掌握大语言模型技术: 推理优化
掌握大语言模型技术_推理优化

堆叠 Transformer 层来创建大型模型可以带来更好的准确性、少样本学习能力,甚至在各种语言任务上具有接近人类的涌现能力。 这些基础模型的训练成本很高,并且在推理过程中可能会占用大量内存和计算资源(经常性成本)。 当今最流行的大型语言模型 (LLM) 的参数大小可以达到数百到数千亿,并且根据用例,可能需要摄取长输入(或上下文),这也会增加费用。
这篇文章讨论了LLM推理中最紧迫的挑战,以及一些实用的解决方案。 读者应该对 Transformer 架构和一般的注意力机制有基本的了解。 掌握 LLM 推理的复杂性至关重要,我们将在下一节中讨论。
了解LLM推理
大多数流行的纯解码器 LLM(例如 GPT-3)都是针对因果建模目标进行预训练的,本质上是作为下一个词预测器。 这些 LLM 将一系列标记作为输入,并自回归生成后续标记,直到它们满足停止条件(例如,生成标记数量的限制或停止词列表)或直到生成特殊的 <end> 标记生成结束的令牌。 该过程涉及两个阶段:预填充阶段和解码阶段。
请注意,标记是模型处理的语言的原子部分。 一个令牌大约是四个英文字符。 所有自然语言输入在输入模型之前都会转换为标记。
预填充阶段或处理输入
在预填充阶段,LLM 处理输入令牌以计算中间状态(键和值),用于生成“第一个”新令牌。 每个新标记都依赖于所有先前的标记,但由于输入的全部范围已知,因此在较高级别上,这是高度并行化的矩阵-矩阵运算。 它有效地使 GPU 利用率饱和。
解码阶段或生成输出
在解码阶段,LLM 一次自回归生成一个输出标记,直到满足停止条件。 每个顺序输出令牌需要知道所有先前迭代的输出状态(键和值)。 与预填充阶段相比,这就像矩阵向量运算未充分利用 GPU 计算能力。 数据(权重、键、值、激活)从内存传输到 GPU 的速度决定了延迟,而不是计算实际发生的速度。 换句话说,这是一个内存限制操作。
本文中的许多推理挑战和相应的解决方案都涉及此解码阶段的优化:高效的注意力模块、有效管理键和值等等。
不同的LLM可能使用不同的标记器,因此比较它们之间的输出标记可能并不简单。 在比较推理吞吐量时,即使两个 LLM 每秒输出的令牌相似,如果它们使用不同的令牌生成器,它们也可能不相等。 这是因为相应的标记可能代表不同数量的字符。
批处理
提高 GPU 利用率和有效吞吐量的最简单方法是通过批处理。 由于多个请求使用相同的模型,因此权重的内存成本被分散。 较大批量传输到 GPU 一次处理将利用更多可用计算。
然而,批量大小只能增加到一定限制,此时可能会导致内存溢出。 为了更好地理解为什么会发生这种情况,需要查看键值 (KV) 缓存和 LLM 内存要求。
传统批处理(也称为静态批处理)不是最佳的。 这是因为对于批次中的每个请求,LLM 可能会生成不同数量的完成令牌,并且随后它们具有不同的执行时间。 因此,批次中的所有请求都必须等待最长的请求完成,而生成长度的巨大差异可能会加剧这种情况。 有一些方法可以缓解这种情况,例如稍后将讨论的动态批处理。
键值缓存
解码阶段的一种常见优化是 KV 缓存。 解码阶段在每个时间步生成单个令牌,但每个令牌取决于所有先前令牌的键和值张量(包括预填充时计算的输入令牌的 KV 张量,以及当前时间步之前计算的任何新 KV 张量) 。
为了避免在每个时间步重新计算所有标记的所有这些张量,可以将它们缓存在 GPU 内存中。 每次迭代,当计算出新元素时,它们都会被简单地添加到正在运行的缓存中,以便在下一次迭代中使用。 在一些实现中,模型的每一层都有一个KV缓存。

