Graph Partition: Edge cut and Vertex cut
Graph Partition
- Edge cut and Vertex cut
- Edge cut
- Vertex cut
- 实际如何进行点分割和边分割的呢?
- Graph store format
- 情况1:按照边列表存储:
- 情况2:按照邻接表存储:
Edge cut and Vertex cut
图结构描述了数据流动,分布式图计算系统或核外图计算系统均依赖于图划分。
良好的图划分策略可以最小化通信和存储开销,并确保计算平衡。
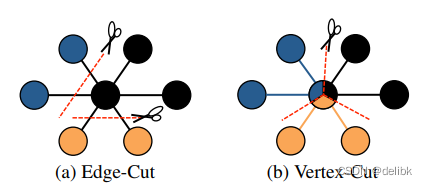
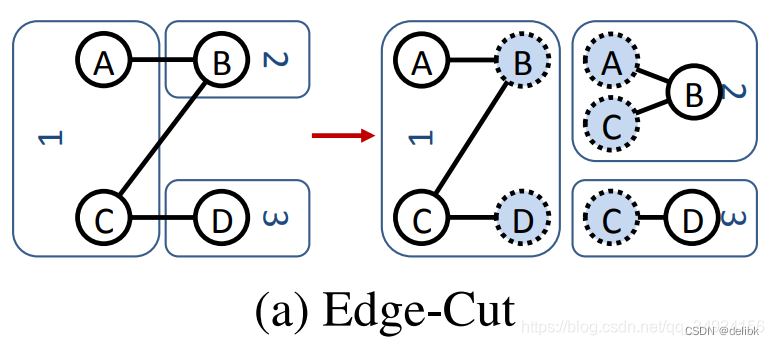
Edge cut
如下图所示,Edge cut 将节点分配到不同的机器,边横跨各机器,通信开销和存储开销直接与切割的数量呈比例.因此需要通过最小化边的切割数目,将节点尽量多的分给机器来减少通信开销和确保计算平衡。
但是规模巨大的图想要计算出一个最优的切割会付出巨大的花费,因此大多数都采用了随机切割,随机将节点分配给机器。随机的切割工作的时候接近最佳情况下的平衡,但是这也消耗了最坏的通信花费,切割了最多的边。
定理:如果节点被随机分配给p个机器,那么edge cut 的 expected fraction 为:
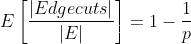
对于一个exponent 为 \partial的 power-law graph 每个节点期望的edge cut 为:
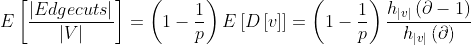
注:power-law degree distributios原来是一种描述网络图中结点度的分布,中文可叫做“幂律度分布”。
每次边的切割都会在本地保存一个邻近节点的备份,因此会增加网络和存储开销。
如图所示,切割成三份,增加了7个节点副本,每个节点都被复制了至少一次。
任何节点或边的变化都会通过网络同步到其他机器。
如上图所示,切割成三份,增加了5个节点副本,每个节点都被复制了至少一次。
对于频繁遍历的边,应该减少cut edge的存在,从而减少跨设备间的通信,提高查询效率。即把进行遍历的相邻顶点放在相同的分区,减少通信消耗。
顶点的id分配:一个分区就是一个有序的id区间,顶点被分配到一个分区就会为该顶点分配一个id,也就是顶点的id决定了该顶点属于哪一个分区。给一个顶点分配id:JanusGraph就会从顶点所属分区的id范围中选一个id值分配给该顶点。(先定分区,在分配id)
