Java集合总览
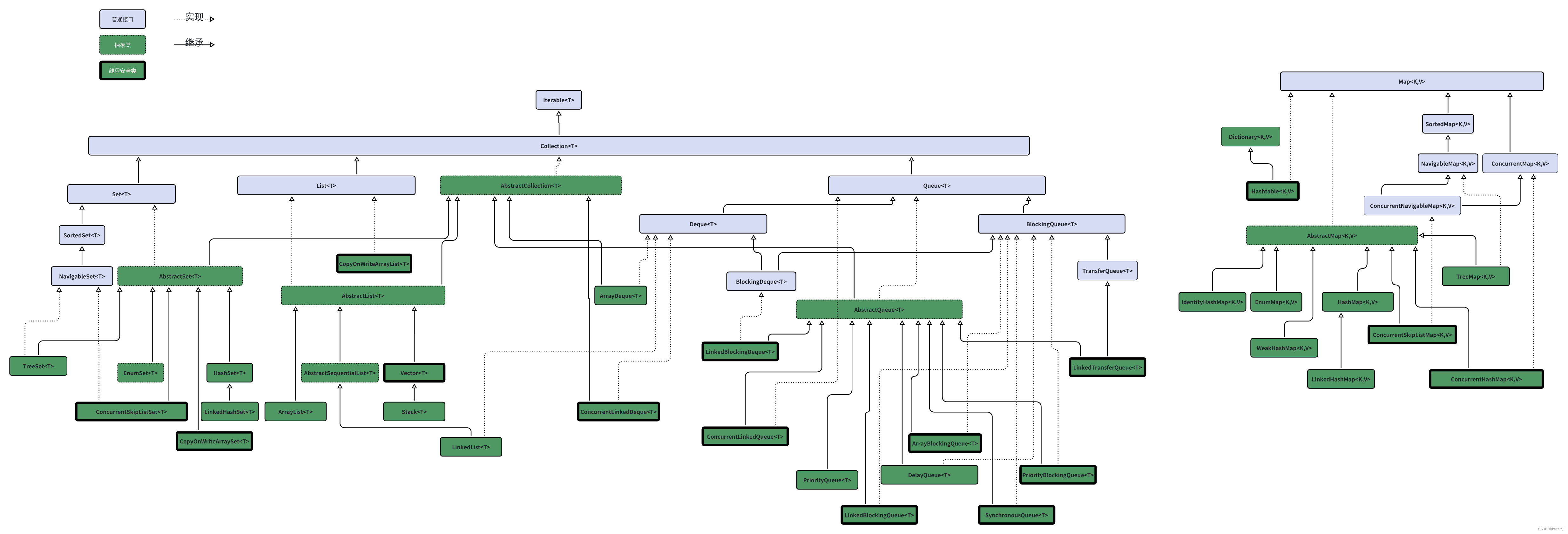
1.总览
Java中的集合分List、Set、Queue、Map 4种类型。
List:大多数实现元素可以为null,可重复,底层是数组或链表的结构,支持动态扩容
Set:大多数实现元素可以为null但只能是1个,不能重复,
2.List
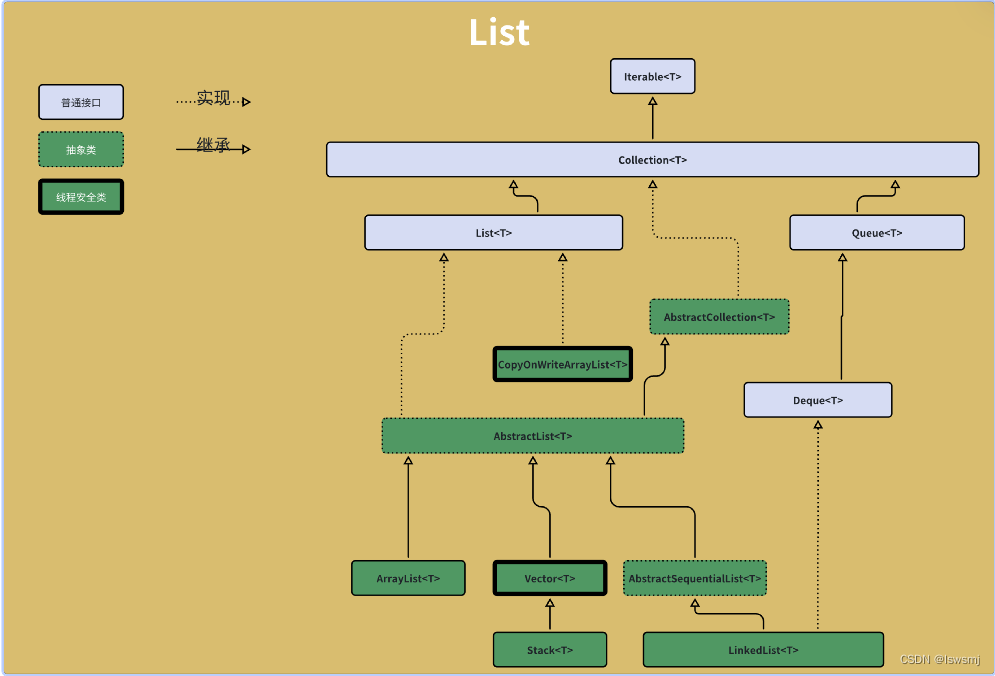
2.1 ArrayList
ArrayList继承AbstractList实现List接口,底层是对象数组,Object[]
可以有多个null,初始大小为10,每次扩容为原容量的1.5倍,
注意:通过下表查找元素效率高,查询要便利所有、插入、删除要大量移动元素效率低
2.2 LinkedList
LinkedList继承AbstractSequentialList实现List、Deque接口,底层是Node链表,可以双向遍历
可以有多个null,初始化没有没有初始任何存储,当有元素进来时,默认从last节点插入,构造链表
注意:通过下标查找元素效率低要遍历到下标位置,查询要遍历所有,插入头和尾很快,插入和删除索引位置需要先遍历到那里再插入和删除
2.3 Vector(线程安全)
Vector继承AbstractList实现List接口,底层和ArrayList一样也是对象数组,Object[]
它和ArrayList的唯一区别是: 它是线程安全的,实现的方式是每个有线程安全风险的方法上添加 synchronized 进行同步
2.4 Stack(线程安全)
Stack继承Vector,是个先进后出的结构,底层和ArrayList一样也是对象数组,Object[]
2.5 CopyOnWriteArrayList(线程安全)
CopyOnWriteArrayList实现了List接口,底层和ArrayList一样也是对象数组,volatile Object[] array,注意这里用volatile进行了修饰,保证当array引用更改时,所有线程都能获取到最新的引用。
CopyOnWriteArrayList原理:读支持多线程并发读,写时复制原则
set(index, e) 过程:
- 先加锁,
- 获取原数组引用,
- 获取原值,
- 原值和新值不同时拷贝新数组,新数组值更新,更新array指向,返回旧值
- 原值和新值相同是,更新array指向(还是原来的),返回旧值(还是原来的)
- 解锁
add(e)过程:
- 先加锁,
- 获取原数组引用,
- 拷贝新数组,新数组值更新,更新array指向,返回true,解锁
3.Set
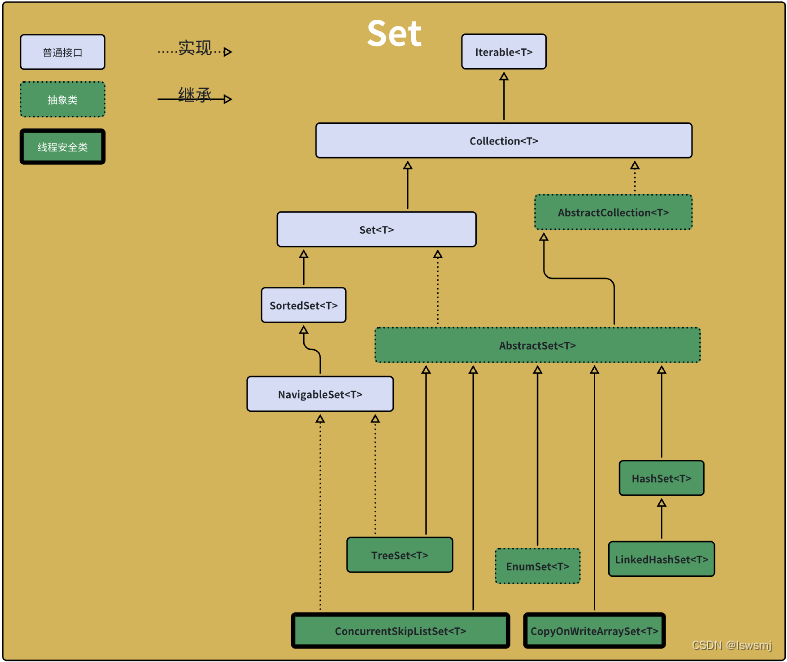
3.1 HashSet
HashSet继承AbstractHashSet实现Set接口,底层实际是HashMap或LinkedHashMap,在底层数据结构是:Node[]数组+单链表+红黑树
可以为null,但只会有一个null,初始大小为16,加载因子是0.75,扩容时是2的倍数