LLM内存要求
实际上,GPU LLM 内存需求的两个主要贡献者是模型权重和 KV 缓存。
- 模型权重:模型参数占用内存。 例如,具有 70 亿个参数的模型(例如 Llama 2 7B),以 16 位精度(FP16 或 BF16)加载,将占用大约 7B * sizeof(FP16) ~= 14 GB 的内存。
- KV缓存:自注意力张量的缓存占用内存以避免冗余计算。
使用批处理时,批处理中每个请求的 KV 缓存仍然必须单独分配,并且可能会占用大量内存。 下面的公式描述了 KV 缓存的大小,适用于当今最常见的 LLM 架构。
每个令牌的 KV 缓存大小(以字节为单位) = 2 * (num_layers) * (num_heads * dim_head) * precision_in_bytes
第一个因子 2 代表 K 和 V 矩阵。 通常,(num_heads * dim_head)的值与transformer的hidden_size(或模型的维度,d_model)相同。 这些模型属性通常可以在模型卡或关联的配置文件中找到。
输入批次中输入序列中的每个标记都需要此内存大小。 假设半精度,KV缓存的总大小由以下公式给出。
KV 缓存的总大小(以字节为单位) = (batch_size) * (sequence_length) * 2 * (num_layers) * (hidden_size) * sizeof(FP16)
例如,对于 16 位精度的 Llama 2 7B 模型,批量大小为 1,KV 缓存的大小将为 1 * 4096 * 2 * 32 * 4096 * 2 字节,即约 2 GB。
有效管理此 KV 缓存是一项具有挑战性的工作。 内存需求随着批量大小和序列长度线性增长,可以快速扩展。 因此,它限制了可服务的吞吐量,并对长上下文输入提出了挑战。 这就是本文中介绍的多项优化背后的动机。
通过模型并行化扩展LLM
减少模型权重的每设备内存占用的一种方法是将模型分布在多个 GPU 上。 分散内存和计算占用空间可以运行更大的模型或更大批量的输入。 模型并行化是训练或推理模型所必需的,该模型需要比单个设备上可用的内存更多的内存,并使训练时间和推理测量(延迟或吞吐量)适合某些用例。 根据模型权重的划分方式,有多种方法可以并行化模型。
请注意,数据并行性也是一种经常在与下面列出的其他技术相同的上下文中提到的技术。 在这种情况下,模型的权重被复制到多个设备上,并且输入的(全局)批量大小在每个设备上被分成微批次。 它通过处理较大的批次来减少总体执行时间。 然而,这是一种训练时间优化,在推理过程中不太相关。
管道并行性
管道并行性涉及将模型(垂直)分片为块,其中每个块包含在单独设备上执行的层的子集。 下图说明了四路管道并行性,其中模型按顺序分区,并且所有层的四分之一子集在每个设备上执行。 一个设备上的一组操作的输出被传递到下一个设备,后者继续执行后续块。 F_n和B_n分别表示设备n上的前向传播和后向传播。 每个设备上存储模型权重的内存需求被有效地四分。
该方法的主要限制是,由于处理的顺序性质,某些设备或层在等待前一层的输出(激活、梯度)时可能保持空闲状态。 这会导致前向和后向传递效率低下或出现“管道气泡”。 在图 2b 中,白色空白区域是具有幼稚管道并行性的大管道气泡,其中设备闲置且未得到充分利用。
微批处理可以在一定程度上缓解这种情况,如下图所示。 输入的全局批次大小被分成子批次,这些子批次被一一处理,最后累积梯度。 请注意,F_{n,m} 和 B_{n,m} 分别表示设备 n 上具有微批次 m 的前向传播和后向传播。 这种方法缩小了管道气泡的尺寸,但并没有完全消除它们。

张量并行性
张量并行性涉及将模型的各个层(水平)分片为更小的、独立的计算块,这些计算块可以在不同的设备上执行。 注意力块和多层感知器(MLP)层是可以利用张量并行性的变压器的主要组成部分。 在多头注意力块中,每个头或一组头可以分配给不同的设备,以便它们可以独立且并行地计算。

上图显示了两层 MLP 上双向张量并行的示例,每一层都由一个圆角框表示。 在第一层中,权重矩阵 A 被分为 A_1 和 A_2。 计算 XA_1 和 XA_2 可以在两个不同设备上的输入 X 的同一批次(f 是恒等运算)上独立执行。 这有效地将每个设备上存储权重的内存需求减半。 归约运算 g 组合第二层中的输出。
上图是自注意力层中双向张量并行的示例。 多个注意力头本质上是并行的,并且可以跨设备分割。
序列并行性
张量并行性有局限性,因为它需要将层划分为独立的、可管理的块。 它不适用于 LayerNorm 和 Dropout 等操作,而是在张量并行组中复制。 虽然 LayerNorm 和 Dropout 的计算成本较低,但它们确实需要大量内存来存储(冗余)激活。
如减少大型变压器模型中的激活重新计算所示,这些操作在输入序列中是独立的,并且这些操作可以沿着“序列维度”进行分区,从而提高内存效率。 这称为序列并行性。

