OpenAI视频生成模型Sora的全面解析:从扩散Transformer到ViViT、DiT、NaViT、VideoPoet
前言
真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了
- 自打2.16日OpenAI发布sora以来(其开发团队包括DALLE 3的4作Tim Brooks、DiT一作Bill Peebles等13人),不但把同时段Google发布的Gemmi Pro 1.5干没了声音,而且网上各个渠道,大量新闻媒体、自媒体(含公号、微博、博客、视频)做了大量的解读,也引发了圈内外的大量关注
很多人因此认为,视频生成领域自此进入了大规模应用前夕,好比NLP领域中GPT3的发布 - 一开始,我还自以为视频生成这玩意对于有场景的人,是重大利好,比如在影视行业的
对于没场景的人,只能当热闹看看,而且我司去年年底还考虑过是否做视频生成的应用,但当时想了好久,没找到场景,做别的应用去了
可当我接连扒出sora相关的10多篇论文之后,觉得sora和此前发布的视频生成模型有了质的飞跃(不只是一个60s),而是再次印证了大力出奇迹,大模型似乎确实可以在力大砖飞的情况下开始建模整个物理世界了,使得我司大模型项目组也愿意重新考虑开发视频生成的相关应用
本文主要分为三个部分
- 第一部分,侧重sora的核心技术解读
方便大家把握重点,且会比一切新闻稿都更准确,此外
如果之前没有了解过DPPM、ViT的,建议先阅读下此文《从VAE、扩散模型DDPM、DETR到ViT、Swin transformer》
如果之前没有了解过图像生成的,建议先阅读下此文《从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》 - 第二部分,侧重背后技术的发展演变
把sora涉及到的关键技术在本文中全部全面、深入、细致的阐述清楚,毕竟如果人云亦云就不用我来写了 - 第三部分,根据sora的32个reference以窥探其背后的更多细节
由于sora实在了太火了,除了专业的解读外,还有大量解读显得真假难辨(有的看上去一本正经,其实在胡说八道),为方便大家辨别什么样的解读是不对的,特把一些更深入的细节也介绍下
第一部分 OpenAI Sora的技术报告解读
1.1 Sora核心技术架构:把视觉数据转为Patches + 扩散Transformer
1.1.1 从前置工作(DALLE 2、NLP中token的预测、ViT)起步,逐步理解sora的视频生成思路
为方便大家更好的理解sora背后的原理,我们先来快速回顾下AI绘画的原理
以DALLE 2为例
- CLIP训练过程:学习文字与图片的对应关系
如上图所示,CLIP的输入是一对对配对好的的图片-文本对(根据对应文本一条狗,去匹配一条狗的图片),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征,然后在这些输出的文字特征和图片特征上进行对比学习- DALL·E2:prior + decoder
上面的CLIP训练好之后,就将其冻住了,不再参与任何训练和微调,DALL·E2训练时,输入也是文本-图像对,下面就是DALL·E2的两阶段训练:阶段一 prior的训练:根据文本特征(即CLIP text encoder编码后得到的文本特征),预测图像特征(CLIP image encoder编码后得到的图片特征)
换言之,prior模型的输入就是上面CLIP编码的文本特征,然后利用文本特征预测图片特征(说明白点,即图中右侧下半部分预测的图片特征的ground truth,就是图中右侧上半部分经过CLIP编码的图片特征),就完成了prior的训练
推理时,文本还是通过CLIP text encoder得到文本特征,然后根据训练好的prior得到类似CLIP生成的图片特征,此时图片特征应该训练的非常好,不仅可以用来生成图像,而且和文本联系的非常紧(包含丰富的语义信息)
这里的decoder就是升级版的GLIDE(GLIDE基于扩散模型),所以说DALL·E2 = CLIP + GLIDE

所以对于DALLE 2来说,正因为经过了大量上面这种训练,所以便可以根据人类给定的prompt画出人类预期的画作,说白了,可以根据text预测画作长什么样(其实,人类画画不也是这样么,先脑海中构思这幅画长什么样,只是描述该画的prompt不说出来,而只是口中默念而已)
- 那如果给定一个动态视频的一系列描述,是不可以把该动态视频给预测出来呢?最简单粗暴的做法就是,根据一句句的描述分别预测出来一张张静态图片,最后,把再把所有静态图片串联起来,不就是一个动态视频了么?
- 然,其中有个问题是,需要保证每张静态图片之间的一致性,就像NLP中预测token时,根据当前已有的tokens,不只是根据「transformer的自注意力机制」预测出来下一个token就完事了,还得让最终的整句话连起来是一句人话,那怎么样让每张静态图片上的各个元素在时间轴上是一致连贯的呢

- 可以根据当前已有的视频运动(一帧帧静态图像组成)去预测接下来的视频运动,相当于根据已有的一帧帧静态图像去预测之后的一帧帧图像
但其中有个问题是,因为像素的关系,一张图像有着比较大的维度(比如250 x 250),即一张图片上可能有着5万多个元素,如果根据上一张图片的5万多元素去逐一预测下一张图片的5万多个元素,未免工程过于浩大(而且,图片各个像素点之间两两做self-attention时,你会发现计算复杂度瞬间爆炸) - 故为降低处理的复杂度,ViT把一张图像划分为九宫格(如下图的左下角),如此,处理9个图像块总比一次性处理250 x 250个像素维度 要好不少吧

- 当我们理解了一张静态图像的patch表示之后(比如是九宫格,还是16 x 9个格),再来理解所谓的时空Patches就简单多了,无非就是在纵向上加上时间的维度,比如t1 t2 t3 t4 t5 t6,其实际处理时,可以每三个时间点聚合下,当然 也可以每五个时间点聚合下,如下图所示
那我们的任务就变成了:对于上图一系列视频帧的左上角而言,便是已知当前“时空batch” :推测下一个“时空batch”,组合视频画面中各个位置的推测结果,便得到了整个视频画面的持续运动
最终,OpenAI 训练了一个降低视频数据维度的网络(关于视频压缩网络,Sora可能采用的就是VAE架构,区别就是经过原始视频数据训练,而VAE一般是一个ConvNet)

