【Kafka】开发实战和Springboot集成kafka
目录
- 消息的发送与接收
- 生产者
- 消费者
- SpringBoot 集成kafka
- 服务端参数配置
消息的发送与接收
生产者
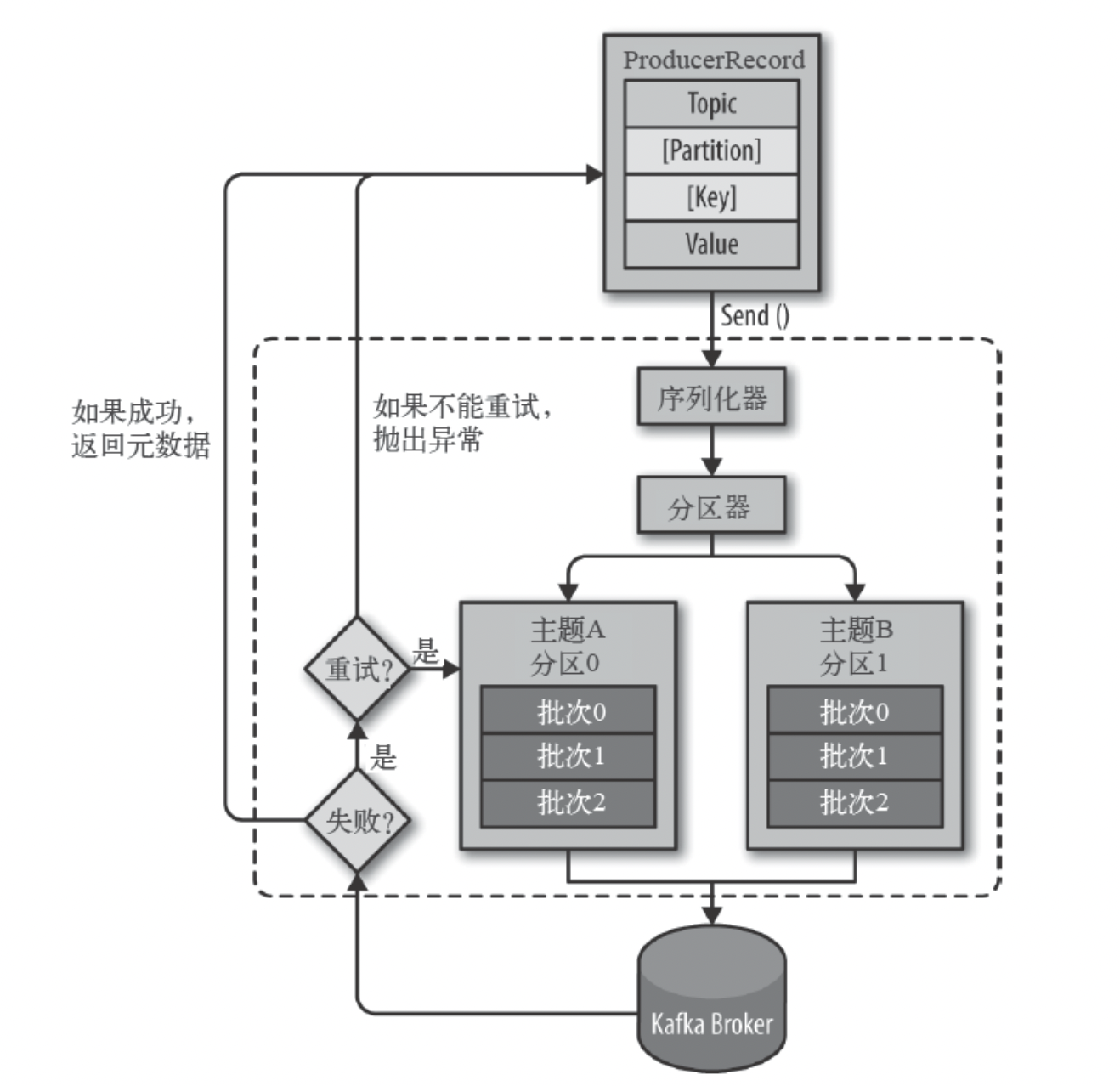
生产者主要的对象有: KafkaProducer , ProducerRecord 。
其中 KafkaProducer 是用于发送消息的类, ProducerRecord 类用于封装Kafka的消息。
KafkaProducer 的创建需要指定的参数和含义:
bootstrap.servers:配置生产者如何与broker建立连接。该参数设置的是初始化参数。如果生产者需要连接的是Kafka集群,则这里配置集群中几个部分broker的地址,而不是全部,当生产者连接上此处指定的broker之后,在通过该连接发现集群中的其他节点。key.serializer:要发送信息的key数据的序列化类。设置的时候可以写类名,也可以使用该类的Class对象。value.serializer:要发送消息的value数据的序列化类。设置的时候可以写类名,也可以使用该类的Class对象。acks:默认值:all。- acks=0:生产者不等待broker对消息的确认,只要将消息放到缓冲区,就认为消息已经发送完成。该情形不能保证broker是否真的收到了消息,retries配置也不会生效。发送的消息的返回的消息偏移量永远是-1。
- acks=1:表示消息只需要写到主分区即可,然后就响应客户端,而不等待副本分区的确认。在该情形下,如果主分区收到消息确认之后就宕机了,而副本分区还没来得及同步该消息,则该消息丢失。
- acks=all:leader分区会等待所有的ISR副本分区确认记录。该处理保证了只要有一个ISR副本分区存活,消息就不会丢失。这是Kafka最强的可靠性保证,等效于 acks=-1。
retries:retries重试次数。当消息发送出现错误的时候,系统会重发消息。跟客户端收到错误时重发一样。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1,否则在重试此失败消息的时候,其他的消息可能发送成功了。
其他参数可以从 org.apache.kafka.clients.producer.ProducerConfig 中找到。后面的内容会介绍到。
消费者生产消息后,需要broker端的确认,可以同步确认,也可以异步确认。同步确认效率低,异步确认效率高,但是需要设置回调对象。
示例如下:
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.internals.RecordHeader;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;public class MyProducer1 {public static void main(String[] args) throws ExecutionException, InterruptedException {Map<String, Object> configs = new HashMap<>();// 指定初始连接用到的broker地址configs.put("bootstrap.servers", "192.168.100.101:9092");// 指定key的序列化类configs.put("key.serializer", IntegerSerializer.class);// 指定value的序列化类configs.put("value.serializer", StringSerializer.class);// configs.put("acks", "all");
// configs.put("reties", "3");KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(configs);// 用于设置用户自定义的消息头字段List<Header> headers = new ArrayList<>();headers.add(new RecordHeader("biz.name", "producer.demo".getBytes()));ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("topic_1", // topic0, // 分区0, // key"hello lagou 0", // valueheaders // headers);// 消息的同步确认final Future<RecordMetadata> future = producer.send(record);final RecordMetadata metadata = future.get();System.out.println("消息的主题:" + metadata.topic());System.out.println("消息的分区号:" + metadata.partition());System.out.println("消息的偏移量:" + metadata.offset());// 关闭生产者producer.close();}
