机器学习基础(三)监督学习的进阶探索
导语:上一节我们深入地探讨监督学习和非监督学习的知识,重点关注它们的理论基础、常用算法及实际应用场景,详情可见:
机器学习基础(二)监督与非监督学习-CSDN博客文章浏览阅读769次,点赞15次,收藏8次。更深入地探讨监督学习和非监督学习的知识,重点关注它们的理论基础、常用算法及实际应用场景。https://blog.csdn.net/qq_52213943/article/details/136163917?spm=1001.2014.3001.5501 这一节,我们将详细探索监督学习的进阶应用。
目录
监督学习
数据集的构成与模型学习
损失函数的选择与应用
分类与回归的深入应用
线性回归实战案例:房价预测
决策树的构建与应用
支持向量机(SVM)的高效应用
股票市场预测实战
应用概述
数据加载
特征工程
模型选择
性能评估
监督学习

监督学习作为机器学习的一个主要分支,专注于从带有标签的数据中学习和建立预测模型。这些模型可以预测新数据的标签,广泛应用于各种行业和领域,从简单的邮件分类到复杂的医疗诊断。
数据集的构成与模型学习
在监督学习中,数据集包含输入(特征)和输出(标签),这种结构使得模型能够学习输入与输出之间的关系。通过分析训练数据集中的模式,监督学习模型学习如何将输入映射到正确的输出。例如,在邮件分类中,模型学习识别垃圾邮件和正常邮件的特征。
损失函数的选择与应用
损失函数是衡量模型预测准确度的关键,它计算了模型预测结果和实际结果之间的差异,不同类型的任务需选择不同的损失函数。例如,回归任务常用均方误差(MSE),而分类任务常用交叉熵损失。
除此之外,常用的损失函数还有:平均绝对误差 (MAE):也用于回归任务,衡量模型预测值与真实值的绝对差异,对异常值不敏感;对数损失 (Log Loss):用于二元分类任务,评估模型的概率估计与真实标签之间的关系;希望风险损失 (Hinge Loss):用于支持向量机的二元分类任务,最大化分类边界的间隔。
分类与回归的深入应用
分类任务的实际案例很丰富,例如,电子邮件分类器通过学习标记为垃圾邮件和非垃圾邮件的电子邮件的特征,来预测新邮件的类别。而回归任务的实际案例,如房价预测,模型通过学习房屋的特征如面积、位置等数据和历史价格数据,来预测新房屋的市场价值。
在实际应用中,选择分类或回归方法取决于问题的性质:回归适用于连续数值预测,如股票价格,而分类适用于二元或多类别分类,如垃圾邮件检测。正确选择方法有助于模型更准确地满足任务需求,提高预测结果的可信度。
线性回归实战案例:房价预测
线性回归是一个基本的预测模型,适用于预测与多个变量有线性关系的输出。在房价预测的例子中,开发者将看到如何将这个理论应用于实际数据。
延续上一节关于房价预测的讨论,本节将更深入地探讨如何使用房屋的特征(如面积、位置和房龄)来预测其市场价格。本节案例展示了如何从实际数据中提取特征,以及这些特征如何影响预测结果。
这个代码示例展示了如何使用标准的Python库来加载数据、划分数据集、训练线性回归模型以及评估模型效果。图表中展示了模型预测价格与实际价格之间的关系,从而直观地评估模型性能。线性回归房价预测代码如下:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_csv('housing_data.csv')
X = data[['size', 'location', 'age']]
y = data['price']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=42)# 创建线性回归模型并训练
model = LinearRegression()
model.fit(X_train, y_train)# 预测和评估
y_pred = model.predict(X_test)
plt.scatter(y_test, y_pred)
plt.xlabel("Actual Prices")
plt.ylabel("Predicted Prices")
plt.title("Actual Prices vs Predicted Prices")
plt.show()首先,通过pd.read_csv('housing_data.csv')加载名为'housing_data.csv'的数据集。数据集包括了各个房屋的特征,如尺寸、地理位置、房龄等,以及相应的价格信息;其次,从数据集中选择了三个特征:'size'(房屋尺寸)、'location'(地理位置)和'age'(房龄),以及一个目标列'price'(房价)。这些特征将被用于训练和测试模型。
