pytorch 实现中文文本分类
🍨 本文为[🔗365天深度学习训练营学习记录博客🍦 参考文章:365天深度学习训练营🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)![]()
train.csv 链接:https://pan.baidu.com/s/1Vnyvo5T5eSuzb0VwTsznqA?pwd=fqok 提取码:fqok import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def coustom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
1.构建词典:
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text, in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])

调用vocab(词汇表)对一个中文句子进行索引转换,这个句子被分词后得到的词汇列表会被转换成它们在词汇表中的索引。
print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))
生成一个标签列表,用于查看在数据集中所有可能的标签类型。
label_name = list(set(train_data[1].values[:]))
print(label_name) 创建了两个lambda函数,一个用于将文本转换成词汇索引,另一个用于将标签文本转换成它们在label_name列表中的索引。
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))
2.生成数据批次和迭代器
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)
collate_batch函数用于处理数据加载器中的批次。它接收一个批次的数据,处理它,并返回适合模型训练的数据格式。- 在这个函数内部,它遍历批次中的每个文本和标签对,将标签添加到
label_list,将文本通过text_pipeline函数处理后转换为tensor,并添加到text_list。 offsets列表用于存储每个文本的长度,这对于后续的文本处理非常有用,尤其是当你需要知道每个文本在拼接的大tensor中的起始位置时。text_list用torch.cat进行拼接,形成一个连续的tensor。offsets列表的最后一个元素不包括,然后使用cumsum函数在第0维计算累积和,这为每个序列提供了一个累计的偏移量。
3.搭建模型与初始化
from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)num_class = len(label_name) # 类别数,根据label_name的长度确定
vocab_size = len(vocab) # 词汇表的大小,根据vocab的长度确定
em_size = 64 # 嵌入向量的维度设置为64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device) # 创建模型实例并移动到计算设备4.模型训练及评估函数
train 和 evaluate分别用于训练和评估文本分类模型。
训练函数 train 的工作流程如下:
- 将模型设置为训练模式。
- 初始化总准确率、训练损失和总计数变量。
- 记录训练开始的时间。
- 遍历数据加载器,对每个批次:
- 进行预测。
- 清零优化器的梯度。
- 计算损失(使用一个损失函数,例如交叉熵)。
- 反向传播计算梯度。
- 通过梯度裁剪防止梯度爆炸。
- 执行一步优化器更新模型权重。
- 更新总准确率和总损失。
- 每隔一定间隔,打印训练进度和统计信息。
评估函数 evaluate 的工作流程如下:
- 将模型设置为评估模式。
- 初始化总准确率和总损失。
- 不计算梯度(为了节省内存和计算资源)。
- 遍历数据加载器,对每个批次:
- 进行预测。
- 计算损失。
- 更新总准确率和总损失。
- 返回整体的准确率和平均损失。
代码实现:
import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_count
5.模型训练
- 设置训练的轮数、学习率和批次大小。
- 定义交叉熵损失函数、随机梯度下降优化器和学习率调度器。
- 将训练数据转换为一个map样式的数据集,并将其分成训练集和验证集。
- 创建训练和验证的数据加载器。
- 开始训练循环,每个epoch都会训练模型并在验证集上评估模型的准确率和损失。
- 如果验证准确率没有提高,则按计划降低学习率。
- 打印每个epoch结束时的统计信息,包括时间、准确率、损失和学习率。
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)
运行结果:
| epoch 1 | 50/ 152 batches | accuracy 0.423 | loss 0.03079
| epoch 1 | 100/ 152 batches | accuracy 0.700 | loss 0.01912
| epoch 1 | 150/ 152 batches | accuracy 0.776 | loss 0.01347
---------------------------------------------------------------------
| end of epoch 1 | time: 1.53s | valid accuracy 0.777 | valid loss 2420.000 | lr 5.000000
| epoch 2 | 50/ 152 batches | accuracy 0.812 | loss 0.01056
| epoch 2 | 100/ 152 batches | accuracy 0.843 | loss 0.00871
| epoch 2 | 150/ 152 batches | accuracy 0.844 | loss 0.00846
---------------------------------------------------------------------
| end of epoch 2 | time: 1.45s | valid accuracy 0.842 | valid loss 2420.000 | lr 5.000000
| epoch 3 | 50/ 152 batches | accuracy 0.883 | loss 0.00653
| epoch 3 | 100/ 152 batches | accuracy 0.879 | loss 0.00634
| epoch 3 | 150/ 152 batches | accuracy 0.883 | loss 0.00627
---------------------------------------------------------------------
| end of epoch 3 | time: 1.44s | valid accuracy 0.865 | valid loss 2420.000 | lr 5.000000
| epoch 4 | 50/ 152 batches | accuracy 0.912 | loss 0.00498
| epoch 4 | 100/ 152 batches | accuracy 0.906 | loss 0.00495
| epoch 4 | 150/ 152 batches | accuracy 0.915 | loss 0.00461
---------------------------------------------------------------------
| end of epoch 4 | time: 1.50s | valid accuracy 0.876 | valid loss 2420.000 | lr 5.000000
| epoch 5 | 50/ 152 batches | accuracy 0.935 | loss 0.00386
| epoch 5 | 100/ 152 batches | accuracy 0.934 | loss 0.00390
