0,1, 0 ],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)kernel_down = torch.FloatTensor( [[0,0,0],[0,1, 0],[0,-1,0]]).cuda().unsqueeze(0).unsqueeze(0)self.weight_left = nn.Parameter(data=kernel_left, requires_grad=False)self.weight_right = nn.Parameter(data=kernel_right, requires_grad=False)self.weight_up = nn.Parameter(data=kernel_up, requires_grad=False)self.weight_down = nn.Parameter(data=kernel_down, requires_grad=False)self.pool = nn.AvgPool2d(4)def forward(self, org , enhance ):b,c,h,w = org.shapeorg_mean = torch.mean(org,1,keepdim=True)enhance_mean = torch.mean(enhance,1,keepdim=True)org_pool = self.pool(org_mean) enhance_pool = self.pool(enhance_mean) weight_diff =torch.max(torch.FloatTensor([1]).cuda() + 10000*torch.min(org_pool - torch.FloatTensor([0.3]).cuda(),torch.FloatTensor([0]).cuda()),torch.FloatTensor([0.5]).cuda())E_1 = torch.mul(torch.sign(enhance_pool - torch.FloatTensor([0.5]).cuda()) ,enhance_pool-org_pool)D_org_letf = F.conv2d(org_pool , self.weight_left, padding=1)D_org_right = F.conv2d(org_pool , self.weight_right, padding=1)D_org_up = F.conv2d(org_pool , self.weight_up, padding=1)D_org_down = F.conv2d(org_pool , self.weight_down, padding=1)D_enhance_letf = F.conv2d(enhance_pool , self.weight_left, padding=1)D_enhance_right = F.conv2d(enhance_pool , self.weight_right, padding=1)D_enhance_up = F.conv2d(enhance_pool , self.weight_up, padding=1)D_enhance_down = F.conv2d(enhance_pool , self.weight_down, padding=1)D_left = torch.pow(D_org_letf - D_enhance_letf,2)D_right = torch.pow(D_org_right - D_enhance_right,2)D_up = torch.pow(D_org_up - D_enhance_up,2)D_down = torch.pow(D_org_down - D_enhance_down,2)E = (D_left + D_right + D_up +D_down)# E = 25*(D_left + D_right + D_up +D_down)return E首先,定义了四个卷积核分别用于计算图像在左、右、上和下方向上的差异。
然后,在向前传播过程中进行如下计算:
- 计算权重差异
weight_diff。 - 计算增强图像的差异
E_1,该差异受到阈值0.5的控制。 - 利用卷积运算分别计算原始图像和增强图像在四个方向上的梯度差异。
- 计算每个方向上的梯度差异的平方,并将它们相加,得到
E。
最后,返回计算得到的空间损失 E。
☀️3.2 Lexp—Exposure Control Loss(曝光控制损失)
目的
抑制曝光不足/过度区域,控制曝光水平。
方法
测量的是局部区域的平均强度值与良好曝光水平(E=0.6 ,经验设置)之间的距离。
-
首先将增强图像转为灰度图
-
然后分解为若干 16×16 patches(不重复,覆盖全图)
-
最后计算 patch 内的平均值
公式

-
:大小为16×16的不重叠局部区域个数
-
代码
class L_exp(nn.Module):def __init__(self,patch_size,mean_val):super(L_exp, self).__init__()# print(1)self.pool = nn.AvgPool2d(patch_size)self.mean_val = mean_valdef forward(self, x ):b,c,h,w = x.shapex = torch.mean(x,1,keepdim=True)mean = self.pool(x)d = torch.mean(torch.pow(mean- torch.FloatTensor([self.mean_val] ).cuda(),2))return d这段代码比较简单,就是通过初始化平均池化层和均值函数,比较输入图像的全局均值与指定均值之间的差异。
最后,返回计算得到的亮度损失 d。
☀️3.3 Lcol—Color Constancy Loss(颜色恒定损失)
目的
用于纠正增强图像中的潜在色偏,同时也建立了三个调整通道之间的关系。
方法
-
首先将提亮图像分成RGB三通道,计算每个通道的平均亮度
-
然后将不同通道的平均亮度两两相减,求平均和
Color Constancy Loss值越小,说明提亮图像颜色越平衡,损失越大则说明提亮图像可能有色偏的问题
