【多模态】27、Vary | 通过扩充图像词汇来提升多模态模型在细粒度感知任务(OCR等)上的效果

文章目录
- 一、背景
- 二、方法
- 2.1 生成 new vision vocabulary
- 2.1.1 new vocabulary network
- 2.1.2 Data engine in the generating phrase
- 2.1.3 输入的格式
- 2.2 扩大 vision vocabulary
- 2.2.1 Vary-base 的结构
- 2.2.2 Data engine
- 2.2.3 对话格式
- 三、效果
- 3.1 数据集
- 3.2 图像细粒度感知能力
- 3.3 下游任务
- 3.4 通用效果
- 3.5 其他效果展示
- 四、代码
- 4.1 模块解释
论文:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
代码:https://github.com/Ucas-HaoranWei/Vary
出处:旷视
时间:2023.12
一、背景
当前流行的大型视觉-语言模型 Large Vision-Language Models (LVLMs) 一般都使用共享的 vision vocabulary,这个词库就是 CLIP,因为 CLIP 是公认的包含了很多图像-语言信息的模型,可以 cover 大多数通用的视觉任务。
但对于一些特殊的任务,需要对视觉信息进行更密集细致的提取,比如需要对 document-level 进行 OCR 或字符的理解的任务,或者非英文的场景,CLIP vision vocabulary 就无法表现的很好了。
mPlug-Owl [49] 和 Qwen-VL 尝试了将 vision vocabulary 网络解冻来解决这个问题,但作者认为,有三个不合理的地方:
-
其一:这样会覆盖掉之前学习的知识:
这意味着如果你尝试通过向大型语言模型(如7B大小的模型)添加或更新视觉词汇,可能会导致原有的、模型已经学习的词汇知识被新的信息覆盖。因为语言模型通常是在大量文本数据上训练的,它们已经内化了丰富的语言知识和结构。如果试图将视觉元素的信息强加给这些已经存在的词汇,可能会扰乱模型对这些词汇原有的理解。
-
其二:vision vocabulary 更新的速度更快,大的 LLM(7B)的更新速度慢:
在一个相对较大的语言模型上更新视觉词汇,训练效率可能会很低。这是因为大型模型参数众多,训练它们需要大量的计算资源和时间。尤其是当试图整合视觉数据时,这个过程可能会变得更加复杂和低效,因为视觉数据通常比文本数据更为复杂并且维度更高。
-
其三:不能让视觉词汇网络多次“看到”图像:
由于大型语言模型(LLMs)具有很强的记忆能力,它们在处理信息时不需要多次“看到”同一个输入。这意味着,一旦模型学习了某个图像的信息,它就能够记住这些信息,而不需要像传统的视觉识别网络那样通过多个训练周期(epochs)多次学习同一个数据集。这种强记忆能力可能会限制模型在学习视觉词汇时的灵活性。
基于此,作者提出了一个问题:是否存在一种策略可以简化并有效增强视觉词汇?
简化并增强视觉词汇的策略可能包括创建更高效的模型架构,使用更先进的训练技术,或者开发新的算法来更好地整合视觉信息和文本信息,而不会受到上述限制的影响。
这篇论文提出了一个名为 Vary 的方法,它是一个高效且用户友好的方法,用于解决上述问题。Vary 的灵感来源于传统大型语言模型(LLMs)中文本词汇扩展的方式,即,当将一个英语 LLM 转移到另一种外语(如中文)时,需要扩展文本词汇以提高新语言下的编码效率和模型性能。直观地说,对于视觉分支,如果我们向模型输入“外语” 图像(也就是没有见过的图像或者说不理解的图像),也需要扩大视觉词汇。
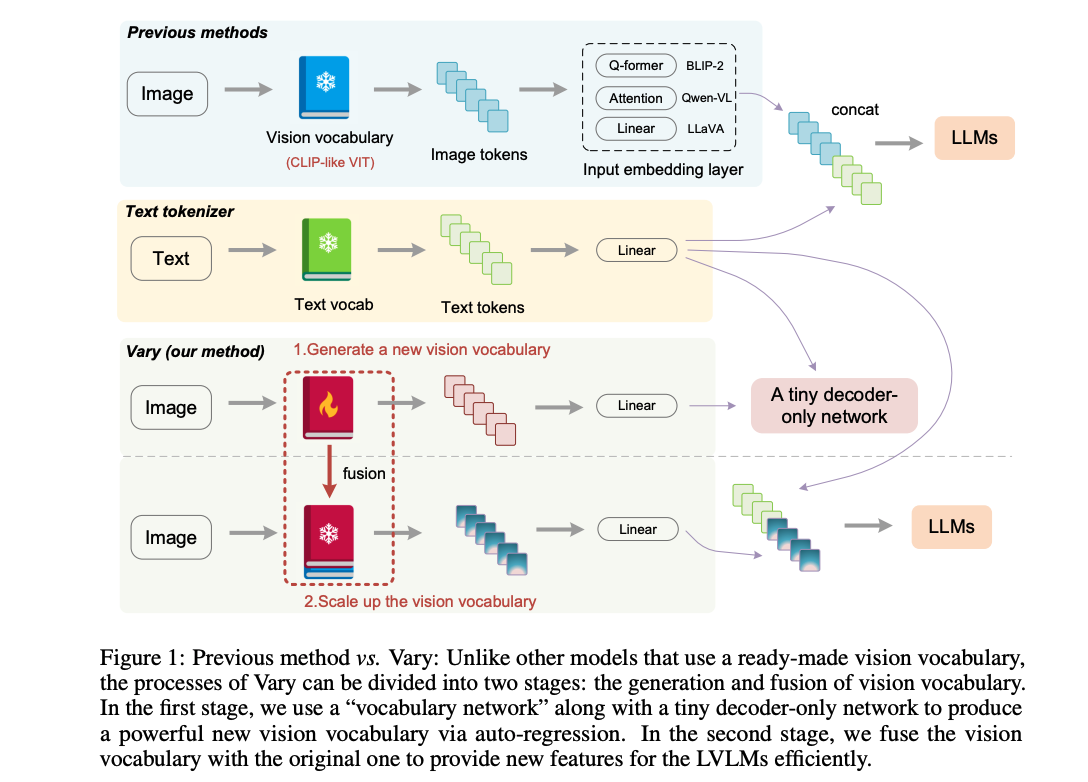
Vary,也就是一个扩大 LVLM 的 Vision vocabulary 的方法:
-
第一阶段:生成一个新的视觉词汇表:使用 vocabulary network 和一个 tiny decoder-only transformer 来通过自回归产生需要的 vocabulary
