Java高级 / 架构师 场景方案 面试题(二)
1.双十一亿级用户日活统计如何用 Redis快速计算
在双十一这种亿级用户日活统计的场景中,使用Redis进行快速计算的关键在于利用Redis的数据结构和原子操作来高效地统计和计算数据。以下是一个基于Redis的日活统计方案:
选择合适的数据结构:
- 使用Redis的
SET数据结构来存储每日活跃用户(DAU)的唯一标识(如用户ID)。SET数据结构自动去重,并且提供了高效的添加和查询操作。 - 如果需要支持更复杂的统计,比如小时级别的活跃用户(HAU),可以使用Redis的
HyperLogLog数据结构,它能够在有限的内存空间内对大量数据进行基数统计。
原子操作保证数据一致性:
- 使用Redis的原子操作来确保在并发环境下数据的一致性。例如,使用
SADD命令来向SET中添加用户ID,这样即使在多个请求同时尝试添加同一个用户ID,Redis也能保证操作的原子性,避免重复计数。
利用Redis的事务功能:
- 在统计日活时,可能需要执行一系列的操作,如先清空旧的日活集合,再添加新的日活用户。这些操作可以通过Redis的事务功能(MULTI/EXEC)来确保原子性执行。
使用Lua脚本:
- 对于更复杂的统计逻辑,可以使用Redis的Lua脚本功能。Lua脚本在Redis服务器上执行,保证了操作的原子性,并且可以执行多个Redis命令。通过Lua脚本,可以实现更复杂的统计逻辑,比如统计日活的同时计算其他相关指标。
定期持久化数据:
- 虽然Redis主要用于缓存和快速访问数据,但是为了数据安全和长期统计,还是需要定期将日活数据持久化到磁盘或其他持久化存储中。这可以通过Redis的RDB或AOF持久化机制实现,或者通过定期将Redis中的数据导出到数据库或其他存储系统中。
水平扩展和分片:
- 如果日活数据量极大,单个Redis实例可能无法满足需求,此时可以考虑使用Redis集群进行水平扩展。通过将数据分散到多个Redis节点上,可以提高系统的吞吐量和容量。需要注意的是,分片策略需要事先设计好,以确保数据均匀分布和查询效率。
监控和告警:
- 在双十一这种关键时期,需要实时监控Redis的性能指标和日活统计结果,确保系统稳定运行。同时,还需要设置合理的告警阈值,以便在出现异常时及时通知运维人员进行处理。
2.双十一电商推荐系统如何用Redis实现
在双十一电商推荐系统中,Redis可以扮演多个角色来提高性能和响应速度。以下是如何使用Redis实现电商推荐系统的一些建议:
缓存热门商品和推荐列表:
- 使用Redis的列表(List)或有序集合(Sorted Set)来缓存热门商品或推荐商品列表。这些列表可以基于用户的浏览历史、购买历史、搜索历史等进行个性化推荐。
- 当用户访问推荐页面时,首先从Redis中读取缓存的推荐列表,如果缓存不存在或已过期,则再从后端服务中拉取最新数据并更新到Redis中。
缓存用户画像和偏好:
- 用户画像和偏好是推荐系统的核心,可以使用Redis的哈希表(Hash)结构来存储这些信息。每个用户都有一个唯一的键,对应的值是一个哈希表,包含了用户的各种属性和偏好。
- 当需要为用户生成推荐列表时,直接从Redis中读取用户的画像和偏好,然后根据这些信息进行个性化推荐。
使用Redis的过期策略管理推荐时效性:
- 推荐系统中的很多数据都有时效性,比如热门商品、促销活动等。Redis支持为键值对设置过期时间,可以利用这一特性来管理这些时效性数据。
- 当数据过期后,Redis会自动删除这些键值对,保证了数据的实时性和准确性。
利用Redis的发布/订阅模型实现实时推荐:
- 如果推荐系统需要支持实时推荐,比如基于用户实时行为的推荐,可以使用Redis的发布/订阅模型。当用户发生某个行为(如点击、购买等)时,发布一个消息到指定的频道,订阅了该频道的推荐系统可以实时接收到这些消息,并立即为用户生成新的推荐列表。
使用Redis的事务和Lua脚本处理复杂逻辑:
- 对于一些复杂的推荐逻辑,可能需要执行多个Redis命令。可以使用Redis的事务功能(MULTI/EXEC)来确保这些命令的原子性执行。
