【文生视频】Diffusion Transformer:OpenAI Sora 原理、Stable Diffusion 3 同源技术
文生视频 Diffusion Transformer:Sora 核心架构、Stable Diffusion 3 同源技术
- 提出背景
- 输入输出
- 生成流程
- 变换器的引入
- Diffusion Transformer (DiT)架构
- Diffusion Transformer (DiT)总结
- OpenAI Sora 设计思路
- 阶段1: 数据准备和预处理
- 阶段2: 架构设计
- 阶段3: 输入数据的结构化
- 阶段4: 视频压缩和表示
- 阶段5: 模型训练和优化
- 阶段6: 输出生成
- OpenAI Sora 工作流程
- 步骤1: 视频数据的压缩和转换
- 步骤2: 时空补丁的提取
- 步骤3: 使用Transformer处理补丁
- 步骤4: 生成视频内容
- 步骤5: 视频解码
前置知识(保证非常易懂):
- Transformer
- ViT:视觉 Transformer
- Diffusion 扩散模型
提出背景
论文:https://arxiv.org/pdf/2212.09748.pdf
代码:https://github.com/facebookresearch/DiT
在传统的DDPMs中,使用卷积U-Net作为骨干网络是常见的选择。
尽管这些模型在图像生成任务上取得了显著的成功,但是随着生成图像分辨率的提高以及对更复杂图像特征的需求增加,需要寻找更高效和可扩展的模型架构。
假设我们想要生成一系列高质量的图像,这些图像模仿了某种特定的艺术风格,例如梵高的画风。
传统的方法可能依赖于复杂的卷积网络,如U-Net,这种网络通过大量的层次和参数来捕捉图像的细节和风格特征。
然而,这种方法在处理更高分辨率的图像或更复杂的图像风格时,可能会遇到性能瓶颈。
用变换器替代U-Net骨干网络:U-Net是一种流行的用于图像处理任务(特别是图像分割)的卷积神经网络架构。
- 它的特点是有一个对称的结构,能够有效地捕获图像的局部和全局信息。
- 在这里,研究者选择用变换器替换U-Net,意味着他们采用了一种基于注意力机制的方法来处理图像,而不是传统的卷积方法。
- 这种替换旨在利用变换器处理复杂数据依赖关系的能力,以提高扩散模型生成图像的质量和效率。
变换器作用于潜在的补丁上:这意味着变换器模型不是直接在整个图像上一次性操作,而是将图像分割成小块(即补丁),然后在这些小块的潜在表示上应用其注意力机制。
- 这种方法可以让模型更有效地学习图像的局部细节,同时保持对全局结构的理解。
输入输出
- 输入:
- 带有噪声的图像块(Noisy Patches):这些是经过特定噪声过程处理后的图像片段,DiT需要从这些噪声图像块中恢复出原始的“干净”图像。
- 条件信息(如文本提示):文本提示提供了生成内容的上下文信息,使得DiT能够根据这些提示生成与之匹配的图像或视频内容。
- 输出:
- 原始的“干净”图像块:DiT的目标是从带噪声的输入中恢复出无噪声的原始图像块。
生成流程
-
视频数据的压缩与编码:首先,视频数据被压缩到一个低维度潜在空间中,这个过程通过一个视频压缩网络(即视频编码器)完成。
压缩的结果是对视频内容的紧凑表征。
-
时空补丁的分解:接下来,压缩后的视频表征被分解成一系列的时空补丁。
这些补丁被视为Transformer模型的输入tokens,每个补丁包含了视频的一部分时空信息。
-
DiT训练过程:DiT接受带有噪声的补丁和相应的条件信息作为输入,通过训练学习去除噪声并恢复出原始的“干净”补丁。
这一过程涉及到逐步降低噪声水平,直至生成高质量的图像或视频内容。
-
视频内容的生成:通过将恢复的“干净”补丁重新组合,DiT能够生成新的视频内容。
如果需要,这些生成的潜在表征还可以通过一个解码器转换回像素级的视频图像。
-
输出调整:生成的视频内容可以根据需要调整大小和格式,以适应不同的分辨率、持续时间和宽高比需求。
