kafka集群和Filebeat+Kafka+ELK
一、Kafka 概述
1.1 为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka、Pulsar 等。
1.2 使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.3 消息队列的两种模式
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
1.4 Kafka 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据领域的实时计算以及日志收集。
1.5 Kafka 简介
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,
Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
1.6 Kafka 的特性
●高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
●可扩展性
kafka 集群支持热扩展
●持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
●容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
●高并发
支持数千个客户端同时读写
1.7 Kafka 系统架构
(1)Broker
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
##Partation 数据路由规则:
1.指定了 patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和 key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。
每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。
●broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
●如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
●如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
1.8 分区的原因
●方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
●可以提高并发,因为可以以Partition为单位读写了。
(4)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(5)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(6)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(7)Producer
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(8)Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
(9)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(10)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)。
(11)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
也就是说,zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费。
二、部署 kafka 集群
1.下载安装包
官方下载地址:http://kafka.apache.org/downloads.htmlcd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz
2.安装 Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
3. 修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}vim server.propertiesbroker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.80.10:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 ●123行,配置连接Zookeeper集群地址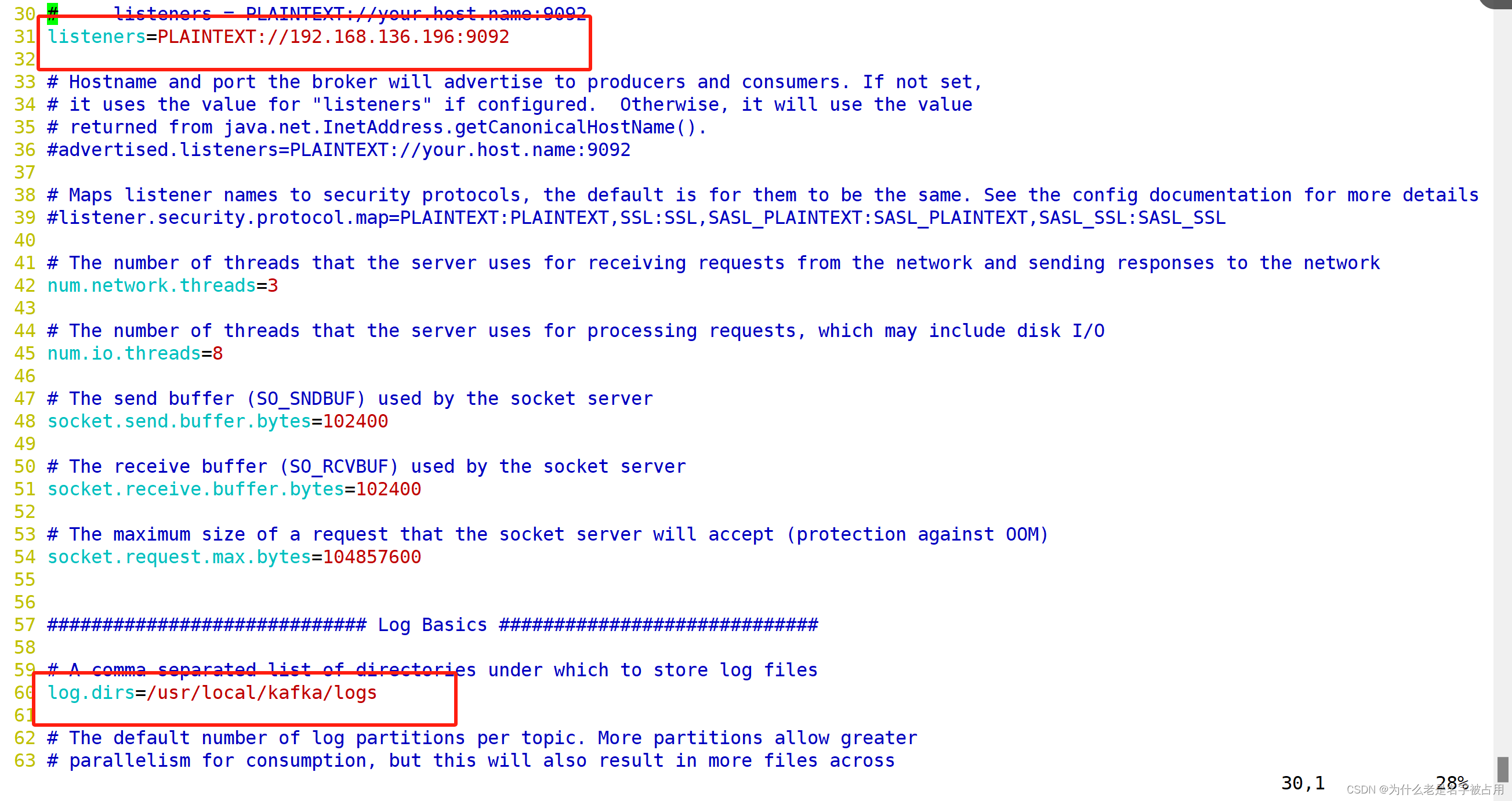