| epoch 5 | 150/ 152 batches | accuracy 0.932 | loss 0.00362
---------------------------------------------------------------------
| end of epoch 5 | time: 1.59s | valid accuracy 0.881 | valid loss 2420.000 | lr 5.000000
| epoch 6 | 50/ 152 batches | accuracy 0.947 | loss 0.00313
| epoch 6 | 100/ 152 batches | accuracy 0.949 | loss 0.00307
| epoch 6 | 150/ 152 batches | accuracy 0.949 | loss 0.00286
---------------------------------------------------------------------
| end of epoch 6 | time: 1.68s | valid accuracy 0.891 | valid loss 2420.000 | lr 5.000000
| epoch 7 | 50/ 152 batches | accuracy 0.960 | loss 0.00243
| epoch 7 | 100/ 152 batches | accuracy 0.963 | loss 0.00224
| epoch 7 | 150/ 152 batches | accuracy 0.959 | loss 0.00252
---------------------------------------------------------------------
| end of epoch 7 | time: 1.53s | valid accuracy 0.892 | valid loss 2420.000 | lr 5.000000
| epoch 8 | 50/ 152 batches | accuracy 0.972 | loss 0.00186
| epoch 8 | 100/ 152 batches | accuracy 0.974 | loss 0.00184
| epoch 8 | 150/ 152 batches | accuracy 0.967 | loss 0.00201
---------------------------------------------------------------------
| end of epoch 8 | time: 1.43s | valid accuracy 0.895 | valid loss 2420.000 | lr 5.000000
| epoch 9 | 50/ 152 batches | accuracy 0.981 | loss 0.00138
| epoch 9 | 100/ 152 batches | accuracy 0.977 | loss 0.00165
| epoch 9 | 150/ 152 batches | accuracy 0.980 | loss 0.00147
---------------------------------------------------------------------
| end of epoch 9 | time: 1.48s | valid accuracy 0.900 | valid loss 2420.000 | lr 5.000000
| epoch 10 | 50/ 152 batches | accuracy 0.987 | loss 0.00117
| epoch 10 | 100/ 152 batches | accuracy 0.985 | loss 0.00121
| epoch 10 | 150/ 152 batches | accuracy 0.984 | loss 0.00121
---------------------------------------------------------------------
| end of epoch 10 | time: 1.45s | valid accuracy 0.902 | valid loss 2420.000 | lr 5.000000
---------------------------------------------------------------------6.模型评估
test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))![]()
7.模型测试
def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])

8.全部代码(部分修改):
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def custom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))label_name = list(set(train_data[1].values[:]))
print(label_name)text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])
9.代码改进及优化
9.1优化器: 尝试不同的优化算法,如Adam、RMSprop替换原来的SGD优化器部分
9.1.1使用Adam优化器:

import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def custom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))label_name = list(set(train_data[1].values[:]))
print(label_name)text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=LR)
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])
效果略差于SGD优化器
9.1.2调参:

效果较SGD优化器提升1个百分点

9.1.2使用RMSprop优化器:

import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore") # 忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)import pandas as pd# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()# 构建数据集迭代器
def custom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))label_name = list(set(train_data[1].values[:]))
print(label_name)text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即词汇的起始位置offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和return text_list.to(device), label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)import timedef train(dataloader):model.train() # 切换到训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # 梯度归零loss = criterion(predicted_label, label) # 计算损失loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 优化器更新权重# 记录acc和losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:3d} | {:5d}/{:5d} batches ''| accuracy {:8.3f} | loss {:8.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换到评估模式total_acc, total_count = 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算losstotal_acc += (predicted_label.argmax(1) == label).sum().item()total_count += label.size(0)return total_acc/total_count, total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
