【数据库学习】PostgreSQL优化
1,思路
2,执行计划
explain sql语句; #查看执行计划。也可以使用navicat的解释功能查看。
结果说明:
QUERY PLAN
Index Scan using tenk1_unique1 on tenk1 (cost=0.00..10.01 rows=1 width=244)
--Index 使用索引
--cost:启动开销..总开销。不过事实总开销可能会低一点:带有 LIMIT 子句的查询将会在 Limit 规划节点的输入节点里很快停止。
--rows:预计输出的行数
--Filter:过滤条件Index Cond: (unique1 < 3) --从索引中检索出的行的过滤器Filter: (stringu1 = 'xxx'::name)QUERY PLAN
--嵌套循环Nested Loop (cost=2.37..553.11 rows=106 width=488) -> Bitmap Heap Scan on tenk1 t1 (cost=2.37..232.35 rows=106 width=244) Recheck Cond: (unique1 < 100)--位图索引-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..2.37 rows=106 width=0)Index Cond: (unique1 < 100)-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.00..3.01 rows=1 width=244)Index Cond: ("outer".unique2 = t2.unique2)QUERY PLAN
--内存 Hash 表Hash Join (cost=232.61..741.67 rows=106 width=488)Hash Cond: ("outer".unique2 = "inner".unique2)-> Seq Scan on tenk2 t2 (cost=0.00..458.00 rows=10000 width=244)-> Hash (cost=232.35..232.35 rows=106 width=244)-> Bitmap Heap Scan on tenk1 t1 (cost=2.37..232.35 rows=106 width=244)Recheck Cond: (unique1 < 100)-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..2.37 rows=106 width=0)Index Cond: (unique1 < 100)
1)多表连接查询
①Nest Loop Join(嵌套循环连接)
1>场景
适合两个表的数据量都比较少的情况(最简单的 table join 方式)。
- 外表为小表,且过滤后的数据量较少。
- 内表的关联列上有高效索引(主键或者唯一性索引)。
2>举例
# 内表(t4)被外表(t5)驱动。外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合)
select t4.*,t5.*from tmp_t4 t4,tmp_t5 t5where 1=1and t4.id = t5.idand t4.id = 1;
相当于for循环:
for(t4.data in tmp_t4) { t5.data in tmp_t5 on t5.data = t4.data}
②Hash JOIN(哈希、散列连接)
1>场景
针对那些没有索引或者其中任一个有索引的大表。
哈希连接只能应用于等值连接(如WHERE A.COL3 = B.COL4)、非等值连接(WHERE A.COL3 > B.COL4)、外连接(WHERE A.COL3 = B.COL4(+))。
2>操作步骤
优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
③Sort Merge JOIN
1>场景
通常Hash JOIN的性能都优于Merge JOIN,对于那些连接列上有索引的表(已排好序)Merge JOIN性能会优于Hash JOIN。
2>操作步骤
mrege join的性能开销几乎都在前两步。
- 对连接的每个表做全表扫描(table access full);
- 对table access full的结果进行排序。
- 进行merge join对排序结果进行合并。
在全表扫描比索引范围扫描再通过rowid进行表访问更可取的情况下,merge join会比nested loops性能更佳。当表特别小或特别巨大的时候,实行全表访问可能会比索引范围扫描更有效。
3,SQL优化
对于重复的代码逻辑,sql执行速度远远大于代码逻辑。
但是,由于sql难以测试、难以复用、难以加工变量,对于复杂的逻辑不建议用在sql中。代码可以分成模块、逻辑独立、方便测试。