4. 修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile
5. 配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
service kafka start
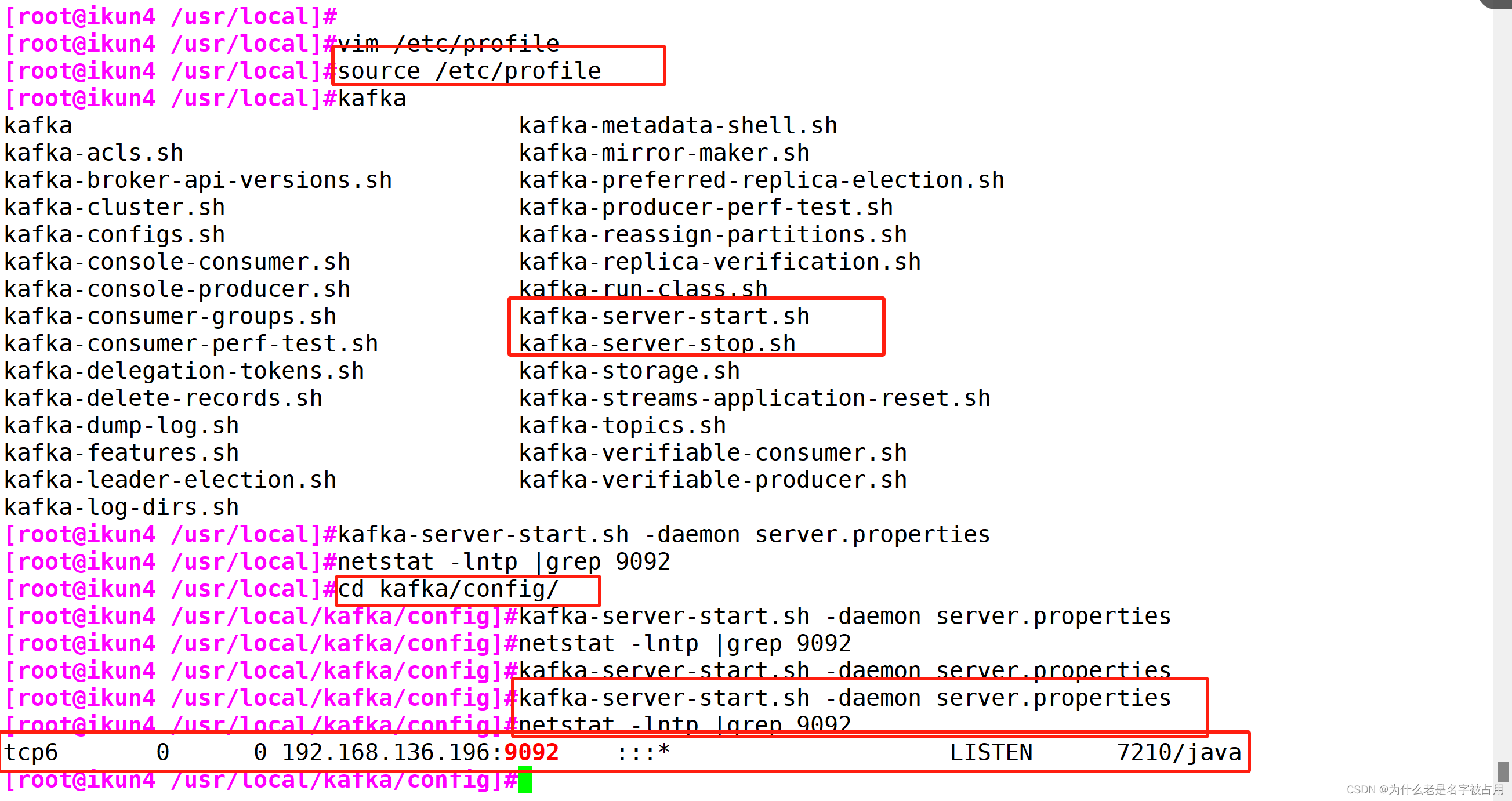
6. Kafka 命令行操作
创建topic
kafka-topics.sh --zookeeper 192.168.136.196:2181,192.168.136.197:2181,192.168.136.198:2181 --partitions 1 --replication-factor 2 --create --topic CXK--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称

