MySQL中的高级查询
通过条件查询可以查询到符合条件的数据,但如同要实现对字段的值进行计算、根据一个或多个字段对查询结果进行分组等操作时,就需要使用更高级的查询,MySQL提供了聚合函数、分组查询、排序查询、限量查询、内置函数以实现更复杂的查询需求。接下来将针对这些高级查询的知识进行讲解。
1.聚合函数
在实际开发中,经常需要做一些数据统计操作,例如统计某个字段的最大值、最小值、平均值等。像这样对一组值执行计算并将计算后的值返回的操作称为聚合操作,聚合操作一般通过聚合函数实现。使用聚合函数实现查询的基本语法格式如下。
SELECT [字段名1,字段名2,···,字段名n] 聚合函数 FROM 数据表名;
MySQL中常用的聚合函数如下:
| COUNT(e) | 返回查询的记录总数,参数e可以是字段名或* |
| SUM(e) | 返回e字段中值的总和 |
| AVG(e) | 返回e字段中值的平均值 |
| MAX(e) | 返回e字段中的最大值 |
| MIN(e) | 返回e字段中的最小值 |
上面的聚合函数都是MySQL中内置的函数,使用者根据函数的语法格式直接调用即可。
接下来,通过一些例子学习聚合函数在数据统计中的使用。
为了方面演示,我把之前的员工表删了,又创建了一个员工表并插入了一些数据:
mysql> CREATE TABLE emp(-> empno INT PRIMARY KEY,-> ename VARCHAR(16),-> job VARCHAR(16),-> sal INT,-> bon INT-> );
Query OK, 0 rows affected (0.01 sec)mysql> DESC emp;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| empno | int | NO | PRI | NULL | |
| ename | varchar(16) | YES | | NULL | |
| job | varchar(16) | YES | | NULL | |
| sal | int | YES | | NULL | |
| bon | int | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
5 rows in set (0.00 sec)表格介绍:
empno:员工编号
ename :员工姓名
job:职位
sal:工资
bon:奖金
插入语句:
mysql> INSERT INTO emp VALUES-> (9880,'张三','销售',3000,200),-> (9885,'李四','保洁',2500,100),-> (9775,'王五','销售',3500,500),-> (9900,'孙七','销售',2500,200),-> (9990,'周八','经理',7000,1000)-> (9770,'吴九','保洁',2500,null),-> (9888,'郑十','销售',3500,null);
Query OK, 7 rows affected (0.01 sec)
Records: 7 Duplicates: 0 Warnings: 0表中的具体内容如下:
mysql> SELECT*FROM emp;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9770 | 吴九 | 保洁 | 2500 | NULL |
| 9775 | 王五 | 销售 | 3500 | 500 |
| 9880 | 张三 | 销售 | 3000 | 200 |
| 9885 | 李四 | 保洁 | 2500 | 100 |
| 9888 | 郑十 | 销售 | 3500 | NULL |
| 9900 | 孙七 | 销售 | 2500 | 200 |
| 9990 | 周八 | 经理 | 7000 | 1000 |
+-------+--------+--------+------+------+
7 rows in set (0.00 sec)1.COUNT()函数
COUNT()函数用于检索数据表行中的值的计数,COUNT(*)可以统计数据表中记录的总条数,即数据表中有多少行记录。例如,想要使用SQL语句查询员工表中有多少个员工的记录。在查询时可以使用COUNT()函数进行统计,具体SQL语句及执行结果如下。
mysql> SELECT COUNT(*) FROM emp;
+----------+
| COUNT(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
由上述执行结果可以得出,数据表emp中有7条记录,也就是说员工表中有7个员工的记录。
COUNT()函数中的参数除可以使用*号,还可以使用字段的名称。两者不同的是,使用COUNT(*)统计结果时,相当于统计数据表的行数,不会忽略字段中值为NULL的行;如果使用COUNT(字段)统计,那么字段值为NULL的记录不会被统计。例如,想要使用SQL语句查询员工表中奖金不为NULL的员工个数,具体SQL语句及执行结果如下。
mysql> SELECT COUNT(bon) FROM emp;
+------------+
| COUNT(bon) |
+------------+
| 5 |
+------------+
1 row in set (0.00 sec)由上述执行结果可以得出,数据表emp中奖金不为NULL的员工有5个。
2.SUN()函数
如果字段中存放的是数值型数据,需要统计该字段中所有值的总数,可以使用SUM()函数。SUM()函数会对指定字段中的值进行累加,并且在数据累加时忽略字段中的NULL值。
例如,想要使用SQL语句查询员工表中员工奖金的总和。可以在查询时使用SUM()函数进行统计,具体SQL语句及执行结果如下。
mysql> SELECT SUM(bon) FROM emp;
+----------+
| SUM(bon) |
+----------+
| 2000 |
+----------+
1 row in set (0.00 sec)上述SELECT语句使用SUM()函数对COMM字段中的值进行求和统计,执行结果中显示员工奖金总和为2000元。
3.AVG()函数
如果字段中存放的是数值型数据,需要统计该字段中所有值的平均值,可以使用AVG()函数。AVG()函数会计算指定字段值的平均值,并且计算时会忽略字段中的NULL值。
例如,想要使用SQL语句查询员工表中员工的平均奖金。查询时可以使用AVG()函数进行统计,具体SQL语句及执行结果如下。
mysql> SELECT AVG(bon) FROM emp;
+----------+
| AVG(bon) |
+----------+
| 400.0000 |
+----------+
1 row in set (0.00 sec)上述SELECT语句使用AVG()函数计算bon字段的平均值。由执行结果可以得出,bon字段的平均值为400.0000。AVG()函数在计算时会忽略bon字段中的NULL值,即只对非NULL的数值进行累加,然后将累加和除以非NULL的行数计算出平均值。