sql优化的思路有两种:一是:
The fastest way to do something is don’t do it
即去掉无用的步骤;二是优化算法,如让sql走更优的执行计划上。
①基于规则优化(RBO)和基于代价优化(CBO)
RBO和CBO是两种数据库引擎在执行sql语句时的优化策略。
基于规则的优化(Rule Based Optimizer)
这是一种比较老的技术,简单说基于规则的优化就是当数据库执行一条query语句的时候必须遵循预先定义好的一系列规则(比如oracle的15条规则,排名越靠前的执行引擎认为效率越高)来确定执行过程,它不关心访问表的数据分布情况,仅仅凭借规则经验来确定,所以说是一种比较粗放的优化策略。
基于代价的优化(Cost Based Optimizer)
基于代价的优化的产生就是为了解决上面RBO的弊端,让执行引擎依据预先存储到数据库中表的一些实时更新的统计信息来选择出最优代价最小的执行计划来执行query语句,CBO会根据统计信息来生成一组可能被使用到的执行计划,进而估算出每个计划的代价,从而选择出代价最小的交给执行器去执行,其中表的统计信息一般会有表大小,行数,单行长度,单列数据分布情况,索引情况等等。
总结:
基于规则的优化器更像是一个经验丰富熟知各条路段的老司机,大部分情况可以根据自己的经验来判断走哪条路可以更快的到达目的地,而基于代价的优化更像手机里面的地图,它可以选择出许多不同的路径根据实时的路况信息综合考虑路程长度,交通状况来挑出最优的路径。
4,配置优化
pg中与内存有关的配置参数:
1>shared_buffers(共享缓存区)
i>工作原理
shared_buffers是一个8KB的数组,postgres在从磁盘中查询数据前,会先查找shared_buffers的页,如果命中,就直接返回,避免从磁盘查询。
多个进程通过共享内存技术来共享缓存中的数据。
-
shared_buffers存储什么?
表数据;
索引,索引也存储在8K块中;
执行计划,存储基于会话的执行计划,会话结束,缓存的计划也就被丢弃。 -
什么时候加载shared_buffers?
1)在访问数据时,数据会先加载到os缓存,然后再加载到shared_buffers,这个加载过程可能是一些查询,也可以使用pg_prewarm预热缓存。
2)当然也可能同时存在os和shared_buffers两份一样的缓存(双缓存)。
3)查找到的时候会先在shared_buffers查找是否有缓存,如果没有再到os缓存查找,最后再从磁盘获取。
4)os缓存使用简单的LRU(移除最近最久未使用的缓存),而数据库采用的优化的时钟扫描,即缓存使用频率高的会被保存,低的被移除。
ii>优化策略
提高shared_buffers,增加缓存命中率,提高查询效率。
同时为了避免Double Buffering问题,将shared_buffers设置较小,更多的内存留给文件系统使用。
-
【Double Buffering(双缓存)】问题:
pg的数据文件都存储在文件系统中,os的文件系统也有缓存,这导致pg的数据库副本可能同时存在于共享内存和文件系统中,造成内存利用率低的问题。
Oracle中通过设置Birect I/O避免双缓存问题,但pg不支持。 shared_buffers的大小不应该超过内存的1/4。 -
shared_buffers设置的合理范围
1)windows服务器有用范围是64MB到512MB,默认128MB
2)linux服务器建议设置为25%,亚马逊服务器设置为75%(避免双缓存,数据会存储在os和shared_buffers两份)
os缓存的重要性:数据写入时,从内存到磁盘,这个页面就会被标记为脏页,一旦被标记为脏页,它就会被刷新到os缓存,然后写入磁盘。所以如果os高速缓存大小较小,则它不能重新排序写入并优化io,这对于繁重的写入来说非常致命,因此os的缓存大小也非常重要。给予shared_buffers太大或太小都会损害性能。 -
shared_buffers调整策略
2> work_mem
为每个进程单独分配的内存,主要用于group by, sort, hash agg, hash join 等操作。
注意:work_mem是每次分配的内存,加入有M个并发进程,每个进程有N个HASH操作,那么需要分配的内存为 MNwork_mem。因此work_mem不宜设置太大,通常保持默认的4MB即可,如果设置的太大超过256MB,很容易因为瞬间的大并发操作导致oom。
3>maintenance_work_mem
为每个进程单独分配的内存,主要进行维护操作时需要的内存,如VACUUM、create index、ALTER TABLE ADD FOREIGN KEY等操作需要的内存。
4>autovacuum_work_mem
pg9.4版本新增参数。
9.4之后,AutoVacuum的worker进程分配的内存由参数autovacuum_work_mem控制,手动Vacuum时分配的内存由maintenance_work_mem 控制。9.4之前都用maintenance_work_mem 参数。