查看当前服务器中的所有 topic
kafka-topics.sh --zookeeper 192.168.136.196:2181,192.168.136.197:2181,192.168.136.198:2181 --list
查看某个 topic 的详情
kafka-topics.sh --zookeeper 192.168.136.196:2181,192.168.136.197:2181,192.168.136.198:2181 --describe
发布消息
kafka-console-producer.sh --broker-list 192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092 --topic test 
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.136.196:9092,192.168.136.197:9092,192.168.136.198:9092 --topic CXK --from-beginning--from-beginning:会把主题中以往所有的数据都读取出来
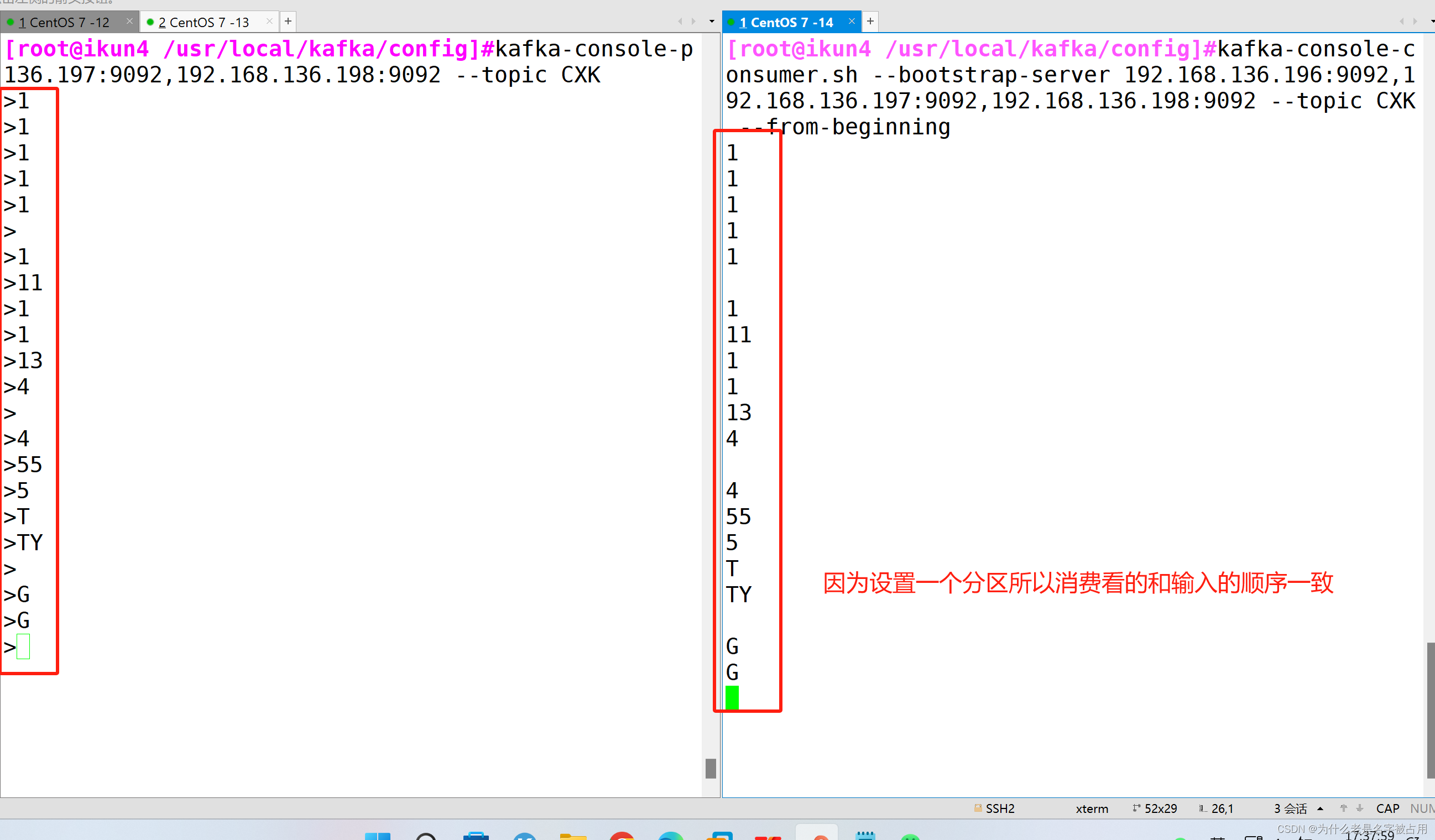
修改分区数
kafka-topics.sh --zookeeper 192.168.136.196:2181,192.168.136.197:2181,192.168.136.198:2181 --alter --topic CXK --partitions 3

