MySQL基础查询操作
文章目录
- 🚏 Select语句
- 🚀 一、SQL底层执行原理
- 🚬 (一)、查询的结构
- 🚬 (二)、SQL语句的执行过程
- 🚭 1、WHERE 为什么不包含聚合函数的过滤条件?(面试题)
- 🚭 2、为什么where 的效率要比 having的效率高?(面试题)
- 🚭 3、WHERE 与 HAVING 的对比
- 🚄 二、基本的SELECT语句
- 🚬 (一)基本的SELECT语句
- 🚭 SELECT...
- 🚭 SELECT ... FROM
- 🚭 列的别名 AS
- 🚭 去除重复行 DISTINCT
- 🚭 空值参与运算
- 🚭 着重号 ``
- 🚭 查询常数
- 🚭 显示表结构 DESCRIBE/DESC
- 🚬 (二)、过滤数据 where
- 🚬 (三)、BETWEEN AND 运算符
- 🚬 (四)、IN/NOT IN 运算符
- 🚬 (五)、模糊匹配 LIKE 运算符
- 🚬 (六)、ORDER BY
- 🚭 排序规则
- 🚭 单列排序
- 🚭 多列排序
- 🚬 (七)、分页 lIMIT
- 🚭 规则
- 🚬 (八)、MySQL 8 分页新特性 LIMIT ... OFFSET ...
- 🚄 三、运算符
- 🚬 (一)、算数运算符
- 🚬 (二)、比较运算符
- 🚭 1、符号类型的运算符
- 🚭 2、非符号类型的运算符
- 🛹 空运算符 IS NULL \ ISNULL 和 非空运算符 IS NOT NULL
- 🛹 最大小值运算符 LEAST 、GREATEST
- 🛹 REGEXP \ RLIKE :正则表达式
- 🚬 (三)、逻辑运算符 OR || AND && NOT ! XOR 要保证条件完整
- 🚬 (四)、位运算符 & | ^ ~ >> <<
- 🚬 (五)、运算符的优先级
- 🚬 (六)、拓展:使用正则表达式查询
- 🚒 四、子查询
- 🚬 (一)、实际问题
- 🚬 (二)、子查询的基本语法结构
- 🚬 (三)、子查询的分类
- 🚭 1、角度1:从内查询返回的结果的条目数 单行子查询 vs 多行子查询
- 🚭 2、角度2:内查询是否被执行多次 相关子查询 vs 不相关子查询
- 🌟 非相关子查询操作
- 🚬 (四)、单行子查询 ---> 非相关子查询
- 🚭 1、单行子查询操作符
- 🚭 2、WHERE中的子查询
- 🚭 3、HAVING 中的子查询
- 🚭 4、CASE中的子查询
- 🚭 5、子查询中的空值问题
- 🚭 6、非法使用子查询
- 🚬 (五)、多行子查询 ---> 非相关子查询
- 🚭 1、多行子查询的操作符 IN、ANY、ALL、SOME(同ANY)
- 🚭 2、In
- 🚭 3、ANY / ALL:
- 🚭 4、多行子查询空值问题
- 🌟 相关子查询操作
- 🚬 (六)、相关子查询执行流程
- 🚬 (七)、在 FROM 中使用子查询(相关子查询)
- 🚬 (八)、在ORDER BY 中使用子查询(相关子查询)
- 🚬 (九)、EXISTS 与 NOT EXISTS关键字
- 🚭 1、EXISTS 案例:
- 🚭 2、NOT EXISTS案例:
- 🚭 3、子查询 更新
- 🚭 4、子查询 删除
- 🚬 (十)、问题:自连接和子查询有好坏之分吗?
- 🚬 (十一)、相关子查询和非相关子查询的经典题型
- 🚭 1、非相关子查询
- 🚭 2、相关子查询
- 🚤 五、多表查询
- 🚬 (一)、7种SQL JOINS的实现
- 🚬 (二)、多表查询分类
- 🚭 1、方式一:等值连接 vs 非等值连接
- 🛹 ① 等值连接
- 🛹 ② 非等值连接
- 🚭 2、方式二:自连接 vs 非自连接
- 🚭 3、方式三:内连接 vs 外连接
- 🚬 (三)、SQL92:使用(+)创建连接
- 🚬 (四)、SQL99语法实现多表查询
- 🛹 基本语法:使用JOIN...ON子句创建连接的语法
- 🛹 ① SQL99 内连接语句 INNER JOIN ON / JOIN ON
- 🛹 ② SQL99 左外连接语句 LEFT OUTER JOIN / **LEFT** JOIN
- 🛹 ③ SQL99 右外连接语句 RIGHT OUTER JOIN
- 🛹 ④ 满外连接(FULL OUTER JOIN)
- 🚬 (五)、合并查询 UNION的使用
- 🚬 (六)、SQL99语法新特性
- 🚭 1、自然连接
- 🚭 2、USING连接
😹 作者: gh-xiaohe
😻 gh-xiaohe的博客
😽 觉得博主文章写的不错的话,希望大家三连(✌关注,✌点赞,✌评论),多多支持一下!!
🚏 Select语句
🚀 一、SQL底层执行原理
🚬 (一)、查询的结构
sql92语法:
- SELECT (存在聚合函数)
- FROM
- WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件、不可以使用别名
- HAVING 包含聚合函数的过滤条件
- ORDER BY (ASC / DESC )
- LIMIT
sql99语法:
- SELECT (存在聚合函数)
- FROM (LEFT / RIGHT)JOIN …ON 多表的连接条件
- (LEFT / RIGHT)JOIN …ON…
- WHERE 不包含聚合函数的过滤条件、不可以使用别名
- GROUP BY AND/OR 不包含聚合函数的过滤条件
- HAVING 包含聚合函数的过滤条件
- ORDER BY (ASC / DESC )
- LIMIT
总结:
- from:从哪些表中筛选
- on:关联多表查询时,去除笛卡尔积
- where:从表中筛选的条件
- group by:分组依据
- having:在统计结果中再次筛选
- order by:排序
- limit:分页
🚬 (二)、SQL语句的执行过程
FROM …,…-> ON -> (LEFT/RIGNT JOIN) -> WHERE -> GROUP BY ->HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT

🚭 1、WHERE 为什么不包含聚合函数的过滤条件?(面试题)
从执行过程来看 可以向前引用,但是没有办法向下引用
🚭 2、为什么where 的效率要比 having的效率高?(面试题)
由SQL的执行顺序可知,where的执行在 having的前面,现在where 中过滤一些条件,分组时效率高很多,提升很大,如果此时 过滤条件写在 having 中 先分组后进行条件筛选,很多数据都是不需要的数据,无用功
🚭 3、WHERE 与 HAVING 的对比
-
1、从适用范围上来讲,HAVING的适用范围更广。
-
2、如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING
| 优点 | 缺点 | |
|---|---|---|
| WHERE | 先筛选数据再关联,执行效率高 | 不能使用分组中的计算函数进行筛选 |
| HAVING | 可以使用分组中的计算函数 | 在最后的结果集中进行筛选,执行效率较低 |
🚄 二、基本的SELECT语句
🚬 (一)基本的SELECT语句
🚭 SELECT…
SELECT 1; #没有任何子句
SELECT 9/2; #没有任何子句SELECT 1 + 1,3 * 2
FROM DUAL; #dual:伪表
🚭 SELECT … FROM
不推荐你直接使用 SELECT * 进行查询
🚭 列的别名 AS
使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。不要使用 ’ ’ 单引号
MySql 中 ’ ’ 单号好使 mysql 不严谨 order 中就不可以 (规定中也不可以)
🚭 去除重复行 DISTINCT
🚭 空值参与运算
所有运算符或列值遇到null值,运算的结果都为null
MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
🚭 着重号 ``
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在SQL语句中使用一对``(着重号)引起来。
🚭 查询常数
🚭 显示表结构 DESCRIBE/DESC
使用DESCRIBE 或 DESC 命令,表示表结构。
DESCRIBE employees; #显示了表中字段的详细信息
或
DESC employees;
🚬 (二)、过滤数据 where
🚬 (三)、BETWEEN AND 运算符
between and 先写小值、在写大值,不可交换
#查询工资在6000 到 8000的员工信息
SELECT employee_id,last_name,salary
FROM employees
#where salary between 6000 and 8000;
WHERE salary >= 6000 && salary <= 8000;
🚬 (四)、IN/NOT IN 运算符
- in: 判断给定的值是否是IN列表中的一个值,如果是则返回1,否则返回0。如果给定的值为NULL,或者IN列表中存在NULL,则结果为NULL。
- not in: 用于判断给定的值是否不是IN列表中的一个值,如果不是IN列表中的一个值,则返回1,否则返回0。
#练习:查询部门为10,20,30部门的员工信息
SELECT last_name,salary,department_id
FROM employees
#where department_id = 10 or department_id = 20 or department_id = 30;
WHERE department_id IN (10,20,30);#练习:查询工资不是6000,7000,8000的员工信息
SELECT last_name,salary,department_id
FROM employees
WHERE salary NOT IN (6000,7000,8000);
🚬 (五)、模糊匹配 LIKE 运算符
- LIKE运算符主要用来匹配字符串,通常用于模糊匹配,如果满足条件则返回1,否则返回0。如果给定的值或者匹配条件为NULL,则返回结果为NULL。
- “%”:匹配0个或多个字符。
- “_”:只能匹配一个字符。
- 此时使用了转移字符 \ 后 _ 在此时就不表示任意一人字符
#练习:查询last_name中包含字符'a'且包含字符'e'的员工信息
#写法1:
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%' AND last_name LIKE '%e%';
#写法2:
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%e%' OR last_name LIKE '%e%a%';#练习:查询第3个字符是'a'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';# 此时使用了转移字符 \ 后 _ 在此时就不表示任意一人字符
SELECT job_id
FROM jobs
WHERE job_id LIKE 'IT\_%';
🚬 (六)、ORDER BY
🚭 排序规则
- ASC(ascend): 升序
- DESC(descend):降序
- ORDER BY 子句在SELECT语句的结尾
- 没有使用排序操作: 默认情况下查询返回的数据是按照添加数据的顺序显示的。
- 在ORDER BY 后没有指名排序的方式 默认按照升序排列。
- 可以使用列的别名,进行排序
🚭 单列排序
# 练习1:按照salary从高到低的顺序显示员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC;
🚭 多列排序
#练习:显示员工信息,按照department_id的降序排列,salary的升序排列
SELECT employee_id,salary,department_id
FROM employees
ORDER BY department_id DESC,salary ASC;
🚬 (七)、分页 lIMIT
🚭 规则
- 公式: (当前页数-1)* 每页条数,每页条数
- 位置: LIMIT 子句必须放在整个SELECT语句的最后。
- 好处: 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回,减少数据表的网络传输量,也可以提升查询效率
SELECT employee_id,last_name,salary
FROM employees
WHERE salary > 6000
ORDER BY salary DESC
#limit 0,10;
LIMIT 10;
🚬 (八)、MySQL 8 分页新特性 LIMIT … OFFSET …

