logback日志回滚原理
日志输出主要依赖RollingFileAppender、TimeBasedRollingPolicy、SizeAndTimeBasedFNATP。
- RollingFileAppender
主要用于生成日志文件,格式化内容再输出到日志文件 - TimeBasedRollingPolicy
设置回滚策略,如果发现日志输出的时间超过单位时间,则进行回滚,在RollingFileAppender的日志文件添加FileNamePattern后缀,同时清理掉MaxHistory时间之前的日志。例如如果fileNamePattern是%d{yyyy-MM-dd_HH-mm}.%i.gz,最后的时间单位是分钟,则在每一分钟之后进行回滚,将原始日志文件后打成gz压缩包,同时添加yyyy-MM-dd_HH-mm.i.gz作为后缀。如果maxHistory的值是30,则会在回滚时删除30分钟之前的日志。 - SizeAndTimeBasedFNATP
基于文件大小进行回滚,例如maxFileSize的值为1MB,则当文件大小超过1MB时进行回滚。
// RollingFileAppender用于定义日志输出的格式和路径RollingFileAppender<Object> rollingFileAppender = (RollingFileAppender<Object>) appender;rollingFileAppender.setContext(getContext());rollingFileAppender.setLayout(layout);if (getFileNamePattern() != null) {// 基于时间的回滚策略TimeBasedRollingPolicy<Object> policy = new TimeBasedRollingPolicy<Object>();policy.setFileNamePattern(rollingFileAppender.rawFileProperty()+"."+getFileNamePattern());policy.setContext(getContext());policy.setMaxHistory(getMaxHistory());policy.setParent(rollingFileAppender);if (getMaxFileSize() != null) {//基于文件大小的回滚策略SizeAndTimeBasedFNATP<Object> triggeringPolicy = new SizeAndTimeBasedFNATP<Object>();triggeringPolicy.setMaxFileSize(FileSize.valueOf(getMaxFileSize()));triggeringPolicy.setTimeBasedRollingPolicy(policy);triggeringPolicy.setContext(getContext());policy.setTimeBasedFileNamingAndTriggeringPolicy(triggeringPolicy);}policy.start();rollingFileAppender.setRollingPolicy(policy);rollingFileAppender.start();}
在TimeBasedRollingPolicy#start()中,主要是根据FileNamePattern的后缀名生成Compressor压缩对象,用来压缩日志文件,同时启动TimeBasedFileNamingAndTriggeringPolicy,TimeBasedFileNamingAndTriggeringPolicy是用来根据时间找到日志并清理的对象。
public void start() {// set the LR for our utility objectrenameUtil.setContext(this.context);// find out period from the filename patternif (fileNamePatternStr != null) {fileNamePattern = new FileNamePattern(fileNamePatternStr, this.context);determineCompressionMode();} else {addWarn(FNP_NOT_SET);addWarn(CoreConstants.SEE_FNP_NOT_SET);throw new IllegalStateException(FNP_NOT_SET + CoreConstants.SEE_FNP_NOT_SET);}compressor = new Compressor(compressionMode);compressor.setContext(context);// wcs : without compression suffixfileNamePatternWithoutCompSuffix = new FileNamePattern(Compressor.computeFileNameStrWithoutCompSuffix(fileNamePatternStr, compressionMode), this.context);addInfo("Will use the pattern " + fileNamePatternWithoutCompSuffix + " for the active file");if (compressionMode == CompressionMode.ZIP) {String zipEntryFileNamePatternStr = transformFileNamePattern2ZipEntry(fileNamePatternStr);zipEntryFileNamePattern = new FileNamePattern(zipEntryFileNamePatternStr, context);}if (timeBasedFileNamingAndTriggeringPolicy == null) {timeBasedFileNamingAndTriggeringPolicy = new DefaultTimeBasedFileNamingAndTriggeringPolicy<E>();}timeBasedFileNamingAndTriggeringPolicy.setContext(context);timeBasedFileNamingAndTriggeringPolicy.setTimeBasedRollingPolicy(this);timeBasedFileNamingAndTriggeringPolicy.start();if (!timeBasedFileNamingAndTriggeringPolicy.isStarted()) {addWarn("Subcomponent did not start. TimeBasedRollingPolicy will not start.");return;}// the maxHistory property is given to TimeBasedRollingPolicy instead of to// the TimeBasedFileNamingAndTriggeringPolicy. This makes it more convenient// for the user at the cost of inconsistency here.if (maxHistory != UNBOUND_HISTORY) {archiveRemover = timeBasedFileNamingAndTriggeringPolicy.getArchiveRemover();archiveRemover.setMaxHistory(maxHistory);archiveRemover.setTotalSizeCap(totalSizeCap.getSize());if (cleanHistoryOnStart) {addInfo("Cleaning on start up");Date now = new Date(timeBasedFileNamingAndTriggeringPolicy.getCurrentTime());cleanUpFuture = archiveRemover.cleanAsynchronously(now);}} else if (!isUnboundedTotalSizeCap()) {addWarn("'maxHistory' is not set, ignoring 'totalSizeCap' option with value ["+totalSizeCap+"]");}super.start();}
TimeBasedFileNamingAndTriggeringPolicy对应的实现是SizeAndTimeBasedFNATP,因此start()方法会被调用,主要就是设置日志文件的起始时间,计算下次回滚的时间computeNextCheck(),当时间超过时就会进行回滚,同时创建ArchiveRemover用于删除日志文件。