模型并行技术不是唯一的,可以结合使用。 它们可以帮助扩展和减少 LLM 的每 GPU 内存占用量,但也有专门针对注意力模块的优化技术。
优化注意力机制
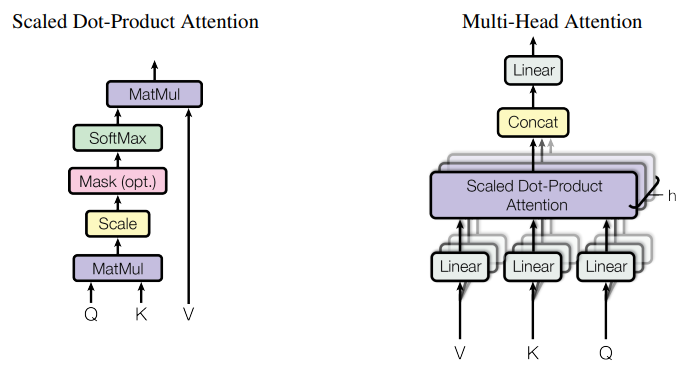
缩放点积注意力 (SDPA) 操作将查询和键值对映射到输出,如 Attention Is All You Need 中所述。
多头注意力
作为 SDPA 的增强,与 Q、K 和 V 矩阵的不同学习投影并行多次执行注意力层,使模型能够共同关注来自不同位置的不同表示子空间的信息。 这些子空间是独立学习的,使模型能够更丰富地理解输入中的不同位置。
如图所示,多个并行注意力操作的输出被串联并线性投影以将它们组合起来。 每个并行注意力层称为“头”,这种方法称为多头注意力(MHA)。
在原始工作中,当使用八个并行注意力头时,每个注意力头在模型的缩减维度(例如 d m o d e l / 8 d_{model}/8 dmodel/8)上运行。 这使得计算成本与单头注意力相似。
多查询注意力
MHA 的推理优化之一称为多查询注意力 (MQA),如 Fast Transformer Decoding 中提出的,在多个注意力头之间共享键和值。 与以前一样,查询向量仍然被投影多次。
虽然 MQA 中完成的计算量与 MHA 相同,但从内存读取的数据量(键、值)只是以前的一小部分。 当受内存带宽限制时,这可以实现更好的计算利用率。 它还减少了内存中 KV 缓存的大小,为更大的批量大小留出了空间。
键值头的减少会带来潜在的准确性下降。 此外,需要在推理时利用这种优化的模型需要在启用 MQA 的情况下进行训练(或至少使用大约 5% 的训练量进行微调)。
分组查询注意力
分组查询注意力 (GQA) 通过将键和值投影到几组查询头,在 MHA 和 MQA 之间取得平衡(下图)。 在每个组中,它的行为类似于多查询注意力。
下图显示多头注意力有多个键值头(左)。 分组查询注意力(中心)的键值头多于一个,但少于查询头的数量,这是内存需求和模型质量之间的平衡。 多查询注意力(右)具有单个键值头,有助于节省内存。

最初使用 MHA 训练的模型可以使用原始训练计算的一小部分通过 GQA 进行“升级训练”。 它们获得接近 MHA 的质量,同时保持接近 MQA 的计算效率。 Llama 2 70B 是利用 GQA 的模型示例。
MQA 和 GQA 等优化通过减少存储的键头和值头的数量来帮助减少 KV 缓存所需的内存。 KV 缓存的管理方式可能仍然效率低下。 与优化注意力模块本身不同,下一节将介绍一种更高效的 KV 缓存管理技术。
Flash attention
优化注意力机制的另一种方法是修改某些计算的顺序,以更好地利用 GPU 的内存层次结构。 神经网络通常用层来描述,大多数实现也以这种方式布局,每次按顺序对输入数据进行一种计算。 这并不总是能带来最佳性能,因为对已经进入内存层次结构的更高、性能更高级别的值进行更多计算可能是有益的。
在实际计算过程中将多个层融合在一起可以最大限度地减少 GPU 需要读取和写入内存的次数,并将需要相同数据的计算分组在一起,即使它们是神经网络中不同层的一部分。
一种非常流行的融合是 FlashAttention,这是一种 I/O 感知精确注意算法,详细信息请参阅 FlashAttention:具有 IO 感知的快速且内存高效的精确注意。 精确注意力意味着它在数学上与标准多头注意力相同(具有可用于多查询和分组查询注意力的变体),因此可以无需修改即可交换到现有的模型架构,甚至是已经训练的模型 。
I/O 感知意味着在将操作融合在一起时,它会考虑前面讨论的一些内存移动成本。 特别是,FlashAttention 使用“平铺”一次性完全计算并写出最终矩阵的一小部分,而不是分步对整个矩阵进行部分计算,写出中间的中间值。
下图显示了 40 GB GPU 上的平铺 FlashAttention 计算模式和内存层次结构。 右图显示了对注意力机制的不同组件进行融合和重新排序所带来的相对加速。

通过分页高效管理 KV 缓存
有时,KV 缓存会静态地“过度配置”,以考虑最大可能的输入(支持的序列长度),因为输入的大小是不可预测的。 例如,如果模型支持的最大序列长度为 2,048,则无论请求中输入和生成的输出的大小如何,都将在内存中保留大小为 2,048 的数据。 该空间可以是连续分配的,并且通常其中大部分未被使用,从而导致内存浪费或碎片。 该保留空间在请求的生命周期内被占用。