#练习:表里有107条数据,我们只想要显示第 32、33 条数据怎么办呢?
SELECT employee_id,last_name
FROM employees
LIMIT 2 OFFSET 31;
🚄 三、运算符
🚬 (一)、算数运算符
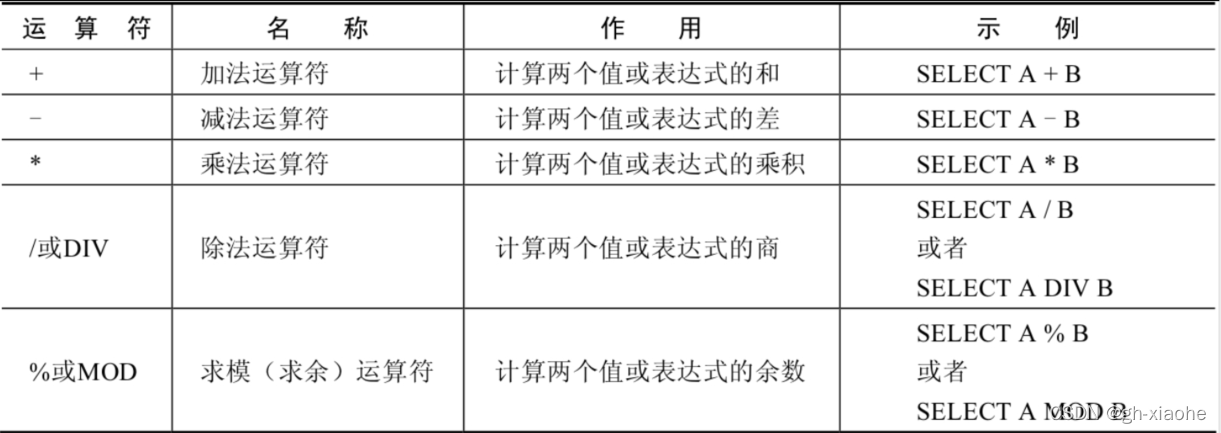
连接运算符前后的两个数值或表达式,对数值或表达式进行 加(+)、减(-)、乘(*)、除(/)和取模(%)运算
🚬 (二)、比较运算符
🚭 1、符号类型的运算符
<>(!=)、<=>、<、<=、>、>=,比较运算符用来对表达式左边的操作数和右边的操作数进行比较
- 结果为真: 返回1
- 结果为真: 返回0
- 其他情况则: 返回null
- 经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。
🚭 2、非符号类型的运算符
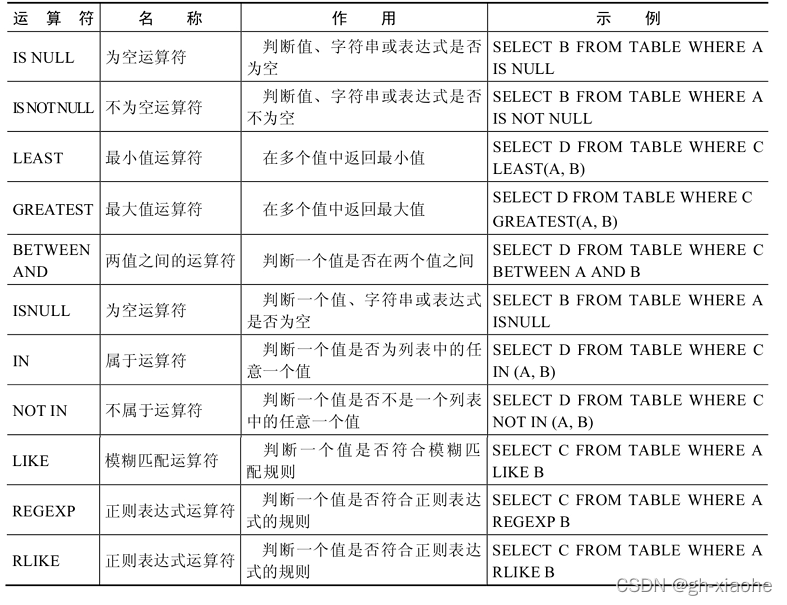
🛹 空运算符 IS NULL \ ISNULL 和 非空运算符 IS NOT NULL
判断一个值是否为NULL,如果为NULL则返回1,否则返回0
#练习:查询表中commission_pct为null的数据有哪些
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct IS NULL;
#或
SELECT last_name,salary,commission_pct
FROM employees
WHERE ISNULL(commission_pct);#查询commission_pct不等于NULL
SELECT employee_id,commission_pct FROM employees WHERE commission_pct IS NOT NULL;
SELECT employee_id,commission_pct FROM employees WHERE NOT commission_pct <=> NULL;
SELECT employee_id,commission_pct FROM employees WHERE NOT ISNULL(commission_pct);
🛹 最大小值运算符 LEAST 、GREATEST
GREATEST(值1,值2,…,值n)。其中,n表示参数列表中有n个值。当有两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值NULL。
SELECT LEAST (1,0,2), LEAST('b','a','c'), LEAST(1,NULL,2);
🛹 REGEXP \ RLIKE :正则表达式
🚬 (三)、逻辑运算符 OR || AND && NOT ! XOR 要保证条件完整

逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL。
🚬 (四)、位运算符 & | ^ ~ >> <<
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数
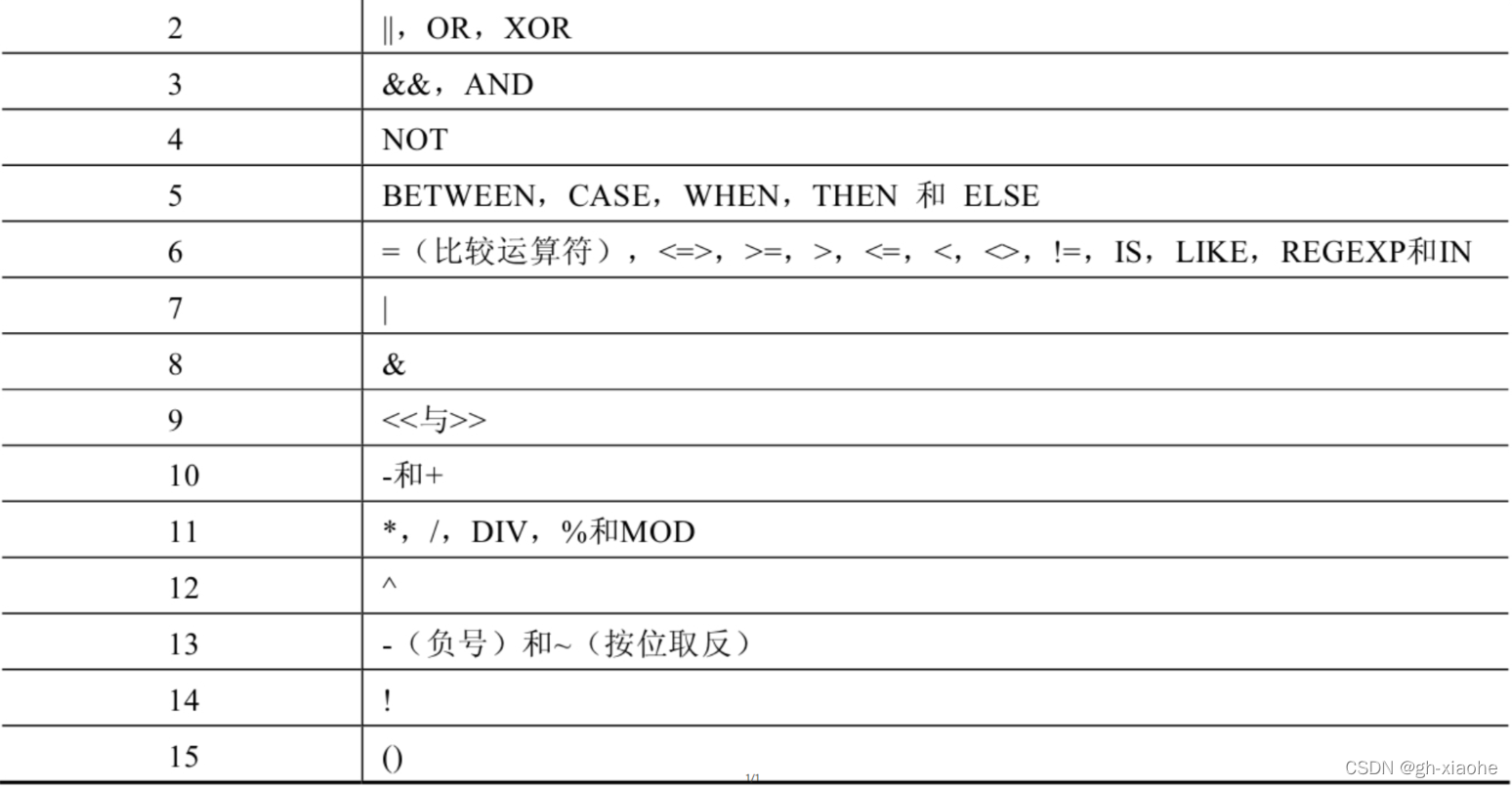
🚬 (五)、运算符的优先级
数字编号越大,优先级越高,优先级高的运算符先进行计算。赋值运算符的优先级最低,使用“()”括起来的表达式的优先级最高。
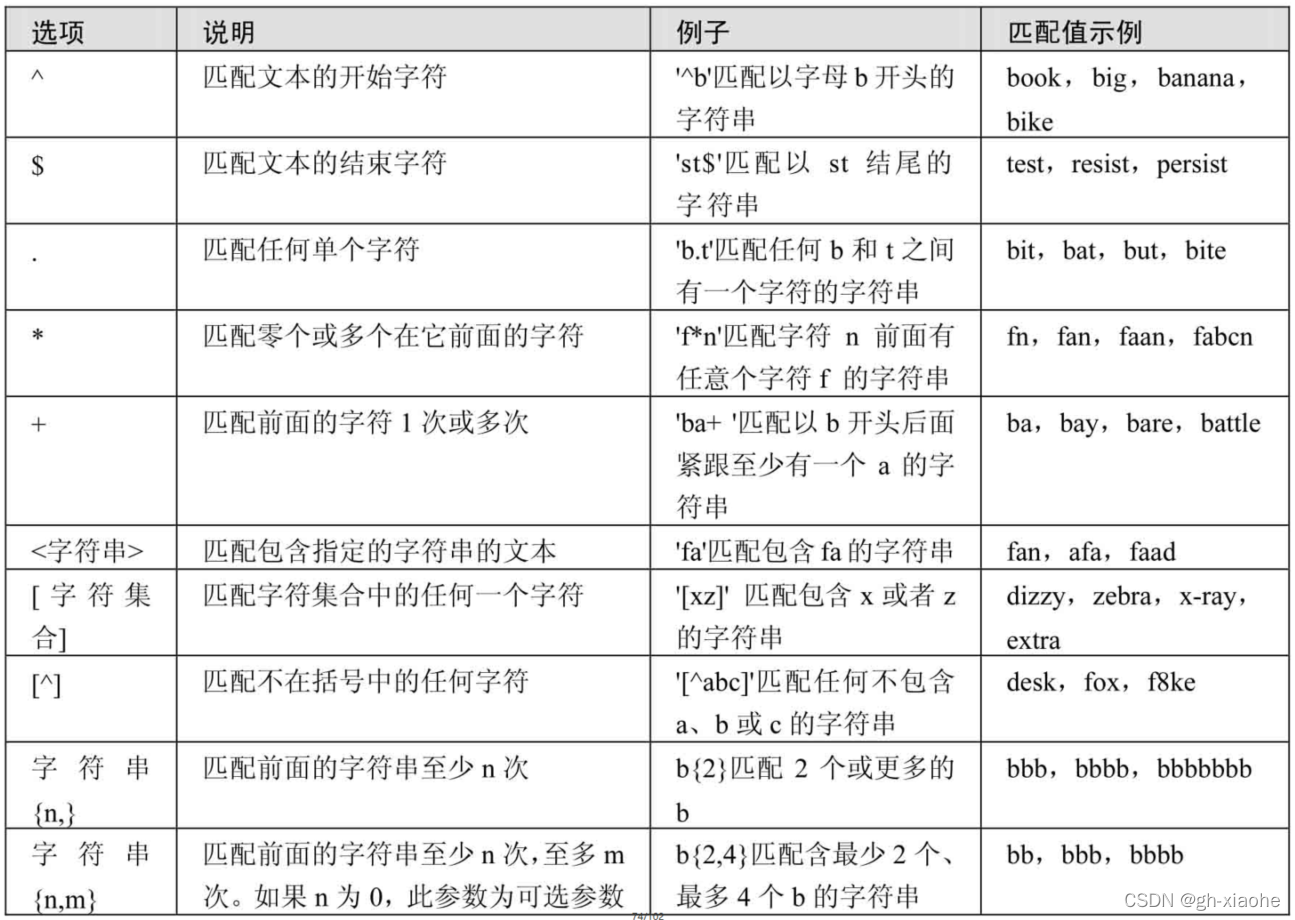
🚬 (六)、拓展:使用正则表达式查询
🚒 四、子查询
子查询可以应用的位置:
结论:除了GROUP BY 和 LIMIT 之外,其他位置都可以声明子查询!
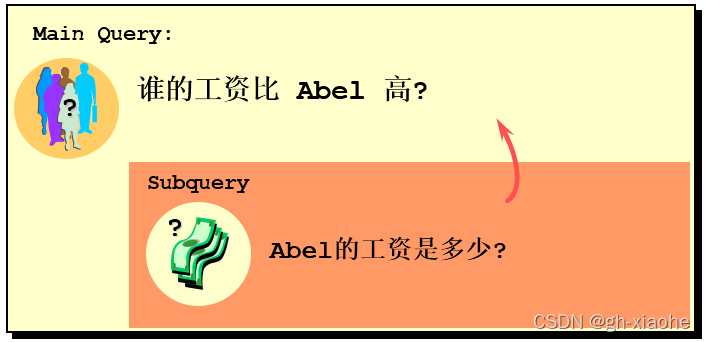
🚬 (一)、实际问题
方式一:进行两次查询SELECT salary FROM employees WHERE last_name = 'Abel';SELECT last_name,salary FROM employees WHERE salary > 11000 ;方式二:自连接
SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e1.last_name = 'Abel' #多表的连接条件 AND e2.`salary` > e1.`salary`;方式三:子查询
SELECT last_name,salary FROM employees WHERE salary > (SELECT salaryFROM employeesWHERE last_name = 'Abel');
🚬 (二)、子查询的基本语法结构