}
如果需要异步发送,如下:
package com.lagou.kafka.demo.producer;import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.internals.RecordHeader;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;public class MyProducer1 {public static void main(String[] args) throws ExecutionException, InterruptedException {Map<String, Object> configs = new HashMap<>();// 指定初始连接用到的broker地址configs.put("bootstrap.servers", "192.168.100.101:9092");// 指定key的序列化类configs.put("key.serializer", IntegerSerializer.class);// 指定value的序列化类configs.put("value.serializer", StringSerializer.class);// configs.put("acks", "all");
// configs.put("reties", "3");KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(configs);// 用于设置用户自定义的消息头字段List<Header> headers = new ArrayList<>();headers.add(new RecordHeader("biz.name", "producer.demo".getBytes()));ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("topic_1", // topic0, // 分区0, // key"hello lagou 0", // valueheaders // headers);// 消息的异步确认producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) {System.out.println("消息的主题:" + metadata.topic());System.out.println("消息的分区号:" + metadata.partition());System.out.println("消息的偏移量:" + metadata.offset());} else {System.out.println("异常消息:" + exception.getMessage());}}});// 关闭生产者producer.close();}
}
消费者
kafka不支持消息的推送(当然可以自己已实现),采用的消息的拉取(poll方法)。
消费者主要的对象是kafkaConsumer,用于消费消息的类。
其主要参数:
bootstrap.servers:与kafka建立初始连接的broker地址列表key.deserializer:key的反序列化器value.deserializer:value的反序列化器group.id:指定消费者组id,用于标识该消费者属于哪个消费者组auto.offset.reset:当kafka中没有初始化偏移量或当前偏移量在服务器中不存在(如数据被删除了),处理办法earliest:自动重置偏移量到最早的偏移量latest:自动重置偏移量到最新的偏移量none:如果消费者组原来的偏移量(previous)不存在,向消费者抛出异常anything:向消费者抛异常
ConsumerConfig类中包含了所有的可以给kafkaConsumer的参数。
示例:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Consumer;public class MyConsumer1 {public static void main(String[] args) {Map<String, Object> configs = new HashMap<>();// node1对应于192.168.100.101,windows的hosts文件中手动配置域名解析configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");// 使用常量代替手写的字符串,配置key的反序列化器configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);// 配置value的反序列化器configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);// 配置消费组IDconfigs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer_demo1");// 如果找不到当前消费者的有效偏移量,则自动重置到最开始// latest表示直接重置到消息偏移量的最后一个configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");KafkaConsumer<Integer, String> consumer = new KafkaConsumer<Integer, String>(configs);// 先订阅,再消费consumer.subscribe(Arrays.asList("topic_1"));// 如果主题中没有可以消费的消息,则该方法可以放到while循环中,每过3秒重新拉取一次// 如果还没有拉取到,过3秒再次拉取,防止while循环太密集的poll调用。