llm的inference(二)
文章目录
- Tokenizer
- 分词
- 1.单词分词法
- 2.单字符分词法
- 3.子词分词法
- BPE(字节对编码,Byte Pair Encoding)
- WordPiece
- Unigram Language Model(ULM)
- embedding的本质
- 推理时的一些指标
- 参考链接
Tokenizer
在使用模型前,都需要将sequence过一遍Tokenizer,进去的是word序列(句子级),出来的是number序列。事实上,HuggingFace的tokenizer总体上做了三件事情:
- 分词。将字符串分为一些
sub-word token string。再将token string映射到ID,并保留来回映射的mapping。从string映射到ID为tokenizer encode过程,从ID映射回token string 为tokenizer decode过程。映射方法有很多,如BERT用的是WordPiece,GPT-2和RoERTa用的是BPE。 - 扩展词汇表。部分
tokenizer会用一种统一的方法将训练语料中出现的但是词汇表中本来没有的token加入词汇表。 - 识别并处理特殊token。特殊token包括[MASK],等。
tokenzier会将它们加入词汇表中,并且保证它们在模型中不被切成sub-word,而是完整保留。
分词
从本质来说,文本数据整体上先是文档集合,然后是每一篇文档,然后是每一个段落,然后是每一个句子,然后是每一个短语,然后是每一个词,然后是每一个子词,最后是每一个字符。
不同的分词粒度,会导致分词的结果不同,当然也就影响了网络最终的输出结果。下面我们一一介绍。
1.单词分词法
最直观的分词是单词级分词法。单词分词法将一个word作为最小单元,也就是根据空格或者标点分词。
例如Today is Sunday.使用word-base来进行分词会变成['Today','is','Sunday','.']。这种分词方法简单容易理解,每个word都分配一个ID,则所需要的Vocabulary根据语料大小而不同,而且这种分词方式,会将两个本身意思一致的词分成两个毫不相同的ID,例如:cat,cats。
2.单字符分词法
最细粒度的分词方法是单字符分词法(character-base)。它会穷举所有出现的字符,所以是最完整的。在上面的例子中,单字符分词法会生成['T','o','d','a','y',...,'a','y','.']。
这种分词方式会导致Vocabulary相对小的多,但分词后的每个字符是毫无意义的,而且输出长度变长不少,只有组装后才有意义。这种分词在模型的初始character embedding是毫无意义的。英文中尤为明显,但是中文却是较为合理,中文中用此种方式较多。
3.子词分词法
这是一种最常用的,介于以上两种方法之间的分词方法,我们称为子词分词法。
子词分词法会把上面的句子分成最小可分的子词['To','day','is','S','un','day','.']。子词分词法有很多种取得最小可分子词的方法,例如BPE,WordPiece,SentencePiece,Unigram等等。
BPE(字节对编码,Byte Pair Encoding)
这是目前应用最多的分词方法,GPT以及Llama系列都在使用这种分词方法。具体过程请参考这篇博客。
完成了上述的BPE训练过程,我们就会得到一个词表(vocabulary),但是如何对输入语句进行编码(也就是BPE分词)呢?