为顶点确定分区:JanusGraph通过配置好的 placement strategy来控制vertex-to-partition的分配。
默认策略:在相同事务中创建的顶点分配在相同分区上。
缺点:如果在一个事务中加载大量数据,会导致分配不平衡。
定制分配策略:实现IDPlacementStragegy接口,并在通过配置文件的ids.placement项进行注册。
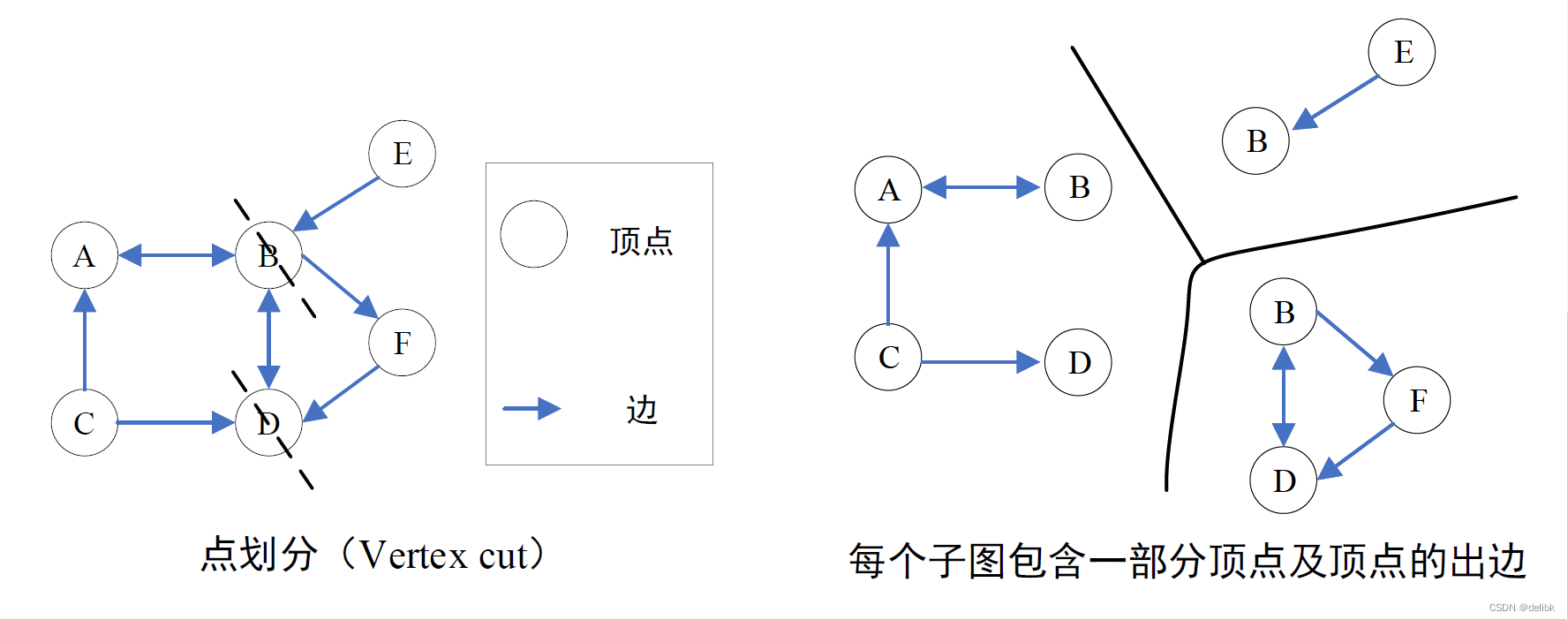
Vertex cut
顶点切割,即把一个顶点进行切割,把一个顶点的邻接表分成多个子邻接表存储在图中各个分区上。
如图所示,vertex cut将边分配给不同机器,允许节点跨不同机器,节点的变化都需要同步到其他机器上,故通信开销与存储开销与每个节点跨机器的数呈正比,因此我们需要最小化每个节点跨机器的数。
比起edge cut,vertex cut 从理论和实践上,都显示出更好的性能。
通过为边定义一个hash函数, 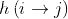
可以保证每个节点最多在 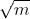 个机器上(m为机器集群的数量)。
个机器上(m为机器集群的数量)。
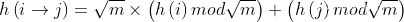
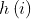 是一个在节点ID上统一hash函数。
是一个在节点ID上统一hash函数。
对于一个均衡的 p-way vertex cut ,将边集合 分配给机器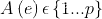 ,节点横跨机器集
,节点横跨机器集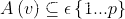 ,因此可定义均衡切割如下所示:
,因此可定义均衡切割如下所示:
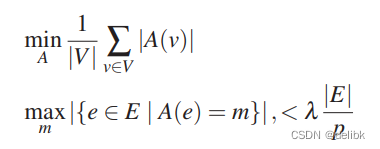
平衡因子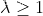 是一个很小的常量,
是一个很小的常量,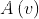 里的每一个机器都将会有一个节点v的副本,每次节点的修改会传到每个副本,
里的每一个机器都将会有一个节点v的副本,每次节点的修改会传到每个副本,
因此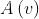 的大小将会影响通信开销。