删除 topic
kafka-topics.sh --zookeeper 192.168.136.196:2181,192.168.136.197:2181,192.168.136.198:2181 --delete --topic CXK
三、Filebeat+Kafka+ELK
1.部署 Zookeeper+Kafka 集群
2.部署 Filebeat
cd /usr/local/filebeatvim filebeat.yml
filebeat.prospectors:
- type: logenabled: truepaths:- /var/log/httpd/access_logtags: ["access"]- type: logenabled: truepaths:- /var/log/httpd/error_logtags: ["error"]........
#添加输出到 Kafka 的配置
output.kafka:enabled: truehosts: ["192.168.80.10:9092","192.168.80.11:9092","192.168.80.12:9092"] #指定 Kafka 集群配置topic: "httpd" #指定 Kafka 的 topic#启动 filebeat
./filebeat -e -c filebeat.yml


3.部署 ELK,在 Logstash 组件所在节点上新建一个 Logstash 配置文件
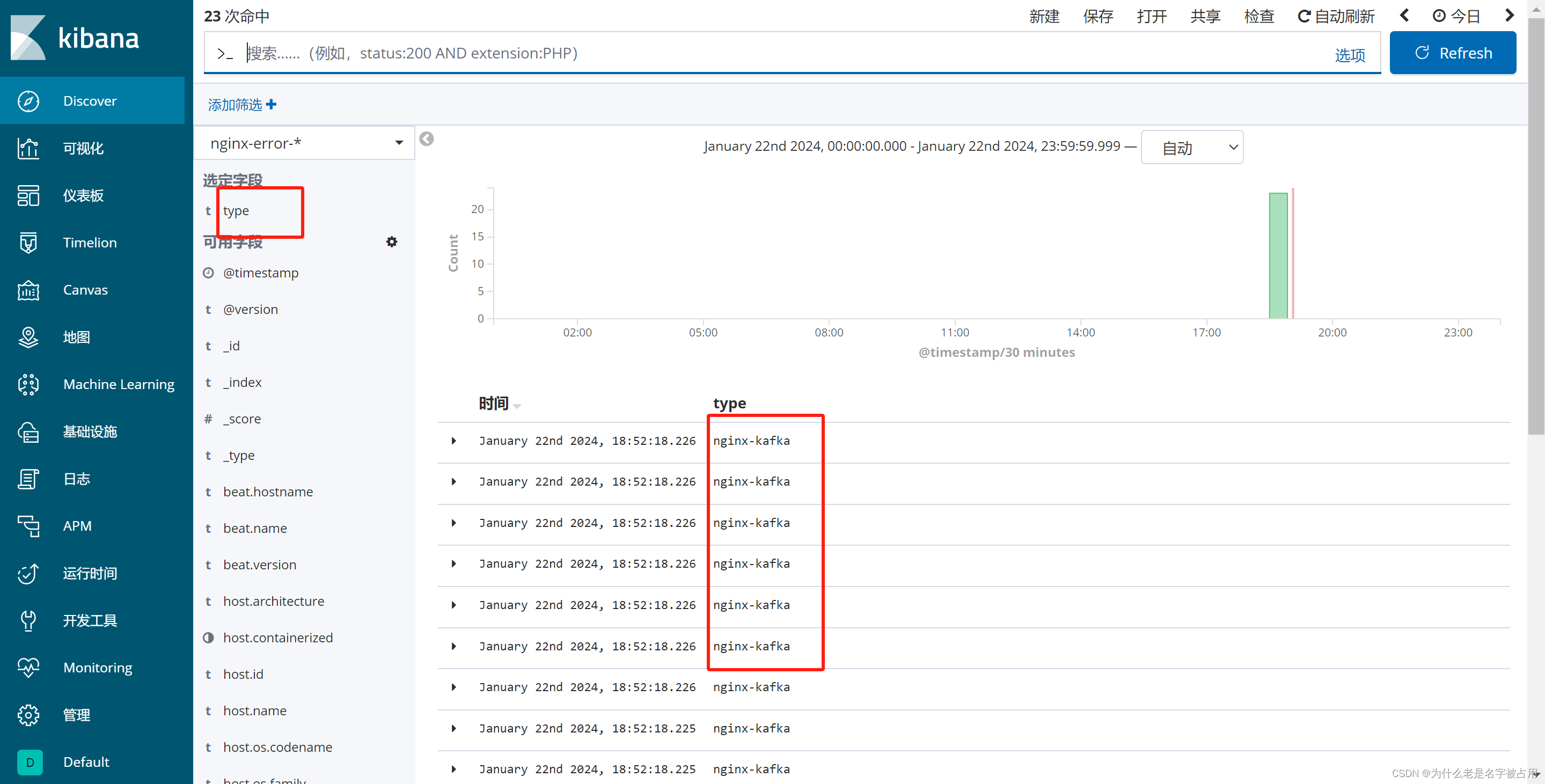
