【Kettle-佛系总结】
Kettle-佛系总结
- Kettle-佛系总结
- 1.kettle介绍
- 2.kettle安装
- 3.kettle目录介绍
- 4.kettle核心概念
- 1.转换
- 2.步骤
- 3.跳(Hop)
- 4.元数据
- 5.数据类型
- 6.并行
- 7.作业
- 5.kettle转换
- 1.输入控件
- 1.csv文件输入
- 2.文本文件输入
- 3.Excel输入
- 4.XML输入
- 5.JSON输入
- 6.表输入
- 2.输出控件
- 1.Excel输出
- 2.文本文件输出
- 3.sql文件输出
- 4.表输出
- 5.更新
- 6.插入/更新
- 7.删除
- 3.转换控件
- 1.Concat fields
- 2.值映射
- 3.增加常量
- 4.增加序列
- 5.字段选择
- 6.计算器
- 7.字符串剪切&替换&操作
- 8.排序记录&去除重复记录
- 9.唯一行(哈希值)
- 10.拆分字段
- 11.列拆分多行
- 12.行扁平化
- 13.列转行
- 14.行转列
- 4.应用控件
- 1.替换NULL值
- 2.写日志
- 5.流程控件
- 1.Switch/case
- 2.过滤记录
- 3.空操作
- 4.中止
- 6.查询控件
- 1.数据库查询
- 2.流查询
- 7.连接控件
- 1.合并记录
- 2.记录集连接
- 8.统计控件
- 1.分组
- 9.映射控件
- 1.映射(子转换)
- 10.脚本控件
- 1.执行sql脚本
- 6.kettle作业
- 1.作业项
- 2.作业跳
- 3.kettle发送邮件相关配置
- 7.kettle使用案例
- 1.转换案例
- 2.作业案例
- 3.Hive-HDFS案例
- 4.HDFS-HBase案例
- 8.kettle资源库
- 1.数据库资源库
- 2.文件资源库
- 9.kettle相关优化
Kettle-佛系总结
1.kettle介绍
- kettle中有两种脚本,transformation和job,
- transformation完成针对数据的基础转换;
- job则完成整个工作流的控制。
- 作业 job 和 步骤 transformation 类似于spark/flink中的 整个job以及各种算子。
- 两者的区别:
- 1.作业是步骤流,转换是数据流。这是最大区别
- 2.作业的每个步骤,必须等到前面步骤运行完毕,才能执行;而转换会一次性把所有空间全部先启动(一个控件对应启动一个线程),然后数据流会从第一个控件开始,一条记录、一条记录的流向最后的控件
- kettle 现在已经更名为PDI (Pentaho Data Intergration-Pentaho数据集成)
2.kettle安装
- kettle 官网下载地址,推荐8.2版本:https://sourceforge.net/projects/pentaho/files/
- kettle国内镜像地址:https://mirrors.bit.edu.cn/pentaho/Pentaho%208.2/client-tools/,直接下载 pdi-ce-8.2.0.0-342.zip即可
- 数据库驱动汇总:
- mysql: mysql-connector-java-5.1.46-bin.jar
- 直接下载解压,运行即可,开箱即用。
- 启动时相关优化:
1、检查jdk和系统变量是否配置正确:cmd下 java、javac、java - version 三个命令都能执行说明没问题;
2、修改spoon.bat里内存配置,参数调整根据自己电脑配置, set PENTAHO_DI_JAVA_OPTIONS="-Xms512m" "-Xmx1024m" "-XX:MaxPermSize=256m" 默认1024M和2048M,如果闪退或者一直等待,调小一个等级,512M和1024M
3、增加系统变量:kettle_home 变量值为kettle文件位置:E:\software\kettle\data-integration
4、更换jdk版本,kettle-8.2把jdk换成了1.8版本;
5、增加系统变量:PENTAHO_JAVA_HOME 变量值为jdk下的jre目录:E:\software\java8\jre
3.kettle目录介绍
- kettle目录介绍
4.kettle核心概念
1.转换
- 转换(transaformation)负责数据的输入、转换、校验和输出等工作。