-
子查询(内查询)在主查询之前一次执行完成
-
子查询的结果被主查询(外查询)使用 。
-
注意事项
-
子查询要包含在括号内
-
将子查询放在比较条件的右侧
-
单行操作符对应单行子查询,多行操作符对应多行子查询
-
🚬 (三)、子查询的分类
🚭 1、角度1:从内查询返回的结果的条目数 单行子查询 vs 多行子查询
按内查询的结果返回一条还是多条记录,将子查询分为 单行子查询 、多行子查询
🚭 2、角度2:内查询是否被执行多次 相关子查询 vs 不相关子查询
按内查询是否被执行多次,分为 相关(或关联)子查询 和 不相关(或非关联)子查询
- 不相关子查询:子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行
- 相关子查询:如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部嵌套的执行方式:
举例:
- 相关子查询的需求:查询工资大于本部门平均工资的员工信息。(变化)
- 不相关子查询的需求:查询工资大于本公司平均工资的员工信息。(固定)
🌟 非相关子查询操作
🚬 (四)、单行子查询 —> 非相关子查询
🚭 1、单行子查询操作符
| 操作符 | 含义 |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
🚭 2、WHERE中的子查询
#题目1:查询工资大于149号员工工资的员工的信息
SELECT employee_id,last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE employee_id = 149);#题目2:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT last_name,`job_id`,salary
FROM employees
WHERE job_id = (SELECT job_idFROM employeesWHERE `employee_id` = 141)
AND salary > (SELECT salaryFROM employeesWHERE `employee_id` = 143);#题目3:返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name,job_id,salary
FROM employees
WHERE salary = (SELECT MIN(salary)FROM employees);#题目4:查询与141号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id。
#方式1:
SELECT employee_id,manager_id,department_id
FROM employees
WHERE manager_id = (SELECT manager_idFROM employeesWHERE employee_id = 141)
AND department_id = (SELECT department_idFROM employeesWHERE employee_id = 141)
AND employee_id <> 141;-----------------------------------------#方式2:了解
SELECT employee_id,manager_id,department_id
FROM employees
WHERE (manager_id,department_id) = (SELECT manager_id,department_idFROM employeesWHERE employee_id = 141)
AND employee_id <> 141;
🚭 3、HAVING 中的子查询
- 首先执行子查询
- 向主查询中的HAVING 子句返回结果。
#题目1:查询最低工资大于110号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING MIN(salary) > (SELECT MIN(salary)FROM employeesWHERE department_id = 110);
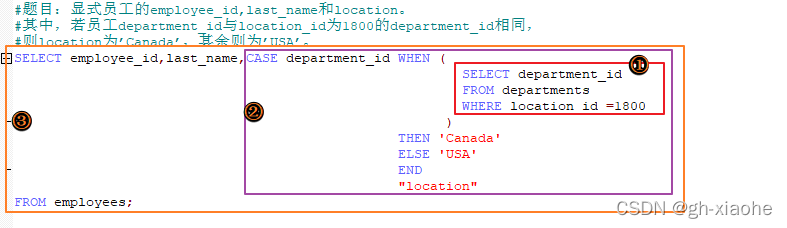
🚭 4、CASE中的子查询
在CASE表达式中使用单列子查询
#题目:显式员工的employee_id,last_name和location。
#其中,若员工department_id与location_id为1800的department_id相同,
#则location为’Canada’,其余则为’USA’。
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_idFROM departmentsWHERE location_id =1800)THEN 'Canada' ELSE 'USA'END"location"
FROM employees;
🚭 5、子查询中的空值问题
子查询不返回任何行
# 子查询中的空值问题
SELECT last_name, job_id
FROM employees
WHERE job_id =(SELECT job_idFROM employeesWHERE last_name = 'Haas'); # 没有此人,无job_id,无法查询出结果,返回空值

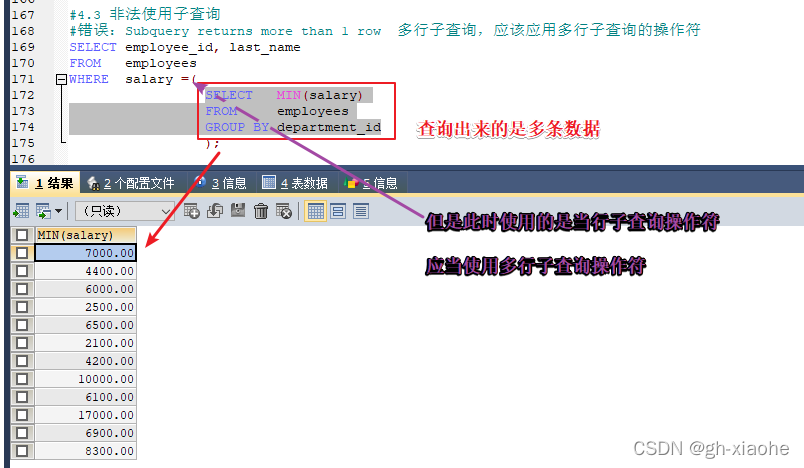
🚭 6、非法使用子查询

🚬 (五)、多行子查询 —> 非相关子查询
🚭 1、多行子查询的操作符 IN、ANY、ALL、SOME(同ANY)
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
🚭 2、In
# 案例1:返回每组员工中工资最少的的 员工id 和 姓名
SELECT employee_id, last_name
FROM employees
WHERE salary IN(SELECT MIN(salary)FROM employeesGROUP BY department_id);
🚭 3、ANY / ALL:
# 体会 ANY 和 ALL 的区别# 非诚勿扰综艺,五个女生给你亮灯,# ANY 随便牵手哪一个都可以 只选一个# ALL 全部都带走#题目1:返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY (SELECT salaryFROM employeesWHERE job_id = 'IT_PROG' ); # 小于 9000 就可以 #题目2:返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、姓名、job_id 以及salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ALL (SELECT salaryFROM employeesWHERE job_id = 'IT_PROG');# 小于 4200 最小工资才可以 #题目3:查询平均工资最低的部门id
# 让查询的结果充当一张表,此时列叫 avg_sal 而不是一个函数 MIN(avg_sal)#MySQL中聚合函数是不能嵌套使用的。 Order中支持聚合函数嵌套
#方式1:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (SELECT MIN(avg_sal)FROM(SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal# Every derived table must have its own alias 每一个保留下来的表,起个别名);#方式2:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL( # <= ALL 小于等于所有的 相当于小于最小的 SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id)
🚭 4、多行子查询空值问题
# 空值问题
# 结果中含有空值 内查询还有null值 在含有null的情况下 再去判断 结果 就是一个空的情况
SELECT last_name
FROM employees
WHERE employee_id NOT IN (SELECT manager_id FROM employees# where manager_id IS NOT NULL);
注意:结果中含有空值 内查询还有null值 在含有null的情况下 再去判断 结果 就是一个空的情况
结果:返回的结果为空
🌟 相关子查询操作
🚬 (六)、相关子查询执行流程
子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表并进行了条件关联因此每执行一次外部查询,子查询都要重新计算一次这样的子查询就称之为关联子查询 。
相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。