cd /etc/logstash/conf.d/input {kafka {bootstrap_servers => "192.168.136.196:9092,192.168.136.197:9092,192.168.136.198:9092"topics => "nginx_logs"type => "nginx-kafka"codec => "json"auto_offset_reset => "latest"decorate_events => true}
}
#filter {}output {if "nginx_access" in [tags] {elasticsearch {hosts => ["192.168.136.180:9200" ,"192.168.136.190:9200" ,"192.168.136.195:9200"]index => "nginx-access-%{+YYYY.MM.dd}"}}if "nginx_error" in [tags] {elasticsearch {hosts => ["192.168.136.180:9200" ,"192.168.136.190:9200" ,"192.168.136.195:9200"]index => "nginx-error-%{+YYYY.MM.dd}"}}
stdout { codec => rubydebug }
}

4.浏览器访问





相关文章:
kafka集群和Filebeat+Kafka+ELK
一、Kafka 概述 1.1 为什么需要消息队列(MQ) 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从…...

golang map真有那么随机吗?——map遍历研究
在随机选取map中元素时,本想用map遍历的方式来返回,但是却并没有通过测试。 那么难道map的遍历并不是那么的随机吗? 以下代码参考go1.18 hiter是map遍历的结构,主要记录了当前遍历的元素、开始位置等来完成整个遍历过程 // A ha…...