上面已经设置了是五个人有奖金,有两个是没有奖金的,奖金是空值,因此那两个人也不会计算入内。
如果想要统计所有员工的平均奖金,即奖金平均到所有员工身上,可以借助IFNULL()函数。
IFNULL(v1,v2)
上述格式表示,如果v1的值不为NULL,则返回v1的值,否则返回v2。例如,想要使用SQL语句查询所有员工的平均奖金。查询时可以调用AVG()函数和IFNULLO函数进行统计,先调用IFNULL()函数将bon字段中所有的NULL值转换为0,再调用AVG()函数统计平均值,具体SQL语句及执行结果如下。
mysql> SELECT AVG(IFNULL(BON,0)) FROM emp;
+--------------------+
| AVG(IFNULL(BON,0)) |
+--------------------+
| 285.7143 |
+--------------------+
1 row in set (0.00 sec)上述SELECT语句在执行AVG()函数之前调用IFNULL()函数对bon字段中的值进行判断,如果是NULL值就转换成0返回;由执行结果并结合数据表中的数据可以得出,本次统计的平均奖金是所有员工的平均奖金。
4.MAX()函数
MAX(函数用于计算指定字段中的最大值,如果字段的值是数值类型,则比较的是值的大小。例如,想要使用SQL语句查询员工表中最高的工资。查询时可以使用MAX()函数进行计算,具体SQL语句及执行结果如下。
mysql> SELECT MAX(sal) FROM emp;
+----------+
| MAX(sal) |
+----------+
| 7000 |
+----------+
1 row in set (0.00 sec)上述SELECT语句使用MAX()函数获取了sal字段中最大的数值。
5.MIN()函数
MIN()函数用于计算指定字段中的最小值,如果字段的值是数值类型,则比较的是值的大小。例如,想要使用SQL语句查询员工表中最低的工资。查询时可以使用MIN()函数进行计算,具体SQL语句及执行结果如下。
mysql> SELECT MIN(sal) FROM emp;
+----------+
| MIN(sal) |
+----------+
| 2500 |
+----------+
1 row in set (0.00 sec)在上述代码中,使用MIN()函数获取了sal字段中最小的数值。
分组查询
在对数据表中的数据进行统计时,有时需要按照一定的类别作统计。例如,财务在统计每个部门的工资总数时,属于同一个部门的所有员工就是一个分组。在MySQL中,可以使用GROUP BY根据指定的字段结果集进行分组,如果某些记录的指定字段具有相同的价值,那么分组后被合并为一条数据。使用GROUP BY分组查询的语法如下:
1.单独使用GROUP BY 分组
单独使用GROUP BY进行分组时将根据指定的字段合并数据行。例如,我们想要使用SQL语句查询员工表的职位有有哪几种,具体SQL语句及执行结果如下:
mysql> SELECT job FROM emp GROUP BY job;
+--------+
| job |
+--------+
| 保洁 |
| 销售 |
| 经理 |
+--------+
3 rows in set (0.00 sec)在上述SELECT语句中,使用GROUP BY根据job字段中的值对数据表中的记录进行分组;从执行结果来看,员工的职位一共有三种。
2.GROUP BY和聚合函数一起使用
如果分组查询时要进行统计汇总,此时需要将GROUP BY和聚合函数一起使用。例如,统计员工表各部门的薪资总和或平均薪资,可以使用GROUP BY和聚合函数AVG()、SUM()进行统计,具体SQL语句及执行结果如下:
mysql> SELECT job,AVG(sal),SUM(sal) FROM emp GROUP BY job;
+--------+-----------+----------+
| job | AVG(sal) | SUM(sal) |
+--------+-----------+----------+
| 保洁 | 2500.0000 | 5000 |
| 销售 | 3125.0000 | 12500 |
| 经理 | 7000.0000 | 7000 |
+--------+-----------+----------+
3 rows in set (0.01 sec)在上述SELECT语句中,使用GROUP BY根据job字段中的值对数据表的记录进行分组,值相同的为一组,并计算出各个职位的总工资和平均工资。
3.GROUP BY和HAVING关键字一起使用
通常情况下GROUP BY和HAVING关键字一起使用,用于对分组后的结果进行条件过滤。例如,假如我们想要使用SQL语句查询员工表中的平均工资小于3000的部门编号及这些部门的平均工资。查询时可以使用GROUP BY和HAVING进行统计,具体SQL语句及执行结果如下:
mysql> SELECT empno,AVG(sal) FROM emp GROUP BY empno HAVING AVG(sal)<3000;
+-------+-----------+
| empno | AVG(sal) |
+-------+-----------+
| 9770 | 2500.0000 |
| 9885 | 2500.0000 |
| 9900 | 2500.0000 |
+-------+-----------+
3 rows in set (0.00 sec)在上述SELECT语句中,使用GROUP BY根据empno字段中的值对数据表的记录进行分组,并且使用HAVING筛选平均工资小于3000的数据,最终返回了平均工资小于3000的部门编号及平均工资。
在MySQL中,HAVING 子句用于在 GROUP BY 子句后对聚合结果进行过滤。它通常与聚合函数(如 SUM(), COUNT(), AVG(), MAX(), MIN() 等)一起使用,以筛选满足特定条件的分组。
与 WHERE 子句不同,WHERE 子句在聚合之前对单个记录进行过滤,而 HAVING 子句在聚合之后对分组进行过滤。这一点不要弄错哦。
排序查询
对数据表的数据进行查询时,可能查询出来的数据是无序的,或者其排列顺序不是用户期望的。如果想要对查询结果按指定的方式排序,例如对员工信息按姓名顺序排列等,可以使用ORDER BY对查询结果进行排序。查询语句中使用ORDER BY的基本语法格式如下。
SELECT*|{字段名1,字段名2,···} FROM 表名 ORDER BY 字段名1 [ASC | DESC], 字段名2 [ASC | DESC]......
在上面的语法格式中,ORDER BY后指定的字段名1、字段名2等是对查询结果排序的依据,即按照哪一个字段进行排序。参数ASC表示按照升序进行排序,DESC表示按照降序进行排序。
使用ORDER BY对查询结果进行排序时,如果不指定排序方式,默认按照ASC方式进行排序。例如,技术人员想要使用SQL语句查询员工表中职位为销售的员工信息,查询出的结果根据员工工资升序排列,具体SQL语句及执行结果如下:
mysql> SELECT * FROM emp WHERE job='销售' ORDER BY sal;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9900 | 孙七 | 销售 | 2500 | 200 |
| 9880 | 张三 | 销售 | 3000 | 200 |
| 9775 | 王五 | 销售 | 3500 | 500 |
| 9888 | 郑十 | 销售 | 3500 | NULL |
+-------+--------+--------+------+------+
4 rows in set (0.00 sec)上述SELECT语句使用ORDER BY对job字段值为销售的所有记录按照工资从低到高进行排序,即sal字段的值按升序排序。因为没有设置怎么排序,所以默认ASC升序排序。
要注意的是如果有字段中的值为NULL,那么NULL会被当做最小值进行排序,下面按照奖金对销售员工进行排序:
mysql> SELECT * FROM emp WHERE job='销售' ORDER BY bon;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9888 | 郑十 | 销售 | 3500 | NULL |
| 9880 | 张三 | 销售 | 3000 | 200 |
| 9900 | 孙七 | 销售 | 2500 | 200 |
| 9775 | 王五 | 销售 | 3500 | 500 |
+-------+--------+--------+------+------+
4 rows in set (0.00 sec)上述SELECT语句查询职位为销售的员工信息,并且根据员工奖金值进行升序排序。从执行结果可以看出,奖金值为NULL的员工信息排在第一位,说明排序时NULL被当作最小值。
ORDER BY可以对多个字段的值进行排序,并且每个排序字段可以有不同的排序顺序。例如,技术人员想要使用SQL语句查询员工表中工资为2500的员工所有记录,查询出的记录先按职位的升序排序,再按员工编号降序排序,具体SQL语b 句及执行结果如下。
mysql> SELECT * FROM emp WHERE sal=2500 ORDER BY job,empno DESC;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9885 | 李四 | 保洁 | 2500 | 100 |
| 9770 | 吴九 | 保洁 | 2500 | NULL |
| 9900 | 孙七 | 销售 | 2500 | 200 |
+-------+--------+--------+------+------+
3 rows in set (0.00 sec)在上述SELECT语句中,查询sal字段工资为2500的所有记录,先将这些记录按照job字段的值升序排序,如果job字段的值相同,则按照empno字段的值进行降序排序。如果排序字段的值是字符串类型,则会按字符串中字符的ASCII码值进行排序。
上面的例子job字段后面没有设置排序,因此默认是升序,然后又给empno字段设置了降序,大家不要迷了啊。
mysql> SELECT * FROM emp WHERE sal=2500 ORDER BY bon DESC,empno DESC;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9900 | 孙七 | 销售 | 2500 | 200 |
| 9885 | 李四 | 保洁 | 2500 | 100 |
| 9770 | 吴九 | 保洁 | 2500 | NULL |
+-------+--------+--------+------+------+
3 rows in set (0.00 sec)这个是两个字段都设置了排序,并且都是降序。
限量查询
查询数据时,SELECT语句可能会返回很多条记录,而用户需要的记录可能只是其中的一条或几条。中的一条或几条。例如,在员工管理系统中,希望每一页默认展示10条员工信息,并且可以通过下拉框更改每页展示的员工信息数。MySQL中提供了一个关键字LIMIT可以指定查询结果从哪一条记录开始以及一共查询多少条信息。在SELECT语句中使用LIMIT的基本语法格式如下。
SELECT 字段名1,字段名2,..… FROM 数据表名 LIMIT [OFFSET,] 记录数;
在上面的语法格式中,LIMIT后面可以跟2个参数。第一个参数OFFSET为可选值,表示偏移量,如果偏移量为0则从查询结果的第一条记录开始,偏移量为1则从查询结果的第二条记录开始,以此类推。如果不指定OFFSET的值,其默认值为0。第二个参数“记录数”表示返回查询记录的条数。
例如,技术人员想要使用SQL语句查询员工表中工资最高的前3名的员工信息,查询时可以使用LIMIT进行限量,具体SQL语句及执行结果如下。
mysql> SELECT * FROM emp ORDER BY sal DESC LIMIT 3;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9990 | 周八 | 经理 | 7000 | 1000 |
| 9775 | 王五 | 销售 | 3500 | 500 |
| 9888 | 郑十 | 销售 | 3500 | NULL |
+-------+--------+--------+------+------+
3 rows in set (0.00 sec)在上述SELECT语句中,首先使用ORDER BY根据字段sal的值对数据表中的记录进行降序排序,接着使用LIMIT指定返回第1~3条记录。
除了指定查询记录数,LIMIT还可以通过指定OFFSET的值指定查询的偏移量,也就是查询时跳过几条记录。
例如,我们要使用SQL语句查询员工表中工资第二名到第五名的员工信息。具体SQL语句及执行结果如下:
mysql> SELECT * FROM emp ORDER BY sal DESC LIMIT 1,4;
+-------+--------+--------+------+------+
| empno | ename | job | sal | bon |
+-------+--------+--------+------+------+
| 9775 | 王五 | 销售 | 3500 | 500 |
| 9888 | 郑十 | 销售 | 3500 | NULL |
| 9880 | 张三 | 销售 | 3000 | 200 |
| 9770 | 吴九 | 保洁 | 2500 | NULL |
+-------+--------+--------+------+------+
4 rows in set (0.00 sec)在上述SELECT语句中,先使用ORDER BY根据字段sal的值对数据表中的记录进行降序排序,然后指定返回记录的偏移量为1,查询记录的条数为4.执行结果跳过了排序后的第一条员工信息,返回工资前2~5名的员工信息。
这里和Python的索引有点像,可以联系理解一下,下标就像偏移量,都是从0开始。
下篇文章是MySQL中的内置函数的讲解。点个关注不迷路。
相关文章:

MySQL中的高级查询
通过条件查询可以查询到符合条件的数据,但如同要实现对字段的值进行计算、根据一个或多个字段对查询结果进行分组等操作时,就需要使用更高级的查询,MySQL提供了聚合函数、分组查询、排序查询、限量查询、内置函数以实现更复杂的查询需求。接下…...

leetcode383赎金信
用字符数组ch来记录magazine每个字母出现频率,用ransomNote的字母减去字符数组ch对应的字符出现频率,如果该字符对应的频率小于0,则不够,无法组成ransomNote! class Solution { public:bool canConstruct(string rans…...
【Unity3D】ASE制作天空盒
找到官方shader并分析 下载对应资源包找到\DefaultResourcesExtra\Skybox-Cubed.shader找到\CGIncludes\UnityCG.cginc观察变量, 观察tag, 观察代码 需要注意的内容 ASE要处理的内容 核心修改 添加一个Custom Expression节点 code内容为: return DecodeHDR(In0, In1);outp…...
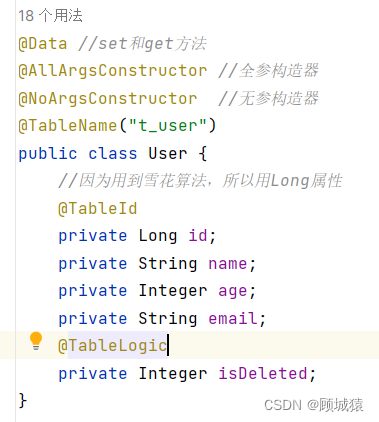
MyBatisPlus常用注解
目录 一、TableName 二、TableId 三、TableField 四、TableLogic 一、TableName 在使用MyBatis-Plus实现基本的CRUD时,我们并没有指定要操作的表,只是在Mapper接口继承BaseMapper时,设置了泛型User,而操作的表为user表 由此得出…...

