【论文精读】多模态情感分析 —— VLP-MABSA
Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
本篇论文发表于ACL-2022
原文链接
https://arxiv.org/abs/2204.07955
源码
GitHub - NUSTM/VLP-MABSA
模态:图像+文本
基于多模态方面的情感分析(MABSA)近年来越来越受到关注。然而,以前的方法要么(i)单独使用预训练的视觉和文本模型,忽略了跨模态的对齐;要么(ii)使用预训练的视觉语言模型,这些模型带有一般的预训练任务,这不足以识别细粒度的方面、观点及其跨模态的对齐。
本文提出了一个针对MABSA的任务特定的视觉语言预训练框架(VLPMABSA),这是一个统一的多模态编码器-解码器架构,用于所有预训练和下游任务。进一步从语言、视觉和多模态三个方面分别设计了三种特定任务的预训练任务。
1 Introduction
以往的研究主要集中在其两个子任务上,包括多模式方面词提取(MATE)和多模式面向方面的情感分类(MASC)。
给定一对文本图像作为输入,MATE旨在提取文本中提到的所有方面术语,MASC旨在对提取的每个方面术语的情感进行分类。由于这两个子任务彼此密切相关,Ju等人(2021)最近引入了联合多模式方面情感分析(JMASA)任务,旨在联合提取方面术语及其相应的情感。例如,给定表中的textimage对。JMASA的目标是识别所有方面情绪对,即(Sergio Ramos,Positive)和(UCL,Neutral)。

上述对MABSA的大多数研究主要集中在使用预先训练的单峰模型(例如,用于文本的BERT和用于图像的ResNet)来分别获得文本和视觉特征。视觉和文本特征的单独预训练忽略了文本和图像之间的对齐。因此,进行视觉语言预训练以捕捉这种跨模态对齐是至关重要的。然而,对于MABSA任务,关于视觉语言预训练的研究仍然缺乏。
据我们所知,很少有研究关注MABSA子任务之一,即MATE的视觉语言预训练(Sun et al.,202021)。这些研究的一个主要缺点是,它们主要采用一般的视觉语言理解任务(例如,文本图像匹配和掩蔽语言建模)来捕获文本图像对齐。这种一般的预训练不足以识别细粒度 fine-grained的方面、观点及其在语言和视觉模式中的一致性。因此,重要的是设计特定任务的视觉语言预训练,为MABSA任务建模方面、观点及其对齐。
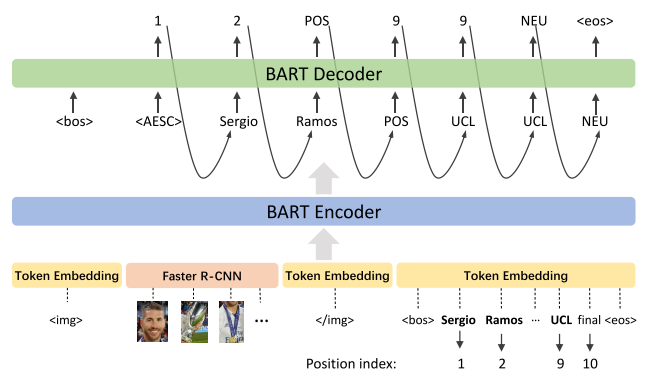
为了解决这个问题,在本文中,我们提出了一个用于基于多模式方面的情感分析的特定任务视觉语言预训练框架。具体而言,受基于BART的生成模型最近在基于文本的ABSA中的成功启发(Yan et al.,2021),我们首先构建了一个基于BART(Lewis et al.,2020)的生成多模式架构,用于视觉语言预训练和下游MABSA任务。然后,我们提出了三种类型的视觉语言预训练任务,包括来自语言模态的掩蔽语言建模(MLM)和文本方面意见提取(AOE),来自视觉模态的掩蔽区域建模(MRM)和视觉方面意见生成(AOG),以及跨两种模态的多模态情感预测(MSP)。图1展示了我们提出的预培训方法的整个框架。与一般的预训练方法相比,我们的任务专用预训练方法结合了多模态方面、观点和情绪监督,指导预训练模型为MABSA任务捕获重要的客观和主观信息。
为了评估我们预训练方法的有效性,我们采用MVSA Multi作为我们的预训练数据集,这是一个广泛使用的用于粗粒度 coarse-grained 文本图像情感分析的多模式Twitter数据集(Niu et al.,2016)。然后,我们使用几个有代表性的预训练模型和基于规则的方法来获得AOE和AOG任务的方面和意见监督。由于数据集为每条多模式推文提供了情感标签,我们将其作为MSP任务的监督。
我们在这项工作中的贡献如下:
- 我们为MABSA引入了一个名为VLP-MABSA的任务专用视觉语言预训练框架,它是一种用于所有预训练和下游任务的统一多模式编码器-解码器架构。
- 除了一般的MLM和MRM任务外,我们还介绍了三个特定任务的预训练任务,包括文本方面的意见提取、视觉方面意见生成和多模式情绪预测,以识别细粒度的方面、意见及其跨模态比对。
- 在三个MABSA子任务上的实验表明,我们的预训练方法通常比现有技术的方法获得显著的性能增益。对监督和弱监督设置的进一步分析表明了每个预训练任务的有效性。
2 Related Work
视觉-语言预训练。受BERT等预训练语言模型成功的启发(Devlin et al.,2019),人们提出了许多多模式预训练模型(Chen et al.,2020b;Yu et al.,2021;Zhang et al.,2020)来执行许多视觉语言任务,并取得了惊人的成功。相应地,提出了许多通用的预训练任务,如掩蔽语言建模(MLM)、掩蔽区域建模(MRM)和图像-文本匹配(ITM)(Chen et al.,2020b;Yu et al.,2021)。此外,为了使预训练模型更好地理解下游任务,研究人员还为不同的下游任务设计了特定任务的预训练模型(Hao et al.,2020;Xing et al.,2021)。在我们的工作中,除了流行的一般预训练任务外,我们还为MABSA任务设计了三种特定任务的预训练任务。
基于文本的联合方面情感分析(JASA)。JASA旨在提取文本中的方面术语,并预测其情感极性。已经提出了许多方法,包括流水线方法(Zhang et al.,2015;Hu等人,2019)、多任务学习方法(He et al.,2019;Hu等,2019)和基于折叠标签的方法(Li等人,2019;胡等,2019;Chen等人,2020a)。最近,Yan等人(2021)提出了一种统一的生成框架,该框架在JASA的几个基准数据集上实现了极具竞争力的性能。
多模态情绪分析。社交媒体帖子中的多模态情绪分析(MSA)是情绪分析的一个重要方向。文献中提出了许多神经网络方法来执行粗粒度MSA,旨在检测每个输入社交帖子的整体情绪(You et al.,20152016;Luo et al.,2017;Xu et al.,2018;Yang et al.,2021b)。不同于这些研究,我们的工作集中在细粒度的MABSA任务上,该任务旨在识别对每个输入社交帖子中提到的所有方面的情绪。