- 如果逻辑非常复杂,还可以考虑使用Lua脚本在Redis服务器上执行。Lua脚本在Redis服务器上运行,可以减少网络延迟,提高性能。
水平扩展和分片:
- 如果推荐系统的数据量非常大,单个Redis实例可能无法满足需求。此时可以考虑使用Redis集群进行水平扩展和分片。通过将数据分散到多个Redis节点上,可以提高系统的吞吐量和容量。
监控和告警:
- 在双十一这种关键时期,需要实时监控Redis的性能指标和推荐系统的运行状况,确保系统稳定运行。同时,还需要设置合理的告警阈值,以便在出现异常时及时通知运维人员进行处理。
综上所述,Redis在电商推荐系统中可以发挥重要作用,通过缓存热门商品、用户画像和偏好、管理时效性数据、实现实时推荐等方式,提高推荐系统的性能和响应速度。同时,还需要注意监控和告警的设置,确保系统的稳定性和可靠性。
3. 日均百亿级微信红包系统架构如何设计
构建一个日均百亿级微信红包系统是一个复杂且庞大的工程,涉及多方面的架构设计和优化。以下是一个简化的架构设计方案,用于支持如此大规模的红包系统:
系统垂直SET化:
- 将整个红包系统垂直切分为多个独立的SET(逻辑服务器和数据库)。每个SET处理一部分用户或红包流量,保证系统的可扩展性和高可用性。
- 每个SET内部逻辑服务器和数据库都是独立的,确保互不影响,通过负载均衡器分配流量到各个SET。
逻辑Server层设计:
- 使用高性能的服务器框架(如Golang),能够处理高并发请求。
- 逻辑Server层负责处理请求排队,避免数据库并发抢锁问题。
- 使用消息队列(如Kafka、RabbitMQ等)来异步处理红包发放请求,减少系统延迟。
数据库设计:
- 使用分布式数据库系统(如MySQL集群、Cassandra等),能够水平扩展,并提供高可用性和容错性。
- 采用双维度分库分表策略,如按用户ID和红包ID进行分片,确保数据均匀分布和查询效率。
- 数据库操作应尽可能减少锁的竞争,如使用乐观锁、减少事务的粒度等。
缓存策略:
- 使用Redis等内存数据库缓存红包的库存数量、用户抢红包状态等信息,减少对数据库的访问压力。
- 设置合理的缓存过期时间,确保数据实时性。
负载均衡和容错:
- 使用负载均衡器(如Nginx、HAProxy等)分发流量到不同的逻辑Server和数据库SET,确保系统负载均衡。
- 部署冗余的服务器和数据库节点,使用负载均衡和故障转移机制(如Kubernetes),确保系统的高可用性。
异步处理与消息队列:
- 使用消息队列来异步处理红包发放、抢红包等操作,减少系统延迟,提高并发处理能力。
- 消息队列应保证消息的可靠传输和顺序性,避免数据不一致问题。
监控与告警:
- 部署完善的监控系统,实时监控系统的性能指标、错误率、响应时间等关键指标。
- 设置合理的告警阈值,及时发现并处理潜在问题,确保系统稳定运行。
系统优化与性能调优:
- 定期对系统进行性能分析和调优,如优化数据库查询语句、调整缓存策略、增加服务器资源等。
- 结合业务特点和技术发展趋势,持续迭代和优化系统架构,确保系统始终保持最佳性能。
注意:此方案仅为一个简化的设计方案,实际部署时需要根据业务特点和系统需求进行详细的规划和优化。同时,还需要考虑系统的安全性、合规性等方面的问题。
4.类似微信的社交 App朋友圈关注模型如何设计实现
设计一个类似微信的社交App朋友圈关注模型,需要考虑用户之间的关系、内容展示、权限控制以及性能优化等方面。以下是一个简化的设计实现方案:
用户关系管理:
- 设计用户关系表,存储用户之间的关注关系,如关注者(follower)和被关注者(followee)。
- 提供API接口,允许用户进行关注、取消关注操作,并更新关系表。
- 考虑使用缓存技术(如Redis)来加速用户关系查询,减少数据库访问压力。
朋友圈内容管理:
- 设计朋友圈内容表,存储用户发布的朋友圈动态,包括内容、时间戳、发布者等信息。
- 提供API接口,允许用户发布、编辑和删除朋友圈动态,并更新内容表。