- 具体而言,给定一个原始视频,视觉压缩网络将视频压缩到较低维的潜在空间(潜在空间这个概念在stable diffusion中用的可谓炉火纯青了,详见此文的第三部分),然后把视频分解为在时间和空间上压缩的潜在表示,即所谓的一系列时空Patches
当然,这里的patch数量就不止上面提到的九宫格那般大小了,比如上图的横切面已是16 x 9个格了 - Sora 在这个压缩的潜在空间中接受训练
- OpenAI 还训练了相应的解码器模型,将生成的潜在表示映射回像素空间,从而生成视频
1.1.2 时空编码SpaceTime latent patch的好处
“时空patch” 最大的好处, 是可以兼容所有的数据素材:一个静态图像不过是时间=0的一系列时空patch,不同的像素尺寸、不同的时间长短,都可以通过组合一系列 “时空patch” 得到
总之,OpenAI 基于 patches 的表示,使 Sora 能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。在推理时,OpenAI 可以通过在适当大小的网格中排列随机初始化的 patches 来控制生成视频的大小
而过去的图像和视频生成方法通常需要调整大小、进行裁剪或者是将视频剪切到标准尺寸,例如 4 秒的视频分辨率为 256x256。相反,该研究发现在原始大小的数据上进行训练,最终提供以下好处:
- 首先是采样的灵活性:Sora 可以采样宽屏视频 1920x1080p,垂直视频 1920x1080p 以及两者之间的视频。这使 Sora 可以直接以其天然纵横比为不同设备创建内容。Sora 还允许在生成全分辨率的内容之前,以较小的尺寸快速创建内容原型 —— 所有内容都使用相同的模型
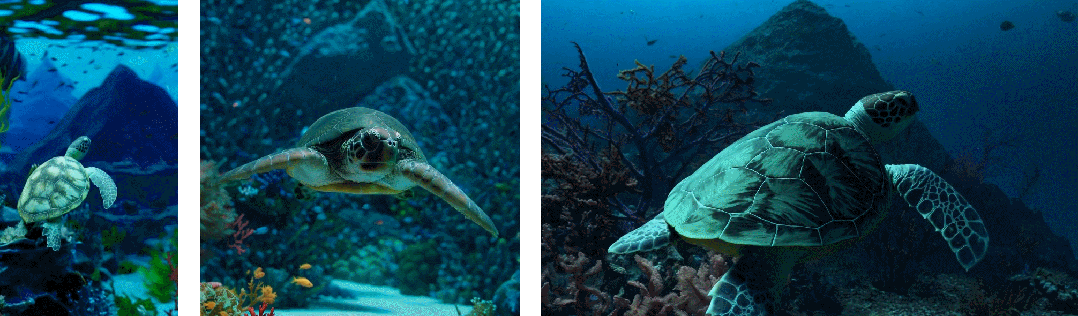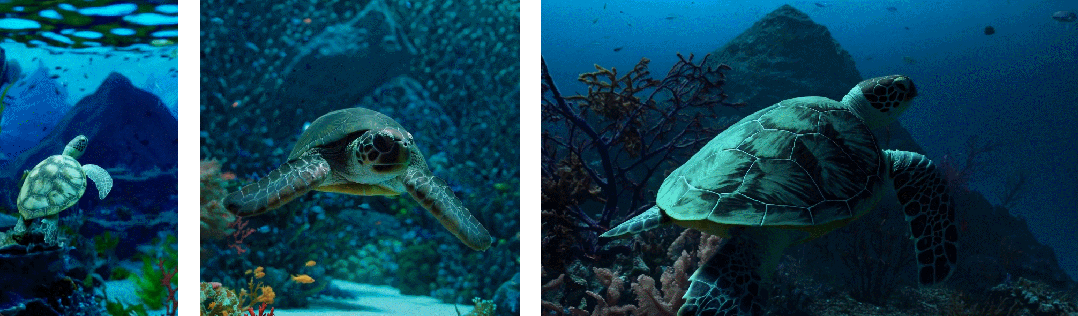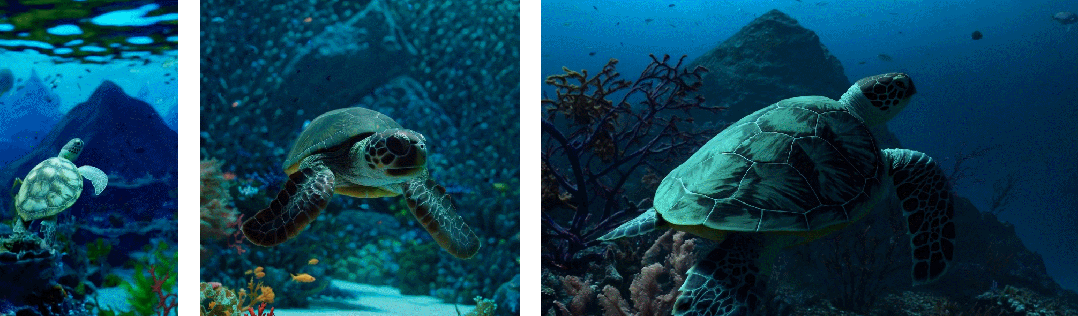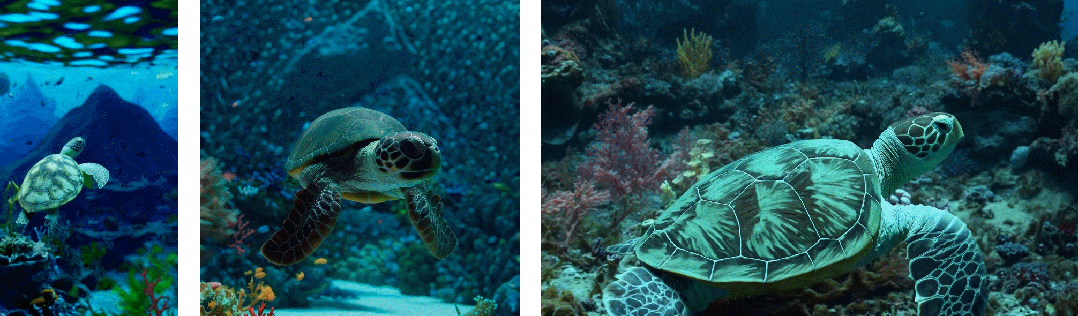
- 其次是改进帧和内容组成:研究者通过实证发现,使用视频的原始长宽比进行训练可以提升内容组成和帧的质量。将 Sora 在与其他模型的比较中,后者将所有训练视频裁剪成正方形,这是训练生成模型时的常见做法。经过正方形裁剪训练的模型生成的视频(如下图左侧),其中的视频主题只是部分可见。相比之下,Sora 生成的视频具有改进的帧内容(如下图右侧)