基于多模态方面的情绪分析。作为一项重要的情绪分析任务,人们已经采用了许多方法来解决MABSA的三个子任务,包括多模态方面术语提取(Zhang et al.,2018;Yu et al.,2020b;Wu et al.;2020a,b;Sun et al.,2020;Zhang et al,2021a),多模态方面情感分类(Xu et al.,2019;余等,2020a;杨等,2021a;Khan和Fu,2021)和联合多模态方面情绪分析(Ju et al.,2021)。在这项工作中,我们旨在提出一个通用的预训练框架,以提高所有三个子任务的性能。
3 Methodology
图1显示了我们的模型体系结构的概述。我们模型的支柱是BART(Lewis et al.,2020),它是一种用于序列到序列模型的去噪自动编码器。我们将BART扩展为对文本和视觉输入进行编码,并解码来自不同模态的预训练和下游任务。在下面的小节中,我们首先介绍了我们的特征提取器,然后说明了我们模型的编码器和解码器,然后描述了三种类型的预训练任务和下游MABSA任务的细节。
3.1 Feature Extractor
Image Representation
根据许多现有的视觉语言预训练模型(Chen et al.,2020b;Yu et al.,2021),我们使用更快的R-CNN(Anderson et al.)来提取视觉特征。具体来说,我们采用faster R-CNN从输入图像中提取所有候选区域。然后,我们只保留了36个置信度最高的区域。同时,我们还保留了每个区域的语义类分布,这些分布将用于遮罩区域建模 Masked Region Modeling 任务。对于保留的区域,我们使用由Faster R-CNN处理的平均池卷积特征作为我们的视觉特征。
让我们使用![]() 来表示视觉特征,其中
来表示视觉特征,其中![]() 表示第i个区域的视觉特征。为了与文本表示一致,我们采用线性变换层将视觉特征投影到d维向量,用
表示第i个区域的视觉特征。为了与文本表示一致,我们采用线性变换层将视觉特征投影到d维向量,用![]() 表示。
表示。
Text Representation
对于文本输入,我们首先对文本进行标记,然后向嵌入矩阵提供标记。文本标记的嵌入被用作文本特征。让我们使用![]() 来表示文本输入的标记索引,其中T表示输入文本的长度,
来表示文本输入的标记索引,其中T表示输入文本的长度,![]() 来表示标记的嵌入。
来表示标记的嵌入。
3.2 BART-based Generative Framework
我们使用基于BART的生成框架进行视觉语言预训练和下游MABSA任务。
Encoder
我们模型的编码器是一个多层双向transforer。如图1所示,为了区分不同模态的输入,我们遵循Xing等人(2021),使用<img> 和</img> 指示视觉特征的开始和结束,以及<bos> 和<eos>以指示文本输入。在本文的下一部分中,我们用X表示级联的多模式输入。

Decoder
我们模型的解码器也是一个多层Transformer。不同之处在于解码器在生成输出时是单向的,而编码器是双向的。由于所有预训练任务共享相同的解码器,我们在解码器输入的开头插入两个特殊标记,以指示不同的预训练任务。继Yan等人(2021)之后,我们插入了一个特殊的token<bos> 以指示生成的开始,然后插入特定于任务的特殊令牌来指示任务类型。具体来说,掩蔽语言建模、文本方面意见提取、掩蔽区域建模、视觉方面意见生成和多模式情绪预测的特殊标记是<bos><mlm>, <bos><aoe>, <bos><mrm>, <bos><aog>, 和<bos><msp>。
3.3 Pre-training Tasks
我们用于预训练的数据集是MVSAMulti(Niu et al.,2016),它被广泛用于多模式Twitter情绪分析(Yadav和Vishwakarma,2020;Yang et al.,2021b)。该数据集提供图像-文本输入对和图像-文本对的粗粒度情感。数据集的统计数据如表2所示。使用数据集,我们设计了三种类型的预训练任务,包括文本、视觉和多模式预训练,如下所示。
3.3.1 Textual Pre-training
文本预训练包含两个任务:一个是在文本和视觉特征之间建立一致性的通用掩蔽语言建模任务,另一个是从文本中提取方面和意见的特定任务文本方面意见提取任务。
遮蔽语言建模(MLM)。在传销前训练任务中,我们使用了与Bert(Devlin等人,2019年)相同的策略,以15%的概率随机掩蔽输入文本标记。MLM任务的目标是基于图像和掩码文本生成原始文本,因此MLM任务的损失函数为:

其中ei和X~分别表示输入文本和掩码的多模式输入的第i个标记。T是输入文本的长度。
文本方面意见提取(AOE)。AOE任务旨在从文本中提取方面和观点术语。由于MVSA多数据集不提供方面和意见术语的注释,我们采用预先训练的方面提取模型和基于规则的意见提取方法。具体而言,对于方面提取,我们使用来自众所周知的推文命名实体识别(NER)工具(Ritter et al.,2011)的预训练模型对数据集中的每条推文执行NER,并将识别的实体视为方面项。对于意见提取,我们利用一个广泛使用的名为SentiWordNet的情感词典(Esuli和Sebastiani,2006)来获得意见词词典。给定每条推文,如果其子序列(即单词或短语)与词典中的单词匹配,我们将其视为意见术语。这些提取的方面和意见术语被用作我们AOE任务的监督信号。
在文本方面的意见监督下,我们遵循Yan等人的观点。(2021)将AOE任务制定为索引生成任务。给定输入文本作为源序列,目标是生成一个目标索引序列,该序列由所有方面和观点术语的开始索引和结束索引组成。让我们使用![]() 表示目标索引序列,其中M和N是方面术语和意见术语的数量,as、ae和os、oe分别表示方面术语和观点术语的开始索引和结束索引,<sep> 用于分离方面术语和意见术语,以及<eos> 通知提取结束。例如,如图1所示,提取的方面和意见项分别为 Justin Bieber and best,目标序列为
表示目标索引序列,其中M和N是方面术语和意见术语的数量,as、ae和os、oe分别表示方面术语和观点术语的开始索引和结束索引,<sep> 用于分离方面术语和意见术语,以及<eos> 通知提取结束。例如,如图1所示,提取的方面和意见项分别为 Justin Bieber and best,目标序列为![]() . 对于目标序列Y中的yt ,
. 对于目标序列Y中的yt , ![]() 我们使用
我们使用![]() 以表示特殊令牌的集合,并且Cd作为它们的嵌入。
以表示特殊令牌的集合,并且Cd作为它们的嵌入。
我们假设He表示级联的多模式输入的编码器输出,He T表示He的文本部分,而He V表示He的视觉部分。解码器将多模式编码器输出He和先前解码器输出Y<t作为输入,并预测token概率分布P(yt)如下:
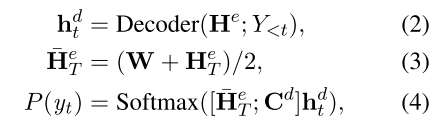
其中W表示输入tokens的嵌入。AOE任务的损失函数如下:
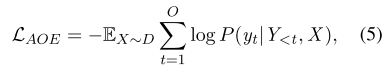
其中O=2M 2N 2是Y的长度,X表示多模式输入。
3.3.2 Visual Pre-training
视觉预训练包含两个任务:一个是通用的蒙版区域建模任务,另一个是特定任务的视觉方面意见生成任务,用于捕捉图像中的主观和客观信息。
遮罩区域建模(MRM)。继Xing等人(2021)之后,我们的MRM任务旨在预测掩蔽区域的语义类分布。如图1所示,对于编码器的输入,我们以15%的概率随机屏蔽图像区域,这些区域被零向量取代。对于解码器的输入,我们首先添加两个特殊的tokens<bos><mrm>, 然后用<zero> 并且每个剩余区域具有<feat>。在将输入馈送到解码器之后,MLP分类器被堆叠在每个的输出上<zero>以预测语义类分布。让我们使用p(vz)来表示第z个掩蔽区域的预测类分布,并且使用q(vz)来表示由Faster R-CNN检测到的类分布。MRM的损失函数是最小化两类分布的KL发散:
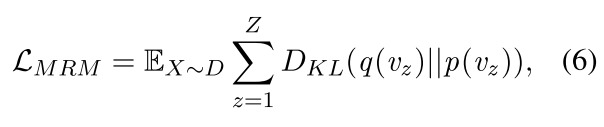
其中Z是掩蔽区域的数量。
视觉方面意见生成(AOG)。AOG任务旨在生成从输入图像中检测到的方面意见对。在计算机视觉领域,Borth等人(2013)提出在图像中检测视觉情感概念,即形容词-名词对(ANP),如微笑的男人和美丽的风景。由于ANP的名词和形容词分别捕捉图像中细粒度的方面和观点,我们将ANP视为视觉方面-观点对。为了检测每个输入图像的ANP,我们采用了预先训练的ANP检测器DeepSentriBank2(Chen et al.,2014)来预测2089个预定义ANP上的类别分布。选择概率最高的ANP作为我们AOG任务的监督信号。例如,在图1中,从输入图像中检测到的ANP是英俊的家伙,我们将其视为监督。
通过视觉方面的意见监督,我们将AOG任务制定为序列生成任务。具体地,让我们使用G={g1,…,G|G|}来表示目标ANP的tokens,并且使用|G|来表示ANP tokens的数量。解码器然后将多模式编码器输出He和先前解码器输出G<i作为输入,并预测令牌概率分布P(gi):

其中E表示词汇表中所有标记的嵌入矩阵。AOG任务的损失函数为:
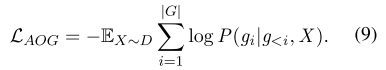
3.3.3 Multimodal Pre-training
多模式预训练有一个任务叫做多模式情绪预测(MSP)。与上述监督信号仅来自一种模态的预训练任务不同,MSP的监督信号来自多模态,这可以增强模型识别语言和视觉中的主观信息,并捕捉它们的丰富对齐。
多模式情绪预测(MSP)。由于MVSA多数据集为所有文本图像对提供了粗粒度的情感标签,我们使用情感标签作为MSP任务的监督信号。形式上,我们将MSP任务建模为分类任务,其中我们首先提供两个特殊的tokens<bos><msp>到解码器,然后如下预测情绪分布P(s):
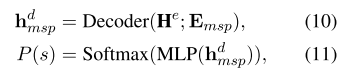
其中Emsp是两个特殊令牌的嵌入。
我们对MSP任务使用交叉熵损失:![]()
其中s是数据集中注释的黄金情感。
3.3.4 Full Pre-training Loss
为了优化所有的模型参数,我们采用交替优化策略来迭代优化我们的五个预训练任务。目标函数如下: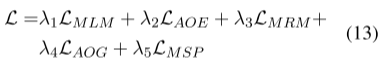
其中λ1、λ2、λ3、λ4和λ5是控制每个任务贡献的权衡超参数。
3.4 Downstream Tasks
我们将MABSA中的所有三个子任务视为我们的下游任务,包括联合多模式方面情感分析(JMASA)、多模式方面术语提取(MATE)和多模式面向方面的情感分类(MASC)。我们在视觉语言预训练中基于相同的基于BART的生成框架对这些下游任务进行建模,以便下游任务在微调阶段可以从预训练中受益更多。继Yan等人(2021)之后,我们将三个子任务的输出公式化如下:
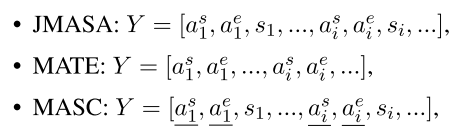
其中as i、ae i和si表示文本中一个方面术语的开始索引、结束索引和情感。带下划线的标记是在推理过程中给出的。
与第3.3.1节中的AOE任务类似,我们将所有子任务公式化为索引生成任务,并使用方程(2)至方程(4) 以生成tokens分发。不同之处在于,特殊tokens集被修改为C=![]() ,通过添加情绪类别。图2显示了JMASA的一个示例。由于方面情绪对是(Sergio Ramos,Positive)和(UCL,Neutral),其目标序列是
,通过添加情绪类别。图2显示了JMASA的一个示例。由于方面情绪对是(Sergio Ramos,Positive)和(UCL,Neutral),其目标序列是![]()
4 Experiment
4.1 Settings
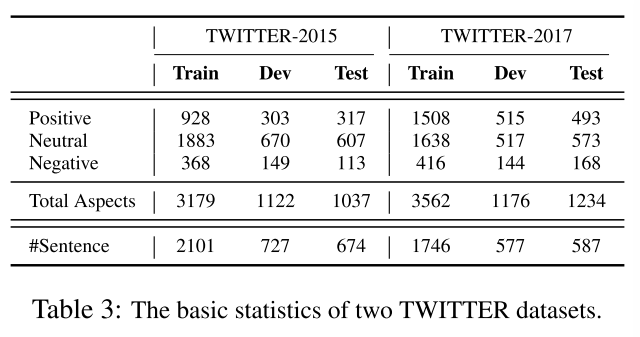
下游基准集。我们采用Yu和Jiang(2019)注释的两个基准数据集,即TWITTER-2015和TWITTER-2017来评估我们的模型。这两个数据集的统计数据如表3所示。
实施细节。我们采用BARTbase(Lewis等人,2020)作为我们的框架。具体地,编码器和解码器都具有六个层,并且利用BART基本参数进行初始化。我们在开发集上对所有超参数进行调整后修复它们。预训练任务被训练了40个时期,下游任务被微调了35个时期。批次大小分别设置为64和16。学习率设置为5e-5。我们模型的隐藏大小设置为768,与BART相同。权衡超参数λ1、λ2、λ3、λ4和λ5都设置为1。注意,对于子任务MASC,与Ju等人不同。(2021)对正确预测的方面进行评估,我们在推理阶段将所有黄金方面提供给我们框架的解码器,并对所有方面进行评估。我们用PyTorch实现了所有的模型,并在RTX3090 GPU上进行了实验。
评估指标。我们在MABSA的三个子任务上评估了我们的模型,并采用MicroF1分数(F1)、精度(P)和召回率(R)作为评估指标来衡量性能。对于MASC来说为了与其他方法进行比较,我们也使用了Acc。
4.2 Compared System
在本节中,我们将介绍用于不同任务的四种类型的比较系统。
