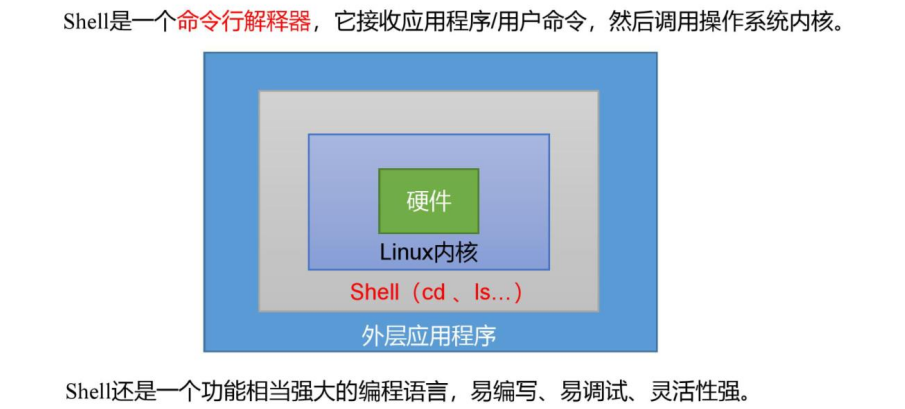
Linux之Shell
第 1 章 Shell 概述
1)Linux 提供的 Shell 解析器有
[zhao@hadoop101 ~]$ cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
/bin/tcsh
/bin/csh
2)bash 和 sh 的关系
[zhao@hadoop101 bin]$ ll | grep bash
-rwxr-xr-x. 1 root root 941880 5 月 11 2016 bash
lrwxrwxrwx. 1 root root 4 5 月 27 2017 sh -> bash
3)Centos 默认的解析器是 bash
[zhao@hadoop101 bin]$ echo $SHELL
/bin/bash
第 2 章 Shell 脚本入门
1)脚本格式
脚本以#!/bin/bash开头(指定解析器)
2)第一个 Shell 脚本:helloworld.sh
(1)需求:创建一个 Shell 脚本,输出 helloworld
(2)案例实操:
[zhao@hadoop101 shells]$ touch helloworld.sh
[zhao@hadoop101 shells]$ vim helloworld.sh在 helloworld.sh 中输入如下内容
#!/bin/bash
echo "helloworld"
(3)脚本的常用执行方式
第一种:采用 bash 或 sh+脚本的相对路径或绝对路径(不用赋予脚本+x 权限)
sh+脚本的相对路径
[zhao@hadoop101 shells]$ sh ./helloworld.sh
Helloworld
sh+脚本的绝对路径
[zhao@hadoop101 shells]$ sh /home/zhao/shells/helloworld.sh
helloworld
bash+脚本的相对路径
[zhao@hadoop101 shells]$ bash /home/zhao/shells/helloworld.sh
Helloworld
第二种:采用输入脚本的绝对路径或相对路径执行脚本(必须具有可执行权限+x)
①首先要赋予 helloworld.sh 脚本的+x 权限
[zhao@hadoop101 shells]$ chmod +x helloworld.sh
②执行脚本
相对路径
[zhao@hadoop101 shells]$ ./helloworld.sh
Helloworld
绝对路径
[zhao@hadoop101 shells]$ /home/zhao/shells/helloworld.sh
Helloworld
注意:第一种执行方法,本质是 bash 解析器帮你执行脚本,所以脚本本身不需要执行权限。第二种执行方法,本质是脚本需要自己执行,所以需要执行权限。
【了解】第三种:在脚本的路径前加上“.”或者 source
①有以下脚本
[zhao@hadoop101 shells]$ cat test.sh
#!/bin/bash
A=5
echo $A
②分别使用 sh,bash,./ 和 . 的方式来执行,结果如下:
[zhao@hadoop101 shells]$ bash test.sh
[zhao@hadoop101 shells]$ echo $A[zhao@hadoop101 shells]$ sh test.sh
[zhao@hadoop101 shells]$ echo $A[zhao@hadoop101 shells]$ ./test.sh
[zhao@hadoop101 shells]$ echo $A[zhao@hadoop101 shells]$ . test.sh
[zhao@hadoop101 shells]$ echo $A
5
原因:
前两种方式都是在当前 shell 中打开一个子 shell 来执行脚本内容,当脚本内容结束,则子 shell 关闭,回到父 shell 中。
第三种,也就是使用在脚本路径前加“.”或者 source 的方式,可以使脚本内容在当前shell 里执行,而无需打开子 shell!这也是为什么我们每次要修改完/etc/profile 文件以后,需要 source 一下的原因。
开子 shell 与不开子 shell 的区别就在于,环境变量的继承关系,如在子 shell 中设置的当前变量,父 shell 是不可见的。
第 3 章 变量
3.1 系统预定义变量
1)常用系统变量
$HOME、$PWD、$SHELL、$USER 等
2)案例实操
(1)查看系统变量的值
[zhao@hadoop101 shells]$ echo $HOME
/home/zhao
(2)显示当前 Shell 中所有变量:set
[zhao@hadoop101 shells]$ set
BASH=/bin/bash
BASH_ALIASES=()
BASH_ARGC=()
BASH_ARGV=()
3.2 自定义变量
1)基本语法
(1)定义变量:变量名=变量值,注意,=号前后不能有空格</span
(2)撤销变量:unset 变量名
(3)声明静态变量:readonly 变量,注意:不能 unset
2)变量定义规则
(1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
(2)等号两侧不能有空格
(3)在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算。
(4)变量的值如果有空格,需要使用双引号或单引号括起来。
3)案例实操
(1)定义变量 A
[zhao@hadoop101 shells]$ A=5
[zhao@hadoop101 shells]$ echo $A
5
(2)给变量 A 重新赋值
[zhao@hadoop101 shells]$ A=8
[zhao@hadoop101 shells]$ echo $A
8
(3)撤销变量 A
[zhao@hadoop101 shells]$ unset A
[zhao@hadoop101 shells]$ echo $A
(4)声明静态的变量 B=2,不能 unset
[zhao@hadoop101 shells]$ readonly B=2
[zhao@hadoop101 shells]$ echo $B
2
[zhao@hadoop101 shells]$ B=9
-bash: B: readonly variable
(5)在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算
[zhao@hadoop102 ~]$ C=1+2
[zhao@hadoop102 ~]$ echo $C
1+2
(6)变量的值如果有空格,需要使用双引号或单引号括起来
[zhao@hadoop102 ~]$ D=I love banzhang
-bash: world: command not found
[zhao@hadoop102 ~]$ D="I love banzhang"
[zhao@hadoop102 ~]$ echo $D
I love banzhang
(7)可把变量提升为全局环境变量,可供其他 Shell 程序使用