#EPOCHS = 10 # epoch数量
#LR = 5 # 学习速率
#BATCH_SIZE = 64 # 训练的batch大小
EPOCHS = 10 # epoch数量
LR = 0.001 # 通常Adam的学习率设置为一个较小的值,例如0.001
BATCH_SIZE = 64 # 训练的batch大小
# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=LR)
#optimizer = torch.optim.Adam(model.parameters(), lr=LR)
optimizer = torch.optim.RMSprop(model.parameters(), lr=LR)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)# 训练循环
for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 更新学习率的策略lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| end of epoch {:3d} | time: {:4.2f}s | ''valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"model = model.to("cpu")print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])
最佳训练结果略优于其他两种优化器
9.2使用预训练的词嵌入,如Word2Vec、GloVe或者直接使用预训练的语言模型,如BERT,作为特征提取器
在原始代码中使用预训练的词嵌入或BERT模型,需要在定义模型类
TextClassificationModel之前加载嵌入,并相应地修改该类。以下是整个流程的步骤:
加载预训练嵌入:
- 如果使用Word2Vec或GloVe,加载词嵌入并创建一个嵌入层。
- 如果使用BERT,加载BERT模型和分词器。
修改模型定义:
- 对于Word2Vec或GloVe,替换模型中的
nn.EmbeddingBag为使用预训练嵌入的层。- 对于BERT,定义一个新的模型类,其中包含BERT模型和一个分类层。
修改数据预处理:
- 对于BERT,使用BERT分词器处理文本。
更新训练和评估函数:
- 适应BERT模型的输入格式。
修改模型初始化:
- 使用新的模型定义来创建模型实例。
9.2.1使用预训练的词嵌入
如果要使用预训练的Word2Vec或GloVe词嵌入,需要在模型定义之前加载词嵌入,并替换嵌入层,并将它们设置为模型中nn.Embedding层的初始权重。
替换选中部分
from torchtext.vocab import GloVe# 加载GloVe词嵌入
embedding_glove = GloVe(name='6B', dim=100)def get_embedding(word):return embedding_glove.vectors[embedding_glove.stoi[word]]# 用预训练的嵌入来替换模型中的初始权重
def create_emb_layer(weights_matrix, non_trainable=False):num_embeddings, embedding_dim = weights_matrix.size()emb_layer = nn.Embedding.from_pretrained(weights_matrix, freeze=non_trainable)return emb_layer# 创建权重矩阵
weights_matrix = torch.zeros((vocab_size, em_size))
for i, word in enumerate(vocab.get_itos()):try:weights_matrix[i] = get_embedding(word)except KeyError:# 对于词汇表中不存在于GloVe的词,随机初始化一个嵌入weights_matrix[i] = torch.randn(em_size)# 重写模型定义以使用预训练的嵌入
class TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = create_emb_layer(weights_matrix, True) # 设置为True表示不训练嵌入self.fc = nn.Linear(embed_dim, num_class)def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
创建模型实例:
# 创建新的模型实例(Word2Vec/GloVe或BERT)
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)
# 或者对于BERT
# model = BertTextClassificationModel(num_class).to(device)
运行展示:
运行后自动下载GloVe嵌入截图
9.2.2 使用BERT预训练模型(同上)
from transformers import BertModel, BertTokenizer# 加载预训练的BERT模型和分词器
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
bert_model = BertModel.from_pretrained('bert-base-chinese')class BertTextClassificationModel(nn.Module):def __init__(self, num_class):super(BertTextClassificationModel, self).__init__()self.bert = bert_modelself.fc = nn.Linear(self.bert.config.hidden_size, num_class)def forward(self, text, offsets):# 因为BERT需要特殊的输入格式,所以您需要在这里调整text的处理方式# 这里仅是一个示例,您需要根据实际情况进行调整inputs = bert_tokenizer(text, return_tensors='pt', padding=True, truncation=True)outputs = self.bert(**inputs)# 使用CLS标记的输出来进行分类cls_output = outputs.last_hidden_state[:, 0, :]return self.fc(cls_output)
相关文章:

pytorch 实现中文文本分类
🍨 本文为[🔗365天深度学习训练营学习记录博客🍦 参考文章:365天深度学习训练营🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mi…...
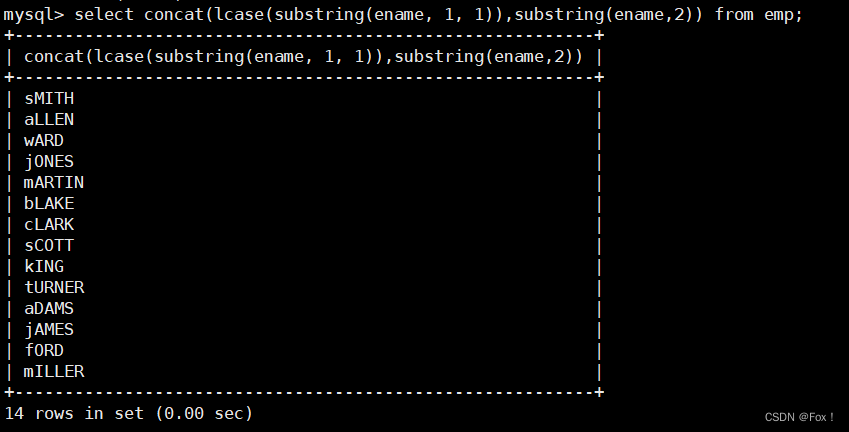
【MySQL】聚合函数和内置函数
文章目录 1 :peach:聚合函数:peach:2 :peach:group by子句的使用:peach:3 :peach:内置函数:peach:3.1 :apple:日期函数:apple:3.2 :apple:字符串函数:apple:3.3 :apple:数学函数:apple: 4 :peach:其它函数:peach: 1 🍑聚合函数🍑 函数说明COUNT([DISTIN…...
