Python机器学习17——极限学习机(ELM)
本系列基本不讲数学原理,只从代码角度去让读者们利用最简洁的Python代码实现机器学习方法。
背景:

极限学习机(ELM)也是学术界常用的一种机器学习算法,严格来说它应该属于神经网络,应该属于深度学习栏目,但是我这里把它放在了机器学习栏目里面,主要还是这个方法不是像别的神经网络一样方向传播误差去更新参数的。他是一个静态的模型 ,虽然它结构类似于多层感知机,只不过多层感知机的参数会随着迭代次数增加通过方向传播误差进行更新,而ELM不会,所以ELM的效果肯定是不如MLP的。
但是我也不知道为什么效果不好的模型学术界这么喜欢用......一堆论文不用MLP而是去用ELM....可能因为它不需要深度学习框架就可以搭建,而且运行速度快吧,门槛低,可能是不懂深度学习的人接触的最简单的神经网络实现的方法了。
sklearn库没有现成的接口调用,我们下面的ELM都是自定义的类,模仿sklearn的接口使用。
当然单纯的ELM由于它的权重矩阵都是静态的,效果不好,所以可以使用拟牛顿法或者别的梯度下降的方法根据误差去优化其参数矩阵,达到更好的效果。(说实话这不就是MLP嘛....)
下面会自定义ELM和优化的ELM两个类,还给出了一个基于优化的ELM结合ER回归的类。
(请注意我这里都是回归问题的ELM代码,分类问题还需要进行改动)
代码实现
原理就不多介绍了,别的文章都有,我直接给ELM的代码案例。本次使用一个回归问题,16的特征变量,响应变量是一个数值,使用ELM预测。
导入包,然后读取数据,取出X和y,我数据的最后一列就是y,然后给它划分训练集和测试集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error,r2_score
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号# 加载数据
data =pd.read_csv('CS2_35的特征.csv')
X = data.iloc[:,:-1]
y = data.iloc[:,-1]# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)标准化一下:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)
print('训练数据形状:')
print(X_train_s.shape,y_train.shape)
print('测试数据形状:')
print(X_test_s.shape,y_test.shape)
自定义ELM类
class ELMRegressor():def __init__(self, n_hidden):self.n_hidden = n_hiddendef fit(self, X, y):self.X = Xself.y = yn_samples, n_features = X.shapeself.W = np.random.randn(n_features+1, self.n_hidden)H = np.dot(np.concatenate((X, np.ones((n_samples, 1))), axis=1), self.W)H = np.maximum(H, 0)self.beta = np.dot(np.linalg.pinv(H), y)def predict(self, X):n_samples = X.shape[0]H = np.dot(np.concatenate((X, np.ones((n_samples, 1))), axis=1), self.W)H = np.maximum(H, 0)y_pred = np.dot(H, self.beta)return y_pred自定义优化参数矩阵的ELM类