- Kettle 中使用转换完成数据 ETL 全部工作。
- 转换由多个步骤(Step)组成,如文本文件输入,过滤输出行,执行SQL脚本等。各个步骤使用跳(Hop)(连接箭头) 来链接。
- 跳定义了一个数据流通道,即数据由一个步骤流(跳)向下一个步骤 。
- 在 Kettle中数据的最小单位是数据行(row),数据流中流动其实是缓存的行集(RowSet)。
2.步骤
- 步骤(控件)是转换里的基本的组成部分。
- 步骤的特性:
- 1.步骤需要有一个名字,这个名字在同一个转换范围内唯一;
- 2.大多数的步骤都可以有多个输出跳。–个步骤的数据发送可以被设置为分发和复制:
- 分发是目标步骤轮流接收记录,轮询模式;
- 复制是所有的记录被同时发送到所有的目标步骤。
3.跳(Hop)
- 跳(Hop):两个步骤之间的数据通道,称为:行集的数据行缓存;
- 上个步骤跟下个步骤之间:
- 当行集满了,向行集写数据的步骤将停止写入, 直到行集有了空间。
- 当行集空了,从行集读数据的步骤将停止读取,直到行集有了可读数据行。
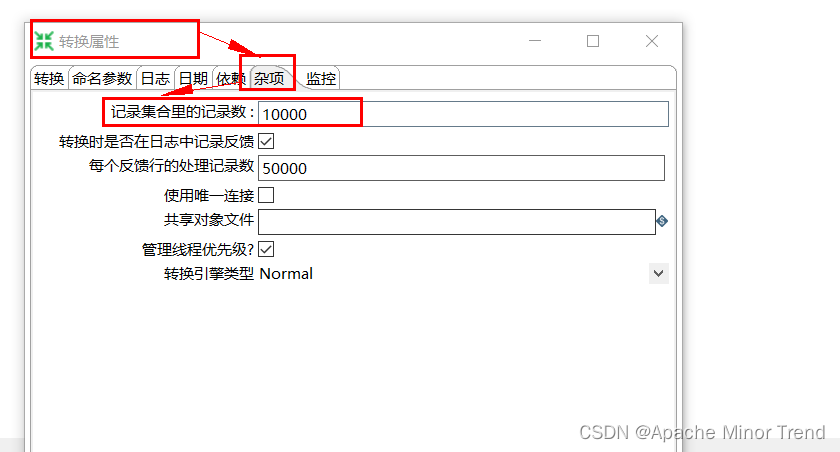
- 行集的大小默认是10000,可以在转换页面,双击,调整杂项里面的“记录集合里的记录数”
4.元数据
- 每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据
- 元数据如下:
5.数据类型
- kettle中字段类型如下:
- String:字符类型数据
- Number:双精度浮点数。
- Integer:带符号长整型(64位)。
- BigNumber:任意精度数据。
- Date:带毫秒精度的日期时间值。
- Boolean:取值为true和false的布尔值。
- Binary:二进制字段可以包含图像、声音、视频及其他类型的二进制数据。
6.并行
- 跳的这种基于行集缓在的规则允许每个步骤都是由一个独立线程运行,这样并发程度最高。
- 这一规则也允许数据以最小消耗内存的数据流的方式来处理,全部的数据处理都是基于内存来实现的。
- 在数据仓库里,我们经常要处理大量数据,所以这种高并发低消耗的方式也是 ETL 工具的核心需求。
- 并行 对于kettle的转换来说,不能定义一个执行顺序,因为所有步骤都以并发方式执行(并行):
- 当转换启动后,所有步骤都同时启动;
- 从输入跳中读取数据,
- 并把处理过的数据写到输出跳,
- 直到输入跳里不再有数据,就中止步骤的运行。
- 当所有的步骤都中止了,整个转换就中止了。
7.作业
- 作业(Job),负责定义一个完成整个工作流的控制,比如将转换的结果发送邮件给相关人员。因为转换(transformation) 以并行方式执行,所以必须存在一个串行的调度工具来执行转换,这就是Kettle 中的作业。
5.kettle转换
1.输入控件
1.csv文件输入
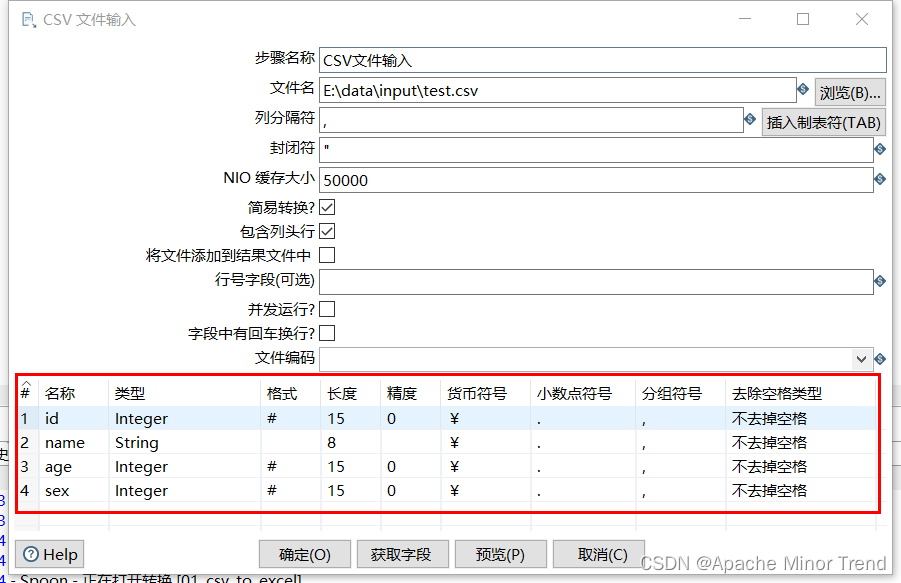
- 重点细节整合:
- 包含列头行:意思是文件中第一行是字段名称行,表头不进行读写,这个需要观察文件中的第一行,是否为字段名称。
- 行号字段:如果文件第一行不是字段名称或者需要从某行开始读写,可在此输入行号。
- 其他配置根据自己的需求进行调整即可。
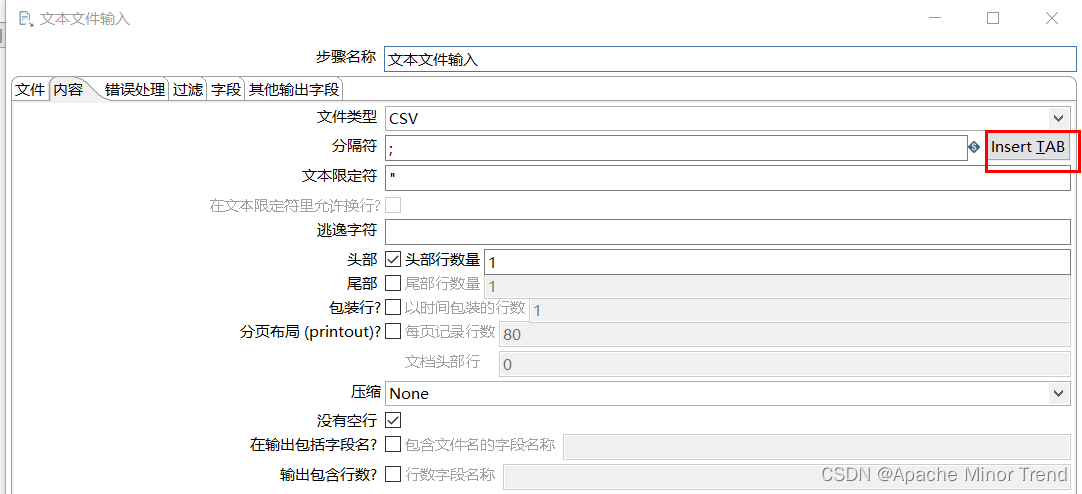
2.文本文件输入
- 类似于csv文件的转换,csv文件是默认以","进行分割,文本文件中间分隔符可能有多种,需要参考文件中的分隔符,来进行数据的转换。
- \t分割的话,需要点击一下后面的insert TAB
3.Excel输入
- Excel输入控件也是很常用的输入控件,一般企业里会用此控件对大量的Excel文件进行ETL操作。
4.XML输入
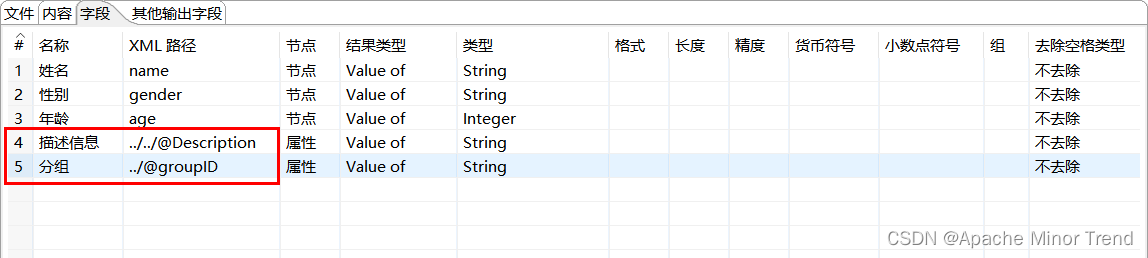
- XPath 即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。XPath使用路径表达式在XML文档中选取节点。下面列出了最有用的路径表达式
- 相关语法如下:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置,类似于相对路径 |
| . | 选择当前节点 |
| … | 选择当前节点的父节点 |
| @ | 选择 节点对应的属性值 |
- 案例的配置信息
5.JSON输入