多模式方面项提取方法(MATE)。1) RAN(Wu et al.,2020a),其通过协同网络将文本与对象区域对齐。2) UMT(Yu et al.,2020b),它使用跨模态变换器来融合文本和图像表示,用于多模态命名实体识别(MNER)。3) OSCGA(Wu et al.,2020b),另一种使用视觉对象作为图像表示的MNER方法。4) RpBERT(Sun等人,2021),其使用多任务训练模型进行MNER和图像-文本关系检测。
多模态方面情绪分类方法(MASC)。1) TomBERT(Yu和Jiang,2019),通过使用BERT来捕捉模态内动态来处理MASC任务。2) CapTrBERT(Khan和Fu,2021),将图像翻译成字幕,作为情感分类的辅助句子
基于文本的联合方面情感分析方法(JASA)。1) SPAN(Hu et al.,2019),将JASA任务表述为跨度预测问题。2) D-GCN(Chen et al.,2020a),提出了一种方向图卷积网络来捕捉单词之间的相关性。3) BART(Yan et al.,2021),通过将JASA任务公式化为指数生成问题,使其适应BART。
联合多模态方面情绪分析(JMASA)的多模态方法。1) UMT TomBERT和OSCGA TomBERT,它们是通过组合上述子任务的方法而实现的简单流水线方法。2)UMT-collapsed(Yu等人,2020b)、OSCGA-collapsed(Wu等人,2020年B)和RpBERT-collapsed(Sun等人,2021),它们用崩溃的标签(如B-POS和I-POS)对JMASA任务进行建模。3) JML(Ju et al.,2021),这是最近提出的一种多任务学习方法,具有辅助跨模态关系检测任务。
4.3 Main Results
在本节中,我们分析了MABSA的三个子任务的不同方法的结果。
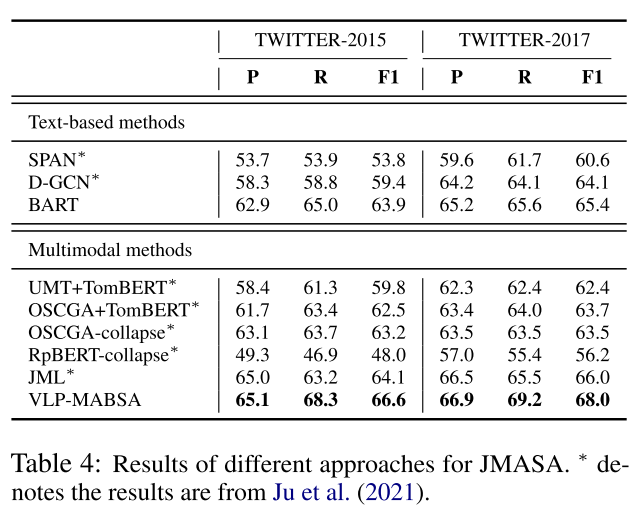
JMASA的结果。表4显示了JMASA不同方法的结果。从表中可以看出,在基于文本的方法中,BART的性能最好,甚至优于一些多模式方法,这证明了我们的基本框架的优越性。对于多模式方法,JML比以前的方法获得了更好的性能,这主要是因为它在图像和文本之间的关系检测方面具有辅助任务。在所有方法中,VLP-MABSA是具有所有预训练任务的整个模型,在两个数据集上表现最好。具体而言,它在TWITTER-2015和TWITTER-2017上分别以2.5和2.0的绝对百分点显著优于第二好的系统JML。这主要得益于我们针对特定任务的培训前任务,这些任务确定了两种模式的方面和观点以及它们的一致性。
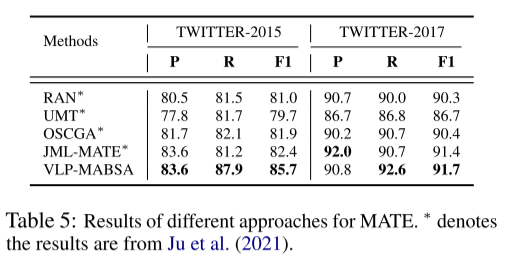
MATE和MASC的结果。表5和表6显示了MATE和MASC的结果,与JMASA子任务的趋势类似,我们可以清楚地观察到,我们提出的方法VLP-MABSA通常在两个数据集上实现了最佳性能,但在TWITTER-2015的准确性指标上除外。这些观察结果进一步证明了我们提出的预训练方法的总体有效性。
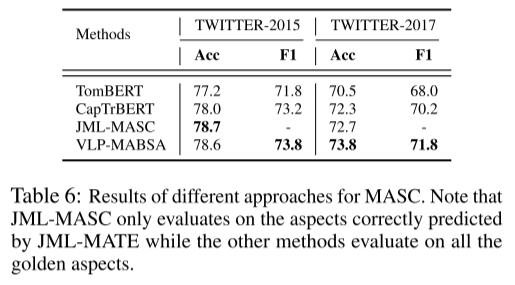
4.4 In-depth Analysis of Pre-training Tasks
为了探索每个预训练任务的影响,我们对使用完整训练数据集的全监督设置和仅随机选择200个训练样本进行微调的弱监督设置进行了彻底的消融研究。
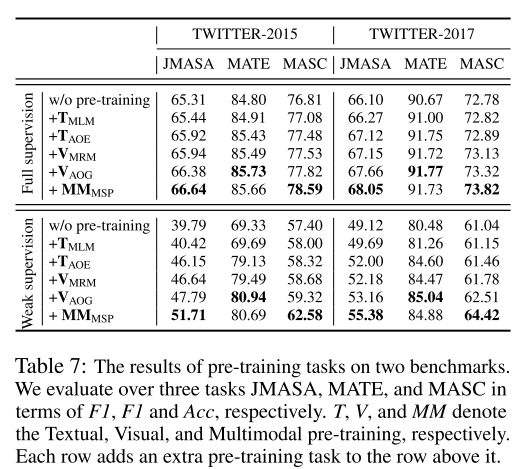
每个预训练任务的影响。正如我们从表7中看到的,当添加更多的预训练任务时,相对于大多数指标,性能通常会提高。为了更好地分析每个预训练任务的效果,我们以TWITTER-2015上的弱监督实验为例。当只使用MLM来预训练我们的模型时,性能只得到了轻微的改进。在添加AOE任务后,MATE的结果在F1上获得了9.44%的巨大改进。这表明AOE任务大大增强了我们的模型识别方面项的能力。当添加MRM任务时,性能再次得到轻微改善。这反映了一般的预训练任务(例如MLM和MRM)不足以使我们的模型处理下游任务,这些任务需要模型理解图像和文本中的主观和客观信息。当添加AOG任务时,三个子任务的性能得到了适度的提高,这证明了 AOE任务的有效性。最后,添加MSP任务可以显著提高性能,尤其是在MASC任务上。这表明MSP任务可以增强我们的模型对语言和图像模式中情感的理解。通过组合所有预训练任务,无论是在完全监督还是弱监督环境中,我们的完整模型通常都能在大多数子任务上获得最佳结果。
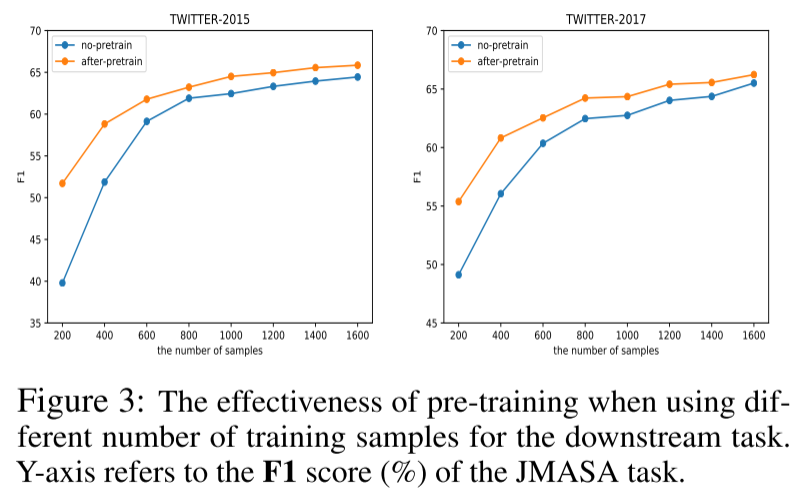
使用不同数量的下游训练样本时预训练的影响。为了更好地理解预训练的影响,当采用不同数量的样本进行下游训练时,我们比较了有预训练和没有预训练的结果。我们以JMASA任务为例来观察其影响。如图3,当样本量较小时,预训练可以带来巨大的改进。相反,当样本量变大时,预训练带来的改进相对较小。这进一步说明了我们的预训练方法的稳健性和有效性,尤其是在低资源的情况下。
4.5 Case study
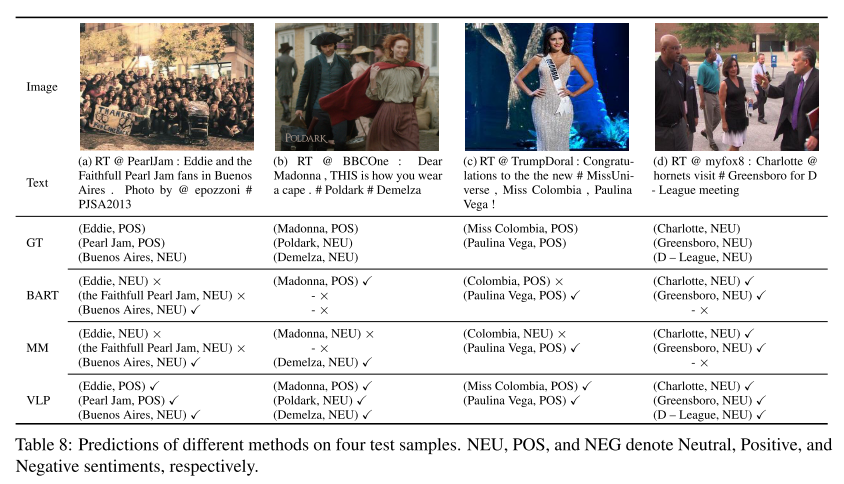
为了进一步证明我们的方法的有效性,我们给出了四个测试示例,其中包含来自不同方法的预测。比较的方法分别是BART、我们的框架使用不带预训练的多模式输入(用MM表示)和我们的框架,使用带完全预训练的多模输入(用VLP表示)。如表8所示,例如(a),BART和MM都提取了错误的方面术语(即,忠实珍珠果酱),并给出了对Eddie的错误情绪预测。例如(b),BART只提取了一个方面术语Madonna,而MM识别了一个额外的方面术语Demelza。然而,对麦当娜的情绪被MM错误地预测了。例如(c),BART只有完全监督弱监督F1 F1 承认了“哥伦比亚”一词的一部分,MM错误地将对哥伦比亚小姐的看法预测为“中立”。例如(d),BART和MM都未能识别方面术语DLeague。在所有情况下,我们的完全预训练的VLP模型正确地提取了所有方面的术语并对情绪进行了分类,这表明了我们的生成框架和特定任务预训练任务的优势。
![]()
5 Conclusion
在本文中,我们提出了一个用于多模式基于方面的情绪分析(VLP-MABSA)的特定任务视觉语言预训练框架。我们进一步分别从语言、视觉和多模态模式设计了三种预训练任务。实验结果表明,对于MABSA的三个子任务,我们提出的方法总体上优于最先进的方法。我们的工作是迈向MABSA统一视觉语言预训练框架的第一步。未来,我们计划将我们的预训练方法应用于更大的数据集,并在预训练框架中考虑图像和文本之间的关系。我们希望这项工作能够为MABSA的研究带来新的见解和视角。
一些问题
Q:语言通常是象征性的,而音频和视觉模式将被表示为信号。什么叫语言是象征性的?