这里采用scipy.optimize 里面的minimize方法,使用拟牛顿法进行优化参数矩阵。
from scipy.optimize import minimize
class OP_ELMRegressor():def __init__(self, n_hidden):self.n_hidden = n_hiddendef fit(self, X, y):self.X = Xself.y = yn_samples, n_features = X.shapeself.W = np.random.randn(n_features + 1, self.n_hidden)def loss_func(W_vec):W = W_vec.reshape((n_features + 1, self.n_hidden))H = np.dot(np.hstack((X, np.ones((n_samples, 1)))), W)H = np.maximum(H, 0)beta = np.dot(np.linalg.pinv(H), y)y_pred = np.dot(H, beta)mse = np.mean((y - y_pred) ** 2)return mse# 用拟牛顿法优化权重矩阵res = minimize(loss_func, self.W.ravel(), method='BFGS')self.W = res.x.reshape((n_features + 1, self.n_hidden))H = np.hstack((X, np.ones((n_samples, 1)))) # 添加偏置项H = np.dot(H, self.W)H = np.maximum(H, 0)self.beta = np.dot(np.linalg.pinv(H), y)def predict(self, X):n_samples = X.shape[0]H = np.hstack((X, np.ones((n_samples, 1))))H = np.dot(H, self.W)H = np.maximum(H, 0)y_pred = np.dot(H, self.beta)return y_pred自定义优化参数矩阵的ELM结合ER回归的类
不懂什么是ER回归可以去搜一下....核心改动就是损失函数改了,不是MSE损失,而是ER损失。总之这是一种机器学习结合统计学的方法,算得上创新。
class OP_ELMRegressor_ER():def __init__(self, n_hidden,tau):self.n_hidden = n_hiddenself.tau = taudef fit(self, X, y):self.X = Xself.y = yn_samples, n_features = X.shapeself.W = np.random.randn(n_features + 1, self.n_hidden)def loss_func(W,tau=self.tau):W = W.reshape((n_features + 1, self.n_hidden))H = np.dot(np.hstack((X, np.ones((n_samples, 1)))), W)H = np.maximum(H, 0)beta = np.dot(np.linalg.pinv(H), y)y_pred = np.dot(H, beta)loss=np.mean(np.where(np.greater(y,y_pred),np.power((y-y_pred),2)*tau,np.power((y-y_pred),2)*(1-tau)))return