// 批量从主题的分区拉取消息final ConsumerRecords<Integer, String> consumerRecords = consumer.poll(3_000);// 遍历本次从主题的分区拉取的批量消息consumerRecords.forEach(new Consumer<ConsumerRecord<Integer, String>>() {@Overridepublic void accept(ConsumerRecord<Integer, String> record) {System.out.println(record.topic() + "\t"+ record.partition() + "\t"+ record.offset() + "\t"+ record.key() + "\t"+ record.value());}});consumer.close();}
}
SpringBoot 集成kafka
这里把生产者和消费者放在一个项目中,实际可能是在两个里的。
1、引入依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId>
</dependency>
2、 配置
spring.application.name=springboot-kafka-02
server.port=8080 # 用于建立初始连接的broker地址
spring.kafka.bootstrap-servers=node1:9092
# producer用到的key和value的序列化类
spring.kafka.producer.key- serializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.value- serializer=org.apache.kafka.common.serialization.StringSerializer
# 默认的批处理记录数
spring.kafka.producer.batch-size=16384
# 32MB的总发送缓存
spring.kafka.producer.buffer-memory=33554432
# consumer用到的key和value的反序列化类
spring.kafka.consumer.key- deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.value- deserializer=org.apache.kafka.common.serialization.StringDeserializer
# consumer的消费组id
spring.kafka.consumer.group-id=spring-kafka-02-consumer
# 是否自动提交消费者偏移量
spring.kafka.consumer.enable-auto-commit=true
# 每隔100ms向broker提交一次偏移量
spring.kafka.consumer.auto-commit-interval=100
# 如果该消费者的偏移量不存在,则自动设置为最早的偏移量
spring.kafka.consumer.auto-offset-reset=earliest
3、启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Demo02SpringbootKafkaApplication {public static void main(String[] args) {SpringApplication.run(Demo02SpringbootKafkaApplication.class, args);}}
4、生产者
这里我们就写在Controller里就好,如下:
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.concurrent.ExecutionException;@RestController