- 将词表按照其中token的长度,从长到短进行排列;
例如排序好之后的词表为:
[“errrr</w>”, “tain</w>”, “moun”, “est</w>”, “high”, “the</w>”, “a</w>”]
- 对输入语句word-level的分词结果进行转化,例如输入语句为:
[“the</w>”, “highest</w>”, “mountain</w>”]
则转化为:
"the</w>" -> ["the</w>"]
"highest</w>" -> ["high", "est</w>"]
"mountain</w>" -> ["moun", "tain</w>"]
注:在编码过程结束后,如果输入语句中仍然有子字符串没被替但是词表中的所有token都已经迭代完毕,则将剩余的子词替换为特殊的token,如< unk >。原则上< unk >这个token出现的越少越好,我们也往往用< unk >的数量来评价一个tokenizer的好坏程度,这个token出现的越少,tokenizer的效果往往越好。
那么如何对网络的输出进行解码呢?将所有的tokens拼在一起即可,例如:
# 网络输出
["the</w>", "high", "est</w>", "moun", "tain</w>"]# 解码序列
"the</w> highest</w> mountain</w>"
BPE是一种贪婪算法,因为它一直在搜索,知道遇到终止条件才会停止。
WordPiece
WordPiece是BERT使用的分词方法,可以看作是BPE的变种。两者很重要的区别是如何选择两个子词进行合并:WordPiece选择能够提升语言模型概率最大的相邻子词构造词表,但是BPE选择频数最高的相邻子词合并。大致的数学原理请参考这篇博客。
Unigram Language Model(ULM)
ULM与上面的两种分词方法相比,不同之处在于BPE和WordPiece算法的词表都是从小到大变化,属于增量法,而ULM则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词汇,直到满足限定条件。
embedding的本质
我们知道tokenization后就要进行embedding,它的表象是将one-hot的高维向量转为更密集的低维向量的过程,数学上就是对one-hot向量乘以一个矩阵。参考这篇博客,在其中说明了embedding矩阵的本质是什么。在其中指出,Embedding矩阵的本质是一个查找表,由于输入向量是one-hot的,embedding矩阵中有且仅有一行被激活。 博客中作者给出的图如下所示:
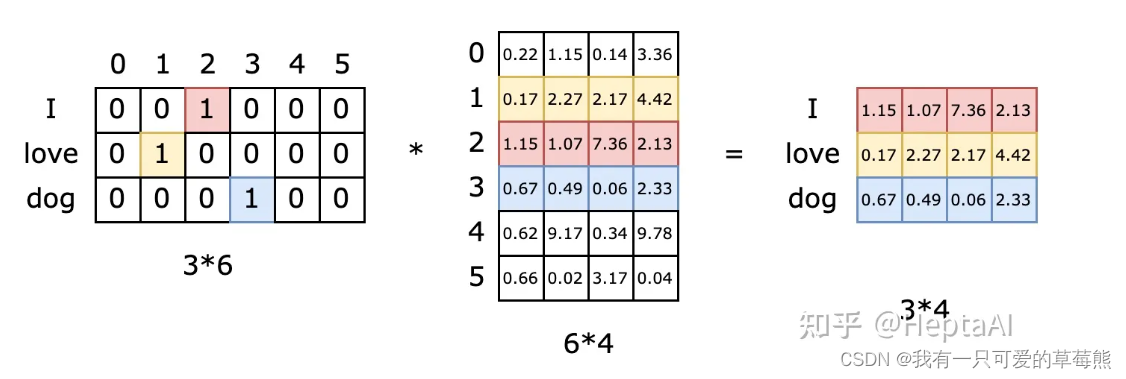
对于第一个单词"I",one-hot编码为[0,0,1,0,0],将其与embedding矩阵相乘,相当于去除embedding矩阵的第3行(index为2),其他的同理。每个单词会定位这个表中的每一行,而这一行就是这个单词学习到的在**嵌入空间(低维密集空间)**的语义。
推理时的一些指标
- First Token Latency(首字延迟):指的是当一批用户进入推理系统之后,用户完成prefill阶段(有关prefill的内容参考这篇博客)的过程需要花费多长时间,也称为首个词元生成时间(Time To First Token,简称TTFT)。这也是系统生成第一个字符所需要的响应时间,希望用户在系统上输入问题后得到回答的时间小于2~3秒。
- Throughput(吞吐量):当系统的负载达到最大的时候,单位时间内,能够执行多少个Decode,即生成多少个字符。
- 单个输出词元的生成时间(Time Per Output Token,简称TOPT):为每个用户生成一个输出词元所需要的时间。
- 时延:系统为用户生成完整相应的总时间。整体 相应时延可使用下面的计算方式:时延=TTFT + TPOT*待生成的词元数。
参考链接
- https://zhuanlan.zhihu.com/p/360290118
- https://martinlwx.github.io/zh-cn/the-bpe-tokenizer/
- https://zhuanlan.zhihu.com/p/631463712
- https://zhuanlan.zhihu.com/p/198964217
- https://www.zhihu.com/question/595001160/answer/3401487634
- https://zhuanlan.zhihu.com/p/663282469
相关文章:
llm的inference(二)
文章目录 Tokenizer分词1.单词分词法2.单字符分词法3.子词分词法BPE(字节对编码,Byte Pair Encoding)WordPieceUnigram Language Model(ULM) embedding的本质推理时的一些指标参考链接 Tokenizer 在使用模型前,都需要将sequence过一遍Tokenizer…...