export 变量名
[zhao@hadoop101 shells]$ vim helloworld.sh
在 helloworld.sh 文件中增加 echo $B
#!/bin/bashecho "helloworld"
echo $B[zhao@hadoop101 shells]$ ./helloworld.sh
Helloworld
发现并没有打印输出变量 B 的值。
[zhao@hadoop101 shells]$ export B
[zhao@hadoop101 shells]$ ./helloworld.sh
helloworld
2
3.3 特殊变量
3.3.1 $n
1)基本语法
$n (功能描述:n 为数字,$0 代表该脚本名称,$1-$9 代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10})
2)案例实操
[zhao@hadoop101 shells]$ touch parameter.sh
[zhao@hadoop101 shells]$ vim parameter.sh
#!/bin/bash
echo '==========$n=========='
echo $0
echo $1
echo $2[zhao@hadoop101 shells]$ chmod 777 parameter.sh
[zhao@hadoop101 shells]$ ./parameter.sh cls xz
==========$n==========
./parameter.sh
cls
xz
3.3.2 $#
1)基本语法
$# (功能描述:获取所有输入参数个数,常用于循环,判断参数的个数是否正确以及加强脚本的健壮性)。
2)案例实操
[zhao@hadoop101 shells]$ vim parameter.sh
#!/bin/bash
echo '==========$n=========='
echo $0
echo $1
echo $2
echo '==========$#=========='
echo $#[zhao@hadoop101 shells]$ chmod 777 parameter.sh
[zhao@hadoop101 shells]$ ./parameter.sh cls xz
==========$n==========
./parameter.sh
cls
xz
==========$#==========
2
3.3.3 ∗ 、 *、 ∗、@
1)基本语法
$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
$@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
2)案例实操
[zhao@hadoop101 shells]$ vim parameter.sh
#!/bin/bash
echo '==========$n=========='
echo $0
echo $1
echo $2
echo '==========$#=========='
echo $#
echo '==========$*=========='
echo $*
echo '==========$@=========='
echo $@
[zhao@hadoop101 shells]$ ./parameter.sh a b c d e f g
==========$n==========
./parameter.sh
a
b
==========$#==========
7
==========$*==========
a b c d e f g
==========$@==========
a b c d e f g
3.3.4 $?
1)基本语法
$? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为 0,证明上一个命令正确执行;如果这个变量的值为非 0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)
2)案例实操
判断 helloworld.sh 脚本是否正确执行
[zhao@hadoop101 shells]$ ./helloworld.sh
hello world
[zhao@hadoop101 shells]$ echo $?
0
第 4 章 运算符
1)基本语法
“$((运算式))” 或 “$[运算式]”
2)案例实操:
计算(2+3)* 4 的值
[zhao@hadoop101 shells]# S=$[(2+3)*4]
[zhao@hadoop101 shells]# echo $S
第 5 章 条件判断
1)基本语法
(1)test condition
(2)[ condition ](注意 condition 前后要有空格)
注意:条件非空即为 true,[ zhao ]返回 true,[ ] 返回 false。
2)常用判断条件
(1)两个整数之间比较
-eq 等于(equal)
| -eq 等于(equal) | -ne 不等于(not equal) |
|---|---|
| -lt 小于(less than) | -le 小于等于(less equal) |
| -gt 大于(greater than) | -ge 大于等于(greater equal) |
注:如果是字符串之间的比较 ,用等号“=”判断相等;用“!=”判断不等。
(2)按照文件权限进行判断
-r 有读的权限(read)
-w 有写的权限(write)
-x 有执行的权限(execute)
(3)按照文件类型进行判断
-e 文件存在(existence)
-f 文件存在并且是一个常规的文件(file)
-d 文件存在并且是一个目录(directory)
3)案例实操
(1)23 是否大于等于 22
[zhao@hadoop101 shells]$ [ 23 -ge 22 ]
[zhao@hadoop101 shells]$ echo $?
0
(2)helloworld.sh 是否具有写权限
[zhao@hadoop101 shells]$ [ -w helloworld.sh ]
[zhao@hadoop101 shells]$ echo $?
0
(3)/home/zhao/cls.txt 目录中的文件是否存在
[zhao@hadoop101 shells]$ [ -e /home/zhao/cls.txt ]
[zhao@hadoop101 shells]$ echo $?
1
(4)多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一条命令执行失败后,才执行下一条命令),类似于java中的三元运算
[zhao@hadoop101 ~]$ [ zhao ] && echo OK || echo notOK
OK
[zhao@hadoop101 shells]$ [ ] && echo OK || echo notOK
notOK
第 6 章 流程控制(重点)
6.1 if 判断
1)基本语法
(1)单分支
if [ 条件判断式 ];then程序
fi
或者
if [ 条件判断式 ]
then程序
fi