的大小将会影响通信开销。
随机将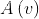 中的一个副本设为master,维持着节点的主版本,其他副本都从此节点上复制。
中的一个副本设为master,维持着节点的主版本,其他副本都从此节点上复制。
vertex cut 能够更好的作用在power-law graph,通过切割部分度非常高的节点就能将整个图切分。同时每条边都保证了只存在于一个机器上。
在真实的大规模图上,Vertex cut 找到一个最优的切割也会付出巨大的花费,但是《Powergraph: Distributed graph-parallel computation on natural graphs》里为边的分区提出了几个简单的启发式data-parallel算法。最简单的策略就是随机的将边分给机器,随机的vertex cut 比随机的edge cut 更有效果,随机切分也能几乎达到最优均衡。
在集群数为p时,随机切割期望副本为:
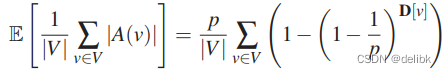
对于power-law graph来说,副本期望由power-law 常量\alpha决定:
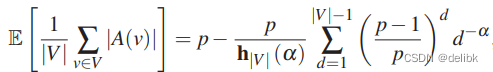
其中: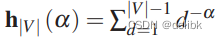
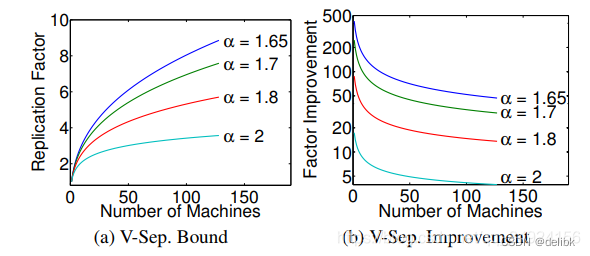
从上图(a)可以看到,虽然越小(度很高的节点越多),replication factor越大,但是相对于edge cut,vertex cut的有效增益实际上随着α的降低而增加。图(b)显示的是随机edge cut的期望花费与随机vertex cut的期望花费,显示出了使用vertex cut的数量级增量。
对于一个给定的edge cut 有 g个镜像副本,使用 vertex cut 进行分区能使副本的数量少于g。
目的:一个拥有大量边的顶点,在加载或者访问时会造成热点问题。Vertex Cut通过分散压力到集群中所有实例从而缓解单顶点产生的负载。
方法:JanusGraph通过label来切割顶点,通过定义vertex label成partition,那么具有该label的所有顶点将被分配在集群中所有机器上。
案例:对于product和user顶点,product顶点应该被定义为partition,因为用户和商品有购买记录(edge),热销商品就会产生大量的购买记录,从而会造成热点问题。
