挑战30天学完Python:Day18 正则表达式
📘 Day 18
🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点知识,但又没有系统学习的使用者。总之如果你想提升自己的Python技能,欢迎加入《挑战30天学完Python》
- 📘 Day 18
- 正则表达式
- re 模块
- re 函数
- match
- search
- findall
- sub
- split
- 正则语法
- 方括号 []
- 转义 \
- 一或多次 +
- 任意字符 .
- 零或多次 *
- 零或一次 ?)
- 数量 {}
- 开头 ^
- 不包含 [^]
- 💻 第18天练习
- 练习1级
- 练习2级
- 练习3级
- 正则表达式
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。要在python中使用RegEx,首先我们应该导入名为 re 的模块。
re 模块
导入模块以后,我们就可以使用它来检查或者查找了。
import re
re 函数
为了使用不同的模式进行查找, re 提供了一些函数方法来进行匹配。
- re.match: 只在字符串的第一行开始搜索,如果找到则返回匹配的对象,否则返回None。
- re.search: 如果字符串(包括多行字符串)中有匹配对象,则返回匹配对象。
- re.findall: 返回包含所有匹配项的列表,如果没有匹配则返回空列表。
- re.split: 方法按照能够匹配的子串将字符串分割后返回列表。
- re.sub: 查找并替换一个或者多个匹配项。
Match
# 语法形式
match(pattern, string, flags=0)
# pattern: 匹配的正则表达式
# string:要匹配的字符串
# flags:[可选] 用来控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
import retxt = 'I love to teach python and javaScript'
# 本身反馈一个 span 对象
match = re.match('I love to teach', txt, re.I) # re.I 不区分大小写
print(match) # <re.Match object; span=(0, 15), match='I love to teach'># 进一步我们可以使用span()获取匹配的起始位置和结束位置的元组值
span = match.span()
print(span) # (0, 15)# 再进一步可以打印出拆分的起始和结束索引,以及使用分片获取匹配字符串
start, end = span
print(start, end) # 0, 15
substring = txt[start:end]
print(substring) # I love to teach
如例上边例子中示,我们在目标字符串中查找是否有 I love to teach 的字符串匹配。其中从开始的位置我们找到了对应匹配,进而得到了一个对象的返回。
import retxt = 'I love to teach python and javaScript'
match1 = re.match('I like to teach', txt, re.I)
print(match1) # Nonematch2 = re.match('love', txt)
print(match2) # None此例子中字符串不包含 I like to teach,或者没用匹配开头字符,因此匹配方法返回None。
Search
# 语法
re.search(pattern, string, flags=0)
# 参数说明同match
import retxt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''# 返回匹配对象span
match = re.search('first', txt, re.I)
print(match) # <re.Match object; span=(100, 105), match='first'># 获取匹配开始和结束位置元组
span = match.span()
print(span) # (100, 105)# 获取开始和结束值,并获截取字字符串
start, end = span
print(start, end) # 100 105
substring = txt[start:end]
print(substring) # first# 没有任何匹配返回None
nom = re.search('weather', txt, re.I)
print(nom) # None正如你所见,搜索要比匹配方式好的多。因为它可以在整个文本中进行查找匹配。并返回第一找到的对象,否则返回None。接下来还有一个更好的函数 findall 它可以匹配所有并以列表形式返回。
findall
findall() 以列表的形式返回所有匹配
import retxt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''matches = re.findall('language', txt, re.I)
print(matches) # ['language', 'language']
可以看到,单词 language 在字符串中出现了两次。现在我们将在字符串中寻找Python和Python单词:
txt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''# It returns list
matches = re.findall('python', txt, re.I)
print(matches) # ['Python', 'python']这个例子中因为我们使用标记位(re.I) 忽略大小写,所以返回两个。如果我们没有使用它,看看是什么结果。
import re
matches = re.findall('Python', txt)
print(matches) # ['Python']当然我们如果想要达到其他效果,也可以用其他方法,不过就没有上边使用标记位那么优雅了。
import re
txt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''matches = re.findall('Python|python', txt)
print(matches) # ['Python', 'python']#
matches = re.findall('[Pp]ython', txt)
print(matches) # ['Python', 'python']sub
匹配并替换字符串,直接看例子:
import re
txt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''match_replaced = re.sub('Python|python', 'JavaScript', txt, re.I)
print(match_replaced) # JavaScript is the most beautiful language that a human being has ever created.# 或者
match_replaced = re.sub('[Pp]ython', 'JavaScript', txt, re.I)
print(match_replaced) # JavaScript is the most beautiful language that a human being has ever created.