🚬 (七)、在 FROM 中使用子查询(相关子查询)
from型的子查询:子查询是作为from的一部分,子查询要用()引起来,并且要给这个子查询取别名, 把它当成一张“临时的虚拟的表”来使用。
#回顾:查询员工中工资大于公司平均工资的员工的last_name,salary和其department_id#方式1:使用相关子查询
SELECT last_name,salary,department_id
FROM employees e1
WHERE salary > ( SELECT AVG(salary)FROM employees e2 WHERE department_id = e1.department_id # 比较的是那个部门); #方式2:在FROM中声明子查询
SELECT e1.last_name,e1.salary,e1.department_id
FROM employees e1,(SELECT department_id,AVG(salary) avg_sal # 需要传入department_id 用于做链接条件FROM employeesGROUP BY department_id) t_dept_avg_sal
WHERE e1.department_id = t_dept_avg_sal.department_id
AND e1.salary > t_dept_avg_sal.avg_sal; # avg_sal 此时是字段 不是函数 必须有别名
🚬 (八)、在ORDER BY 中使用子查询(相关子查询)
# 案例1 查询员工的id,salary,按照department_name 排序
SELECT employee_id,salary
FROM employees e
ORDER BY (SELECT department_nameFROM departments dWHERE e.`department_id` = d.`department_id`) ASC;# 案例2 若employees表中employee_id与job_history表中employee_id相同的数目不小于2,
# 输出这些相同id的员工的employee_id,last_name和其job_idSELECT e.employee_id,last_name,e.job_id
FROM employees e
WHERE 2 <= (SELECT COUNT(*)FROM `job_history` jWHERE j.employee_id = e.employee_id);
🚬 (九)、EXISTS 与 NOT EXISTS关键字
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
- 子查询中不存在满足条件的行
- 条件返回 FALSE
- 继续在子查询中查找
- 子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
🚭 1、EXISTS 案例:
#题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
#方式1:自连接
SELECT DISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id
FROM employees emp JOIN employees mgr
ON emp.manager_id = mgr.employee_id;#方式2:子查询
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN (SELECT DISTINCT manager_idFROM employees);#方式3:使用EXISTS
SELECT employee_id,last_name,job_id,department_id
FROM employees e1
WHERE EXISTS (SELECT * # 此时 与 * 还是什么字段 已经不重要了,找到记录就要,没有找到记录就不要了FROM employees e2WHERE e1.`employee_id` = e2.`manager_id` # 相当于一条条数据往下找,找到满足的数据 为 true 就不像下寻找);
🚭 2、NOT EXISTS案例:
# 查询departments表中,不存在于employees表中的部门的department_id和department_name
#方式1: 外连接 相当于 只需要个 一个表 去除 两个表的交集部门
SELECT d.department_id,d.department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;#方式2:
SELECT department_id,department_name
FROM departments d
WHERE NOT EXISTS (SELECT *FROM employees eWHERE d.`department_id` = e.`department_id`);
🚭 3、子查询 更新
# 使用相关子查询依据一个表中的数据更新另一个表的数据。
# 1)
ALTER TABLE employees
ADD(department_name VARCHAR2(14));
# 2)
UPDATE employees e
SET department_name = (SELECT department_nameFROM departments dWHERE e.department_id = d.department_id);
🚭 4、子查询 删除
# 使用相关子查询依据一个表中的数据删除另一个表的数据
DELETE FROM employees e
WHERE employee_id in (SELECT employee_idFROM emp_historyWHERE employee_id = e.employee_id);
🚬 (十)、问题:自连接和子查询有好坏之分吗?
-
解答:自连接方式好因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
-
可以这样理解:子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表进行条件判断,因此在大部分 DBMS 中都对自连接处理进行了优化。
# 问题:谁的工资比Abel的高?
# 方式1:自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e2.`salary` > e1.`salary` #多表的连接条件
AND e1.last_name = 'Abel';# 方式2:子查询
SELECT last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE last_name = 'Abel');
🚬 (十一)、相关子查询和非相关子查询的经典题型
🚭 1、非相关子查询
#8.查询平均工资最低的部门信息
#方式1:
SELECT *
FROM departments
WHERE department_id = (SELECT department_idFROM employeesGROUP BY department_idHAVING AVG(salary ) = (SELECT MIN(avg_sal)FROM (SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal));
#方式2:
SELECT *
FROM departments
WHERE department_id = (SELECT department_idFROM employeesGROUP BY department_idHAVING AVG(salary ) <= ALL(SELECT AVG(salary)FROM employeesGROUP BY department_id));#方式3: LIMITSELECT *
FROM departments
WHERE department_id = (SELECT department_idFROM employeesGROUP BY department_idHAVING AVG(salary ) =(SELECT AVG(salary) avg_salFROM employeesGROUP BY department_idORDER BY avg_sal ASCLIMIT 1 ));#方式4:SELECT d.*
FROM departments d,(SELECT department_id,AVG(salary) avg_salFROM employeesGROUP BY department_idORDER BY avg_sal ASCLIMIT 0,1) t_dept_avg_sal
WHERE d.`department_id` = t_dept_avg_sal.department_id#9.查询平均工资最低的部门信息和该部门的平均工资(相关子查询)
#方式1:
SELECT d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal
FROM departments d
WHERE department_id = (SELECT department_idFROM employeesGROUP BY department_idHAVING AVG(salary ) = (SELECT MIN(avg_sal)FROM (SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal));#方式2:SELECT d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal
FROM departments d
WHERE department_id = (SELECT department_idFROM employeesGROUP BY department_idHAVING AVG(salary ) <= ALL(SELECT AVG(salary)FROM employeesGROUP BY department_id));#方式3: LIMITSELECT d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal
FROM departments d
WHERE department_id = (SELECT department_idFROM employeesGROUP BY department_idHAVING AVG(salary ) =(SELECT AVG(salary) avg_salFROM employeesGROUP BY department_idORDER BY avg_sal ASCLIMIT 1 ));#方式4:SELECT d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_sal
FROM departments d,(SELECT department_id,AVG(salary) avg_salFROM employeesGROUP BY department_idORDER BY avg_sal ASCLIMIT 0,1) t_dept_avg_sal
WHERE d.`department_id` = t_dept_avg_sal.department_id
🚭 2、相关子查询
#19.查询每个部门下的部门人数大于 5 的部门名称(相关子查询)SELECT department_name
FROM departments d
WHERE 5 < (SELECT COUNT(*)FROM employees eWHERE d.department_id = e.`department_id`);
🚤 五、多表查询
表连接的约束条件可以有三种方式:WHERE, ON, USING
- WHERE:适用于所有关联查询
- ON:只能和JOIN一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
- USING:只能和JOIN一起使用,而且要求两个关联字段在关联表中名称一致,而且只能表示关联字段值相等
注意关联条件:
- 把关联条件写在where后面
- 把关联条件写在on后面,只能和JOIN一起使用
- 把关联字段写在using()中,只能和JOIN一起使用,而且两个表中的关联字段必须名称相同,而且只能表示=
- n张表关联,需要n-1个关联条件
注意:
我们要 控制连接表的数量 。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。
【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时, 保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能
多表查询的好处:相对于把所有字段整合到一张表中
- 减少了冗余的字段
- 查询时,数据量过大 io次数也增加 减少了io次数
- 方便维护
- 不涉及表锁定问题
🚬 (一)、7种SQL JOINS的实现
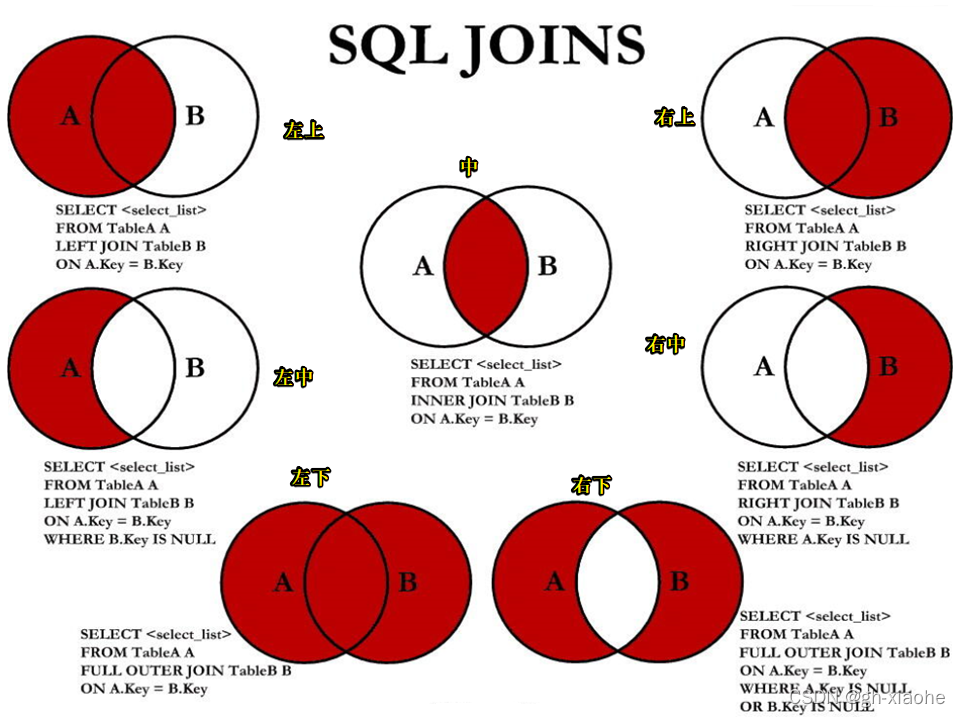
# 中图:内连接
SELECT employee_id,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;# 左上图:左外连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;# 右上图:右外连接
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;# 左中图:
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL;# 右中图:
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;# 左下图:满外连接
# 方式1:左上图 UNION ALL 右中图SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;# 方式2:左中图 UNION ALL 右上图SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;# 右下图:左中图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
🚬 (二)、多表查询分类
🚭 1、方式一:等值连接 vs 非等值连接
🛹 ① 等值连接
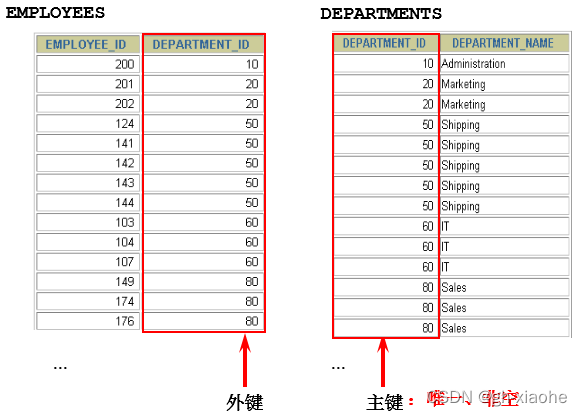
# 查询员工名 Abel 的在那个城市工作#1、先查出 员工白中叫Abel 的人 的部门id
SELECT *
FROM employees
WHERE last_name = 'Abel'; #2、根据部门 id 查询出 他所在的地点id
SELECT *
FROM departments
WHERE `department_id` = 80;#3、根据他所在的地点id 查询出所在的城市
SELECT city
FROM locations
WHERE `location_id` = 2500;# 查询员工名 Abel 的在那个城市工作SELECT last_name,locations.`city`
FROM employees,departments,`locations`
WHERE employees.department_id = departments.department_id
AND last_name = 'Abel'
AND departments.location_id = locations.`location_id`;
-
拓展:
-
1、多个连接条件与 AND 操作符
-
2、区分重复的列名
-
多个表中有相同列时,必须在列名之前加上表名前缀。
-
在不同表中具有相同列名的列可以用 表名 加以区分。
-
-
3、表的别名
-
使用别名可以简化查询。
-
列名前使用表名前缀可以提高查询效率。
-
-
3、连接n个表,至少需要n-1个连接条件。
-
注意:如果给表起了别名,一旦在SELECT或WHERE中使用表名的话,则必须使用表的别名,而不能再使用表的原名。
🛹 ② 非等值连接
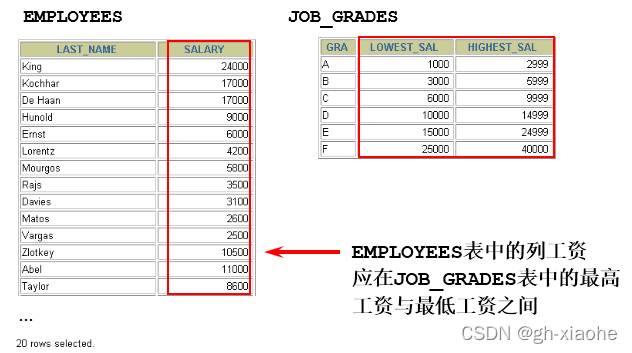
# 查询员工的工资水平
SELECT em.last_name,em.`salary`,job.`grade_level`
FROM `employees` em,`job_grades` job
WHERE em.`salary` BETWEEN job.`lowest_sal` AND job.`highest_sal`;
🚭 2、方式二:自连接 vs 非自连接
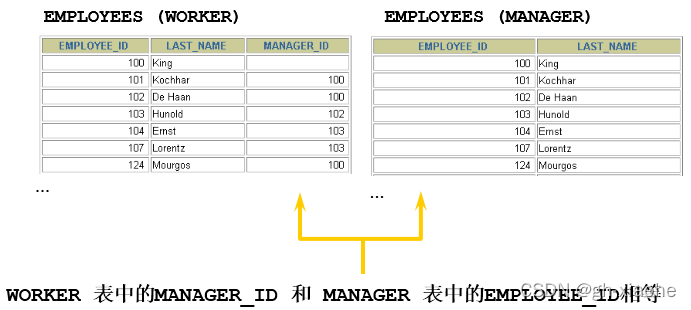
当table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。然后两个表再进行内连接,外连接等查询。
#练习:查询员工id,员工姓名及其管理者的id和姓名SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name FROM employees emp ,employees mgr WHERE emp.`manager_id` = mgr.`employee_id`;
🚭 3、方式三:内连接 vs 外连接
除了查询满足条件的记录以外,外连接还可以查询某一方不满足条件的记录。
- 内连接:合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
- 外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
- 如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。