自回归的方式就是通过预测下一个 token 的方式来训练词汇模型,因为基于自回归的生成词汇的过程可能比基于对比学习的方式(如CLIP)更适合密集感知任务,原因有两个:
① 预测下一个 token 的方式可以允许视觉词汇压缩更长的文本
② 这种方式可以使用的数据格式更为多样,例如带有提示的VQA数据。在准备好新的视觉词汇后,我们将其添加到传统的 LVLMs 中以引入新特性。在此过程中,冻结了新旧词汇网络,以避免视觉知识被覆盖。
-
第二阶段:整合新旧词汇表:通过将新产生的 vocabulary 和原来的 CLIP vocabulary 结合起来,让 LVLM 能很快的获得新的特征,在扩大视觉词汇后,LVLM 可以实现更细粒度的视觉感知,此外,作者提供了产生合成数据的方法
效果:
- 相比于 BLIP-2, MiniGPT4 和 LLaVA, Vary 能在保持 LVLM 原始性能的同时,提供更好的精细感知和理解能力
- Vary 能够在文档理解(document parsing,包括 OCR 或 markdown 转换),在 DocVQA 上获得了 78.2% ANLS,在 MMVet 上获得了 36.2% ANLS
二、方法
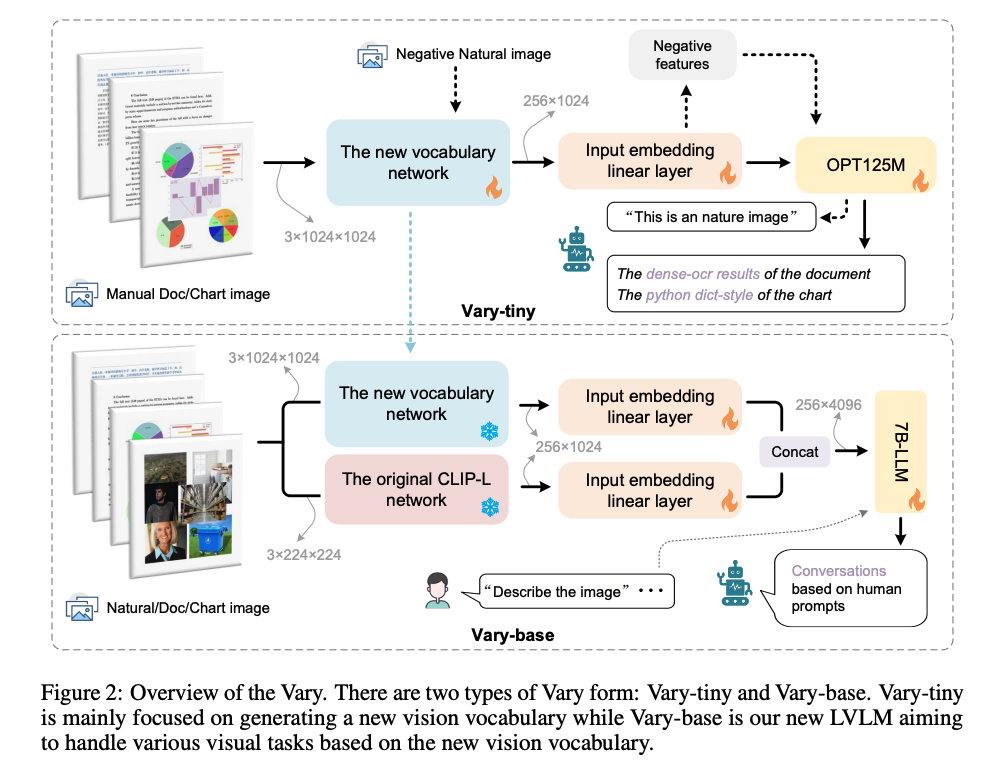
Vary 的整体结构如图 2 所示:
-
Vary-tiny:生成新的 vision vocabulary:
- 由 vocabulary network 和 tiny OPT-125M 组成,在两个模块中间使用了线性层来进行通道维度对齐
- 因为 Vary-tiny 主要是用于精细粒度的感知,所以 Vary-tiny 没有 text 输入分支
- 作者期望 vision vocabulary network 是能够处理文档、表格等人造图像来弥补 CLIP 的不足,但同时又不能是 CLIP 的噪声,所以在训练的时候,是将人工造的文档或表格数据作为 positive samples,自然图片作为 negetives samples 来训练 vary-tiny 的
-
Vary-base:使用新的 vision vocabulary:
- 在训练完 vary-tiny 之后,使用训练好的 vocabulary network 加到更大的模型上来构建 vary-base,如图 2 下半部分,新的和旧的 vocabulary network 的 input embedding layer 是独立的,在送入 LLM 之前会合并起来,在这个阶段,新旧 vocabulary network 的参数都是冻结的,其他模块的参数都是放开的
2.1 生成 new vision vocabulary
2.1.1 new vocabulary network
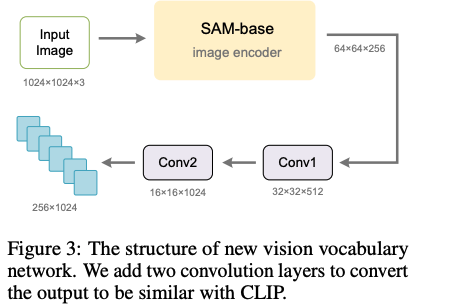
作者使用经过 SAM 预训练的 ViTDet 的 image encoder(base scale)作为 new vocabulary network 的主要部分
由于 SAM-base 的输入分辨率是 1024x1024,输出是 16x 下采样后的,最后一层的输出大小是 64x64x256,没法和 CLIP-L (256x1024 for NxC)的输出匹配上
所以,作者在 SAM 的最后一层后面加了两层卷积层,如图 3 所示,第一层卷积核大小为 3,将特征转换为 32x32x512,第二层卷积和第一层一样,将输出进一步转换成 16x16x1024,这样,就可以将输出和 CLIP-VIT 的 256x1024 对齐了
2.1.2 Data engine in the generating phrase
1、文档数据
作者选择高分辨率的文档图像-文本对作为新视觉词汇预训练的主要 positive 数据集,因为密集的OCR可以有效验证模型的细粒度图像感知能力。
据作者所知,目前没有公开可用的包含英文和中文文档的数据集,因此作者自己创建了一个。
作者首先从 arXiv 和 CC-MAIN-2021-31-PDF上来收集英文部分的 PDF 风格文档,并从互联网上的电子书中收集中文部分。
然后,使用 PyMuPDF 的 fitz 提取每个 PDF 页面的文本信息,并同时通过 pdf2image 将每页转换成 PNG 图像。在此过程中,作者构建了100万中文和100万英文的文档图像-文本对进行训练。