Putty中运行matlab文件
首先使用命令 cd /home/ya/CodeTest/Matlab进入路径:到Matlab文件夹下 然后键入matlab,进入matlab环境,如果main.m文件在Matlab文件夹下,直接键入main即可运行该文件。细节代码如下: Unable to use key file "y…...
ES6 | (一)ES6 新特性(上) | 尚硅谷Web前端ES6教程
文章目录 📚ES6新特性📚let关键字📚const关键字📚变量的解构赋值📚模板字符串📚简化对象写法📚箭头函数📚函数参数默认值设定📚rest参数📚spread扩展运算符&a…...

生产环境下,应用模式部署flink任务,通过hdfs提交
前言 通过通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到hdfs文件管理系统 1. 实践 (1)生产集群为cdh集群,从cm上下载配置文件,设置环境 export HADOOP_CONF_DIR/home/conf/auth export HADOOP_CL…...

【lesson59】线程池问题解答和读者写者问题
文章目录 线程池问题解答什么是单例模式什么是设计模式单例模式的特点饿汉和懒汉模式的理解STL中的容器是否是线程安全的?智能指针是否是线程安全的?其他常见的各种锁 读者写者问题 线程池问题解答 什么是单例模式 单例模式是一种 “经典的, 常用的, 常考的” 设…...