受操作系统分页的启发,PagedAttention 算法能够将连续的键和值存储在内存中的不连续空间中。 它将每个请求的 KV 缓存划分为代表固定数量令牌的块,这些块可以不连续存储。
在注意力计算期间,使用记录帐户的块表根据需要获取这些块。 当新的代币产生时,就会进行新的区块分配。 这些块的大小是固定的,消除了因不同请求需要不同分配等挑战而产生的低效率。 这极大地限制了内存浪费,从而实现了更大的批量大小(从而提高了吞吐量)。
模型优化技术
到目前为止,我们已经讨论了 LLM 消耗内存的不同方式、跨多个不同 GPU 分配内存的一些方式,以及优化注意力机制和 KV 缓存。 还有多种模型优化技术可以通过修改模型权重本身来减少每个 GPU 上的内存使用。 GPU 还具有专用硬件来加速这些修改值的运算,从而为模型提供更多加速。
量化
量化是降低模型权重和激活精度的过程。 大多数模型都以 32 或 16 位精度进行训练,其中每个参数和激活元素占用 32 或 16 位内存(单精度浮点)。 然而,大多数深度学习模型可以用每个值八个甚至更少的位来有效表示。
下图显示了一种可能的量化方法之前和之后的值分布。 在这种情况下,舍入会丢失一些精度,并且剪裁会丢失一些动态范围,从而允许以更小的格式表示值。

降低模型的精度可以带来多种好处。 如果模型占用的内存空间较少,则可以在相同数量的硬件上安装更大的模型。 量化还意味着您可以在相同的带宽上传输更多参数,这有助于加速带宽有限的模型。
LLM 有许多不同的量化技术,涉及降低激活、权重或两者的精度。 量化权重要简单得多,因为它们在训练后是固定的。 然而,这可能会留下一些性能问题,因为激活仍然保持在更高的精度。 GPU 没有用于乘以 INT8 和 FP16 数字的专用硬件,因此必须将权重转换回更高精度以进行实际运算。
还可以量化激活、变压器块和网络层的输入,但这也有其自身的挑战。 激活向量通常包含异常值,有效地增加了它们的动态范围,并使以比权重更低的精度表示这些值变得更具挑战性。
一种选择是通过模型传递代表性数据集并选择以比其他激活更高的精度表示某些激活来找出这些异常值可能出现的位置 (LLM.int8())。 另一种选择是借用易于量化的权重的动态范围,并在激活中重用该范围。
稀疏性
与量化类似,事实证明,许多深度学习模型对于修剪或用 0 本身替换某些接近 0 的值具有鲁棒性。 稀疏矩阵是许多元素为 0 的矩阵。这些矩阵可以用压缩形式表示,比完整的稠密矩阵占用的空间更少。

GPU 尤其具有针对某种结构化稀疏性的硬件加速,其中每四个值中有两个由零表示。 稀疏表示还可以与量化相结合,以实现更大的执行速度。 寻找以稀疏格式表示大型语言模型的最佳方法仍然是一个活跃的研究领域,并为未来提高推理速度提供了一个有希望的方向。
蒸馏
缩小模型大小的另一种方法是通过称为蒸馏的过程将其知识转移到较小的模型。 此过程涉及训练较小的模型(称为学生)来模仿较大模型(教师)的行为。
蒸馏模型的成功例子包括 DistilBERT,它将 BERT 模型压缩了 40%,同时保留了 97% 的语言理解能力,速度提高了 60%。
虽然LLM中的蒸馏是一个活跃的研究领域,但神经网络的一般方法首先在“蒸馏神经网络中的知识”中描述:
- 学生网络经过训练,可以反映较大教师网络的性能,使用损失函数来测量其输出之间的差异。 该目标还可能包括将学生的输出与真实标签进行匹配的原始损失函数。
- 匹配的教师输出可以是最后一层(称为 logits)或中间层激活。
下图显示了知识蒸馏的总体框架。 教师的 logits 是学生使用蒸馏损失进行优化的软目标。 其他蒸馏方法可能会使用其他损失措施来从老师那里“蒸馏”知识。