让我们再来看一个例子。下边是一个包含很多多余 % 字符的字符串,让人晦涩难懂。让我们用此方法清楚掉它。
import re
txt = '''%I a%m te%%a%%che%r% a%n%d %% I l%o%ve te%ach%ing.
T%he%re i%s n%o%th%ing as r%ewarding a%s e%duc%at%i%ng a%n%d e%m%p%ow%er%ing p%e%o%ple.
I fo%und te%a%ching m%ore i%n%t%er%%es%ting t%h%an any other %jobs.
D%o%es thi%s m%ot%iv%a%te %y%o%u to b%e a t%e%a%cher?'''matches = re.sub('%', '', txt)
print(matches)
得到整洁的文本输出
I am teacher and I love teaching.
There is nothing as rewarding as educating and empowering people.
I found teaching more interesting than any other jobs.
Does this motivate you to be a teacher?
split
返回分割后的列表。
txt = '''I am teacher and I love teaching.
There is nothing as rewarding as educating and empowering people.
I found teaching more interesting than any other jobs.
Does this motivate you to be a teacher?'''
print(re.split('\n', txt)) # 按照换行符 \n 进行分割返回# 其实等同于字符直接调用split方法
print(txt.split('\n'))
['I am teacher and I love teaching.', 'There is nothing as rewarding as educating and empowering people.', 'I found teaching more interesting than any other jobs.', 'Does this motivate you to be a teacher?']
正则语法
在以往我们声明一个变量,使用的是单引号或者双引号。如果要声明一个正则变量则是 r''
下面的模式仅用小写字母标识apple,为了使其不区分大小写,我们要么重写模式,要么添加一个标志。
import reregex_pattern = r'apple'
txt = 'Apple and banana are fruits. An old cliche says an apple a day a doctor way has been replaced by a banana a day keeps the doctor far far away. '
matches = re.findall(regex_pattern, txt)
print(matches) # ['apple']# 添加标记位使其大小写不敏感
matches = re.findall(regex_pattern, txt, re.I)
print(matches) # ['Apple', 'apple']# 或者我们使用一组规则匹配方法
regex_pattern = r'[Aa]pple' # [Aa]表示匹配字符串首字符可以是大写A,也可以是小写a
matches = re.findall(regex_pattern, txt)
print(matches) # ['Apple', 'apple']这里先附上标记位包含哪些:
- re.I:匹配对大小写不敏感
- re.M:多行匹配(影响 ^ 和 $)
- re.S:使 . 匹配包括换行在内的所有字符
然后就详细看下正则里的一些语法符
- []: 一组字符
- [a-c] 表示 a 或 b 或 c
- [a-z] 表示 小写 a 到 z 任意字符
- [A-Z] 表示 大写 A to Z 任意字符
- [0-3] 表示 0 或 1 或 2 或 3
- [0-9] 表示0 到 9 任意数字
- [A-Za-z0-9] 表示任意单字符, 即 小写字母a到z, 大写字母A到Z 或数字0到9
- \: 转义特殊字符
- \d 表示 匹配任意数字,相当于 [0-9].
- \D 表示 匹配任意非数字
- . : 匹配任意字符(除了换行符 \n)
- ^: 匹配开头
- r’^substring’ 例如 r’^love’, 必须以love开头的句子
- r’[^] 表示不在[]中的字符,例如 r’[^abc] 表示不是a, 不是b, 不是c。即除a,b,c之外的字符
- $: 匹配结尾
- r’substring ′ 举例 r ′ l o v e ' 举例 r'love ′举例r′love’, 必须以love结尾的句子
- *: 0或多个次
- r’[a]*’ 表示可以不出现,或者可以出现多次
- +: 0或多个次
- r’[a]+’ 表示至少一次或多次
- ?: 0或1次
- r’[a]?’ 表示零次或一次
- {n}:精确匹配个数
- {3}: 表示 正好3个字符
- {3,}: 表示 至少3个字符
- {3,8}: 表示 3到8个字符
- |: 不是就是(或)
- r’apple|banana’ 表示要么是 apple 要么是 banana
- (): 正则表达式分组并记住匹配的文本

让我们用一些例子来上边这些匹配字符是如何使用的。
方括号 []
让我们用方括号来匹配小写和大写
import reregex_pattern = r'[Aa]pple'
txt = 'Apple and banana are fruits. An old cliche says an apple a day a doctor way has been replaced by a banana a day keeps the doctor far far away.'