- JSONPath 类似于 XPath 在 xml 文档中的定位,JsonPath 表达式通常是用来路径检索或设置Json的。其表达式可以接受“dot - notation”(点记法)和“bracket -notation”(括号记法)
- 格式:
- 点记法:$.store.book[0]title
- 括号记法:$[‘store’][‘book’ ][0][ ‘ title’ ]
- 格式:
- json里面如果是多层嵌套,并且需要获取到嵌套里面的数据,需要进行多次json解析,不能跨层解析,否则对应数据会出现空指针。
- 相关语法如下:
| 符号 | 描述 |
|---|---|
| $ | 查询的根节点对象,用于表示一个json数据,可以使数据或对象 |
| @ | 过滤器断言(filter predicate)处理的当前节点对象,类似于java中的this字段 |
| * | 通配符,可以表示一个名字或数字 |
| … | 可以理解为递归搜索 |
.<name> | 表示一个子节点 |
[.<name>(,.<name>)] | 表示一个或多个子节点 |
[.<number>(,.<number>)] | 表示一个或多个数组下标 |
| [start:end] | 数组片段,区间为[start:end),不包含end |
[?(<expression>)] | 过滤器表达式,表达式结果必须是boolean |
- 案例的配置信息如下:


6.表输入
- 数据库连接先配置完成,如果别的转换需要用到这块数据库对应表数据,需要对数据库连接进行共享。
- 关联mysql的话,kettle的8.2版本,mysql版本是:5.7.28,推荐使用的驱动:mysql-connector-java-5.1.49.jar
2.输出控件
1.Excel输出
2.文本文件输出
3.sql文件输出
4.表输出
5.更新
- 更新:只能做到源表和目标表数据一致,如果目标表的数据比源表少,那么运行程序的时候,直接报错。
6.插入/更新
- 插入/更新 :将源表的数据全部更新到目标表,且目标表的数据跟源表数据完全一致。
7.删除
- 删除:源表中有的数据,在目标表如果有的话,直接删除,目标表只保留源表中没有的数据。
3.转换控件
1.Concat fields
- 实现字符串的拼接功能
2.值映射
- 将字段中的数据转成我们希望的枚举值,对应关系梳理好,就可实现。
3.增加常量
- 对应数据表格 会新增一列,此列都是我们设置的默认值
4.增加序列
- 对应数据表格,会新增一列,此列中的值,是按照起始值和增长根据(步长)来进行递增。
- 通过DB来获取Sequence:只有数据库为Oracle时支持此功能,别的数据库不支持
5.字段选择
- 在对应表格中字段选择的时候,必须在 “选择和修改”这一栏,选择出所有字段:
- 如果要对字段名进行修改,可以在后面写上即可;
- 如果要移除字段,直接选择字段名即可。
6.计算器
- 计算器中,根据需求,需要对两个字段进行算数运算的时候,在计算栏,找出对应的计算逻辑,然后将两个字段添加到计算器转换控件中,最终获取的结果表中会新增一列,此列就是计算完毕的数据。
7.字符串剪切&替换&操作
- 字符串剪切:剪切字符串,按对应下标剪切,然后生成一个新字段
- 字符串操作:转换大小写等字符串操作,然后生成一个新字段
- 字符串替换:按照需求,对选中的字符串进行替换操作,可以使用正则等,最后生成一个新字段。
8.排序记录&去除重复记录
- 去除重复记录是去除数据流中相同的数据行;
- 但是使用去除重复记录控件之前,要求必须先对数据进行排序,对数据排序用的空间是排序记录;
- 排序记录空间可以按照指定字段的升序或者降序对数据流进行排序。
- 综上:排序记录控件+去除重复记录控件 配合一起使用。
9.唯一行(哈希值)
- 唯一行,实现的效果跟排序记录+去除重复记录 最终效果是一样的,但是原理不同:
- 唯一行是给每一行的数据建立哈希值,通过哈希值来比较数据是否重复。
- 唯一行的去重效率比上面的 排序记录+去除重复记录 的效率高。
10.拆分字段
- 拆分字段是把字段按照分隔符拆分成两个或多个字段。需要注意的是,字段拆分以后,原字段就会从数据流中消失。
11.列拆分多行
- 类似于sql中的炸裂函数(explode函数)
12.行扁平化
- 行扁平化:把同一组的多行数据合并成一行。即列拆分为多行的逆向操作。
- 行扁平化使用需要两个条件:
-
- 使用前,需要对数据进行排序,使用排序控件
-
- 每个分组的数据条数要保证一致,否则数据会出现错乱。
