【多模态大模型】视觉大模型SAM:如何使模型能够处理任意图像的分割任务?
SAM:如何使模型能够处理任意图像的分割任务?
- 核心思想
- 起始问题: 如何使模型能够处理任意图像的分割任务?
- 5why分析
- 5so分析
- 总结
- 子问题1: 如何编码输入图像以适应分割任务?
- 子问题2: 如何处理各种形式的分割提示?
- 子问题3: 如何快速生成准确的分割掩码?
- 子问题4: 如何应对分割提示的模糊性?
- 子问题5: 如何有效地训练SAM模型?
- 子问题6: 如何收集并利用大规模的分割掩码数据?
论文:https://arxiv.org/pdf/2304.02643.pdf
代码:https://github.com/facebookresearch/segment-anything
核心思想
"Segment Anything"模型是为了解决图片中对象识别和分割的问题提出的,它通过理解指令(Segment)和利用大量图片数据(Anything)来精确地标出图片中指定的对象。
- 你只要告诉它“找猫”,它就能在图片上精确地标出猫的位置。
- 为了让这个模型学会这么多东西,他们收集了超过一亿个这样的“标记”,覆盖了1100万张图片。
- 这个模型非常聪明,甚至不需要特别训练就能处理新的图片和任务。
针对“Segment Anything”项目的核心子问题,我们将进行5why分析来探索问题的根本原因,然后通过5so分析来探讨可能的解决方案及其潜在影响。以下是关于这个项目的一个核心子问题的示例分析。
起始问题: 如何使模型能够处理任意图像的分割任务?
5why分析
- Why 1: 为什么需要模型处理任意图像的分割任务?原因是因为现实世界中的应用场景非常多样,用户需要在不同的环境下识别和分割各种对象。
- Why 2: 这个需求为什么会导致挑战?原因是因为现有的分割模型通常针对特定类型的图像进行优化,缺乏足够的泛化能力。
- Why 3: 为什么现有模型缺乏泛化能力?原因是因为它们通常在有限的、特定的数据集上训练,没有被设计来理解和适应新的、未见过的图像类型或分割任务。
- Why 4: 这个原因背后的更深层次原因是什么?原因是数据收集和标注的高成本限制了数据集的规模和多样性。
- Why 5: 最根本的原因是什么?原因是缺乏一种有效的方法来自动化数据收集和增强模型的泛化能力。
5so分析
- So 1: 因此,我们可以通过开发一种新的模型架构和训练策略,使模型能够理解自然语言的提示并从大规模、多样化的数据集中学习。
- So 2: 这个解决方案会使模型能够零样本学习,即在未直接训练过的新任务上表现良好。
- So 3: 这个结果将极大扩展模型的应用范围,使其能够适应更广泛的实际场景和用户需求。
- So 4: 进一步的影响是促进计算机视觉领域的发展,开辟新的研究和应用方向。
- So 5: 最终,我们希望达到的目标是实现一个能够理解几乎任何图像分割任务的通用模型,提供高效、准确的分割结果,满足广泛的实际需求。
具体算法设计:
-
灵活性 - 零样本学习(Zero-Shot Learning):
- 问题:当设计一个能够处理未见过任务的模型时,零样本学习成为一个核心问题。这要求模型能够理解广泛的任务描述并正确执行,即使它在训练期间没有看到过这些具体的任务。这种需求直接导致了需要开发一种解法来处理新的图像分布和任务,而不依赖于特定任务的训练数据。
- 零样本学习的解决方案 是使用Prompt Engineering,这是因为通过让模型学习理解自然语言指令,可以使模型在没有看到特定任务数据的情况下,对新的任务进行泛化。
-
实时性 - 发一个轻量级掩码解码器,快速响应:
- 问题: 为了使模型能够在实际应用中被实时使用(例如,在线图像编辑或实时图像分析),模型必须能够快速响应用户的指令。这导致了对一个既能支持灵活的提示又能实时输出分割掩码的模型架构的需求。