1.1.3 用于视频生成的扩散型Transformer
有的新闻稿说,Sora 是个扩散模型,原因在于它类似扩散模型那一套流程,给定输入噪声 patches(以及文本提示等调节信息),训练出的模型来预测原始的「干净」patches
也有的新闻稿会说,Sora 是一个扩散 Transformer,原因在于它把图像打散成块后,计算块与块之间的注意力,从而基于已有的「块」去预测接下来的「块」,而这套计算模式便是transformer的流程

总之,总的来说,Sora是一个在不同时长、分辨率和宽高比的视频及图像上训练而成的扩散模型,同时采用了Transformer架构,是一种扩散型Transformer
至于想更好的理解这个扩散Transformer,请看下文第二部分
1.2 其他关键技术点:DALLE 3的重字幕技术和对环境的模拟能力
1.2.1 DALLE 3的重字幕技术:为文本-视频数据集打上详细字幕
训练文本到视频生成系统需要大量带有相应文本字幕的视频,研究团队将 DALL・E 3 中的重字幕(re-captioning)技术应用于视频
- 具体来说,研究团队首先训练一个高度描述性的字幕生成器模型,然后使用它为训练集中所有视频生成文本字幕
- 与DALLE 3类似,研究团队还利用 GPT 将简短的用户 prompt 转换为较长的详细字幕,然后发送到视频模型,这使得 Sora 能够生成准确遵循用户 prompt 的高质量视频
关于DALLE 3的重字幕技术更具体的细节请见此文2.3节《AI绘画与多模态原理解析:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》
2.3 DALLE 3:Improving Image Generation with Better Captions
2.3.1 为提高文本图像配对数据集的质量:基于谷歌的CoCa微调出图像字幕生成器
2.3.1.1 什么是谷歌的CoCa
2.1.1.2 分别通过短caption、长caption微调预训练好的image captioner
2.1.1.3 为提高合成caption对文生图模型的性能:采用描述详细的长caption,训练的混合比例高达95%
..
1.2.2 对环境的模拟能力
OpenAI 发现,视频模型在经过大规模训练后,会表现出许多有趣的新能力。这些能力使 Sora 能够模拟物理世界中的人、动物和环境的某些方面。这些特性的出现没有任何明确的三维、物体等归纳偏差 — 它们纯粹是规模现象
- 三维一致性(下图左侧)
Sora 可以生成动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中的移动是一致的
针对这点,sora一作Tim Brooks说道,sora学习了大量关于3D几何的知识,但是我们并没有事先设定这些,它完全是从大量数据中学习到的

