AutoTimes:通过大语言模型的自回归时间序列预测器
论文标题: AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
作者:Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, Mingsheng Long
链接:https://arxiv.org/abs/2402.02370
机构:清华大学
Cool Paper:https://papers.cool/arxiv/2402.02370

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注

摘要
由于大规模时间序列的可用性有限以及可扩展预训练的探索不足,时间序列的基础模型尚未完全开发。 基于时间序列和自然语言相似的顺序结构,越来越多的研究证明了利用大型语言模型(LLM)处理时间序列的可行性。 然而,先前的方法可能忽略了时间序列和自然语言对齐的一致性,导致LLM潜力的利用不足。 为了充分利用从语言建模中学到的通用token转换,本文提出AutoTimes——将 LLM 重新用作自回归时间序列预测器,这与在不更新参数的情况下获取和利用LLM 是一致的。该预测器可以处理灵活的序列长度并实现与流行模型一样的有竞争力的性能。 此外,本文提出了token-wise prompting,利用相应的时间戳使该方法适用于多模态场景。 分析表明,该预测器继承了LLM的零样本和上下文学习能力。 根据经验,AutoTimes 表现出显着的通用性,并通过基于更大的 LLM、附加文本或时间序列作为指令来实现增强的性能。

Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何充分利用大型语言模型(LLM)的能力来改进时间序列预测。具体来说,论文提出了以下几个关键点:
- 时间序列基础模型的发展受限:由于大规模时间序列数据集的可用性有限,以及开发大型时间序列模型的技术不确定性,时间序列的基础模型发展受到了阻碍。
- 利用LLM进行时间序列预测的可行性:研究显示,由于时间序列和自然语言具有相似的序列结构,利用大型语言模型(LLM)进行时间序列预测是可行的。然而,现有方法可能忽视了在对齐时间序列和自然语言时保持一致性的重要性,导致LLM的潜力没有得到充分利用。
- AutoTimes方法的提出:为了充分挖掘LLM在时间序列预测中的潜力,论文提出了AutoTimes方法,该方法将LLM重新定位为自回归时间序列预测器,同时保持了与LLM获取和利用的一致性,而无需更新参数。
- 灵活性和性能:AutoTimes能够处理灵活的序列长度,并在性能上与现有模型竞争。
- 多模态场景的适用性:通过引入基于时间戳的标记提示,AutoTimes方法适用于多模态场景,能够利用相应的时间戳来增强预测。
- 零样本和上下文学习能力:分析表明,AutoTimes继承了LLM的零样本和上下文学习能力。
- 方法的通用性和性能提升:通过基于更大的LLM、额外文本或时间序列作为指令,AutoTimes展示了显著的方法通用性和性能提升。
总的来说,这篇论文旨在通过AutoTimes方法,克服现有时间序列预测模型的局限性,充分利用LLM的强大能力,以实现更准确和灵活的时间序列预测。
Q: 有哪些相关研究?
A: 这篇论文提到了以下相关研究:
- 时间序列基础模型(Foundation models of time series):这些模型旨在通过预训练和迁移学习来提高时间序列预测的能力。然而,由于大规模时间序列数据集的有限性,这些模型的发展受到了限制。
- 大型语言模型(Large Language Models, LLM):这些模型在自然语言处理领域取得了显著进展,特别是在语言建模和文本生成任务中。论文指出,LLM的快速发展为时间序列预测提供了新的可能性。
- 自回归时间序列预测(Autoregressive Time Series Forecasting):自回归模型是时间序列预测中的一个基本概念,它基于序列中前面的元素来预测下一个元素。论文提出的AutoTimes方法采用了这种自回归生成方式。
- 多模态语言模型(Multimodal Language Models):这些模型结合了视觉和文本信息,如视觉语言模型(Vision Language Models, VLM),在处理图像和文本数据时表现出色。论文提出的方法在时间序列预测中也采用了类似的多模态策略。
- 零样本学习(Zero-shot Learning):这是一种模型在没有见过目标任务数据的情况下进行预测的能力。论文展示了AutoTimes在零样本时间序列预测任务中的性能。
- 上下文学习(In-context Learning):这是LLM的一种能力,可以在没有额外训练的情况下,根据提供的上下文信息生成响应。论文探讨了AutoTimes在时间序列预测中的上下文学习能力。
- 时间序列预测的自回归方法(Autoregressive Models for Time Series Forecasting):这些方法遵循自回归原则,能够处理可变上下文长度和长序列生成。论文强调了自回归原则在统计预测器(如ARIMA和指数平滑)中的重要性。
- 时间序列的多模态分析(Multimodal Analysis of Time Series):一些研究已经展示了利用辅助语言信息来辅助时间序列分析的可能性。论文提出的方法在这方面进行了进一步的探索。
这些相关研究为AutoTimes方法提供了理论基础和实践背景,使得该方法能够在时间序列预测领域取得创新和突破。