matches = re.findall(regex_pattern, txt)
print(matches) # ['Apple', 'apple']
如我我们想再额外查找 banana,我们可以优化匹配如下:
import reregex_pattern = r'[Aa]pple|[Bb]anana'
txt = 'Apple and banana are fruits. An old cliche says an apple a day a doctor way has been replaced by a banana a day keeps the doctor far far away.'
matches = re.findall(regex_pattern, txt)
print(matches) # ['Apple', 'banana', 'apple', 'banana']
我们在方括号中使用了字符或 | ,因此设法提取出了 Apple, Apple, Banana 和 Banana。
转义 \
import reregex_pattern = r'\d' #
txt = 'This regular expression example was made on December 6, 2019 and revised on July 8, 2021'
matches = re.findall(regex_pattern, txt)
print(matches) # ['6', '2', '0', '1', '9', '8', '2', '0', '2', '1'], 提取了所有数字,但这却不是我们想要的效果
一或多次 +
结合上边 \d 使用+做个组合优化
import reregex_pattern = r'\d+' # d表示匹配数字, +表示一次或多次
txt = 'This regular expression example was made on December 6, 2019 and revised on July 8, 2021'
matches = re.findall(regex_pattern, txt)
print(matches) # ['6', '2019', '8', '2021'] - 现在才是我们想要的效果
任意字符 .
import reregex_pattern = r'[a].' # 小写a和任意
txt = '''Apple and banana are fruits'''
matches = re.findall(regex_pattern, txt) # 匹配多个项目
print(matches) # ['an', 'an', 'an', 'a ', 'ar'] 分别对应and中an,banana中an、an、a空格,are中ar regex_pattern = r'[a].+' # . 任意字符, + 一次或多次(连续)
matches = re.findall(regex_pattern, txt)
print(matches) # ['and banana are fruits']
零或多次 *
零次或多次。即可能不会出现,也可能多次出现。
import reregex_pattern = r'[a].*'
txt = '''Apple and banana are fruits'''
matches = re.findall(regex_pattern, txt)
print(matches) # ['and banana are fruits']
零或一次 ?
零次或一次。即可能不会出现,也可能只出现一次。
import retxt = '''I am not sure if there is a convention how to write the word e-mail.
Some people write it as email others may write it as Email or E-mail.'''
regex_pattern = r'[Ee]-?mail' # ? 表示 - 是个可选项
matches = re.findall(regex_pattern, txt)
print(matches) # ['e-mail', 'email', 'Email', 'E-mail']
正则数量 {}
我们可以使用花括号指定我们在文本中寻找的子字符串的长度。让我们想一下,我们如果对一个长度为4个字符的子字符串感兴趣的话:
import retxt = '今年的大年三十日期是2023年1月23日,去年的则是2022年1月31日,真是一年比一年早'
regex_pattern = r'\d{4}' # 精准匹配有四个数字的
matches = re.findall(regex_pattern, txt)
print(matches) # ['2023', '2022']regex_pattern = r'\d{1,4}' # 匹配1,2,3,4 贪婪模式
matches = re.findall(regex_pattern, txt)
print(matches) # ['2023', '1', '23', '2022', '1', '31']
开头 ^
- 匹配字符串的开头
import retxt = '今天天气很好,所以今天你的心情好吗?'
regex_pattern = r'^今天' # ^ 表示必须以“今天”开头
matches = re.findall(regex_pattern, txt)
print(matches) # ['今天'] 注意只返回了一个
不包含 [^]
import retxt = '今年的大年三十日期是2023年1月23日,去年的则是2022年1月31日,真是一年比一年早'
regex_pattern = r'[^\u4e00-\u9fa5, ]+' # ^ 排除中文字符,逗号和空格
matches = re.findall(regex_pattern, txt)
print(matches) # ['2023', '1', '23', '2022', '1', '31']
💻 第18天练习
练习1级
- 下面这段话中出现频率最高的单词是什么?
paragraph = 'I love teaching. If you do not love teaching what else can you love. I love Python if you do not love something which can give you all the capabilities to develop an application what else can you love.