公式
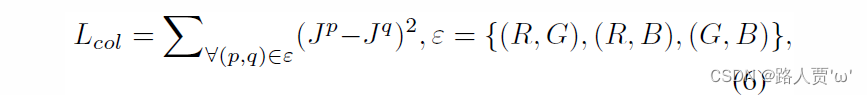
-
:增强后图像中p通道的平均强度值
-
:一对颜色通道
代码
class L_color(nn.Module):def __init__(self):super(L_color, self).__init__()def forward(self, x ):b,c,h,w = x.shapemean_rgb = torch.mean(x,[2,3],keepdim=True)mr,mg, mb = torch.split(mean_rgb, 1, dim=1)Drg = torch.pow(mr-mg,2)Drb = torch.pow(mr-mb,2)Dgb = torch.pow(mb-mg,2)k = torch.pow(torch.pow(Drg,2) + torch.pow(Drb,2) + torch.pow(Dgb,2),0.5)return k这段代码也比较简单,主要进行以下的计算:
- 计算图像在每个像素位置的RGB均值,这是通过对每个通道在高度和宽度上进行平均计算得到的。
- 将RGB均值分割成单独的通道(mr、mg、mb)。
- 计算颜色差异,分别为红绿差异
Drg、红蓝差异Drb和绿蓝差异Dgb。
最后,返回计算得到的最终的颜色损失 k。
☀️3.4 LtvA—Illumination Smoothness Loss(照明平滑度损失)
目的
保持相邻像素之间的单调关系。
启发
将所有通道、所有迭代次数的 A (也就是网络的输出),其横竖的梯度平均值应该很小。
公式

-
:迭代次数
-
:水平梯度
-
:垂直梯度
代码
class L_TV(nn.Module):def __init__(self,TVLoss_weight=1):super(L_TV,self).__init__()self.TVLoss_weight = TVLoss_weightdef forward(self,x):batch_size = x.size()[0]h_x = x.size()[2]w_x = x.size()[3]count_h = (x.size()[2]-1) * x.size()[3]count_w = x.size()[2] * (x.size()[3] - 1)h_tv = torch.pow((x[:,:,1:,:]-x[:,:,:h_x-1,:]),2).sum()w_tv = torch.pow((x[:,:,:,1:]-x[:,:,:,:w_x-1]),2).sum()return self.TVLoss_weight*2*(h_tv/count_h+w_tv/count_w)/batch_size首先,定义了一个 TVLoss_weight 属性,表示总变差损失的权重,默认为1。
然后,在向前传播过程中进行如下计算:
- 计算图像在水平方向上的总变差
h_tv和在垂直方向上的总变差w_tv。 - 计算总变差损失(包括水平和垂直方向上的总变差),以及权重调整。
最后,返回计算得到的总变差损失。
🚀四、Zero-DCE代码复现
☀️4.1 环境配置
- Python 3.7
- Pytorch 1.0.0
- opencv
- torchvision 0.2.1
- cuda 10.0
☀️4.2 运行过程
这个运行比较简单,配好环境就行。如果有报错可以参考以下博文:
【代码复现Zero-DCE详解:Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement】_zerodce代码解读-CSDN博客 跑微光图像增强程序遇到的问题汇总_userwarning: nn.functional.tanh is deprecated. use-CSDN博客
暗光增强——Zero-DCE网络推理测试(详细图文教程)-CSDN博客
☀️4.3 运行效果



相关文章:
【低照度图像增强系列(5)】Zero-DCE算法详解与代码实现(CVPR 2020)
前言 ☀️ 在低照度场景下进行目标检测任务,常存在图像RGB特征信息少、提取特征困难、目标识别和定位精度低等问题,给检测带来一定的难度。 🌻使用图像增强模块对原始图像进行画质提升,恢复各类图像信息,再使用目标…...

三维重建衡量指标记录
1、完整性比率 Completeness Rati (CR) 完整性比率 完整性比率是用于评估三维重建质量的指标之一,它衡量了重建结果中包含的真实物体表面或点云的百分比。完整性比率通常是通过比较重建结果中的点云或三维模型与真实或标准点云或模型之间的重叠来计算的。 具体计算…...

在WinForms中控制模态对话框的关闭行为
博客文章:在WinForms中控制模态对话框的关闭行为 引言 在Windows Forms (WinForms) 应用程序中,对话框的行为控制是提升用户体验的关键部分。特别是在使用模态对话框时,防止用户不经意间关闭它变得尤为重要。本文将探讨如何通过重写 FormClo…...

java web mvc-02-struts2
拓展阅读 Spring Web MVC-00-重学 mvc mvc-01-Model-View-Controller 概览 web mvc-03-JFinal web mvc-04-Apache Wicket web mvc-05-JSF JavaServer Faces web mvc-06-play framework intro web mvc-07-Vaadin web mvc-08-Grails Struts2 Apache Struts是一个用于创…...

文件上传之大文件分块上传
分久必合,合久必分 优势部分:减少了内存占用,可实现断点续传,并发处理,利用带宽,提高效率 不足之处:增加复杂性,增加额外计算存储 应用场景:云存储大文件上传、多媒体平台…...

测试用例评审流程
1:评审的过程 A:开始前做好如下准备 1、确定需要评审的原因 2、确定进行评审的时机 3、确定参与评审人员 4、明确评审的内容 5、确定评审结束标准 6、提前至少一天将需要评审的内容以邮件的形式发送给评审会议相关人员。并注明详审时间、地点及偿参与人员等。 7、 在邮件中提醒…...