pytorch -- torch.nn.Module
基础 torch.nn 是 PyTorch 中用于构建神经网络的模块。nn.Module包含网络各层的定义及forward方法。 在用户自定义神经网络时,需要继承自nn.Module类。通过继承 nn.Module 类,您可以创建自己的神经网络模型,并定义模型的结构和操作。 torch.n…...

Microsoft Edge 越用越慢、超级卡顿?网页B站播放卡顿?
记录10个小妙招 Microsoft Edge 启动缓慢、菜单导航卡顿、浏览响应沉闷?这些情况可能是由于系统资源不足或浏览器没及时更新引起的。接下来,我们将介绍 10 种简单的方法,让 Edge 浏览器的速度重新起飞。 基础检查与问题解决 如果 Microsoft…...

XGB-9: 分类数据
从1.5版本开始,XGBoost Python包为公共测试提供了对分类数据的实验性支持。对于数值数据,切分条件被定义为 v a l u e < t h r e s h o l d value < threshold value<threshold ,而对于分类数据,切分的定义取决于是否使用…...

FreeRTOS学习第8篇--同步和互斥操作引子
目录 FreeRTOS学习第8篇--同步和互斥操作引子同步和互斥概念实现同步和互斥的机制PrintTask_Task任务相关代码片段CalcTask_Task任务相关代码片段实验现象本文中使用的测试工程 FreeRTOS学习第8篇–同步和互斥操作引子 本文目标:学习与使用FreeRTOS中的同步和互斥操…...
,c++STL算法的理解与使用(sort, find, binary_search等))
c++STL容器的使用(vector, list, map, set等),c++STL算法的理解与使用(sort, find, binary_search等)
cSTL容器的使用(vector, list, map, set等) 在C的STL(Standard Template Library)中,容器是重要的一部分,它们提供了各种数据结构来存储和管理数据。以下是一些常见的STL容器及其使用方法的简要说明&#x…...

选择VR全景行业,需要了解哪些内容?
近年来,随着虚拟现实、增强现实等技术的持续发展,VR全景消费市场得以稳步扩张。其次,元宇宙行业的高速发展,也在进一步拉动VR全景技术的持续进步,带动VR产业的高质量发展。作为一种战略性的新兴产业,国家和…...

830. 单调栈
Problem: 830. 单调栈 文章目录 思路解题方法复杂度Code 思路 这是一个单调栈的问题。单调栈是一种特殊的栈结构,它的特点是栈中的元素保持单调性。在这个问题中,我们需要找到每个元素左边第一个比它小的元素,这就需要使用到单调递增栈。 我们…...

H5 个人引导页官网型源码
H5 个人引导页官网型源码 源码介绍:源码无后台、无数据库,H5自检测适应、无加密,直接修改可用。 源码含有多选项,多功能。可展示自己站点、团队站点。手机电脑双端。 下载地址: https://www.changyouzuhao.cn/1434.…...