#练习:查询所有的员工的last_name,department_name信息
# 注意:所有 ---->且来自不同的表,外连接(有不匹配的数据)# 此时是错误的。
SELECT employee_id,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.department_id; # 查出数据为106条数据 不正确 少了一个 为null的 数据
🚬 (三)、SQL92:使用(+)创建连接
- SQL92 中采用(+)代表从表所在的位置。即左或右外连接中,(+) 表示哪个是从表。
- Oracle 对 SQL92 支持较好,而 MySQL 则不支持 SQL92 的外连接。
- 而且在 SQL92 中,只有左外连接和右外连接,没有满(或全)外连接。
SELECT employee_id,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.department_id(+);
🚬 (四)、SQL99语法实现多表查询
🛹 基本语法:使用JOIN…ON子句创建连接的语法
SQL99 采用的这种嵌套结构非常清爽、层次性更强、可读性更强,即使再多的表进行连接也都清晰可见。如果你采用 SQL92,可读性就会大打折扣。
语法说明:
- 可以使用 ON 子句指定额外的连接条件。
- 这个连接条件是与其它条件分开的。
- ON 子句使语句具有更高的易读性。
- 关键字 JOIN、INNER JOIN、CROSS JOIN 的含义是一样的,都表示内连接
分类:
- 内连接:INNER JOIN ON
- 外连接:OUTER JOIN
- 左外连接:LEFT OUTER JOIN
- 右外连接:RIGHT OUTER JOIN
- 满外连接:FULL OUTER JOIN(MySQL 不支持,但是我们有办法实现)
🛹 ① SQL99 内连接语句 INNER JOIN ON / JOIN ON
# 两个表
SELECT last_name,department_name
FROM `employees` e,`departments` d
WHERE e.`department_id` = d.`department_id`;# 三个表
#SQL
SELECT last_name,department_name,city
FROM `employees` e
JOIN `departments` d ON e.`department_id` = d.`department_id`
JOIN locations l ON d.`location_id` = l.`location_id`;
🛹 ② SQL99 左外连接语句 LEFT OUTER JOIN / LEFT JOIN
语法
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句
SELECT last_name,department_name
FROM `employees` e
LEFT OUTER JOIN `departments` d ON e.`department_id` = d.`department_id`;# 或者 可以省略 OUTER
SELECT last_name,department_name
FROM `employees` e
LEFT JOIN `departments` d ON e.`department_id` = d.`department_id`;SELECT last_name,department_name
FROM `employees` e
LEFT OUTER JOIN `departments` d
ON (e.`department_id` = d.`department_id`);
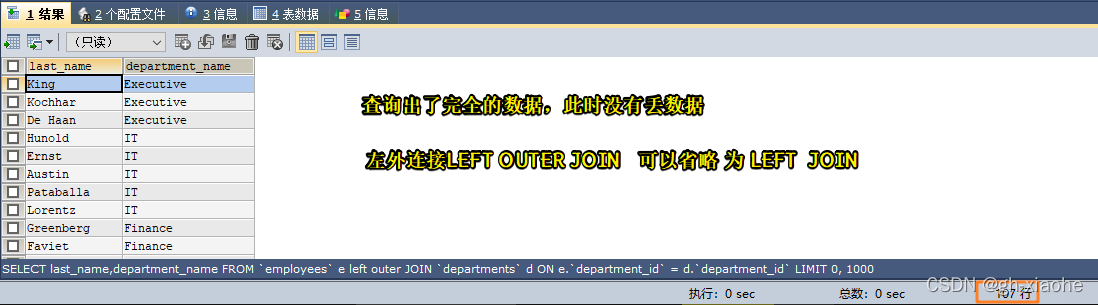
🛹 ③ SQL99 右外连接语句 RIGHT OUTER JOIN
语法
#实现查询结果是B
SELECT 字段列表
FROM A表 RIGHT JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id);
🛹 ④ 满外连接(FULL OUTER JOIN)
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
- 需要注意的是,MySQL不支持FULL JOIN,但是可以用 LEFT JOIN UNION RIGHT JOIN 代替。
#满外连接:mysql不支持FULL OUTER JOIN
SELECT last_name,department_name
FROM employees e FULL OUTER JOIN departments d
ON e.`department_id` = d.`department_id`;
🚬 (五)、合并查询 UNION的使用
合并查询结果:
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNIONALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
- UNION 操作符:操作符返回两个查询的结果集的并集,去除重复记录。
- UNION ALL 操作符:操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:
-
执行UNION ALL语句时所需要的资源比UNION语句少。
-
如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
# 实例 :查询部门编号>90或邮箱包含a的员工信息
# 方式一
SELECT *
FROM employees
WHERE email LIKE '%a%' OR `department_id` >= 90;# 方式二
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE`department_id` >= 90;
🚬 (六)、SQL99语法新特性
🚭 1、自然连接
SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 用来表示自然连接。我们可以把自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中 所有相同的字段 ,然后进行 等值连接 。
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
AND e.`manager_id` = d.`manager_id`;# NATURAL JOIN : 它会帮你自动查询两张连接表中`所有相同的字段`,然后进行`等值连接`。
SELECT employee_id,last_name,department_name
FROM employees e NATURAL JOIN departments d;
🚭 2、USING连接
SQL99还支持使用 USING 指定数据表里的 同名字段 进行等值连接。但是只能配合JOIN一起使用。
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
USING (department_id);
相关文章:
MySQL基础查询操作
文章目录🚏 Select语句🚀 一、SQL底层执行原理🚬 (一)、查询的结构🚬 (二)、SQL语句的执行过程🚭 1、WHERE 为什么不包含聚合函数的过滤条件?(面试…...

