java动态导入excel按照表头生成数据库表
1、创建接口接收文件
//controller层
@PostMapping("/importExcel1")public void importExcel1(HttpServletRequest request, MultipartFile file) {try {waterMeterService.importExcel1(request,file);} catch (Exception e) {throw new RuntimeException(e);}}//service层
void importExcel1(HttpServletRequest request, MultipartFile file);//实现类层
@Overridepublic void importExcel1(HttpServletRequest request, MultipartFile file) {try {//获取用户信息String fileName = file.getOriginalFilename().substring(0, file.getOriginalFilename().lastIndexOf("."));//文件后缀String fileSuffix = file.getOriginalFilename().substring(file.getOriginalFilename().lastIndexOf("."));//1.首先获取文件名生成一条记录String directoryName = StringUtils.isEmpty("sheet1") ? fileName : "sheet1";
// String uuid = createDataSets(directoryName, null, excelReq.getId(), sysUser, excelReq.getDataType(), excelReq.getAddressType());String uuid = UUID.randomUUID().toString();EasyExcel.read(file.getInputStream(), new ConfigFilterListener(waterMeterMapper)).sheet(0).doRead();} catch (IOException e) {throw new RuntimeException(e);}}
2、创建easyexcel导入监听器
package com.wang.test.listener;import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.metadata.data.ReadCellData;
import com.alibaba.excel.read.listener.ReadListener;
import com.wang.test.mapper.WaterMeterMapper;
import lombok.SneakyThrows;
import org.springframework.scheduling.annotation.Async;import javax.annotation.Resource;
import java.util.*;
import java.util.stream.Collectors;/*** @BelongsPackage: com.wang.test.listener* @Author: wangqian* @CreateTime: 2024-01-24 09:51:59* @Describe:*/
public class ConfigFilterListener implements ReadListener<LinkedHashMap<String, String>> {/*** 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收*/private static final int BATCH_COUNT = 1000;private String tableName;//表名private String columnNames;//字段名private List<LinkedHashMap<String, String>> dataSetList = new ArrayList<>();@Resourceprivate WaterMeterMapper waterMeterMapper;//构造函数public ConfigFilterListener(WaterMeterMapper waterMeterMapper) {this.waterMeterMapper = waterMeterMapper;}/*** 这个每一条数据解析都会来调用* 这个接口作用是将excel数据全部添加到dataSetList中,然后达到BATCH_COUNT的时候触发新增数据操作*/@SneakyThrows@Overridepublic void invoke(LinkedHashMap<String, String> linkedHashMap, AnalysisContext analysisContext) {//log.info("解析到一条数据:{}", linkedHashMap);LinkedHashMap<String, String> map = new LinkedHashMap<>();map.put("uuid", UUID.randomUUID().toString());Set set = linkedHashMap.keySet();Iterator iterator = set.iterator();while (iterator.hasNext()) {Object next = iterator.next();map.put(next.toString(), linkedHashMap.get(next));}dataSetList.add(map);// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOMif (dataSetList.size() >= BATCH_COUNT) {//创建插入语句StringBuffer sb = new StringBuffer("insert into ");sb.append(this.tableName + " (");sb.append(this.columnNames + " )");// 这里也要保存数据,确保最后遗留的数据也存储到数据库batchInsert(sb.toString(), dataSetList);// 存储完成清理 listdataSetList.clear();}}/*** 所有数据解析完成了 都会来调用*这个方法的作用就是将excel数据插入到生成的表中如果数据大于BATCH_COUNT,则不足与BATCH_COUNT的会做新增操作* @param analysisContext*/