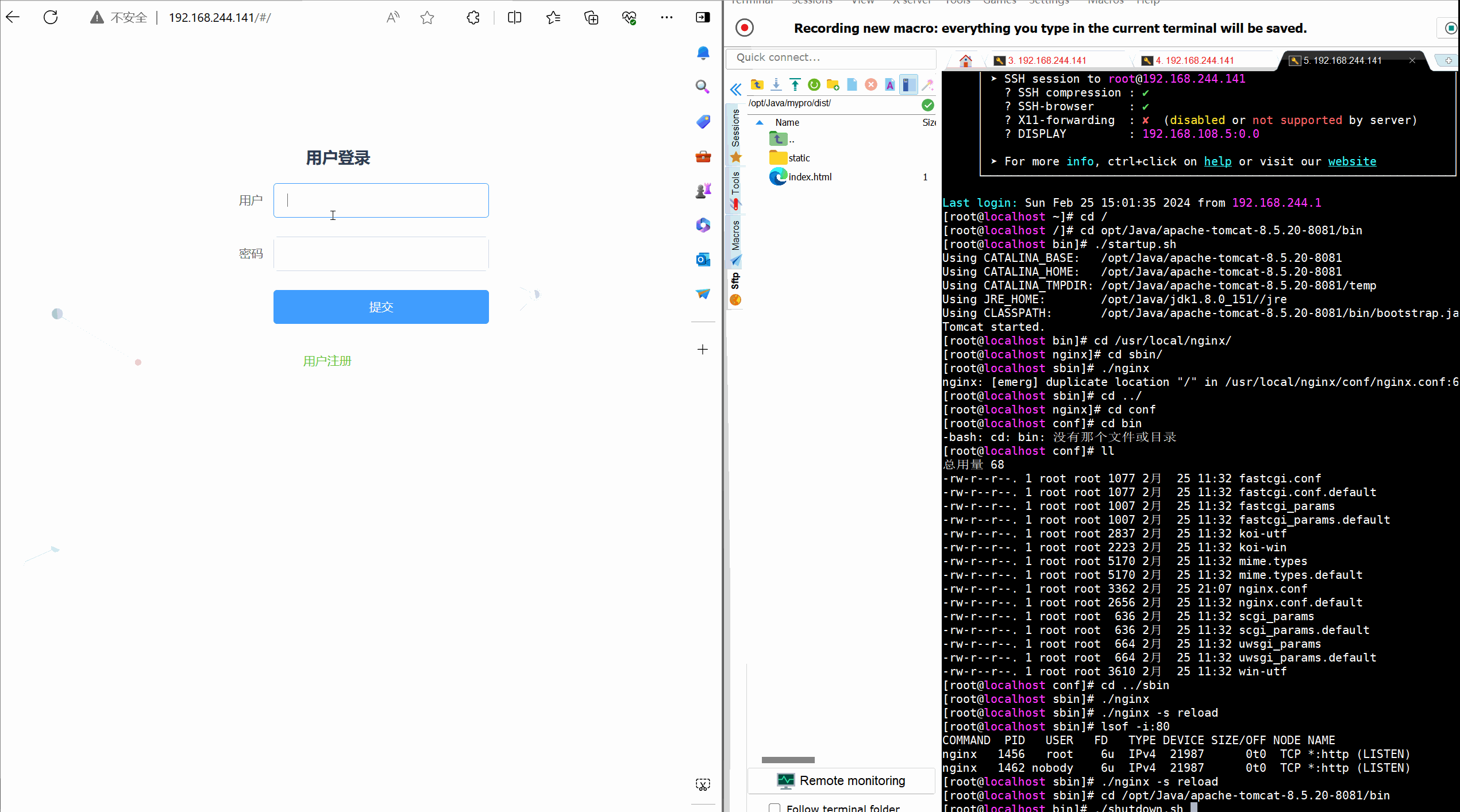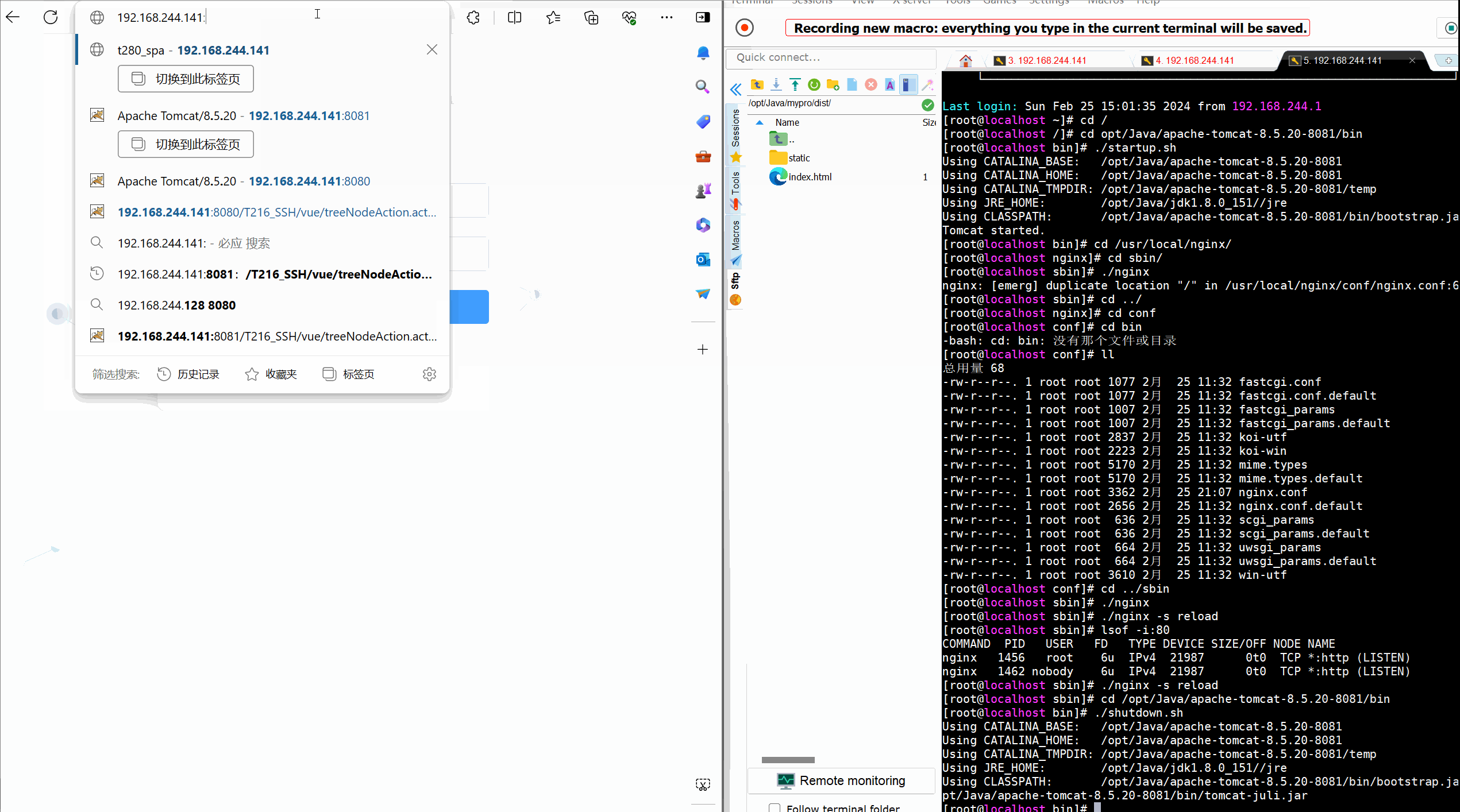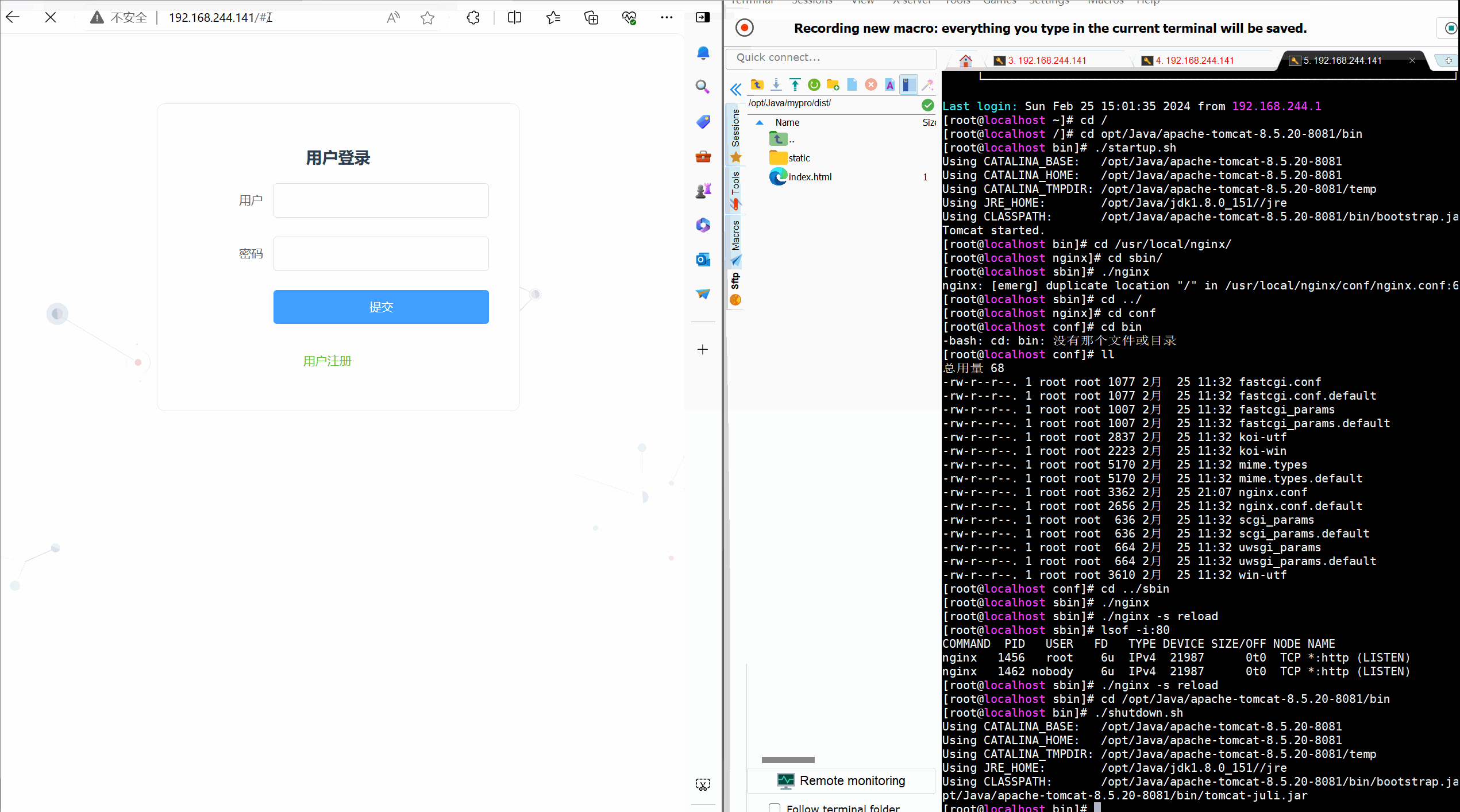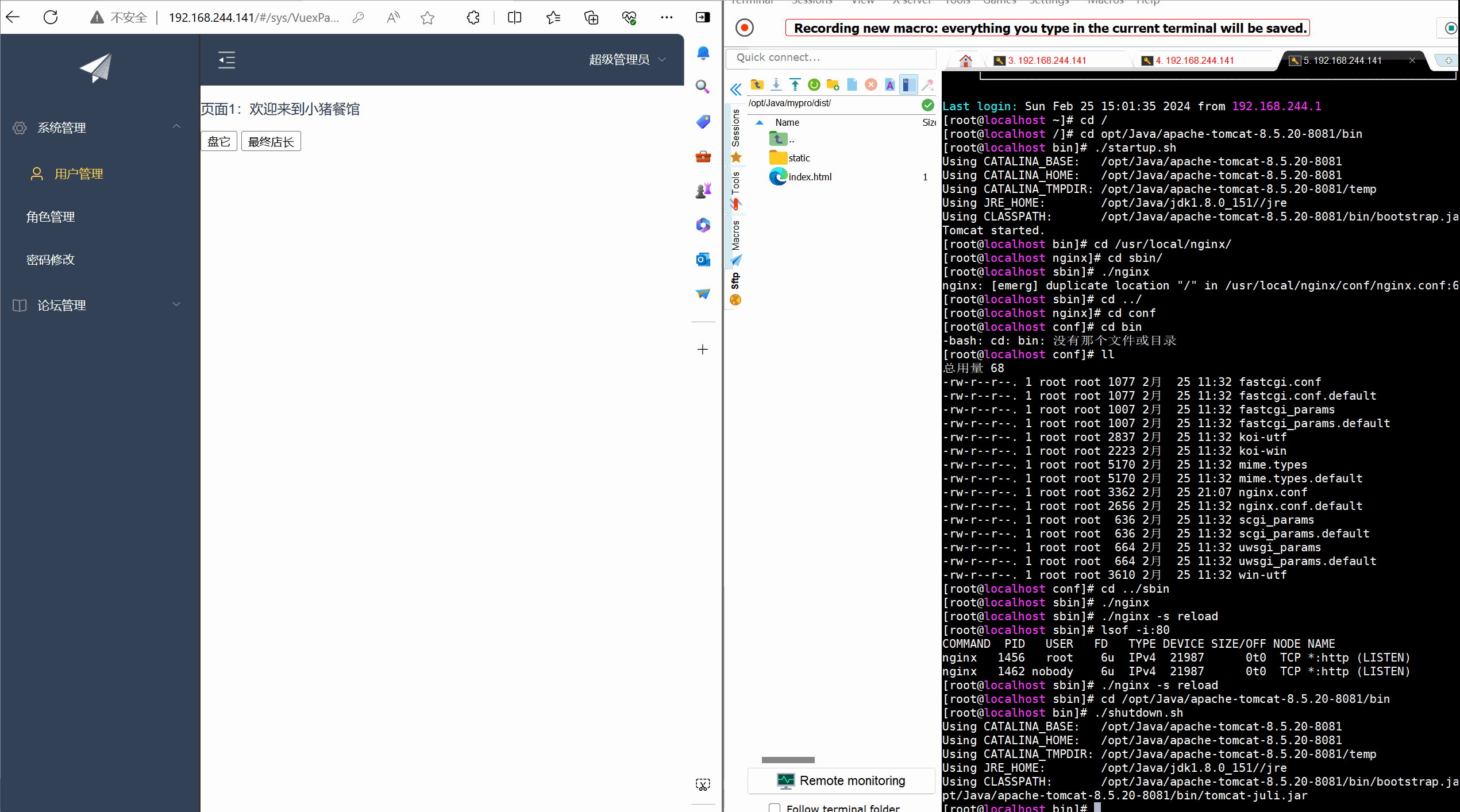
【Linux】部署前后端分离项目---(Nginx自启,负载均衡)
目录 前言 一 Nginx(自启动) 2.1 Nginx的安装 2.2 设置自启动Nginx 二 Nginx负载均衡tomcat 2.1 准备两个tomcat 2.1.1 复制tomcat 2.1.2 修改server.xml文件 2.1.3 开放端口 2.2 Nginx配置 2.2.1 修改nginx.conf文件 2.2.2 重启Nginx服务 2…...
WPF Style样式设置
1.本window设置样式 <Window x:Class"WPF_Study.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schemas.microsoft.com/expressi…...

【STM32】软件SPI读写W25Q64芯片
目录 W25Q64模块 W25Q64芯片简介 硬件电路 W25Q64框图 Flash操作注意事项 状态寄存器 编辑 指令集 INSTRUCTIONS编辑 编辑 SPI读写W25Q64代码 硬件接线图 MySPI.c MySPI.h W25Q64 W25Q64.c W25Q64.h W25Q64_Ins.h main.c 测试 SPI通信(W25…...