举个例子,一只狗在公园追逐飞盘。
步骤1: 视频数据的压缩与编码
- 首先,我们需要大量包含狗、公园和飞盘等元素的视频素材。
- 这些视频通过视频压缩网络(视频编码器)被压缩,每个视频被转换成一个低维度的潜在空间表征。
- 这个压缩过程保留了视频的关键信息,但大幅减少了数据的复杂性。
步骤2: 时空补丁的分解
- 接下来,每个压缩后的视频表征被分解成一系列的时空补丁。
- 例如,如果压缩后的表征是一个3D数组(考虑时间和两个空间维度),它会被分解成多个包含视频特定时刻和位置信息的小块(补丁)。
步骤3: DiT训练过程
- DiT模型接受这些带有噪声的补丁和文本提示 “一只狗在公园追逐飞盘” 作为输入。
- 在训练过程中,模型学习如何从带噪声的输入中恢复出清晰的补丁,从而能够基于文本提示重建视频场景。
步骤4: 视频内容的生成
- 一旦模型训练完成,就可以使用它来生成新的视频内容。
- 为此,向模型提供一组随机初始化的噪声补丁和相同的文本提示。
- 模型将这些噪声补丁转换成对应于文本描述的“干净”补丁,然后这些补丁被重新组合成连贯的视频。
步骤5: 输出调整
- 生成的视频可以根据需要调整大小和格式。
- 例如,如果最终视频需要在不同的设备上播放,可以调整其分辨率和宽高比以适配手机、平板或电脑屏幕。
整个生成流程:
- 首先准备好与这一场景相关的文本提示,并将其输入模型。
- 模型通过训练好的网络处理一系列随机初始化的噪声补丁,基于文本提示恢复出清晰的补丁。
- 这些补丁最终被合并,生成一段高质量的视频,准确地展示了文本提示描述的场景。
引入基于变换器的扩散模型(DiTs)后,我们采取不同的策略:
-
模型设计:我们设计一个基于变换器的架构,该架构能够更有效地处理图像的潜在表示。
变换器以其强大的注意力机制著称,能够捕捉图像不同部分之间的复杂关系,这对于图像生成尤其有用。
-
潜在空间操作:与直接在像素级别操作不同,我们的模型在所谓的潜在空间中工作,这是一个通过某种形式的编码器得到的压缩图像表示。
这种表示捕捉了图像的关键特征,但用更少的数据表示,使得模型更加高效。
-
可扩展性:为了生成更高质量的图像,我们可以通过增加变换器的深度(即层数)或宽度(即每层的大小),或是增加处理的潜在补丁的数量来提高模型的计算复杂度(Gflops)。
随着复杂度的提高,模型能够更好地学习复杂的图像特征,生成更接近真实的高分辨率艺术风格图像。
-
性能验证:我们通过在一系列图像生成任务上测试我们的模型,特别是在模仿梵高画风的任务上,来验证模型的性能。
通过计算FID得分,我们发现随着模型复杂度的增加(更多的Gflops),生成的图像与真实的梵高画作在视觉上更为相似,FID得分更低,表明图像质量更高。
-
成就:我们的最大型号,DiT-XL/2,在这些图像生成任务中表现出色,不仅在模仿梵高画风方面达到了新的高度,而且在一系列基准测试中设置了新的记录。
基于变换器的扩散模型提供了一种强大且可扩展的方法来生成高质量的图像,能够应对不同分辨率和复杂度的挑战,同时在保持或提高图像质量的同时提高计算效率。
实验结论:
通过增加模型的规模和计算资源投入,能够生成更高质量的图像。这表明DiTs模型是可扩展的,即它们可以通过增加资源投入来实现更好的性能。
变换器的引入
-
目标:探索变换器架构在DDPMs中的应用,旨在利用其强大的可扩展性和处理大规模数据集的能力来提升图像生成的质量。
-
实现步骤:
- 替换骨干网络:用标准变换器架构替换DDPM中的U-Net骨干网络。
这一步骤需要考虑如何有效地将图像数据转换为适合变换器处理的格式(例如,将图像切分为小块或补丁)。
- 模型训练:在变换器骨干的DDPM上进行训练,使用大规模图像数据集并采用适当的训练技巧,如注意力机制和位置编码,以捕捉图像的全局依赖性和局部细节。
- 性能评估:通过FID(Fréchet Inception Distance)等指标评估生成图像的质量,验证变换器架构的有效性。