详细分析对比copliot和ChatGPT的差异
Copilot 和 ChatGPT 是两种不同的AI工具,分别在不同领域展现出了强大的功能和潜力: GitHub Copilot 定位与用途:GitHub Copilot 是由GitHub(现为微软子公司)和OpenAI合作开发的一款智能代码辅助工具。它主要集成于Visu…...

TENT:熵最小化的Fully Test-Time Adaption
摘要 在测试期间,模型必须自我调整以适应新的和不同的数据。在这种完全自适应测试时间的设置中,模型只有测试数据和它自己的参数。我们建议通过test entropy minimization (tent[1])来适应:我们通过其预测的熵来优化模型的置信度。我们的方法估计归一化…...
研发日记,Matlab/Simulink避坑指南(五)——CAN解包 DLC Bug
文章目录 前言 背景介绍 问题描述 分析排查 解决方案 总结 前言 见《研发日记,Matlab/Simulink避坑指南(一)——Data Store Memory模块执行时序Bug》 见《研发日记,Matlab/Simulink避坑指南(二)——非对称数据溢出Bug》 见《…...

机器人3D视觉引导半导体塑封上下料
半导体塑封上下料是封装工艺中的重要环节,直接影响到产品的质量和性能。而3D视觉引导技术的引入,使得这一过程更加高效、精准。它不仅提升了生产效率,减少了人工操作的误差,还为半导体封装技术的智能化升级奠定了坚实的基础。 传统…...
(十二)Head first design patterns代理模式(c++)
代理模式 代理模式:创建一个proxy对象,并为这个对象提供替身或者占位符以对这个对象进行控制。 典型例子:智能指针... 例子:比如说有一个talk接口,所有的people需要实现talk接口。但有些人有唱歌技能。不能在talk接…...
)
C++从零开始的打怪升级之路(day21)
这是关于一个普通双非本科大一学生的C的学习记录贴 在此前,我学了一点点C语言还有简单的数据结构,如果有小伙伴想和我一起学习的,可以私信我交流分享学习资料 那么开启正题 今天分享的是关于vector的题目 1.删除有序数组中的重复项 26. …...

《设计模式的艺术》笔记 - 观察者模式
介绍 观察者模式定义对象之间的一种一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新。 实现 myclass.h // // Created by yuwp on 2024/1/12. //#ifndef DESIGNPATTERNS_MYCLASS_H #define DESIGNPATTERNS_MYCLA…...
Java如何对OSS存储引擎的Bucket进行创建【OSS学习】
在前面学会了如何开通OSS,对OSS的一些基本操作,接下来记录一下如何通过Java代码通过SDK对OSS存储引擎里面的Bucket存储空间进行创建。 目录 1、先看看OSS: 2、代码编写: 3、运行效果: 1、先看看OSS: 此…...

ModuleNotFoundError: No module named ‘half_json‘
问题: ModuleNotFoundError: No module named ‘half_json’ 原因: 缺少jsonfixer包 解决方法: pip install jsonfixerjson修正包地址: https://github.com/half-pie/half-json...