- 考虑使用数据库索引和时间戳范围查询来优化朋友圈内容的读取性能。
内容展示逻辑:
- 当用户进入朋友圈页面时,根据用户的关注关系,查询其关注者的朋友圈动态。
- 可以根据时间戳倒序展示最新发布的动态,确保用户看到的是最新的内容。
- 考虑使用分页技术,将朋友圈内容分页展示,提高用户体验。
权限控制:
- 对朋友圈动态进行权限控制,确保只有被关注者的好友才能看到其发布的动态。
- 实现访问控制列表(ACL)或基于角色的访问控制(RBAC),对用户访问朋友圈内容进行权限验证。
- 考虑使用令牌(token)或会话(session)管理用户登录状态,确保用户身份的验证和授权。
性能优化:
- 使用缓存技术(如Redis)来缓存朋友圈动态数据,减少对数据库的访问次数。
- 考虑使用异步加载和懒加载技术,在用户滚动页面时动态加载更多内容,提高页面加载速度。
- 对数据库查询进行优化,使用合适的索引和查询条件,提高查询效率。
推送通知:
- 实现推送通知功能,当用户关注的用户发布新动态时,及时推送通知给用户。
- 可以使用第三方推送服务(如Firebase Cloud Messaging、APNs等)来发送推送通知。
隐私保护:
- 提供用户隐私设置选项,允许用户控制其朋友圈动态的可见范围,如仅好友可见、公开等。
- 在设计数据库和查询逻辑时,确保用户隐私设置得到严格遵循。
注意:此方案仅为一个简化的设计实现方案,实际部署时需要根据业务特点和系统需求进行详细的规划和优化。同时,还需要考虑系统的安全性、可扩展性、可维护性等方面的问题。
5.美团单车如何基于Redis快速找到附近
美团单车基于Redis快速找到附近的车,主要可以利用Redis的地理位置索引功能,即Geo模块。Geo模块支持存储和查询地理位置信息,提供了添加地理位置、查询附近位置、计算两点间距离等功能。
以下是一个基于Redis Geo模块查找附近单车的简化方案:
存储单车位置:
- 当单车被停放在某个位置时,使用Redis的
GEOADD命令将单车的经纬度信息存储到Redis的Geo集合中。例如,可以使用一个key来表示所有单车的位置,每个单车都有一个唯一的成员名。
查询附近单车:
- 当用户需要查找附近的单车时,使用Redis的
GEORADIUS或GEORADIUSBYMEMBER命令来查询指定范围内的单车。GEORADIUS命令接受一个中心点(经纬度)和半径作为参数,返回该范围内的所有单车。GEORADIUSBYMEMBER命令则接受一个成员名(表示单车的位置)和半径作为参数,返回与给定单车距离在指定范围内的所有单车。
排序和限制结果数量:
- 可以使用
WITHDIST和WITHCOORD选项来获取每个单车与查询点的距离以及单车的位置坐标。同时,可以使用COUNT选项来限制返回结果的数量,以满足分页或性能要求。
处理结果:
- 将查询结果从Redis取出后,可以进一步处理,例如按照距离排序、过滤掉已被预约或损坏的单车等。
缓存和更新策略:
- 为了提高性能,可以将查询结果缓存到Redis或其他缓存系统中,设置合适的过期时间。同时,需要定期更新单车的位置信息,以确保查询结果的准确性。
6.Redis分布式锁主从架构锁失效问题如何解决
使用RedLock算法:
- RedLock是一个分布式锁算法,可以在多个Redis节点上实现分布式锁。RedLock算法通过在多个节点上获取锁,并对锁进行多次检查来增加安全性,可以有效避免单点故障和网络分区等问题。但需要注意,RedLock算法并不是完全可靠的,可能会存在误判的情况。
设置合理的过期时间:
- 在获取锁时,为锁设置一个合理的过期时间,保证锁能够在一定时间内释放。可以根据业务需求和锁的使用场景来设置过期时间。
续约机制:
- 获取锁后,可以周期性地对锁进行续约操作,延长锁的过期时间。续约操作可以通过定时任务或者其他方式进行。
设置唯一标识:
- 在获取锁时,为每个锁设置一个唯一的标识,可以使用当前线程的ID或者其他唯一标识符。在释放锁时,只有拥有相同标识的线程才能释放锁,避免其他线程错误地释放锁。