通过将变换器架构应用于DDPMs,我们能够生成具有更高分辨率、更丰富细节和更低FID得分的图像。
Diffusion Transformer (DiT)架构
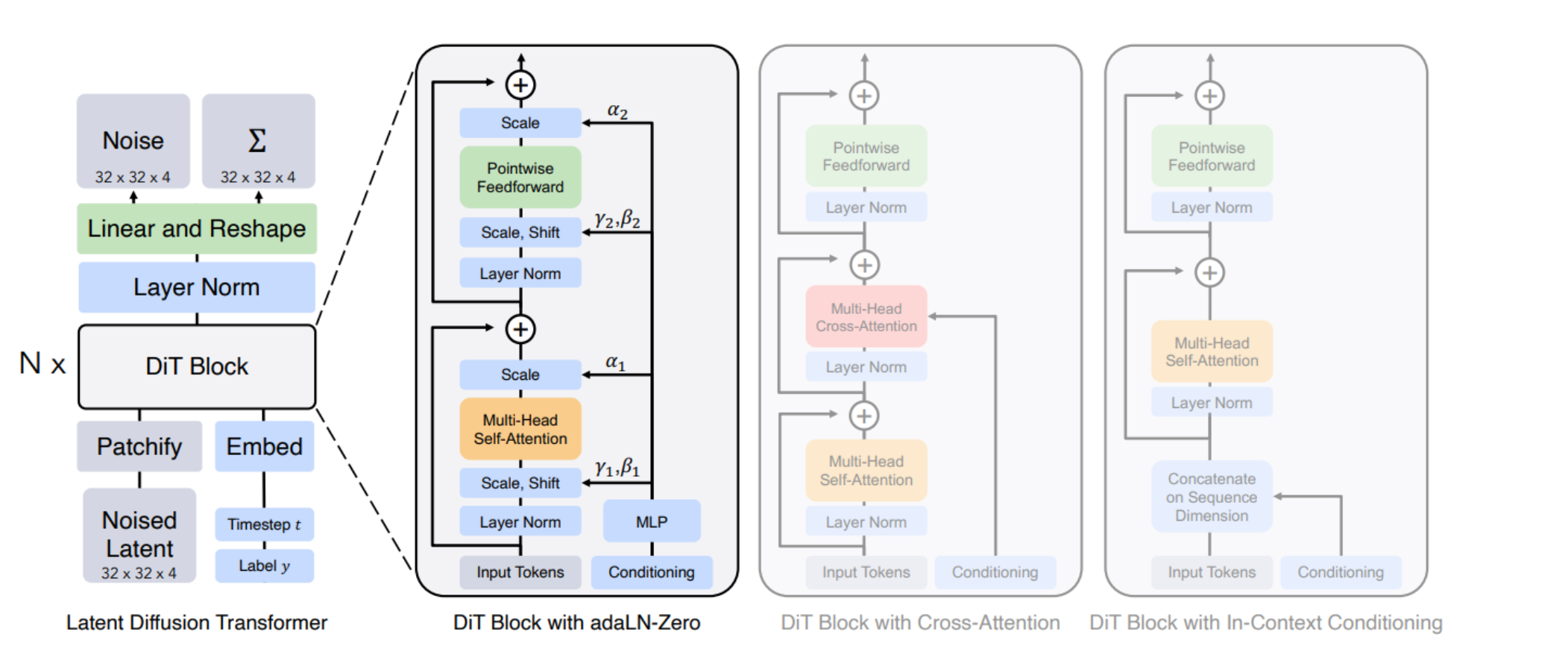
左侧描述了条件潜在DiT模型的训练过程,其中输入的潜在信息被分解为补丁并由多个DiT块处理。
右侧展示了DiT块的详细信息,并说明了标准变换器块的不同变体。
在这些变体中,适应性层归一化(adaptive layer norm)表现得最好。
图中的结构包括:
- 多头自注意力(Multi-Head Self-Attention)
- 多头交叉注意力(Multi-Head Cross-Attention)
- 前馈网络(Pointwise Feedforward)
- 层归一化(Layer Norm)
- 缩放、平移以及时步和条件信息的整合
- 每个DiT块都包含了这些元素,这些元素共同工作以学习和生成图像数据的复杂分布。
通过实验不同的变换器块配置,研究人员可以找到最优的模型设置,以提高模型的性能和生成图像的质量。
这张图表明,DiT模型是对传统扩散模型的一个显著改进,因为它们整合了变换器架构的强大能力,尤其是在处理和生成高质量图像方面。
DiT的输入规格:
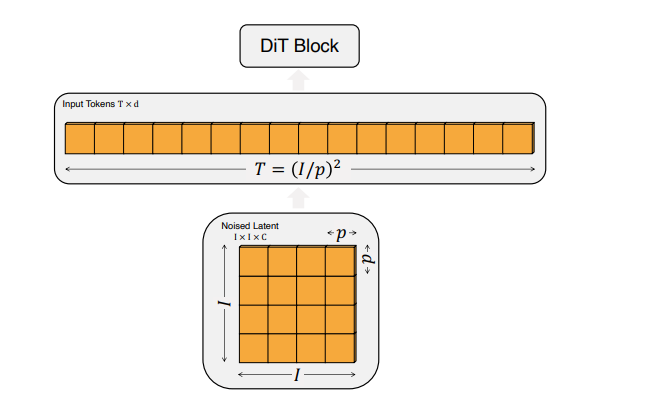
输入图像首先被处理成大小为 ( p × p ) ( p \times p) (p×p) 的补丁,然后这些补丁被线性化为具有隐藏维度( d )的输入令牌序列。
令牌总数( T )由公式 T = ( I / p ) 2 T = (I/p)^2 T=(I/p)2 确定,其中( I )是以像素为单位的输入图像大小。
这种表示方式表明,较小的补丁大小会导致更长的令牌序列,从而增加计算复杂度,以Gflops衡量。
以图像分辨率为256x256像素,补丁大小为16x16像素的情况为例:
首先,输入图像会被分割成大小为 p × p p \times p p×p(在这个例子中是 16 × 16 16 \times 16 16×16)的补丁。
如果输入图像的大小为 I × I I \times I I×I(在这个例子中是 256 × 256 256 \times 256 256×256),那么会有 T = ( I / p ) 2 T = (I/p)^2 T=(I/p)2(即 T = ( 256 / 16 ) 2 = 256 T = (256/16)^2 = 256 T=(256/16)2=256)个这样的补丁。
接下来,每个补丁会被线性化为具有隐藏维度 ( d ) 的输入令牌。
这意味着我们最终会有一个长为256的令牌序列,每个令牌都是一个 ( d ) 维的向量。
在此基础上:
-
特征1(ViT架构的应用):这些令牌序列会被用作DiT模型的输入,模型会利用ViT架构的特点来处理这些序列,捕捉图像内部的复杂结构和特征。
-
特征2(补丁大小对序列长度和Gflops的影响):较小的补丁大小会导致更长的序列,这意味着模型需要处理更多的令牌,从而增加了模型的Gflops。
当我们把输入图像分割成更小的patches(或补丁)时,我们得到更多的tokens来表示这些patches。
由于每个token都需要被模型处理(例如,通过神经网络层的前向和后向传播),这就增加了模型所需执行的总计算操作数。
因此,模型的Gflops也会相应增加,表明它需要更多的计算资源来处理相同数量的数据。
换句话说,当你减少patch的大小时,为了处理这些更细粒度的数据,模型需要做更多的工作,因此计算复杂度就会提高。
在给定的例子中,如果将补丁大小从16x16减少到8x8,令牌数从256增加到1024,相应地,模型处理这些令牌所需的计算量(Gflops)也会增加,因为现在有更多的令牌需要经过模型的神经网络层。
-
特征3(DiT块的设计差异):不同的DiT块设计会影响模型处理这些令牌的方式,从而影响整体模型的性能和计算效率。例如,adaLN-Zero块通过特定的初始化策略来提高模型性能,同时保持计算效率。