A:
语言是象征性的,意味着语言的符号(词汇、语法规则等)与所表示的对象之间没有必然的联系。换句话说,语言中的词汇和语法结构并非直接反映现实世界中的事物,而是通过共同约定的符号系统来表示概念和意义。
具体来说,语言是一种人类创造的工具,通过将符号与特定的概念或意义进行关联,来传达信息和进行交流。这种关联是基于社会共识和文化约定的,并因此在不同语言和文化之间存在差异。
例如,一个词语在不同的语言中可能有不同的含义,甚至相同的词在同一语言中也可能有多种不同的解释。这是因为语言的符号是通过共同约定的方式建立起来的,而不是由自然规律决定的。因此,语言的象征性使得我们能够用抽象的符号系统来表示和交流各种概念和意义。
Q:什么是噪声拓扑?
A:
噪声拓扑(Noise Topology)是一种用于描述和分析复杂系统中的噪声行为的数学工具和概念。它主要应用于理论物理、统计物理、动力系统等领域。
噪声拓扑的核心思想是将噪声视为系统中存在的随机扰动,并研究这些扰动对系统动力学的影响。噪声可以是来自外部环境或系统内部的不确定性因素,可能是随机的、非线性的或者具有某种特定的结构。
噪声拓扑关注的是噪声引起的系统状态的变化,以及这些变化在拓扑空间中的表现。拓扑空间是一种描述对象之间关系的数学结构,它忽略了度量和距离的概念,而关注的是空间中的连通性、区域的分割和形状等特征。
通过噪声拓扑的方法,研究者可以分析噪声对系统稳定性、相变行为、异质性和复杂性等方面的影响。噪声拓扑的应用包括但不限于混沌系统、神经网络、量子系统、生物系统等领域。
Q: 多模态和跨模态有什么区别?
A:
多模态(Multimodal)和跨模态(Cross-modal)是在信息处理和人机交互领域中常用的两个术语,它们描述了不同模态之间的关系和交互方式。
多模态指的是同时利用多个感官模态(如视觉、听觉、触觉等)来获取信息或进行交流的方式。在多模态系统中,不同的感官模态可以互相补充、协同工作,以提供更丰富、全面的信息和交互体验。例如,视频会议系统通过结合视频、音频和文字聊天等模态,实现远程的视听交流。
跨模态则指的是在不同感官模态之间进行信息转换或匹配的过程。它强调的是将一种模态的信息转化为另一种模态的表示形式,以实现跨越感官模态的信息交流和理解。例如,语音识别系统将语音信号转化为文本表示,从而实现语音和文本之间的跨模态转换。
简而言之,多模态强调的是同时利用多个感官模态,而跨模态则强调的是不同感官模态之间的信息转换和交互。它们都涉及到在不同模态之间进行信息的传递、转换和融合,旨在提高信息处理和人机交互的效率和质量。
Q:smooth-ness, temporal and spatial coherence, sparsity, and natural clustering amongst others.这个amongst是什么意思?
A:
在这个句子中,"amongst" 是 "among" 的同义词,表示在一组事物或概念之间。它用来强调所列举的特征不仅仅局限于上述列举的那些,还包括其他未明确提及的特征。这个句子的意思是,除了已经提到的特征(如平滑度、时间和空间的连贯性、稀疏性和自然聚类)之外,还有其他一些特征也是相关的。
这种使用方式是为了强调列举的特征并不是全部,还有其他重要的特征没有被具体列出。
Q:para-linguistic analysis,很多词都有para这个前缀?
A:
"Para-" 是一个前缀,源自希腊语,表示“旁边”、“相似”或“准”的意思。在这种情况下,“para-” 表示“准”,与某个特定领域或概念相关。
在 "para-linguistic analysis"(声语分析)中,"para-" 强调了声语分析是与语言学相关的、但又略有不同的一种分析方法。它研究的是非语言的元素,如说话者的声音、语调、节奏、身体语言、面部表情等,这些元素传达了语言之外的信息和意义。所以,“para-” 在这里表示与语言相关的、但又稍微有所不同的分析范围。类似地,其他词中的 "para-" 前缀也具有类似的含义,表示与原词相关但有所区别的概念。
Q:unimodel representation是什么意思
A:
"Unimodal representation"(单模态表示)指的是一种仅基于单个模态或源的表示形式。在多模态数据处理领域,我们通常面临多种类型的信息来源,例如图像、文本、语音等。而单模态表示则特指只使用其中一种模态的数据进行建模和表示。
以图像为例,传统的计算机视觉任务往往是基于图像数据进行处理和分析。在这种情况下,图像本身就是单模态数据,并且使用图像的像素值来进行表示和分析。类似地,在自然语言处理任务中,文本可以被视为单模态数据,并且使用词、句子或字符来表示。
相比之下,多模态表示涉及到多个模态的数据,将它们结合起来进行综合建模和分析。这样可以更全面地捕捉不同模态之间的关联和互补信息。
总结来说,"unimodal representation" 指的是仅基于单个模态或源的表示形式,而不考虑跨模态的数据组合和综合。
深度信念网络(Deep Belief Network,DBN)是一种深度学习模型,由Geoffrey Hinton等人于2006年提出。它是一种概率生成模型,用于无监督学习和特征学习。
深度信念网络由多个堆叠的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成。每个RBM由可见层和隐藏层组成,其中可见层表示输入数据的特征,隐藏层则学习到了更高级别的抽象特征。
DBN的训练过程分为两个阶段:预训练和微调。在预训练阶段,逐层地对每个RBM进行训练,从而初始化网络的权重参数。每层的RBM通过最大似然估计或对比散度等方法进行训练,其中上一层的隐藏层作为下一层的输入。在预训练完成后,可以使用反向传播算法进行微调,以进一步优化整个网络。
深度信念网络在特征学习方面具有很强的能力,可以自动地从原始数据中学习到高级别的、有意义的特征表示。这些特征可以用于后续的分类、聚类或生成任务。DBN在计算机视觉、自然语言处理和推荐系统等领域得到了广泛的应用。
概率图模型(Probabilistic Graphical Model,PGM)是一种用于建模和推断概率关系的图结构模型。它通过图的形式表示变量之间的依赖关系,并使用概率分布描述这些变量之间的联合概率分布。
概率图模型可以分为两类:有向图模型(Directed Graphical Models,DGM)和无向图模型(Undirected Graphical Models,UGM)。
-
有向图模型(DGM):也称为贝叶斯网络(Bayesian Networks)或信念网络(Belief Networks)。它使用有向边表示变量之间的因果关系,并使用条件概率分布来描述变量的依赖关系。常见的有向图模型包括贝叶斯网络和隐马尔可夫模型(Hidden Markov Models)等。
-
无向图模型(UGM):也称为马尔可夫随机场(Markov Random Fields)。它使用无向边表示变量之间的相关关系,没有明确的因果关系。无向图模型使用势函数(Potential Function)来描述变量之间的依赖关系,其中势函数定义了一个能量函数,用于衡量变量的联合状态的可能性。常见的无向图模型包括高斯随机场(Gaussian Random Fields)和条件随机场(Conditional Random Fields)等。
概率图模型能够提供一种直观且紧凑的方式来表示复杂的概率关系,并支持进行推断、学习和预测等任务。它在机器学习、人工智能、自然语言处理和计算机视觉等领域广泛应用,例如推荐系统、图像分割、自然语言理解等。
Q:para-verbal information是什么?