2、表格数据
作者发现当前的 LVLMs(大型视觉语言模型)在图表理解方面不是很好,尤其是中文图表,所以选择它作为另一个需要“编入”新词汇的主要知识。
对于图表图像-文本对,作者选择 matplotlib 和 pyecharts 作为渲染工具。对于 matplotlib 风格的图表,作者分别构建了25万中文和英文的图表。而对于 pyecharts,作者分别构建了50万中文和英文的图表。此外,作者将每个图表的文本真实值转换为 python 字典形式。图表中使用的文本,例如标题、x轴和y轴,是从互联网上下载的自然语言处理(NLP)语料库中随机选取的。
3、自然数据(作为负样本)
对于 CLIP-VIT 擅长的自然图像数据,作者需要确保新引入的词汇不会造成噪音。因此,作者构建了负面自然图像-文本对,以使新词汇网络在看到自然图像时能够正确编码。作者从COCO数据集[22]中提取了12万张图像,每张图像对应一段文本。
文本部分是随机选自以下句子:“这是一张自然图像”;“这里有一张自然图片”;“这是一张自然照片”;“这是一张自然图像”;“那是来自大自然的一张照片”。
2.1.3 输入的格式
作者使用自回归的方式,使用 image-text pairs 来训练 vary-tiny 的所有参数
输入的形式和现有的 LVLM 一致:
- image token 和 text token 被打包起来,使用前缀区分
- “” 和 “” 用来界定图像数据在输入序列中的位置。这样做可以让模型知道哪部分是图像,哪部分是文本。这些数据被输入到一个叫做OPT-125M的模型中,这个模型可以处理长达4096个令牌(token)的序列。这里的令牌可以是图像的一部分,也可以是文本的一部分。
- 在训练过程中,尽管输入包含图像和文本,Vary-tiny 模型的输出仅为文本。此外,文本的结束标记符号是 “/s”,也就是 eos token,这告诉模型一段文本何时结束。
2.2 扩大 vision vocabulary
2.2.1 Vary-base 的结构
在完成词汇网络的训练之后,将其引入到语言-视觉多模态模型(LVLM)——Vary-base 中。
新的视觉词汇与原始的 CLIP-VIT 是并行的,这两个视觉词汇都拥有各自的输入嵌入层,即一个简单的线性层。
如图2所示,线性层的输入通道是1024,输出是2048,确保在拼接后图像令牌的通道数为4096,这正好与大型语言模型(LLM)的输入对齐(无论是Qwen-7B还是Vicuna-7B)
2.2.2 Data engine
作者通过下面这些方法来进行数据扩充
1、Latex 渲染的方式
除过上面收集的文档,还需要一些公式或表格数据,作者使用 latex 渲染的方式来生成一些相关数据
-
首先,作者收集了一些 arxiv 上的 .txt 源文件
-
然后,使用正则表达式提取了表格、数学公式和纯文本。
在提取表格和公式的应用场景中,正则表达式可以这样工作:提取表格:在LaTeX文档中,表格通常使用\begin{table}和\end{table}标签包围。正则表达式可以被设计来搜索这些特定的标签及其之间的所有内容,从而提取整个表格。提取公式:类似地,数学公式在LaTeX中通常被 \begin{equation}和\end{equation}或者 . . . ... ...(对于内联公式)和 . . . ... ...或者[…](对于展示公式)所包围。正则表达式可以匹配这些模式来提取公式。
-
最后,使用 pdflatex 重新渲染这些内容。作者收集了10多个模板来执行批量渲染。此外,每个文档页面的文本真实内容转换 为mathpix markdown 风格,以统一格式。通过这个构建过程,获得了50万页英文页面和40万页中文页面。一些样本展示在图4中。
pdflatex是一个用于将LaTeX文档转换成PDF格式的命令行工具。LaTeX是一种基于TeX的排版系统,广泛用于生成科学和数学文献的复杂和高质量的文档。当你编写了一个LaTeX文档(通常是一个.tex文件)后,你需要通过一个编译过程将其转换成可读的文档,通常是PDF格式。pdflatex正是用于这种转换的工具之一。

