ViT: transformer在图像领域的应用
文章目录
- 1. 概要
- 2. 方法
- 3. 实验
- 3.1 Compare with SOTA
- 3.2 PRE-TRAINING DATA REQUIREMENTS
- 3.3 SCALING STUDY
- 3.4 自监督学习
- 4. 总结
- 参考
论文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
代码:https://github.com/google-research/vision_transformer
代码2:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
我们在Transformer详解(1)—原理部分详细介绍了transformer在NLP领域应用的原理,transformer架构自发布以来已经在自然语言处理任务上广泛应用,今天我们将介绍如何将transformer架构应用在图像领域。
1. 概要
基于self-attention的网络架构在NLP领域中取得了很大的成功,但是在CV领域卷积网络架构仍然占据主导地位。受到transformer在NLP中应用成功的启发,也有很多工作尝试将self-attention与CNN网络结合,甚至有些工作直接替换CNN网络,理论上这些模型是高效的,由于这些特殊的注意力机制未与硬件加速器有效适配,因此在大规模的图像检测中,经典的ResNet网络架构仍然是SOTA
受到Transformer网络在NLP领域中成功适配的启发,作者提出对transformer尽可能少的修改,直接在图片上应用标准的transformer。为了实现这个目标,首先需要将图片分割成多个patch,并将这些patch转换成embedding作为transformer的输入。图片的patch就相当于NLP中的token。
最后作者得到结论:在数据量不足的情况下进行训练时,ViT不能很好地泛化,效果不如CNN,不过在训练大规模数据时,vit的效果会反超CNN
2. 方法
在模型设计方面,version transformer尽量与原始transformer结构保持一致,因为NLP中的transformer具有高效的实现方式,这样可以开箱即用。模型的整体结构如下所示:
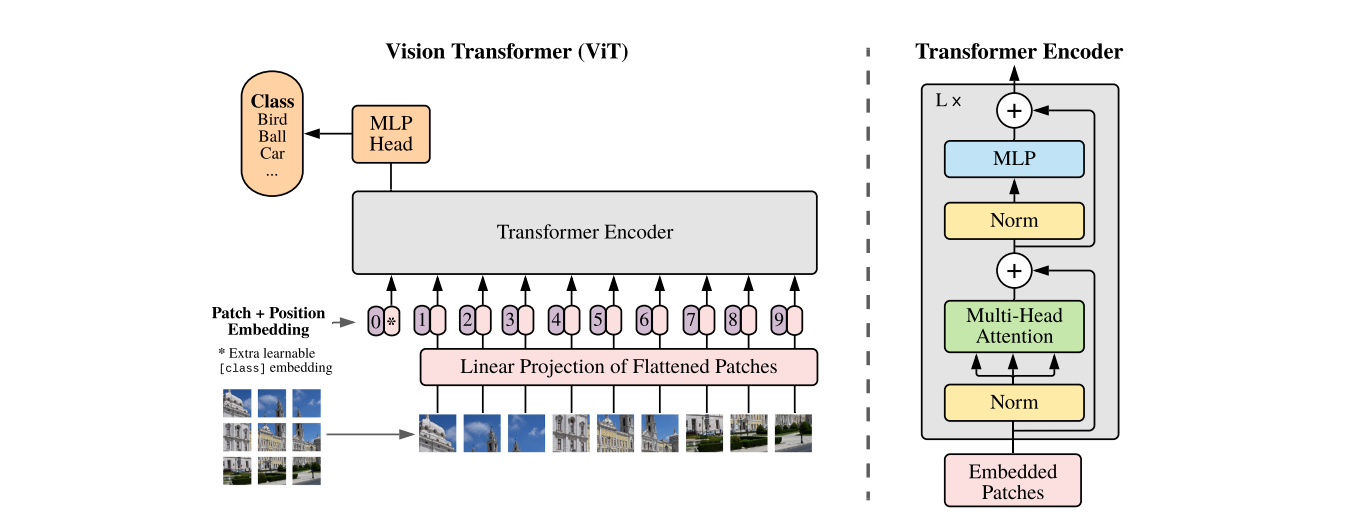
标准的 transformer 输入是一维向量序列,为了处理二维图像,将输入图片 x ∈ R H × W × C \mathbf{x}\in\mathbb{R}^{H\times W\times C} x∈RH×W×C 分割成一系列的patch,并将这些patch平整成一维向量,最终得到 x p ∈ R N × ( P 2 ⋅ C ) \mathbf{x}_p\in\mathbb{R}^{N\times(P^2\cdot C)} xp∈RN×(P2⋅C),其中 ( H , W ) (H,W) (H,W)是原始图片分辨率, C C C 是图片的通道数, ( P , P ) (P,P) (P,P)是每个patch的分辨率, N = H W P 2 N=\frac{HW}{P^2} N=P2HW 是patch的个数,也可以看作是输入序列的长度。由于transformer每一层的输入向量维度都是固定的 D D D,因此需要通过一个可训练的线性层将 flatten patch 的维度从 P 2 C P^2C P2C转换成 D D D,这个线性层的输出称为patch的embedding.
和BERT的 [class] token 类似,在path embedding序列的首位增加了一个可学习向量 z 0 0 = x c l a s s z_0^0=x_{class} z00=xclass,该向量在transformer encoder的输出部分看做是图片的表征,在预训练和微调阶段,该表征后都会接一个分类层。
为了保持位置信息,位置embedding会加到patch embedding上,这里作者使用了一个一维可学习的位置向量,因为通过实验发现使用二维位置向量并没有获得很大的性能提升,通过以上流程处理后的embedding就是transformer的输入embedding。从输入图片到transformer encoder输出可由以下式子表示:
z 0 = [ x class ; x p 1 E ; x p 2 E ; ⋯ ; x p N E ] + E p o s ; E ∈ R ( P 2 ⋅ C ) × D , E p o s ∈ R ( N + 1 ) × D z ′ ℓ = M S A ( L N ( z ℓ − 1 ) ) + z ℓ − 1 ; ℓ = 1 … L z ℓ = M L P ( L N ( z ′ ℓ ) ) + z ′ ℓ ; ℓ = 1 … L y = L N ( z L 0 ) \begin{align} z_0 =&[\mathbf{x}_\text{class};\mathbf{x}_p^1\mathbf{E};\mathbf{x}_p^2\mathbf{E};\cdots;\mathbf{x}_p^N\mathbf{E}]+\mathbf{E}_{pos}; \ \ \ \mathbf{E}\in\mathbb{R}^{(P^{2}\cdot C)\times D}, \mathbf{E}_{pos}\in\mathbb{R}^{(N+1)\times D}\\ \mathbf{z}^{\prime}{}_{\ell} =& \mathrm{MSA(LN(z_{\ell-1}))+z_{\ell-1}};\ \ \ell=1\ldots L \\ \mathbf{z}_{\ell} = &\mathrm{MLP}(\mathrm{LN}(\mathbf{z^{\prime}}_\ell))+\mathbf{z^{\prime}}_\ell; \ \ \ \ell=1\ldots L \\ y =& \mathrm{LN}(\mathbf{z}_{L}^{0}) \end{align} z0=z′ℓ=zℓ=y=[xclass;xp1E;xp2E;⋯;xpNE]+Epos; E∈R(P2⋅C)×D,Epos∈R(N+1)×DMSA(LN(zℓ−1))+zℓ−1; ℓ=1…LMLP(LN(z′ℓ))+z′ℓ; ℓ=1…LLN(zL0)
其中 E E E 是patch维度转换矩阵, M S A MSA MSA是多头注意力层(multi-head self attention), L N LN LN是layer normalization 层, M L P MLP MLP是transformer中前馈网络层
另外,也可以使用CNN网络的特征图作为输入序列,在这种混合模型中,patch embeding 投影层将被用于改变CNN特征图的形状。