Q: 论文如何解决这个问题?
A: 论文通过提出AutoTimes方法来解决利用大型语言模型(LLM)进行时间序列预测的问题。以下是AutoTimes解决这个问题的关键步骤和特点:
- 模态对齐:AutoTimes通过将时间序列数据转换为LLM可以理解的格式,实现了时间序列和自然语言之间的模态对齐。这包括将时间序列分割成段(tokenization),并将其映射到LLM的嵌入空间。
- 自回归生成:AutoTimes保持了LLM的自回归生成特性,这意味着在预测时,模型会基于前面的元素来预测下一个元素。这种方法与LLM的训练目标(即下一个token预测)保持一致。
- 参数冻结:为了充分利用LLM的预训练知识,AutoTimes在预测过程中冻结了LLM的Transformer层,只训练与时间序列相关的tokenizer和detokenizer。
- 时间戳提示(Token-wise Prompting):AutoTimes利用时间戳作为文本提示,将其与时间序列数据结合,以增强模型对时间序列中周期性和频率信息的理解。
- 零样本和上下文学习能力:AutoTimes继承了LLM的零样本和上下文学习能力,这意味着模型可以在没有额外训练的情况下,处理新的、未见过的时间序列数据。
- 多模态利用:AutoTimes能够处理多模态数据,如将时间序列与相关的文本信息(如新闻、日志等)结合,以提高预测的准确性。
- 灵活性和性能:AutoTimes能够处理不同长度的时间序列,并且通过基于更大的LLM、额外文本或时间序列作为指令,实现了性能的提升。
- 实验验证:论文通过在多个真实世界数据集上的实验,验证了AutoTimes方法的有效性,展示了其在长期和短期时间序列预测任务中的竞争力。
总的来说,AutoTimes通过结合LLM的强大能力,提出了一种简单而有效的方法来解决时间序列预测问题,同时保持了模型的灵活性和高性能。


Q: 论文做了哪些实验?


 | |
A: 论文中进行了以下实验来验证AutoTimes方法的有效性:
- 时间序列预测实验:
- 使用了多个真实世界的数据集,包括ETTh1、ECL、Traffic、Weather、Solar-Energy和M4竞赛数据集。
- 比较了AutoTimes与现有的时间序列预测方法,包括LLM4TS方法(如TimeLLM、LLM4TS、FPT和UniTime)和深度学习模型(如iTransformer、DLinear、PatchTST和TimesNet)。
- 在长期预测和短期预测任务上评估了AutoTimes的性能,包括不同预测长度和上下文长度的设置。
- 零样本预测实验:
- 在M4和M3竞赛数据集上进行了零样本预测实验,即在源域上训练模型,然后在未见过的目标域上进行预测。
- 比较了AutoTimes与FPT(Fine-tuned Pre-trained Transformer)等LLM4TS方法的性能。
- 上下文学习实验:
- 在M3竞赛数据集上进行了上下文学习实验,即利用目标域的时间序列作为提示,增强模型的预测能力。
- 展示了AutoTimes在利用时间序列提示进行预测时的性能提升。
- 方法通用性实验:
- 在不同的LLM(如GPT-2、OPT和LLaMA)上评估了AutoTimes的通用性,验证了该方法在不同模型上的适用性和性能。
- 效率和参数分析:
- 分析了AutoTimes在不同数据集上的预测误差、训练速度和参数数量,以评估方法的效率。
- 比较了AutoTimes与其他LLM4TS方法在参数效率和模型规模方面的性能。
- 可变上下文长度实验:
- 评估了AutoTimes在不同上下文长度下的性能,以展示其在处理不同长度时间序列时的灵活性。
- 时间戳提示效果分析:
- 对AutoTimes中使用时间戳作为提示的效果进行了消融研究,以验证时间戳信息对预测性能的贡献。
这些实验旨在全面评估AutoTimes在不同场景下的性能,包括其在处理不同长度序列、零样本学习、上下文学习能力以及在不同LLM上的通用性。通过这些实验,论文展示了AutoTimes在时间序列预测任务中的有效性和潜力。