【LeetCode每日一题】单调栈316去除重复字母
题目:去除重复字母 给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。 示例 1: 输入:s “bcabc” 输…...
【Git】Gitbash使用ssh 上传本地项目到github
SSH Git上传项目到GitHub(图文)_git ssh上传github-CSDN博客 前提 ssh-keygen -t rsa -C “自己的github电子邮箱” 生成密钥,公钥保存到自己的github的ssh里 1.先创建一个仓库,复制ssh地址 git init git add . git commit -m …...

activeMq将mqtt发布订阅转成消息队列
1、activemq.xml置文件新增如下内容 2、mqttx测试发送: 主题(配置的模糊匹配,为了并发):VirtualTopic/device/sendData/12312 3、mqtt接收的结果 4、程序处理 package comimport cn.hutool.core.date.DateUtil; imp…...

Go语言教程
一、引言 Go(又称Golang)是由Google开发的一种静态类型、编译型的开源编程语言。它旨在提供简单、快速和可靠的软件开发体验。Go语言结合了动态语言的开发效率和静态语言的安全性能,特别适用于网络编程、系统编程和并发编程。本教程将介绍Go…...
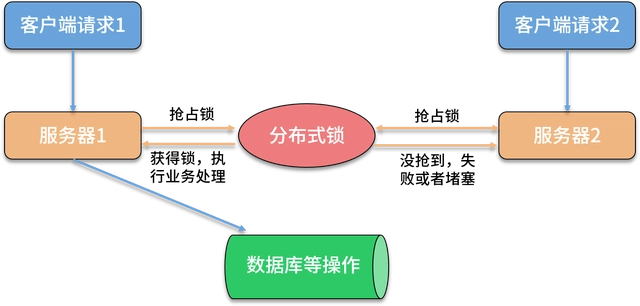
分布式锁的应用场景及实现
文章目录 分布式锁的应用场景及实现1. 应用场景2. 分布式锁原理3. 分布式锁的实现3.1 基于数据库 分布式锁的应用场景及实现 1. 应用场景 电商网站在进行秒杀、特价等大促活动时,面临访问量激增和高并发的挑战。由于活动商品通常是有限库存的,为了避免…...

嵌入式Linux中apt、apt-get命令用法汇总
在Linux环境开发过程中接触ubuntu虚拟机时,在安装软件或者更新软件时apt和apt-get命令使用相对较频繁,下面对这两个命令的用法进行汇总。 apt(Advanced Package Tool)和 apt-get 是用于在基于 Debian 的 Linux 发行版中进行软件包…...

Unity之ShaderGraph如何实现水面波浪
前言 这几天通过一个水的波浪数学公式,实现了一个波浪效果,感觉成就感满满,下面给大家分享一下 首先先给大家看一下公式; 把公式转为ShaderGraph 第一行公式:waveType = z*-1*Mathf.Cos(wave.WaveAngle/360*2*Mathf.PI)+x*Mathf.Sin(WaveAngle/360*-2*Mathf.PI) 转换…...