[(6, 'love'),(5, 'you'),(3, 'can'),(2, 'what'),(2, 'teaching'),(2, 'not'),(2, 'else'),(2, 'do'),(2, 'I'),(1, 'which'),(1, 'to'),(1, 'the'),(1, 'something'),(1, 'if'),(1, 'give'),(1, 'develop'),(1, 'capabilities'),(1, 'application'),(1, 'an'),(1, 'all'),(1, 'Python'),(1, 'If')]
- 从以下这段对话中提取数字 “The position of some particles on the horizontal x-axis are -12, -4, -3 and -1 in the negative direction, 0 at origin, 4 and 8 in the positive direction.” 并计算出最远距离点。
points= ['-12', '-4', '-3', '-1', '0', '4', '8']
sorted_points= [-12, -4, -3, -1, 0, 4, 8]
distance = |-12| + |8| # 20
练习2级
- 编写一个方法来识别字符串是否是有效的python变量
is_valid_variable('first_name') # True is_valid_variable('first-name') # False is_valid_variable('1first_name') # False is_valid_variable('firstname') # True
练习3级
-
清除以下文本无用的字符。且统计出优化后的文本中出现频率最高的三个单词。
sentence = '''%I $am@% a %tea@cher%, &and& I lo%#ve %tea@ching%;. There $is nothing; &as& mo@re rewarding as educa@ting &and& @emp%o@wering peo@ple. ;I found tea@ching m%o@re interesting tha@n any other %jo@bs. %Do@es thi%s mo@tivate yo@u to be a tea@cher!?'''print(clean_text(sentence)) I am a teacher and I love teaching There is nothing as more rewarding as educating and empowering people I found teaching more interesting than any other jobs Does this motivate you to be a teacher print(most_frequent_words(cleaned_text)) # [(3, 'I'), (2, 'teaching'), (2, 'teacher')]
练习参考答案请移步 github项目地址 18_exercise.py
<< Day 17 | Day 19 >>
相关文章:
挑战30天学完Python:Day18 正则表达式
📘 Day 18 🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点…...
力扣● 343. 整数拆分 ● 96.不同的二叉搜索树
● 343. 整数拆分 想不到,要勇于看题解。 关键在于理解递推公式。 1、DP数组及其下标的含义:dp[i]是分解i这个数得到的最大的乘积。 2、DP数组如何初始化:dp[0]和dp[1]都没意义,所以直接不赋值,初始化dp[2]1即可。…...
游戏同步+游戏中的网络模块
原文链接:游戏开发入门(九)游戏同步技术_游戏数据同步机制流程怎么开发-CSDN博客 游戏开发入门(十)游戏中的网络模块_游戏开发组网-CSDN博客 3.同步技术的基本常识: a.同步给谁?某个用户&…...
【03】逆序数组
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 一、逆序函数是什么? 二、逆序函数原码 1.直接逆序 2.创建临时数组逆序 三、结言 💥一、逆序函数是什么? 示例:输入1 4 …...
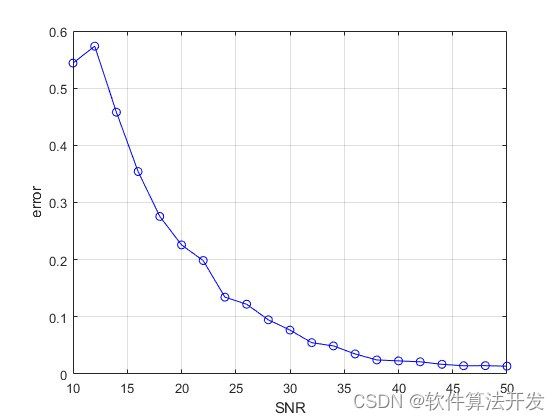
基于Prony算法的系统参数辨识matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 Prony算法是一种用于信号处理和系统辨识的经典方法,特别适用于线性时不变系统(LTI)的频率响应分析以及模拟复指数信号序列。其…...

创建第一个React项目
React脚手架 npx create-react-app react-demonpx是直接从互联网网上拉最新的脚手架进行创建react 运行React项目 npm start若想找到Webpack配置文件 npm ejectReact的基本使用 基本步骤 导入react和react-dom vue 创建react元素 渲染react元素到页面中导入 import React…...