Q: 有什么可以进一步探索的点?
A: 尽管AutoTimes在时间序列预测方面取得了显著的进展,但仍有一些潜在的研究方向可以进一步探索:
- 更大规模的LLM:目前的研究主要基于LLaMA-7B模型。探索更大、更先进的LLM(如GPT-3或未来的GPT-4)可能会进一步提升预测性能。
- 多模态数据融合:虽然AutoTimes已经展示了利用时间戳作为文本提示的能力,但进一步研究如何更有效地融合多模态数据(如文本、图像、音频等)可能会带来新的视角和改进。
- 模型解释性和透明度:LLM通常被认为是“黑箱”模型,研究如何提高AutoTimes的可解释性,以便用户理解模型的预测过程,这对于实际应用尤为重要。
- 长期依赖和复杂模式:研究AutoTimes在处理具有长期依赖和复杂模式的时间序列数据(如金融市场数据)时的性能和局限性。
- 实时预测和在线学习:探索AutoTimes在实时预测场景中的应用,以及如何实现在线学习,以便模型能够适应新的数据和趋势。
- 模型压缩和加速:研究如何减少AutoTimes所需的计算资源,使其更适合在资源受限的环境中部署,例如通过模型压缩或量化技术。
- 跨领域迁移学习:研究AutoTimes在不同领域(如医疗、金融、交通等)之间的迁移学习能力,以及如何优化迁移策略以提高跨领域预测性能。
- 异常检测和预测:利用AutoTimes进行异常检测,识别时间序列中的异常模式,并研究如何利用这些信息来改进预测模型。
- 交互式预测:开发交互式预测系统,允许用户通过提供额外的上下文信息(如专家知识)来指导预测过程。
- 模型稳健性:研究AutoTimes在面对噪声、缺失数据或数据分布变化时的稳健性,并探索提高模型稳健性的策略。
这些研究方向不仅有助于进一步提升AutoTimes的性能,还能够扩展其在更广泛领域的应用,推动时间序列预测技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
标题:AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
摘要:论文提出了AutoTimes,一种利用大型语言模型(LLM)进行时间序列预测的方法。AutoTimes通过将时间序列数据转换为LLM可以理解的格式,并采用自回归生成方式进行预测,从而充分利用LLM的预训练知识。这种方法不需要更新LLM的参数,同时保持了与LLM训练和推理的一致性。AutoTimes在多模态场景下表现出色,能够处理灵活的序列长度,并在性能上与现有模型竞争。此外,AutoTimes继承了LLM的零样本学习和上下文学习能力,使其在更广泛的预测场景中具有应用潜力。
引言:介绍了时间序列预测在现实世界应用中的重要性,并指出了现有时间序列基础模型发展的局限性。同时,论文强调了LLM在自然语言处理领域的快速发展,并探讨了将LLM应用于时间序列预测的可行性。
相关工作:回顾了自回归模型、大型语言模型在时间序列预测中的应用(LLM4TS),以及多模态语言模型的发展。这些工作为AutoTimes提供了理论和实践基础。
方法:详细介绍了AutoTimes的方法,包括时间序列的模态对齐、自回归生成、参数冻结、时间戳提示等关键技术。此外,还介绍了如何通过LLM进行时间序列预测的具体步骤。
实验:在多个真实世界数据集上进行了广泛的实验,验证了AutoTimes在长期和短期时间序列预测任务中的性能。实验结果表明,AutoTimes在多种预测场景下均表现出色,尤其是在零样本学习和上下文学习方面。
结论:论文总结了AutoTimes的主要贡献,包括其在时间序列预测中的有效性、灵活性和通用性。同时,论文提出了未来可能的研究方向,如利用更大的LLM、多模态数据融合、模型解释性等。
整体而言,这篇论文提出了一种创新的时间序列预测方法,通过有效地利用LLM的能力,为时间序列预测领域带来了新的视角和可能性。
完整实验结果
时间序列预测