蒸馏的另一种方法是使用教师合成的数据对LLM学生进行监督培训,这在人工注释稀缺或不可用时特别有用。 一步一步蒸馏! 更进一步,除了作为基本事实的标签之外,还从LLM教师那里提取基本原理。 这些基本原理作为中间推理步骤,以数据有效的方式培训规模较小的LLM。
值得注意的是,当今许多最先进的LLM都拥有限制性许可证,禁止使用他们的成果来培训其他LLM,这使得找到合适的教师模型具有挑战性。
模型服务技术
模型执行经常受到内存带宽的限制,特别是权重中的带宽限制。 即使在应用了前面描述的所有模型优化之后,它仍然很可能受到内存限制。 因此,您希望在加载模型权重时尽可能多地处理它们。 换句话说,尝试并行做事。 可以采取两种方法:
- 动态批处理涉及同时执行多个不同的请求。
- 推测推理涉及并行执行序列的多个不同步骤以尝试节省时间。
动态批处理
LLM 具有一些独特的执行特征,这些特征可能导致在实践中难以有效地批量请求。 一个模型可以同时用于多种看起来非常不同的任务。 从聊天机器人中的简单问答响应到文档摘要或长代码块的生成,工作负载是高度动态的,输出大小变化几个数量级。
这种多功能性使得批处理请求并有效地并行执行它们变得具有挑战性——这是服务神经网络的常见优化。 这可能会导致某些请求比其他请求更早完成。
为了管理这些动态负载,许多LLM服务解决方案包括一种称为连续或动态批处理的优化调度技术。 这利用了这样一个事实:LLM的整个文本生成过程可以分解为模型上的多次执行迭代。
通过动态批处理,服务器运行时会立即从批处理中逐出已完成的序列,而不是等待整个批处理完成后再继续处理下一组请求。 然后,它开始执行新请求,而其他请求仍在进行中。 因此,动态批处理可以极大地提高实际用例中 GPU 的整体利用率。
推测性推理
推测推理也称为推测采样、辅助生成或分块并行解码,是并行执行 LLM 的另一种方式。 通常,GPT 风格的大语言模型是自回归模型,逐个生成文本标记。
生成的每个标记都依赖于它之前的所有标记来提供上下文。 这意味着在常规执行中,不可能从同一个序列并行生成多个令牌——必须等待第 n 个令牌生成后才能生成 n+1 个令牌。
下图显示了推测推理的示例,其中草稿模型临时预测并行验证或拒绝的多个未来步骤。 在这种情况下,草稿中的前两个预测令牌被接受,而最后一个在继续生成之前被拒绝并删除。
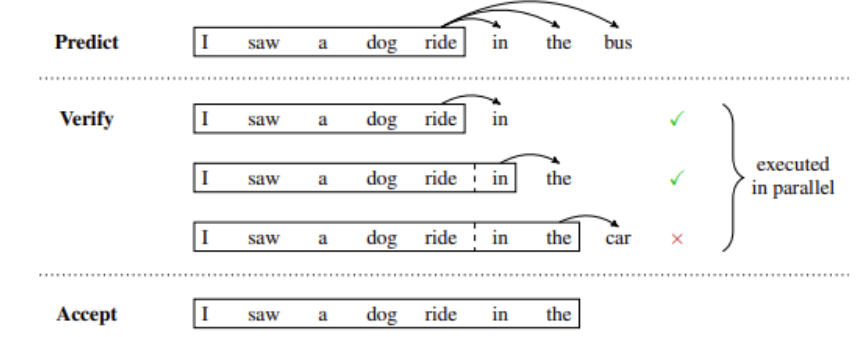
推测性抽样提供了一种解决方法。 这种方法的基本思想是使用一些“更便宜”的过程来生成几个令牌长的草案延续。 然后,并行执行多个步骤的主要“验证”模型,使用廉价草案作为需要的执行步骤的“推测”上下文。
如果验证模型生成与草稿相同的令牌,那么您就知道接受这些令牌作为输出。 否则,您可以丢弃第一个不匹配标记之后的所有内容,并使用新的草稿重复该过程。
如何生成草稿代币有许多不同的选项,每个选项都有不同的权衡。 您可以训练多个模型,或在单个预训练模型上微调多个头,以预测未来多个步骤的标记。 或者,您可以使用小型模型作为草稿模型,使用更大、功能更强大的模型作为验证器。
相关文章:
掌握大语言模型技术: 推理优化
掌握大语言模型技术_推理优化 堆叠 Transformer 层来创建大型模型可以带来更好的准确性、少样本学习能力,甚至在各种语言任务上具有接近人类的涌现能力。 这些基础模型的训练成本很高,并且在推理过程中可能会占用大量内存和计算资源(经常性成…...

git如何导出提交记录及修改的文件清单?
导出git提交日志及修改文件 # 所有人的提交记录 git log --pretty=format:"%ai,%an:%s" --since="10 day ago" >> ~/Desktop/commit10.log#某一个人的提交记录 git log --pretty=format:"%ai,%an:%s" --since="30 day ago" |...

从零开始:Ubuntu Server中MySQL 8.0的安装与Django数据库配置详解
Ubuntu系统纯净安装MySQL8.0 1、安装Mysql8.0 sudo apt install mysql-server2、检查MySQL状态 sudo systemctl status mysql如下所示看见Active: active (running)说明mysql状态正常 ● mysql.service - MySQL Community ServerLoaded: loaded (/lib/systemd/system/mysql…...

Vue基础知识
Vue Vue基础知识 v-bind:动态绑定属性值 Vue 修改,标签内也修改 在methods 中可以定义很多函数 在 data 中可以定义很多变量 v-if / v-show:对符合条件的元素进行展示 v-for:把数据遍历出现在网页中 案例 <!DOCTYPE html><html lang"e…...

瀑布流布局 (初版)
瀑布流布局 文章目录 瀑布流布局前言1. 背景2. 点⬇️🔗去体验效果如下图所示: 一、初版waterfall布局和问题暴露?1.效果图如下:2.暴露问题如下图所示:第一张问题图:第二张问题图: 3.HTML代码如…...