English Learning - L2 语音作业打卡 小元音 [ʌ] [ɒ] Day9 2023.3.1 周三
English Learning - L2 语音作业打卡 小元音 [ʌ] [ɒ] Day9 2023.3.1 周三💌发音小贴士:💌当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音 [ʌ]&…...
Condition 源码解读
一、Condition 在并发情况下进行线程间的协调,如果是使用的 synchronized 锁,我们可以使用 wait/notify 进行唤醒,如果是使用的 Lock 锁的方式,则可以使用 Condition 进行针对性的阻塞和唤醒,相较于 wait/notify 使用…...
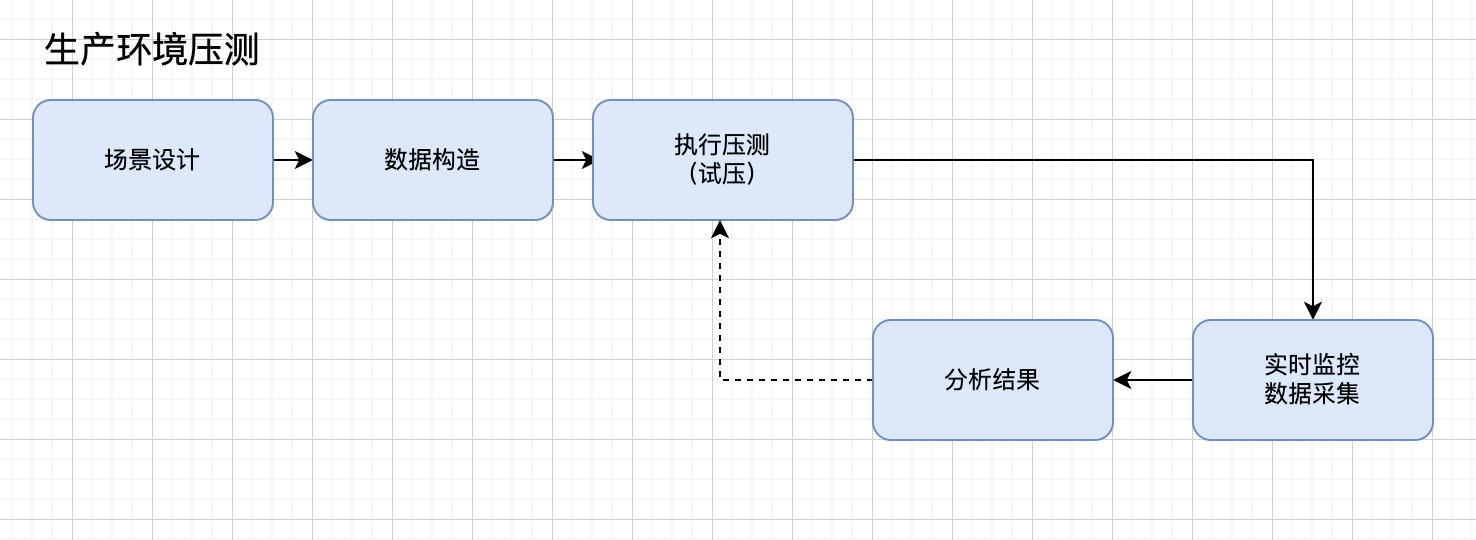
看完这篇入门性能测试
大家好,我是洋子。最近组内在进行服务端高并发接口的性能压测工作,起因是2023年2月2日,针对胡某宇事件进行新闻发布会直播,几十万人同时进入某媒体直播间,造成流量激增 从监控上可以看出,QPS到达某峰值后&…...

推导部分和——带权并查集
题解: 带权并查集 引言: 带权并查集是一种进阶的并查集,通常,结点i的权值等于结点i到根节点的距离,对于带权并查集,有两种操作需要掌握——Merge与Find,涉及到路径压缩与维护权值等技巧。 带…...
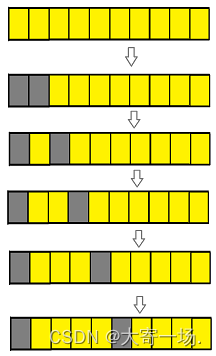
费解的开关/翻硬币
🌱博客主页:大寄一场. 🌱系列专栏: 算法 😘博客制作不易欢迎各位👍点赞⭐收藏➕关注 题目:费解的开关 你玩过“拉灯”游戏吗? 25盏灯排成一个 55 的方形。 每一个灯都有一个开关&…...
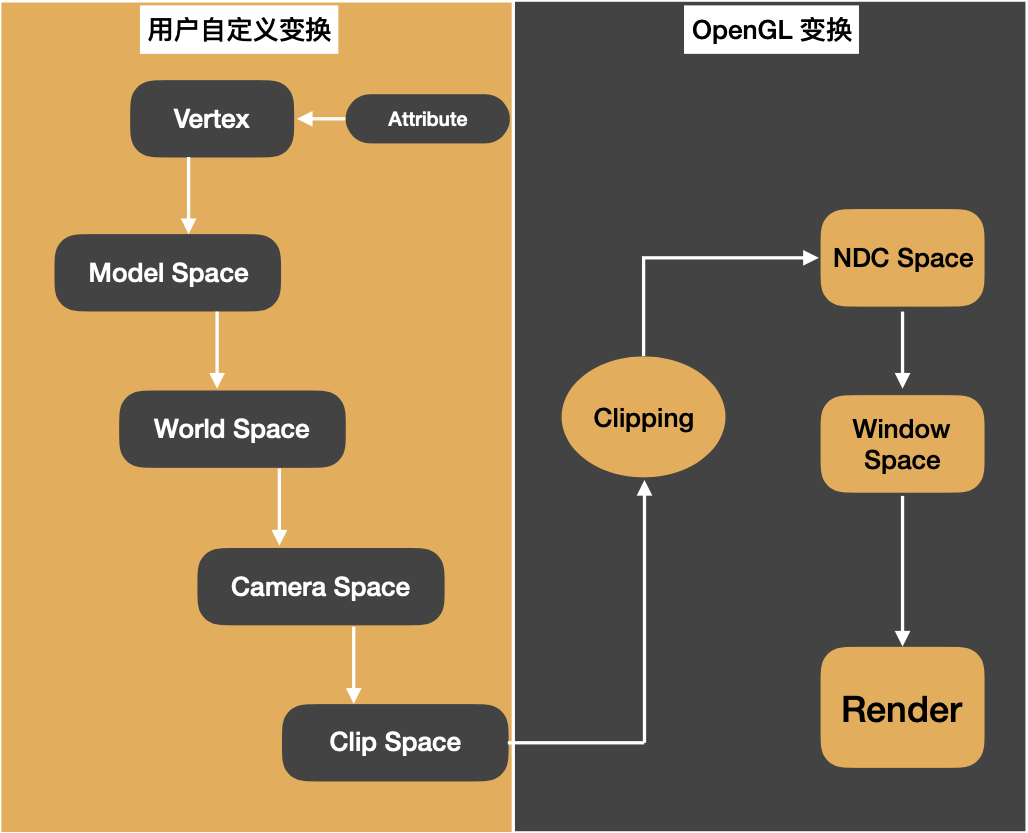
OpenGL中的坐标系
1、2D笛卡尔坐标系2D笛卡尔坐标系跟我们高中的时候学习的坐标系一样,是由x、y决定的。2、3D笛卡尔坐标系3D笛卡尔坐标系坐标由x、y、z决定,满足右手定则。3、视口glViewport(GLint x,GLint y,GLsizei width,GLsizei height)窗口和视口大小可以相同&#…...

Spring——Spring介绍和IOC相关概念
Spring是以Spring Framework为核心,其余的例如Spring MVC, Spring Cloud,Spring Data,Spring Security SpringBoot的基础都是Spring Framework。 Spring Boot可以在简化开发的基础上加速开发。 Spring Cloud分布式开发 Spring有…...

A+B Problem
AB Problem 题目描述 输入两个整数 a,ba, ba,b,输出它们的和(∣a∣,∣b∣≤109|a|,|b| \le {10}^9∣a∣,∣b∣≤109)。 注意 Pascal 使用 integer 会爆掉哦!有负数哦!C/C 的 main 函数必须是 int 类型,…...
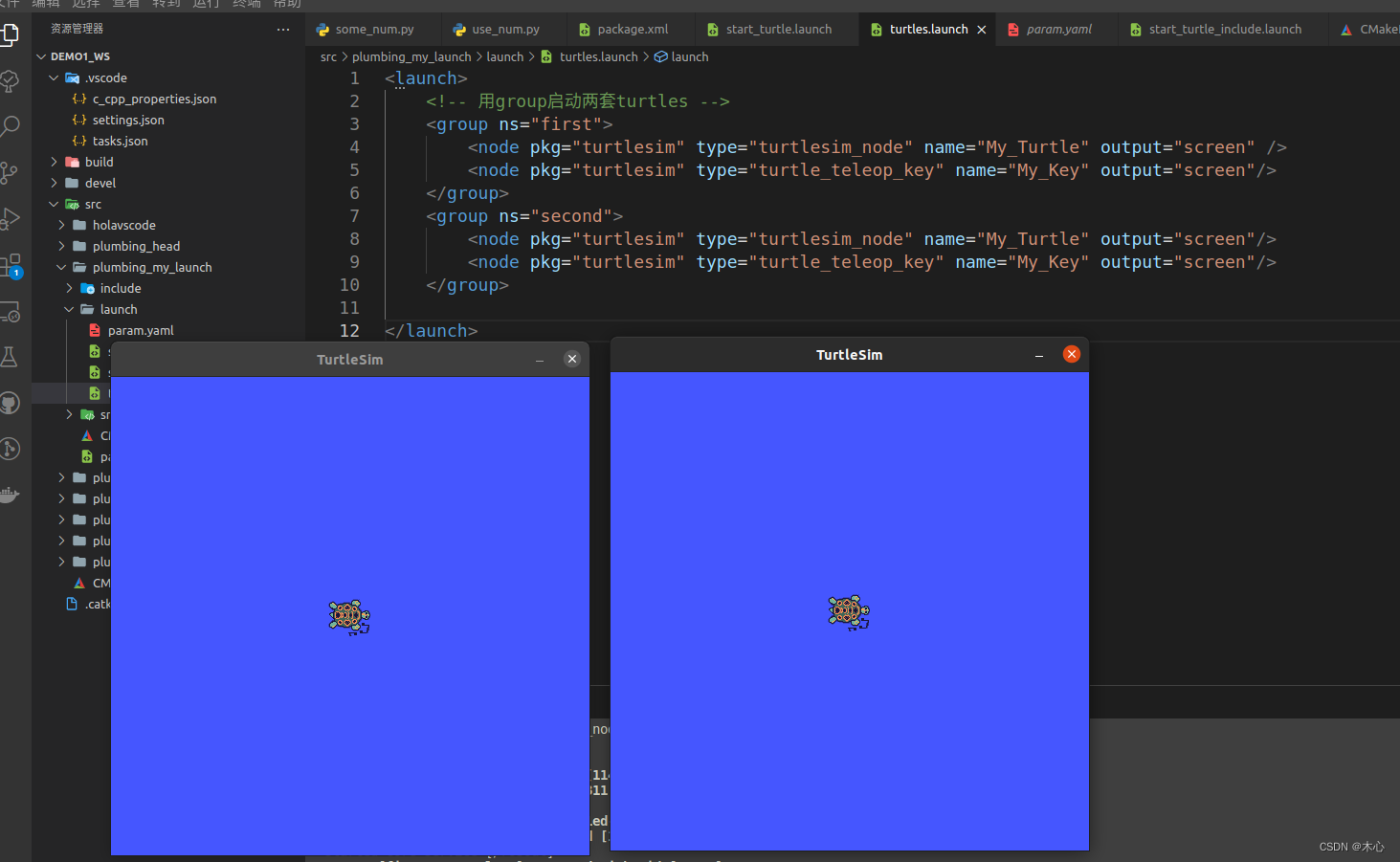
【ROS学习笔记11】ROS元功能包与launch文件的使用
【ROS学习笔记11】ROS元功能包与launch文件的使用 文章目录【ROS学习笔记11】ROS元功能包与launch文件的使用前言一、ROS元功能包二、ROS节点运行管理launch文件2.1 launch文件标签之launch2.2 launch文件标签之node2.3 launch文件标签之include2.4 launch文件标签之remap2.5 l…...