)
python第五节:集合set(4)
集合其他方法: len(s) set 的长度 x in s x 是否是 s 的成员 x not in s x 是否不是 s 的成员 s.issubset(t) 是否 s 中的每一个元素都在 t 中 s.issuperset(t) 是否 t 中的每一个元素都在 s s.union(t) 返回一个新的 set 包含 s 和 t 中的每一个元素 …...
———什么是okhttp?)
知识笔记(一百)———什么是okhttp?
OkHttp简介: OkHttp 是一个开源的、高效的 HTTP 客户端库,由 Square 公司开发和维护。它为 Android 和 Java 应用程序提供了简单、强大、灵活的 HTTP 请求和响应的处理方式。OkHttp 的设计目标是使网络请求变得更加简单、快速、高效,并且支持…...
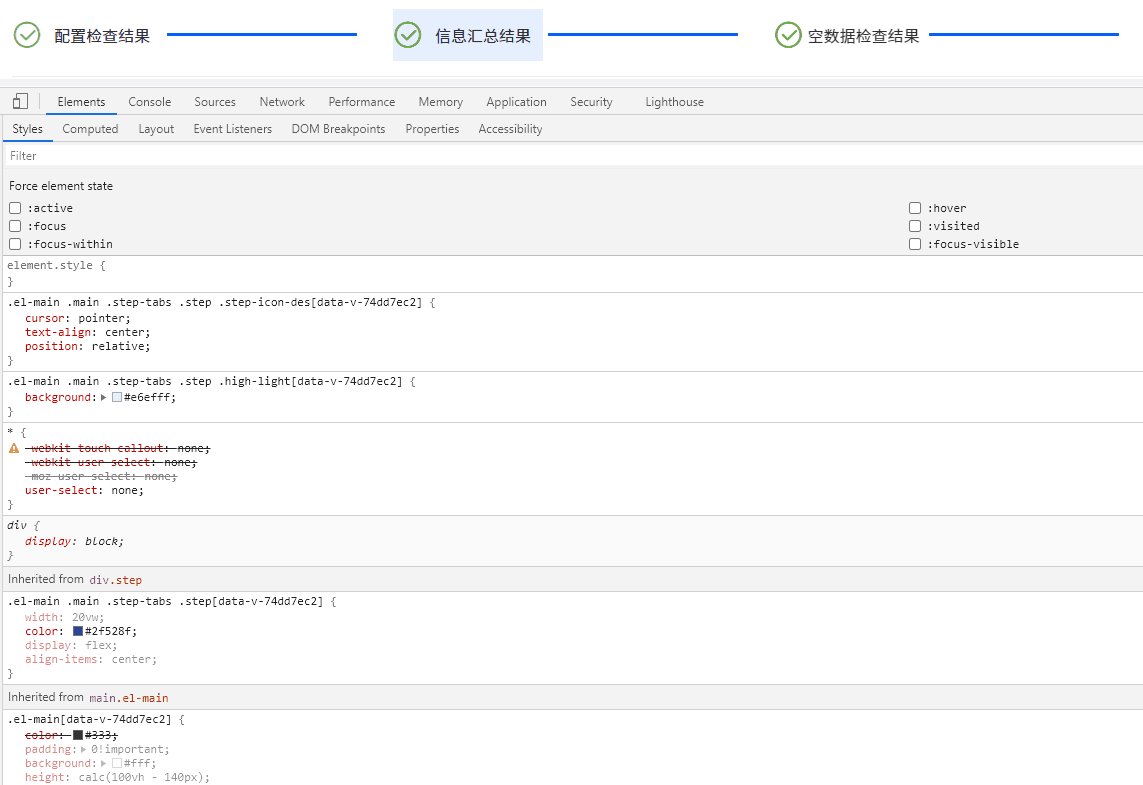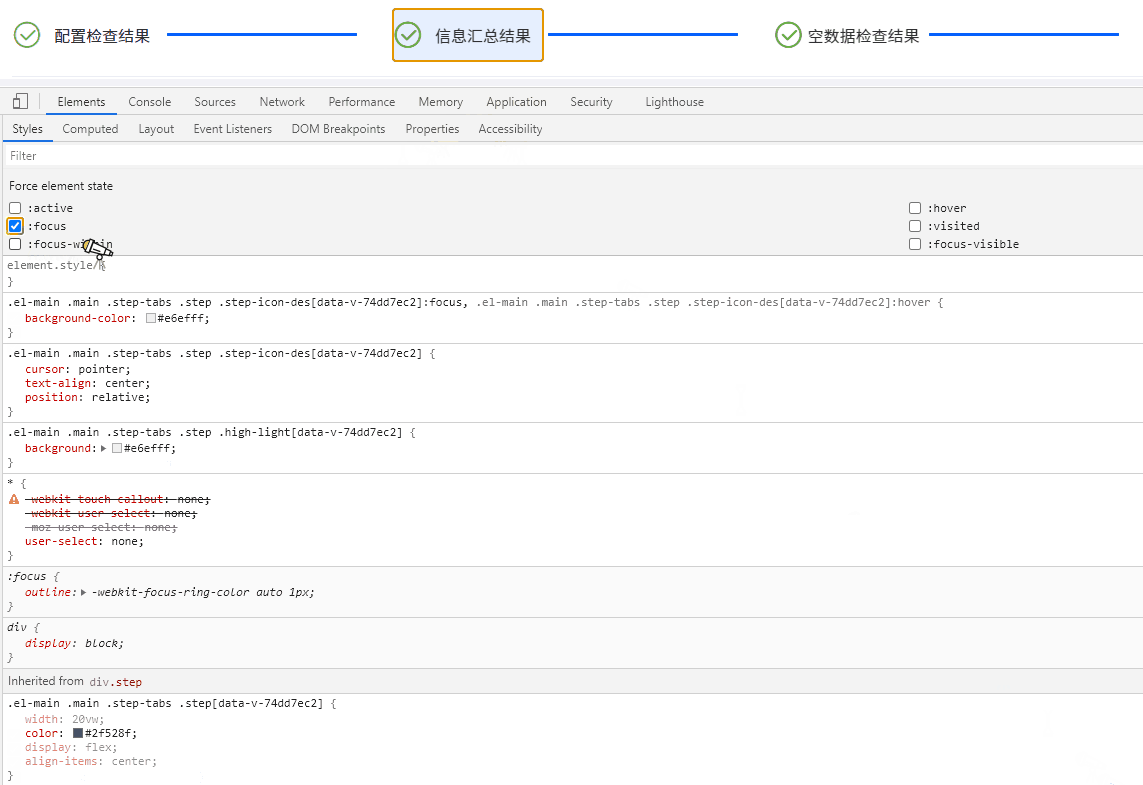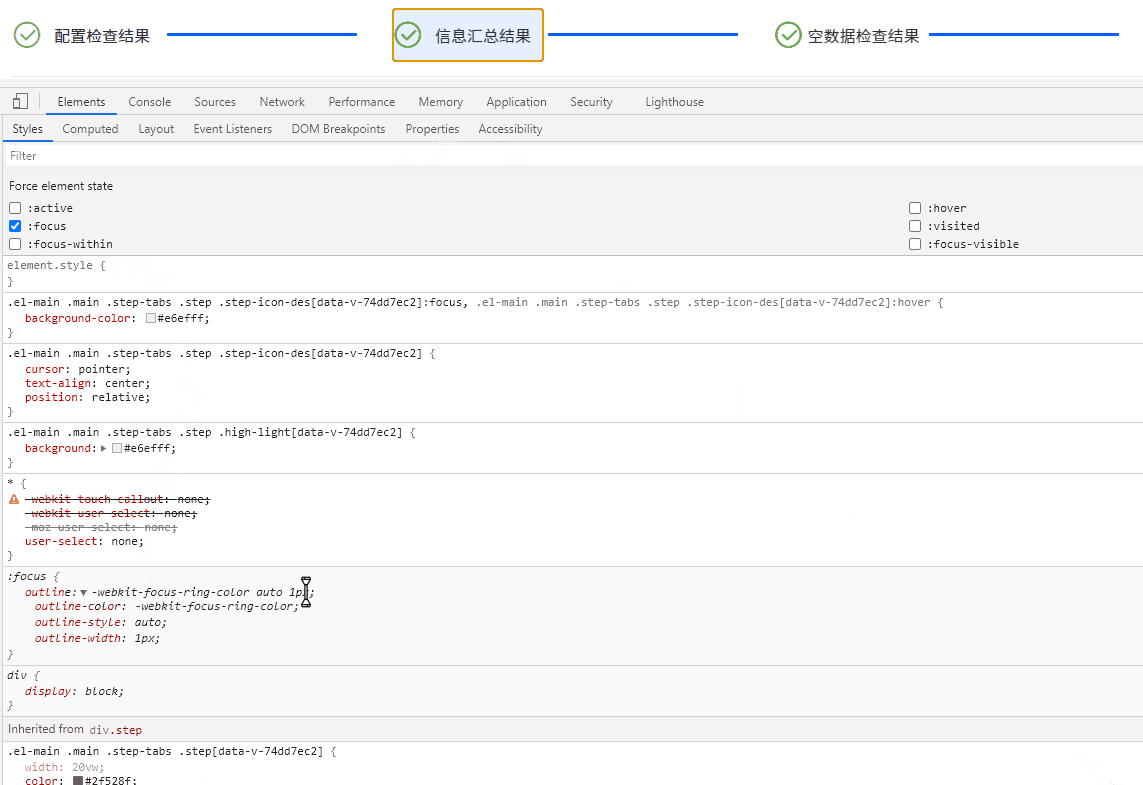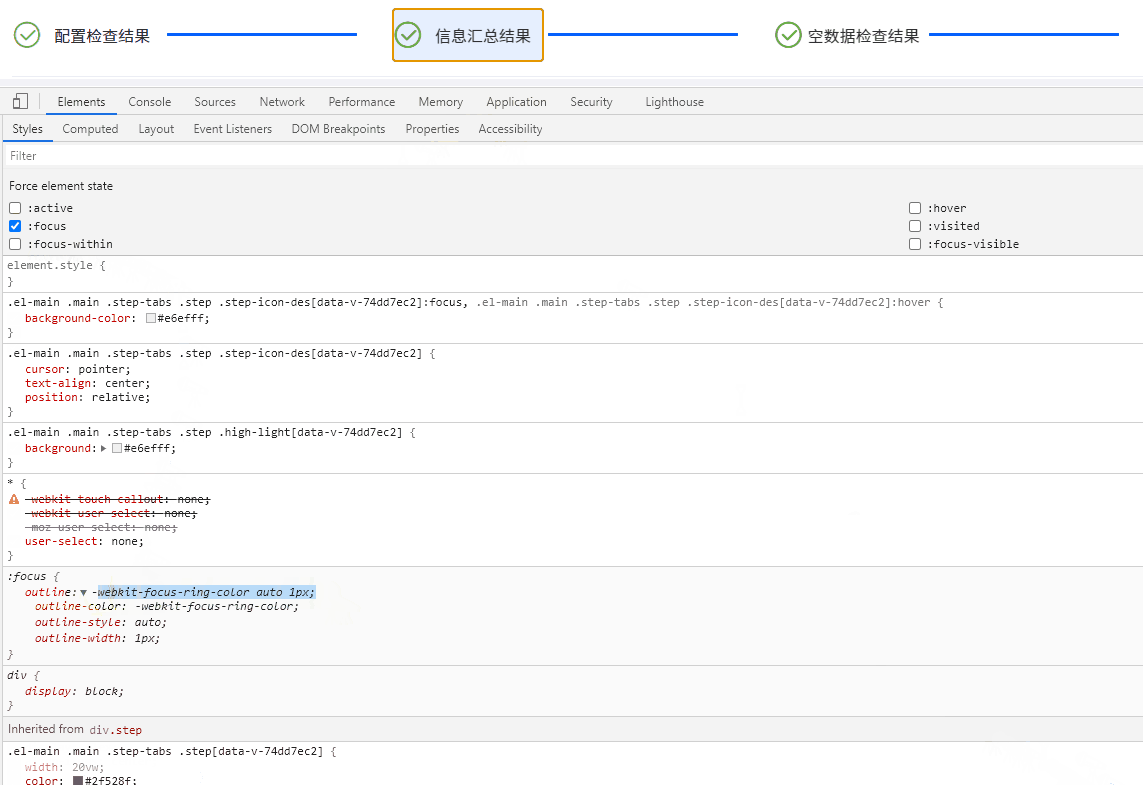
Electron桌面应用实战:Element UI 导航栏橙色轮廓之谜与Bootstrap样式冲突解决方案