2、语义关联图表渲染
在 2.1.2 节中,批量渲染图表数据来训练新的词汇网络。然而,这些渲染图表中的文本(标题、x轴值和y轴值)相关性较低,因为它们是随机生成的。这个问题在词汇生成过程中并不是问题,因为生成任务只希望新的词汇能够有效压缩视觉信息。然而,在Vary-base的训练阶段,由于解冻了LLM,希望使用更高质量(内容强相关)的数据进行训练。因此,使用 GPT-4[32] 来生成一些使用相关语料库的图表,然后我们利用高质量的语料库额外渲染了20万个图表数据用于Vary-base训练。
3、通用数据
Vary-base 的训练过程遵循流行的 LVLMs,例如 LLaVA[25],包括预训练和 SFT 阶段。与 LLaVA 不同的是,作者冻结了所有的词汇网络并解冻了输入嵌入层和 LLM,这更像是纯 LLM 的预训练设置。
作者使用自然图像-文本对数据来向 Vary-base 介绍通用概念。这些图像-文本对是从 LAION-COCO[37] 中随机提取的,数量为 400万。在 SFT 阶段,作者使用 LLaVA-80k 或 LLaVA-CC665k[24] 以及 DocVQA[29] 和 ChartQA[28] 的训练集作为微调数据集。
2.2.3 对话格式
当使用 Vicuna-7B 作为 LLM 时,对话的格式是和 Vicuna v1 [8] 相同的:
- USER: “” “texts input”
- ASSITANT: “texts output”
因为 Vicuna 处理中文很慢,所示使用 Qwen-7B [2] 作为 LLM 来处理中文,当使用 Qwen-7B [2] 处理中文的时候,对话格式参考的是 LLaVA-MPT [25, 41]:
- <|im_start|>user: “” “texts input”<|im_end|> <|im_start|>assistant: “texts output” <|im_end|>.
三、效果
3.1 数据集
作者使用了多个数据集进行了测试:
- 作者构建的 document-level OCR 测试集,主要是为了测试密集视觉感知能力:包括纯 OCR 和 markdown 转换任务
- 纯 OCR 任务的测试集包括 100 张中英文数据,是随机从 arxiv 和 ebook 上抽取的
- markdown 转换任务重,测试集包括 200 pages,其中 100 包括表格,另外 100 包括数学公式
- DocVQA[29] 和 ChartQA [28],主要测试下游任务上的能力
- MMVet[51],测试整体模型的效果
document parsing 测评指标:
- Normalized Edit Distance
- F1-Score
- precision
- recall
DocVQA, ChartQA, 和 MMVet 使用原来的测评
训练细节:
- 对于词汇扩充任务,作者训练 vary-tiny 的全部参数,使用的 batch=512,epoch=3,optimizer=AdamW(cosine 退化),lr=5e-5
- 在训练 vary-tiny 的时候,作者冻结了 new 和 vanilla(CLIP)的 vision vocabulary network,优化的是 input embedding layers 和 LLM
- pretrain 预训练的时候 lr=5e-5,训练 SFT 的时候 lr=1e-5,预训练和 SFT 时 batch=256,epoch=1
归一化编辑距离:
-
OCR(光学字符识别)中的归一化编辑距离(Normalized Edit Distance,也称为Levenshtein距离)是一种衡量两个字符串相似度的方法。它通过计算将一个字符串转换成另一个字符串所需要的最少单字符编辑操作次数来实现。单字符编辑操作包括插入、删除和替换。
-
编辑距离(Levenshtein距离):这是一个衡量两个字符串差异的指标,通过计算一个字符串转换成另一个字符串所需要的最小编辑操作数。这些操作通常包括:
- 插入:在一个字符串中插入一个字符。