深入探究 Android 内存泄漏检测原理及 LeakCanary 源码分析
深入探究 Android 内存泄漏检测原理及 LeakCanary 源码分析 一、什么是内存泄漏二、内存泄漏的常见原因三、我为什么要使用 LeakCanary四、LeakCanary介绍五、LeakCanary 的源码分析及其核心代码六、LeakCanary 使用示例 一、什么是内存泄漏 在基于 Java 的运行时中࿰…...
)
Linux CentOS使用Docker搭建laravel项目环境(实践案例详细说明)
一、安装docker # 1、更新系统软件包: sudo yum update# 2、安装Docker依赖包 sudo yum install -y yum-utils device-mapper-persistent-data lvm2# 3、添加Docker的yum源: sudo yum-config-manager --add-repo https://download.docker.com/linux/cen…...
第六课:Prompt
文章目录 第六课:Prompt1、学习总结:Prompt介绍预训练和微调模型回顾挑战 Pre-train, Prompt, PredictPrompting是什么?prompting流程prompt设计 课程ppt及代码地址 2、学习心得:3、经验分享:4、课程反馈:5、使用Mind…...
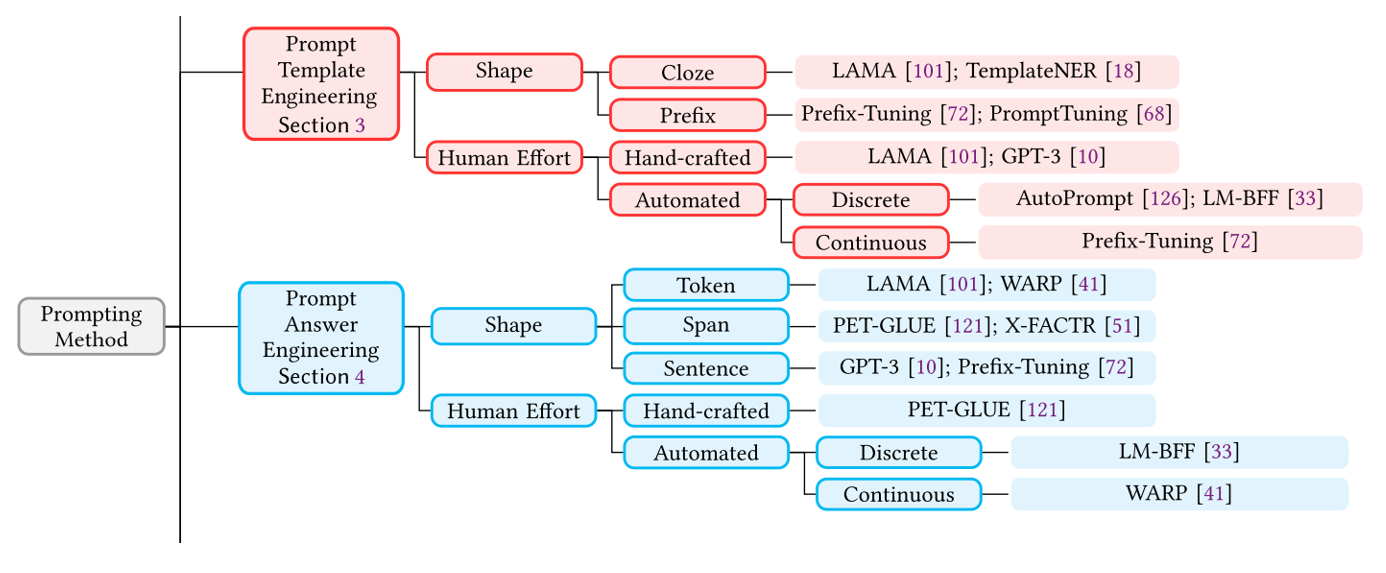
网络安全(初版,以后会不断更新)
1.网络安全常识及术语 资产 任何对组织业务具有价值的信息资产,包括计算机硬件、通信设施、IT 环境、数据库、软件、文档 资料、信息服务和人员等。 漏洞 上边提到的“永恒之蓝”就是windows系统的漏洞 漏洞又被称为脆弱性或弱点(Weakness)&a…...
开始学习Vue2(脚手架,组件化开发)
一、单页面应用程序 单页面应用程序(英文名:Single Page Application)简 称 SPA,顾名思义,指的是一个 Web 网站中只有唯一的 一个 HTML 页面,所有的功能与交互都在这唯一的一个页面内完成。 二、vue-cli …...