改进Vertex cuts随机分配算法:
这是一顺序贪心启发式算法,能使边在不同的机器上从而最小化conditional expected replication factor。
现假设在放置边i后,任务是放置边i+1,定义conditional expectation如下:
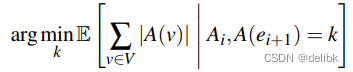
Ai是前一个边i的分配。使用前面得到的定理,对于边我们可以有以下规则:
如果A(v)与A(u)相交,那么该边(u,v)应存于交集的机器中。
如果A(v)与A(u)不为空并且没有交集,应该将该边分给节点中最多边未分配边的那个节点的A(i)中的任意机器。
如果一个或着两个vertex已经被分配,那么选择被分配了节点的机器。
如果两个节点都没被分配,那么将边分给负载最小的机器。
Vertex cut as table
GraphX resilient distributed graph (RDG)数据结构在vertex cuts 实现时将其分为三个无序平行的表 。
分别如下所示: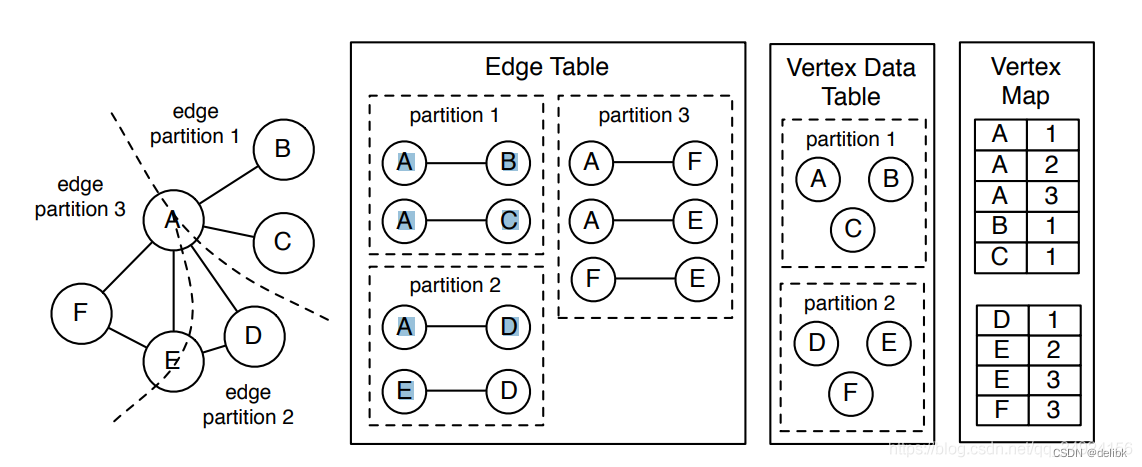
EdgeTable(pid, src, dst, data),存储相邻结构以及边的数据。(pid 表示分区编号,src 表示起始节点,dst 表示结束节点)这个表只包含节点的id,不包含节点数据。依据pid 分区。
VertexDataTable(id, data),存储节点的数据,由 vertex id 进行分区。
VertexMap(id, pid),显示了节点ID和邻接边的虚拟分区的映射。此表通过vertex id进行分区。
The partitioner is a hint to Spark to ensure the join site would be local to the edge table. This allows GraphX to shuffle only the vertex data and avoid moving any of the edge data.
vertex data table 与 vertex map table 可以组合为一个表,但是因为他们的功能不同,所以将其划分为了两个表。vertex data table 包含与在图形计算过程中发生变化的顶点的相关状态,vertex map table 保留了静态的图结构.
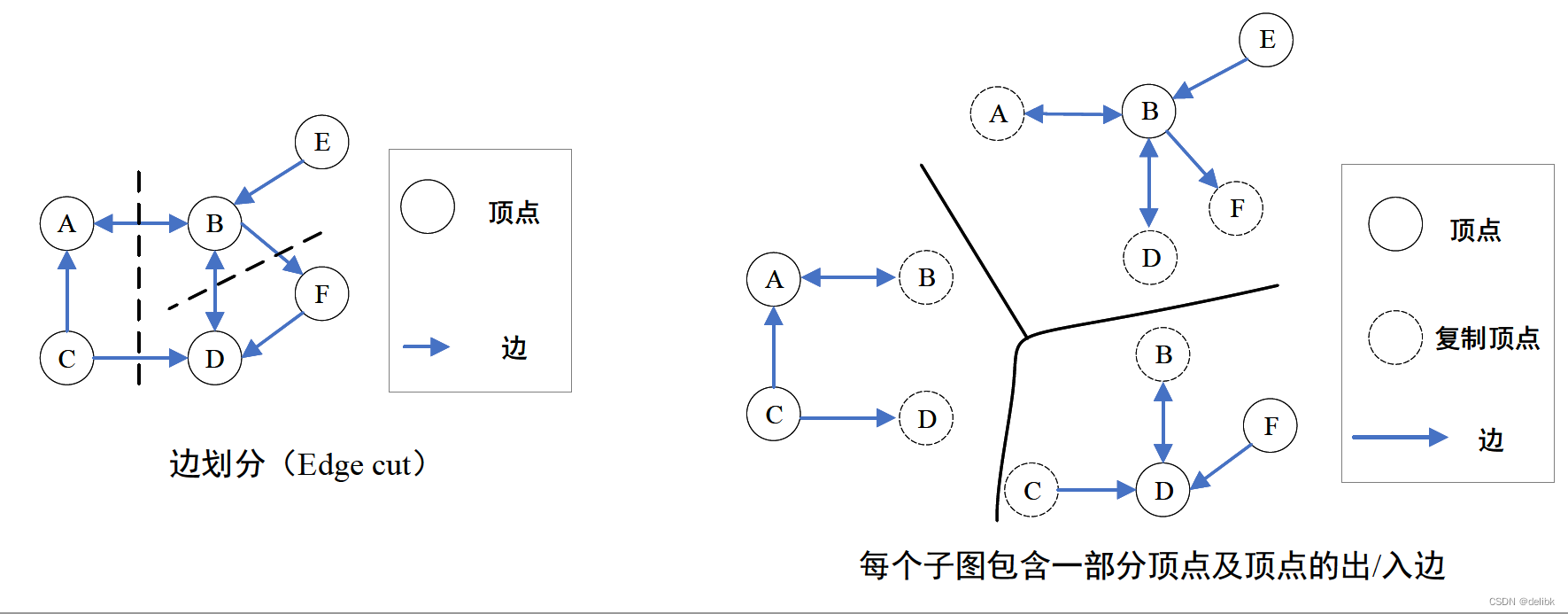
实际如何进行点分割和边分割的呢?