使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占总数据的30%。这个步骤是为了在模型训练完成后,能够用独立的数据来评估模型的性能,以检验其泛化能力。创建一个线性回归模型,通过model = LinearRegression()实例化,并使用训练集数据进行训练,即model.fit(X_train, y_train)。在训练过程中,模型将学习如何根据给定的特征来预测房价。使用训练好的模型对测试集进行预测,将预测结果存储在y_pred中。这一步骤将生成模型对每个测试样本的房价预测值。
最后,通过使用plt.scatter()和matplotlib库,创建一个散点图,将实际房价(y_test)与模型预测的房价(y_pred)进行可视化比较。这个图表有助于直观地了解模型的性能,以及模型是否能够准确地预测房价。如果点在一条对角线上分布,表示模型的预测与实际值非常接近,而点的偏离则代表了预测误差。
决策树的构建与应用
决策树通过一系列规则对数据进行分类。例如,使用决策树对患者数据进行分类,预测疾病类型,代码如下:
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 加载数据
# 假设data是Pandas DataFrame,包含特征和标签
X = data.drop('disease', axis=1)
y = data['disease']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)# 创建决策树模型并训练
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, y_train)# 进行预测和评估
y_pred = tree_model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred)这段代码使用了Scikit-Learn库中的决策树分类器(DecisionTreeClassifier)来构建一个疾病预测模型。首先,从Pandas DataFrame中加载数据,将特征存储在X中,将标签存储在y中。然后,使用train_test_split函数将数据集分成训练集和测试集,其中测试集占总数据的30%。接下来,通过DecisionTreeClassifier()创建一个决策树模型,并使用训练集对其进行训练。最后,使用训练好的模型对测试集进行预测,计算模型的准确性(Accuracy)作为评估指标,并将结果打印出来。
支持向量机(SVM)的高效应用
SVM通过找到最佳超平面来区分不同类别的数据。在文本分类或图像识别等高维数据中应用SVM。使用支持向量机(SVM)进行分类任务的基本步骤代码如下:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 假设data是含有特征和标签的DataFrame
# 请确保data已经被正确加载和准备好
# 分离特征和标签
X = data.drop('label', axis=1)
y = data['label']
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM模型并训练
svm_model = SVC(kernel='linear')
svm_model.fit(X_train, y_train)
# 预测和评估
y_pred = svm_model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))这段代码演示了使用Scikit-Learn中的SVM分类器构建分类模型的过程。首先,从DataFrame中提取特征和标签,然后将数据集分为训练集和测试集。接着,创建SVM模型,使用线性核函数进行训练,并对测试集进行预测。最后,计算并打印出模型的准确性,以评估模型性能。这段代码涵盖了典型的机器学习任务步骤。
股票市场预测实战
金融领域中,股票市场预测一直是一个富有挑战性的课题,因为它受到多种不可预测因素的影响,如政治事件、经济数据发布、公司业绩报告以及市场情绪等。然而,借助监督学习的方法,我们可以通过分析历史股票价格数据和相关因素,构建模型来预测未来的股票走势
应用概述