- 实时交互需求的解决方案 是开发一个具有快速响应能力的模型架构,其中包括一个高效的图像编码器和一个轻量级的掩码解码器,能够迅速生成分割掩码。
跟语言大模型一样,需要给 SAM 模型一个prompt提示,这个提示可以是一个点(point),也可以是几个点(points),也可以是一个框(box),也可以是一个文本(text),而SAM就根据prompt提示分割目标物体,就像下面这样:
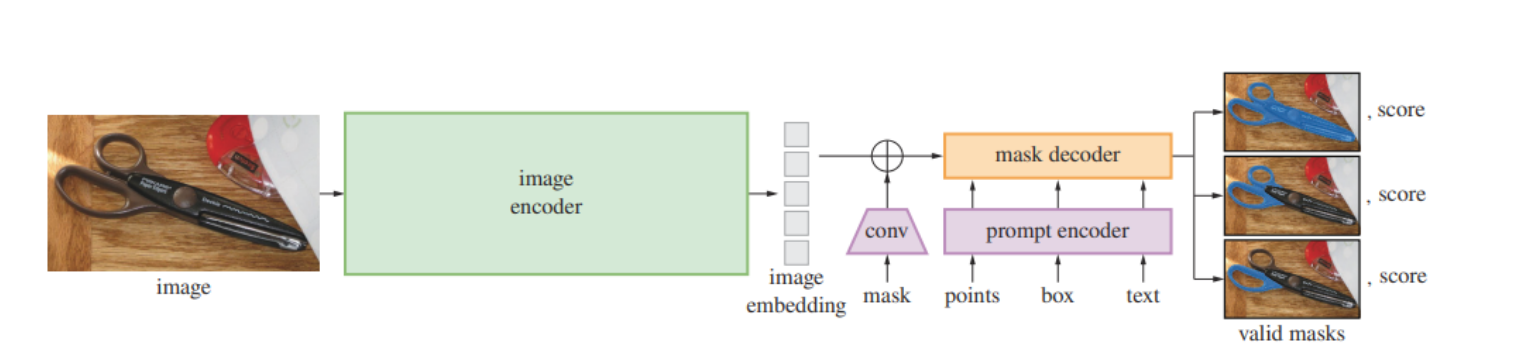
- SAM的概览图,一个重量级的图像编码器输出图像嵌入,然后可以被多种输入提示高效查询以产生对象掩码,实现了摊销的实时速度(50毫秒以下)。
- 对于可以对应多个对象的模糊提示,SAM能输出多个有效的掩码以及相关的置信分数。
- 准确性 - 给深度学习模型喂大规模、多样化训练数据:
- 问题: 为了训练一个能广泛适用于各种图像和任务的模型,需要大量的、多样化的训练数据。鉴于现有的数据集无法满足这一需求,因此产生了如何有效收集这种数据的问题。
- 大规模、多样化数据收集的解决方案 是构建一个“数据引擎”,利用模型辅助的方法来高效生成和收集训练数据。
补充一下,解码器、掩码解码器、分割掩码:
-
解码器是一种算法或模型组件,它的任务是从某种编码的数据中重构或解释信息。在机器学习和深度学习中,解码器通常用于将编码的表示(例如,一个深度神经网络中间层的输出)转换为更容易理解或更有用的格式(如文本、图像等)。
-
掩码解码器是一种特殊类型的解码器,专门设计用于生成图像的分割掩码。在图像分割任务中,掩码解码器接收图像的编码表示(通常由图像编码器产生)和可能的其他信息(如分割任务的指令),并输出一个或多个分割掩码。这些掩码精确地指示图像中的特定区域,如哪些像素属于特定的对象或背景。
-
分割掩码是一个与原图像大小相同的图像,其中每个像素的值指示该像素属于图像中的哪个部分或对象。在最简单的形式中,分割掩码可以是二值的,即像素值为0表示该像素不属于目标对象,值为1表示属于目标对象。在更复杂的场景中,分割掩码可以有多个值,每个值代表图像中不同的对象或区域。
你有一张包含猫和狗的照片,你想分别标出猫和狗的位置。
- 图像编码器首先处理这张照片,提取出重要的视觉特征并将它们编码成一种密集的表示形式。
- 掩码解码器然后接收这个编码,加上一个指令(比如“找出所有的猫”),并工作于将编码转换为一个分割掩码,这个掩码准确地标示出图片中猫的位置。
- 分割掩码最终是一张与原图大小相同的图,但只有标示出猫的部分被标记为1(或其他非零值),其余部分为0,清晰地区分出猫和背景(以及狗,如果指令是分割出猫)。
优势在于能够快速并准确地响应复杂的图像分割请求,使之适用于实时交互场景,如在线图像编辑工具或实时监控系统中的对象识别和跟踪。
SAM 的设计取决于三个主要组件:
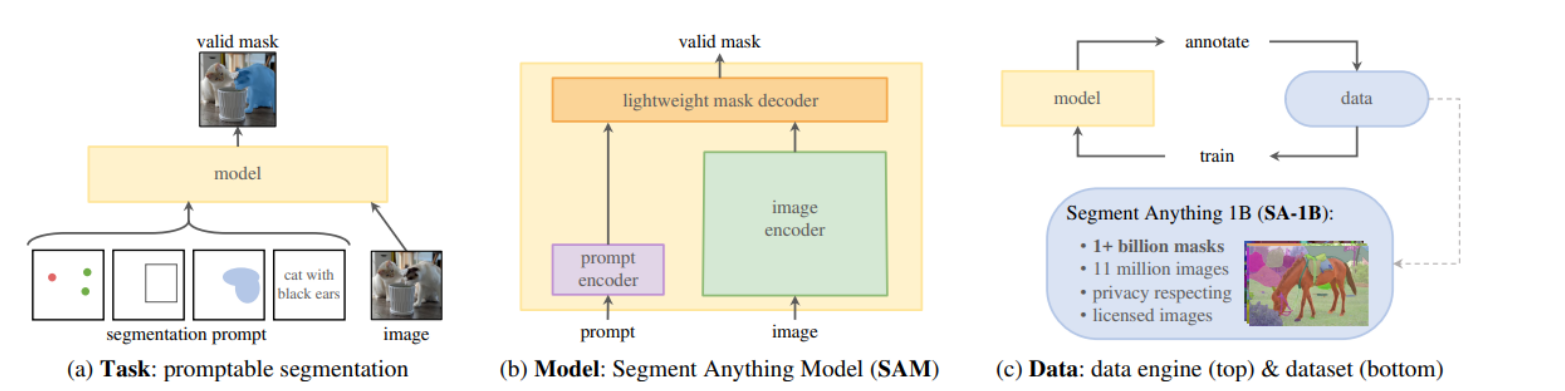
-
图1 (a) Task: promptable segmentation
- 展示了SAM模型的基本任务——可提示的图像分割。
- 图中展示了不同类型的提示(如点、框、文本)和模型如何根据这些提示生成有效的分割掩码。
-
图1 (b) Model: Segment Anything Model (SAM)
- SAM的三个主要组成部分:图像编码器、提示编码器和快速掩码解码器。
- 这表明了SAM的结构是怎样根据各种输入提示产生分割掩码的。
-
图1 © Data: data engine (top) & dataset (bottom)
- 数据引擎、大规模数据集。
- 顶部是SAM模型的数据引擎,说明了数据如何通过人工标注和模型训练来收集;
- 底部是SAM的数据集,SA-1B,它包含超过11M的图片和1B的分割掩码。
- 模型标注数据,再用标注好的数据用来优化模型,以此循环,迭代优化模型以及数据质量。