默认值为-1,表示与maintenance_work_mem 一样。
vacuum 大小 = autovacuum_max_workers * autovacuum_work_mem
5>temp_buffers(临时表缓存)
为每个不同的进程单独分配的内存,不在共享内存中,默认为8MB。
6>wal_buffers(WAL日志缓存大小)
默认为-1,表示根据shared_buffer的大小自动设置。
7>huge_pages(是否使用大页)
默认值为try,表示尽量使用大页。若os未开启大页,不使用大页内存,不影响数据库正常使用。
8>effective_cache_size(sql执行中的实际磁盘缓存)
与具体内存分配无关
5,sql审计
相关配置:
| 参数调整 | 说明 |
|---|---|
| log_min_duration_statement | sql审计记录的标准,超过该时长的sql将被记录到日志文件。默认为-1,不记录超时sql。 |
| log_statement | none默认,不记录;all-记录所有语句;ddl-记录所有数据定义语句;mod记录所有ddl和数据修改语句; |
| log_min_error_statement | 控制日志中是否记录导致数据库出现错误的SQL语句。默认为error |
6,排查sql
-- 查看表结构
SELECT column_name,data_type FROM information_schema.columns WHERE table_name = '表名'; -- 查看慢查询日志是否开启
SHOW log_min_duration_statement; -- 设置慢查询日志
ALTER DATABASE test SET log_min_duration_statement TO 10000; --慢sql 添加\watch 1监控
select query,wait_event_type,wait_event from pg_stat_activity
where wait_event is not null and now()-state_change>interval '5 second';--长wait事件
select query,wait_event_type,wait_event from pg_stat_activity where state='active' and wait_event is not null and now()-state_change>interval '5 second';-- 查找经常被扫描的大型表
SELECT schemaname, relname, seq_scan, seq_tup_read, idx_scan, seq_tup_read / seq_scan AS avg FROM pg_stat_user_tables WHERE seq_scan > 0 ORDER BY seq_tup_read DESC LIMIT 20; -- 跟踪 vacuum 进度
SELECT * FROM pg_stat_progress_vacuum ;
7,pg统计收集器
比较耗费性能,默认关闭,可在postgresql.conf进行配置( stats_start_collector = true )。
这些表的具体说明参见:华为 openGauss (GaussDB) v2.1 使用手册
1>pg_stat_activity
常见应用
-- 展示在数据库中当前正在执行多少查询
SELECTdatname,COUNT ( * ) AS OPEN,COUNT ( * ) FILTER ( WHERE STATE = 'active' ) AS active,COUNT ( * ) FILTER ( WHERE STATE = 'idle' ) AS idle,COUNT ( * ) FILTER ( WHERE STATE = 'idle in transaction' ) AS idle_in_trans
FROMpg_stat_activity
GROUP BYROLLUP ( 1 )-- 查看事务已经打开了多久
SELECTpid,xact_start,now( ) - xact_start AS duration
FROMpg_stat_activity
WHERESTATE LIKE'%transaction%'
ORDER BY3 DESC;-- 检查是否有长查询运行
SELECT now() - query_start AS duration, datname, query FROM pg_stat_activity WHERE state = 'active' ORDER BY 1 DESC; --查询服务进程PID: 通过count(*)获取当前连接数
select pid,usename,client_addr,client_port from pg_stat_activity;
相关文章:

【数据库学习】PostgreSQL优化
1,思路 2,执行计划 explain sql语句; #查看执行计划。也可以使用navicat的解释功能查看。结果说明: QUERY PLAN Index Scan using tenk1_unique1 on tenk1 (cost0.00..10.01 rows1 width244) --Index 使用索引 --cost&#x…...

微信小程序分页加载功能,结合后端实现上拉底部加载下一页数据,数据加载中和暂无数据提示
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回&#…...

idea 打包跳过测试
IDEA操作 点击蓝色的小球 手动命令 mvn clean package -Dmaven.test.skiptrue...

python sqlite3 线程池封装
1. 封装 sqlite3 1.1. 依赖包引入 # -*- coding: utf-8 -*- #import os import sys import datetime import loggingimport sqlite31.2. 封装类 class SqliteTool(object):#def __init__(self, host, port, user, password, database):def __init__(self, host, database):s…...

亚马逊运营:如何通过自养号测评有效防关联,避免砍单
店铺安全对于跨境电商卖家至关重要,它是我们业务稳定运营的基础。一旦店铺遭到亚马逊的封禁,往往意味着巨大的损失。因此,合规运营已经成为了卖家们的共识。然而,许多卖家可能会因为一些看似微小的失误,导致店铺被关联…...

winfrom图像加速渲染时图像不显示
winform中加入这段代码,即使不调用也会起作用;当图像不显示时,可以注释掉这段代码...

Redash 默认key漏洞(CVE-2021-41192)复现
Redash是以色列Redash公司的一套数据整合分析解决方案。该产品支持数据整合、数据可视化、查询编辑和数据共享等。 Redash 10.0.0及之前版本存在安全漏洞,攻击者可利用该漏洞来使用已知的默认值伪造会话。 1.漏洞级别 中危 2.漏洞搜索 fofa "redash"…...

Git学习笔记:3 git tag命令
文章目录 git tag 基本用法1. 创建标签2. 查看标签3. 删除标签4. 推送标签到远程仓库5. 检出标签 普通提交和标签的区别1. 提交(Commit)2. 标签(Tag) git tag 基本用法 git tag 是 Git 中用于管理和操作标签(tag&…...

10年软件测试经验,该有什么新的职业规划?
个人觉得,最关键是识别个人的兴趣和长期目标,以及市场需求,制定符合自己职业发展的规划,列了几个常见的方向: 1. 技术深化 专业领域专长:在某一测试领域(如自动化测试、性能测试、安全测试等&am…...

重构改善既有代码的设计-学习(四):简化条件逻辑
1、分解条件表达式(Decompose Conditional) 可以将大块代码分解为多个独立的函数,根据每个小块代码的用途,为分解而得的新函数命名。对于条件逻辑,将每个分支条件分解成新函数还可以带来更多好处:可以突出条…...

【代码---利用一个小程序,读取文件夹中图片,将其合成为一个视频】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言程序详细说明总结 前言 提示:这里可以添加本文要记录的大概内容: 创建一个程序将图像合成为视频通常需要使用图像处理和视频编码库。 …...

MVC 和 MVVM的区别
MVC: M(model数据)、V(view视图),C(controlle控制器) 缺点是前后端无法独立开发,必须等后端接口做好了才可以往下走; 前端没有自己的数据中心,太…...
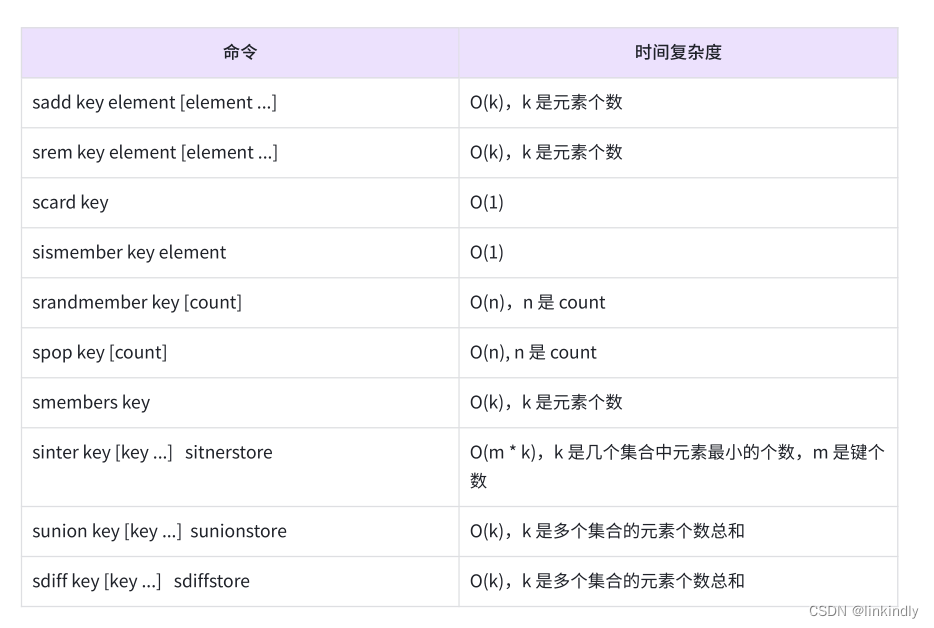
redis—Set集合
目录 前言 1.常见命令 2.使用场景 前言 集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中1)元素之间是无序的2)元素不允许重复,如图2-24所示。一个集合中最多可以存储22 - 1个元素。Redis 除了支持集合内的增删查改操…...
【jetson笔记】vscode远程调试
vscode安装插件 vscode安装远程插件Remote-SSH 安装完毕点击左侧远程资源管理器 打开SSH配置文件 添加如下内容,Hostname为jetson IP,User为登录用户名需替换为自己的 Host aliasHostName 192.168.219.57User jetson配置好点击连接,控制台输…...