使用历史数据来预测股票市场的未来趋势是一个典型的监督学习应用场景,其中涉及到复杂的数据分析和特征工程。我们首先需要收集历史股票价格数据,这些数据通常包括开盘价、最高价、最低价、收盘价以及成交量等。此外,还可以包括一些宏观经济指标、公司财报数据等,以提供更全面的分析视角。可以从数据文件夹下stock_market_data.csv获得模拟数据集。
数据加载
分析历史股价数据,包括开盘价、收盘价、最高价、最低价以及交易量等。从数据文件夹下stock_market_data.csv加载数据集,使用Pandas库的read_csv()函数读取CSV文件,代码如下:
import pandas as pd #导入Pandas模块# 加载股票市场数据stock_data = pd.read_csv('stock_market_data.csv') #加载数据集print(stock_data.head()) #打印数据集的前5行特征工程
从原始数据中提取有用的特征,例如移动平均线、相对强弱指数(RSI)等技术指标。提取特征数据的代码如下:
# 计算简单移动平均线(SMA)和相对强弱指数(RSI)stock_data['SMA'] = stock_data['Close'].rolling(window=15).mean()stock_data['RSI'] = compute_RSI(stock_data['Close'], 14) # 假设compute_RSI是一个计算RSI的函数模型选择
讨论不同的预测模型,如线性回归、时间序列分析(如ARIMA模型)和机器学习方法(如随机森林和神经网络)。由于股票价格预测是一个时间序列问题,我们选择使用线性回归模型作为起始点。这是一个简单但有效的模型,适合初步尝试和基线建立。代码如下:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 使用开盘价、高、低、交易量以及计算的SMA和RSI作为特征
X = stock_data[['Open', 'High', 'Low', 'Volume', 'SMA', 'RSI']]
y = stock_data['Close']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=0)# 创建线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 进行预测
y_pred = model.predict(X_test)这段代码利用Scikit-Learn库中的线性回归模型,使用开盘价、最高价、最低价、交易量、SMA和RSI等多个特征,构建了一个股票价格预测模型。它将数据分为训练集和测试集,通过线性回归模型对训练集进行训练,并使用该模型对测试集进行预测,最终可用于评估模型的性能表现
性能评估
使用诸如均方误差(MSE)、绝对平均误差(MAE)等指标来评估模型的准确性。在这个例子中,我们使用均方误差(MSE)作为评估指标。它可以衡量预测值与实际股价之间的平均差异。
mse = mean_squared_error(y_test, y_pred)print(f'Mean Squared Error: {mse}')下一节我们将进行非监督学习的进阶探索
机器学习基础(四)非监督学习的进阶探索-CSDN博客非监督学习像一位探险家,挖掘未标记数据的未知领域。它不依赖预先定义的类别或标签,而是试图揭示数据自身的结构和关系。这种学习方式在处理复杂数据集时尤其有价值,因为它能发现人类可能未曾预见的模式和联系。https://blog.csdn.net/qq_52213943/article/details/136188233?spm=1001.2014.3001.5502-----------------
以上,欢迎点赞收藏、评论区交流
相关文章:
机器学习基础(三)监督学习的进阶探索
导语:上一节我们深入地探讨监督学习和非监督学习的知识,重点关注它们的理论基础、常用算法及实际应用场景,详情可见: 机器学习基础(二)监督与非监督学习-CSDN博客文章浏览阅读769次,点赞15次&a…...

avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目
avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目 avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目avidemux下载avidemux源代码参考资料 avidemux-一个免费的视频编辑器,用于剪切、过滤和编码项目 avidemux下载 avidemux …...