- 图3
- 展示了从单一模糊提示(绿圈)生成的三个有效掩码的例子。
- 这展示了SAM模型在处理模糊或多义性提示时能够生成多个有效选项的能力。
图3显示了SAM模型如何对一个给定的模糊提示(绿圈)生成多个有效的分割掩码。
在图像分割任务中,一个模糊的提示可能对应于图像中多个不同的对象。
例如,如果提示是图像中的一个点,那么这个点可能位于多个重叠物体的交叉点上,或者无法清楚地指明是指哪个物体。
在这种情况下,模型面临的挑战是如何解释这个模糊的提示并决定哪个对象应该被分割。
SAM模型采用的方法是生成多个可能的分割掩码,每个掩码代表了一个潜在的对象。
这样,即使一个提示可能对应于多个对象,SAM也能提供多个合理的分割选项,用户随后可以从中选择最合适的掩码。
这种方法提高了模型在处理不明确或多义性情况时的实用性和灵活性。
总结
SAM模型的逻辑结构。
子问题1: 如何编码输入图像以适应分割任务?
- 子解法1: 使用Vision Transformer (ViT)作为图像编码器
- 之所以用ViT解法,是因为它能够处理高分辨率输入,并通过自注意力机制捕获图像的全局特征,这对于图像分割任务至关重要。
子问题2: 如何处理各种形式的分割提示?
- 子解法2: 设计灵活的提示编码器
- 之所以用灵活的提示编码器解法,是因为分割任务需要能够理解从简单的点和框到复杂的文本描述等各种提示形式,这要求提示编码器具有处理多种输入类型的能力。
子问题3: 如何快速生成准确的分割掩码?
- 子解法3: 创建快速掩码解码器
- 之所以用快速掩码解码器解法,是因为实时(50毫秒以下)应用要求模型必须在接收到输入提示后迅速生成分割掩码,以保证用户体验。
子问题4: 如何应对分割提示的模糊性?
- 子解法4: 预测多个可能的分割掩码
- 之所以用预测多个可能的分割掩码解法,是因为某些提示可能指向多个可能的对象,模型需要能够为单个提示生成多个合理的掩码。
子问题5: 如何有效地训练SAM模型?
- 子解法5: 模拟提示序列的预训练算法
- 之所以用模拟提示序列的预训练算法解法,是因为能模拟真实世界中的分割任务,通过在训练过程中提供各种假设的用户输入(即提示),来训练模型。
在预训练过程中,模型会尝试理解这些提示并产生对应的分割掩码。模型的输出会与真实的分割掩码(即ground truth)进行比较,并根据这些比较进行优化。
随着训练的进行,模型会越来越好地学习如何解释各种提示并生成高质量的分割掩码,这样在实际应用中,当用户提供一个提示时,模型就能够生成一个准确的分割掩码,即使这个提示在不同的情境下可能会引用到多个不同的对象。
子问题6: 如何收集并利用大规模的分割掩码数据?
- 子解法6: 构建数据引擎来自动化数据收集
- 之所以用构建数据引擎解法,是因为分割掩码数据通常不如图像数据那样容易获取,需要一个自动化系统来高效地收集和标注数据,模型标注数据,数据优化模型,循环。
任务是从一张充满人群的街景照片中,分割出特定穿红衣服的人:
- 图像编码器首先将输入图像编码成一个特征丰富的表示。
- 提示编码器接收一个文本提示“穿红衣服的人”,将其转换成模型可以理解的编码。
- 掩码解码器使用图像特征和提示编码快速生成可能的分割掩码。
- 如果提示指向多个穿红衣服的人,模型会生成多个掩码,每个掩码代表一个可能的红衣人物。
- 在预训练阶段,模型通过模拟真实世界的分割任务来学习如何处理各种复杂的提示。
- 利用数据引擎,模型能够在不需要人工标注的情况下,自动从成千上万的街景照片中收集和利用分割掩码数据。
相关文章:
【多模态大模型】视觉大模型SAM:如何使模型能够处理任意图像的分割任务?
SAM:如何使模型能够处理任意图像的分割任务? 核心思想起始问题: 如何使模型能够处理任意图像的分割任务?5why分析5so分析 总结子问题1: 如何编码输入图像以适应分割任务?子问题2: 如何处理各种形式的分割提示?子问题3:…...