loss# 用拟牛顿法优化权重矩阵res = minimize(loss_func, self.W.ravel(), method='BFGS')self.W = res.x.reshape((n_features + 1, self.n_hidden))H = np.hstack((X, np.ones((n_samples, 1)))) # 添加偏置项H = np.dot(H, self.W)H = np.maximum(H, 0)self.beta = np.dot(np.linalg.pinv(H), y)def predict(self, X):n_samples = X.shape[0]H = np.hstack((X, np.ones((n_samples, 1))))H = np.dot(H, self.W)H = np.maximum(H, 0)y_pred = np.dot(H, self.beta)return y_pred
导入别的模型对比
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor定义评价函数,这里计算MAE,RMSE,MAPE,R2来评价预测效果。
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_scoredef evaluation(y_test, y_predict):mae = mean_absolute_error(y_test, y_predict)mse = mean_squared_error(y_test, y_predict)rmse = np.sqrt(mean_squared_error(y_test, y_predict))mape=(abs(y_predict -y_test)/ y_test).mean()r_2=r2_score(y_test, y_predict)return mae, rmse, mape,r_2 #mse生成11个模型类的实例化,装入列表。
#线性回归
model1 = LinearRegression()#弹性网回归
model2 = ElasticNet(alpha=0.05, l1_ratio=0.5)#K近邻
model3 = KNeighborsRegressor(n_neighbors=10)#决策树
model4 = DecisionTreeRegressor(random_state=77)#随机森林
model5= RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)#梯度提升
model6 = GradientBoostingRegressor(n_estimators=500,random_state=123)#支持向量机
model7 = SVR(kernel="rbf")#神经网络
model8 = MLPRegressor(hidden_layer_sizes=(64,40), random_state=77, max_iter=10000)#MLE
model9=ELMRegressor(32)#优化MLE
model10=OP_ELMRegressor(16)#优化MLE_ER
model11=OP_ELMRegressor_ER(16,tau=0.5)model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10,model11]
model_name=['线性回归','惩罚回归','K近邻','决策树','随机森林','梯度提升','支持向量机','神经网络','极限学习机','优化极限学习机','优化极限学习机+ER']训练,评价,计算误差指标