- 一般在生产中,不建议使用,生产中没法保证分组后数据的条数一致,或者先补全,每组数据条数一致,再进行行扁平化。
-
13.列转行
- 多列转一行:如果数据表中,有一列有相同的值,按照指定的字段,将其中一列的字段内容变成不同的列,然后把多行数据转为一行数据的过程,具体如下图所示:
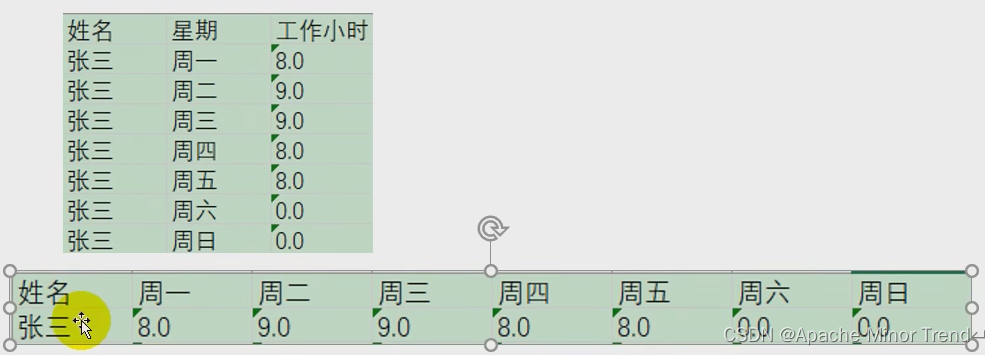
- 注意:列转行之前,数据必须按照分组字段进行排序,否则会出现数据错乱。
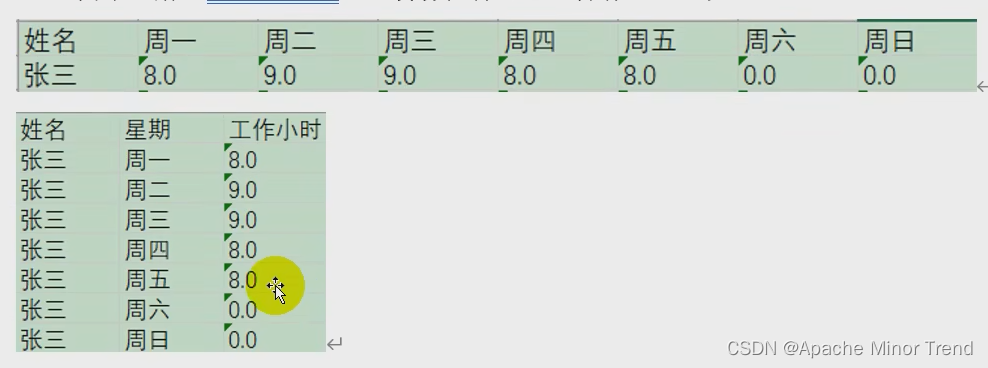
14.行转列
- 一行转多列,将数据字段的字段名转为一列,把数据行变为数据列。
4.应用控件
1.替换NULL值
- 将数据中的null值替换为空值。
2.写日志
- 写日志控件 :调试程序的时候使用,此控件可以将数据流的每行数据打印到控制台,方便调试程序。
5.流程控件
流程控件主要是用来控制数据流程和数据流向。
1.Switch/case
- Switch/case控件,最典型的数据分类控件,可以利用一个字段对应的数据中不同的值,让数据流从一路到多路。
- 必须要将对应多路的对应下一个步骤要规定好,不然switch/case在选择的时候,不能选择了。
2.过滤记录
- 按照我们给定的条件进行过滤,过滤出用户需要的数据。
- 在进行跳的时候,选择true的就是用户想要的数据。
3.空操作
- 空操作,任何事情都不做,此控件作为数据流的终点。
4.中止
- 中止:数据流的终点,如果有数据流到此控件,整个转换程序将中止,并且在控制台输出报错信息。
- 此控件一般用来校验数据,或者调试程序。
- 中止有三个状态:
- Abort the running transformation :中止程序,不回滚数据,最终生成excel表,但是excel中存在中止之前的几条数据,但是数据不全。
- Abort and log as an error:中止程序,并回滚数据,最终生成excel表,但是excel没有任何数据。
- Stop input processing :中止当前程序,并继续处理至最后,最终生成excel表,里面有符合条件的全量数据,不符合的直接舍弃,日志会报错,但不影响正常运行。
6.查询控件
- 查询控件:是用来查询数据源里面的数据,并合并到主数据流中。
1.数据库查询
- 数据库查询:从数据库中查询出来数据,跟数据流中数据进行左连接的过程。
- 左连接:数据流中数据全部保留,但是数据库查询控件查询出来的数据不一定全部列出,只能按照输入的匹配条件进行关联。
- 这块sql可以实现功能,但是sql只能基于本库的数据进行查询,此插件可以基于不同库之间进行查询操作。
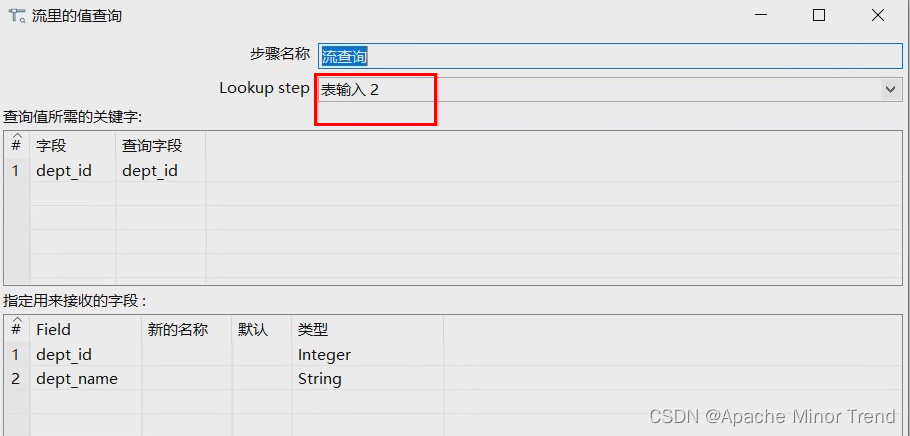
2.流查询
- 流查询控件:查询两条数据流中的数据,然后按照指定的字段做等值匹配,支持跨库查询。
- 注意:流查询在查询之前把数据全部加载到内存中,并且只能进行等值查询。
- 左右两个流进行join的时候,使用哪个表作为左表,在书写控件里面的“Lookup step”就体现另一个表信息,此表就作为右表,如下图所示:
7.连接控件
- 连接控件:连接分类下的控件,一般都是将多个数据集通过关键字进行连接起来,形成一个数据集的过程。
1.合并记录
- 使用此插件,两个表格必须有相同的字段名称,主要用于比较两个表格的比较。
- 适应场景:如果源表数据同步到目标表时,中间发生了宕机情况,那么需要简单判断一下,这两张表格是否一致,使用合并记录 的控件即可实现。
- 合并记录是用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。注意旧数据和新数据需要事先按照关键字段排序,并且旧数据和新数据要有相同的字段名称。
- 合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
- 案例的合并如下:
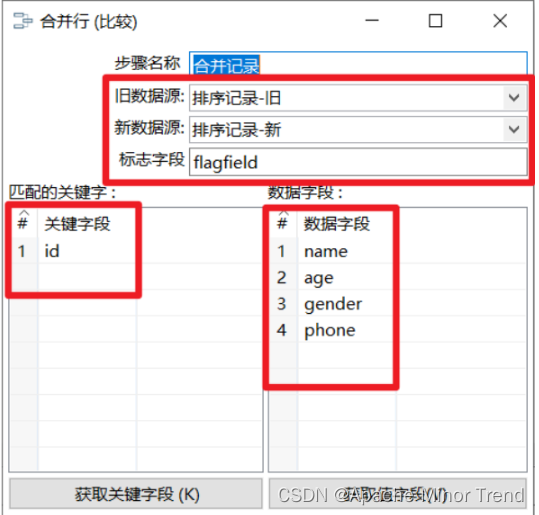
- 1.旧数据源:选择旧数据来源的步骤
- 2.新数据源:选择新数据来源的步骤
- 3.标志字段:设置标志字段的名称,标志字段用于保存比较的结果,比较结果有下列几种:
- ①“identical” – 旧数据和新数据一样
- ②“changed” – 数据发生了变化;
- ③“new” – 新数据中有而旧数据中没有的记录
- ④“deleted” –旧数据中有而新数据中没有的记录