(2)多分支
if [ 条件判断式 ]
then程序
elif [ 条件判断式 ]
then程序
else程序
fi
注意事项:
①[ 条件判断式 ],中括号和条件判断式之间必须有空格
②if 后要有空格
2)案例实操
输入一个数字,如果是 1,则输出 banzhang zhen shuai,如果是 2,则输出 cls zhen mei,如果是其它,什么也不输出。
[zhao@hadoop101 shells]$ touch if.sh
[zhao@hadoop101 shells]$ vim if.sh#!/bin/bash
if [ $1 -eq 1 ]
thenecho "banzhang zhen shuai"
elif [ $1 -eq 2 ]
thenecho "cls zhen mei"
fi[zhao@hadoop101 shells]$ chmod 777 if.sh
[zhao@hadoop101 shells]$ ./if.sh 1
banzhang zhen shuai
6.2 case 语句
1)基本语法
case $变量名 in
"值 1")如果变量的值等于值 1,则执行程序 1
;;
"值 2")如果变量的值等于值 2,则执行程序 2
;;…省略其他分支…
*)如果变量的值都不是以上的值,则执行此程序
;;
esac
注意事项:
(1)case 行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
(2)双分号“;;”表示命令序列结束,相当于 java 中的 break。
(3)最后的“*)”表示默认模式,相当于 java 中的 default。
2)案例实操
输入一个数字,如果是 1,则输出 banzhang,如果是 2,则输出 cls,如果是其它,输出renyao。
[zhao@hadoop101 shells]$ touch case.sh
[zhao@hadoop101 shells]$ vim case.sh!/bin/bash
case $1 in
"1")echo "banzhang"
;;"2")echo "cls"
;;
*)echo "renyao"
;;
esac[zhao@hadoop101 shells]$ chmod 777 case.sh
[zhao@hadoop101 shells]$ ./case.sh 1
1
6.3 for 循环
1)基本语法 1
for (( 初始值;循环控制条件;变量变化 ))
do程序
done
2)案例实操
从 1 加到 100
[zhao@hadoop101 shells]$ touch for1.sh
[zhao@hadoop101 shells]$ vim for1.sh#!/bin/bashsum=0
for((i=0;i<=100;i++))
dosum=$[$sum+$i]
done
echo $sum[zhao@hadoop101 shells]$ chmod 777 for1.sh
[zhao@hadoop101 shells]$ ./for1.sh
5050
3)基本语法 2
for 变量 in 值 1 值 2 值 3…
do程序
done
4)案例实操
(1)打印所有输入参数
[zhao@hadoop101 shells]$ touch for2.sh
[zhao@hadoop101 shells]$ vim for2.sh#!/bin/bash
#打印数字for i in cls mly wls
doecho "ban zhang love $i"
done[zhao@hadoop101 shells]$ chmod 777 for2.sh
[zhao@hadoop101 shells]$ ./for2.sh
ban zhang love cls
an zhang love mly
ban zhang love wls
(2)比较 ∗ 和 *和 ∗和@区别
∗ 和 *和 ∗和@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 $2 …$n的形式输出所有参数。
[zhao@hadoop101 shells]$ touch for3.sh
[zhao@hadoop101 shells]$ vim for3.sh#!/bin/bash
echo '=============$*============='
for i in $*
doecho "ban zhang love $i"
doneecho '=============$@============='
for j in $@
doecho "ban zhang love $j"
done[zhao@hadoop101 shells]$ chmod 777 for3.sh
[zhao@hadoop101 shells]$ ./for3.sh cls mly wls
=============$*=============
banzhang love cls
banzhang love mly
banzhang love wls
=============$@=============
banzhang love cls
banzhang love mly
banzhang love wls
当它们被双引号“”包含时,$*会将所有的参数作为一个整体,以“$1 2 … 2 … 2…n”的形式输出所有参数;$@会将各个参数分开,以“$1” “$2”…“$n”的形式输出所有参数。
[zhao@hadoop101 shells]$ vim for4.sh#!/bin/bash
echo '=============$*============='
for i in "$*"
#$*中的所有参数看成是一个整体,所以这个 for 循环只会循环一次
doecho "ban zhang love $i"
doneecho '=============$@============='
for j in "$@"
#$@中的每个参数都看成是独立的,所以“$@”中有几个参数,就会循环几次
doecho "ban zhang love $j"
done[zhao@hadoop101 shells]$ chmod 777 for4.sh
[zhao@hadoop101 shells]$ ./for4.sh cls mly wls
=============$*=============
banzhang love cls mly wls
=============$@=============
banzhang love cls
banzhang love mly
banzhang love wls
6.4 while 循环
1)基本语法
while [ 条件判断式 ]
do程序
done
2)案例实操
从 1 加到 100
[zhao@hadoop101 shells]$ touch while.sh
[zhao@hadoop101 shells]$ vim while.sh#!/bin/bash
sum=0
i=1
while [ $i -le 100 ]
dosum=$[$sum+$i]i=$[$i+1]
doneecho $sum[zhao@hadoop101 shells]$ chmod 777 while.sh
[zhao@hadoop101 shells]$ ./while.sh
5050
第 7 章 read 读取控制台输入
1)基本语法
read (选项) (参数)
①选项:
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)如果-t 不加表示一直等待
②参数
变量:指定读取值的变量名
2)案例实操
提示 7 秒内,读取控制台输入的名称
[zhao@hadoop101 shells]$ touch read.sh
[zhao@hadoop101 shells]$ vim read.sh#!/bin/bashread -t 7 -p "Enter your name in 7 seconds :" NN
echo $NN[zhao@hadoop101 shells]$ ./read.sh
Enter your name in 7 seconds : zhao
zhao