在这个例子中,通过选择合适的补丁大小和DiT块设计,可以优化模型的计算负载,并提高图像生成任务的性能。
Diffusion Transformer (DiT)总结
-
特征1(模型架构):DiT采用了变换器架构,特别是在处理序列化的图像数据方面,这是因为变换器架构在捕捉长期依赖关系方面表现出色。
-
特征2(序列化输入):通过将图像分割成小patches并将它们序列化为tokens,DiT能够有效地在变换器模型中处理图像数据。
-
特征3(位置编码):位置编码被应用于tokens以保留空间信息,这对于保持图像中的相对位置关系至关重要。
-
特征4(计算复杂度):通过调整补丁大小,DiT可以在保持精细度的同时增加或减少模型的计算负担(Gflops)。
-
特征5(性能优化):模型的性能通过调整不同的块设计(例如,使用adaLN或adaLN-Zero)来优化,这些设计影响着模型在特定任务上的效率和效果。
-
特征6(训练策略):适当的训练策略,如使用指数移动平均(EMA)和特定的优化器(如AdamW),对于达到高性能至关重要。
OpenAI Sora 设计思路
在Sora中,Diffusion Transformer(DiT)通常承担着生成模型的角色,就是负责生成高质量图像或视频的核心组件,是核心的生成组件。
负责从噪声化数据中生成清晰、高质量的图像或视频内容。
DiT结合了Transformer架构的能力和扩散模型的生成能力,使得Sora能够根据文本提示来创造逼真的视频序列。
阶段1: 数据准备和预处理
-
子特征1(文本到视频的训练数据):这是链条的起点,涉及收集大量的视频及其描述性文字说明。
例如,可能会从YouTube等平台获取视频,并提取或生成相关的描述性文字。
阶段2: 架构设计
-
子特征2(基本架构):确定了将使用基于Transformer的扩散模型架构。
在这个阶段,设计者需要决定模型的关键架构元素,例如如何集成文本提示和噪声图像块。
在设计阶段,确定Sora模型将采用基于Transformer的扩散模型架构。
这意味着DiT是用来构建模型的基本框架,它将负责处理和生成图像或视频块。
阶段3: 输入数据的结构化
-
子特征3(视频的类token化):将预处理后的视频数据转换成模型可以理解的形式,这类似于NLP中的tokenization过程。
视频被压缩并分割成时空补丁,为后续的模型训练准备。
DiT需要能够处理序列化后的视频数据,即将视频分割成的时空补丁,这些补丁类似于自然语言处理中的tokens。
阶段4: 视频压缩和表示
-
子特征4(视频压缩网络):使用视频压缩网络进一步处理视频数据,生成与视频大小成正比的3D visual patch array。
这一步是为了将视频信息密集地封装成可处理的形式。
在视频压缩和表示阶段,DiT需要从视频压缩网络接收压缩后的3D visual patch array,并将其转换为1D array of patches,这是DiT进行训练的直接输入。
阶段5: 模型训练和优化
-
这个阶段并未在您的列表中直接提及,但在实际应用中是至关重要的。
在这里,模型会根据设计好的架构和输入数据进行训练,以学习如何根据文本提示生成视频内容。
在这个阶段,DiT被训练以预测从噪声中恢复出原始“清晰”图像块。
这涉及到将带有噪声的输入补丁和条件信息(例如文本提示)作为输入,DiT必须学会如何去噪声化这些输入并恢复原始内容。
阶段6: 输出生成
-
最终阶段是利用训练好的模型生成新的视频内容。
模型会将潜在的视觉补丁转化为实际的视频输出,以匹配输入的文本提示。
训练好的DiT能够接收新的噪声化的补丁,结合文本提示来生成新的视频内容。
这个生成的过程涉及到逐步减少噪声并且细化细节,直到生成高质量的视频输出。
以制作一段根据文本提示 “一只猫坐在窗台上看雨” 的视频为例。
阶段1: 数据准备和预处理