在微调阶段,将移除预训练的prediction layer,并新增一个零初始化的预测层,一般来说,在更高分辨率图像上微调是非常有益的。在喂入更高分辨率图像时,保持patch的尺寸不变,这样会造成输入序列长度增加,虽然ViT模型可以处理任意长的输入序列(直到内存不够),但是预训练的位置编码将无效,因此作者根据当前位置在原始图片中的位置,对预训练的位置编码采用2D插值的方法获取最新的位置编码
3. 实验
下文中将用一些简写来代表模型的尺寸和输入patch的尺寸,如ViT-L/16 代表模型为ViT-Large,输入patch的尺寸为 16 × 16 16 \times 16 16×16,下表展示了不同尺寸模型的配置及参数量
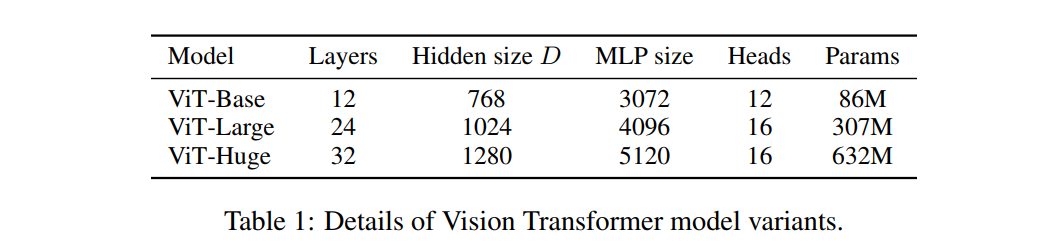
这里需要注意,由于输入序列长度与patch的尺寸成反比,所以,patch 尺寸越小,反而计算量越大
3.1 Compare with SOTA
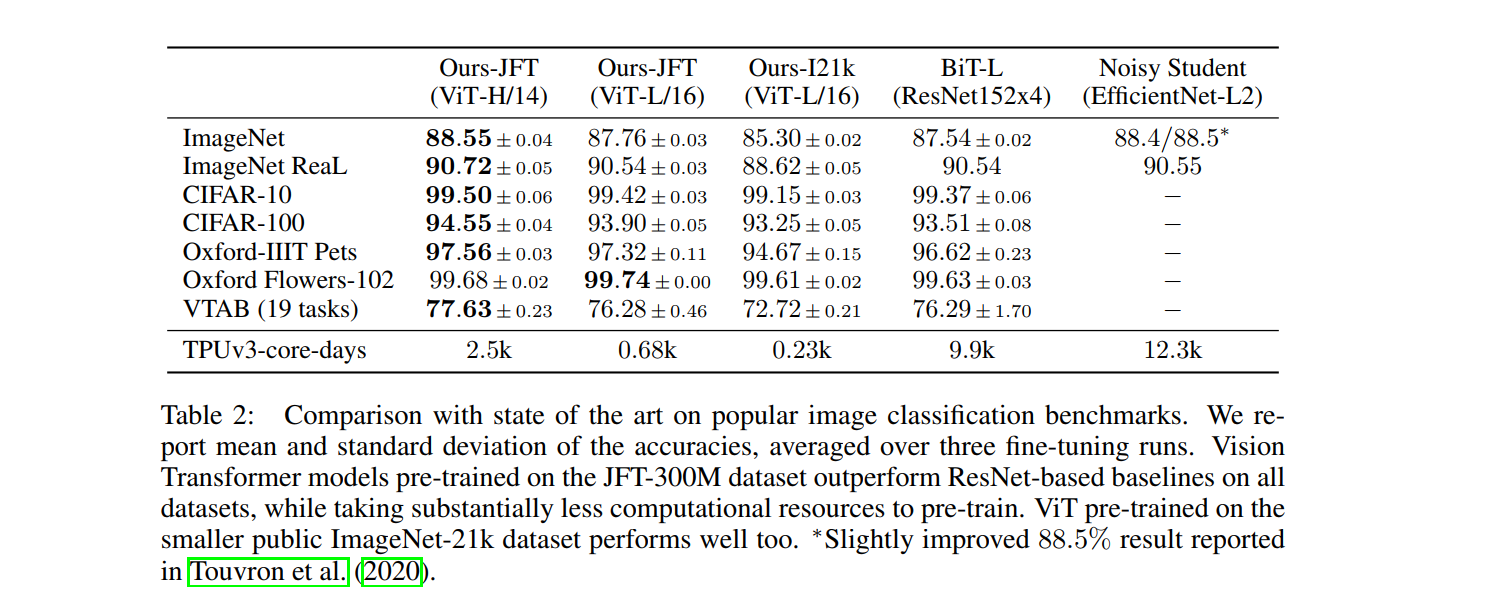
TPU v3-core-days:代表计算量,All models were trained on TPUv3 hardware, and we
report the number of TPUv3-core-days taken to pre-train each of them, that is, the number of TPU
v3 cores (2 per chip) used for training multiplied by the training time in days
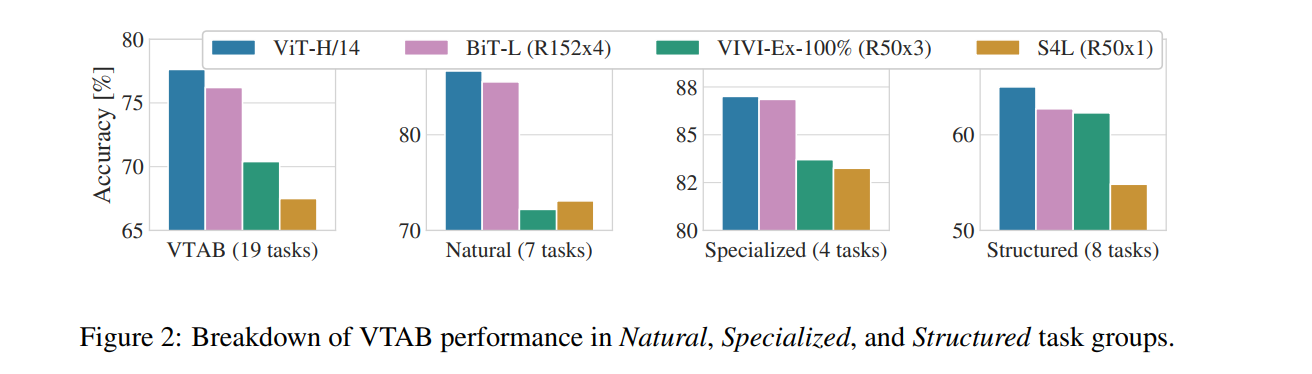
不同模型简介:
- Big Transfer (BiT), which performs supervised transfer learning with large ResNets
- VIVI – a ResNet co-trained on ImageNet and Youtube
- S4L – supervised plus semi-supervised learning on ImageNet
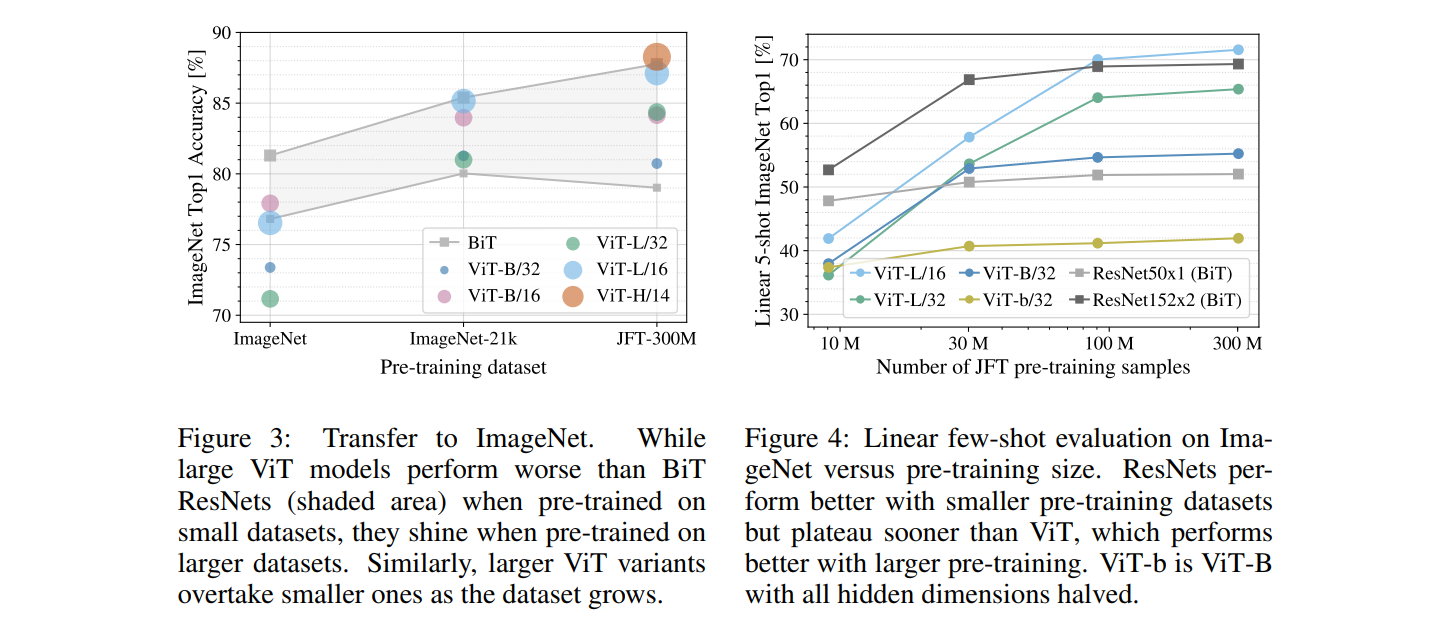
3.2 PRE-TRAINING DATA REQUIREMENTS
作者经过实验得到如下结论:
- 在小数据集上预训练,ViT-Large比ViT-Base要差,在大数据集上训练对ViT-Large比较有益
- 在小数据集上预训练,ViT的效果比CNN还要差,在大数据集上预训练ViT的效果超过CNN
- CNN网络的归纳有偏性在小数据集上是有用的,但是在大数据集上,直接从数据中学习相关的模式更有效
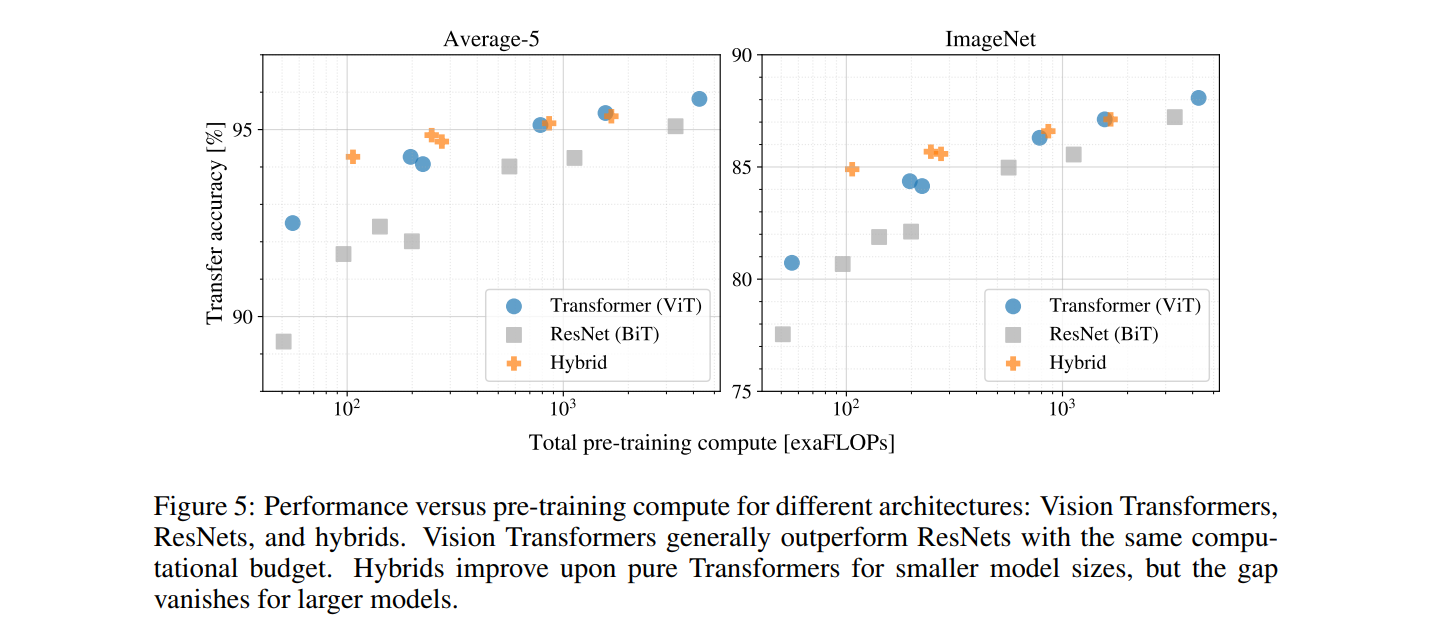
3.3 SCALING STUDY
如下图所示,作者得到如下结论:
- ViT在效果和计算量平衡之间相比ResNet占绝对优势,ResNet需要使用约3倍的算力来获得与ViT相似的结果
- 混合模型在小计算量上相比ViT具有一定的优势,但是这种优势在大模型(大计算量)上逐渐消失
- ViT在当前实验中貌似并没有饱和,这激励着未来的研究
3.4 自监督学习
作者模仿BERT通过mask patch prediction任务进行自监督预训练,ViT-B/16在ImageNet上获得了79.9%的准确率,相比从随机初始化开始训练提升了2%,但是相比于监督学习仍然落后4%。
4. 总结
作者将图片看作是patch序列,并使用标准的Transformer对patch序列进行处理,最终在大数据集上预训练取得了很不错的效果,在图片分类任务上超过了很多SOTA模型。但也还存在一些挑战等待后期处理:
- 将ViT应用在其他计算机视觉任务中,如目标检测、语义分割等
- 还需进一步探索自监督预训练方法
- 进一步扩大ViT模型的规模,可能会取得更好的效果
参考
如何理解Inductive bias?
Translation Equivariance
CNN中的Translation Equivariance【理解】
2D插值(2D interpolation)
相关文章:
ViT: transformer在图像领域的应用
文章目录 1. 概要2. 方法3. 实验3.1 Compare with SOTA3.2 PRE-TRAINING DATA REQUIREMENTS3.3 SCALING STUDY3.4 自监督学习 4. 总结参考 论文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 代码:https://github.com…...