Shell之sed
sed是什么 Linux sed 命令是利用脚本来处理文本文件。 可依照脚本的指令来处理、编辑文本文件。主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。 sed命令详解 语法 sed [-hnV][-e <script>][-f<script文件>][文本文件] sed [-nefr] [动作…...

AJAX——认识URL
1 什么是URL? 统一资源定位符(英语:Uniform Resource Locator,缩写:URL,或称统一资源定位器、定位地址、URL地址)俗称网页地址,简称网址,是因特网上标准的资源的地址&…...

《Docker极简教程》--Docker环境的搭建--在Linux上搭建Docker环境
更新系统:首先确保所有的包管理器都是最新的。对于基于Debian的系统(如Ubuntu),可以使用以下命令:sudo apt-get update sudo apt-get upgrade安装必要的依赖项:安装一些必要的工具,比如ca-certi…...

开源微服务平台框架的特点是什么?
借助什么平台的力量,可以让企业实现高效率的流程化办公?低代码技术平台是近些年来较为流行的平台产品,可以帮助很多行业进入流程化办公新时代,做好数据管理工作,从而提升企业市场竞争力。流辰信息专业研发低代码技术平…...
)
C#系列-C#操作UDP发送接收数据(10)
在C#中,发送UDP数据并接收响应通常涉及创建两个UdpClient实例:一个用于发送数据,另一个用于接收响应。以下是发送UDP数据并接收响应的示例代码: 首先,我们需要定义一个方法来发送UDP数据,并等待接收服务器…...
))
突破编程_C++_面试(基础知识(10))
面试题29:什么是嵌套类,它有什么作用 嵌套类指的是在一个类的内部定义的另一个类。嵌套类可以作为外部类的一个成员,但它与其声明类型紧密关联,不应被用作通用类型。嵌套类可以访问外部类的所有成员,包括私有成员&…...