// @SneakyThrows@Overridepublic void doAfterAllAnalysed(AnalysisContext analysisContext) {if (dataSetList.size() > 0) {//创建插入语句StringBuffer sb = new StringBuffer("insert into ");sb.append(this.tableName + " (");//表名称sb.append(this.columnNames + " )");//插入的数据// 这里也要保存数据,确保最后遗留的数据也存储到数据库batchInsert(sb.toString(), dataSetList);dataSetList.clear();}}/**** 读取Excel表格表头* 这个方法的作用就是获取表头,创建数据库表* @param headMap* @param context*/@Overridepublic void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) {try {//每次执行前需求清除上次的结果this.columnNames = null;// 当前sheet的名称 编码获取类似String tableName = context.readSheetHolder().getSheetName();int tableCount = waterMeterMapper.existsTable(tableName);//判断表名是否存在List<String> heads = new ArrayList<>();heads.add("uuid");if (tableCount > 0) {//按照业务需求是创建新表还是提示错误tableName += "_"+System.currentTimeMillis();}StringBuffer createTableStr = new StringBuffer("CREATE TABLE ");createTableStr.append(tableName);createTableStr.append(" (uuid varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,");Collection<ReadCellData<?>> values = headMap.values();//这个是我自己写的,大家按照自己的需求来设置for (int i = 0; i < values.size(); i++) {createTableStr.append("column_"+(i+1) + " varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,");heads.add("column_"+(i+1));}
//这个value.getStringValue()会获取表头的数据,生成的表字段则是按照表头配置的
// for (ReadCellData<?> value : values) {
// createTableStr.append(value.getStringValue() + " varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,");
// heads.add(value.getStringValue());
// }createTableStr.append("PRIMARY KEY (`uuid`) USING BTREE)");int updateCount = waterMeterMapper.createTable(createTableStr.toString());if (updateCount != 0) {throw new RuntimeException("创建数据库表失败!");}//创建成功后,得插入一条对应记录
// createDataSets(tableName, tableName, uuid, sysUser, dataType, sort, addressType);this.tableName = tableName;this.columnNames = heads.stream().collect(Collectors.joining(","));} catch (Exception ex) {//waterMeterService.removeById(uuid);//throw new RuntimeException("导入失败!请联系管理员!");}}@Overridepublic boolean hasNext(AnalysisContext context) {return true;}@Asyncpublic void batchInsert(String tableString, List<LinkedHashMap<String, String>> list){try {waterMeterMapper.insertTableData(tableString, list);} catch (Exception e) {throw new RuntimeException(e);}}
}3、mapper层
//判断表是否存在int existsTable(@Param("tableName") String tableName);//生成新的表int createTable(@Param("tableString")String tableString);void insertTableData(@Param("tableString") String tableString,@Param("dataSetList") List<LinkedHashMap<String, String>> dataSetList);
4、xml层
<!-- 判断表是否存在--><select id="existsTable" resultType="java.lang.Integer">SELECT COUNT(*) FROM information_schema.tables WHERE table_name = #{tableName} AND table_schema = 'test';</select><!-- 创建新表--><update id="createTable">${tableString}</update><!-- 新增数据--><insert id="insertTableData">insert into ${tableString} values<foreach collection='dataSetList' item='line' index='index' separator=','><foreach collection='line.values' item='value' open='(' separator=',' close=')'>#{value}</foreach></foreach></insert>
5、里面有些逻辑按照需求来处理,比如表重复,中间出现异常等
后面查询这些数据的时候,可以做配置表(建立一张表),文件名和表名做配置关系,如果要查询这些动态导入数据,则需要知道查哪些表,还有别的需求可以讨论,一起学习
相关文章:

java动态导入excel按照表头生成数据库表
1、创建接口接收文件 //controller层 PostMapping("/importExcel1")public void importExcel1(HttpServletRequest request, MultipartFile file) {try {waterMeterService.importExcel1(request,file);} catch (Exception e) {throw new RuntimeException(e);}}//se…...

Java 集合List相关面试题
📕作者简介: 过去日记,致力于Java、GoLang,Rust等多种编程语言,热爱技术,喜欢游戏的博主。 📗本文收录于java面试题系列,大家有兴趣的可以看一看 📘相关专栏Rust初阶教程、go语言基…...
k8s-基础知识(Pod,Deployment,ReplicaSet)
k8s职责 自动化容器部署和复制随时扩展或收缩容器容器分组group,并且提供容器间的负载均衡实时监控,即时故障发现,自动替换 k8s概念及架构 pod pod是容器的容器,可以包含多个container pod是k8s最小可部署单元,容器…...

matlab查看源代码
matlab函数源代码-查看 CtrlD 最简单方便的一种方法,鼠标划中函数名,按CTRLD即可打开函数的m文件...

【数据库学习】PostgreSQL优化
1,思路 2,执行计划 explain sql语句; #查看执行计划。也可以使用navicat的解释功能查看。结果说明: QUERY PLAN Index Scan using tenk1_unique1 on tenk1 (cost0.00..10.01 rows1 width244) --Index 使用索引 --cost&#x…...

微信小程序分页加载功能,结合后端实现上拉底部加载下一页数据,数据加载中和暂无数据提示
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回&#…...

idea 打包跳过测试
IDEA操作 点击蓝色的小球 手动命令 mvn clean package -Dmaven.test.skiptrue...

python sqlite3 线程池封装
1. 封装 sqlite3 1.1. 依赖包引入 # -*- coding: utf-8 -*- #import os import sys import datetime import loggingimport sqlite31.2. 封装类 class SqliteTool(object):#def __init__(self, host, port, user, password, database):def __init__(self, host, database):s…...

亚马逊运营:如何通过自养号测评有效防关联,避免砍单
店铺安全对于跨境电商卖家至关重要,它是我们业务稳定运营的基础。一旦店铺遭到亚马逊的封禁,往往意味着巨大的损失。因此,合规运营已经成为了卖家们的共识。然而,许多卖家可能会因为一些看似微小的失误,导致店铺被关联…...

winfrom图像加速渲染时图像不显示
winform中加入这段代码,即使不调用也会起作用;当图像不显示时,可以注释掉这段代码...

Redash 默认key漏洞(CVE-2021-41192)复现
Redash是以色列Redash公司的一套数据整合分析解决方案。该产品支持数据整合、数据可视化、查询编辑和数据共享等。 Redash 10.0.0及之前版本存在安全漏洞,攻击者可利用该漏洞来使用已知的默认值伪造会话。 1.漏洞级别 中危 2.漏洞搜索 fofa "redash"…...

Git学习笔记:3 git tag命令
文章目录 git tag 基本用法1. 创建标签2. 查看标签3. 删除标签4. 推送标签到远程仓库5. 检出标签 普通提交和标签的区别1. 提交(Commit)2. 标签(Tag) git tag 基本用法 git tag 是 Git 中用于管理和操作标签(tag&…...

10年软件测试经验,该有什么新的职业规划?
个人觉得,最关键是识别个人的兴趣和长期目标,以及市场需求,制定符合自己职业发展的规划,列了几个常见的方向: 1. 技术深化 专业领域专长:在某一测试领域(如自动化测试、性能测试、安全测试等&am…...

重构改善既有代码的设计-学习(四):简化条件逻辑
1、分解条件表达式(Decompose Conditional) 可以将大块代码分解为多个独立的函数,根据每个小块代码的用途,为分解而得的新函数命名。对于条件逻辑,将每个分支条件分解成新函数还可以带来更多好处:可以突出条…...

【代码---利用一个小程序,读取文件夹中图片,将其合成为一个视频】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言程序详细说明总结 前言 提示:这里可以添加本文要记录的大概内容: 创建一个程序将图像合成为视频通常需要使用图像处理和视频编码库。 …...