A:
Para-verbal information是指言语中的非文字部分,即通过语音、声调、音量、节奏、语速和语调等方式传达的信息。它是一种非语言性的沟通方式,可以传递出对话者的情感、态度、意图以及其他非文字信息。与语言的字面含义相比,para-verbal信息更多地依赖于声音的特征和表达方式来传达信息。例如,一个人的语调和节奏可以表达出他们的情绪状态,声音的音量可以传递出讲话者的强烈程度,语速可以反映出紧迫感或放松感等。通过注意和解读para-verbal信息,我们可以更好地理解和回应他人的言语。
Q:zero-shot是什么?
A:
Zero-shot(零-shot)是一种机器学习和自然语言处理领域的技术。它的目标是在没有进行针对特定任务的训练的情况下,使模型能够进行预测和处理新的、未知的任务。
传统的机器学习模型通常需要通过大量的标记数据进行训练,以便能够对特定任务进行准确的预测。但是,当面临新的任务或领域时,需要重新收集和标记大量的数据,这是非常耗时和昂贵的。
Zero-shot技术尝试解决这个问题。它使用了预训练的模型,并通过将任务的描述性输入与预训练的模型进行交互,来实现对新任务的预测。通过在预训练模型中学习一些通用的语言表示和语义知识,Zero-shot技术允许模型在没有特定训练的情况下进行推理和预测。
这种技术在自然语言处理任务中非常有用,例如文本分类、命名实体识别、关系抽取等。它为处理新任务提供了一种更加灵活和高效的方法,并减少了重新训练模型的需求。
大多数机器学习模型在训练阶段需要使用大量的标记数据进行训练,以便能够准确地进行预测。但是,这样的训练过程可能非常耗时和昂贵。
为了解决这个问题,一些新的技术被引入,包括few-shot和zero-shot学习。这些技术旨在在少量甚至没有标记数据的情况下,使模型能够进行准确的预测和学习。
Few-shot学习是指通过使用少量标记数据来进行训练,以实现对新任务的预测。它通常使用一种称为元学习的方法,通过从少量样本中学习到通用的知识和适应性,使模型能够在新任务上表现良好。
Zero-shot学习是指在没有进行特定任务的训练的情况下,使模型能够进行预测和处理新任务。它利用预训练的模型和语言表示学习的知识,通过将任务描述性输入与模型进行交互,实现对新任务的预测。
这些技术在面对新任务或领域时非常有用,因为它们可以减少数据收集和标记的工作量,并提供更加灵活和高效的学习方法。
Q:few-shot是元学习吗?
A:
是的,Few-shot学习通常使用一种称为元学习(Meta-Learning)的方法来实现。元学习是一种学习如何学习的框架,通过从少量样本中学习到通用的知识和适应性,使模型能够在新任务上表现良好。
在Few-shot学习中,基于元学习的方法可以通过在少量样本上进行训练,以学习到如何适应新的、未见过的任务。元学习的目标是学习到一个通用的表示方式,使得模型可以更快速地适应新任务。
例如,在Few-shot分类任务中,元学习方法可以通过在少量训练数据上训练一个分类模型,使其能够在测试时准确地识别出新类别的样本。这个过程中,元学习算法会学习到一个通用的表示方式,使得模型可以在少量的数据上迅速适应新任务。
因此,Few-shot学习是一种基于元学习的方法,通过在少量样本上进行训练,来实现对新任务的预测。
Q:Multimodal Aspect-Based Sentiment Analysis和多模态情感分析有什么区别?
A:
"Multimodal Aspect-Based Sentiment Analysis"(多模态方面情感分析)是一种更具体的多模态情感分析方法。它结合了多个数据模态,以分析和理解对于特定方面(aspect)的情感。
传统的多模态情感分析关注整体情感的分类或预测,而多模态方面情感分析进一步细化到对于不同方面的情感进行分析。例如,在对一部电影的评论进行情感分析时,不仅可以考虑整体情感如正面或负面,还可以针对电影的不同方面(如演员表演、剧情、音乐等)进行情感分析。
多模态方面情感分析结合了文本、图像、音频、视频等多个模态的信息,以深入了解和推断用户在不同方面上的情感倾向。例如,通过分析文本中的关键词、图像中的视觉元素、音频中的情感声调,可以确定用户对于特定方面的情感倾向,比如对于电影中的演员表演的喜爱或厌恶。
因此,多模态方面情感分析相对于传统的多模态情感分析更加细粒度,侧重于不同方面的情感分析,使得分析结果更加详尽和准确。
Q:Masked Language Modeling应该怎么翻译?
A:
"Masked Language Modeling" 可以翻译为 "遮蔽语言建模" 或 "掩码语言建模"。这是一种在自然语言处理中常用的技术,用于预训练语言模型。
在遮蔽语言建模中,输入的文本序列中的某些标记(一般是单词或字)会被特定的掩码符号所替代。模型的目标是通过上下文信息来预测被掩码的标记。这个过程可以帮助模型学习到词语之间的关联以及上下文的语义理解。
遮蔽语言建模通常与 Transformer 网络结构一起使用,例如 BERT(Bidirectional Encoder Representations from Transformers)。通过预先训练一个遮蔽语言建模模型,我们可以得到一个具有丰富语言理解能力的模型。然后,我们可以将该模型用于各种下游任务,如文本分类、命名实体识别、问答等。
因此,"Masked Language Modeling" 是一种通过掩码部分文本序列并利用上下文信息进行预测的技术,用于提升自然语言处理模型的语言理解能力。
Q:where s is the golden sentiment annotated in dataset. 金色情感是什么?
A:
在该语境中,"金色情感"(golden sentiment)是指在数据集中经过人工标注或专家评估的正确、准确的情感分类结果。
情感分类是一种自然语言处理任务,旨在将文本或句子分为不同的情感类别,如积极、消极、中性等。为了训练和评估情感分类模型,通常需要一个经过标注的数据集,其中每个文本样本都被赋予了正确的情感类别。
在这种情况下,"金色情感"指的是通过人工标注或专家评估认定为正确的情感分类结果。它代表了标注者对文本的情感类别判断的最佳认可,是作为模型训练和评估的基准标准。
因此,"金色情感"可以理解为来自于数据集中经过认定为准确的情感分类结果,用于指导情感分类模型的训练和评估。
Q:where λ1, λ2, λ3, λ4, and λ5 are tradeoff hyperparameters to control the contribution of each task. 其中tradeoff是什么意思?
A:
在这个语境中,"tradeoff" 意指权衡或折衷。在机器学习或优化问题中,"tradeoff hyperparameters"(权衡超参数)通常用于调节不同任务或目标之间的平衡或权衡关系。
这些超参数控制着每个任务对最终模型性能的贡献程度,帮助调整模型在多任务学习或多目标优化时的表现。通过调整这些权衡超参数的值,可以更好地平衡不同任务之间的重要性,以获得更好的整体性能。
因此,在这个上下文中,"tradeoff hyperparameters" 用于调整每个任务对模型整体性能的影响程度,以实现不同任务间的权衡和折衷,从而达到更好的综合效果。
Q:开发集是什么?