public class KafkaSyncProducerController {@Autowiredprivate KafkaTemplate<Integer, String> template;@RequestMapping("send/sync/{message}")public String send(@PathVariable String message) {final ListenableFuture<SendResult<Integer, String>> future = template.send("topic-spring-01", 0, 0, message);// 同步发送消息try {final SendResult<Integer, String> sendResult = future.get();final RecordMetadata metadata = sendResult.getRecordMetadata();System.out.println(metadata.topic() + "\t" + metadata.partition() + "\t" + metadata.offset());} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}return "success";}}
上面是同步发送消息,如果异步发送消息,可改为如下:
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class KafkaAsyncProducerController {@Autowiredprivate KafkaTemplate<Integer, String> template;@RequestMapping("send/async/{message}")public String send(@PathVariable String message) {final ListenableFuture<SendResult<Integer, String>> future = this.template.send("topic-spring-01", 0, 1, message);// 设置回调函数,异步等待broker端的返回结果future.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() {@Overridepublic void onFailure(Throwable throwable) {System.out.println("发送消息失败:" + throwable.getMessage());}@Overridepublic void onSuccess(SendResult<Integer, String> result) {final RecordMetadata metadata = result.getRecordMetadata();System.out.println("发送消息成功:" + metadata.topic() + "\t" + metadata.partition() + "\t" + metadata.offset());}});return "success";}}
5、消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;@Component
public class MyConsumer {@KafkaListener(topics = "topic-spring-01")public void onMessage(ConsumerRecord<Integer, String> record) {System.out.println("消费者收到的消息:"+ record.topic() + "\t"+ record.partition() + "\t"+ record.offset() + "\t"+ record.key() + "\t"+ record.value());}}
6、kafka配置类
上面当我们启动生产者和消费者时,kafka会自动为我们创建好topic和分区等。那是因为kafka的KafkaAutoConfigration里有个KafkaAdmin,他负责自动检测需要创建的topic和分区等。如果我们想自己创建,或者自定义KafkaTemplate(一般不会这么做),可以使用配置类,如下:
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaAdmin;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;import java.util.HashMap;
import java.util.Map;@Configuration
public class KafkaConfig {@Beanpublic NewTopic topic1() {return new NewTopic("nptc-01", 3, (short) 1);}@Beanpublic NewTopic topic2() {return new NewTopic("nptc-02", 5, (short) 1);}@Beanpublic KafkaAdmin kafkaAdmin() {Map<String, Object> configs = new HashMap<>();configs.put("bootstrap.servers", "node1:9092");KafkaAdmin admin = new KafkaAdmin(configs);return admin;}@Bean@Autowiredpublic