Graph store format
例如,图G中9个顶点,V={0,1,2,3,4,5,6,7,8}。
8条边E={<01>,<02>,<03>,<04>,<05>,<56>,<67>,<68>}。
分成两个子图G1和G2。
情况1:按照边列表存储:
Edge List:
0 1
0 2
0 3
0 4
0 5
5 6
6 7
6 8
G1存储的顶点为:{01234};
4条边:{<01>,<02>,<03>,<04>}。
0 1
0 2
0 3
0 4
G2存储的顶点为:{05678};
4条边:{<05>,<56>,<67>,<68>}。
0 5
5 6
6 7
6 8
这是点分割方式。因为顶点0被划分到两个子图。
出现Hot-Vertex(一个顶点有大量的边,且该顶点会被经常访问):
采用VertexCut(又叫Edge-centric)策略,将边(及其依附的顶点)分配在不同的机器上。
情况2:按照邻接表存储:
Adjacency list:
0 1 2 3 4 5
5 6
6 7 8
G1存储的顶点为:{01234};其中,顶点5为子图G2中顶点5的副本。
4条边:{<01>,<02>,<03>,<04>}
0 1 2 3 4 5
G2存储的顶点为:{5678};3条边{<56>,<67>,<68>}:
5 6
6 7 8
这是边分割方式。
因为边<05>中,顶点0分配在G1中,顶点5分配在G2中。
顶点0和顶点5被划分到两个子图。
参考:
GraphX
PowerGraph
相关文章:
Graph Partition: Edge cut and Vertex cut
Graph PartitionEdge cut and Vertex cutEdge cutVertex cut实际如何进行点分割和边分割的呢?Graph store format情况1:按照边列表存储:情况2:按照邻接表存储:Edge cut and Vertex cut 图结构描述了数据流动ÿ…...

Javascript周学习小结(初识,变量,数据类型)
JS的三大书写方式行内式如图所示:几点说明:JS的行内式写在HTML的标签内部,(常以on开头),如onclick行内式常常使用单引号括住字符串以区分HTML的双引号可读性差,不建议使用引号易出错,不建议使用特殊情况下使…...
C语言-基础了解-10-C函数
C函数 一、C函数 函数是一组一起执行一个任务的语句。每个 C 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。 您可以把代码划分到不同的函数中。如何划分代码到不同的函数中是由您来决定的,但在逻辑上&…...
【LeetCode】剑指 Offer(16)
目录 题目:剑指 Offer 33. 二叉搜索树的后序遍历序列 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:剑指 Offer …...
)
第三十九章 linux-并发解决方法二(互斥锁mutex)
第三十九章 linux-并发解决方法二(互斥锁mutex) 文章目录第三十九章 linux-并发解决方法二(互斥锁mutex)互斥锁的定义与初始化互斥锁的DOWN操作互斥锁的UP操作用count1的信号量实现的互斥方法还不是Linux下经典的用法,…...

脚本方式本地仓库jar包批量导入maven私服
脚本内容,将以下内容保存为mavenimport.sh,放置于需要上传的目录下,可以是顶层目录,或者某个分包的目录,若私服已有待上传的包,则执行会被替换 #!/bin/bash # copy and run this script to the root of th…...

【c++】引用的学习
引用的定义和声明 引用是一种别名,它允许使用与原变量相同的内存位置。在C中,引用是使用&符号来定义的。引用必须在定义时初始化,并且可以与原变量分别使用。 int a 10; int& b a; // 定义了一个引用b,它指向a引用的作用…...

linux 软件安装及卸载
1.联网在线安装及卸载ubuntu环境下:使用apt-get 工具apt-get install - 安装软件包apt-get remove - 移除(卸载)软件包CentOS环境下:使用yum工具 (银河麒麟系统属于centos)yum install - 安装软件包yum rem…...