普通中小学校管理信息系统V1.1
普通中小学校管理信息系统 Ordinary Primary and Secondary Schools Management Information System 普通中小学校管理信息系统 Ordinary Primary and Secondary Schools Management Information System...

中国水果采摘机器人行业市场研究及发展趋势分析报告
全版价格:壹捌零零 报告版本:下单后会更新至最新版本 交货时间:1-2天 第一章 2016-2026年中国水果采摘机器人行业总概 1.1 中国水果采摘机器人行业发展概述 机器人技术的发展是一个国家高科技水平和工业自动化程度的重要标志和体现。机器…...

Linux多进程与信号
在多进程的服务程序中,如果子进程收到退出信号,子进程自行退出。如果父进程收到退出信号,应该先向全部的子进程发送退出信号,然后自己再退出。 演示demo程序 #include <iostream> // 包含输入输出流库,用于输…...

Self-attention与Word2Vec
Self-attention(自注意力)和 Word2Vec 是两种不同的词嵌入技术,用于将单词映射到低维向量空间。它们之间的区别: Word2Vec: Word2Vec 是一种传统的词嵌入(word embedding)方法,旨在为…...
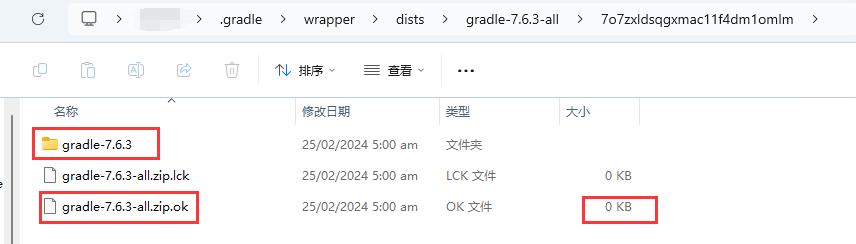
【Flutter/Android】运行到安卓手机上一直卡在 Running Gradle task ‘assembleDebug‘... 的终极解决办法
方法步骤简要 查看你的Flutter项目需要什么版本的 Gradle 插件: 下载这个插件: 方法一:浏览器输入:https://services.gradle.org/distributions/gradle-7.6.3-all.zip 方法二:去Gradle官网找对应的版本:h…...

医疗实施-客户需求分析
在我的日常系统实施过程中,总会遇到不同角色的客户提出不同类别的需求。有的需求,客户目的想提高操作便携,但会对系统稳定性存在风险,应该拒掉。有些需求紧急而且影响重大,应该紧急处理。有些需求可以做,但…...
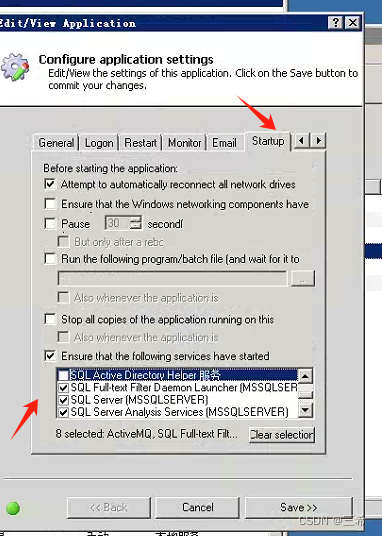
调度服务看门狗配置
查看当前服务器相关的sqlserver服务 在任务栏右键,选择点击启动任务管理器 依次点击,打开服务 找到sqlserver 相关的服务, 确认这些服务是启动状态 将相关服务在看门狗中进行配置 选择调度服务,双击打开 根据上面找的服务进行勾…...

AI时代 编程高手的秘密武器:世界顶级大学推荐的计算机教材
文章目录 01 《深入理解计算机系统》02 《算法导论》03 《计算机程序的构造和解释》04 《数据库系统概念》05 《计算机组成与设计:硬件/软件接口》06 《离散数学及其应用》07 《组合数学》08《斯坦福算法博弈论二十讲》 清华、北大、MIT、CMU、斯坦福的学霸们在新学…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...