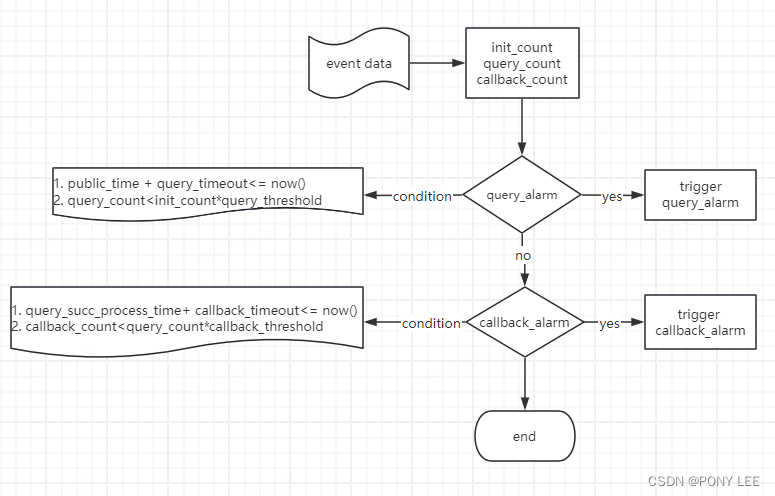
RisingWave最佳实践-利用Dynamic filters 和 Temporal filters 实现监控告警
心得的体会 刚过了年刚开工,闲暇之余调研了分布式SQL流处理数据库–RisingWave,本人是Flink(包括FlinkSQL和Flink DataStream API)的资深用户,但接触到RisingWave令我眼前一亮,并且拿我们生产上的监控告警…...

【Qt学习】QRadioButton 的介绍与使用(性别选择、模拟点餐)
文章目录 介绍实例使用实例1(性别选择 - 单选 隐藏)实例2(模拟点餐,多组单选) 相关资源文件 介绍 这里简单对QRadioButton类 进行介绍: QRadioButton 继承自 QAbstractButton ,用于创建单选按…...

基于java springboot的图书管理系统设计和实现
基于java springboot的图书管理系统设计和实现 博主介绍:5年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获取源码联…...
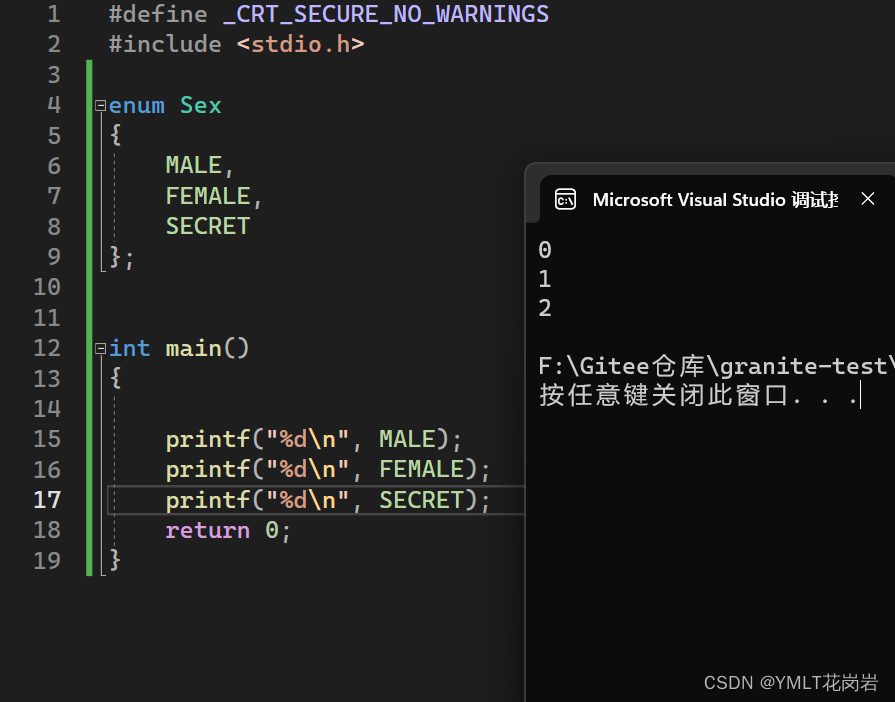
自定义类型:联合和枚举
目录 1. 联合体 1.1 联合体类型的声明及特点 1.2 相同成员的结构体和联合体对比 1.3 联合体大小的计算 1.4 联合体的应用举例 2. 枚举类型 2.1 枚举类型的声明 2.2 枚举类型的优点 1. 联合体 1.1 联合体类型的声明及特点 像结构体一样,联合体也是由一个或…...