当调用HashSet的add方法时,实际是调用HashMap的put方法,key是add的值,value是一个共享的Object变量。
注意:因为不是线程安全的,调用size方法,返回的size可能会和真实元素个数不一致
3.2 LinkedHashSet
LinkedHashSet继承HashSet,它的代码很少,因为它借助HashSet的LinkedHashMap为底层实现,完成插入顺序的HashSet
其余都和HashSet一致
3.3 TreeSet
TreeSet继承AbstractSet实现NavigableSet接口,和HashSet相比:
- 集合种的元素不保证插入排序,默认使用元素自然排序,可以自定义排序器
- jdk1.8之后,集合中的元素不可以为null
TreeSet使用TreeMap实现,底层用的是红黑树。
注意:与HashSet相比,TreeSet的性能稍低,add、remove、search等操作时间复杂度为O(log n),按照顺序打印n个元素为O(n)
3.4 CopyOnWriteArraySet(线程安全)
CopyOnWriteArraySet继承AbstractSet,底层使用的是CopyOnWriteArrayList,
当加入的数据不存在时,再添加
3.5 ConcurrentSkipListSet(线程安全)
ConcurrentSkipListSet继承了AbstractSet实现了NavigableSet接口,底层使用ConcurrentNavigableMap实现,和HashSet使用HashMap实现一致
数据不能为null,使用ConcurrentNavigableMap的key存储值,Boolean.TRUE最为ConcurrentNavigableMap的value
注意:此类线程安全且有序,可以传递一个排序器
4.Queue
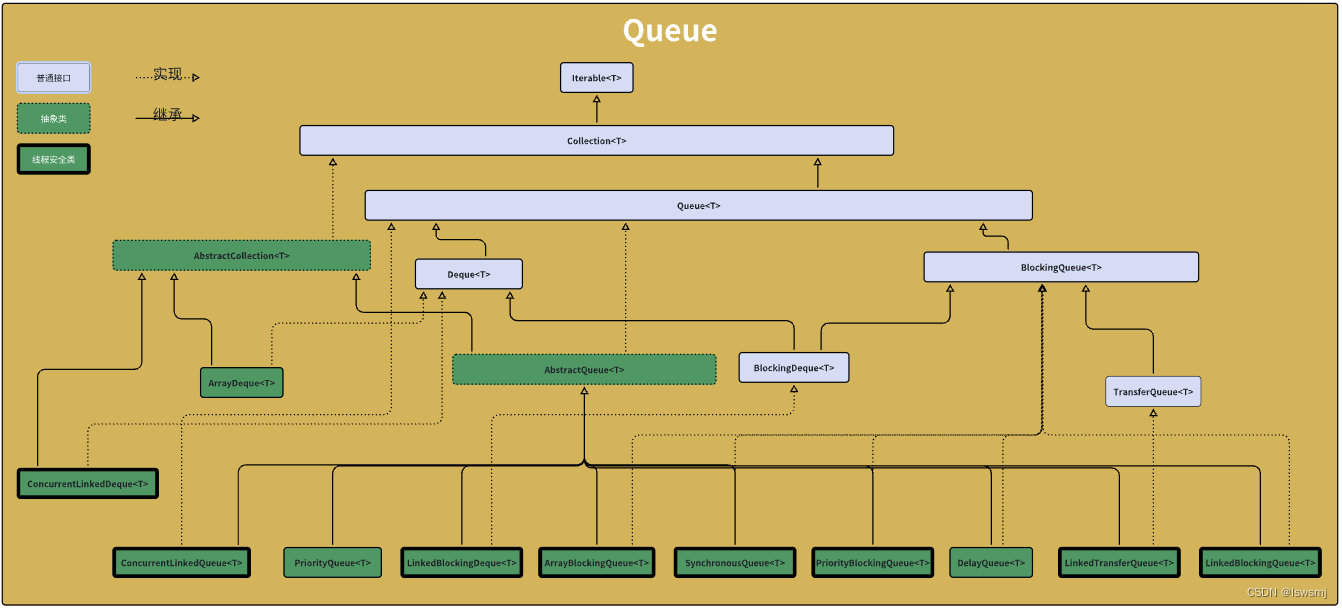
Queue是一种先进先出的数据结构,形如我们现时生活中的排队,第一个到的排在最前面,后面到的依次向后排,第一个处理完后处理第二个。
Deque是在Queue的基础上支持从尾部取数据的功能,Deque能适合更多的场合
4.1ArrayDeque
ArrayDeque继承AbstractCollection实现了Deque接口,它底层是一个Object[]数组,它支持自动扩容,默认初始容量是16,当元素达到队列的容量后就自动以2的倍数扩容,元素不能是null。
原理:ArrayDeque里面维护了head和tail两个指针,两个指针初始都是0,表示的是Object[]数组的下标,
正常使用队列使用的是offer方法,offer调用的是addLast方法,此方法是先在tail位置放置元素,然后再移动tail指针指向下一个位置,如果下一个位置就是head指针指向的位置则表示数组已全部放置了数据,需要对其进行扩容
addFirst使用的是head指针,head指针向左移动,[head = (head - 1) & (elements.length - 1)] = 15,在数组的最后一个位置放入元素,如果再addFirst就是向14这个位置放置元素,