MVC 和 MVVM的区别
MVC: M(model数据)、V(view视图),C(controlle控制器) 缺点是前后端无法独立开发,必须等后端接口做好了才可以往下走; 前端没有自己的数据中心,太…...
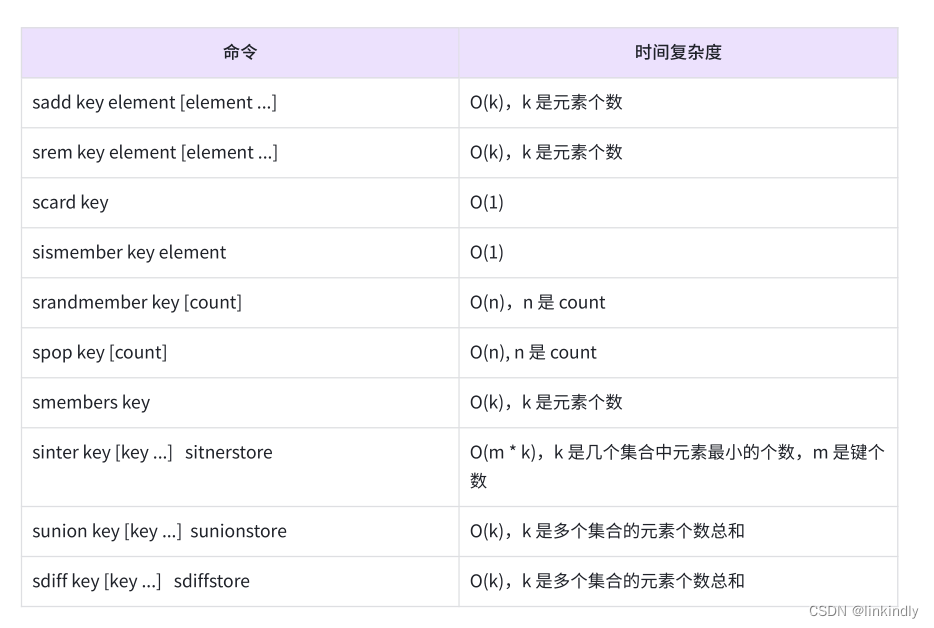
redis—Set集合
目录 前言 1.常见命令 2.使用场景 前言 集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中1)元素之间是无序的2)元素不允许重复,如图2-24所示。一个集合中最多可以存储22 - 1个元素。Redis 除了支持集合内的增删查改操…...
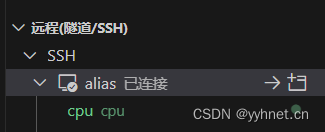
【jetson笔记】vscode远程调试
vscode安装插件 vscode安装远程插件Remote-SSH 安装完毕点击左侧远程资源管理器 打开SSH配置文件 添加如下内容,Hostname为jetson IP,User为登录用户名需替换为自己的 Host aliasHostName 192.168.219.57User jetson配置好点击连接,控制台输…...

大数据处理流程包括哪些环节
大数据处理流程作为当今信息时代的关键技术之一,已经成为各个行业的必备工具。这个流程涵盖了从数据收集、存储、处理、分析到应用的各个环节,确保了数据的有效利用和价值的最大化。 一、数据收集 随着物联网、移动互联网、社交媒体等领域的快速发展&a…...
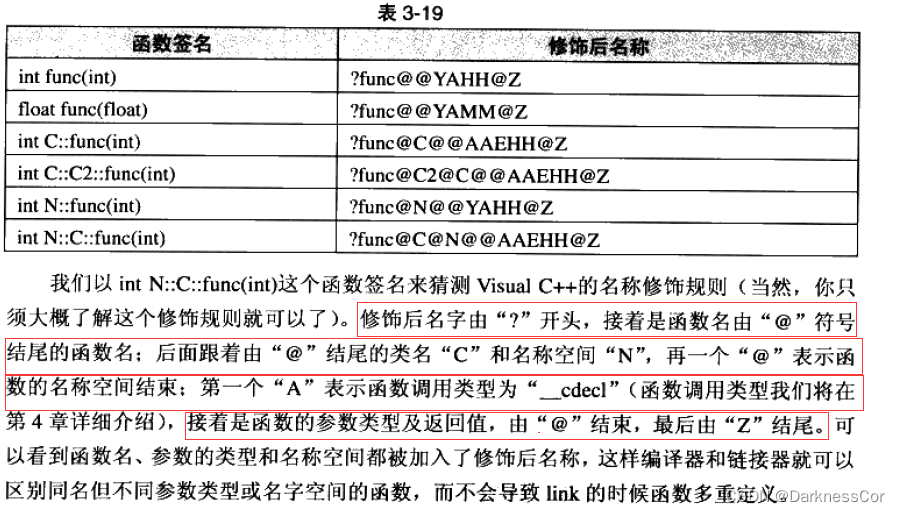
C++入门篇章1(C++是如何解决C语言不能解决的问题的)
目录 1.C关键字(以C98为例)2.命名空间2.1 命名空间定义2.2命名空间使用 3.C输入&输出4.缺省参数4.1缺省参数概念4.2 缺省参数分类 5. 函数重载5.1函数重载概念5.2 C支持函数重载的原理--名字修饰(name Mangling) 1.C关键字(以C98为例) C总计63个关键字,C语言32…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...