第 8 章 函数
8.1 系统函数
8.1.1 basename
1)基本语法
basename [string / pathname] [suffix] (功能描述:basename 命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。
basename 可以理解为取路径里的文件名称
选项:
suffix 为后缀,如果 suffix 被指定了,basename 会将 pathname 或 string 中的 suffix 去掉。
2)案例实操
截取该/home/zhao/banzhang.txt 路径的文件名称。
[zhao@hadoop101 shells]$ basename /home/zhao/banzhang.txt
banzhang.txt
[zhao@hadoop101 shells]$ basename /home/zhao/banzhang.txt .txt
banzhang
8.1.2 dirname
1)基本语法
dirname 文件绝对路径 (功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分))
dirname 可以理解为取文件路径的绝对路径名称
2)案例实操
获取 banzhang.txt 文件的路径。
[zhao@hadoop101 ~]$ dirname /home/zhao/banzhang.txt
/home/zhao
8.2 自定义函数
1)基本语法
[ function ] funname[()]
{Action;[return int;]
}
2)经验技巧
(1)必须在调用函数地方之前,先声明函数,shell 脚本是逐行运行。不会像其它语言一样先编译。
(2)函数返回值,只能通过$?系统变量获得,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。return 后跟数值 n(0-255)
3)案例实操
计算两个输入参数的和。
[zhao@hadoop101 shells]$ touch fun.sh
[zhao@hadoop101 shells]$ vim fun.sh
#!/bin/bash
function sum()
{s=0s=$[$1+$2]echo "$s"
}read -p "Please input the number1: " n1;
read -p "Please input the number2: " n2;
sum $n1 $n2;[zhao@hadoop101 shells]$ chmod 777 fun.sh
[zhao@hadoop101 shells]$ ./fun.sh
Please input the number1: 2
Please input the number2: 5
7
第 9 章 正则表达式入门
正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在 Linux 中 ,grep,sed,awk 等文本处理工具都支持通过正则表达式进行模式匹配。
9.1 常规匹配
一串不包含特殊字符的正则表达式匹配它自己,例如:
[zhao@hadoop101 shells]$ cat /etc/passwd | grep zhao
就会匹配所有包含 zhao 的行。
9.2 常用特殊字符
1)特殊字符:^
^ 匹配一行的开头,例如:
[zhao@hadoop101 shells]$ cat /etc/passwd | grep ^a
会匹配出所有以 a 开头的行
2)特殊字符:$
$ 匹配一行的结束,例如
[zhao@hadoop101 shells]$ cat /etc/passwd | grep t$
会匹配出所有以 t 结尾的行
思考:^$ 匹配什么?
^$ 表达式表示只匹配不包含任何字符的行,即空行。
cat 某个文件 | grep -n ^$
查找文件中的空行并显示其行号
3)特殊字符:.
. 匹配一个任意的字符,例如
[zhao@hadoop101 shells]$ cat /etc/passwd | grep r..t
会匹配包含 rabt,rbbt,rxdt,root 等的所有行
4)特殊字符:*
* 不单独使用,他和上一个字符连用,表示匹配上一个字符 0 次或多次,例如
[zhao@hadoop101 shells]$ cat /etc/passwd | grep ro*t
会匹配 rt, rot, root, rooot, roooot 等所有行
思考:.* 匹配什么?
.*在正则表达式中表示匹配任意字符的任意长度的字符串。
5)字符区间(中括号):[ ]
[ ] 表示匹配某个范围内的一个字符,例如
[6,8]------匹配 6 或者 8
[0-9]------匹配一个 0-9 的数字
[0-9]*------匹配任意长度的数字字符串
[a-z]------匹配一个 a-z 之间的字符
[a-z]* ------匹配任意长度的字母字符串
[a-c, e-f]-匹配 a-c 或者 e-f 之间的任意字符
[zhao@hadoop101 shells]$ cat /etc/passwd | grep r[a,b,c]*t
会匹配 rt,rat, rbt, rabt, rbact,rabccbaaacbt 等等所有行
6)特殊字符:\
\ 表示转义,并不会单独使用。由于所有特殊字符都有其特定匹配模式,当我们想匹配某一特殊字符本身时(例如,我想找出所有包含 ‘$’ 的行),就会碰到困难。此时我们就要将转义字符和特殊字符连用,来表示特殊字符本身,例如
[zhao@hadoop101 shells]$ cat /etc/passwd | grep ‘a\$b’
就会匹配所有包含 a$b 的行。注意需要使用单引号将表达式引起来。
第 10 章 文本处理工具
10.1 cut
cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
1)基本用法
cut [选项参数] filename
说明:默认分隔符是制表符
2)选项参数说明
| 选项参数 | 功能 |
|---|---|
| -f | 列号,提取第几列 |
| -d | 分隔符,按照指定分隔符分割列,默认是制表符“\t” |
| -c | 按字符进行切割 后加加 n 表示取第几列 比如 -c 1 |
3)案例实操
(1)数据准备
[zhao@hadoop101 shells]$ touch cut.txt
[zhao@hadoop101 shells]$ vim cut.txt
dong shen
guan zhen
wo wo
lai lai
le le
(2)切割 cut.txt 第一列
[zhao@hadoop101 shells]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le
(3)切割 cut.txt 第二、三列
[zhao@hadoop101 shells]$ cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
le
(4)在 cut.txt 文件中切割出 guan
[zhao@hadoop101 shells]$ cat cut.txt |grep guan | cut -d " " -f 1
guan
(5)选取系统 PATH 变量值,第 2 个“:”开始后的所有路径:
[zhao@hadoop101 shells]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/zhao/.local/bin:/home/zhao/bin
zhao@hadoop101 shells]$ echo $PATH | cut -d ":" -f 3- /usr/local/sbin:/usr/sbin:/home/zhao/.local/bin:/home/zhao/bin
(6)切割 ifconfig 后打印的 IP 地址
[zhao@hadoop101 shells]$ ifconfig ens33 | grep netmask | cut -d " " -f 10 192.168.111.101