目录 引言 问题现象及排查过程 描述问题 深入探索 查明原因 解决方案与策略探讨 重写样式 禁用 Bootstrap 样式片段 深度定制 Element UI 组件 隔离样式作用域 结语 引言 在基于 Electron 开发桌面应用的过程中,我们可能时常遇到各种意想不到的问题…...
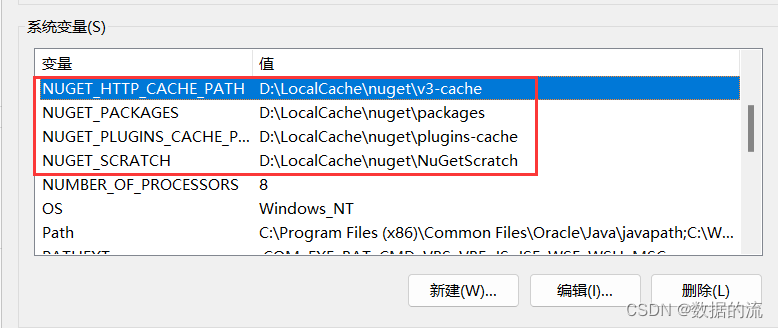
Nuget包缓存存放位置迁移
一、背景 默认情况下,NuGet会将项目中使用的包缓存到C盘,随着项目开发积累nuget包越来越多,这会逐渐挤占大量C盘空间,所以我们可以将nuget包缓存位置指定到其他盘中存放。 二、软件环境 win10、vs2022 三、查看当前缓存存放位…...