- 删除:从一个字符串中删除一个字符。
- 替换:将一个字符串中的一个字符替换成另一个字符。
-
归一化编辑距离是将编辑距离除以两个字符串中较长的那个的长度,使得得到的值在0到1之间。这样可以消除字符串长度对比较结果的影响,让结果更加标准化。归一化编辑距离可以定义为:
归一化编辑距离 = 编辑距离 max ( 字符串1的长度 , 字符串2的长度 ) \text{归一化编辑距离} = \frac{\text{编辑距离}}{\max(\text{字符串1的长度}, \text{字符串2的长度})} 归一化编辑距离=max(字符串1的长度,字符串2的长度)编辑距离
-
归一化编辑距离的值越接近 0,表示两个字符串越相似;值越接近1,则表示两个字符串差异越大。
-
在OCR系统中,归一化编辑距离常用来评估OCR输出和实际文本之间的差异,以此来衡量OCR系统的准确性。如果OCR输出的文本和实际文本的归一化编辑距离很小,那么可以认为OCR系统具有较高的识别准确率。反之,如果归一化编辑距离较大,则说明OCR系统可能在文本识别上存在较多错误。
3.2 图像细粒度感知能力
作者通过密集文本识别能力来衡量 Vary 的细粒度感知性能。
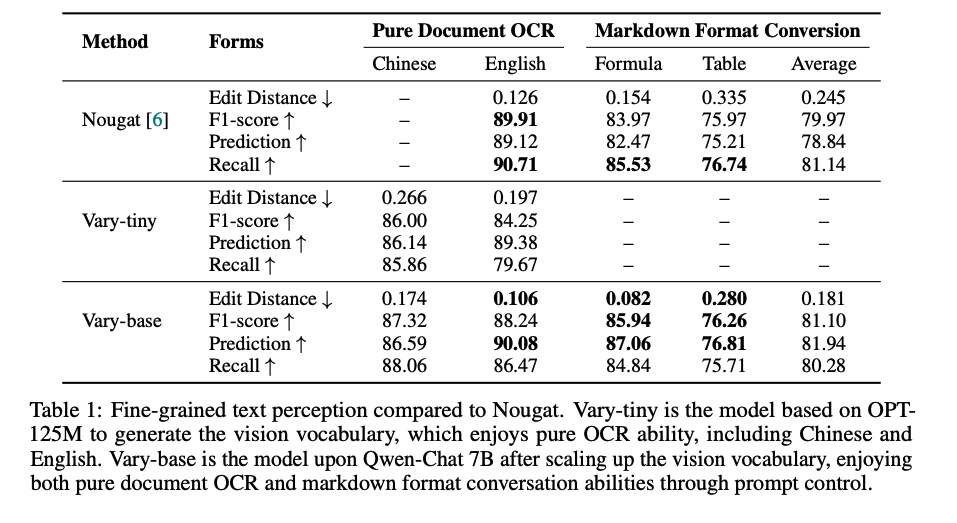
如表1所示,Vary-tiny 通过视觉词汇生成过程,集合了中文和英文的密集OCR能力:
- 它在中文和英文文件(纯文本)OCR上分别实现了0.266和0.197的编辑距离,这证明了新视觉词汇具有良好的细粒度文本编码能力。
- 对于Vary-base,它在英文纯文本文件上可以达到与 nougat(一种特殊的文档解析模型)相当的性能。
此外,使用不同的提示(例如,将图像转换为markdown格式),Vary-base 可以实现文档图像到 markdown 格式的转换。
值得注意的是,在这样的任务中,Vary-base(在数学和表格平均值上具有0.181的编辑距离和81.10%的F1得分)在某种程度上比nougat(平均0.245的编辑距离和79.97%的F1得分)要好,这可能是由于7B LLM(Qwen)超强的文本纠正能力。
所有上述结果表明,通过扩展视觉词汇,新的LVLM可以提升其细粒度感知性能。
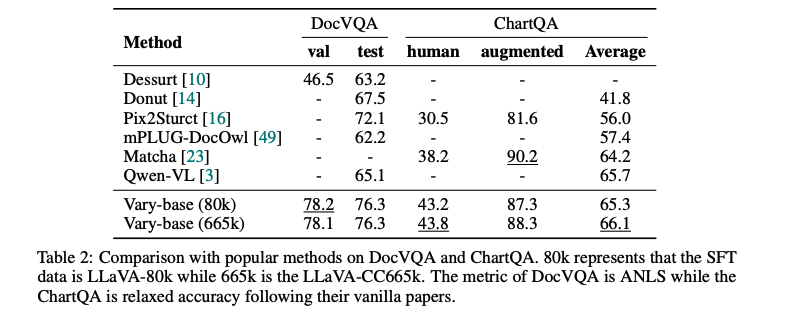
3.3 下游任务
作者在 DocVQA [29] 和 ChartQA [28] 两个下游视觉问答(VQA)任务上测试了性能提升。
作者使用了额外的提示:“使用单个单词或短语回答以下问题:”[24],以便模型输出简短且精确的答案。
如表 2 所示,Vary-base(以Qwen-7B作为大型语言模型LLM)在DocVQA上,基于LLaVA-80k [25] 的 SFT(特定任务微调)数据,可以达到 78.2%(测试集)和 76.3%(验证集)的 ANLS 得分。
使用 LLaVA-665k [24] 数据进行 SFT,Vary-base 在 ChartQA 上的平均性能可以达到 66.1%。
在这两个具有挑战性的下游任务上的表现可与 Qwen-VL [4]相媲美,甚至更好,这证明了本文提出的视觉词汇扩展方法对于下游任务也是有前景的。
3.4 通用效果
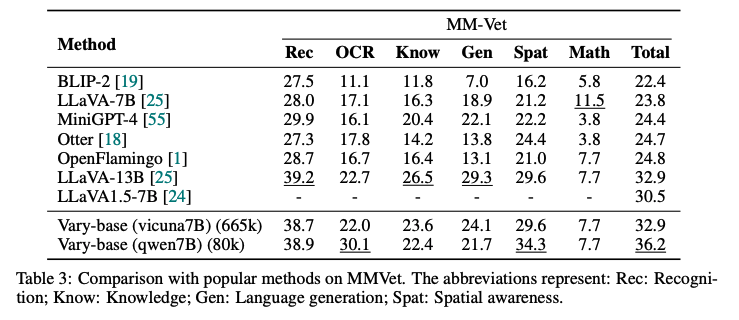
作者通过 MMVet [51] 基准测试来监控 Vary 的整体性能。
如表3所示,使用相同的大型语言模型(Vicuna-7B)和特定任务微调数据(LLaVA-CC665k),Vary的性能提升了 2.4%(从 30.5% 提升至 32.9%),这证明了本文的数据和训练策略没有损害模型的通用能力。
此外,结合 Qwen-7B 和 LLaVA-80k 的 Vary 可以达到 36.2% 的性能,进一步证明了我们扩大视觉词汇量的有效性。
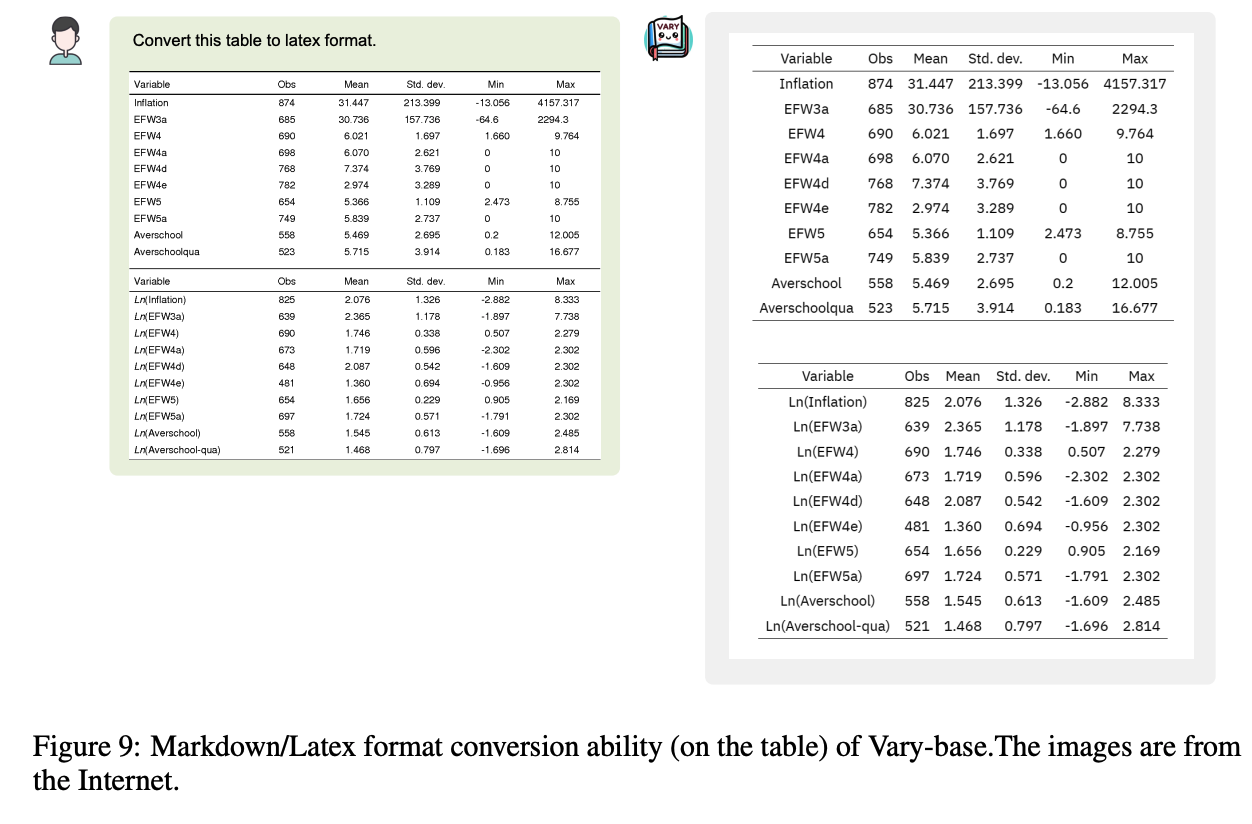
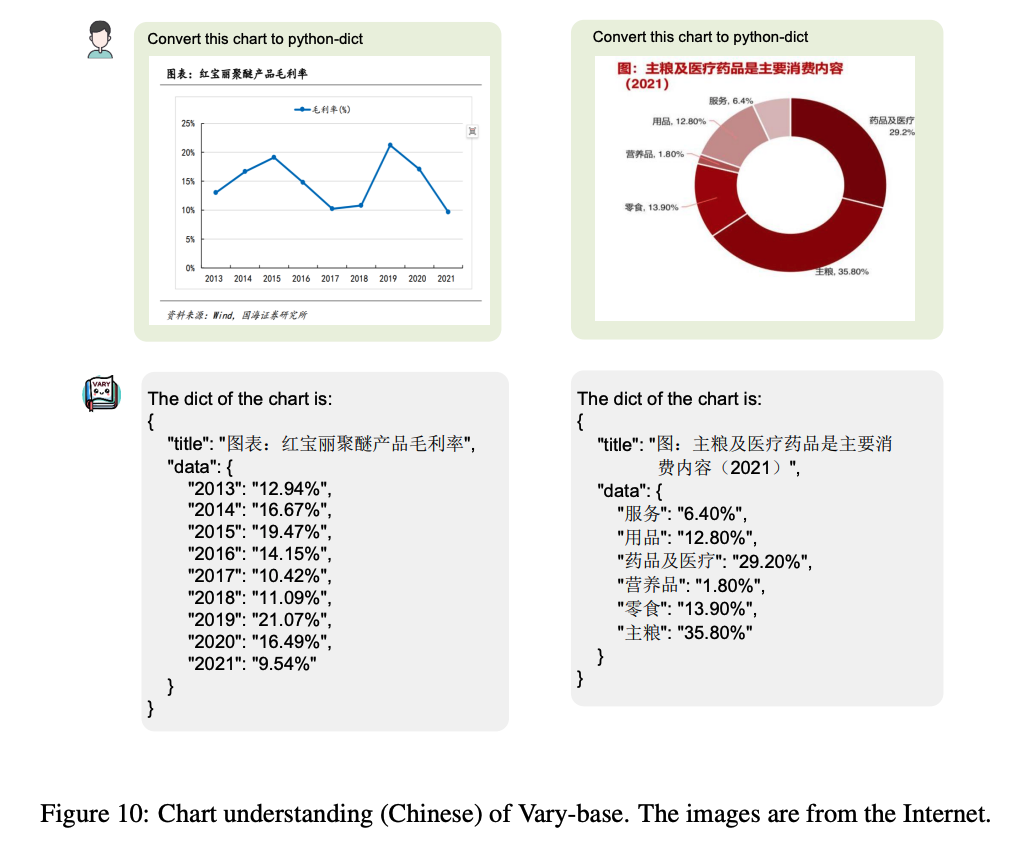
3.5 其他效果展示