// SizeAndTimeBasedFNATPpublic void start() {// we depend on certain fields having been initialized in super classsuper.start();archiveRemover = createArchiveRemover();archiveRemover.setContext(context);String regex = tbrp.fileNamePattern.toRegexForFixedDate(dateInCurrentPeriod);String stemRegex = FileFilterUtil.afterLastSlash(regex);computeCurrentPeriodsHighestCounterValue(stemRegex);}
// TimeBasedFileNamingAndTriggeringPolicyBasepublic void start() {DateTokenConverter<Object> dtc = tbrp.fileNamePattern.getPrimaryDateTokenConverter();if (dtc == null) {throw new IllegalStateException("FileNamePattern [" + tbrp.fileNamePattern.getPattern() + "] does not contain a valid DateToken");}if (dtc.getTimeZone() != null) {rc = new RollingCalendar(dtc.getDatePattern(), dtc.getTimeZone(), Locale.getDefault());} else {rc = new RollingCalendar(dtc.getDatePattern());}addInfo("The date pattern is '" + dtc.getDatePattern() + "' from file name pattern '" + tbrp.fileNamePattern.getPattern() + "'.");rc.printPeriodicity(this);if (!rc.isCollisionFree()) {addError("The date format in FileNamePattern will result in collisions in the names of archived log files.");addError(CoreConstants.MORE_INFO_PREFIX + COLLIDING_DATE_FORMAT_URL);withErrors();return;}setDateInCurrentPeriod(new Date(getCurrentTime()));if (tbrp.getParentsRawFileProperty() != null) {File currentFile = new File(tbrp.getParentsRawFileProperty());if (currentFile.exists() && currentFile.canRead()) {setDateInCurrentPeriod(new Date(currentFile.lastModified()));}}addInfo("Setting initial period to " + dateInCurrentPeriod);computeNextCheck();}到这里,模块启动完毕,开始正式的处理日志,处理日志是从RollingFileAppender#doAppend()方法开始,最终是到RollingFileAppender#subAppend()方法开始进行正式的处理,着重分析这个方法即可。这个方法逻辑很简单,先判断是否能够进行回滚,然后rollover()回滚处理,再调用父类OutputStreamAppender#subAppend()输出内容到日志文件,我们主要关系回滚过程。
protected void subAppend(E event) {synchronized (triggeringPolicy) {if (triggeringPolicy.isTriggeringEvent(currentlyActiveFile, event)) {rollover();}}super.subAppend(event);}
首先根据TimeBasedRollingPolicy#isTriggeringEvent()判断是否能够进行回滚,会调用内置的TimeBasedFileNamingAndTriggeringPolicy对象进行判断,在两种情况下会进行回滚,一是如果时间到了,二是文件超过我们设置的maxFileSize。
// TimeBasedRollingPolicypublic boolean isTriggeringEvent(File activeFile, final E event) {return timeBasedFileNamingAndTriggeringPolicy.isTriggeringEvent(activeFile, event);}
// SizeAndTimeBasedFNATPpublic boolean isTriggeringEvent(File activeFile, final E event) {long time = getCurrentTime();// first check for roll-over based on timeif (time >= nextCheck) {Date dateInElapsedPeriod = dateInCurrentPeriod;elapsedPeriodsFileName = tbrp.fileNamePatternWithoutCompSuffix.convertMultipleArguments(dateInElapsedPeriod, currentPeriodsCounter);currentPeriodsCounter = 0;setDateInCurrentPeriod(time);computeNextCheck();return true;}......if (activeFile.length() >= maxFileSize.getSize()) {elapsedPeriodsFileName = tbrp.fileNamePatternWithoutCompSuffix.convertMultipleArguments(dateInCurrentPeriod, currentPeriodsCounter);currentPeriodsCounter++;return true;}return false;}
回滚的处理是在RollingFileAppender#rollover()中。
public void rollover() {lock.lock();try {//关闭原始文件流this.closeOutputStream();//回滚attemptRollover();//新建日志文件attemptOpenFile();} finally {lock.unlock();}}
首先获取回滚时生成的文件名,然后进行回滚,如果没有指定压缩策略的就重命名,指定了就进行压缩。
public void rollover() throws RolloverFailure {String elapsedPeriodsFileName = timeBasedFileNamingAndTriggeringPolicy.getElapsedPeriodsFileName();String elapsedPeriodStem = FileFilterUtil.afterLastSlash(elapsedPeriodsFileName);if (compressionMode == CompressionMode.NONE) {if (getParentsRawFileProperty() != null) {renameUtil.rename(getParentsRawFileProperty(), elapsedPeriodsFileName);} // else { nothing to do if CompressionMode == NONE and parentsRawFileProperty == null }} else {if (getParentsRawFileProperty() == null) {compressionFuture = compressor.asyncCompress(elapsedPeriodsFileName, elapsedPeriodsFileName, elapsedPeriodStem);} else {compressionFuture = renameRawAndAsyncCompress(elapsedPeriodsFileName, elapsedPeriodStem);}}if (archiveRemover != null) {Date now = new Date(timeBasedFileNamingAndTriggeringPolicy.getCurrentTime());this.cleanUpFuture = archiveRemover.cleanAsynchronously(now);}}
如果需要进行定制的话,可以考虑重写RollingFileAppender、TimeBasedRollingPolicy,让日志按照我们的期望输出。
相关文章:

logback日志回滚原理
日志输出主要依赖RollingFileAppender、TimeBasedRollingPolicy、SizeAndTimeBasedFNATP。 RollingFileAppender 主要用于生成日志文件,格式化内容再输出到日志文件TimeBasedRollingPolicy 设置回滚策略,如果发现日志输出的时间超过单位时间,…...

[C#]winform基于opencvsharp结合pairlie算法实现低光图像增强黑暗图片变亮变清晰
【低光图像增强介绍】 在图像处理领域,低光图像增强是一个具有挑战性的任务。由于光线不足,这些图像往往呈现出低对比度、高噪声和细节丢失等问题,严重影响了图像的视觉效果和后续分析的准确性。因此,开发有效的低光图像增强方法…...
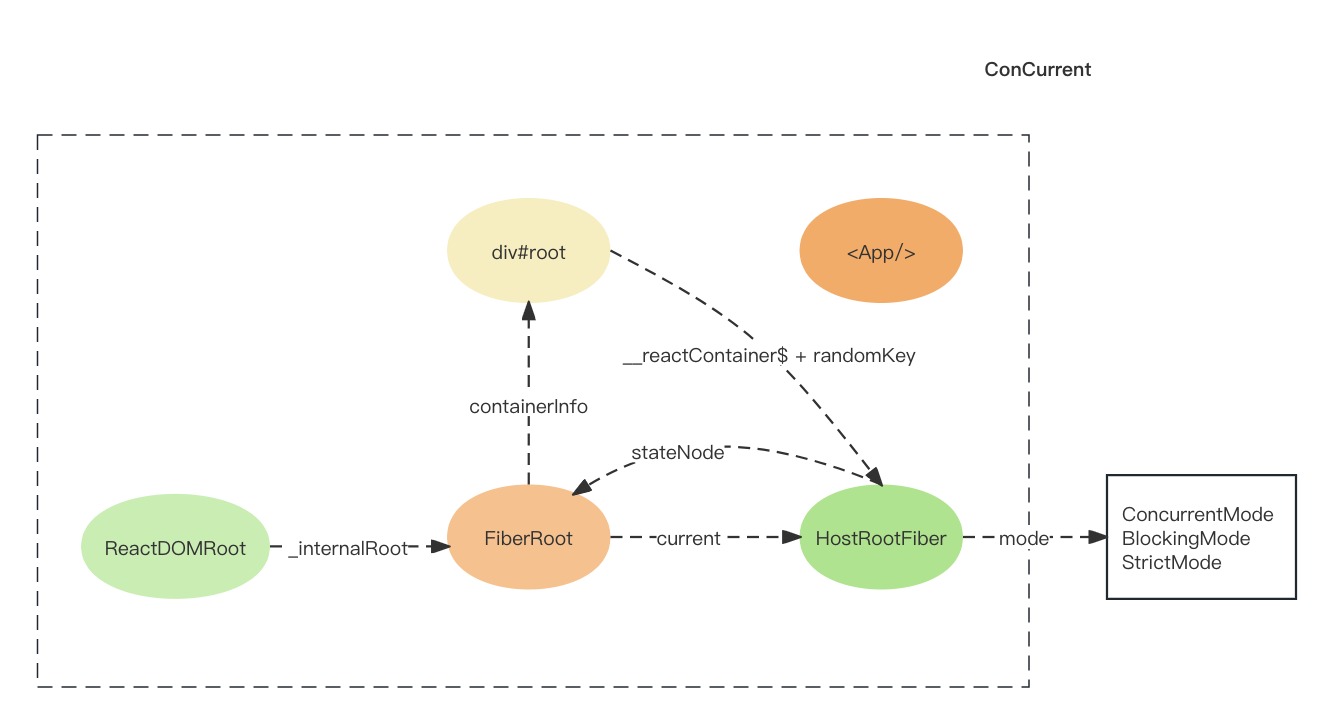
React18源码: reconcliler启动过程
Reconcliler启动过程 Reconcliler启动过程实际就是React的启动过程位于react-dom包,衔接reconciler运作流程中的输入步骤.在调用入口函数之前,reactElement(<App/>) 和 DOM对象 div#root 之间没有关联,用图片表示如下: 在启…...
【RN】为项目使用React Navigation中的navigator
简言 移动应用基本不会只由一个页面组成。管理多个页面的呈现、跳转的组件就是我们通常所说的导航器(navigator)。 React Navigation 提供了简单易用的跨平台导航方案,在 iOS 和 Android 上都可以进行翻页式、tab 选项卡式和抽屉式的导航布局…...