KafkaTemplate<Integer, String> kafkaTemplate(ProducerFactory<Integer, String> producerFactory) {// 覆盖ProducerFactory原有设置Map<String, Object> configsOverride = new HashMap<>();configsOverride.put(ProducerConfig.BATCH_SIZE_CONFIG, 200);KafkaTemplate<Integer, String> template = new KafkaTemplate<Integer, String>(producerFactory, configsOverride);return template;}}
服务端参数配置
$KAFKA_HOME/config/server.properties文件中的一些配置。
1、zookeeper.connect
该参数用于配置Kafka要连接的Zookeeper/集群的地址。
它的值是一个字符串,使用逗号分隔Zookeeper的多个地址。Zookeeper的单个地址是 host:port形式的,可以在最后添加Kafka在Zookeeper中的根节点路径。
如:
zookeeper.connect=node2:2181,node3:2181,node4:2181/myKafka 1
2、listeners
用于指定当前Broker向外发布服务的地址和端口。
配置项为
listeners=PLAINTEXT://:9092
如下:
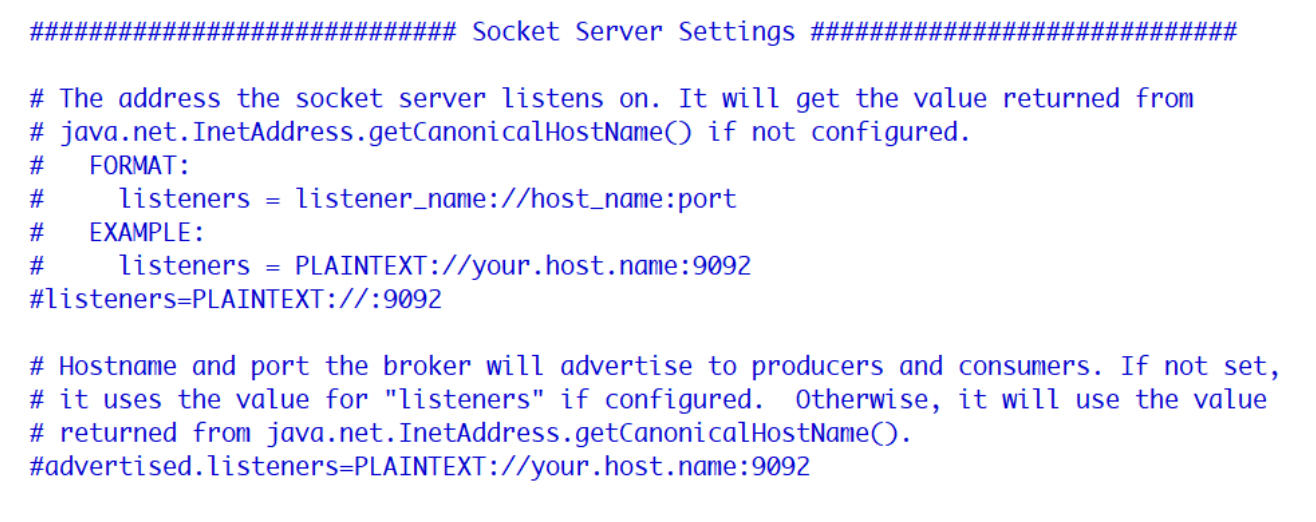
PLAINTEXT是一种协议名称;上面ip地址没写,可以配置成listeners=PLAINTEXT://0.0.0.0:9092,则只有本机可以访问。也可以是其他配置。
可以配置多个,逗号分割。但是多个listener的协议名称不能相同,且端口号不能相同。如果想用一个协议,则需要在listener.security.protocol.map维护听器名称和协议的map。
可以与 advertised.listeners 配合,用于做内外网隔离,比如创建topic和分区的等管理方面的使用一个地址,发送和消费消息则使用另一个地址,即管理和使用分开。
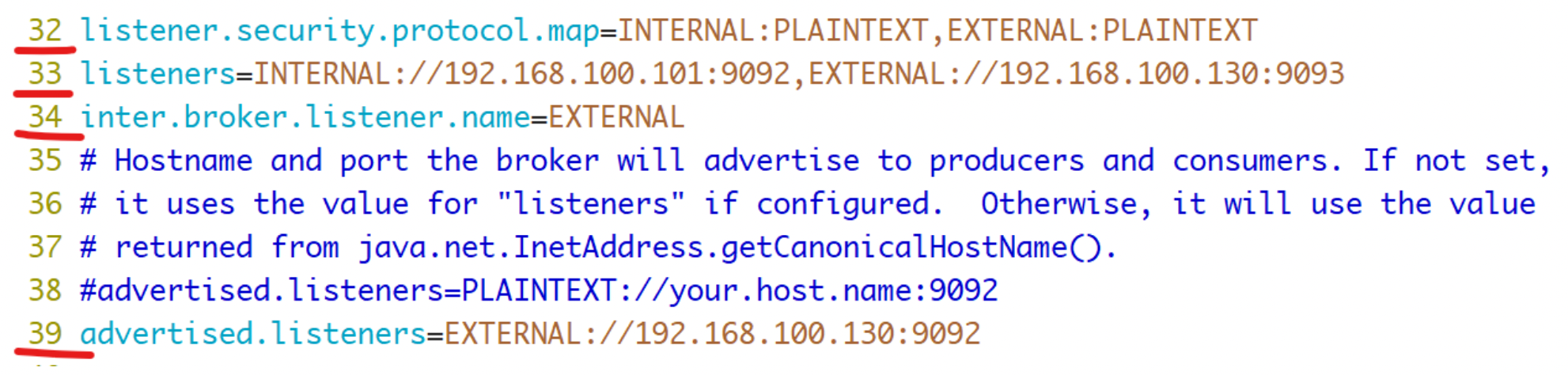
内外网隔离配置:
listener.security.protocol.map
监听器名称和安全协议的映射配置。比如,可以将内外网隔离,即使它们都使用SSL。
listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL
冒号前面代表监听器名称,后面代表真正的协议。每个监听器的名称只能在map中出现一次。
listeners
用于配置broker监听的URI以及监听器名称列表,使用逗号隔开多个URI及监听器名称。如果监听器名称代表的不是安全协议,必须配置listener.security.protocol.map。每个监听器必须使用不同的网络端口。
advertised.listeners
需要将该地址发布到zookeeper供客户端使用。
可以在zookeeper的 get /myKafka/brokers/ids/<broker.id> 中找到。
在IaaS环境,该条目的网络接口得与broker绑定的网络接口不同。
如果不设置此条目,就使用listeners的配置。跟listeners不同,该条目不能使用0.0.0.0网络端口。
advertised.listeners的地址必须是listeners中配置的或配置的一部分。
inter.broker.listener.name
用于配置broker之间通信使用的监听器名称,该名称必须在advertised.listeners列表中。
inter.broker.listener.name=EXTERNAL
典型配置如下:
3、 broker.id
该属性用于唯一标记一个Kafka的Broker,它的值是一个任意integer值。当Kafka以分布式集群运行的时候,尤为重要。
最好该值跟该Broker所在的物理主机有关的,如主机名为 host1.lagou.com ,则 broker.id=1 ;如果主机名为 192.168.100.101 ,则 broker.id=101 等等。
4、 log.dir
通过该属性的值,指定Kafka在磁盘上保存消息的日志片段的目录。它是一组用逗号分隔的本地文件系统路径。
如果指定了多个路径,那么broker 会根据“最少使用”原则,把同一个分区的日志片段保存到同一个路径下。
broker 会往拥有最少数目分区的路径新增分区,而不是往拥有最小磁盘空间的路径新增分区。
相关文章:
【Kafka】开发实战和Springboot集成kafka
目录 消息的发送与接收生产者消费者 SpringBoot 集成kafka服务端参数配置 消息的发送与接收 生产者 生产者主要的对象有: KafkaProducer , ProducerRecord 。 其中 KafkaProducer 是用于发送消息的类, ProducerRecord 类用于封装Kafka的消息…...