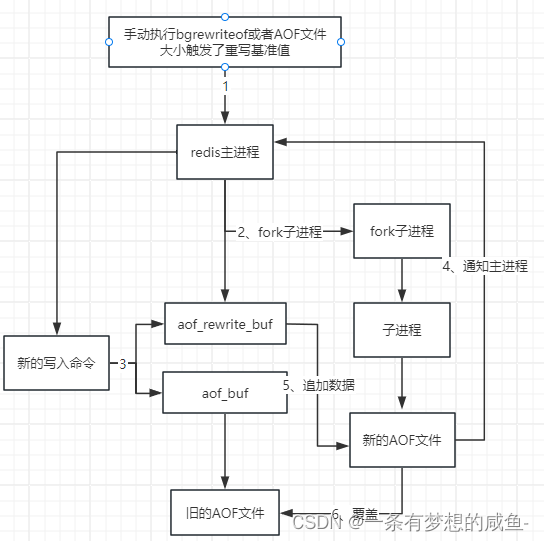
Redis篇之Redis持久化的实现
持久化即把数据保存到可以永久保存的存储设备当中(磁盘)。因为Redis是基于内存存储数据的,一旦redis实例当即数据将会全部丢失,所以需要有某些机制将内存中的数据持久化到磁盘以备发生宕机时能够进行恢复,这一过程就称…...
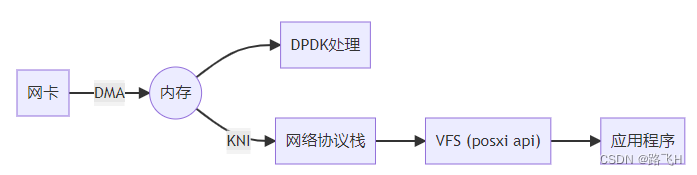
dpdk环境搭建和工作原理
文章目录 1、DPDK环境搭建1.1、环境搭建1.2、编译DPDK 2、DPDK工作原理 1、DPDK环境搭建 1.1、环境搭建 工具准备:VMware、ubuntu16.04。 (1)VMware添加两个网卡。桥接网卡作为 DPDK 运行的网卡,NAT 网卡作为 ssh 连接的网卡。 …...

接口测试实战--自动化测试流程
一、项目前期准备 常见项目软件架构: springMvc:tomcat里运行war包(在webapps目录下) springboot:java -jar xx.jar -xms(**) 运行参数 springCloud:k8s部署,使用kubectl create -f xx.yaml 接口自动化测试介入需越早越好,只要api定义好就可以编写自动化脚本; 某个…...
babylonjs中文文档
经过咨询官方,文档已经添加了开源协议。 基于目前babylonjs没有中文文档,为了打造更好的babylonjs生态圈 ,特和小伙伴们翻译了官方文档。 相关链接: 欢迎加群:464146715 官方文档 中文文档 Babylonjs案例分享...
WordPress使用
WordPress功能菜单 仪表盘 可以查看网站基本信息和内容。 文章 用来管理文章内容,分类以及标签。编辑文章以及设置分类标签,分类和标签可以被添加到 外观-菜单 中。 分类名称自定义;别名为网页url链接中的一部分,最好别设置为中文…...