- 收集包含猫在不同环境中的视频和相应描述。使用类似DALL·E 3的技术为这些视频生成详细的描述性文字说明。
阶段2: 架构设计
- 设计基于Transformer的扩散模型Sora,确保它能够理解文本提示并生成相应的视频内容。
- 此时,DiT作为模型的核心部分被确定下来,它将处理视频和图像的潜在编码。
阶段3: 输入数据的结构化
- 将视频压缩并分割成时空补丁(tokens),以符合DiT处理的格式。
- 例如,将 “一只猫坐在窗台上看雨” 的场景视频压缩和分割,准备成可训练的数据格式。
阶段4: 视频压缩和表示
- 通过视频压缩网络将输入视频的时间和空间维度同时进行压缩,为DiT提供训练数据。
阶段5: 模型训练和优化
- 在这个阶段,DiT学习如何基于文本提示和带有噪声的视频补丁(tokens),预测出原始的“清晰”视频补丁。
- 模型通过大量的训练数据学习 “一只猫坐在窗台上看雨” 的文本提示对应的视频内容特征。
阶段6: 输出生成
- 使用训练好的DiT模型,输入带有噪声的补丁和 “一只猫坐在窗台上看雨” 的文本提示,模型能够生成匹配这一描述的新视频内容。
- 通过逐步去噪和细化补丁,DiT最终输出一段高质量的视频,展示了一只猫坐在窗台上看着外面的雨景。
在这个逻辑链条中,DiT起着核心作用,它不仅处理了从文本到视频内容生成的关键步骤,还确保了生成的视频内容能够尽可能地贴近用户的文本提示。
OpenAI Sora 工作流程
Sora是一个基于文本条件的扩散模型,使用了Transformer架构来生成视频。
步骤1: 视频数据的压缩和转换
想象你有一个视频,里面是一只猫在玩耍。
首先,Sora会将这个视频压缩到一个低维度的潜在空间中。
这就像是把视频简化成一系列基本的图像特征,这样做的目的是为了减少处理视频时需要的数据量。
步骤2: 时空补丁的提取
接下来,Sora会将压缩后的视频分解成一系列小块,称为时空补丁。
这些补丁包含了视频的时间和空间信息。
你可以将每个补丁视为视频中的一个小片段。
这一步骤类似于将一篇文章分割成单词或句子,以便更好地理解和处理。
步骤3: 使用Transformer处理补丁
这些补丁接着被送入一个基于Transformer的模型中进行处理。
Sora通过分析这些补丁和相应的文本提示(例如,“一只猫在玩耍”),学习如何根据文本提示生成对应的视频内容。
Transformer在这里的作用是理解补丁之间的关系,并根据文本提示来预测每个补丁应该展示的内容。
步骤4: 生成视频内容
一旦Sora模型训练完成,它就能够接受新的文本提示和带有噪声的补丁作为输入,生成新的视频内容。
Sora会预测这些噪声补丁背后的原始“干净”图像,然后将它们组合起来形成完整的视频。
步骤5: 视频解码
最后,Sora使用一个解码器将这些潜在的视觉补丁转换回像素级的视频图像。
这就像是将简化后的图像特征重新转换成详细的视频片段。
假设你想要Sora生成一段视频,视频内容是“一只猫坐在窗台上看雨”。
你会给Sora输入这段文本提示。
Sora会使用它训练好的模型,根据这个文本提示生成一系列代表视频的补丁,这些补丁最终会被转换成你想要的视频内容。
简而言之,Sora通过将视频转换成更易于处理的格式(时空补丁),然后利用Transformer模型的强大能力来理解和生成视频内容,最终再将这些内容转换回实际的视频。
这个过程允许Sora根据文本提示来创造出新的、高质量的视频内容。
相关文章:
【文生视频】Diffusion Transformer:OpenAI Sora 原理、Stable Diffusion 3 同源技术
文生视频 Diffusion Transformer:Sora 核心架构、Stable Diffusion 3 同源技术 提出背景输入输出生成流程变换器的引入Diffusion Transformer (DiT)架构Diffusion Transformer (DiT)总结 OpenAI Sora 设计思路阶段1: 数据准备和预处理阶段2: 架构设计阶段3: 输入数据…...