每日一学—由面试题“Redis 是否为单线程”引发的思考
文章目录 📋 前言🌰 举个例子🎯 什么是 Redis(知识点补充)🎯 Redis 中的多线程🎯 I/O 多线程🎯 Redis 中的多进程📝 结论🎯书籍推荐🔥参与方式 &a…...
chatGPT PLUS 绑卡提示信用卡被拒的解决办法
chatGPT PLUS 绑卡提示信用卡被拒的解决办法 一、 ChatGPT Plus介绍 作为人工智能领域的一项重要革新,ChatGPT Plus的上线引起了众多用户的关注,其背后的OpenAI表现出傲娇的态度,被誉为下一个GTP 4.0。总的来说,ChatGPT Plus的火…...

opencv鼠标操作与响应
//鼠标事件 Point sp(-1, -1); Point ep(-1, -1); Mat temp; static void on_draw(int event, int x, int y, int flags, void *userdata) {Mat image *((Mat*)userdata);if (event EVENT_LBUTTONDOWN) {sp.x x;sp.y y;std::cout << "start point:"<<…...
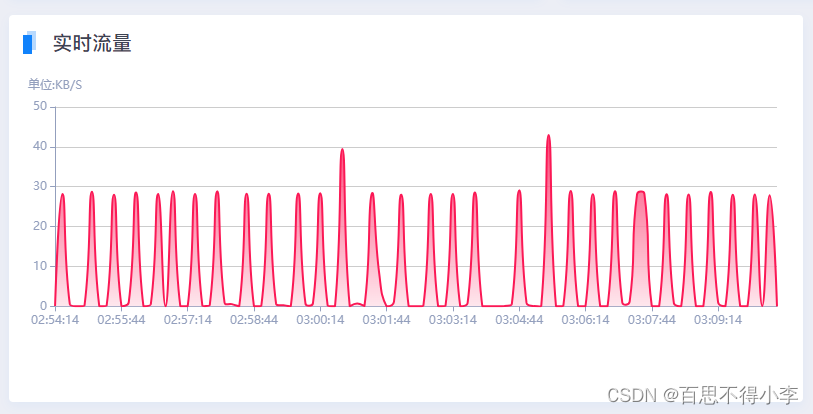
vue里echarts的使用:画饼图和面积折线图
vue里echarts的使用,我们要先安装echarts,然后在main.js里引入: //命令安装echarts npm i echarts//main.js里引入挂载到原型上 import echarts from echarts Vue.prototype.$echarts = echarts最终我们实现的效果如下: 头部标题这里我们封装了一个全局公共组件common-he…...
插件unplugin-auto-import的使用)
个人建站前端篇(六)插件unplugin-auto-import的使用
vue3日常项目中定义变量需要引入ref,reactive等等比较麻烦,可以通过unplugin-auto-import给我们自动引入 * unplugin-auto-import 解决了vue3-hook、vue-router、useVue等多个插件的自动导入,也支持自定义插件的自动导入,是一个功能强大的typ…...
【Python】 剪辑法欠采样 CNN压缩近邻法欠采样
借鉴:关于K近邻(KNN),看这一篇就够了!算法原理,kd树,球树,KNN解决样本不平衡,剪辑法,压缩近邻法 - 知乎 但是不要看他里面的代码,因为作者把代码…...