长序列连贯性和目标持久性(上图右侧)
视频生成系统面临的一个重大挑战是在对长视频进行采样时保持时间一致性
例如,即使人、动物和物体被遮挡或离开画面,Sora 模型也能保持它们的存在。同样,它还能在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观 - 与世界互动(下图左侧)
Sora 有时可以模拟以简单方式影响世界状态的动作。例如,画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而持续
模拟数字世界(上图右侧)
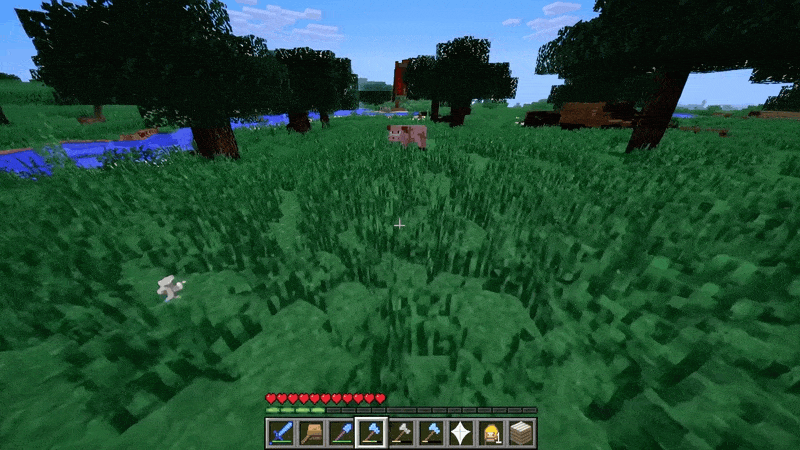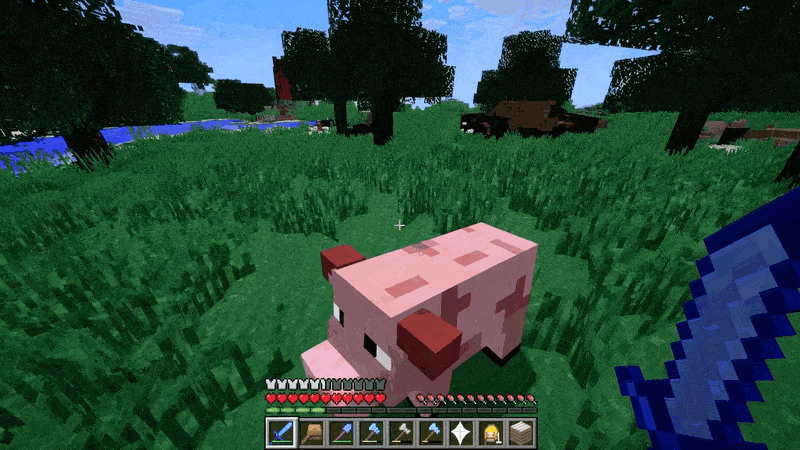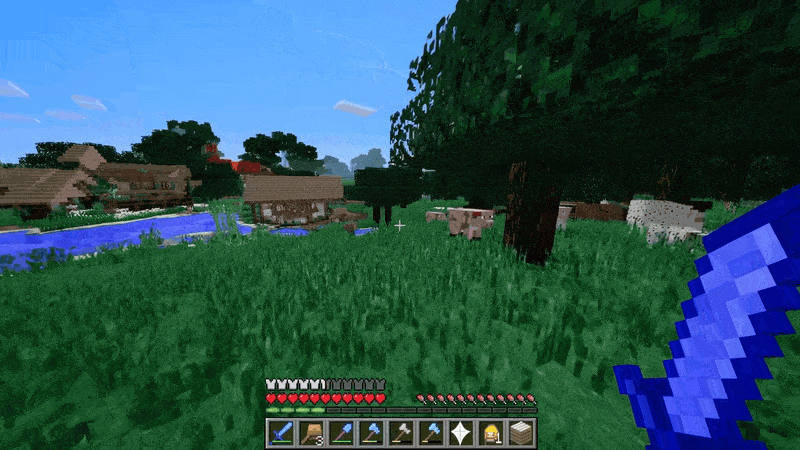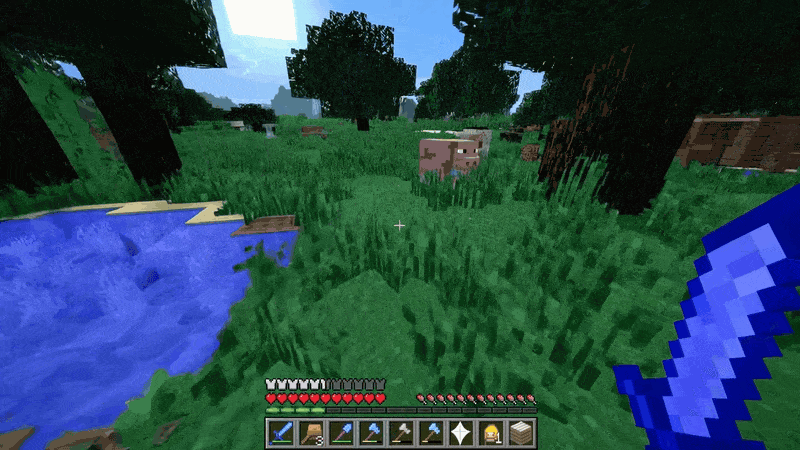
视频游戏就是一个例子。Sora 可以通过基本策略同时控制 Minecraft 中的玩家,同时高保真地呈现世界及其动态。只需在 Sora 的提示字幕中提及 「Minecraft」,就能零样本激发这些功能
第二部分 Sora相关技术的发展史:ViViT、DiT、MAGVIT v2、VideoPoet
2.1 ViT在视频上的应用:ViViT
Transformer在NLP领域大获成功,ViT(Vision Transformer)将Transformer架构应用到视觉领域,它将图片按给定大小分为不重叠的patches,再将每个patch线性映射为一个token,随位置编码和cls token(可选)一起输入到Transformer的编码器中
而Google于2021年提出的「ViViT: A Video Vision Transformer」便要尝试在视频中使用ViT模型,探究Video Vision Transformer的优化方式
视频作为输入会产生大量的时空token,处理时必须考虑这些长范围token序列的上下文关系,同时要兼顾模型效率问题,作者在空间和时间维度上分别对Transformer编码器各组件进行分解,在ViT模型的基础上提出了三种用于视频分类的纯Transformer模型(ViViT)

// 待更
2.2 DiT:将 U-Net 架构逐渐转换成 transformer
对于基于 transformer 的工作,不管是 latent diffusion 还是 language model,它们之间的区别很小,都是 token-based,最大的区别在于基于 diffusion 的生成是连续的 token,language model 处理的是离散的 token
2022年年底,William Peebles(当时在加州伯克利,Peebles在𝕏上用昵称Bill,在Linkedin上及论文署名时用大名William)、Saining Xie(当时在纽约大学)的两人通过论文《Scalable Diffusion Models with Transformers》提出了一种叫 DiT 的神经网络结构
其结合了视觉 transformer 和 diffusion 模型的优点,即DiT = VAE encoder + ViT + DDPM + VAE decoder