10.2 awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
1)基本用法
awk [选项参数] ‘/pattern1/{action1} /pattern2/{action2}…’ filename
pattern:表示 awk 在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
2)选项参数说明
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件分隔符 |
| -v | 赋值一个用户定义变量 |
3)案例实操
(1)数据准备
[zhao@hadoop101 shells]$ sudo cp /etc/passwd ./
passwd 数据的含义
用户名:密码(加密过后的):用户 id:组 id:注释:用户家目录:shell 解析器
(2)搜索 passwd 文件以 root 关键字开头的所有行,并输出该行的第 7 列。
[zhao@hadoop101 shells]$ awk -F : '/^root/{print $7}' passwd
/bin/bash
(3)搜索 passwd 文件以 root 关键字开头的所有行,并输出该行的第 1 列和第 7 列,中间以“,”号分割。
[zhao@hadoop101 shells]$ awk -F : '/^root/{print $1","$7}' passwd
root,/bin/bash
注意:只有匹配了 pattern 的行才会执行 action。
(4)只显示/etc/passwd 的第一列和第七列,以逗号分割,且在所有行前面添加列名 user,shell 在最后一行添加"dahaige,/bin/zuishuai"。
[zhao@hadoop101 shells]$ awk -F : 'BEGIN{print "user, shell"} {print $1","$7}
END{print "dahaige,/bin/zuishuai"}' passwd
user, shell
root,/bin/bash
bin,/sbin/nologin
。。。zhao,/bin/bash
dahaige,/bin/zuishuai
注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
(5)将 passwd 文件中的用户 id 增加数值 1 并输出
[zhao@hadoop101 shells]$ awk -v i=1 -F : '{print $3+i}' passwd
1
2
3
4
4)awk 的内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数(行号) |
| NF | 浏览记录的域的个数(切割后,列的个数) |
5)案例实操
(1)统计 passwd 文件名,每行的行号,每行的列数
[zhao@hadoop101 shells]$ awk -F : '{print "filename:" FILENAME ",linenum:"
NR ",col:"NF}' passwd
filename:passwd,linenum:1,col:7
filename:passwd,linenum:2,col:7
filename:passwd,linenum:3,col:7
...
(2)查询 ifconfig 命令输出结果中的空行所在的行号
[zhao@hadoop101 shells]$ ifconfig | awk '/^$/{print NR}'
9
18
26
(3)切割 IP
[zhao@hadoop101 shells]$ ifconfig ens33 | awk '/netmask/ {print $2}'
192.168.6.101
第 11 章 综合应用案例
11.1 归档文件
实际生产应用中,往往需要对重要数据进行归档备份。
需求:实现一个每天对指定目录归档备份的脚本,输入一个目录名称(末尾不带/),
将目录下所有文件按天归档保存,并将归档日期附加在归档文件名上,放在/root/archive 下。
这里用到了归档命令:tar
后面可以加上-c 选项表示归档,加上-z 选项表示同时进行压缩,得到的文件后缀名
为.tar.gz。
脚本实现如下:
#!/bin/bash# 首先判断输入参数个数是否为 1
if [ $# -ne 1 ]
thenecho "参数个数错误!应该输入一个参数,作为归档目录名"exit
fi
# 从参数中获取目录名称
if [ -d $1 ]
thenecho
elseechoecho "目录不存在!"echoexit
fiDIR_NAME=$(basename $1)
DIR_PATH=$(cd $(dirname $1); pwd)# 获取当前日期
DATE=$(date +%y%m%d)# 定义生成的归档文件名称
FILE=archive_${DIR_NAME}_$DATE.tar.gz
DEST=/root/archive/$FILE# 开始归档目录文件echo "开始归档..."
echotar -czf $DEST $DIR_PATH/$DIR_NAMEif [ $? -eq 0 ]
thenechoecho "归档成功!"echo "归档文件为:$DEST"echo
elseecho "归档出现问题!"echo
fiexit
11.2 发送消息
我们可以利用 Linux 自带的 mesg 和 write 工具,向其它用户发送消息。
需求:实现一个向某个用户快速发送消息的脚本,输入用户名作为第一个参数,后面直接跟要发送的消息。脚本需要检测用户是否登录在系统中、是否打开消息功能,以及当前发送消息是否为空。
脚本实现如下:
#!/bin/bashlogin_user=$(who | grep -i -m 1 $1 | awk '{print $1}')if [ -z $login_user ]
thenecho "$1 不在线!"echo "脚本退出.."exit
fiis_allowed=$(who -T | grep -i -m 1 $1 | awk '{print $2}')if [ $is_allowed != "+" ]
thenecho "$1 没有开启消息功能"echo "脚本退出.."exit
fiif [ -z $2 ]
thenecho "没有消息发出"echo "脚本退出.."exit
fiwhole_msg=$(echo $* | cut -d " " -f 2- )user_terminal=$(who | grep -i -m 1 $1 | awk '{print $2}')echo $whole_msg | write $login_user $user_terminalif [ $? != 0 ]
thenecho "发送失败!"
elseecho "发送成功!"
fiexit
相关文章:
Linux之Shell
第 1 章 Shell 概述 1)Linux 提供的 Shell 解析器有 [zhaohadoop101 ~]$ cat /etc/shells /bin/sh /bin/bash /usr/bin/sh /usr/bin/bash /bin/tcsh /bin/csh2)bash 和 sh 的关系 [zhaohadoop101 bin]$ ll | grep bash -rwxr-xr-x. 1 root root 941880…...