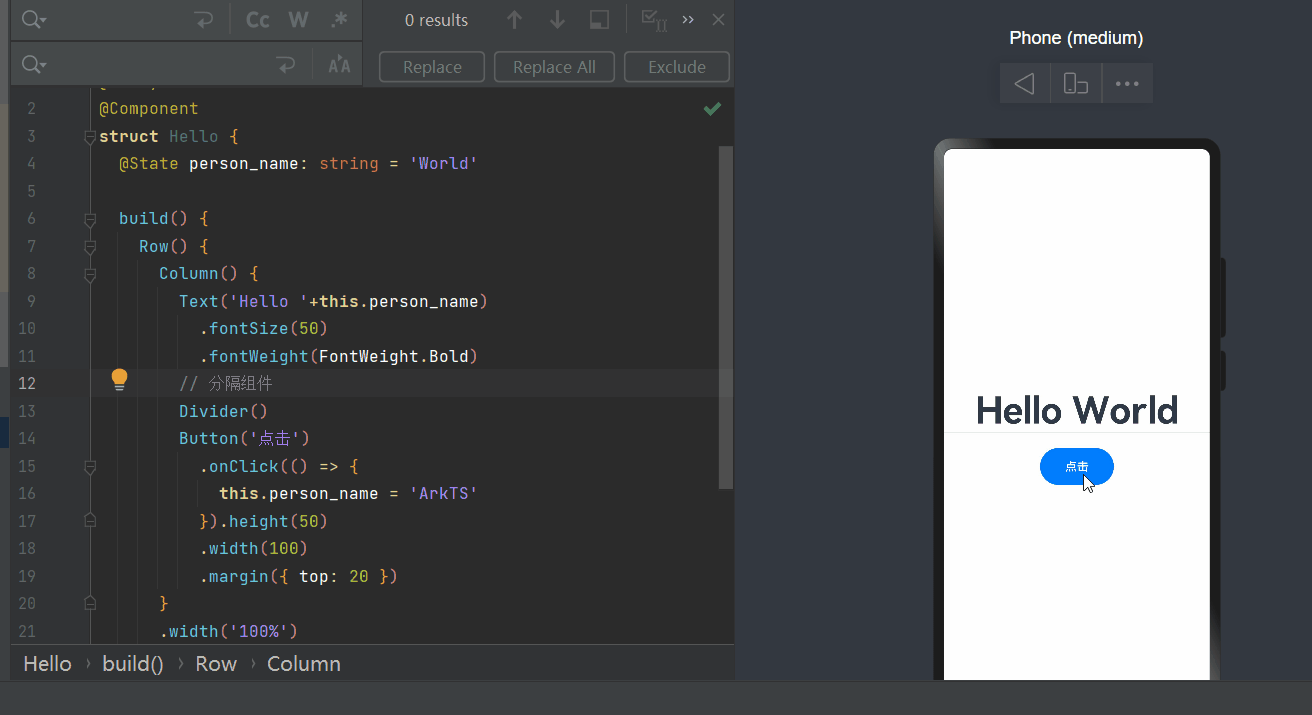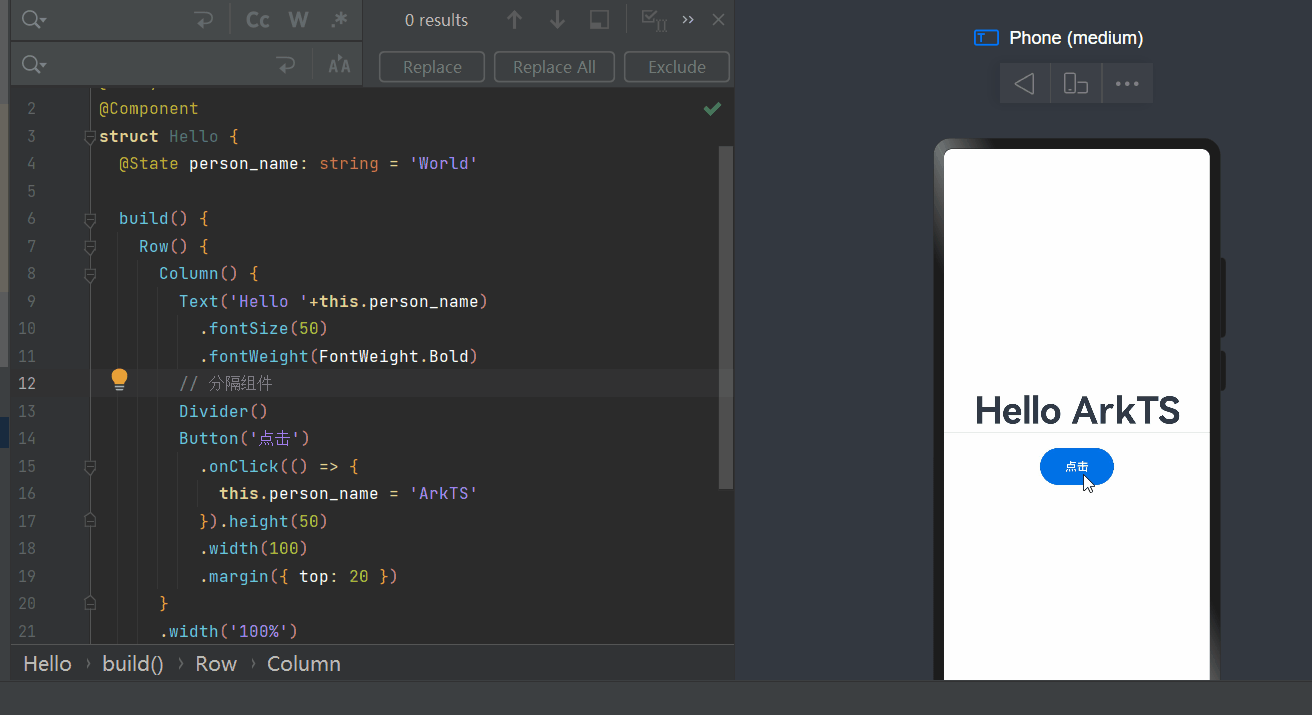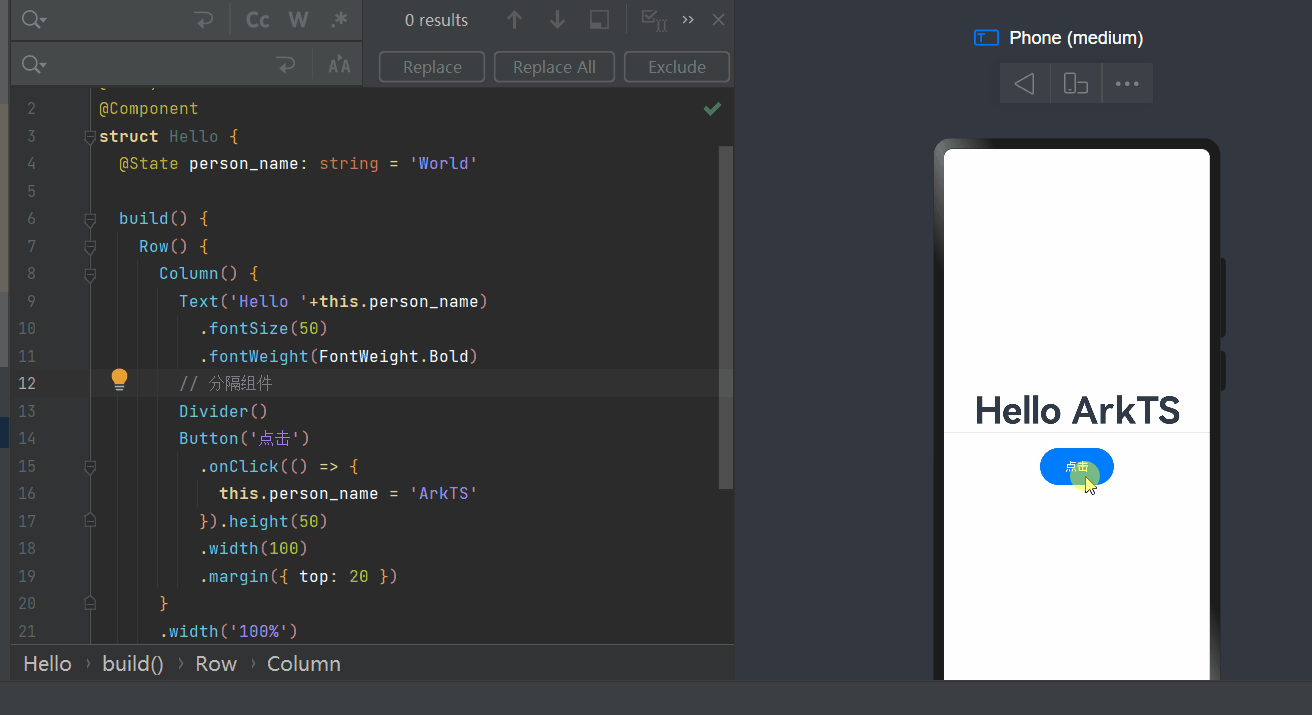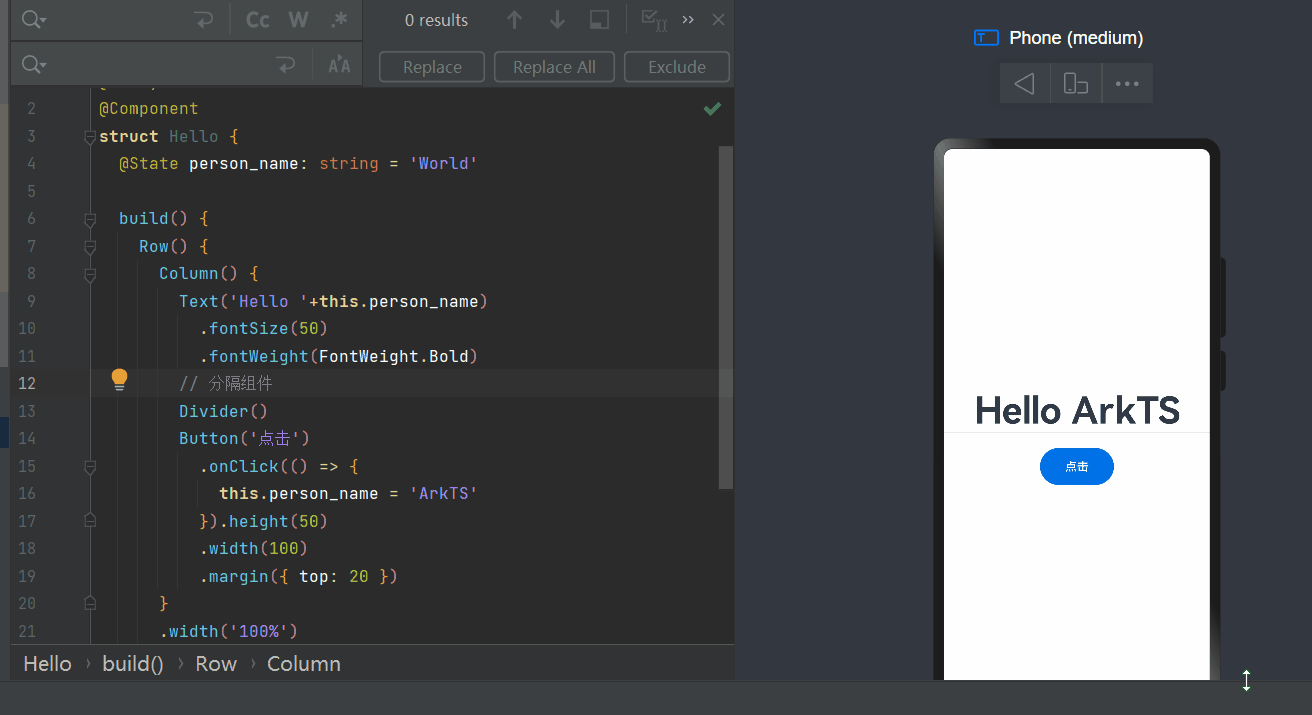
鸿蒙开发案列一