使用Lua脚本:
- 可以使用Lua脚本在Redis端执行获取锁和释放锁的操作,确保获取锁和释放锁是原子操作,避免由于网络延迟等问题导致的锁失效。
!!!在使用Redis分布式锁时,还需要注意避免死锁、锁粒度、锁超时等问题。
7.超大并发的分布式锁架构该如何设计
设计超大并发的分布式锁架构需要考虑多个方面,包括锁的粒度、性能、可靠性、容错性和可扩展性等。以下是一个可供参考的分布式锁架构设计方案:
锁的粒度:
- 在分布式系统中,锁的粒度决定了锁的范围和性能。为了支持超高并发,可以考虑使用细粒度的锁,例如基于行、列或对象的锁,以减少锁的竞争和等待时间。
高性能锁服务:
- 建立一个高性能的锁服务,使用高吞吐量的存储和计算资源。可以考虑使用Redis集群来提供锁服务,因为Redis具有高性能和可扩展性。
锁续约机制:
- 为避免锁因网络故障或其他原因而意外丢失,引入锁续约机制。在锁被持有时,可以定期更新锁的过期时间,确保锁在需要时仍然有效。
锁超时和失效处理:
- 为锁设置一个合理的超时时间,当锁持有者未能在超时时间内续约时,锁将自动释放,防止死锁。同时,需要处理锁失效的情况,例如当锁持有者崩溃时,其他请求者可以竞争获取锁。
分布式锁算法:
- 可以考虑使用RedLock算法或其他分布式锁算法来确保锁的可靠性和容错性。通过在多个节点上同时获取锁,并在多数节点上达成一致,可以减少单点故障和网络分区的影响。
锁冲突解决:
- 当多个请求者竞争同一个锁时,需要有一种冲突解决机制。可以考虑使用基于时间戳、随机数或其他策略来决定哪个请求者应该获得锁。
负载均衡和容错:
- 使用负载均衡技术将锁请求分发到多个锁服务节点上,以提高系统的吞吐量和容错能力。同时,需要实现容错机制,例如当某个锁服务节点出现故障时,可以将请求重定向到其他可用节点。
监控和告警:
- 部署监控系统来实时监控分布式锁的性能、可靠性和故障情况。设置合理的告警阈值,及时发现并处理潜在问题。
扩展性:
- 设计分布式锁架构时需要考虑系统的扩展性。可以通过水平扩展锁服务节点、增加存储资源或使用更高效的算法来提高系统的处理能力。
总之,设计超大并发的分布式锁架构需要综合考虑多个方面,包括锁的粒度、性能、可靠性、容错性和可扩展性等。通过合理的架构设计和优化,可以实现高性能、可靠和可扩展的分布式锁服务,支持超大并发的业务需求。
8.Redis底层ZSet跳表是如何设计与实现
Redis的底层ZSet(有序集合)是通过跳表(Skiplist)来实现的。跳表是一种可以进行对数级别查找、插入和删除操作的数据结构,它通过在每个节点上维护多个指向其他节点的指针,以实现数据的快速访问。
在Redis的ZSet实现中,每个节点(zskiplistNode)包含一个元素(ele)和一个分数(score),元素用于唯一标识节点,分数用于对节点进行排序。每个节点还包含一个指向其后继节点的指针(backward),以及一个跳表层级数组(level),每个层级包含一个指向下一个节点的指针(forward)和一个表示该层级跨越节点数的跨度(span)。
跳表的构建过程:
- 当插入一个节点时,首先根据节点的分数随机确定其高度(即跳表层级数组的长度)。每增加一层的概率通常为0.5或0.25,这样层数越高的节点就越少,与平衡树类似。
- 节点的高度确定后,将其插入到每个层级的适当位置。插入过程中,需要比较节点的分数和当前层级后继节点的分数,以确定插入位置。
- 插入节点后,需要更新相关节点的跨度信息。每个节点的跨度等于其所在层级后继节点的跨度加1(如果后继节点存在)。此外,还需要更新从根节点到该节点的所有层级的跨度信息。
跳表的查找过程:
- 从跳表的最高层级开始查找,沿着当前层级的后继节点指针遍历,直到找到一个节点的分数大于或等于目标分数。
- 如果找到节点的分数等于目标分数,则返回该节点。否则,沿着当前节点的下一层级继续查找。
- 重复步骤1和步骤2,直到找到目标节点或遍历到最低层级。
跳表的删除过程与查找过程类似,也是从最高层级开始查找,找到目标节点后,将其从所在层级的链表中删除,并更新相关节点的跨度信息。如果删除节点后,某些层级的链表变为空,则需要将这些层级从跳表中删除。