Redis 服务集群、哨兵、缓存及持久化的实现原理和应用场景
Redis 是一种高性能的键值存储系统,已经成为了许多企业和互联网公司的核心技术之一。本文将介绍 Redis 的服务集群、哨兵以及缓存实现原理和应用场景,以帮助读者更好地理解和使用 Redis。 引言: 随着互联网应用规模不断扩大,Redi…...

通过Redis增减库存避坑
问题: 先执行get获取值,判断符合条件再执行incr、decr操作。在临界缓存失效的情况下,会默认赋值当前key为永不过期的0,再执行加减法,导致程序异常。 推荐解决方案: 1、限制接口频率:先incr&…...
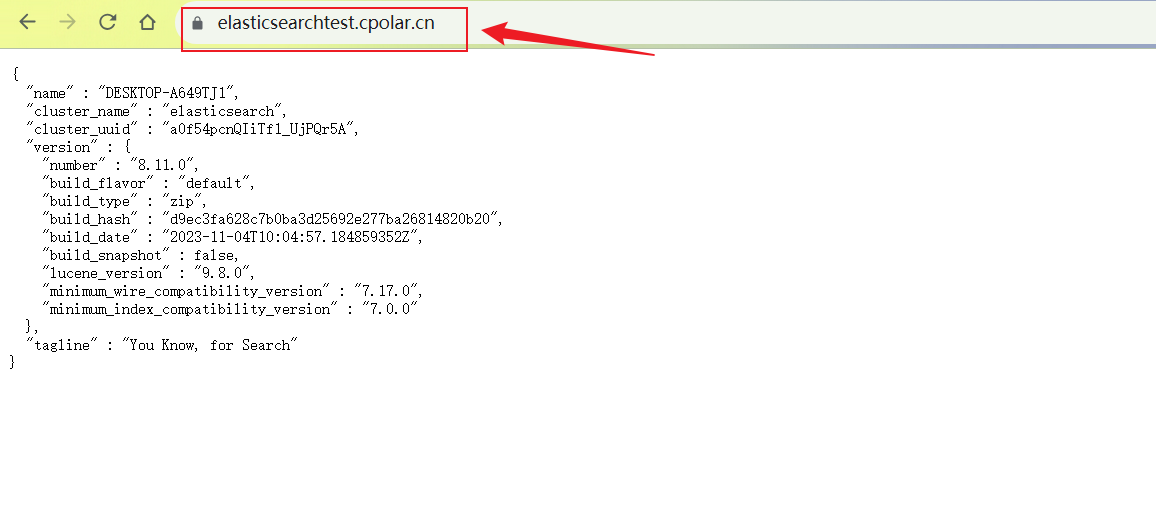
Windows系统搭建Elasticsearch引擎结合内网穿透实现远程连接查询数据
文章目录 系统环境1. Windows 安装Elasticsearch2. 本地访问Elasticsearch3. Windows 安装 Cpolar4. 创建Elasticsearch公网访问地址5. 远程访问Elasticsearch6. 设置固定二级子域名 Elasticsearch是一个基于Lucene库的分布式搜索和分析引擎,它提供了一个分布式、多…...

Java爬虫使用JSoup获取静态资源图片
import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.FileOutputStream;/*** 获取静态图片*/public class ImageDownloader {public static void main…...

LeetCode 2433.找出前缀异或的原始数组
给你一个长度为 n 的 整数 数组 pref 。找出并返回满足下述条件且长度为 n 的数组 arr : pref[i] arr[0] ^ arr[1] ^ … ^ arr[i]. 注意 ^ 表示 按位异或(bitwise-xor)运算。 可以证明答案是 唯一 的。 示例 1: 输入…...

C++面试:系统网络性能评估与优化
系统网络性能评估与优化是指对计算机系统中的网络部分进行评估分析,并采取一系列措施来提升网络性能的能力。在面试中,涉及这一主题的问题可能会围绕以下几个方面展开。 网络性能评估 基于网络延迟、带宽、吞吐量等指标对网络性能进行评估。使用工具&a…...