A:
开发集(Development Set),也称为验证集(Validation Set)或调整集(Tuning Set),是在机器学习和模型开发中用于评估和优化模型性能的数据集。
开发集通常是从原始数据集中独立划分出来的一部分数据,用于模型的训练过程中进行中间评估和调整超参数。与测试集不同,开发集的标签信息是已知的,可以用于评估模型在训练过程中的性能表现。
通过在开发集上进行评估,可以快速了解模型在训练过程中的性能,并根据评估结果进行模型的改进和调整。开发集的使用有助于调整模型结构、超参数选择、特征工程等方面,以达到更好的模型性能。
需要注意的是,在使用开发集进行模型调整和优化时,需要避免过度拟合开发集,即仅针对开发集进行调整而导致模型在测试集或实际应用中表现不佳。因此,在模型调整完成后,通常还需要使用独立的测试集进行最终的性能评估。
Q:In this section, we introduce four types of compared systems for different tasks. Approaches for Multimodal Aspect Term Extraction (MATE). 什么是比较系统?
A:
在这个语境中,"比较系统"是指用于进行对比和比较的不同方法或系统。在介绍多模态方面术语提取(Multimodal Aspect Term Extraction,MATE)任务时,可能会提到四种不同类型的比较系统。
这些比较系统是为了研究和评估在特定任务中的不同方法或系统的性能表现而设计的。通过比较不同系统的结果,可以评估它们在处理特定任务时的优劣,帮助研究者了解各种方法的优点和局限性,从而指导进一步的改进和研究。
在MATE任务中,这些比较系统可能是不同的模型架构、算法或方法的变体,用于识别和提取多模态数据中的方面术语。研究人员可能会设计和实现多个系统,并使用相同的评估指标来比较它们的性能,以确定最佳的方法或系统。
因此,在这个上下文中,"比较系统"指的是被用于对比和评估不同方法或系统性能的多个系统。这些比较系统通过比较它们在特定任务中的性能表现,有助于研究人员理解不同方法的优缺点,并推动相关领域的进一步发展。
Q:什么是消融实验?
A:
消融实验(Ablation Study)是一种科学实验方法,旨在评估系统某个组成部分对整体系统性能的影响。该方法通过逐步去除系统中的某些元素,来研究这些元素对系统性能和结果的影响。
在机器学习和人工智能领域,消融实验通常用于评估模型的各个组成部分对最终结果的影响。例如,在深度学习模型中,研究人员可能会逐步去除模型中的某些层或特征,来评估这些层或特征对模型性能的贡献。
消融实验的主要优点在于可以确定系统的不同组成部分对系统整体性能的贡献,从而帮助研究人员更好地理解系统的工作原理,并进行进一步的改进和优化。此外,消融实验还可以帮助避免研究人员过度依赖某些组成部分,从而导致模型性能下降的情况发生。
需要注意的是,消融实验不能完全反映真实场景下的系统表现,因为它忽略了系统元素之间的相互作用和联合效应。因此,消融实验通常需要结合其他实验方法和评估指标一起使用,以全面评估系统的性能和效果。
Q:全监督设置和弱监督设置有什么区别?
A:
全监督学习和弱监督学习是机器学习中常见的两种学习范式,它们之间的主要区别在于标记数据的丰富程度和使用方式。
-
全监督学习(Supervised Learning):
- 在全监督学习中,训练数据集包含了输入特征和对应的标记(即输出),模型通过学习输入和标记之间的映射关系来进行训练。这意味着每个训练样本都有明确的标记信息,模型可以直接从中学习到输入和输出之间的对应关系。
-
弱监督学习(Weakly Supervised Learning):
- 弱监督学习则是一种学习范式,其中训练数据的标记信息相对不完整或不准确。这可能包括标记噪声、部分标记、标记的粒度较粗等情况。在弱监督学习中,模型需要能够从这些不完整或不准确的标记信息中学习,并尽可能准确地进行预测。
总的来说,全监督学习要求训练数据具有高质量的标记信息,而弱监督学习则更加灵活,可以应对标记信息不完整或不准确的情况。弱监督学习通常需要开发特定的算法和技术来处理带噪声的标记数据,以实现对模型的有效训练和预测。
【论文解读之情感分析系列】——VLP-MABSA - 知乎
2.1 Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis-CSDN博客
相关文章:
【论文精读】多模态情感分析 —— VLP-MABSA
Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis 本篇论文发表于ACL-2022 原文链接 https://arxiv.org/abs/2204.07955 源码 GitHub - NUSTM/VLP-MABSA 模态:图像文本 基于多模态方面的情感分析(MABSA)近年来越来越受到关注。然而&am…...

SQL SELECT TOP, LIMIT, ROWNUM 子句
在数据库中,LIMIT是一个用于限制结果集的关键字,它可以与SELECT语句一起使用。它有以下几种用法: LIMIT n:返回前n条记录。例如,LIMIT 10将返回结果集中的前10条记录。 LIMIT m, n:返回从第m1条记录开始的…...
金融信贷风控评分卡模型
评分卡模型概念 评分模型是根据借款人的历史数据,选取不同维度的数据类型,通过计算而得出的对借款人信用情况打分的模型。不同等级的信用分数代表了借款人信用情况的好坏,以此来分析借款人按时还款的可能性。 评分卡模型分类 A卡ÿ…...
【java苍穹外卖项目实战二】苍穹外卖环境搭建
文章目录 1、前端环境搭建2、后端环境搭建1、项目结构搭建2、Git版本控制3、数据库创建 开发环境搭建主要包含前端环境和后端环境两部分。 前端的页面我们只需要导入资料中的nginx, 前端页面的代码我们只需要能看懂即可。 1、前端环境搭建 前端运行环境的nginx&am…...

在 Ubuntu 22.04 上安装 Django Web 框架的方法
简介 Django 是一个功能齐全的 Python Web 框架,用于开发动态网站和应用程序。使用 Django,您可以快速创建 Python Web 应用程序,并依赖框架来完成大部分繁重的工作。 在本指南中,您将在 Ubuntu 22.04 服务器上启动 Django。安装…...
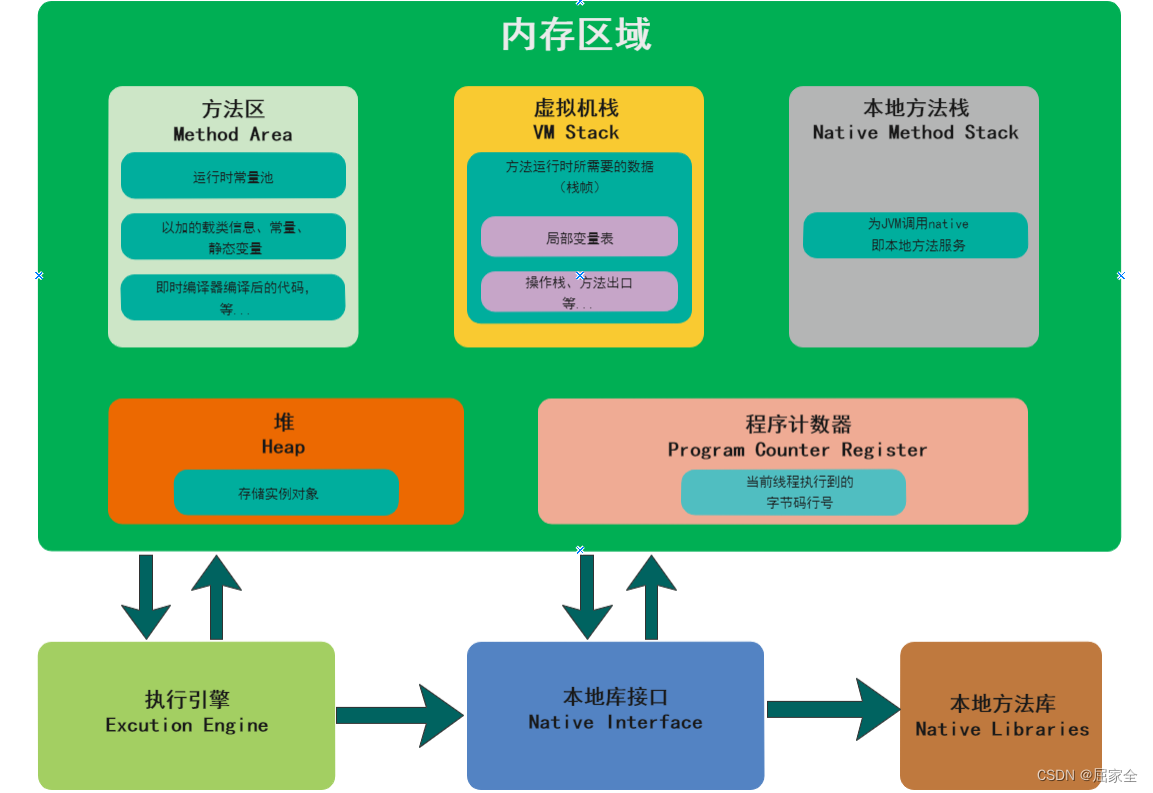
JVM Java虚拟机入门指南
文章目录 为什么学习JVMJVM的执行流程JVM的组成部分类加载运行时数据区本地方法接口执行引擎 垃圾回收什么样的对象是垃圾呢内存溢出和内存泄漏定位垃圾的方法对象的finalization机制垃圾回收算法分代回收垃圾回收器 JVM调优参数JVM调优工具Java内存泄漏排查思路CPU飙高排查方案…...