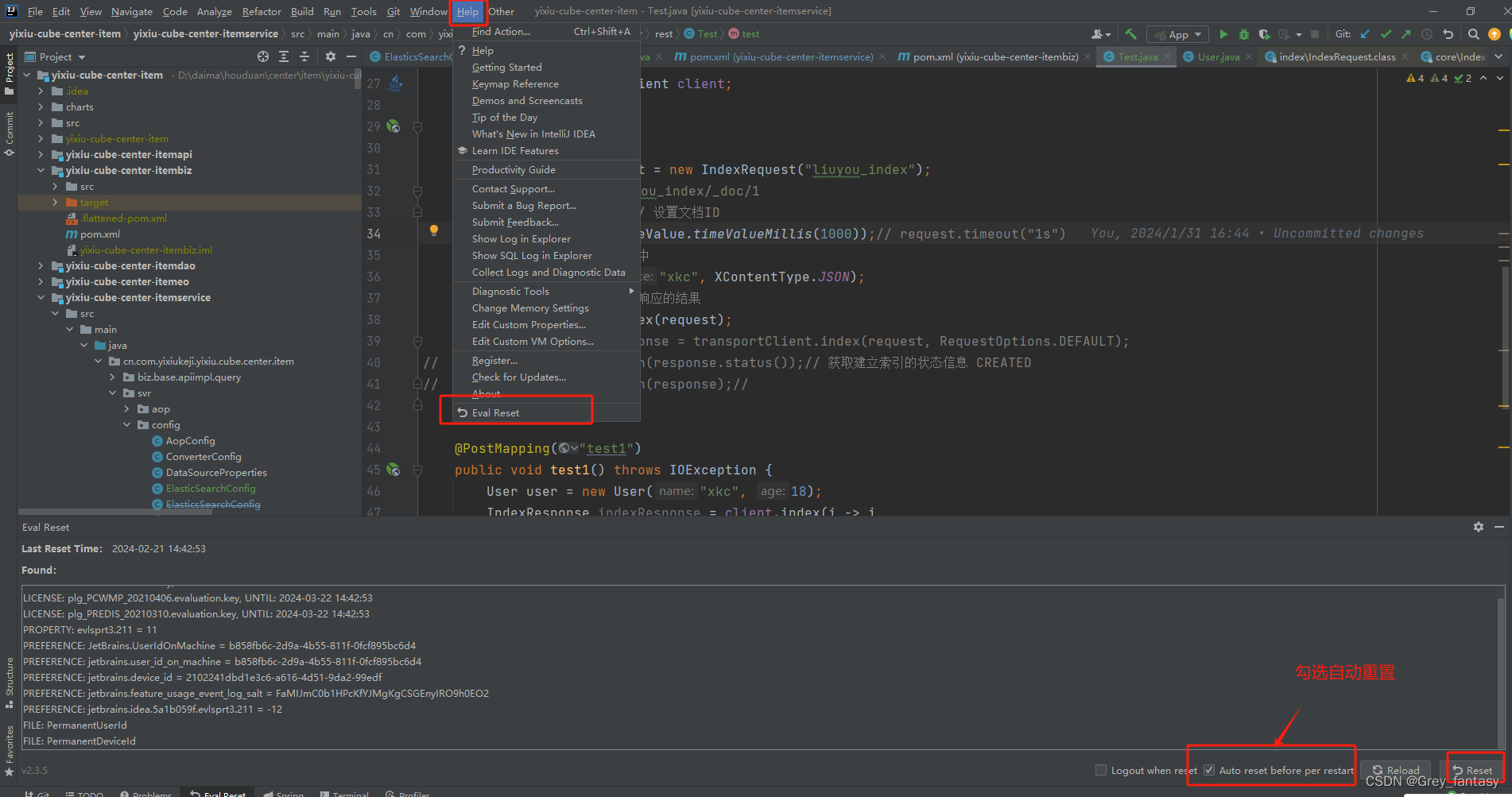
IDEA 2021.3激活
1、打开idea,在设置中查找Settings/Preferences… -> Plugins 内手动添加第三方插件仓库地址:https://plugins.zhile.io搜索:IDE Eval Reset 插件进行安装。应用和使用,如图...

进度条小程序
文章目录 铺垫回车换行缓冲区概述强制冲刷缓冲区 简单实现倒计时功能进度条小程序版本一实例代码效果展示分析 版本二 铺垫 回车换行 回车和换行是两个独立的动作 回车是将光标移动到当前行的最开始(最左侧) 换行是竖直向下平移一行 在C语言中&…...
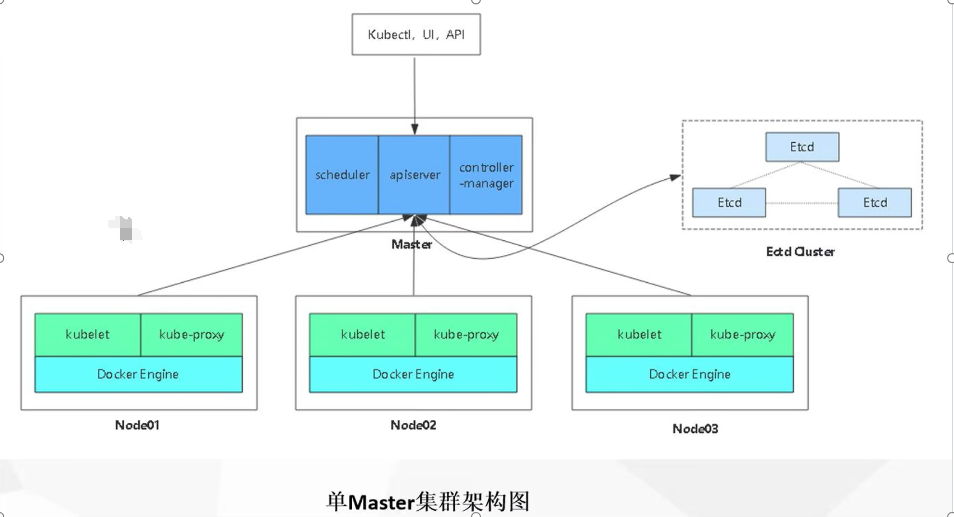
K8S安装部署
常见的K8S安装部署方式 Minikube Minikube是一个工具,可以在本地快速运行一个单节点微型K8S,仅用于学习、预览K8S的一些特性使用。 部署地址:Install Tools | Kubernetes Kubeadm Kubeadm也是一个工具,提供kubeadm init和kube…...