Java适配器模式 - 灵活应对不匹配的接口
Java适配器模式 - 灵活应对不匹配的接口 引言: 在软件开发中,我们经常遇到不同系统、库或框架之间的接口不兼容问题。为了解决这些问题,我们可以使用适配器模式。适配器模式是一种结构型设计模式,它允许不兼容的接口之间进行协作…...
[ai笔记12] chatGPT技术体系梳理+本质探寻
欢迎来到文思源想的ai空间,这是技术老兵重学ai以及成长思考的第12篇分享! 这周时间看了两本书,一本是大神斯蒂芬沃尔弗拉姆学的《这就是ChatGPT》,另外一本则是腾讯云生态解决方案高级架构师宋立恒所写的《AI制胜机器学习极简入门》…...
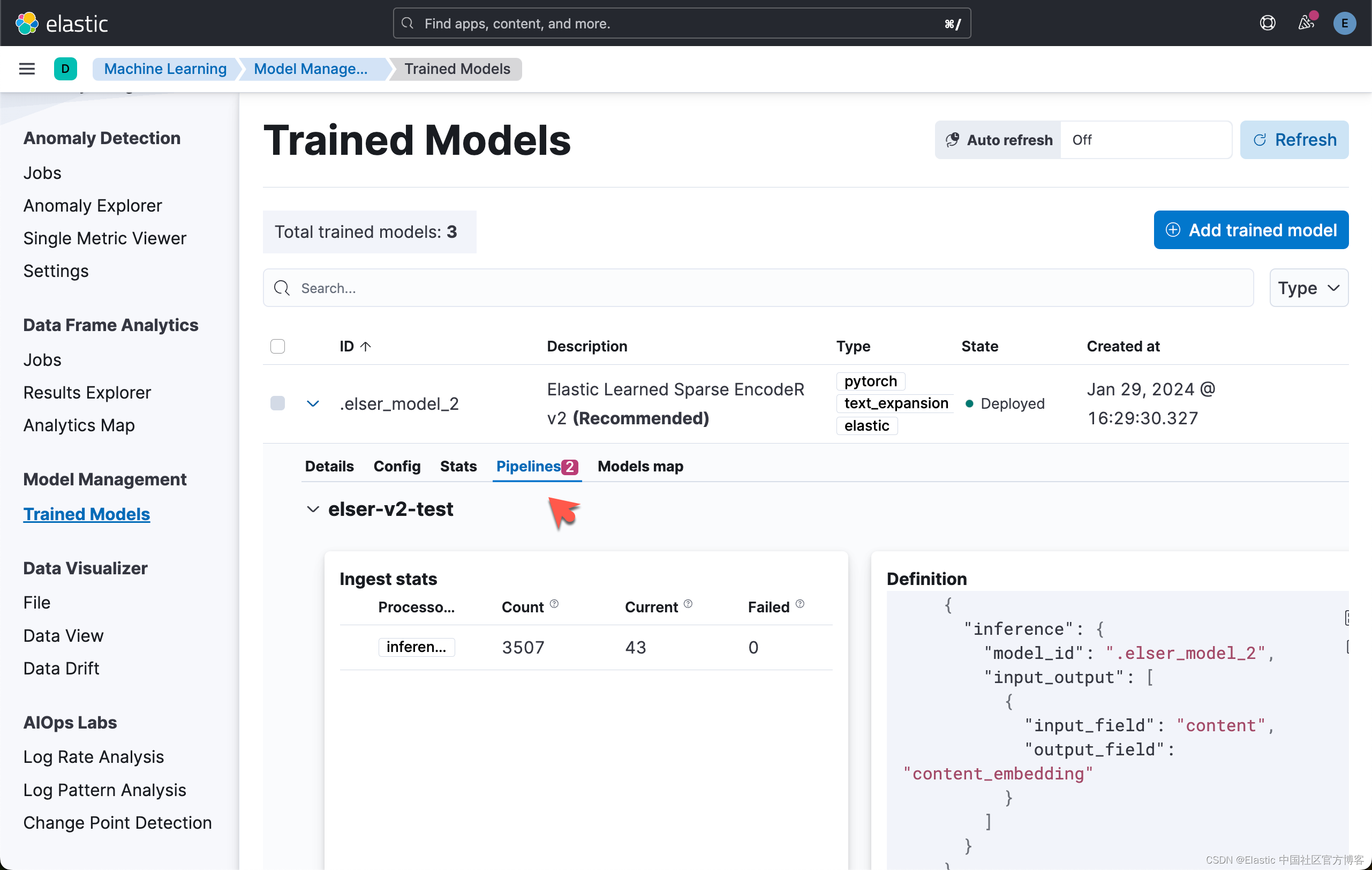
Elasticsearch:使用 ELSER v2 进行语义搜索
在我之前的文章 “Elasticsearch:使用 ELSER 进行语义搜索”,我们展示了如何使用 ELESR v1 来进行语义搜索。在使用 ELSER 之前,我们必须注意的是: 重要:虽然 ELSER V2 已正式发布,但 ELSER V1 仍处于 [预览…...