硕士毕业论文写作笔记
一、写作顺序 1.标题、研究问题、研究方法 2.文献综述(占比1/5-1/6) 3.论证章节 4.结论、不足、启示 5.处理图表、参考文献的格式 6.绪论或引言 7.摘要、关键词 8.查重、装订 http://【硕士毕业论文写不下去,多亏听了张博士的论文写…...
成本更低、更可控,云原生可观测新计费模式正式上线
云布道师 在上云开始使用云产品过程中,企业一定遇见过两件“讨厌”事: 难以理解的复杂计费逻辑,时常冒出“这也能收费”的感叹; 某个配置参数调节之后,云产品使用成本不可预估的暴涨。 可观测作为企业 IT 运维必须品…...

5.列表选择弹窗(BottomListPopup)
愿你出走半生,归来仍是少年! 环境:.NET 7、MAUI 从底部弹出的列表选择弹窗。 1.布局 <?xml version"1.0" encoding"utf-8" ?> <toolkit:Popup xmlns"http://schemas.microsoft.com/dotnet/2021/maui"xmlns…...
Head first design patterns原型模式(c++))
(十三)Head first design patterns原型模式(c++)
原型模式 原型模式就是就是对对象的克隆。有一些私有变量外界难以访问,而原型模式可以做到对原型一比一的复刻。 其关键代码为下面的clone方法。此方法将本对象进行复制传递出去。 class ConcretePrototype1 : public Prototype{ public:ConcretePrototype1(stri…...
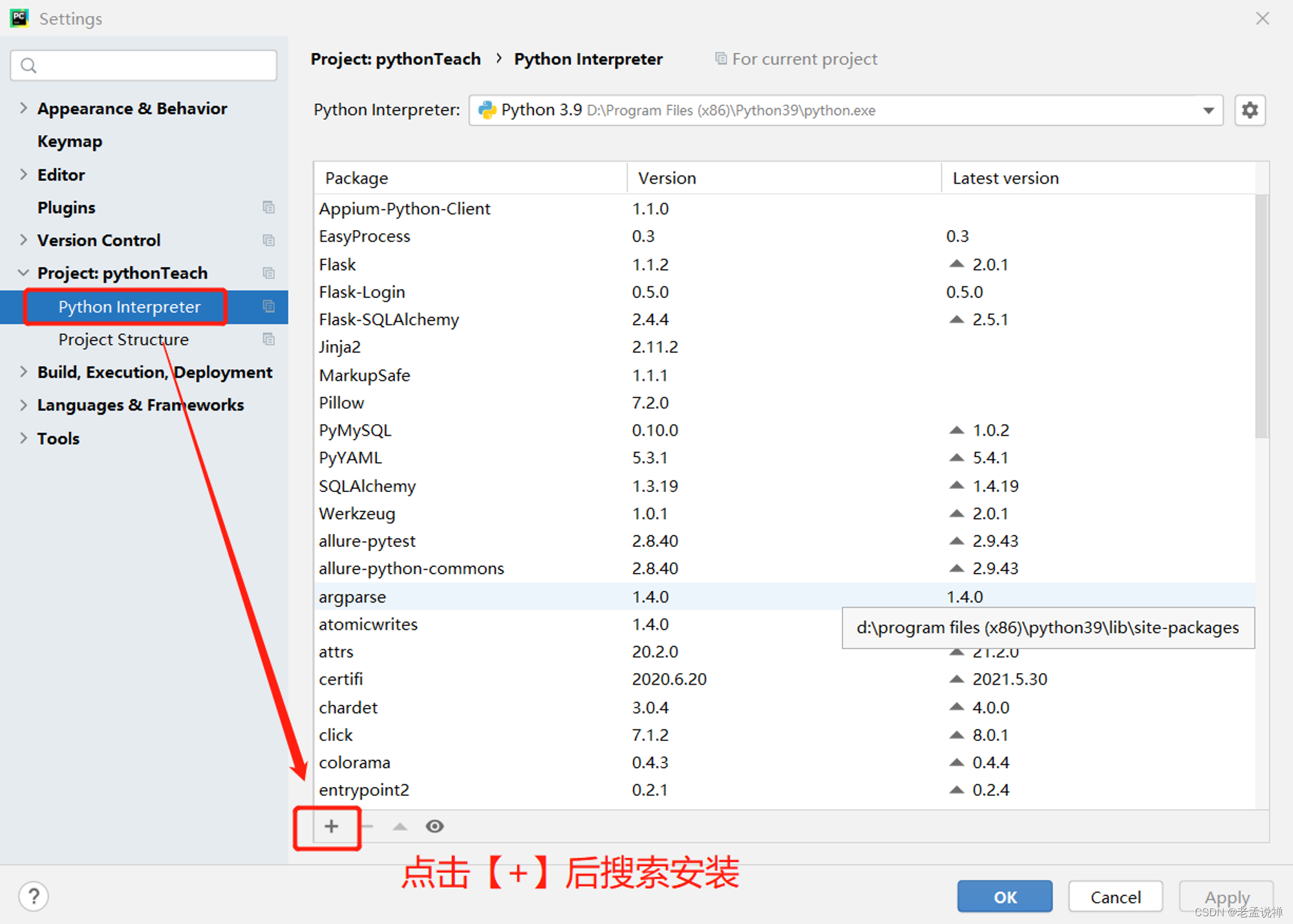
Python基础之数据库操作
一、安装第三方库PyMySQL 1、在PyCharm中通过 【File】-【setting】-【Python Interpreter】搜索 PyMySQL进行安装 2、通过PyCharm中的 Terminal 命令行 输入: pip install PyMySQL 注:通过pip安装,可能会提示需要更新pip,这时可执行&#…...
redis-发布缓存
一.redis的发布订阅 什么 是发布和订阅 Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。 Redis 客户端可以订阅任意数量的频道。 Redis的发布和订阅 客户端订阅频道发布的消息 频道发布消息 订阅者就可…...