大数据处理流程包括哪些环节
大数据处理流程作为当今信息时代的关键技术之一,已经成为各个行业的必备工具。这个流程涵盖了从数据收集、存储、处理、分析到应用的各个环节,确保了数据的有效利用和价值的最大化。 一、数据收集 随着物联网、移动互联网、社交媒体等领域的快速发展&a…...
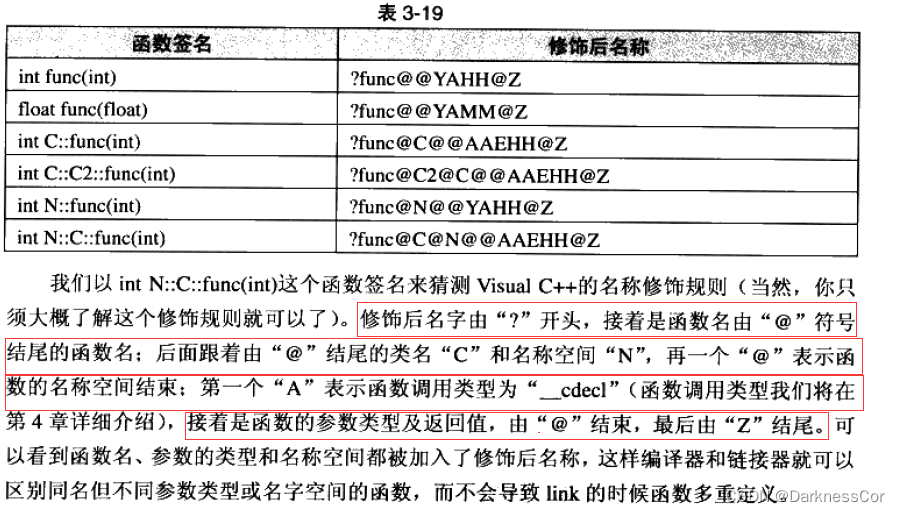
C++入门篇章1(C++是如何解决C语言不能解决的问题的)
目录 1.C关键字(以C98为例)2.命名空间2.1 命名空间定义2.2命名空间使用 3.C输入&输出4.缺省参数4.1缺省参数概念4.2 缺省参数分类 5. 函数重载5.1函数重载概念5.2 C支持函数重载的原理--名字修饰(name Mangling) 1.C关键字(以C98为例) C总计63个关键字,C语言32…...
java复习篇 数据结构:链表第一节
目录 单向链表 初始 头插 思路 情况一 情况二 代码 尾插 思路 遍历 优化遍历 遍历验证头插 尾插代码 优化 尾插测试 get 思路 代码 测试 insert 思路 代码 优化 测试 remove 移除头结点 提问 移除指定位置 测试 单向链表 每个元素只知道自己的下一个…...

深入理解与运用Lombok的@Cleanup注解:自动化资源管理利器
前言 在Java编程中,正确地管理和释放诸如文件流、数据库连接等资源至关重要。若处理不当,可能会引发内存泄漏或系统资源耗尽等问题。为此,Lombok库提供了一个名为Cleanup的便捷注解,它允许我们以简洁且安全的方式自动关闭实现了j…...