对于 DiT 在 Sora 中的应用,DiT 作者之一 Saining Xie 在推文中提到:
- 由 batch size 大小相关的计算推导,Sora 可能有大约 30 亿个参数。 “训练 Sora 模型可能不需要像人们预期的那样多的 GPU;我预计未来会有非常快的迭代。”
- Sora“可能还使用了谷歌的 Patch n’ Pack (NaViT) 论文成果,使其能够适应可变的分辨率/持续时间/长宽比。”
// 待更
2.3 NaViT:多个patches打包成一个单一序列以实现可变分辨率
2023年7月,Google DeepMind通过此篇论文《Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution》提出了NaViT(Native Resolution ViT)
- 该模型在训练过程中采用序列封装的方式处理任意分辨率和纵横比的输入(uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios)
- 除了具备灵活性的模型应用外,还展示了通过大规模监督和对比图像-文本预训练来提高训练效率
具体而言
- 视觉Transformer(ViT)输入图像会被调整为固定的平方纵横比,并分割成固定数量的patch(input images are resized to a fixed square aspect ratio and then split into a fixed number of patches)
这是通过在每个训练步骤中对patch大小进行随机采样和调整算法来实现的,以支持多种初始卷积嵌入尺寸(This is achieved via random sampling of a patch size at each training step and a resizing algorithm to allow the initial convolutional embedding to support multiple patch sizes) - Pix2Struct引入了一种替代方法来保留纵横比(introduced an alternative patching approach which preserves the aspect ratio),在图表和文档理解等任务中尤其有用
Google从而提出了一种替代方法NaViT,将来自不同图像的多个patches打包成一个单一序列——称为Patch n’ Pack——从而实现可变分辨率并保持长宽比(Multiple patches from different images are packed in a single sequence— termed Patch n’ Pack—which enables variable resolution while preserving the aspect ratio)
2.4 MAGVIT v2:用好tokenizer可以超越diffusion
Google和CMU于2023年10月份联合发布的MAGVIT v2(这是其论文Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation),首次证明了LLM不仅擅长文本方面的任务,而且在视觉任务上也能取得比扩散模型更好的效果
而其中的关键在于一个好的 tokenizer 接入到语言模型后,能够立即可以获得比当时最好的 diffusion 还要好的效果
2.5 Google VideoPoet:基于MAGVIT V2和Transformer而来
2023年年底,Google推出了VideoPoet(这是其论文:VideoPoet: A Large Language Model for Zero-Shot Video Generation),包含两个阶段:预训练和微调(pretraining and task-specific adaptation)
与通常使用外部交叉注意力网络或潜在混合进行风格化基于扩散的方法相比(In contrast to the diffusion-based approaches that usually use external cross-attention networks or latent blending for styliza-tion),Google的这个方法更加类似于利用大型语言模型进行机器翻译,因为只需将结构和文本作为语言模型的前缀
2.5.1 通过自然语言随心所欲的编辑视频,且其zero-shot能力强悍
如下图所示,其可以将输入图像动画化以生成一段视频,并且可以编辑视频或扩展视频
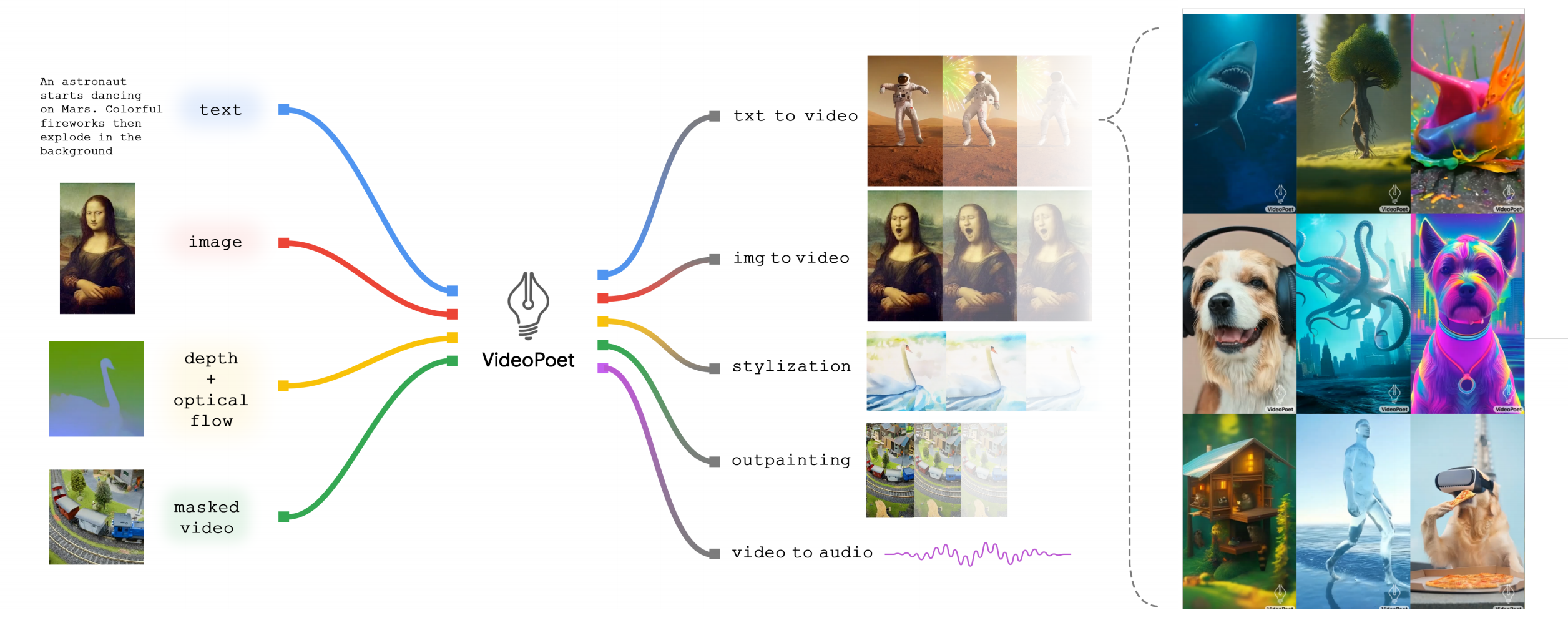
在风格化方面,该模型接收表征深度和光流的视频,以文本指导的风格绘制内容
2.5.2 视频生成器:借鉴LLM离散化token的处理思路
LLM在过去一年已经取得了巨大成功,那可否用于视频生成领域呢
- 然而,LLM 是在离散 token 上运行的,好在一些「视频和音频 tokenizer(比如用于视频和图像的 MAGVIT V2 和用于音频的 SoundStream)」,可以将视频和音频剪辑编码为离散 token 序列,并且也可以转换回原始表征形式
- 如此,通过使用多个 tokenizer,VideoPoet 便可以训练自回归语言模型来学习跨视频、图像、音频和文本的多个模态
一旦模型生成以某些上下文为条件的 token,就可以使用 tokenizer 解码器将它们转换回可视化的表征形式
如下图所示,VideoPoet将所有模态编码映射到离散的标记空间中,以便能够直接利用大型语言模型架构进行视频生成,特定标记使用<>表示,其中