Redis的ZSet跳表实现是一种高效、灵活的有序数据结构,通过随机化的高度和跨度信息,实现了快速查找、插入和删除操作。
9.Redis底层ZSet实现压缩列表和跳表如何选择
在Redis中,ZSet(有序集合)的底层实现可以选择使用压缩列表(ziplist)或者跳表(skiplist)。选择哪种实现取决于ZSet的大小以及元素的特性。
压缩列表(ziplist):
当ZSet中的元素较少,且元素本身的大小也比较小时,Redis会选择使用压缩列表来实现ZSet。压缩列表是一种为节省内存而设计的连续内存块数据结构,它特别适合存储小列表和小哈希表。
使用压缩列表实现ZSet的优点包括:
- 内存占用更少,因为压缩列表是连续的内存块,没有额外的指针开销。
- 插入和删除操作的性能较好,因为不需要调整内存结构。
然而,压缩列表的缺点是在进行查找操作时,需要遍历整个列表,时间复杂度为O(N)。
跳表(skiplist):
当ZSet中的元素数量较多,或者元素本身的大小较大时,Redis会选择使用跳表来实现ZSet。跳表是一种通过维护多个有序链表来提高查找效率的数据结构。
使用跳表实现ZSet的优点包括:
- 查找、插入和删除操作的性能较好,因为跳表可以实现对数级别的时间复杂度(O(log N))。
- 跳表更加灵活,可以方便地调整高度以适应不同的性能需求。
然而,跳表的缺点是需要额外的内存来存储指针信息,相对于压缩列表来说内存占用更多。
选择准则
在选择压缩列表和跳表时,Redis会根据以下因素进行权衡:
- 元素数量:当ZSet中的元素数量较少时,更倾向于使用压缩列表;当元素数量较多时,更倾向于使用跳表。
- 元素大小:如果元素本身的大小较小,使用压缩列表可以节省内存;如果元素大小较大,使用跳表可能更加合适。
- 性能需求:如果对ZSet的查找、插入和删除操作有较高的性能要求,通常会选择使用跳表。
需要注意的是,Redis会根据实际情况动态地调整ZSet的底层实现。例如,当ZSet中的元素数量增加到一定程度时,Redis可能会将压缩列表转换为跳表以提高性能。这种动态调整的策略使得Redis能够根据实际情况平衡内存使用和性能需求。
10.Redis6.0多线程模型比单线程优化在哪里
Redis 6.0的多线程模型相较于之前的单线程模型有以下几个方面的优化:
并发处理能力提升:
- 多线程模型允许Redis同时处理多个客户端请求,从而提高了并发处理能力。在单线程模型中,Redis一次只能执行一个操作,而多线程模型允许同时执行多个操作,提升了系统的整体性能。
更好的多核利用:
- Redis 6.0的多线程模型允许服务器同时处理多个客户端请求,每个请求都可以在一个独立的线程中执行。这意味着Redis可以更好地利用多核处理器,从而提高了性能。通过配置参数,用户可以指定Redis服务器使用的线程数,以充分利用可用的多核资源。
提高吞吐量:
- 多线程模型允许Redis同时处理多个命令,从而提高整体吞吐量。特别是在面临大量并发的写操作时,多线程可以有效提高性能。这对于需要处理高负载和高并发的应用场景非常有利。
减少网络IO消耗:
- 对于单线程的Redis来说,性能瓶颈主要在于网络的IO消耗。多线程模型通过充分利用多核处理器,可以更有效地处理网络请求和响应,从而减少了网络IO消耗。这有助于提高Redis的整体性能和响应时间。
值得注意的是,虽然多线程模型带来了上述优势,但也引入了一些新的挑战和复杂性。例如,线程间的同步和协作需要额外的开销和管理。因此,在决定是否升级到Redis 6.0或使用多线程模型时,需要根据实际应用场景和需求进行权衡和评估。
相关文章:
)
Java高级 / 架构师 场景方案 面试题(二)
1.双十一亿级用户日活统计如何用 Redis快速计算 在双十一这种亿级用户日活统计的场景中,使用Redis进行快速计算的关键在于利用Redis的数据结构和原子操作来高效地统计和计算数据。以下是一个基于Redis的日活统计方案: 选择合适的数据结构: …...