Sora 的工作原理(及其意义)
原文:How Sora Works (And What It Means) 作者: DAN SHIPPER OpenAI 的新型文本到视频模型为电影制作开启了新篇章 DALL-E 提供的插图。 让我们先明确一点,我们不会急急忙忙慌乱。我们不会预测乌托邦或预言灾难。我们要保持冷静并... 你…...

Java学习笔记2024/2/16
知识点 面向对象 题目1(完成) 定义手机类,手机有品牌(brand),价格(price)和颜色(color)三个属性,有打电话call()和sendMessage()两个功能。 请定义出手机类,类中要有空参、有参构造方法,set/get方法。 …...

XLNet做文本分类
import torch from transformers import XLNetTokenizer, XLNetForSequenceClassification from torch.utils.data import DataLoader, TensorDataset # 示例文本数据 texts ["This is a positive example.", "This is a negative example.", "Anot…...

Swift 5.9 新 @Observable 对象在 SwiftUI 使用中的陷阱与解决
概览 在 Swift 5.9 中,苹果为我们带来了全新的可观察框架 Observation,它是观察者开发模式在 Swift 中的一个全新实现。 除了自身本领过硬以外,Observation 框架和 SwiftUI 搭配起来也能相得益彰,事倍功半。不过 Observable 对象…...
分享一个学英语的网站
名字叫:公益大米网 Freerice 这个网站是以做题的形式来记忆单词,题干是一个单词,给出4个选项,需要选出其中最接近题干单词的选项。 答对可以获得10粒大米,网站的创办者负责捐赠。如图 触发某些条件&a…...