四、代码
4.1 模块解释
1、AutoTokenizer
这个类用于加载预训练的tokenizer(词元化器)。Tokenizer负责将原始文本转换成模型能够理解的格式,即将句子分解成词或子词单元(tokens),这些单元可以是单词、字母或者是词根等。此外,它还负责将这些tokens转换为模型需要的数字ID,并且可以自动处理添加特殊token,比如序列开始和结束标记。
2、AutoModelForCausalLM
这个类用于加载预训练的因果语言模型(Causal Language Model)。因果语言模型是一种自回归模型,它基于给定的一系列词元(例如一个句子中的单词)来预测下一个词元。这种模型常用于生成文本,如聊天机器人、文本补全、故事生成等。“Causal”(因果的)一词意味着模型的预测只依赖于先前的词元,而不是未来的词元。
简而言之,使用 AutoTokenizer 可以准备数据,然后使用 AutoModelForCausalLM 来生成或者继续生成文本
3、CLIPImageProcessor
不直接提取图像特征,而是准备图像数据,使其能够被 CLIP 模型正确处理。它通常执行的操作包括调整图像大小、归一化像素值等,以匹配训练时使用的格式。这是数据预处理的一个步骤,它确保输入数据与模型在训练时接收的数据格式相同。
具体提取图像特征的是 CLIP 模型的图像编码器部分。在 CLIP 模型中,有两个主要的组件:
图像编码器(Image Encoder):它负责将图像转换成嵌入向量(即特征表示)。这通常是一个预训练的卷积神经网络(CNN)或者变换器(Transformer)架构,它将输入图像转换为一维的特征向量。
文本编码器(Text Encoder):它负责将文本输入转换成嵌入向量,使其与图像嵌入处于相同的嵌入空间。
CLIP 模型的核心思想是同时训练图像和文本编码器,使得它们能够将图像和文本映射到共同的嵌入空间中,从而可以比较图像和文本的相似度。
CLIPImageProcessor {"crop_size": {"height": 224,"width": 224},"do_center_crop": true,"do_convert_rgb": true,"do_normalize": true,"do_rescale": true,"do_resize": true,"feature_extractor_type": "CLIPFeatureExtractor","image_mean": [0.48145466,0.4578275,0.40821073],"image_processor_type": "CLIPImageProcessor","image_std": [0.26862954,0.26130258,0.27577711],"resample": 3,"rescale_factor": 0.00392156862745098,"size": {"shortest_edge": 224}
}相关文章:
【多模态】27、Vary | 通过扩充图像词汇来提升多模态模型在细粒度感知任务(OCR等)上的效果
文章目录 一、背景二、方法2.1 生成 new vision vocabulary2.1.1 new vocabulary network2.1.2 Data engine in the generating phrase2.1.3 输入的格式 2.2 扩大 vision vocabulary2.2.1 Vary-base 的结构2.2.2 Data engine2.2.3 对话格式 三、效果3.1 数据集3.2 图像细粒度感…...
【包括石头剪刀布判断程序(模拟版)】)
|Python新手小白低级教程|第二十章:函数(2)【包括石头剪刀布判断程序(模拟版)】
文章目录 前言一、复习一、函数实战之——if语句特殊系统1.判断等第分数(函数名为mark(参数num))2.石头剪刀布判断程序 二、练习总结 前言 Hello,大家好,我是你们的BoBo仔,感谢你们来阅读我的文…...