Stata17安装教程
文章目录 **Stata17安装教程**前言系统要求Windows:macOS:Linux: 软件下载正式安装1.下载Stata 17安装包2.双击Stata17.exe开启安装3.接受同意条款,然后继续安装4.选择想要安装的版本,Stata BE为基础版、Stata SE为特别…...

Java PDFBox 提取页数、PDF转图片
PDF 提取 使用Apache 的pdfbox组件对PDF文件解析读取和转图片。 Maven 依赖 导入下面的maven依赖: <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.30</version> &l…...
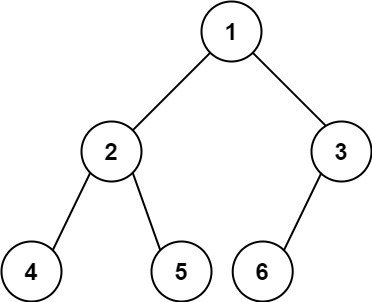
【代码随想录14】104.二叉树的最大深度 111.二叉树的最小深度 222.完全二叉树的节点个数
目录 104.二叉树的最大深度题目描述参考代码 111.二叉树的最小深度题目描述参考代码 222.完全二叉树的节点个数题目描述参考代码 104.二叉树的最大深度 题目描述 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径…...
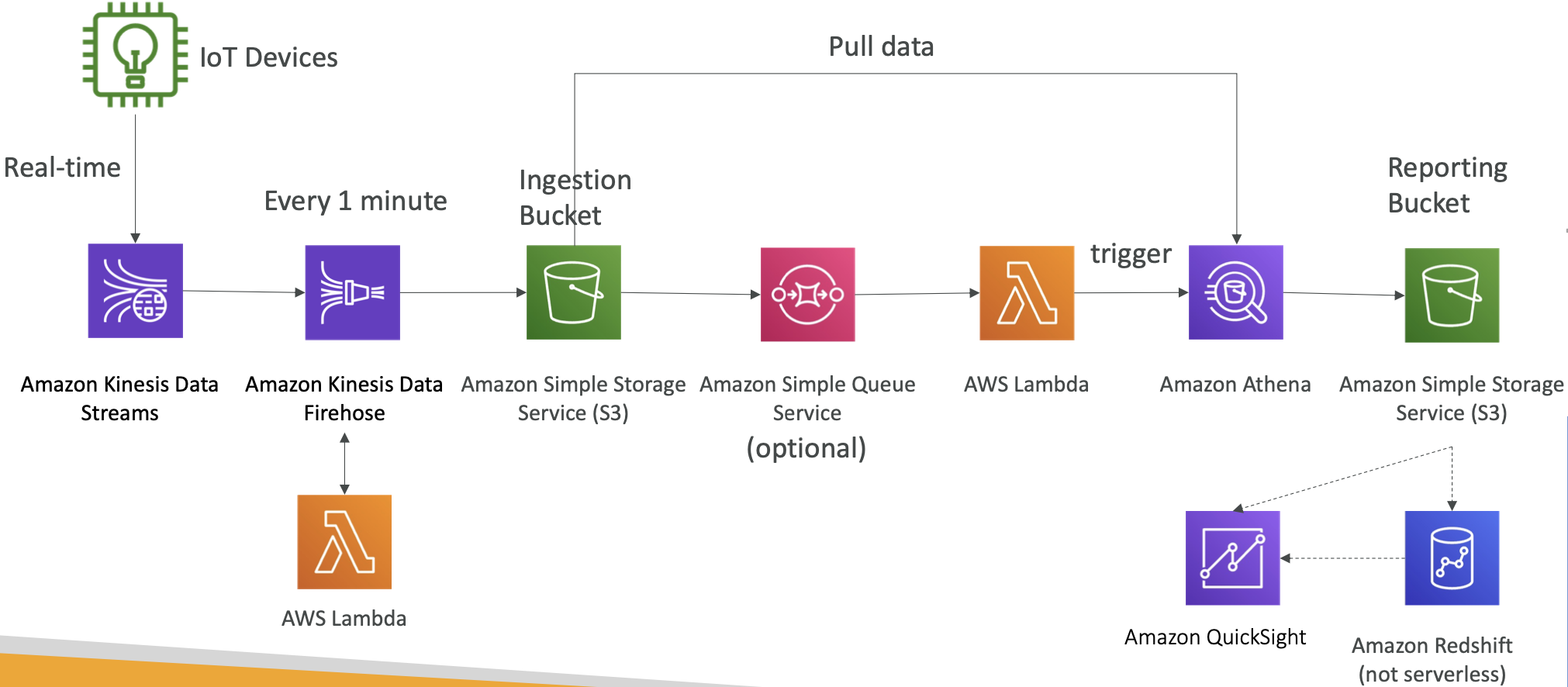
AWS 专题学习 P10 (Databases、 Data Analytics)
文章目录 专题总览1. Databases1.1 选择合适的数据库1.2 数据库类型1.3 AWS 数据库服务概述Amazon RDSAmazon AuroraAmazon ElastiCacheAmazon DynamoDBAmazon S3DocumentDBAmazon NeptuneAmazon Keyspaces (for Apache Cassandra)Amazon QLDBAmazon Timestream 2. Data & …...