初识C语言)
【C语言】(1)初识C语言
什么是C语言 C语言是一种广泛应用的计算机编程语言,它具有强大的功能和灵活性,使其成为系统编程和底层开发的首选语言。C语言的设计简洁、高效,且不依赖于特定的硬件或系统,因此在各种计算平台上都能稳定运行。 C语言的特点 高…...
)
SpringCloudStream整合MQ(待完善)
概念 Spring Cloud Stream 的主要目标是各种各样MQ的学习成本,提供一致性的编程模型,使得开发者能够更容易地集成消息组件(如 Apache Kafka、RabbitMQ、RocketMQ) 官网地址:Spring Cloud Stream 组件 1. Binder 2…...
【Java 数据结构】包装类简单认识泛型
包装类&简单认识泛型 1 包装类1.1 基本数据类型和对应的包装类1.2 装箱和拆箱1.3 自动装箱和自动拆箱 2 什么是泛型3 引出泛型3.1 语法 4 泛型类的使用4.1 语法4.2 示例4.3 类型推导(Type Inference) 5 泛型如何编译的5.1 擦除机制5.2 为什么不能实例化泛型类型数组 6 泛型…...
第139期 做大还是做小-Oracle名称哪些事(20240125)
数据库管理139期 2024-01-25 第139期 做大还是做小-Oracle名称哪些事(20240125)1 问题2 排查3 扩展总结 第139期 做大还是做小-Oracle名称哪些事(20240125) 作者:胖头鱼的鱼缸(尹海文) Oracle A…...

驱动开发--多路复用-信号
一、多路复用 每个进程都有一个描述符数组,这个数组的下标为描述符, 描述符的分类: 文件描述符:设备文件、管道文件 socket描述符 1.1 应用层:三套接口select、poll、epoll select:位运算实现 监控的描…...

LeetCode 2859. 计算 K 置位下标对应元素的和【位操作】1000
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
composer安装hyperf后,nginx配置hyperf
背景 引入hyperf项目用作微服务,使用composer 安装hyperf后,对hyperf进行nginx配置。 配置步骤 因为hyperf监听的是端口,不像其他laravel、lumen直接指向文件即可。所有要监听端口号。 1 配置nginx server {listen 80;//http:…...

Flink对接Kafka的topic数据消费offset设置参数
scan.startup.mode 是 Flink 中用于设置消费 Kafka topic 数据的起始 offset 的配置参数之一。 scan.startup.mode 可以设置为以下几种模式: earliest-offset:从最早的 offset 开始消费数据。latest-offset:从最新的 offset 开始消费数据。…...
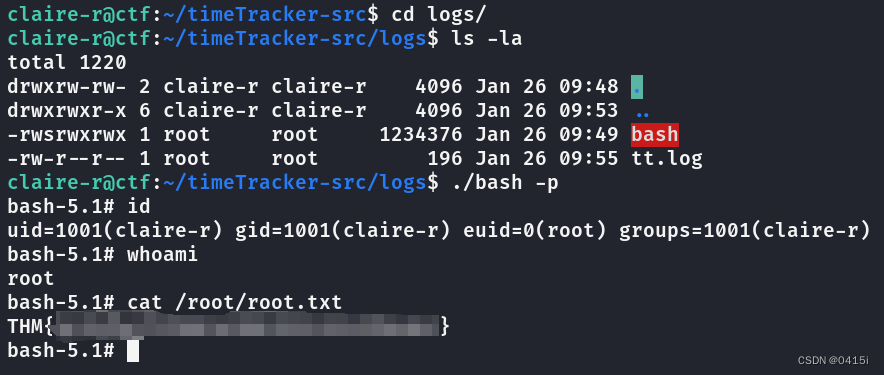
TryHackMe-Umbrella
靶场介绍 Breach Umbrella Corp’s time-tracking server by exploiting misconfigurations around containerisation. 利用集装箱化的错误配置,破坏Umbrella公司的时间跟踪服务器。 Task 1 What is the DB password? 数据库的密码是多少? 端口扫描&am…...