平替heygen的开源音频克隆工具—OpenVoice
截止2024-1-26日,全球范围内语音唇形实现最佳的应该算是heygen,可惜不但要魔法,还需要银子;那么有没有可以平替的方案,答案是肯定的。 方案1: 采用国内星火大模型训练自己的声音,然后再用下面…...
【自动化测试】读写64位操作系统的注册表
自动化测试经常需要修改注册表 很多系统的设置(比如:IE的设置)都是存在注册表中。 桌面应用程序的设置也是存在注册表中。 所以做自动化测试的时候,经常需要去修改注册表 Windows注册表简介 注册表编辑器在 C:\Windows\regedit…...

php二次开发股票系统代码:腾讯股票数据接口地址、批量获取股票信息、转换为腾讯接口指定的股票格式
1、腾讯股票数据控制器 <?php namespace app\index\controller;use think\Model; use think\Db;const BASE_URL http://aaaaaa.aaaaa.com; //腾讯数据地址class TencentStocks extends Home { //里面具体的方法 }2、请求接口返回内容 function juhecurl($url, $params f…...
uniapp 在static/index.html中添加全局样式
前言 略 在static/index.html中添加全局样式 <style>div {background-color: #ccc;} </style>static/index.html源码: <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"utf-8"><meta http-…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...

深入理解 React 样式方案
React 的样式方案较多,在应用开发初期,开发者需要根据项目业务具体情况选择对应样式方案。React 样式方案主要有: 1. 内联样式 2. module css 3. css in js 4. tailwind css 这些方案中,均有各自的优势和缺点。 1. 方案优劣势 1. 内联样式: 简单直观,适合动态样式和…...
——统计抽样学习笔记(考试用))
统计学(第8版)——统计抽样学习笔记(考试用)
一、统计抽样的核心内容与问题 研究内容 从总体中科学抽取样本的方法利用样本数据推断总体特征(均值、比率、总量)控制抽样误差与非抽样误差 解决的核心问题 在成本约束下,用少量样本准确推断总体特征量化估计结果的可靠性(置…...
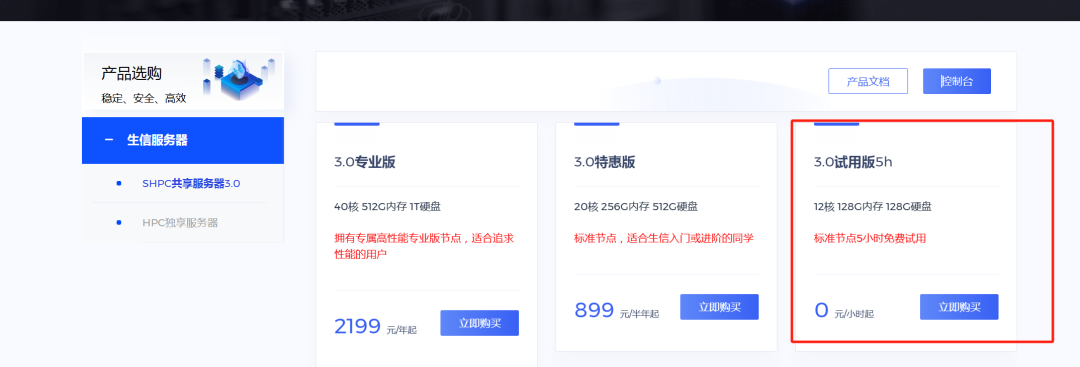
生信服务器 | 做生信为什么推荐使用Linux服务器?
原文链接:生信服务器 | 做生信为什么推荐使用Linux服务器? 一、 做生信为什么推荐使用服务器? 大家好,我是小杜。在做生信分析的同学,或是将接触学习生信分析的同学,<font style"color:rgb(53, 1…...