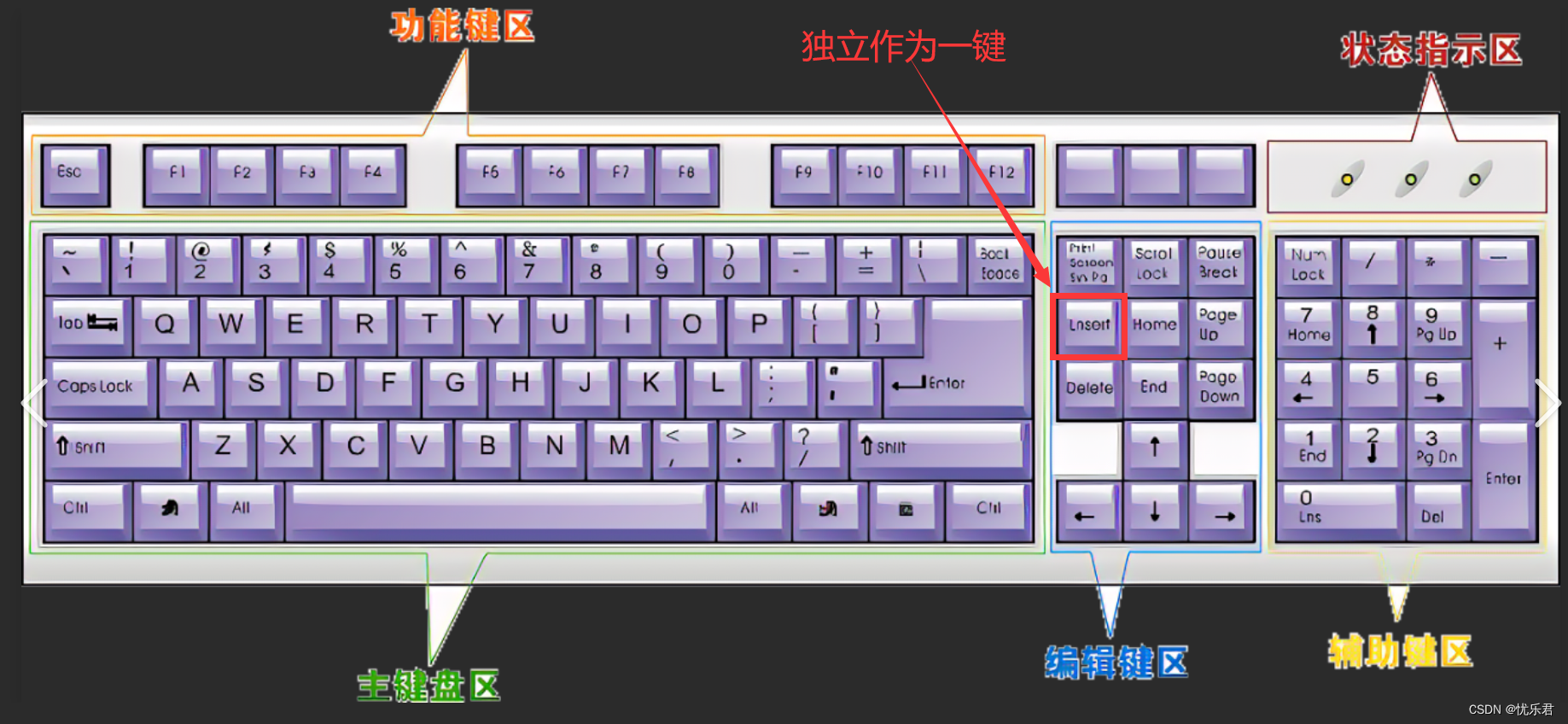
键盘上Ins键的作用
前几天编写文档时,发现一个问题:插入内容时,输入的字符将会覆盖光标位置后的字符。原来是按到了键盘上的 Ins键,解决方法是:再按一次 Ins键(Ins键如果独立作为一键时,否则使用 “Fn Ins”组合键…...

css display 左右对齐 技巧
.list_number{ display: flex; } .list_name_number{ width:100px; } //左边固定width .list_name_type{ //右边给flex:2 自动撑开 flex:2; }...
【Linux操作系统】:Linux开发工具编辑器vim
目录 Linux 软件包管理器 yum 什么是软件包 注意事项 查看软件包 如何安装软件 如何卸载软件 Linux 开发工具 Linux编辑器-vim使用 vim的基本概念 vim的基本操作 vim正常模式命令集 插入模式 插入模式切换为命令模式 移动光标 删除文字 复制 替换 撤销 跳至指…...