- 深红色代表模态不可知部分
蓝色代表文本相关组件,即text tokens (embeddings): the pre-extracted T5 embed-dings for any text.
黄色代表视觉相关组件,即visual tokens: the MAGVIT-v2 tokens representing the images, video subsection, or COMMIT encoded video-to-video task.
绿色代表音频相关组件,即audio tokens: the SoundStream tokens representing au-dio - 上图左侧的浅黄色区域表示双向前缀输入
而上午右侧的深红色区域则表示带有因果注意机制的自回归生成输出
2.5.3 Tokenization:图像视频标记MAGVIT-v2与音频标记SoundStream
图像和视频分词器(Image and video tokenizer)是生成高质量视频内容的关键
具体而言,它将图像和视频编码为一串整数,并通过解码器将其映射回像素空间,作为标记和像素空间之间的桥梁
- 视觉分词器的性能决定了视频生成质量的上限。同时,为了实现有效且高效的任务设置,压缩比决定了LLM序列长度
- MAGVIT-v2对8 fps采样率下17帧、2.125秒、128×128分辨率的视频进行分词,产生(5, 16, 16)形状,并扁平化为1280个标记,词汇表大小为2-18
MAGVIT-v2tokenizes17-frame2.125-second128×128 resolution videos sampled at 8 fps to pro-duce a latent shape of (5, 16, 16), which is then flattenedinto 1280 tokens, with a vocabulary size of 2-18 - 此外,在移动端生成短形式内容时,我们还将视频按纵横比分割成128×224分辨率,并产生(5, 28, 16)形状或2240个标记。在评估协议中使用16帧时,我们会舍弃最后一帧以制作16帧视频
第三部分 根据sora的32个reference以窥其背后更多技术细节

3.1 早期对视频的研究——使用LSTM的视频表示的无监督学习
sora的第一个reference为这篇论文《Unsupervised learning of video representations using lstms》,该论文考虑了目标序列的不同选择
- 一种选择是预测与输入相同的序列,动机类似于自动编码器(比如VAE)——我们希望捕获所有重现输入所需的信息,同时克服模型施加的归纳偏差
The motivation is similar to that of auto encoders –we wish to capture all that is needed to reproducethe input but at the same time go through the inductive bi-ases imposed by the model
- 另一种选择是预测未来的帧。这里的动机是学习一种表示,提取所有需要推断的运动和外观,而非仅限于观察到的内容

这两种自然而合理地选择也可以结合起来。在这种情况下,有两个解码器LSTM——一个将表示解码为输入序列,另一个则利用相同表示进行解码以预测未来
在模型输入方面,理论上可以采用任何表示单个视频帧的方式。然而,为了本文目的的考虑,我们将限制注意力在两种输入上
- 第一种是图像块,即image patches
- 第二种是通过应用在ImageNet上训练过的卷积网络提取出来的高级“感知”。这些感知指代卷积神经网络模型中最后一层和/或倒数第二层校正线性隐状态所得到的结果
3.2 早期对世界的模拟和对环境的学习
3.2.1 把RNN用于对环境的模拟:预测时确保时空上的一致性
在sora的第二个reference中,引入了循环神经网络来提升以前的高维像素观测环境模拟器。这些网络能够对未来数百个时间步进行时间和空间上的一致预测,从而使智能体能够有效地计划和行动
为了解决计算效率低下的问题,我们采用了一个不需要在每个时间步生成高维图像的模型。通过这个方法,可以改善探索并适应多种不同环境,包括10个雅达利游戏、3D赛车环境和复杂的3D迷宫
3.2.2 世界模型World Models
在sora的第三个reference中,研究了构建流行的强化学习环境生成神经网络模型的方法
世界模型可以通过无监督方式快速训练,以学习环境的时空压缩表示(to learn acompressed spatial and temporal representation of the environment)
通过将从世界模型中提取的特征作为Agent的输入,我们能够训练出一种非常紧凑和简洁的策略来解决所需任务。甚至可以完全在由世界模型生成的幻觉梦中(hallucinated dream generated by its world model)对Agent进行训练,并将该策略迁移到实际环境中
3.2.3 Generating Videos with Scene Dynamics
在sora的第四个reference中,利用大量未标记的视频,以学习场景动态模型,应用于视频识别任务(如动作分类)和视频生成任务(如未来预测)
- 其提出了一种具备时空卷积架构的视频生成对抗网络,该架构能够将场景中的前景与背景分离
- 实验证明,该模型能够以全帧率生成长达一秒的小视频,并且相较于简单基线方法表现更优,在预测静态图像方面也展示出可信度
- 此外,实验和可视化结果显示,该模型在最小监督下内部学习到了有益特征来识别动作,证明了场景动态是良好表示学习信号
3.2.4 Generating Long Videos of Dynamic Scenes
在sora的第7个reference中,提出了一个视频生成模型,可以精确地再现物体运动、摄像机视角的变化以及随时间推移而出现的新内容
- 在它之前,已有的视频生成方法通常无法作为时间函数产生新内容,并同时保持真实环境中所期望的一致性,如可信的动态和对象持久性。一个常见失败案例是过度依赖归纳偏差来提供时间一致性,例如指定整个视频内容的单个潜在代码,导致内容永远不会改变
- 另一种极端情况下,如果没有长期一致性,则生成的视频可能会在不同场景之间失去真实感并发生形变
为了解决这些限制,我们优先考虑时间轴,并通过重新设计时间潜在表示以及通过在更长视频上进行训练来学习长期一致性
为此,我们采用两阶段训练策略,在低分辨率下使用更长视频进行训练,在高分辨率下使用更短视频进行训练。为了评估模型能力,我们引入了两个新的基准数据集,明确关注长期时间动态
// 待更
参考文献与推荐阅读
- OpenAI sora的技术报告:Video generation models as world simulators
- 我在模拟世界!OpenAI刚刚公布Sora技术细节:是数据驱动物理引擎
- 爆火Sora参数规模仅30亿?谢赛宁等大佬技术分析来了
- 请教英伟达小哥哥,解读 Sora 真正的技术突破
- Sora 的一些个人思考
- ViViT论文阅读
- 专访 VideoPoet 作者:视频模型技术会收敛,LLM 将取代diffusion带来真正的视觉智能
- sora的32个reference
- Sora背后团队:应届博士带队,00后入列,还专门招了艺术生
相关文章:
OpenAI视频生成模型Sora的全面解析:从扩散Transformer到ViViT、DiT、NaViT、VideoPoet
前言 真没想到,距离视频生成上一轮的集中爆发(详见《视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日OpenAI发布sora以来(其开发团队包…...