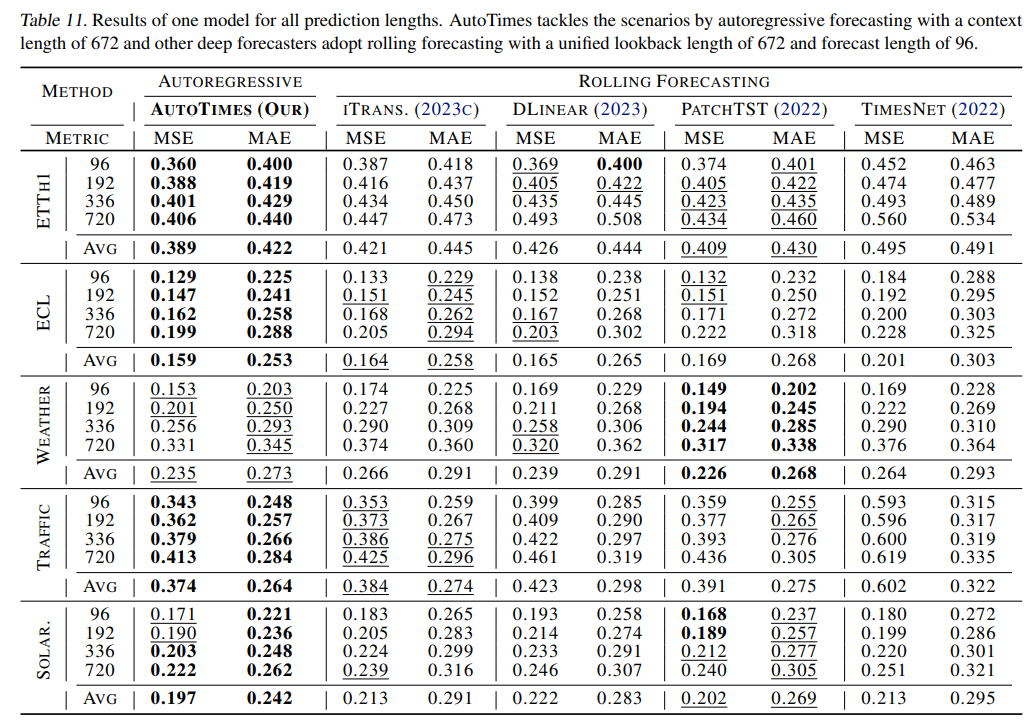
(没有太理解)大概意思是AutoTimes采用672-672( 4 × 7 × 24 = 672 4\times7\times24=672 4×7×24=672,4周)预测来训练,其余模型采用672预测96。
零样本预测

泛化能力
n-1708502837451)]
(没有太理解)大概意思是AutoTimes采用672-672( 4 × 7 × 24 = 672 4\times7\times24=672 4×7×24=672,4周)预测来训练,其余模型采用672预测96。
零样本预测
[外链图片转存中…(img-BzQX9oe8-1708502837451)]
泛化能力

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注
相关文章:
AutoTimes:通过大语言模型的自回归时间序列预测器
论文标题: AutoTimes: Autoregressive Time Series Forecasters via Large Language Models 作者:Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, Mingsheng Long 链接:https://arxiv.org/abs/2402.02370 机构:清华大学 …...