vue3 之 商城项目—home
home—整体结构搭建 根据上面五个模块建目录图如下: home/index.vue <script setup> import HomeCategory from ./components/HomeCategory.vue import HomeBanner from ./components/HomeBanner.vue import HomeNew from ./components/HomeNew.vue import…...

git flow与分支管理
git flow与分支管理 一、git flow是什么二、分支管理1、主分支Master2、开发分支Develop3、临时性分支功能分支预发布分支修补bug分支 三、分支管理最佳实践1、分支名义规划2、环境与分支3、分支图 四、git flow缺点 一、git flow是什么 Git 作为一个源码管理系统,…...
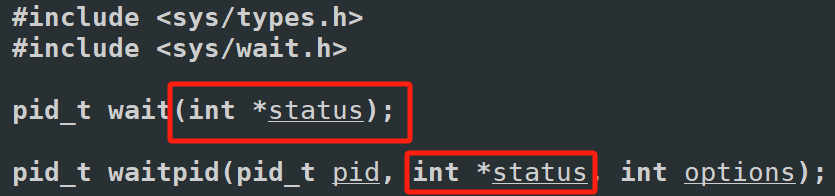
【Linux】学习-进程信号
进程信号 信号入门 生活角度的信号 你在网上买了很多件商品,再等待不同商品快递的到来。但即便快递没有到来,你也知道快递来临时,你该怎么处理快递。也就是你能“识别快递”,也就是你意识里是知道如果这时候快递员送来了你的包裹,你知道该如何处理这些包裹当快递员到了你…...
webgis后端安卓系统部署攻略
目录 前言 一、将后端项目编译ARM64 二、安卓手机安装termux 1.更换为国内源 2.安装ssh远程访问 3.安装文件远程访问 三、安装postgis数据库 1.安装数据库 2.数据库配置 3.数据导入 四、后端项目部署 五、自启动设置 总结 前言 因为之前一直做的H5APP开发…...