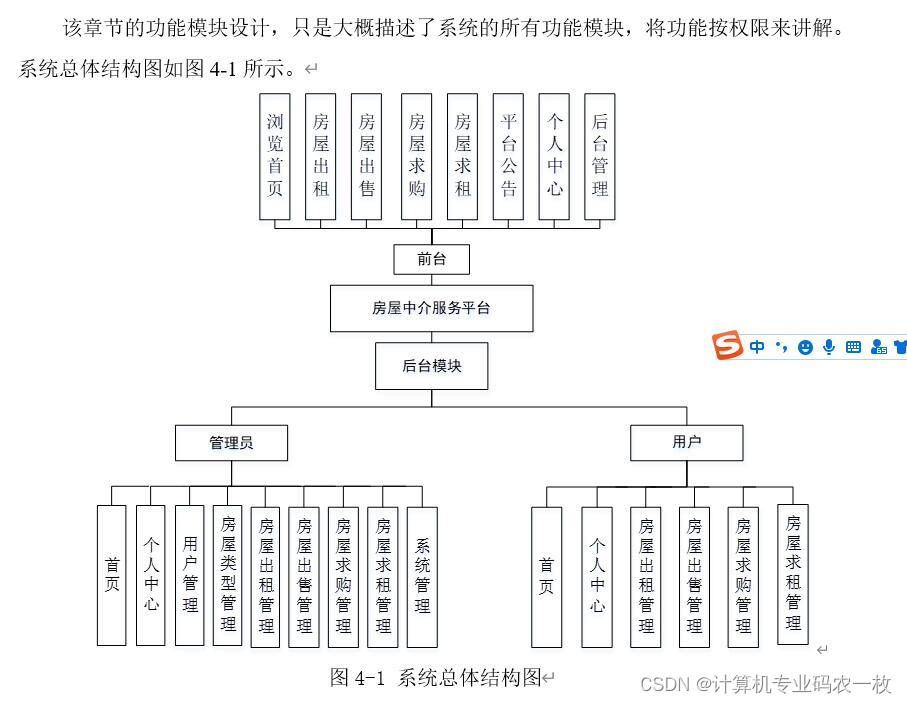
springmvc+ssm+springboot房屋中介服务平台的设计与实现 i174z
本论文拟采用计算机技术设计并开发的房屋中介服务平台,主要是为用户提供服务。使得用户可以在系统上查看房屋出租、房屋出售、房屋求购、房屋求租,管理员对信息进行统一管理,与此同时可以筛选出符合的信息,给笔者提供更符合实际的…...

挑战30天学完Python:Day19 文件处理
📘 Day 19 🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点…...
Spring Boot application.properties和application.yml文件的配置
在Spring Boot中,application.properties 和 application.yml 文件用于配置应用程序的各个方面,如服务器端口、数据库连接、日志级别等。这两个文件是Spring Boot的配置文件,位于 src/main/resources 目录下。 application.properties 示例 …...

Unity单元测试
Unity单元测试是一个专门用于嵌入式单元测试的库, 现在简单讲下移植以及代码结构. 源码地址: GitHub - ThrowTheSwitch/Unity: Simple Unit Testing for C 1.我们只需要移植三个文件即可: unity.c, unity.h, unity_internals.h 2.然后添加需要测试的函数. 3.在main.c中添加…...

Spring Bean 的生命周期了解么?
Spring Bean 的生命周期基本流程 一个Spring的Bean从出生到销毁的全过程就是他的整个生命周期, 整个生命周期可以大致分为3个大的阶段 : 创建 使用 销毁 还可以分为5个小步骤 : 实例化(Bean的创建) , 初始化赋值, 注册Destruction回调 , Bean的正常使用 以及 Bean的销毁 …...

.ryabina勒索病毒数据怎么处理|数据解密恢复
导言: 随着网络安全威胁的不断增加,勒索软件已成为严重的威胁之一,.ryabina勒索病毒是其中之一。本文将介绍.ryabina勒索病毒的特点、数据恢复方法和预防措施,以帮助用户更好地应对这一威胁。当面对被勒索病毒攻击导致的数据文件…...