无线局域网(WLAN)简单概述
无线局域网 无线局域网概述 无限局域网(Wireless Local Area Network,WLAN)是一种短距离无线通信组网技术,它是以无线信道为传输媒质构成的计算机网络,通过无线电传播技术来实现在空间传输数据。 WLAN是传输范围在1…...
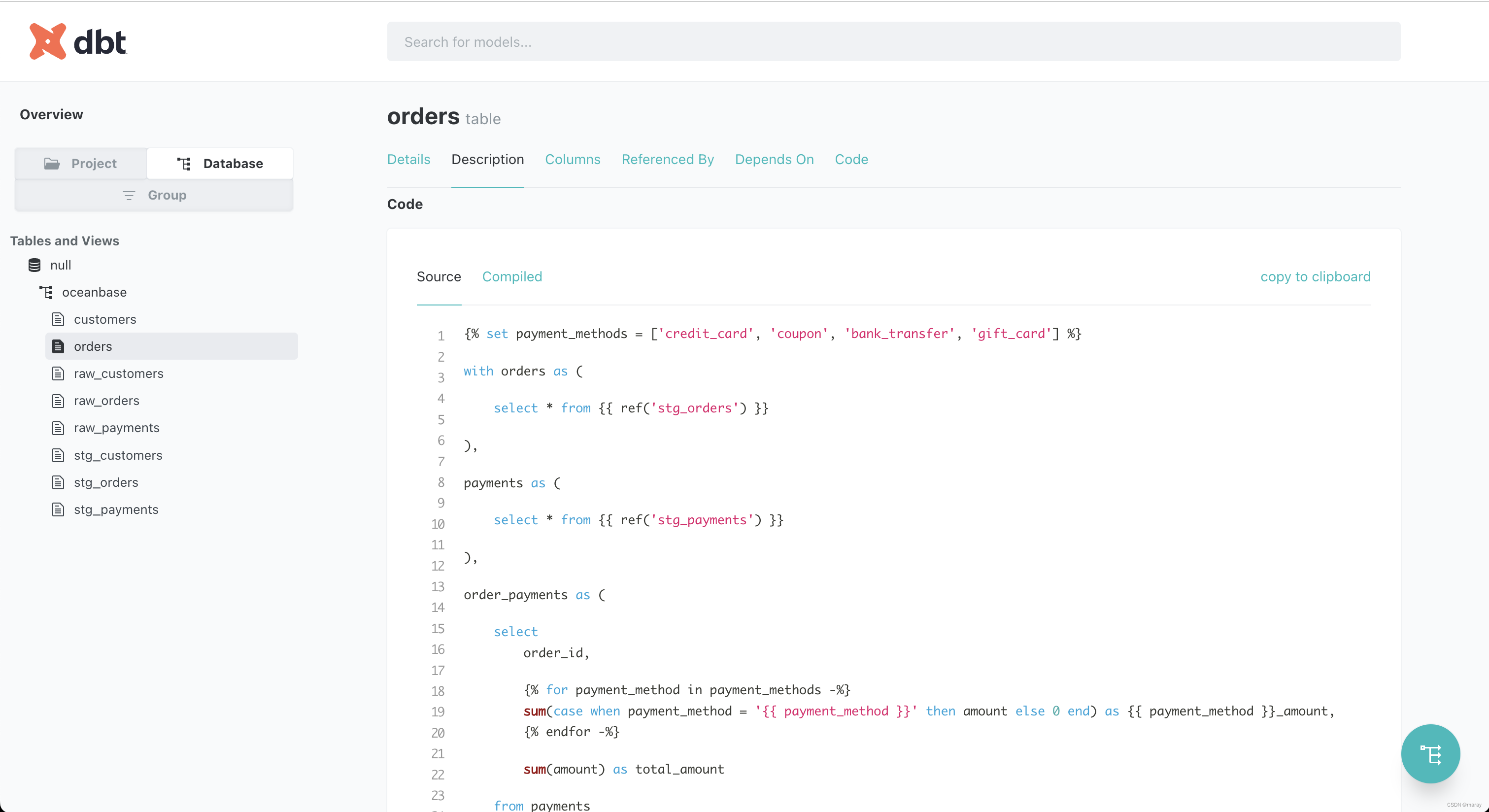
学习数仓工具 dbt
DBT 是一个有趣的工具,它通过一种结构化的方式定义了数仓中各种表、视图的构建和填充方式。 dbt 面相的对象是数据开发团队,提供了如下几个最有价值的能力: 支持多种数据库通过 select 来定义数据,无需编写 DML构建数据时&#…...

高录用快见刊【最快会后两个月左右见刊】第三届社会科学与人文艺术国际学术会议 (SSHA 2024)
第三届社会科学与人文艺术国际学术会议 (SSHA 2024) 2024 3rd International Conference on Social Sciences and Humanities and Arts *文章投稿均可免费参会 *高录用快见刊【最快会后两个月左右见刊】 重要信息 会议官网:icssha.com 大会时间:202…...
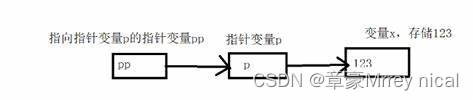
C语言-指针初学速成
1.指针是什么 C语言指针是一种特殊的变量,用于存储内存地址。它可以指向其他变量或者其他数据结构,通过指针可以直接访问或修改存储在指定地址的值。指针可以帮助我们在程序中动态地分配和释放内存,以及进行复杂的数据操作。在C语言中&#…...

MQL语言实现单元测试
文章目录 一、单元测试是什么二、单元测试的过程三、为什么需要单元测试四、MQL测试代码实现 一、单元测试是什么 单元测试是对软件中最小可测单元(如类或函数)进行独立验证和检查的过程。它是由开发工程师完成的,旨在确保每个单元的功能和逻…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...