【Java】图解 JVM 垃圾回收(一):GC 判断策略、引用类型、垃圾回收算法
图解 JVM 垃圾回收(一) 1.前言1.1 什么是垃圾1.2 内存溢出和内存泄漏 2.垃圾回收的定义与重要性3.GC 判断策略3.1 引用计数算法3.2 可达性分析算法 4.引用类型5.垃圾回收算法5.1 标记-复制(Copying)5.2 标记-清除(Mark…...

做抖店需要注意的几大点,新手最易踩坑,都给你们总结到这了!
我是电商珠珠 抖店的运营流程很简单,选品上架、获取流量(找达人、自播、投千川等)、出单发货、做体验分等。出新手期就会有体验分,体验分就是店铺的权重,体验分越高店铺的权重也就越大。 但是作为新手的话࿰…...
)
小程序API能力汇总——基础容器API(三)
ty.getAccountInfo 获取小程序账号信息 需引入MiniKit,且在>3.1.0版本才可使用 参数 Object object 属性类型默认值必填说明completefunction否接口调用结束的回调函数(调用成功、失败都会执行)successfunction否接口调用成功的回调函数…...

处理目标检测中的类别不均衡问题
目标检测中,数据集中类别不均衡是一个常见的问题,其中一些类别的样本数量明显多于其他类别。这可能导致模型在训练和预测过程中对频繁出现的类别偏向,而忽略掉罕见的类别。本文将介绍如何处理目标检测中的类别不均衡问题,以提高模…...
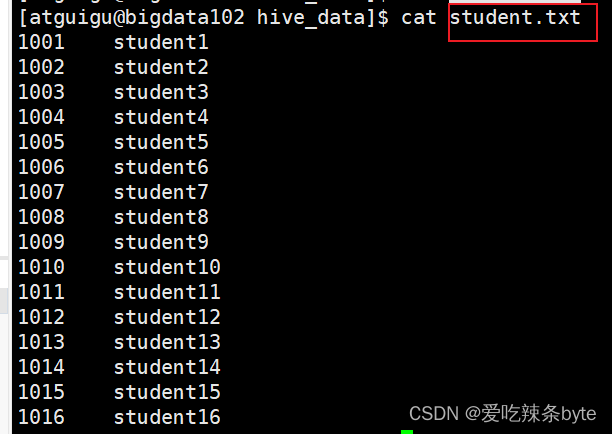
(03)Hive的相关概念——分区表、分桶表
目录 一、Hive分区表 1.1 分区表的概念 1.2 分区表的创建 1.3 分区表数据加载及查询 1.3.1 静态分区 1.3.2 动态分区 1.4 分区表的本质及使用 1.5 分区表的注意事项 1.6 多重分区表 二、Hive分桶表 2.1 分桶表的概念 2.2 分桶表的创建 2.3 分桶表的数据加载 2.4 …...

2024年首发!高级界面控件Kendo UI全新发布2024 Q1
Kendo UI是带有jQuery、Angular、React和Vue库的JavaScript UI组件的最终集合,无论选择哪种JavaScript框架,都可以快速构建高性能响应式Web应用程序。通过可自定义的UI组件,Kendo UI可以创建数据丰富的桌面、平板和移动Web应用程序。通过响应…...

stable diffusion webui学习总结(2):技巧汇总
一、脸部修复:解决在低分辨率下,脸部生成异常的问题 勾选ADetailer,会在生成图片后,用更高的分辨率,对于脸部重新生成一遍 二、高清放大:低分辨率照片提升到高分辨率,并丰富内容细节 1、先通过…...
java 培训班预定管理系统Myeclipse开发mysql数据库web结构jsp编程servlet计算机网页项目
一、源码特点 java 培训班预定管理系统是一套完善的java web信息管理系统 采用serlvetdaobean,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5开发…...

Python内置函数06——join
文章目录 概述语法实例展示注意事项 概述 Python内置函数join()用于将序列中的元素连接成一个字符串。 语法 str.join(iterable) 参数:iterable——一个可迭代对象中元素连接而成,元素之间用str分隔。 实例展示 eg1:用join()连接列表中…...

linux安装单机版redis详细步骤,及python连接redis案例
文章目录 linux相关工具yum方式安装redis使用编译安装redis配置redis为systemctl启动其它: 安装redis6.0python连接redis案例 linux相关工具 ./redis-benchmark #用于进行redis性能测试的工具 ./redis-check-dump #用于修复出问题的dump.rdb文件 ./redis-cli …...

ts总结大全
ts类型 TS类型除了原始js类型之外,还增加类型,例如:枚举、接口、泛型、字面量、自定义、类型断言、any、类型声明文件 数组类型两种写法:类型 [] 或 Array <类型> let arr:number[][1,2,3,4] let arr:string[][a] let arr…...
前端登录随机数字字母组合验证
背景:系统登录页面只有用户名密码一种校验方式,没有验证码,可能导致暴力破解。 实现逻辑: <el-form-item prop="code"><el-inputv-model="loginForm.captchaCode"auto-complete="off"placeholder="验证码"style="wi…...