CS50x 2024 - Lecture 8 - HTML, CSS, JavaScript
00:00:00 - Introduction 关于互联网是怎么工作的,如何在他的基础上构建软件 HTML和CSS是描述性语言 javascript一种编程语言,在浏览器上下文中很有用,使得界面更具交互性,也用于服务器 00:01:01 - Bingo Board 00:01:51 - T…...
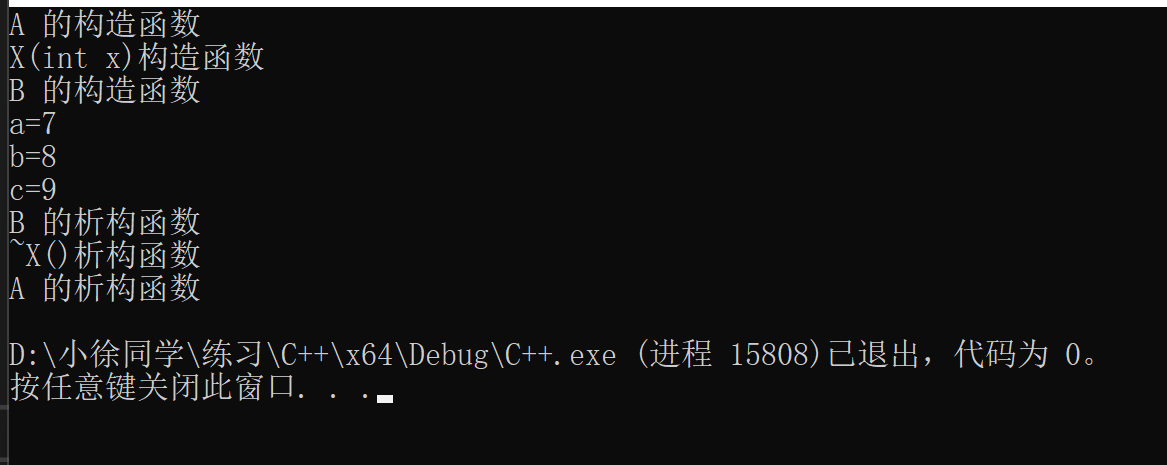
C++:派生类的生成过程(构造、析构)
目录 派生类的生成过程 派生类的构造函数与析构函数: 构造函数: 派生类组合类的构造和析构: 构造函数和析构函数调用顺序: 派生类的生成过程 三步骤: 吸收基类(父类)成员:实现代…...