总结:ArrayDeque是一个双端队列,内部使用head和tail指针进行控制元素的进队和出队
注意:数字在计算机中是以补码的方式存储的,正数的补码等于自己的原码,负数的补码等于自己的原码除符号位取反再+1,如1的原码和补码都是00000001,-1的原码是10000001,反码是11111110,补码是11111111
4.2 PriorityQueue
PriorityQueue继承AbstractQueue,它底层是一个Object[]数组,它支持自动扩容,默认初始容量是11,当元素达到队列的容量后,它会判断当前容量是否小于64,小于64的话,容量+2否则容量扩大一倍;元素不能是null。
原理:PriorityQueue其实是一种堆排序结构,默认是小根堆,堆底层使用Object[]数组实现。
堆:1.堆中的某个节点总是大于或者不小于其父亲节点的值 2.堆总是一颗完全二叉树
重要方法逻辑:
插入元素:1.先将元素放入到堆的最后一个节点的位置(也就是数组的有效元素的最后的一个位置)注:此时空间不够时需要进行扩容。 2. 将最后插入的节点向上调整,直到满足堆的性质
删除元素(弹出堆的第一个元素):1. 将堆顶元素和堆中的最后一个元素进行交换 2.删除堆的最后一个元素 3.对堆顶元素进行向下调整
效率:加入一个数的时间复杂度是logN;取最大数且继续维持大根堆的时间复杂度是logN;
4.3 DelayQueue(线程安全)
DelayQueue继承AbstractQueue实现BlockingQueue。它底层是PriorityQueue,依赖PriorityQueue的能力来存储元素。DelayQueue里的元素都有一个延期时间实现Delayed接口,PriorityQueue按照延期时间进行排序。当还未到延期时间,DelayQueue弹出的数据为空。DelayQueue的线程安全是使用ReentrantLock进行控制。
4.3.1 Thread lead 成员变量的用处
leader来减少不必要的等待时间,那么这里我们的DelayQueue是怎么利用leader来做到这一点的呢:
这里我们想象着我们有个多个消费者线程用take方法去取,内部先加锁,然后每个线程都去peek第一个节点.如果leader不为空说明已经有线程在取了,设置当前线程等待
if (leader != null)available.await();如果为空说明没有其他线程去取这个节点,设置leader并等待delay延时到期,直到poll后结束循环
else {Thread thisThread = Thread.currentThread();leader = thisThread;try {available.awaitNanos(delay);} finally {if (leader == thisThread)leader = null;}}take方法中 为什么释放first元素
first = null; // don't retain ref while waiting我们可以看到doug lea后面写的注释,那么这段代码有什么用呢?