df_eval=pd.DataFrame(columns=['MAE','RMSE','MAPE','R2'])
for i in range(len(model_list)):model_C=model_list[i]name=model_name[i]print(f'{name}正在训练...')model_C.fit(X_train_s, y_train)pred=model_C.predict(X_test_s)s=evaluation(y_test,pred)df_eval.loc[name,:]=list(s)
查看:
df_eval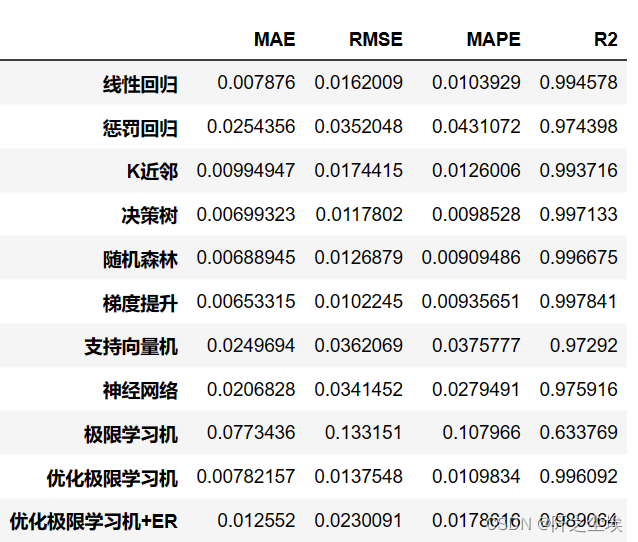
画图:
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','purple']
fig, ax = plt.subplots(2,2,figsize=(7,5),dpi=256)
for i,col in enumerate(df_eval.columns):n=int(str('22')+str(i+1))plt.subplot(n)df_col=df_eval[col]m =np.arange(len(df_col))#hatch=['-','/','+','x'],plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)#plt.xlabel('Methods',fontsize=12)names=df_col.indexplt.xticks(range(len(df_col)),names,fontsize=8)plt.xticks(rotation=40)if col=='R2':plt.ylabel(r'$R^{2}$',fontsize=14)else:plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()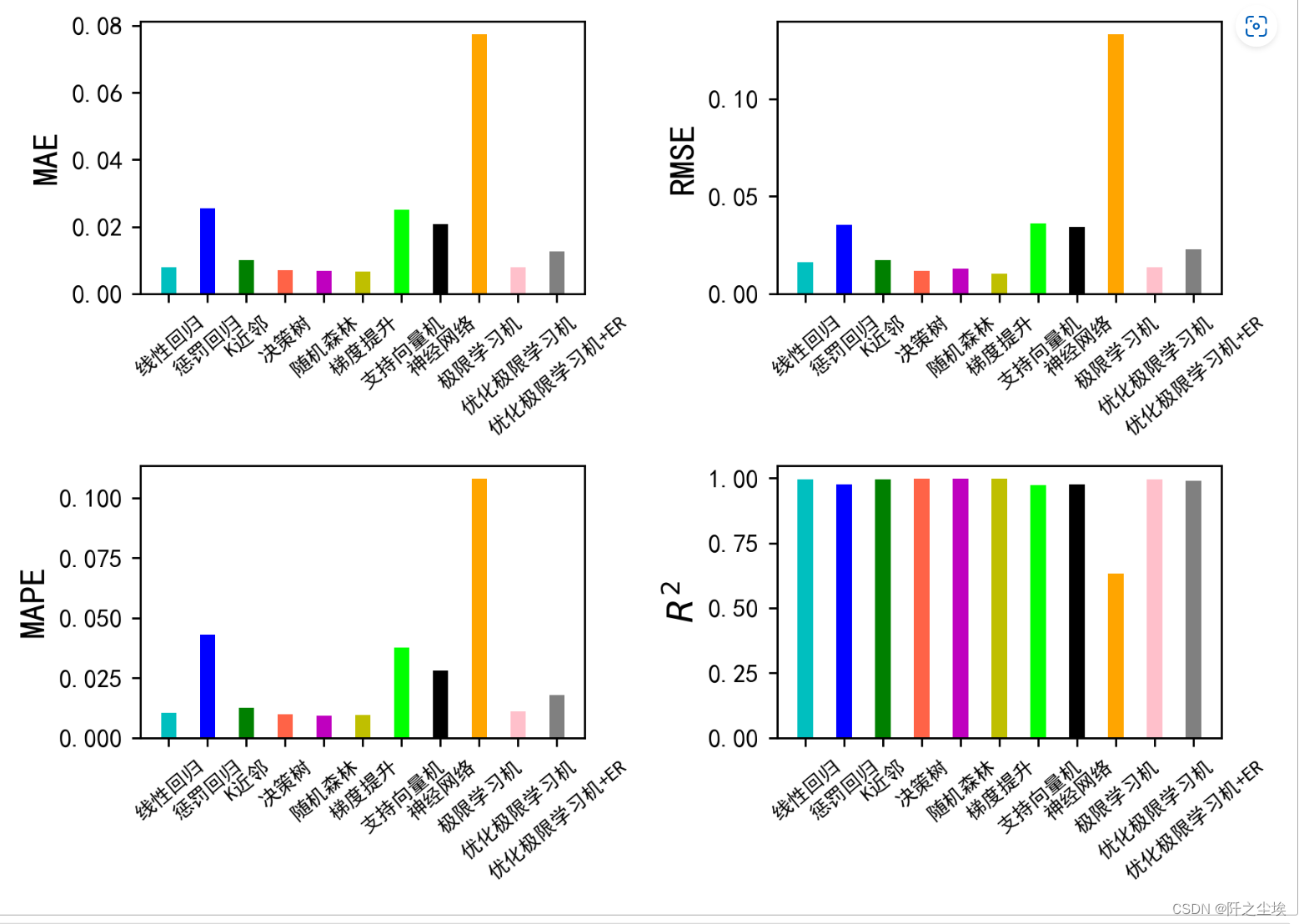
从效果上来看,这个数据集的X对y的解释能力还是很强的,线性回归的拟合优度都到了99%,所以基本模型都差不多是这个表现。单纯的ELM的表现比线性回归还差,但是用拟牛顿法优化过后效果还不错,加了ER效果也是差不多的。ER还有分位数tau这个参数可以改,说不定能出更好的效果。
整体来说是一个效果一般的机器学习模型,但是原理简单,可以很容易去改动和创新,然后发文章,所以学术界都喜欢用这个吧。。。
相关文章:
Python机器学习17——极限学习机(ELM)
本系列基本不讲数学原理,只从代码角度去让读者们利用最简洁的Python代码实现机器学习方法。 背景: 极限学习机(ELM)也是学术界常用的一种机器学习算法,严格来说它应该属于神经网络,应该属于深度学习栏目,但是我这里把它…...
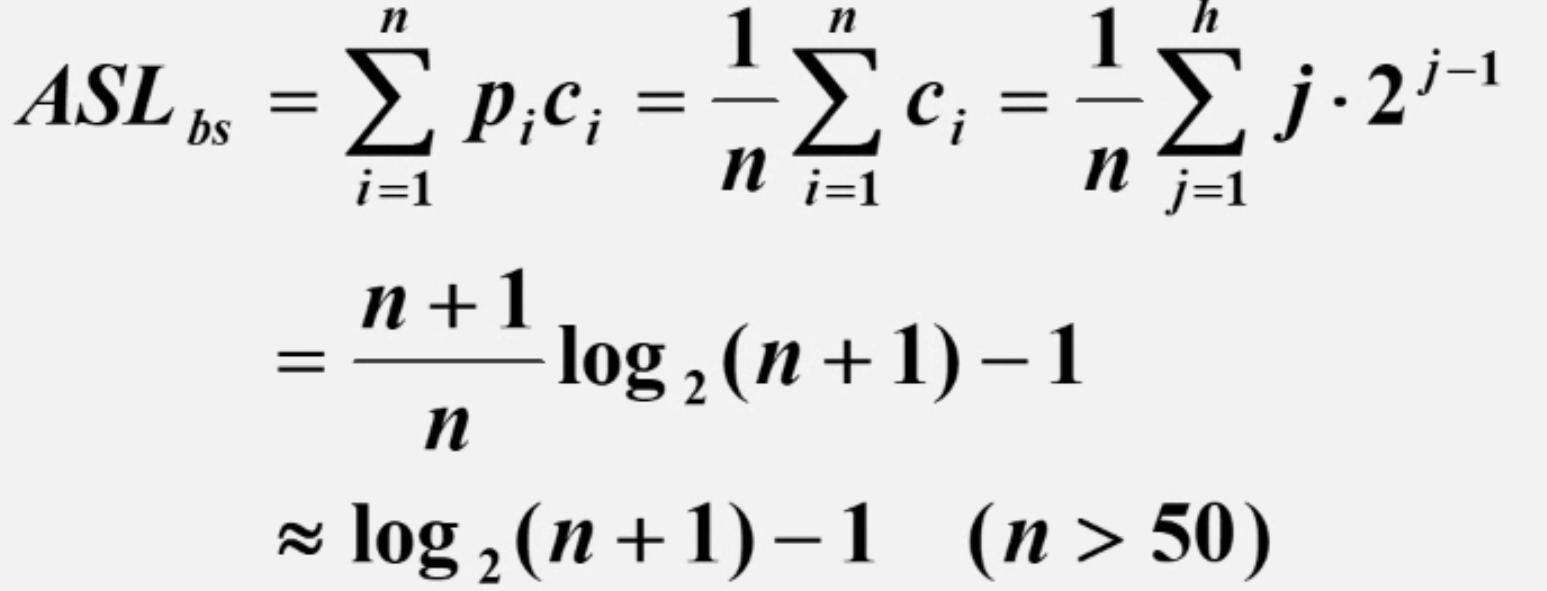
二分查找与判定树
二分查找的算法思想二分查找也称“折半查找”,要求查找表为采用顺序存储结构的有序表。本例一律采用升序排列。二分查找每一次都会比较给定值与序列[low,high]的中间元素,该元素的下标为mid (lowhigh)/2,若两者相等,则返回元素的下标为mid;如…...
反转链表(精美图示详解哦)
全文目录引言反转链表题目描述与思路实现总结引言 在学习了单链表的相关知识后,尝试实现一些题目可以帮助我们更好的理解单链表的结构以及对其的使用。 从这篇文章开始,将会介绍一些编程题来帮助我们更好的掌握单链表: 分别是反转链表、链表…...