【LeetCode每日一题】2865. 美丽塔 I
2024-1-24 文章目录 [2865. 美丽塔 I](https://leetcode.cn/problems/beautiful-towers-i/) 2865. 美丽塔 I 初始化变量 ans 为0,用于记录最大的和值。获取整数列表的长度,保存到变量 n 中。使用一个循环遍历列表中的每个位置,从0到n-1。在循…...
Cute Http File Server 使用文章
下载 官网:http://iscute.cn/chfs 蓝奏下载:https://wwts.lanpw.com/iKP1i1m9572h 开源:https://github.com/docblue/chfsgui 介绍 Cute Http File Server 是国内免费开源的局域网传输服务器软件。 可以不用借助QQ、某信软件传输文件&am…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...
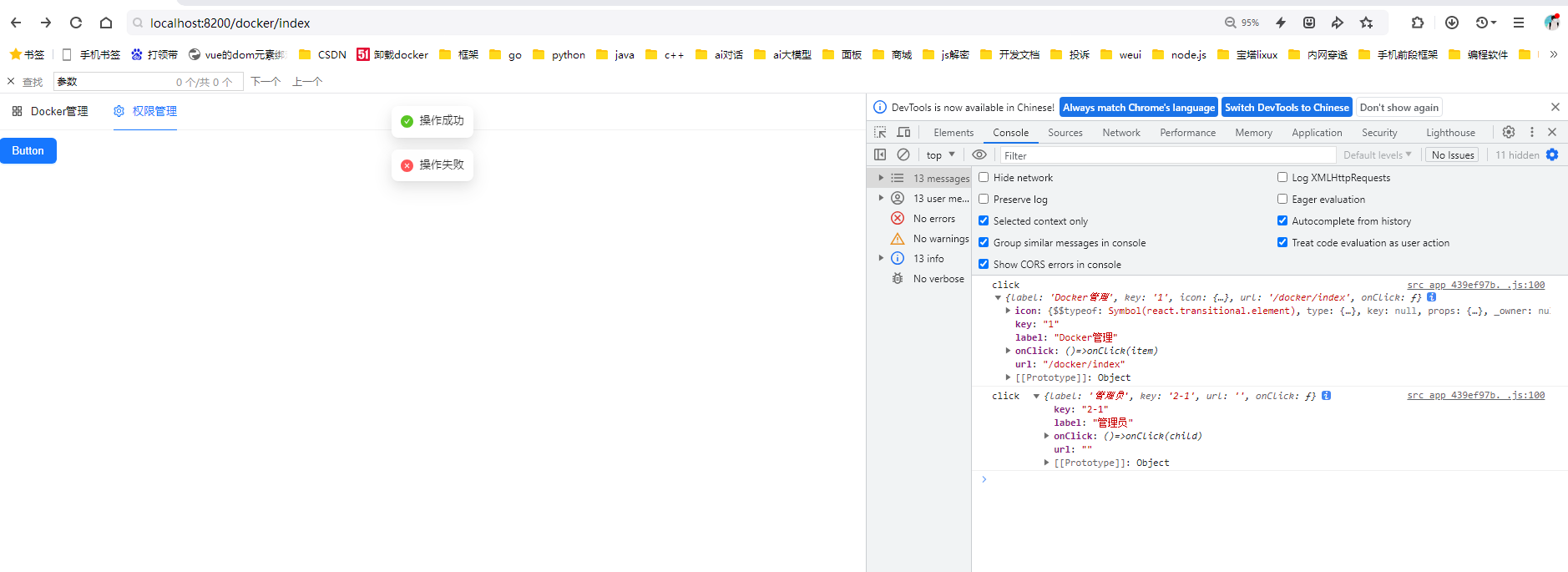
react菜单,动态绑定点击事件,菜单分离出去单独的js文件,Ant框架