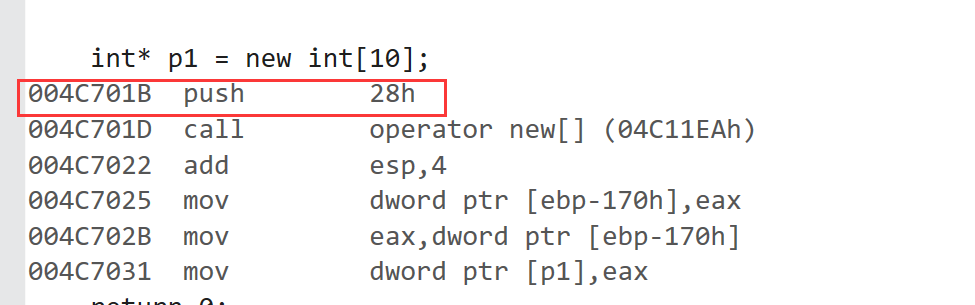
C/C++内存管理学习【new】
文章目录 一、C/C内存分布二、C语言中动态内存管理方式:malloc/calloc/realloc/free三、C内存管理方式3.1 new/delete操作内置类型3.2 new和delete操作自定义类型四、operator new与operator delete函数五、new和delete的实现原理5.1 内置类型 六、定位new表达式(pl…...

选择适合你的编程语言
引言 在当今瞬息万变的技术领域中,选择一门合适的编程语言对于个人职业发展和技术成长至关重要。每种语言都拥有独特的设计哲学、应用场景和市场需求,因此,在决定投入时间和精力去学习哪种编程语言时,我们需要综合分析多个因素&a…...

【力扣每日一题】力扣106从中序和后序遍历序列构造二叉树
题目来源 力扣106从中序和后序遍历序列构造二叉树 题目概述 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 思路分析 后序遍历序列的最末尾数…...

logback日志回滚原理
日志输出主要依赖RollingFileAppender、TimeBasedRollingPolicy、SizeAndTimeBasedFNATP。 RollingFileAppender 主要用于生成日志文件,格式化内容再输出到日志文件TimeBasedRollingPolicy 设置回滚策略,如果发现日志输出的时间超过单位时间,…...

[C#]winform基于opencvsharp结合pairlie算法实现低光图像增强黑暗图片变亮变清晰
【低光图像增强介绍】 在图像处理领域,低光图像增强是一个具有挑战性的任务。由于光线不足,这些图像往往呈现出低对比度、高噪声和细节丢失等问题,严重影响了图像的视觉效果和后续分析的准确性。因此,开发有效的低光图像增强方法…...