nginx upstream server主动健康检测模块添加https检测功能[完整版]
目录 1 缘起1.1 功能定义2. 实现后的效果2.1 配置文件2.2 运行效果3. 代码实现3.1 配置指令3.1.1 配置指令定义:3.1.2 配置指令结构体:3.1.3 配置指令源码定义:3.2 模块的初始化3.3 添加新的健康检测类型的定义3.4 握手完成后的处理3. 5 发送http请求3.6 接收http响应3.7 连…...

django中admin页面汉化
在Django中,将admin界面汉化为中文需要进行一些配置和翻译文件的添加。下面是一个基本的步骤指南,帮助你实现Django admin的汉化: 一:安装并配置Django: 如果你还没有安装Django,首先通过pip安装它: pip…...
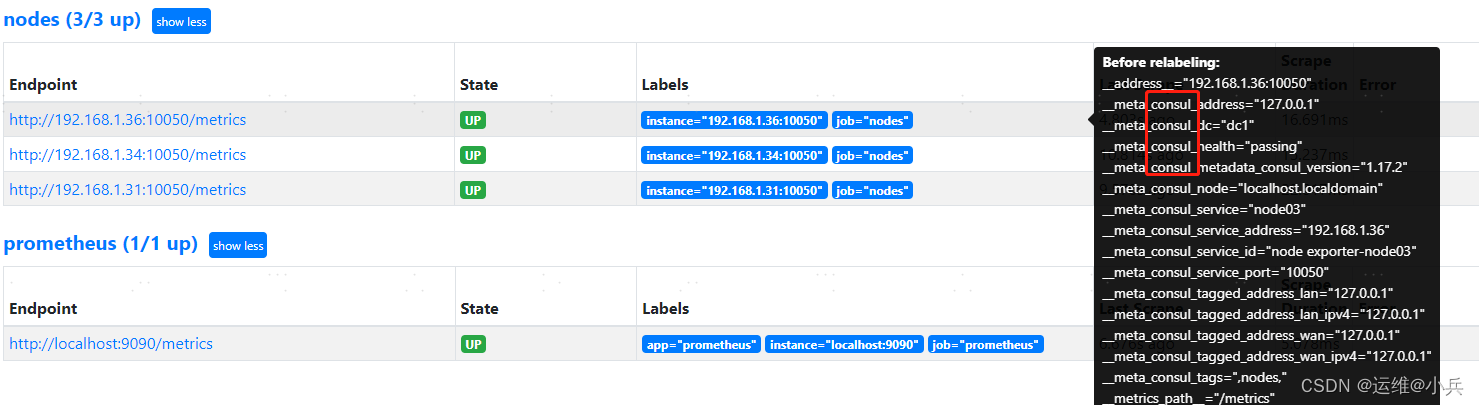
prometheus基于consul的服务发现
文章目录 一、基础二、安装consul下载地址启动consul访问consul 三、编写服务发现文件nodes.json四、prometheus配置consul发现修改prometheus.yml重启Prometheus 参考 一、基础 二、安装consul 下载地址 https://developer.hashicorp.com/consul/install 启动consul mkdi…...
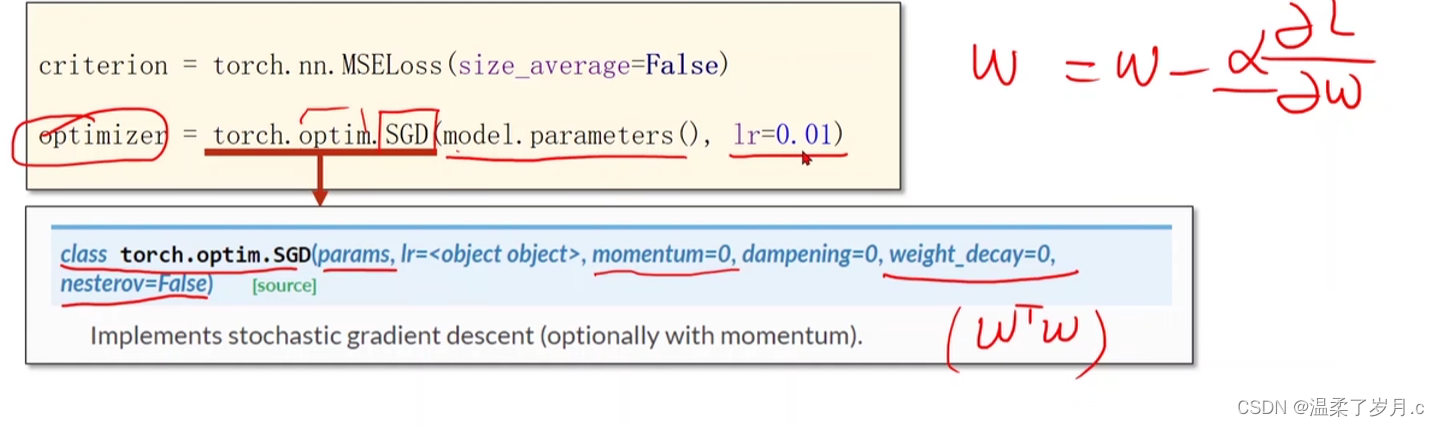
深度学习之pytorch实现线性回归
度学习之pytorch实现线性回归 pytorch用到的函数torch.nn.Linearn()函数torch.nn.MSELoss()函数torch.optim.SGD() 代码实现结果分析 pytorch用到的函数 torch.nn.Linearn()函数 torch.nn.Linear(in_features, # 输入的神经元个数out_features, # 输出神经元个数biasTrue # 是…...