【数据分享】1929-2023年全球站点的逐日平均风速数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、能见度等指标,说到气象数据,最详细的气象数据是具体到气象监测站点的数据! 有关气象指标的监测站点数据,之前我们分享过1929-2023年全球气象站…...

【多模态大模型】视觉大模型SAM:如何使模型能够处理任意图像的分割任务?
SAM:如何使模型能够处理任意图像的分割任务? 核心思想起始问题: 如何使模型能够处理任意图像的分割任务?5why分析5so分析 总结子问题1: 如何编码输入图像以适应分割任务?子问题2: 如何处理各种形式的分割提示?子问题3:…...

Shell之sed
sed是什么 Linux sed 命令是利用脚本来处理文本文件。 可依照脚本的指令来处理、编辑文本文件。主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。 sed命令详解 语法 sed [-hnV][-e <script>][-f<script文件>][文本文件] sed [-nefr] [动作…...

AJAX——认识URL
1 什么是URL? 统一资源定位符(英语:Uniform Resource Locator,缩写:URL,或称统一资源定位器、定位地址、URL地址)俗称网页地址,简称网址,是因特网上标准的资源的地址&…...

《Docker极简教程》--Docker环境的搭建--在Linux上搭建Docker环境
更新系统:首先确保所有的包管理器都是最新的。对于基于Debian的系统(如Ubuntu),可以使用以下命令:sudo apt-get update sudo apt-get upgrade安装必要的依赖项:安装一些必要的工具,比如ca-certi…...

开源微服务平台框架的特点是什么?
借助什么平台的力量,可以让企业实现高效率的流程化办公?低代码技术平台是近些年来较为流行的平台产品,可以帮助很多行业进入流程化办公新时代,做好数据管理工作,从而提升企业市场竞争力。流辰信息专业研发低代码技术平…...
)
C#系列-C#操作UDP发送接收数据(10)
在C#中,发送UDP数据并接收响应通常涉及创建两个UdpClient实例:一个用于发送数据,另一个用于接收响应。以下是发送UDP数据并接收响应的示例代码: 首先,我们需要定义一个方法来发送UDP数据,并等待接收服务器…...
))
突破编程_C++_面试(基础知识(10))
面试题29:什么是嵌套类,它有什么作用 嵌套类指的是在一个类的内部定义的另一个类。嵌套类可以作为外部类的一个成员,但它与其声明类型紧密关联,不应被用作通用类型。嵌套类可以访问外部类的所有成员,包括私有成员&…...

初步探索Pyglet库:打造轻量级多媒体与游戏开发利器
目录 pyglet库 功能特点 安装和导入 安装 导入 基本代码框架 导入模块 创建窗口 创建控件 定义事件 运行应用 程序界面 运行结果 完整代码 标签控件 常用事件 窗口事件 鼠标事件 键盘事件 文本事件 其它场景 网页标签 音乐播放 图片显示 祝大家新…...

【npm】安装全局包,使用时提示:不是内部或外部命令,也不是可运行的程序或批处理文件
问题 如图,明明安装Vue是全局包,但是使用时却提示: 解决办法 使用以下命令任意一种命令查看全局包的配置路径 npm root -g 然后将此路径(不包括node_modules)添加到环境变量中去,这里注意,原…...

Go 语言 for 的用法
For statements 本文简单翻译了 Go 语言中 for 的三种用法,可快速学习 Go 语言 for 的使用方法,希望本文能为你解开一些关于 for 的疑惑。详细内容可见文档 For statements。 For statements with single condition 在最简单的形式中,只要…...
熵权法Python代码实现
文章目录 前言代码数据熵权法代码结果 前言 熵权法做实证的好像很爱用,matlab的已经实现过了,但是matlab太大了早就删了,所以搞一搞python实现的,操作空间还比较大 代码 数据 import pandas as pd data [[100,90,100,84,90,1…...

浏览器提示ERR_SSL_KEY_USAGE_INCOMPATIBLE解决
ERR_SSL_KEY_USAGE_INCOMPATIBLE报错原因 ERR_SSL_KEY_USAGE_INCOMPATIBLE 错误通常发生在使用 SSL/TLS 连接时,指的是客户端和服务器之间进行安全通信尝试失败,原因是证书中的密钥用途(Key Usage)或扩展密钥用途(Extended Key Usage, EKU)与正在尝试的操作不兼容。这意味…...

使用深度学习进行“序列到序列”分类
目录 加载序列数据 定义 LSTM 网络架构 测试 LSTM 网络 此示例说明如何使用长短期记忆 (LSTM) 网络对序列数据的每个时间步进行分类。 要训练深度神经网络以对序列数据的每个时间步进行分类,可以使用“序列到序列”LSTM 网络。通过“序列到序列”LSTM 网络,可以对…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...