深入理解多线程
一、线程基本概念 1、概述 线程是允许应用程序并发的一种机制。线程共享进程内的所有资源。 线程是调度的基本单位。 每个线程都有自己的 errno。 所有 pthread 函数均以返回 0 表示成功,返回一个正值表示失败。 编译 pthread 程序需要添加链接库(…...
)
华为OD机试题 - 英文输入法(JavaScript)
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解: 英文输入法题目输入输出示例一输入输出说明示例一输入输出Code…...

64 云原生容器化
文章目录 一、什么是rancher二、为什么使用rancher三、 Rancher与[k8s](https://so.csdn.net/so/search?q=k8s&spm=1001.2101.3001.7020)的关系及区别1、Rancher具有的优势三、rancher安装1、细部介绍四、图形化操作1、执行2、图形化操作1、进行客户机登录rancher2、Ranch…...

IronXL for .NET 2023.2.5 Crack
关于适用于 .NET 的 IronXL 在 C# 中阅读和编辑 Excel 电子表格,无需 MS Office 或 Excel Interop。 IronXL for .NET 允许开发人员在 .NET 应用程序和网站中读取、生成和编辑 Excel(和其他电子表格文件)。您可以读取和编辑 XLS/XLSX/CSV/TS…...
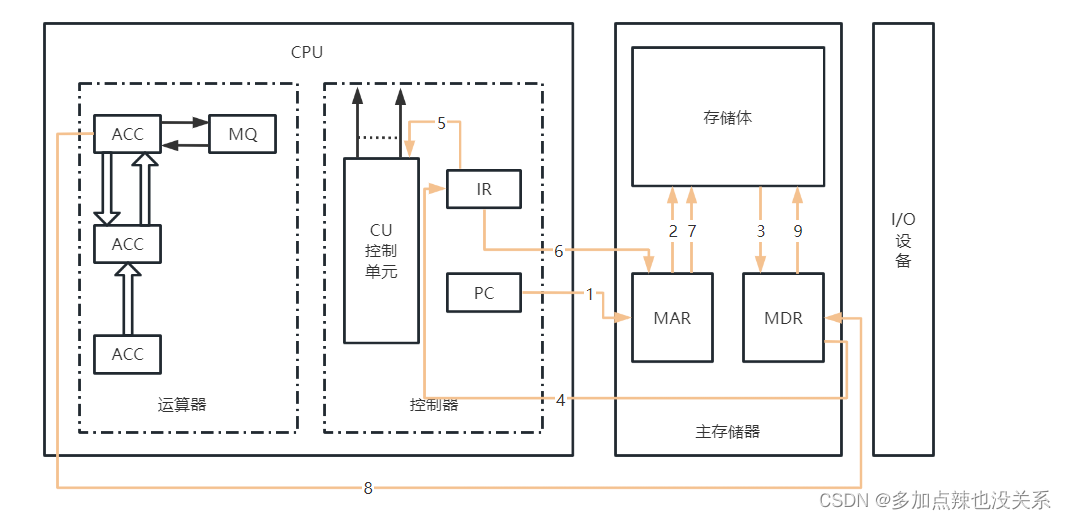
计算机组成原理|第一章(笔记)
目录第一章 计算机系统概论1.1 计算机系统简介1.1.1 计算机的软硬件概念1.1.2 计算机系统的层次结构1.1.3 计算机组成和计算机体系结构1.2 计算机的基本组成1.2.1 冯 诺伊曼计算机的特点1.2.2 计算机的硬件框图1.2.3 计算机的工作过程1.3 计算机硬件的主要技术指标1.3.1 机器字…...
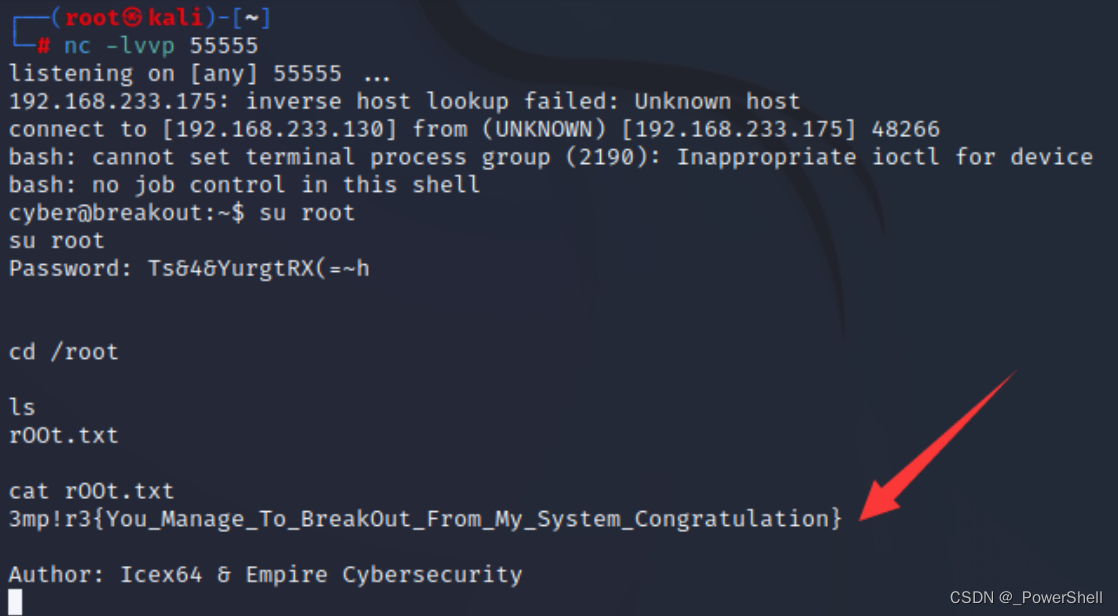
[ vulnhub靶机通关篇 ] Empire Breakout 通关详解
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
IP定位离线库有什么作用?
IP离线是什么意思?我们以丢失手机为例来寻找它,现在手机都有IP定位功能,只要手机开通了IP定位,就能找到手机。iPhone定位显示离线一般是iPhone手机关机了或者iPhone手机中“查找我的iPhone”功能关闭了。如果手机在手中的话可以打…...