 1925D)
Good Trip Codeforces Round 921 (Div. 2) 1925D
Problem - D - Codeforces 题目大意:有n个数,其中有m个匹配对,对于一个匹配对(x,y),他们的除湿贡献为z,一共有k轮行动,每一轮从n个数中独立等概率的选出两个数,如果这两…...
推荐一款Linux、数据库、Redis、MongoDB统一管理平台!
官方演示 状态查看 ssh 终端 文件操作 数据库操作 sql 编辑器 在线增删改查数据 Redis 操作 Mongo 操作 系统管理 账号管理 角色管理 资源管理 一.安装 1.下载安装包 cd /opt wget https://gitee.com/dromara/mayfly-go/releases/download/v1.7.1/mayfly-go-linux-amd64.zi…...
TensorFlow2实战-系列教程6:迁移学习实战
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 1、迁移学习 用已经训练好模型的权重参数当做自己任务的模型权重初始化一般全连接层需…...

怎样开发adobe indesign插件,具体流程?
文章目录 第一.流程步骤第二.如何调试indesign插件第三.相关资源第四.总结 第一.流程步骤 开发Adobe InDesign插件通常涉及以下步骤: 获取SDK和工具: 从Adobe官方网站下载最新的Adobe InDesign SDK(Software Development Kit)&am…...

Docker 安装与基本操作
目录 一、Docker 概述 1、Docker 简述 2、Docker 的优势 3、Docker与虚拟机的区别 4、Docker 的核心概念 1)镜像 2)容器 3)仓库 二、Docker 安装 1、命令: 2、实操: 三、Docker 镜像操作 1、命令࿱…...

译文带你理解Python的dataclass装饰器
dataclass 是 Python dataclasses 模块中的一个 decorator。当使用 dataclass 装饰器时,它会自动生成一些特殊方法,包括: _ _ init _ _:用于初始化字段的构造函数_ _ repr _ _:对象的字符串表示_ _ eq _ _:…...

【C语言】实现程序的暂停
编写程序时,有时候需要让程序在某些地方暂停执行,等待用户输入或者观察程序执行结果。在 C 语言中,有多种方法可以实现程序的暂停,包括 system("pause")、getchar() 和 while ((c getchar()) ! \n && c ! EOF)…...

Hana SQL+正则表达式
目录 一、Pre 前言 二、知识点拆解 1)case when…then…else 2)json_value 函数 拓展资料 3)CAST 函数 拓展资料 4) ROUND 函数 5)occurences_regexpr 函数 拓展资料 6)正则表达式 拓展资料 三、整合分析…...

【笔记】顺利通过EMC试验(16-41)-视频笔记
目录 视频链接 P1:电子设备中有哪些主要骚扰源 P2:怎样减小DC模块的骚扰 P3:PCB上的辐射源究竟在哪里 P4:怎样控制PCB板的电磁辐射 P5:多层线路板是解决电磁兼容问题的简单方法 P6:怎样处理地线上的裂缝 P7:怎样降低时钟信号的辐射 P8:为什么IO接口的处理特别重要 P9…...
Qlik Sense 调用NPrinting生成On-Demand报表
安装 Qlik Sense On-Demand 报表控件 On-Demand 报表控件添加按钮,该按钮按需生成 Qlik NPrinting 报表。它包括在 Dashboard bundle 中。 当您希望用户能够使用应用程序中的选择作为过滤器在 Qlik Sense 中打印预定义 Qlik NPrinting 报表时,On-Deman…...
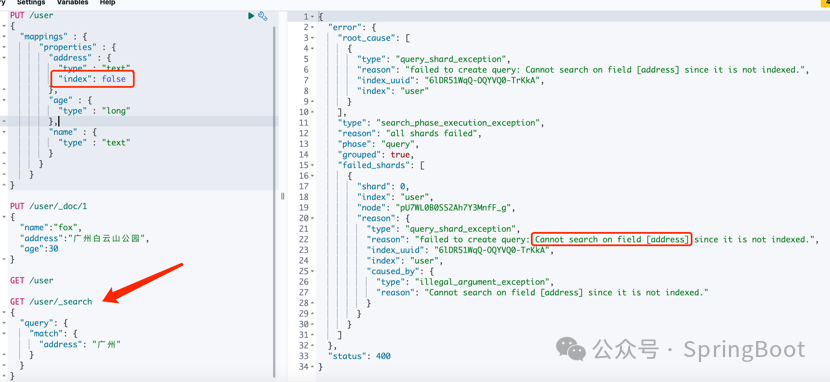
ElasticSearch重建/创建/删除索引操作 - 第501篇
历史文章(文章累计500) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 E…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...