1、菜单文件treeTop.js // 顶部菜单 import { AppstoreOutlined, SettingOutlined } from ant-design/icons; // 定义菜单项数据 const treeTop [{label: Docker管理,key: 1,icon: <AppstoreOutlined />,url:"/docker/index"},{label: 权限管理,key: 2,icon:…...
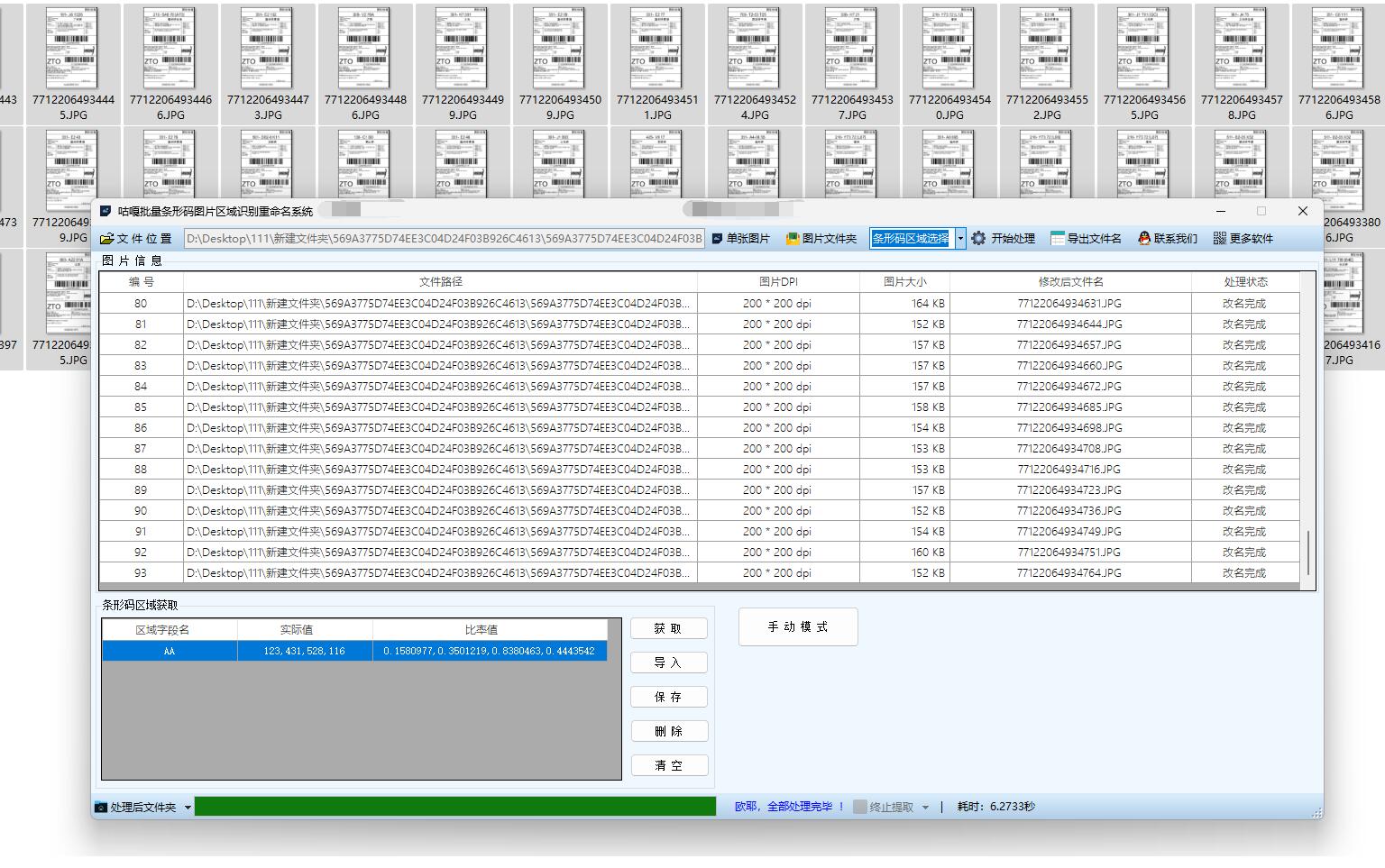
【工具教程】多个条形码识别用条码内容对图片重命名,批量PDF条形码识别后用条码内容批量改名,使用教程及注意事项
一、条形码识别改名使用教程 打开软件并选择处理模式:打开软件后,根据要处理的文件类型,选择 “图片识别模式” 或 “PDF 识别模式”。如果是处理包含条形码的 PDF 文件,就选择 “PDF 识别模式”;若是处理图片文件&…...
)
iOS 项目怎么构建稳定性保障机制?一次系统性防错经验分享(含 KeyMob 工具应用)
崩溃、内存飙升、后台任务未释放、页面卡顿、日志丢失——稳定性问题,不一定会立刻崩,但一旦积累,就是“上线后救不回来的代价”。 稳定性保障不是某个工具的功能,而是一套贯穿开发、测试、上线全流程的“观测分析防范”机制。 …...