Vue3快速上手(八) toRefs和toRef的用法
顾名思义,toRef 就是将其转换为ref的一种实现。详细请看: 一、toRef 1.1 示例 <script langts setup name"toRefsAndtoRef"> // 引入reactive,toRef import { reactive, toRef } from vue // reactive包裹的数据即为响应式对象 let p…...

《数学建模》专栏导读
文章分类 相关概念入门快速建模相关混合整数线性规划(MILP)加速技巧数值问题探讨相关问题解决技巧 相关概念入门 文章相关概念离散优化模型的松弛模型线性松弛问题混合整数线性规划MILP问题中增添约束的影响约束的影响 快速建模相关 文章求解器涉及步…...

App启动优化笔记 1
app大致的启动流程。有Launcher进程,system_server进程,zygote进程,APP进程。 Launcher进程:启动activity来启动应用 system_server进程:(ams是其中的一个binder):发送一个socket消息给Zygote。 zygote进程:收到消息后,fork新的进程,---》app进程启动 APP进程:…...

Spring Boot 笔记 027 添加文章分类
1.1.1 添加分类 <!-- 添加分类弹窗 --> <el-dialog v-model"dialogVisible" title"添加弹层" width"30%"><el-form :model"categoryModel" :rules"rules" label-width"100px" style"padding…...

【SQL】sql记录
1、start with star with 是一种用于层次结构查询的语法,它允许我们从指定的起始节点开始,递归查询与该节点相关联的所有子节点。 SELECT id, name, parent_id from test001 START WITH id 1 CONNECT BY PRIOR id parent_id 2、row_number() over pa…...
-Linux ARM驱动编程第六天-ARM Linux编程之SMP系统 (物联技术666))
嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM驱动编程第六天-ARM Linux编程之SMP系统 (物联技术666)
链接:https://pan.baidu.com/s/1V0E9IHSoLbpiWJsncmFgdA?pwd1688 提取码:1688 SMP(Symmetric Multi-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系…...

html5播放 m3u8
注意:m3u8地址要为网络地址,直接把代码复制为html直接在本地打开,可能不行,需要放在nginx或者apache或者其他的web服务器上运行。 <!DOCTYPE html> <html> <head><meta charsetutf-8 /><title>测试…...

微信小程序按需注入和用时注入
官网链接 按需注入 {"lazyCodeLoading": "requiredComponents" }注意事项 启用按需注入后,小程序仅注入当前访问页面所需的自定义组件和页面代码。未访问的页面、当前页面未声明的自定义组件不会被加载和初始化,对应代码文件将不…...

iPhone 16 组件泄露 揭示了新的相机设计
iPhone 16 的发布似乎已经等了很长一段时间,但下一个苹果旗舰系列可能会在短短 7 个月内与我们见面——而新的组件泄漏让我们对可能即将到来的重新设计有了一些了解。后置摄像头模块。 爆料者 Majin Bu(来自 MacRumors)获得的示意图显示&…...
网络工程师学习笔记——IPV6
20世纪80年代,IETF(Internet Engineering Task Force,因特网工程任务组)发布RFC791,即IPv4协议,标志IPv4正式标准化。在此后的几十年间,IPv4协议成为最主流的协议之一。无数人在IPv4的基础上开发…...
)
【零基础学习CAPL】——CAN报文的发送(LiveCounter——生命信号)
🙋♂️【零基础学习CAPL】系列💁♂️点击跳转 文章目录 1.概述2.面板创建3.系统变量创建4.CAPL实现5.效果5.1.0~15循环发送5.2.固定值发送6.全量脚本1.概述 本章主要介绍带有生命信号LiveCounter的报文发送脚本 一般报文可使用CANoe的IG模块直接发送,但存在循环冗余…...

git提交代码冲突
用idea2023中的git提交代码,出现 error: Your local changes to the following files would be overwritten by merge: ****/****/****/init.lua Please commit your changes or stash them before you merge. Aborting 出现这个错误可能是因为你的本地修改与远…...