- 4.关键字段:用于定位判断两个数据源中的同一条记录的字段。
- 5.比较字段:对于两个数据源中的同一条记录,指定需要比较的字段
- 6.最终执行结果如下:
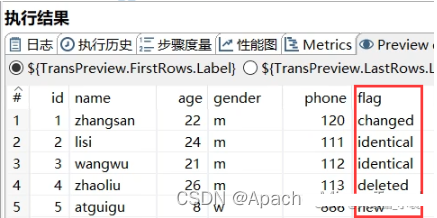
2.记录集连接
- 记录集连接可以对两个步骤中的数据流进行左连接,右连接,内连接,外连接。此控件功能比较强大,企业做ETL开发会经常用到此控件,但是需要注意在进行记录集连接之前,需要对记录集的数据进行排序,并且排序的字段还一定要选两个表关联的字段,否则数据错乱,出现null值。
- 使用记录集连接 控件的时候,左右两张表首先需要排序,排序必须按照左右两张表的关联关系字段进行排序,否则会出现数据错乱问题。

8.统计控件
- 统计控件:可以提供数据的采样和统计功能
1.分组
- 分组:类似sql中的group by,可以按照指定的一个或者几个字段进行分组,然后其余字段可以按照聚合函数进行合并计算。
- 注意,在进行分组之前,数据先按照分组字段进行排序。
9.映射控件
- 映射可以定义子转换,方便代码封装和重用。
1.映射(子转换)
- 进行映射(子转换)的时候,获取数据库查询时,不需要更改字段类型,否则在外面引用映射的时候,会报类型不匹配的问题。
10.脚本控件
- 脚本控件:直接通过写程序代码,完成一些复杂的操作。
1.执行sql脚本
- 执行sql脚本控件就是连接到数据库里面,然后执行自己写的一些sql语句
6.kettle作业
- 大多数ETL项目都需要完成各种各样的维护工作。例如,如何传送文件;验证数据库表是否存在等等。而这些操作都是按照一定顺序完成。
- 因为转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。
- 一个作业包含一个或者多个作业项,这些作业项以某种顺序来执行。
- 作业执行顺序由作业项之间的跳(job hop)和每个作业项的执行结果来决定。
1.作业项
- 作业项是作业的基本构成部分。如同转换的步骤,作业项也可以使用图标的方式图形化展示。
- 作业项和转换中步骤的区别:
- 1.转换步骤与步骤之间是数据流,作业项之间是步骤流。
- 2.转换启动以后,所有步骤一起并行启动等待数据行的输入,而作业项是严格按照执行顺序启动,一个作业项执行完以后,再执行下一个作业项。
- 3.在作业项之间可以传递一个结果对象(result object)。这个结果对象里面包含了数据行,它们不是以数据流的方式来传递的。而是等待一个作业项执行完了,再传递个下一个作业项。
- 4.因为作业顺序执行作业项,所以必须定义一个起点。有一个叫“开始”的作业项就定义了这个点。一个作业只能定一个开始作业项。
2.作业跳
- 作业的跳是作业项之间的连接线,他定义了作业的执行路径。作业里每个作业项的不同运行结果决定了做作业的不同执行路径。
- 作业跳分为三种情况
- ①无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,上面有一个锁的图标。

- ②当运行结果为真时执行:当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情况下使用。这是一种绿色的连接线,上面有一个对钩号的图标。
- ③当运行结果为假时执行:当上一个作业项的执行结果为假或者没有成功执行是,执行下一个作业项。这是一种红色的连接线,上面有一个红色的停止图标。

- ①无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,上面有一个锁的图标。
3.kettle发送邮件相关配置
- python 自动邮件 yagmail,可以去试一下。
- 发送邮件,需要注意的地方:
-
- 发件人邮箱所对应的服务器,需要在服务器这一栏,需要设置服务器相关信息,如果使用163邮箱,需要在163邮箱里面找到SMTP服务器,需要开启此服务,开启后,系统会发送我们一个密码,将此密码填上即可。
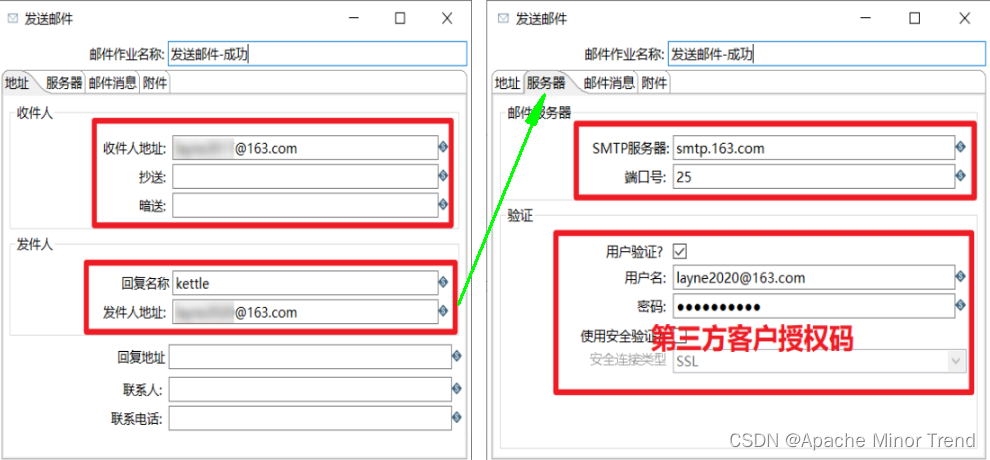
- 发件人邮箱所对应的服务器,需要在服务器这一栏,需要设置服务器相关信息,如果使用163邮箱,需要在163邮箱里面找到SMTP服务器,需要开启此服务,开启后,系统会发送我们一个密码,将此密码填上即可。
-
- 2.邮箱服务器相关配置

7.kettle使用案例
1.转换案例
- 案例:把stu1的数据按id同步到stu2,stu2有相同id则更新数据
2.作业案例