[C++]vector模拟实现
目录 前言: 1. vector结构 2. 默认成员函数 2.1 构造函数 无参构造: 有参构造: 有参构造重载: 2.2 赋值运算符重载、拷贝构造(难点) 2.3 析构函数: 3. 扩容 3.1 reserve 3.2 resize…...

DevOps实战50讲-(2)Jenkins配置
1. Docker镜像方式安装拉取Jenkins镜像docker pull jenkins/jenkins编写docker-compose.ymlversion: "3.1" services:jenkins:image: jenkins/jenkinscontainer_name: jenkinsports:- 8080:8080- 50000:50000volumes:- ./data/:/var/jenkins_home/首次启动会因为数据…...
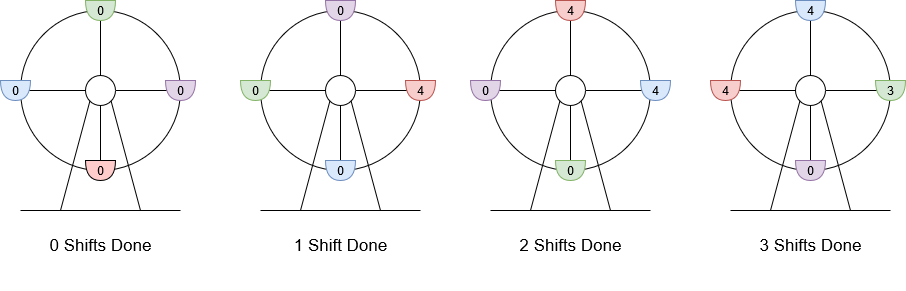
LC-1599. 经营摩天轮的最大利润(贪心)
1599. 经营摩天轮的最大利润 难度中等39 你正在经营一座摩天轮,该摩天轮共有 4 个座舱 ,每个座舱 最多可以容纳 4 位游客 。你可以 逆时针 轮转座舱,但每次轮转都需要支付一定的运行成本 runningCost 。摩天轮每次轮转都恰好转动 1 / 4 周。…...
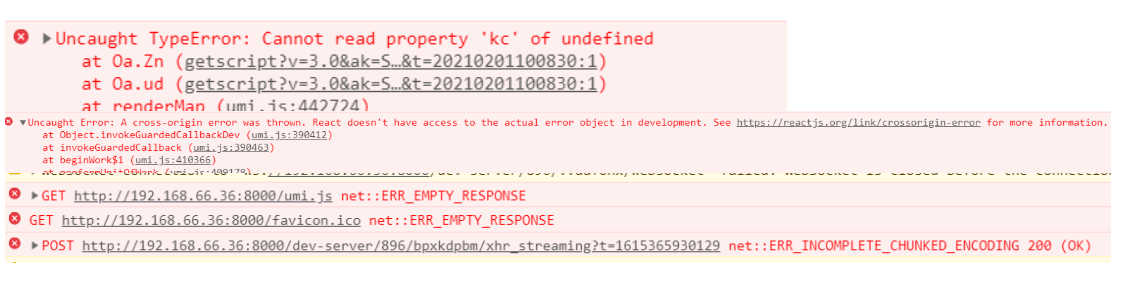
Umi使用百度地图服务
需求描述 需要在前端页面中使用地图定位功能,所以在前端umi项目中使用百度地图服务,由于umi项目默认没有入口的html文件,所以无法通过常规的在head中加入外链js的方式使用 百度ak zyqeLCzvQPCCNImRu9yRGOqWlEUicxxGreact使用百度api 链接:…...

js中getBoundingClientRect()方法
getBoundingClientRect()返回值是一个 DOMRect 对象,是包含整个元素的最小矩形(包括 padding 和 border-width)。该对象使用 left、top、right、bottom、x、y、width 和 height 这几个以像素为单位的只读属性描述整个矩形的位置和大小。除了 …...

Unity记录2.2-动作-动画、相机、Debug与总结
文章首发及后续更新:https://mwhls.top/4453.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 汇总:Unity 记录 摘要:重写了动画触…...

分享十个前端Web3D可视化框架附地址
Three.js:Three.js是一个流行的3D库,提供了大量的3D功能,包括基本几何形状、材质、灯光、动画、特效等。它是一个功能强大、易于使用的框架,广泛用于Web3D可视化应用程序的开发。Three.js:https://threejs.org/Babylon…...
基于WSL2和Clion搭建Win下C开发环境
系列文章目录 一、基于WSL2和Clion搭建Win下C开发环境 二、make、makeFile、CMake、CMakeLists的使用 三、全面、详细、通俗易懂的C语言语法和标准库 文章目录系列文章目录前言WSL2安装WSL常用命令VSCode连接WSLroot密码以systemd启动配置sshClion结语前言 Win下C语言开发环境…...

考研第一天,汤家凤基础班,连续与极限复习笔记
函数连续极限性质保号性证明极值点:夹逼准则二项式展开根号下,大于一,小于一的讨论直接放缩求和分子分母齐次,且分母大一次,用积分单调有界存在极限几个重要的切线放缩证明有界,然后放缩求单调证明有界&…...

聊一聊代码重构——关于变量的代码实践
提炼变量 其目标是将一个复杂表达式或语句分解成更小的部分,并将其存储在变量中。提高代码可读性和复用性 复杂的表达式 有些时候为了方便我们会把业务处理的逻辑写在一起,如果参与处理的内容较多时我们就会创造出一个非常长且难以理解的表达式。当其他…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

[特殊字符] Spring Boot底层原理深度解析与高级面试题精析
一、Spring Boot底层原理详解 Spring Boot的核心设计哲学是约定优于配置和自动装配,通过简化传统Spring应用的初始化和配置流程,显著提升开发效率。其底层原理可拆解为以下核心机制: 自动装配(Auto-Configuration) 核…...

旋量理论:刚体运动的几何描述与机器人应用
旋量理论为描述刚体在三维空间中的运动提供了强大而优雅的数学框架。与传统的欧拉角或方向余弦矩阵相比,旋量理论通过螺旋运动的概念统一了旋转和平移,在机器人学、计算机图形学和多体动力学领域具有显著优势。这种描述不仅几何直观,而且计算…...