1、开发需求 案例app一打开是“Hello world” 界面,开发者点击“Hello world”变成“Hello ArkUI”’ 2、源代码 Entry Component struct Hello {State person_name: string Worldbuild() {Row() {Column() {Text(Hello this.person_name).fontSize(50).fontWei…...
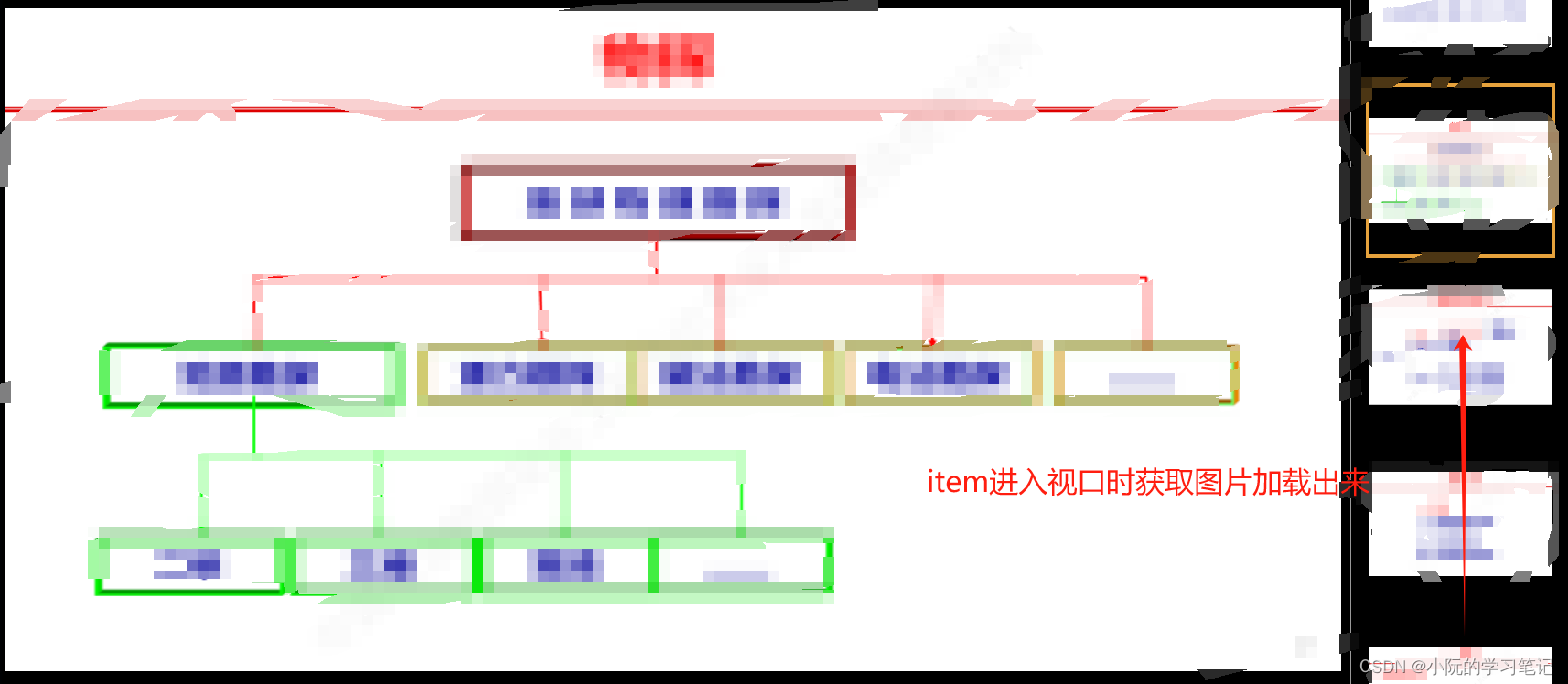
Vue实现图片预览,侧边栏懒加载,不用任何插件,简单好用
实现样式 需求 实现PDF上传预览,并且不能下载 第一次实现:用vue-pdf,将上传的文件用base64传给前端展示 问题: 水印第一次加载有后面又没有了。当上传大的pdf文件后,前端获取和渲染又长又慢,甚至不能用 修…...