- 案例:使用作业执行上述转换,并且额外在表stu2中添加一条数据,整个作业运行成功的话发邮件提醒
3.Hive-HDFS案例
- 1.配置kettle中的与hdfs关联的相关配置文件,将hdfs上的文件添加到kettle的plugins中。
- 2.hdfs相关服务都正常运行:hadoop服务:hdfs(dn,nn),yarn(rm,nm),hive服务,hiveservice2,zk
- 3.配置kettle中的DB连接
- 4.配置转换信息
- 5.配置 输出到hdfs上的相关ip的端口,hdfs上nn的ip和端口:高可用服务的端口:8020;非高可用服务端口:9000;yarn的rm的ip和端口:8032;zk的ip和端口。
- 6.测试转换是否成功,观察hdfs是否生成文件。
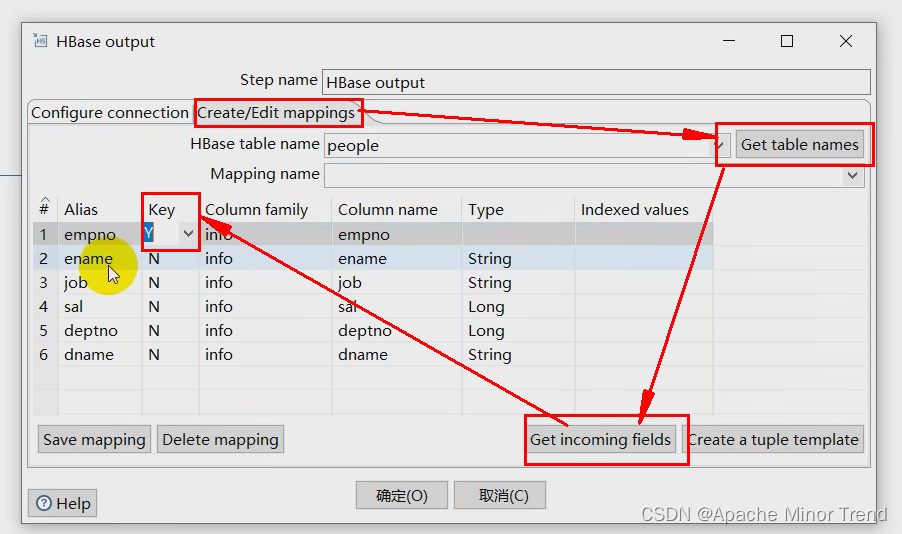
4.HDFS-HBase案例
-
获取hbase映射的时候需要注意,按照下面的配置进行细心配置即可。
-
1.数据写入hbase的时候,需要在配置中指定,需要往hbase写使用哪一个字段作为rowkey。
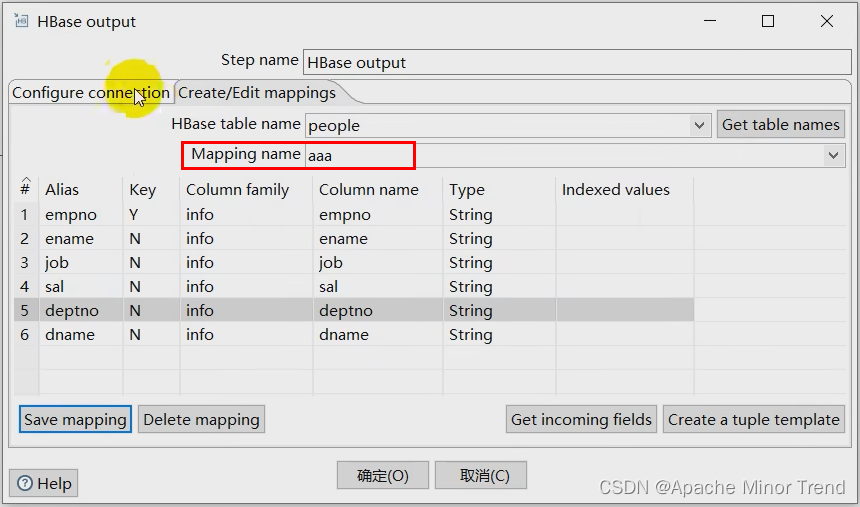
-
2.设置hbase中表对应的映射关系:
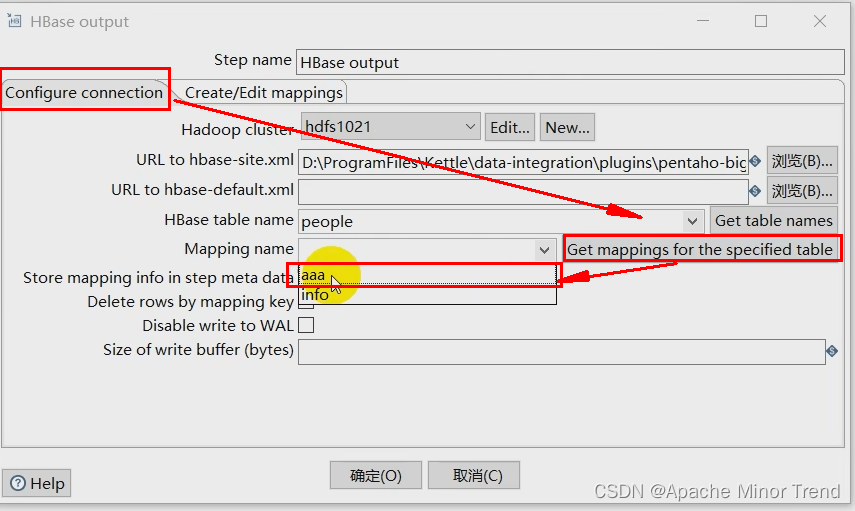
-
3.然后在配置中先获取一下映射,然后才能获取到
-
8.kettle资源库
1.数据库资源库
- 数据库资源库是将作业和转换相关信息存储在数据库汇总,执行的时候,直接去数据库读取信息,这样做很容易跨平台使用。
- 配置相关的信息,然后作业以及转换都会存储到数据库中,只要能连接数据库,就可以实现不同用户登录使用。
- 上传文件的时候,直接上传本地xml文件到资源库,保存后,就能直接查看了。
2.文件资源库
- 创建的作业或者转换都在本地。
9.kettle相关优化
- 1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。
参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
-
3、尽量使用数据库连接池;
-
4、尽量提高批处理的commit size;
-
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
-
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
-
7、可以使用sql来做的操作尽量用sql;Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免使用,原则:能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)。
相关文章:
【Kettle-佛系总结】
Kettle-佛系总结Kettle-佛系总结1.kettle介绍2.kettle安装3.kettle目录介绍4.kettle核心概念1.转换2.步骤3.跳(Hop)4.元数据5.数据类型6.并行7.作业5.kettle转换1.输入控件1.csv文件输入2.文本文件输入3.Excel输入4.XML输入5.JSON输入6.表输入2.输出控件…...

JavaSE网络编程
JavaSE网络编程一、基本概念二、常用类三、使用方法1、创建服务器端Socket2、创建客户端Socket3、创建URL对象JavaSE中的网络编程模块提供了一套完整的网络编程接口,可以方便地实现各种基于网络的应用程序。本文将介绍JavaSE中网络编程模块的基本知识、常用类以及使…...

9万字“联、管、用”三位一体雪亮工程整体建设方案
本资料来源公开网络,仅供个人学习,请勿商用。部分资料内容: 1、 总体设计方案 围绕《公共安全视频监控建设联网应用”十三五”规划方案》中的总体架构和一总两分结构要求的基础上,项目将以“加强社会公共安全管理,提高…...

springboot自动装配原理
引言 springboot的自动装配是其重要特性之一,在使用中我们只需在maven中引入需要的starter,然后相应的Bean便会自动注册到容器中。例如: <dependency><groupId>org.springframework.boot</groupId><artifactId>spr…...
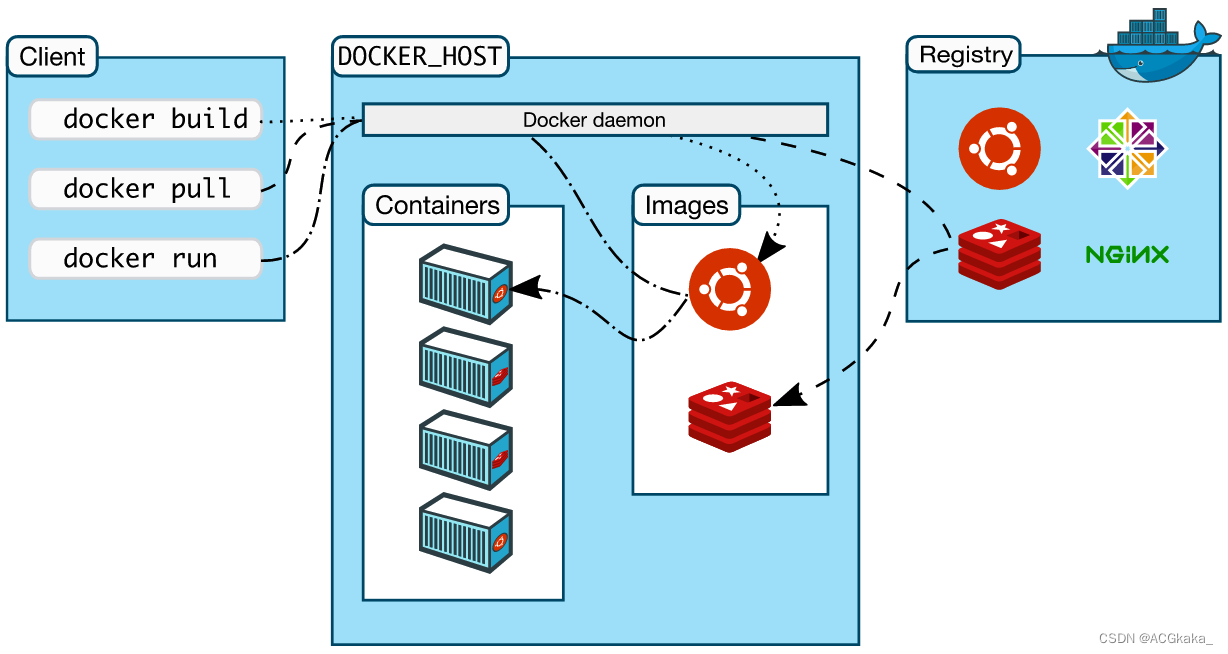
Docker学习(二十)什么是分层存储?