Excel导出警告:文件格式和拓展名不匹配
原因描述: Content-Type 原因:Content-Type,即内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件,这就是经常…...
kafka集群和Filebeat+Kafka+ELK
一、Kafka 概述 1.1 为什么需要消息队列(MQ) 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从…...

golang map真有那么随机吗?——map遍历研究
在随机选取map中元素时,本想用map遍历的方式来返回,但是却并没有通过测试。 那么难道map的遍历并不是那么的随机吗? 以下代码参考go1.18 hiter是map遍历的结构,主要记录了当前遍历的元素、开始位置等来完成整个遍历过程 // A ha…...

详细分析对比copliot和ChatGPT的差异
Copilot 和 ChatGPT 是两种不同的AI工具,分别在不同领域展现出了强大的功能和潜力: GitHub Copilot 定位与用途:GitHub Copilot 是由GitHub(现为微软子公司)和OpenAI合作开发的一款智能代码辅助工具。它主要集成于Visu…...

TENT:熵最小化的Fully Test-Time Adaption
摘要 在测试期间,模型必须自我调整以适应新的和不同的数据。在这种完全自适应测试时间的设置中,模型只有测试数据和它自己的参数。我们建议通过test entropy minimization (tent[1])来适应:我们通过其预测的熵来优化模型的置信度。我们的方法估计归一化…...
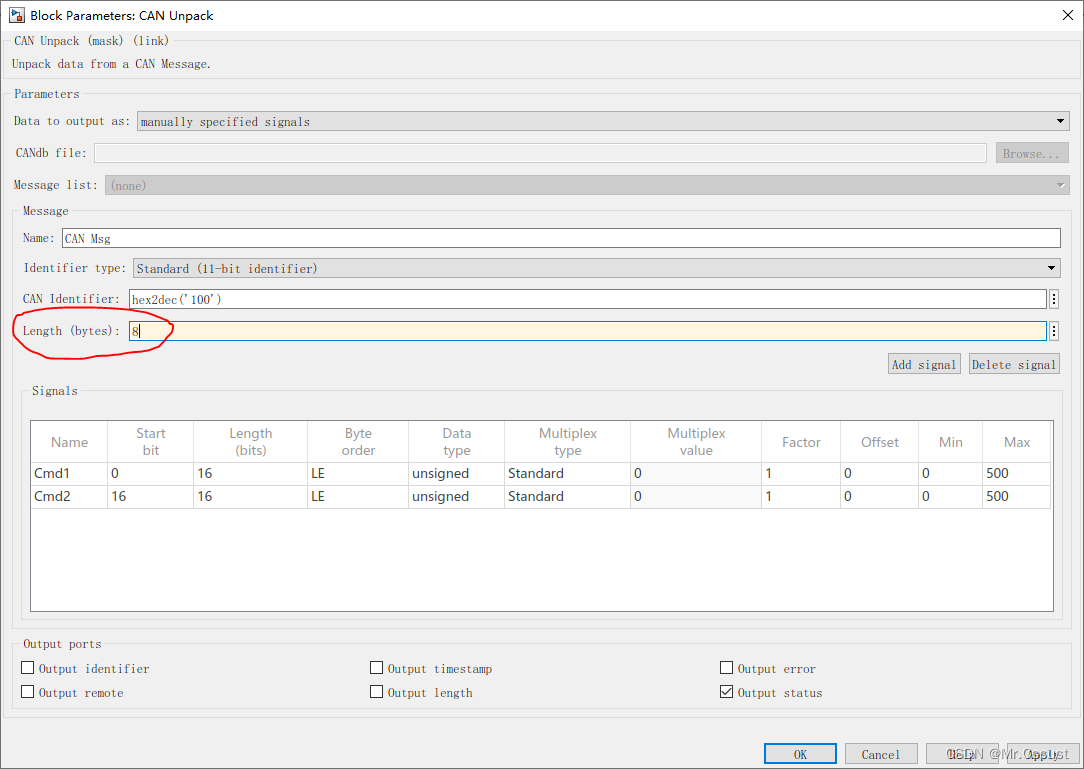
研发日记,Matlab/Simulink避坑指南(五)——CAN解包 DLC Bug
文章目录 前言 背景介绍 问题描述 分析排查 解决方案 总结 前言 见《研发日记,Matlab/Simulink避坑指南(一)——Data Store Memory模块执行时序Bug》 见《研发日记,Matlab/Simulink避坑指南(二)——非对称数据溢出Bug》 见《…...