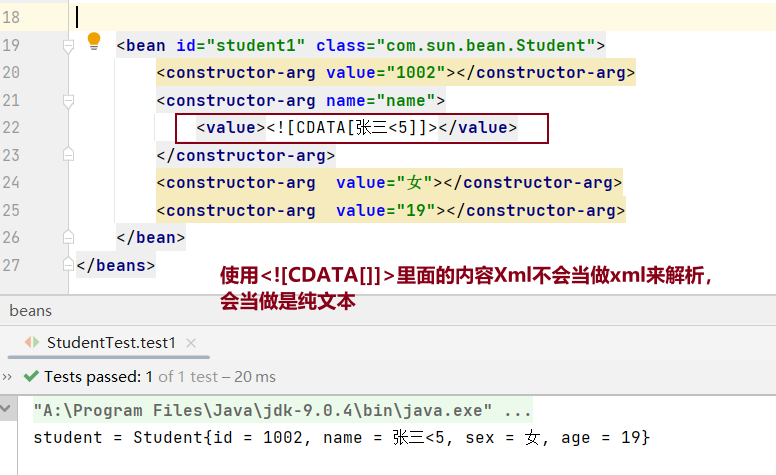
Spring依赖注入之setter注入与构造器注入以及applicationContext.xml配置文件特殊值处理
依赖注入之setter注入 在管理bean对象的组件的时候同时给他赋值,就是setter注入,通过setter注入,可以将某些依赖项标记为可选的,因为它们不是在构造对象时立即需要的。这种方式可以减少构造函数的参数数量,使得类的构…...
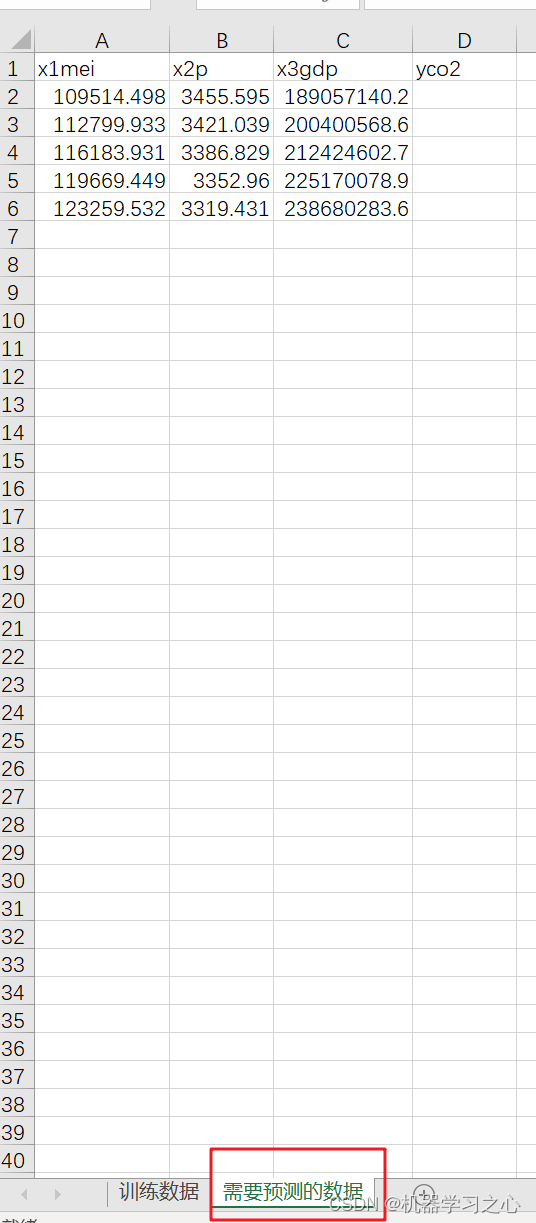
碳排放预测 | Matlab实现LSTM多输入单输出未来碳排放预测,预测新数据
碳排放预测 | Matlab实现LSTM多输入单输出未来碳排放预测,预测新数据 目录 碳排放预测 | Matlab实现LSTM多输入单输出未来碳排放预测,预测新数据预测效果基本描述程序设计参考资料 预测效果 基本描述 1.Matlab实现LSTM长短期记忆神经网络多输入单输出未来…...
手拉手JavaFX UI控件与springboot3+FX桌面开发
目录 javaFx文本 javaFX颜色 字体 Label标签 Button按钮 //按钮单击事件 鼠标、键盘事件 //(鼠标)双击事件 //键盘事件 单选按钮RadioButton 快捷键、键盘事件 CheckBox复选框 ChoiceBox选择框 Text文本 TextField(输入框)、TextArea文本域 //过滤 (传入一个参数&a…...