想想假设现在延迟队列里面有三个对象。
- 线程A进来获取first,然后进入 else 的else ,设置了leader为当前线程A
- 线程B进来获取first,进入else的阻塞操作,然后无限期等待
- 这时他是持有first引用的
- 如果线程A阻塞完毕,获取对象成功,出队,这个对象理应被GC回收,但是他还被线程B持有着,GC链可达,所以不能回收这个first.
- 假设还有线程C 、D、E.. 持有对象1引用,那么无限期的不能回收该对象1引用了,那么就会造成内存泄露.
4.4 ConcurrentLinkedQueue(线程安全)
ConcurrentLinkedQueue继承AbstractQueue实现Queue接口。它是一个线程安全的先进先出队列实现,内部维护了head和tail两个volatile的指针,它底层是链表,自定义了Node节点,Node类中用volatile声明了item和next变量,并使用CAS的方式设置节点的next节点等,不支持null元素。
下面以offer方法的注释来详细说明下ConcurrentLinkedQueue
public boolean offer(E e) {// 检查e是不是null,是的话抛出NullPointerException异常。checkNotNull(e);// 创建新的节点final Node<E> newNode = new Node<E>(e);// 将“新的节点”添加到链表的末尾。for (Node<E> t = tail, p = t;;) {Node<E> q = p.next;// 情况1:q为空,p是尾节点插入if (q == null) {// CAS操作:如果“p的下一个节点为null”(即p为尾节点),则设置p的下一个节点为newNode。// 如果该CAS操作成功的话,则比较“p和t”(若p不等于t,则设置newNode为新的尾节点),然后返回true。// 如果该CAS操作失败,这意味着“其它线程对尾节点进行了修改”,则重新循环。if (p.casNext(null, newNode)) {if (p != t) // hop two nodes at a timecasTail(t, newNode); // Failure is OK.return true;}}// 情况2:p和q相等else if (p == q)p = (t != (t = tail)) ? t : head;// 情况3:其它elsep = (p != t && t != (t = tail)) ? t : q;}
}5.5 LinkedBlockingQueue(线程安全)
LinkedBlockingQueue继承AbstractQueue实现BlockQueue接口,底层是链表,使用ReentrantLock进行并发安全控制。不允许添加null。
注意:如果不传入参数则默认大小是Integer.max,如果传入参数则大小就是传入的数值,当queue中元素达到最大值时,put 添加元素操作会被阻塞,等queue中不满时才能继续插入,使用Condition notEmpty进行await和signal进行等待和唤醒
5.6 ArrayBlockingQueue(线程安全)
ArrayBlockingQueue继承AbstractQueue实现BlockingQueue,底层是数组,使用ReentrantLock进行并发安全控制。不允许添加null。
原理:使用takeIndex和putIndex对取出和放入的位置进行控制,当take时,取taskIndex的位置元素,当put时put putIndex位置的元素,take和put后,判断takeIndex和putIndex是否等于数组的长度,等于的话从0继续开始
注意:传入参数就是底层数组的大小,当queue中元素达到最大值时,put 添加元素操作会被阻塞,等queue中不满时才能继续插入,使用Condition notEmpty notFull两个进行控制
5.Map
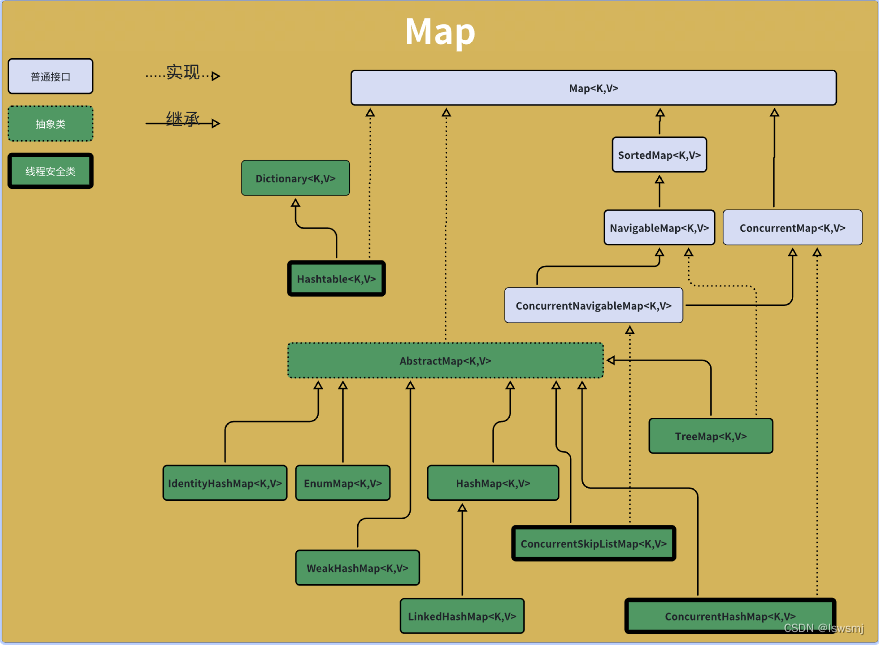
5.1 HashMap
HashMap继承AbstractMap实现Map接口。底层是数组+链表+红黑树。允许key和value为null
扩容:HashMap初始容量是16,默认负载因子是0.75,当HashMap中的元素数量大于 容量*负载因子则进行容量*2的扩容操作。
引入红黑树的原因:降低查找相同hash值节点的速度,红黑树也是一种平衡二叉树,当节点数量大于等于8且HashMap中的元素大于等于64的时候才会将链表转化成红黑树,当节点数量小于等于6的时候红黑树退化成链表
5.1.1 put方法
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}// 这就是那个扰动函数 作用:让key的hash值的高16位也参与路由运算(在hash表数组长度还不是很大的情况下,让hash值的高16位也参与进来)
// key如果是null则就放到 数组的0位置
// h = 0010 1100 1010 0011 1000 0101 1101 1100
// ^
// h>>>16 = 0000 0000 0000 0000 0010 1100 1010 0011
// = 0010 1100 1010 0011 1010 1001 0111 1111