【python】
print函数 同时输出多行变量 print(a, b, sep\n) (23条消息) python3 中print函数参数详解,print(*values, sep , end\n, filesys.stdout, flushFalse)中参数介绍_sep,_phantom-dapeng的博客-CSDN博客 input() 输入浮点数,不能用int(input()) int()…...
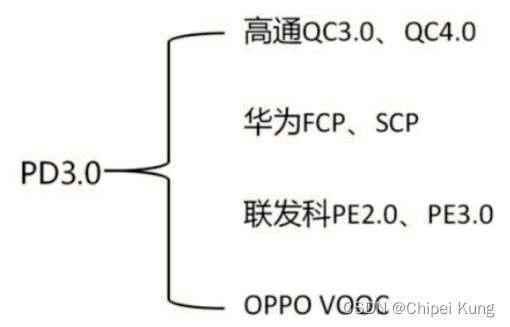
充电协议: 快充协议,如何选充电宝?
快充协议(存在两种:电压; 电流) 目前市面上的快充技术大多遵循2个技术方向: 以高通QC、联发科PEP、华为FCP为首的高压低电流快充技术; 另一种就是以OPPO的VOOC以及华为SCP为首的低电压大电流快充技术。 目前常见的快充标准还有三星AFC、联发…...
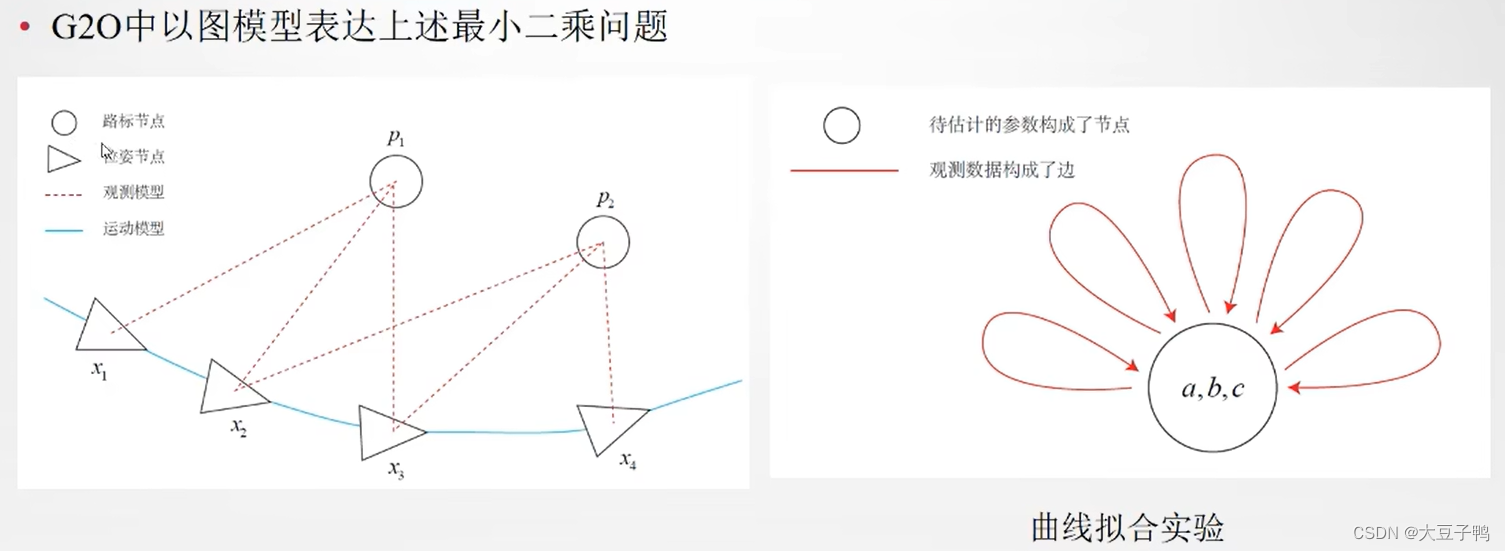
视觉SLAM十四讲ch6 非线性优化笔记
视觉SLAM十四讲ch6 非线性优化笔记本讲目标上讲回顾状态估计问题非线性最小二乘Gauss-Newton:高斯牛顿Levenburg-Marquadt:列文伯格-马夸尔特小结实践:CERES实践:G2O本讲目标 理解最小二乘法的含义和处理方式。 理解Gauss-Newton…...

Nikto工具使用指南
NiktoNikto是一款开源网站服务器扫描器,使用Perl开发,可以对服务器进行全面扫描,包括6400多个潜在危险的文件/cgi(通用网关接口(Common Gateway Interface)),废话不多说,直接上命令:基本测试&am…...
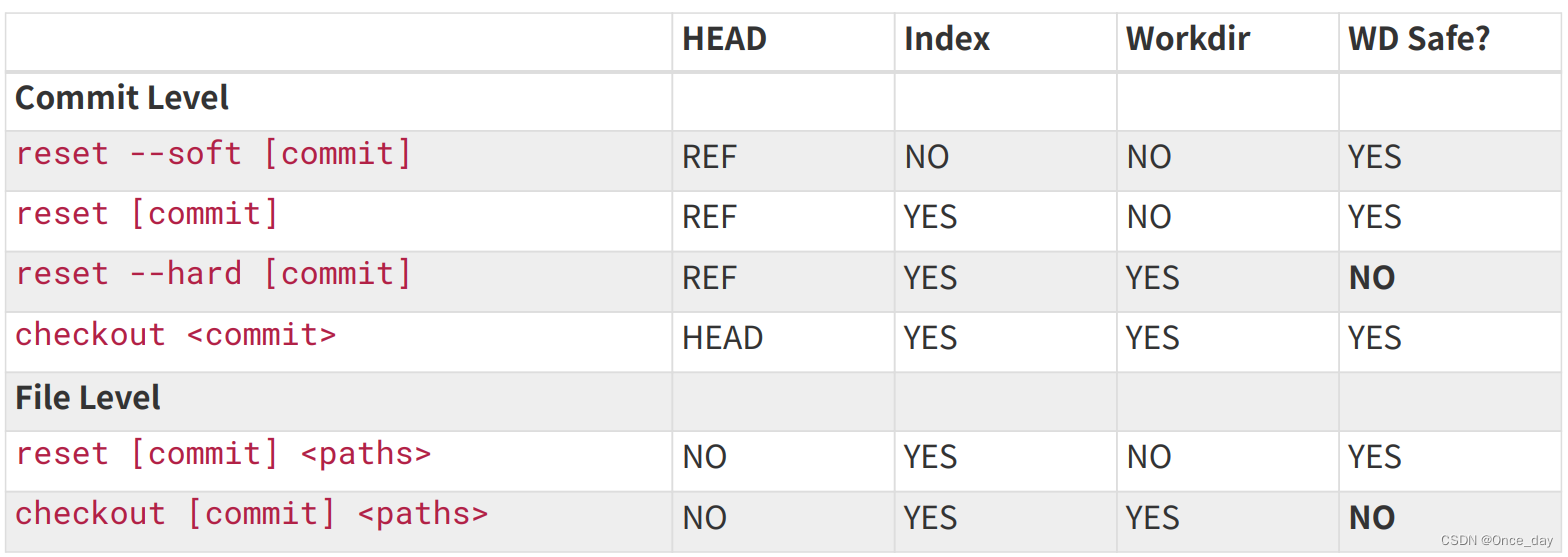
Git(4)之基本工具
Git基础之基本工具 Author:onceday date:2023年3月5日 满满长路有人对你微笑过嘛… windows安装可参考文章:git简易配置_onceday_CSDN博客 參考文档: 《progit2.pdf》,Progit2 Github。《git-book.pdf》 文章目录…...

好书推荐。
个人喜欢看传记,散文,历史等 二战名人传记,苏联列宁,朱可夫,斯大林等 英国首相丘吉尔,美国富兰克林,中国毛泽东等 创业:比尔盖,扎克伯格,苹果公司创始人乔…...