记录 | go与C/C++交互
Go语言是类C的语言,与C语言有着千丝万缕的联系,在Go语言的代码中可以直接调用C语言代码,但不支持直接调用 C。 Go 调用 C/C 的方式: C:直接调用 C API;C:通过实现一层封装的 C 接口来调用 C 接…...

B3623枚举排列
题目描述 今有 n 名学生,要从中选出 k 人排成一列拍照。 请按字典序输出所有可能的排列方式。 输入格式 仅一行,两个正整数 n,k。 输出格式 若干行,每行 k 个正整数,表示一种可能的队伍顺序。 输入输出样例 输入 #1复制 …...

vuex怎么防止数据刷新丢失?
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式和库。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。为了防止 Vuex 中的数据在刷新时丢失,你可以采取以下策略: 持久化插件:…...
)
OpenGL ES 渲染 NV21、NV12、I420、YV12、YUYV、UYVY、I444(建议收藏)
本文主要讲解常见的 YUV 格式图像渲染方式,如果对 YUV 格式不是很熟悉的同学可以翻看旧文一文掌握 YUV 图像的基本处理,YUV 格式的介绍这里不再展开。 渲染 NV21、NV12 格式图像 NV21、NV12 可以看成同一种结构,区别只是 uv 的交错排列顺序不同。 渲染 NV21/NV12 格式图像…...

云计算的两地三中心和灾备介绍
两地三中心是指在不同的地理位置建立两个数据中心和一个灾备中心,其中一个数据中心为主数据中心,另一个数据中心为备用数据中心,灾备中心则用于备份数据和在主数据中心或备用数据中心发生故障或灾难时提供应急支持。 异地灾备则是指在不同的地…...

Spring Bean
Spring的配置方式 1、xml配置文件 2、基于注解的方式 3、基于Java的方式 Spring Bean的生命周期 1、通过构造器或工厂方法创建bean实例 2、为bean的属性赋值 3、调用bean的初始化方法 4、使用bean 5、当容器关闭时,调用bean的销毁方法 Spring inner beans …...

Linux的时间操作
当涉及到时间操作时,Linux提供了一系列函数和结构体来处理时间的获取、转换和操作。 time_t 别名 time_t 是 C/C 中用来表示时间的类型,通常被定义为整数类型。它通常用来存储从纪元(通常是1970年1月1日)到某一特定时间点之间的…...
2024-02-21 作业
作业要求: 复习课上内容 //已完成结构体字节对齐,64位没做完的做完,32位重新都做一遍,课上指定2字节对齐的做一遍,自己验证 //已完成两种验证大小端对齐的代码写一遍复习指针内容 //已完成完善顺序表已写出的…...