机器人3D视觉引导半导体塑封上下料
半导体塑封上下料是封装工艺中的重要环节,直接影响到产品的质量和性能。而3D视觉引导技术的引入,使得这一过程更加高效、精准。它不仅提升了生产效率,减少了人工操作的误差,还为半导体封装技术的智能化升级奠定了坚实的基础。 传统…...
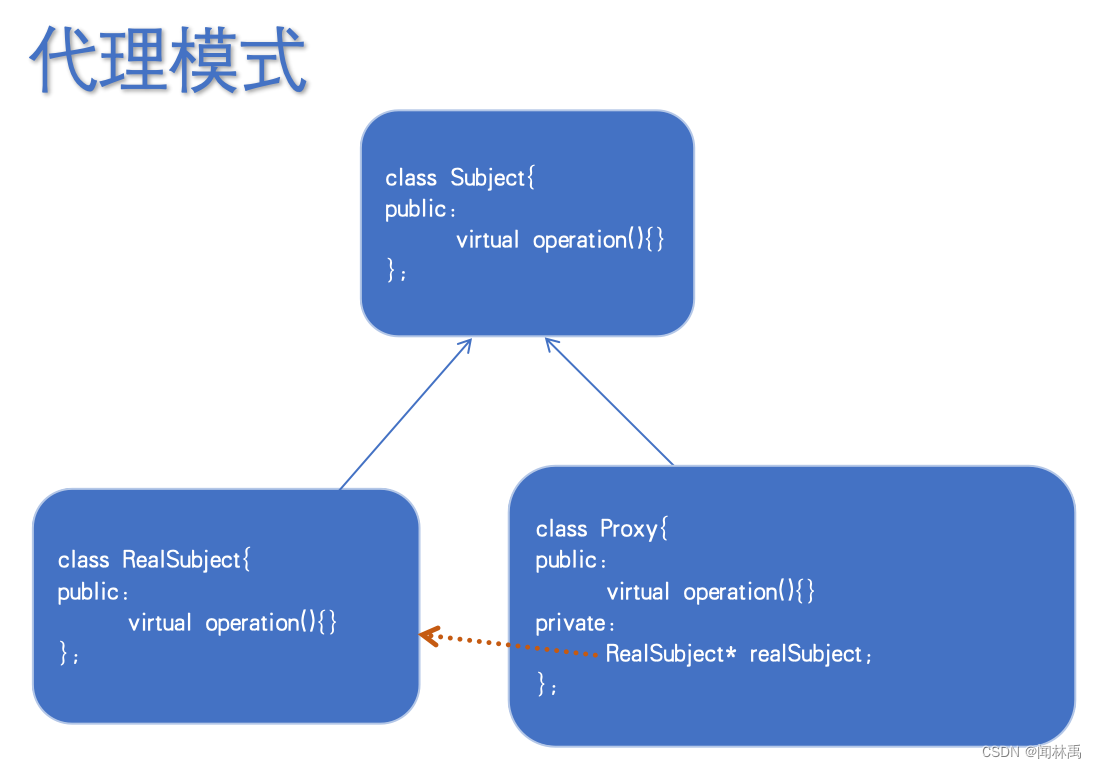
(十二)Head first design patterns代理模式(c++)
代理模式 代理模式:创建一个proxy对象,并为这个对象提供替身或者占位符以对这个对象进行控制。 典型例子:智能指针... 例子:比如说有一个talk接口,所有的people需要实现talk接口。但有些人有唱歌技能。不能在talk接…...
)
C++从零开始的打怪升级之路(day21)
这是关于一个普通双非本科大一学生的C的学习记录贴 在此前,我学了一点点C语言还有简单的数据结构,如果有小伙伴想和我一起学习的,可以私信我交流分享学习资料 那么开启正题 今天分享的是关于vector的题目 1.删除有序数组中的重复项 26. …...

《设计模式的艺术》笔记 - 观察者模式
介绍 观察者模式定义对象之间的一种一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新。 实现 myclass.h // // Created by yuwp on 2024/1/12. //#ifndef DESIGNPATTERNS_MYCLASS_H #define DESIGNPATTERNS_MYCLA…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...