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {// tab: 引用当前哈希表的数组// p: 当前哈希表的元素// n: 哈希表数组的长度// i: 路由寻址的结果 Node<K,V>[] tab; Node<K,V> p; int n, i;// 如果当前hashmap的数组为null或数据为0, hashmap设计为第一次向其插入数据的时候会初始化(延迟初始化)if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 最简单的情况,寻址找到的数组的位置正好是null,则直接把当前k v封装成node放进去 if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else { // 存在和要插入元素相同hash值的元素// e: node临时元素// k: 临时的一个keyNode<K,V> e; K k;// 表示数组中的元素与当前要插入的元素 完全一致,表示后续需要进行替换操作if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// P元素已经树化了else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 还是链表结构,且链表的头元素和要插入的元素的key不一致for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) { // 当前元素是最后一个元素,// 则将新节点放到p的后面p.next = newNode(hash, key, value, null);// 判断后的元素是否达到 TREEIFY_THRESHOLD(8)if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); // 树化操作break;}// 在链表中找到一个key和当前要插入元素的key一致的元素if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // 找到了要替换的数据, 判断onlyIfAbsent后进行替换数据操作V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}5.1.2 resize方法
// 为什么需要扩容:为了解决哈希冲突导致的链化影响查询效率的问题,通过扩容来缓解
final Node<K,V>[] resize() {// oldTab:扩容前的哈希表Node<K,V>[] oldTab = table;// oldCap:扩容之前的table数组的长度int oldCap = (oldTab == null) ? 0 : oldTab.length;// oldThr:扩容之前的扩容阈值,触发本次扩容的阈值int oldThr = threshold;// newCap:扩容之后哈希数组的大小// newThr:扩容之后,下次再次触发扩容的条件int newCap, newThr = 0;// 下面if else 就是计算本次扩容之后 数组的大小newCap, 以及下次再次触发扩容的大小newThr if (oldCap > 0) {// 哈希表已经初始化过了,这是一次正常扩容if (oldCap >= MAXIMUM_CAPACITY) { // 扩容之前的哈希数组大小已经达到最大阈值了,则不扩容,且设置扩容条件为threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)// 容量翻倍newThr = oldThr << 1; }else if (oldThr > 0) // 哈希表还是null,如下情况:1.new HashMap(initCapacity, loadFatory) 2.new HashMap(initCapacity) 3.new HashMap(map)newCap = oldThr;else {// 哈希表还是null,且 只有 new HashMap()时newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//newThr为0时,通过newCap和loadFactory计算出一个newThrif (newThr == 0) { float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 创建一个更大的数组table = newTab;if (oldTab != null) { // 说明扩容之前,哈希里面已经有数据了for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) { // 当前哈希数组位置有数据oldTab[j] = null; // 置空,方便JVM回收内存if (e.next == null) // 当前元素没有和任何数据发生碰撞, 最简单情况newTab[e.hash & (newCap - 1)] = e; // 新计算哈希表的索引将值放进去就行else if (e instanceof TreeNode) // 当前节点已树化((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // 链表情况// 低位链表:存放在扩容之后的数组的下标位置,与当前数组的下标位置一致Node<K,V> loHead = null, loTail = null;// 高位链表:存放在扩容之后的数组的下标位置为当前数组的下标位置 + 扩容之前数组的长度Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// hash -> ... 