初步探索Pyglet库:打造轻量级多媒体与游戏开发利器
目录 pyglet库 功能特点 安装和导入 安装 导入 基本代码框架 导入模块 创建窗口 创建控件 定义事件 运行应用 程序界面 运行结果 完整代码 标签控件 常用事件 窗口事件 鼠标事件 键盘事件 文本事件 其它场景 网页标签 音乐播放 图片显示 祝大家新…...

【npm】安装全局包,使用时提示:不是内部或外部命令,也不是可运行的程序或批处理文件
问题 如图,明明安装Vue是全局包,但是使用时却提示: 解决办法 使用以下命令任意一种命令查看全局包的配置路径 npm root -g 然后将此路径(不包括node_modules)添加到环境变量中去,这里注意,原…...

Go 语言 for 的用法
For statements 本文简单翻译了 Go 语言中 for 的三种用法,可快速学习 Go 语言 for 的使用方法,希望本文能为你解开一些关于 for 的疑惑。详细内容可见文档 For statements。 For statements with single condition 在最简单的形式中,只要…...
熵权法Python代码实现
文章目录 前言代码数据熵权法代码结果 前言 熵权法做实证的好像很爱用,matlab的已经实现过了,但是matlab太大了早就删了,所以搞一搞python实现的,操作空间还比较大 代码 数据 import pandas as pd data [[100,90,100,84,90,1…...

浏览器提示ERR_SSL_KEY_USAGE_INCOMPATIBLE解决
ERR_SSL_KEY_USAGE_INCOMPATIBLE报错原因 ERR_SSL_KEY_USAGE_INCOMPATIBLE 错误通常发生在使用 SSL/TLS 连接时,指的是客户端和服务器之间进行安全通信尝试失败,原因是证书中的密钥用途(Key Usage)或扩展密钥用途(Extended Key Usage, EKU)与正在尝试的操作不兼容。这意味…...

使用深度学习进行“序列到序列”分类
目录 加载序列数据 定义 LSTM 网络架构 测试 LSTM 网络 此示例说明如何使用长短期记忆 (LSTM) 网络对序列数据的每个时间步进行分类。 要训练深度神经网络以对序列数据的每个时间步进行分类,可以使用“序列到序列”LSTM 网络。通过“序列到序列”LSTM 网络,可以对…...
)
Python和Java的区别(不断更新)
主要通过几个方面区分Python和Java,让大家有一个对比: 语言类型 Java是一种静态类型、编译型语言。 Python是一种动态类型、解释型语言,注重简洁和灵活的语法。 语法 在Java中,变量需要显式地声明,指定其类型。例如&am…...
Ubuntu22.04 gnome-builder gnome C 应用程序习练笔记(三)
八、ui窗体创建要点 .h文件定义(popwindowf.h), TEST_TYPE_WINDOW宏是要创建的窗口样式。 #pragma once #include <gtk/gtk.h> G_BEGIN_DECLS #define TEST_TYPE_WINDOW (test_window_get_type()) G_DECLARE_FINAL_TYPE (TestWindow, test_window, TEST, WI…...

vue electron 应用在windows系统上以管理员权限打开应用
打开package.json文件,在build下的win增加配置 "requestedExecutionLevel": "requireAdministrator",...