目录1.简介2.什么是 Union Mount?3.分层介绍1)lowerdir 层(镜像层)2)upperdir 层(容器层)3)merged 层4.工作原理1)读:2)写:3ÿ…...
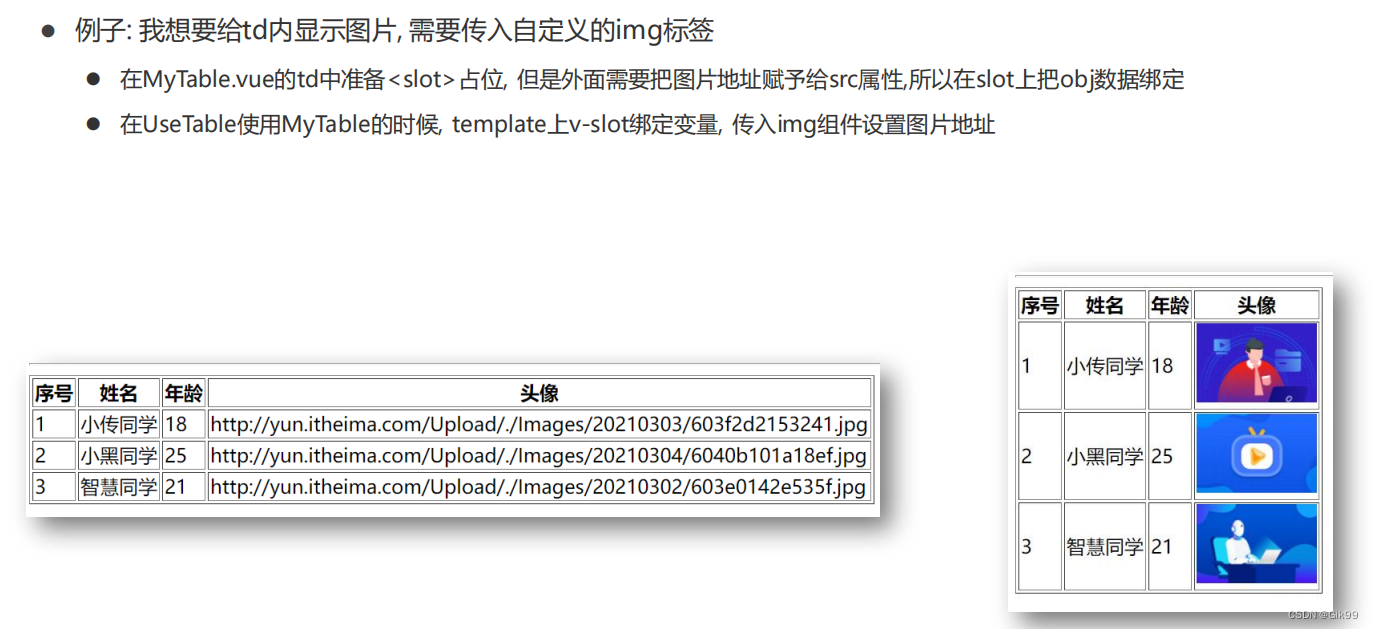
Vue组件进阶(动态组件,组件缓存,组件插槽,具名插槽,作用域插槽)与自定义指令
Vue组件进阶与自定义指令一、Vue组件进阶1.1 动态组件1.2 组件缓存1.3 组件激活和非激活1.4 组件插槽1.5 具名插槽1.6 作用域插槽1.7 作用域插槽使用场景二、自定义指令2.1 自定义指令--注册2.2 自定义指令-传参一、Vue组件进阶 1.1 动态组件 多个组件使用同一个挂载点&#x…...

僵尸进程与孤儿进程
概念 在 Unix/Linux 系统中,正常情况下,子进程是通过父进程创建的,且两者的运行是相互独立的,父进程永远无法预测子进程到底什么时候结束。当一个进程调用 exit 命令结束自己的生命时,其实它并没有真正的被销毁&#…...
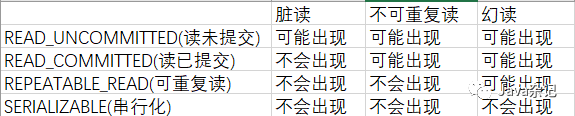
基于注解@Transactional事务基本用法
关于概念性的放在最下面,熟读几遍 在使用时候也没多关注,总是加个Transactional 初识下 一般查询 Transactional(propagation Propagation.SUPPORTS) 增删改 Transactional(propagation Propagation.REQUIRED) 当然不能这么马虎 Spring中关于事务的传播 一个个测试,事…...
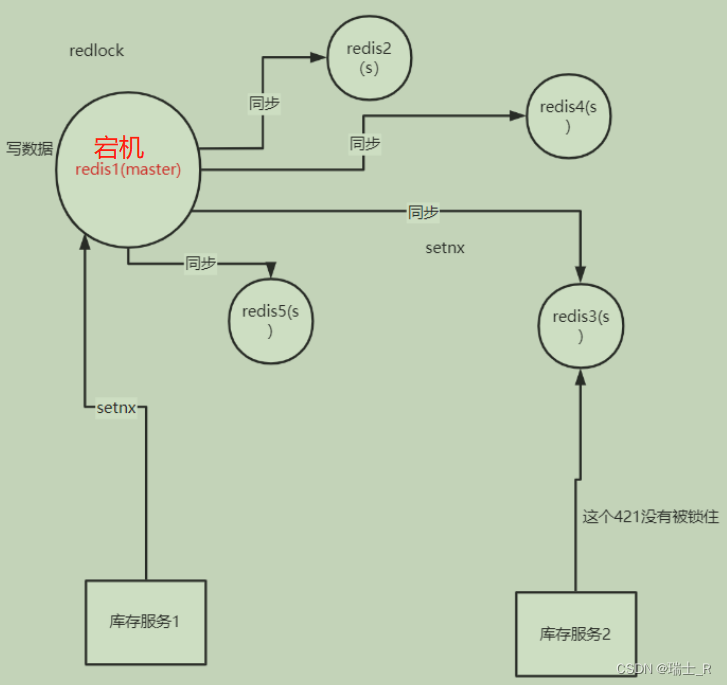
Go项目(商品微服务-2)
文章目录简介handler商品分类轮播图品牌和品牌与分类oss前端直传库存服务数据不一致redis 分布式锁小结简介 开发商品微服务 API 层类似的,将 user-web 目拷贝一份,全局替换掉 user-web修改 config 去掉不用的配置更新本地和远程 nacos 配置文件 把 pro…...
无头盔PICO-unity开发日记1(抓取、传送)
目录 可传送的地面 锚点传送 修改射线颜色(可交互/不可交互) 球、抓手组件 ||刚体(重力)组件 可传送的地面 1.地面添加组件 2.XR交互管理器添加传送提供者 3.地面设置传送提供者 4.XR交互管理器添加locomotion system 5.拖拽 完…...