基于Java+SpringBoot+vue+elementui 实现即时通讯管理系统
目录 系统简介效果图源码结构试用地址源码下载地址技术交流 博主介绍: 计算机科班人,全栈工程师,掌握C、C#、Java、Python、Android等主流编程语言,同时也熟练掌握mysql、oracle、sqlserver等主流数据库,能够为大家提供…...
 ● 322. 零钱兑换 ● 279.完全平方数)
代码随想录算法训练营第50天(动态规划07 ● 70. 爬楼梯 (进阶) ● 322. 零钱兑换 ● 279.完全平方数
动态规划part07 70. 爬楼梯 (进阶)解题思路总结 322. 零钱兑换解题思路总结 279.完全平方数解题思路 70. 爬楼梯 (进阶) 这道题目 爬楼梯之前我们做过,这次再用完全背包的思路来分析一遍 文章讲解: 70. 爬…...
【软考问题】-- 13 - 知识精讲 - 项目绩效域管理
一、基本问题 问题1:干系人绩效域的预期目标主要包含什么? ①与干系人建立高效的工作关系;②干系人认同项目目标;③支持项目的干系人提高了满意度,并从中收益;④反对项目的干系人没有对项目产生负面影响。问…...
VSCode无法连接远程服务器的两种解决方法
文章目录 VSCode Terminal 报错解决方式1解决方式2you are connected to an OS version that is unsupported by Visual Studio Code解决方法 VSCode Terminal 报错 直接在terminal或cmd中使用ssh命令可以连接服务器,但是在vscode中存在报错,最后一行为…...
【Kuiperinfer】笔记01 项目预览与环境配置
学习目标 实现一个深度学习推理框架设计、编写一个计算图实现常见的算子,例如卷积、池化、全连接学会如何进行算子的优化加速使用自己的推理框架推理常见模型,检查结果是否能够和torch对齐 什么是推理框架? 推理框架用于对已经训练完成的模…...
都2024了,你还在使用websocket实现实时消息推送吗?
前言 在日常的开发中,我们经常能碰见服务端需要主动推送给客户端数据的业务场景,比如数据大屏的实时数据,比如消息中心的未读消息,比如聊天功能等等。 本文主要介绍SSE的使用场景和如何使用SSE。 服务端向客户端推送数据的实现…...

javaScript实现客户端直连华为云OBS实现文件上传、断点续传、断网重传
写在前面:在做这个调研时我遇到的需求是前端直接对接华为云平台实现文件上传功能。上传视频文件通常十几个G、客户工作环境网络较差KB/s,且保证上传是稳定的,支持网络异常断点重试、文件断开支持二次拖入自动重传等。综合考虑使用的华为云的分…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...
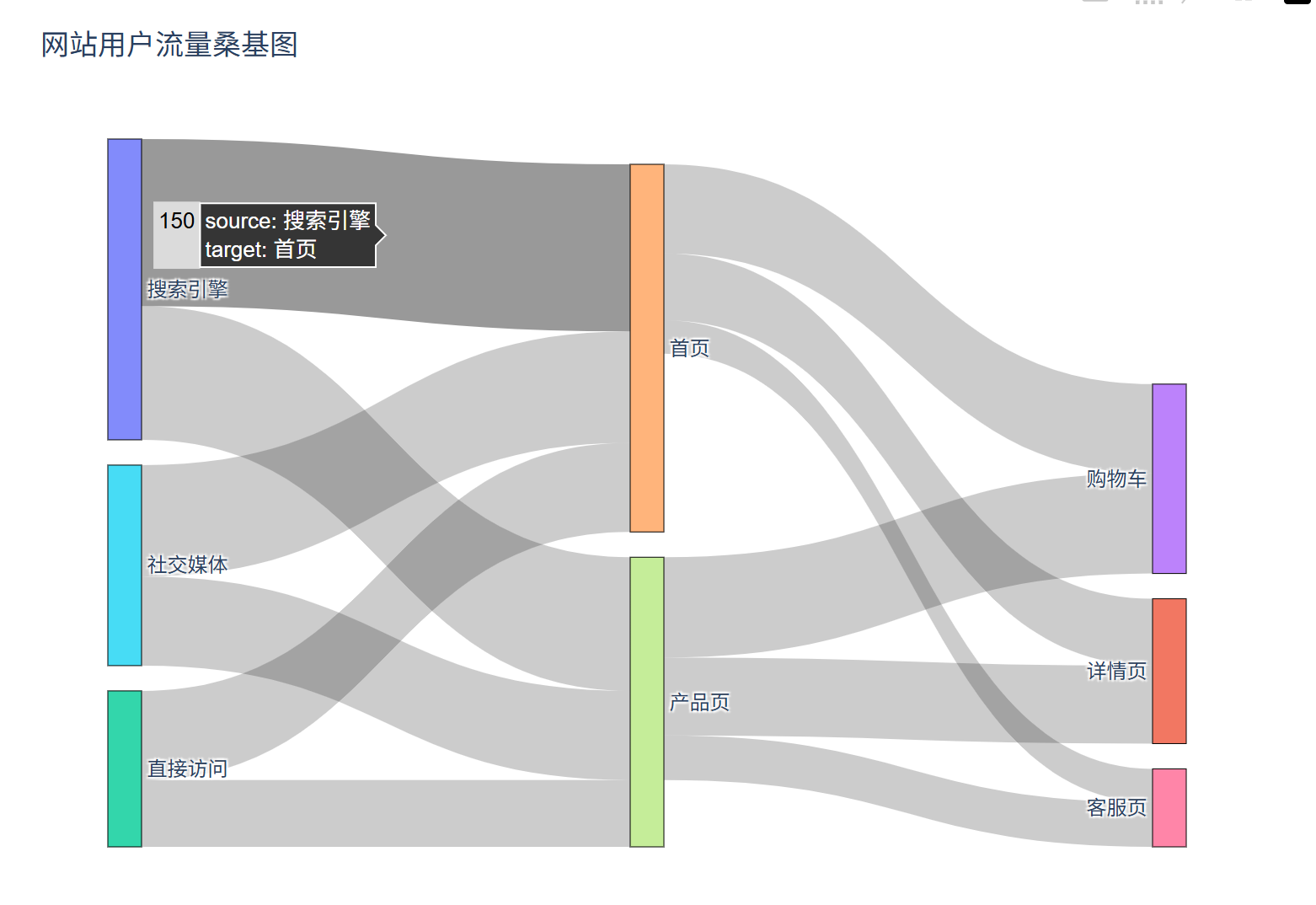
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...