平台组成-监控服务
监控服务和其他服务不同,不是一个单一的微服务,准确来说是一个体系。每个微服务都集成了Actuator,通过Actuator对外提供微服务的运行状况。关于Actuator大家可以阅读这篇文章。《Spring boot——Actuator 详解》 其上是Micrometer&…...
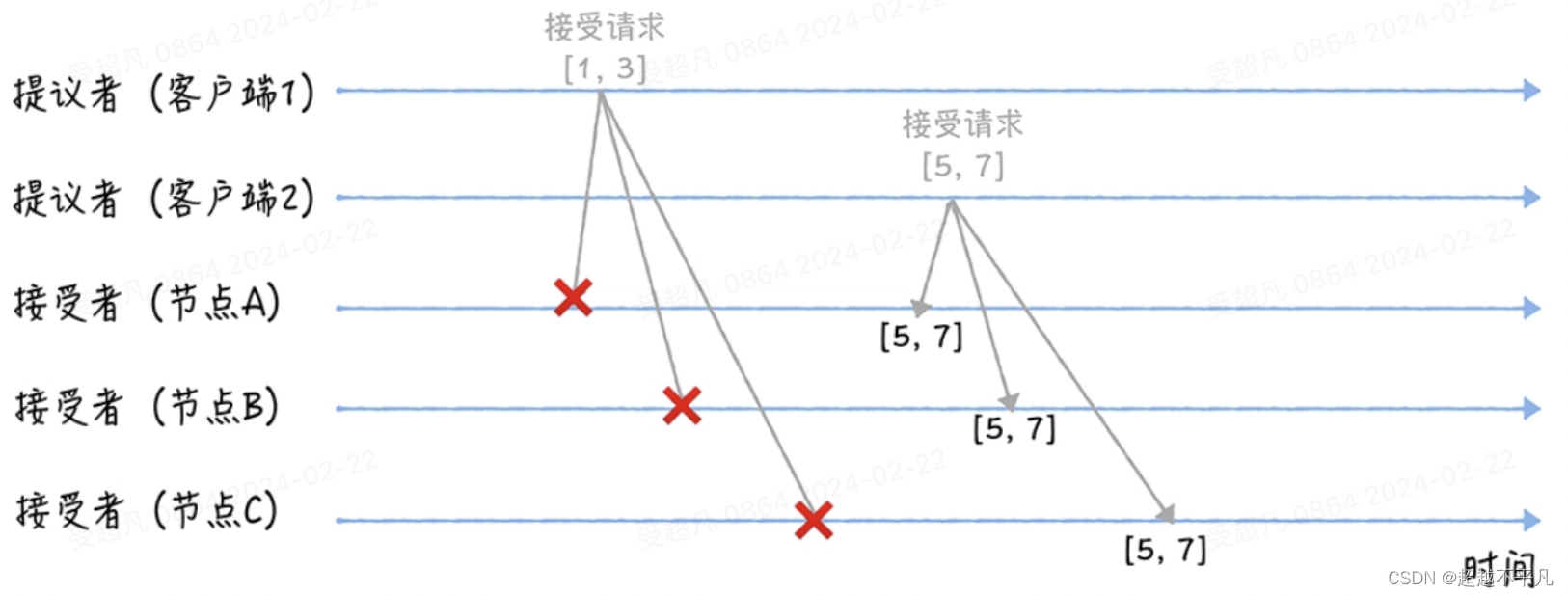
探索分布式强一致性奥秘:Paxos共识算法的精妙之旅
提到分布式算法,就不得不提 Paxos 算法,在过去几十年里,它基本上是分布式共识的代名词,因为当前一批常用的共识算法都是基于它改进的。比如,Fast Paxos 算法、Cheap Paxos、Raft 算法等。 由莱斯利兰伯特(L…...

使用 ES|QL 优化可观察性:简化 Kubernetes 和 OTel 的 SRE 操作和问题解决
作者:Bahubali Shetti 作为一名运营工程师(SRE、IT 运营、DevOps),管理技术和数据蔓延是一项持续的挑战。 简单地管理大量高维和高基数数据是令人难以承受的。 作为单一平台,Elastic 帮助 SRE 将无限的遥测数据&#…...

Docker 第十九章 : 阿里云个人镜像仓使用
Docker 第十九章 : 阿里云个人镜像仓使用 本章知识点: 如何创建镜像库,如何设置密码,如何登录与退出个人镜像仓,如何本地打镜像,如何将本地镜像推送到个人镜像库。 背景 在项目YapiDocker部署中,因读取mongo:latest 版本不一致,导致后续执行步骤的异常。遇到此场景…...

二、系统知识笔记-系统架构概述
一、系统架构定义 系统架构是指对一个系统的整体结构和组成部分进行描述和规划的过程。系统架构定义决定了系统的设计、开发和实施过程中的关键方向和决策。是系统的骨架和根基,支撑和链接各个部分,包括组件、连接件、约束规范以及指导这些内容设计与演…...