02 分解质因子
一、数n的质因子分解 题目描述: 输入一个数n(n<10^6),将数n分解质因数,并按照质因数从小到大的顺序输出每个质因数的底数和指数。 输入 5 输出 5 1 输入 10 输出 2 1 5 1 朴素解法: 首先求出1~n的所有质数…...

科技赋能智慧水利——山海鲸软件水利方案解析
作为山海鲸可视化软件的开发者,我们深感荣幸能为我国智慧水利建设提供强大助力。作为钻研数字孪生领域的开创者,我们希望不仅能为大家带来免费好用,人人都能用起来的数字孪生产品,还希望以其独特的技术优势和创新设计理念…...

C4.5决策树的基本建模流程
C4.5决策树的基本建模流程 作为ID3算法的升级版,C4.5在三个方面对ID3进行了优化: (1)它引入了信息值(information value)的概念来修正信息熵的计算结果,以抑制ID3更偏向于选择具有更多分类水平…...
)
本科毕业设计过程中应该锻炼的能力 (深度学习方向)
摘要: 本文以本科毕业设计做深度学习方向, 特别是全波形反演为例, 描述学生应在此过程中锻炼的能力. 搭建环境的能力. 包括 Python, PyTorch 等环境的安装.采集数据的能力. 包括 OpenFWI 等数据集.查阅资料的能力. 包括自己主要参考的文献, 以及其它相关文献 (不少于 20 篇). …...

深度学习——pycharm远程连接
目录 远程环境配置本地环境配置(注意看假设!!!这是很多博客里没写的)步骤1步骤2步骤2.1 配置Connection步骤2.2 配置Mappings 步骤3 配置本地项目的远程解释器技巧1 pycharm中远程终端连接技巧2 远程目录技巧3 上传代码文件技巧4 …...

信号量机制解决经典同步互斥问题