金蝶字段添加过滤条件
金蝶字段加过滤条件 F_PLDE_Date<GetValue(FDate) and F_PLDE_Date1>GetValue(FDate)...

SQLite 知识整理
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录 SQLite 类型数据…...
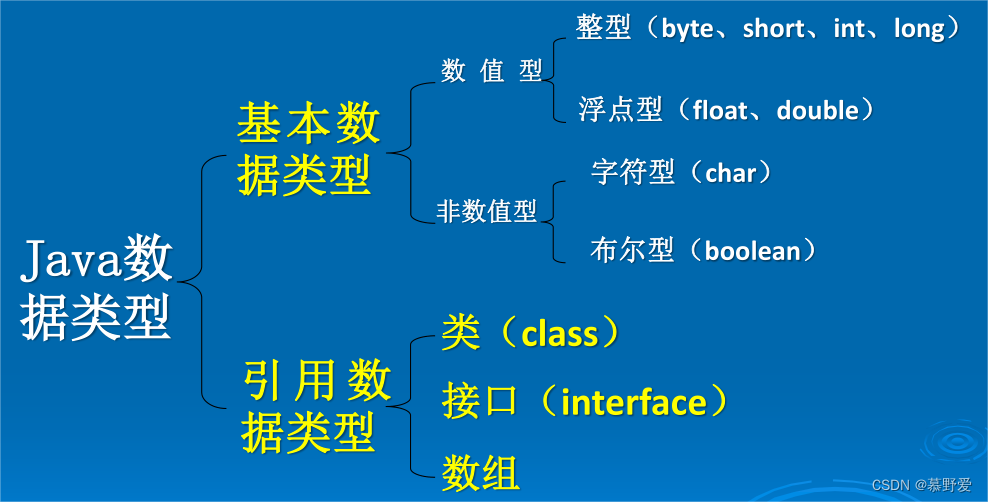
0基础JAVA期末复习最终版
啊啊啊啊啊啊啊啊啊啊,根据网上各位大佬的复习资料,看了很多大多讲的是基础但对内容的整体把握上缺乏系统了解。但是很不幸最终挂科了,那个出题套路属实把我整神了,所以我决定痛改前非,酣畅淋漓的写下这篇文章。。。。…...
【办公类-16-07-04】合并版“2023下学期 中班户外游戏(有场地和无场地版,一周一次)”(python 排班表系列)
背景需求: 把 无场地版(贴周计划用) 和 有场地版(贴教室墙壁上用) 组合在一起,一个代码生成两套。 【办公类-16-07-02】“2023下学期 周计划-户外游戏 每班1周五天相同场地,6周一次循环”&…...