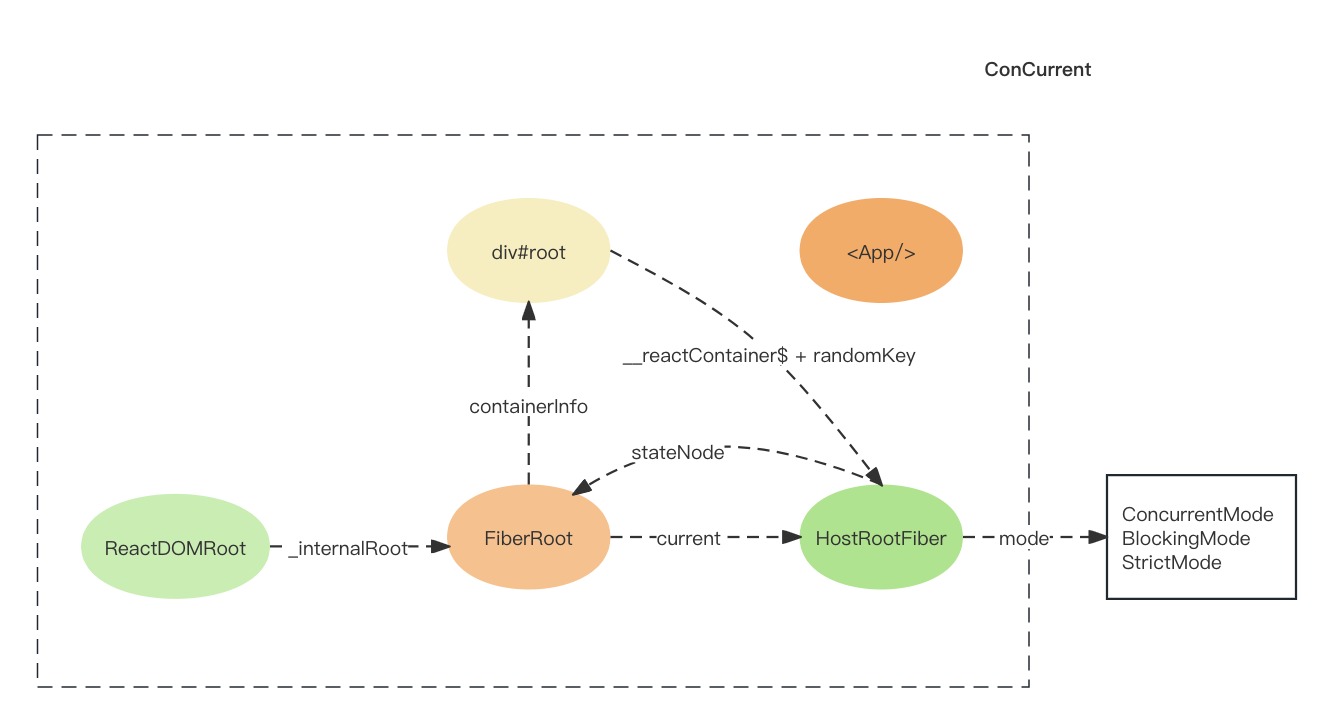
React18源码: reconcliler启动过程
Reconcliler启动过程 Reconcliler启动过程实际就是React的启动过程位于react-dom包,衔接reconciler运作流程中的输入步骤.在调用入口函数之前,reactElement(<App/>) 和 DOM对象 div#root 之间没有关联,用图片表示如下: 在启…...
【RN】为项目使用React Navigation中的navigator
简言 移动应用基本不会只由一个页面组成。管理多个页面的呈现、跳转的组件就是我们通常所说的导航器(navigator)。 React Navigation 提供了简单易用的跨平台导航方案,在 iOS 和 Android 上都可以进行翻页式、tab 选项卡式和抽屉式的导航布局…...

CS50x 2024 - Lecture 8 - HTML, CSS, JavaScript
00:00:00 - Introduction 关于互联网是怎么工作的,如何在他的基础上构建软件 HTML和CSS是描述性语言 javascript一种编程语言,在浏览器上下文中很有用,使得界面更具交互性,也用于服务器 00:01:01 - Bingo Board 00:01:51 - T…...
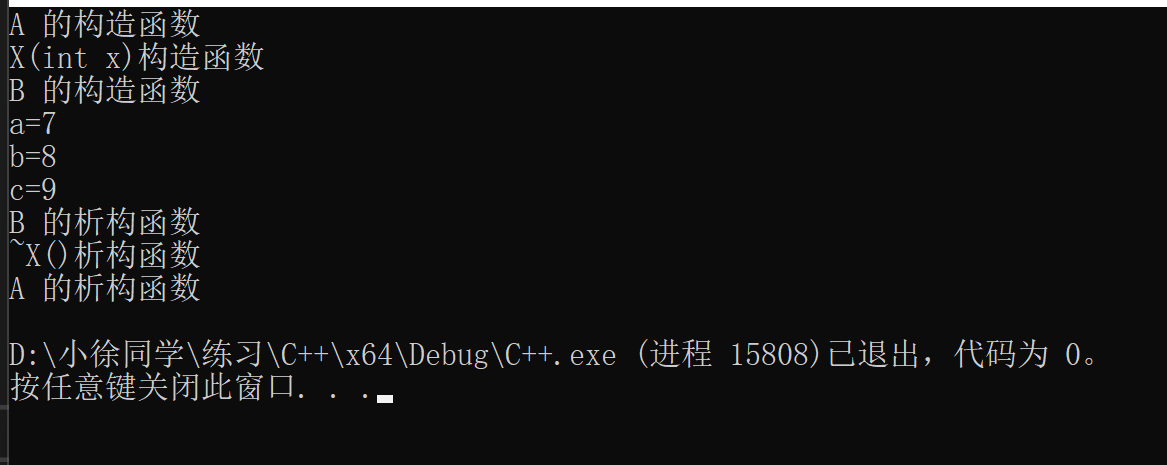
C++:派生类的生成过程(构造、析构)
目录 派生类的生成过程 派生类的构造函数与析构函数: 构造函数: 派生类组合类的构造和析构: 构造函数和析构函数调用顺序: 派生类的生成过程 三步骤: 吸收基类(父类)成员:实现代…...