一键拥有你的GPT4
这几天我一直在帮朋友升级ChatGPT,现在已经可以闭眼操作了哈哈😝。我原本以为大家都已经用上GPT4,享受着它带来的巨大帮助时,但结果还挺让我吃惊的,还是有很多人仍苦于如何进行升级。所以就想着写篇教程来教会大家如何…...
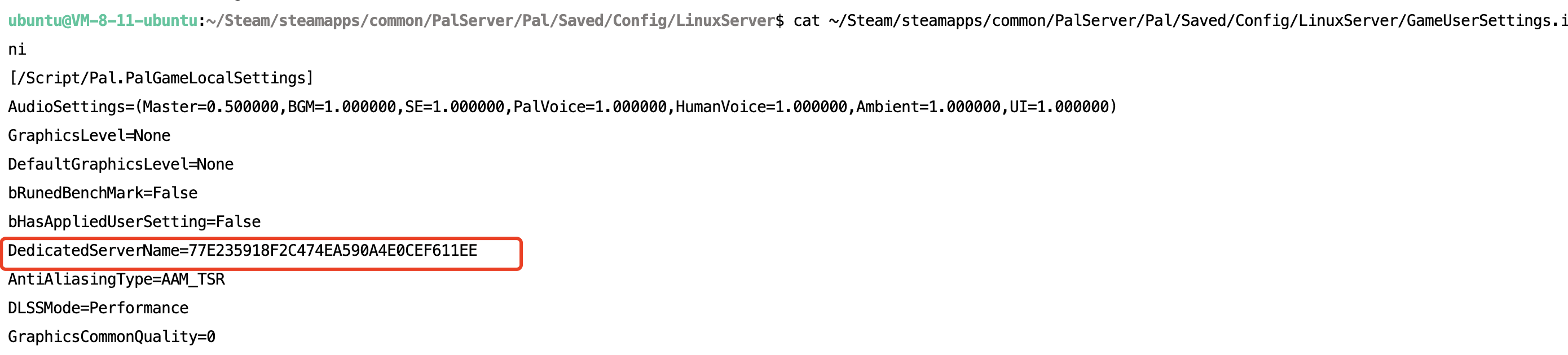
幻兽帕鲁服务器数据备份
搭建幻兽帕鲁个人服务器,最近不少用户碰到内存不足、游戏坏档之类的问题。做好定时备份,才能轻松快速恢复游戏进度 这里讲一下如何定时将服务器数据备份到腾讯云轻量对象存储服务,以及如何在有需要的时候进行数据恢复。服务器中间的数据迁移…...

【Digester解析XML文件的三种方式】
Digester解析XML文件的三种方式 1. Digester解析XML文件的三种方式1.1 作用及依赖jar包 2. 重点和难点3. XML文件4. 通过不同的方式解析这个xml文件4.1 通过java编码方式解析(javabean存储)4.2 通过java编码方式解析(list和map存储࿰…...
MATLAB curve fitting toolbox没有怎么办?
版本:MATLAB R2023b 如果在安装MATLAB时仅仅选择了安装MATLAB,而并未选择其他选项,则在进入MATLAB后会发现顶部的APP栏中无法找到曲线拟合工具箱。 本人跟随MATLAB中的教程进行下载时,出现了如下报错: 最终解决方案&a…...

Linux之快速入门(CentOS 7)
文章目录 一、Linux目录结构二、常用命令2.1 切换用户2.2查看ip地址2.3 cd2.4 目录查看2.5 查看文件内容2.6 创建目录及文件2.7 复制和移动2.8 其他2.9 tar3.0 which3.1 whereis3.2 find(这个命令尽量在少量用户使用此软件时运行,因为此命令是真的读磁盘…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...