【动态规划】【C++算法】2742. 给墙壁刷油漆
作者推荐 【数位dp】【动态规划】【状态压缩】【推荐】1012. 至少有 1 位重复的数字 本文涉及知识点 动态规划汇总 LeetCode2742. 给墙壁刷油漆 给你两个长度为 n 下标从 0 开始的整数数组 cost 和 time ,分别表示给 n 堵不同的墙刷油漆需要的开销和时间。你有…...
【后端高频面试题--设计模式上篇】
🚀 作者 :“码上有前” 🚀 文章简介 :后端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 往期精彩内容 【后端高频面试题–设计模式上篇】 【后端高频面试题–设计模式下篇】 【后端高频…...

P3141 [USACO16FEB] Fenced In P题解
题目 如果此题数据要小一点,那么我们可以用克鲁斯卡尔算法通过,但是这个数据太大了,空间会爆炸,时间也会爆炸。 我们发现,如果用 MST 做,那么很多边的边权都一样,我们可以整行整列地删除。 我…...

Android Compose 一个音视频APP——Magic Music Player
Magic Music APP Magic Music APP Magic Music APP概述效果预览-视频资源功能预览Library歌曲播放效果预览歌曲播放依赖注入设置播放源播放进度上一首&下一首UI响应 歌词歌词解析解析成行逐行解析 视频播放AndroidView引入Exoplayer自定义Exoplayer样式横竖屏切换 歌曲多任…...

Nginx实战:安装搭建
目录 前言 一、yum安装 二、编译安装 1.下载安装包 2.解压 3.生成makefile文件 4.编译 5.安装执行 6.执行命令软连接 7.Nginx命令 前言 nginx的安装有两种方式: 1、yum安装:安装快速,但是无法在安装的时候带上想要的第三方包 2、…...
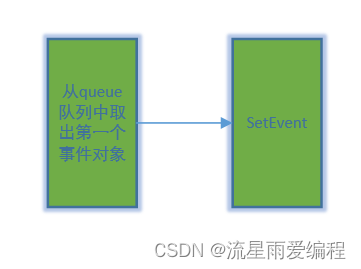
Qt之条件变量QWaitCondition详解(从使用到原理分析全)
QWaitCondition内部实现结构图: 相关系列文章 C之Pimpl惯用法 目录 1.简介 2.示例 2.1.全局配置 2.2.生产者Producer 2.3.消费者Consumer 2.4.测试例子 3.原理分析 3.1.源码介绍 3.2.辅助函数CreateEvent 3.3.辅助函数WaitForSingleObject 3.4.QWaitCo…...

OpenSource - 一站式自动化运维及自动化部署平台
文章目录 orion-ops 是什么重构特性快速开始技术栈功能预览添砖加瓦License orion-ops 是什么 orion-ops 一站式自动化运维及自动化部署平台, 使用多环境的概念, 提供了机器管理、机器监控报警、Web终端、WebSftp、机器批量执行、机器批量上传、在线查看日志、定时调度任务、应…...
【后端高频面试题--设计模式下篇】
🚀 作者 :“码上有前” 🚀 文章简介 :后端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 后端高频面试题--设计模式下篇 往期精彩内容设计模式总览模板方法模式怎么理解模板方法模式模板方…...
这才是大学生该做的副业,别再痴迷于游戏了!
感谢大家一直以来的支持和关注,尤其是在我的上一个公众号被关闭后,仍然选择跟随我的老粉丝们,你们的支持是我继续前行的动力。为了回馈大家长期以来的陪伴,我决定分享一些实用的干货,这些都是我亲身实践并且取得成功的…...
Ubuntu20.04 安装jekyll
首先使根据官方文档安装:Jekyll on Ubuntu | Jekyll • Simple, blog-aware, static sites 如果没有报错,就不用再继续看下去了。 我这边在执行gem install jekyll bundler时报错,所以安装了rvm,安装rvm可以参考这篇文章Ubuntu …...

AWK语言
一. awk awk:报告生成器,格式化输出。 在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令。而awk比较倾向于将一行…...

精通Nmap:网络扫描与安全的终极武器
一、引言 Nmap,即NetworkMapper,是一款开源的网络探测和安全审计工具。它能帮助您发现网络中的设备,并识别潜在的安全风险。在这个教程中,我们将一步步引导您如何有效地使用Nmap,让您的网络更加安全。 因为Nmap还有图…...

Java 学习和实践笔记(11)
三大神器: 官方网址: http://www.jetbrains.com/idea/ 官方网址: https://code.visualstudio.com/ 官方网址: http://www.eclipse.org 装好了idea社区版,并试运行以下代码,OK! //TIP To <b>Run</b> code, press &l…...

开发实体类
开发实体类之间先在pom文件中加入该依赖 <!-- 开发实体类--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided</scope></dependency>我们在实体类中声明各个属…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...