0 1111// oldCap->000 1 0000// ->000 0 0000 这样就巧妙的分出 loHead和hiHead了if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) { // 低位链表有数据, 处理链表指向loTail.next = null;newTab[j] = loHead;}if (hiTail != null) { // 高位链表有数据, 处理链表指向hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}5.1.3 get方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {// tab:当前哈希表的数组// first:哈希表数组桶位的头元素// e:临时node元素// n:哈希表的数组的长度Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) { // 哈希表不等于空,且要取的数据的key的哈希值在哈希表中存在if (first.hash == hash && // 哈希表数组中的头元素就是需要查找的数据,则直接返回((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) { // 当前桶位不止一个元素,可能树、可能链表if (first instanceof TreeNode) // 树return ((TreeNode<K,V>)first).getTreeNode(hash, key);do { // 循环每个节点判断是否相等,是则返回if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}5.1.4 remove方法
public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;
}final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {//tab:引用哈希表中的数组//p:当前Node元素//n:哈希表的长度//index:寻址结果Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) { // 哈希有数据,且路由到的数组索引也是有数据的,需要进行查找操作并且删除// node:查找到的结果// e:当前node的下一个节点Node<K,V> node = null, e; K k; V v;if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 第一种情况 当前数组索引中的元素就是你要删除的元素node = p;else if ((e = p.next) != null) { // 当前数组索引不是你要删除的元素,且数组索引的头节点后续还有节点,不是树就是链表if (p instanceof TreeNode) // 第二种情况 是树node = ((TreeNode<K,V>)p).getTreeNode(hash, key);else { // 第三种情况 链表do {// 循环链表查询if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode) // 树 情况删除节点((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);else if (node == p) // 数组头节点是要删除的元素tab[index] = node.next;else // 链表元素删除 node是p.nextp.next = node.next;++modCount;--size;afterNodeRemoval(node);return node;}}return null;
}public boolean remove(Object key, Object value) {return removeNode(hash(key), key, value, true, true) != null;
}5.1.5 replace方法
// key和oldValue都相同 替换value
public boolean replace(K key, V oldValue, V newValue) {Node<K,V> e; V v;if ((e = getNode(hash(key), key)) != null &&((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {e.value = newValue;afterNodeAccess(e);return true;}return false;
}// key相同,替换value
public V replace(K key, V value) {Node<K,V> e;if ((e = getNode(hash(key), key)) != null) {V oldValue = e.value;e.value = value;afterNodeAccess(e);return oldValue;}return null;
}5.2 TreeMap
TreeMap继承AbstractMap实现NavigableMap接口,底层是红黑树结构
可以传一个自定义排序器,对元素进行排序,元素的key不能为null
5.3 LinkedHashMap
LinkedHashMap继承HashMap实现Map接口,底层使用哈希表与双向链表来保存所有元素,哈希表使用的是HashMap,双向链表实现是LinkedHashMap重新定义了哈希表的数组中保存元素的Entry,它除了保存当前对象的引用外,还保存了其上一个元素-before和下一个元素-after的引用,从而在哈希标的基础上又构建了双向链表。
- put方法
当用户调用put方法时,实际时调用HashMap的put方法,LinkedHashMap没有重写put方法,但是重写了put方法中的newNode方法,此方法会生成一个LinkedHashMap的Entry并构建好链表结构后返回