【高德地图】Android高德地图绘制标记点Marker
📖第4章 Android高德地图绘制标记点Marker ✅绘制默认 Marker✅绘制多个Marker✅绘制自定义 Marker✅Marker点击事件✅Marker动画效果✅Marker拖拽事件✅绘制默认 Infowindow🚩隐藏InfoWindow 弹框 ✅绘制自定义 InfoWindow🚩实现 InfoWindow…...
每天一个知识点 - 如何快速熟悉后端项目
入职一家新公司的时候,不可避免的就是接触到新公司的项目,有些项目一启动就是好几年,业务功能极其复杂,下面我总结几个方法让大家快速熟悉后端项目(图文结合) 用例图简析 用例是系统中的一个功能单元&…...
如何将cocos2d-x js打包部署到ios上 Mac M1系统
项目环境 cocos2d-x 3.13 xcode 12 mac m1 big sur 先找到你的项目 使用xcode软件打开上面这个文件 打开后应该是这个样子 执行编译运行就好了 可能会碰到的错误 在xcode11版本以上都会有这个错误,这是因为iOS11废弃了system。 将上面代码修改为 #if (CC_TARGE…...

pdffactory pro 8中文破解版
详细介绍 PdfFactory,PDF文档虚拟打印机,无须Acrobat即可创建Adobe PDF文件,创建PDF文件的方法比其他方法更方便和高效。支持将多个文档整合到一个PDF文件、增加字体和便签、PDF加密、去水印、压缩优化。 FinePrint,Windows虚拟…...

常用ADB命令整理已经ADB键盘输入
我们在测试Android app过程中 需要经常更换安装包的操作 熟练使用ADB命令可以提升测试效率 * 查看设备 adb devices ps这个命令是查看当前连接的设备, 连接到计算机的android设备或者模拟器将会列出显示 若有多台安卓设备,可以通过在adb后面加上 -s <设备id>…...
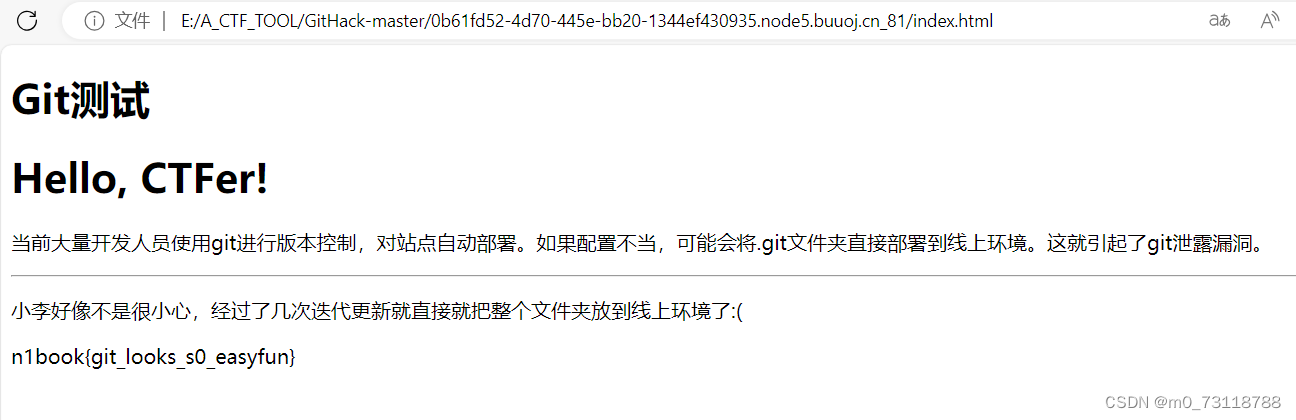
buuctf_N1BOOK_粗心的小李
题目: 看完题目,git下载文件?然后将.git文件传到线上环境?(which 会造成git泄露的安全威胁)<这个背景抱歉我不太了解哈,可能后续有补充> 这里主要记录做法过程: 工具…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...