[Pytorch]DataSet和DataLoader逐句详解
将自己的数据集引入Pytorch是搭建属于自己的神经网络的重要一步,这里我设计了一个简单的实验,结合这个实验代码,我将逐句教会大家如何将数据引入DataLoader。 这里以目标检测为例,一个batch中包含图片文件、先验框的框体坐标、目标…...
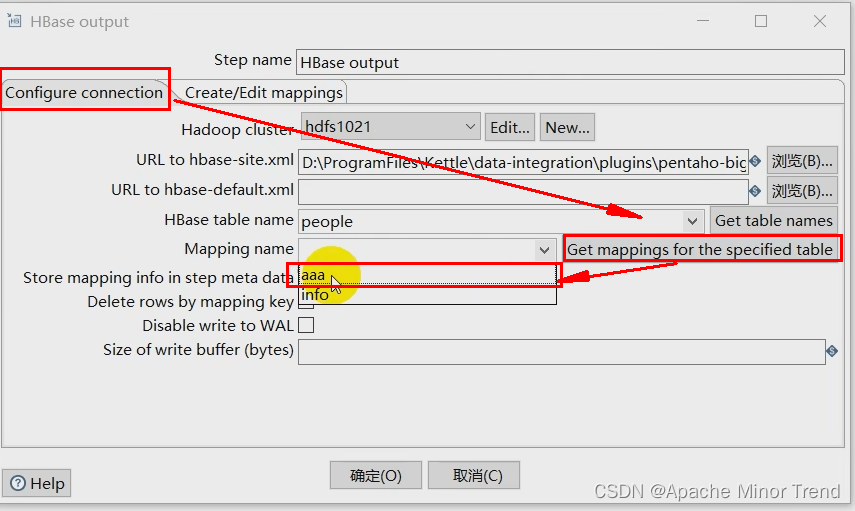
【Kettle-佛系总结】
Kettle-佛系总结Kettle-佛系总结1.kettle介绍2.kettle安装3.kettle目录介绍4.kettle核心概念1.转换2.步骤3.跳(Hop)4.元数据5.数据类型6.并行7.作业5.kettle转换1.输入控件1.csv文件输入2.文本文件输入3.Excel输入4.XML输入5.JSON输入6.表输入2.输出控件…...

JavaSE网络编程
JavaSE网络编程一、基本概念二、常用类三、使用方法1、创建服务器端Socket2、创建客户端Socket3、创建URL对象JavaSE中的网络编程模块提供了一套完整的网络编程接口,可以方便地实现各种基于网络的应用程序。本文将介绍JavaSE中网络编程模块的基本知识、常用类以及使…...

9万字“联、管、用”三位一体雪亮工程整体建设方案
本资料来源公开网络,仅供个人学习,请勿商用。部分资料内容: 1、 总体设计方案 围绕《公共安全视频监控建设联网应用”十三五”规划方案》中的总体架构和一总两分结构要求的基础上,项目将以“加强社会公共安全管理,提高…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...
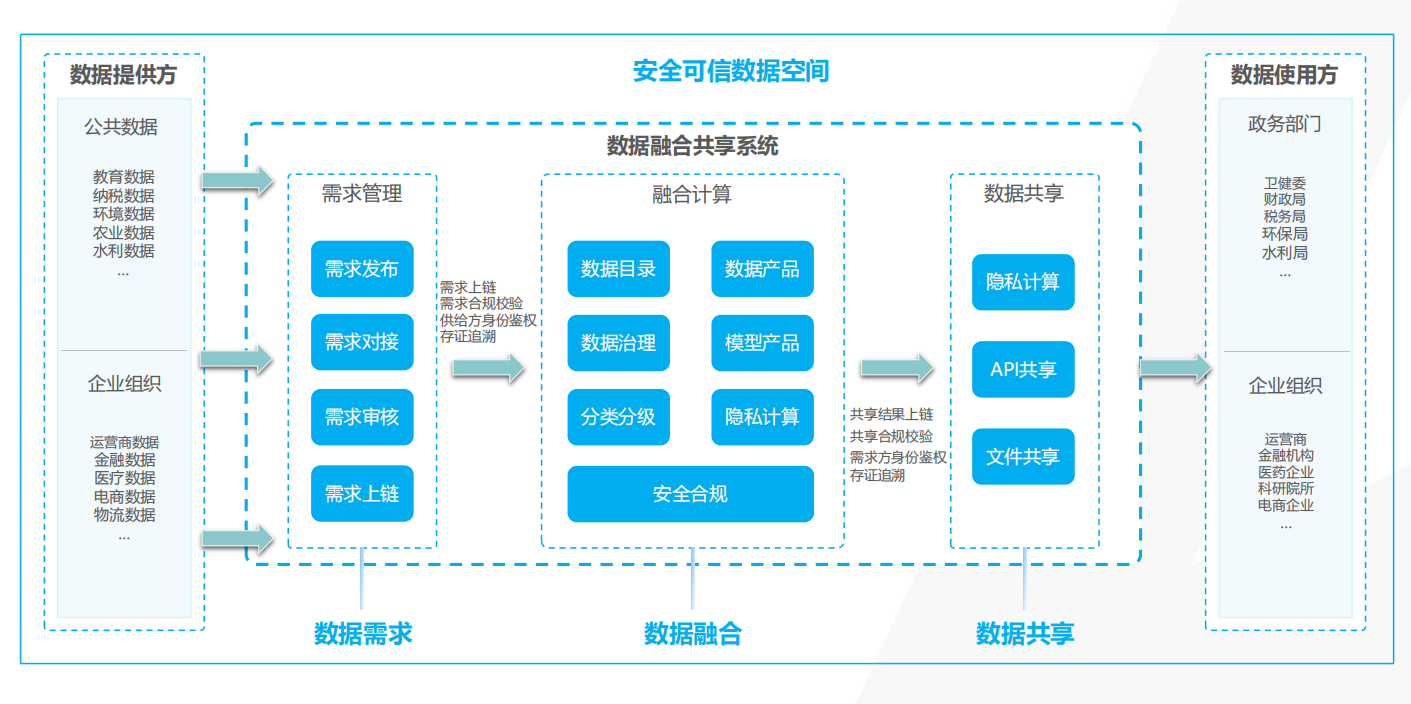
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...
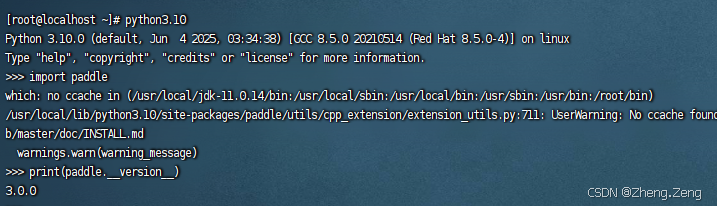
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

深度解析:etcd 在 Milvus 向量数据库中的关键作用
目录 🚀 深度解析:etcd 在 Milvus 向量数据库中的关键作用 💡 什么是 etcd? 🧠 Milvus 架构简介 📦 etcd 在 Milvus 中的核心作用 🔧 实际工作流程示意 ⚠️ 如果 etcd 出现问题会怎样&am…...
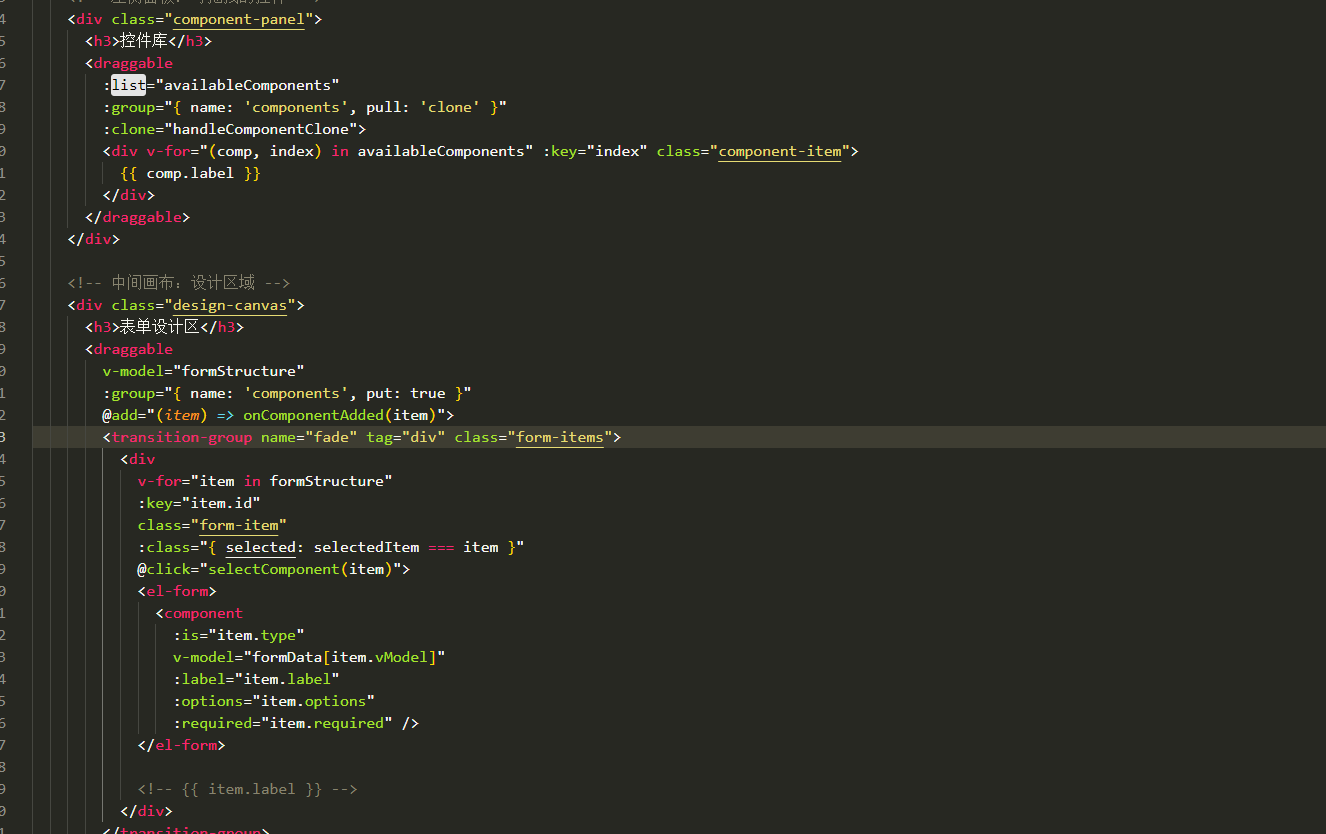
表单设计器拖拽对象时添加属性
背景:因为项目需要。自写设计器。遇到的坑在此记录 使用的拖拽组件时vuedraggable。下面放上局部示例截图。 坑1。draggable标签在拖拽时可以获取到被拖拽的对象属性定义 要使用 :clone, 而不是clone。我想应该是因为draggable标签比较特。另外在使用**:clone时要将…...