- remove方法
当用户调用remove方法,实际还是调用HashMap的remove方法,在remove方法最后,会调用afterNodeRemove方法,此方法LinkedHashMap进行了重写,在这个方法里,LinkedHashMap重新维护的双向链表结构
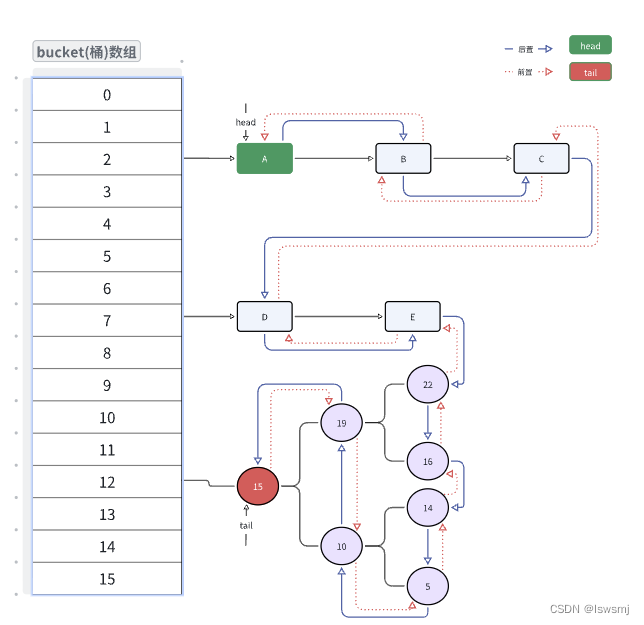
LinkedHashMap支持insert排序和访问排序,默认insert排序。
支持key和value都为null
5.4 ConcurrentHashMap(线程安全)
ConcurrentHashMap继承AbstractMap实现ConcurrentMap接口,jdk1.8采用了更细粒度的锁,采用Node+Synchronized+CAS算法实现,降低了锁粒度,并发性能更好,并且结构上与HashMap更加一致
key和value都不允许为null,
- size方法:
size方法并不简单返回一个计数器的值,每次调用它,它都会调用sumCount()方法进行计算,baseCount+countCells数组存储的值,baseCount会在每次修改Map影响个数的时候修改,如果CAS的方式修改失败,修改数放入countCells。
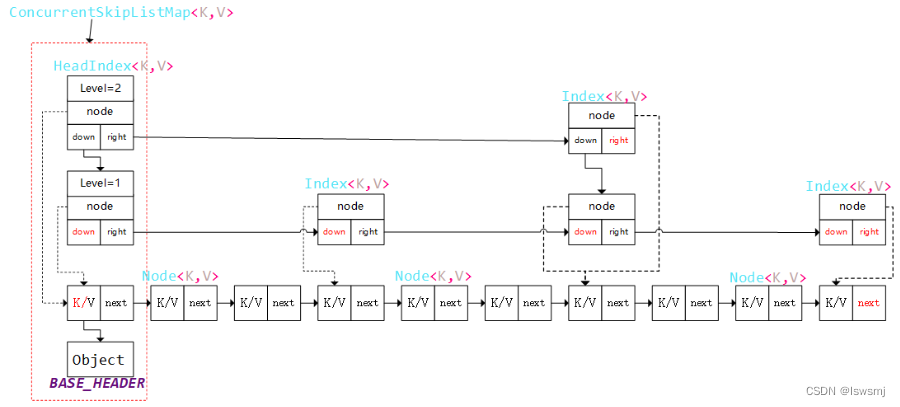
5.5 ConcurrentSkipListMap(线程安全)
ConcurrentSkipListMap继承AbstractMap实现了ConcurrentNavigableMap接口,底层是一个跳表的并发Map集合,没有使用哈希表。
其元素可以通过自定义排序器进行排序,不允许key和value的值为null
原理:
- 底层结构:HeadIndex、Index、Node
Node:key value和指向下一个Node节点的next,单向链表
Index:SkipList的索引节点。内部2个指针,down:指向下一层,right:指向右边的index,还有一个代表当前节点的node
HeadIndex:index的子类,多了一个level属性,只在头部使用
相关文章:
Java集合总览
1.总览 Java中的集合分List、Set、Queue、Map 4种类型。 List:大多数实现元素可以为null,可重复,底层是数组或链表的结构,支持动态扩容 Set:大多数实现元素可以为null但只能是1个,不能重复, …...
C# 设置一个定时器函数
C#中,创建设置一个定时器,能够定时中断执行特定操作,可以用于发送心跳、正计时和倒计时等。 本文对C#的定时器简单封装一下,哎,以方便定时器的创建。 定义 using Timer System.Timers.Timer;class SetTimer {Timer …...

第十四届蓝桥杯省赛pythonB组题。 管道
5407. 管道 - AcWing题库 有一根长度为 len的横向的管道,该管道按照单位长度分为 len 段,每一段的中央有一个可开关的阀门和一个检测水流的传感器。 一开始管道是空的,位于 Li 的阀门会在 Si 时刻打开,并不断让水流入管道。…...
淘宝扭蛋机小程序:新时代的互动营销与娱乐体验
随着科技的快速发展,小程序已经成为人们日常生活中不可或缺的一部分。在众多的小程序中,淘宝扭蛋机小程序以其独特的互动性和趣味性,吸引了大量用户。本文将深入探讨淘宝扭蛋机小程序的特色、用户体验以及未来发展。 一、淘宝扭蛋机小程序的…...

深度强化学习(王树森)笔记02
深度强化学习(DRL) 本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。 参考链接 Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL 源代码链接:https://github.c…...

【分布式技术专题】「分布式技术架构」 探索Tomcat技术架构设计模式的奥秘(Server和Service组件原理分析)
探索Tomcat技术架构设计模式的奥秘 Tomcat系统架构分析Tomcat 整体结构Tomcat总体结构图以 Service 作为“婚姻”1) Service 接口方法列表 2) StandardService 的类结构图方法列表 3) StandardService. SetContainer4) StandardService. addConnector 以 Server 为“居”1) Ser…...

常用的gpt-4 prompt words收集8
本文介绍我最近收集的一些好用的chatgpt-4的prompts,如果你也有好用的提示词可以互相交流一下。 1. I ran into some trouble on my way to work. 迟到原因 2. In my heart, the most delicious coffee is the Hawaii Dirty from Manner. Only the Nong series a…...

【GitHub项目推荐--开源2D 游戏引擎】【转载】
microStudio 是一个可在浏览器中运行的游戏引擎,它拥有一套精美、设计精良、全面的工具,可以非常轻松地帮助你创建 2D 游戏。 你可以在浏览器中访问 microStudio.dev 开始搭建你的游戏,当然你可以克隆现有项目或创建新游戏并开始编码&#x…...

鸿蒙APP的应用场景
鸿蒙APP可以用于多种场合和设备类型,这是鸿蒙系统的分布式能力和多终端适配的优势。以下是一些鸿蒙APP的应用场景,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1.智能手机和平板电脑&am…...