c实现链表
目录 c实现链表 链表的结构定义: 链表的结构操作: 1、初始化链表 2、销毁链表 3、插入结点 4、输出链表数据 5、查找链表数据 扩展 代码实现 c实现链表 链表的结构定义: /*** 链表结构定义 ***/ typedef struct Node {int data; //…...
力扣231. 2 的幂(数学,二分查找,位运算)
Problem: 231. 2 的幂 文章目录 题目描述思路即解法复杂度Code 题目描述 思路即解法 思路1:位运算 1.易验证2的幂为正数; 2.易得2的幂用二进制表示只能有一个位为数字1 3.即将其转换为二进制统计其二进制1的个数 思路2:数学 当给定数n大于1时…...
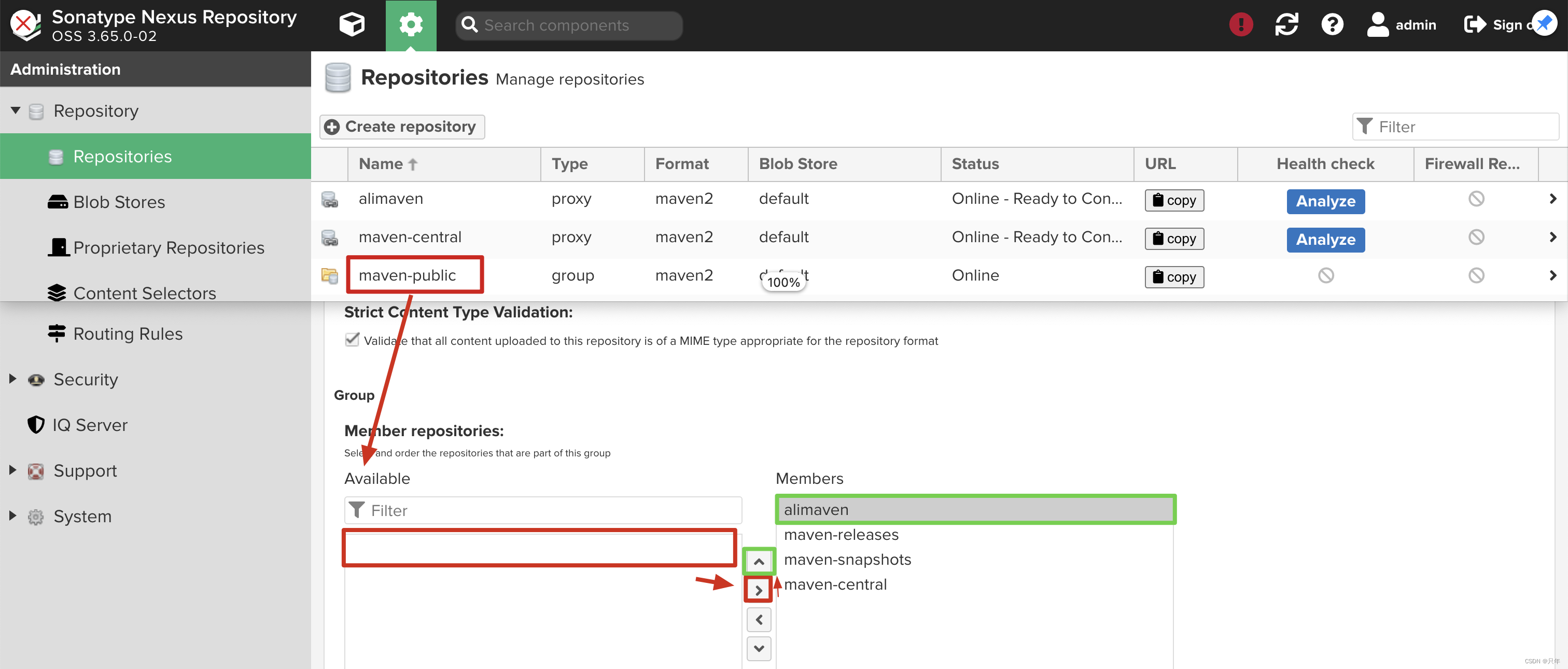
Maven私服部署与JAR文件本地安装
Nexus3 是一个仓库管理器,它极大地简化了本地内部仓库的维护和外部仓库的访问。 平常我们在获取 maven 仓库资源的时候,都是从 maven 的官方(或者国内的镜像)获取。团队的多人员同样的依赖都要从远程获取一遍,从网络方…...

【MySQL】字符串函数的学习
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-J7VN4RbrBi51ozap {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...
如何做好一份技术文档?从规划到实践的完整指南
如何做好一份技术文档?从规划到实践的完整指南 🌟 嗨,我是IRpickstars! 🌌 总有一行代码,能点亮万千星辰。 🔍 在技术的宇宙中,我愿做永不停歇的探索者。 ✨ 用代码丈量世界&…...

k8s从入门到放弃之Pod的容器探针检测
k8s从入门到放弃之Pod的容器探针检测 在Kubernetes(简称K8s)中,容器探测是指kubelet对容器执行定期诊断的过程,以确保容器中的应用程序处于预期的状态。这些探测是保障应用健康和高可用性的重要机制。Kubernetes提供了两种种类型…...