树莓派:使用mdadm为重要数据做RAID 1保护
树莓派作为个人服务器可玩性还是有点的。说到服务器,在企业的生成环境中为了保护数据,基本上都会用到RAID技术。比如,服务器两块小容量但高性能的盘做个RAID-1按装操作系统,余下的大容量中性能磁盘做个RAID-5或者RAID-6存放数据。…...

HTML板块左右排列布局——左侧 DIV 固定宽度,右侧 DIV 自适应宽度,填充满剩余页面
我们可以借助CSS中的 float 属性来实现。 实例: 布局需求: 左侧 DIV 固定宽度,右侧 DIV 自适应宽度,填充满剩余页面。 <!DOCTYPE html> <html><head><meta charset"UTF-8"><meta http-e…...

红旗linux安装32bit依赖库
红旗linux安装32bit依赖库 红旗linux安装32bit依赖库 lib下载 红旗-7.3-lib-32.tar.gz 解压压缩包,根据如下进行操作 1.回退glibc(1)查看当前glibc版本[root192 ~]# rpm -qa | grep glibcglibc-common-2.17-157.axs7.1.x86_64glibc-headers-2.17-260.axs7.5.x86_…...

爆火的“小龙虾“OpenClaw:风口之下,别让便利埋了安全隐患
爆火的"小龙虾"OpenClaw:风口之下,别让便利埋了安全隐患写在开头一、顶流"小龙虾":凭什么刷爆全网?职场办公神器运维得力助手行业深度赋能二、急转直下!官方预警 企业禁令,风险彻底暴…...

C++做石头剪刀布
运作原理程序里1代表石头;2代表布;3代表剪刀,然后让计算机随机从1~3抽一个数,再来判断。界面std::cout << " 石头剪刀布 \n";std::cout << " Rock Paper Scissors \n";std::cout << …...

ofa_image-caption_coco_distilled_en保姆级部署指南:GPU显存优化+免配置启动
ofa_image-caption_coco_distilled_en保姆级部署指南:GPU显存优化免配置启动 本文详细讲解如何快速部署OFA图像英文描述模型,无需复杂配置,自动优化GPU显存使用,让小白也能轻松上手AI图像理解应用。 1. 项目介绍:让图片…...

深入理解ps4-exploit-host工作原理:DNS重定向与HTTP服务解析
深入理解ps4-exploit-host工作原理:DNS重定向与HTTP服务解析 【免费下载链接】ps4-exploit-host Easy Exploit Hosting 项目地址: https://gitcode.com/gh_mirrors/ps/ps4-exploit-host ps4-exploit-host是一款功能强大的开源工具,主要通过DNS重定…...

MATLAB 编程计算lamb波频散曲线。 有限元算lamb波频散曲线 代码可以得到lamb波...
MATLAB 编程计算lamb波频散曲线。 有限元算lamb波频散曲线 代码可以得到lamb波的频散曲线和群速度曲线。 完整MATLAB程序。 可运行。 有限元可以得到频散曲线 相速度曲线#频散曲线 #MATLAB程序 不同要求可议价最近在搞超声导波检测,发现Lamb波的频散曲线计算是个绕不…...

DASD-4B-Thinking医疗问答效果展示:专业医学知识应用
DASD-4B-Thinking医疗问答效果展示:专业医学知识应用 最近在测试各种AI模型时,我遇到了一个挺有意思的模型——DASD-4B-Thinking。这个模型虽然参数规模不算特别大,只有40亿,但它有个很特别的能力:长链式思维推理。简…...

AIGlasses OS Pro 智能视觉系统网络协议分析:视觉API通信优化
AIGlasses OS Pro 智能视觉系统网络协议分析:视觉API通信优化 最近在深度体验AIGlasses OS Pro这款智能眼镜,它的视觉识别能力确实让人印象深刻。无论是实时翻译路牌,还是识别眼前的物体,响应都相当迅速。不过,作为一…...

Kimi-VL-A3B-Thinking企业落地:银行柜面业务凭证图→合规要素自动核验与标记
Kimi-VL-A3B-Thinking企业落地:银行柜面业务凭证图→合规要素自动核验与标记 1. 引言:银行业务凭证处理的痛点与机遇 银行柜面每天需要处理大量业务凭证,传统人工核验方式面临三大挑战: 效率瓶颈:每张凭证平均需要3…...

Git-RSCLIP图文检索模型实战:基于Python爬虫的自动化数据采集与清洗
Git-RSCLIP图文检索模型实战:基于Python爬虫的自动化数据采集与清洗 1. 引言 你有没有遇到过这样的情况:需要收集大量商品图片和描述来做市场分析,或者想从社交媒体上抓取特定主题的图文内容,但手动下载整理太费时间?…...

告别Photoshop!RMBG-2.0一键抠图实测,效果惊艳
告别Photoshop!RMBG-2.0一键抠图实测,效果惊艳 1. 抠图这件事,真的可以变得这么简单吗? 如果你还在用Photoshop的钢笔工具,一根一根地描边,或者用魔棒工具反复调整容差,就为了把一张图片的背景…...