XShell连接ubuntu20.04.LTS
1 下载XshellXShell官方下载地址打开XSHELL官方下载地址,我们可以选择【家庭和学校用户的免费许可证】,输入邮箱之后即可获得下载链接安装非常简单,跟着提示进行即可。2 连接ubuntu2.1 查看ubuntu的ip地址输入命令查看ip地址ifconfig刚开始可…...

【FPGA】Verilog:MSI/LSI 组合电路之解码器 | 多路分解器
写在前面:本章将理解编码器与解码器、多路复用器与多路分解器的概念,通过使用 Verilog 实现多样的解码器与多路分解器,通过 FPGA 并使用 Verilog 实现。 Ⅰ. 前置知识 0x00 解码器与编码器(Decoder / Encoder) 解码器…...

深入理解JDK动态代理原理,使用javassist动手写一个动态代理框架
文章目录一、动手实现一个动态代理框架1、初识javassist2、使用javassist实现一个动态代理框架二、JDK动态代理1、编码实现2、基本原理(1)getProxyClass0方法(2)总结写在后面一、动手实现一个动态代理框架 1、初识javassist Jav…...
一、策略模式的使用
1、策略模式定义: 策略模式(Strategy Pattern)定义了一组策略,分别在不同类中封装起来,每种策略都可以根据当前场景相互替换,从而使策略的变化可以独立于操作者。比如我们要去某个地方,会根据距…...

Verilog使用always块实现时序逻辑
这篇文章将讨论 verilog 中一个重要的结构---- always 块(always block)。verilog 中可以实现的数字电路主要分为两类----组合逻辑电路和时序逻辑电路。与组合逻辑电路相反,时序电路电路使用时钟并一定需要触发器等存储元件。因此,…...
面向对象设计模式:行为型模式之迭代器模式
一、迭代器模式,Iterator Pattern aka:Cursor Pattern 1.1 Intent 意图 Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation. 提供一种按顺序访问聚合对象的元素而不公开其基…...
如何快速在企业网盘中找到想要的文件
现在越来越多的企业采用企业网盘来存储文档和资料,而且现在市面上的企业网盘各种各样。在使用企业网盘过程中,很多用户会问到企业网盘中如何快速搜索文件的问题。但是无论是“标签”功能还是普通的“关键词搜索”功能,都是单层级的࿰…...
香橙派5使用NPU加速yolov5的实时视频推理(二)
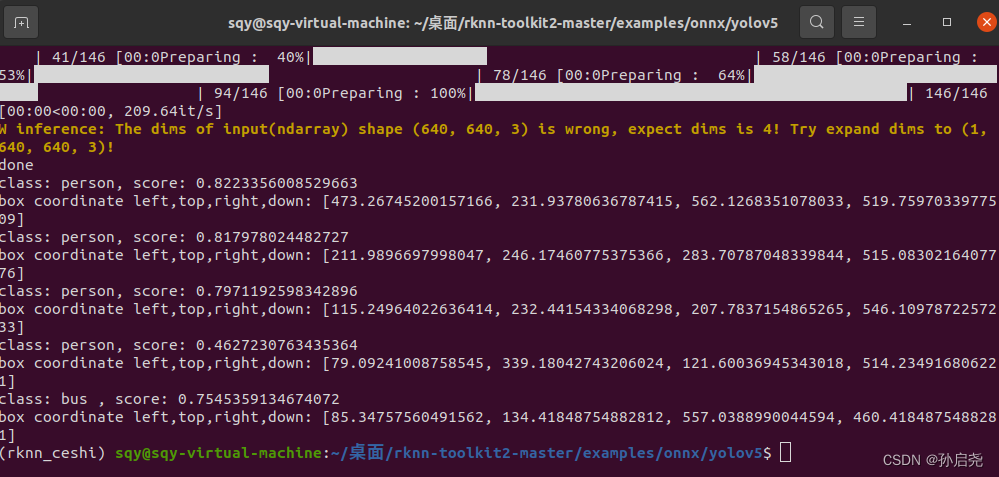
三、将best.onnx转为RKNN格式 这一步就需要我们进入到Ubuntu20.04系统中了,我的Ubuntu系统中已经下载好了anaconda,使用anaconda的好处就是可以方便的安装一些库,而且还可以利用conda来配置虚拟环境,做到环境与环境之间相互独立。…...
)
算法练习-二分查找(一)
算法练习-二分查找 1 代码实现 1.1 非递归实现 public int bsearch(int[] a, int n, int value) {int low 0;int high n - 1;while (low < high) {int mid (low high) / 2;if (a[mid] value) {return mid;} else if (a[mid] < value) {low mid 1} else {high …...