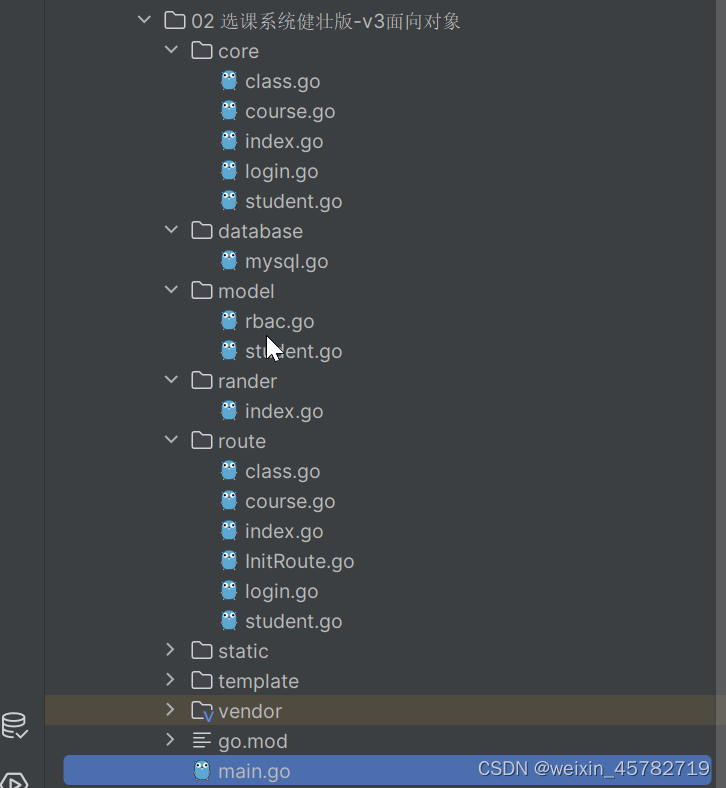
goland课程管理(6)
项目目录结构如下图所示: core包下面: class.go package coreimport "github.com/gin-gonic/gin"func Class1(ctx *gin.Context) {}course.go package coreimport (. "cookie/database". "cookie/model""fmt"…...
)
04.Elasticsearch应用(四)
Elasticsearch应用(四) 1.什么是索引 索引是文档的容器,是一类文档的结合索引是一个逻辑命名空间,它映射到一个或多个主分片,并且可以具有零个或多个副本分片索引中数据分散在Shard上索引的Mapping定义文档字段的类型…...
Python之数据可视化(地图)
目录 一 基础地图应用 二 全国疫情图 一 数据准备 二 数据处理 二 湖北省疫情图 一 数据准备 二 数据处理 一 基础地图应用 导入map地图对象 from pyecharts.charts import Map map Map() 写入数据 data [("北京市",100),("上海市"…...
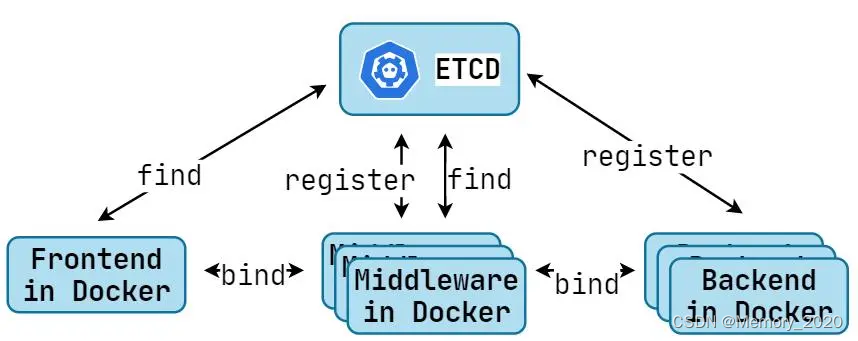
etcd技术解析:构建高可用分布式系统的利器
1. 引言 随着云原生技术的兴起,分布式系统的构建变得愈发重要。etcd作为一个高可用的分布式键值存储系统,在这个领域发挥着至关重要的作用。本文将深入探讨etcd的技术细节,以及如何利用它构建高可用的分布式系统。 2. etcd简介 etcd是一个开…...

Pillow图像处理:从零开始的奇妙之旅
图像处理,就像是一场神奇的冒险,让我们的照片变得更有趣、更生动。而在这个冒险的旅途中,Pillow就如同一位魔法师,为我们开启了无尽的可能性。无论你是刚刚踏入图像处理领域的小白,还是已经略有基础的程序员࿰…...
缓存)
设计一个LRU(最近最少使用)缓存
约束和假设 我们正在缓存什么? 我们正在缓存Web Query的结果我们可以假设输入是有效的,还是需要对其验证? 假设输入是有效的我们可以假设它适应内存吗? 对 编码实现 class Node(object):def __init__(self, results):self.res…...

shell 循环语句
一、命令补充 1. echo 命令 echo -n 表示不换行输出 echo -e 表示输出转义符 常用的转义符有: 选项作用\r光标移至行首,并且不换行\s当前shell的名称,如bash\t插入Tab键,制表符\n输出换行\f换行,但光标仍停留在…...
 命名空间)
C++(1) 命名空间
文章目录 C1. C 概述2.C 相对于 C 语言的增强2.1C 第一行代码2.2 C 补充 bool 类型2.3 作用域运算符2.4 命名空间 namespace2.4.1 命名空间基本内容和开放性2.4.2 多个命名空间操作2.4.3 命名空间函数定义和实现分离2.4.4 匿名命名空间2.4.5 命名空间别名 C 1. C 概述 C 之父…...

【机组】单元模块实验的综合调试与驻机键盘和液晶显示器的使用方式
🌈个人主页:Sarapines Programmer🔥 系列专栏:《机组 | 模块单元实验》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录 1. 综合实验的调试 1.1 实验…...

React中实现虚拟加载滚动
前言:当一个页面中需要接受接口返回的全部数据进行页面渲染时间,如果数据量比较庞大,前端在渲染dom的过程中需要花费时间,造成页面经常出现卡顿现象。 需求:通过虚拟加载,优化页面渲染速度 缺点:…...

vue中的Mutations
目录 一:介绍 二:例子 一:介绍 Vuex 中的 mutation 非常类似于事件: 每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。这个回调函数就是我们实际进行状态更改的函数,并且它会接受 sta…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...