智慧农业之智能物流
智慧物流属于农业生产环节中的重要节点,上游为农业生产环节,下游为销售与商贸环节,因此,通过联通生产与销售环节,通过合理调配物流过程,可以实现对于农产品的快速运输与销售,减少中间环节中的无效损耗,从而实现增收节支,实实在在地解决了农产品利润偏低的问题。 生产…...

Redis主从、哨兵、Redis Cluster集群架构
Redis主从、哨兵、Redis Cluster集群架构 Redis主从架构 Redis主从架构搭建 主从搭建的问题 如果同步数据失败,查看log日志报错无法连接,检查是否端口未开放出现”Error reply to PING from master:...“日志,修改参数protected-mode no …...

Javascript 运算符、流程控制语句和数组
【三】运算符 【1】算数运算符 (1)分类 加减乘除:*/取余:%和python不一样的点:没有取整// (2)特殊的点 只要NaN参与运算得到的结果也是NaNnull转换成0,undefined转换成NaN 【2…...

电机驱动死区时间
电机驱动死区时间 电机驱动死区时间死区时间(Dead Time)自己话补充说明 电机驱动死区时间 电机驱动死区时间一般在几纳秒到几微秒之间,具体长度取决于所使用的电子器件。 一、什么是电机驱动死区时间? 电机驱动死区时间指的是在电…...

图像的压缩感知的MATLAB实现(第3种方案)
前面介绍了两种不同的压缩感知实现: 图像压缩感知的MATLAB实现(OMP) 压缩感知的图像仿真(MATLAB源代码) 上述两种方法还存在着“速度慢、精度低”等不足。 本篇介绍一种新的方法。 压缩感知(Compressed S…...
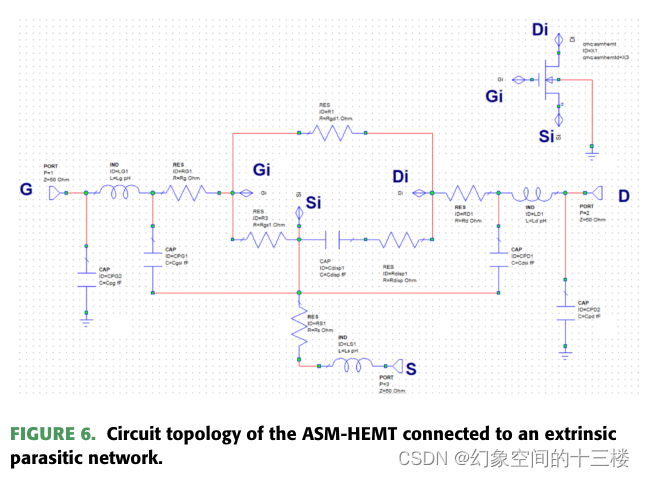
高温应用中GaN HEMT大信号建模的ASM-HEMT
来源:An ASM-HEMT for Large-Signal Modeling of GaN HEMTs in High-Temperature Applications(JEDS 23年) 摘要 本文报道了一种用于模拟高温环境下氮化镓高电子迁移率晶体管(GaN HEMT)的温度依赖性ASM-HEMT模型。我…...

文件上传---->生僻字解析漏洞
现在的现实生活中,存在文件上传的点,基本上都是白名单判断(很少黑名单了) 对于白名单,我们有截断,图片马,二次渲染,服务器解析漏洞这些,于是今天我就来补充一种在upload…...

Ubuntu中Python3找不到_sqlite3模块
今天跑一个代码,出现了一个找不到sqlite3模块的错误,错误如下: from _sqlite3 import * ModuleNotFoundError: No module named _sqlite3 网上查资料说,因为python3没有自带sqlite3相关方面的支持,要自己先安装然后再重新编译Py…...

HarmonyOS4.0系统性深入开发37 改善布局性能
改善布局性能 Flex为采用弹性布局的容器。容器内部的所有子元素,会自动参与弹性布局。子元素默认沿主轴排列,子元素在主轴方向的尺寸称为主轴尺寸。 在单行布局场景下,容器里子组件的主轴尺寸长度总和可能存在不等于容器主轴尺寸长度的情况…...

Internet协议
文章目录 Internet协议网络层协议IPV4协议IP地址:IPv4数据报格式IP数据报的封装和分片 Internet路由协议路由信息协议RIP开放最短路径优先协议OSPF外部网关协议BGP组播协议PIM和MOSPF ARP和RARPARP协议:RARP协议: Internet控制报文协议ICMPIP…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...