【错误文档】This与Here的区别、主系表结构、如何合并两个句子、祈使句结构
目录 This与Here的区别 主系表结构 如何合并两个句子 祈使句结构 原句中文1: “就是这件。” 我的翻译: This is it. 正确翻译: 书上原句: Here it is! 正确解释: 两个翻译都对,只是强调点不同&…...
Java入门之JavaSe(韩顺平p1-p?)
学习背景: 本科搞过一段ACM、研究生搞了一篇B会后,本人在研二要学Java找工作啦~~(宇宙尽头是Java?)爪洼纯小白入门,C只会STL、python只会基础Pytorch、golang参与了一个Web后端项目,可以说项目小…...
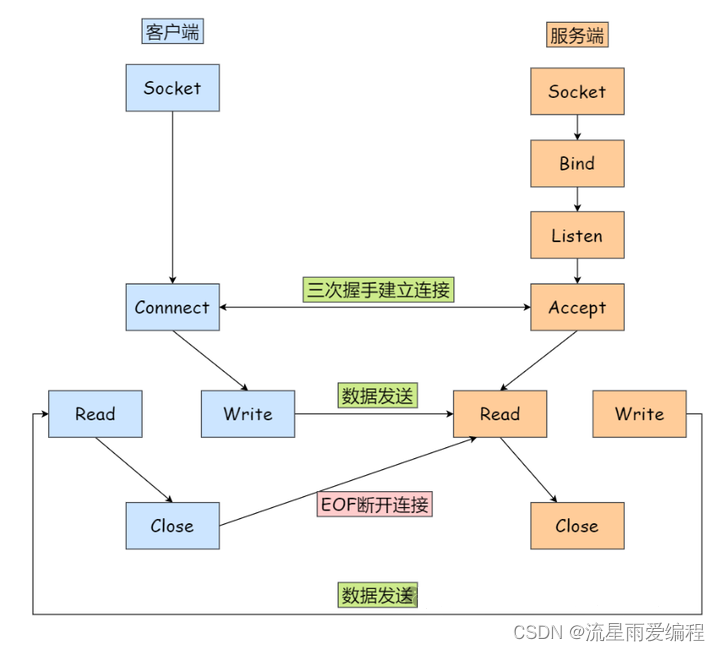
TCP的连接和断开详解
目录 1.TCP基础知识 1.1.TCP 头格式 1.2.TCP协议介绍 1.3.UDP协议介绍 1.4.TCP 和 UDP 区别 1.5.TCP 和 UDP 应用场景 1.6.计算机网络相关术语(缩写) 2.TCP 连接建立:三次握手 2.1.TCP 三次握手过程 2.2.三次握手原理 2.3.异常分析…...
armbian ddns
参考https://mp.weixin.qq.com/s/0Uu_nbGH_W6vAYHPH4kHqg Releases jeessy2/ddns-go GitHub mkdir -p /usr/local/ddns-go cd /usr/local/ddns-gowget https://github.com/jeessy2/ddns-go/releases/download/v6.1.1/ddns-go_6.1.1_freebsd_armv7.tar.gztar zxvf ddns-go_…...
MQTT 服务器(emqx)搭建及使用
推荐阅读: MQTT 服务器(emqx)搭建及使用 - 哔哩哔哩 (bilibili.com) 一、EMQX 服务器搭建 1、下载EMQX https://www.emqx.com/zh/try?productbroker 官方中文手册: EMQX Docs 2、安装使用 1、该软件为绿色免安装版本,解压缩后即安装完…...
】MemoryStateBackend的实现)
【flink状态管理(四)】MemoryStateBackend的实现
文章目录 1.基于MemoryStateBackend创建KeyedStateBackend1.1. 状态初始化1.2. 创建状态 2. 基于MemoryStateBackend创建OperatorStateBackend3.基于MemoryStateBackend创建CheckpointStorage 在Flink中,默认的StateBackend实现为MemoryStateBackend,本文…...

前端架构: 脚手架在前端研发流程中的意义
关于脚手架 脚手架又被成为 CLI (command-line interface)基于文本界面,通过中断输入命令执行常见的脚手架:npm, webpack-cli, vue-cli拿 npm 这个脚手架来说 在终端当中输入 npm 命令, 系统就会通过文本方式返回 npm 的使用方法它这种通过命令行执行的…...

Qt网络编程-QTcpServer的封装
简单封装Tcp服务器类,将QTcpServer移入线程 头文件: #ifndef TCPSERVER_H #define TCPSERVER_H#include <QObject>class QTcpSocket; class QTcpServer; class QThread; class TcpServer : public QObject {Q_OBJECT public:explicit TcpServer(…...
【MySQL】_JDBC编程
目录 1. JDBC原理 2. 导入JDBC驱动包 3. 编写JDBC代码实现Insert 3.1 创建并初始化一个数据源 3.2 和数据库服务器建立连接 3.3 构造SQL语句 3.4 执行SQL语句 3.5 释放必要的资源 4. JDBC代码的优化 4.1 从控制台输入 4.2 避免SQL注入的SQL语句 5. 编写JDBC代码实现…...

微信小程序编译出现 project.config.json 文件内容错误
问题描述: 更新微信开发工具后,使用微信开发工具编译时出现project.config.json 文件内容错误。 原因:当前使用的微信开发工具非稳定版本。 解决方法: 在 manifest.json中加入以下代码: "mp-weixin" : …...
一周学会Django5 Python Web开发-Django5创建项目(用命令方式)
锋哥原创的Python Web开发 Django5视频教程: 2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计11条视频,包括:2024版 Django5 Python we…...

DockerUI如何部署结合内网穿透实现公网环境管理本地docker容器
文章目录 前言1. 安装部署DockerUI2. 安装cpolar内网穿透3. 配置DockerUI公网访问地址4. 公网远程访问DockerUI5. 固定DockerUI公网地址 前言 DockerUI是一个docker容器镜像的可视化图形化管理工具。DockerUI可以用来轻松构建、管理和维护docker环境。它是完全开源且免费的。基…...

UML之在Markdown中使用Mermaid绘制类图
1.UML概述 UML(Unified modeling language UML)统一建模语言,是一种用于软件系统分析和设计的语言工具,它用于帮助软件开发人员进行思考和记录思路。 类图是描述类与类之间的关系的,是UML图中最核心的。类图的是用于…...
Spring Boot + 七牛OSS: 简化云存储集成
引言 Spring Boot 是一个非常流行的、快速搭建应用的框架,它无需大量的配置即可运行起来,而七牛云OSS提供了稳定高效的云端对象存储服务。利用两者的优势,可以为应用提供强大的文件存储功能。 为什么选择七牛云OSS? 七牛云OSS提供了高速的…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...