chat GPT第一讲
计算机的语言奇迹:探秘ChatGPT的智能回答和写作能力 目前我们这个行业,最火的话题无疑是AI人工智能,类似ChatGPT这样的智能Ai,今天剩下的时间不多,每天一个主题,我给大家讲一下计算机回答问题和写作的能力,…...
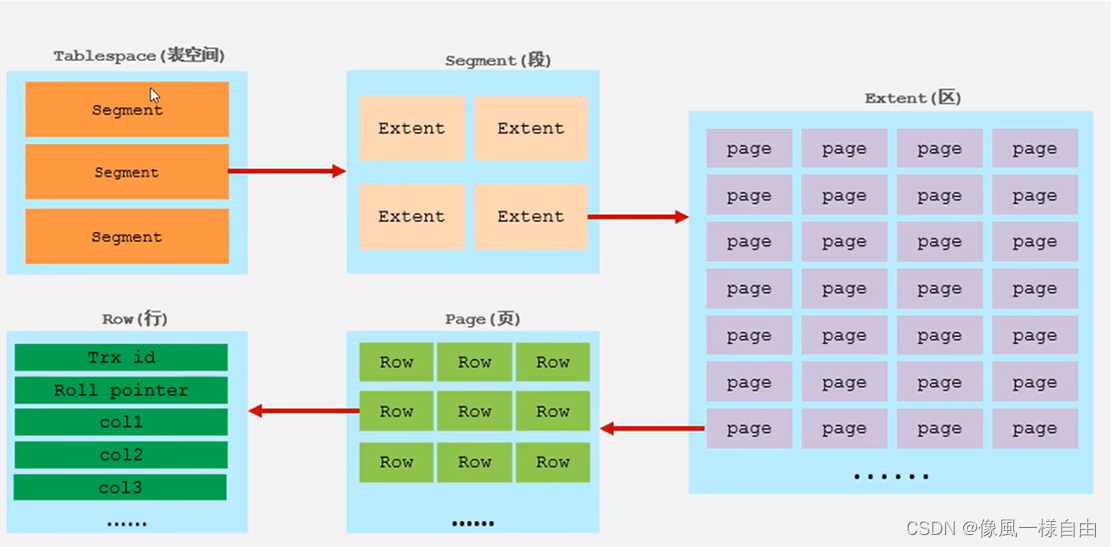
JAVA工程师面试专题-Mysql篇
一、基础 1、mysql可以使用多少列创建索引? 16 2、mysql常用的存储引擎有哪些 存储引擎Storage engine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。常用的存储引擎有以下: Innodb引擎:In…...

vue中使用echarts绘制双Y轴图表时,刻度没有对齐的两种解决方法
文章目录 1、原因2、思路3、解决方法3.1、使用alignTicks解决3.2、结合min和max属性去配置interval属性1、首先固定两边的分隔的段数。2、结合min和max属性去配置interval。 1、原因 刻度在显示时,分割段数不一样,导致左右的刻度线不一致,不…...

编程笔记 Golang基础 022 数组
编程笔记 Golang基础 022 数组 一、数组定义和初始化二、访问数组元素三、遍历数组四、数组作为参数六、特点七、注意事项 在Go语言中,数组是一种基本的数据结构,用于存储相同类型且长度固定的元素序列。 一、数组定义和初始化 // 声明并初始化一个整数…...
【kubernetes】二进制部署k8s集群之,多master节点负载均衡以及高可用(下)
↑↑↑↑接上一篇继续部署↑↑↑↑ 之前已经完成了单master节点的部署,现在需要完成多master节点以及实现k8s集群的高可用 一、完成master02节点的初始化操作 二、在master01节点基础上,完成master02节点部署 步骤一:准备好master节点所需…...

哈希表在Java中的使用和面试常见问题
当谈到哈希表在Java中的使用和面试常见问题时,以下是一些重要的点和常见问题: 哈希表在Java中的使用 HashMap 和 HashTable 的区别: HashMap 和 HashTable 都实现了 Map 接口,但它们有一些重要的区别: HashMap 是非线…...

LeetCode刷题小记 三、【哈希表】
1. 哈希表 文章目录 1. 哈希表写在前面1.1 理论基础1.2 有效的字母异位词1.3 两个数组的交集1.4 快乐数1.5 两数之和1.6 四数相加||1.7 赎金信1.8 三数之和(哈希法梦碎的地方)1.9 四数之和 Reference 写在前面 本系列笔记主要作为笔者刷题的题解&#x…...