AI大模型与小模型之间的“脱胎”与“反哺”(第一篇)
一、AI小模型脱胎于AI大模型,而AI小模型群又可以反哺AI大模型 AI大模型(如GPT、BERT等)通常拥有大量的参数和训练数据,能够生成或理解复杂的文本内容。这些大模型在训练完成后,可以通过剪枝、微调等方式转化为小模型&…...
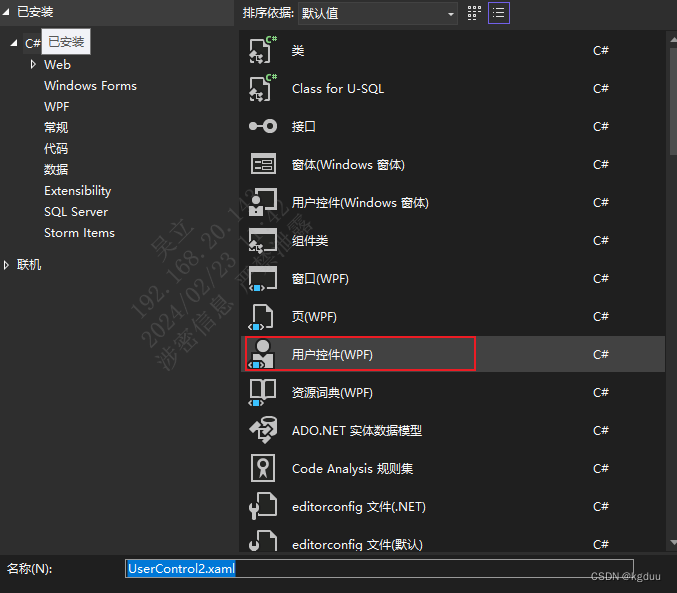
C#学习总结
1、访问权限 方法默认访问修饰符:private 类默认访问修饰符:internal 类的成员默认访问修饰符:private 2、UserControl的使用 首先添加用户控件 使用时一种是通过代码添加,一种是通过拖动组件到xaml中...

计算机网络-网络互联
文章目录 网络互联网络互联方法LAN-LAN:网桥及其互连原理使用网桥实现LAN-LAN使用交换机扩展局域网使用路由器连接局域网 LAN-WANWAN-WAN路由选择算法非自适应路由选择算法自适应路由选择算法广播路由选择算法:分层路由选择算法 网络互联 网络互联是指利…...

免费的ChatGPT网站( 7个 )
ChatGPT 是由 OpenAI 公司研发的一款大型语言模型,它可以实现智能聊天、文本生成、语言翻译等多种功能。以下是 ChatGPT 的详细介绍: 智能聊天:ChatGPT 可以与用户进行自然语言对话,回答用户的问题,提供相关的信息和建…...

Opencv3.2 ubuntu20.04安装过程
##1、更新源 sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main" sudo apt update##2、安装依赖库 sudo apt-get install build-essential sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavfor…...

OpenGL ES (OpenGL) Compute Shader 计算着色器是怎么用的?
OpenGL ES (OpenGL) Compute Shader 是怎么用的? Compute Shader 是 OpenGL ES(以及 OpenGL )中的一种 Shader 程序类型,用于在GPU上执行通用计算任务。与传统的顶点着色器和片段着色器不同,Compute Shader 被设计用于在 GPU 上执行各种通用计算任务,而不是仅仅处理图形…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...