金蝶字段添加过滤条件
金蝶字段加过滤条件 F_PLDE_Date<GetValue(FDate) and F_PLDE_Date1>GetValue(FDate)...

SQLite 知识整理
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录 SQLite 类型数据…...
0基础JAVA期末复习最终版
啊啊啊啊啊啊啊啊啊啊,根据网上各位大佬的复习资料,看了很多大多讲的是基础但对内容的整体把握上缺乏系统了解。但是很不幸最终挂科了,那个出题套路属实把我整神了,所以我决定痛改前非,酣畅淋漓的写下这篇文章。。。。…...
【办公类-16-07-04】合并版“2023下学期 中班户外游戏(有场地和无场地版,一周一次)”(python 排班表系列)
背景需求: 把 无场地版(贴周计划用) 和 有场地版(贴教室墙壁上用) 组合在一起,一个代码生成两套。 【办公类-16-07-02】“2023下学期 周计划-户外游戏 每班1周五天相同场地,6周一次循环”&…...

chat GPT第一讲
计算机的语言奇迹:探秘ChatGPT的智能回答和写作能力 目前我们这个行业,最火的话题无疑是AI人工智能,类似ChatGPT这样的智能Ai,今天剩下的时间不多,每天一个主题,我给大家讲一下计算机回答问题和写作的能力,…...
JAVA工程师面试专题-Mysql篇
一、基础 1、mysql可以使用多少列创建索引? 16 2、mysql常用的存储引擎有哪些 存储引擎Storage engine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。常用的存储引擎有以下: Innodb引擎:In…...

vue中使用echarts绘制双Y轴图表时,刻度没有对齐的两种解决方法
文章目录 1、原因2、思路3、解决方法3.1、使用alignTicks解决3.2、结合min和max属性去配置interval属性1、首先固定两边的分隔的段数。2、结合min和max属性去配置interval。 1、原因 刻度在显示时,分割段数不一样,导致左右的刻度线不一致,不…...

编程笔记 Golang基础 022 数组
编程笔记 Golang基础 022 数组 一、数组定义和初始化二、访问数组元素三、遍历数组四、数组作为参数六、特点七、注意事项 在Go语言中,数组是一种基本的数据结构,用于存储相同类型且长度固定的元素序列。 一、数组定义和初始化 // 声明并初始化一个整数…...
【kubernetes】二进制部署k8s集群之,多master节点负载均衡以及高可用(下)
↑↑↑↑接上一篇继续部署↑↑↑↑ 之前已经完成了单master节点的部署,现在需要完成多master节点以及实现k8s集群的高可用 一、完成master02节点的初始化操作 二、在master01节点基础上,完成master02节点部署 步骤一:准备好master节点所需…...

哈希表在Java中的使用和面试常见问题
当谈到哈希表在Java中的使用和面试常见问题时,以下是一些重要的点和常见问题: 哈希表在Java中的使用 HashMap 和 HashTable 的区别: HashMap 和 HashTable 都实现了 Map 接口,但它们有一些重要的区别: HashMap 是非线…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...

【Java】Ajax 技术详解
文章目录 1. Filter 过滤器1.1 Filter 概述1.2 Filter 快速入门开发步骤:1.3 Filter 执行流程1.4 Filter 拦截路径配置1.5 过滤器链2. Listener 监听器2.1 Listener 概述2.2 ServletContextListener3. Ajax 技术3.1 Ajax 概述3.2 Ajax 快速入门服务端实现:客户端实现:4. Axi…...
Linux 内存管理调试分析:ftrace、perf、crash 的系统化使用
Linux 内存管理调试分析:ftrace、perf、crash 的系统化使用 Linux 内核内存管理是构成整个内核性能和系统稳定性的基础,但这一子系统结构复杂,常常有设置失败、性能展示不良、OOM 杀进程等问题。要分析这些问题,需要一套工具化、…...