Material3设计指南笔记
Material3设计指南笔记Table of Contents1. 颜色color1.1. 颜色分类1.2. 强调色accent color1.3. 中性色neutral color1.4. 辅助色additional color1.5. 调色盘tonal palettes1.6. 颜色规范2. z轴高度 elevation3. 图标 icon4. 动画 motion5. 形状 shape6. 字体1. 颜色color1.1…...

JavaWeb--会话技术
会话技术1 会话跟踪技术的概述2 Cookie2.1 Cookie的基本使用2.2 Cookie的原理分析2.3 Cookie的使用细节2.3.1 Cookie的存活时间2.3.2 Cookie存储中文3 Session3.1 Session的基本使用3.2 Session的原理分析3.3 Session的使用细节3.3.1 Session钝化与活化3.3.2 Session销毁目标 理…...

Git图解-为啥是Git?怎么装?
目录 零、学习目标 一、版本控制 1.1 团队开发问题 1.2 版本控制思想 1.2.1 版本工具 二、Git简介 2.1 简介 2.2 Git环境的搭建 三、转视频版 零、学习目标 掌握git的工作流程 熟悉git安装使用 掌握git的基本使用 掌握分支管理 掌握IDEA操作git 掌握使用git远程仓…...

HTML 框架
HTML 框架 <iframe>标签规定一个内联框架。 一个内联框架被用来在当前 HTML 文档中嵌入另一个文档。 通过使用框架,你可以在同一个浏览器窗口中显示不止一个页面。 iframe 语法: <iframe src"URL"></iframe> 该URL指向不同的…...
)
Rust特征(Trait)
特征(Trait) 特征(trait)是rust中的概念,类似于其他语言中的接口(interface)。在之前的代码中,我们也多次见过特征的使用,例如 #[derive(Debug)],它在我们定义的类型(struct)上自动…...
详解七大排序算法
对于排序算法,是我们在数据结构阶段,必须要牢牢掌握的一门知识体系,但是,对于排序算法,里面涉及到的思路,代码……各种时间复杂度等,都需要我们,记在脑袋瓜里面!…...
Vue+ECharts实现可视化大屏
由于项目需要一个数据大屏页面,所以今天学习了vue结合echarts的图标绘制 首先需要安装ECharts npm install echarts --save因为只是在数据大屏页面绘制图表,所以我们无需把它设置为全局变量。 可以直接在该页面引入echarts,就可以在数据大…...
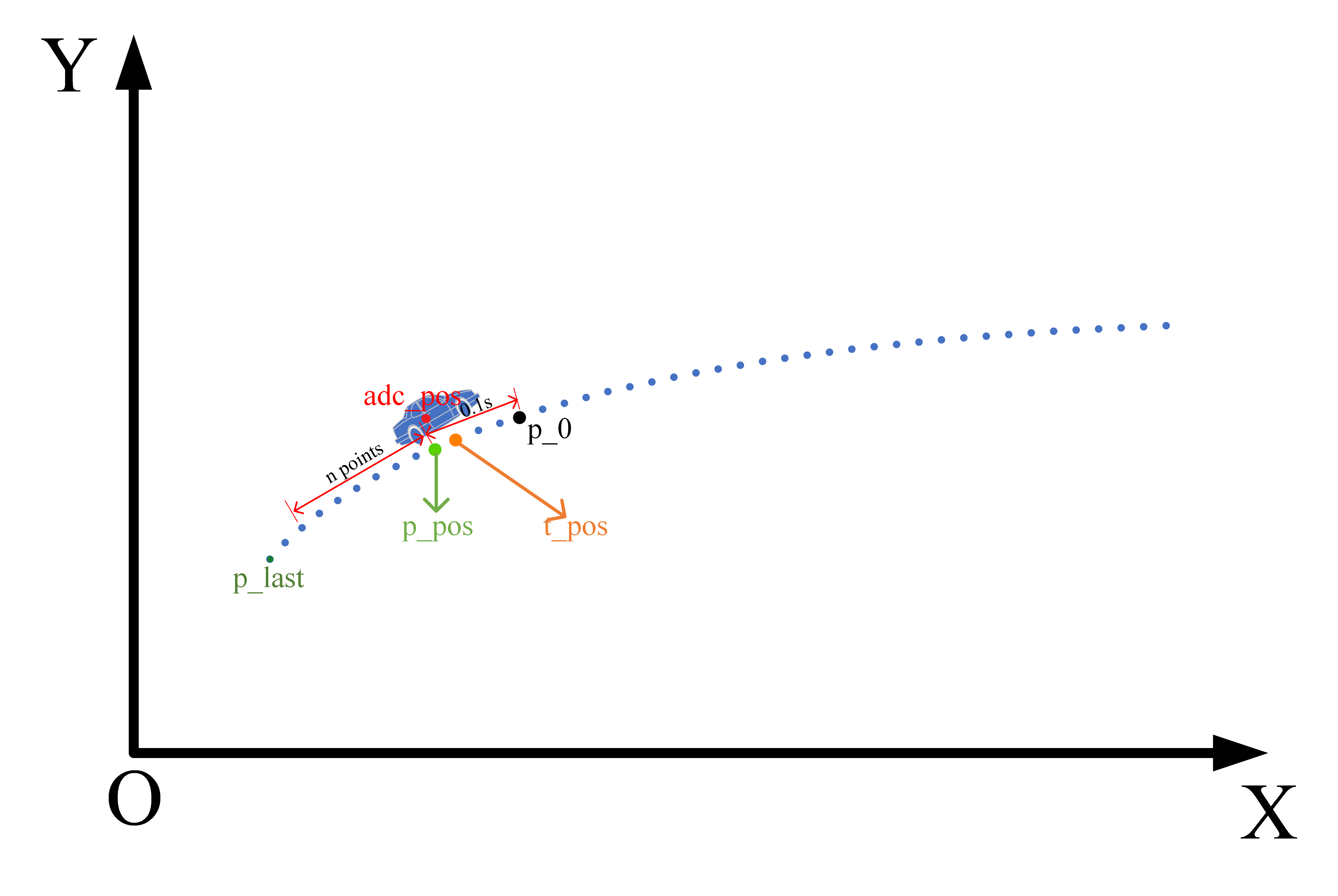
百度Apollo规划算法——轨迹拼接
百度Apollo规划算法——轨迹拼接引言轨迹拼接1、什么是轨迹拼接?2、为什么要进行轨迹拼接?3、结合Apollo代码为例理解轨迹拼接的细节。参考引言 在apollo的规划算法中,在每一帧规划开始时会调用一个轨迹拼接函数,返回一段拼接轨迹…...
6. unity之脚本
1. 说明 当整个游戏运行起来之后,我们无法再借助鼠标来控制物体,此时可以使用脚本来更改物体的各种姿态,驱动游戏的整体运动逻辑。 2. 脚本添加 首先在Assets目录中,新创建一个Scripts文件夹,在该文件内右键鼠标选择…...
解析)
flink-note笔记:flink-state模块中broadcast state(广播状态)解析
github开源项目flink-note的笔记。本博客的实现代码都写在项目的flink-state/src/main/java/state/operator/BroadcastStateDemo.java文件中。 项目github地址: github 1. 广播状态是什么 网上关于flink广播变量、广播状态的讲解很杂。我翻了flink官网发现,实际上在1.15里面…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...