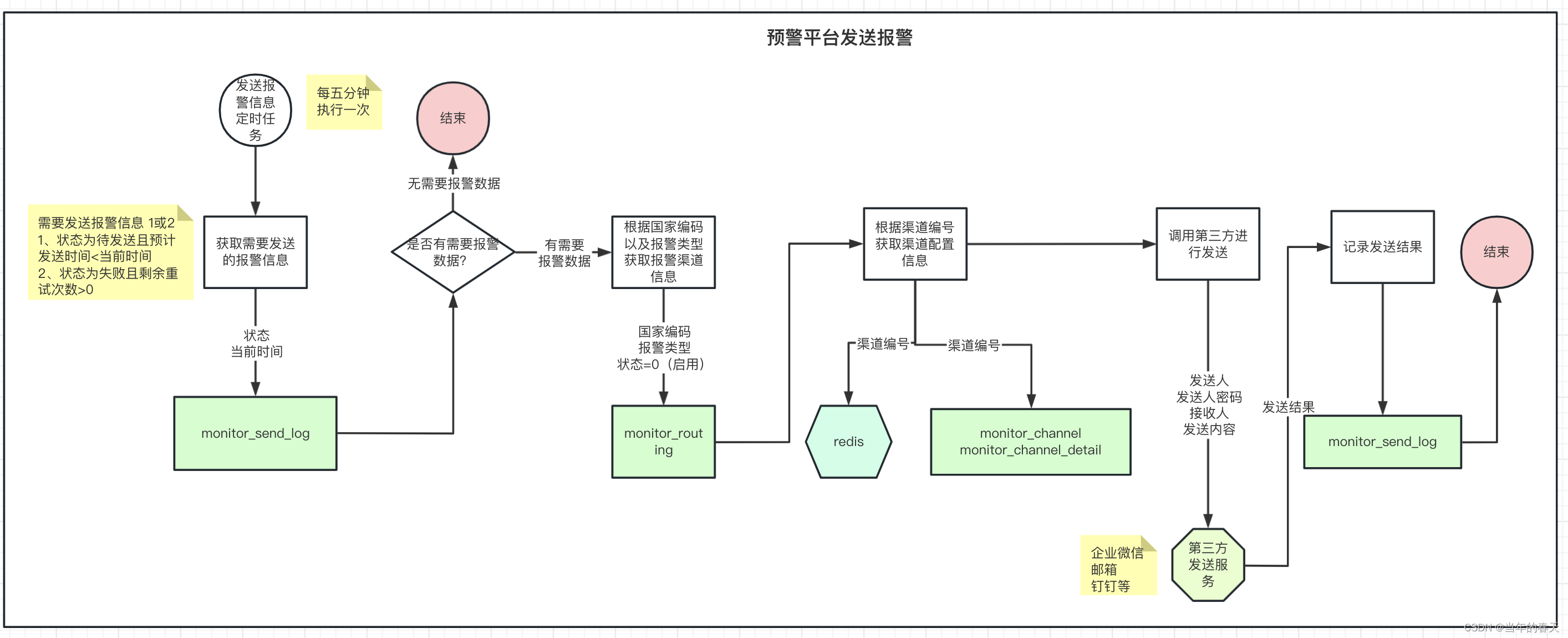
通用业务平台设计(五):预警平台建设
前言 在上家公司,随着业务的不断拓展(从支持单个国家单个主体演变成支持多个国家多个主体),对预警的诉求越来越紧迫;如何保障业务的稳定性那?预警可以帮我们提前甄别风险,从而让我们可以在风险来临前将其消灭ÿ…...

Windows openssl-1.1.1d vs2017编译
工具: 1. perl(https://strawberryperl.com/) 2. nasm(https://nasm.us/) 3. openssl源码(https://www.openssl.org/) 可以自己去下载 或者我的网盘提供下载: 链接:…...

【深蓝学院】手写VIO第2章--IMU传感器--笔记
0. 内容 1. 旋转运动学 角速度的推导: 左ω∧\omega^{\wedge}ω∧,而ω\omegaω是在z轴方向运动,θ′[0,0,1]T\theta^{\prime}[0,0,1]^Tθ′[0,0,1]T 两边取模后得到结论: 线速度大小半径 * 角速度大小 其中,对旋转矩…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...