生产者 / 消费者问题、读者 / 写者问题和哲学家问题是操作系统的三大经典同步互斥问题。本文将介绍这三个问题的基本特点以及如何用信号量机制进行解决。 在分析这三个问题之前,我们首先需要了解用信号量机制解决同步互斥问题的一般规律: 实现同步与互斥…...
的区别,附代码举例)
java基础09-==和equals()的区别,附代码举例
和equals()的区别 在Java中,和equals()是两个不同的运算符,它们在比较对象时有着本质的区别。 运算符: 用于比较两个基本数据类型(如int、char等)或两个对象的引用。 当用于比较基本数据类型时,它会比较它们的值。 当…...
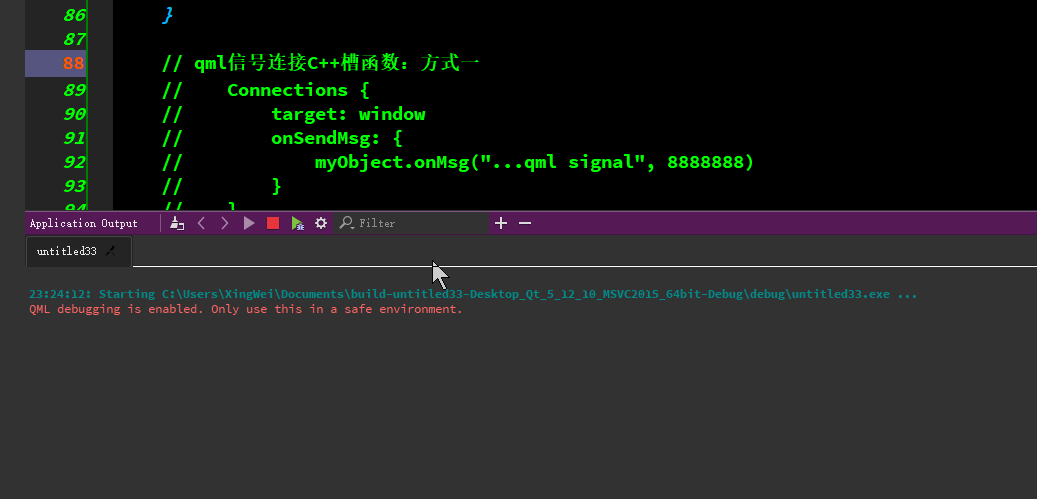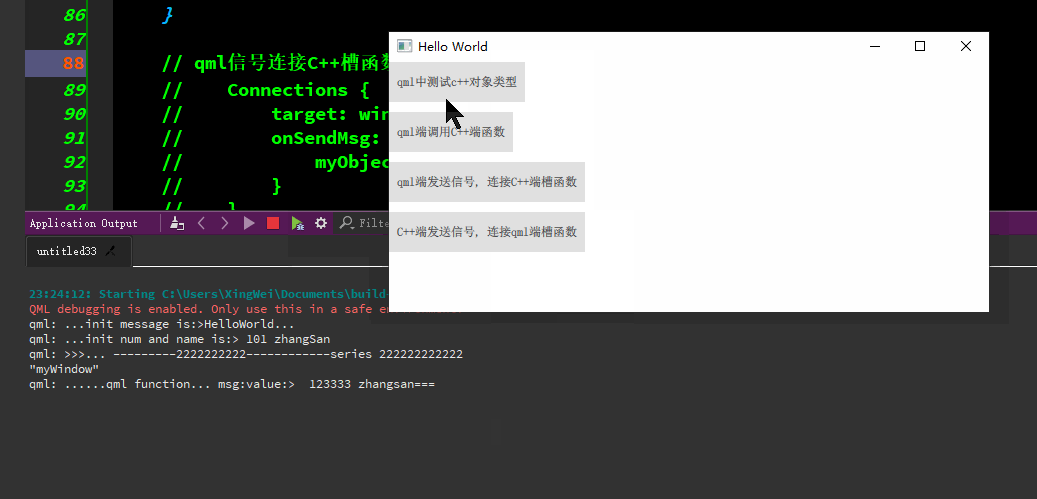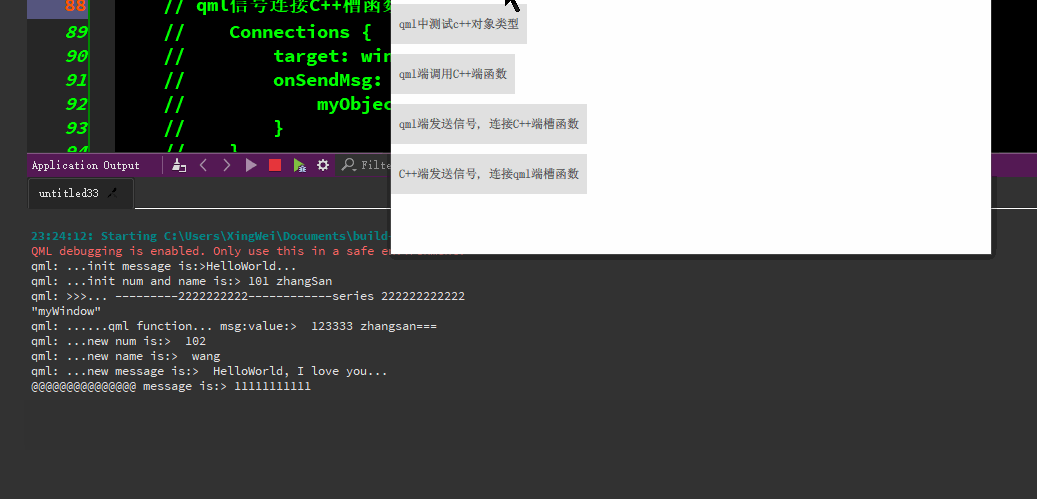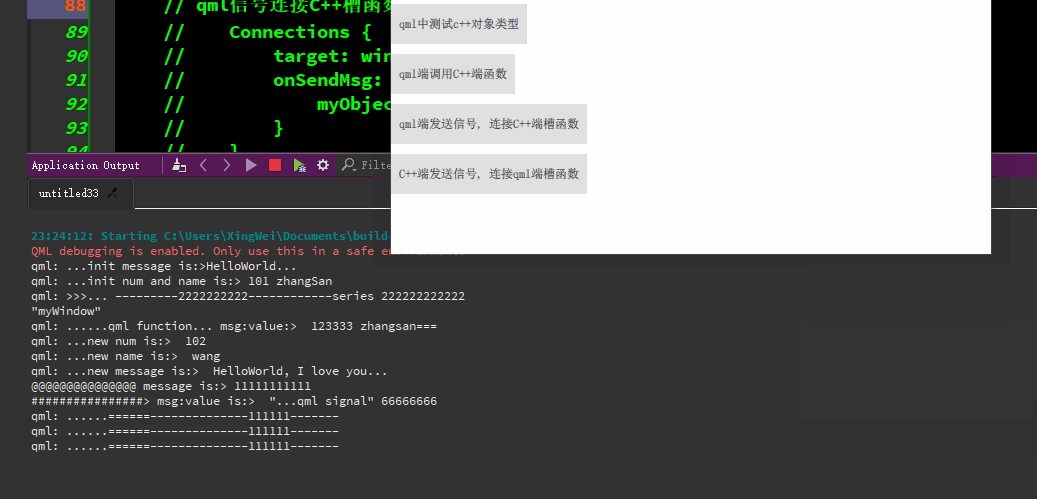
qml与C++的交互
qml端使用C对象类型、qml端调用C函数/c端调用qml端函数、qml端发信号-连接C端槽函数、C端发信号-连接qml端函数等。 代码资源下载: https://download.csdn.net/download/TianYanRen111/88779433 若无法下载,直接拷贝以下代码测试即可。 main.cpp #incl…...
LabVIEW电路板插件焊点自动检测系统
LabVIEW电路板插件焊点自动检测系统 介绍了电路板插件焊点的自动检测装置设计。项目的核心是使用LabVIEW软件,开发出一个能够自动检测电路板上桥接、虚焊、漏焊和多锡等焊点缺陷的系统。 系统包括成像单元、机械传动单元和软件处理单元。首先,利用工业相…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...