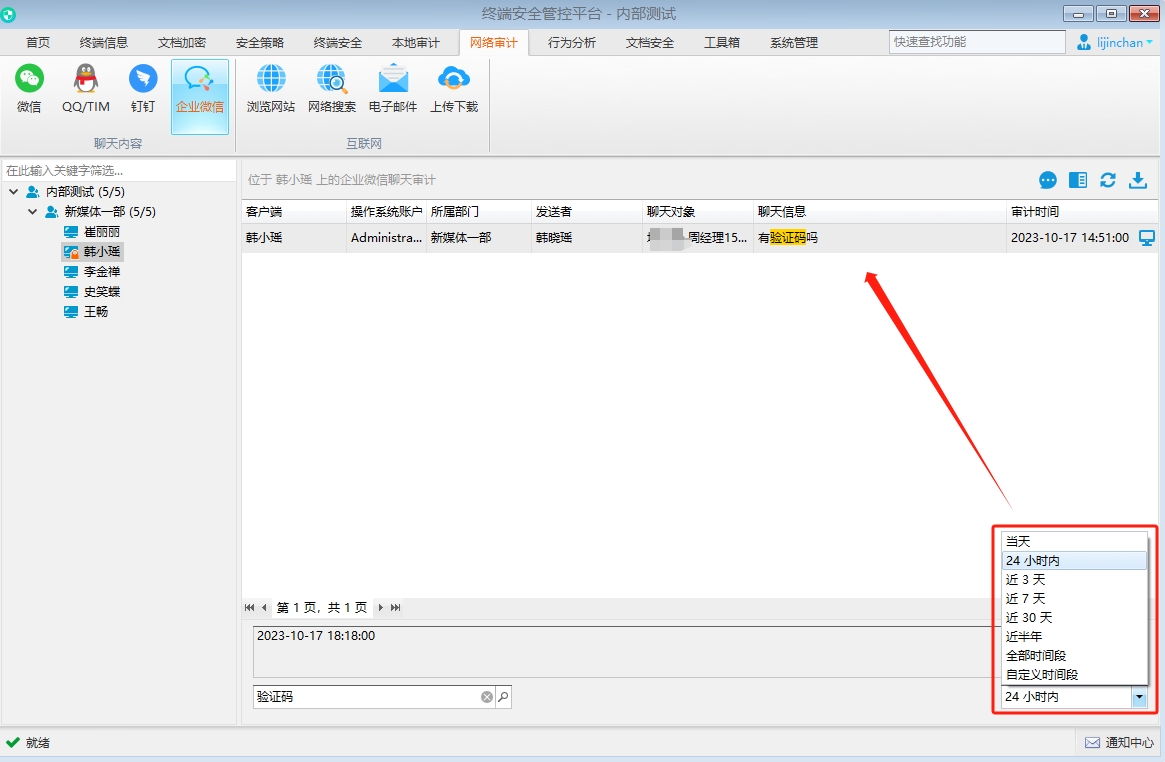
上网行为监控软件能够看到聊天内容吗
随着信息技术的不断发展,上网行为监控软件在企业网络安全管理中扮演着越来越重要的角色。 这类软件主要用于监控员工的上网行为,以确保工作效率和网络安全。 而在这其中,域智盾软件作为一款知名的上网行为监控软件,其功能和使用…...

Java知识点一
hello,大家好!我们今天开启Java语言的学习之路,与C语言的学习内容有些许异同,今天我们来简单了解一下Java的基础知识。 一、数据类型 分两种:基本数据类型 引用数据类型 (1)整型 八种基本数…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...
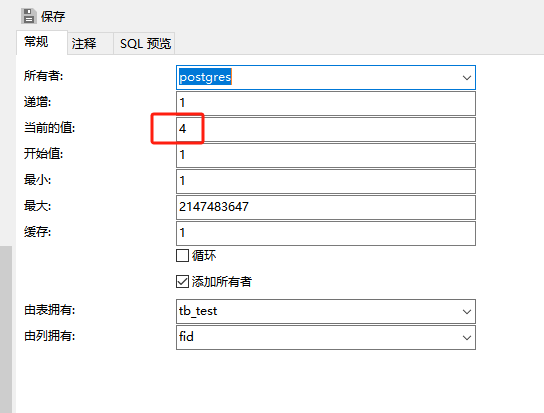
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...