Zookeeper选举Leader源码剖析
Zookeeper选举Leader源码剖析 leader选举流程 参数说明 myid: 节点的唯一标识,手动设置zxid: 当前节点中最大(新)的事务idepoch-logic-clock: 同一轮投票过程中的逻辑时钟值相同,每投完一次值会增加 leader选举流程 默认投票给自己,优先选择…...
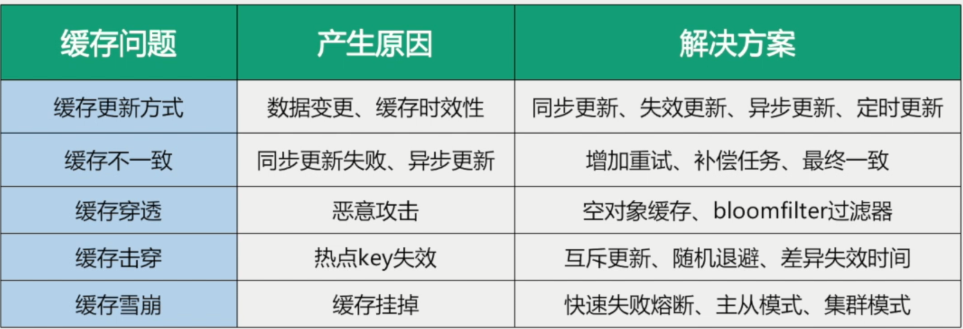
Redis(十六)缓存预热+缓存雪崩+缓存击穿+缓存穿透
文章目录 面试题缓存预热缓存雪崩解决方案 缓存穿透解决方案 缓存击穿解决方案案例:高并发聚划算业务 总结表格 面试题 缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?缓存预热你是怎么做的?如何避免或者减少缓存雪崩?穿透和击穿有什么区别?他两是…...
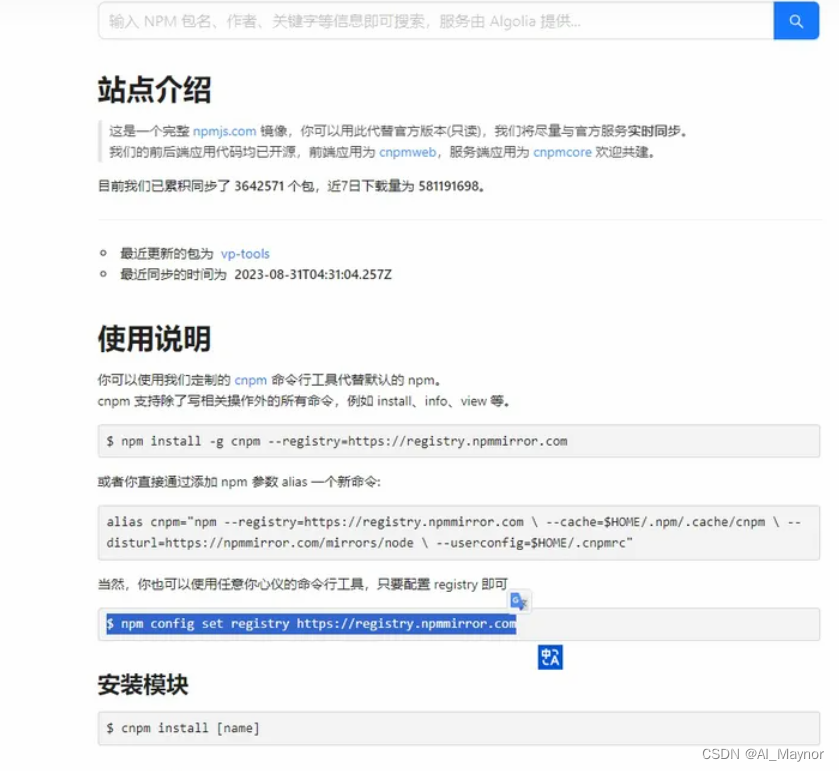
[已解决]npm淘宝镜像最新官方指引(2023.08.31)
最新的配置淘宝镜像的淘宝官方提供的方法 npm config set registry https://registry.npmmirror.com原来的 registry.npm.taobao.org 已替换为 registry.npmmirror.com ,当点击 registry.npm.taobao.org 会默认跳转到 registry.npmmirror.com 如果你想将npm的下载…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

高效的后台管理系统——可进行二次开发
随着互联网技术的迅猛发展,企业的数字化管理变得愈加重要。后台管理系统作为数据存储与业务管理的核心,成为了现代企业不可或缺的一部分。今天我们要介绍的是一款名为 若依后台管理框架 的系统,它不仅支持跨平台应用,还能提供丰富…...

多模态大语言模型arxiv论文略读(112)
Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文标题:Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文作者:Jea…...